1. Introduction
Interactions between students in collaborative learning activities are often studied within face-to-face learning environments. Considerable evidence indicates that students sharing ideas or questions in pursuit of knowledge demonstrate improved learning outcomes compared to those learning in isolation [
1,
2]. Thus, teachers are encouraged to incorporate collaborative activities where students engage in the co-development of a shared mental model with one or more peers [
3]. Within these collaborative environments, learners engaging in academic discourse have a shared set of rules, including social cues that guide their communication. For example, when one peer is confused about what the other is saying, they may shift their eye gaze or shrug their shoulders [
4]. Such exhibition of social cues may result in a dialogic exchange in which participants make connections between utterances to co-construct knowledge. This coordinated discourse is representative of shared language reflecting commonality or connection that unites the members of the learning community [
5,
6]. Shared language further contributes to the cohesion of a community [
7]. Coordinated communication representing community members’ shared conceptualizations and perspectives is associated with positive social outcomes not only in face-to-face interactions but also in technology-mediated settings [
8]. Given the recent increased adoption of online learning environments, it is increasingly important to better understand the nature of effective communication in asynchronous and collaborative environments such as discussion boards. The quality of discourse in asynchronous, collaborative digital spaces enhances the learning experience and contributes to the attainment of learning goals. Hence, promoting student engagement and participation in academic discourse benefits learning through collaborative problem-solving, peer instruction, and co-construction of knowledge.
Asynchronous discussion boards are often implemented as a mechanism to build learning communities and introduce collaborative learning activities [
9]. However, student participation in discussion boards continues to be one of the hurdles to successful discussion board implementation. Students’ participation in discussions is linked to course satisfaction, feelings of belonging, and positive learning outcomes [
10,
11]. While collaboration and interaction among students enhance their overall learning experience, student participation remains a challenge in discussion board deployments [
12,
13,
14]. Despite the goal of discussion boards to facilitate community development, build social interactions, and scaffold meaning-making, students may not develop a feeling of belonging or a sense of affinity toward their fellow students. However, student perceptions of affinity and belonging are more pronounced and easier to capture within face-to-face classroom settings as compared to an online modality.
This study investigates the factors that are associated with collaboration and social interactions among discourse participants by looking at the discourse through the lens of shared language, i.e., lexical entrainment and semantic similarity. In addition to probing the similarity of students’ lexical choices in the discussion threads, we simulate the linguistic markers of affinity and trust within a technology-mediated setting designed for learning algebra. For example, lexical and semantic dimensions of language are indicators of affective expressions (i.e., valence and arousal) from naturalistic dialogues within an intelligent tutoring system [
15]. Valence is a dimension of emotion that represents a continuum of negative/unpleasant to positive/pleasant. Arousal is the dimension that depicts the intensity of emotional activation ranging from low/calm to high/excited. Another social factor that we simulate in modeling shared language and social interactions among discourse participants is affinity. Coordinated communication through mimicry, which includes word choice and syntactic structure [
16], is linked to affinity [
17]. When discourse participants use the same shared language, it serves as evidence of “membership” or inclusion and, at the same time, contributes to the cohesion of a community [
7]. Discourse participants must have coordinated notions of how to use and interpret language within the discourse [
18]. This coordination is descriptive of a shared language that reflects the commonality of world views or conventions that unite the members of a discourse community [
5].
Understanding the nature of language within discourse communities in this study provides valuable insights into students’ engagement, trust, and affinity amongst participants, as evidenced by their lexical choices and linguistic similarity. Evidence of engagement, trust, and affinity indicates that students have adequately participated in the discourse, and thus, the pedagogical goals of discussion forums are attained. Hence, the potential benefits of discussion boards, which include increased opportunities for interaction and enhanced learning experiences, will materialize. Multiple methods used for analyzing this discourse leverage natural language processing (NLP) methods, including deep learning for NLP models, and the integration of qualitative analysis to theoretically and contextually validate the findings.
1.1. Lexical Entrainment and Semantic Similarity
In the pursuit of effective communication, parties in a conversation act cooperatively, and this is reflected in their lexical choices to increase understanding and reduce miscommunication. The conversing parties use common terminologies or, at times, agree to a change in terminology to overcome language ambiguities as conversations progress. Linguistic or lexical mimicry describes coordinated communication that involves the repetition of words and phrases among discourse participants [
19]. Lexical entrainment is a related phenomenon that encompasses lexical mimicry, the commonality of words used, and the similarity of the linguistic choices pertaining to lexical and syntactic dimensions of language. Lexical entrainment reflects the process of adopting a shared lexicon of terms that parties in a conversation employ. This process represents the shared mental model of discourse as evident in their lexical choices while communicating. Lexical entrainment usually involves coming to an understanding and collaboratively co-constructing knowledge using the agreed-upon lexical symbols or “shared language” throughout the discourse. The presence and extent of lexical entrainment have been observed in discourse communities characterized by trust [
20,
21] and group success [
22].
