
Can ChatGPT Solve Undergraduate Exams from Warehousing Studies? An Investigation

 , , , , and
, , , , and
Abstract
1. Introduction
2. Related Work
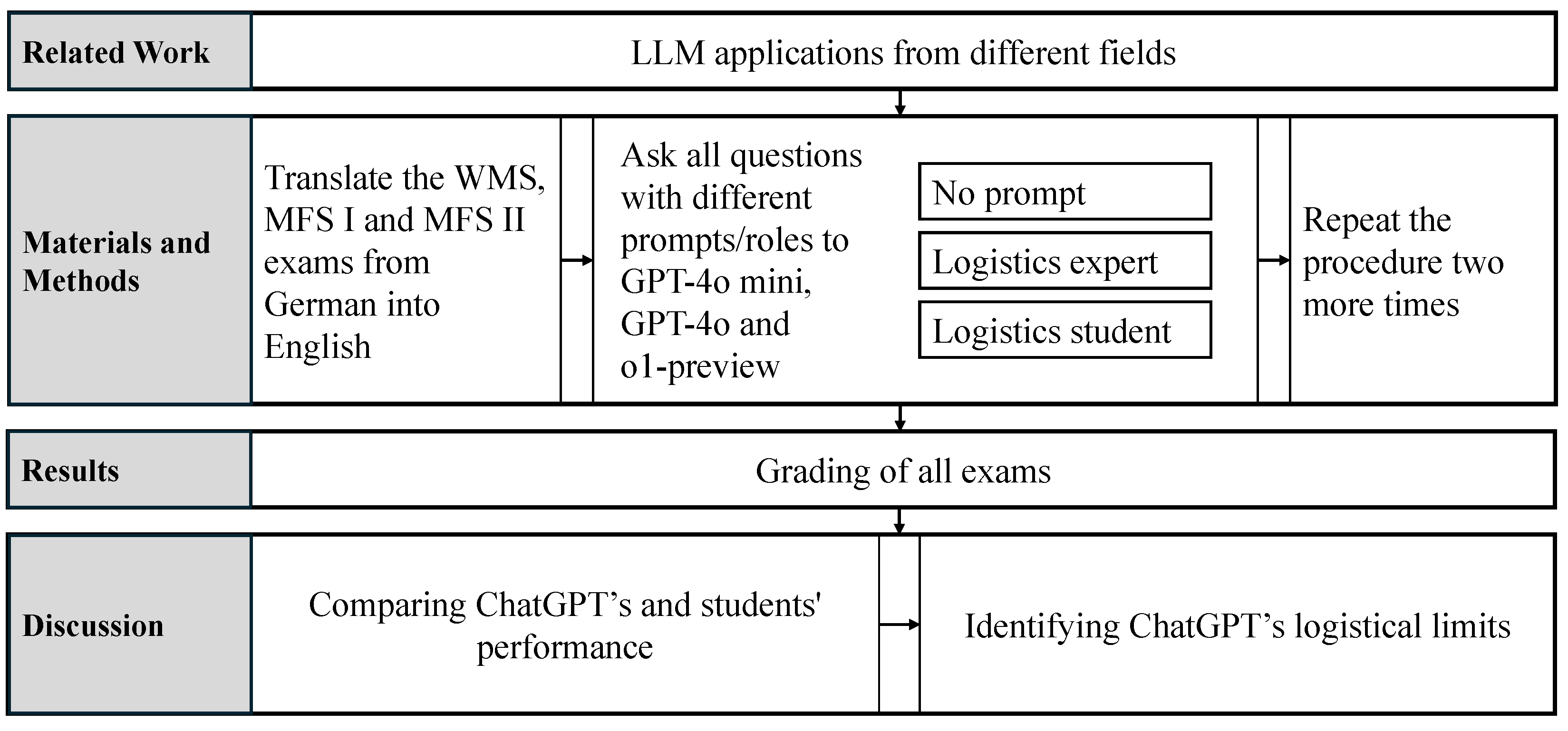
3. Materials and Methods
- Please put yourself in the role of a logistics expert and answer all the questions below.
- Please put yourself in the role of a logistics student and answer all the questions below.
4. Results
5. Discussion
5.1. ChatGPT’s Limited Knowledge of Warehousing
- Which cross-docking process has picking as a key feature? [Single Choice] (1/60)
- a.
- Cross-docking with collection in the storage system
- b.
- Cross-docking as a throughput system
- c.
- Cross-docking with breaking up the load units
- d.
