
Understanding Quality of Products from Customers’ Attitude Using Advanced Machine Learning Methods


Abstract
1. Introduction
- The development of annotation guidelines for a lexicon dictionary to identify product quality based on an appraisal framework.
- To the best of our knowledge, the proposed model is the first to identify the quality of a product from customers’ attitude based on an appraisal framework using a lexicon approach with N-grams and the utilization of a pre-trained BERT word embeddings model in combination with BiLSTM.
2. Related Work
3. Methodology
3.1. Text Proprocessing
3.1.1. Tokenization
3.1.2. Text Conversion into Lower Case
3.1.3. Removal of Punctuations
3.1.4. Removal of Stop Words
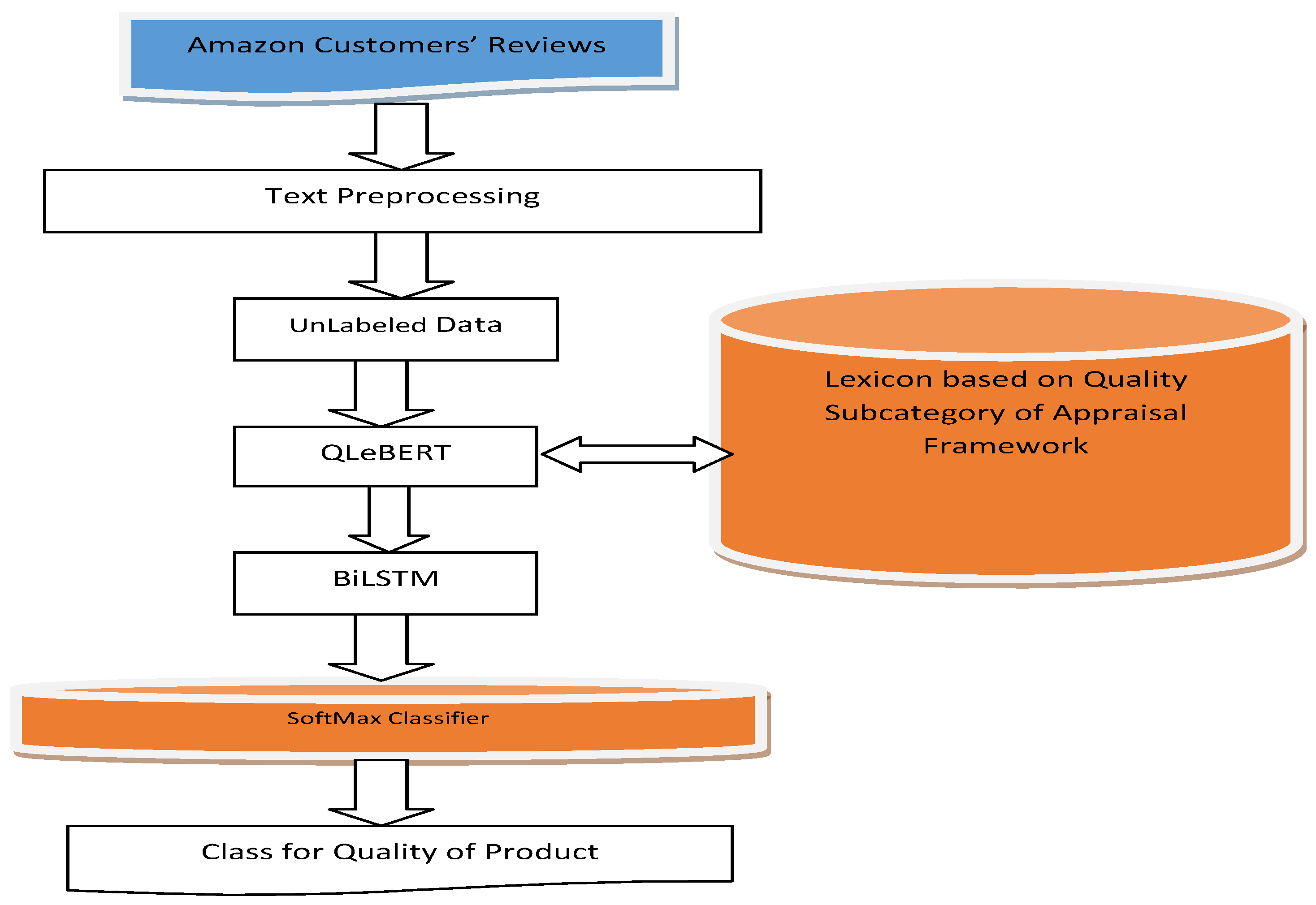
3.2. Description of Proposed QLeBERT Model
3.3. Algorithm: QLeBERT Model
| Algorithm 1: Psecudocodes of the QLeBERT model |
| //This algorithm takes customer reviews CRi having words Wi and generates high //quality and low products h and l, respectively.
