
Model Compression for Deep Neural Networks: A Survey

Abstract
1. Introduction
1.1. Contributions of This Paper
- Conserves storage space, especially on edge devices.
- Reduces computational demand and speeds up model inference.
- Reduces the complexity of the model and prevents over-fitting.
- Reduces training time and computational resource consumption, thus reducing training costs.
- Improves the deployability of the model, as smaller models are easier to deploy on edge devices.
1.2. Organization of This Paper
2. Model Pruning
2.1. Structured Pruning
2.2. Unstructured Pruning
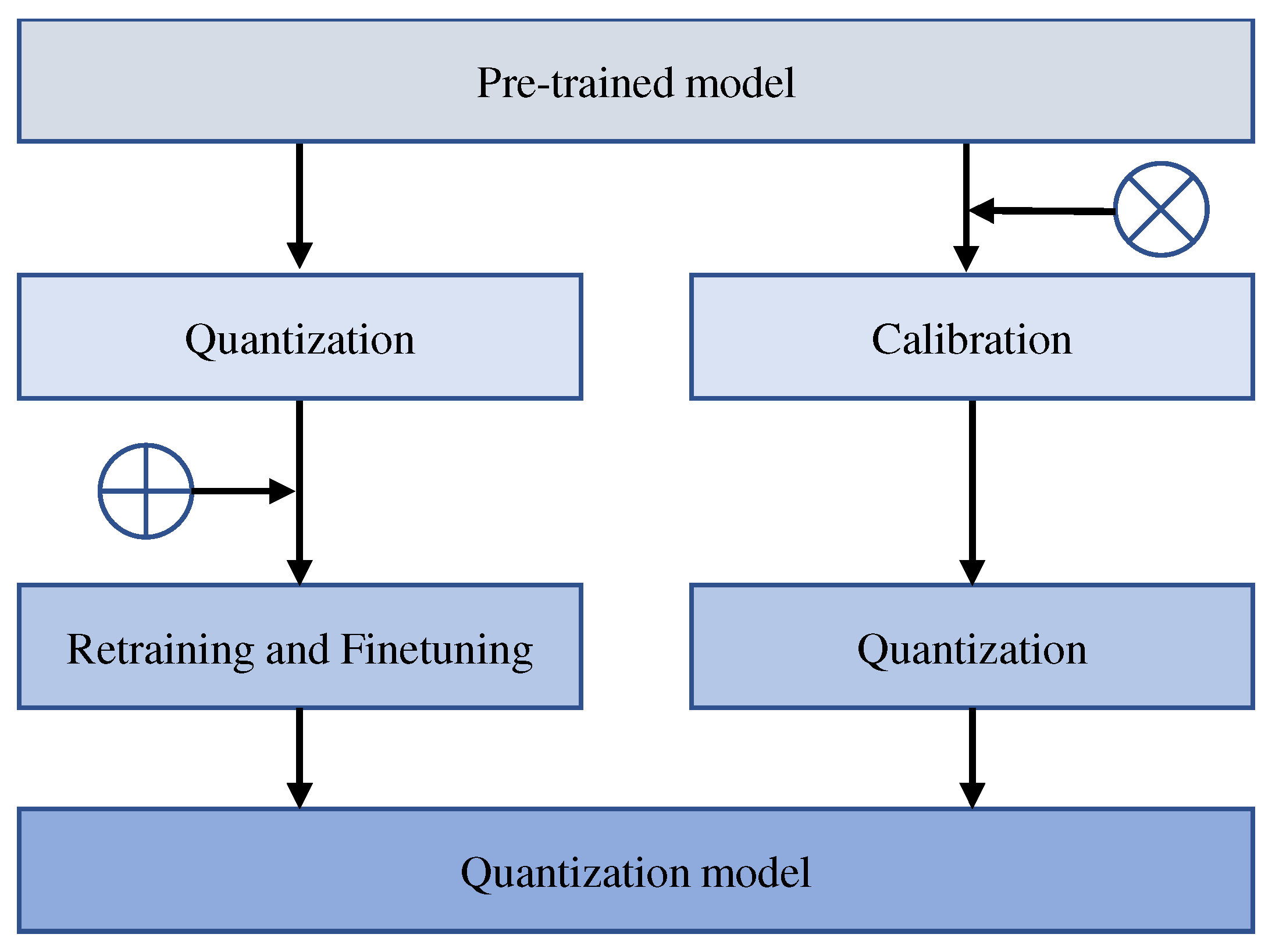
3. Parameter Quantization
- Less storage overhead and bandwidth requirements.
- Lower power consumption.
- Faster calculation speed.
