



Continuous Authentication in the Digital Age: An Analysis of Reinforcement Learning and Behavioral Biometrics



Abstract
1. Introduction
- Innovative Approach to existing Continuous Authentication: Investigated the most advanced continuous authentication technology currently available, with a focus on keystroke dynamics as a form of the behavioral biometrics. This approach aims to enhance existing static authentication systems.
- Development of Reinforcement Learning Model: Developed a novel reinforcement learning-based anomaly detection model for continuous authentication of keystroke dynamics. Evaluated the proposed model using real-world data, and a comparison with existing methods. The reinforcement learning (RL) environment gym is developed and the proposed model has been implemented from scratch to provide a proof of concept application.
- Open Source Contribution: This reinforcement learning (RL) gym-based environment code is made available on GitHub (GitHub: to the domain researchers to explore and utilize. https://github.com/PriyaBansal68/Continuous-Authentication-Reinforcement-Learning-and-Behavioural-Biometrics) (accessed on 18 April 2024).
2. Background and Literature Review
3. Deep-Dive Analysis for the Proposed Methodology
3.1. Traditional Frameworks
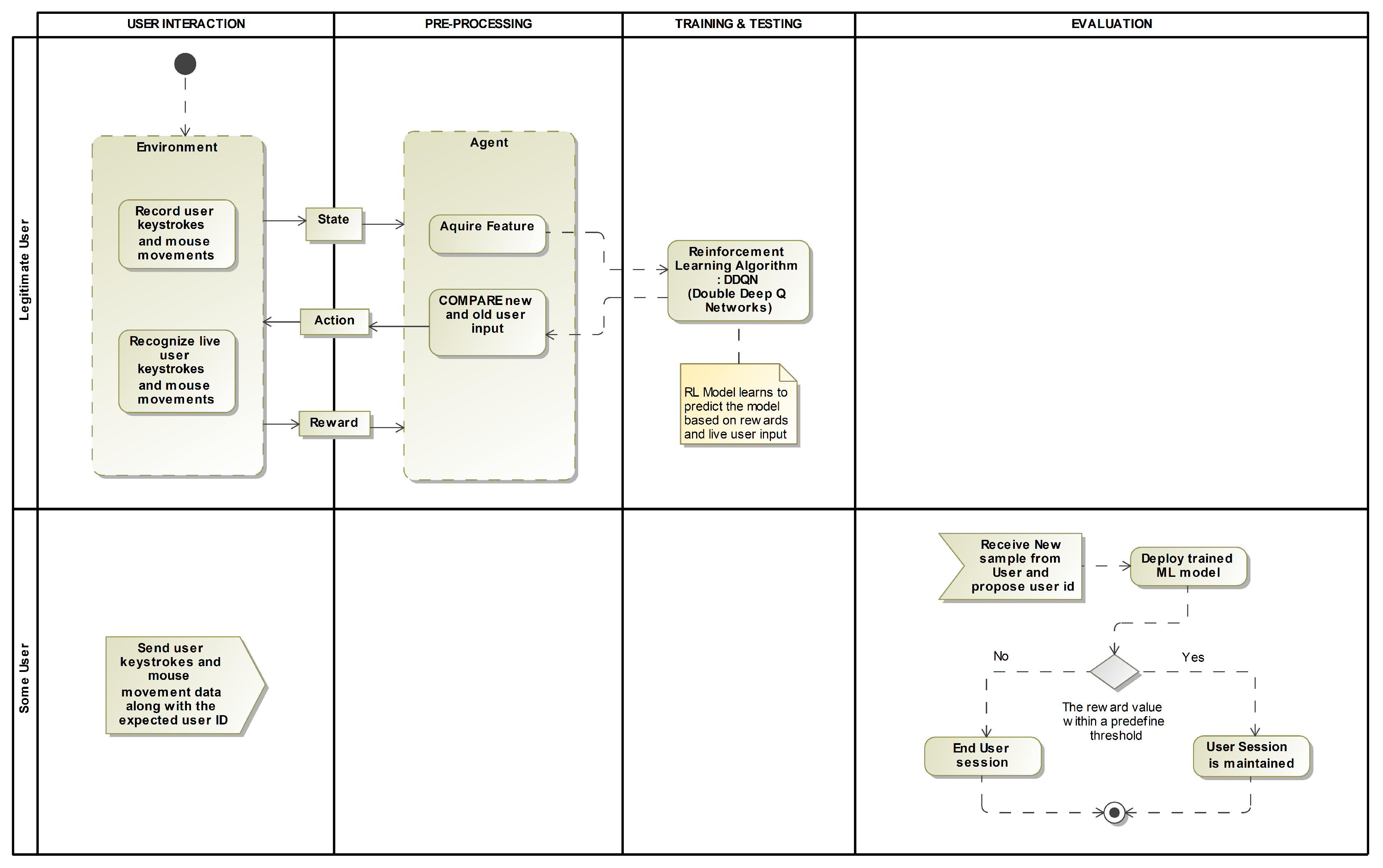
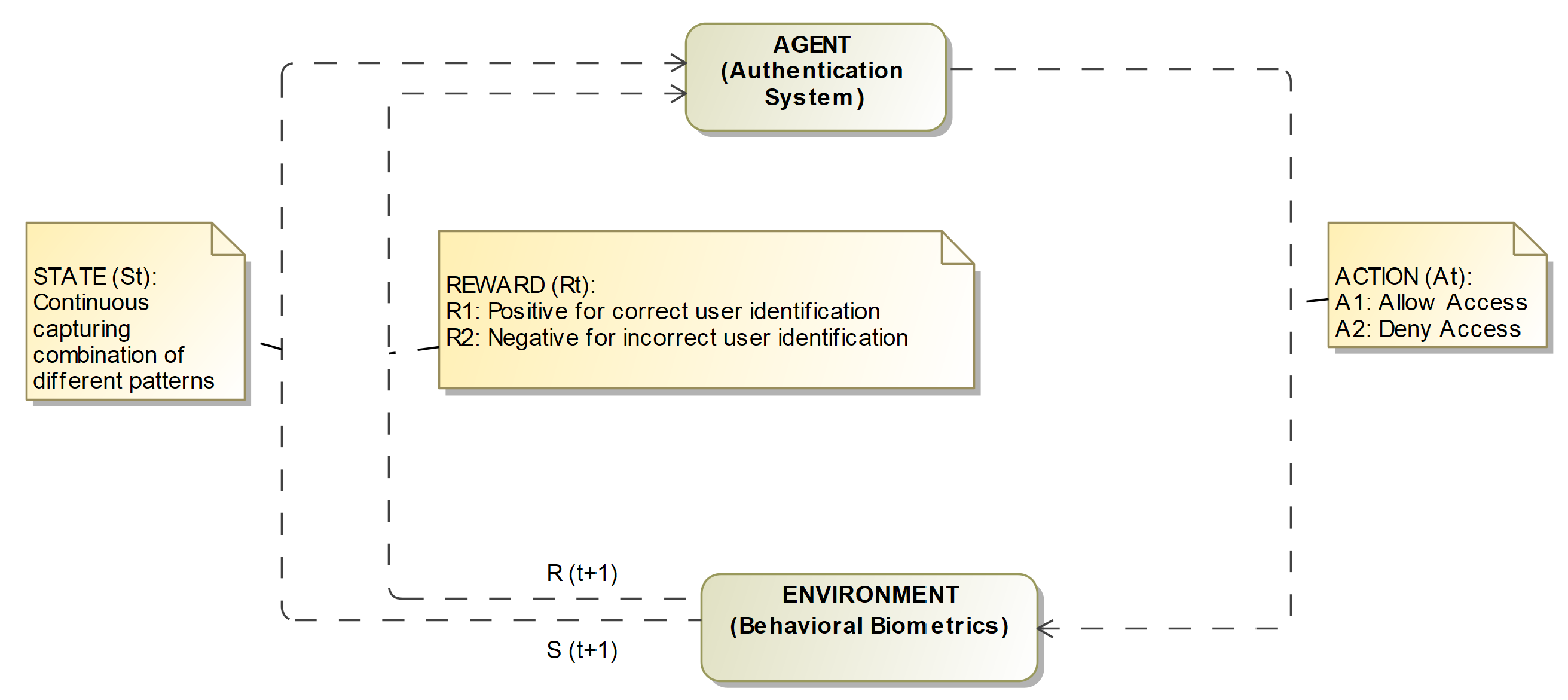
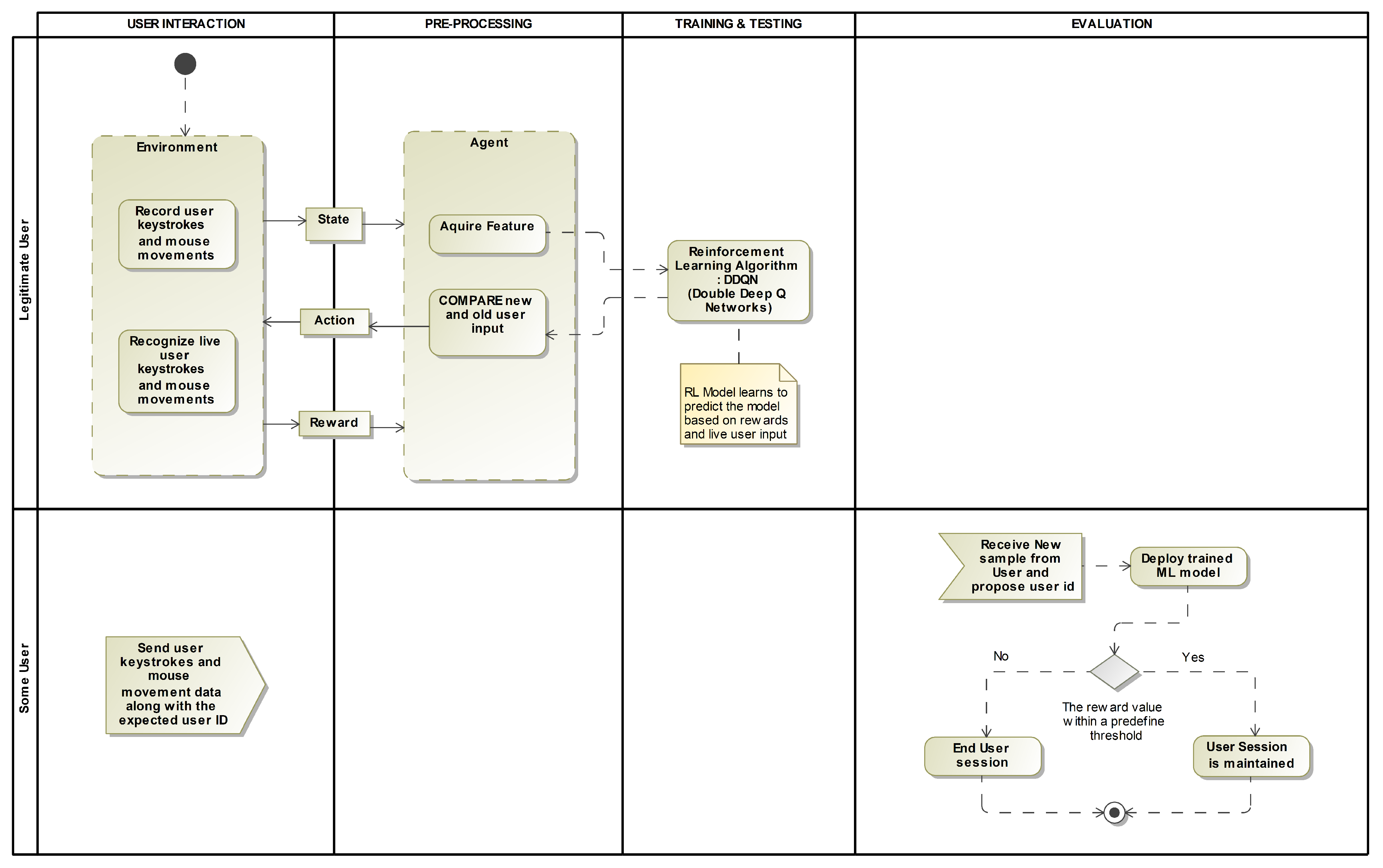
3.2. The Proposed RL Framework
- Agent: The agent is the system that makes decisions based on the keystroke data. The agent is responsible for analyzing the user’s keystroke patterns and determining whether the user is who they claim to be.