- Cross-docking with pick families (clustering)
- Give two examples of the risk of industrial trucks tipping over. [2 pt]
5.2. Limitations and Future Work
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | Artificial intelligence |
| API | Application Programming Interface |
| IT | Information technology |
| LE | Logistics expert |
| LLM | Large Language Model |
| LS | Logistics student |
| MFS I | Material Flow Systems I |
| MFS II | Material Flow Systems II |
| NP | No prompt |
| WMS | Warehouse Management Systems |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Percentage Points [%] | Grade | German Grading System |
|---|---|---|
| 94–100 | A | 1.0 |
| 88–93.99 | A- | 1.3 |
| 82–87.99 | B+ | 1.7 |
| 76–81.99 | B | 2.0 |
| 70–75.99 | B- | 2.3 |
| 64–69.99 | C+ | 2.7 |
| 58–63.99 | C | 3.0 |
| 52–57.99 | C- | 3.3 |
| 46–51.99 | D+ | 3.7 |
| 40–45.99 | D | 4.0 |
| 0–39.99 | F | 5.0 |

| Version | Prompt 1 | Total Points | Passed | Percentage [%] | Grade |
|---|---|---|---|---|---|
| WMS | |||||
| GPT-4o mini | NP | 42 | Yes | 70 | B- |
| GPT-4o mini | LE | 41 | Yes | 68 | C+ |
| GPT-4o mini | LS | 42 | Yes | 70 | B- |
| GPT-4o | NP | 47 | Yes | 78 | B |
| GPT-4o | LE | 44 | Yes | 73 | B- |
| GPT-4o | LS | 48 | Yes | 80 | B |
| o1-preview | NP | 56 | Yes | 93 | A- |
| MFS I | |||||
| GPT-4o mini | NP | 25.5 | Yes | 43 | D |
| GPT-4o mini | LE | 25.5 | Yes | 43 | D |
| GPT-4o mini | LS | 22.5 | No | 38 | F |
| GPT-4o | NP | 30 | Yes | 50 | D+ |
| GPT-4o | LE | 30 | Yes | 50 | D+ |
| GPT-4o | LS | 28.5 | Yes | 48 | D+ |
| o1-preview | NP | Model could not analyze pictures or answer all questions. | |||
| MFS II | |||||
| GPT-4o mini | NP | 22 | No | 37 | F |
| GPT-4o mini | LE | 26.5 | Yes | 44 | D |
| GPT-4o mini | LS | 18.5 | No | 31 | F |
| GPT-4o | NP | 25 | Yes | 42 | D |
| GPT-4o | LE | 28 | Yes | 47 | D+ |
| GPT-4o | LS | 21 | No | 35 | F |
| o1-preview | NP | 25 | Yes | 42 | D |
| Version | Prompt 1 | Total Points | Passed | Percentage [%] | Grade |
|---|---|---|---|---|---|
| WMS | |||||
| GPT-4o mini | NP | 42 | Yes | 70 | B- |
| GPT-4o mini | LE | 43 | Yes | 72 | B- |
| GPT-4o mini | LS | 42 | Yes | 70 | B- |
| GPT-4o | NP | 49 | Yes | 82 | B+ |
| GPT-4o | LE | 48 | Yes | 80 | B |
| GPT-4o | LS | 49 | Yes | 82 | B+ |
| o1-preview | NP | 56 | Yes | 93 | A- |
| MFS I | |||||
| GPT-4o mini | NP | 26.5 | Yes | 44 | D |
| GPT-4o mini | LE | 24.5 | Yes | 41 | D |
| GPT-4o mini | LS | 28.5 | Yes | 48 | D+ |
| GPT-4o | NP | 29 | Yes | 48 | D+ |
| GPT-4o | LE | 27 | Yes | 45 | D |
| GPT-4o | LS | 24.5 | Yes | 41 | D |
| o1-preview | NP | Model could not analyze pictures or answer all questions. | |||
| MFS II | |||||
| GPT-4o mini | NP | 18.5 | No | 31 | F |
| GPT-4o mini | LE | 16 | No | 27 | F |
| GPT-4o mini | LS | 19.5 | No | 33 | F |
| GPT-4o | NP | 23 | No | 38 | F |
| GPT-4o | LE | 21.5 | No | 36 | F |
| GPT-4o | LS | 24 | Yes | 40 | D |
| o1-preview | NP | 34 | Yes | 57 | C- |
| Version | Prompt 1 | Total Points | Passed | Percentage [%] | Grade |
|---|---|---|---|---|---|
| WMS | |||||
| GPT-4o mini | NP | 38 | Yes | 63 | C |
| GPT-4o mini | LE | 40 | Yes | 67 | C+ |
| GPT-4o mini | LS | 41 | Yes | 68 | C+ |
| GPT-4o | NP | 53 | Yes | 88 | A- |
| GPT-4o | LE | 43 | Yes | 72 | B- |
| GPT-4o | LS | 47 | Yes | 78 | B |
| o1-preview | NP | 51 | Yes | 85 | B+ |
| MFS I | |||||
| GPT-4o mini | NP | 24.5 | Yes | 41 | D |
| GPT-4o mini | LE | 24 | Yes | 40 | D |
| GPT-4o mini | LS | 26.5 | Yes | 44 | D |
| GPT-4o | NP | 29 | Yes | 48 | D+ |
| GPT-4o | LE | 29 | Yes | 48 | D+ |
| GPT-4o | LS | 29 | Yes | 48 | D+ |
| o1-preview | NP | Model could not analyze pictures or answer all questions. | |||
| MFS II | |||||
