
Cross-Dataset Data Augmentation Using UMAP for Deep Learning-Based Wind Speed Prediction


Abstract
1. Introduction
- We use the uniform manifold approximation and projection (UMAP) [48] as a non-linear dimensionality reduction algorithm to find and encode local relationships in wind speed time-series samples. The low-dimensional representation of the data preserves its neighborhood structures.
- A localized cross-dataset DA approach is introduced from the UMAP-reduced spaces, which leverages localized neighborhoods to mitigate data variability across multiple wind speed datasets, enhancing the diversity and robustness of the augmented training data [47].
- Recurrent neural networks (RNNs) are trained using the augmented datasets, capitalizing on their ability to model temporal dependencies and non-linear patterns in wind speed time-series data.
2. Materials and Methods
2.1. Wind Speed Time-Series Datasets
2.2. Uniform Manifold Approximation and Projection (UMAP)
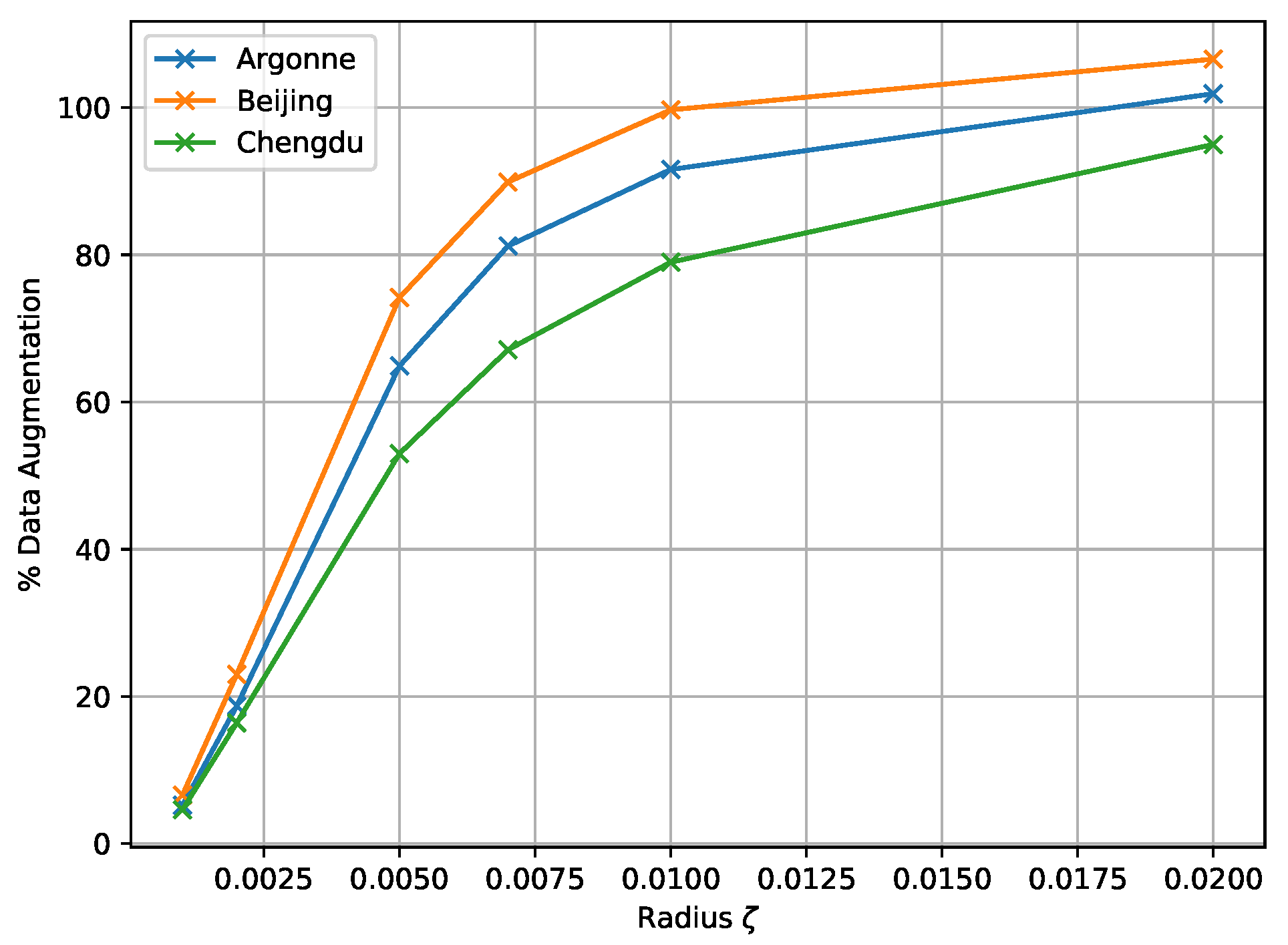
2.3. UMAP-Based Cross-Dataset Data Augmentation
