
Employing Different Algorithms of Lightweight Convolutional Neural Network Models in Image Distortion Classification


Abstract
1. Introduction
- An analysis is conducted on how image distortion affects both lightweight and non-lightweight deep CNN models.
- Experimental findings indicate that the proposed approach exhibits resilience against different kinds of image distortion. The performance under 25 types of distortion across five levels of severity are examined.
- Several important features are extracted from the last fully connected layers of lightweight and non-lightweight deep CNN models such as SqueezeNet, DenseNet201, and MobileNetv2 models.
- The training process is simplified by leveraging models such as MobileNet-v2, SqueezeNet, and DenseNet201, which are initially trained as feature extractors, followed by using PCA to produce smaller feature sets.
- Utilizing the KADID-10k dataset, the proposed distortion image classification method combining SqueezeNet and KNN achieved the best performance across all evaluation metrics.
- The proposed distortion image classification technique is based on a lightweight structure that needs minimal time and effort.
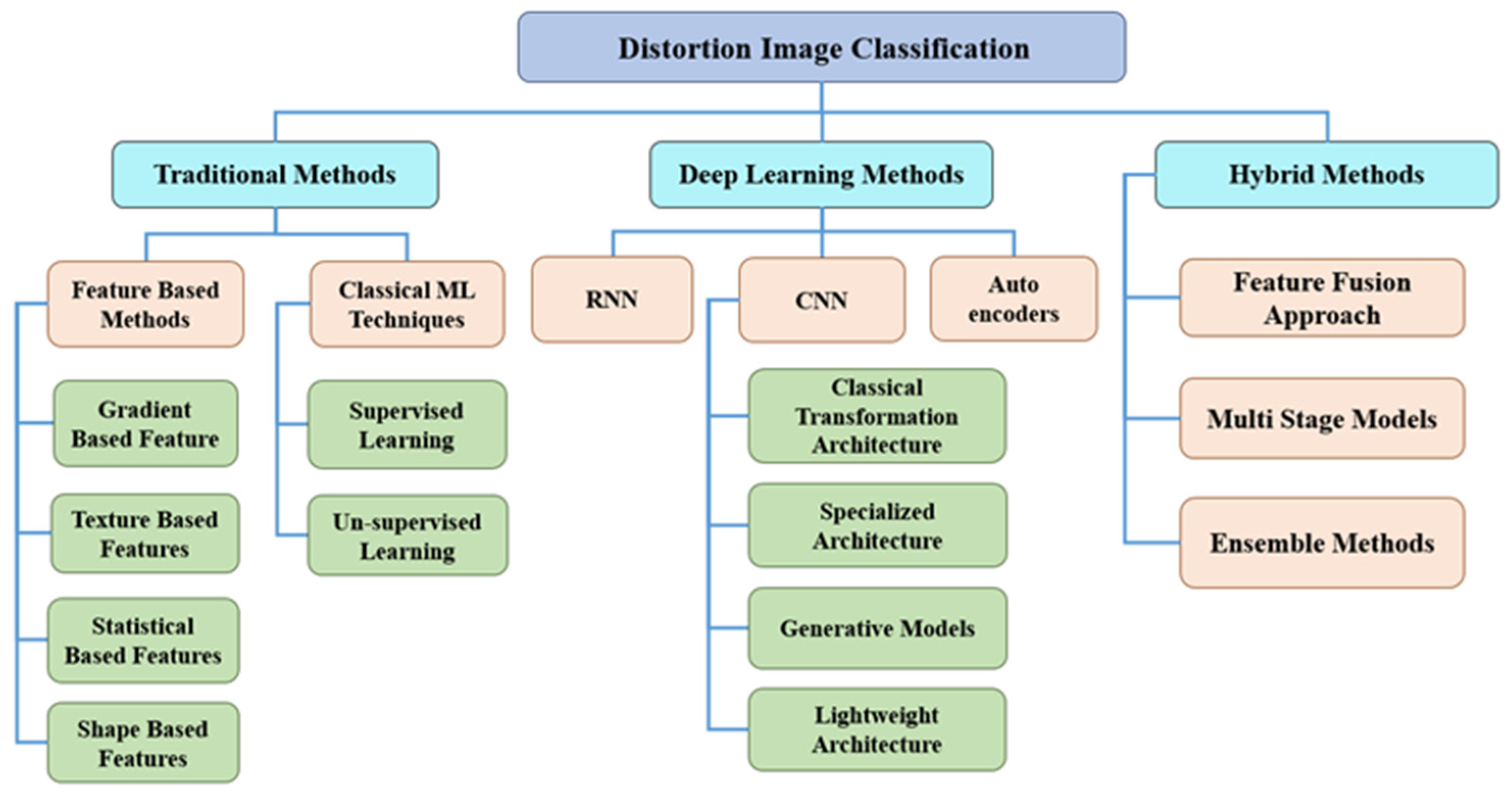
2. Related Works
3. Preliminaries: Classic CNN Models
3.1. Lightweight Deep CNN Models
3.1.1. SqueezeNet
3.1.2. MobileNetv2
3.2. Non-Lightweight Deep CNN Models
4. Our Proposed Method
- STEP 1: Data Preparation
- STEP 2: Feature Extraction
- STEP 2.1: DenseNet201 Feature Extraction
| Algorithm 1 DenseNet201 model as feature extraction |
| Input: Distorted Image from dataset. Output: 1 × 1000 features vector dimension. Begin For 1: Import the dataset images and perform the following preprocessing steps in accordance with DenseNet201 requirements: 1.1: Every image entry should be limited to a value between 0 and 255. 1.2: For every image, adjust the resolution to (224 × 224). 2: Import Pre-trained DenseNet201 Model: 3: Import DenseNet201 model weights. 4: Eliminate the layer of classification. The final fully connected (FC) layers of the model are either absent or have been removed. 5: Select the Feature Extraction Layer: Create a brand-new model only for the feature extraction, then carry out the subsequent loop steps: 5.1: Go over every image in the dataset one by one. 5.2: Send the image up to the selected feature extraction layer via the Pre-trained DenseNet201 Model. 5.3: Extract features from the selected layer (“fc1000”). 5.4: Save the features that were extracted into an array. 6: Apply the flattened method to reduce the dimensions of the features array into one. 7: Print the flattened array. 8: Save the 1000 feature vector that was produced. End for End |
- STEP 2.2: SqueezeNet Features Extraction
| Algorithm 2 SqueezeNet model as feature extraction |
