



A Methodological Framework for Designing Personalised Training Programs to Support Personnel Upskilling in Industry 5.0



Abstract
:1. Introduction
2. State of the Art
2.1. Personnel Training
2.2. Zero Defect Manufacturing (ZDM)
2.3. Natural Language Processing (NLP) and Large Language Models (LLM)
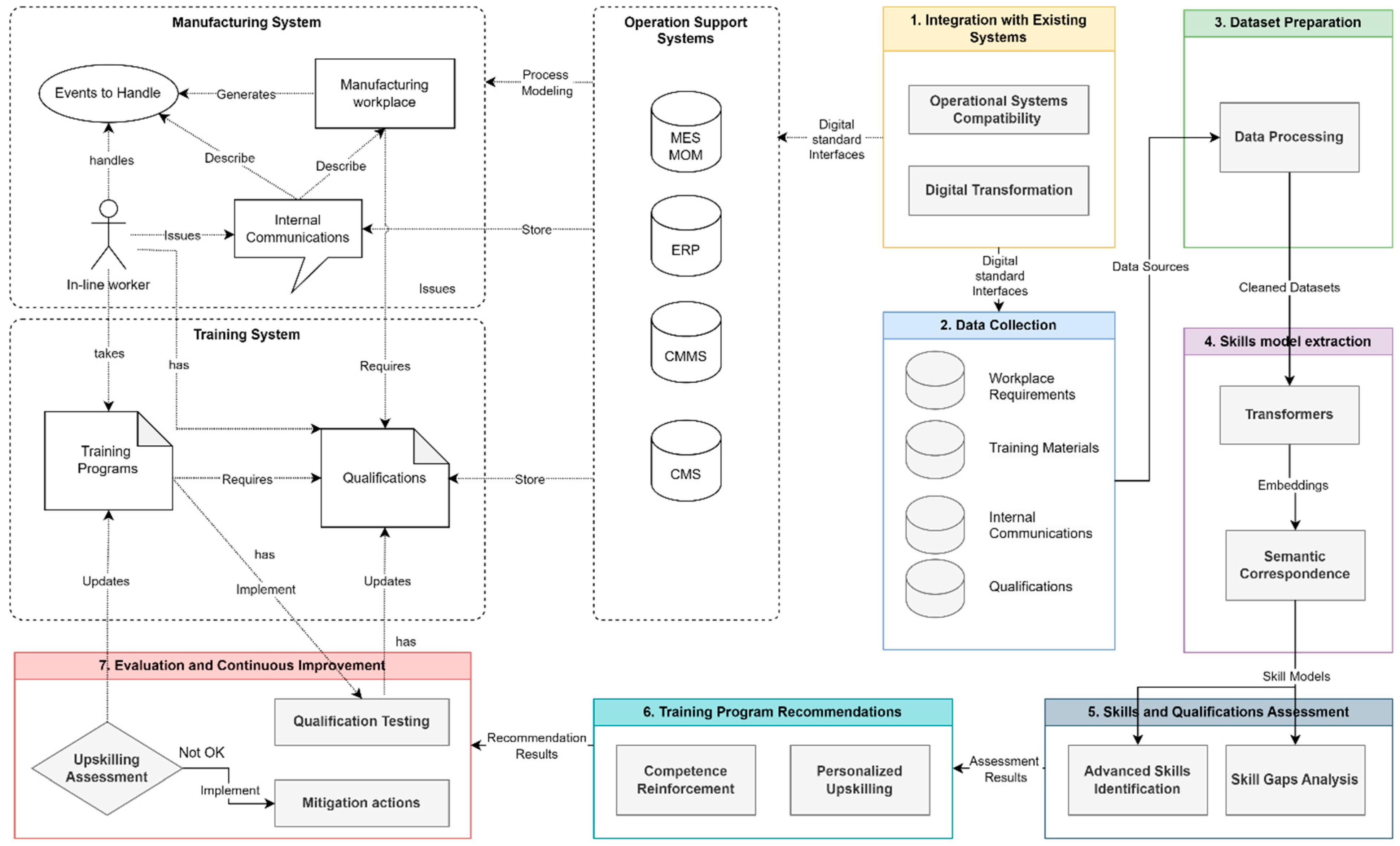
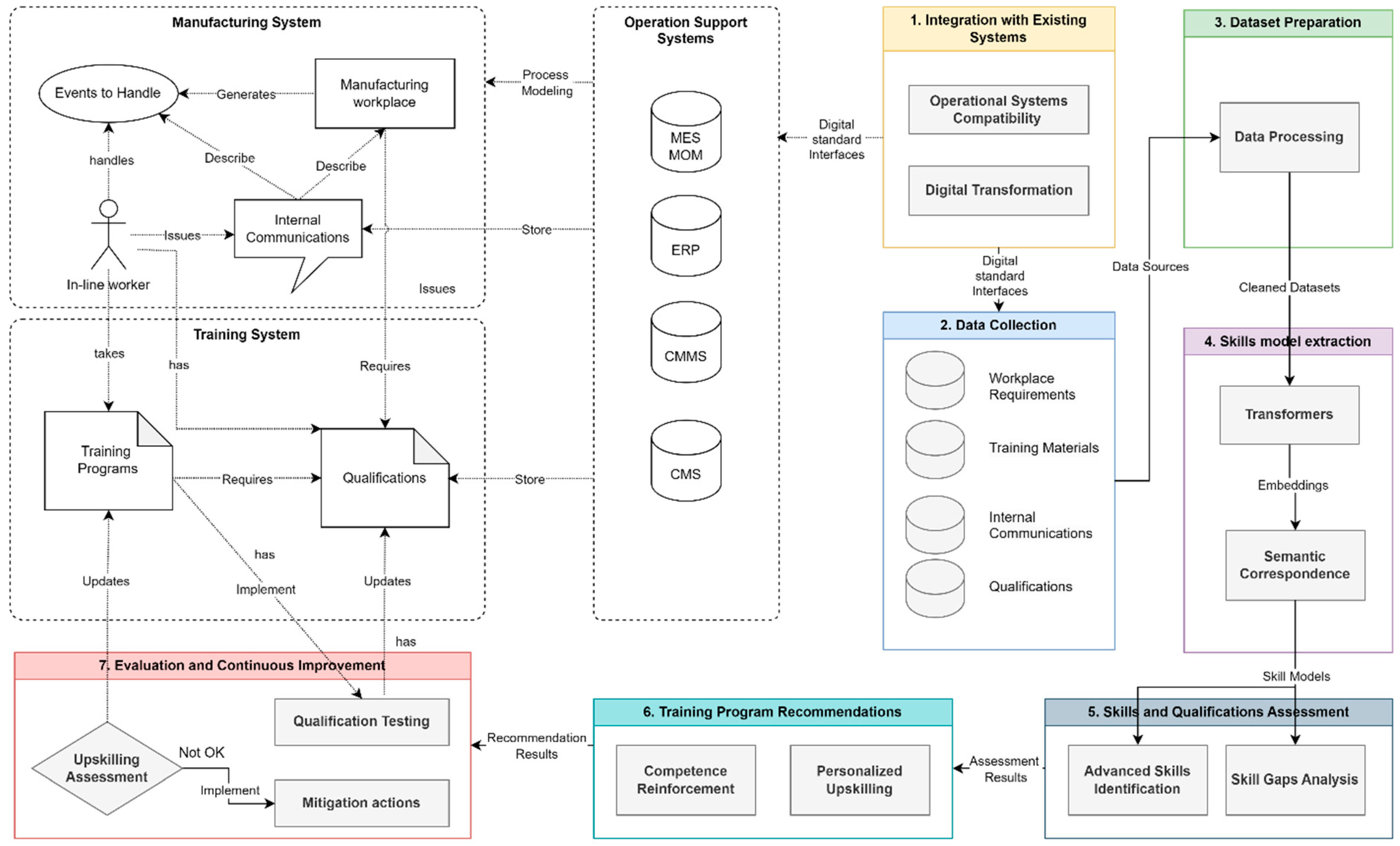
3. Methodological Framework
3.1. Integration with Existing Systems
3.1.1. Digital Transformation
3.1.2. Operational Systems Compatibility
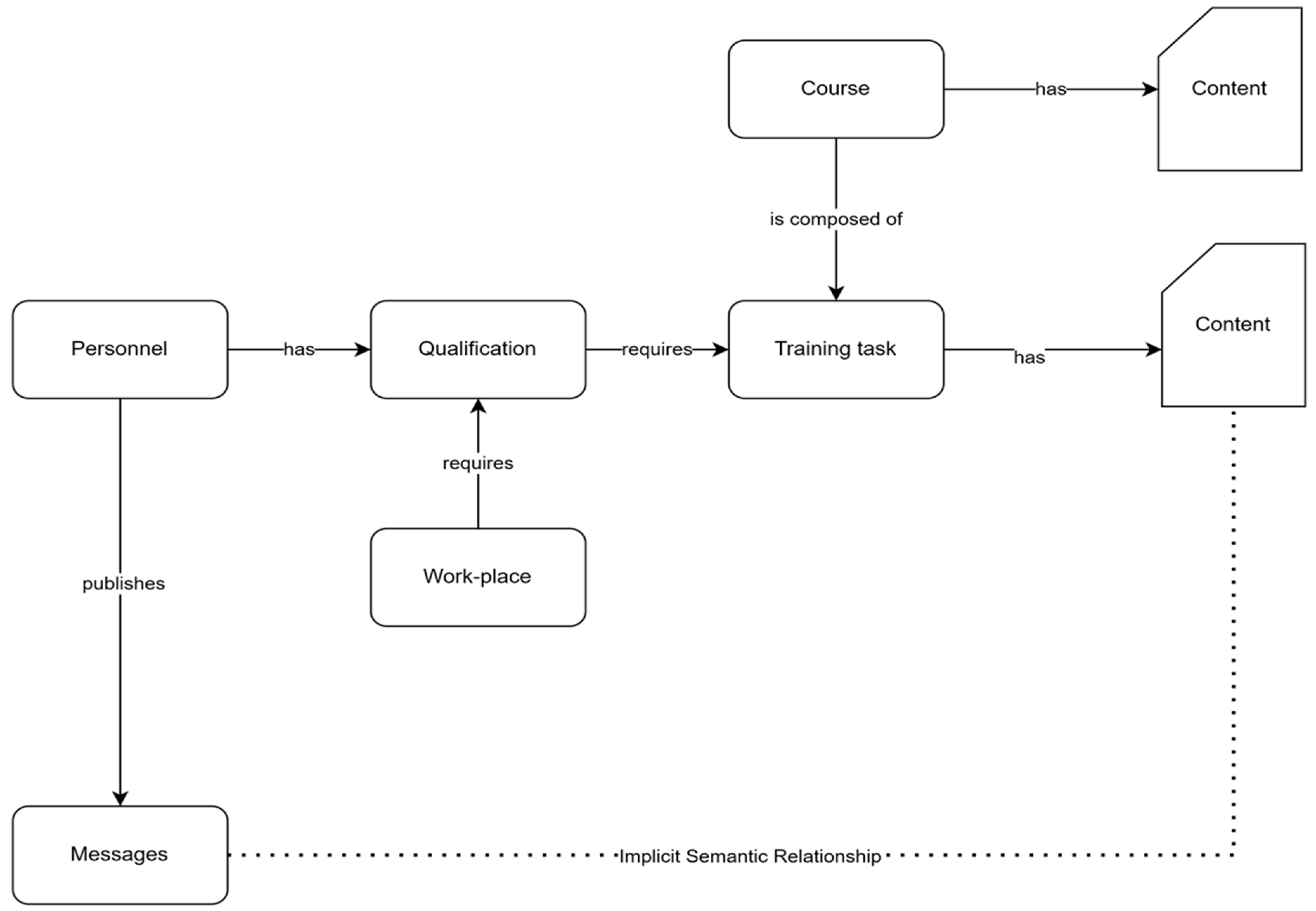
3.2. Data Collection
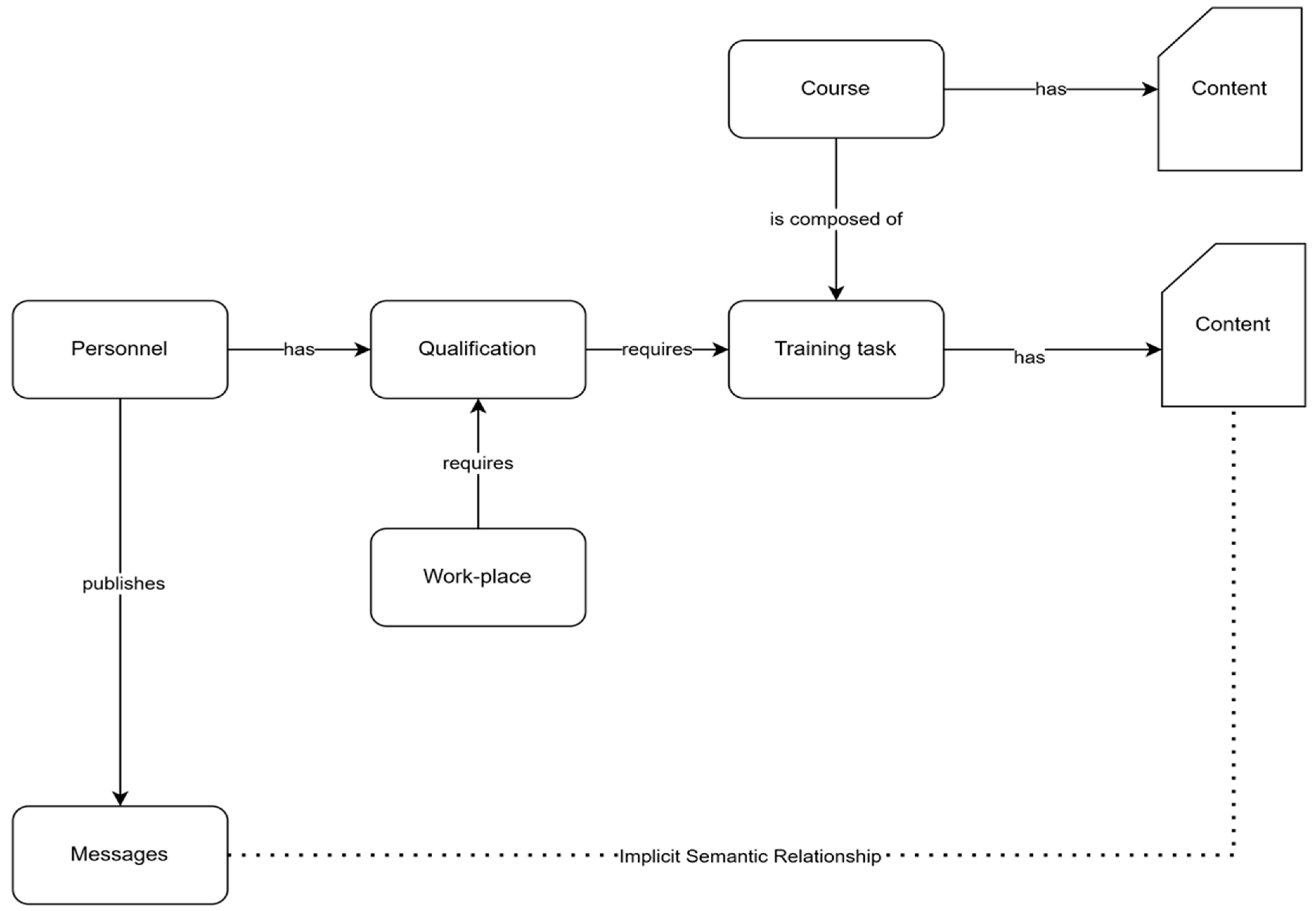
3.2.1. Identification of Workplace Requirements (Roles, Task, and Skills), Data Collection, and Dataset Preparation
3.2.2. Identification of Training Materials, Data Collection, and Dataset Preparation
3.2.3. Collection of Internal Communications Data and Dataset Preparation
3.2.4. Collection of Qualifications Data and Dataset Preparation
3.3. Dataset Preparation
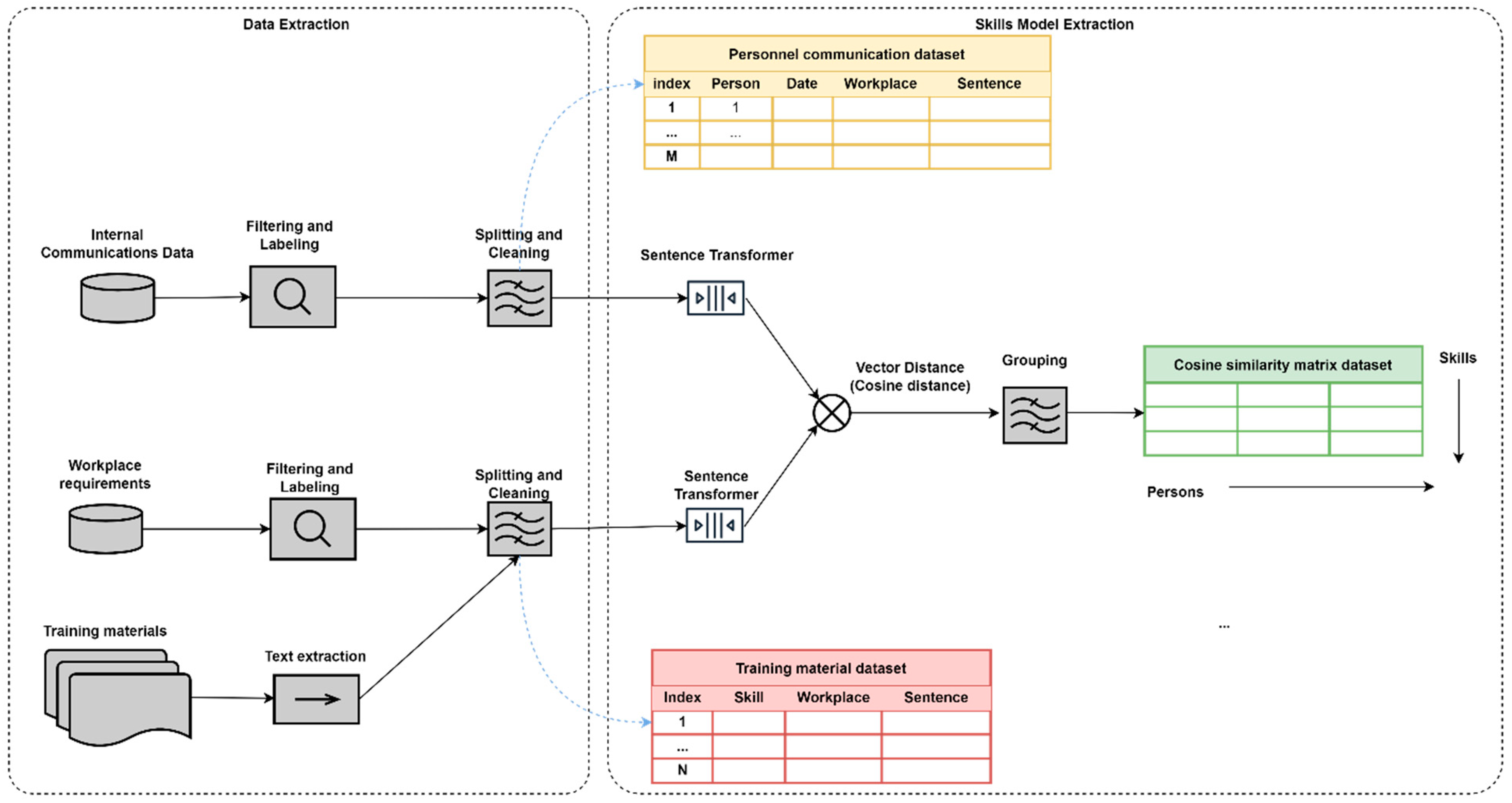
3.4. Skills-Models Extraction
3.4.1. Generation of Embeddings Using Transformers
3.4.2. Semantic Correspondence
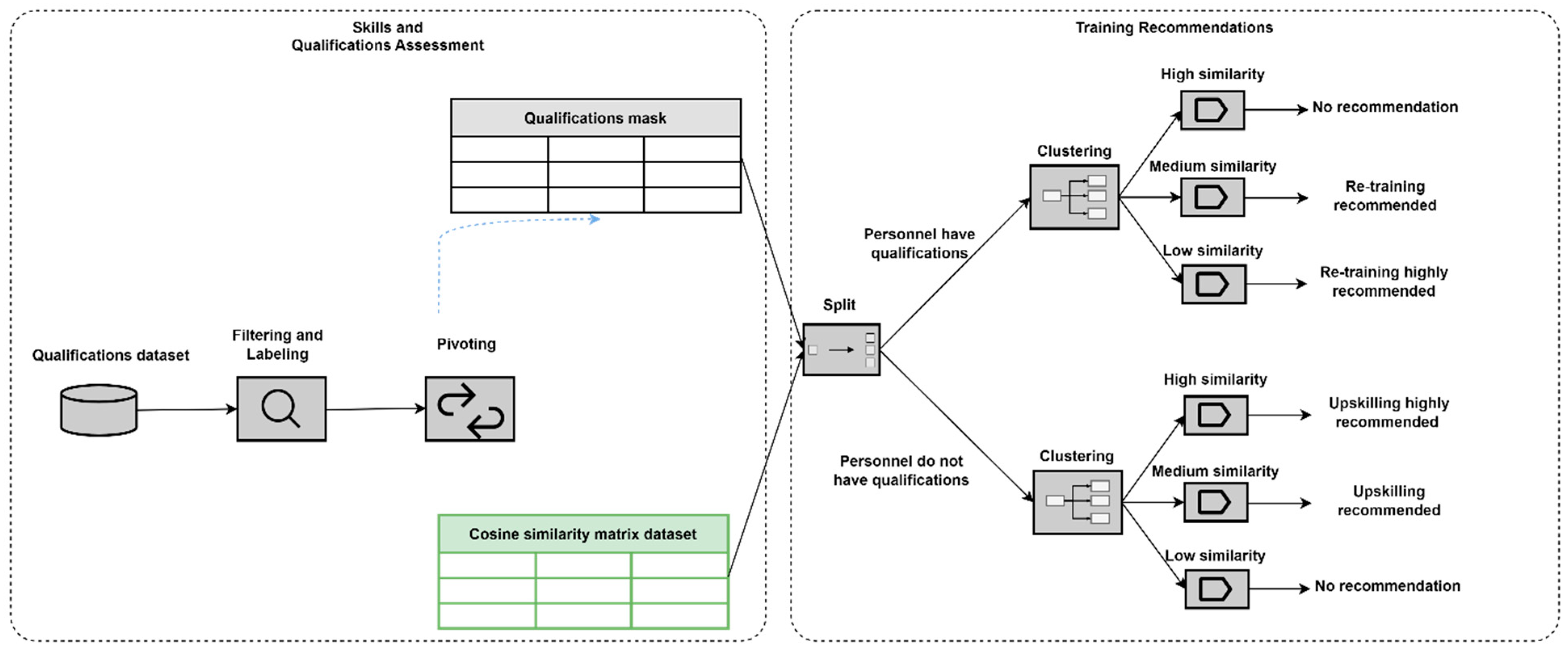
3.5. Assessment of Skills and Qualifications
3.5.1. Skills-Gap Analysis
3.5.2. Identification of Advanced Skills
3.6. Recommendations for Training Programs
3.6.1. Competence Reinforcement
3.6.2. Personalized Upskilling
3.7. Evaluation and Continuous Improvement
3.7.1. Personalized Upskilling Assessment
3.7.2. Qualification Testing
3.8. Dataset Preparation and Skills-Model Extraction
3.8.1. Dataset Preparation
3.8.2. Skills Extraction
3.9. Assessment of Skills and Qualifications and Training Recommendations
3.10. Evaluation and Continuous Improvement
4. Implementation Use Case
4.1. Description
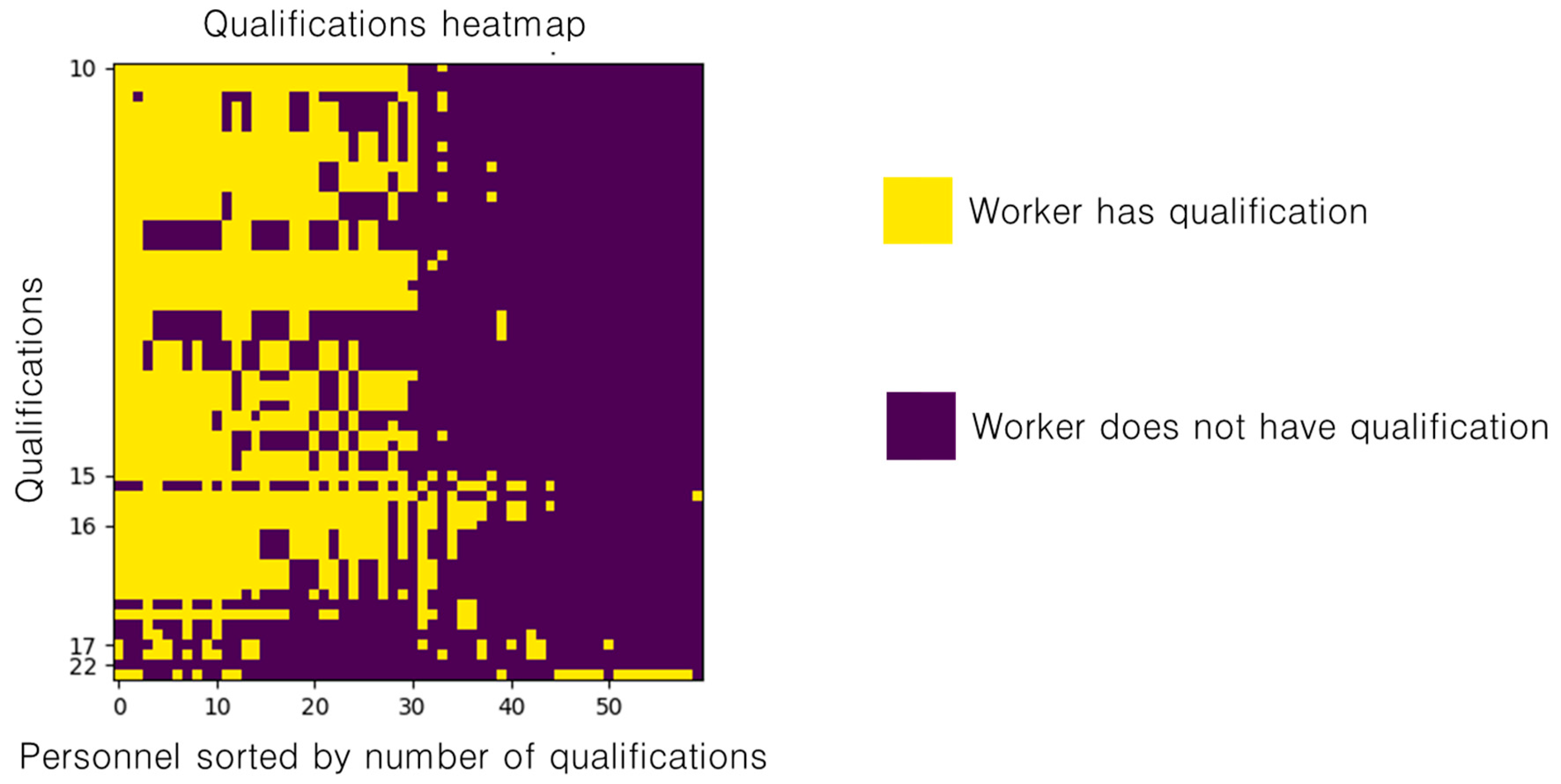
4.2. Preliminary Data Analysis
4.3. Experimentation Example
5. Results
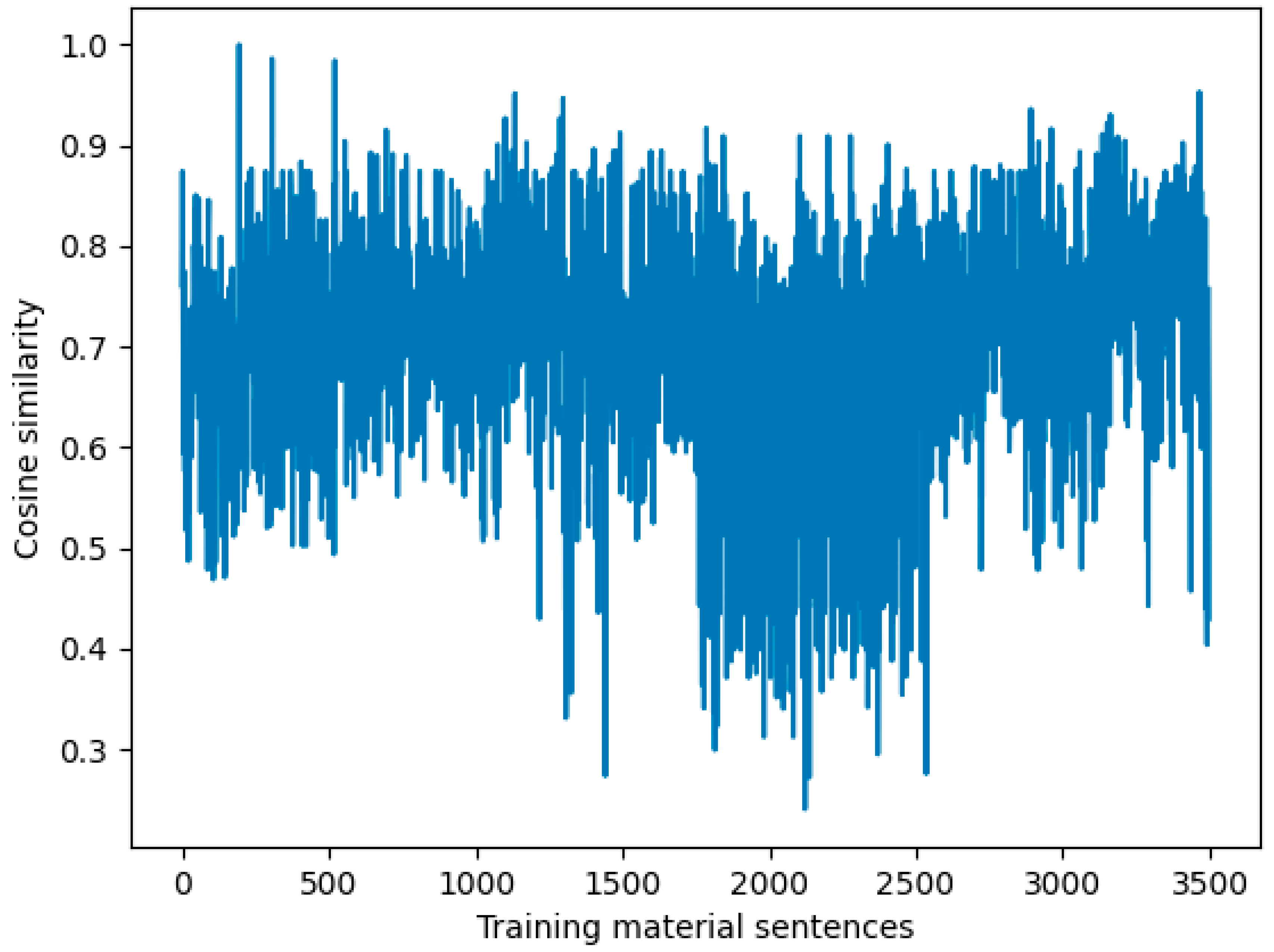
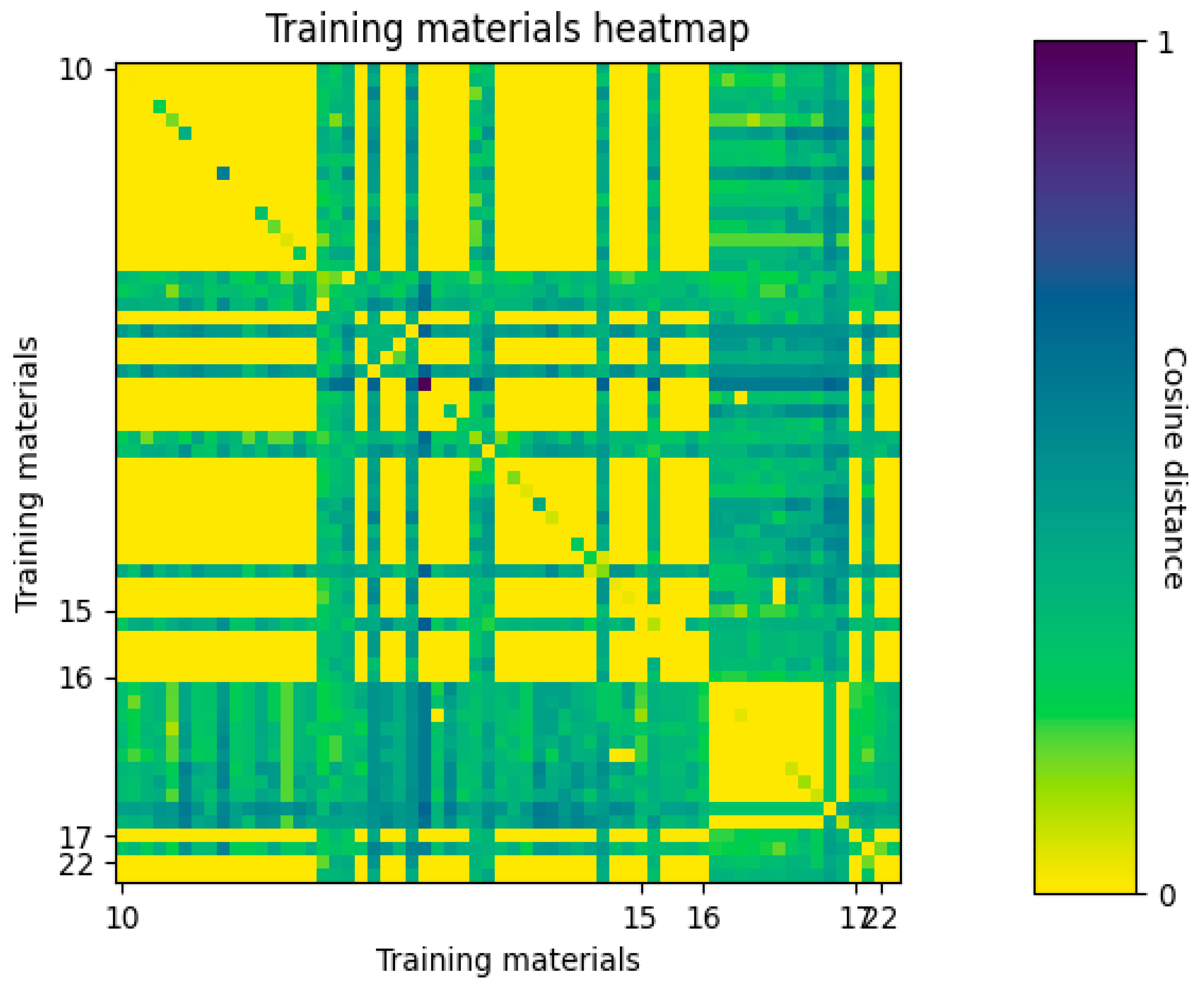
5.1. Semantic Similarity between Training-Material Documents
Semantic Similarity of Communications and Training Materials
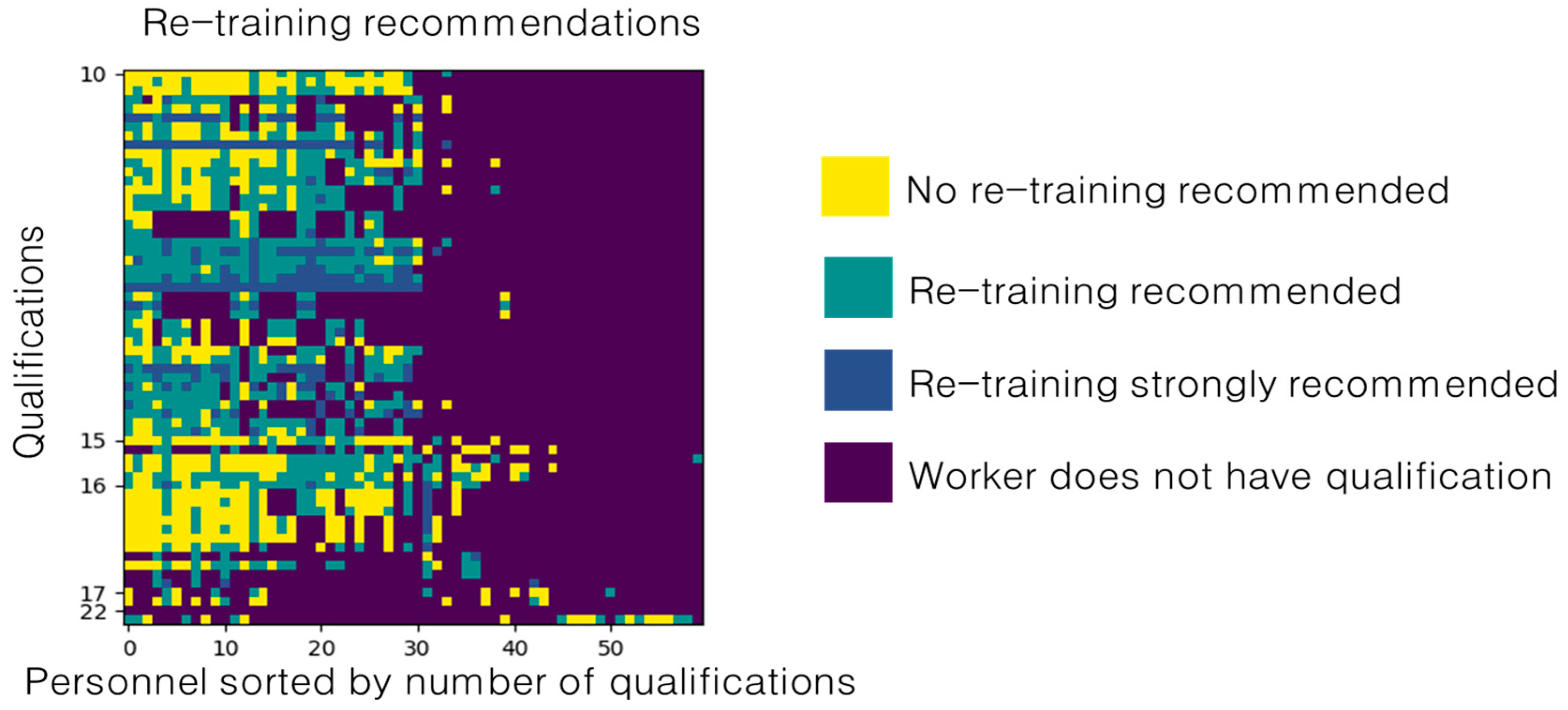
5.2. Recommendations
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Psarommatis, F.; Bravos, G. A Holistic Approach for Achieving Sustainable Manufacturing Using Zero Defect Manufacturing: A Conceptual Framework. Procedia CIRP 2022, 107, 107–112. [Google Scholar] [CrossRef]
- Mourtzis, D.; Vasilakopoulos, A.; Zervas, E.; Boli, N. Manufacturing System Design Using Simulation in Metal Industry towards Education 4.0. In Proceedings of the Procedia Manufacturing; Elsevier: Amsterdam, The Netherlands, 2019; Volume 31, pp. 155–161. [Google Scholar]
- Kuhn, C.; Lucke, D. Supporting the Digital Transformation: A Low-Threshold Approach for Manufacturing Related Higher Education and Employee Training. Procedia CIRP 2021, 104, 647–652. [Google Scholar] [CrossRef]
- Filz, M.-A.; Bosse, J.P.; Herrmann, C. Digitalization Platform for Data-Driven Quality Management in Multi-Stage Manufacturing Systems. J. Intell. Manuf. 2023. [Google Scholar] [CrossRef]
