The present paper concerns specification mining for temporal data, where properties to be verified
are expressed in
linear time logic for finite traces (LTL
f) or the extensions. The LTL
f formalism [
3] extends
modal logic to include linear, discrete, and future-oriented time, where each event represents a single relevant instant of time. LTL
f quantifies only on events reported in the trace, so each event of interest is fully observable, as the events represented in each trace are totally ordered. The
syntax of a well-formed LTL
f formula
is defined as follows:
where
represents an atomic proposition,
determines that the condition
must hold from the subsequent temporal step,
requires that such a condition must always hold from the current instant of time,
specifies that the current condition must happen at any time in the future, and
shows that
must hold until the first occurrence of
does. The remainder are interpreted as classical logical connectives, where the implication connective
can be interpreted as
[
30]. The
semantics are usually defined in terms of the first-order logic [
3] for a given trace
at a current time
j (e.g., for event
).
2.3.1. Formal Temporal Verification
In the context of LTL
f and temporal data, a counterexample of temporal verification is usually expressed as a non-empty edit sequence for a specific trace invalidating
, thus showing which events have to be removed or added to make a trace compliant to
[
31]. On the other hand, the certificate of correctness associated with traces often reflects the association between the atomic propositions in the formula and the events satisfying such conditions [
2,
30], and are often referred to as
activation B,
target B, and
correlation conditions (see the following paragraph). As the present paper focuses on positive specification mining, we are only going to consider the latter aspect.
‘Declare’ [
12] expresses properties
as conjunctions of clauses providing a specification (or model)
, where each clause is an instantiation of a specific temporal template. A Declare template differs from customary association rules as the latter enforces no temporal occurrence pattern between the conditions at the head and the tail of the rule. Declare can be assessed over a finite multiset of finite traces.
Templates express abstract parameterised temporal properties (first column of
Table 1), where semantics can be expressed in terms of the LTL
f (third column). The provided definitions align with the prevailing literature’s interpretations, subject to
-renaming (
Section 6.4). We assert that a trace
satisfies a Declare clause
c if it meets the associated semantic representation in LTL
f; we denote this as
. We also state that a trace
conforms to a
(conjunctive) Declare specification (or
model) if the trace satisfies each of the clauses
composing the aforementioned specification, i.e.,
. This verification process is also referred to as conformance checking in the business process management literature. We also state that an LTL
f formula
implies if all the traces satisfying the former also satisfy the latter. We denote this as
, where we state that
is more general than
by interpreting the coverage set as the set of all traces in the log satisfying a given declarative clause (Lemma A3).
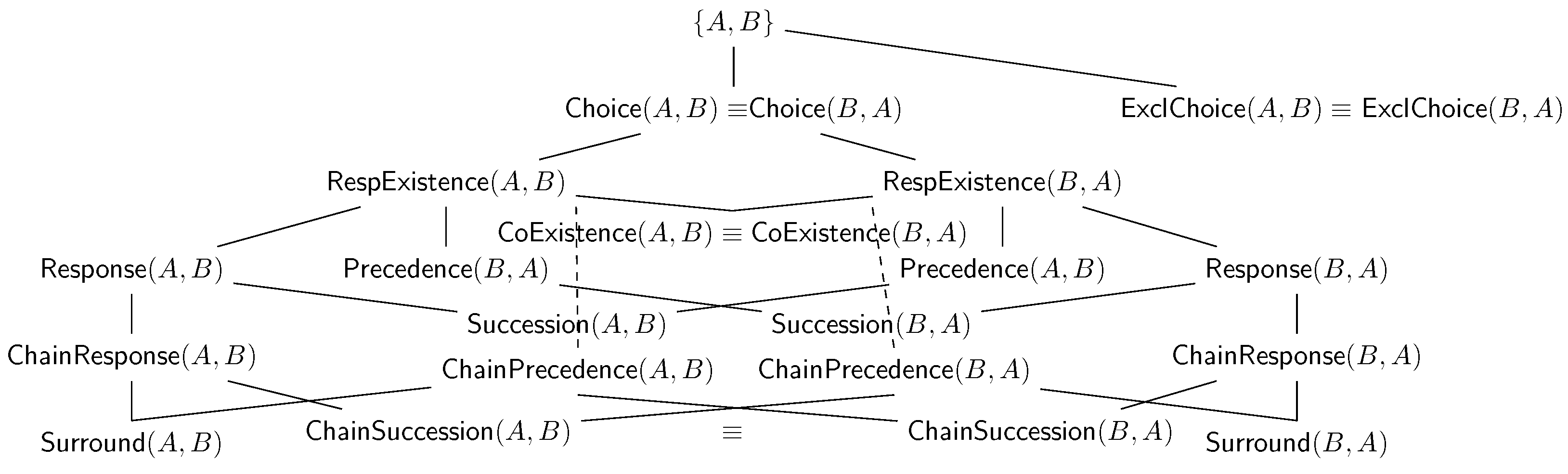
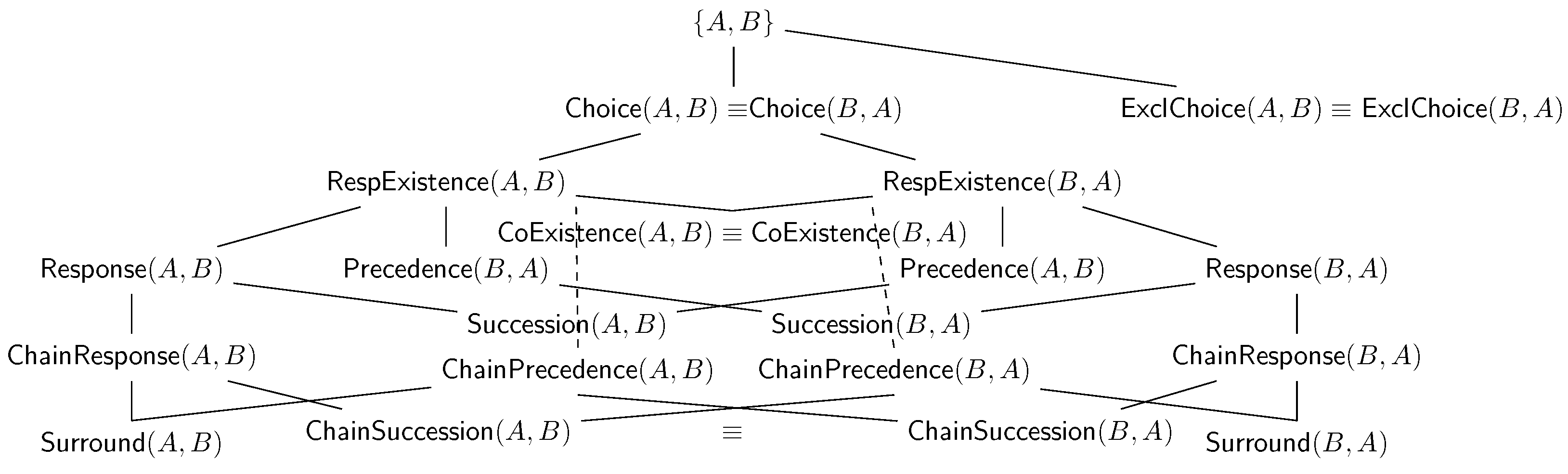
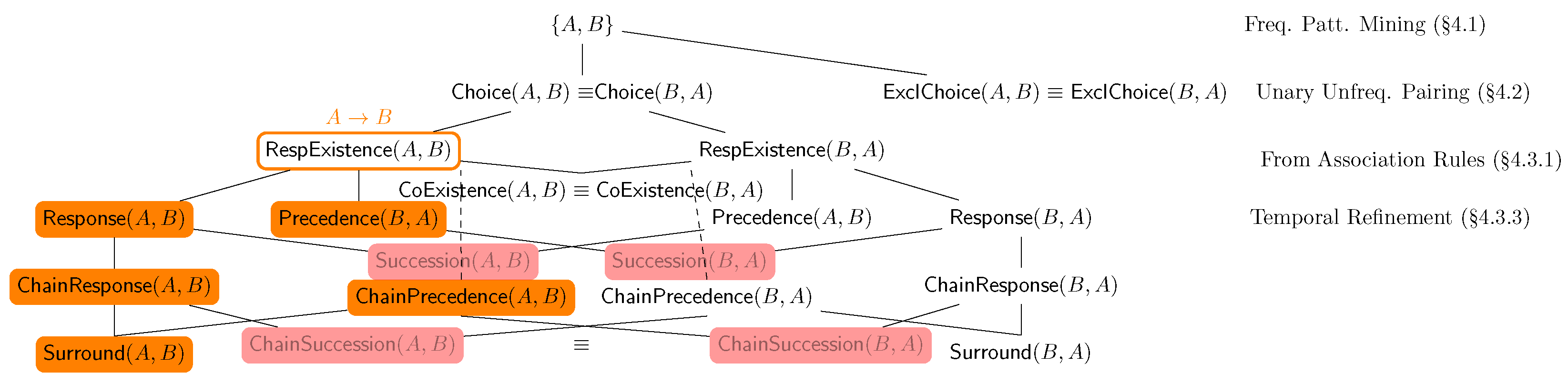
The implication notion can also be extended to declarative clauses in terms of their associated LTL
f semantics;
Figure 2 represents the entailment lattice of such declarative clauses, expressed as a Hasse diagram [
32], and depicting the relationship among such clauses under the assumption of non-zero confidence (
Section 6.1).
If a Declare specification contains one clause that predicates over event payloads as an activation/target/correlation condition, we refer to this as data-aware specification; otherwise, we refer to this as dataless. We state that the log is dataless if each event has an empty payload, otherwise, it is data-aware. For data-aware specifications, we can identify correlation conditions denoting disjunction conditions across target/activation conditions, as well as correlations between them. In this paper, we only consider dataless specifications and logs; thus, we omit the true data predicates associated with the activation/target conditions and only provide the activity labels. Therefore, throughout the rest of the paper, we denote each event by only its associated activity label, A when all activity labels are considered as one character, we might represent each trace as a string of activity labels.
Example 1. Our current logs of interest are dataless; thus, having events that contain empty payload functions ∅, we use ABC as the shorthand for A,∅ 〉 〈 B,∅ 〉 〈 C, ∅〉.
