

YOLOv8-Based Drone Detection: Performance Analysis and Optimization


Abstract
1. Introduction
2. Literature Review
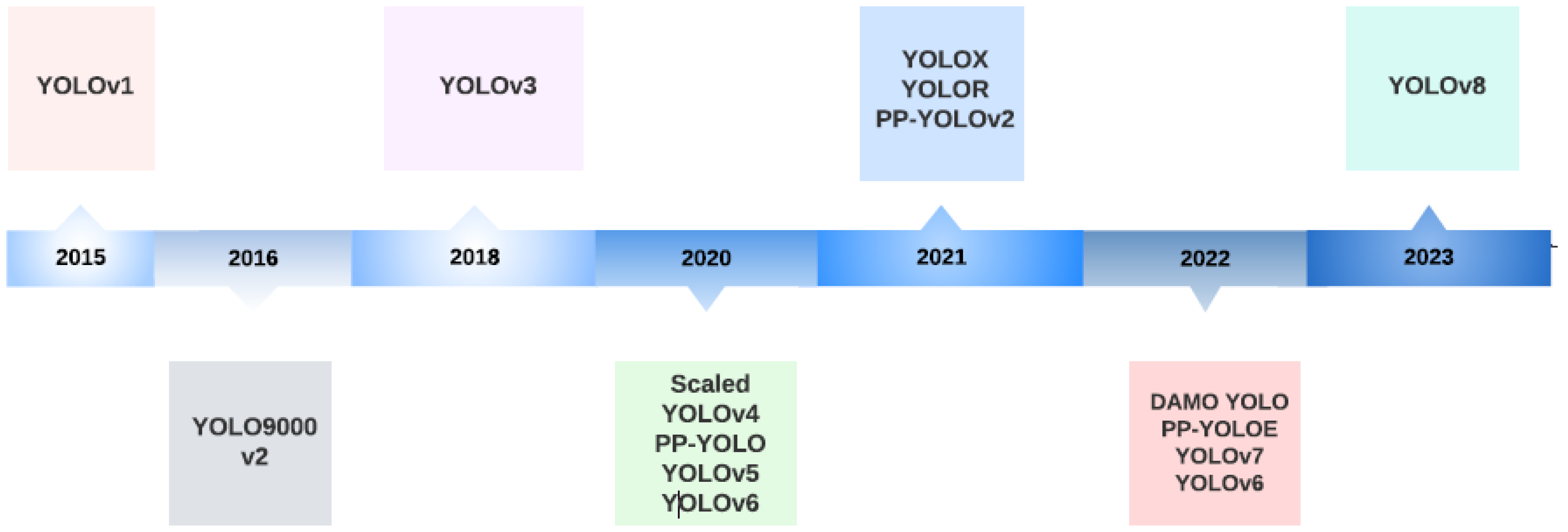
History of YOLO
3. Materials and Methods
3.1. Experimental Environment and Dataset
3.2. Evaluation Indicators
4. Results Discussion
4.1. Hyperparameter Settings
4.2. Dataset Augmentation
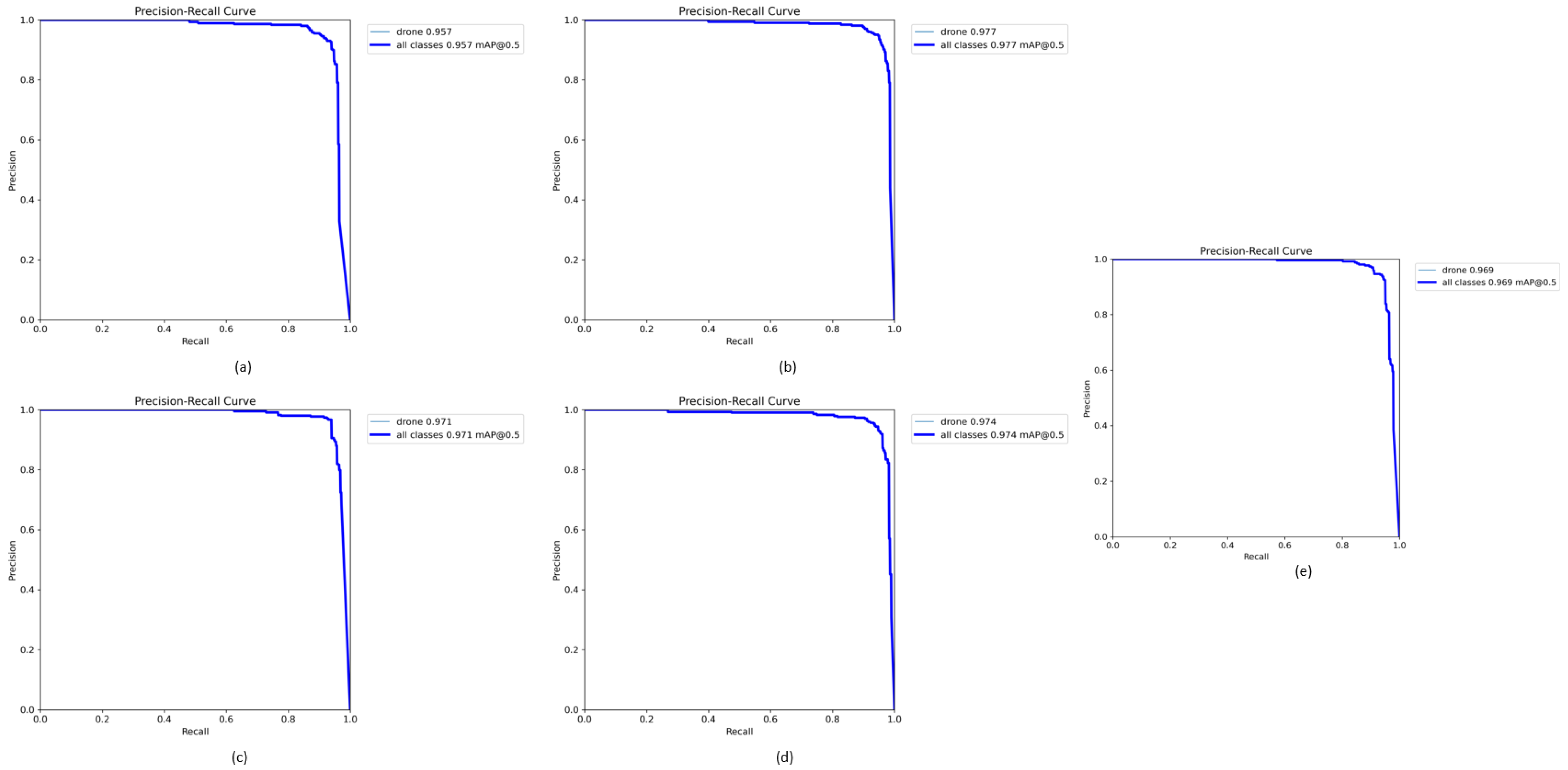
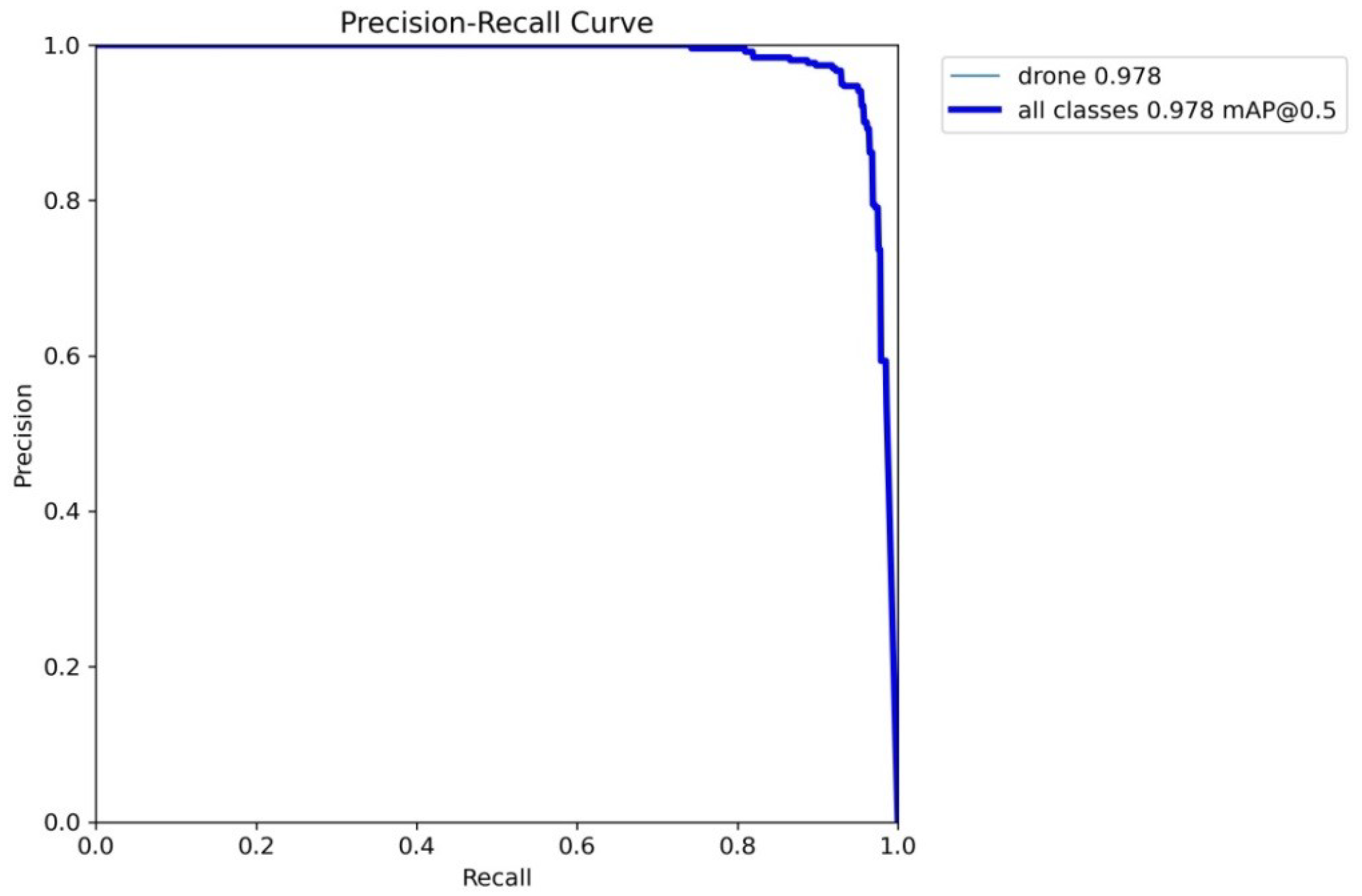
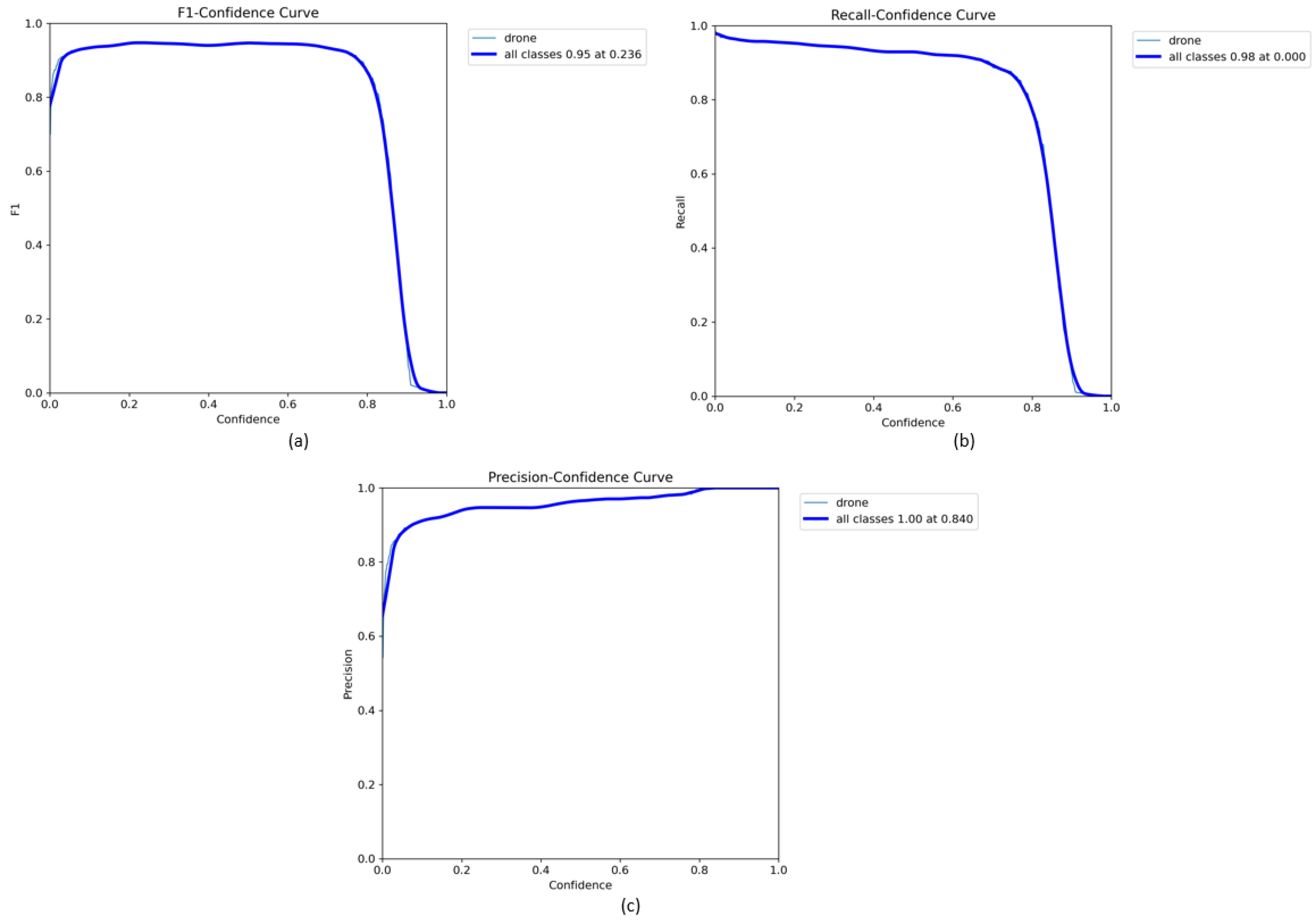
4.3. Model Performance
4.4. Comparison with Other Models
5. Future Works
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| YOLO | You Only Look Once |
| CNN | Convolutional Neural Networks |
| UAV | Unmanned Aerial Vehicle |
| SVM | Support Vector Machine |
| EMA | Efficient Multiscale Attention |
References
- Mohsan, S.A.H.; Khan, M.A.; Noor, F.; Ullah, I.; Alsharif, M.H. Towards the unmanned aerial vehicles (UAVs): A comprehensive review. Drones 2022, 6, 147. [Google Scholar] [CrossRef]
- Niu, R.; Zhi, X.; Jiang, S.; Gong, J.; Zhang, W.; Yu, L. Aircraft Target Detection in Low Signal-to-Noise Ratio Visible Remote Sensing Images. Remote Sens. 2023, 15, 1971. [Google Scholar] [CrossRef]
- Sivakumar, M.; Tyj, N.M. A literature survey of unmanned aerial vehicle usage for civil applications. J. Aerosp. Technol. Manag. 2021, 13, e4021. [Google Scholar] [CrossRef]
- Udeanu, G.; Dobrescu, A.; Oltean, M. Unmanned aerial vehicle in military operations. Sci. Res. Educ. Air Force 2016, 18, 199–206. [Google Scholar] [CrossRef]