Semantic entrainment is likewise observed in this linguistic adaptation among discourse participants, leveraging semantic similarity as a measure of entrainment [
23]. Semantics, in linguistics, is the study of the meanings of words and sentences. Lexical semantics represents how the meanings of words are understood in the context in which they are used and is derived from the relationships between words in a sentence. Semantic similarity, which represents semantic entrainment, indicates whether two texts have similar or different meanings [
24]. It is mathematically derived using word embeddings, sentence embeddings, or both and calculates a similarity metric representing the distance between the texts being compared. Semantic similarity NLP indices are used in various applications, such as text categorization, summarization, question answering, feedback, and information retrieval. Word similarities may be computed based on plain co-occurrence using measures such as raw co-occurrence count, text frequency—inverse document frequency (TF-IDF), or pointwise mutual information (PMI), or using second-order co-occurrences wherein word contexts, also called word embeddings, are used in the distance calculation. Lexical databases, such as Wordnet [
25], are also used in calculating the semantic similarity between words. While semantic similarity captures overlap at the word level (i.e., local context), textual similarity reflects the semantic equivalence beyond words (i.e., longer strings of lexemes—sentences and paragraphs). Similarity between texts is also calculated using various distance computation approaches that are also used in word-level similarity. The most noteworthy innovations in similarity computations involve deep learning in NLP, a.k.a. deep NLP. These state-of-the-art models can represent context beyond word occurrence methods through advances in machine learning algorithms and word and sentence embeddings. Textual similarity measures can efficiently approximate semantic, lexical, and syntactic similarity [
26]. This work on linguistic similarity represents the discourse participants’ shared language based on the similarity of their word choices and understanding of these words (i.e., meaning-making) [
27].
1.2. Math Discussion Boards and Math Language Processing (MLP)
Language is an essential resource in mathematics learning and provides the students the ability to participate in math instructional activities. Meaningful discourse within math discussion boards allows the students to ask questions and supplement learning from the lessons and instructional content. Discussion boards facilitate knowledge co-construction and transfer. Further, math knowledge construction is comprised of procedural and conceptual language as students conceptualize abstract ideas and collaborate in real-time problem-solving. In prior work extracting the linguistic profiles of online math discourse, we found that the dominant communicative goals that were prevalent in a math discussion board include elaboration, providing instruction, establishing explicit relations and analogies between mathematical constructs, and presenting information [
28].
The application of natural language processing tasks and machine learning in mathematics has been limited. Specifically, in the field of information retrieval and semantic extraction, mathematics emerges among the complex because of the inherent ambiguity and context-dependence of mathematical language. Embeddings in MLP have been effective in capturing term similarity, math analogies, concept modeling, query expansion, and semantic knowledge extraction [
29]. However, even with the success of embeddings in MLP, the need for extensive math-specific benchmarks is still prevalent. There is an extensive need for the development of implementable, robust embedding models that accurately represent mathematical artifacts and structures [
30].
1.3. Current Study
We measure word and textual semantic similarity in threaded discussions within an online math tutoring platform using NLP and machine learning. The challenge is the scalability of state-of-the-art NLP models to the nuances of mathematical discourse [
31]. NLP semantic models need to capture mathematical reasoning on top of extracting relevant information from natural language text [
32]. As such, we model the similarity of the students’ word choice and lexical processes (i.e., mental modeling and lexical representation of their ideas) within mathematical discourse gathered from Algebra I discussion boards in the Math Nation online tutoring system. In doing so, we determine the presence of shared language by looking for indicators of linguistic entrainment and semantic similarity (i.e., linguistic similarity). We also investigate words that reflect the lexical choices of the students, which could depict lexical entrainment. In addition, we investigate the relationship profiles between the shared language indicators and affect and trust as constructs that represent student engagement and affinity.
The research questions that guide this study are as follows:
Does discourse within an online Math tutoring platform exhibit shared language?
- 1.1.
Do the posts become more linguistically similar as the discussion progresses?
- 1.2.
Are words indicative of similarity between the discourse participants’ posts?
How is linguistic similarity associated with known desirable social constructs (affect measures and trust) related to student engagement and feelings of affinity and belonging within discourse communities?
In answering these research questions, we address the limitations of discussion board deployments as a pedagogical tool for collaborative learning. We envision that student participation and engagement can be enhanced with the understanding of the online discourse in math discussion boards.
2. Methods
2.1. Math Nation
Math Nation [
33] is an interactive and comprehensive math teaching and learning platform used extensively as either the main curriculum or supplemental material in all school districts in Florida. This learning platform provides video tutorials, practice questions, workbooks, and teacher resources aligned with the Florida Mathematics Standards. Student and teacher use of Math Nation in middle and high school has been shown to increase student achievement on the standardized algebra assessment required for high school graduation by the state of Florida [
34,
35]. Math Nation features an online discussion forum called Math Wall, where students can collaborate with other students. Participation in this student-facilitated discussion forum is incentivized by the karma points system, where every student who posts is awarded 100 points on their first post. Students subsequently earn more points when they offer meaningful advice or extended help, such as (1) asking guiding questions, (2) critiquing work, and (3) offering feedback. These types of posts often lead to students’ queries being fully addressed. Further, Math Wall is designed such that course mentors play a minimal role. Mentors only post when necessary, and their posts are often related to moderating inappropriate online behavior or thread-management tasks. For example, when a student posts about irrelevant topics or replies to an old post, mentors will recall the attention of the students and remind them of the proper protocols for forum participation. Sample mentor posts include: “
The student ambassadors were correct originally”, “
Please don’t reply to very old posts,
you may start a new post instead”, and “
Where is that option? Check your scores”. In addition, the mentors also reply to unanswered and unresolved queries.