| Input: Distorted Image from dataset. Output: 1 × 1000 features vector dimension. Begin For 1: Import the dataset images and perform the following preprocessing steps in accordance with SqueezeNet requirements: 1.1: Every image entry should be limited to a value between 0 and 255. 1.2: For every image, adjust the resolution to (227 × 227). 2: Import Pre-trained SqueezeNet Model: 3: Import SqueezeNet model weights. 4: Eliminate the layer of classification. The final fully connected (FC) layers of the model are either absent or have been removed. 5: Select the Feature Extraction Layer: Create a brand-new model only for the feature extraction, then carry out the subsequent loop steps: 5.1: Go over every image in the dataset one by one. 5.2: Send the image up to the selected feature extraction layer via the Pre-trained SqueezeNet Model. 5.3: Extract features from the selected layer (“avg_pool10”). 5.4: Save the features that were extracted into an array. 6: Apply the flattened method to reduce the dimensions of the features array into one. 7: Print the flattened array. 8: Save the 1000 feature vector that was produced. End for End |
- STEP 2.3: MobileNetv2 Feature Extraction
| Algorithm 3 MobileNetV2 model as feature extraction |
| Input: Distorted Image from dataset. Output: 1 × 1344 features vector dimension. Begin For 1: Import the dataset images and perform the following preprocessing steps in accordance with MobileNetV2 requirements: 1.1: Every image entry should be limited to a value between 0 and 255. 1.2: For every image, adjust the resolution to (224 × 224). 2: Import Pre-trained MobileNetV2 Model: 3: Import MobileNetV2 model weights. 4: Eliminate the layer of classification. The final fully connected (FC) layers of the model are either absent or have been removed. 5: Select the Feature Extraction Layer: Create a brand-new model only for the feature extraction, then carry out the subsequent loop steps: 5.1: Go over every image in the dataset one by one. 5.2: Send the image up to the selected feature extraction layer via the Pre-trained MobileNetV2 Model. 5.3: Extract features from the selected layer (“block_12_add”). 5.4: Save the features that were extracted into an array. 6: Apply the flattened method to reduce the dimensions of the features array into one. 7: Print the flattened array. 8: Save the 1344 feature vector that was produced. End for End |
- STEP 3: Apply Feature Selection Method
| Algorithm 4 PCA Feature selection |
| Input: Feature Extracted Vector. Output: Selected Feature Vector. Begin For 1: Import the Feature extracted vector. 2: To guarantee that every feature has an equal scale, standardize or normalize the feature extraction vector using the following sub steps: 2.1: Calculate the mean of each feature and divide it by the standard deviation. 2.2: As required by PCA, this guarantees that every feature has a mean of 0 and a standard deviation of 1. 3: Determine the standardized features’ covariance matrix. The correlations between various features are revealed by the covariance matrix. 4: Determine the eigenvalues and eigenvectors covariance matrixes. To determine the eigenvalues and eigenvectors of the covariance matrix, apply eigen decomposition. 5: Choose Principal Components: Choose the top k eigenvectors that match the biggest eigenvalues by sorting the eigenvalues in descending order. These outputs are the Principal components. 6: Project Data onto Principal Components: To generate the reduced dimensional feature space, project the standardized data onto the principal components that have been chosen. End for End |
- STEP 4: Classification
- STEP 4.1: K-Nearest Neighbor (KNN) Classifier.
