Abstract
Spam reviews pose a significant challenge to the integrity of online platforms, misleading consumers and undermining the credibility of genuine feedback. This paper introduces an innovative AI-generated spam review detection framework that leverages Deep Learning algorithms and Natural Language Processing (NLP) techniques to identify and mitigate spam reviews effectively. Our framework utilizes multiple Deep Learning models, including Convolutional Neural Networks (CNNs), Long Short-Term Memory (LSTM) networks, Gated Recurrent Unit (GRU), and Bidirectional LSTM (BiLSTM), to capture intricate patterns in textual data. The system processes and analyzes large volumes of review content to detect deceptive patterns by utilizing advanced NLP and text embedding techniques such as One-Hot Encoding, Word2Vec, and Term Frequency-Inverse Document Frequency (TF-IDF). By combining three embedding techniques with four Deep Learning algorithms, a total of twelve exhaustive experiments were conducted to detect AI-generated spam reviews. The experimental results demonstrate that our approach outperforms the traditional machine learning models, offering a robust solution for ensuring the authenticity of online reviews. Among the models evaluated, those employing Word2Vec embeddings, particularly the BiLSTM_Word2Vec model, exhibited the strongest performance. The BiLSTM model with Word2Vec achieved the highest performance, with an exceptional accuracy of 98.46%, a precision of 0.98, a recall of 0.97, and an F1-score of 0.98, reflecting a near-perfect balance between precision and recall. Its high F2-score (0.9810) and F0.5-score (0.9857) further highlight its effectiveness in accurately detecting AI-generated spam while minimizing false positives, making it the most reliable option for this task. Similarly, the Word2Vec-based LSTM model also performed exceptionally well, with an accuracy of 97.58%, a precision of 0.97, a recall of 0.96, and an F1-score of 0.97. The CNN model with Word2Vec similarly delivered strong results, achieving an accuracy of 97.61%, a precision of 0.97, a recall of 0.96, and an F1-score of 0.97. This study is unique in its focus on detecting spam reviews specifically generated by AI-based tools rather than solely detecting spam reviews or AI-generated text. This research contributes to the field of spam detection by offering a scalable, efficient, and accurate framework that can be integrated into various online platforms, enhancing user trust and the decision-making processes.
1. Introduction
The proliferation of online reviews has become a cornerstone of the digital economy, profoundly influencing consumer purchasing decisions and the reputations of businesses. With the vast majority of consumers relying on online reviews to inform their choices, the integrity and authenticity of these reviews are paramount. However, the burgeoning prevalence of spam reviews, which are often fabricated to manipulate public perception, poses a significant threat to the credibility of online platforms. This necessitates the development of robust mechanisms for spam review detection. The advent of artificial intelligence (AI) and its subfields, particularly Deep Learning and Natural Language Processing (NLP), has revolutionized the way we address complex data analysis tasks. AI technologies offer powerful tools for the automatic identification and mitigation of spam reviews. Deep Learning algorithms, with their ability to learn hierarchical representations from large datasets, and NLP techniques, which enable the understanding and manipulation of human language, together provide a formidable approach to spam review detection. Online reviews are integral to the digital marketplace, providing valuable insights and influencing consumer behavior. However, the anonymity and reach of the internet have made it a fertile ground for fraudulent activities, including the posting of spam reviews. These reviews are often generated to artificially inflate or deflate product ratings, leading to misleading information for potential buyers and unfair competition among businesses. Fake reviews pose significant threats to companies’ profits and consumers’ well-being, presenting a serious concern for online users [1]. Given the widespread reliance on reviews, they can greatly impact the online marketplace [2]. Reviews have become a crucial component of social media and e-commerce experiences due to platforms’ algorithmic decision-making mechanisms. Therefore, the quality of reviews is vital for brands, e-commerce sites, social media platforms, and other stakeholders invested in online business. Identifying fake reviews, especially those generated by AI-based tools and algorithms, is therefore of paramount importance.
Fake reviews can be created through two primary methods: first, in a (a) human-generated manner, by paying content creators to write realistic-looking but fictitious reviews of products they have never used; and, second, in a (b) computer-generated manner, using next-generation tools such as ChatGPT, Bard, etc., to automate the creation of fake reviews. Traditionally, human-generated fake reviews have been traded like commodities in a “market of fakes” [3], where one can order reviews in bulk, and human writers produce them. However, advancements in text generation—specifically in Natural Language Processing (NLP) and machine learning (ML)—have promoted the automation of fake reviews. With generative language models, fake reviews can now be produced at scale and at a fraction of the cost compared to human-generated fake reviews.
The traditional methods for spam review detection, such as rule-based systems and simple machine learning models, have proven to be insufficient in the face of increasingly sophisticated spam techniques. These methods often rely on predefined patterns and fail to adapt to new and evolving spam strategies. Consequently, there is a pressing need for more advanced and adaptable detection systems. Deep Learning has emerged as a powerful paradigm in AI, capable of learning complex patterns and representations from data. Techniques such as Convolutional Neural Networks (CNNs), Long Short-Term Memory (LSTM) networks, and Transformer models have achieved remarkable success in various domains, including image recognition, speech processing, and, crucially, text analysis. NLP, on the other hand, focuses on the interaction between computers and human language. By employing techniques such as tokenization, Term Frequency-Inverse Document Frequency (TF-IDF), and word embeddings, NLP enables machines to process and understand textual data. When combined with Deep Learning, NLP can enhance the ability to detect and interpret the subtle cues that differentiate spam reviews from genuine ones.
Despite advancements in AI, detecting spam reviews remains a challenging issue. Spam reviews are often meticulously crafted to closely resemble genuine ones, making them difficult to identify through surface-level analysis. Individuals and organizations frequently create and manage networks of fake or anonymous profiles on social media platforms to produce these spam reviews [4]. Numerous studies, including [5,6,7], have been conducted to combat these falsified identities. However, these deceptive practices continue to evolve with new strategies over time. Furthermore, the dynamic nature of spam tactics requires detection systems that can continuously learn and adapt. The primary objective of this research is to develop a comprehensive AI-generated spam review detection framework that leverages the strengths of Deep Learning and NLP. Our framework aims to accurately detect spam reviews by analyzing large volumes of textual data, identifying deceptive patterns, and adapting to new spam techniques.
This research paper presents an AI-generated spam review detection framework that leverages state-of-the-art Deep Learning algorithms and advanced NLP techniques. Our framework is designed to capture the nuanced and often deceptive patterns present in spam reviews, thereby improving the accuracy and reliability of detection systems. By addressing the critical issue of spam review detection through advanced AI techniques, this research aims to enhance the reliability of online reviews, thereby fostering greater trust and transparency in the digital marketplace.
This paper makes several significant contributions to the field of spam review detection:
- Integration of Deep Learning Models: We incorporate multiple Deep Learning architectures, including CNNs, LSTMs, and Transformer models, to capture various aspects of textual data and enhance the detection accuracy.
- Advanced NLP Techniques: By utilizing NLP methods such as tokenization, TF-IDF, and word embeddings, our framework can process and analyze the intricacies of human language in reviews.
- Comprehensive Evaluation: We train and evaluate our framework on a large, diverse dataset, demonstrating its effectiveness and robustness in identifying spam reviews across different contexts and platforms.
- Scalability and Efficiency: Our framework is designed to be scalable, ensuring that it can handle large volumes of data in real time, making it suitable for integration into existing online platforms.
- Adaptability: The framework is capable of learning and adapting to new spam tactics, ensuring long-term effectiveness in the ever-evolving landscape of online reviews.
The remainder of this paper is organized as follows: Section 2 provides a review of the related work in spam review detection and the application of AI in this domain. Section 3 details the process of data collection and preprocessing. The experimental setup is described in Section 4. In Section 5, we present the results of 12 different experiments, along with observations and a discussion of our framework’s performance. This section also presents the statistical analysis of classifier performance via the Analysis of Variance (ANOVA) test. A comparative study is included in Section 6. Section 7 provides a discussion on the ethical issues in AI-generated fake reviews. Finally, Section 8 concludes the paper, and Section 9 outlines the directions for future research.
2. Background Study
A fake review is a review created or generated without any genuine experience of the product or service being reviewed [8]. These reviews can be produced manually by human writers or, increasingly, through advanced AI text-generation tools. Advances in natural language generation technology have made it possible to produce fake reviews on a large scale, making it nearly impossible for humans to distinguish between content created by real individuals and that generated by AI tools [9]. At the same time, online platforms facilitate the widespread dissemination of these fake reviews. With millions of consumers reading online reviews at any given moment, there is a strong incentive to exploit this channel of influence. This creates opportunities for fake reviews to benefit from economies of scale and scope, complicating the efforts to develop effective countermeasures. Opinion spamming, a concept related to fake reviews, involves writing false opinions to sway other users [1], or creating “fictitious opinions” that are deliberately made to appear authentic [10]. Another related concept is incentivized reviews, which are generated through marketing campaigns, such as obtaining influencer endorsements [11] or offering products in exchange for reviews [12]. Unlike fake reviews, which are often authored by anonymous users or generated by algorithms, incentivized reviews are typically associated with identifiable influencers or real individuals.
AI-generated spam reviews are particularly challenging to detect compared to those written by humans. This is due to several factors: AI systems are adept at mimicking human writing styles through advanced Natural Language Processing, making it difficult to distinguish between authentic and fake reviews. AI’s ability to produce reviews in large quantities can overwhelm the traditional detection systems, complicating spam filtering efforts. Moreover, sophisticated algorithms allow AI to generate reviews with nuanced, seemingly genuine language, reducing the effectiveness of keyword-based or heuristic detection methods. AI’s ability to adapt and evolve in response to detection attempts further enhances its ability to bypass filters. Additionally, AI-generated content often appears contextually relevant and well-structured, which can mislead both automated systems and human reviewers. The potential for AI to replicate real user writing styles and tones further complicates spam identification, underscoring the need for robust detection frameworks that leverage Deep Learning and advanced Natural Language Processing techniques to address this issue effectively.
Studies such as [13,14] have utilized traditional machine learning algorithms to distinguish between AI-generated text and content authored by humans. The first of these studies concentrates on applications within the health sector, while the latter analyzes written responses from students. In addition, some researchers, including [15,16], have proposed statistical outlier detection techniques that rely on measures such as entropy, perplexity, and n-gram frequency to differentiate between human-written and machine-generated texts. With the advent of OpenAI’s ChatGPT, a novel statistical detection method named DetectGPT is introduced [17]. This method operates on the principle that the text generated by the model tends to exist in areas of negative curvature within the model’s log probability. DetectGPT creates multiple altered versions of the machine-generated text and compares them to the original, using log probability to assess whether the text is machine-generated. This approach has demonstrated superior performance over many existing zero-shot methods for identifying model-generated samples, achieving notably high AUC scores. Furthermore, another study [18] proposes a Contrastive Domain Adaptation framework called ConDA to tackle the challenge of detecting AI-generated text when labeled target data are unavailable. Similarly, the research presented in [19] employs a range of traditional machine learning techniques, such as Support Vector Machines (SVMs) and Decision Trees, alongside conventional Deep Learning methods like Convolutional Neural Networks (CNNs) and Long Short-Term Memory (LSTM) networks, to differentiate between two datasets. The authors introduce a Tunicate Swarm Algorithm (TSA) paired with a Long Short-Term Memory Recurrent Neural Network (TSA-LSTMRNN) model to detect both human-written and ChatGPT-generated content.
Researchers have employed various strategies over time to detect fake reviews. One fundamental approach involves manually analyzing reviews, operating on the hypothesis that humans can recognize fraudulent behavior based on their understanding of the “psychology of lying” [20]. For instance, ref. [12] identifies a set of rules to distinguish between incentivized and non-incentivized reviews, such as the review’s length, sentiment, and helpfulness rate. Another study [21] recognizes general patterns in online reviews, like a limited number of reviews per user and product and minimal feedback on the reviews. Reviews that deviate from these patterns are more likely to be fake. Additionally, ref. [22] investigates how people assess the trustworthiness of online reviews, considering factors such as content, writing style, the inclusion of pictures, length, detail, and extreme positivity or negativity. However, human judgment is not always reliable. For example, ref. [10] finds that humans could identify fake reviews with 65% accuracy, whereas a machine learning model achieved 86%. Other studies, like [23,24], report even lower human detection accuracy at 57% and 52%, respectively, despite being informed about fake reviews.
One major challenge of manual detection is the exponential growth of online reviews. TripAdvisor, for example, has reported receiving over 200 million reviews [2]. Given that a single product can receive thousands of reviews and there are millions of products, the manual methods are not scalable. As a result, researchers have turned to automatic methods to address the fake review detection problem. Algorithms can mine data for patterns, including those that are not easily interpretable by humans. According to [25], the automated methods can be divided into (a) content-based detection (focused on the textual content of reviews), (b) behavior-based detection (focused on unusual and suspicious behaviors), (c) information-based detection (focused on product characteristics), and (d) spammer group detection (focused on identifying connections between reviewers).