- Kaiser, J.; McFarlane, D.; Hawkridge, G.; André, P.; Leitão, P. A Review of Reference Architectures for Digital Manufacturing: Classification, Applicability and Open Issues. Comput. Ind. 2023, 149, 103923. [Google Scholar] [CrossRef]
- Maretto, L.; Faccio, M.; Battini, D. The Adoption of Digital Technologies in the Manufacturing World and Their Evaluation: A Systematic Review of Real-Life Case Studies and Future Research Agenda. J. Manuf. Syst. 2023, 68, 576–600. [Google Scholar] [CrossRef]
- Carluccio, J.; Cuñat, A.; Fadinger, H.; Fons-Rosen, C. Offshoring and Skill-Upgrading in French Manufacturing. J. Int. Econ. 2019, 118, 138–159. [Google Scholar] [CrossRef]
- Cirillo, V.; Rinaldini, M.; Staccioli, J.; Virgillito, M.E. Technology vs. Workers: The Case of Italy’s Industry 4.0 Factories. Struct. Chang. Econ. Dyn. 2021, 56, 166–183. [Google Scholar] [CrossRef]
- Arai, Y.; Ichimura, H.; Kawaguchi, D. The Educational Upgrading of Japanese Youth, 1982–2007: Are All Japanese Youth Ready for Structural Reforms? J. Jpn. Int. Econ. 2015, 37, 100–126. [Google Scholar] [CrossRef]
- Psarommatis, F.; Sousa, J.; Mendonça, J.P.; Kiritsis, D. Zero-Defect Manufacturing the Approach for Higher Manufacturing Sustainability in the Era of Industry 4.0: A Position Paper. Int. J. Prod. Res. 2022, 60, 73–91. [Google Scholar] [CrossRef]
- Wang, B.; Zheng, P.; Yin, Y.; Shih, A.; Wang, L. Toward Human-Centric Smart Manufacturing: A Human-Cyber-Physical Systems (HCPS) Perspective. J. Manuf. Syst. 2022, 63, 471–490. [Google Scholar] [CrossRef]
- Wan, P.K.; Leirmo, T.L. Human-Centric Zero-Defect Manufacturing: State-of-the-Art Review, Perspectives, and Challenges. Comput. Ind. 2023, 144, 103792. [Google Scholar] [CrossRef]
- Leng, J.; Sha, W.; Wang, B.; Zheng, P.; Zhuang, C.; Liu, Q.; Wuest, T.; Mourtzis, D.; Wang, L. Industry 5.0: Prospect and Retrospect. J. Manuf. Syst. 2022, 65, 279–295. [Google Scholar] [CrossRef]
- Xu, X.; Lu, Y.; Vogel-Heuser, B.; Wang, L. Industry 4.0 and Industry 5.0—Inception, Conception and Perception. J. Manuf. Syst. 2021, 61, 530–535. [Google Scholar] [CrossRef]
- European Commission. Industry 5.0; Elsevier: Amsterdam, The Netherlands, 2021. [Google Scholar]
- Barata, J.; Kayser, I. Industry 5.0—Past, Present, and Near Future. Procedia Comput. Sci. 2023, 219, 778–788. [Google Scholar] [CrossRef]
- Wang, B.; Zhou, H.; Li, X.; Yang, G.; Zheng, P.; Song, C.; Yuan, Y.; Wuest, T.; Yang, H.; Wang, L. Human Digital Twin in the Context of Industry 5.0. Robot. Comput. Integr. Manuf. 2024, 85, 102626. [Google Scholar] [CrossRef]
- Leng, J.; Zhong, Y.; Lin, Z.; Xu, K.; Mourtzis, D.; Zhou, X.; Zheng, P.; Liu, Q.; Zhao, J.L.; Shen, W. Towards Resilience in Industry 5.0: A Decentralized Autonomous Manufacturing Paradigm. J. Manuf. Syst. 2023, 71, 95–114. [Google Scholar] [CrossRef]
- Ghobakhloo, M.; Iranmanesh, M.; Foroughi, B.; Babaee Tirkolaee, E.; Asadi, S.; Amran, A. Industry 5.0 Implications for Inclusive Sustainable Manufacturing: An Evidence-Knowledge-Based Strategic Roadmap. J. Clean. Prod. 2023, 417, 138023. [Google Scholar] [CrossRef]
