Figure 1.
Examples of augmentations, rows from left to right: original; flipped; random zoom and rotation; flipped with (different) random zoom and rotation. The colours show the red, green and blue (RGB) values stored, which are mapped on to (x,y,z) directions.
Figure 1.
Examples of augmentations, rows from left to right: original; flipped; random zoom and rotation; flipped with (different) random zoom and rotation. The colours show the red, green and blue (RGB) values stored, which are mapped on to (x,y,z) directions.
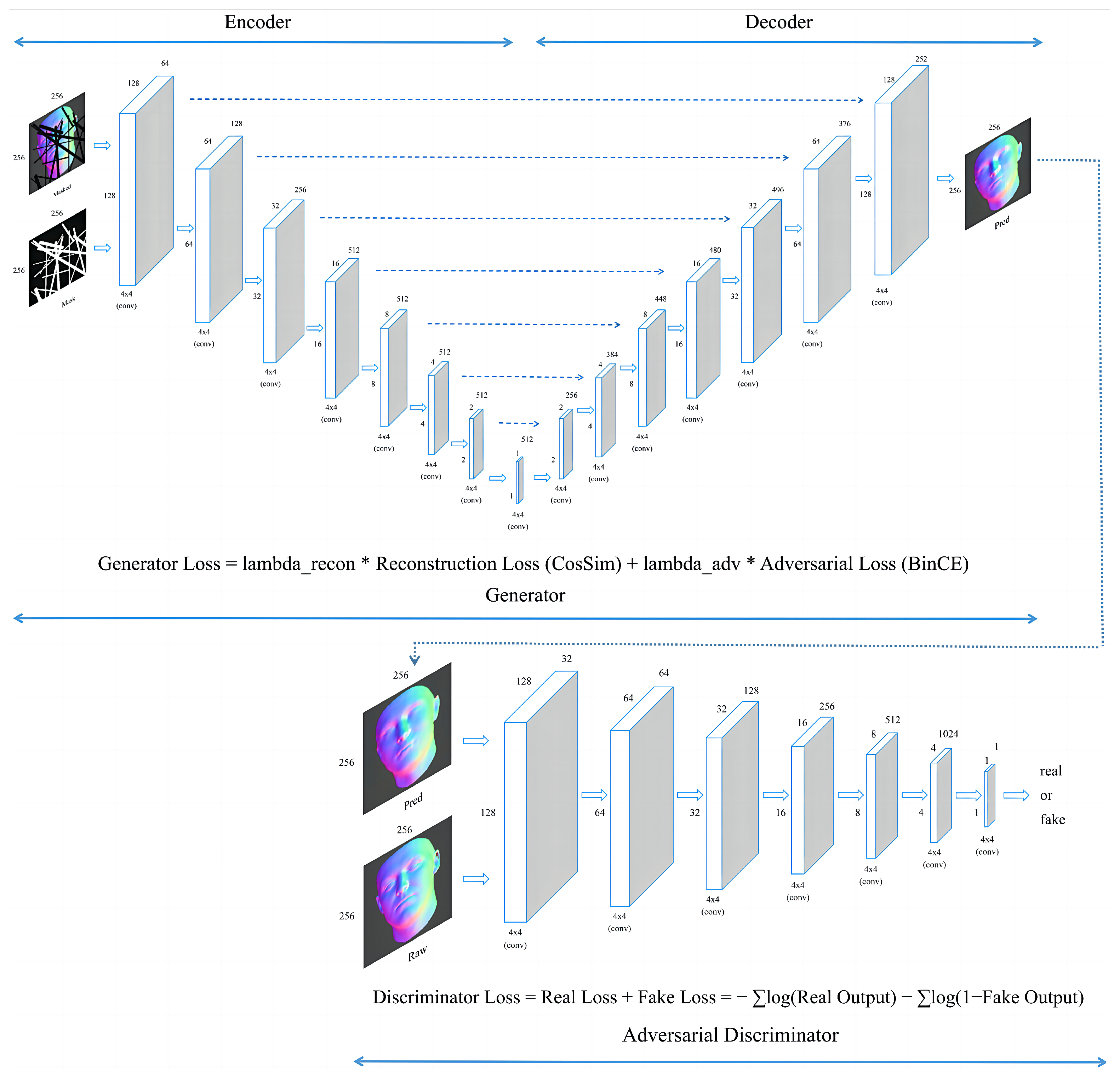
Figure 2.
A schematic of a U-Net-based generative adversarial network (GAN) with skip connections, showing the input and output image dimensions as 256 × 256 pixels and detailing the loss functions for the generator and discriminator.
Figure 2.
A schematic of a U-Net-based generative adversarial network (GAN) with skip connections, showing the input and output image dimensions as 256 × 256 pixels and detailing the loss functions for the generator and discriminator.