2.2. Participants
The participants included 12 Math Nation mentors who monitored the discussions and 1719 students in grade levels 7, 8, and 9 from multiple Florida school districts. This includes only the students who interacted with the Math Wall by either posting a question/query or replying to an original post to resolve a query, or, at times, just posting random replies. Student information was anonymized prior to the analyses; hence, only limited demographic information (e.g., gender, ethnicity, grade level, and school district) was made available.
2.3. Discussion Threads
Math Wall threaded discussions were collected for the 2020–2021 academic year. Discussion threads are chronologically ordered posts with an initial post that represents a query from a student. Other students subsequently post their replies, oftentimes in consideration of or elaborating on the most recent reply within a thread. A thread can be represented as an ordered list of posts (p1, p2, … pn) that varies in length. Posts are timestamped to reveal their sequence, but the time interval between each post is varied. There are 4305 threads with a total of 50,975 posts, of which 4244 are the “initial” posts, and 46,731 are the “subsequent replies”. The majority of these posts are from the students (50,950), with the mentors having only 25 posts. The average turn-around time from the initial post to the last reply in a thread is 5.72 h. However, some outlying threads took longer than usual, with the greatest time interval between the original post and the last post being 70 days and the shortest interval being 7 min. The number of posts in the threads ranged from 1 to 142, with a mean of 12 posts (SD = 14.5). With the high variability in the number of posts per thread, we used threads with at least 4 posts (1st quartile) and at most 16 posts (3rd quartile). Hence, 2139 threads were included in this analysis. These exclusion criteria eliminated threads that were extremely short or lengthy.
2.4. Natural Language Processing
The NLP methods used in this study were: (1) textual similarity calculation using pre-trained deep NLP and neural language models (i.e., spaCy language model and Universal Sentence Encoder); (2) emotion feature extraction (i.e., valence, arousal, polarity) using VADER; (3) derivation of trust affect measures using EmoLex; (4) textual classification modeling using TF-IDF word vectors as features; and (5) explainable AI using the LIME package for model interpretation. In the next section, we describe these methods and how the combination of multiple NLP methods was adopted to address our research questions.
2.4.1. Feature Engineering
Textual similarity features. SpaCy [
36] is an open-source NLP library for Python with pipeline components (for tokenization, part-of-speech tagging, parsing, and named entity recognition), modules, and language models that can be used for calculating semantic similarity. SpaCy calculates semantic similarity using cosine similarity as default with the word vectors and context-sensitive tensors in the vector space. Word vectors are multi-dimensional representations of words, which can be implemented using word2vec algorithms. There are many approaches to calculating sentence or document semantic similarity. Straightforward approaches use sentence embeddings or powerful models, such as transformers, to generate their embeddings and subsequently use any distance computation to calculate their similarity metric.
In this study, we purposely use both word embeddings and sentence embeddings to capture our description of semantic similarity involving similar lexical choices (word use) and semantics in terms of the overall meaning of an individual post. Hence, a high similarity score would indicate similar word use and similar meaning between the posts in comparison (i.e., high lexical and semantic similarity). We used spaCy with the en_core_web_lg (release 3.2.0) language model composed of pre-trained statistical models and word vectors. The spaCy pre-trained, multi-task CNN model has been trained on OntoNotes 5 in English with GloVe vectors trained on Common Crawl [
37]. One characteristic of spaCy’s word similarity calculations is that it averages the token vectors, with words as tokens, that comprise a document or a short sentence. Hence, even if the sentences are semantically different (i.e., have opposite meanings) but use the same words or use common words, spaCy will result in a high similarity score. In the same manner, comparing semantically similar sentences that use dissimilar words will result in a lower similarity score than sentences with different meanings but using the same words. To address this limitation brought about by spaCy’s vector averaging, we further employed sentence embedding through the Universal Sentence Encoder (USE) [
38,
39] to improve spaCy’s similarity score computation. Similarity scores of the sentence embeddings range between −1 and 1. Similarity scores closer to 1 reflect greater semantic similarity between items (i.e., posts in our case) and scores closer to −1 reflect extremely dissimilar posts. We used these features to investigate whether the discussion board discourse similarity converges, diverges, or remains the same as the discussion progresses. Further, these features were also used to discover inherent patterns that depict the phenomenon of interest—lexical entrainment or shared language within the Math Wall discourse.
Affect valence, polarity, and arousal features. VADER’s Sentiment Intensity Analyzer was used to extract the sentiment polarity (compound score) of the posts. VADER is a rule-based model for general sentiment analysis that has outperformed human raters and generalizes across contexts [
40]. VADER provides not just the polarity (compound score) of sentiments that reflect both the valence and arousal levels of a sentiment. VADER is known to accurately classify sentiments in social media contexts; thus, it was an appropriate choice due to the informal discourse in Math Wall, which has some semblance of social media stylistic language. We also used the expanded database for Affective Norms for English Words (ANEW) for valence and arousal scores [
41]. To account for varying length, both valence and arousal scores were normalized. Both valence and arousal scores provided finer-grained insights even as the polarity (VADER’s compound score) encompassed both measures (i.e., valence and arousal).