| GPT-4o mini | NP | 18.5 | No | 31 | F |
| GPT-4o mini | LE | 19 | No | 32 | F |
| GPT-4o mini | LS | 19.5 | No | 33 | F |
| GPT-4o | NP | 24.5 | Yes | 41 | D |
| GPT-4o | LE | 20.5 | No | 34 | F |
| GPT-4o | LS | 22 | No | 37 | F |
| o1-preview | NP | 25.5 | Yes | 43 | D |
References
- Biever, C. ChatGPT broke the Turing test-the race is on for new ways to assess AI. Nature 2023, 619, 686–689. [Google Scholar] [CrossRef]
- Wu, C.; Tang, R. Performance Law of Large Language Models. arXiv 2024, arXiv:2408.09895. [Google Scholar]
- Chatbot Arena LLM Leaderboard: Community-Driven Evaluation for Best LLM and AI Chatbots. Available online: https://lmarena.ai/?leaderboard (accessed on 5 December 2024).
- GitHub OpenAI Repository Simple-Evals. Available online: https://github.com/openai/simple-evals?tab=readme-ov-file#benchmark-results (accessed on 5 December 2024).
- Zhou, K.; Zhu, Y.; Chen, Z.; Chen, W.; Zhao, W.X.; Chen, X.; Lin, Y.; Wen, J.R.; Han, J. Don’t make your llm an evaluation benchmark cheater. arXiv 2023, arXiv:2311.01964. [Google Scholar]
- Rutinowski, J.; Franke, S.; Endendyk, J.; Dormuth, I.; Roidl, M.; Pauly, M. The Self-Perception and Political Biases of ChatGPT. Hum. Behav. Emerg. Technol. 2024, 2024, 7115633. [Google Scholar] [CrossRef]
- Snyder, B.; Moisescu, M.; Zafar, M.B. On early detection of hallucinations in factual question answering. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Barcelona, Spain, 25–29 August 2024; pp. 2721–2732. [Google Scholar]
- Ji, Z.; Yu, T.; Xu, Y.; Lee, N.; Ishii, E.; Fung, P. Towards mitigating LLM hallucination via self reflection. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2023, Singapore, 6–10 December 2023; pp. 1827–1843. [Google Scholar]
- Palen-Michel, C.; Wang, R.; Zhang, Y.; Yu, D.; Xu, C.; Wu, Z. Investigating LLM Applications in E-Commerce. arXiv 2024, arXiv:2408.12779. [Google Scholar]
- Huang, Y.; Gomaa, A.; Semrau, S.; Haderlein, M.; Lettmaier, S.; Weissmann, T.; Grigo, J.; Tkhayat, H.B.; Frey, B.; Gaipl, U.; et al. Benchmarking ChatGPT-4 on a radiation oncology in-training exam and Red Journal Gray Zone cases: Potentials and challenges for ai-assisted medical education and decision making in radiation oncology. Front. Oncol. 2023, 13, 1265024. [Google Scholar] [CrossRef]
- Weber, E.; Rutinowski, J.; Pauly, M. Behind the Screen: Investigating ChatGPT’s Dark Personality Traits and Conspiracy Beliefs. arXiv 2024, arXiv:2402.04110. [Google Scholar]
- Bureau, S.U.C. Industry Revenue of “General Warehousing and Storage“ in the U.S. from 2012 to 2024. Available online: https://www.statista.com/forecasts/409692/general-warehousing-and-storage-revenue-in-the-us (accessed on 22 January 2025).
- Chen, J.; Zhao, W. Logistics automation management based on the Internet of things. Clust. Comput. 2019, 22, 13627–13634. [Google Scholar] [CrossRef]
- Gouda, A.; Ghanem, A.; Reining, C. DoPose-6d dataset for object segmentation and 6d pose estimation. In Proceedings of the 2022 21st IEEE International Conference on Machine Learning and Applications (ICMLA), Nassau, Bahamas, 12–14 December 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 477–483. [Google Scholar]
- Franke, S.; Bommert, A.; Brandt, M.J.; Kuhlmann, J.L.; Olivier, M.C.; Schorning, K.; Reining, C.; Kirchheim, A. Smart pallets: Towards event detection using imus. In Proceedings of the 2024 IEEE 29th International Conference on Emerging Technologies and Factory Automation (ETFA), Padova, Italy, 10–13 September 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1–4. [Google Scholar]
- 4flow. Warehouse and Distribution. Available online: https://www.4flow.com/solutions/warehouse-and-distribution.html (accessed on 28 January 2025).