| Algorithm 1 Parameter quantization. |
|
3.1. Quantization-Aware Training
3.2. Post-Training Quantization
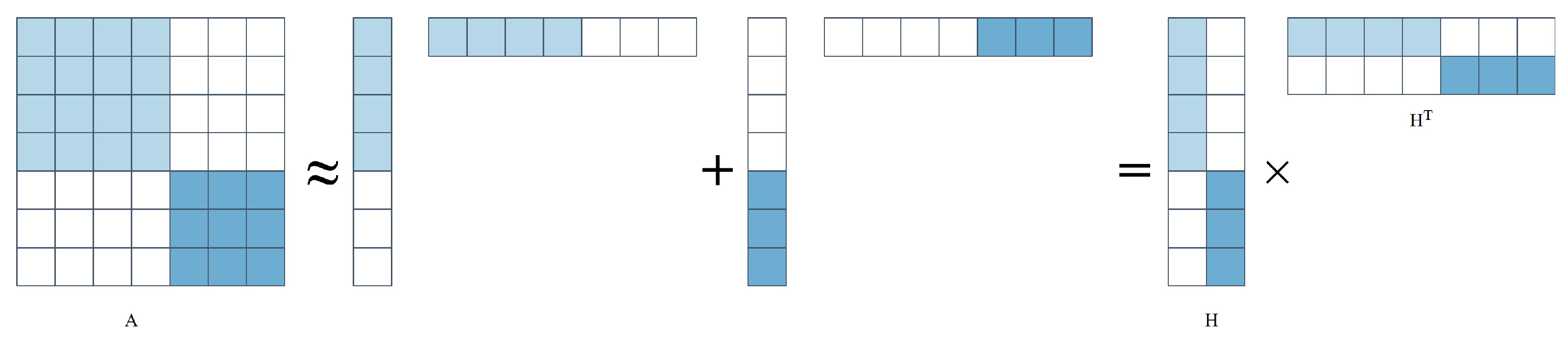
4. Low-Rank Decomposition
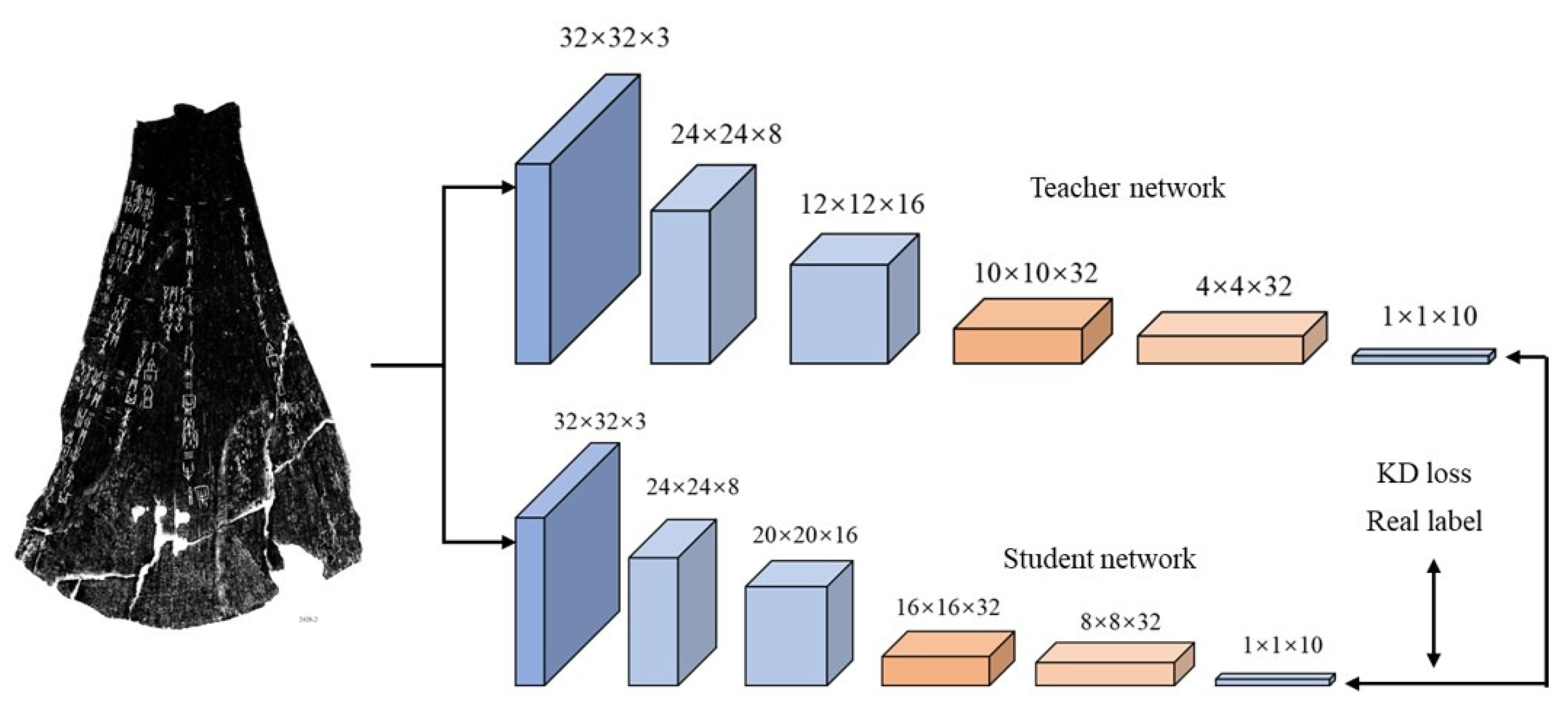
5. Knowledge Distillation
5.1. Response-Based Knowledge
5.2. Feature-Based Knowledge
5.3. Relation-Based Knowledge
6. Lightweight Model Design
- Increase the width of the network.
- Increase the depth of the network.
- Increase the resolution of input images.
7. Discussion
8. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yuan, T.; Liu, W.; Han, J.; Lombardi, F. High Performance CNN Accelerators Based on Hardware and Algorithm Co-Optimization. IEEE Trans. Circuits Syst. I Regul. Pap. 2021, 68, 250–263. [Google Scholar] [CrossRef]
- Barinov, R.; Gai, V.; Kuznetsov, G.; Golubenko, V. Automatic Evaluation of Neural Network Training Results. Computers 2023, 12, 26. [Google Scholar] [CrossRef]
- Cong, S.; Zhou, Y. A review of convolutional neural network architectures and their optimizations. Artif. Intell. Rev. 2022, 56, 1905–1969. [Google Scholar] [CrossRef]
- Zhong, C.; Mu, X.; He, X.; Wang, J.; Zhu, M. SAR Target Image Classification Based on Transfer Learning and Model Compression. IEEE Geosci. Remote Sens. Lett. 2019, 16, 412–416. [Google Scholar] [CrossRef]
- Chandio, A.; Gui, G.; Kumar, T.; Ullah, I.; Ranjbarzadeh, R.; Roy, A.M.; Hussain, A.; Shen, Y. Precise single-stage detector. arXiv 2022, arXiv:2210.04252. [Google Scholar]
- Yue, X.; Li, H.; Shimizu, M.; Kawamura, S.; Meng, L. YOLO-GD: A deep learning-based object detection algorithm for empty-dish recycling robots. Machines 2022, 10, 294. [Google Scholar] [CrossRef]
- Ge, Y.; Yue, X.; Meng, L. YOLO-GG: A slight object detection model for empty-dish recycling robot. In Proceedings of the 2022 International Conference on Advanced Mechatronic Systems (ICAMechS), Toyama, Japan, 17–20 December 2022; pp. 59–63. [Google Scholar]
- Minaee, S.; Boykov, Y.; Porikli, F.; Plaza, A.; Kehtarnavaz, N.; Terzopoulos, D. Image Segmentation Using Deep Learning: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 3523–3542. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.E.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Boston, MA, USA, 7–12 June 2015; IEEE Computer Society: Washington, DC, USA, 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Las Vegas, NV, USA, 27–30 June 2016; IEEE Computer Society: Washington, DC, USA, 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Honolulu, HI, USA, 21–26 July 2017; IEEE Computer Society: Washington, DC, USA, 2017; pp. 2261–2269. [Google Scholar]
- Xie, S.; Girshick, R.B.; Dollár, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Honolulu, HI, USA, 21–26 July 2017; IEEE Computer Society: Washington, DC, USA, 2017; pp. 5987–5995. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Salt Lake City, UT, USA, 18–22 June 2018; IEEE Computer Society: Washington, DC, USA, 2018; pp. 7132–7141. [Google Scholar]
- Yue, X.; Li, H.; Fujikawa, Y.; Meng, L. Dynamic Dataset Augmentation for Deep Learning-based Oracle Bone Inscriptions Recognition. J. Comput. Cultural Heritage 2022, 15, 1–20. [Google Scholar] [CrossRef]
- Wen, S.; Deng, M.; Inoue, A. Operator-based robust non-linear control for gantry crane system with soft measurement of swing angle. Int. J. Model. Identif. Control 2012, 16, 86–96. [Google Scholar] [CrossRef]
- Ishibashi, R.; Kaneko, H.; Yue, X.; Meng, L. Grasp Point Calculation and Food Waste Detection for Dish-recycling Robot. In Proceedings of the 2022 International Conference on Advanced Mechatronic Systems (ICAMechS), Toyama, Japan, 17–20 December 2022; pp. 41–46. [Google Scholar]
- Li, Z.; Meng, L. Research on Deep Learning-based Cross-disciplinary Applications. In Proceedings of the 2022 International Conference on Advanced Mechatronic Systems (ICAMechS), Toyama, Japan, 17–20 December 2022; pp. 221–224. [Google Scholar]
- Li, H.; Wang, Z.; Yue, X.; Wang, W.; Tomiyama, H.; Meng, L. A Comprehensive Analysis of Low-Impact Computations in Deep Learning Workloads. In Proceedings of the GLSVLSI ’21: Great Lakes Symposium on VLSI, Virtual Event, 22–25 June 2021; pp. 385–390. [Google Scholar]
- Matsui, A.; Iinuma, M.; Meng, L. Deep Learning Based Real-time Visual Inspection for Harvesting Apples. In Proceedings of the 2022 International Conference on Advanced Mechatronic Systems (ICAMechS), Toyama, Japan, 17–20 December 2022; pp. 76–80. [Google Scholar]
- Lawal, M.O. Tomato detection based on modified YOLOv3 framework. Sci. Rep. 2021, 11, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Marcel, B.; Eldert, V.H.; John, B.; John, R.; Deng, M. IEEE robotics and automation society technical committee on agricultural robotics and automation. IEEE Robot. Autom. Mag. 2013, 20, 20–23. [Google Scholar]
- Zhang, X.; Wang, Y.; Geng, G.; Yu, J. Delay-Optimized Multicast Tree Packing in Software-Defined Networks. IEEE Trans. Serv. Comput. 2021, 16, 261–275. [Google Scholar] [CrossRef]
- Hanson, S.; Pratt, L. Comparing Biases for Minimal Network Construction with Back-Propagation. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 1 January 1988; Volume 1. [Google Scholar]