- Pedrozo, S. Swiss military drones and the border space: A critical study of the surveillance exercised by border guards. Geogr. Helv. 2017, 72, 97–107. [Google Scholar] [CrossRef]
- Zheng, Z.; Lei, L.; Sun, H.; Kuang, G. A review of remote sensing image object detection algorithms based on deep learning. In Proceedings of the 2020 IEEE 5th International Conference on Image, Vision and Computing (ICIVC), Beijing, China, 10–12 July 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 34–43. [Google Scholar]
- Elsayed, M.; Reda, M.; Mashaly, A.S.; Amein, A.S. Review on real-time drone detection based on visual band electro-optical (EO) sensor. In Proceedings of the 2021 Tenth International Conference on Intelligent Computing and Information Systems (ICICIS), Cairo, Egypt, 5–7 December 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 57–65. [Google Scholar]
- Basak, S.; Rajendran, S.; Pollin, S.; Scheers, B. Combined RF-based drone detection and classification. IEEE Trans. Cogn. Commun. Netw. 2021, 8, 111–120. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Hummel, R.; Stoica, P.; Zelnio, E.G. Radar Signal Processing and Its Applications; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Anwar, M.Z.; Kaleem, Z.; Jamalipour, A. Machine learning inspired sound-based amateur drone detection for public safety applications. IEEE Trans. Veh. Technol. 2019, 68, 2526–2534. [Google Scholar] [CrossRef]