- Reward: The reward is a scalar value that the agent receives after each step of the authentication process. A positive reward is given when the agent correctly identifies the user, while a negative reward is given when the agent fails to identify the user. The agent attempts to maximize the long-term reward accumulated.
- Action: This is the decision that the agent makes, based on the keystroke data. In this case, the action would be to either authenticate or reject the user.
- Environment: This is the overall system that the agent interacts with. It includes the user’s keystroke data, the decision-making process of the agent, and the feedback from the system.
- State: The state represents the current typing pattern of a user, including factors such as typing speed, rhythm, and key press duration. The state could also include other features such as mouse movement, website activity, and other behavioral data that can be used to identify the user [28]. The state is an essential component of the MDP because it is used to inform the decision-making process of the agent and determine which action to take. This process is dependent on the present/current state and the rewards it receives for different actions.
4. Methodology
- Collect a dataset of keystroke dynamics data from several users. This should include a variety of different typing patterns, such as the time difference between key presses and the duration of time of each key press. In our case, we used the data from IEEE dataport website called BB-MA DATASET [30], as the data collection is a time-consuming task. As an addition, we collected our own data of keystrokes and trained the agent for testing purposes.
- Preprocess the data to extract relevant features that can be used as inputs to the reinforcement learning algorithm. This might include mean, median, or the standard deviation of various keystroke features, and other statistical measures.
- Define the reinforcement learning (RL) environment. This could be a simple decision tree, where the agent must choose between two actions: “accept” or “reject” the user’s authentication request.
- Define the reward function. This will determine what the agent is trying to optimize for. In the case of user authentication, the reward could be dependent on the accuracy of the agent’s predictions. For example, the agent could receive a high reward for correctly accepting an authentic user and a low reward for incorrectly rejecting an authentic user.
- Train the agent using the collected keystroke dynamics data and the defined reward function. This could be performed using a variety of reinforcement learning (RL) algorithms, such as Q-learning or SARSA.
- Test the trained agent on a separate dataset to evaluate its performance.
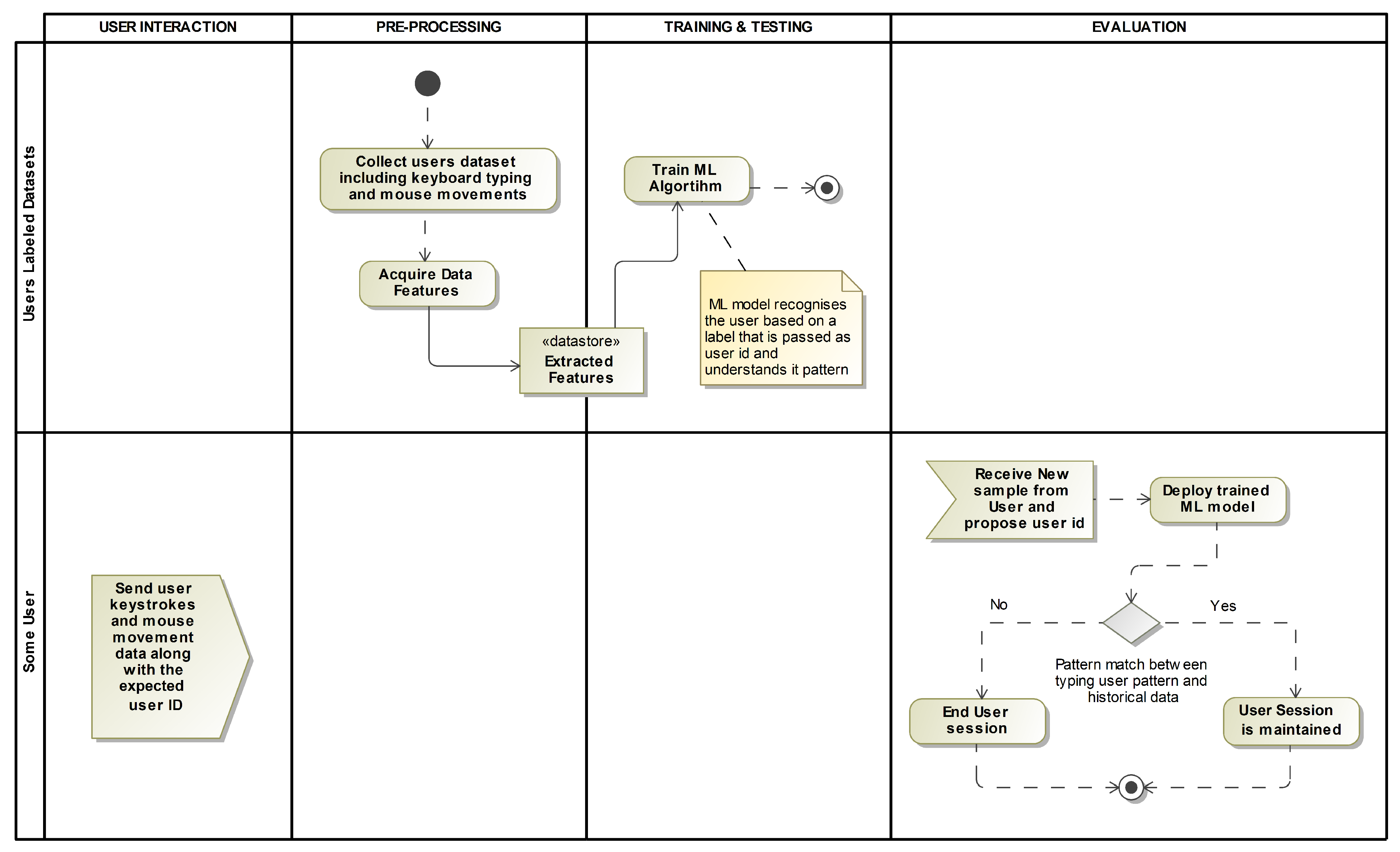
4.1. Process Flow
- Preprocessing the historical data: The first step is to gather a dataset of historical keystroke data from users. These data are then preprocessed to clean and format them for training. This may include removing any irrelevant data, normalizing the data, and dividing the data into sets for training and testing.
- Creating episodes on the cleaned data: Next, the cleaned data are used to create episodes for training the agent. An episode is a sequence of observations and actions that the agent takes to learn from. Each episode is created by randomly selecting a user from the dataset and creating a sequence of observations and actions based on their keystroke data.
- Fetching observation from the environment: The agent then fetches an observation from the environment. An observation is a set of data that the agent uses to decide. In this case, the observation is the keystroke data for a user.
- Predicting user or hacker on the given observation: Using the observation, the agent makes a prediction of whether the user is an authorized user or a hacker. The agent’s prediction is according to the user typing patterns and characteristics it has learned from the training data.
- Giving feedback to user in form of rewards: The agent then receives feedback in the rewards form. A reward is a value that the agent receives for making a prediction. The reward is according to the accuracy of the agent’s prediction. A positive reward is given for correctly identifying an authorized user and a negative reward is given for incorrectly identifying a hacker.
- Train on multiple-episode runs: The agent is then trained on multiple episodes, with each episode providing the agent with new observations and rewards. As the agent receives feedback in the form of rewards, it updates its parameters and improves its ability to predict whether a user is an authorized user or a hacker. This process is repeated over multiple episodes until the agent reaches a satisfactory level of accuracy. This process flow is repeated for every user, to create an agent per user, which can be used to continuously authenticate users throughout a session by monitoring their behavior and predicting whether they are authorized users or imposters.
4.1.1. Data Preprocessing
- Standardized key names: To establish consistent naming conventions to make it easier to read and understand what each event mean [28].
- Removed consecutive duplicate pairs (key, direction): This can help to reduce the number of data the agent needs to process, making the training process more efficient.