- Psarommatis, F. A Generic Methodology and a Digital Twin for Zero Defect Manufacturing (ZDM) Performance Mapping towards Design for ZDM. J. Manuf. Syst. 2021, 59, 507–521. [Google Scholar] [CrossRef]
- Psarommatis, F.; May, G.; Dreyfus, P.-A.; Kiritsis, D. Zero Defect Manufacturing: State-of-the-Art Review, Shortcomings and Future Directions in Research. Int. J. Prod. Res. 2020, 7543, 1–17. [Google Scholar] [CrossRef]
- Jun, J.; Chang, T.-W.; Jun, S. Quality Prediction and Yield Improvement in Process Manufacturing Based on Data Analytics. Processes 2020, 8, 1068. [Google Scholar] [CrossRef]
- Psarommatis, F.; Kiritsis, D. A Hybrid Decision Support System for Automating Decision Making in the Event of Defects in the Era of Zero Defect Manufacturing. J. Ind. Inf. Integr. 2021, 26, 100263. [Google Scholar] [CrossRef]
- Kumar, P.; Maiti, J.; Gunasekaran, A. Impact of Quality Management Systems on Firm Performance. Int. J. Qual. Reliab. Manag. 2018, 35, 1034–1059. [Google Scholar] [CrossRef]
- Cromwell, S.E.; Kolb, J.A. An Examination of Work-Environment Support Factors Affecting Transfer of Supervisory Skills Training to the Workplace. Hum. Resour. Dev. Q. 2004, 15, 449–471. [Google Scholar] [CrossRef]
- Kumar Sharma, A.; Bajpai, B.; Adhvaryu, R.; Dhruvi Pankajkumar, S.; Parthkumar Gordhanbhai, P.; Kumar, A. An Efficient Approach of Product Recommendation System Using NLP Technique. Mater. Today Proc. 2021, 80, 3730–3743. [Google Scholar] [CrossRef]
- Müller, M.; Metternich, J. Production Specific Language Characteristics to Improve NLP Applications on the Shop Floor. Procedia CIRP 2021, 104, 1890–1895. [Google Scholar] [CrossRef]
- Garcia Fracaro, S.; Glassey, J.; Bernaerts, K.; Wilk, M. Immersive Technologies for the Training of Operators in the Process Industry: A Systematic Literature Review. Comput. Chem. Eng. 2022, 160, 107691. [Google Scholar] [CrossRef]
- Abidi, M.H.; Al-Ahmari, A.; Ahmad, A.; Ameen, W.; Alkhalefah, H. Assessment of Virtual Reality-Based Manufacturing Assembly Training System. Int. J. Adv. Manuf. Technol. 2019, 105, 3743–3759. [Google Scholar] [CrossRef]
- Srinivasan, R.; Srinivasan, B.; Iqbal, M.U.; Nemet, A.; Kravanja, Z. Recent Developments towards Enhancing Process Safety: Inherent Safety and Cognitive Engineering. Comput. Chem. Eng. 2019, 128, 364–383. [Google Scholar] [CrossRef]
- Rosero, M.; Pogo, R.; Pruna, E.; Andaluz, V.H.; Escobar, I. Immersive Environment for Training on Industrial Emergencies. In Augmented Reality, Virtual Reality, and Computer Graphics; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2018; Volume 10851, pp. 451–466. [Google Scholar]
- Nakai, A.; Kajihara, Y.; Nishimoto, K.; Suzuki, K. Information-Sharing System Supporting Onsite Work for Chemical Plants. J. Loss Prev. Process Ind. 2017, 50, 15–22. [Google Scholar] [CrossRef]
- Brambilla, S.; Manca, D. Recommended Features of an Industrial Accident Simulator for the Training of Operators. J. Loss Prev. Process Ind. 2011, 24, 344–355. [Google Scholar] [CrossRef]
- Nazir, S.; Totaro, R.; Brambilla, S.; Colombo, S.; Manca, D. Virtual Reality and Augmented-Virtual Reality as Tools to Train Industrial Operators. Comput. Aided Chem. Eng. 2012, 30, 1397–1401. [Google Scholar] [CrossRef]