Other researchers have primarily focused on either textual or non-textual techniques. Studies using Natural Language Processing (NLP) techniques [21,26,27,28] analyze lexical features such as keywords, phrases, n-grams, punctuation, semantic similarity, latent topics, and linguistic style indicators to detect fake reviews. The authors in [27] examine non-textual predictive features, like user ID, user location, and the number of reviews generated by a user, to differentiate between genuine and fake (human-authored or AI-generated) reviews. Some studies [2,10] have combined textual and non-textual features to evaluate the performance of review detection systems.
One notable approach is the use of statistical data compression models for spam filtering, as highlighted by the researchers in [29]. In their work, they suggest that spam emails often contain repetitive, patterned content, making them suitable for compression-based classifiers. These models analyze the redundancy in email data, allowing them to distinguish between spam and legitimate emails. Focusing on the compressibility of the text offers a unique and efficient method of spam detection, which is particularly useful when handling large volumes of data. Another study in [30] highlights that Support Vector Machines (SVMs), AdaBoost, and Maximum Entropy models outperform other classifiers in spam filtering, being robust to feature selection strategies. In contrast, Naive Bayes struggles with small feature sets and high false-positive penalties. The study also advises against aggressive feature pruning and reveals that email headers, often overlooked, can be as effective as body features for spam detection. The authors in the study [31] tackle the challenge of detecting fake reviews amidst the rise of online purchases. They highlight the limitations of traditional machine learning methods, which often overlook the linguistic context of words. To address this, the study proposes a novel approach that combines bag-of-words and word context through n-grams and the skip-gram word embedding technique, creating high-dimensional feature representations. These features are classified using a deep feed-forward neural network. Experimental results from two hotel review datasets show that the proposed method outperforms existing algorithms in accuracy and ROC curve area while maintaining balanced performance across legitimate and spam reviews. This research underscores the effectiveness of integrating deep learning with contextual word embeddings for improved review spam detection.
Our study is distinct in that it focuses on detecting fake reviews generated by AI-based tools and distinguishing them from human-written ones. This approach ensures that reviews likely to be fake or spam are identified. Our classification method will use combined features to differentiate AI-generated reviews from human-authored ones. One of the primary goals of this study is to detect AI-generated reviews on e-commerce platforms.
3. Data Collection and Preprocessing
In this section, we detail the data collection and preprocessing process, which forms the foundation of our research. The integrity and quality of the dataset are paramount for the effective training and evaluation of any AI model. Here, we describe the steps taken to gather relevant datasets, including human-authored and AI-generated fake reviews, and the methods employed to prepare these data for analysis. This includes cleaning, filtering, and transforming the raw data into a format suitable for the application of Deep Learning algorithms, ensuring that the models receive accurate and representative inputs.
3.1. Data Collection
As illustrated in Figure 1, our research began by utilizing publicly available datasets containing fake or spam reviews. These datasets comprised samples that were either fake/spam or genuine/non-spam, predominantly written by humans.
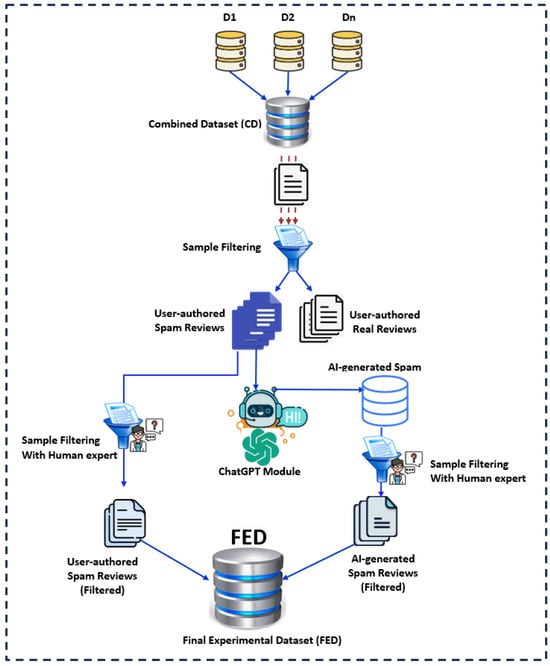
Figure 1.
Detailed data collection procedure.
One of the primary datasets utilized in this research is derived from the study by authors in [32]. This dataset comprises both human-authored and computer-generated review samples. Our objective is to distinguish between spam reviews generated by AI and other reviews, whether spam or non-spam. To achieve this, we isolated the human-authored reviews from the dataset and processed each instance using the AI tool previously discussed, thereby generating AI-crafted spam review instances. The inclusion of this particular study in our research is primarily due to its provision of ground-truth samples. In this study, crowd workers were employed to evaluate whether a given review was written by a human or generated by a computer. Each review underwent evaluation by three different crowd workers, resulting in a total of 3000 individual ratings. The data collection process was conducted through the Appen crowdsourcing platform, for which we had an institutional license. To ensure the quality of the data, the platform’s higher quality setting was activated. This setting, as described by Appen, limits the pool of contributors to a smaller, more experienced group with a proven track record of higher accuracy based on their performance in previous tasks on the platform.
We first combined these datasets and then separated them into two distinct files, as depicted in the subsequent figure. This separation was crucial because our research focuses on analyzing spam reviews, whether they are human-written or AI-generated. Our ultimate goal is to develop a method to differentiate between these two types of spam reviews.
As illustrated in the figure, data were gathered from multiple existing datasets (denoted as D1, D2, …Dn) and consolidated into a single combined dataset (CD). This combined dataset underwent a filtering process, resulting in two sets of samples: S1, containing user-authored spam review samples, and S2, containing user-authored real review samples. Since the focus of this research is on fake or spam reviews, the S2 set was discarded. The user-authored spam review samples from S1 were then processed through the ChatGPT [33] module to generate AI-based spam instances, followed by a human filtering process to eliminate any irrelevant or unwanted samples. The refined user-authored spam review samples were then combined with the newly generated AI-based spam instances to create the final experimental dataset (FED). In our FED databases, we have approximately 19,000 samples of human-written spam reviews. Using these as a base, we generated around 22,000 AI-generated spam reviews.
One of the key motivations behind generating 22,000 AI-based spam reviews was to maintain a balanced dataset, which is critical for effective training and evaluation in machine/Deep Learning models, especially when comparing human-written and AI-generated spam reviews. After the filtering process (discussed in the Data Preprocessing section), we were left with approximately 19,000 human-written samples. To ensure the dataset was balanced, we aimed to generate and filter a similar number of AI-generated samples, which resulted in approximately 22,000 AI-generated reviews. Maintaining the balance between the two classes (human-written and AI-generated spam) was essential for avoiding biased model performance. An imbalanced dataset can lead to overfitting toward the majority class, compromising the model’s ability to generalize across both types of reviews. By ensuring a near-equal number of samples in both categories, we improved the reliability of the evaluation and reduced the risk of skewed results. This comprehensive dataset will serve as a critical foundation for further analysis and experimentation, providing a robust framework for understanding and mitigating the impact of spam in various contexts.
In the second stage of data collection, we took the human-written spam samples and input them into an AI text-generation tool, specifically ChatGPT, to create AI-generated fake reviews for our experiments. The process of generating these AI-driven fake/spam reviews is detailed in the pseudocode provided in Figure 2. This step is integral to our study, enabling us to generate a substantial dataset of AI-created spam reviews, which will be instrumental in developing and testing our detection methods later in this research.

Figure 2.
Generating AI-based spam/fake reviews based on human-authored samples.
The algorithm is designed to generate AI-based spam or fake reviews by using existing human-authored fake reviews and specific prompts. It begins with an initialization phase where a string variable, Strcat, is set as an empty string (“”). This variable will later be used to concatenate prompts with human-authored fake reviews. The algorithm relies on two input files: human_fake_reviews.csv, which contains human-written fake reviews, and prompt.csv, which holds a series of prompts to guide the AI models in generating new fake reviews. The main part of the algorithm involves looping through each sample in the human_fake_reviews.csv file. For each review, the algorithm iterates through each prompt in the prompt.csv file. During each iteration, the current prompt and review are concatenated into a single string using Strcat. This string is then fed into the ChatGPT module, which generates a new AI-based fake review based on the combined content. The output from this module is stored temporarily in Output_file.csv. After processing all prompts for each review sample, the algorithm enters a post-processing phase. It examines each item in the Output_file.csv. If an item is found to be empty, it is skipped to avoid including invalid or incomplete data. For non-empty items, the AI-generated fake reviews are written into a final output file named ai-generated_fake_samples.csv, which will contain all the valid AI-generated reviews produced during the process. The algorithm concludes by printing a message to indicate that the AI-generated spam review file has been successfully created. This output file, ai-generated_fake_samples.csv, can then be used for further analysis, such as testing the effectiveness of fake review detection systems. The algorithm automates the generation of AI-based fake reviews, providing a useful tool for researchers investigating the challenges posed by AI in online review manipulation.
The CheckEmptyRows function is defined to accept a file path as input and initializes a counter—empty_row_count—to zero for tracking the number of empty rows. The function begins a TRY block, enabling error handling in the event of exceptions. It then opens the specified file for reading and iterates through each line using a loop that includes the row number. During each iteration, the function checks if the line is empty, containing only white space. If an empty line is detected, a message is printed to indicate the row number and that it returned null, while the empty_row_count is incremented accordingly for each empty row found. In addition to identifying empty rows, the function also tracks the number of invalid or incomplete data points that were skipped during processing. By implementing a robust error-handling mechanism, the system effectively filters out entries that do not meet the required criteria, ensuring that the dataset remains clean and reliable. After processing the entire file, the function prints the total count of empty rows identified and generates a report that indicates the total count of invalid or incomplete data points excluded, providing valuable insights into data quality and the effectiveness of the filtering process. In the event of any errors during file processing, a CATCH Exception block is triggered to catch these errors and print an appropriate error message. Furthermore, another function is incorporated to check if the required GPT model responds to the user prompts properly. The algorithmic function is presented in Figure 3.

Figure 3.
Check for the working of GPT Module.
In the process of generating AI-based spam reviews from user-written spam reviews, this function includes a crucial step to ensure the proper functioning of the ChatGPT module. A try block is used to initialize the ‘ChatGPT-module.mdl’, verifying if the module is responding correctly. If the module is unresponsive, the system raises an exception, generating a custom error message to indicate that the ChatGPT module is not functioning as expected. This exception is then caught in a catch block, which handles the error by capturing the issue related to the ChatGPT module and printing an appropriate error message. This approach ensures that the system can gracefully handle any failures with the module and notify the user when the module is not responding.
3.2. Data Preprocessing
It is well established that most machine learning and Deep Learning algorithms struggle with raw, unprocessed data as such content is not inherently machine-understandable. To ensure that the data are suitable for analysis, a thorough preprocessing phase is essential before they are fed into any learning algorithm. In this study, we have conducted meticulous data preprocessing, as depicted in Figure 4. The initial data, collected from various sources, are stored in separate databases as CSV files. Prior to analysis, these data undergo a series of cleaning, normalization, and preprocessing steps, which are crucial for enhancing the quality and reliability of the dataset.
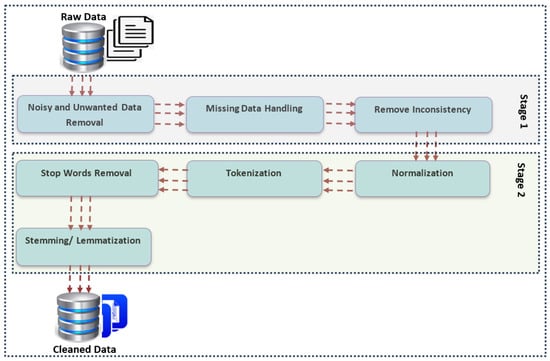
Figure 4.
Data preparation and preprocessing with NLTK toolkit.
The following strategies have been applied to identify and exclude irrelevant or unwanted samples from the dataset. The collected data samples from various existing sources were initially stored in a temporary database before being merged with AI-generated data, including outputs from tools like ChatGPT. Due to the heterogeneous nature of the datasets, which differed in terms of column structures and data formats, a preprocessing step was crucial to standardize and integrate the data. For example, the dataset referenced in [32], containing both spam and AI-generated reviews, had multiple columns. To simplify this, we retained only the essential columns and introduced a new label titled “User-authored Spam Review”, where all records were initially assigned the label “human-written” (class 0). This step ensured that the dataset was streamlined for our subsequent analysis.
To enhance the relevance and quality of the dataset, we applied several filtering criteria. Specifically, any reviews with fewer than two keywords were excluded as such samples are difficult to represent meaningfully through common embedding techniques. We also systematically removed records from other datasets that were irrelevant to our study, such as reviews that discussed off-topic subjects or were duplicates of existing entries. Furthermore, samples with unclear classifications, as determined by human annotations, or those written in languages other than English, were eliminated to maintain consistency. Each data instance underwent a thorough cleaning and validation process to ensure high data quality. This involved detecting and correcting errors, inconsistencies, and anomalies. During the data cleaning phase, we addressed issues such as missing values, duplicates, and outliers. Moreover, data formatting issues, including the presence of HTML tags, excessive white spaces, numbers, and special characters, were resolved.
To maintain the dataset’s robustness and reliability, instances with more than 50% missing data or predominantly NaN entries were excluded. For the remaining records, missing values were imputed using either the mean of the corresponding feature or the minimum feasible value, ensuring that the data’s underlying statistical properties and distribution remained intact.