Trust features. Trust is a basic emotion and is observed in the social interactions of discourse communities. This study used the NRC Word-Emotion Association Lexicon (EmoLex). EmoLex [
42] is a dictionary of words labeled via crowdsourcing that are associated with the 8 basic emotions (anger, fear, anticipation, trust, surprise, sadness, joy, and disgust). This study only focused on trust. EmoLex also provides associations with either negative or positive sentiments but does not provide any sentiment or emotion intensity information. Some example words associated with trust are {advice, congruence, constant, eager, familiar, guide, and helpful}.
2.4.2. Text Classification
We also built a bag-of-words model to represent students’ word choices as discourse participants. Bag-of-words is a representation that models the specific words used within documents and can be used to determine the company a specific word keeps across large corpora of texts and language models [
27]. We particularly focused on the words they used to understand lexical choice and detect the presence of word mimicry within the threaded discussions. Word choice is a strong indicator of the speakers’ lexical processes [
43], and better word choice relates to increased precision of their lexical representations at the individual difference level [
44]. From the bag-of-words model, we investigated the predictive role of words to aid in the understanding of the role that words play in textual similarity.
Python’s Scikit learn library was used for the preprocessing pipeline (i.e., vectorization, feature selection, cross-validation, and logistic regression). Prior to any processing, the posts were anonymized and cleaned such that the data did not reveal the students’ identity (i.e., names). The posts were also preprocessed to remove noise and stop words. The TF-IDF vectorizer is calculated from the cleaned posts’ unigram and bigram counts. The Similarity outcome variable was coded as a dichotomous class, with Not Similar representing threads with a mean similarity score below the overall mean and Similar representing threads that are greater than or equal to the overall mean similarity score (i.e., 0 would be threads that are not semantically similar on average, and 1 would be threads that are, on average, semantically similar). We qualitatively evaluated the validity of the dichotomous classes by randomly checking a select number of posts (n = 20) for each class and found that the dichotomous categories appropriately represented the semantic similarity of the threaded discussions. We ensured that the qualitative verification involved threads with outlying extreme aggregated similarity values and values that are nearest to the dichotomization cut-off/threshold mean similarity score. The feature selection/dimensionality reduction method used was SelectKBest, which selects the best features based on the X2 value. Using the reduced feature matrix, the logistic regression classification model was trained with 10-fold cross-validation at the thread-level repeated three times. Finally, the model performance was evaluated using the F1-score as the metric.
2.4.3. Model Explainability
The Local Interpretable Model-Agnostic Explanations (LIME) package was used to interpret and explain model classifications. While we were able to derive the most relevant words in the model (best features based on X
2), we wanted to supplement the findings by understanding word contributions at the local prediction level. LIME provides a means to explain and visualize individual predictions. Even with acceptable levels of accuracy and other measures of performance, model explainability at prediction-level granularity provides more relevant and useful insights. LIME interprets individual instances of predictions without looking into the model and learns an interpretable model to explain individual predictions [
45]. We ran repeated iterations of LIME to find more stable results to facilitate the interpretations.
2.5. Cluster Analysis
One goal was to discover innate patterns that potentially exist between linguistic similarity and valence, polarity, arousal, and trust and extract underlying thread profiles. We implemented a two-step cluster analysis as it performs better than traditional hierarchical clustering methods [
46]. This technique determines the optimal number of clusters based on the Bayesian information criterion (BIC) as the measure of fit [
47]. Further, we measured cluster quality fitness using the silhouette measure of cohesion and separation to evaluate the overall cluster model quality. In defining the thread profiles based on the resulting clusters, we referenced relevant theories and prior work.