2.4. Deep Learning-Based Wind Speed Predictions
- –
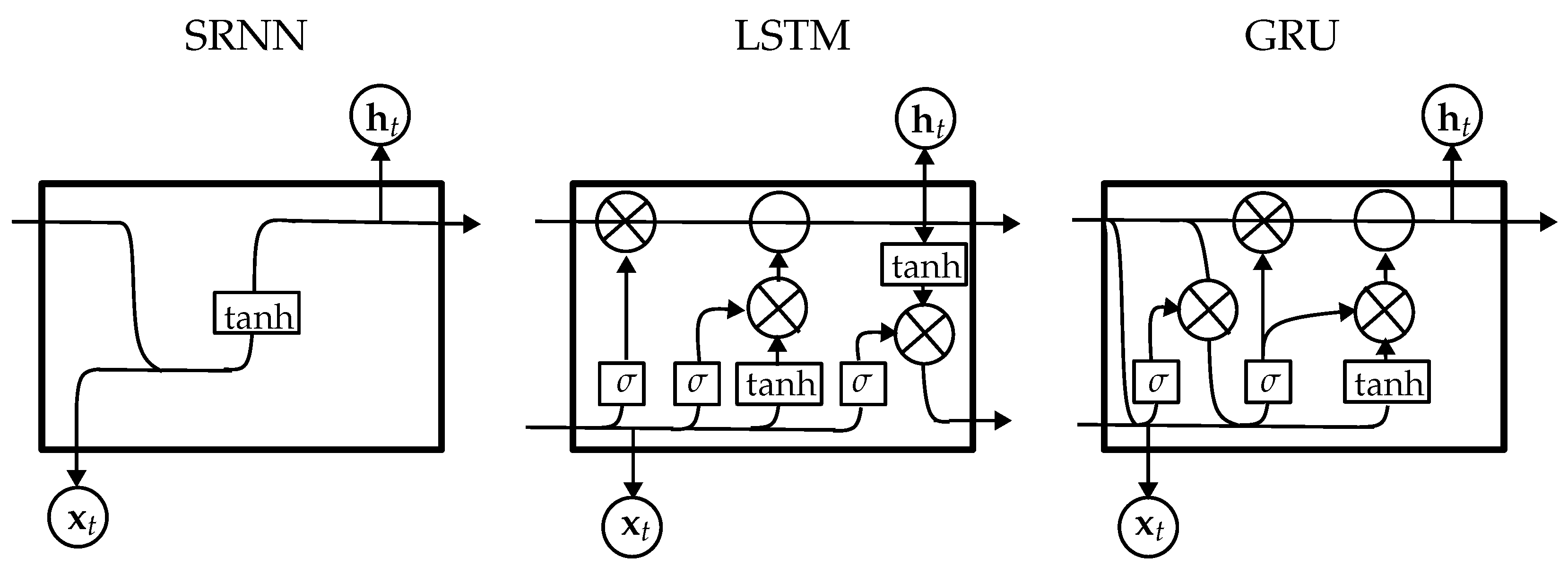
- Simple recurrent neural networks (SRNNs) are a foundational deep learning architecture designed to model sequential data by capturing temporal dependencies. RNNs process the augmented data generated by the UMAP-based cross-dataset approach. In short, the RNN architecture iteratively processes the input sequences, maintaining a hidden state that carries information from previous time steps, enabling the network to learn patterns and trends over time [50].
- –
- Long short-term memory (LSTM) networks are an advanced architecture specifically designed to overcome the limitations of SRNNs, such as vanishing or exploding gradients, when modeling long-range temporal dependencies. The LSTM architecture introduces memory cells and gating mechanisms—input, forget, and output gates—that enable the selective retention and propagation of relevant information over extended time sequences. This allows for effectively capturing the temporal dynamics and complex non-linear data patterns [35].