These cleaning operations were essential to create a uniform dataset suitable for further processing. Once the data were cleaned, a manual annotation process was conducted, where each sample was reviewed and labeled by three independent human annotators to ensure the accuracy of the assigned labels. Any ambiguous or mislabeled entries were removed during this step. After all datasets were standardized and converted into a consistent format, they were merged into a single cohesive dataset named “user-authored-spam-reviews(filtered).csv”. This consolidated dataset was then used for subsequent analyses, providing a reliable foundation for detecting and understanding AI-generated spam reviews.
In the second stage of data preparation, as shown in Figure 4, the cleaned data are processed through the Natural Language Toolkit (NLTK) libraries [34] for further analysis. NLTK provides a suite of text-processing libraries that are essential for the Natural Language Processing (NLP) tasks in this study. The NLTK pipeline includes several key steps: normalization, tokenization, stop word removal, stemming, and lemmatization.
Normalization standardizes the text by converting all characters to lowercase, which helps to maintain consistency across the dataset. Tokenization breaks down the raw text into smaller units, or tokens, which are crucial for understanding context and building NLP models. NLTK’s tokenization tools include models like word tokenization and sentence tokenization, which are used to dissect the text into manageable components. Stop words, such as “the”, “is”, and “and”, are common in English but provide little value for classification tasks, so they are removed to reduce noise in the data. Stemming reduces words to their root forms, effectively mapping a group of words to a common base, even if that base is not a valid word. Lemmatization, similar to stemming, ensures that words are reduced to their base or root form, but it goes further by producing valid words in the language.
It has been noted that, beyond data preprocessing, other factors are also essential in designing an effective text-based prediction system. For instance, feature selection plays a critical role in enhancing classifier performance by identifying the most relevant features. Prior research, including studies [35,36] on citation intent classification and Arabic sentiment analysis, has demonstrated the effectiveness of word embeddings and Deep Learning, which can be adapted to improve spam detection models. Furthermore, the MPAN model presented in [37], with its multilevel parallel attention mechanisms, enhances precision and recall by concentrating on key aspects of the review text. Its robustness across different domains underscores its potential to handle the diverse nature of spam reviews, making detection methods more resilient and effective.
4. Experimental Setup
After preprocessing the raw and unstructured data using the NLTK Python package [34], the output consists of cleaned data samples. Before proceeding with data analysis using various classification models, these cleaned samples undergo a manual filtering process. In this step, each data instance is carefully labeled by three human annotators. This ensures the accuracy of the labeling and eliminates any ambiguous tuples. The resulting annotated samples are then passed through several text embedding techniques, including One-Hot Encoding, Word2Vec, and TF-IDF, to prepare the data for training Deep Learning models such as Convolutional Neural Networks (CNNs), Long Short-Term Memory (LSTM) networks, Gated Recurrent Unit (GRU), and Bidirectional LSTM (BiLSTM). These three sample representation techniques, when combined with the four Deep Learning models, result in a total of 12 (3 × 4) individual experiments. The schematic representation of the comprehensive experimental configuration is depicted in Figure 5. For each experiment, the dataset is divided into a training set and a validation set with an 80:20 ratio, respectively. After training, the performance of each algorithm is evaluated using a separate subset of the original dataset.
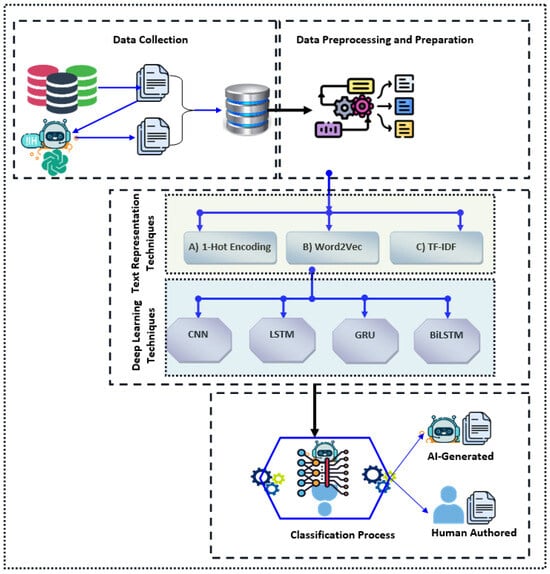
Figure 5.
Experimental setup and configuration.
To assess the performance of the models, we employed several evaluation metrics, including accuracy, precision, recall, F1-score, and the Matthews Correlation Coefficient (MCC). The confusion matrix, provided in Table 1, forms the basis for these evaluations.

Table 1.
Confusion matrix.
To achieve a balanced performance evaluation that considers both precision and recall, we utilized the Fβ-score (or F-measure). The Fβ-score estimates the model’s performance on a given dataset by combining its precision and recall, and it is defined as the harmonic mean of these two metrics. The formula for calculating the Fβ-score is as follows:
The Fβ-score is a generalization of the standard F-score, incorporating a configuration parameter called beta (). The default beta value is 1.0, which corresponds to the standard F1-score. A lower beta value (e.g., ) places greater emphasis on precision, while a higher beta value (e.g., ) prioritizes recall. This flexibility is particularly useful when the importance of false negatives versus false positives varies, allowing the metric to be adjusted accordingly. The specific method used to calculate the F1-score in our study is detailed in Equation (5).
The Matthews Correlation Coefficient (MCC), also known in statistics as the phi coefficient, measures the association between two binary variables. In the context of machine learning, MCC is a robust metric for evaluating the quality of binary classifications. Unlike the F1-score, MCC provides a more balanced assessment, producing a high score only when the classification performs well across all four categories of the confusion matrix (true positives, false negatives, true negatives, and false positives). Due to this balance, MCC is often preferred over the F1-score for a more comprehensive evaluation of classification models, regardless of which class is designated as positive. The mathematical formula for calculating MCC is presented in Equation (6).
5. Experimental Results and Observations
As already mentioned in Section 3, the final experimental dataset (FED) contains a total of 41,000 samples, including 19,000 samples for human-written spam reviews and and around 22,000 for AI-generated samples. These samples are presented with text embedding techniques including One-Hot Encoding, Word2Vec, and TF-IDF to train Deep Learning models including Convolutional Neural Networks (CNNs), Long Short-Term Memory (LSTM) networks, Gated Recurrent Unit (GRU), and Bidirectional LSTM (BiLSTM). In evaluating the performance of these classification models, the elements of the confusion matrix, namely true positives (TPs), false negatives (FNs), true negatives (TNs), and false positives (FPs), play crucial roles in assessing accuracy and effectiveness. Each of these elements is briefly discussed below:
- True Positives (TPs) are the cases where the model correctly identifies positive instances. High TP values indicate that the model is effective at recognizing and classifying relevant positive cases, which is essential for tasks where correctly identifying positive instances is critical, such as in spam detection or medical diagnosis. The mathematical formula for calculating number of true positives (TPs) is presented below:
- False Negatives (FNs) represent the cases where the model fails to identify positive instances, misclassifying them as negative. A high FN count suggests that the model is missing important positive cases, which can be problematic in scenarios where failing to detect positives could have significant consequences, like in fraud detection or disease screening. Formally, false negatives (FNs) can be estimated as shown in Equation (8):
- True Negatives (TNs), as shown in Equation (9), are instances where the model correctly identifies negative cases. High TN values demonstrate that the model effectively excludes non-relevant cases. This is important for ensuring that the model is good at identifying positive cases and accurate in ruling out irrelevant ones.
- False Positives (FPs) are the cases where the model incorrectly classifies negative instances as positive. A high FP count indicates that the model is over-predicting positive cases, which can lead to unnecessary actions or interventions. This is particularly critical in scenarios where false alarms can lead to inefficiencies or increased costs, such as in automated email filtering or security screening. Mathematically, false positives (FPs) can be calculated as shown in Equation (10):
Overall, these metrics provide a comprehensive view of a model’s performance by highlighting its strengths and weaknesses in correctly identifying and excluding instances. Balancing these elements is key to developing models that are both accurate and reliable in real-world applications. Regarding the values obtained for each of the confusion matrix elements against each embedding technique and Deep Learning algorithm, the best-performing models for each embedding technique demonstrate varying strengths in text classification.
For One-Hot Encoding, the LSTM_One-Hot Encoding model stands out with an impressive performance. It achieved 18,455 true positives (TPs) and 545 false negatives (FNs), indicating its strong ability to correctly identify positive instances while minimizing missed positive cases. The model also correctly identified 21,299 negative instances (TNs) with 701 false positives (FPs), reflecting its overall effectiveness in classification with One-Hot Encoding. This performance highlights the LSTM’s ability to capture sequential information effectively, even though One-Hot Encoding limits semantic depth. Similarly, in the realm of Word2Vec, the BiLSTM_Word2Vec model excels as the top performer. It recorded 18,609 true positives and only 391 false negatives, showcasing its exceptional accuracy in identifying positive instances while minimizing errors. The model also achieved 21,760 true negatives and just 240 false positives, underscoring its ability to distinguish between positive and negative instances accurately. The BiLSTM’s bidirectional processing combined with Word2Vec’s rich semantic embeddings result in superior performance, capturing both contextual and semantic nuances effectively. As shown in the Figure 6, for TF-IDF, the CNN_TF-IDF model is the best performer. It achieved 18,107 true positives and 893 false negatives, demonstrating its effectiveness in detecting positive instances while managing a reasonable number of missed cases. The model identified 21,291 true negatives and 709 false positives, indicating good performance despite the limitations of TF-IDF in capturing semantic relationships. CNN’s pattern recognition capabilities combined with TF-IDF’s term importance scoring contribute to its effective performance in text classification. Now, we can clearly state that the BiLSTM with Word2Vec embedding was the best-performing model, followed by the LSTM with One-Hot Encoding, in detecting AI-generated spam. The BiLSTM with Word2Vec achieved the highest true positives (18,609) and true negatives (21,760), with the lowest false negatives (391) and false positives (240), making it the most accurate. Its superior performance is due to BiLSTM’s bidirectional processing and Word2Vec’s ability to capture semantic relationships, improving context understanding. The LSTM with One-Hot Encoding was the second-best, with 18,455 true positives and 21,299 true negatives. Despite the limitations of One-Hot Encoding, LSTM’s strength in modeling sequences allowed it to perform well by capturing dependencies between words that signal spam.
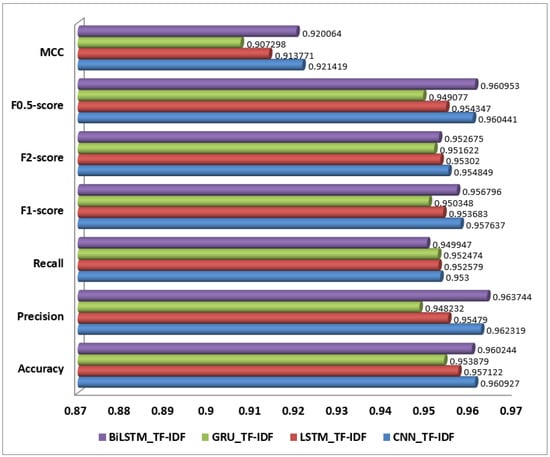
Figure 6.
Performance of selected Deep Learning models on TF-IDF representation.
Overall, these results reflect the strengths of different models and embedding techniques in handling text classification tasks. LSTM with One-Hot Encoding performs well in sequence modeling, BiLSTM with Word2Vec excels in capturing deep semantic and contextual information, and CNN with TF-IDF shows robust pattern recognition capabilities. Furthermore, the values obtained for all 12 experiments are presented in Table 2.
Table 2.
Model confusion matrix elements.
Based on the performance metrics (including accuracy, precision, recall, F1-score, and MCC) obtained for each model, the results presented in the Table 3 highlight the effectiveness of various combinations of model architectures and text embeddings in text classification tasks.
Table 3.
Performance of CNN, LSTM, GRU, and BiLSTM.
The BiLSTM with Word2Vec model achieved the highest performance with an accuracy of 98.46%, precision of 0.98, recall of 0.97, and an F1-score of 0.98. This exceptional performance can be attributed to BiLSTM’s ability to process text in both forward and backward directions, capturing dependencies from all contexts in the text. Word2Vec embeddings further enhance this ability by providing rich semantic representations of words, leading to the model’s superior ability to understand and classify nuanced text accurately. The LSTM model with the Word2Vec model also performed exceptionally well, with an accuracy of 97.58%, precision of 0.97, recall of 0.96, and an F1-score of 0.97. The LSTM’s effectiveness in capturing sequential dependencies, combined with the semantic depth of Word2Vec embeddings, contributes to its strong performance. Although slightly lower than the BiLSTM model, it still demonstrates robust capabilities in handling text classification tasks, particularly in the case of detecting AI-generated content where context and sequence are crucial. Furthermore, CNN with Word2Vec achieved an accuracy of 97.61%, precision of 0.97, recall of 0.96, and an F1-score of 0.97. CNN’s strength lies in its ability to identify local patterns and phrases, which is enhanced by Word2Vec embeddings that provide semantic meaning. While it performs very well, its ability to capture long-range dependencies is not as strong as LSTM or BiLSTM models, which explains why it ranks just below them in overall performance. The GRU with the Word2Vec model showed an accuracy of 97.35%, precision of 0.97, recall of 0.96, and an F1-score of 0.97. The GRU effectively handles sequential information but does not match the LSTM in capturing complex sequence dependencies. Nevertheless, Word2Vec embeddings still contribute significantly to its performance, providing a solid understanding of text. The performance of each model on Word2Vec feature representation is shown in Figure 7.