|
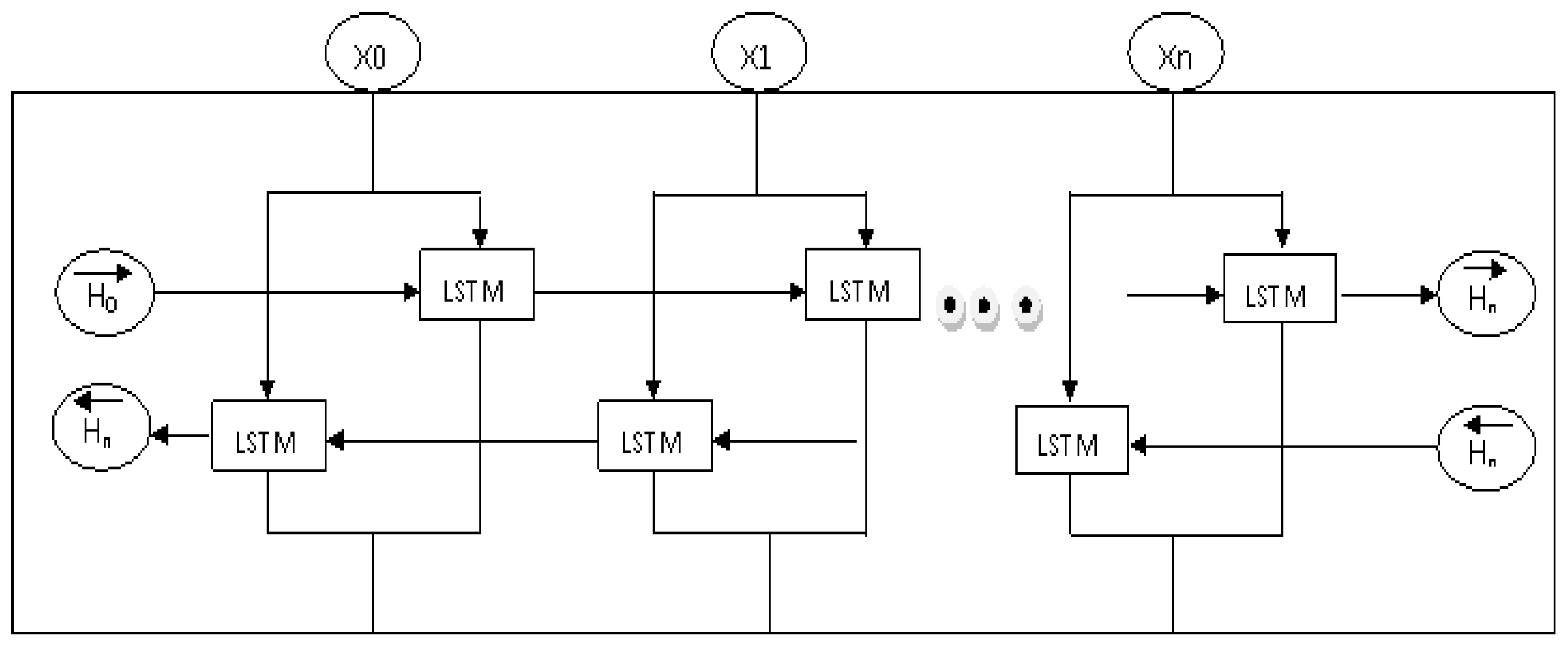
3.4. BiLSTM
3.5. Focal Loss Function
4. Experiment
4.1. Datasets
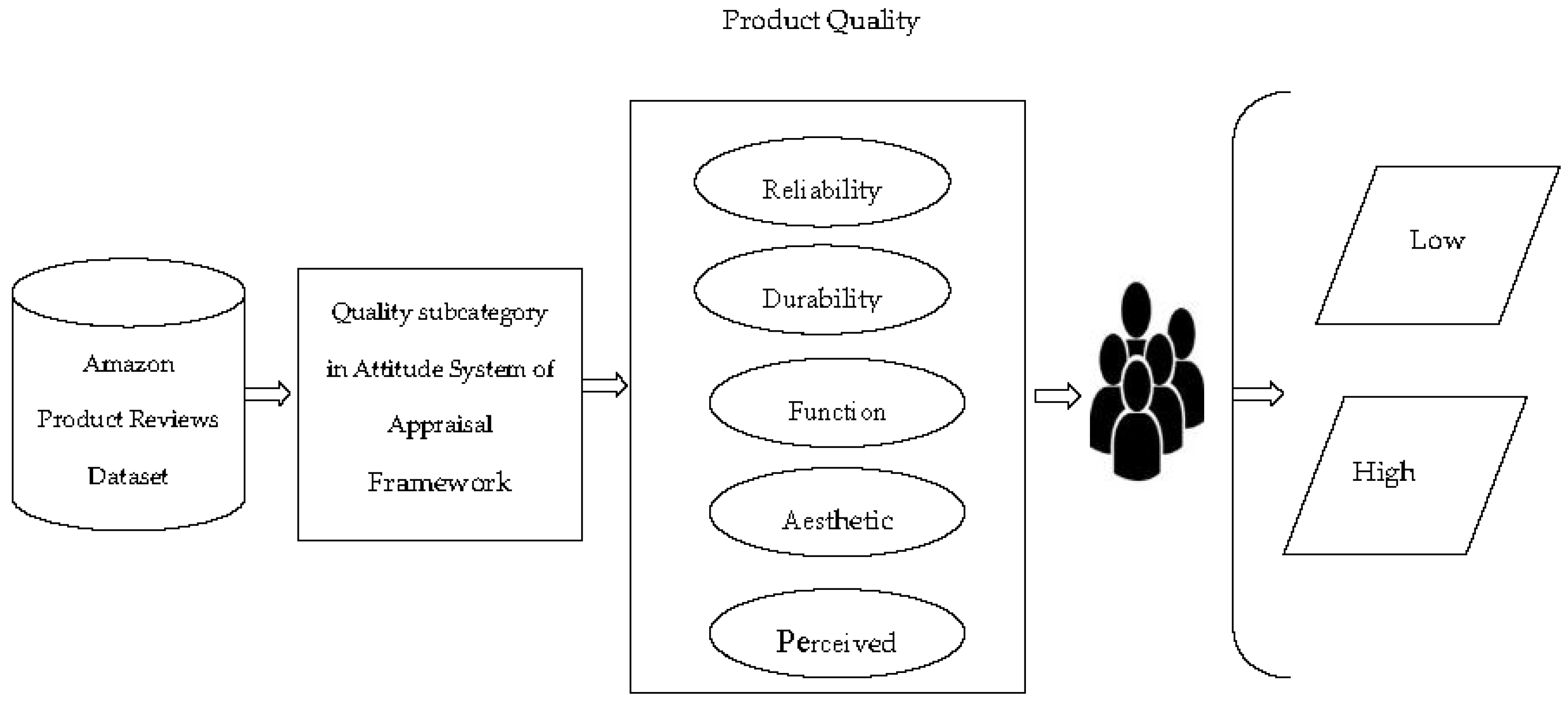
4.2. Lexicon-Based Customers’ Attitude Analysis to Predict Product’ Quality Using Appraisal Framework
4.3. Experiment Setup
4.4. Evaluation Metrics
5. Results and Discussion
5.1. Performance Measurement of QLeBERT Model in Comparison to Different Models
5.2. Comparison of Proposed QLeBERT with Baseline Model
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hogg, M.V. Social Psychology, 4th ed.; Prentice Hall: London, UK, 2005; Chapter 5. [Google Scholar]
- Liu, B. Sentiment Analysis: Mining Opinions, Sentiments, and Emotions; Cambridge University Press: Cambridge, UK, 2020. [Google Scholar]
- Khoja, S.S.; Prajapati, A.M.; Khoja, S.S.; Panjwani, K.R.; Ray, J. A review on quality aspects, evolution of quality, dimension of quality and action plan for enhancing quality culture. Pharma Sci. Monit. 2017, 8, 335–352. [Google Scholar]
- Litvin, S.W.; Goldsmith, R.E.; Pan, B. Electronic word-of-mouth in hospitality and tourism management. Tour. Manag. 2008, 29, 458–468. [Google Scholar] [CrossRef]
- Yoo, K.-H.; Gretzel, U. Influence of personality on travel-related consumer-generated media creation. Comput. Hum. Behav. 2010, 27, 609–621. [Google Scholar] [CrossRef]
- von Helversen, B.; Abramczuk, K.; Kopeć, W.; Nielek, R. Influence of consumer reviews on online purchasing decisions in older and younger adults. Decis. Support Syst. 2018, 113, 1–10. [Google Scholar] [CrossRef]
- Zhao, S. Thumb Up or Down? A Text-Mining Approach of Understanding Consumers through Reviews. Decis. Sci. 2019, 52, 699–719. [Google Scholar] [CrossRef]
- Reichheld, F.F. The one number you need to grow. Harv. Bus. Rev. 2003, 81, 46–54. [Google Scholar]
- Socher, R.; Perelygin, A.; Wu, J.; Chuang, J.; Manning, C.D.; Ng, A.Y.; Potts, C. Recursive deep models for semantic composi-tionality over a sentiment treebank. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; pp. 1631–1642. [Google Scholar]