- Training Phase:
- Training and testing data sets are divided according to the preceding selected feature vectors.
- KNN is an instance-based learning algorithm; that is, it memorizes the training cases instead of learning a model explicitly.
- All of the training data points and the labels that go with them are stored.
- Prediction Phase:
- Determine the distance using a distance metric (such as the Euclidean distance) between each training instance and the test instance.
- Determine which K training instances are nearest to the test instance in order to find neighbors. In this work, a KNN with a 9-neighbor arrangement was used since overfitting reduces as K increases.
- Popular Vote (for Classification): Choose the class label that the K nearest neighbors share the greatest amount of.
- Average (for Regression): Determine the expected value by averaging the values of the K nearest neighbors.
- STEP 4.2: Naïve Bayes (NB) Classifier
- STEP 4.3: The Logistic Regression Classifier.
5. Experimental Results and Analysis
5.1. Datasets
5.2. Performance Evaluation Measures
5.3. Evaluation Results
5.3.1. Analysis of Lightweight Deep CNN Model Performance Results
5.3.2. Analysis of Non-Lightweight Deep CNN Model Performance Results
5.4. Comparison with Previous Works
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H.; Shao, L. Learning enriched features for real image restoration and enhancement. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Part XXV 16; Springer: New York, NY, USA, 2020; pp. 492–511. [Google Scholar]
- Ahmed, I.T.; Der, C.S.; Jamil, N.; Hammad, B.T. Analysis of Probability Density Functions in Existing No-Reference Image Quality Assessment Algorithm for Contrast-Distorted Images. In Proceedings of the 2019 IEEE 10th Control and System Graduate Research Colloquium (ICSGRC), Shah Alam, Malaysia, 2–3 August 2019; pp. 133–137. [Google Scholar]
- Li, X.; Li, C.; Rahaman, M.M.; Sun, H.; Li, X.; Wu, J.; Yao, Y.; Grzegorzek, M. A comprehensive review of computer-aided whole-slide image analysis: From datasets to feature extraction, segmentation, classification and detection approaches. Artif. Intell. Rev. 2022, 55, 4809–4878. [Google Scholar] [CrossRef]
- Hammad, B.T.; Ahmed, I.T.; Jamil, N. An secure and effective copy move detection based on pretrained model. In Proceedings of the 2022 IEEE 13th Control and System Graduate Research Colloquium (ICSGRC), Shah Alam, Malaysia, 23 July 2022; IEEE: Pictaway, NJ, USA, 2022; pp. 66–70. [Google Scholar]
- Dodge, S.; Karam, L. Understanding how image quality affects deep neural networks. In Proceedings of the 2016 Eighth International Conference on Quality of Multimedia Experience (QoMEX), Lisbon, Portugal, 6–8 June 2016; IEEE: Pictaway, NJ, USA, 2016; pp. 1–6. [Google Scholar]
- Zhou, Y.; Do, T.-T.; Zheng, H.; Cheung, N.-M.; Fang, L. Computation and memory efficient image segmentation. IEEE Trans. Circuits Syst. Video Technol. 2016, 28, 46–61. [Google Scholar] [CrossRef]
- Zhou, Y.; Song, S.; Cheung, N.-M. On classification of distorted images with deep convolutional neural networks. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; IEEE: Pictaway, NJ, USA, 2017; pp. 1213–1217. [Google Scholar]
- Li, Y.; Liu, L. Image quality classification algorithm based on InceptionV3 and SVM. In MATEC Web of Conferences, Proceeding of the 2018 International Joint Conference on Metallurgical and Materials Engineering (JCMME 2018), Wellington, New Zealand, 10–12 December 2018; EDP Sciences: Les Ulis, France, 2019; Volume 277, p. 2036. [Google Scholar]
- Dodge, S.; Karam, L. A study and comparison of human and deep learning recognition performance under visual distortions. In Proceedings of the 2017 26th International Conference on Computer Communication and Networks (ICCCN), Vancouver, BC, Canada, 31 July–3 August 2017; IEEE: Pictaway, NJ, USA, 2017; pp. 1–7. [Google Scholar]
- Hsieh, M.; Duffau, R.; He, A. Image Distortion Classification with Deep CNN Final Report. Available online: https://cs230.stanford.edu/projects_winter_2020/reports/32163271.pdf (accessed on 18 September 2024).