- –
- Gated recurrent units (GRUs) are a simplified but powerful variant of LSTM networks, designed to efficiently model sequential data by capturing temporal dependencies with reduced computational complexity. GRUs utilize gating mechanisms—update and reset gates—to regulate the flow of information, enabling the network to retain or discard information dynamically over time. This design allows GRUs to learn complex temporal patterns while maintaining a lighter computational footprint compared to LSTMs [51]. Figure 2 summarizes the main SRNN, LSTM, and GRU layers.
3. Experimental Set-Up
4. Results and Discussion
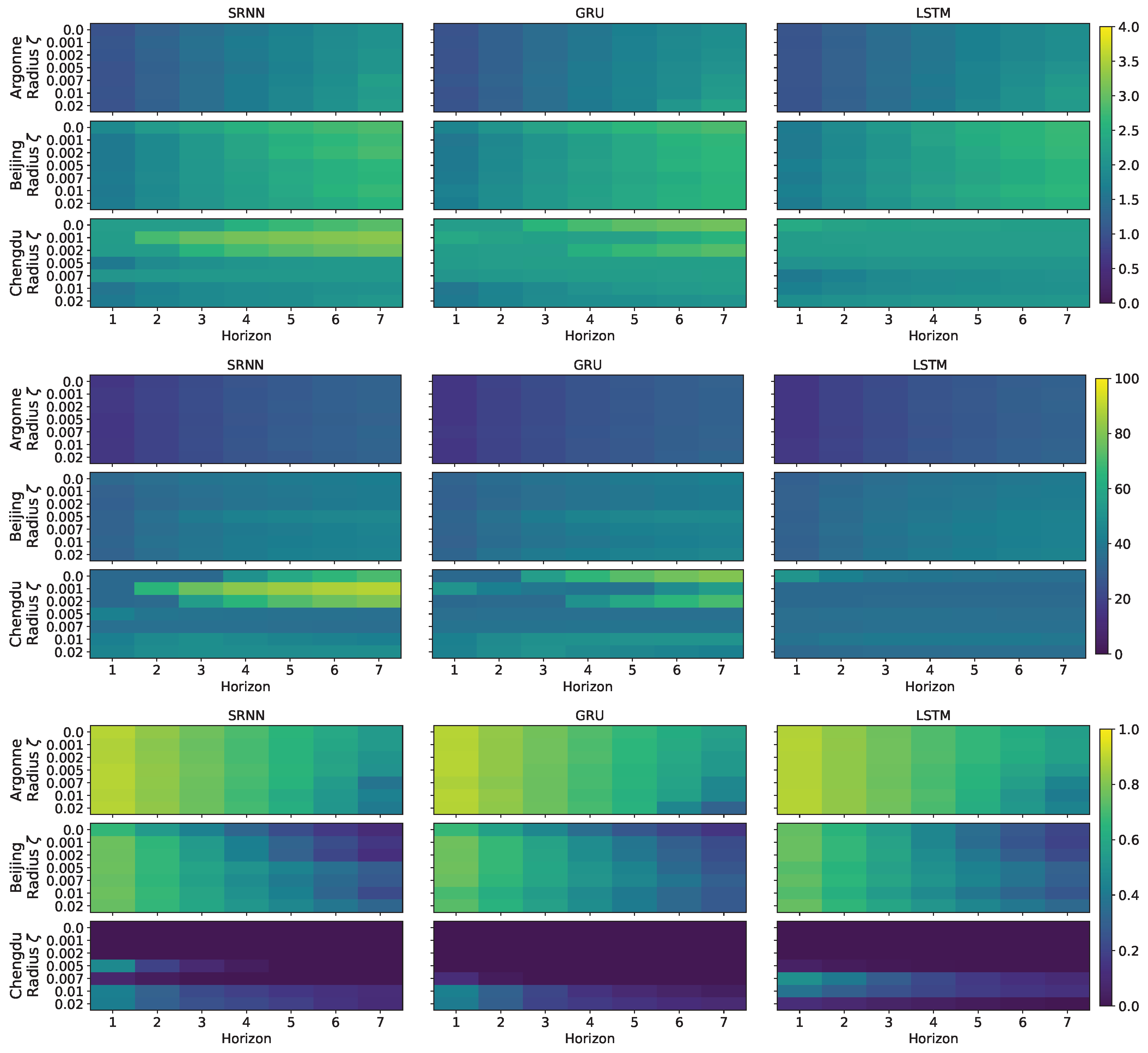
4.1. UMAP-CDDA Visual Inspection Results
4.2. Wind Speed Prediction Method Comparison Results
4.3. UMAP-CDDA Limitations
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Musial, W.; Spitsen, P.; Duffy, P.; Beiter, P.; Shields, M.; Mulas Hernando, D.; Hammond, R.; Marquis, M.; King, J.; Sathish, S. Offshore Wind Market Report: 2023 Edition; Technical Report; National Renewable Energy Laboratory (NREL): Golden, CO, USA, 2023.