- Cambria, E.; Havasi, C.; Hussain, A. Senticnet 2: A semantic and affective resource for opinion mining and sentiment analysis. In Proceedings of the Twenty-Fifth International FLAIRS Conference, Marco Island, FL, USA, 16 May 2012. [Google Scholar]
- Senecal, S.; Nantel, J. The influence of online product recommendations on consumers’ online choices. J. Retail. 2004, 80, 159–169. [Google Scholar] [CrossRef]
- Jun Lee, S.; Siau, K. A review of data mining techniques. Ind. Manag. Data Syst. 2001, 101, 41–46. [Google Scholar] [CrossRef]
- Hoontrakul, P.; Sahadev, S. Application of data mining techniques in the on-line travel industry: A case study from Thailand. Mark. Intell. Plan. 2008, 26, 60–76. [Google Scholar] [CrossRef]
- Mishra, D.K.; Kumar, J.; Chaudhary, J.K.; Upadhyay, A.K.; Sharma, S. Role of Text Mining to Enhance the Quality of Product Using an Unsupervised Machine Learning Approach. ECS Trans. 2022, 107, 12553–12560. [Google Scholar] [CrossRef]
- Xu, H.; Wei, R.; Degroof, R.; Carberry, J. Evaluating Online Products Using Text Mining: A Reliable Evidence-Based Approach. Int. J. Semantic Comput. 2022, 16, 585–611. [Google Scholar] [CrossRef]
- Suresh, P.; Gurumoorthy, K. Mining of Customer Review Feedback Using Sentiment Analysis for Smart Phone Product. In International Conference on Computing, Communication, Electrical and Biomedical Systems; EAI Springer: Cham, Switzerland, 2022; pp. 247–259. [Google Scholar]
- Garvin, D.A. Managing Quality: The Strategic and Competitive Edge; Simon and Schuster: New York, NY, USA, 1988. [Google Scholar]
- Udeh, C.; Ifekanandu, C.; Idoko, E.; Ugwuanyi, C.; Okeke, C. Pay TV Product quality and customer satisfaction: An investigation. Int. J. Inf. Syst. Inform. 2022, 3, 25–35. [Google Scholar] [CrossRef]
- Mostafa, M.M. More than words: Social networks’ text mining for consumer brand sentiments. Expert Syst. Appl. 2013, 40, 4241–4251. [Google Scholar] [CrossRef]
- Lee, T.Y.; Bradlow, E.T. Automated Marketing Research Using Online Customer Reviews. J. Mark. Res. 2011, 48, 881–894. [Google Scholar] [CrossRef]
- Netzer, O.; Feldman, R.; Goldenberg, J.; Fresko, M. Mine Your Own Business: Market-Structure Surveillance Through Text Mining. Mark. Sci. 2012, 31, 521–543. [Google Scholar] [CrossRef]