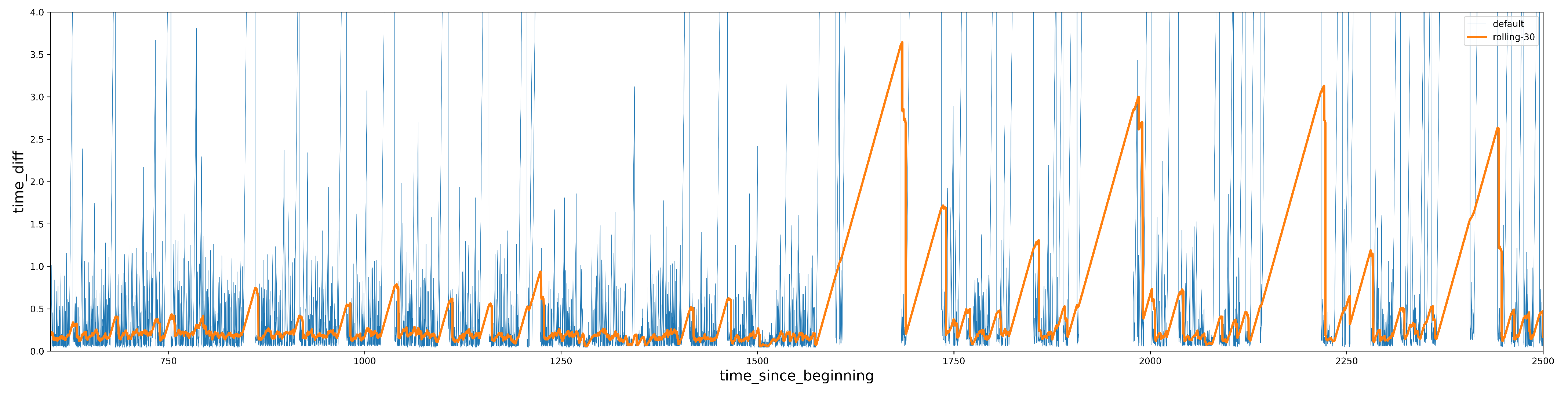
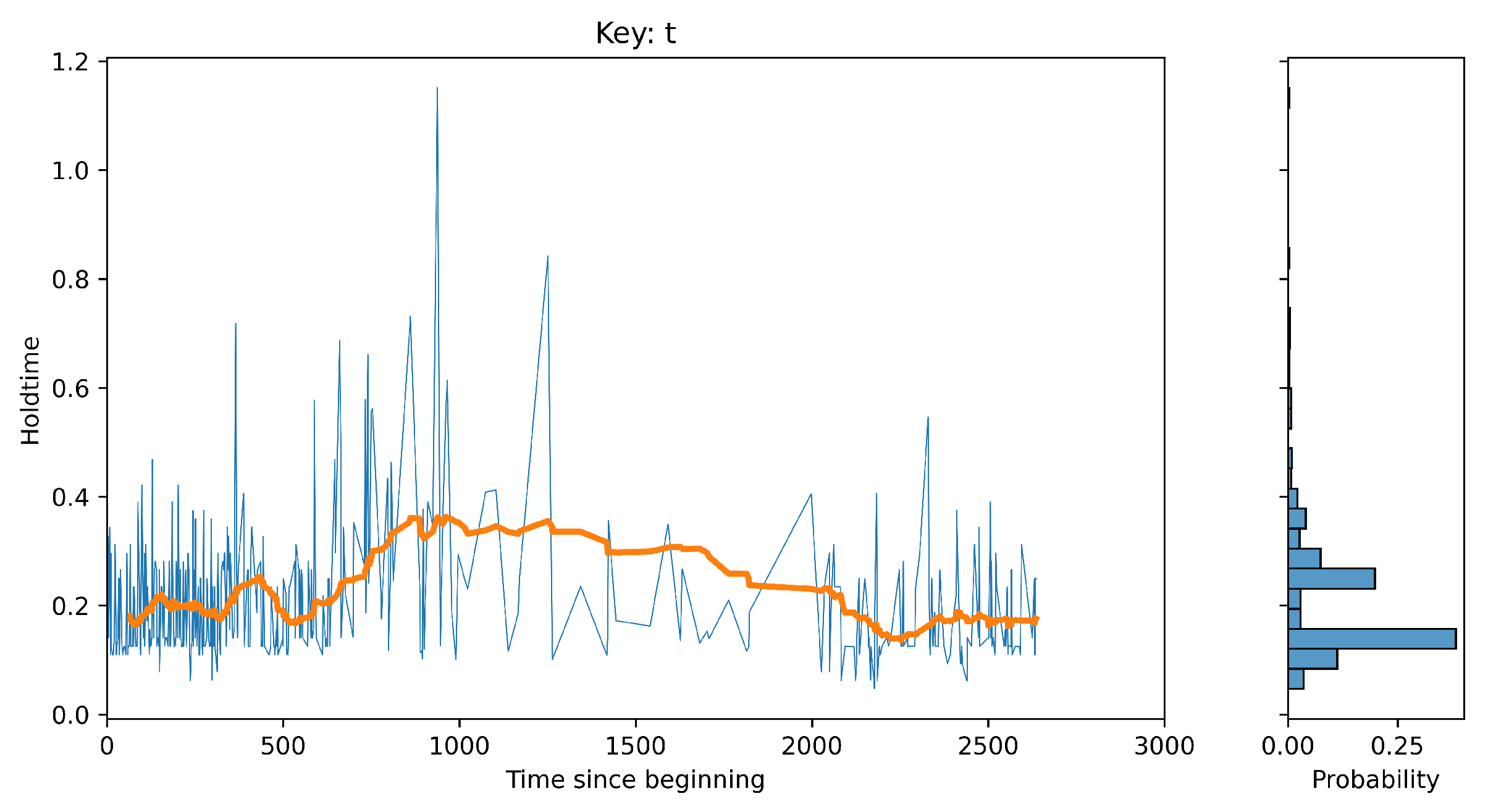
- Added column “time_diff”, which is the time difference between consecutive events: This can help to capture the unique typing rhythm of an individual, which is a key behavioral biometric.
- Added column “time_since_beginning”, which is the cumulative sum of the time difference column: This column is used to capture the changes in behavior over time, which can be useful for detecting anomalies or changes in the user’s behavior that may indicate a security threat [19].
- Added new flight features such as press_to_press (P2P), release_to_press (R2P), hold_time (HT).press_to_press: Assuming, we have two keys, say, I and K, then press time is I presstime- K presstime. release_to_press: I presstime – K releasetimehold_time: I releasetime – I presstime
- Removed direction of the key as the features: We only considered press direction for our analysis.
4.1.2. Feature Engineering
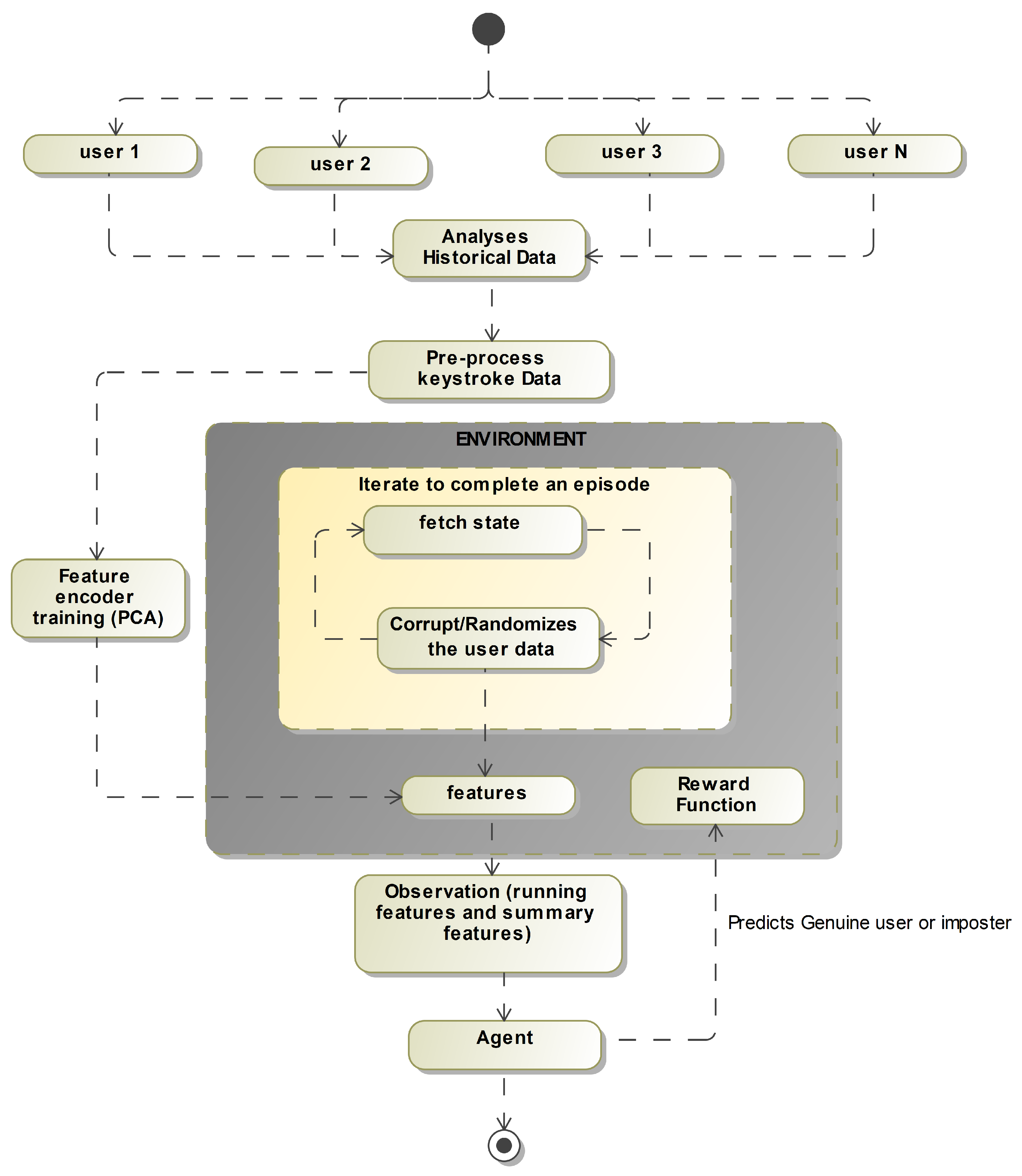
4.2. Environment
4.2.1. Fetch State
- No: Number of events in an observation. This parameter determines the number of keystroke events that will be included in each observation.
- Nh: Events that must occur before moving on to the following observation. This parameter determines the number of keystroke events that will be skipped before creating the next observation.
4.2.2. Corruption/Randomization
4.2.3. Process to Create Observation
- Calculate running features of the state: Running features provide the agent with information about the dynamics of the behavior over time.
- Encode the running features using trained encoder model: This helps to reduce the data dimensionality and make it more manageable for the agent to learn from.
- Calculate summary features and concatenate it with the encoded features: The final step is to calculate summary features and concatenate them with the encoded features. Summary features are a set of aggregate characteristics of the user’s behavior, such as typing speed, time_diff standard deviation, etc. By concatenating the summary and encoded features, the agent can learn from both the dynamics of the user’s behavior over time and the overall patterns and characteristics of the user’s behavior.