4. Discussion
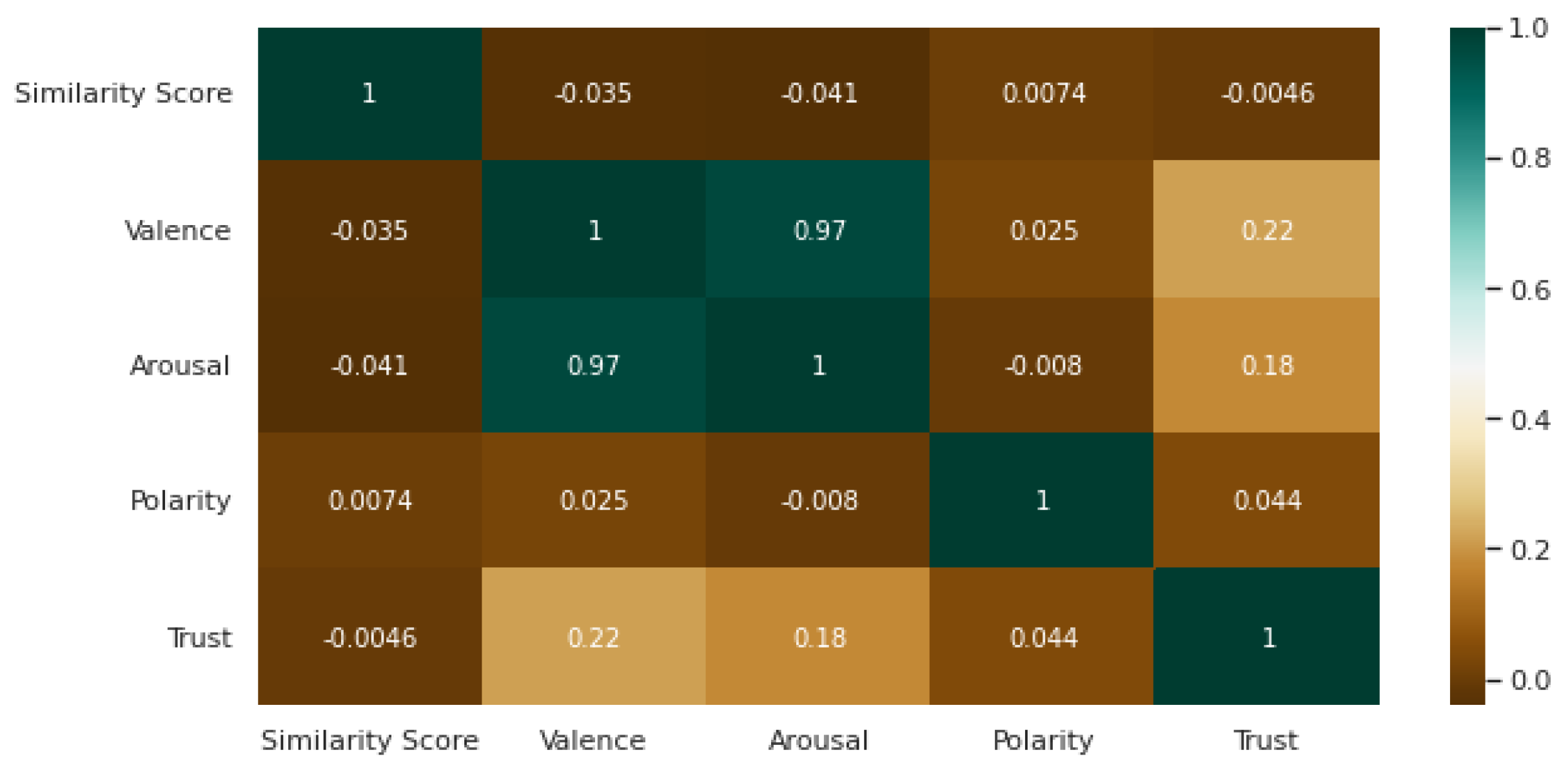
The objective of this study was to investigate the presence of shared language or linguistic similarity in students’ posts as they participated in threaded discussions within Math Wall. We analyzed the behavior of linguistic similarity as the discussion progressed. In examining linguistic similarity, we examined math-specific semantics (meaning) and lexical choices of the discourse. Further, through cluster analysis, we investigated the relationship profiles between linguistic similarity as a shared language indicator and constructs that represent student engagement and affinity, namely trust and affect measures of valence, arousal, and polarity.
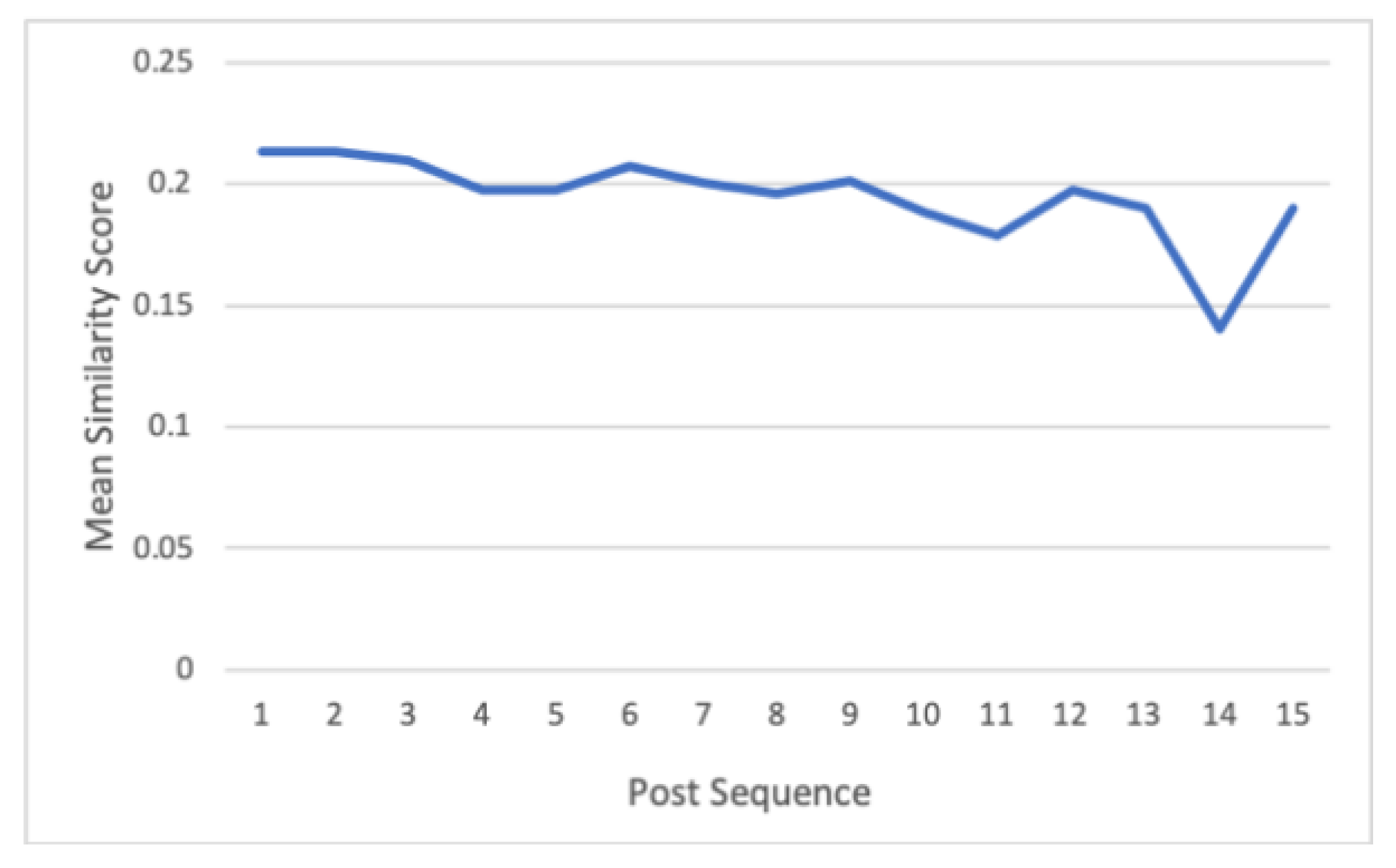
We found that the Math Wall threaded discussions exhibit shared language. Linguistic similarity exists between the posts in a threaded discussion. Significant differences in the linguistic similarity within the threads are found for the two post similarity scores (i.e., OP similarity and P2P similarity). The observed high similarity at the beginning of the discussion was qualitatively verified to match the nature of the threaded discussions. Specifically, individuals aim to derive an understanding of the query in the initial post and, hence, subsequent replies tend to repeat, rephrase, or elaborate on the initial posts. Subsequent posts are, then, characterized by individual solutions and responses to solve the query. This phenomenon of higher similarity scores at the beginning of turn-by-turn discussions is also observed in similar work by Liebman and Gergle [
8]. Further, toward the end of the discussion, there is also an observable shift to increased similarity. This is again qualitatively explained by a common practice of expressing gratitude and appreciation or bidding goodbye as the discussion ends.
Overall, the high variability of thread similarity reveals the dynamic nature of how individuals contribute to these threaded discussions. Even when there is one common goal (i.e., a specific query), some threads (14%) have highly cohesive discussions from beginning to end (i.e., low variability in similarity). Some threads (27%) have varied views and then reach an agreement (i.e., converging similarity), while others (42%) do not come to an understanding (i.e., diverging similarity). Some (17%) start out as confused, then end up in agreement or resolve the confusion (i.e., increasing similarity). These scenarios depict similarity shifts and the high variability of similarity among the threads. Hence, the threaded discussions do not always become more linguistically similar as the discussion progresses.