- Weritz, P. Hey Leaders, It’s Time to Train the Workforce: Critical Skills in the Digital Workplace. Adm. Sci. 2022, 12, 94. Available online: https://www.mdpi.com/2076-3387/12/3/94 (accessed on 26 October 2023). [CrossRef]
- Fake, H.; Dabbagh, N. The Personalized Learning Interaction Framework: Expert Perspectives on How to Apply Dimensions of Personalized Learning to Workforce Training and Development Programs. In Proceedings of the Ninth International Conference on Technological Ecosystems for Enhancing Multiculturality (TEEM’21), Barcelona, Spain, 26–29 October 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 501–509. [Google Scholar]
- Nair, S.; Kaushik, A.; Dhoot, H. Conceptual Framework of a Skill-Based Interactive Employee Engaging System: In the Context of Upskilling the Present IT Organization. Appl. Comput. Inform. 2020, 19, 82–107. [Google Scholar] [CrossRef]
- Shemshack, A.; Spector, J.M. A Systematic Literature Review of Personalized Learning Terms. Smart Learn. Environ. 2020, 7, 33. [Google Scholar] [CrossRef]
- Kucirkova, N.; Gerard, L.; Linn, M.C. Designing Personalised Instruction: A Research and Design Framework. Br. J. Educ. Technol. 2021, 52, 1839–1861. [Google Scholar] [CrossRef]
- Kluge, A.; Nazir, S.; Manca, D. Advanced Applications in Process Control and Training Needs of Field and Control Room Operators. IIE Trans. Occup. Ergon. Hum. Factors 2015, 2, 121–136. [Google Scholar] [CrossRef]
- Tatić, D.; Tešić, B. The Application of Augmented Reality Technologies for the Improvement of Occupational Safety in an Industrial Environment. Comput. Ind. 2017, 85, 1–10. [Google Scholar] [CrossRef]
- Leder, J.; Horlitz, T.; Puschmann, P.; Wittstock, V.; Schütz, A. Comparing Immersive Virtual Reality and Powerpoint as Methods for Delivering Safety Training: Impacts on Risk Perception, Learning, and Decision Making. Saf. Sci. 2019, 111, 271–286. [Google Scholar] [CrossRef]
- Avveduto, G.; Tanca, C.; Lorenzini, C.; Tecchia, F.; Carrozzino, M.; Bergamasco, M. Safety Training Using Virtual Reality: A Comparative Approach. In Augmented Reality, Virtual Reality, and Computer Graphics; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2017; Volume 10324, pp. 148–163. [Google Scholar]
- Tay, J.; Goh, Y.M.; Safiena, S.; Bound, H. Designing Digital Game-Based Learning for Professional Upskilling: A Systematic Literature Review. Comput. Educ. 2022, 184, 104518. [Google Scholar] [CrossRef]
- Pedota, M.; Grilli, L.; Piscitello, L. Technology Adoption and Upskilling in the Wake of Industry 4.0. Technol. Forecast. Soc. Chang. 2023, 187, 122085. [Google Scholar] [CrossRef]
- Doyle-Kent, M.; Shanahan, B.W. The Development of a Novel Educational Model to Successfully Upskill Technical Workers for Industry 5.0: Ireland a Case Study. IFAC-Papers 2022, 55, 425–430. [Google Scholar] [CrossRef]
- Yin, T.; Zhang, Z.; Wu, T.; Zeng, Y.; Zhang, Y.; Liu, J. Multimanned Partial Disassembly Line Balancing Optimization Considering End-of-Life States of Products and Skill Differences of Workers. J. Manuf. Syst. 2023, 66, 107–126. [Google Scholar] [CrossRef]