- LeCun, Y.; Denker, J.; Solla, S. Optimal Brain Damage. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 27–30 November 1989; Volume 2. [Google Scholar]
- Hassibi, B.; Stork, D. Second order derivatives for network pruning: Optimal Brain Surgeon. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 30 November–3 December 1992; Volume 2. [Google Scholar]
- Luo, J.; Zhang, H.; Zhou, H.; Xie, C.; Wu, J.; Lin, W. ThiNet: Pruning CNN Filters for a Thinner Net. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 2525–2538. [Google Scholar] [CrossRef]
- Zhou, H.; Alvarez, J.M.; Porikli, F. Less Is More: Towards Compact CNNs. In Proceedings of the Computer Vision—ECCV 2016—14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Volume 9908, pp. 662–677. [Google Scholar]
- Wang, X.; Yu, F.; Dou, Z.; Darrell, T.; Gonzalez, J.E. SkipNet: Learning Dynamic Routing in Convolutional Networks. In Proceedings of the Computer Vision—ECCV 2018—15th European Conference, Munich, Germany, 8–14 September 2018; Volume 11217, pp. 420–436. [Google Scholar]
- Xiang, Q.; Wang, X.; Song, Y.; Lei, L.; Li, R.; Lai, J. One-dimensional convolutional neural networks for high-resolution range profile recognition via adaptively feature recalibrating and automatically channel pruning. Int. J. Intell. Syst. 2021, 36, 332–361. [Google Scholar] [CrossRef]
- Molchanov, P.; Tyree, S.; Karras, T.; Aila, T.; Kautz, J. Pruning convolutional neural networks for resource efficient inference. arXiv 2016, arXiv:1611.06440. [Google Scholar]
- Li, H.; Kadav, A.; Durdanovic, I.; Samet, H.; Graf, H.P. Pruning Filters for Efficient ConvNets. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017. [Google Scholar]
- He, Y.; Liu, P.; Wang, Z.; Hu, Z.; Yang, Y. Filter pruning via geometric median for deep convolutional neural networks acceleration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 4340–4349. [Google Scholar]
- Li, Q.; Li, H.; Meng, L. Feature Map Analysis-Based Dynamic CNN Pruning and the Acceleration on FPGAs. Electronics 2022, 11, 2887. [Google Scholar] [CrossRef]
- Lin, S.; Ji, R.; Li, Y.; Wu, Y.; Huang, F.; Zhang, B. Accelerating Convolutional Networks via Global & Dynamic Filter Pruning. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence (IJCAI), Stockholm, Sweden, 13–19 July 2018; Volume 2, pp. 2425–2432. [Google Scholar]
- Li, H.; Yue, X.; Meng, L. Enhanced mechanisms of pooling and channel attention for deep learning feature maps. PeerJ Comput. Sci. 2022, 8, e1161. [Google Scholar] [CrossRef]
- Kuang, J.; Shao, M.; Wang, R.; Zuo, W.; Ding, W. Network pruning via probing the importance of filters. Int. J. Mach. Learn. Cybern. 2022, 13, 2403–2414. [Google Scholar] [CrossRef]
- Li, H.; Yue, X.; Wang, Z.; Chai, Z.; Wang, W.; Tomiyama, H.; Meng, L. Optimizing the deep neural networks by layer-wise refined pruning and the acceleration on FPGA. Comput. Intell. Neurosci. 2022, 2022, 8039281. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Yue, X.; Wang, Z.; Wang, W.; Tomiyama, H.; Meng, L. A survey of Convolutional Neural Networks—From software to hardware and the applications in measurement. Meas. Sens. 2021, 18, 100080. [Google Scholar] [CrossRef]
- Sawant, S.S.; Bauer, J.; Erick, F.; Ingaleshwar, S.; Holzer, N.; Ramming, A.; Lang, E.; Götz, T. An optimal-score-based filter pruning for deep convolutional neural networks. Appl. Intell. 2022, 52, 17557–17579. [Google Scholar] [CrossRef]
- Evci, U.; Gale, T.; Menick, J.; Castro, P.S.; Elsen, E. Rigging the lottery: Making all tickets winners. In Proceedings of the International Conference on Machine Learning, ICML, Virtual Event, 13–18 July 2020; pp. 2943–2952. [Google Scholar]
- Huang, Q.; Zhou, K.; You, S.; Neumann, U. Learning to prune filters in convolutional neural networks. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 709–718. [Google Scholar]
- Chu, Y.; Li, P.; Bai, Y.; Hu, Z.; Chen, Y.; Lu, J. Group channel pruning and spatial attention distilling for object detection. Appl. Intell. 2022, 52, 16246–16264. [Google Scholar] [CrossRef]
- Chang, J.; Lu, Y.; Xue, P.; Xu, Y.; Wei, Z. Automatic channel pruning via clustering and swarm intelligence optimization for CNN. Appl. Intell. 2022, 52, 17751–17771. [Google Scholar] [CrossRef]
- Liu, Z.; Li, J.; Shen, Z.; Huang, G.; Yan, S.; Zhang, C. Learning efficient convolutional networks through network slimming. In Proceedings of the IEEE International Conference on Computer Vision, ICCV, Venice, Italy, 22–29 October 2017; pp. 2736–2744. [Google Scholar]
- Anwar, S.; Hwang, K.; Sung, W. Structured Pruning of Deep Convolutional Neural Networks. ACM J. Emerg. Technol. Comput. Syst. 2017, 13, 1–18. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on Machine Learning, ICML, Lille, France, 6–11 July 2015; Volume 37, pp. 448–456. [Google Scholar]
- Yang, T.J.; Chen, Y.H.; Sze, V. Designing energy-efficient convolutional neural networks using energy-aware pruning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Honolulu, HI, USA, 21–26 July 2017; pp. 5687–5695. [Google Scholar]