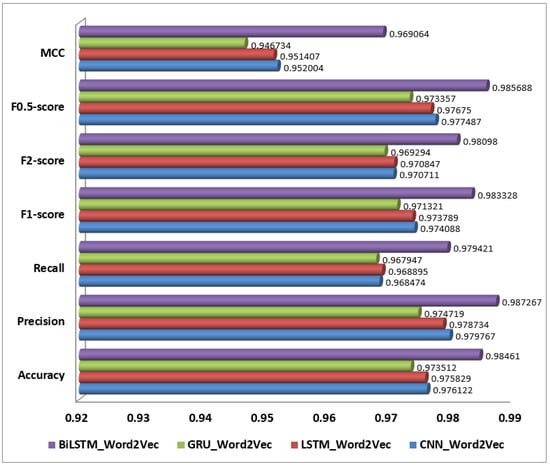
Figure 7.
Performance of selected Deep Learning models on Word2Vec feature representation.
On the other hand, and as presented in Figure 8, models using One-Hot Encoding generally performed lower due to the limitations of this encoding method. The BiLSTM with One-Hot Encoding achieved an accuracy of 96.79%, precision of 95.88%, recall of 97.26%, and an F1-score of 96.56%. While BiLSTM’s bidirectional context capture is beneficial, the lack of semantic depth in One-Hot Encoding restricts overall performance. Similarly, LSTM with One-Hot Encoding had an accuracy of 96.96%, precision of 96.34%, recall of 97.13%, and an F1-score of 96.73%, reflecting good performance but limited by the encoding method.
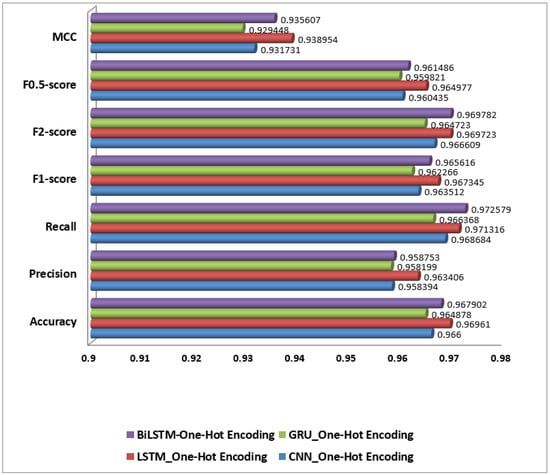
Figure 8.
Performance of selected Deep Learning models on One-Hot Encoding.
CNN with One-Hot Encoding recorded an accuracy of 96.69%, precision of 95.84%, recall of 96.87%, and an F1-score of 96.35%. Despite CNN’s ability to identify local patterns, One-Hot Encoding’s lack of semantic meaning affects its performance. The GRU with One-Hot Encoding achieved an accuracy of 96.49%, precision of 95.82%, recall of 96.64%, and an F1-score of 96.23%, showing similar limitations.
Models using TF-IDF generally performed the lowest for differentiating between human-authored and AI-generated spam reviews. The CNN with TF-IDF had an accuracy of 96.09%, precision of 96.23%, recall of 95.30%, and an F1-score of 95.76%. TF-IDF captures word importance but lacks contextual information, limiting the model’s effectiveness. BiLSTM with TF-IDF achieved an accuracy of 96.02%, precision of 96.37%, recall of 94.99%, and an F1-score of 95.68%, performing slightly better than other TF-IDF models but still below those using Word2Vec. LSTM with TF-IDF had an accuracy of 95.71%, precision of 95.48%, recall of 95.26%, and an F1-score of 95.37%, showing limited performance. Finally, GRU with TF-IDF had the lowest metrics, with an accuracy of 95.39%, precision of 94.82%, recall of 95.25%, and an F1-score of 95.03%, reflecting the challenges of using TF-IDF with sequential models.
It is to be noted that, in the context of detecting AI-generated spam reviews, relying solely on accuracy can lead to an overestimation of model performance, particularly when dealing with imbalanced datasets. While models like LSTM_One-Hot Encoding show high accuracy (e.g., 0.9696), this metric alone does not reflect the model’s ability to effectively distinguish between spam and legitimate reviews. A model might classify the majority class (legitimate reviews) correctly, boosting accuracy but failing to detect spam effectively, which undermines the reliability of the system. To better evaluate model performance, metrics like precision, recall, and MCC (Matthews Correlation Coefficient) are crucial. Precision, as observed in CNN_Word2Vec (0.9798) and BiLSTM_Word2Vec (0.9873), measures how accurately the model identifies spam, minimizing false positives—vital in preserving user trust. Recall, exemplified by BiLSTM_Word2Vec (0.9794), ensures that the model catches the majority of spam, reducing false negatives and preventing spam from bypassing detection. This balance is well reflected in the F1-score, where BiLSTM_Word2Vec achieved 0.9833, demonstrating a superior balance between precision and recall. The MCC offers a holistic view, accounting for true positives, true negatives, and both types of errors. Models like BiLSTM_Word2Vec, with an MCC of 0.9691, exhibit a comprehensive understanding of the task, handling the complexities of imbalanced data better than accuracy alone. Now, we can say that just accuracy performance measure is insufficient for AI-generated spam review detection, especially when class imbalance is present. Precision, recall, F1-score, and MCC provide a deeper understanding of model performance, making them indispensable metrics for developing robust spam detection systems that maintain content integrity and user experience.
Among the models tested, those utilizing Word2Vec embeddings, particularly the BiLSTM_Word2Vec model, demonstrated the strongest performance. The BiLSTM_Word2Vec model achieved an outstanding F1-score of 0.9833, indicating a near-perfect balance between precision and recall. Its high F2-score (0.9810) and F0.5-score (0.9857) further underscore its effectiveness in both identifying AI-generated spam and minimizing false positives, making it the most reliable choice for this task. The CNN_Word2Vec and LSTM_Word2Vec models also performed well, but slightly less effectively than the BiLSTM, with slight variances favoring either precision or recall depending on the specific F-score considered. In contrast, models using One-Hot Encoding and TF-IDF embeddings did not perform as well. Among these, the LSTM_One-Hot Encoding model had the highest F1-score (0.9673), showing a good balance between precision and recall, making it the best option for scenarios where computational simplicity is preferred over complex embeddings. However, TF-IDF-based models like BiLSTM_TF-IDF, while still effective, showed slightly lower F-scores, indicating that they might struggle more with the semantic complexity of AI-generated text.
Now, we can conclude that, for the task of detecting AI-generated spam reviews, the BiLSTM model with Word2Vec embeddings is the top performer, providing an excellent balance of precision and recall, essential for accurately identifying spam while minimizing the risk of false positives. This makes it highly suited for applications where both catching spam and avoiding unnecessary interventions are crucial.
As mentioned earlier, the Matthews Correlation Coefficient (MCC) is a key metric for evaluating the performance of binary classification models, particularly when dealing with imbalanced datasets. Unlike accuracy, MCC provides a more balanced assessment by considering true positives, false negatives, true negatives, and false positives. An MCC score ranges from −1 to +1, where +1 indicates perfect classification, 0 indicates random guessing, and −1 signifies total misclassification. In the context of detecting AI-generated spam reviews, the BiLSTM_Word2Vec model emerges as the top performer, with an impressive MCC score of 0.9691. This high score suggests that the model is highly accurate and reliable in distinguishing between spam and genuine reviews. Other models using Word2Vec embeddings, like CNN_Word2Vec and LSTM_Word2Vec, also show strong performance, with MCC scores of 0.9520 and 0.9514, respectively.
Models using One-Hot Encoding, such as LSTM_One-Hot Encoding and BiLSTM-One-Hot Encoding, perform well, with MCC scores of 0.9390 and 0.9356, but they are slightly less effective compared to their Word2Vec counterparts. Meanwhile, models employing TF-IDF embeddings, particularly CNN_TF-IDF, with an MCC of 0.9214, show relatively lower performance, indicating that these models might struggle more with the nuanced task of identifying AI-generated spam reviews.
Overall, models utilizing Word2Vec embeddings, especially when combined with BiLSTM or LSTM architectures, demonstrated superior performance due to their ability to capture complex contextual and semantic information. In contrast, models using One-Hot Encoding or TF-IDF, while still effective, showed reduced performance due to their limitations in capturing semantic relationships and contextual understanding.
Statistical Analysis of Classifier Performance via ANOVA
ANOVA (Analysis of Variance) is a powerful statistical test used to determine if there are significant differences between the means of three or more groups. When comparing the performance of multiple models or methods, it is particularly valuable to evaluate whether the observed variations are meaningful or simply the result of random chance. In the context of AI-generated spam review detection, ANOVA can help to assess the effectiveness of different classifiers and encoding methods by analyzing performance metrics such as accuracy, precision, recall, and other evaluation scores. In an ANOVA test, the F-statistic is a key measure that compares the variability between the group means with the variability within the groups. A higher F-statistic indicates that the differences between groups are more pronounced than the differences within each group. The p-value, on the other hand, quantifies the probability that the observed F-statistic is due to chance, assuming there are no real differences between the groups. If the p-value is lower than a commonly used threshold (typically 0.05), we reject the null hypothesis, indicating that at least one group is significantly different from the others. In this study, we conducted an ANOVA analysis on various performance metrics, including accuracy, F1-score, F2-score, and F0.5-score, generated by our classifiers. The ANOVA results, detailing the F-statistic and p-value for each classifier and embedding technique, are summarized in Table 4.
Table 4.
ANOVA results for performance measures.
In our analysis of model accuracy, the one-way ANOVA test produced an F-statistic of 1.1809 and a p-value of 0.3318. The low F-statistic indicates minimal differences between the classifiers, and the p-value, being significantly higher than the threshold of 0.05, suggests that we cannot reject the null hypothesis. This implies that the accuracy differences between models are not statistically significant and may be due to random chance rather than meaningful variations in performance. As a result, we broaden our evaluation by exploring other performance metrics, such as variants of F-score, which could provide further insight into model effectiveness.
When evaluating the F1-scores of the classifiers, ANOVA yielded an F-statistic of 3.2709 and a p-value of 0.0464. The higher F-statistic suggests notable variability between the F1-scores of different models, while the p-value, being below 0.05, allows us to reject the null hypothesis. This indicates that at least one classifier differs significantly from the others in terms of its balance between precision and recall, highlighting the importance of further analysis to determine which model performs best in this regard.
For the F2-scores, the ANOVA test produced an F-statistic of 2.4587 and a p-value of 0.0846. While the F-statistic indicates some level of variability between the encoding methods, the p-value is slightly above the 0.05 significance threshold. Although we cannot conclude that the differences in F2-scores are statistically significant, the result suggests a potential trend toward a meaningful difference, particularly with Word2Vec showing some advantage over One-Hot Encoding and TF-IDF.
Lastly, the one-way ANOVA test results on the F0.5-scores, with an F-statistic of 3.4429 and a p-value of 0.0417, indicate that there are statistically significant differences between the classifiers. Since the p-value is less than 0.05, we can conclude that at least one classifier performs better in terms of F0.5-score, which places more emphasis on precision than recall. In the context of AI-generated spam review detection, precision is key to minimizing false positives (i.e., mistakenly flagging legitimate reviews as spam). Among the classifier groups, the Word2Vec models demonstrate higher F0.5-scores (ranging from 0.9734 to 0.9857), outperforming both One-Hot Encoding and TF-IDF models, which have scores in the lower range of 0.9491 to 0.9650. This suggests that Word2Vec-based models are better at achieving a balance that favors precision, making them the most reliable choice for detecting spam reviews with fewer false positives. Thus, Word2Vec models should be preferred for the AI-generated spam review detection task as they offer superior performance in scenarios where precision is critical.
6. Comparative Analysis
The table compares the effectiveness of various models and feature combinations for detecting AI-generated spam reviews, with seven approaches proposed by the authors in [10] and eight approaches proposed by us. These models are evaluated based on key performance metrics: accuracy, precision, recall, and F-score, which together provide a comprehensive view of each model’s ability to correctly identify spam reviews. It is important to highlight that this study is unique in its focus on detecting spam reviews specifically generated by AI-based tools rather than solely detecting spam reviews or AI-generated text. Consequently, the study in [10] serves as a more relevant benchmark for comparing our proposed approaches. Table 5 presents the comparative results of the proposed approach with the existing approaches regarding the detection of spam reviews.
Table 5.
Performance comparison of the proposed approach with existing methods based on accuracy (A), precision (P), recall (R), and F-score.