4.2.4. Reward Function
4.2.5. Feature Encoder
4.3. Agent
- Hidden layer 1: 32 nodes
- Hidden layer 2: 16 nodes
- Output layer: 2 nodes
- The activation function used in each layer except the last one is the ReLU activation function.
- The activation function used in the last layer is the SoftMax activation function.
- The optimizer used is the Adam optimizer, with a learning rate of 0.001.
RL Algorithm: DDQN
5. Results and Discussion
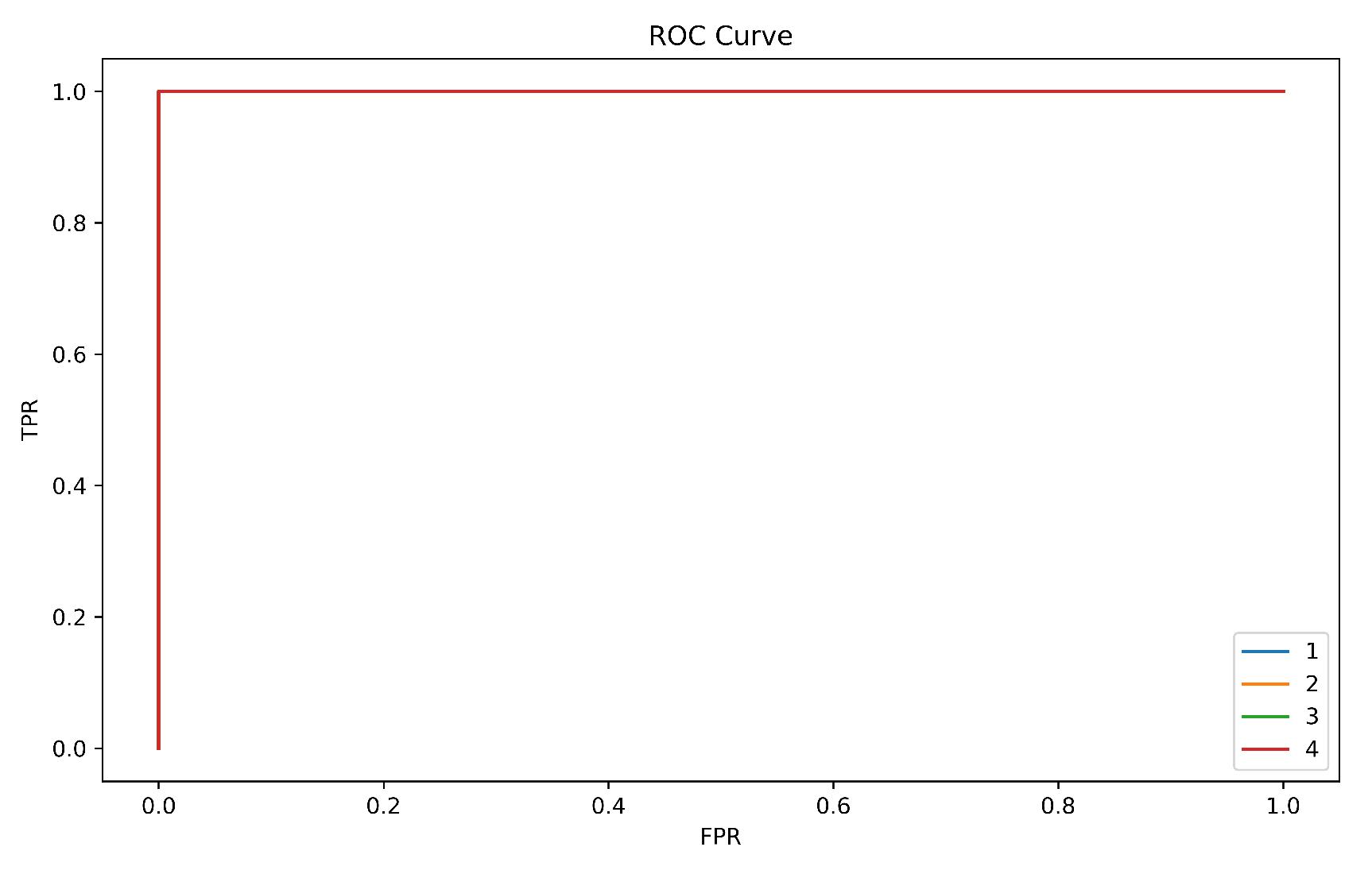
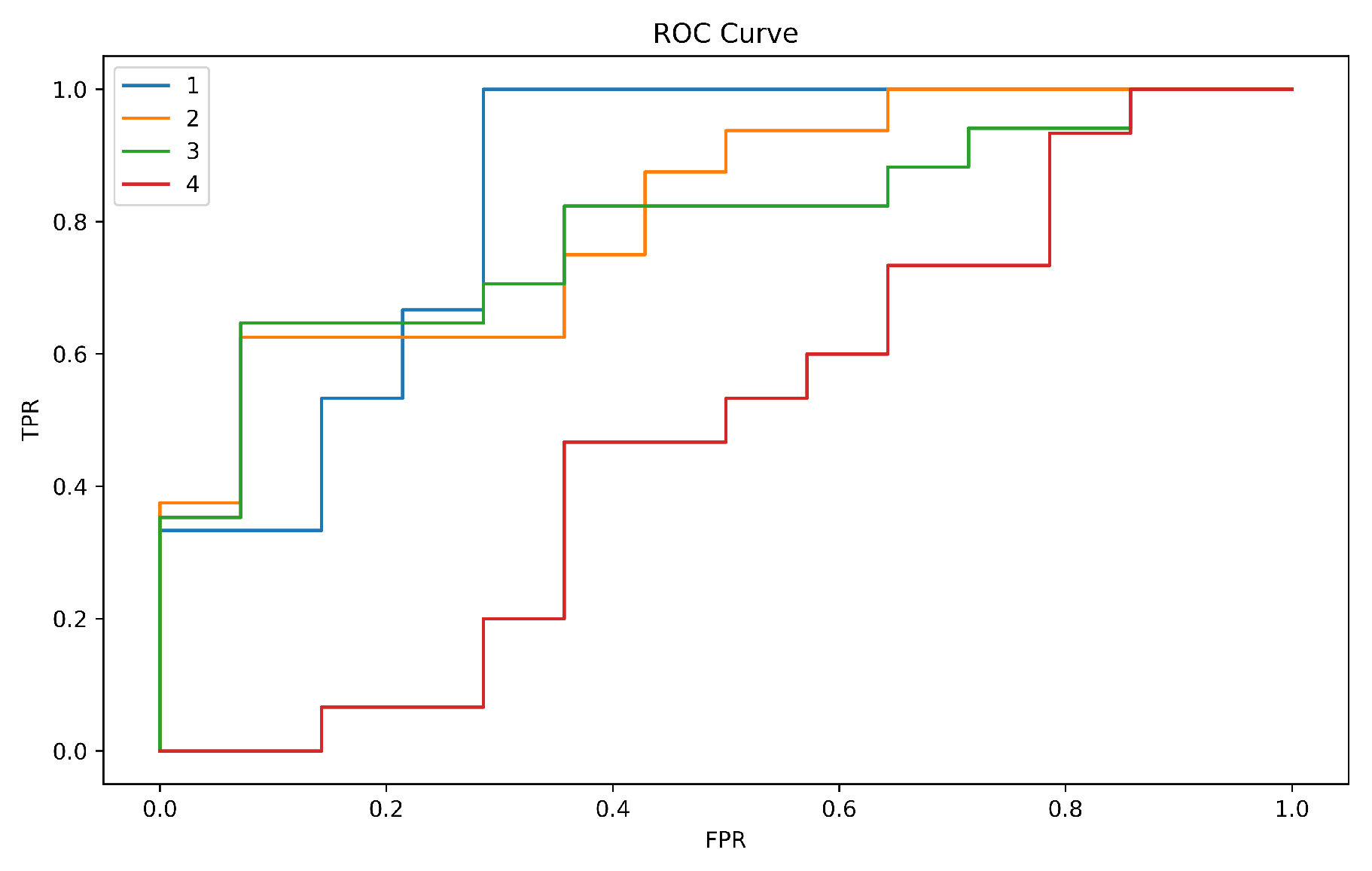
5.1. Evaluation Metrics
5.2. Hyperparameter Tuning
- No: 100;
- Nh: 50;
- num_encoder_features: 10;
- num_corrupted_users: 10;
- corrupt_bad_probability: 0.5;
- num_episodes: 20;
- c_update: 2;
- eps_start: 0.1;
- eps_decay: 200;
- eps_end: 0.01;
- train_split: 0.7.