- Gielen, D.; Gorini, R.; Wagner, N.; Leme, R.; Gutierrez, L.; Prakash, G.; Asmelash, E.; Janeiro, L.; Gallina, G.; Vale, G.; et al. Global Energy Transformation: A Roadmap to 2050; International Renewable Energy Agency (IRENA): Abu Dhabi, United Arab Emirates, 2019. [Google Scholar]
- Hassan, Q.; Viktor, P.; Al-Musawi, T.J.; Ali, B.M.; Algburi, S.; Alzoubi, H.M.; Al-Jiboory, A.K.; Sameen, A.Z.; Salman, H.M.; Jaszczur, M. The renewable energy role in the global energy Transformations. Renew. Energy Focus 2024, 48, 100545. [Google Scholar]
- Asmelash, E.; Prakash, G.; Gorini, R.; Gielen, D. Role of IRENA for global transition to 100% renewable energy. In Accelerating the Transition to a 100% Renewable Energy Era; Springer International Publishing: Cham, Switzerland, 2020; pp. 51–71. [Google Scholar]
- Summerfield-Ryan, O.; Park, S. The power of wind: The global wind energy industry’s successes and failures. Ecol. Econ. 2023, 210, 107841. [Google Scholar]
- Liu, Y.; Cai, W.; Lin, X.; Li, Z.; Zhang, Y. Nonlinear El Niño impacts on the global economy under climate change. Nat. Commun. 2023, 14, 5887. [Google Scholar] [CrossRef] [PubMed]
- Simankov, V.; Buchatskiy, P.; Teploukhov, S.; Onishchenko, S.; Kazak, A.; Chetyrbok, P. Review of estimating and predicting models of the wind energy amount. Energies 2023, 16, 5926. [Google Scholar] [CrossRef]
- Zhang, J.; Fu, H. An integrated modeling strategy for wind power forecasting based on dynamic meteorological visualization. IEEE Access 2024, 12, 69423–69433. [Google Scholar] [CrossRef]
- Bernal, S.; STEVANATO, N.; Mereu, R.; Osorio-Gómez, G. A Systematic Approach for Modeling and Planning a Sustainable Electricity System in Colombia. Access SSRN 2024, 19, 4735802. [Google Scholar]
- Yan, B.; Shen, R.; Li, K.; Wang, Z.; Yang, Q.; Zhou, X.; Zhang, L. Spatio-temporal correlation for simultaneous ultra-short-term wind speed prediction at multiple locations. Energy 2023, 284, 128418. [Google Scholar]
- Joseph, L.P.; Deo, R.C.; Prasad, R.; Salcedo-Sanz, S.; Raj, N.; Soar, J. Near real-time wind speed forecast model with bidirectional LSTM networks. Renew. Energy 2023, 204, 39–58. [Google Scholar] [CrossRef]
- Lydia, M.; Edwin Prem Kumar, G.; Akash, R. Wind speed and wind power forecasting models. Energy Environ. 2024. [Google Scholar] [CrossRef]
- Lin, X.; Huang, G.; Zhou, X.; Zhai, Y. An inexact fractional multi-stage programming (IFMSP) method for planning renewable electric power system. Renew. Sustain. Energy Rev. 2023, 187, 113611. [Google Scholar] [CrossRef]
- de Burgh-Day, C.O.; Leeuwenburg, T. Machine learning for numerical weather and climate modelling: A review. Geosci. Model Dev. 2023, 16, 6433–6477. [Google Scholar]
- Choi, S.; Jung, E.S. Optimizing Numerical Weather Prediction Model Performance using Machine Learning Techniques. IEEE Access 2023, 11, 86038–86055. [Google Scholar] [CrossRef]
- Huang, X.; Wang, J.; Huang, B. Two novel hybrid linear and nonlinear models for wind speed forecasting. Energy Convers. Manag. 2021, 238, 114162. [Google Scholar] [CrossRef]