- Apostolopoulos, G.; Andronas, D.; Fourtakas, N.; Makris, S. Operator Training Framework for Hybrid Environments: An Augmented Reality Module Using Machine Learning Object Recognition. Procedia CIRP 2022, 106, 102–107. [Google Scholar] [CrossRef]
- Checa, D.; Bustillo, A. A Review of Immersive Virtual Reality Serious Games to Enhance Learning and Training. Multimed. Tools Appl. 2020, 79, 5501–5527. [Google Scholar] [CrossRef]
- Gajek, A.; Fabiano, B.; Laurent, A.; Jensen, N. Process Safety Education of Future Employee 4.0 in Industry 4.0. J. Loss Prev. Process Ind. 2022, 75, 104691. [Google Scholar] [CrossRef]
- Kulkarni, P.M.; Appasaba, L.V.; Gokhale, P.; Tigadi, B. Role of Digital Simulation in Employee Training. Glob. Transit. Proc. 2022, 3, 149–156. [Google Scholar] [CrossRef]
- Martínez-Gutiérrez, A.; Díez-González, J.; Verde, P.; Perez, H. Convergence of Virtual Reality and Digital Twin Technologies to Enhance Digital Operators’ Training in Industry 4.0. Int. J. Hum. Comput. Stud. 2023, 180, 103136. [Google Scholar] [CrossRef]
- Monetti, F.M.; de Giorgio, A.; Yu, H.; Maffei, A.; Romero, M. An Experimental Study of the Impact of Virtual Reality Training on Manufacturing Operators on Industrial Robotic Tasks. Procedia CIRP 2022, 106, 33–38. [Google Scholar] [CrossRef]
- Dantan, J.Y.; El Mouayni, I.; Sadeghi, L.; Siadat, A.; Etienne, A. Human Factors Integration in Manufacturing Systems Design Using Function–Behavior–Structure Framework and Behaviour Simulations. CIRP Ann. 2019, 68, 125–128. [Google Scholar] [CrossRef]
- Kolus, A.; Wells, R.; Neumann, P. Production Quality and Human Factors Engineering: A Systematic Review and Theoretical Framework. Appl. Ergon. 2018, 73, 55–89. [Google Scholar] [CrossRef] [PubMed]
- Hosseini, M.; Malric, F.; Georganas, N.D. A Haptic Virtual Environment for Industrial Training. In Proceedings of the HAVE 2002—IEEE International Workshop on Haptic Virtual Environments and their Applications, Ottawa, ON, Canada, 17–18 November 2002; pp. 25–30. [Google Scholar] [CrossRef]
- Lin, F.; Ye, L.; Duffy, V.G.; Su, C.J. Developing Virtual Environments for Industrial Training. Inf. Sci. 2002, 140, 153–170. [Google Scholar] [CrossRef]
- Bao, L.; Tran, S.V.-T.; Nguyen, T.L.; Pham, H.C.; Lee, D.; Park, C. Cross-Platform Virtual Reality for Real-Time Construction Safety Training Using Immersive Web and Industry Foundation Classes. Autom. Constr. 2022, 143, 104565. [Google Scholar] [CrossRef]
- Zhu, Q.-X.; Zhang, H.-T.; Tian, Y.; Zhang, N.; Xu, Y.; He, Y.-L. Co-Training Based Virtual Sample Generation for Solving the Small Sample Size Problem in Process Industry. ISA Trans. 2023, 134, 290–301. [Google Scholar] [CrossRef]
- Garcia Fracaro, S.; Chan, P.; Gallagher, T.; Tehreem, Y.; Toyoda, R.; Bernaerts, K.; Glassey, J.; Pfeiffer, T.; Slof, B.; Wachsmuth, S.; et al. Towards Design Guidelines for Virtual Reality Training for the Chemical Industry. Educ. Chem. Eng. 2021, 36, 12–23. [Google Scholar] [CrossRef]
- Kazemi Kheiri, S.; Vahedi, Z.; Sun, H.; Megahed, F.M.; Cavuoto, L.A. Human Reliability Modeling in Occupational Environments toward a Safe and Productive Operator 4.0. Int. J. Ind. Ergon. 2023, 97, 103479. [Google Scholar] [CrossRef]