As shown in the table, the models of the existing approaches primarily employ traditional machine learning techniques like SVM (Support Vector Machine) and Naive Bayes (NB), combined with different n-gram features (unigrams, bigrams, and trigrams) and linguistic features (LIWC). Among these, the LIWC+BIGRAMS+SVM model demonstrates the best performance, achieving an accuracy of 89.8%, which is the highest among Ott et al.’s proposed methods. It also has balanced precision, recall, and F-score metrics, with an F-score of 0.898. This indicates that, while the model is fairly effective at distinguishing spam from non-spam reviews, there is still room for improvement, especially when aiming for more nuanced detection in diverse datasets. Other models proposed in this study, such as BIGRAMS+SVM and TRIGRAMS+SVM, also perform reasonably well, with accuracies of 89.6% and 89.0%, respectively. These models maintain a consistent F-score of around 0.89, suggesting that their precision and recall are well-aligned. However, these methods slightly lag behind the LIWC+BIGRAMS+SVM model, indicating that the incorporation of linguistic features might offer some advantage in capturing the subtleties of AI-generated content.
In contrast, the methods proposed by us, which leverage Deep Learning models combined with advanced feature representations like Word2Vec, significantly outperform the traditional approaches. The BiLSTM-Word2Vec model stands out as the top performer, with an outstanding accuracy of 98.4%, far surpassing the best models proposed in [10]. It also achieves a precision of 0.987, a recall of 0.979, and an F-score of 0.983. This demonstrates not only the model’s ability to accurately detect spam reviews but also its robustness in maintaining high precision without compromising recall.
The Deep Learning models using Word2Vec embeddings consistently show superior performance. The CNN-Word2Vec and LSTM-Word2Vec models, with accuracies of 97.6% and 97.5%, respectively, also exhibit strong precision, recall, and F-score values, underscoring their effectiveness in this task. These models outperform the approaches proposed in [10] by a significant margin, highlighting the advantage of using Deep Learning architectures, which can capture complex patterns in data more effectively than the traditional machine learning models. Even within our proposed models, there is a clear pattern indicating that the combination of Deep Learning techniques with Word2Vec embeddings is particularly powerful. For instance, BiLSTM-One-Hot Encoding, which uses a simpler encoding scheme, still outperforms Ott et al.’s best model but falls short when compared to the Word2Vec-based models, with an accuracy of 96.7%. This suggests that, while the Deep Learning architecture is crucial, the choice in feature representation (Word2Vec versus One-Hot Encoding) also plays a significant role in achieving higher accuracy. The performance of all the proposed approaches (except TF-IDF-based) against the methods proposed by Ott et al. in [10] is also depicted in the radar plot in Figure 9.
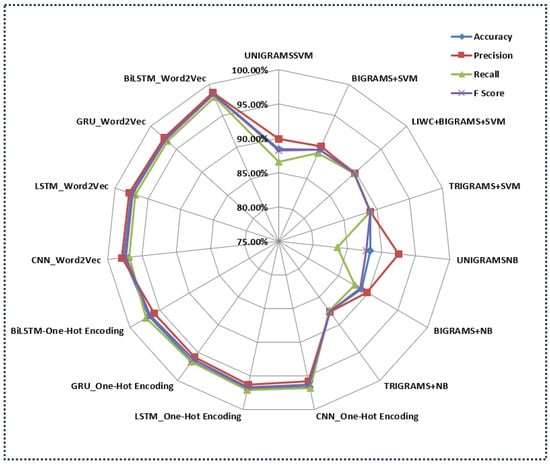
Figure 9.
The radar plot showing proposed approaches. Particularly, Word2Vec-based BiLSTM outperformed the existing methods.
Overall, the comparison highlights a clear trend: while the traditional machine learning methods with n-grams and linguistic features can provide decent performance, the integration of Deep Learning techniques with sophisticated feature embeddings like Word2Vec leads to a substantial improvement in the ability to detect AI-generated spam reviews. The significant jump in accuracy from 89.8% (the existing study’s best model) to 98.4% (our best model) underscores the effectiveness of our proposed approaches, marking a significant advancement in the field.
7. Ethical Issues in AI-Generated Fake Reviews
The explosion of AI technologies capable of generating human-like text has significant implications, particularly in the context of review generation. While such advancements offer opportunities to improve Natural Language Processing tasks, there are substantial ethical concerns that must be addressed to prevent misuse, including the generation of fake reviews that can misrepresent public opinion, mislead consumers, and undermine the credibility of review platforms. In this section, we will briefly mention the abuse of generated fake reviews, what is the impact on the overall market, and the challenges in detecting AI-generated fake reviews.
Misuse in Fake Review Generation: One of the most pressing ethical concerns is the potential abuse of AI to generate fake reviews. Malicious actors can use AI-generated reviews to deceive consumers, unfairly boost or damage the reputation of products and services, or influence market dynamics. These fake reviews may appear indistinguishable from human-generated content, making it difficult for both consumers and platforms to identify inauthentic feedback. This misuse can have widespread consequences, such as manipulating consumer trust, damaging businesses’ reputations, and degrading the overall integrity of online review systems.
Impact on Consumer Trust and Market Integrity: AI-generated fake reviews can significantly erode consumer trust. When users rely on reviews to make informed purchasing decisions, the presence of inauthentic reviews can lead to poor decision-making, resulting in consumer dissatisfaction or financial harm. Moreover, businesses that are targeted by fake reviews (either positive or negative) may experience financial impacts, while platforms that host these reviews risk losing credibility and user engagement.
Challenges in Detection and Prevention: Current AI technology can generate text that closely mimics the style and structure of human-written reviews, making it challenging to develop automated detection mechanisms. While there are ongoing efforts to create algorithms to detect fake reviews, the continuous evolution of AI-generated content poses a significant challenge in staying ahead of such misuse.
Preventing Abuse and Ensuring Ethical Use
Given the ethical concerns related to the abuse of AI-generated reviews, it is critical to implement strategies and safeguards to mitigate these risks. The heptagon shown in Figure 10 presents seven suggested ways to ensure that AI-generated data is not leaked or misused:
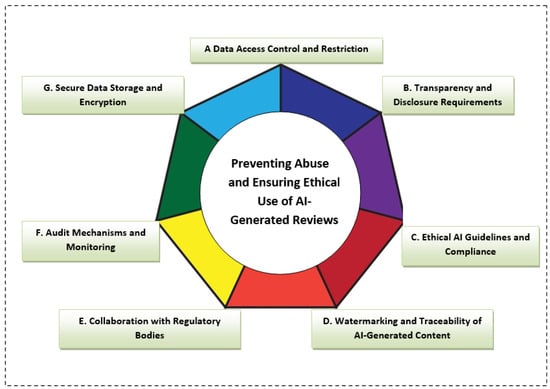
Figure 10.
Heptagon: seven ways to prevent abuse and ensure ethical use of AI-generated reviews.
- A.
- Data Access Control and Restriction:
- To prevent the unauthorized use of AI-generated content, it is important to implement strict access control mechanisms. Only authorized individuals involved in the research or application should have access to the models and the generated data. Access can be restricted through role-based permissions and secure authentication protocols. By limiting access, the risk of misuse or leakage is minimized.
- B.
- Transparency and Disclosure Requirements:
- AI-generated reviews should be transparently labeled as such. Platforms can implement policies requiring disclosure when content is generated by AI to maintain consumer awareness and trust. This allows consumers to differentiate between human-authored reviews and AI-generated content, preventing deception. Additionally, research and development in this area should be openly communicated to ensure stakeholders are aware of the potential implications of the technology.
- C.
- Ethical AI Guidelines and Compliance:
- Research projects involving AI-generated content should comply with ethical guidelines that prioritize the responsible development and use of AI technologies. This includes adhering to principles such as fairness, accountability, and transparency. Ethical AI frameworks can provide a foundation for ensuring that AI models are used responsibly and that potential harms are minimized.
- D.
- Watermarking and Traceability of AI-Generated Content:
- To prevent the misuse of AI-generated reviews, watermarking or embedding traceable metadata within the generated content can be employed. This allows for the origin of the content to be tracked and verified, ensuring that if AI-generated reviews are misused, they can be traced back to their source. This method of traceability ensures accountability and helps mitigate the risk of abuse.
- E.
- Collaboration with Regulatory Bodies:
- Working closely with regulatory authorities and consumer protection agencies can help create guidelines and standards for the ethical use of AI in review generation. Collaborative efforts can result in more robust policies to prevent the spread of misleading AI-generated content while ensuring accountability in its deployment.
- F.
- Audit Mechanisms and Monitoring:
- Regular audits and monitoring of AI-generated data should be conducted to ensure that the technology is being used appropriately and ethically. Auditing mechanisms should be in place to identify any signs of data leakage or misuse. Additionally, monitoring tools can help detect abnormal patterns in AI-generated reviews, allowing for timely interventions if unethical behavior is identified.
- G.
- Secure Data Storage and Encryption:
- Ensuring the security of the data generated by AI models is paramount. Sensitive data, such as model parameters or training data, should be securely stored using encryption techniques. By implementing secure data storage protocols, researchers can prevent unauthorized access or leakage of the generated data, reducing the risk of unethical usage.
8. Conclusions
The study presented a novel AI-generated spam review detection framework that effectively addresses the growing challenge of deceptive reviews on online platforms. By integrating advanced Deep Learning algorithms and Natural Language Processing techniques, this framework demonstrated superior performance in identifying spam reviews, particularly those generated by AI tools. The comprehensive evaluation across multiple models and embedding techniques, such as Word2Vec, highlighted the BiLSTM model’s outstanding capability, achieving an accuracy of 98.46% and excellent precision, recall, and F1-score values of 0.987, 0.979, and 0.983, respectively. The second-best performer proved to be a One-Hot Encoding-based GRU model with an accuracy of 96.4% and values achieved for precision, recall, and F1-score of 0.958, 0.966, and 0.962, respectively. The research’s findings underscore the importance of sophisticated AI-driven solutions in maintaining the integrity of online platforms. The framework not only outperformed the traditional machine learning models but also provided a scalable and accurate method for detecting AI-generated spam, contributing significantly to enhancing the reliability of online reviews. This work lays the foundation for the future developments in spam detection, offering a robust tool that can be seamlessly integrated into various online environments to safeguard consumer trust and improve the decision-making processes.
9. Future Research Directions
Building on the foundation laid by this research, several avenues can be explored to enhance the effectiveness and scope of AI-generated spam review detection. One promising direction is the inclusion of additional features that delve deeper into the linguistic and emotional aspects of the text. While this study primarily focused on text embedding techniques such as One-Hot Encoding, Word2Vec, and TF-IDF, incorporating features related to the linguistic structure of the text, such as syntactic patterns, sentence complexity, and grammatical errors, could provide valuable insights into the detection of spam reviews. By analyzing the nuances in sentence construction and the use of complex versus simple language, the detection model could potentially differentiate between genuine and deceptive reviews more effectively. Another important area of expansion is the incorporation of emotion-based features. Emotions play a significant role in consumer reviews, often reflecting genuine experiences. Using sentiment analysis and emotion detection techniques, future research could examine how the emotional tone, intensity, and variability in reviews correlate with authenticity. For instance, excessively positive or negative reviews, or those that display inconsistent emotional patterns, might be indicative of AI-generated content. Integrating these emotional cues into the detection framework could further refine the model’s ability to identify deceptive reviews with higher precision.
Moreover, expanding the research to include multilingual analysis is a critical next step. As global online platforms cater to diverse audiences, the ability to detect AI-generated spam reviews across multiple languages is essential. This study, while comprehensive, was limited to analyzing reviews in a single language, which constrains its applicability in a global context. The future research could focus on developing multilingual models that can process and analyze text in various languages, leveraging techniques like multilingual word embeddings and machine translation to adapt the existing framework. However, challenges may arise, including variations in grammar, syntax, and idiomatic expressions across languages, which could affect the accuracy of the detection models. Additionally, the availability of high-quality labeled datasets for training these multilingual models can be a significant hurdle. Addressing these challenges will be vital to ensuring the effective detection of AI-generated spam reviews in different linguistic environments, thereby broadening the model’s utility and making it more versatile for international platforms.
In addition to these enhancements, the future research could explore the application of domain-specific models that are fine-tuned for particular industries, such as e-commerce, hospitality, or healthcare. Each of these domains may have unique patterns of review content, and specialized models could be trained to detect spam reviews more effectively within these contexts. However, developing these models presents several challenges. For instance, the variation in the review language and structure across different domains can complicate model training and require extensive domain knowledge to identify the relevant features. Moreover, the availability of sufficient labeled datasets for training these specialized models may be limited, particularly in niche industries. Finally, as AI technology evolves, the methods used for generating spam reviews will likely become more sophisticated, making it essential to continually update and adapt the spam detection frameworks. Addressing these challenges will be crucial for ensuring the effectiveness and relevance of domain-specific models in an ever-changing landscape of AI-generated content.
Author Contributions
Conceptualization, M.A.W., M.E. and K.A.S.; methodology, M.A.W., M.E. and K.A.S.; software, M.A.W.; validation, M.A.W. and K.A.S.; formal analysis, M.A.W. and K.A.S.; investigation, M.A.W. and K.A.S.; resources, M.E. and M.A.W.; writing—original draft, M.A.W. and K.A.S.; writing—review and editing, M.A.W. and K.A.S.; supervision, M.E.; funding acquisition, M.E. and M.A.W. All authors have read and agreed to the published version of the manuscript.
Funding
The authors would like to thank Prince Sultan University for paying the APC of this article.
Data Availability Statement
The link to the data repository related to this project can be made available upon request. If required, it will be made publicly available at the GitHub profile (https://github.com/mudasirahmadwani, accessed on 23 September 2024) under the title of the paper.