- Hu, J.; Wang, J.; Xiao, L. A hybrid approach based on the Gaussian process with t-observation model for short-term wind speed forecasts. Renew. Energy 2017, 114, 670–685. [Google Scholar] [CrossRef]
- Naik, J.; Satapathy, P.; Dash, P. Short-term wind speed and wind power prediction using hybrid empirical mode decomposition and kernel ridge regression. Appl. Soft Comput. 2018, 70, 1167–1188. [Google Scholar] [CrossRef]
- Vassallo, D.; Krishnamurthy, R.; Sherman, T.; Fernando, H.J. Analysis of Random Forest Modeling Strategies for Multi-Step Wind Speed Forecasting. Energies 2020, 13, 5488. [Google Scholar] [CrossRef]
- Wang, X.; Yu, Q.; Yang, Y. Short-term wind speed forecasting using variational mode decomposition and support vector regression. J. Intell. Fuzzy Syst. 2018, 34, 3811–3820. [Google Scholar] [CrossRef]
- Valdivia-Bautista, S.M.; Domínguez-Navarro, J.A.; Pérez-Cisneros, M.; Vega-Gómez, C.J.; Castillo-Téllez, B. Artificial intelligence in wind speed forecasting: A review. Energies 2023, 16, 2457. [Google Scholar] [CrossRef]
- Yao, H.; Tan, Y.; Hou, J.; Liu, Y.; Zhao, X.; Wang, X. Short-Term Wind Speed Forecasting Based on the EEMD-GS-GRU Model. Atmosphere 2023, 14, 697. [Google Scholar] [CrossRef]
- Jiang, W.; Liu, B.; Liang, Y.; Gao, H.; Lin, P.; Zhang, D.; Hu, G. Applicability analysis of transformer to wind speed forecasting by a novel deep learning framework with multiple atmospheric variables. Appl. Energy 2024, 353, 122155. [Google Scholar] [CrossRef]
- Band, S.S.; Ameri, R.; Qasem, S.N.; Mehdizadeh, S.; Gupta, B.B.; Pai, H.T.; Shahmirzadi, D.; Salwana, E.; Mosavi, A. A two-stage deep learning-based hybrid model for daily wind speed forecasting. Heliyon 2025, 11, e41026. [Google Scholar] [CrossRef]
- Jiang, P.; Liu, Z.; Niu, X.; Zhang, L. A combined forecasting system based on statistical method, artificial neural networks, and deep learning methods for short-term wind speed forecasting. Energy 2021, 217, 119361. [Google Scholar] [CrossRef]
- Singh, S.K.; Jha, S.; Gupta, R. Enhancing the accuracy of wind speed estimation model using an efficient hybrid deep learning algorithm. Sustain. Energy Technol. Assess. 2024, 61, 103603. [Google Scholar] [CrossRef]
- Yan, X.; Liu, Y.; Xu, Y.; Jia, M. Multistep forecasting for diurnal wind speed based on hybrid deep learning model with improved singular spectrum decomposition. Energy Convers. Manag. 2020, 225, 113456. [Google Scholar] [CrossRef]
- Zhu, F.; Ma, S.; Cheng, Z.; Zhang, X.Y.; Zhang, Z.; Liu, C.L. Open-world machine learning: A review and new outlooks. arXiv 2024, arXiv:2403.01759. [Google Scholar]
- Bandara, K.; Hewamalage, H.; Liu, Y.H.; Kang, Y.; Bergmeir, C. Improving the accuracy of global forecasting models using time series data augmentation. Pattern Recognit. 2021, 120, 108148. [Google Scholar] [CrossRef]
- Iglesias, G.; Talavera, E.; González-Prieto, Á.; Mozo, A.; Gómez-Canaval, S. Data augmentation techniques in time series domain: A survey and taxonomy. Neural Comput. Appl. 2023, 35, 10123–10145. [Google Scholar] [CrossRef]
- Iwana, B.K.; Uchida, S. An empirical survey of data augmentation for time series classification with neural networks. PLoS ONE 2021, 16, e0254841. [Google Scholar] [CrossRef]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A comprehensive survey on transfer learning. Proc. IEEE 2020, 109, 43–76. [Google Scholar] [CrossRef]