- Fan, Y.; Pang, W.; Lu, S. HFPQ: Deep neural network compression by hardware-friendly pruning-quantization. Appl. Intell. 2021, 51, 7016–7028. [Google Scholar] [CrossRef]
- Chen, T.; Ji, B.; Ding, T.; Fang, B.; Wang, G.; Zhu, Z.; Liang, L.; Shi, Y.; Yi, S.; Tu, X. Only Train Once: A One-Shot Neural Network Training And Pruning Framework. In Proceedings of the Advances in Neural Information Processing Systems, NeurIPS, Denver, CO, USA, 6–14 December 2021; Volume 34, pp. 19637–19651. [Google Scholar]
- Chung, G.S.; Won, C.S. Filter pruning by image channel reduction in pre-trained convolutional neural networks. Multimed. Tools Appl. 2021, 80, 30817–30826. [Google Scholar] [CrossRef]
- Chen, T.; Zhang, H.; Zhang, Z.; Chang, S.; Liu, S.; Chen, P.Y.; Wang, Z. Linearity Grafting: Relaxed Neuron Pruning Helps Certifiable Robustness. arXiv 2022, arXiv:2206.07839. [Google Scholar]
- Han, S.; Mao, H.; Dally, W.J. Deep Compression: Compressing Deep Neural Network with Pruning, Trained Quantization and Huffman Coding. In Proceedings of the 4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Han, S.; Pool, J.; Tran, J.; Dally, W. Learning both weights and connections for efficient neural network. In Proceedings of the Advances in Neural Information Processing Systems, NeurIPS, Montreal, QC, Canada, 7–12 December 2015; pp. 1135–1143. [Google Scholar]
- Molchanov, P.; Mallya, A.; Tyree, S.; Frosio, I.; Kautz, J. Importance Estimation for Neural Network Pruning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Long Beach, CA, USA, 16–20 June 2019; pp. 11264–11272. [Google Scholar]
- Dong, X.; Chen, S.; Pan, S. Learning to prune deep neural networks via layer-wise optimal brain surgeon. In Proceedings of the Advances in Neural Information Processing Systems, NeurIPS, Long Beach, CA, USA, 4–9 December 2017; pp. 4857–4867. [Google Scholar]
- Risso, M.; Burrello, A.; Pagliari, D.J.; Conti, F.; Lamberti, L.; Macii, E.; Benini, L.; Poncino, M. Pruning In Time (PIT): A Lightweight Network Architecture Optimizer for Temporal Convolutional Networks. In Proceedings of the 58th ACM/IEEE Design Automation Conference, DAC, San Francisco, CA, USA, 5–9 December 2021; pp. 1015–1020. [Google Scholar]
- Yang, T.J.; Howard, A.; Chen, B.; Zhang, X.; Go, A.; Sandler, M.; Sze, V.; Adam, H. NetAdapt: Platform-Aware Neural Network Adaptation for Mobile Applications. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 289–304. [Google Scholar]
- Guo, Y.; Yao, A.; Chen, Y. Dynamic network surgery for efficient dnns. Adv. Neural Inf. Process. Syst. 2016, 29. [Google Scholar]
- Neill, J.O.; Dutta, S.; Assem, H. Aligned Weight Regularizers for Pruning Pretrained Neural Networks. arXiv 2022, arXiv:2204.01385. [Google Scholar]
- Frankle, J.; Carbin, M. The lottery ticket hypothesis: Finding sparse, trainable neural networks. arXiv 2018, arXiv:1803.03635. [Google Scholar]
- Yue, X.; Li, H.; Meng, L. An Ultralightweight Object Detection Network for Empty-Dish Recycling Robots. IEEE Trans. Instrum. Meas. 2023, 72, 1–12. [Google Scholar]
- Nagel, M.; Fournarakis, M.; Amjad, R.A.; Bondarenko, Y.; van Baalen, M.; Blankevoort, T. A White Paper on Neural Network Quantization. arXiv 2021, arXiv:2106.08295. [Google Scholar]
- Krishnamoorthi, R. Quantizing deep convolutional networks for efficient inference: A whitepaper. arXiv 2018, arXiv:1806.08342. [Google Scholar]
- Wu, J.; Leng, C.; Wang, Y.; Hu, Q.; Cheng, J. Quantized Convolutional Neural Networks for Mobile Devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4820–4828. [Google Scholar]
- Courbariaux, M.; Bengio, Y.; David, J. BinaryConnect: Training Deep Neural Networks with binary weights during propagations. In Proceedings of the Advances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Systems 2015, Montreal, QC, Canada, 7–12 December 2015; pp. 3123–3131. [Google Scholar]
- Gysel, P. Ristretto: Hardware-Oriented Approximation of Convolutional Neural Networks. arXiv 2016, arXiv:1605.06402. [Google Scholar]
- Gysel, P.; Pimentel, J.J.; Motamedi, M.; Ghiasi, S. Ristretto: A Framework for Empirical Study of Resource-Efficient Inference in Convolutional Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 5784–5789. [Google Scholar] [CrossRef]
- Hubara, I.; Courbariaux, M.; Soudry, D.; El-Yaniv, R.; Bengio, Y. Binarized Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems 29: Annual Conference on Neural Information Processing Systems 2016, Barcelona, Spain, 5–10 December 2016; pp. 4107–4115. [Google Scholar]
- Lin, X.; Zhao, C.; Pan, W. Towards Accurate Binary Convolutional Neural Network. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 345–353. [Google Scholar]
- Lin, Z.; Courbariaux, M.; Memisevic, R.; Bengio, Y. Neural Networks with Few Multiplications. In Proceedings of the 4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Ni, R.; Chu, H.; Castañeda, O.; Chiang, P.; Studer, C.; Goldstein, T. WrapNet: Neural Net Inference with Ultra-Low-Resolution Arithmetic. arXiv 2020, arXiv:2007.13242. [Google Scholar]
- Rastegari, M.; Ordonez, V.; Redmon, J.; Farhadi, A. XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks. In Proceedings of the Computer Vision—ECCV 2016—14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Volume 9908, pp. 525–542. [Google Scholar]
