
Constructing a Shariah Document Screening Prototype Based on Serverless Architecture


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Background of Research
2. Past Literature
2.1. Adoption of Financial Technology (Fintech) in the Financial Industry
- a consortium of Boost Holdings Sdn. Bhd. (Kuala Lumpur, Malaysia) and RHB Bank Berhad;
- a consortium led by GXS Bank Pte. Ltd. (Singapore) and Kuok Brothers Sdn. Bhd (Kuala Lumpur, Malaysia); and
- a consortium led by Sea Limited (Singapore) and YTL Digital Capital Sdn Bhd (Kuala Lumpur, Malaysia).
- a consortium of AEON Financial Service Co., Ltd. (Tokyo, Japan), AEON Credit Service (Hong Kong, China) (M) Berhad and MoneyLion Inc. (New York, NY, USA); and
- a consortium led by KAF Investment Bank Sdn. Bhd.
2.2. Fintech and Banking Business
3. Methodology
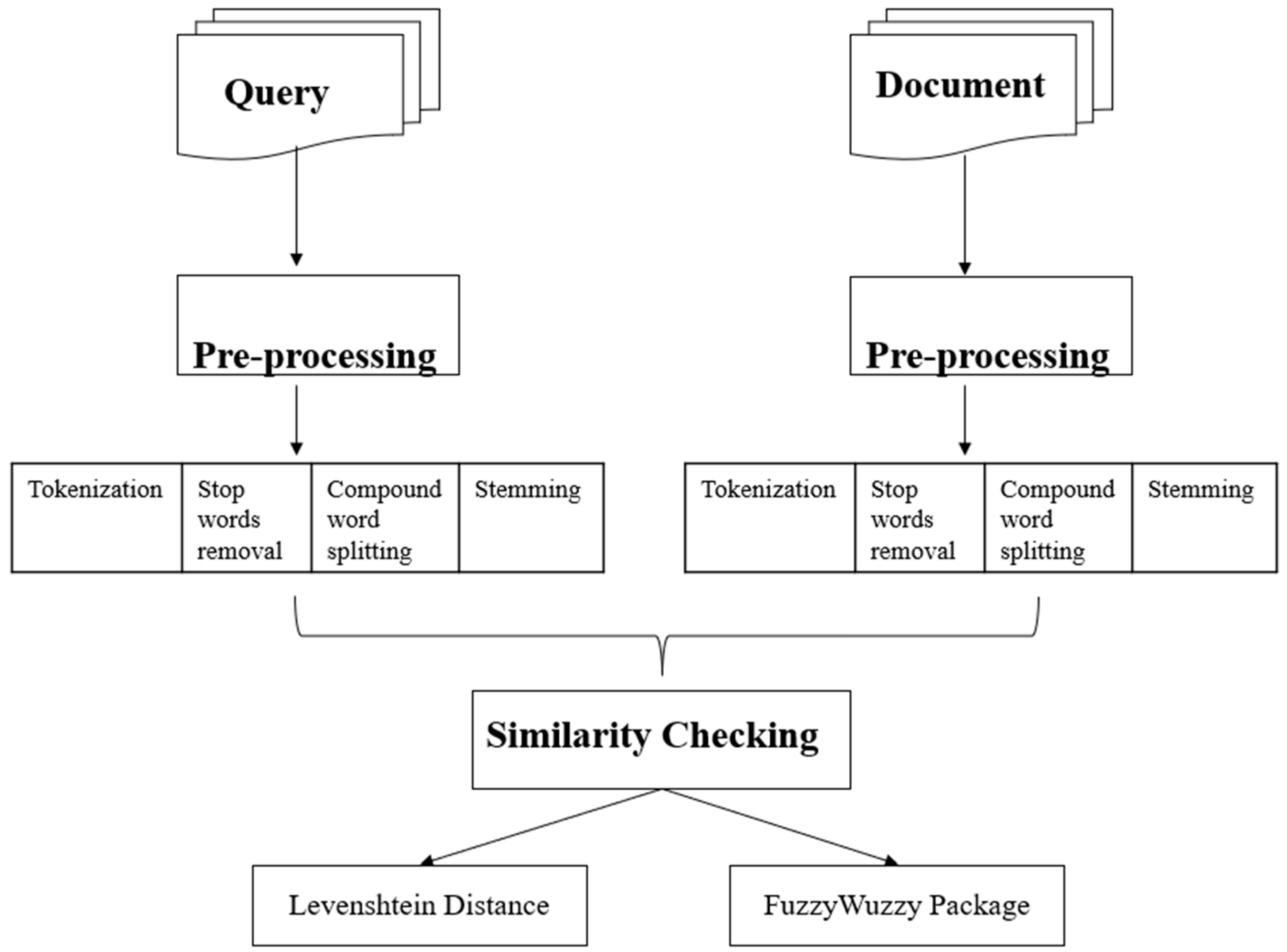
3.1. Data Preprocessing
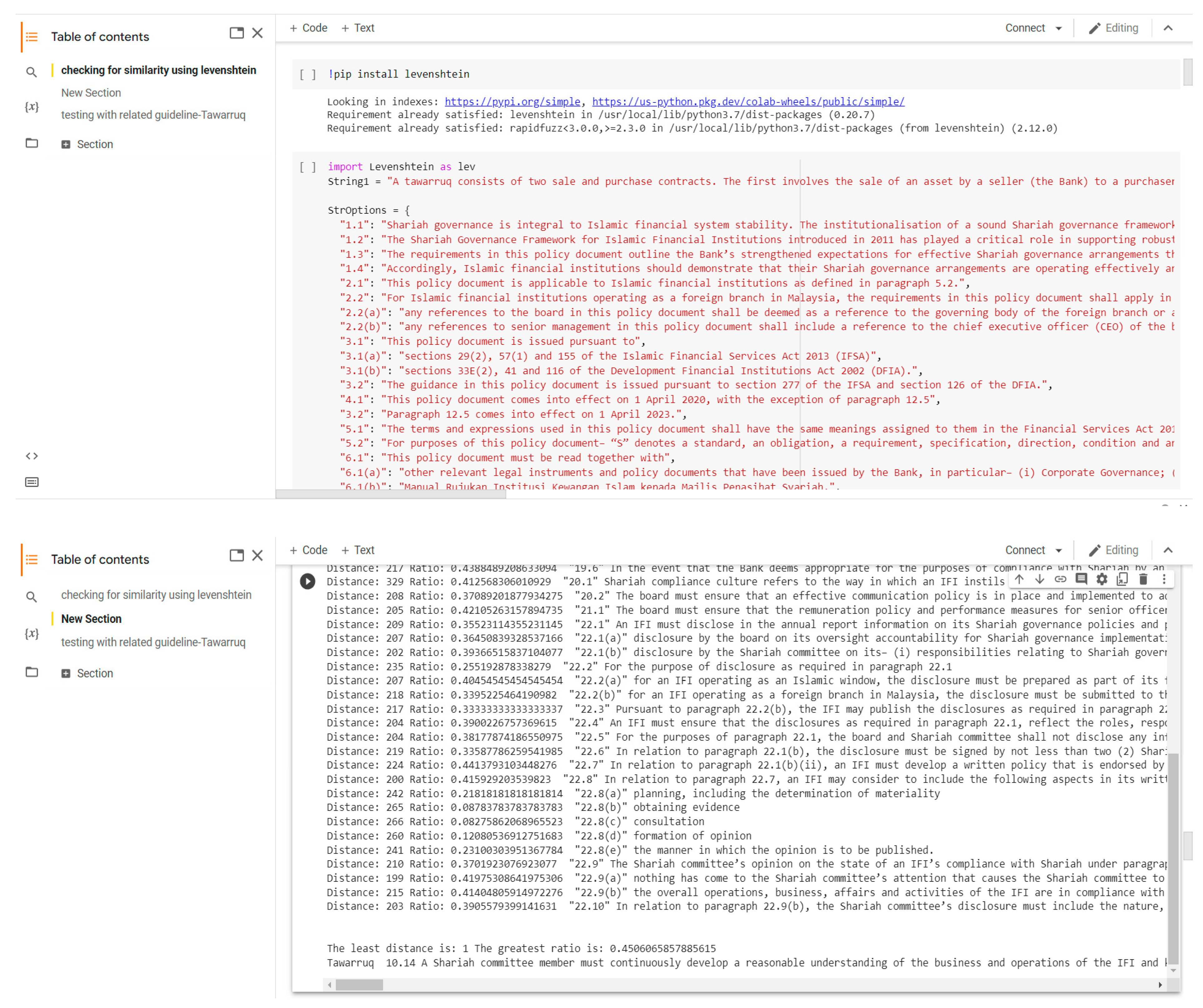
3.2. Measure of Similarity
Levenshtein Distance
4. Serverless Architecture for Shariah Document Screening Prototype
4.1. Serverless Design Principles
- Simplicity and speed. Concise functions should be written that are intended to carry out transactional operations or finish computing tasks applied to one or more entities. These transactions must be completed quickly because they have time and capacity restrictions.