- Bansal, M.; Kumar, M.; Sachdeva, M.; Mittal, A. Transfer learning for image classification using VGG19: Caltech-101 image data set. J. Ambient. Intell. Humaniz. Comput. 2023, 14, 3609–3620. [Google Scholar] [CrossRef]
- Ali, A.H.; Yaseen, M.G.; Aljanabi, M.; Abed, S.A. Transfer learning: A new promising techniques. Mesopotamian J. Big Data 2023, 2023, 29–30. [Google Scholar]
- Liu, X.; Lin, Z.; Feng, Z. Short-term offshore wind speed forecast by seasonal ARIMA-A comparison against GRU and LSTM. Energy 2021, 227, 120492. [Google Scholar]
- Liao, Y.; Gao, Z.; Li, X. Wind Farm Meteorological Prediction Model based on Frequency Domain Feature Extraction Fusion Mechanism. IEEE Access 2024. [Google Scholar] [CrossRef]
- Sajol, M.S.I.; Islam, M.S.; Hasan, A.J.; Rahman, M.S.; Yusuf, J. Wind Power Prediction across Different Locations using Deep Domain Adaptive Learning. In Proceedings of the 2024 6th Global Power, Energy and Communication Conference (GPECOM), Budapest, Hungary, 4–7 June 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 518–523. [Google Scholar]
- Ji, L.; Fu, C.; Ju, Z.; Shi, Y.; Wu, S.; Tao, L. Short-Term canyon wind speed prediction based on CNN—GRU transfer learning. Atmosphere 2022, 13, 813. [Google Scholar] [CrossRef]
- Oh, J.; Park, J.; Ok, C.; Ha, C.; Jun, H.B. A Study on the Wind Power Forecasting Model Using Transfer Learning Approach. Electronics 2022, 11, 4125. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 60. [Google Scholar]
- Islam, Z.; Abdel-Aty, M.; Cai, Q.; Yuan, J. Crash data augmentation using variational autoencoder. Accid. Anal. Prev. 2021, 151, 105950. [Google Scholar] [CrossRef]
- Tanaka, F.H.K.D.S.; Aranha, C. Data augmentation using GANs. arXiv 2019, arXiv:1904.09135. [Google Scholar]
- Liu, R.; Song, Y.; Yuan, C.; Wang, D.; Xu, P.; Li, Y. GAN-Based Abrupt Weather Data Augmentation for Wind Turbine Power Day-Ahead Predictions. Energies 2023, 16, 7250. [Google Scholar] [CrossRef]
- Vega-Bayo, M.; Pérez-Aracil, J.; Prieto-Godino, L.; Salcedo-Sanz, S. Improving the prediction of extreme wind speed events with generative data augmentation techniques. Renew. Energy 2024, 221, 119769. [Google Scholar] [CrossRef]
- Flores, A.; Tito-Chura, H.; Yana-Mamani, V. Wind speed time series prediction with deep learning and data augmentation. In Intelligent Systems and Applications: Proceedings of the 2021 Intelligent Systems Conference (IntelliSys), Amsterdam, The Netherlands, 2–3 September 2021; Springer: Cham, Switzerland, 2022; Volume 1, pp. 330–343. [Google Scholar]
- Chen, H.; Birkelund, Y.; Zhang, Q. Data-augmented sequential deep learning for wind power forecasting. Energy Convers. Manag. 2021, 248, 114790. [Google Scholar] [CrossRef]
- Vega-Bayo, M.; Gómez-Orellana, A.M.; Yun, V.M.V.; Guijo-Rubio, D.; Cornejo-Bueno, L.; Pérez-Aracil, J.; Salcedo-Sanz, S. Data Augmentation Techniques for Extreme Wind Prediction Improvement. In Proceedings of the International Work-Conference on the Interplay Between Natural and Artificial Computation, Olhão, Portugal, 4–7 June 2024; Springer: Cham, Switzerland, 2024; pp. 303–313. [Google Scholar]