We found that deriving lexical and semantic textual similarity with the state-of-the-art word and embedding models successfully captured the domain-specific semantics within the Math Nation discourse. The non-latent words used in the discourse can predict similarity. Further, the use of the bag-of-words (TF-IDF) model in fitting the predictive model contributed to insights on the nature of the lexicons used in the discourse that aligned with the algebra curriculum and reflected the specific mathematical content and actions. Studying the predictions at the individual level using LIME revealed that words represent algebra constructs (e.g., exponent, integer, irrational), and words that depict frequent action (e.g., help) contribute to a prediction of 1 (i.e., high likelihood of similarity). This can be explained by the students’ reference to uniform math constructs and common action words when discussing the topic at hand. Conversely, words that represent specific artifacts in Math Nation (e.g., a section, topic, or problem) contribute to a prediction of 0 (low likelihood of similarity). This could be attributed to the diverse solutions referencing various parts of the curriculum that discourse participants suggest in their attempts to solve a problem.
We also found that specific words can efficiently distinguish the likelihood of similarity of the posts within threads. These words, in particular, are math constructs (rational, square root), Math Nation artifacts (e.g., section, unit), emotion (e.g., glad), and action (e.g., help, mean). These agreed-upon lexical choices echo lexical entrainment as the students did not identify what specific keywords or terms they would adhere to in the conversation. For example, one thread would unanimously use
raise to the 3rd power, while another thread would use
cube root. The presence of commonly used and “implicitly agreed-upon” words within a threaded discussion explains the phenomenon of lexical choices that contribute to linguistic convergence [
19,
48,
49].