- DHL. Warehousing Solutions. Available online: https://www.dhl.com/de-en/home/supply-chain/solutions/warehousing.html (accessed on 28 January 2025).
- Maliugina, D. 45 Real-World LLM Applications and Use Cases from Top Companies. Available online: https://www.evidentlyai.com/blog/llm-applications (accessed on 22 January 2025).
- Kmiecik, M. ChatGPT in third-party logistics–The game-changer or a step into the unknown? J. Open Innov. Technol. Mark. Complex. 2023, 9, 100174. [Google Scholar] [CrossRef]
- Voß, S. Successfully Using ChatGPT in Logistics: Are We There Yet? In Proceedings of the International Conference on Computational Logistics, Berlin, Germany, 6–8 September 2023; Springer: Berlin/Heidelberg, Germany, 2023; pp. 3–17. [Google Scholar]
- Frederico, G.F. ChatGPT in supply chains: Initial evidence of applications and potential research agenda. Logistics 2023, 7, 26. [Google Scholar] [CrossRef]
- OpenAI. Model Release Notes. Available online: https://help.openai.com/en/articles/9624314-model-release-notes (accessed on 5 December 2024).
- Zhao, W.X.; Zhou, K.; Li, J.; Tang, T.; Wang, X.; Hou, Y.; Min, Y.; Zhang, B.; Zhang, J.; Dong, Z.; et al. A survey of large language models. arXiv 2023, arXiv:2303.18223. [Google Scholar]
- IBM. What Are Large Language Models (LLMs)? Available online: https://www.ibm.com/think/topics/large-language-models (accessed on 15 December 2024).
- Carlini, N.; Tramer, F.; Wallace, E.; Jagielski, M.; Herbert-Voss, A.; Lee, K.; Roberts, A.; Brown, T.; Song, D.; Erlingsson, U.; et al. Extracting training data from large language models. In Proceedings of the 30th USENIX Security Symposium (USENIX Security 21), Virtual, 11–13 August 2021; pp. 2633–2650. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 2020, 21, 1–67. [Google Scholar]
- Naveed, H.; Khan, A.U.; Qiu, S.; Saqib, M.; Anwar, S.; Usman, M.; Akhtar, N.; Barnes, N.; Mian, A. A comprehensive overview of large language models. arXiv 2023, arXiv:2307.06435. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. Available online: https://proceedings.neurips.cc/paper_files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf (accessed on 12 December 2024).
- Kirchenbauer, J.; Geiping, J.; Wen, Y.; Katz, J.; Miers, I.; Goldstein, T. A watermark for large language models. In Proceedings of the International Conference on Machine Learning. PMLR, Honolulu, HI, USA, 23–29 July 2023; pp. 17061–17084. [Google Scholar]
- OpenAI. Introducing ChatGPT. Available online: https://openai.com/index/chatgpt/ (accessed on 12 December 2024).
- Chang, Y.; Wang, X.; Wang, J.; Wu, Y.; Yang, L.; Zhu, K.; Chen, H.; Yi, X.; Wang, C.; Wang, Y.; et al. A survey on evaluation of large language models. ACM Trans. Intell. Syst. Technol. 2024, 15, 1–45. [Google Scholar] [CrossRef]
- Bubeck, S.; Chandrasekaran, V.; Eldan, R.; Gehrke, J.; Horvitz, E.; Kamar, E.; Lee, P.; Lee, Y.T.; Li, Y.; Lundberg, S.; et al. Sparks of artificial general intelligence: Early experiments with gpt-4. arXiv 2023, arXiv:2303.12712. [Google Scholar]
- Bommasani, R.; Hudson, D.A.; Adeli, E.; Altman, R.; Arora, S.; von Arx, S.; Bernstein, M.S.; Bohg, J.; Bosselut, A.; Brunskill, E.; et al. On the opportunities and risks of foundation models. arXiv 2021, arXiv:2108.07258. [Google Scholar]
- Adeshola, I.; Adepoju, A.P. The opportunities and challenges of ChatGPT in education. Interact. Learn. Environ. 2023, 32, 6159–6172. [Google Scholar] [CrossRef]
- Sok, S.; Heng, K. ChatGPT for education and research: A review of benefits and risks. Cambodian J. Educ. Res. 2023, 3, 110–121. [Google Scholar] [CrossRef]
- Lo, C.K. What is the impact of ChatGPT on education? A rapid review of the literature. Educ. Sci. 2023, 13, 410. [Google Scholar] [CrossRef]
- Montenegro-Rueda, M.; Fernández-Cerero, J.; Fernández-Batanero, J.M.; López-Meneses, E. Impact of the implementation of ChatGPT in education: A systematic review. Computers 2023, 12, 153. [Google Scholar] [CrossRef]
- Grassini, S. Shaping the future of education: Exploring the potential and consequences of AI and ChatGPT in educational settings. Educ. Sci. 2023, 13, 692. [Google Scholar] [CrossRef]
- Rahman, M.M.; Watanobe, Y. ChatGPT for education and research: Opportunities, threats, and strategies. Appl. Sci. 2023, 13, 5783. [Google Scholar] [CrossRef]
- Halaweh, M. ChatGPT in education: Strategies for responsible implementation. Contemp. Educ. Technol. 2023, 15, ep421. [Google Scholar] [CrossRef]
- Kasneci, E.; Seßler, K.; Küchemann, S.; Bannert, M.; Dementieva, D.; Fischer, F.; Gasser, U.; Groh, G.; Günnemann, S.; Hüllermeier, E.; et al. ChatGPT for good? On opportunities and challenges of large language models for education. Learn. Individ. Differ. 2023, 103, 102274. [Google Scholar] [CrossRef]
- Geerling, W.; Mateer, G.D.; Wooten, J.; Damodaran, N. Is ChatGPT Smarter Than a Student in Principles of Economics. Available online: https://ssrn.com/abstract=4356034 (accessed on 4 December 2024).