Acknowledgments
This work is supported by EIAS (Emerging Intelligent Autonomous Systems) Data Science Lab, Prince Sultan University, KSA). The authors would like to acknowledge the support of Prince Sultan University in paying the Article Processing Charges (APCs) for this publication.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Ahmed, H.; Traore, I.; Saad, S. Detecting opinion spams and fake news using text classification. Secur. Priv. 2018, 1, e9. [Google Scholar] [CrossRef]
- Crawford, M.; Khoshgoftaar, T.M.; Prusa, J.D.; Richter, A.N.; Al Najada, H. Survey of review spam detection using machine learning techniques. J. Big Data 2015, 2, 23. [Google Scholar] [CrossRef]
- He, S.; Hollenbeck, B.; Proserpio, D. The market for fake reviews. Mark. Sci. 2022, 41, 896–921. [Google Scholar] [CrossRef]
- Wani, M.A.; Jabin, S.; Yazdani, G.; Ahmadd, N. Sneak into devil’s colony-A study of fake profiles in online social networks and the cyber law. arXiv 2018, arXiv:1803.08810. [Google Scholar]
- Wani, M.A. Fake Profile Detection in Online Social Networks. 2019. Available online: https://shodhganga.inflibnet.ac.in/handle/10603/286155 (accessed on 20 August 2024).
- Agarwal, N.; Jabin, S.; Hussain, S.Z. Analyzing real and fake users in Facebook network based on emotions. In Proceedings of the 2019 11th International Conference on Communication Systems & Networks (COMSNETS), Bengaluru, India, 7–11 January 2019; pp. 110–117. [Google Scholar]
- Wani, M.A.; Jabin, S. Mutual clustering coefficient-based suspicious-link detection approach for online social networks. J. King Saud Univ.-Comput. Inf. Sci. 2022, 34, 218–231. [Google Scholar] [CrossRef]
- Lee, K.D.; Han, K.; Myaeng, S.H. Capturing word choice patterns with LDA for fake review detection in sentiment analysis. In Proceedings of the International Conference on Web Intelligence, Mining and Semantics, Nîmes, France, 13–15 June 2016; pp. 1–7. [Google Scholar]
- Floridi, L.; Chiriatti, M. GPT-3: Its nature, scope, limits, and consequences. Minds Mach. 2020, 30, 681–694. [Google Scholar] [CrossRef]
- Ott, M.; Choi, Y.; Cardie, C.; Hancock, J.T. Finding deceptive opinion spam by any stretch of the imagination. arXiv 2011, arXiv:1107.4557. [Google Scholar]
- Petrescu, M.; O’Leary, K.; Goldring, D.; Mrad, S.B. Incentivized reviews: Promising the moon for a few stars. J. Retail. Consum. Serv. 2018, 41, 288–295. [Google Scholar] [CrossRef]
- Costa, A.; Guerreiro, J.; Moro, S.; Henriques, R. Unfolding the characteristics of incentivized online reviews. J. Retail. Consum. Serv. 2019, 47, 272–281. [Google Scholar] [CrossRef]