- Simeone, A.; Grant, R.; Ye, W.; Caggiano, A. Operator 4.0 Intelligent Health Monitoring: A Cyber-Physical Approach. Procedia CIRP 2023, 118, 1033–1038. [Google Scholar] [CrossRef]
- Ciccarelli, M.; Papetti, A.; Germani, M. Exploring How New Industrial Paradigms Affect the Workforce: A Literature Review of Operator 4.0. J. Manuf. Syst. 2023, 70, 464–483. [Google Scholar] [CrossRef]
- Gladysz, B.; Tran, T.; Romero, D.; van Erp, T.; Abonyi, J.; Ruppert, T. Current Development on the Operator 4.0 and Transition towards the Operator 5.0: A Systematic Literature Review in Light of Industry 5.0. J. Manuf. Syst. 2023, 70, 160–185. [Google Scholar] [CrossRef]
- Özcan, A.M.; Akdoğan, A.; Durakbasa, N.M. Improvements in Manufacturing Processes by Measurement and Evaluation Studies According to the Quality Management System Standard in Automotive Industry. In Proceedings of the Lecture Notes in Mechanical Engineering, Antalya, Turkey, 24–26 September 2021; Springer Science and Business Media: Deutschland, Germany, 2021; pp. 483–492. [Google Scholar]
- Psarommatis, F.; Prouvost, S.; May, G.; Kiritsis, D. Product Quality Improvement Policies in Industry 4.0: Characteristics, Enabling Factors, Barriers, and Evolution toward Zero Defect Manufacturing. Front. Comput. Sci. 2020, 2, 26. [Google Scholar] [CrossRef]
- Psarommatis, F.; Fraile, F.; Ameri, F. Zero Defect Manufacturing Ontology: A Preliminary Version Based on Standardized Terms. Comput. Ind. 2023, 145, 103832. [Google Scholar] [CrossRef]
- Mourtzis, D.; Vlachou, E.; Milas, N. Industrial Big Data as a Result of IoT Adoption in Manufacturing. Procedia CIRP 2016, 55, 290–295. [Google Scholar] [CrossRef]
- Chien, C.F.; Hsu, S.C.; Chen, Y.J. A System for Online Detection and Classification of Wafer Bin Map Defect Patterns for Manufacturing Intelligence. Int. J. Prod. Res. 2013, 51, 2324–2338. [Google Scholar] [CrossRef]
- Kuo, C.F.; Hsu, C.T.M.; Fang, C.H.; Chao, S.M.; Lin, Y.D. Automatic Defect Inspection System of Colour Filters Using Taguchi-Based Neural Network. Int. J. Prod. Res. 2013, 51, 1464–1476. [Google Scholar] [CrossRef]
- Choi, G.; Kim, S.H.; Ha, C.; Bae, S.J. Multi-Step ART1 Algorithm for Recognition of Defect Patterns on Semiconductor Wafers. Int. J. Prod. Res. 2012, 50, 3274–3287. [Google Scholar] [CrossRef]
- Psarommatis, F.; May, G.; Kiritsis, D. Predictive Maintenance Key Control Parameters for Achieving Efficient Zero Defect Manufacturing. Procedia CIRP 2021, 104, 80–84. [Google Scholar] [CrossRef]
- Psarommatis, F.; May, G. A Practical Guide for Implementing Zero Defect Manufacturing in New or Existing Manufacturing Systems. Procedia Comput. Sci. 2023, 217, 82–90. [Google Scholar] [CrossRef]
- Psarommatis, F.; Kiritsis, D. Comparison between Product and Process Oriented Zero-Defect Manufacturing (ZDM) Approaches. In Proceedings of the IFIP Advances in Information and Communication Technology; Springer: Cham, Switzerland, 2021; pp. 105–112. [Google Scholar]