- Susnjak, T.; McIntosh, T.R. ChatGPT: The end of online exam integrity? Educ. Sci. 2024, 14, 656. [Google Scholar] [CrossRef]
- Stutz, P.; Elixhauser, M.; Grubinger-Preiner, J.; Linner, V.; Reibersdorfer-Adelsberger, E.; Traun, C.; Wallentin, G.; Wöhs, K.; Zuberbühler, T. Ch (e) atGPT? an anecdotal approach addressing the impact of ChatGPT on teaching and learning Giscience. GI_Forum 2023, 11, 140–147. [Google Scholar] [CrossRef]
- Buchberger, B. Is ChatGPT Smarter Than Master’s Applicants; Research Institute for Symbolic Computation: Linz, Austria, 2023. [Google Scholar]
- de Winter, J.C. Can ChatGPT pass high school exams on English language comprehension? Int. J. Artif. Intell. Educ. 2023, 34, 915–930. [Google Scholar] [CrossRef]
- Choi, J.H.; Hickman, K.E.; Monahan, A.B.; Schwarcz, D. ChatGPT goes to law school. J. Leg. Educ. 2021, 71, 387. [Google Scholar] [CrossRef]
- Hargreaves, S. Words Are Flowing Out Like Endless Rain Into a Paper Cup’: ChatGPT &. Law School Assessments, SSRN Electronic Journal. 2023. Available online: https://ssrn.com/abstract=4359407 (accessed on 5 December 2024).
- Kung, T.H.; Cheatham, M.; Medenilla, A.; Sillos, C.; De Leon, L.; Elepaño, C.; Madriaga, M.; Aggabao, R.; Diaz-Candido, G.; Maningo, J.; et al. Performance of ChatGPT on USMLE: Potential for AI-assisted medical education using large language models. PLoS Digit. Health 2023, 2, e0000198. [Google Scholar] [CrossRef] [PubMed]
- Gilson, A.; Safranek, C.W.; Huang, T.; Socrates, V.; Chi, L.; Taylor, R.A.; Chartash, D. How does ChatGPT perform on the United States Medical Licensing Examination (USMLE)? The implications of large language models for medical education and knowledge assessment. JMIR Med. Educ. 2023, 9, e45312. [Google Scholar] [CrossRef]
- Fijačko, N.; Gosak, L.; Štiglic, G.; Picard, C.T.; Douma, M.J. Can ChatGPT pass the life support exams without entering the American heart association course? Resuscitation 2023, 185, 109732. [Google Scholar] [CrossRef]
- Wang, X.; Gong, Z.; Wang, G.; Jia, J.; Xu, Y.; Zhao, J.; Fan, Q.; Wu, S.; Hu, W.; Li, X. ChatGPT performs on the Chinese national medical licensing examination. J. Med. Syst. 2023, 47, 86. [Google Scholar] [CrossRef]
- Huh, S. Are ChatGPT’s knowledge and interpretation ability comparable to those of medical students in Korea for taking a parasitology examination?: A descriptive study. J. Educ. Eval. Health Prof. 2023, 20, 1. [Google Scholar] [PubMed]
- Frieder, S.; Pinchetti, L.; Griffiths, R.R.; Salvatori, T.; Lukasiewicz, T.; Petersen, P.; Berner, J. Mathematical capabilities of chatgpt. Adv. Neural Inf. Process. Syst. 2023, 36. [Google Scholar] [CrossRef]
- Jalil, S.; Rafi, S.; LaToza, T.D.; Moran, K.; Lam, W. Chatgpt and software testing education: Promises & perils. In Proceedings of the 2023 IEEE International Conference on Software Testing, Verification and Validation Workshops (ICSTW), Dublin, Ireland, 16–20 April 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 4130–4137. [Google Scholar]
- Newton, P.; Xiromeriti, M. ChatGPT performance on multiple choice question examinations in higher education. A pragmatic scoping review. Assess. Eval. High. Educ. 2024, 49, 781–798. [Google Scholar] [CrossRef]