- Liu, B.; Luo, H. An improved Yolov5 for multi-rotor UAV detection. Electronics 2022, 11, 2330. [Google Scholar] [CrossRef]
- Terven, J.; Córdova-Esparza, D.M.; Romero-González, J.A. A comprehensive review of yolo architectures in computer vision: From yolov1 to yolov8 and yolo-nas. Mach. Learn. Knowl. Extr. 2023, 5, 1680–1716. [Google Scholar] [CrossRef]
- Coluccia, A.; Fascista, A.; Schumann, A.; Sommer, L.; Ghenescu, M.; Piatrik, T.; Cubber, G.D.; Nalamati, M.; Kapoor, A.; Saqib, M.; et al. Drone-vs-Bird Detection Challenge at IEEE AVSS2019. In Proceedings of the 16th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Taipei, Taiwan, 18–21 September 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Coluccia, A.; Parisi, G.; Fascista, A. Detection and classification of multirotor drones in radar sensor networks: A review. Sensors 2020, 20, 4172. [Google Scholar] [CrossRef] [PubMed]
- Mahdavi, F.; Rajabi, R. Drone Detection Using Convolutional Neural Networks. In Proceedings of the 6th Iranian Conference on Signal Processing and Intelligent Systems, ICSPIS 2020, Mashhad, Iran, 23–24 December 2020; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2020; Volume 12. [Google Scholar] [CrossRef]
- Wisniewski, M.; Rana, Z.A.; Petrunin, I. Drone model classification using convolutional neural network trained on synthetic data. J. Imaging 2022, 8, 218. [Google Scholar] [CrossRef] [PubMed]