- Liao, W.; Liu, Z.; Dai, H.; Xu, S.; Wu, Z.; Zhang, Y.; Huang, X.; Zhu, D.; Cai, H.; Liu, T.; et al. Differentiate chatgpt-generated and human-written medical texts. arXiv 2023, arXiv:2304.11567. [Google Scholar]
- Alamleh, H.; AlQahtani, A.A.S.; ElSaid, A. Distinguishing Human-Written and ChatGPT-Generated Text Using Machine Learning. In Proceedings of the 2023 Systems and Information Engineering Design Symposium (SIEDS), Charlottesville, VA, USA, 27–28 April 2023; pp. 154–158. [Google Scholar]
- Lavergne, T.; Urvoy, T.; Yvon, F. Detecting Fake Content with Relative Entropy Scoring. Pan 2008, 8, 4. [Google Scholar]
- Gehrmann, S.; Strobelt, H.; Rush, A.M. Gltr: Statistical detection and visualization of generated text. arXiv 2019, arXiv:1906.04043. [Google Scholar]
- Mitchell, E.; Lee, Y.; Khazatsky, A.; Manning, C.D.; Finn, C. Detectgpt: Zero-shot machine-generated text detection using probability curvature. arXiv 2023, arXiv:2301.11305. [Google Scholar]
- Bhattacharjee, A.; Kumarage, T.; Moraffah, R.; Liu, H. ConDA: Contrastive Domain Adaptation for AI-generated Text Detection. arXiv 2023, arXiv:2309.03992. [Google Scholar]
- Katib, I.; Assiri, F.Y.; Abdushkour, H.A.; Hamed, D.; Ragab, M. Differentiating Chat Generative Pretrained Transformer from Humans: Detecting ChatGPT-Generated Text and Human Text Using Machine Learning. Mathematics 2023, 11, 3400. [Google Scholar] [CrossRef]
- DePaulo, B.M.; Kashy, D.A.; Kirkendol, S.E.; Wyer, M.M.; Epstein, J.A. Lying in everyday life. J. Personal. Soc. Psychol. 1996, 70, 979. [Google Scholar] [CrossRef]
- Jindal, N.; Liu, B. Opinion spam and analysis. In Proceedings of the 2008 International Conference on Web Search and Data Mining, Palo Alto, CA, USA, 11–12 February 2008; pp. 219–230. [Google Scholar]
- Filieri, R. What makes an online consumer review trustworthy? Ann. Tour. Res. 2016, 58, 46–64. [Google Scholar] [CrossRef]
- Plotkina, D.; Munzel, A.; Pallud, J. Illusions of truth—Experimental insights into human and algorithmic detections of fake online reviews. J. Bus. Res. 2020, 109, 511–523. [Google Scholar] [CrossRef]
- Sun, H.; Morales, A.; Yan, X. Synthetic review spamming and defense. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013; pp. 1088–1096. [Google Scholar]
- Cardoso, E.F.; Silva, R.M.; Almeida, T.A. Towards automatic filtering of fake reviews. Neurocomputing 2018, 309, 106–116. [Google Scholar] [CrossRef]
- Mihalcea, R.; Strapparava, C. The lie detector: Explorations in the automatic recognition of deceptive language. In Proceedings of the ACL-IJCNLP 2009 Conference Short Papers; Association for Computational Linguistics: Singapore, 2009; pp. 309–312. [Google Scholar]
