
A Knowledge Representation System for the Indian Stock Market



Abstract
1. Introduction
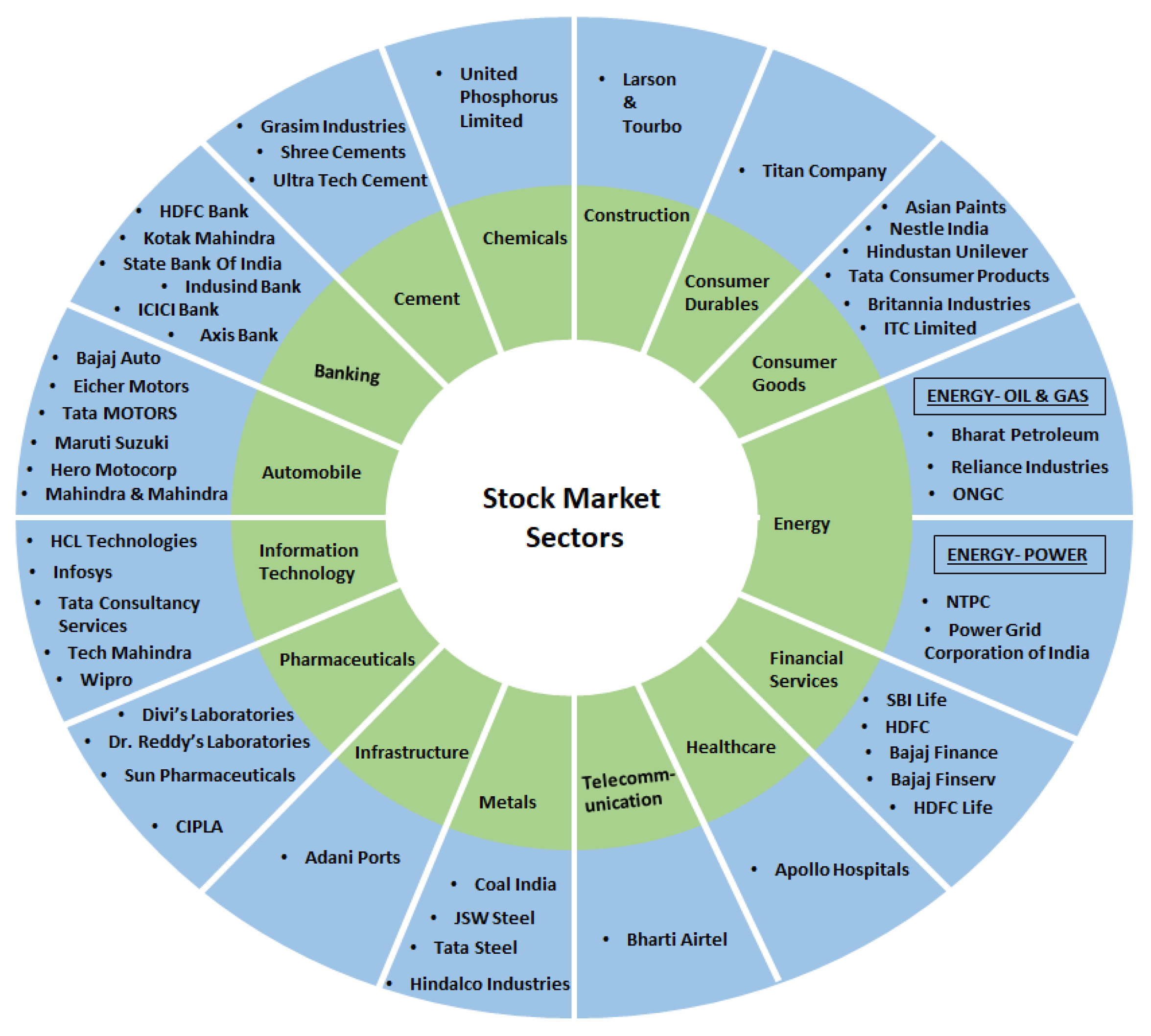
1.1. Indian Stock Market
1.1.1. Bombay Stock Exchange (BSE)
1.1.2. National Stock Exchange (NSE)
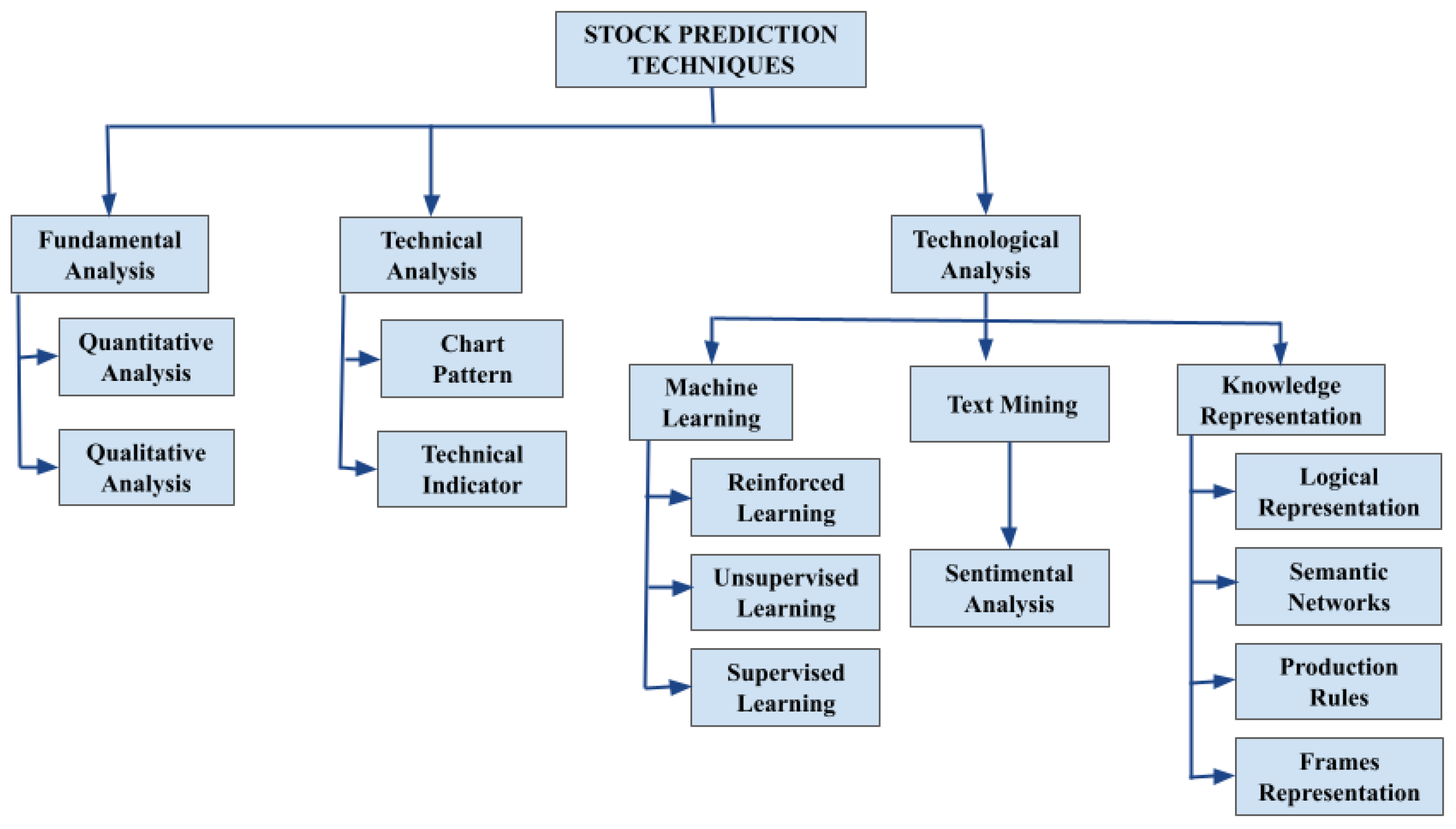
2. Literature Review
2.1. Fundamental Approach
2.2. Technical Approach
2.2.1. Chart Pattern
2.2.2. Technical Indicator
2.3. Machine Learning
2.3.1. Reinforced Learning
2.3.2. Unsupervised Learning
2.3.3. Supervised Learning
2.4. Text Mining
Sentimental Analysis
2.5. Formal Concept Analysis (FCA)
2.6. Knowledge Graphs
3. Terminologies Used
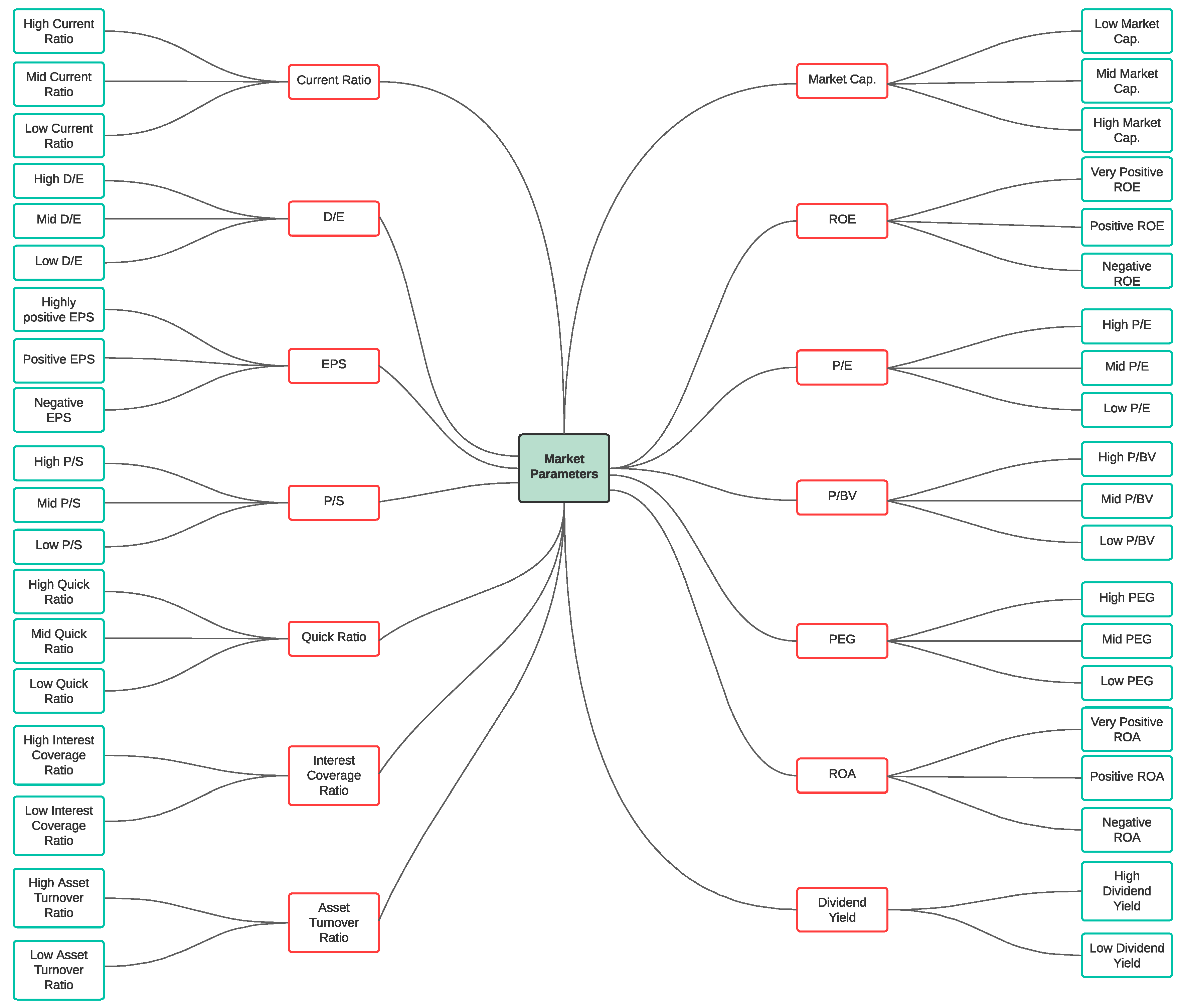
Market Parameters
- —Current market value of a stock traded on various exchanges, such as NSE, BSE, and others. It is the price one frequently sees mentioned in blogs, on the news, investment platforms, media networks, and finance domains.
- —The market capital refers to the overall value of all of the shares of stocks for that company. It is calculated by multiplying the current market price of each share by the number of outstanding company shares. It is often used to calculate a company’s size and evaluate the financial performance of other various-sized companies.
- —It is the return rate for common stockholders who possess shares in a company’s shareholdings. It measures a company’s profits and how effectively it makes those profits.A very high value of ROE, which is caused by a high net income compared to equity, indicates that a company’s performance is good; however, if a high is due to high equity, it means that the company is at risk.