- Oh, N.; Choi, G.S.; Lee, W.Y. ChatGPT goes to the operating room: Evaluating GPT-4 performance and its potential in surgical education and training in the era of large language models. Ann. Surg. Treat. Res. 2023, 104, 269–273. [Google Scholar] [CrossRef] [PubMed]
- Rizzo, M.G.; Cai, N.; Constantinescu, D. The performance of ChatGPT on orthopaedic in-service training exams: A comparative study of the GPT-3.5 turbo and GPT-4 models in orthopaedic education. J. Orthop. 2024, 50, 70–75. [Google Scholar] [CrossRef] [PubMed]
- Currie, G.M. GPT-4 in nuclear medicine education: Does it outperform GPT-3.5? J. Nucl. Med. Technol. 2023, 51, 314–317. [Google Scholar] [CrossRef]
- Takagi, S.; Watari, T.; Erabi, A.; Sakaguchi, K. Performance of GPT-3.5 and GPT-4 on the Japanese medical licensing examination: Comparison study. JMIR Med. Educ. 2023, 9, e48002. [Google Scholar] [CrossRef]
- Jin, H.K.; Lee, H.E.; Kim, E. Performance of ChatGPT-3.5 and GPT-4 in national licensing examinations for medicine, pharmacy, dentistry, and nursing: A systematic review and meta-analysis. BMC Med. Educ. 2024, 24, 1013. [Google Scholar] [CrossRef] [PubMed]
- Savelka, J.; Agarwal, A.; An, M.; Bogart, C.; Sakr, M. Thrilled by your progress! large language models (gpt-4) no longer struggle to pass assessments in higher education programming courses. In Proceedings of the 2023 ACM Conference on International Computing Education Research, Chicago, IL, USA, 7–11 August 2023; Volume 1, pp. 78–92. [Google Scholar]
- Yeadon, W.; Peach, A.; Testrow, C. A comparison of human, GPT-3.5, and GPT-4 performance in a university-level coding course. Sci. Rep. 2024, 14, 23285. [Google Scholar] [CrossRef] [PubMed]
- Tian, J.; Hou, J.; Wu, Z.; Shu, P.; Liu, Z.; Xiang, Y.; Gu, B.; Filla, N.; Li, Y.; Liu, N.; et al. Assessing Large Language Models in Mechanical Engineering Education: A Study on Mechanics-Focused Conceptual Understanding. arXiv 2024, arXiv:2401.12983. [Google Scholar]
- Katz, D.M.; Bommarito, M.J.; Gao, S.; Arredondo, P. Gpt-4 passes the bar exam. Philos. Trans. R. Soc. A 2024, 382, 20230254. [Google Scholar] [CrossRef] [PubMed]
- Manzini, R.; Accorsi, R.; Bozer, Y.A.; Heragu, S. Warehousing and Material Handling Systems for the Digital Industry. In Warehousing and Material Handling Systems for the Digital Industry: The New Challenges for the Digital Circular Economy; Springer: Berlin/Heidelberg, Germany, 2024; pp. 1–6. [Google Scholar]
- Garcia-Diaz, A.; Smith, J.M. Facilities Planning and Design; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- White, J.; Fu, Q.; Hays, S.; Sandborn, M.; Olea, C.; Gilbert, H.; Elnashar, A.; Spencer-Smith, J.; Schmidt, D.C. A prompt pattern catalog to enhance prompt engineering with chatgpt. arXiv 2023, arXiv:2302.11382. [Google Scholar]
- Franke, S. Test Results: Can ChatGPT Solve Undergraduate Exams from Logistics Studies? An Investigation. Zenodo. Available online: https://zenodo.org/records/14412298 (accessed on 12 December 2024).
- TU Dortmund University. Module Description Bachelor’s Degree in Logistics. Available online: https://mb.tu-dortmund.de/storages/mb/r/Formulare/Studiengaenge/B.Sc._Logistik.pdf (accessed on 5 December 2024).