- Tailor, S.A.; Fernández-Marqués, J.; Lane, N.D. Degree-Quant: Quantization-Aware Training for Graph Neural Networks. arXiv 2020, arXiv:2008.05000. [Google Scholar]
- Cai, Y.; Yao, Z.; Dong, Z.; Gholami, A.; Mahoney, M.W.; Keutzer, K. ZeroQ: A Novel Zero Shot Quantization Framework. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, 13–19 June 2020; pp. 13166–13175. [Google Scholar]
- Fang, J.; Shafiee, A.; Abdel-Aziz, H.; Thorsley, D.; Georgiadis, G.; Hassoun, J. Near-Lossless Post-Training Quantization of Deep Neural Networks via a Piecewise Linear Approximation. arXiv 2020, arXiv:2002.00104. [Google Scholar]
- Fang, J.; Shafiee, A.; Abdel-Aziz, H.; Thorsley, D.; Georgiadis, G.; Hassoun, J. Post-training Piecewise Linear Quantization for Deep Neural Networks. In Proceedings of the Computer Vision—ECCV 2020, Glasgow, UK, 23–28 August 2020; Volume 12347, pp. 69–86. [Google Scholar]
- Garg, S.; Jain, A.; Lou, J.; Nahmias, M.A. Confounding Tradeoffs for Neural Network Quantization. arXiv 2021, arXiv:2102.06366. [Google Scholar]
- Garg, S.; Lou, J.; Jain, A.; Nahmias, M.A. Dynamic Precision Analog Computing for Neural Networks. arXiv 2021, arXiv:2102.06365. [Google Scholar] [CrossRef]
- Lee, J.H.; Ha, S.; Choi, S.; Lee, W.; Lee, S. Quantization for Rapid Deployment of Deep Neural Networks. arXiv 2018, arXiv:1810.05488. [Google Scholar]
- Li, Y.; Gong, R.; Tan, X.; Yang, Y.; Hu, P.; Zhang, Q.; Yu, F.; Wang, W.; Gu, S. BRECQ: Pushing the Limit of Post-Training Quantization by Block Reconstruction. In Proceedings of the 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, 3–7 May 2021. [Google Scholar]
- Naumov, M.; Diril, U.; Park, J.; Ray, B.; Jablonski, J.; Tulloch, A. On Periodic Functions as Regularizers for Quantization of Neural Networks. arXiv 2018, arXiv:1811.09862. [Google Scholar]
- Shomron, G.; Gabbay, F.; Kurzum, S.; Weiser, U.C. Post-Training Sparsity-Aware Quantization. In Proceedings of the Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, Virtual, 6–14 December 2021; pp. 17737–17748. [Google Scholar]
- Banner, R.; Nahshan, Y.; Soudry, D. Post training 4-bit quantization of convolutional networks for rapid-deployment. In Proceedings of the Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, Vancouver, BC, Canada, 8–14 December 2019; pp. 7948–7956. [Google Scholar]
- Finkelstein, A.; Almog, U.; Grobman, M. Fighting Quantization Bias with Bias. arXiv 2019, arXiv:1906.03193. [Google Scholar]
- Meller, E.; Finkelstein, A.; Almog, U.; Grobman, M. Same, Same But Different: Recovering Neural Network Quantization Error Through Weight Factorization. In Proceedings of the 36th International Conference on Machine Learning, ICML 2019, Long Beach, CA, USA, 9–15 June 2019; Volume 97, pp. 4486–4495. [Google Scholar]
- Nagel, M.; van Baalen, M.; Blankevoort, T.; Welling, M. Data-Free Quantization Through Weight Equalization and Bias Correction. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, ICCV 2019, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1325–1334. [Google Scholar]
- Choukroun, Y.; Kravchik, E.; Yang, F.; Kisilev, P. Low-bit Quantization of Neural Networks for Efficient Inference. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshops, ICCV Workshops 2019, Seoul, Republic of Korea, 27–28 October 2019; pp. 3009–3018. [Google Scholar]
- Zhao, R.; Hu, Y.; Dotzel, J.; Sa, C.D.; Zhang, Z. Improving Neural Network Quantization without Retraining using Outlier Channel Splitting. In Proceedings of the 36th International Conference on Machine Learning, ICML 2019, Long Beach, CA, USA, 9–15 June 2019; Volume 97, pp. 7543–7552. [Google Scholar]
- Nagel, M.; Amjad, R.A.; van Baalen, M.; Louizos, C.; Blankevoort, T. Up or Down? Adaptive Rounding for Post-Training Quantization. In Proceedings of the 37th International Conference on Machine Learning, ICML 2020, Vienna, Austria, 13–18 July 2020; Volume 119, pp. 7197–7206. [Google Scholar]
- Hubara, I.; Nahshan, Y.; Hanani, Y.; Banner, R.; Soudry, D. Improving Post Training Neural Quantization: Layer-wise Calibration and Integer Programming. arXiv 2020, arXiv:2006.10518. [Google Scholar]
- Li, H.; Wang, Z.; Yue, X.; Wang, W.; Tomiyama, H.; Meng, L. An architecture-level analysis on deep learning models for low-impact computations. Artif. Intell. Rev. 2022, 55, 1–40. [Google Scholar] [CrossRef]
- Lin, S.; Ji, R.; Chen, C.; Tao, D.; Luo, J. Holistic CNN Compression via Low-Rank Decomposition with Knowledge Transfer. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 2889–2905. [Google Scholar] [CrossRef]
- Rigamonti, R.; Sironi, A.; Lepetit, V.; Fua, P. Learning Separable Filters. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2754–2761. [Google Scholar]
- Denton, E.L.; Zaremba, W.; Bruna, J.; LeCun, Y.; Fergus, R. Exploiting Linear Structure Within Convolutional Networks for Efficient Evaluation. In Proceedings of the Advances in Neural Information Processing Systems 27: Annual Conference on Neural Information Processing Systems 2014, Montreal, QC, Canada, 8–13 December 2014; pp. 1269–1277. [Google Scholar]