- Ghose, A.; Ipeirotis, P.G.; Li, B. Designing Ranking Systems for Hotels on Travel Search Engines by Mining User-Generated and Crowdsourced Content. Mark. Sci. 2012, 31, 493–520. [Google Scholar] [CrossRef]
- Ghose, A.; Ipeirotis, P.G. Estimating the Helpfulness and Economic Impact of Product Reviews: Mining Text and Reviewer Characteristics. IEEE Trans. Knowl. Data Eng. 2010, 23, 1498–1512. [Google Scholar] [CrossRef]
- He, L.; Zhang, N.; Yin, L. Research on the evaluation of product quality perceived value based on text mining and fuzzy comprehensive evaluation. In Proceedings of the 2016 International Conference on Identification, Information and Knowledge in the Internet of Things (IIKI), Beijing, China, 20–21 October 2016; pp. 563–566. [Google Scholar]
- Güneş, S. Extracting Online Product Review Patterns and Causes: A New Aspect/Cause Based Heuristic for Designers. Des. J. 2020, 23, 375–393. [Google Scholar] [CrossRef]
- Rangu, C.; Chatterjee, S.; Valluru, S.R. Text mining approach for product quality enhancement:(improving product quality through machine learning). In Proceedings of the 2017 IEEE 7th International Advance Computing Conference (IACC), Hyderabad, India, 5–7 January 2017; pp. 456–460. [Google Scholar]
- Cruz, A.V. Relationship between Product Quality and Customer Satisfaction. Ph.D. Thesis, Walden University, Minneapolis, MN, USA, 2015. [Google Scholar]
- Martin, J.R.; White, P.R. The Language OF Evaluation; Springer: Berlin/Heidelberg, Germany, 2003; Volume 2. [Google Scholar]
- Liu, B. Sentiment analysis and opinion mining. Synth. Lect. Hum. Lang. Technol. 2012, 5, 1–167. [Google Scholar]
- Nasukawa, T.; Yi, J. Sentiment analysis: Capturing favorability using natural language processing. In Proceedings of the 2nd International Conference on Knowledge Capture, Beijing, China, 20–21 October 2016; pp. 70–77. [Google Scholar]
- Dave, K.; Lawrence, S.; Pennock, D.M. Mining the peanut gallery: Opinion extraction and semantic classification of product reviews. In Proceedings of the 12th International Conference on World Wide Web, Budapest, Hungary, 20 May 2003; pp. 519–528. [Google Scholar]