- Bloom, B.S.; Engelhart, M.D.; Furst, E.J.; Hill, W.H.; Krathwohl, D.R. Taxonomy of Educational Objectives; Longmans, Green: New York, NY, USA, 1964; Volume 2. [Google Scholar]
- Krathwohl, D. A Revision Bloom’s Taxonomy: An Overview. In Theory into Practice; Taylor & Francis, Ltd.: Abingdon, UK, 2002. [Google Scholar]
- Forehand, M. Bloom’s taxonomy. Emerg. Perspect. Learn. Teaching Technol. 2010, 41, 47–56. [Google Scholar]
- Liu, H.; Ning, R.; Teng, Z.; Liu, J.; Zhou, Q.; Zhang, Y. Evaluating the logical reasoning ability of chatgpt and gpt-4. arXiv 2023, arXiv:2304.03439. [Google Scholar]
- Großeschallau, W. Materialflussrechnung: Modelle und Verfahren zur Analyse und Berechnung von Materialflusssystemen; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Ten Hompel, M.; Schmidt, T.; Dregger, J. Materialflusssysteme: Förder-und Lagertechnik; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Ichter, B.; Xia, F.; Chi, E.; Le, Q.V.; Zhou, D. Chain-of-thought prompting elicits reasoning in large language models. Adv. Neural Inf. Process. Syst. 2022, 35, 24824–24837. [Google Scholar]
- Wilkinson, M.D.; Dumontier, M.; Aalbersberg, I.J.; Appleton, G.; Axton, M.; Baak, A.; Blomberg, N.; Boiten, J.W.; da Silva Santos, L.B.; Bourne, P.E. The FAIR Guiding Principles for scientific data management and stewardship. Sci. Data 2016, 3, 160018. [Google Scholar] [CrossRef]
- OpenAI. OpenAI’s Reinforcement Fine-Tuning Research Program. 2024. Available online: https://openai.com/form/rft-research-program/ (accessed on 7 December 2024).

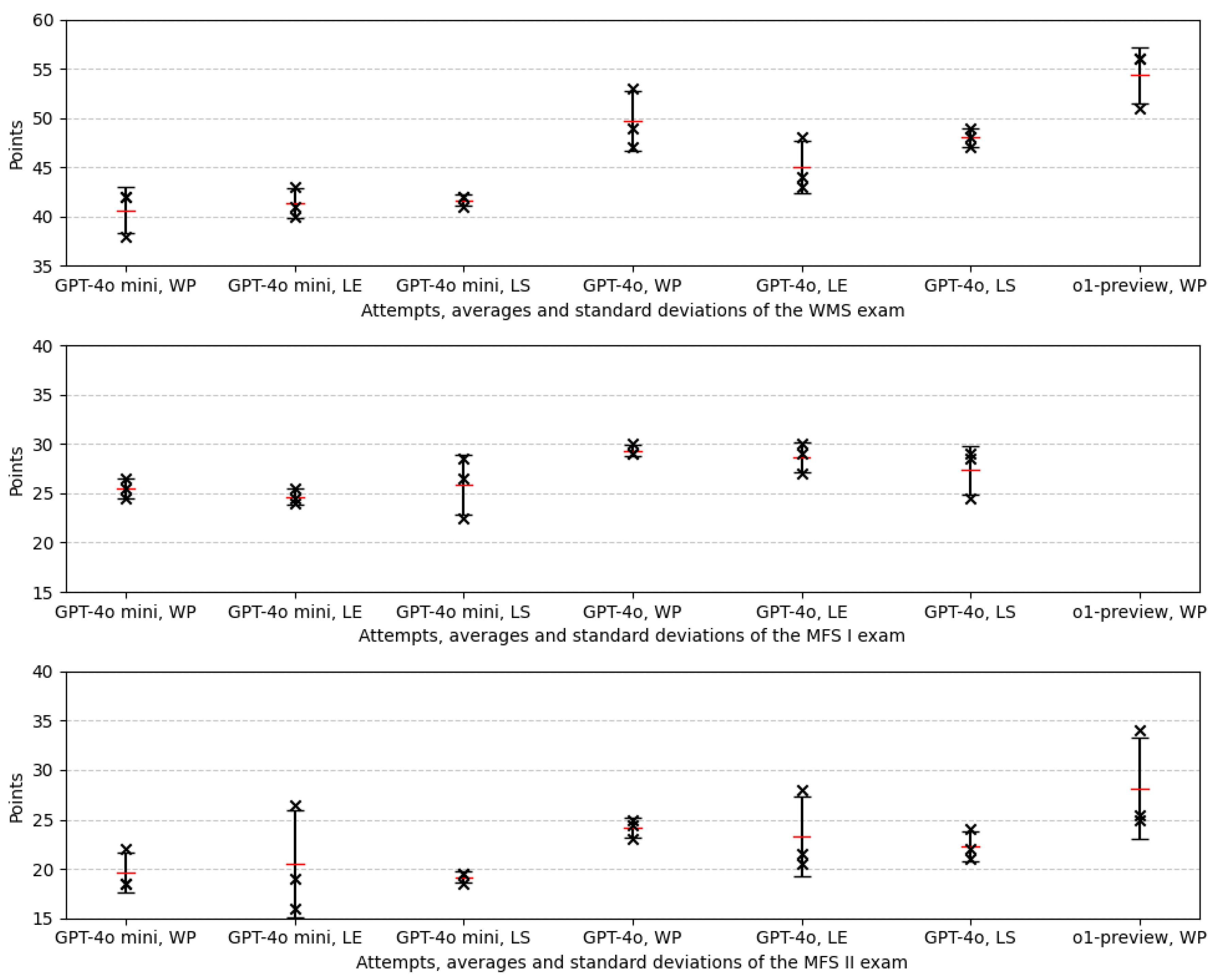

| Version | Prompt 1 | Median | Passed | Percentage [%] | Grade | Points Range | Average | Standard Deviation | Coefficient of Variation [%] |
|---|---|---|---|---|---|---|---|---|---|
| WMS | |||||||||
| GPT-4o mini | NP | 42 | Yes | 70 | B- | 4 | 40.67 | 2.31 | 5.68 |
| GPT-4o mini | LE | 41 | Yes | 68 | C+ | 3 | 41.33 | 1.53 | 3.70 |
| GPT-4o mini | LS | 42 | Yes | 70 | B- | 1 | 41.67 | 0.58 | 1.39 |
| GPT-4o | NP | 49 | Yes | 82 | B+ | 6 | 49.67 | 3.06 | 6.15 |
| GPT-4o | LE | 44 | Yes | 73 | B- | 5 | 45.00 | 2.65 | 5.88 |