- Jaderberg, M.; Vedaldi, A.; Zisserman, A. Speeding up Convolutional Neural Networks with Low Rank Expansions. In Proceedings of the British Machine Vision Conference, BMVC 2014, Nottingham, UK, 1–5 September 2014. [Google Scholar]
- Lebedev, V.; Ganin, Y.; Rakhuba, M.; Oseledets, I.V.; Lempitsky, V.S. Speeding-up Convolutional Neural Networks Using Fine-tuned CP-Decomposition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Tai, C.; Xiao, T.; Wang, X.; E, W. Convolutional neural networks with low-rank regularization. In Proceedings of the 4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Yu, X.; Liu, T.; Wang, X.; Tao, D. On Compressing Deep Models by Low Rank and Sparse Decomposition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 67–76. [Google Scholar]
- Denil, M.; Shakibi, B.; Dinh, L.; Ranzato, M.; de Freitas, N. Predicting Parameters in Deep Learning. In Proceedings of the Advances in Neural Information Processing Systems 26: 27th Annual Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–8 December 2013; pp. 2148–2156. [Google Scholar]
- Sainath, T.N.; Kingsbury, B.; Sindhwani, V.; Arisoy, E.; Ramabhadran, B. Low-rank matrix factorization for Deep Neural Network training with high-dimensional output targets. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP, Vancouver, BC, Canada, 26–31 May 2013; pp. 6655–6659. [Google Scholar]
- Lu, Y.; Kumar, A.; Zhai, S.; Cheng, Y.; Javidi, T.; Feris, R.S. Fully-Adaptive Feature Sharing in Multi-Task Networks with Applications in Person Attribute Classification. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Honolulu, HI, USA, 21–26 July 2017; pp. 1131–1140. [Google Scholar]
- Swaminathan, S.; Garg, D.; Kannan, R.; Andrès, F. Sparse low rank factorization for deep neural network compression. Neurocomputing 2020, 398, 185–196. [Google Scholar] [CrossRef]
- Guo, G.; Han, L.; Han, J.; Zhang, D. Pixel Distillation: A New Knowledge Distillation Scheme for Low-Resolution Image Recognition. arXiv 2021, arXiv:2112.09532. [Google Scholar]
- Qin, D.; Bu, J.; Liu, Z.; Shen, X.; Zhou, S.; Gu, J.; Wang, Z.; Wu, L.; Dai, H. Efficient Medical Image Segmentation Based on Knowledge Distillation. IEEE Trans. Med Imaging 2021, 40, 3820–3831. [Google Scholar] [CrossRef] [PubMed]
- Hinton, G.E.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Bucilă, C.; Caruana, R.; Niculescu-Mizil, A. Model Compression. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Philadelphia, PA, USA, 20–23 August 2006; Association for Computing Machinery: New York, NY, USA, 2006; pp. 535–541. [Google Scholar]
- Ba, J.; Caruana, R. Do Deep Nets Really Need to be Deep? In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; Volume 27, pp. 2654–2662. [Google Scholar]
- Urban, G.; Geras, K.J.; Kahou, S.E.; Aslan, Ö.; Wang, S.; Mohamed, A.; Philipose, M.; Richardson, M.; Caruana, R. Do Deep Convolutional Nets Really Need to be Deep and Convolutional? In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017. [Google Scholar]
- Chen, Z.; Zhang, L.; Cao, Z.; Guo, J. Distilling the Knowledge From Handcrafted Features for Human Activity Recognition. IEEE Trans. Ind. Inform. 2018, 14, 4334–4342. [Google Scholar] [CrossRef]
- Romero, A.; Ballas, N.; Kahou, S.E.; Chassang, A.; Gatta, C.; Bengio, Y. FitNets: Hints for Thin Deep Nets. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Huang, Z.; Wang, N. Like What You Like: Knowledge Distill via Neuron Selectivity Transfer. arXiv 2017, arXiv:1707.01219. [Google Scholar]
- Ahn, S.; Hu, S.X.; Damianou, A.C.; Lawrence, N.D.; Dai, Z. Variational Information Distillation for Knowledge Transfer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, 16–20 June 2019; pp. 9163–9171. [Google Scholar]
- Heo, B.; Lee, M.; Yun, S.; Choi, J.Y. Knowledge Transfer via Distillation of Activation Boundaries Formed by Hidden Neurons. In Proceedings of the The Thirty-Third AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 3779–3787. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Paying More Attention to Attention: Improving the Performance of Convolutional Neural Networks via Attention Transfer. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017. [Google Scholar]
- Yim, J.; Joo, D.; Bae, J.; Kim, J. A Gift from Knowledge Distillation: Fast Optimization, Network Minimization and Transfer Learning. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 7130–7138. [Google Scholar]
- Lee, S.; Song, B.C. Graph-based Knowledge Distillation by Multi-head Attention Network. In Proceedings of the 30th British Machine Vision Conference 2019, BMVC 2019, Cardiff, UK, 9–12 September 2019; p. 141. [Google Scholar]
- Liu, Y.; Cao, J.; Li, B.; Yuan, C.; Hu, W.; Li, Y.; Duan, Y. Knowledge Distillation via Instance Relationship Graph. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Long Beach, CA, USA, 16–20 June 2019; pp. 7096–7104. [Google Scholar]
- Tung, F.; Mori, G. Similarity-Preserving Knowledge Distillation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, ICCV 2019, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1365–1374. [Google Scholar]