- Demir, B.; Ergunay, S.; Nurlu, G.; Popovic, V.; Ott, B.; Wellig, P.; Thiran, J.P.; Leblebici, Y. Real-time high-resolution omnidirectional imaging platform for drone detection and tracking. J. Real-Time Image Process. 2020, 17, 1625–1635. [Google Scholar] [CrossRef]
- Seidaliyeva, U.; Akhmetov, D.; Ilipbayeva, L.; Matson, E.T. Real-time and accurate drone detection in a video with a static background. Sensors 2020, 20, 3856. [Google Scholar] [CrossRef] [PubMed]
- Al-Qubaydhi, N.; Alenezi, A.; Alanazi, T.; Senyor, A.; Alanezi, N.; Alotaibi, B.; Alotaibi, M.; Razaque, A.; Abdelhamid, A.A.; Alotaibi, A. Detection of Unauthorized Unmanned Aerial Vehicles Using YOLOv5 and Transfer Learning. Electronics 2022, 11, 2669. [Google Scholar] [CrossRef]
- Wang, H.; Yang, H.; Chen, H.; Wang, J.; Zhou, X.; Xu, Y. A Remote Sensing Image Target Detection Algorithm Based on Improved YOLOv8. Appl. Sci. 2024, 14, 1557. [Google Scholar] [CrossRef]
- Kumar, B.S.S.; Wani, I.A. Realtime Drone Detection Using YOLOv8 and TensorFlow.JS. J. Eng. Sci. 2024, 15, 261–267. [Google Scholar]
- Ozel, M. Drone Dataset (UAV). WebPage, 12. Available online: https://www.kaggle.com/dasmehdixtr/drone-dataset-uav (accessed on 25 April 2024).
- Wu, Q.; Feng, D.; Cao, C.; Zeng, X.; Feng, Z.; Wu, J.; Huang, Z. Improved mask r-cnn for aircraft detection in remote sensing images. Sensors 2021, 21, 2618. [Google Scholar] [CrossRef] [PubMed]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Confusion Matrix | Real Parameters | ||