- Basu, S.; Karki, M.; Ganguly, S.; DiBiano, R.; Mukhopadhyay, S.; Gayaka, S.; Kannan, R.; Nemani, R. Learning sparse feature representations using probabilistic quadtrees and deep belief nets. Neural Process. Lett. 2017, 45, 855–867. [Google Scholar] [CrossRef]
- Ha, M.; Byun, Y.; Kim, J.; Lee, J.; Lee, Y.; Lee, S. Selective deep convolutional neural network for low cost distorted image classification. IEEE Access 2019, 7, 133030–133042. [Google Scholar] [CrossRef]
- Saurabh, N.; Salian, K.P. Convolutional Neural Network based Classification for automatic segregation of distorted digital images. In Proceedings of the 2022 Second International Conference on Computer Science, Engineering and Applications (ICCSEA), Gunupur, India, 8 September 2022; IEEE: Pictaway, NJ, USA, 2022; pp. 1–6. [Google Scholar]
- Wang, R.; Li, W.; Zhang, L. Blur image identification with ensemble convolution neural networks. Signal Process. 2019, 155, 73–82. [Google Scholar] [CrossRef]
- Wang, R.; Li, W.; Li, R.; Zhang, L. Automatic blur type classification via ensemble SVM. Signal Process. Image Commun. 2019, 71, 24–35. [Google Scholar] [CrossRef]
- Hossain, M.T.; Teng, S.W.; Zhang, D.; Lim, S.; Lu, G. Distortion robust image classification using deep convolutional neural network with discrete cosine transform. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; IEEE: Pictaway, NJ, USA, 2019; pp. 659–663. [Google Scholar]
- Ahmed, I.T.; Hammad, B.T.; Jamil, N. Image Steganalysis based on Pretrained Convolutional Neural Networks. In Proceedings of the 2022 IEEE 18th International Colloquium on Signal Processing & Applications (CSPA), Kuala Lumpur, Malaysia, 12 May 2022; pp. 283–286. [Google Scholar]
- Hammad, B.T.; Jamil, N.; Rusli, M.E.; Z’Aba, M.R.; Ahmed, I.T. Implementation of lightweight cryptographic primitives. J. Theor. Appl. Inf. Technol. 2017, 95, 5126–5141. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50× fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Wang, S.; Kang, B.; Ma, J.; Zeng, X.; Xiao, M.; Guo, J.; Cai, M.; Yang, J.; Li, Y.; Meng, X.; et al. A deep learning algorithm using CT images to screen for Corona Virus Disease (COVID-19). Eur. Radiol. 2021, 31, 6096–6104. [Google Scholar] [CrossRef] [PubMed]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Ahmed, I.T.; Jamil, N.; Din, M.M.; Hammad, B.T. Binary and Multi-Class Malware Threads Classification. Appl. Sci. 2022, 12, 12528. [Google Scholar] [CrossRef]
- Tanveer, M.; Shubham, K.; Aldhaifallah, M.; Ho, S.S. An efficient regularized K-nearest neighbor based weighted twin support vector regression. Knowl. Based Syst. 2016, 94, 70–87. [Google Scholar] [CrossRef]
- Ahmed, I.T.; Hammad, B.T.; Jamil, N. Forgery detection algorithm based on texture features. Indones. J. Electr. Eng. Comput. Sci. 2021, 24, 226–235. [Google Scholar] [CrossRef]
- Lowd, D.; Domingos, P. Naive Bayes models for probability estimation. In Proceedings of the 22nd International Conference on Machine Learning, Bonn, Germany, 7–11 August 2005; pp. 529–536. [Google Scholar]