| GPT-4o | LS | 48 | Yes | 80 | B | 2 | 48.00 | 1.00 | 2.08 |
| o1-preview | NP | 56 | Yes | 93 | A- | 5 | 54.33 | 2.89 | 5.31 |
| MFS I | |||||||||
| GPT-4o mini | NP | 25.5 | Yes | 43 | D | 2 | 25.50 | 1.00 | 3.92 |
| GPT-4o mini | LE | 24.5 | Yes | 41 | D | 1.5 | 24.67 | 0.76 | 3.10 |
| GPT-4o mini | LS | 26.5 | Yes | 44 | D | 6 | 25.83 | 3.06 | 11.83 |
| GPT-4o | NP | 29 | Yes | 48 | D+ | 1 | 29.33 | 0.58 | 1.97 |
| GPT-4o | LE | 29 | Yes | 48 | D+ | 3 | 28.67 | 1.53 | 5.33 |
| GPT-4o | LS | 28.5 | Yes | 48 | D+ | 4.5 | 27.33 | 2.47 | 9.02 |
| o1-preview | NP | Model could not analyze pictures or answer all questions. | |||||||
| MFS II | |||||||||
| GPT-4o mini | NP | 18.5 | No | 31 | F | 3.5 | 19.67 | 2.02 | 10.27 |
| GPT-4o mini | LE | 19 | No | 32 | F | 10.5 | 20.50 | 5.41 | 26.38 |
| GPT-4o mini | LS | 19.5 | No | 33 | F | 1 | 19.17 | 0.58 | 3.01 |
| GPT-4o | NP | 24.5 | Yes | 41 | D | 2 | 24.17 | 1.04 | 4.31 |
| GPT-4o | LE | 21 | No | 36 | F | 7.5 | 23.33 | 4.07 | 17.45 |
| GPT-4o | LS | 22 | No | 37 | F | 3 | 22.33 | 1.53 | 6.84 |
| o1-preview | NP | 25.5 | Yes | 43 | D | 9 | 28.17 | 5.06 | 17.96 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Franke, S.; Pott, C.; Rutinowski, J.; Pauly, M.; Reining, C.; Kirchheim, A. Can ChatGPT Solve Undergraduate Exams from Warehousing Studies? An Investigation. Computers 2025, 14, 52. https://doi.org/10.3390/computers14020052
Franke S, Pott C, Rutinowski J, Pauly M, Reining C, Kirchheim A. Can ChatGPT Solve Undergraduate Exams from Warehousing Studies? An Investigation. Computers. 2025; 14(2):52. https://doi.org/10.3390/computers14020052
Chicago/Turabian StyleFranke, Sven, Christoph Pott, Jérôme Rutinowski, Markus Pauly, Christopher Reining, and Alice Kirchheim. 2025. "Can ChatGPT Solve Undergraduate Exams from Warehousing Studies? An Investigation" Computers 14, no. 2: 52. https://doi.org/10.3390/computers14020052
APA StyleFranke, S., Pott, C., Rutinowski, J., Pauly, M., Reining, C., & Kirchheim, A. (2025). Can ChatGPT Solve Undergraduate Exams from Warehousing Studies? An Investigation. Computers, 14(2), 52. https://doi.org/10.3390/computers14020052