- Argamon, S.; Bloom, K.; Esuli, A.; Sebastiani, F. Automatically Determining Attitude Type and Force for Sentiment Analysis. In Proceedings of the Language and Technology Conference, Poznan, Poland, 5–7 October 2007; pp. 218–231. [Google Scholar]
- Whitelaw, C.; Garg, N.; Argamon, S. Using appraisal groups for sentiment analysis. In Proceedings of the 14th ACM International Conference on Information and Knowledge Management, Bremen, Germany, 5 October 2005; pp. 625–631. [Google Scholar]
- Lyu, K.; Kim, H. Sentiment Analysis Using Word Polarity of Social Media. Wirel. Pers. Commun. 2016, 89, 941–958. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, B.; Shan, L.; Wang, X. Modelling context with neural networks for recommending idioms in essay writing. Neurocomputing 2018, 275, 2287–2293. [Google Scholar] [CrossRef]
- Baharudin, A.K.A.B. Sentiment classification using sentence-level semantic orientation of opinion terms from blogs. In Proceedings of the National Postgraduate Conference, Perak, Malaysia, 19–20 September 2011; pp. 1–7. [Google Scholar]
- Aisopos, F.; Papadakis, G.; Varvarigou, T.A. Sentiment analysis of social media content using N-Gram graphs. In Proceedings of the WSM’11, Scottsdale, AZ, USA, 30 November 2011. [Google Scholar]
- Jain, D.K.; Boyapati, P.; Venkatesh, J.; Prakash, M. An Intelligent Cognitive-Inspired Computing with Big Data Analytics Framework for Sentiment Analysis and Classification. Inf. Process. Manag. 2021, 59, 102758. [Google Scholar] [CrossRef]
- Araque, O.; Corcuera-Platas, I.; Sánchez-Rada, J.F.; Iglesias, C.A. Enhancing deep learning sentiment analysis with ensemble techniques in social applications. Expert Syst. Appl. 2017, 77, 236–246. [Google Scholar] [CrossRef]
- Mudinas, A.; Zhang, D.; Levene, M. Combining lexicon and learning based approaches for concept-level sentiment analysis. In Proceedings of the First International Workshop on Issues of Sentiment Discovery and Opinion Mining, Beijing, China, 12 August 2012; pp. 1–8. [Google Scholar]