- Psarommatis, F.; May, G. A Systematic Analysis for Mapping Product-Oriented and Process-Oriented Zero-Defect Manufacturing (ZDM) in the Industry 4.0 Era. Sustainability 2023, 15, 12251. [Google Scholar] [CrossRef]
- Ameri, F.; Sormaz, D.; Psarommatis, F.; Kiritsis, D. Industrial Ontologies for Interoperability in Agile and Resilient Manufacturing. Int. J. Prod. Res. 2022, 60, 420–441. [Google Scholar] [CrossRef]
- Grevenitis, K.; Psarommatis, F.; Reina, A.; Xu, W.; Tourkogiorgis, I.; Milenkovic, J.; Cassina, J.; Kiritsis, D. A Hybrid Framework for Industrial Data Storage and Exploitation. In Proceedings of the Procedia CIRP; Elsevier: Amsterdam, The Netherlands, 2019; Volume 81, pp. 892–897. [Google Scholar]
- Vaswani, A.; Brain, G.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. Adv. Neural Inf. Process. Systems 2017, 30. [Google Scholar]
- Ayadi, A.; Auffan, M.; Rose, J. Ontology-Based NLP Information Extraction to Enrich Nanomaterial Environmental Exposure Database. Procedia Comput. Sci. 2020, 176, 360–369. [Google Scholar] [CrossRef]
- Lareyre, F.; Nasr, B.; Chaudhuri, A.; Di Lorenzo, G.; Carlier, M.; Raffort, J. Comprehensive Review of Natural Language Processing (NLP) in Vascular Surgery. EJVES Vasc. Forum 2023. [Google Scholar] [CrossRef] [PubMed]
- Ayadi, A.; Samet, A.; de Beuvron, F.d.B.; Zanni-Merk, C. Ontology Population with Deep Learning-Based NLP: A Case Study on the Biomolecular Network Ontology. Procedia Comput. Sci. 2019, 159, 572–581. [Google Scholar] [CrossRef]
- Chung, S.; Moon, S.; Kim, J.; Kim, J.; Lim, S.; Chi, S. Comparing Natural Language Processing (NLP) Applications in Construction and Computer Science Using Preferred Reporting Items for Systematic Reviews (PRISMA). Autom. Constr. 2023, 154, 105020. [Google Scholar] [CrossRef]
- Patel, A.S.; Merlino, G.; Puliafito, A.; Vyas, R.; Vyas, O.P.; Ojha, M.; Tiwari, V. An NLP-Guided Ontology Development and Refinement Approach to Represent and Query Visual Information. Expert. Syst. Appl. 2023, 213, 118998. [Google Scholar] [CrossRef]
- Sala, R.; Pirola, F.; Pezzotta, G.; Cavalieri, S. NLP-Based Insights Discovery for Industrial Asset and Service Improvement: An Analysis of Maintenance Reports. IFAC-PapersOnLine 2022, 55, 522–527. [Google Scholar] [CrossRef]
- Mourtzis, D.; Angelopoulos, J.; Siatras, V.; Panopoulos, N. A Methodology for the Assessment of Operator 4.0 Skills Based on Sentiment Analysis and Augmented Reality. Procedia CIRP 2021, 104, 1668–1673. [Google Scholar] [CrossRef]
- ANSI/ISA-95.00; Enterprise-Control System Integration—Part 2: Object Model Attributes. American National Standard: Washington, DC, USA, 2001.
- SCOR: Supply-Chain Reference Model. ILIM, Institute of Logistics and Warehousing ainia, Technological Centre. Available online: https://www.tecnoali.com/files/emensa/D11/Report%20Ilim.pdf (accessed on 1 September 2023).
- Explosion: Available Trained Pipelines for Spanish; Explosion: Berlin, Germany, 2022.
- Devlin, J.; Chang, M.-W.; Lee, K.; Google, K.T.; Language, A.I. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Guven, Z.A.; Unalir, M.O. Natural Language Based Analysis of SQuAD: An Analytical Approach for BERT. Expert. Syst. Appl. 2022, 195, 116592. [Google Scholar] [CrossRef]