Declarative clauses, therefore, involve the instantiation of declarative templates with activation and target conditions; by restricting our consideration to dataless specifications, such conditions restrict the possible activity label events by the one expressed by the activation (and target) conditions
(and
). For example,
has
A as an activation condition, as an occurrence of the first
A requires checking whether no preceding
B shall occur. We denote
as the set of traces containing at least one event satisfying an activation condition in
c [
2]. The clause activation might require the investigation of a possible
target condition, where temporal occurrence is regulated by the template semantics. To demonstrate this, consider the following example: while
requires that the target conditions always follow the activations,
only requires its existence across the trace, and holds no temporal constraints as the former. Some of the clauses listed in
Table 1 entail others, due to the stricter variation in the “temporal strictness” or the composition of multiple clauses. The previous example focuses on stricter temporal variation, while
entails both
and
.
We state that a trace vacuously satisfies a Declare clause c if the trace satisfies such a clause without providing an event that satisfies the clause’s activation condition (i.e., ). We can similarly frame the concept of vacuous violation. It occurs when a trace fails to satisfy a declarative clause, represented as ().
Declare walks in the footsteps of association rule mining by providing definitions of confidence and support metrics associated with declarative clauses. Still, the current literature provides disparate definitions of those metrics, depending on the specific context of interest [
2,
20], exploiting different clause “applicability” notions. Our previous work [
2] considers “applicability” in terms of mere clause satisfiability, thus considering traces either vacuously or non-vacuously, satisfying a given declarative clause, while straightforwardly considering the traces containing the activation conditions as the denominator for the confidence score:
As the notion of Supp is directly related to the satisfiability of a given declarative clause, despite its inclusion of the vacuously satisfied traces, this makes it the ideal candidate for the basis of an anti-monotonic quality criterion (Lemma A4) for implementing the lattice search within a general-to-specific heuristic algorithm for the hypothesis search. Still, this definition of confidence is not normalised between zero and one, as the number of traces potentially satisfying the clause are much larger than the ones satisfying and providing an activation condition to the clause.
By restricting the notion of “applicability” to the sole traces containing activation conditions, we can have the notion of
restrictive support and
confidence [
20], ensuring that the clause will fully represent the data if the evidence for both activation and (possibly) target conditions are given:
Still, these two definitions each come with an intrinsic limitation.
First, we can easily observe that
RSupp is not anti-monotonic in the same way as
Supp and, therefore, cannot be chosen as a quality criterion candidate for traversing the declarative hypothesis space (
Section 6.2).
Second, the authors showcasing
assumed that, for
Precedence(
A,
B),
B should have been an activation condition, while this should have never really been the case, as the clause only postulates that
B shall not appear before the first
A, but nothing is stated on whether
Bs shall occur after an occurrence of
A. For this particular clause, there is a requirement for a redefined declarative confidence that ranges between 0 and 1. This new definition aims to provide a more restrictive understanding of confidence, especially in the presence of arbitrary activations or vacuous conditions within the trace. These force us to propose a novel specification of this restrictive confidence, which is a topic we will delve into in
Section 3.1.
KnoBAB [
2] is a columnar-based relational database, built with the prime purpose of optimizing formal verification for temporal data represented as event logs. This was achieved through the provision of relational semantics to the LTL
f operators, namely
xtLTL
f, while providing a one-to-one mapping between the provided temporal operators and the LTL
f logical operators. The encoding of specific temporal operators for the relational model was mainly due to the inadequacy of the relational query plans and physical operators to efficiently compute such tasks over customary relational models [
30]. The definition of
xtLTL
f operators facilitates the expression of formal verification tasks as relational database queries. These queries not only return the trace that satisfies the specification but also provide details on the events that activate, target, and correlate with one another.
xtLTL
f also allows the identification of query plan optimisation strategies.