- Hardware is agnostic. It is essential, when developing serverless applications, to remove any dependencies that are hardware related. This is because the resources are only provisioned for the duration of the function’s runtime.
- Optimized for concurrency. Functions should be designed considering the concurrency requests limitation of the serverless architecture. For serverless applications, optimizing for total requests may not be the best design strategy because the total request count may peak less frequently than concurrent request capacity limits.
- Temporary storage. When a function is invoked, the underlying resources are provisioned or accessed for a limited period. The state of the environment, including storage capacity, may change during the execution of a function; therefore, it may be preferable to use persistence to satisfy durable storage requirements.
- Redundancy. Failure must be handled properly by design. A single failure can propagate to subsequent requests and impede the application’s operational workflow.
4.2. Advantages of Serverless Architecture
4.3. Disadvantages of Serverless Architecture
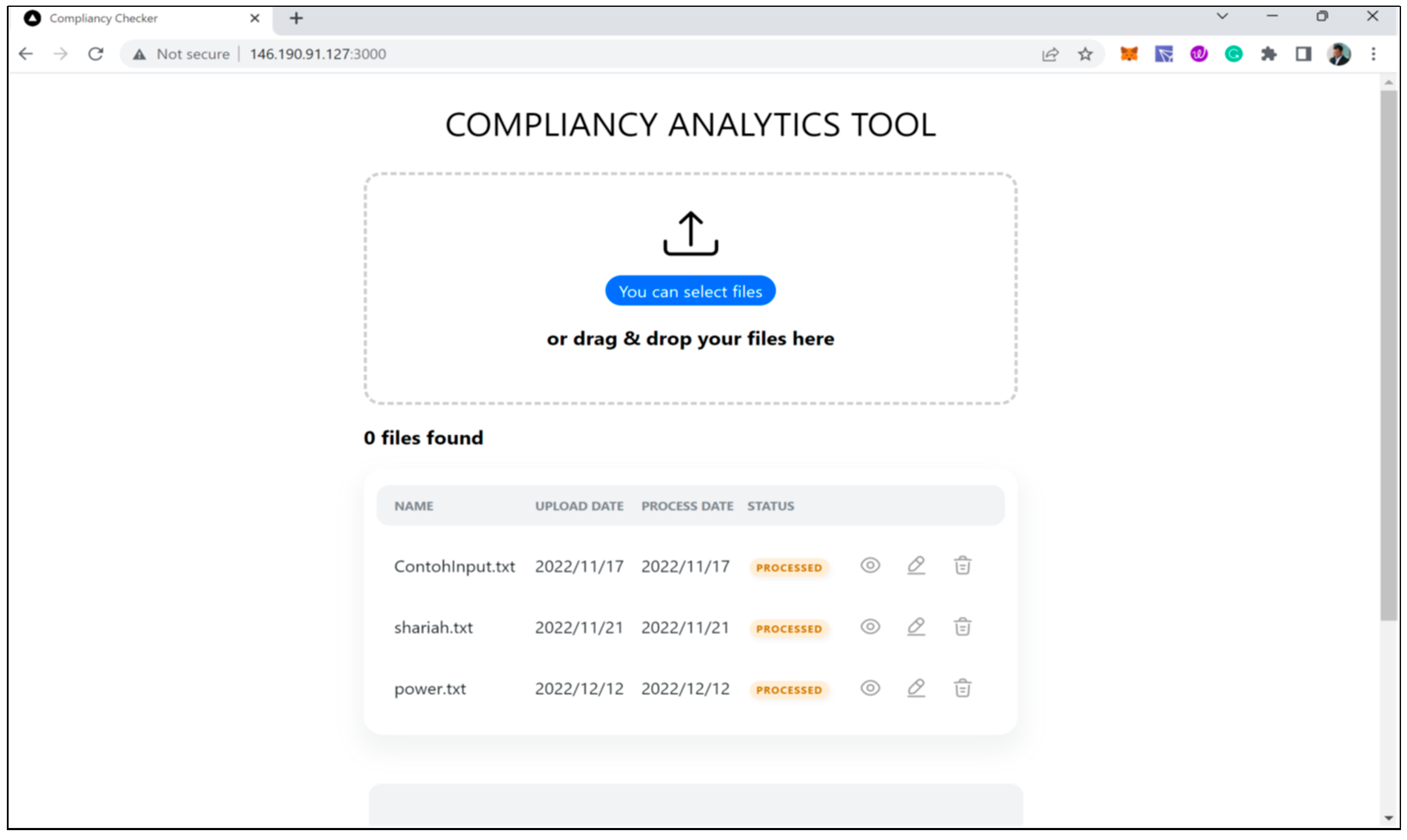
5. Prototype Components
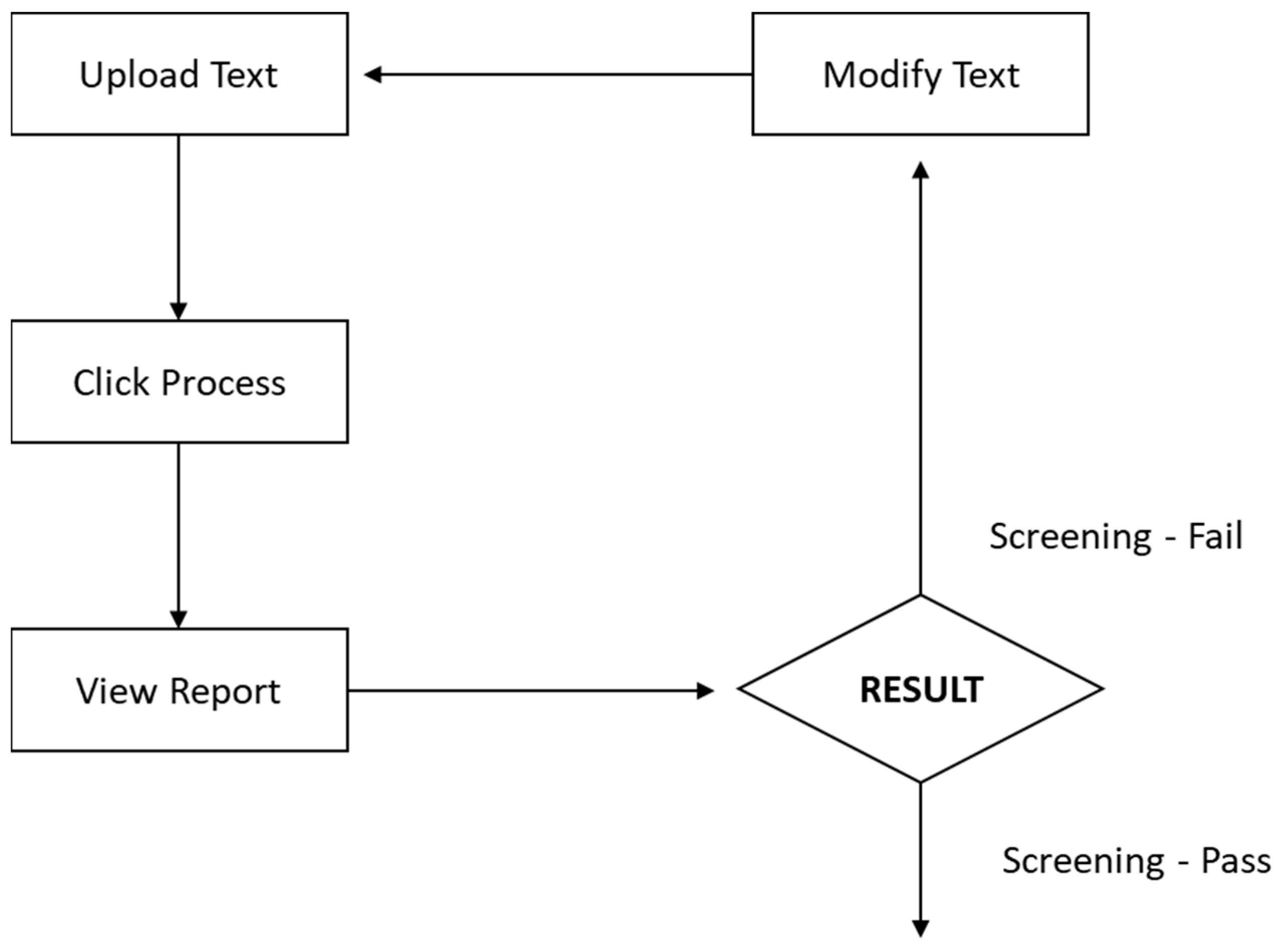
Process Flow of Shariah Document Screening Prototype
6. Conclusions and Discussion
7. Limitations and Suggestions for Future Research