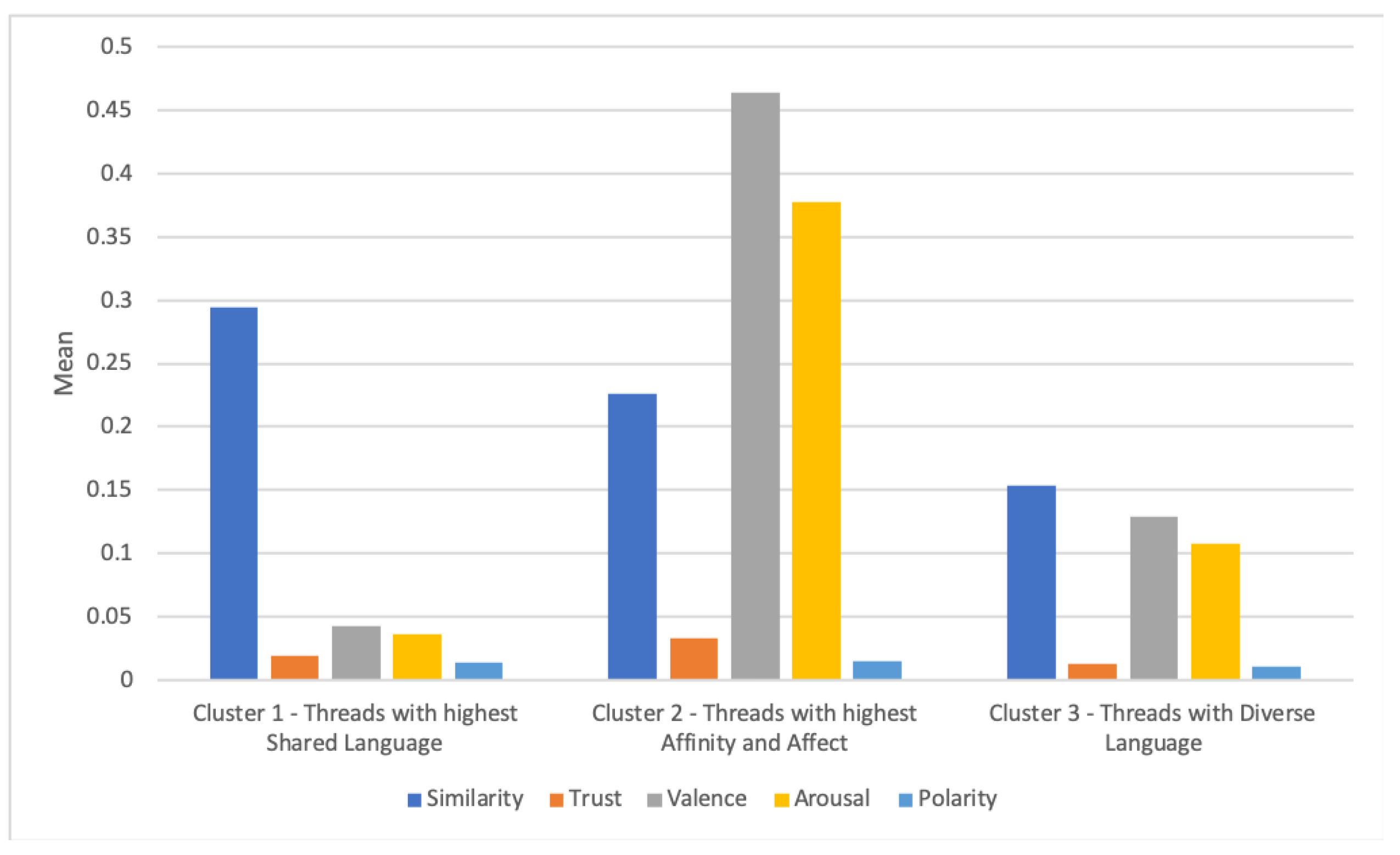
The profiles that emerged, in terms of similarity and the desirable emotional measures of interest (i.e., valence, intensity, polarity, and trust), demonstrate the differences in the threaded discussions. The majority of the threads in the third cluster had the least similar words indicative of trust; however, they were “middle ground” compared to the threads from the other two clusters in terms of emotion measures. After post hoc qualitative analysis, we found that these threads were indicative of posts from students who were confused, did not understand concepts, or had unresolved queries who posted questions hoping to find answers. The second cluster had the highest means for all affect features, including trust, had a relatively high mean similarity, and was comprised of the fewest threads. These threads were cohesive threads (i.e., relatively high similarity) and had the highest presence of words depicting trust. These threads also had the highest means for features of emotion (valence, arousal, intensity) and depicted ideal discussions where collaborative meaning-making was present. The posts reflect a coherent discussion on a single topic and reflect a common goal. This profile shows that Math Wall had some discussion threads (although only 12% of the total number of discussion threads) that depict desirable learning behaviors, i.e., collaboration and coherent discourse. Coherent academic discussions where participants negotiate agreements or disagreements are essential in maintaining the trust and inclusiveness of discourse communities [
50]. Cooperative learning helps students with math anxiety and encourages help-seeking behavior [
51]. We note from our qualitative evaluation that while some threads resolved the queries in the initial post, some threads remained unresolved, but the progression of the discussion revolved around solutions where the participants collaborated in an attempt to achieve resolution.