- Rezaeinia, S.M.; Rahmani, R.; Ghodsi, A.; Veisi, H. Sentiment analysis based on improved pre-trained word embeddings. Expert Syst. Appl. 2018, 117, 139–147. [Google Scholar] [CrossRef]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their com-positionality. Adv. Neural Inf. Process. Syst. 2013, 26, 3136. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching word vectors with subword information. Trans. Sociation Comput. Linguist. 2017, 5, 135–146. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language under-standing. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Prottasha, N.J.; Sami, A.A.; Kowsher, M.; Murad, S.A.; Bairagi, A.K.; Masud, M.; Baz, M. Transfer Learning for Sentiment Analysis Using BERT Based Supervised Fine-Tuning. Sensors 2022, 22, 4157. [Google Scholar] [CrossRef]
- Jain, P.K.; Quamer, W.; Saravanan, V.; Pamula, R. Employing BERT-DCNN with sentic knowledge base for social media sentiment analysis. J. Ambient. Intell. Humaniz. Comput. 2022, 1–13. [Google Scholar] [CrossRef]
- Mutinda, J.; Mwangi, W.; Okeyo, G. Lexicon-pointed hybrid N-gram Features Extraction Model (LeNFEM) for sentence level sentiment analysis. Eng. Rep. 2021, 3, e12374. [Google Scholar] [CrossRef]
- Garg, S.B.; Subrahmanyam, V. Sentiment analysis: Choosing the right word embedding for deep learning model. In Advanced Computing and Intelligent Technologies: Proceedings of ICACIT 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 417–428. [Google Scholar]
- Giatsoglou, M.; Vozalis, M.G.; Diamantaras, K.; Vakali, A.; Sarigiannidis, G.; Chatzisavvas, K.C. Sentiment analysis leveraging emotions and word embeddings. Expert Syst. Appl. 2016, 69, 214–224. [Google Scholar] [CrossRef]
- Chen, Y. Convolutional Neural Network for Sentence Classification; University of Waterloo: Waterloo, NSW, Canada, 2015. [Google Scholar]
- Wang, Y.; Huang, M.; Zhu, X.; Zhao, L. Attention-based LSTM for aspect-level sentiment classification. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1 November 2016; pp. 606–615. [Google Scholar]
- Liu, J.; Zheng, S.; Xu, G.; Lin, M. Cross-domain sentiment aware word embeddings for review sentiment analysis. Int. J. Mach. Learn. Cybern. 2020, 12, 343–354. [Google Scholar] [CrossRef]