- McInnes, L.; Healy, J.; Melville, J. Umap: Uniform manifold approximation and projection for dimension reduction. arXiv 2018, arXiv:1802.03426. [Google Scholar]
- Mittal, M.; Gujjar, P.; Prasad, G.; Devadas, R.M.; Ambreen, L.; Kumar, V. Dimensionality Reduction Using UMAP and TSNE Technique. In Proceedings of the 2024 Second International Conference on Advances in Information Technology (ICAIT), Chikkamagaluru, India, 24–27 July 2024; IEEE: Piscataway, NJ, USA, 2024; Volume 1, pp. 1–5. [Google Scholar]
- Murphy, K.P. Probabilistic Machine Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2022. [Google Scholar]
- Xu, Z.; Yixian, W.; Yunlong, C.; Xueting, C.; Lei, G. Short-term wind speed prediction based on GRU. In Proceedings of the 2019 IEEE Sustainable Power and Energy Conference (iSPEC), Beijing, China, 21–23 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 882–887. [Google Scholar]
- Chen, X.; Yu, R.; Ullah, S.; Wu, D.; Li, Z.; Li, Q.; Qi, H.; Liu, J.; Liu, M.; Zhang, Y. A novel loss function of deep learning in wind speed forecasting. Energy 2022, 238, 121808. [Google Scholar] [CrossRef]
- Choi, H.; Kang, P. Multi-task self-supervised time-series representation learning. Inf. Sci. 2024, 671, 120654. [Google Scholar] [CrossRef]
- Macabiog, R.E.; Dela Cruz, J. Multifeature-Driven Multistep Wind Speed Forecasting Using NARXR and Modified VMD Approaches. Forecasting 2025, 7, 12. [Google Scholar] [CrossRef]
- Zhao, L.; Liu, C.; Yang, C.; Liu, S.; Zhang, Y.; Li, Y. A location-centric transformer framework for multi-location short-term wind speed forecasting. Energy Convers. Manag. 2025, 328, 119627. [Google Scholar] [CrossRef]
- Yang, B.; Zhong, L.; Wang, J.; Shu, H.; Zhang, X.; Yu, T.; Sun, L. State-of-the-art one-stop handbook on wind forecasting technologies: An overview of classifications, methodologies, and analysis. J. Clean. Prod. 2021, 283, 124628. [Google Scholar] [CrossRef]
- Tang, Y.; Zhang, S.; Zhang, Z. A privacy-preserving framework integrating federated learning and transfer learning for wind power forecasting. Energy 2024, 286, 129639. [Google Scholar] [CrossRef]
- Yu, C.; Yan, G.; Yu, C.; Liu, X.; Mi, X. MRIformer: A multi-resolution interactive transformer for wind speed multi-step prediction. Inf. Sci. 2024, 661, 120150. [Google Scholar] [CrossRef]
- Li, S.; Li, X.; Jiang, Y.; Yang, Q.; Lin, M.; Peng, L.; Yu, J. A novel frequency-domain physics-informed neural network for accurate prediction of 3D Spatio-temporal wind fields in wind turbine applications. Appl. Energy 2025, 386, 125526. [Google Scholar] [CrossRef]
 ) in Illinois, USA; Chengdu Airport (green dot
) in Illinois, USA; Chengdu Airport (green dot  ) in Sichuan Province, China; and Beijing Capital International Airport (blue dot
) in Sichuan Province, China; and Beijing Capital International Airport (blue dot  ) in Beijing, China.
) in Illinois, USA; Chengdu Airport (green dot ) in Sichuan Province, China; and Beijing Capital International Airport (blue dot ) in Beijing, China.
) in Beijing, China.