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- El-kenawy, E.M.; Abutarboush, H.F.; Mohamed, A.W.; Ibrahim, A. Advance Artificial Intelligence Technique For Designing Double T-Shaped Monopole Antenna. Comput. Mater. Contin. 2021, 69, 2983–2995. [Google Scholar] [CrossRef]
- Saad, A.; Alhabshi, S.; Noor, A.; Hassan, R. Robo-Advisory for Islamic Financial Institutions: Shari’ah And Regulatory Issues. Eur. J. Islam. Financ. 2020. [Google Scholar] [CrossRef]
- Ali, M.M.; Hassan, R. Survey on Sharīʿah Non-Compliant Events in Islamic Banks in the Practice of Tawarruq Financing in Malaysia. ISRA Int. J. Islam. Financ. 2020, 12, 151–169. [Google Scholar] [CrossRef]
- Tobias, B.; Burg, V.; Gombovic, A.; Puri, M. On the Rise of FinTechs: Credit Scoring Using Digital Footprints. Rev. Financ. Stud. 2020, 33, 2845–2897. [Google Scholar]
- Petralia, K.P.; Rice, T.T.; Veron, N. Banking Disrupted? Financial Intermediation in an Era of Transformational Technology; Centre for Economic Policy Research: London, UK, 2019; ISBN 978-1-912179-26-8. [Google Scholar]
- Soukal, I. Novel Interaction Cost Analysis Applied to Bank Charges Calculator. Computers 2019, 8, 64. [Google Scholar] [CrossRef]
- Togbe, M.U.; Chabchoub, Y.; Boly, A.; Barry, M.; Chiky, R.; Bahri, M. Anomalies Detection Using Isolation in Concept-Drifting Data Streams. Computers 2021, 10, 13. [Google Scholar] [CrossRef]