- D’Silva, J.; Sharma, U. Automatic text summarization of konkani texts using pre-trained word embeddings and deep learning. Int. J. Electr. Comput. Eng. IJECE 2022, 12, 1990–2000. [Google Scholar] [CrossRef]
- Mutinda, J.; Mwangi, W.; Okeyo, G. Sentiment Analysis of Text Reviews Using Lexicon- Enhanced Bert Embedding (LeBERT) Model with Convolutional Neural Network. Appl. Sci. 2023, 13, 1445. [Google Scholar] [CrossRef]
- Rathi, M.; Malik, A.; Varshney, D.; Sharma, R.; Mendiratta, S. Sentiment analysis of tweets using machine learning approach. In Proceedings of the 2018 Eleventh International Conference on Contemporary Computing (IC3), Noida, India, 2–4 August 2018; pp. 1–3. [Google Scholar]
- Yang, H. Network Public Opinion Risk Prediction and Judgment Based on Deep Learning: A Model of Text Sentiment Analysis. Comput. Intell. Neurosci. 2022, 2022, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Xu, G.; Meng, Y.; Qiu, X.; Yu, Z.; Wu, X. Sentiment Analysis of Comment Texts Based on BiLSTM. IEEE Access 2019, 7, 51522–51532. [Google Scholar] [CrossRef]
- Li, X.; Lei, Y.; Ji, S. BERT-and BiLSTM-Based Sentiment Analysis of Online Chinese Buzzwords. Future Internet 2022, 14, 332. [Google Scholar] [CrossRef]
- Chen, E.; Lin, Y.; Xiong, H.; Luo, Q.; Ma, H. Exploiting probabilistic topic models to improve text categorization under class imbalance. Inf. Process. Manag. 2011, 47, 202–214. [Google Scholar] [CrossRef]
- Liu, Y.; Yu, X.; Huang, J.X.; An, A. Combining integrated sampling with SVM ensembles for learning from imbalanced datasets. Inf. Process. Manag. 2011, 47, 617–631. [Google Scholar] [CrossRef]
- Vinodhini, G.; Chandrasekaran, R. A sampling based sentiment mining approach for e-commerce applications. Inf. Process. Manag. 2017, 53, 223–236. [Google Scholar] [CrossRef]
- Laza, R.; Pavón, R.; Reboiro-Jato, M.; Fdez-Riverola, F. Evaluating the effect of unbalanced data in biomedical document classification. J. Integr. Bioinform. 2011, 8, 105–117. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Consumer Reviews of Amazon Products. Available online: https://www.kaggle.com/datasets/datafiniti/consumer-reviews-of-amazon-products (accessed on 20 September 2019).