First, we minimise access to the data tables by fusing entire sub-expressions, providing the same temporal behaviour, including the query plan leaf nodes that directly access the temporal information stored as relational tables.
Second, we can further pre-process this query plan to achieve trivial intra-query parallelism. As the aforementioned query plan transformation converts an abstract syntax tree into a direct acyclic graph, we can now run a topological sort algorithm to determine the operators’ order of execution after representing them as nodes within the query plan. This allows the additional transformation of the aforementioned direct acyclic graph into a dependency graph, represented as a layered graph. As each node belonging to a given layer shares no computational dependencies with the other, we can also define a scheduling order for the
xtLTL
f operators, where the execution can be trivially parallelised, achieving straightforward intra-query parallelism.
Third, we guarantee efficient data access through the provision of indexed relational tables containing temporal, payload, and event-counting information. The results provided in our previous research [
2] show that the system achieves significant performance gains against state-of-the-art dataless and data-aware temporal formal verification systems, either ad hoc solutions or competing relational representations and queries expressing formal verification tasks directly in SQL.
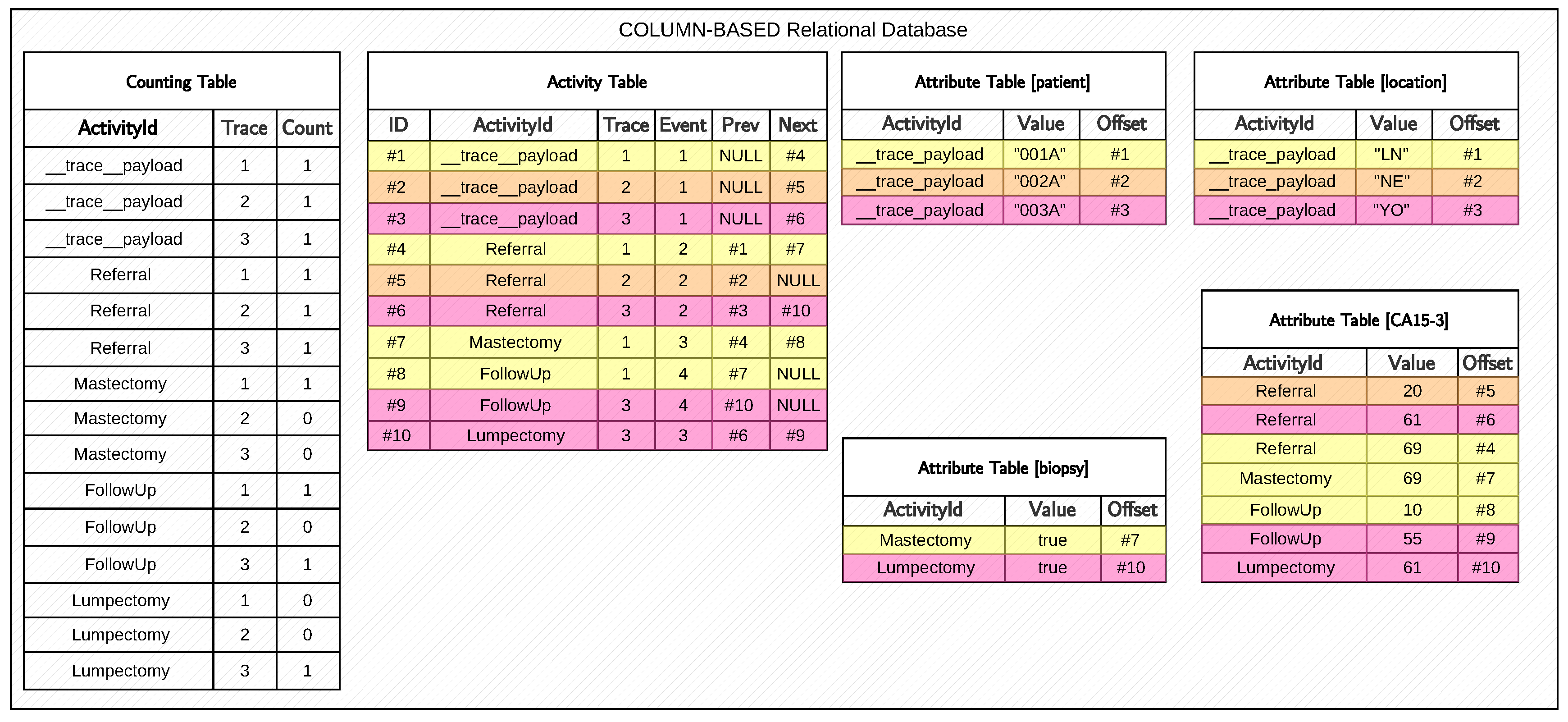
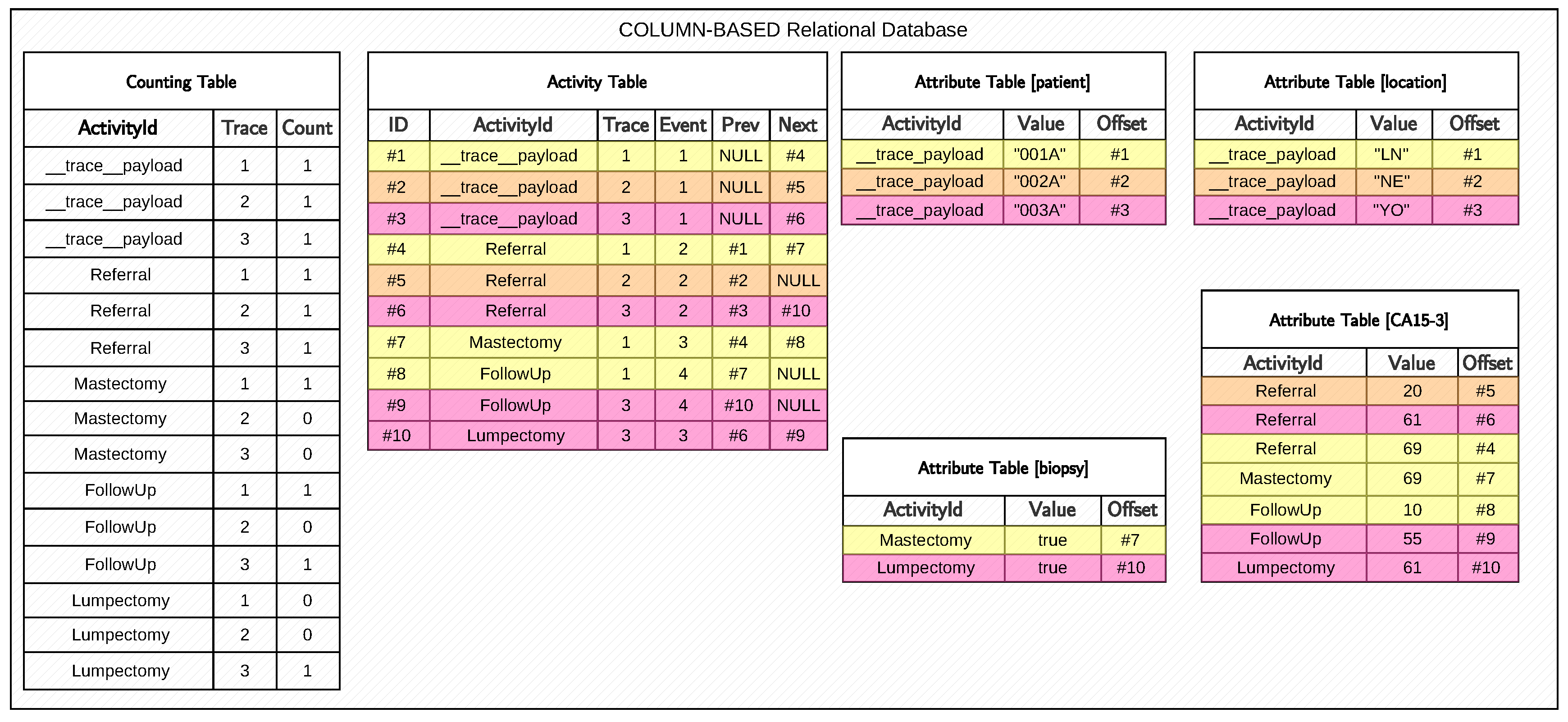
We will now describe in greater detail the relational table being exploited to store the log traces’ temporal behaviour, as both Bolt and the current algorithm leverage such architecture. Temporal data are loaded and processed into three types of tables depicted in
Figure 3:
,
, and
(s).