Figure 3.
A schematic of a bow-tie-like-based generative adversarial network (GAN), showing the input and output image dimensions as 256 × 256 pixels and detailing the loss functions for the generator and discriminator.
Figure 3.
A schematic of a bow-tie-like-based generative adversarial network (GAN), showing the input and output image dimensions as 256 × 256 pixels and detailing the loss functions for the generator and discriminator.
Figure 4.
Performance comparison of U-Net and bow-tie-like model structures across three mask types. Each set of two rows represents a different mask type, with U-Net results in the top row and bow-tie-like results in the bottom row of each set. From top to bottom, the first set is for the irregular lines mask, the second set is for the scattered smaller blobs mask, and the third set is for the single large blob mask. Within each row, from left to right, the images compare the raw image, masked image, predicted image, and predicted image in the masked region only.
Figure 4.
Performance comparison of U-Net and bow-tie-like model structures across three mask types. Each set of two rows represents a different mask type, with U-Net results in the top row and bow-tie-like results in the bottom row of each set. From top to bottom, the first set is for the irregular lines mask, the second set is for the scattered smaller blobs mask, and the third set is for the single large blob mask. Within each row, from left to right, the images compare the raw image, masked image, predicted image, and predicted image in the masked region only.
Figure 5.
Performance comparison of U-Net and bow-tie-like model structures across two types of masks, particularly relevant to real-life cases of missing or damaged regions in face images. Each set of two rows represents a different mask type, with U-Net results in the top row and bow-tie-like results in the bottom row of each set. From top to bottom, the first set is for the rotating large stripe mask, and the second set is for the edge crescent mask. Within each row, from left to right, the images compare the raw image, masked image, predicted image, and predicted image in the masked region only.
Figure 5.
Performance comparison of U-Net and bow-tie-like model structures across two types of masks, particularly relevant to real-life cases of missing or damaged regions in face images. Each set of two rows represents a different mask type, with U-Net results in the top row and bow-tie-like results in the bottom row of each set. From top to bottom, the first set is for the rotating large stripe mask, and the second set is for the edge crescent mask. Within each row, from left to right, the images compare the raw image, masked image, predicted image, and predicted image in the masked region only.
Figure 6.
During the initial epochs of testing on the irregular lines mask, the U-Net model (left) and the bow-tie-like model (right) exhibit distinct performance characteristics. The generator loss, indicated in green, and the SSIM, represented in purple, evolve differently across the epochs for each model.
Figure 6.
During the initial epochs of testing on the irregular lines mask, the U-Net model (left) and the bow-tie-like model (right) exhibit distinct performance characteristics. The generator loss, indicated in green, and the SSIM, represented in purple, evolve differently across the epochs for each model.