- Titov, V.; Shust, P.; Dostov, V.; Leonova, A.; Krivoruchko, S.; Lvova, N.; Guzov, I.; Vashchuk, A.; Pokrovskaia, N.; Braginets, A.; et al. Digital Transformation of Signatures: Suggesting Functional Symmetry Approach for Loan Agreements. Computation 2022, 10, 106. [Google Scholar] [CrossRef]
- Haider Syed, M.; Khan, S.; Rabbani, M.R.; Thalassinos, Y.E. An Artificial Intelligence and NLP based Islamic FinTech Model Combining Zakat and Qardh-Al-Hasan for Countering the Adverse Impact of COVID 19 on SMEs and Individuals. Int. J. Econ. Bus. Adm. 2020, VIII, 351–364. [Google Scholar] [CrossRef]
- Ali, H.; Abdullah, R.; Zaini, M.Z. Fintech and Its Potential Impact on Islamic Banking and Finance Industry: A Case Study of Brunei Darussalam and Malaysia. Int. J. Islam. Econ. Financ. 2019, 2, 73–108. [Google Scholar] [CrossRef]
- Laldin, M.A.; Furqani, H. FinTech and Islamic Finance. In Fintech in Islamic Finance: Theory and Practice; Routledge: Oxfordshire, UK, 2019. [Google Scholar]
- Zubaidi, I.B.; Abdullah, A. Developing a Digital Currency from an Islamic Perspective: Case of Blockchain Technology. Int. Bus. Res. 2017, 10, 79. [Google Scholar] [CrossRef]
- Kuruvilla, V.P. A Comprehensive Guide to Fuzzy Matching/Fuzzy Magic. 2021. Available online: https://nanonets.com/blog/fuzzy-matching-fuzzy-logic/ (accessed on 13 February 2023).