|---|---|---|---|
| POSITIVE | NEGATIVE | ||
| Predicted Parameter | POSITIVE | TP | FP |
| NEGATIVE | FN | TN | |
| Method | Dataset Size | Precision | Recall | mAP |
|---|---|---|---|---|
| CNN [17] | 712 | 96% | 94% | 95% |
| SVM [17] | 712 | 82% | 91% | 88% |
| KNN [17] | 712 | 74% | 94% | 80% |
| MaskRCNN [25] | 1359 | 93.6% | 89.4% | 92.5% |
| YOLOv3 [21] | 1359 | 92% | 70% | 78.5% |
| YOLOv4 [21] | 1359 | 91% | 89% | 93.8% |
| YOLOv5 [21] | 1359 | 94.7% | 92.5% | 94.1% |
| (Transfer Learning) | ||||
| YOLOv8 | 1359 | 95.4% | 93.4% | 97% |
| Proposed Model * | 3212 | 94.6% | 96.05% | 97.8% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yilmaz, B.; Kutbay, U. YOLOv8-Based Drone Detection: Performance Analysis and Optimization. Computers 2024, 13, 234. https://doi.org/10.3390/computers13090234
Yilmaz B, Kutbay U. YOLOv8-Based Drone Detection: Performance Analysis and Optimization. Computers. 2024; 13(9):234. https://doi.org/10.3390/computers13090234
Chicago/Turabian StyleYilmaz, Betul, and Ugurhan Kutbay. 2024. "YOLOv8-Based Drone Detection: Performance Analysis and Optimization" Computers 13, no. 9: 234. https://doi.org/10.3390/computers13090234
APA StyleYilmaz, B., & Kutbay, U. (2024). YOLOv8-Based Drone Detection: Performance Analysis and Optimization. Computers, 13(9), 234. https://doi.org/10.3390/computers13090234