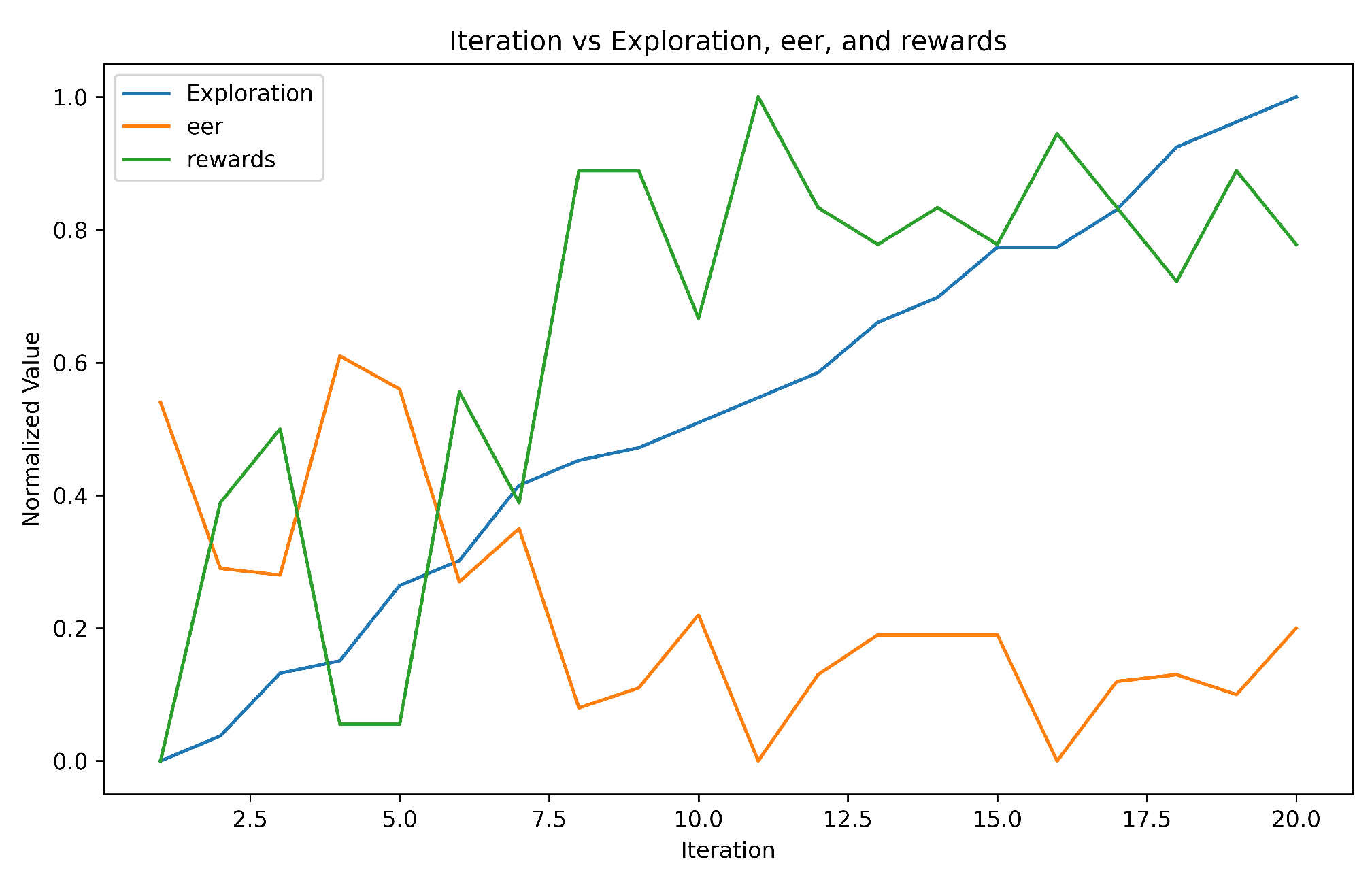
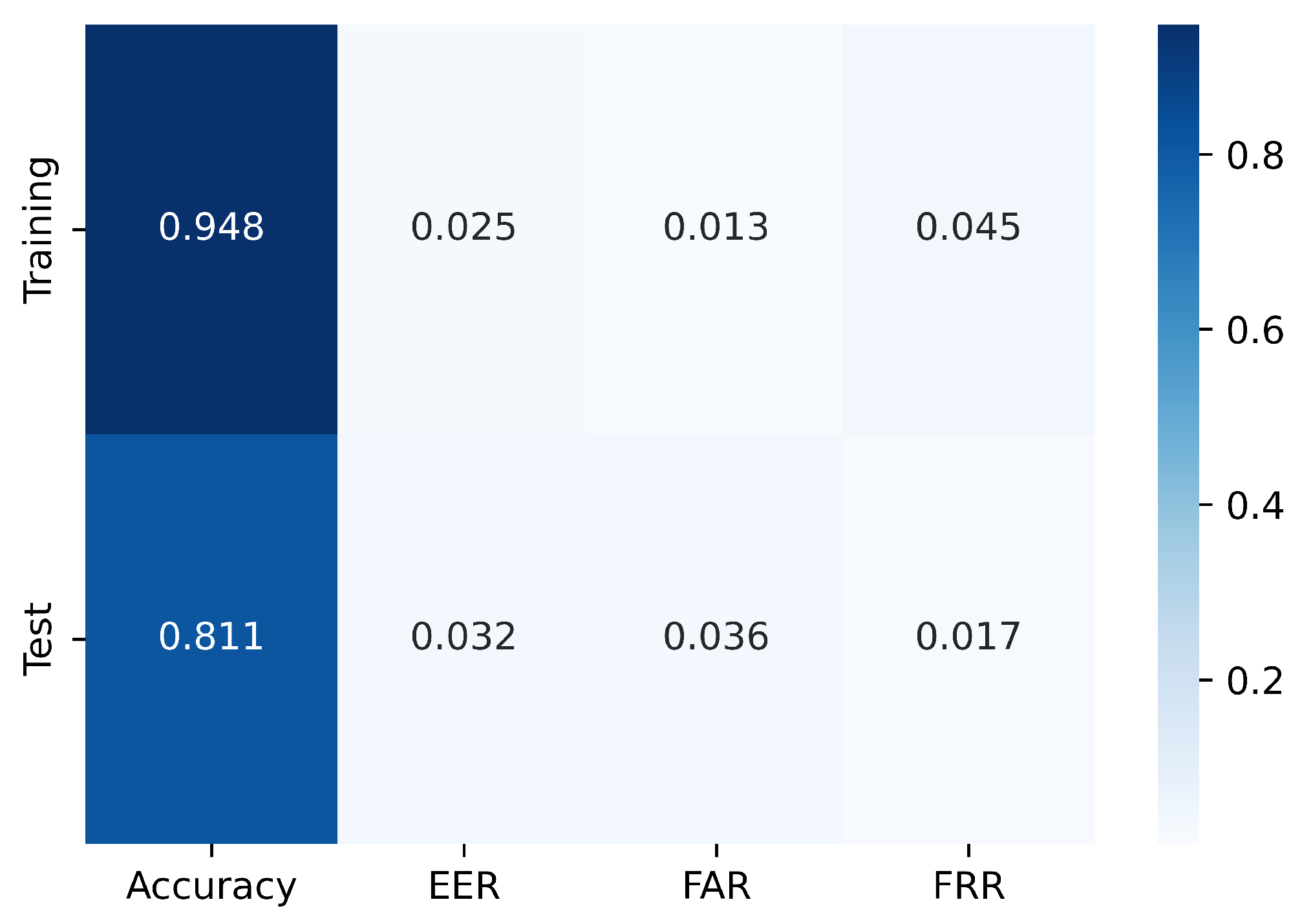
5.3. Results
- In the testing phase, the accuracy achieved was 84.06%, indicating that the system successfully identified users with a high level of accuracy during the testing process.
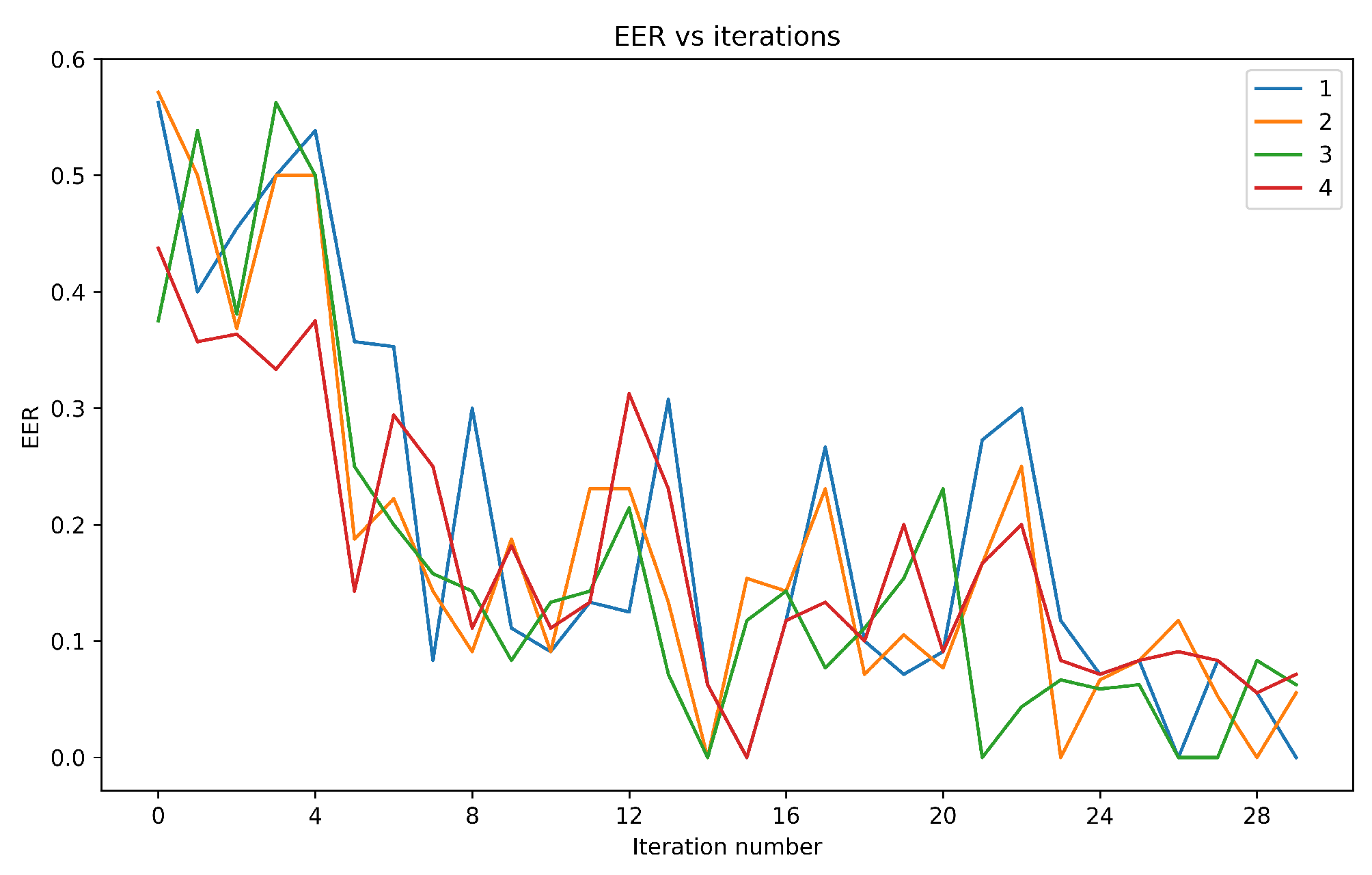
- The EER achieved during testing was 0.0323, indicating that the system reached a balance where the rates of false acceptance and false rejection were roughly equal.
- In the testing phase, the system had a FAR of 0.0356, suggesting that approximately 3.56% of unauthorized users were incorrectly accepted.
- In the testing phase, the FRR achieved was 0.0174, indicating that around 1.74% of legitimate users were falsely rejected.
- The drop in accuracy from train to test is due to the inconsistent typing behavior of users that affect the model’s ability to accurately recognize their keystroke patterns during testing.