- Mukherjee, A.; Venkataraman, V.; Liu, B.; Glance, N. What yelp fake review filter might be doing? Proc. Int. AAAI Conf. Web Soc. Media 2013, 7, 409–418. [Google Scholar] [CrossRef]
- Sandulescu, V.; Ester, M. Detecting singleton review spammers using semantic similarity. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 971–976. [Google Scholar]
- Bratko, A.; Filipič, B.; Cormack, G.V.; Lynam, T.R.; Zupan, B. Spam filtering using statistical data compression models. J. Mach. Learn. Res. 2006, 7, 2673–2698. [Google Scholar]
- Zhang, L.; Zhu, J.; Yao, T. An evaluation of statistical spam filtering techniques. ACM Trans. Asian Lang. Inf. Process. (TALIP) 2004, 3, 243–269. [Google Scholar] [CrossRef]
- Barushka, A.; Hajek, P. Review spam detection using word embeddings and deep neural networks. In Artificial Intelligence Applications and Innovations, Proceedings of the 15th IFIP WG 12.5 International Conference, AIAI 2019, Hersonissos, Crete, Greece, 24–26 May 2019, Proceedings 15; Springer International Publishing: Berlin/Heidelberg, Germany, 2019; Volume 10, pp. 340–350. [Google Scholar]
- Salminen, J.; Kandpal, C.; Kamel, A.M.; Jung, S.g.; Jansen, B.J. Creating and detecting fake reviews of online products. J. Retail. Consum. Serv. 2022, 64, 102771. [Google Scholar] [CrossRef]
- OpenAI. ChatGPT: A Conversational Language Model. GPT-3.5. 2023. Available online: https://openai.com/ (accessed on 30 November 2022).
- Bird, S. NLTK: The natural language toolkit. In Proceedings of the COLING/ACL 2006 Interactive Presentation Sessions, Sydney, Australia, 17–18 July 2006; pp. 69–72. [Google Scholar]
- Roman, M.; Shahid, A.; Khan, S.; Koubaa, A.; Yu, L. Citation intent classification using word embedding. IEEE Access 2021, 9, 9982–9995. [Google Scholar] [CrossRef]
- Elhassan, N.; Varone, G.; Ahmed, R.; Gogate, M.; Dashtipour, K.; Almoamari, H.; El-Affendi, M.A.; Al-Tamimi, B.N.; Albalwy, F.; Hussain, A. Arabic sentiment analysis based on word embeddings and deep learning. Computers 2023, 12, 126. [Google Scholar] [CrossRef]
- El-Affendi, M.A.; Alrajhi, K.; Hussain, A. A novel deep learning-based multilevel parallel attention neural (MPAN) model for multidomain arabic sentiment analysis. IEEE Access 2021, 9, 7508–7518. [Google Scholar] [CrossRef]
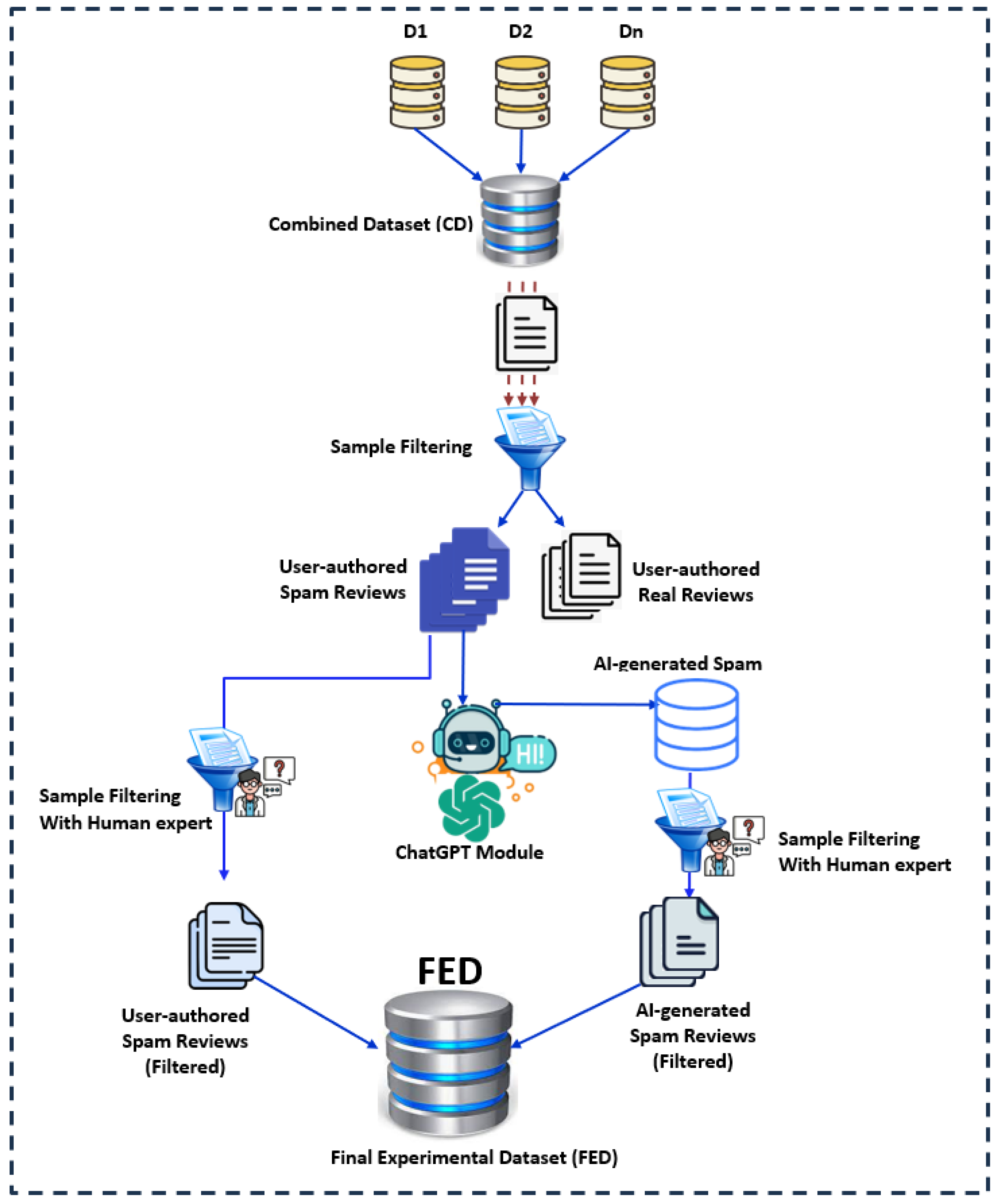


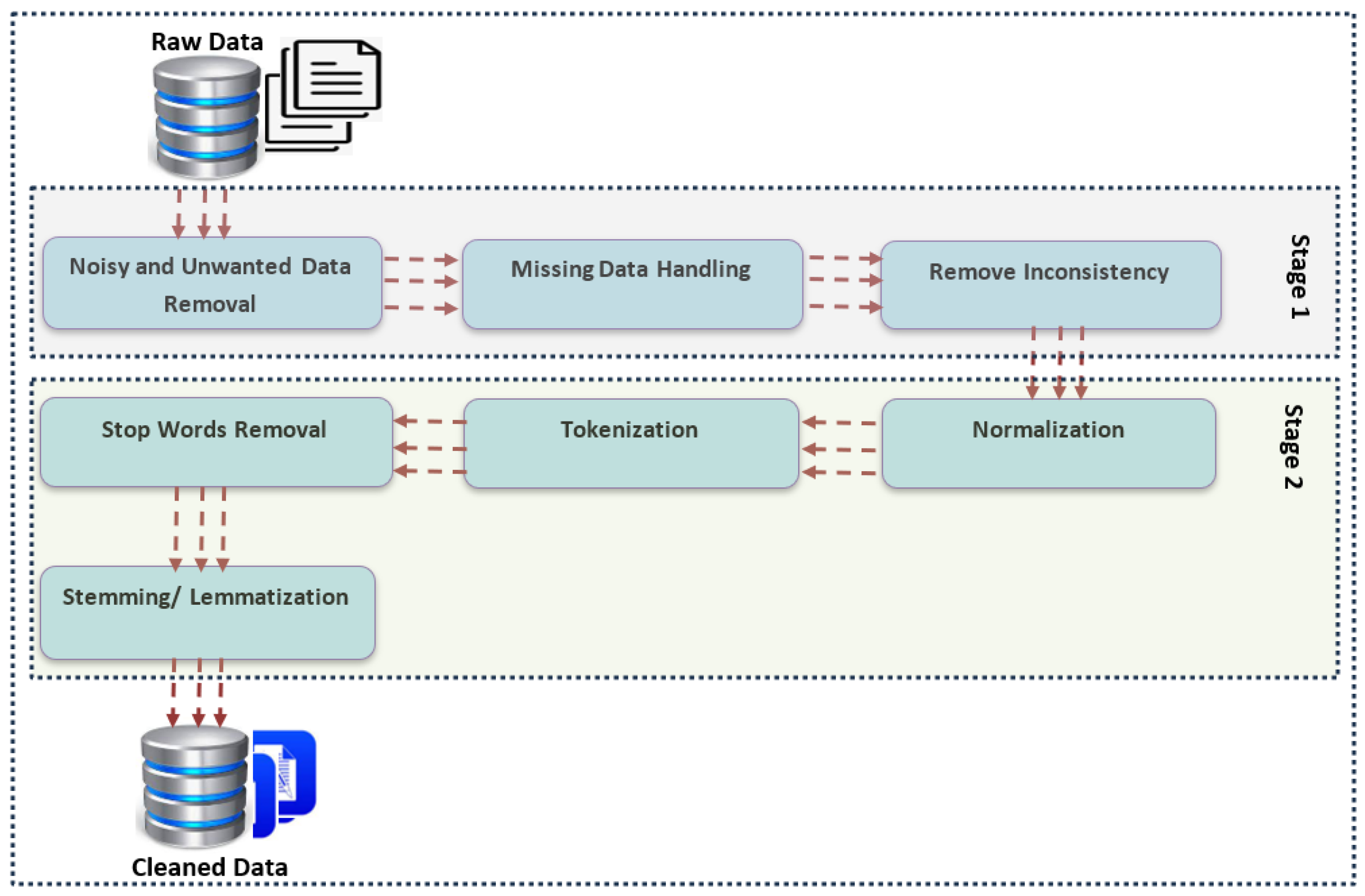
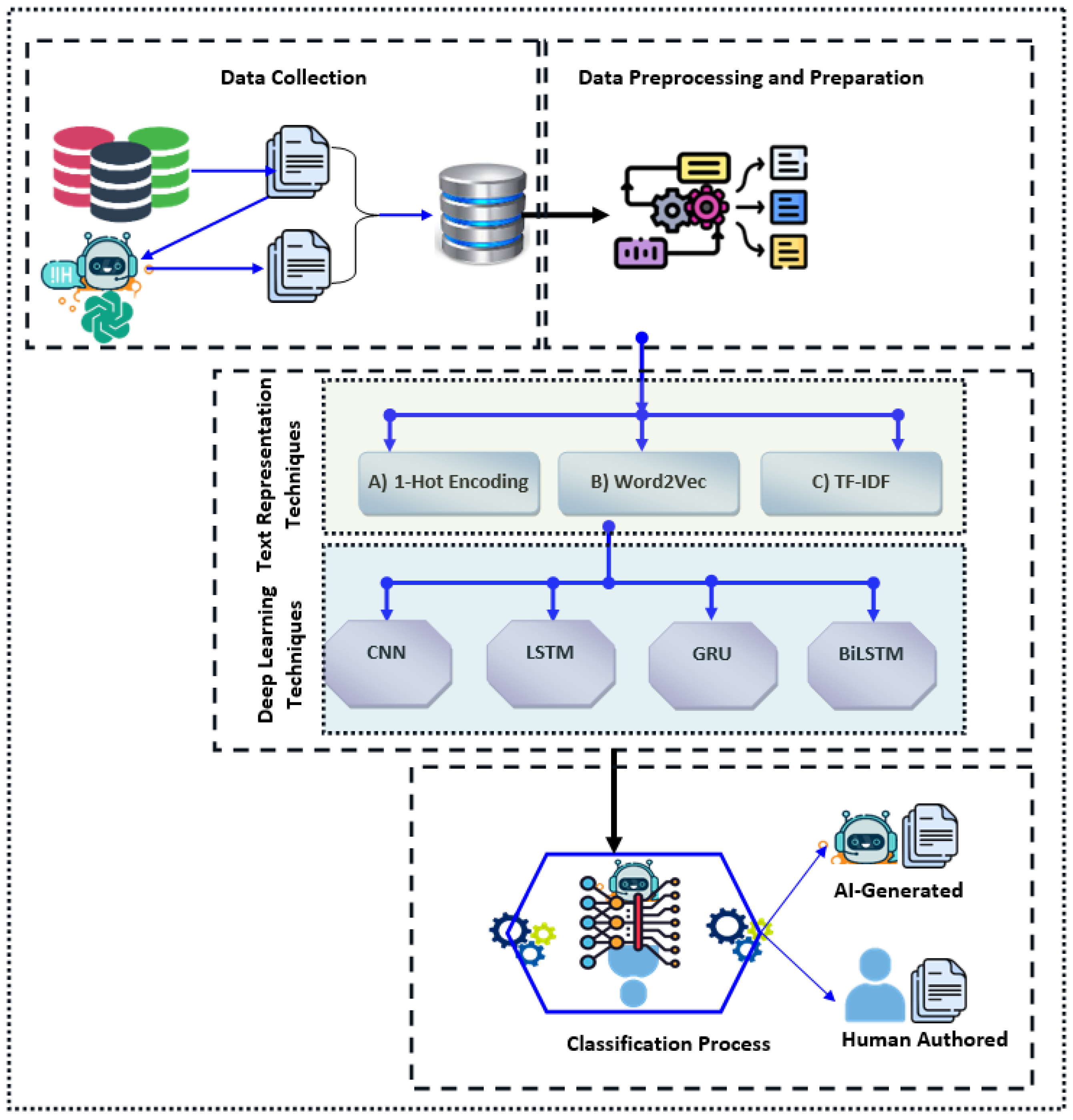
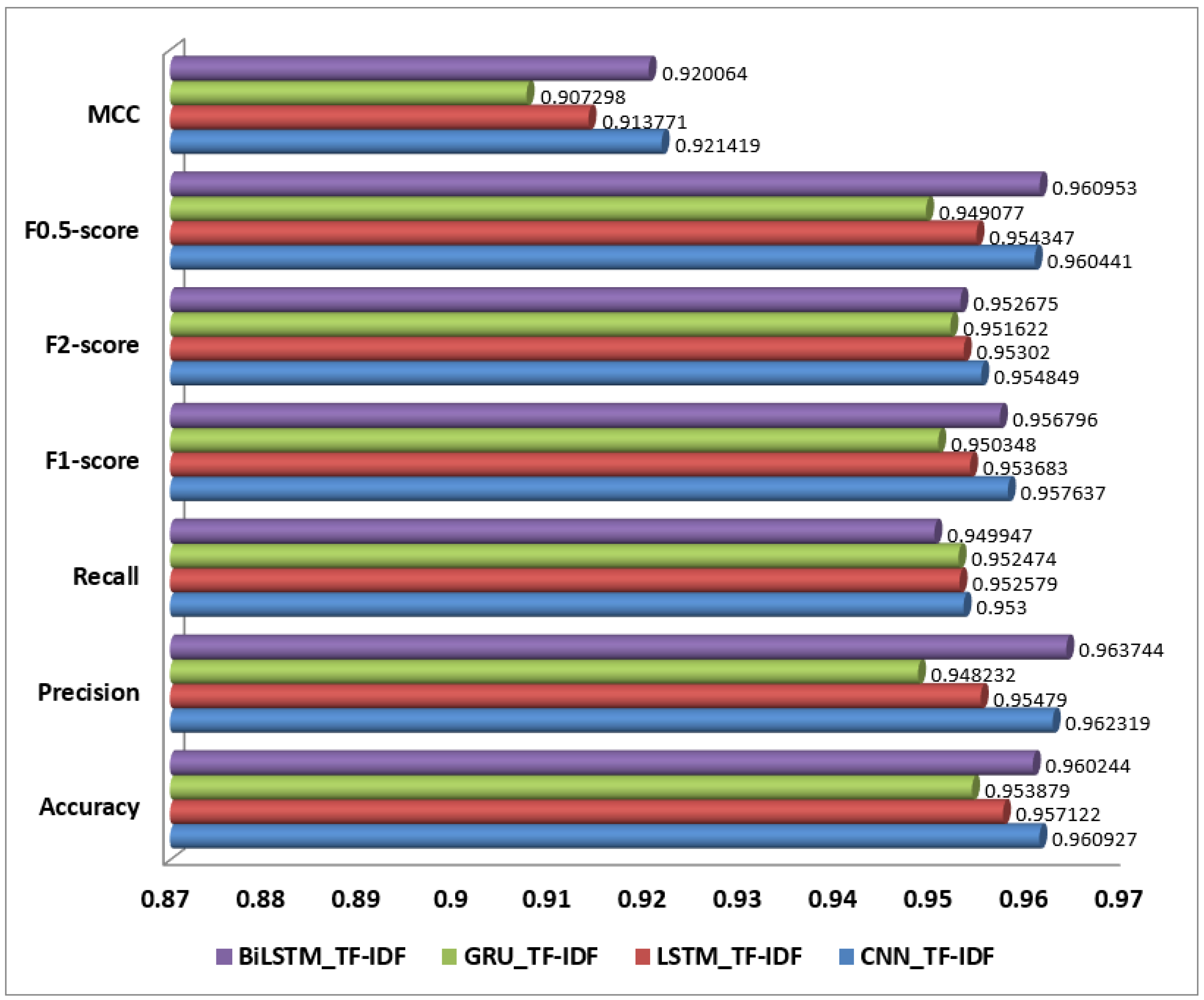
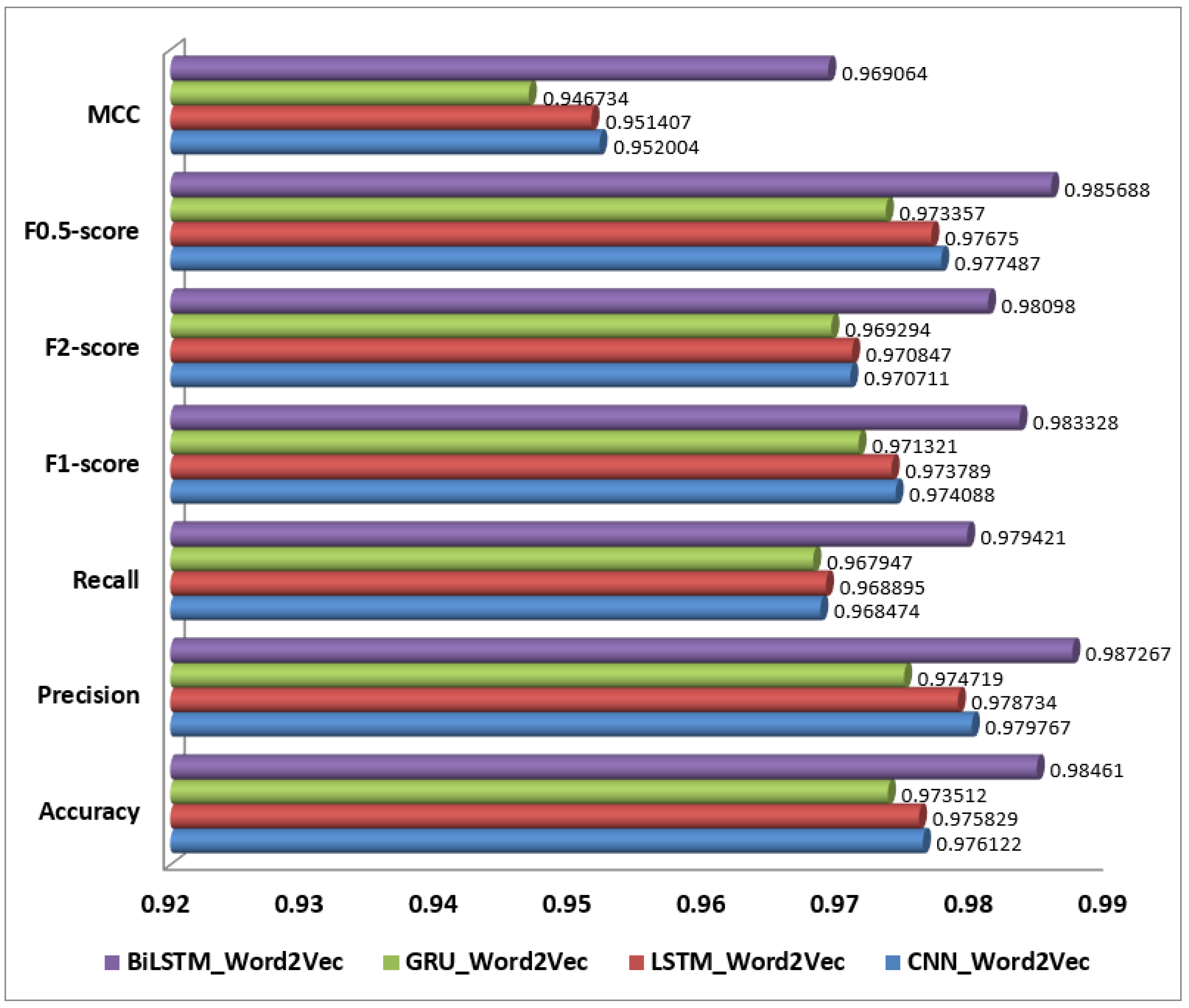
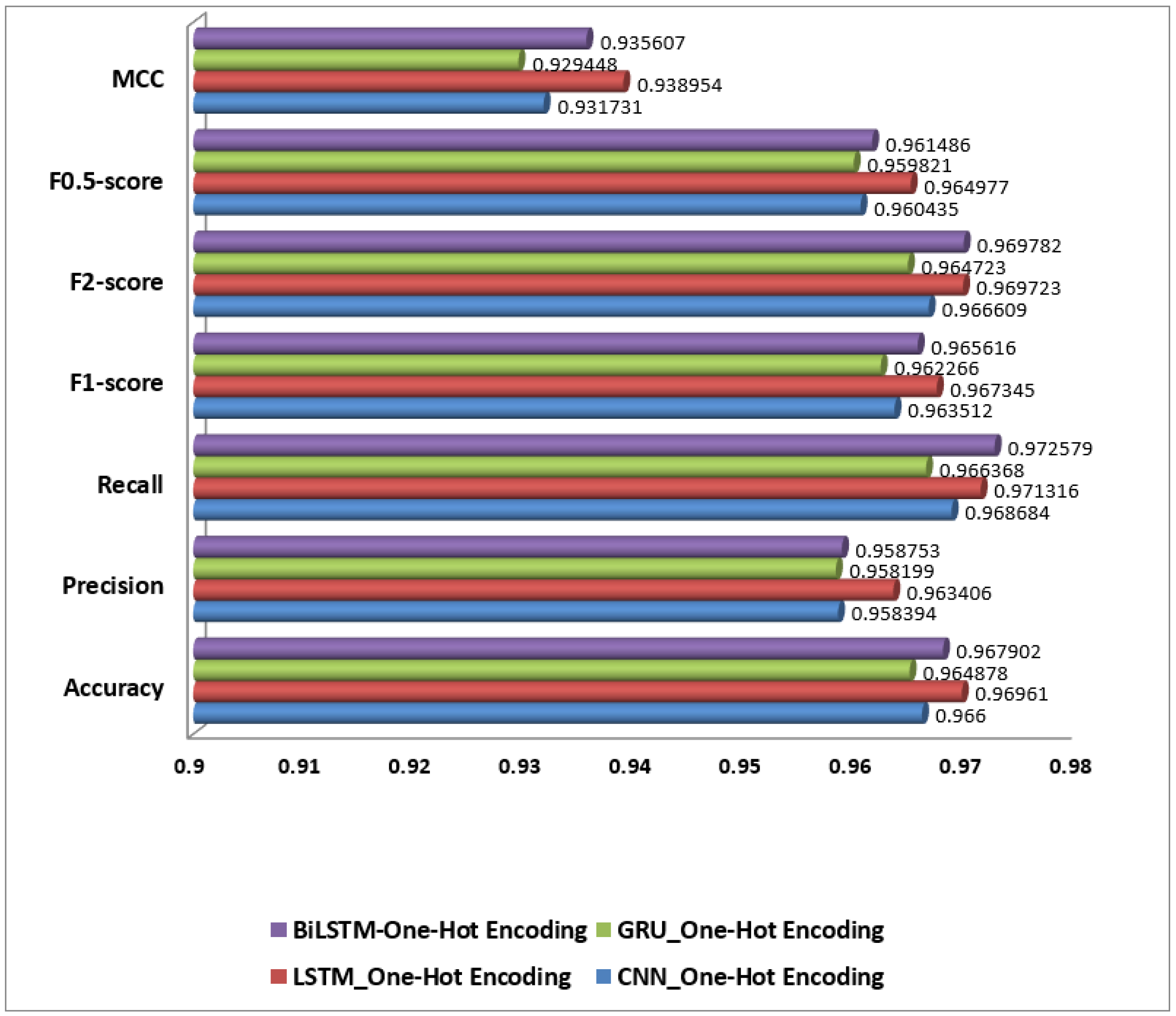
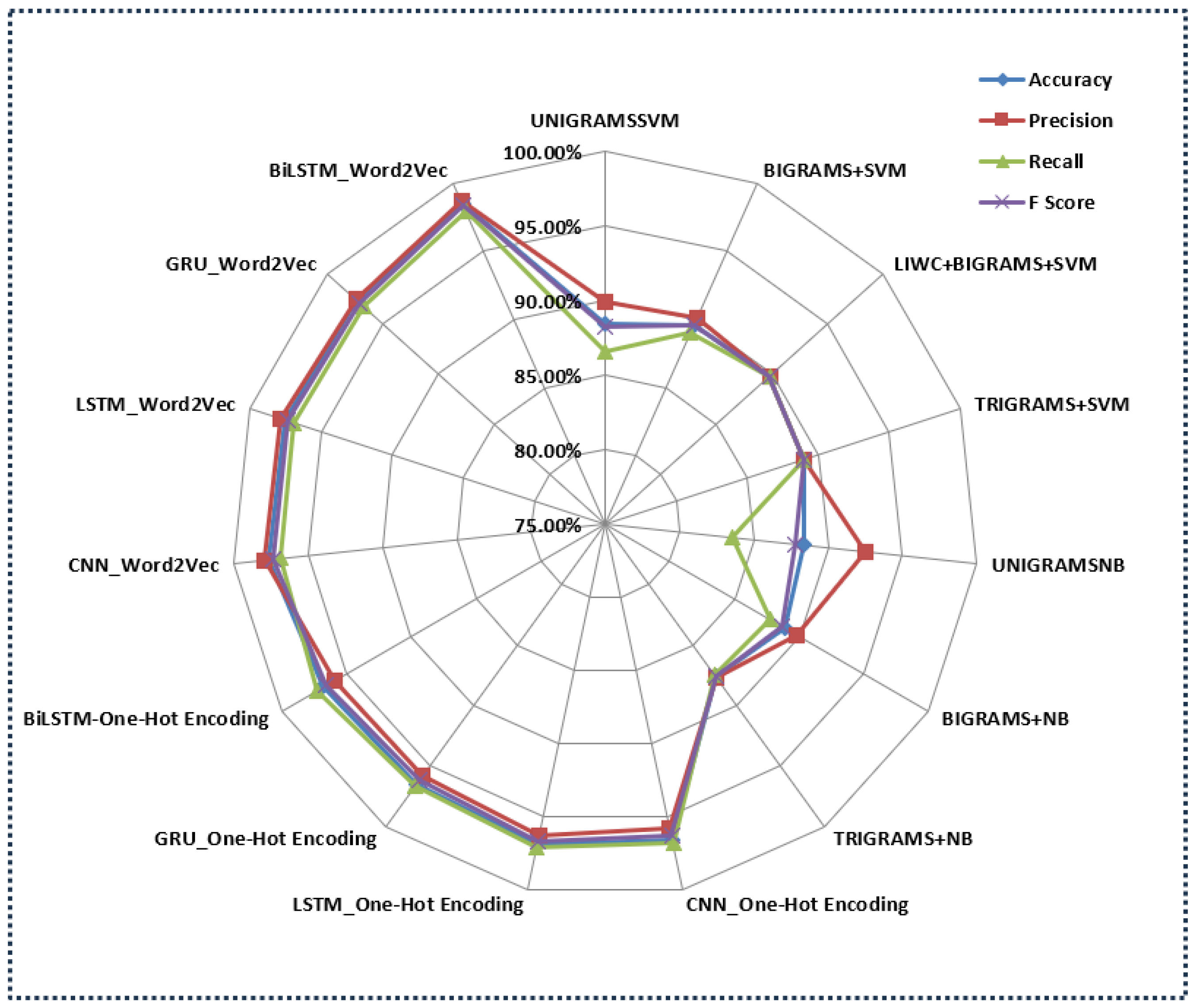
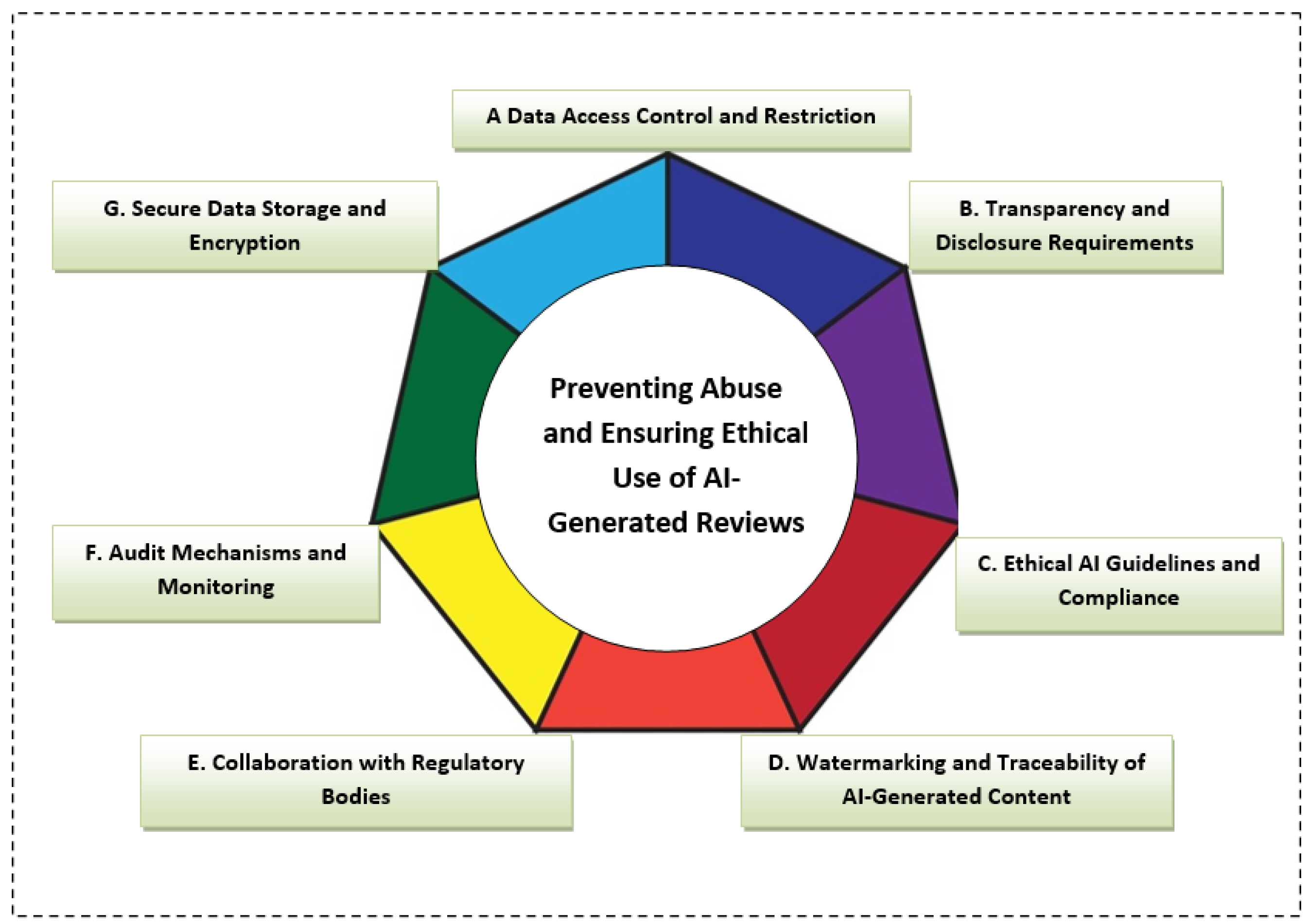
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).