- —This ratio is the most widely used ratio to determine whether a share is overvalued or undervalued. To calculate the ratio, we divide the current market price per share by the company’s earnings per share (EPS). A lower means the stock is undervalued, which is good for buying the stock at that point in time.
- —If we sell all assets and pay all liabilities, then the remaining money is the of a company.
- — is the ratio of the share price divided by the /share. A lower can mean that either a company is underestimated, something is wrong within the company, or the investor is paying extra for what would remain if the company suddenly went bankrupt.
- —It is the profit amount allocated to individual outstanding shares of a company’s common stock.Preferred dividend—a dividend that is issued to, or paid on, a company’s preferred shares.
- —It is the total debt divided by the equity of a non-current. Ideally, < 1 is a comfortable position. In tougher times, companies with low (retail, software) survive better.The ratio can be used to see the amount of leverage that a company uses.
- —A ratio compares a company’s stock price to its revenue generated. This ratio shows how much investors are willing to invest per rupee sales for a stock.The ratio is at its greatest value when comparing companies within the same sector.
- — is a liquidity ratio that indicates a company’s financial position; it measures the company’s ability to meet its financial obligations that are due within a year (short-term).If the is less than 1, it is not a good sign, whereas a current ratio of 3.0 signifies that the company can pay its liabilities 3 times faster.
- —It is an indicator of short-term liquidity and the company’s ability to meet its financial obligations by majorly using liquid assets (considers highly-liquid assets or cash equivalents as part of the current assets).The higher the , the better the company’s financial health and liquidity.
- —The amount of dividend that a company pays each year divided by the price per share; it is expressed in percentage.
- —It is a stock’s P/E ratio divided by its earnings growth rate for a specific time period, i.e., the relationship between growth and the P/E ratio. It is an indicator of a stock’s true value; similar to P/E, the lesser value represents a stock that may be undervalued given its future earnings expectations. In a fairly valued company, the P/E ratio and expected growth will be almost equal, making the PEG ratio = 1.0; a PEG below 1.0 means that the company is undervalued, and 1.0 means that the company is overvalued (for example, if company A has P/E = 22 and a growth rate of 20%).For example if company A has P/E = 22 and a growth rate of 20%, then PEG = 22/20 = 1.1. Company B, has P/E = 30 and a growth rate of 50%; thus, PEG = 30/50 = 0.6. Even though company A has less P/E, its growth rate is less than company B.
- —It indicates how much profit a company is generating in relation to its assets. It shows how well a company is performing.The greater the return value, the more productive and efficient the company is.