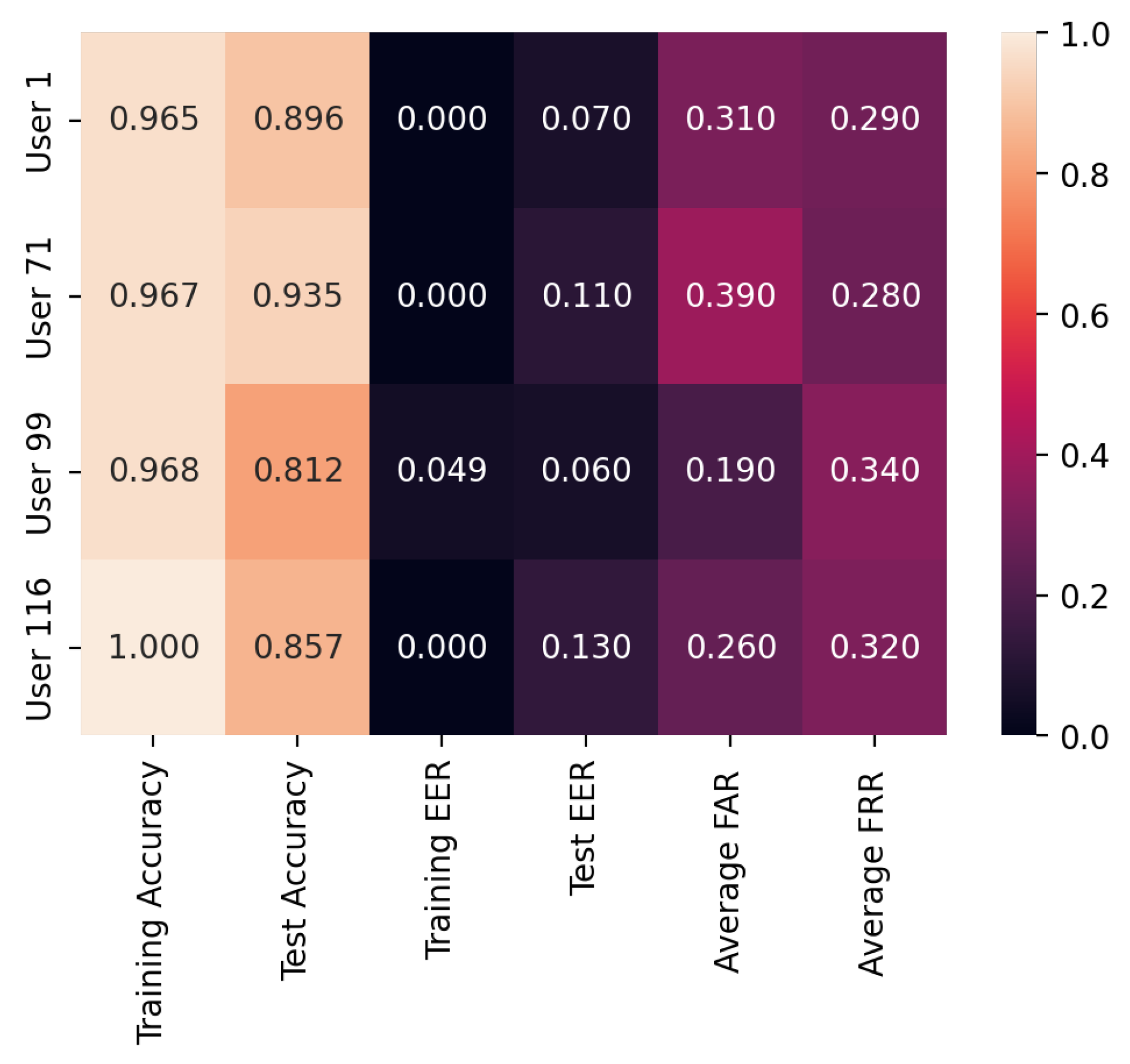
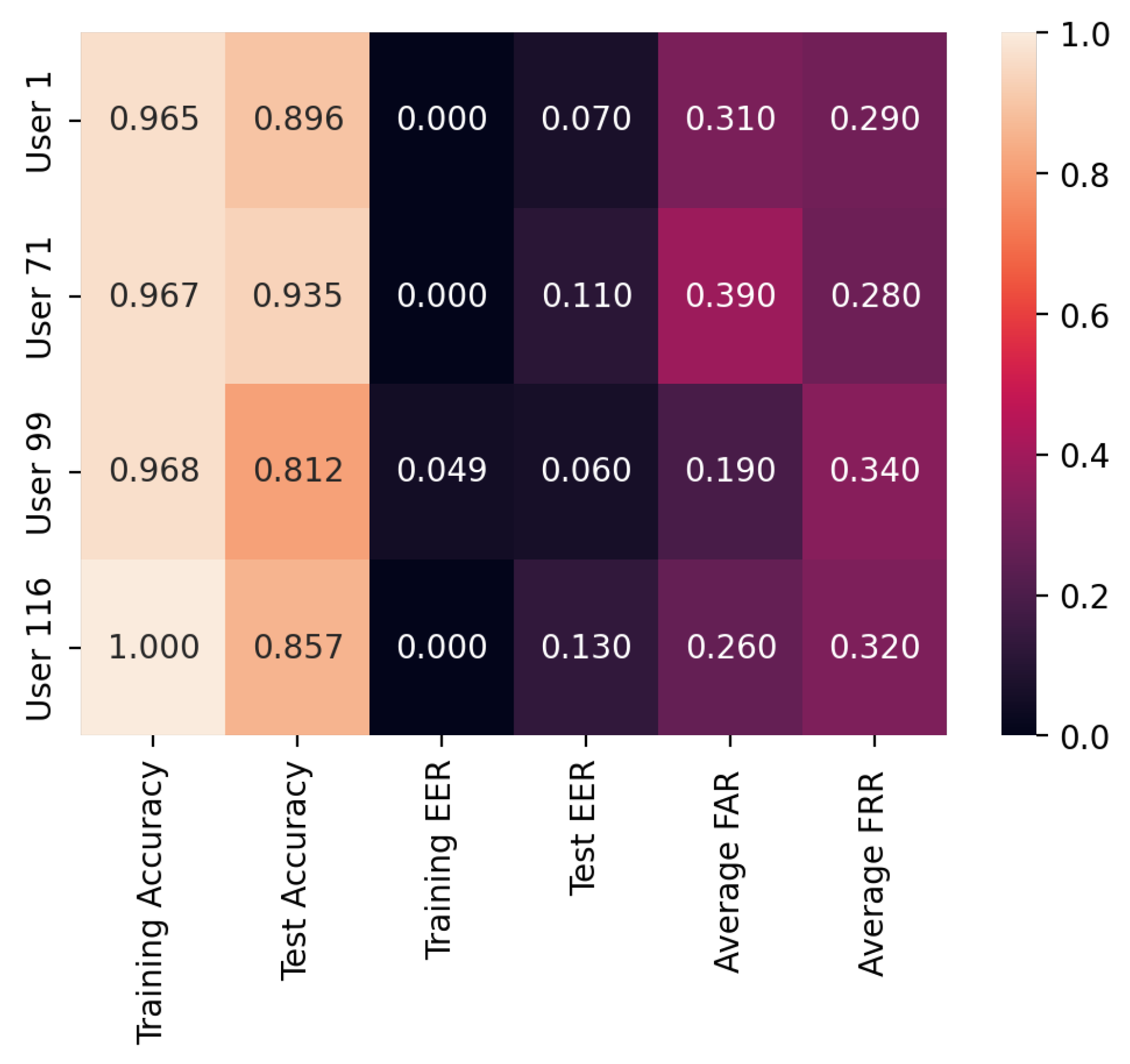
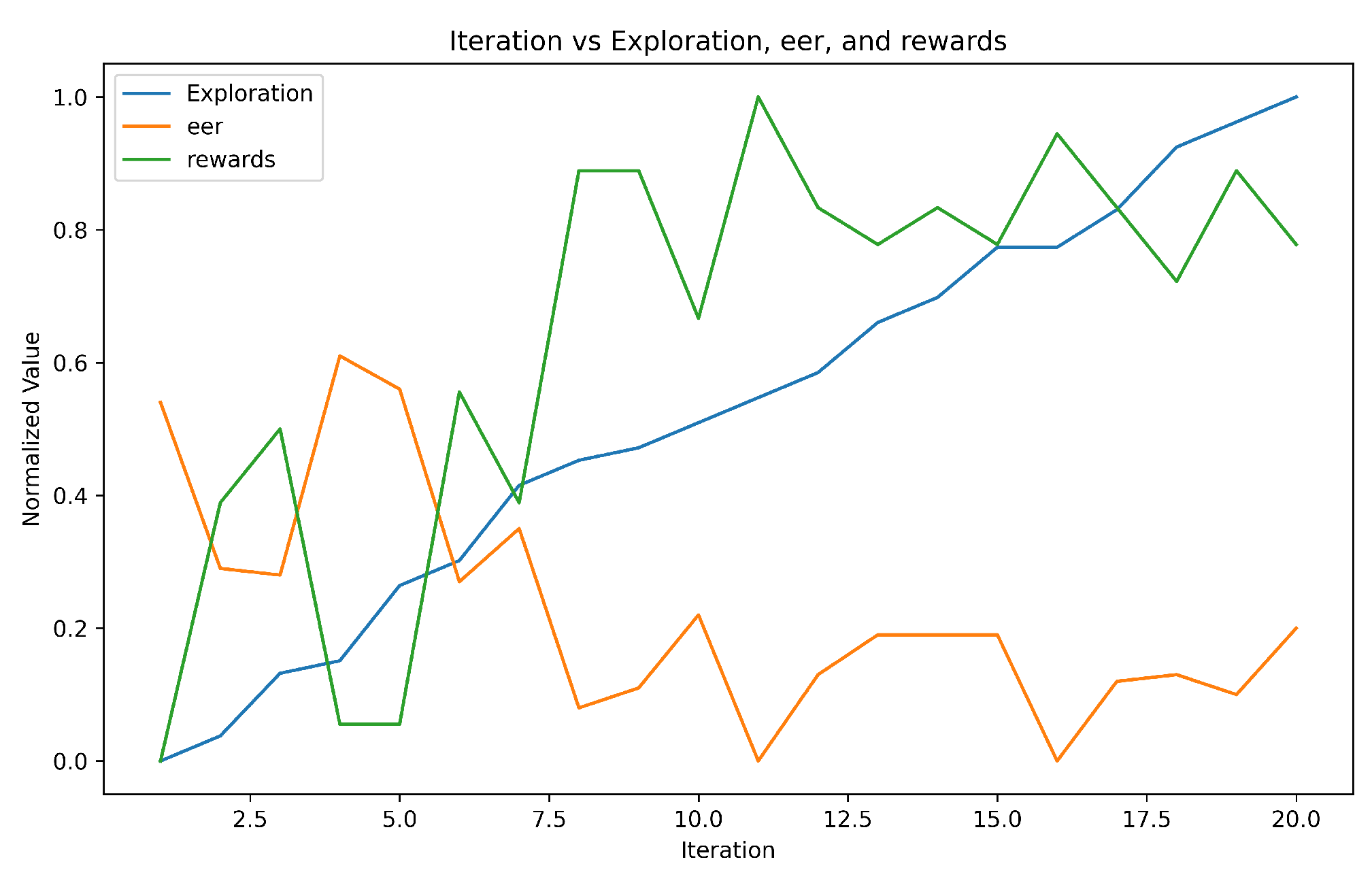
- Individual Differences: Each user has different characteristics, behaviors, or patterns that affect the performance of the model. These individual differences result in variations in accuracy, even if the user parameters are changing linearly.