- Lin, H.; Hosu, V.; Saupe, D. KADID-10k: A large-scale artificially distorted IQA database. In Proceedings of the 2019 Eleventh International Conference on Quality of Multimedia Experience (QoMEX), Berlin, Germany, 5–7 June 2019; IEEE: Pictaway, NJ, USA, 2019; pp. 1–3. [Google Scholar]
- Abdulazeez, F.A.; Ahmed, I.T.; Hammad, B.T. Examining the Performance of Various Pretrained Convolutional Neural Network Models in Malware Detection. Appl. Sci. 2024, 14, 2614. [Google Scholar] [CrossRef]
- Ahmed, I.T.; Der, C.S.; Hammad, B.T.; Jamil, N. Contrast-distorted image quality assessment based on curvelet domain features. Int. J. Electr. Comput. Eng. 2021, 11, 2595–2603. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Mobile Net v2 | DenseNet201 | SqueezeNet |
|---|---|---|---|
| Year | 2018 | 2016 | 2016 |
| Image Dimensions | 224 × 224 × 3 | 224 × 224 × 3 | 227 × 227 |
| Number of Layers | 53 | 201 | 18 |
| Number of Parameters | 3.5 million | 20 million | 1.24 million |
| Feature Dimension | 1344 | 1000 | 1000 |
| Design | lightweight | non-lightweight | lightweight |
| Class_ID | Family | Details | |
|---|---|---|---|
| Distortion_Category | Sample_No. | ||
| #01, #02, #03 | Gaussian blur, Lens blur, Motion blur | Blurs | 1215 |
| #04, #05, #06, #07, #08 | Color diffusion, Color shift, Color quantization, Color saturation 1, Color saturation 2 | Color Distortions | 2025 |
| #09, #10, | JPEG2000, JPEG | Compression | 810 |
| #11, #12, #13, #14, #15 | White noise, White noise in color component, Impulse noise, Multiplicative noise, Denoise | Noise | 2025 |
| #16, #17, #18 | Brighten, Darken, Mean shift | Brightness Change | 1215 |
| #19, #20, #21, #22, #23 | Jitter, Non-eccentricity patch, Pixelate, Quantization, Color block | Spatial Distortions | 2025 |
| # 24, # 25 | High sharpness, Contrast change | Sharpness And Contrast | 810 |
| Total | - | 10,125 | |
| Metric | Description | Formula | Eq No |
|---|---|---|---|
| Accuracy | It represents the proportion of accurately recognized images to all images entered. | Equation (1) | |
| Precision | The percent of all given images that the classification algorithm properly identified is represented by this number. | Equation (2) | |
| Error | This is the proportion of every image to the overall number of images that have been mislabeled. | Equation (3) | |
| Recall | It represents the proportion of all images belonging to that category that have been accurately classified. | Equation (4) |
| No | Model | Full Features | Feature Selection Percentage | ||
|---|---|---|---|---|---|
| 100% | 50% | 25% | |||
| 1 | SqueezeNet | 1000 | 1000 | 500 | 250 |
| 2 | Desnet201 | 1000 | 1000 | 500 | 250 |
| 3 | MobileNet-v2 | 1344 | 1344 | 672 | 236 |
| 4 | AlexNet | 4096 | 4096 | 2048 | 1024 |