- —A company’s ability to honor its debt payment.EBITDA—earnings before interest, taxes, depreciation, and amortization. The greater the ratio, the better the rest; it may vary from industry to industry.
- —It measures how efficiently a company uses its assets to generate revenue. It is calculated as revenue divided by average assets.
3.1. Knowledge Representation
- Logical representation.
- Semantic networks.
- Production rules.
- Frame representation.
3.1.1. Logical Representation
3.1.2. Semantic Network Representation
3.1.3. Production Rules
3.1.4. Frame Representation
3.2. Formal Concept Analysis
Mathematical Definitions
- G represents a set of objects.
- M represents a set of attributes.
- I represents a binary relation.
- A’={ m ∈ M | ∀ g ∈ A : g|m }.
- B’={ g ∈ G | ∀ m ∈ B : g|m }.
- A ⊆ C ⇒ C’ ⊆ A’.
- A ⊆ A”.
- A = A”’.
- A ⊆ G.
- A’ = B.
- B ⊆ M.
- B’ = A.
- Monotonicity: A ⊆ C and A” ⊆ C”.
- Extensivity: A⊆ A”. A is always a subset of A”.
- Idempotency: A”” = A”.
- Monotone: X ⊆ Y ⇒∂X ⊆∂ Y.
- Extensive: X ⊆∂X.
- Idempotent: ∂X = ∂X.
- Reflexivity: (A,B) ≤ (A,B).
- Anti-symmetry: If () ≤ () and () ≤ ()∴ () = ().
- Transitivity: If () ≤ () ≤ ().Then () ≤ ().
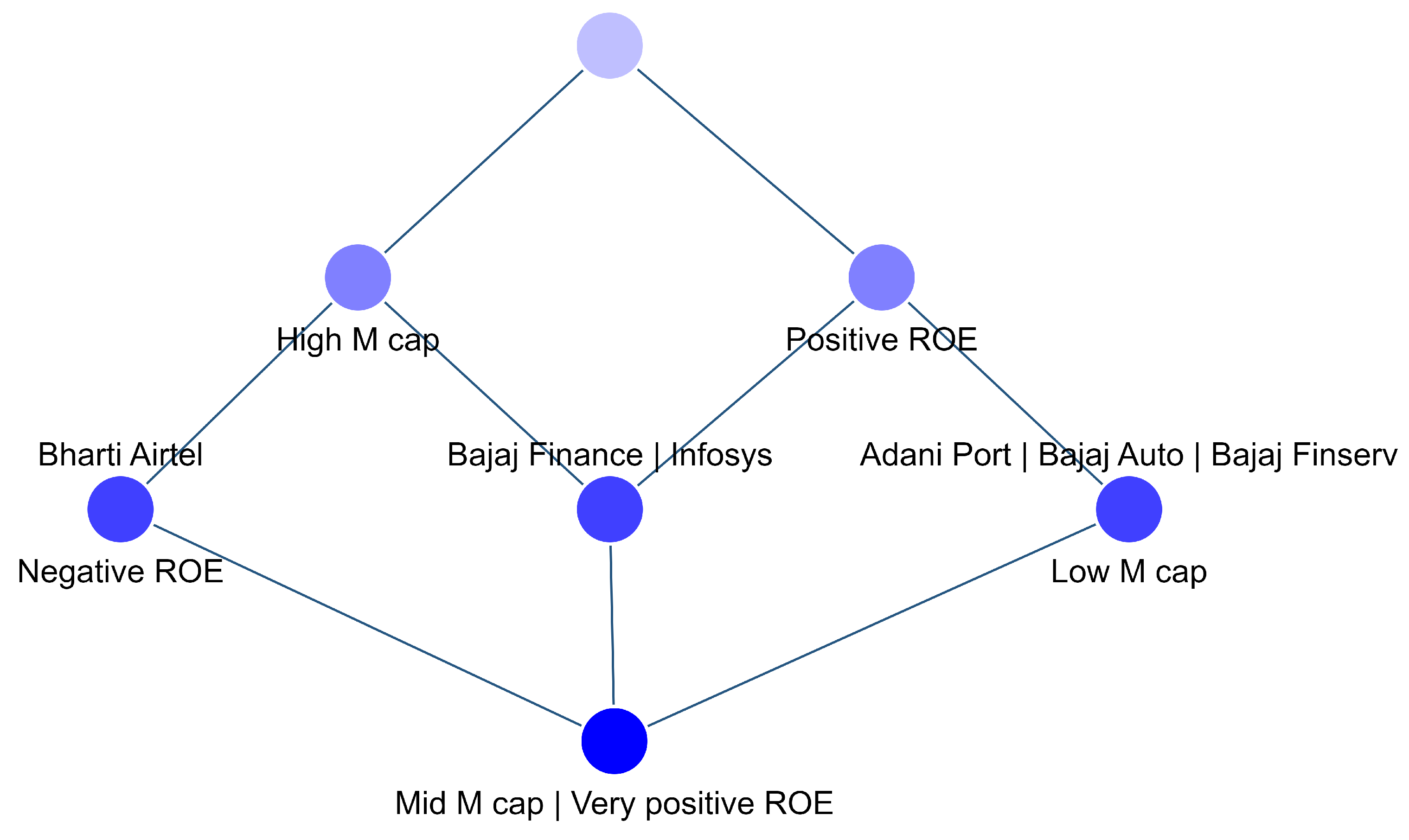
- A = {Adani Port, Bajaj Auto, Bajaj Finance, Bajaj Finserv, Bharti Airtel, Infosys}, a distinct set of objects.