Figure 7.
Comparative performance of three training configurations of a GAN. The top row depicts results when only the generator is trained. The middle row shows outcomes for simultaneous training of both the generator and discriminator. The bottom row presents results from cyclic training, where the generator is trained to convergence first, followed by the discriminator.
Figure 7.
Comparative performance of three training configurations of a GAN. The top row depicts results when only the generator is trained. The middle row shows outcomes for simultaneous training of both the generator and discriminator. The bottom row presents results from cyclic training, where the generator is trained to convergence first, followed by the discriminator.
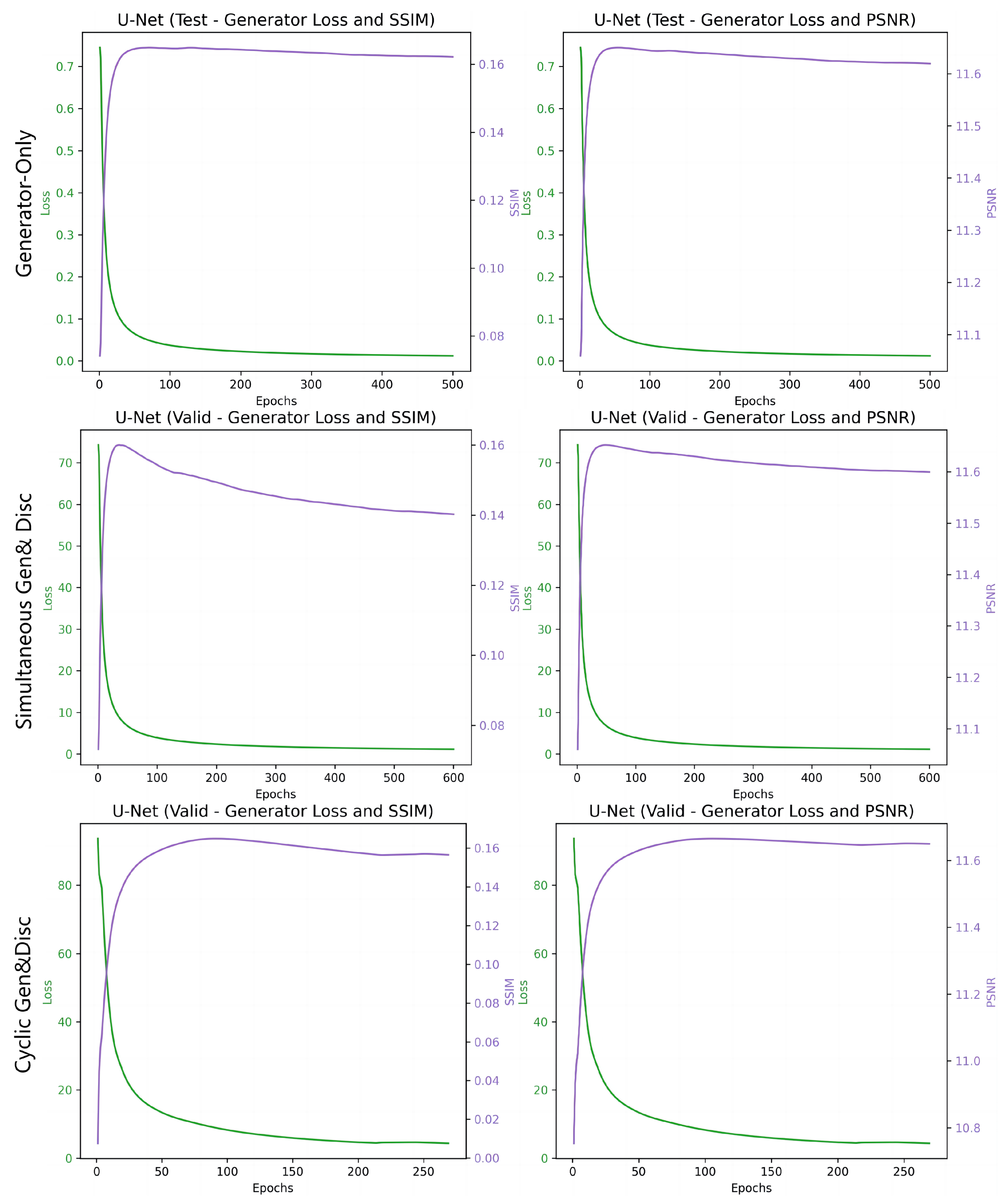
Figure 8.
The figure presents three sets of training configurations for GANs: the top row for ‘Generator-only’ training, the middle for ‘Simultaneous Generator and Discriminator’, and the bottom for ‘Generator to Convergence, then Discriminator’, each displaying generator loss (in green) and image quality metrics SSIM/PSNR (in purple).
Figure 8.
The figure presents three sets of training configurations for GANs: the top row for ‘Generator-only’ training, the middle for ‘Simultaneous Generator and Discriminator’, and the bottom for ‘Generator to Convergence, then Discriminator’, each displaying generator loss (in green) and image quality metrics SSIM/PSNR (in purple).
Figure 9.
Visual results of generator loss experiments with varying and ratios. The top row corresponds to , the middle row to , and the bottom row to .
Figure 9.
Visual results of generator loss experiments with varying and ratios. The top row corresponds to , the middle row to , and the bottom row to .
Figure 10.
From top to bottom, the performance is shown with and without an irregular lines mask used as input for training the generator; from left to right, images compare the raw image, masked image, predicted image, and predicted image in the masked region only.
Figure 10.
From top to bottom, the performance is shown with and without an irregular lines mask used as input for training the generator; from left to right, images compare the raw image, masked image, predicted image, and predicted image in the masked region only.
Table 1.
Comprehensive comparison of U-Net and bow-tie-like architectures across irregular lines mask, scattered smaller blobs mask, single large blob mask, rotating large stripe mask, and edge crescent mask.
Table 1.
Comprehensive comparison of U-Net and bow-tie-like architectures across irregular lines mask, scattered smaller blobs mask, single large blob mask, rotating large stripe mask, and edge crescent mask.
| Mask Type | Model | Loss | SSIM | PSNR | Disc Acc (%) |
|---|
| Irregular lines | U-Net | −0.9936 | 0.1250 | 11.5695 | 37.50 |
| Bow-tie-like | −0.9665 | 0.1161 | 11.5195 | 50.00 |
| Scattered smaller blobs | U-Net | −0.9983 | 0.1301 | 11.5513 | 7.10 |
| Bow-tie-like | −0.9674 | 0.1540 | 11.6088 | 48.58 |
| Single large blob | U-Net | −0.9986 | 0.1205 | 11.5305 | 1.99 |
| Bow-tie-like | −0.9639 | 0.1509 | 11.6056 | 50.00 |
| Rotating large stripe | U-Net | −0.9947 | 0.1276 | 11.5494 | 49.72 |
| Bow-tie-like | −0.9657 | 0.1441 | 11.5916 | 43.47 |
| Edge crescent | U-Net | −0.9913 | 0.1252 | 11.5450 | 48.58 |
| Bow-tie-like | −0.9604 | 0.1566 | 11.5807 | 48.58 |
Table 2.