| Classifier | Class ID | Family Name | Percentage of Selected Features (%) | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SqueezeNet Features-No 100% of Features | SqueezeNet Features-No 50% of Features | SqueezeNet Features-No 25% of Features | |||||||||||||||
| Evaluation Measures (%) | Evaluation Measures (%) | Evaluation Measures (%) | |||||||||||||||
| Accuracy | ER | F1 | Precision | Recall | Accuracy | ER | F1 | Precision | Recall | Accuracy | ER | F1 | Precision | Recall | |||
| KNN | #1 | Blur | 98 | 02 | 98 | 98 | 100 | 99 | 01 | 99 | 98 | 100 | 99 | 01 | 99 | 99 | 100 |
| #2 | Brightness Change | 86 | 14 | 92 | 96 | 100 | 88 | 12 | 93 | 88 | 100 | 89 | 11 | 92 | 89 | 100 | |
| #3 | Color Distortion | 88 | 12 | 94 | 88 | 100 | 89 | 11 | 93 | 87 | 100 | 90 | 10 | 93 | 97 | 100 | |
| #4 | Compression | 81 | 19 | 89 | 81 | 100 | 79 | 21 | 88 | 79 | 100 | 82 | 18 | 89 | 80 | 100 | |
| #5 | Noise | 91 | 09 | 95 | 91 | 100 | 92 | 08 | 96 | 92 | 100 | 93 | 07 | 95 | 93 | 100 | |
| #6 | Original | 79 | 21 | 88 | 79 | 100 | 81 | 19 | 89 | 81 | 100 | 83 | 17 | 88 | 82 | 100 | |
| #7 | Sharpness And Contrast | 92 | 08 | 96 | 92 | 100 | 93 | 07 | 96 | 93 | 100 | 93 | 07 | 95 | 91 | 100 | |
| #8 | Spatial Distortion | 80 | 20 | 89 | 81 | 100 | 81 | 19 | 88 | 78 | 100 | 83 | 17 | 88 | 77 | 100 | |
| Average | 86.8 | 13.1 | 92.6 | 88.25 | 100 | 87.7 | 12.25 | 92.7 | 87 | 100 | 89 | 11 | 92.3 | 88.5 | 100 | ||
| Naïve | #1 | Blur | 89 | 11 | 94 | 100 | 89 | 91 | 09 | 95 | 99 | 91 | 92 | 08 | 95 | 90 | 91 |
| #2 | Brightness Change | 60 | 40 | 73 | 88 | 62 | 81 | 19 | 90 | 87 | 93 | 89 | 11 | 94 | 89 | 100 | |
| #3 | Color Distortion | 58 | 42 | 71 | 89 | 59 | 83 | 17 | 92 | 87 | 96 | 85 | 15 | 90 | 87 | 94 | |
| #4 | Compression | 52 | 48 | 66 | 74 | 60 | 74 | 26 | 85 | 79 | 92 | 78 | 22 | 88 | 78 | 100 | |
| #5 | Noise | 55 | 45 | 69 | 63 | 55 | 91 | 09 | 95 | 91 | 100 | 92 | 08 | 96 | 92 | 100 | |
| #6 | Original | 63 | 37 | 77 | 78 | 76 | 60 | 40 | 74 | 77 | 72 | 82 | 18 | 90 | 82 | 100 | |
| #7 | Sharpness And Contrast | 54 | 46 | 69 | 93 | 54 | 93 | 07 | 95 | 93 | 95 | 91 | 09 | 95 | 91 | 100 | |
| #8 | Spatial Distortion | 62 | 38 | 76 | 75 | 78 | 81 | 19 | 89 | 81 | 100 | 88 | 12 | 88 | 86 | 100 | |
| Average | 61.6 | 38.3 | 74.3 | 82.5 | 66.6 | 81.7 | 18.25 | 89.3 | 86.7 | 92.3 | 87.1 | 12.8 | 92 | 86.8 | 98.12 | ||
| Classifier | Class ID | Family Name | Percentage of Selected Features (%) | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SqueezeNet Features-No 100% of Features | SqueezeNet Features-No 50% of Features | SqueezeNet Features-No 25% of Features | |||||||||||||||
| Evaluation Measures (%) | Evaluation Measures (%) | Evaluation Measures (%) | |||||||||||||||
| Accuracy | ER | F1 | Precision | Recall | Accuracy | ER | F1 | Precision | Recall | Accuracy | ER | F1 | Precision | Recall | |||
| KNN | #1 | Blur | 98 | 02 | 98 | 98 | 100 | 99 | 01 | 99 | 99 | 100 | 99 | 01 | 99 | 99 | 100 |
| #2 | Brightness Change | 86 | 14 | 93 | 88 | 100 | 88 | 12 | 92 | 86 | 100 | 88 | 12 | 94 | 89 | 100 | |