- B = {High-M cap, mid-M cap, low-M cap, very positive ROE, positive ROE, negative ROE}, a distinct set of attributes of the market cap and ROE.
- Concept 1 is generated by taking the closure of the object set A, and since the objects have no attributes in common, their closure is an empty set of attributes.
- Concept 2 is defined for Bharti Airtel, which has a high M cap and negative ROE.
- Concept 3 is defined for multiple objects, including Adani Ports, Bajaj Auto, and Bajaj Finserv, sharing two attributes: a low-M cap and positive ROE.
- Similarly, Concepts 4, 5, and 6 are calculated.
- Concept 7 is defined for an empty object set, which results in an output of the attribute set B.
4. Methodology Used
4.1. Data Description
4.2. Data Prepossessing
4.3. Algorithmic Representation
| Algorithm 1: Closure generation |
Formulate the closure set of the given input set (A, G, M) Input: Input structure (A, G, M) Output: Set of elements forming the closed set B″
|
| Algorithm 2: All closure generation |
Calculate all possible closed sets starting from an empty set A = of a given extent or intent. Input: A closure operator C C ″ on the finite linearly ordered set M. Output: All closed sets in the lectic order.
|
| Algorithm 3: First Closure |
Calculates the closure of the empty set A = . Input: A closure operator X X″ on a finite linearly ordered set Output: Lectic first-closed set, i.e., closure on the empty set .
|
| Algorithm 4: Closure generation |
Formulate the closure set of the given input set (A, G, M) Input: A closure operator X X″ on a finite linearly ordered set M and subset A ⊆ M Output: The lectic next-closed set after A if it exists; otherwise, .
|
| Algorithm 5: Stability Calculator |
Evaluate the stability index of the given input set (A, B, C), Input: Input structure (A, B, C) Output: Stability index whose value will be between 0 and 1.
|
4.4. Algorithm Description
- Suppose the objective is to calculate the first derivative on an empty set of extent E={}. The “ ‘ ” symbol denotes the first derivative.
- (a)
- EE‘ indicates the intent, i.e., a set of all the attributes common to the set of objects in E.
- (b)
- Therefore, an empty set will have all of the attributes common to it.