The clusters that were significantly different in terms of similarity and trust corroborates prior work [
20,
21] that describes the trust that members of discourse communities exhibit. Trust, as a social affect, is a factor that motivates students to seek help from their peers within digital and non-digital learning environments [
52]. The majority of the discussion threads, i.e., those belonging to Clusters 1 and 2, had low trust values. Math Nation could implement design changes to improve trust within Math Wall. For example, increasing the participation of mentors, study experts, and teachers may increase the level of trust in Math Wall as a student-led discussion board. Emotional valence, polarity, and intensity, along with similarity, uniquely describe and differentiate the three clusters. The clusters representing the profiles of discussion threads show that high similarity evokes both positive and negative emotions that may be intense or subtle. Threads that have high similarity and relatively intense, positive emotions were threads that showed delight in the queries being answered and problems being resolved. At the other end of the spectrum, threads that have high similarity and low-intensity negative emotions were characterized by posts that pertain to difficult concepts where confusion is apparent. It should be noted that the posts were still relevant to the topic at hand, but confusion was present. The low arousal scores of these threads show that even as negative emotions are present, the emotions are at a subtle degree to not bring about frustration and other more intense negative emotions. Low similarity associated with low trust described threads that did not have relevant or related posts. These threads did not resolve any Algebra query nor address any concern, and oftentimes were composed of random posts overall.
5. Limitations, Conclusions, and Future Work
As with all studies, this study has several limitations. First, although the sample is considerably large, the threads are vastly unequal in terms of the number of posts. The large variance and small group sizes, when grouped according to threads and sequence, contributed to marginally significant findings in variance and trend analysis. This is typical of many discussion boards but also begs caution, given that this variance may restrict the likelihood of generalization to other discussion boards. Second, the temporal aspect of the posts was not included in this analysis. The threads have unevenly spaced posts and unequal numbers of posts. For this work, our objective was to characterize the discourse, in general, in terms of targeted language and emotional features independent of their temporal arrangement. We recognize the value of conducting a temporal analysis as future work to derive insights on the implications of timely resolution of queries on discussion boards. Lastly, this study aims to specifically focus on the similarity of content as a valuable construct in discussion board implementations and does not include investigations regarding the impact towards desirable learning outcomes. One reason for this choice is practical; it is currently unavailable in this dataset. Nonetheless, another reason is because our overarching objective is to understand and depict the nature of collaborative language, which may or may not be associated with outcomes depending on multiple complex factors (e.g., student skills and classroom contexts). As we better understand and characterize the nature of this language, we will be better situated to explore the relations between the nature of language and learning outcomes, such as student performance measures.
The diverse nature of the discourse, as measured by semantic similarity at the word and semantic textual levels, depicts the dynamic nature of the discussions. While most queries (initial posts) were properly addressed and eventually resolved, the students did not show that they were particularly constrained to only academically related and relevant posts. The students, at times, interjected “unrelated” replies to display humor or just entirely random statements. The threads can be characterized as a rich and diverse collection of posts. Further, while only marginally significant, there was an observed trend of threads starting with high similarity followed by shifts to decreased similarity as the discussion progressed, followed again by shifts to an increase in similarity toward the end of the discussion. We verified this trend with a qualitative validation of the threads depicting the same trend and found that in the early part of the discussion, similarity is “maintained”, and a slight increase or decrease can manifest as an elaboration or a summarization transpires. However, towards the end of the discussion, the thread’s topic, context, and wordings shift to non-algebra-related content, as most threads end with posts such as “thank you”, “goodnight”, “glad I could help”, and “bye”. This explains the shift in the word and textual similarity scores as the discussion comes to a close. The unconstrained and free nature of discussion boards may encourage student participation. Even as students occasionally post directly related or irrelevant replies, student engagement is still better than non-participation. Discussion boards, after all, are venues for social relationships within virtual environments.
The presence of similarity and emotional constructs provide evidence of the value that linguistic similarity could bring to the design of discussion boards. Given the importance of trust and positive emotions in contributing to students’ feelings of affinity [
20,
21], future training of instructors and tutors who monitor discussion boards should focus on proper scaffolding of language and leveraging linguistic similarity when responding to students. Specific approaches would include the use of common and widely used words, adding to or referencing a prior idea, elaborating or summarizing a prior idea, and ensuring the resolution of a query within a reasonable timeframe.
State-of-the-art semantic extraction and information retrieval have made grand strides in terms of capturing context across domains. For mathematical domains, however, there is much room for the desired scalability. The complexity of encompassing mathematical context within deep NLP remains challenging because of the inherent structure of mathematical texts [
29,
30,
53]. Our findings corroborate this scalability challenge. While we found that Math Wall discourse similarity was efficiently captured (i.e., similarity scores reflected the presence of similar references to common algebra constructs and intent and actions on math problem-solving activities), we found instances of this scalability problem in our analysis. Specific mathematical nuances that were not captured include relatively lower similarity scores for posts with mathematical jargon referring to the same constructs as “PEMDAS (order of operations)” and “hierarchy of operations”, as well as “cubed” and “3rd power”. Although, in this study, we addressed this seeming limitation with the use of the bag-of-words (TF-IDF) model, which provided additional insights into the specific words used that existed in our dataset. Our findings, therefore, highlight the need for math-specific deep NLP lexical and semantic models.
In conclusion, we envision and encourage future research in two equally important directions: (1) examining the extent to which the shared language within Math Nation’s discourse community is also descriptive of other instances of math discourse communities and (2) building robust deep NLP language models that adapt specifically to math domains and tasks.




 ,
, 
{kind=link}
{kind=link}
{kind=link}