The compactly stores the number of occurrences (count cell) for each activity label A (activityId cell) occurring in a trace (trace cell) as a 64-bit unsigned integer, which is also used to sort the tables in ascending order. We also show the absence of events associated with a given activity label by setting the count field for a specific trace to zero. The space complexity associated with this table is , while the occurrence count of a given activity for a specific trace can be retrieved in the time complexity. This table facilitates the efficient computation of dataless ‘exists’ and ‘absence’ Declare clauses.
Example 2. With reference to Figure 3 showcasing a KnoBAB relational representation for a healthcare log, determining whether a mastectomy event occurred at least once in boils down to checking whether . As , the aforementioned trace satisfies the desired condition. As this table lacks any temporal information, we need to introduce a novel table that preserves this. Each row
in an
states that the
i-th event of the
j-th trace (
) is labelled as
, while
q (or
) is the pointer to the immediately preceding
(or following,
) event within the trace, if any.
NULLs from
Figure 3 in
highlight the start (finish) event of each trace, where there is no possible reference to past (future) events. The primary index of the
efficiently points to the first and last record associated with a given activity label in the
time complexity. As the table’s records are sorted by the activity label, trace ID, and event ID by storing them as 64-bit integers, we can retrieve all records containing a given activity across the log. Pointers provide efficient access to the events immediately preceding and following a given event without additional access to the table and a subsequent join across accessed data.
Example 3. ChainPrecedence(FollowUp,Mastectomy) in our running example requires accessing all the activation conditions through the primary index of such a table, thus obtaining . Now, we can iterate the table’s records, starting from no. 8 until no. 9 included. By exploiting the q Prev pointers, we can determine that no. 8 has a preceding mastectomy event while no. 9, also belonging to a different trace, has a preceding lumpectomy event, thus violating the aforementioned clause. This leads to the main optimisation of mining ChainPrecedence and ChainSuccession clauses This assumption will be used implicitly in the code for mining such clauses in Section 4.3.3. The secondary index of the maps each trace the ID to the first and last events. This is especially beneficial for declarative mining as we can directly return the first and last events of each trace, and are able to quickly mine Init/End clauses.
Example 4. With reference to our running example, determining whether End(FollowUp) requires accessing the last event for all traces, as we obtain , , and , only the first and the last events are associated with a FollowUp event, while the second is a Referral. This leads to the main optimisation associated with Algorithm 5 for mining Init/Ends clauses.
-s guarantee faithfully reconstructing the entire log information by associating the payload information for each event in the activity table. In particular, we generate one table per key in the data payload. As our current algorithm does not rely on payload information
stored in this table, we refer to [
2] for further information.
2.3.2. Temporal Specification Mining
In traditional machine learning (
Section 2.1), data provide the common specifications from which specifications are extracted. Data points
are usually associated with a classification label
, directly associating the data to the expected class of specifications. This is very different from customary formal methods, where a formula defines the correct expected behaviours over all possible inputs. When we are only interested in distinguishing between behaviour that adheres to a formal specification and that which does not, it is adequate to identify two distinct classes: one for traces conforming to the expected temporal property, and another for those that deviate from it [
21]. Still, doing so when data are biased, limited, or labelled from non-experts might be challenging [
1]. Specification mining attempts to bridge the gap between specifications and data by inferring the former from the latter.
In business process mining literature, specification mining is often referred to as
declarative process (or model) mining. As in specification mining, we are interested in extracting specifications, where the language for the specification is expressed as a Declare clause. Apriori declarative mining (ADM) [
20] represents an advancement in state-of-the-art declarative temporal specification mining algorithms [
33] by limiting the instantiation of all possible declarative clauses to the itemsets being returned by an Apriori algorithm; such clauses are then further pruned through declarative minimum support thresholds, while prior solutions [
33] instantiated every Declare clause with all conceivable templates, leading to a quadratic combination set. This constraint is also evident in the available implementation of Apriori declarative mining + Fisher score (ADM+S) in Python [
21], where the actual implementation instantiates all the templates for all the possible activity labels being available on the current data. In fact, both [
33] and [
21] become easily intractable in real-world logs describing thousands of activities/events. ADM also further creams off infrequent declarative clauses through confidence and support. Notwithstanding the aforementioned improvements for candidate clause pruning, such approaches exploit no efficient heuristics for mining clauses. By only exploiting frequent itemset mining algorithms with support filtering for generating and testing all possible declarative clauses on log traces, the authors achieve suboptimal algorithms that generate and test all the candidate clauses (
propositionalisation [
23]), which are further creamed off through an additional filtering step.