- Similarly, calculating the first derivative for a set F = P,S will give us FF‘ = {A,C}.
- E’ E” is the group of all objects common to the set of attributes in E‘. E‘E” = {S}. Since E’ = {A, B, C}, which is the attribute set, all of these attributes are common to object S.
- F‘F” = {P,S}.
4.5. Asymptotic Analysis
- First closure :
- Next closure: ≤ for one iteration.
- First closure: O(|G||M|)
- Next closure:
4.6. Soundness and Completeness Analysis
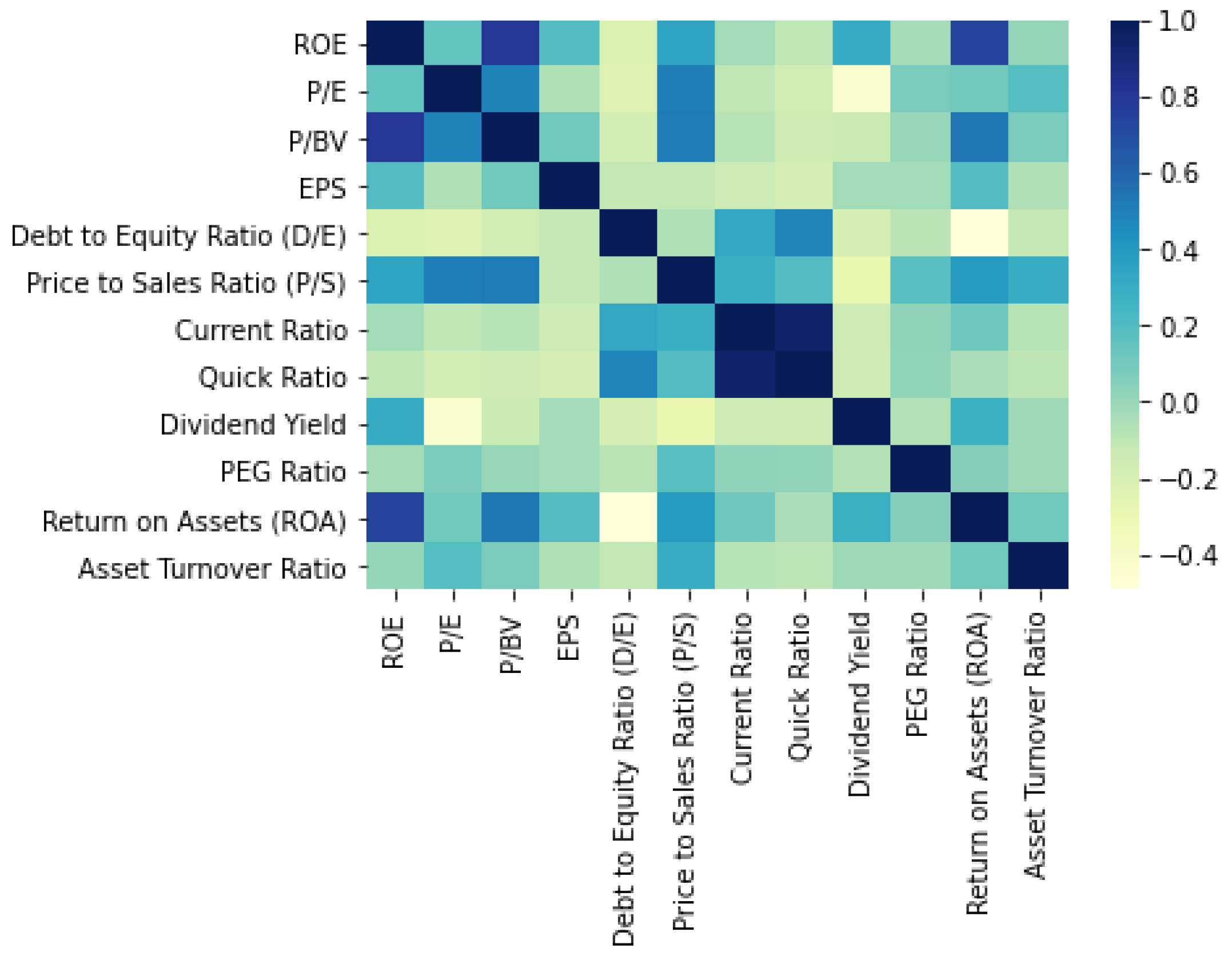
5. Results and Description
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chakraborty, I. Capital structure in an emerging stock market: The case of India. Res. Int. Bus. Financ. 2010, 24, 295–314. [Google Scholar] [CrossRef]
- Paramati, S.R.; Rakesh, G. An empirical analysis of stock market performance and economic growth: Evidence from India. Paramati SR Gupta 2011, 133–149. [Google Scholar] [CrossRef]
- Salameh, S.; Asad, A. A critical review of stock market development in India. J. Public Aff. 2022, 22, E2316. [Google Scholar] [CrossRef]
- Ji, S.; Pan, S.; Cambria, E.; Marttinen, P.; Yu, P.S. A survey on knowledge graphs: Representation, acquisition, and applications. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 494–514. [Google Scholar] [CrossRef] [PubMed]
- Behrendt, S.; Franziska, J.P.; Zimmermann, D.J. An encyclopedia for stock markets? Wikipedia searches and stock returns. Int. Rev. Financ. Anal. 2020, 72, 101563. [Google Scholar] [CrossRef]
- Gahlot, R. An analytical study on effect of FIIs & DIIs on Indian stock market. J. Transnatl. Manag. 2019, 24, 67–82. [Google Scholar]
- Idrees, S.M.; Alam, M.A.; Agarwal, P. A prediction approach for stock market volatility based on time series data. IEEE Access 2019, 7, 17287–17298. [Google Scholar] [CrossRef]
- Mathur, N.; Mathur, H. Application of GARCH Models for Volatility Modelling of Stock Market Returns: Evidences From BSE India. In Proceedings of the Business and Management Conference, Dubai, UAE, 16–18 January 2020; International Institute of Social and Economic Sciences: London, UK, 2020. [Google Scholar]
- Gupta, S.; Bandyopadhyay, G.; Biswas, S.; Mitra, A. An integrated framework for classification and selection of stocks for portfolio construction: Evidence from NSE, India. Decis. Mak. Manag. Eng. 2022.