- Exploration vs. Exploitation: Users need to balance exploration (trying out new actions to learn more about the environment) and exploitation (leveraging known actions for optimal results). The user with 100% accuracy may have effectively balanced exploration and exploitation strategies, leading to superior performance during training. In contrast, the user with 96.5% accuracy might have faced difficulties in finding the right balance, resulting in slightly lower overall accuracy.
- Complexity of User Parameters/Behavior: The user parameters considered in the table capture intricate interactions and dependencies. As a consequence, minor changes in these parameters lead to substantial fluctuations in the model’s performance, resulting in nonlinear relationships between the parameters and accuracy.
- Data Availability and Quality: The number and quality of data available for each user parameter differ. Insufficient or noisy data for certain parameter values affect the model’s ability to accurately learn and generalize, leading to nonlinear accuracy trends.
6. Conclusions
- Healthcare: In a hospital setting, medical professionals access sensitive patient data on computers located in public areas. With continuous authentication, the system verifies that only authorized personnel are accessing the data, reducing the risk of unauthorized access, and protecting patient privacy.
- Financial institutions: In the financial sector, it is crucial to ensure that only authorized personnel can access sensitive financial data. Continuous authentication prevents unauthorized access to banking systems by verifying the identity of users throughout their session.
- Remote work: With an increasing number of employees working from home, it is important for companies to ensure that their networks are secure. Continuous authentication is particularly useful in remote work environments, where employees may be working from unsecured locations or using unsecured devices. It is also used to track employee’s productivity of the day.
- Behavioral Profiling for User Insights: Keystroke dynamics are used for behavioral profiling to gain insights into user behavior, preferences, and typing habits, helping in personalized user experiences and targeted marketing.
Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gold, J. Traditional Security Is Dead—Why Cognitive-Based Security Will Matter. 2016. Available online: https://www.computerworld.com/article/3068185/traditional-security-is-dead-why-cognitive-based-security-will-matter.html (accessed on 25 May 2023).
- Ventures, C. Cybercrime to Cost the World $10.5 Trillion Annually by 2025. 2020. Available online: https://www.prnewswire.com/news-releases/cybercrime-to-cost-the-world-10-5-trillion-annually-by-2025--301172786.html (accessed on 25 May 2023).
- Anderson, R. 67 Percent of Breaches Caused by Credential Theft, User Error, and Social Attacks. 2020. Available online: https://www.netsec.news/67-percent-of-breaches-caused-by-credential-theft-user-error-and-social-attacks/ (accessed on 25 May 2023).
- Burbidge, T. Cybercrime Thrives during Pandemic: Verizon 2021 Data Breach Investigations Report. 2021. Available online: https://www.verizon.com/about/news/verizon-2021-data-breach-investigations-report (accessed on 25 May 2023).
- Ginni. What Are the Disadvantage of Multi-Factor Authentication? 2022. Available online: https://www.tutorialspoint.com/what-are-the-disadvantage-of-multi-factor-authentication (accessed on 25 May 2023).
- Ouda, A. A framework for next generation user authentication. In Proceedings of the 2016 3rd MEC International Conference on Big Data and Smart City (ICBDSC), Muscat, Oman, 15–16 March 2016; pp. 1–4. [Google Scholar] [CrossRef]
- Voege, P.; Abu Sulayman, I.I.; Ouda, A. Smart chatbot for user authentication. Electronics 2022, 11, 4016. [Google Scholar] [CrossRef]
- Abu Sulayman, I.I.M.; Ouda, A. Designing Security User Profiles via Anomaly Detection for User Authentication. In Proceedings of the 2020 International Symposium on Networks, Computers and Communications (ISNCC), Montreal, QC, Canada, 20–22 October 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Li, J.; Chang, H.C.; Stamp, M. Free-Text Keystroke Dynamics for User Authentication. In Artificial Intelligence for Cybersecurity; Springer: Berlin/Heidelberg, Germany, 2022; pp. 357–380. [Google Scholar]
- Verma, N.; Prasad, K. Responsive parallelized architecture for deploying deep learning models in production environments. arXiv 2021, arXiv:2112.08933. [Google Scholar]
- Salem, A.; Zaidan, D.; Swidan, A.; Saifan, R. Analysis of strong password using keystroke dynamics authentication in touch screen devices. In Proceedings of the 2016 Cybersecurity and Cyberforensics Conference (CCC), Amman, Jordan, 2–4 August 2016; pp. 15–21. [Google Scholar]
- Jeanjaitrong, N.; Bhattarakosol, P. Feasibility study on authentication based keystroke dynamic over touch-screen devices. In Proceedings of the 2013 13th International Symposium on Communications and Information Technologies (ISCIT), Surat Thani, Thailand, 4–6 September 2013; pp. 238–242. [Google Scholar]
- Antal, M.; Szabó, L.Z. An evaluation of one-class and two-class classification algorithms for keystroke dynamics authentication on mobile devices. In Proceedings of the 2015 20th International Conference on Control Systems and Computer Science, Bucharest, Romania, 27–29 May 2015; pp. 343–350. [Google Scholar]
- Roh, J.h.; Lee, S.H.; Kim, S. Keystroke dynamics for authentication in smartphone. In Proceedings of the 2016 International Conference on Information and Communication Technology Convergence (ICTC), Jeju, Korea, 19–21 October 2016; pp. 1155–1159. [Google Scholar]
- Saevanee, H.; Bhattarakosol, P. Authenticating user using keystroke dynamics and finger pressure. In Proceedings of the 2009 6th IEEE Consumer Communications and Networking Conference, Las Vegas, NV, USA, 10–13 January 2009; pp. 1–2. [Google Scholar]
- Monrose, F.; Rubin, A.D. Keystroke dynamics as a biometric for authentication. Future Gener. Comput. Syst. 2000, 16, 351–359. [Google Scholar] [CrossRef]
- Araújo, L.C.; Sucupira, L.H.; Lizarraga, M.G.; Ling, L.L.; Yabu-Uti, J.B.T. User authentication through typing biometrics features. IEEE Trans. Signal Process. 2005, 53, 851–855. [Google Scholar] [CrossRef]
- Antal, M.; Nemes, L. The mobikey keystroke dynamics password database: Benchmark results. In Software Engineering Perspectives and Application in Intelligent Systems: Proceedings of the 5th Computer Science Online Conference 2016 (CSOC2016); Springer: Berlin/Heidelberg, Germany, 2016; Volume 2, pp. 35–46. [Google Scholar]
- Stragapede, G.; Vera-Rodriguez, R.; Tolosana, R.; Morales, A. BehavePassDB: Public Database for Mobile Behavioral Biometrics and Benchmark Evaluation. Pattern Recognit. 2023, 134, 109089. [Google Scholar] [CrossRef]
- Siddiqui, N.; Dave, R.; Vanamala, M.; Seliya, N. Machine and deep learning applications to mouse dynamics for continuous user authentication. Mach. Learn. Knowl. Extr. 2022, 4, 502–518. [Google Scholar] [CrossRef]
- Belman, A.K.; Sridhara, S.; Phoha, V.V. Classification of threat level in typing activity through keystroke dynamics. In Proceedings of the 2020 International Conference on Artificial Intelligence and Signal Processing (AISP), Amaravati, India, 10–12 January 2020; pp. 1–6. [Google Scholar]
- Attinà, F. Traditional Security Issues. In China, the European Union, and the International Politics of Global Governance; Wang, J., Song, W., Eds.; Palgrave Macmillan US: New York, NY, USA, 2016; pp. 175–193. [Google Scholar] [CrossRef]
- Kasprowski, P.; Borowska, Z.B.; Harezlak, K. Biometric Identification Based on Keystroke Dynamics. Sensors 2022, 22, 3158. [Google Scholar] [CrossRef] [PubMed]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; A Bradford Book: Cambridge, MA, USA, 2018. [Google Scholar]
- Ananya; Singh, S. Keystroke dynamics for continuous authentication. In Proceedings of the 2018 8th International Conference on Cloud Computing, Data Science & Engineering (Confluence), Noida, India, 11–12 January 2018; pp. 205–208. [Google Scholar]
- Gupta, S. User Attribution in Digital Forensics through Modeling Keystroke and Mouse Usage Data Using Xgboost. Ph.D. Thesis, Purdue University Graduate School, West Lafayette, IN, USA, May 2022. [Google Scholar]
- Çevik, N.; Akleylek, S.; Koç, K.Y. Keystroke Dynamics Based Authentication System. In Proceedings of the 2021 6th International Conference on Computer Science and Engineering (UBMK), Ankara, Turkey, 15–17 September 2021; pp. 644–649. [Google Scholar]
- Liang, Y.; Samtani, S.; Guo, B.; Yu, Z. Behavioral biometrics for continuous authentication in the internet-of-things era: An artificial intelligence perspective. IEEE Internet Things J. 2020, 7, 9128–9143. [Google Scholar] [CrossRef]
- Bansal, P.; Ouda, A. Study on Integration of FastAPI and Machine Learning for Continuous Authentication of Behavioral Biometrics. In Proceedings of the 2022 International Symposium on Networks, Computers and Communications (ISNCC), Shenzhen, China, 19–22 July 2022; pp. 1–6. [Google Scholar]
- Belman, A.K.; Wang, L.; Iyengar, S.S.; Sniatala, P.; Wright, R.; Dora, R.; Baldwin, J.; Jin, Z.; Phoha, V.V. SU-AIS BB-MAS (Syracuse University and Assured Information Security—Behavioral Biometrics Multi-Device and multi-Activity data from Same users) Dataset. IEEE Dataport. 2019. Available online: https://ieee-dataport.org/open-access/su-ais-bb-mas-syracuse-university-and-assured-information-security-behavioral-biometrics (accessed on 18 April 2024).