- Manning, C.D.; Raghavan, P.; Schütze, H. An Introduction to Information Retrieval; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]
- Bigi, B. Using Kullback-Leibler Distance for Text Categorization; Springer: Berlin/Heidelberg, Germany, 2003; pp. 305–319. [Google Scholar]
- Polettini, N. The Vector Space Model in Information Retrieval-Term Weighting Problem. Entropy 2004, 34, 1–9. [Google Scholar]
- Thompson, V.; Panchev, C.; Oakes, M. Performance Evaluation of Similarity Measures on Similar and Dissimilar Text Retrieval. In Proceedings of the 7th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (IC3K 2015), Lisbon, Portugal, 12–14 November 2015; Volume 1, pp. 577–584, ISBN 978-989-758-158-8. [Google Scholar]
- Gad, A.F. Levenshtein Distance for Word Autocompletion and Autocorrection. 2020. Available online: https://blog.paperspace.com/implementing-levenshtein-distance-word-autocomplete-autocorrect/ (accessed on 13 February 2023).
- Binami. The Levenshtein Algorithm. 2019. Available online: https://medium.com/@binaniharsj/the-levenshtein-algorithm-215567a3ab1f (accessed on 13 February 2023).
- Bosker, H.R. Using Fuzzy String Matching for Automated Assessment of Listener Transcripts in Speech Intelligibility Studies. Behav. Res. Methods 2021, 53, 1945–1953. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Li, G.; Fe, J. Fast-Join: An Efficient Method for Fuzzytoken Matching Based String Similarity Join. In Proceedings of the 27th International Conference on Data Engineering, Hannover, Germany, 11–16 April 2011; pp. 458–469. [Google Scholar]
- Wei, C.; Sprague, A.; Warner, G. Clustering Malware-Generated Spam Emails With a Novel Fuzzy String Matching Algorithm. In Proceedings of the 2009 ACM Symposium on Applied Computing, Honolulu, HI, USA, 9–12 March 2009; pp. 889–890. [Google Scholar]
- Schalk, T.B.; Zimmerman, R.S. Knowledge-Based Strategies Applied to N-Best Lists in Automatic Speech Recognition Systems. U.S. Patent No. US6922669B2, 26 July 2005. [Google Scholar]
- Sharma, G. Best React JS Courses. 2023. Available online: https://www.bankersbyday.com/react-js-courses-certifications/ (accessed on 13 February 2023).
- Khuzyatov, S.S.; Galiullin, L.A. Automated Text Translations. Int. J. Criminol. Sociol. 2020, 9, 2320–2324. [Google Scholar]
- Liu, X.; Jiang, Y.; Wang, Z.; Cheung, H.H.; Huang, G.Q. LimseStudio: Blockchain-Enabled Secure Digital Twin Platform for Service Manufacturing. Int. J. Prod. Res. 2021. [Google Scholar] [CrossRef]
- Mahatpure, J.; Motwani, M.; Shukla, P.K. An Electronic Prescription System Powered by Speech Recognition, Natural Language Processing and Blockchain Technology. Int. J. Sci. Technol. Res. 2019, 8, 1454–1462. [Google Scholar]













Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Che Mohd Salleh, M.; Nor, R.M.; Yusof, F.; Amiruzzaman, M. Constructing a Shariah Document Screening Prototype Based on Serverless Architecture. Computers 2023, 12, 50. https://doi.org/10.3390/computers12030050
Che Mohd Salleh M, Nor RM, Yusof F, Amiruzzaman M. Constructing a Shariah Document Screening Prototype Based on Serverless Architecture. Computers. 2023; 12(3):50. https://doi.org/10.3390/computers12030050
Chicago/Turabian StyleChe Mohd Salleh, Marhanum, Rizal Mohd Nor, Faizal Yusof, and Md Amiruzzaman. 2023. "Constructing a Shariah Document Screening Prototype Based on Serverless Architecture" Computers 12, no. 3: 50. https://doi.org/10.3390/computers12030050
APA StyleChe Mohd Salleh, M., Nor, R. M., Yusof, F., & Amiruzzaman, M. (2023). Constructing a Shariah Document Screening Prototype Based on Serverless Architecture. Computers, 12(3), 50. https://doi.org/10.3390/computers12030050