- Nti, I.K.; Adekoya, A.F.; Weyori, B.A. A systematic review of fundamental and technical analysis of stock market predictions. Artif. Intell. Rev. 2020, 53, 3007–3057. [Google Scholar] [CrossRef]
- Sharma, A.; Dinesh, B.; Upendra, S. Survey of stock market prediction using machine learning approach. In Proceedings of the 2017 International conference of Electronics, Communication and Aerospace Technology (ICECA), Coimbatore, India, 20–22 April 2017; pp. 506–509. [Google Scholar]
- Samriti, S.; Singh, G.; Singh, D.N. Role and Performance of Different Traditional Classification and Nature-Inspired Computing Techniques in Major Research Areas. EAI Endorsed Trans. Scalable Inf. Syst. 2019, 6, E2. [Google Scholar]
- Selvamuthu, D.; Vineet, K.; Abhishek, M. Indian stock market prediction using artificial neural networks on tick data. Financ. Innov. 2019, 5, 1–12. [Google Scholar] [CrossRef]
- Chen, Y.-J.; Chen, Y.-M.; Chang, L.L. Enhancement of stock market forecasting using an improved fundamental analysis-based approach. Soft Comput. 2017, 21, 3735–3757. [Google Scholar] [CrossRef]
- Ashish, P.; Shetty, N.P. Indian Stock Market Prediction Using Machine Learning and Sentiment Analysis. In Computational Intelligence in Data Mining; Springer: Berlin/Heidelberg, Germany, 2018; pp. 595–603. [Google Scholar]
- Ha, M.H.; Lee, S.; Moon, B.R. A Genetic Algorithm for Rule-based Chart Pattern Search in Stock Market Prices. In Proceedings of the Genetic and Evolutionary Computation Conference 2016, Denver, CO, USA, 20–24 July 2016; pp. 909–916. [Google Scholar]
- de Warren, W.T.; Menon, V. Informed Trading Support for the Amateur Investoron the New York Stock Exchange. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 2948–2955. [Google Scholar]
- Zhu, J.; Wan, Y.; Si, Y.-W. A Language for Financial Chart Patterns. Int. J. Inf. Technol. Decis. Mak. 2018, 17, 1537–1560. [Google Scholar] [CrossRef]
- Wu, Y.-P.; Wu, K.-P.; Lee, H.-M. Stock Trend Prediction by Sequential Chart Pattern via K-Means and AprioriAll Algorithm. In Proceedings of the 2012 Conference on Technologies and Applications of Artificial Intelligence, Tainan, Taiwan, 16–18 November 2012; pp. 176–181. [Google Scholar] [CrossRef]
- Thammakesorn, S.; Sornil, O. Generating trading strategies based on candlestick chart pattern characteristics. J. Phys. Conf. Ser. 2019, 1195, 12008. [Google Scholar] [CrossRef]
- Ahmar, A.S. Sutte Indicator: A Technical Indicator in the Stock Market. Int. J. Econ. Financ. Issues 2017, 7, 223–226. [Google Scholar]
- Gerardo, A.; Ramírez, D.R. A Nonlinear Technical Indicator Selection Approach for Stock Markets. Mathematics 2020, 8, 1301. [Google Scholar]
- Meng, T.L.; Matloob, K. Reinforcement Learning in Financial Markets. Data 2019, 4, 110. [Google Scholar] [CrossRef]
- Ezzeddine, H.; Achkar, R.R. Ensemble Learning in Stock Market Prediction. In Proceedings of the 2021 13th International Conference on Machine Learning and Computing, Shenzen, China, 26 February–1 March 2021. [Google Scholar]
- Mohapatra, P.R.; Swain, S.K.; Basa, S.S. Unsupervised Learning Based Stock Price Recommendation using Collaborative Filtering. Int. J. Innov. Technol. Explor. Eng. 2019, 8, 11. [Google Scholar] [CrossRef]
- Song, D.-M.; Baek, A.M.C.B. Ulsan National Institute of Science and Technology Forecasting Stock Market Index Based on Pattern-Driven Long Short-Term Memory. Econ. Comput. Econ. Cybern. Stud. Res. 2020, 54, 3. [Google Scholar]
- Golmohammadi, K.; Zaiane, O.R.; Díaz, D. Detecting stock market manipulation using supervised learning algorithms. In Proceedings of the 2014 International Conference on Data Science and Advanced Analytics (DSAA), Shanghai, China, 30 October–1 November 2014; pp. 435–441. [Google Scholar] [CrossRef]
- Masood, K.; Ullah, H.; Khalid, H.A.; Habib, A.; Asghar, M.Z.; Kundi, F.M. Stock Market Trend Prediction using Supervised Learning. In Proceedings of the SoICT 2019, Hanoi Ha Long Bay, Vietnam, 4–6 December 2019; pp. 473–478. [Google Scholar]
- Mahendran, K.; Karthiraman, J.; EbenezerRajadurai, T.; Adhithyan, S. Stock Market Prediction with Historical Time Series Data and Sentimental Analysis of Social Media Data. In Proceedings of the 2020 4th International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, 13–15 May 2020. [Google Scholar]
- Subhi, A.F.; Cheng, X. Recent Advances in Stock Market Prediction Using Text Mining: A Survey. E-Bus. High. Educ. Intell. Appl. 2020. [Google Scholar]
- Rajendiran, P.; Priyadarsini, P.L.K. Survival study on stock market prediction techniques using sentimental analysis. Mater. Today 2021. [CrossRef]
- Škopljanac-Mačina, F.; Blaskovic, B. Formal Concept Analysis—Overview and Applications. Procedia Eng. 2014, 69, 1258–1267. [Google Scholar] [CrossRef]
- Dev, S.; Isah, H.; Zulkernine, F. Stock Market Analysis: A Review and Taxonomy of Prediction Techniques. Int. J. Financ. Stud. 2019, 7, 2. [Google Scholar] [CrossRef]
- Ignatov, D.I. Introduction to Formal Concept Analysis and Its Applications in Information Retrieval and Related Fields. In Information Tetrieval; Springer: Berlin/Heidelberg, Germany, 2015; Volume 505. [Google Scholar] [CrossRef]
- Liu, Y.; Zeng, Q.; Ordieres Meré, J.L.; Yang, H. Anticipating stock market of the renowned companies: A knowledge graph approach. Complexity 2019. [CrossRef]
- Long, J.; Chen, Z.; He, W.; Wu, T.; Ren, J. An integrated framework of deep learning and knowledge graph for prediction of stock price trend: An application in Chinese stock exchange market. Appl. Soft Comput. 2020, 91, 106205. [Google Scholar] [CrossRef]
- Liu, J.; Lu, Z.; Du, W. Combining enterprise knowledge graph and news sentiment analysis for stock price prediction. Decis. Support Smart Cities 2019.