- Yu, L.; Yazici, V.O.; Liu, X.; van de Weijer, J.; Cheng, Y.; Ramisa, A. Learning Metrics From Teachers: Compact Networks for Image Embedding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Long Beach, CA, USA, 16–20 June 2019; pp. 2907–2916. [Google Scholar]
- Bengio, Y.; Courville, A.C.; Vincent, P. Representation Learning: A Review and New Perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef] [PubMed]
- Lyu, B.; Li, H.; Tanaka, A.; Meng, L. The early Japanese books reorganization by combining image processing and deep learning. CAAI Trans. Intell. Technol. 2022, 7, 627–643. [Google Scholar] [CrossRef]
- Tian, Y.; Krishnan, D.; Isola, P. Contrastive Representation Distillation. arXiv 2019, arXiv:1910.10699. [Google Scholar]
- Lee, S.H.; Kim, D.H.; Song, B.C. Self-supervised Knowledge Distillation Using Singular Value Decomposition. In Proceedings of the Computer Vision—ECCV 2018—15th European Conference, Munich, Germany, 8–14 September 2018; Volume 11210, pp. 339–354. [Google Scholar]
- Zhang, C.; Peng, Y. Better and Faster: Knowledge Transfer from Multiple Self-supervised Learning Tasks via Graph Distillation for Video Classification. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, IJCAI 2018, Stockholm, Sweden, 13–19 July 2018; pp. 1135–1141. [Google Scholar]
- Iandola, F.N.; Moskewicz, M.W.; Ashraf, K.; Han, S.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <1MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6848–6856. [Google Scholar]
- Gholami, A.; Kwon, K.; Wu, B.; Tai, Z.; Yue, X.; Jin, P.; Zhao, S.; Keutzer, K. SqueezeNext: Hardware-Aware Neural Network Design. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1638–1647. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 122–138. [Google Scholar]
- Gao, Y.; Zhuang, J.; Li, K.; Cheng, H.; Guo, X.; Huang, F.; Ji, R.; Sun, X. DisCo: Remedy Self-supervised Learning on Lightweight Models with Distilled Contrastive Learning. arXiv 2021, arXiv:2104.09124. [Google Scholar]
- Tan, M.; Chen, B.; Pang, R.; Vasudevan, V.; Sandler, M.; Howard, A.; Le, Q.V. MnasNet: Platform-Aware Neural Architecture Search for Mobile. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Long Beach, CA, USA, 16–20 June 2019; pp. 2820–2828. [Google Scholar]
- Huang, G.; Liu, S.; van der Maaten, L.; Weinberger, K.Q. CondenseNet: An Efficient DenseNet Using Learned Group Convolutions. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2752–2761. [Google Scholar]
- Mehta, S.; Rastegari, M.; Caspi, A.; Shapiro, L.G.; Hajishirzi, H. ESPNet: Efficient Spatial Pyramid of Dilated Convolutions for Semantic Segmentation. In Proceedings of the Computer Vision—ECCV 2018—15th European Conference, Munich, Germany, 8–14 September 2018; Volume 11214, pp. 561–580. [Google Scholar]
- Mehta, S.; Rastegari, M.; Shapiro, L.G.; Hajishirzi, H. ESPNetv2: A Light-Weight, Power Efficient, and General Purpose Convolutional Neural Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Long Beach, CA, USA, 16–20 June 2019; pp. 9190–9200. [Google Scholar]
- Gao, H.; Wang, Z.; Ji, S. ChannelNets: Compact and Efficient Convolutional Neural Networks via Channel-Wise Convolutions. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 2570–2581. [Google Scholar] [CrossRef] [PubMed]
- Zhang, T.; Qi, G.; Xiao, B.; Wang, J. Interleaved Group Convolutions. In Proceedings of the IEEE International Conference on Computer Vision, ICCV 2017, Venice, Italy, 22–29 October 2017; pp. 4383–4392. [Google Scholar]
- Xie, G.; Wang, J.; Zhang, T.; Lai, J.; Hong, R.; Qi, G. Interleaved Structured Sparse Convolutional Neural Networks. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8847–8856. [Google Scholar]
- Sun, K.; Li, M.; Liu, D.; Wang, J. IGCV3: Interleaved Low-Rank Group Convolutions for Efficient Deep Neural Networks. In Proceedings of the British Machine Vision Conference 2018, BMVC Newcastle, UK, 3–6 September 2018; p. 101. [Google Scholar]
- Wu, B.; Dai, X.; Zhang, P.; Wang, Y.; Sun, F.; Wu, Y.; Tian, Y.; Vajda, P.; Jia, Y.; Keutzer, K. FBNet: Hardware-Aware Efficient ConvNet Design via Differentiable Neural Architecture Search. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Long Beach, CA, USA, 16–20 June 2019; pp. 10734–10742. [Google Scholar]
- Wan, A.; Dai, X.; Zhang, P.; He, Z.; Tian, Y.; Xie, S.; Wu, B.; Yu, M.; Xu, T.; Chen, K.; et al. FBNetV2: Differentiable Neural Architecture Search for Spatial and Channel Dimensions. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, 13–19 June 2020; pp. 12962–12971. [Google Scholar]
- Dai, X.; Wan, A.; Zhang, P.; Wu, B.; He, Z.; Wei, Z.; Chen, K.; Tian, Y.; Yu, M.; Vajda, P.; et al. FBNetV3: Joint Architecture-Recipe Search Using Predictor Pretraining. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, Nashville, TN, USA, 19–25 June 2021; pp. 16276–16285. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the 36th International Conference on Machine Learning, ICML, Long Beach, CA, USA, 9–15 June 2019; Volume 97, pp. 6105–6114. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. GhostNet: More Features From Cheap Operations. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR, Seattle, WA, USA, 13–19 June 2020; pp. 1577–1586. [Google Scholar]