Comparison of training and testing times for U-Net and bow-tie-like architectures across irregular lines mask, scattered smaller blobs mask, single large blob mask, rotating large stripe mask, and edge crescent mask. The models were trained on a dataset of 1296 images and tested on a dataset of 162 images, with a batch size of 16.
Table 2.
Comparison of training and testing times for U-Net and bow-tie-like architectures across irregular lines mask, scattered smaller blobs mask, single large blob mask, rotating large stripe mask, and edge crescent mask. The models were trained on a dataset of 1296 images and tested on a dataset of 162 images, with a batch size of 16.
| Mask Type | Model | Training Time (s) | Testing Time (s) |
|---|
| Irregular lines | U-Net | 4895.33 | 3.48 |
| Bow-tie-like | 3488.38 | 1.46 |
| Scattered smaller blobs | U-Net | 9729.63 | 3.51 |
| Bow-tie-like | 4530.37 | 1.50 |
| Single large blob | U-Net | 7752.97 | 3.48 |
| Bow-tie-like | 3755.90 | 1.45 |
| Rotating large stripe | U-Net | 11,045.99 | 4.00 |
| Bow-tie-like | 11,202.25 | 1.89 |
| Edge crescent | U-Net | 5517.66 | 3.61 |
| Bow-tie-like | 2874.90 | 1.49 |
Table 3.
Comparative analysis of different GAN training configurations.
Table 3.
Comparative analysis of different GAN training configurations.
| Training Configuration | LOSS | SSIM | PSNR | Disc Acc (%) |
|---|
| Only generator | −0.9946 | 0.1618 | 11.6132 | - |
| Simultaneous generator and discriminator | −0.9944 | 0.1328 | 11.5730 | 20.45 |
| Generator to convergence, then discriminator | −0.9903 | 0.1435 | 11.6100 | 40.34 |
Table 4.
Evaluation of training and testing times across different GAN training configurations. The models were trained on a dataset of 1296 images and tested on a dataset of 162 images, with a batch size of 16.
Table 4.
Evaluation of training and testing times across different GAN training configurations. The models were trained on a dataset of 1296 images and tested on a dataset of 162 images, with a batch size of 16.
| Training Configuration | Training Time (s) | Testing Time (s) |
|---|
| Only generator | 3784.86 | 3.78 |
| Simultaneous generator and discriminator | 5564.94 | 3.85 |
| Generator to convergence, then discriminator | 1857.34 | 3.82 |
Table 5.
Comparative analysis of generator performance with varied and ratios.
Table 5.
Comparative analysis of generator performance with varied and ratios.
| Configuration | LOSS | SSIM | PSNR | Disc Acc (%) |
|---|
| −0.9968 | 0.1594 | 11.5970 | 49.72 |
| −0.9958 | 0.1238 | 11.5672 | 37.50 |
| −0.9972 | 0.1234 | 11.5488 | 48.86 |
Table 6.
Evaluation of training and testing times for different and ratios. The models were trained on a dataset of 1296 images and tested on a dataset of 162 images, with a batch size of 16.
Table 6.
Evaluation of training and testing times for different and ratios. The models were trained on a dataset of 1296 images and tested on a dataset of 162 images, with a batch size of 16.
| Configuration | Training Time (s) | Testing Time (s) |
|---|
| 4895.12 | 3.77 |
| 4895.33 | 3.49 |
| 6792.58 | 3.52 |
Table 7.
Model performance with and without mask input training.
Table 7.
Model performance with and without mask input training.
| Mask | LOSS | SSIM | PSNR | Disc Acc (%) |
|---|
| With | −0.9955 | 0.1231 | 11.5659 | 37.50 |
| Without | −0.9965 | 0.1406 | 11.5721 | 42.33 |
Table 8.
Comparison of training and testing times for models trained with and without mask input. The models were trained on a dataset of 1296 images and tested on a dataset of 162 images, with a batch size of 16.
Table 8.
Comparison of training and testing times for models trained with and without mask input. The models were trained on a dataset of 1296 images and tested on a dataset of 162 images, with a batch size of 16.
| Mask | Training Time (s) | Testing Time (s) |
|---|
| With | 4895.33 | 3.60 |
| Without | 4672.35 | 3.56 |













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}