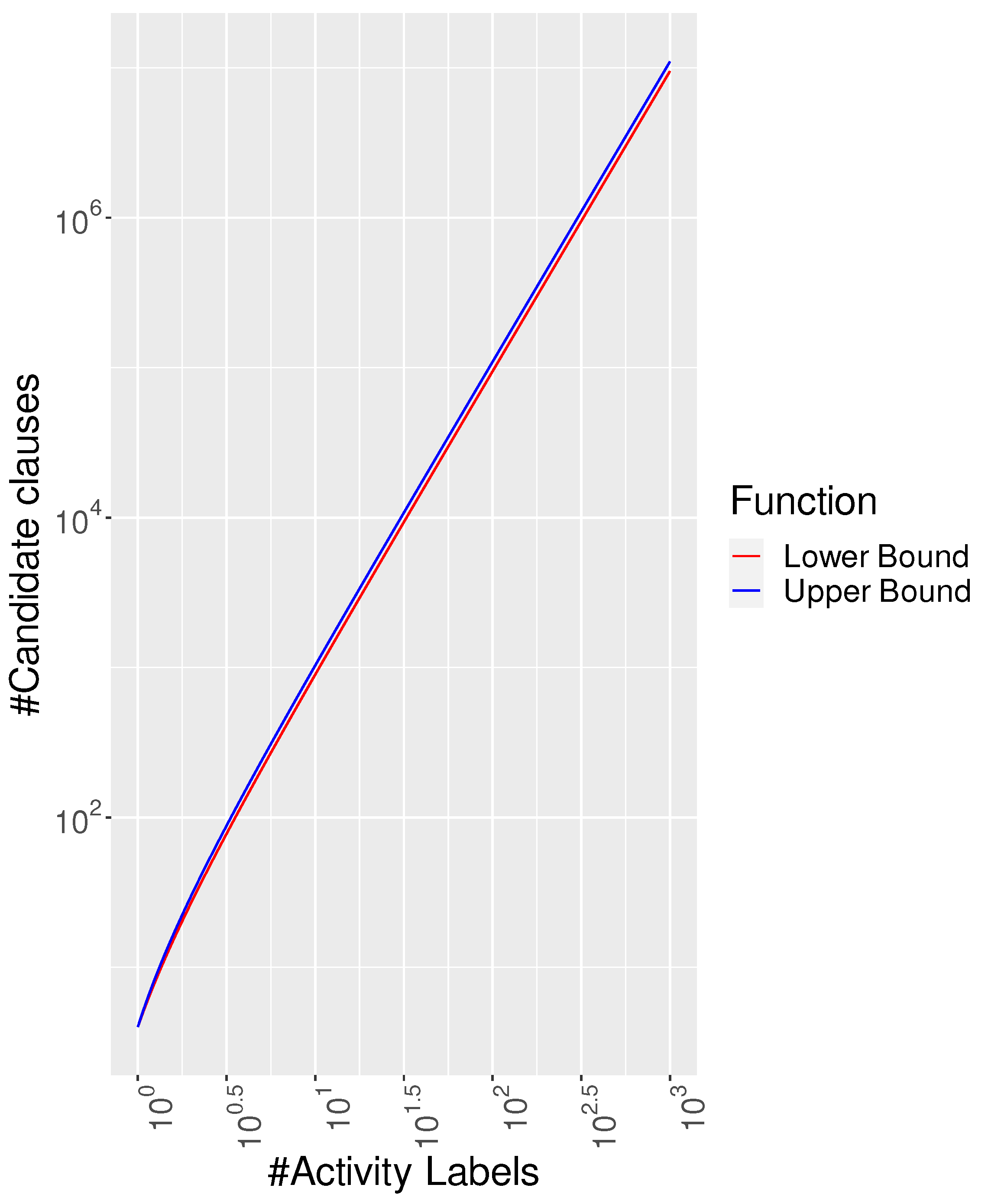
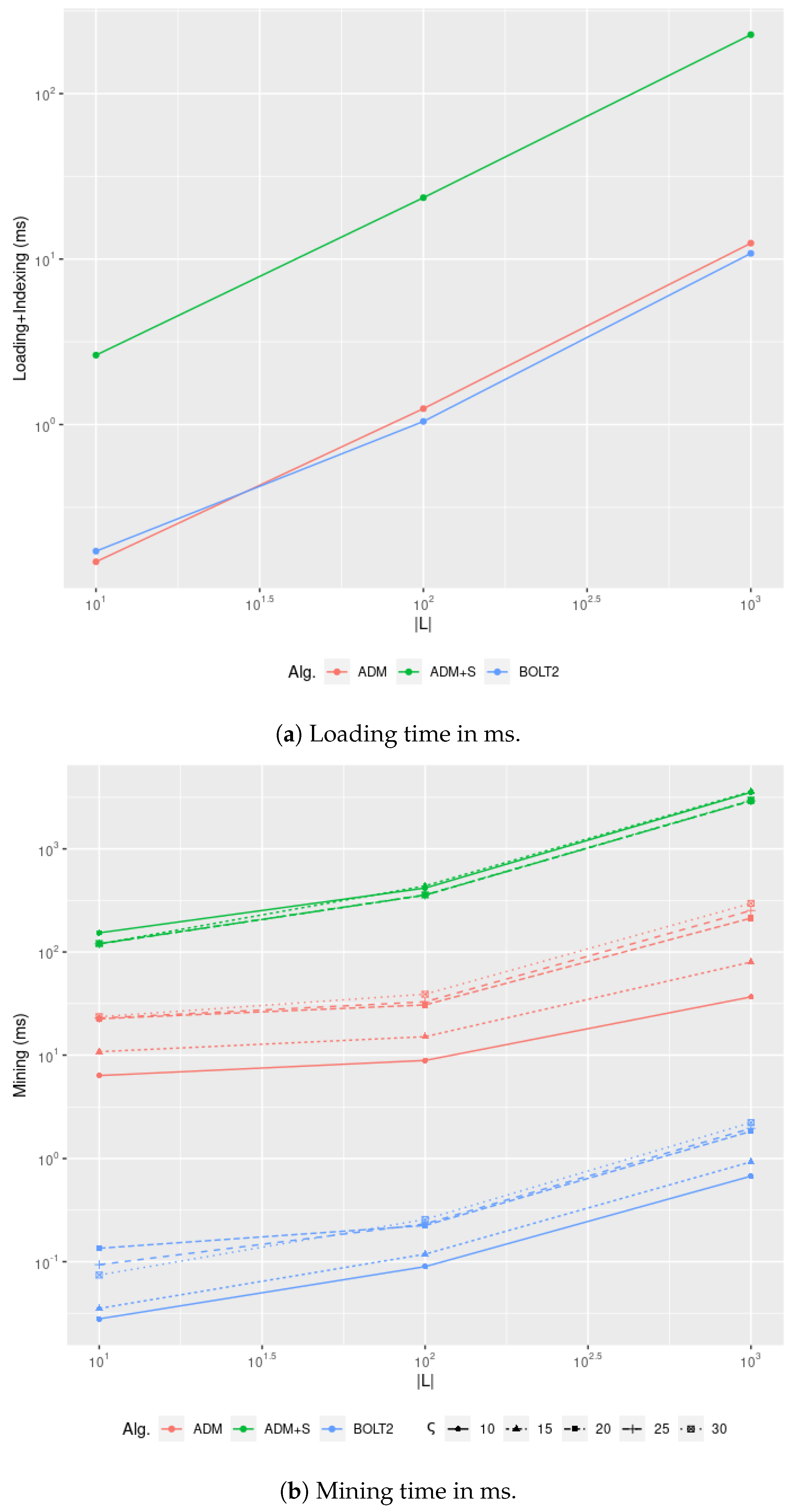
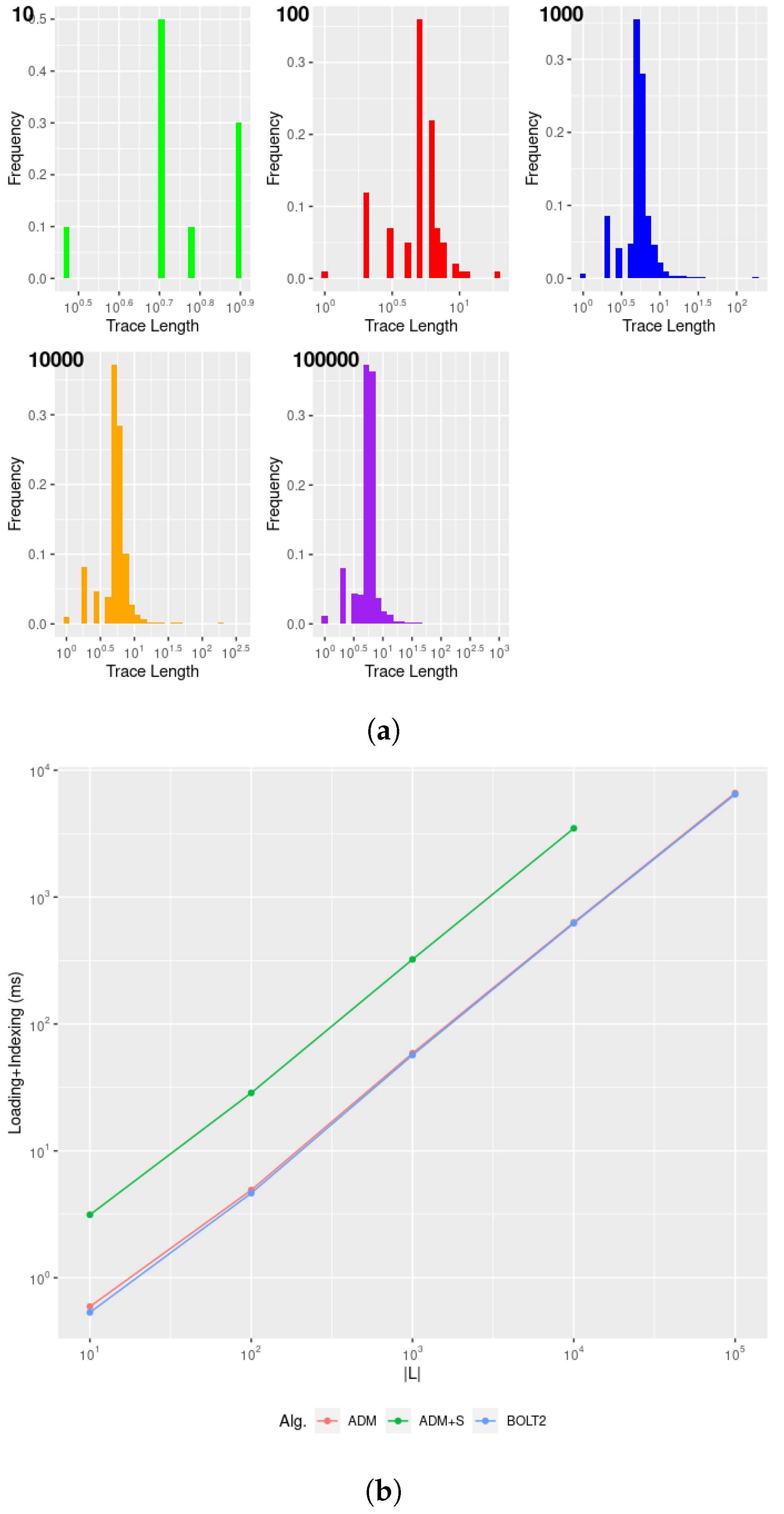
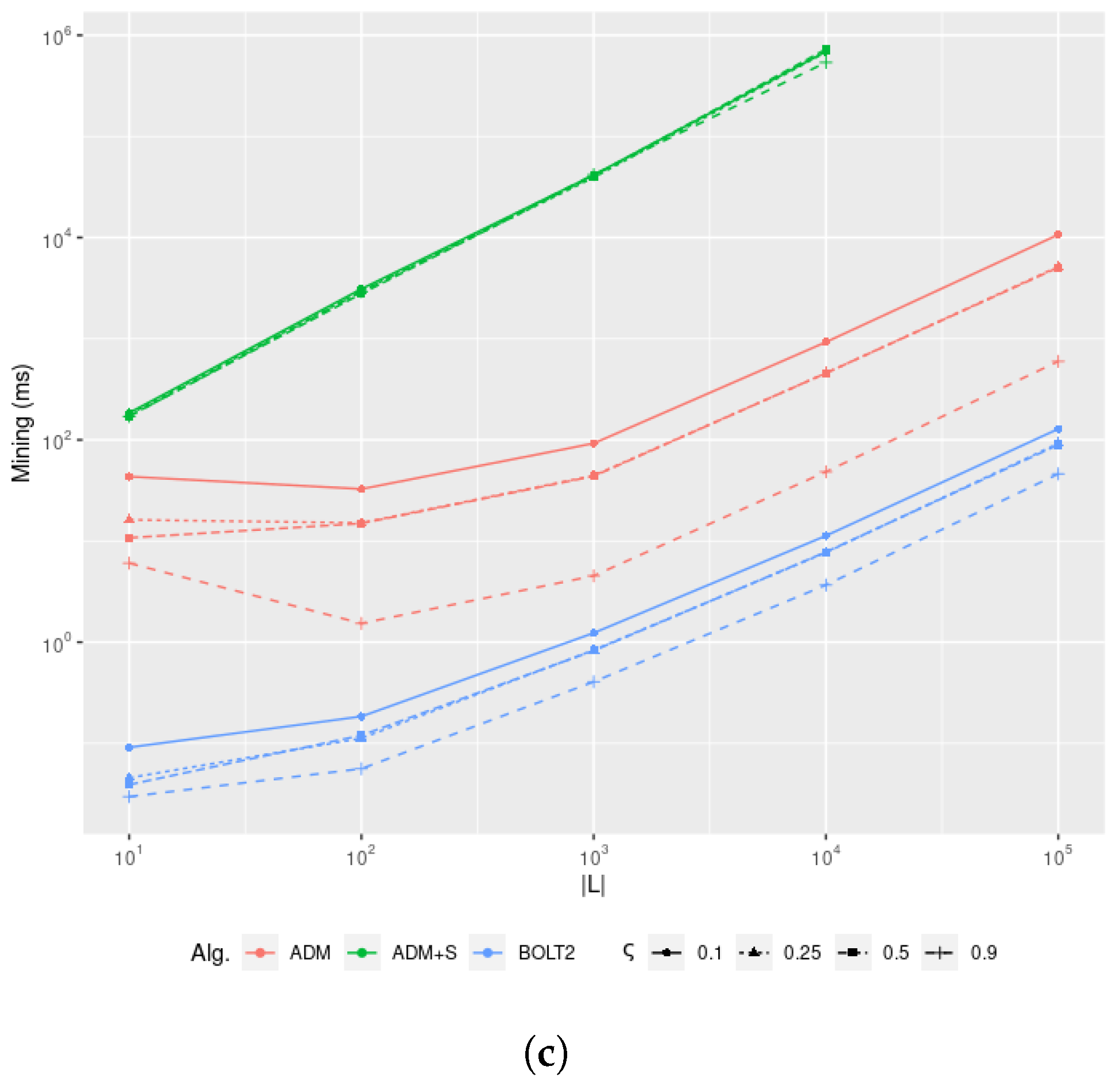
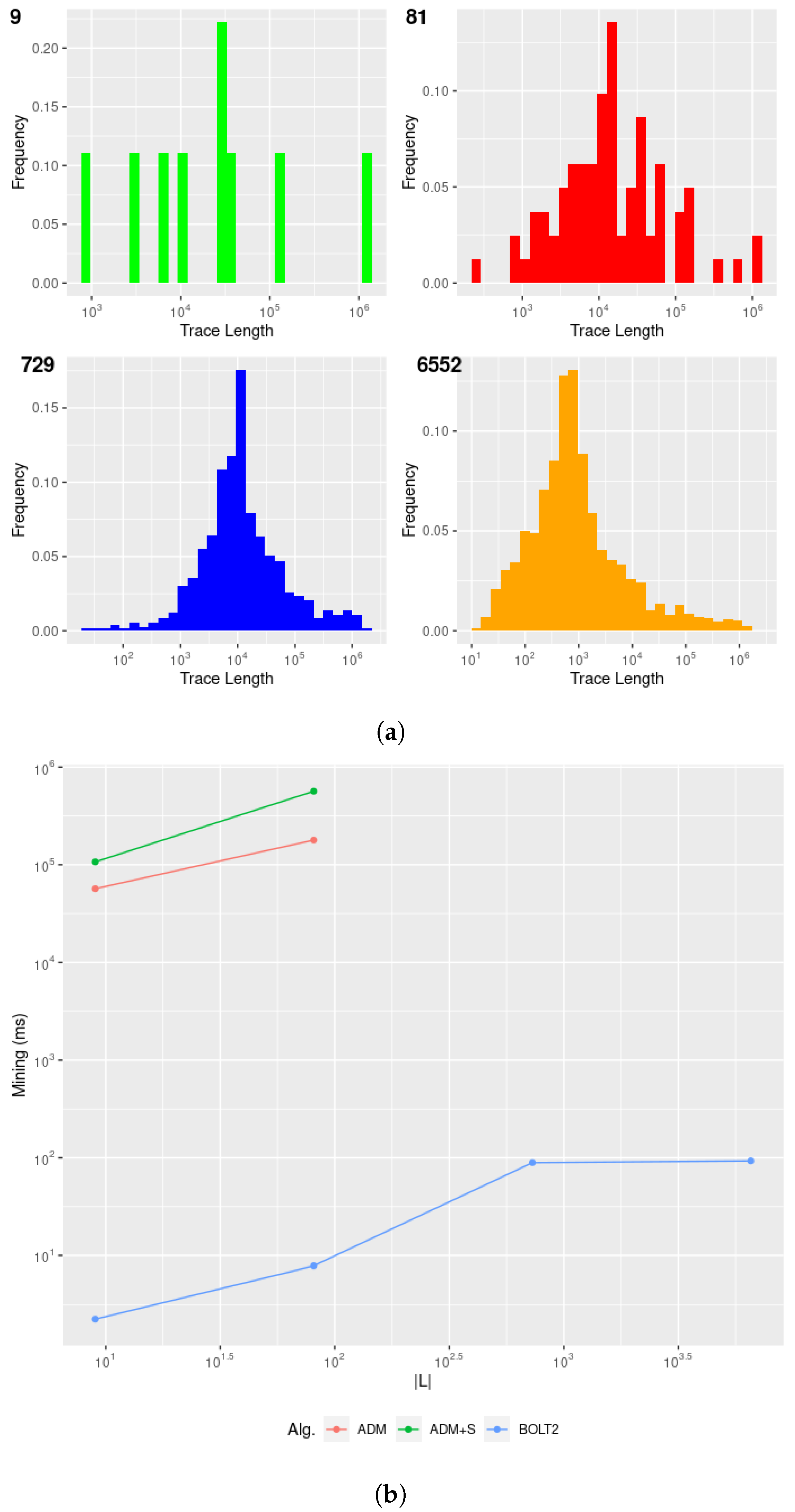
Figure 4 provides a clear picture concerning the impossibility of generating, testing, and returning all possible clauses for realistic datasets containing many distinct events through exhaustive search and propositionalisation within a reasonable amount of time. As an upper bound to the total number of possible clauses to be returned, we can consider instantiating all possible pairs of activity labels for the 11 binary clauses and instantiating the 4 unary clauses with
(
Absence) or
(
Exists), thus obtaining the following:
For the lower bound, we can limit the number of clauses for the 3 symmetric clauses of Choice, ExclChoice, and CoExistence to combinations, thus obtaining . We can easily see that, for hundreds of activity labels, as in realistic cybersecurity datasets, naïve algorithms are required to test an order of one million clauses, which cannot be analysed in a feasible amount of time. This clearly postulates the need for an efficient search algorithm limiting the search to the clauses effectively being representative of the data of interest.