- Huang, J.; Hou, D.; Schuckers, S.; Law, T.; Sherwin, A. Benchmarking keystroke authentication algorithms. In Proceedings of the 2017 IEEE Workshop on Information Forensics and Security (WIFS), Rennes, France, 4–7 December 2017; pp. 1–6. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | # of Users | Behavioral Biometrics | Features Used | ML Type | ML Model | Performance |
|---|---|---|---|---|---|---|
| [11] | 5 | Keystroke | Hold and flight time, latency, interkey time, acceleration | Supervised | Neural network | FAR 2.2%, FRR 8.67%, EER 5.43% |
| [12] | 10 | Keystroke | Dwell and flight time, latency, interkey time | Supervised | Bayesian network classifier | Accuracy 82.18%, FAR 2.0%, FRR 17.8% |
| [13] | 42 | Keystroke | Dwell and flight time, latency, interkey time and pressures | Supervised | Random forest classifier, Bayes network classifier, K-NN | EER 3% (2-class), EER 7% (1-class) |
| [14] | 15 | Keystroke and gyroscope | Hold time, flight time, latency, interkey time | Supervised | Distance algorithm, 1-class classification | EER 6.93% |
| [15] | 10 | Keystroke and finger pressure | Dwell and flight time, latency, interkey time | Supervised | Probabilistic neural network | Accuracy 99%, EER hold-time (H) 35%, EER interkey (I) 40%, EER finger pressure (P) 1% |
| [16] | 63 | Keystroke | Dwell and flight time, latency, interkey time and pressures | Supervised | Weighted probabilistic classifier, Bayesian-like classifiers | Accuracy 83.22% to 92.14% |
| [17] | N/A | Keystroke | Dwell and flight time, latency, interkey time | Unsupervised, supervised | K-means, Bayes net, and neural networks | FRR 1.45% FAR 1.89% |
| [18] | 54 | Keystroke | Dwell and flight time, latency, interkey time, key pressures | Supervised | Random forest classifier, Bayes net algorithms, and KNN | EER random forest classifier: for second-order feature set 5%; for full feature set 3% |
| [19] | 81 | Mouse | Dwell and flight time, latency, interkey time, touch pressure | Supervised | Long short-term memory (LSTM) | Random impostor: 80–87%; AUC skilled impostor: 62–69% AUC |
| [20] | 40 | Mouse | Speed, clicks, movement | Supervised | 1-dimensional CNN, artificial neural network (ANN) | Test accuracy 85.73% for the top 10 users, peak accuracy 92.48% |
| [21] | 73/80 | Keystroke | down–down time, down–up time up–up time, up–down time | Supervised | MLP, CNN, RNN, CNN-RNN | Buffalo dataset: Accuracy: 98.56%, EER: 0.0088; Clarkson Dataset: Accuracy: 91.74, EER:0.0755 |
| [22] | 54 | Keystroke | Interval, dwell time, latency, flight time, up to up | Supervised | Neural network layers—convolutional, recurrent, and LSTM | Accuracy: 88% |
| [23] | 103 | Keystroke | Dwell and flight time, latency, interkey time | Supervised | SVM, random forest (RF), multilayer perceptron (MLP) | Accuracy (93% to 97%), Type I and Type II errors (3% to 8%) |
| This study | 117 | Keystroke | Key, dwell and flight time, interkey | Reinforcement learning (RL) | Double deep Q networks (DDQN) | Train: Acc: 94.77%, EER: 0.0255, FAR: 0.0126, FRR: 0.045, Test: Acc: 81.06%, EER: 0.0323, FAR: 0.0356, FRR: 0.0174 |
| Target Network | There are 2 Q-networks, the primary network, and the target network. The target network estimates the Q-values for the next state, which then updates the primary network. |
| Action Selection | This is dependent on the primary network, and the Q-value estimation is performed using the target network. |
| Learning Stability | DDQN has better learning stability. This is because DDQN reduces the overestimation of Q-values. This improvement in learning stability is due to the use of the target network in DDQN. |
| Exploration–Exploitation Trade-off | In DDQN, the exploration–exploitation trade-off is balanced by using the target network to approximates the Q-values. |
| Performance | DDQN has improved learning stability, which leads to better convergence to the optimal policy. Additionally, DDQN can learn faster and requires fewer training samples. |
| Metrics | Accuracy | EER | FAR | FRR |
|---|---|---|---|---|
| Training | 94.77% | 0.0255 | 0.0126 | 0.045 |
| Test | 81.06% | 0.0323 | 0.0356 | 0.0174 |
| User | Training Accuracy | Test Accuracy | Training EER | Test EER | Average FAR | Average FRR |
|---|---|---|---|---|---|---|
| 1 | 96.5% | 89.6% | 0.0 | 0.07 | 0.31 | 0.29 |
| 71 | 96.7% | 93.5% | 0.0 | 0.11 | 0.39 | 0.28 |
| 99 | 96.8% | 81.2% | 0.049 | 0.06 | 0.19 | 0.34 |
| 116 | 100% | 85.7% | 0.0 | 0.13 | 0.26 | 0.32 |
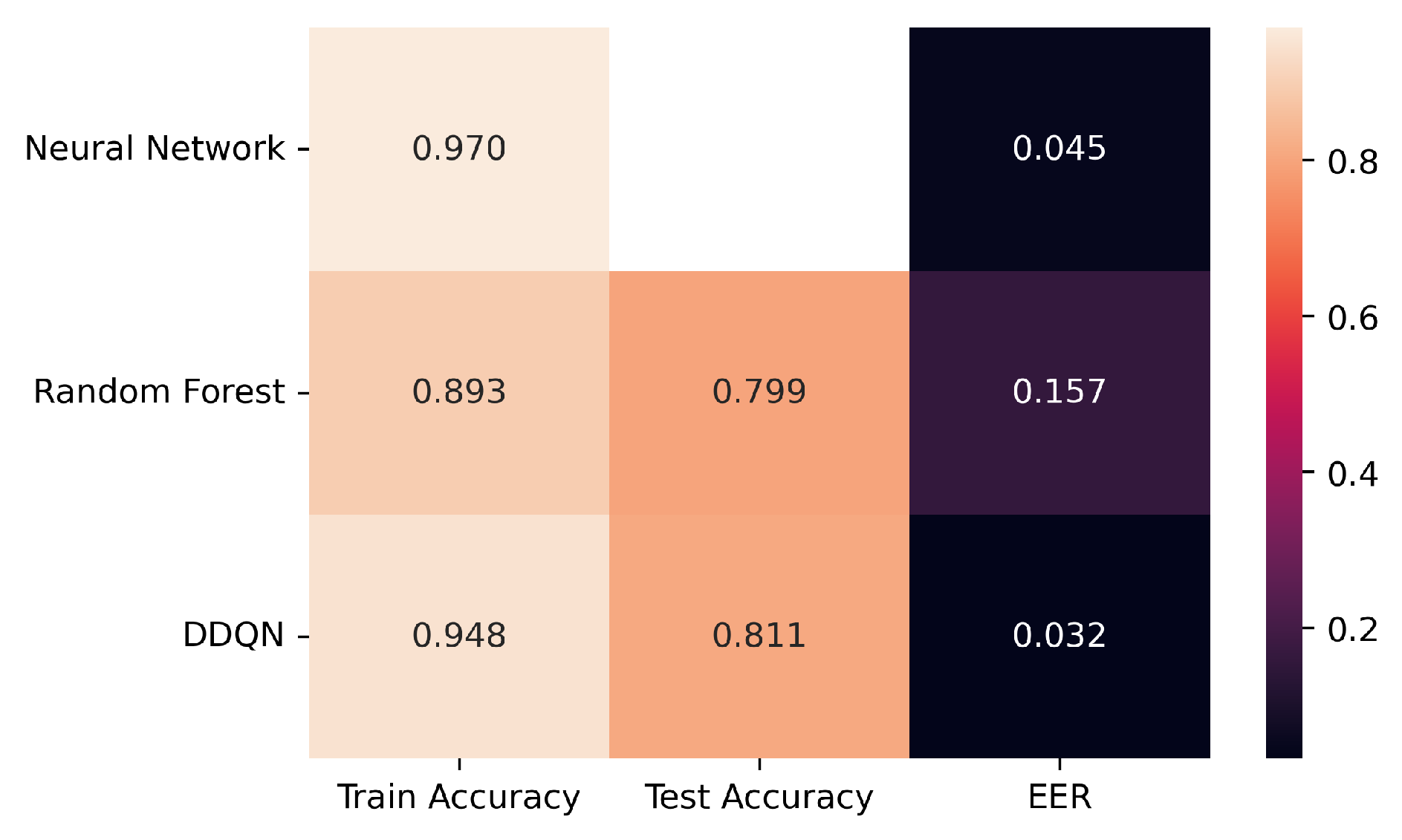
| Metrics | Literature Review [21] | State-of-the-Art Model [23] | This Study (SL) | This Study (RL) |
|---|---|---|---|---|
| ML type | Supervised learning | Supervised learning | Supervised learning | Reinforcement learning |
| Dataset | SU-AIS BBMAS subset | Buffalo and Clarkson dataset | SU-AIS BBMAS [30] | SU-AIS BBMAS [30] |
| No. of users | 102 | 54 | 117 | 117 |
| Keys | 10 unigraphs, 5 digraphs | NA | All keys | All keys |
| Model | Neural network | Neural network | Random forest | DDQN |
| Train/test accuracy | 97%/NA | 88% | 89.34%/79.89% | 94.77%/81.06% |
| EER | 0.03–0.06 = average 0.045 | NA | 0.157 | 0.0323 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bansal, P.; Ouda, A. Continuous Authentication in the Digital Age: An Analysis of Reinforcement Learning and Behavioral Biometrics. Computers 2024, 13, 103. https://doi.org/10.3390/computers13040103
Bansal P, Ouda A. Continuous Authentication in the Digital Age: An Analysis of Reinforcement Learning and Behavioral Biometrics. Computers. 2024; 13(4):103. https://doi.org/10.3390/computers13040103
Chicago/Turabian StyleBansal, Priya, and Abdelkader Ouda. 2024. "Continuous Authentication in the Digital Age: An Analysis of Reinforcement Learning and Behavioral Biometrics" Computers 13, no. 4: 103. https://doi.org/10.3390/computers13040103
APA StyleBansal, P., & Ouda, A. (2024). Continuous Authentication in the Digital Age: An Analysis of Reinforcement Learning and Behavioral Biometrics. Computers, 13(4), 103. https://doi.org/10.3390/computers13040103