- Ma, N.; Zhang, X.; Huang, J.; Sun, J. WeightNet: Revisiting the Design Space of Weight Networks. In Proceedings of the Computer Vision—ECCV 2020—16th European Conference, Glasgow, UK, 23–28 August 2020; Volume 12360, pp. 776–792. [Google Scholar]
- Yang, B.; Bender, G.; Le, Q.V.; Ngiam, J. CondConv: Conditionally Parameterized Convolutions for Efficient Inference. In Proceedings of the Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 1305–1316. [Google Scholar]
- Li, Y.; Chen, Y.; Dai, X.; Chen, D.; Liu, M.; Yuan, L.; Liu, Z.; Zhang, L.; Vasconcelos, N. MicroNet: Improving Image Recognition With Extremely Low FLOPs. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 468–477. [Google Scholar]
- Radosavovic, I.; Kosaraju, R.P.; Girshick, R.B.; He, K.; Dollár, P. Designing Network Design Spaces. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR, Seattle, WA, USA, 13–19 June 2020; pp. 10425–10433. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Layers | Parameter | FLOPs | Top-1 Error (%) |
|---|---|---|---|---|
| AlexNet [9] | 8 | 233(MB) | 4.4G | 43.45 |
| GoogLeNet [12] | 22 | 51(MB) | 8.9G | 34.20 |
| VGGNet-16 [11] | 16 | 528(MB) | 15.5G | 27.30 |
| VGGNet-19 [11] | 19 | 548(MB) | 19.7G | 25.50 |
| DenseNet-121 [14] | 121 | 31(MB) | 13.4G | 25.35 |
| ResNet-50 [13] | 50 | 98(MB) | 17.9G | 24.60 |
| ResNet-152 [13] | 152 | 230(MB) | 49.1G | 23.00 |
| ResNeXt-101 [15] | 101 | 319(MB) | 71.4G | 20.81 |
| SENet-154 [16] | 154 | 440(MB) | 93.8G | 18.68 |
| Core Idea | Operating Object | Architecture | Representative | Advantage | Disadvantage | |
|---|---|---|---|---|---|---|
| Model pruning | Designs parameter evaluation criteria to measure parameter importance. Removes unimportant parameters. | Con layer FC layer | Alter | Structured pruning, unstructured pruning. | Structured pruning narrows the network for hardware acceleration. Unstructured pruning compresses the network to any degree. | Structured pruning leads to accuracy reduction. Unstructured pruning leads to irregular architecture and is difficult to accelerate effectively. |
| Parameter quantization | Convers floating-point calculations to low-bitrate integer calculations. | Conv layer FC layer | Unaltered | Post-training quantization, quantization-aware training. | It reduces parameter storage space and memory, speeds up operation, and reduces equipment energy consumption. | It takes a long time to train and fine-tune and is inflexible. |
| Low-rank decomposition | Decomposes the original tensor into several low-rank tensors. | Conv layer. | Alter | Binary decomposition, multivariate decomposition. | It has good compression and acceleration effects on large convolution kernels and small and medium-sized networks. | Difficult to decompose simplified convolution kernels, layer-by-layer decomposition is not conducive to global parameter compression. |
| Knowledge distillation | Uses a large network with high complexity as a teacher network to guide low-complexity student networks. | Conv layer FC layer | Unaltered | Knowledge distillation for output layer, mutual information, correlation, and adversarial. | Large-scale models are compressed into small models and deployed to resource-constrained devices. | The network needs to be trained at least twice, and the training time is long. |
| Lightweight model design | Employs a compact and efficient network architecture and designs a network for deployment in mobile devices. | The entire network. | Alter | Convolution kernel level, layer level, network architecture level. | The network is simple, the training time is short, and the small network with a small storage amount, low calculation amount, and good performance can be obtained. | It is difficult to combine the special architecture with other compression and acceleration methods; poor generalization is not suitable as a pre-trained model to help other models. |
| Model | Top 5 Accuracy | Speed-Up | Compression Rate |
|---|---|---|---|
| AlexNet | 80.03% | 1.00 | 1.00 |
| BN Low-rank | 80.56% | 1.09 | 4.94 |
| CP Low-rank | 79.66% | 1.82 | 5.00 |
| VGG16 | 90.60% | 1.00 | 1.00 |
| BN Low-rank | 90.47% | 1.53 | 2.72 |
| CP Low-rank | 90.31% | 2.05 | 2.75 |
| GoogleNet | 92.21% | 1.00 | 1.00 |
| BN Low-rank | 91.88% | 1.08 | 2.79 |
| CP Low-rank | 91.79% | 1.20 | 2.84 |
| Model | Methods |
|---|---|
| SqueezeNet [128] |
|
| SqueezeNext [131] |
|
| MobileNetV1 [129] |
|
| MobileNetV2 [132] |
|
| ShuffleNetV1 [130] |
|
| ShuffleNetV2 [133] |
|
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Z.; Li, H.; Meng, L. Model Compression for Deep Neural Networks: A Survey. Computers 2023, 12, 60. https://doi.org/10.3390/computers12030060
Li Z, Li H, Meng L. Model Compression for Deep Neural Networks: A Survey. Computers. 2023; 12(3):60. https://doi.org/10.3390/computers12030060
Chicago/Turabian StyleLi, Zhuo, Hengyi Li, and Lin Meng. 2023. "Model Compression for Deep Neural Networks: A Survey" Computers 12, no. 3: 60. https://doi.org/10.3390/computers12030060
APA StyleLi, Z., Li, H., & Meng, L. (2023). Model Compression for Deep Neural Networks: A Survey. Computers, 12(3), 60. https://doi.org/10.3390/computers12030060