- Rahmath, P.H.; Ahmad, T. Fuzzy based Sentiment Analysis of Online Product Reviews using Machine Learning Techniques. Int. J. Comput. Appl. 2014, 99, 9–16. [Google Scholar] [CrossRef]
- Dragos, V.; Battistelli, D.; Kelodjoue, E. Beyond sentiments and opinions: Exploring social media with appraisal categories. In Proceedings of the 2018 21st International Conference on Information Fusion (FUSION), Cambridge, UK, 10–13 July 2018; pp. 1851–1858. [Google Scholar]
- Guo, H.; Li, Y.; Shang, J.; Gu, M.; Huang, Y.; Gong, B. Learning from class-imbalanced data: Review of methods and applications. Expert Syst. Appl. 2017, 73, 220–239. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Dataset Name/Features→ | Reliability | Durability | Function | Aesthetics | Perceived | Total High Quality Reviews | Total Low Quality Reviews | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Quality--> | High | Low | High | Low | High | Low | High | Low | High | Low | ||
| Amazon Nine Products Customer Reviews | 35 | 28 | 32 | 28 | 49 | 25 | 675 | 300 | 21 | 3 | 812 | 384 |
| Datafiniti Amazon Consumer Reviews of Amazon Products | 1152 | 463 | 3082 | 701 | 2949 | 500 | 2502 | 652 | 6498 | 755 | 16,183 | 3071 |
| Total feature based quality related reviews | 1187 | 491 | 3114 | 729 | 2998 | 525 | 3177 | 952 | 6519 | 758 | 16,995 | 3455 |
| Detail of Data Item | Without Implementing Lexicon-Based Approach | After Implementing Lexicon-Based Approach |
|---|---|---|
| Number of words | 64,378 | 25,667 |
| N-Grams | QLeBERT-BiLSTM | |||
|---|---|---|---|---|
| F1-Micro | F1-Macro | F1-Weighted | Accuracy | |
| N = 1 | 0.76 | 0.72 | 0.71 | 0.76 |
| N = 2 | 0.95 | 0.91 | 0.95 | 0.95 |
| N = 3 | 0.92 | 0.87 | 0.86 | 0.92 |
| N = 4 | 0.89 | 0.86 | 0.88 | 0.89 |
| Entire Words | 0.83 | 0.80 | 0.82 | 0.83 |
| N-Grams | F1 Micro | F1 Macro | F1 Weighted | Accuracy |
|---|---|---|---|---|
| N = 1 | 0.76 | 0.62 | 0.71 | 0.76 |
| N = 2 | 0.76 | 0.71 | 0.76 | 0.76 |
| N = 3 | 0.89 | 0.78 | 0.88 | 0.89 |
| N = 4 | 0.81 | 0.77 | 0.80 | 0.81 |
| Entire Words | 0.72 | 0.70 | 0.72 | 0.72 |
| N-Grams | F1 Micro | F1 Macro | F1 Weighted | Accuracy |
|---|---|---|---|---|
| N = 1 | 0.77 | 0.67 | 0.78 | 0.77 |
| N = 2 | 0.83 | 0.80 | 0.82 | 0.83 |
| N = 3 | 0.80 | 0.77 | 0.80 | 0.80 |
| N = 4 | 0.81 | 0.76 | 0.79 | 0.81 |
| Entire Words | 0.75 | 0.69 | 0.70 | 0.75 |
| Model | F1 Micro | F1 Macro | F1 Weighted | Accuracy |
|---|---|---|---|---|
| Word2Vec | 0.85 | 0.70 | 0.80 | 0.85 |
| Glove | 0.88 | 0.72 | 0.82 | 0.88 |
| Lexicon-Glove | 0.89 | 0.78 | 0.88 | 0.89 |
| Lexicon-Word2Vec | 0.83 | 0.80 | 0.82 | 0.83 |
| BERT | 0.83 | 0.81 | 0.78 | 0.83 |
| QLeBERT(our model) | 0.95 | 0.91 | 0.95 | 0.95 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ullah, A.; Khan, K.; Khan, A.; Ullah, S. Understanding Quality of Products from Customers’ Attitude Using Advanced Machine Learning Methods. Computers 2023, 12, 49. https://doi.org/10.3390/computers12030049
Ullah A, Khan K, Khan A, Ullah S. Understanding Quality of Products from Customers’ Attitude Using Advanced Machine Learning Methods. Computers. 2023; 12(3):49. https://doi.org/10.3390/computers12030049
Chicago/Turabian StyleUllah, Aman, Khairullah Khan, Aurangzeb Khan, and Shoukat Ullah. 2023. "Understanding Quality of Products from Customers’ Attitude Using Advanced Machine Learning Methods" Computers 12, no. 3: 49. https://doi.org/10.3390/computers12030049
APA StyleUllah, A., Khan, K., Khan, A., & Ullah, S. (2023). Understanding Quality of Products from Customers’ Attitude Using Advanced Machine Learning Methods. Computers, 12(3), 49. https://doi.org/10.3390/computers12030049