| #3 | Color Distortion | 87 | 13 | 93 | 87 | 100 | 88 | 12 | 93 | 88 | 100 | 89 | 11 | 93 | 89 | 100 | |
| #4 | Compression | 79 | 21 | 88 | 79 | 100 | 81 | 19 | 89 | 81 | 100 | 82 | 18 | 89 | 80 | 100 | |
| #5 | Noise | 91 | 9 | 95 | 91 | 100 | 93 | 07 | 96 | 93 | 100 | 92 | 8 | 95 | 92 | 100 | |
| #6 | Original | 80 | 20 | 89 | 80 | 100 | 77 | 23 | 87 | 77 | 100 | 79 | 21 | 88 | 79 | 100 | |
| #7 | Sharpness And Contrast | 90 | 10 | 95 | 91 | 100 | 91 | 09 | 95 | 90 | 100 | 93 | 07 | 96 | 93 | 100 | |
| #8 | Spatial Distortion | 76 | 24 | 88 | 78 | 100 | 77 | 23 | 85 | 77 | 100 | 80 | 20 | 89 | 80 | 100 | |
| Average | 85.8 | 14.1 | 92.3 | 86.5 | 100 | 86.7 | 13.25 | 92 | 86.3 | 100 | 87.7 | 12.2 | 92.8 | 87.6 | 100 | ||
| Naïve | #1 | Blur | 80 | 20 | 88 | 80 | 100 | 95 | 05 | 97 | 100 | 95 | 98 | 02 | 99 | 100 | 99 |
| #2 | Brightness Change | 51 | 49 | 65 | 88 | 51 | 94 | 06 | 97 | 95 | 99 | 86 | 14 | 92 | 90 | 89 | |
| #3 | Color Distortion | 65 | 35 | 78 | 86 | 71 | 72 | 28 | 78 | 93 | 74 | 74 | 26 | 78 | 87 | 80 | |
| #4 | Compression | 54 | 46 | 65 | 82 | 54 | 60 | 40 | 62 | 85 | 65 | 64 | 36 | 69 | 82 | 75 | |
| #5 | Noise | 48 | 52 | 61 | 95 | 45 | 68 | 32 | 67 | 80 | 70 | 70 | 30 | 75 | 85 | 77 | |
| #6 | Original | 55 | 45 | 66 | 81 | 56 | 68 | 32 | 69 | 83 | 72 | 69 | 31 | 74 | 81 | 75 | |
| #7 | Sharpness And Contrast | 45 | 54 | 58 | 95 | 41 | 50 | 50 | 56 | 93 | 55 | 53 | 47 | 60 | 60 | 68 | |
| #8 | Spatial Distortion | 51 | 49 | 62 | 81 | 51 | 60 | 40 | 62 | 83 | 69 | 65 | 35 | 70 | 78 | 72 | |
| Average | 56 | 43 | 67 | 86 | 58 | 70 | 29 | 73 | 89 | 74 | 72 | 27 | 77 | 82 | 79 | ||
| Classifier | Class ID | Family Name | Percentage of Selected Features (%) | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SqueezeNet Features-No 100% of Features | SqueezeNet Features-No 50% of Features | SqueezeNet Features-No 25% of Features | |||||||||||||||
| Evaluation Measures (%) | Evaluation Measures (%) | Evaluation Measures (%) | |||||||||||||||
| Accuracy | ER | F1 | Precision | Recall | Accuracy | ER | F1 | Precision | Recall | Accuracy | ER | F1 | Precision | Recall | |||
| KNN | #1 | Blur | 99 | 01 | 99 | 99 | 100 | 98 | 02 | 99 | 98 | 100 | 99 | 01 | 99 | 99 | 100 |
| #2 | Brightness Change | 89 | 11 | 94 | 89 | 100 | 87 | 13 | 93 | 87 | 100 | 89 | 11 | 94 | 89 | 100 | |
| #3 | Color Distortion | 87 | 13 | 93 | 82 | 100 | 86 | 14 | 92 | 86 | 100 | 87 | 13 | 93 | 87 | 100 | |
| #4 | Compression | 77 | 23 | 88 | 78 | 100 | 79 | 21 | 88 | 79 | 100 | 80 | 20 | 88 | 80 | 100 | |
| #5 | Noise | 93 | 07 | 96 | 93 | 100 | 92 | 08 | 96 | 92 | 100 | 91 | 09 | 96 | 93 | 100 | |
| #6 | Original | 80 | 20 | 89 | 80 | 100 | 78 | 22 | 88 | 78 | 100 | 82 | 18 | 90 | 82 | 100 | |
| #7 | Sharpness And Contrast | 90 | 10 | 95 | 90 | 100 | 91 | 09 | 96 | 93 | 100 | 90 | 10 | 95 | 92 | 100 | |
| #8 | Spatial Distortion | 78 | 22 | 87 | 78 | 100 | 80 | 20 | 89 | 80 | 100 | 77 | 23 | 79 | 77 | 100 | |