- Tao, M.; Gao, S.; Mao, D.; Huang, H. Knowledge graph and deep learning combined with a stock price prediction network focusing on related stocks and mutation points. J. King Saud-Univ. Comput. Inf. Sci. 2022, 34, 4322–4334. [Google Scholar] [CrossRef]
- Bonifazi, G.; Corradini, E.; Ursino, D.; Virgili, L. Modeling, Evaluating, and Applying the eWoM Power of Reddit Posts. Big Data Cogn. Comput. 2023, 7, 47. [Google Scholar] [CrossRef]
- Bonifazi, G.; Cauteruccio, F.; Corradini, E.; Marchetti, M.; Sciarretta, L.; Ursino, D.; Virgili, L. A Space-Time Framework for Sentiment Scope Analysis in Social Media. Big Data Cogn. Comput. 2022, 6, 130. [Google Scholar] [CrossRef]
- Bhuyan, B.P. Relative similarity and stability in FCA pattern structures using game theory. In Proceedings of the 2017 2nd International Conference on Communication Systems, Computing and IT Applications (CSCITA), Mumbai, India, NJ, USA, 7–8 April 2017; IEEE: Piscataway; pp. 207–212. [Google Scholar]
- Bhuyan, B.P.; Karmakar, A.; Hazarika, S.M. Bounding Stability in Formal Concept Analysis. In Advanced Computational and Communication Paradigms: Proceedings of International Conference on ICACCP 2017.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Interpretation | Hieroglyph |
|---|---|
| Current Market Price | |
| Market Capital | |
| Return on Equity Ratio | |
| Price to Earning Ratio | |
| Price to Book Value Ratio | |
| Net Income | |
| Shareholder’s Equity | |
| Price per Share | |
| Total Number of shares | |
| Share Value or Market value | |
| Book Value | |
| Number of Shares | |
| Tangible Assets | |
| Liabilities | |
| Price of Fixed Assets | |
| Price of Current Assets | |
| Earning per Share | |
| Net Profit | |
| Preferred Dividend | |
| Number of Common Shares | |
| Debt to Equity Ratio | |
| Price to Sales Ratio | |
| Sales per Share | |
| Current Ratio | |
| Quick Ratio | |
| Current Assets | |
| Liquid Assets | |
| Dividend Yield | |
| Dividend per Share | |
| Price/Earning to Growth Ratio | |
| Growth Rate | |
| Return on Asset Ratio | |
| Total Assets | |
| Interest Coverage Ratio | |
| Earning Before Interest, Taxes, Depreciation, and Amortization | |
| Asset Turnover Ratio | |
| Net Sales |
| Adani Port | # | # | ||||
| Bajaj Auto | # | # | ||||
| Bajaj Finance | # | # | ||||
| Bajaj Finserv | # | # | ||||
| Bharti Airtel | # | # | ||||
| Infosys | # | # |
| Sr. No. | Objects | Attributes |
|---|---|---|
| 1. | Adani Port, Bajaj Auto, Bajaj Finance, Bajaj Finserv, Bajaj Airtel, Infosys | |
| 2. | Bajaj Airtel | High- |
| 3. | Adani Port, Bajaj Auto, Bajaj Finserv | Low-, |
| 4. | Bajaj Finserv, Bajaj Airtel, Infosys | High- |
| 5. | Adani Port, Bajaj Auto, Bajaj Finance, Bajaj Finserv, Infosys | |
| 6. | Bajaj Finserv, Infosys | High-, Positive |
| 7. | Low-, Mid-, High-, , , |
| A | B | C | |
|---|---|---|---|
| P | # | # | |
| Q | # | # | |
| R | # | # | |
| S | # | # | # |
| Adani Ports | # | # | # | ||||||
| Apollo Hospitals | # | # | # | ||||||
| Asian Paints | # | # | # | ||||||
| Axis Bank | # | # | # | ||||||
| Bajaj Auto | # | # | # | ||||||
| Bajaj Finance | # | # | # | ||||||
| Bajaj Finserv | # | # | # | ||||||
| Bharti Airtel | # | # | # | ||||||
| Bharat Petroleum | # | # | # |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bhuyan, B.P.; Jaiswal, V.; Cherif, A.R. A Knowledge Representation System for the Indian Stock Market. Computers 2023, 12, 90. https://doi.org/10.3390/computers12050090
Bhuyan BP, Jaiswal V, Cherif AR. A Knowledge Representation System for the Indian Stock Market. Computers. 2023; 12(5):90. https://doi.org/10.3390/computers12050090
Chicago/Turabian StyleBhuyan, Bikram Pratim, Vaishnavi Jaiswal, and Amar Ramdane Cherif. 2023. "A Knowledge Representation System for the Indian Stock Market" Computers 12, no. 5: 90. https://doi.org/10.3390/computers12050090
APA StyleBhuyan, B. P., Jaiswal, V., & Cherif, A. R. (2023). A Knowledge Representation System for the Indian Stock Market. Computers, 12(5), 90. https://doi.org/10.3390/computers12050090