) in Illinois, USA; Chengdu Airport (green dot ) in Sichuan Province, China; and Beijing Capital International Airport (blue dot ) in Beijing, China.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Start | End | Max | Mean | Min | Median | Std. |
|---|---|---|---|---|---|---|---|
| Argone | 1 January 1998 | 30 August 2005 | 32.44 | 7.28 | 0 | 6.49 | 3.83 |
| Chengdu | 1 January 2011 | 30 December 2018 | 33.53 | 3.52 | 0 | 2.24 | 2.95 |
| Beijing | 1 August 2011 | 30 December 2018 | 40.23 | 6.48 | 0 | 4.47 | 4.85 |
| Layer | Output Dimension |
|---|---|
| Input | |
| Recurrent (Activation: ReLU) | |
| SRNN/GRU/LSTM | |
| Dense (Activation: Linear) |
| Measure | Dataset | SRNN | CDDA-SRNN | GRU | CDDA-GRU | LSTM | CDDA-LSTM | p-Value | Statistic | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MAE | Argonne | 5.14 ± 0.99 | 4.00 ± 1.85 | 0.005 | 1.57 ± 0.49 | 3.86 ± 0.35 | 0.001 | 4.14 ± 1.36 | 2.29 ± 1.48 | 0.001 | 17.36 | |
| Beijing | 6.00 ± 0.00 | 2.14 ± 0.35 | 0.02 | 5.00 ± 0.00 | 2.57 ± 0.73 | 0.007 | 4.00 ± 0.00 | 1.29 ± 0.70 | 0.02 | 32.71 | ||
| Chengdu | 4.57 ± 0.49 | 1.43 ± 0.49 | 0.01 | 5.71 ± 0.45 | 2.86 ± 0.35 | 0.02 | 4.71 ± 0.88 | 1.71 ± 0.70 | 0.07 | 30.83 | ||
| MAPE | Argonne | 5.57 ± 0.72 | 5.28 ± 0.45 | 0.02 | 4.14 ± 0.34 | 2.00 ± 0.76 | 0.001 | 2.71 ± 0.45 | 1.28 ± 0.45 | 0.007 | 31.32 | |
| Beijing | 5.57 ± 0.49 | 2.14 ± 0.34 | 0.002 | 5.42 ± 0.49 | 2.71 ± 0.69 | 0.002 | 1.14 ± 0.34 | 4.00 ± 0.00 | 0.001 | 32.55 | ||
| Chengdu | 3.29 ± 1.98 | 2.86 ± 1.12 | 0.007 | 5.14 ± 1.36 | 3.71 ± 0.70 | 0.005 | 4.57 ± 1.05 | 1.43 ± 0.49 | 0.001 | 17.28 | ||
| Argonne | 4.86 ± 0.99 | 3.86 ± 2.03 | 0.005 | 1.57 ± 0.49 | 4.00 ± 0.53 | 0.001 | 4.14 ± 1.36 | 2.57 ± 1.68 | 0.001 | 14.42 | ||
| Beijing | 6.00 ± 0.00 | 1.43 ± 0.49 | 0.02 | 5.00 ± 0.00 | 2.29 ± 0.70 | 0.007 | 4.00 ± 0.00 | 2.29 ± 0.88 | 0.02 | 31.97 | ||
| Chengdu | 5.00 ± 0.00 | 1.43 ± 0.49 | 0.02 | 6.00 ± 0.00 | 3.00 ± 0.00 | 0.02 | 4.00 ± 0.00 | 1.57 ± 0.49 | 0.07 | 34.02 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Leon-Gomez, E.A.; Álvarez-Meza, A.M.; Castellanos-Dominguez, G. Cross-Dataset Data Augmentation Using UMAP for Deep Learning-Based Wind Speed Prediction. Computers 2025, 14, 123. https://doi.org/10.3390/computers14040123
Leon-Gomez EA, Álvarez-Meza AM, Castellanos-Dominguez G. Cross-Dataset Data Augmentation Using UMAP for Deep Learning-Based Wind Speed Prediction. Computers. 2025; 14(4):123. https://doi.org/10.3390/computers14040123
Chicago/Turabian StyleLeon-Gomez, Eder Arley, Andrés Marino Álvarez-Meza, and German Castellanos-Dominguez. 2025. "Cross-Dataset Data Augmentation Using UMAP for Deep Learning-Based Wind Speed Prediction" Computers 14, no. 4: 123. https://doi.org/10.3390/computers14040123
APA StyleLeon-Gomez, E. A., Álvarez-Meza, A. M., & Castellanos-Dominguez, G. (2025). Cross-Dataset Data Augmentation Using UMAP for Deep Learning-Based Wind Speed Prediction. Computers, 14(4), 123. https://doi.org/10.3390/computers14040123