| Average | 86.6 | 13.3 | 92.6 | 86.12 | 100 | 86.3 | 13.62 | 92.6 | 86.6 | 100 | 86.8 | 13.1 | 91.7 | 87.3 | 100 | ||
| Naïve | #1 | Blur | 80 | 20 | 90 | 77 | 89 | 85 | 15 | 88 | 92 | 94 | 90 | 10 | 95 | 97 | 91 |
| #2 | Brightness Change | 56 | 44 | 70 | 90 | 57 | 80 | 20 | 85 | 90 | 97 | 83 | 17 | 92 | 88 | 97 | |
| #3 | Color Distortion | 58 | 42 | 71 | 89 | 59 | 81 | 19 | 87 | 88 | 94 | 82 | 18 | 90 | 86 | 92 | |
| #4 | Compression | 54 | 46 | 67 | 78 | 58 | 68 | 32 | 78 | 86 | 90 | 85 | 15 | 93 | 90 | 96 | |
| #5 | Noise | 55 | 45 | 68 | 92 | 55 | 82 | 18 | 84 | 78 | 99 | 80 | 20 | 88 | 87 | 81 | |
| #6 | Original | 59 | 41 | 72 | 77 | 68 | 70 | 30 | 79 | 88 | 95 | 90 | 10 | 95 | 91 | 99 | |
| #7 | Sharpness And Contrast | 51 | 49 | 66 | 93 | 51 | 86 | 14 | 90 | 87 | 100 | 81 | 19 | 89 | 81 | 100 | |
| #8 | Spatial Distortion | 58 | 42 | 73 | 74 | 73 | 75 | 25 | 81 | 77 | 96 | 79 | 21 | 88 | 79 | 100 | |
| Average | 58.8 | 41.1 | 72.1 | 83.75 | 63.7 | 78.3 | 21.62 | 84 | 85.7 | 95.6 | 83.7 | 16.2 | 91.2 | 87.3 | 94.5 | ||
| Methods | Design | Feature Extraction | Classifier | Dataset | Accuracy (%) |
|---|---|---|---|---|---|
| Li and Lizhuang [8] | Non-lightweight | Vgg16 | SVM | Dataset collection | 74 |
| He et al. [10] | Non-lightweight | SGDNet | Sklearn MultiOutputClassifier | LIVE | 83 |
| Zhou et al. [7] | Non-lightweight | CNN-LeNet-5 | DNN | MNIST | 77 |
| Saurabh et al. [13] | Non-lightweight | Deep Neural Network | DDICM Classifier | Dataset collection | 95 |
| Hossain et al. [16] | Non-lightweight | DCT-Net | VGG16 | ImageNet | 54 |
| Samuel and Lina [9] | Non-lightweight | VGG16, GoogLeNet, and ResNet50 | DNN | ImageNet | 92 |
| Basu et al. [11] | Non-lightweight | Deep Belief Net | a feed-forward backpropagation neural network | MNIST | 89 |
| Proposed (SqueezeNet-KNN) | Lightweight | SqueezeNet | KNN | kadid10k | 89 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ahmed, I.T.; Abdulazeez, F.A.; Hammad, B.T. Employing Different Algorithms of Lightweight Convolutional Neural Network Models in Image Distortion Classification. Computers 2024, 13, 268. https://doi.org/10.3390/computers13100268
Ahmed IT, Abdulazeez FA, Hammad BT. Employing Different Algorithms of Lightweight Convolutional Neural Network Models in Image Distortion Classification. Computers. 2024; 13(10):268. https://doi.org/10.3390/computers13100268
Chicago/Turabian StyleAhmed, Ismail Taha, Falah Amer Abdulazeez, and Baraa Tareq Hammad. 2024. "Employing Different Algorithms of Lightweight Convolutional Neural Network Models in Image Distortion Classification" Computers 13, no. 10: 268. https://doi.org/10.3390/computers13100268
APA StyleAhmed, I. T., Abdulazeez, F. A., & Hammad, B. T. (2024). Employing Different Algorithms of Lightweight Convolutional Neural Network Models in Image Distortion Classification. Computers, 13(10), 268. https://doi.org/10.3390/computers13100268