Our previous implementation of dataless declarative process mining, i.e., Bolt [
5], was designed to efficiently mine the twelve clauses listed in
Table 1; however, it excluded the two newly introduced clauses,
Succession and
ChainSuccession, and our novel proposal introduced in the present paper,
Surround (
Section 3.2). Bolt outperforms all state-of-the-art dataless declarative mining competitors by leveraging KnoBAB’s aforementioned indexed tables while avoiding costly formal verification computations by only detecting vacuity and violation conditions without the need for combining multiple
xtLTL
f operators, as they can generate considerable overhead due to the intermediate results being generated by the implementation of the relational operators. Moreover, declarative clauses are generated using a general-to-specific search, starting from frequent clauses being directly inferable from association rule mining, such as
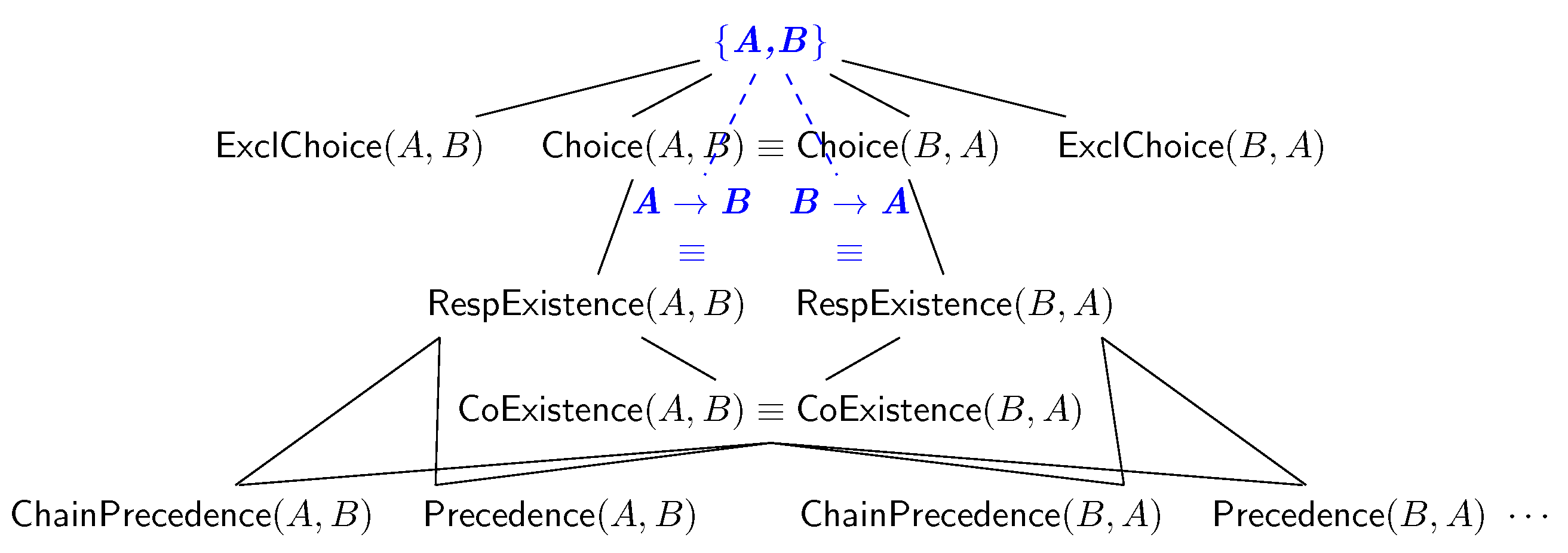
RespExistence and
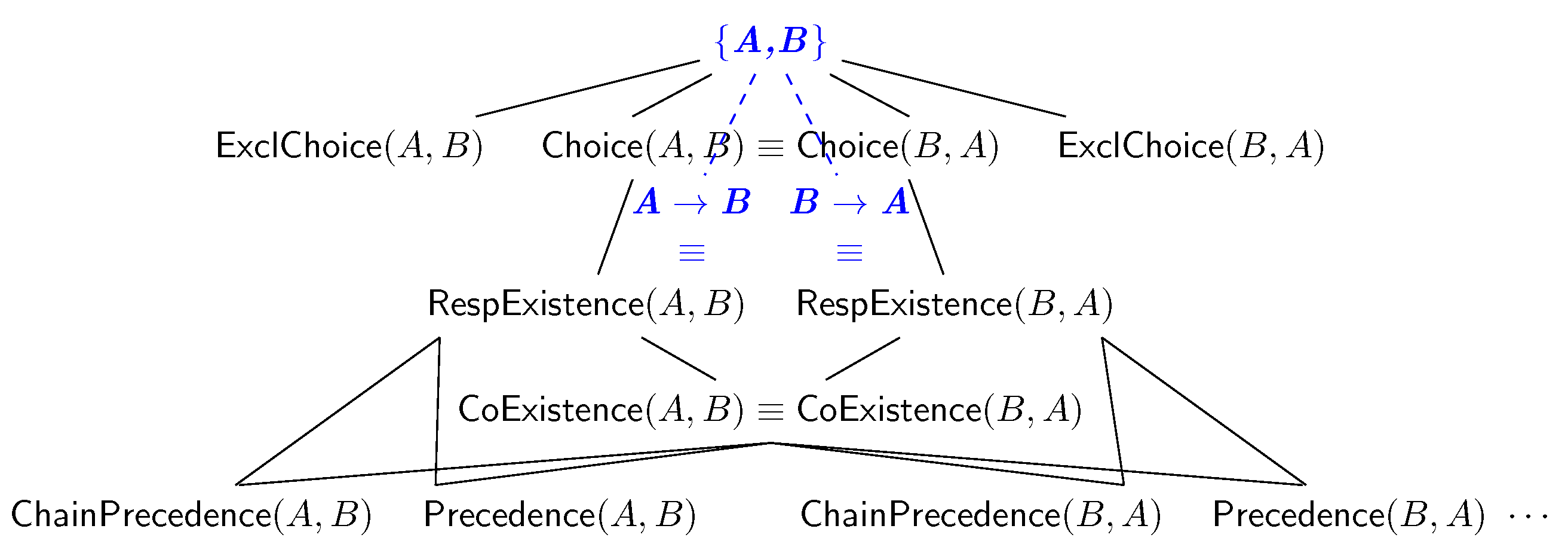
CoExistence, temporally refining them by starting the visit of the lattice in
Figure 5. To avoid generating uninteresting atemporal behaviour when temporal behaviour might be identified, we generate
Choice and
ExclChoice clauses by combining unary infrequent patterns. Our current solution further improves this by discarding the return of such clauses if any more informative temporal behaviour is returned (
Section 4.3.5).
In our previous contribution, we compared our proposed algorithm to [
5] TopN Declare [
30] using KnoBAB’s formal verification pipeline, Apriori declarative mining (ADM) after re-implementation on top of KnoBAB [
20], and Apriori declarative mining + Fisher score (ADM+S) implemented in Python [
21]. Through experiments, we demonstrated that we were both scalable with regard to the trace length and log size, while consistently outperforming the running time for all former competitors. TopN Declare was poor at mining all expected clauses from a log, as just considering all possible pairs among frequently occurring activity labels does not guarantee returning all the relevant clauses, and the others suffered greatly by producing explosive and redundant specifications, achieving hundreds of clauses, even with a strict support threshold
, as these solutions are affected by the curse of propositionalisation required to instantiate and test all possible clauses that might be generated from some mined binary frequent patterns. Bolt avoids the computational overhead from prior approaches due to the reduction of the specification mining task to a conformance checking one and its associated data allocation footprint by directly scanning relational tables without the need for generating intermediate results, as enforced by the adoption of query operators. Different from previous mining approaches that required instantiating all possible declarative clauses over all possible frequent itemsets through extensive clause propositionalisation, Bolt exploits a preliminary branch-and-bound solution for pruning irrelevant or “redundant” clauses, avoiding testing to abide by some irrelevant clauses that are not represented within the data (Example 13). The frequent support and confidence of itemsets serve as heuristics for determining whether specific clauses are frequent or appear in the specification, thus narrowing down the testing of temporal patterns to only the relevant instances.
Despite Bolt outperforming state-of-the-art temporal specification mining algorithms while mining less superfluous and more descriptive specifications, this approach can still be significantly improved.
First, despite Bolt being able to prune many redundant clauses that do not aptly describe the log compared to other solutions, the outputted specification is still far from minimised, as there still exist redundant clauses that imply each other. Improving this requires avoiding returning Choice clauses for temporal declarative clauses that have already been considered if appearing with greater or equal support.
Second, this preliminary solution still returns multiple symmetric clauses, which are deemed as equivalent, e.g.,
is completely equivalent to
, as they refer to the same set of log traces.
Third, we still return multiple clauses entailing each other, not fully exploiting the lattice descent for ensuring specification size minimality via the computation of an
S-border. Any desired improvement of Bolt tackling all these limitations with minimal performance costs will provide specifications returning more specific clauses while being less verbose than Bolt, while outperforming all other competitors by at least one order of magnitude. Our methodology section (
Section 4) shows how our novel solution addresses all such limitations.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}