- Turchin, A.; Masharsky, S.; Zitnik, M. Comparison of BERT Implementations for Natural Language Processing of Narrative Medical Documents. Inform. Med. Unlocked 2023, 36, 101139. [Google Scholar] [CrossRef]
- Jupin-Delevaux, É.; Djahnine, A.; Talbot, F.; Richard, A.; Gouttard, S.; Mansuy, A.; Douek, P.; Si-Mohamed, S.; Boussel, L. BERT-Based Natural Language Processing Analysis of French CT Reports: Application to the Measurement of the Positivity Rate for Pulmonary Embolism. Res. Diagn. Interv. Imaging 2023, 6, 100027. [Google Scholar] [CrossRef]
- Xu, S.; Zhang, C.; Hong, D. BERT-Based NLP Techniques for Classification and Severity Modeling in Basic Warranty Data Study. Insur. Math. Econ. 2022, 107, 57–67. [Google Scholar] [CrossRef]
- Cañete, J.; Chaperon, G.; Fuentes, R.; Ho, J.-H.; Kang, H.; Pérez, J. Spanish Pre-Trained BERT Model and Evaluation Data. arXiv 2023, arXiv:1810.04805. [Google Scholar]
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence Embeddings Using Siamese BERT-Networks. In Proceedings of the EMNLP-IJCNLP 2019 Conference on Empirical Methods in Natural Language Processing and 9th International Joint Conference on Natural Language Processing, Hongkong, China, 3–7 November 2019; pp. 3982–3992. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Modules | Qualifications | Roles |
|---|---|---|
| 10—Packing Operations | Routing and changeover (1 per machine) | Team Leader (1), First Officer (2) |
| 10—Packing Operations | Initial conditions, alarms, and failure states (1 per machine) | Team Leader (1), First Officer (2) |
| 10—Packing Operations | Routing and changeover (1 per machine) | Team Leader (1), First Officer (2) |
| 10—Packing Operations | Initial conditions, alarms, and failure states (1 per machine) | Team Leader (1), First Officer (2) |
| 10—Packing Operations | Cleaning procedures | First Officer (2) |
| 10—Packing Operations | General principles: packing section | First Officer (2), Specialist (5) |
| 15—Quality | Basic hygiene norms and food handling | Team Leader (1), First Officer (2), Specialist (5) |
| 15—Quality | Food-handling certification | Team Leader (1), First Officer (2), Specialist (5) |
| 15—Quality | Allergens management | Team Leader (1), First Officer (2), Specialist (5) |
| 15—Quality | Hazard analysis and Critical control point | Team Leader (1), First Officer (2), Specialist (5) |
| 15—Quality | Potential risks and Individual protective equipment | Team Leader (1), First Officer (2) |
| 15—Quality | Quality procedures | First Officer (2) |
| 15—Quality | Process control | First Officer (2) |
| 16—Packing Cleaning | General principles: cleaning | First Officer (2), Specialist (5) |
| 16—Packing Cleaning | Specific cleaning procedures | First Officer (2), Specialist (5) |
| 17—Specialist Training | Line feeding: operations, security, and process control | Specialist (5) |
| 22—Security | Emergency management and evacuation plan | Team Leader (1), First Officer (2), Specialist (5) |
| 22—Security | General security risks | First Officer (2) |
| 22—Security | Fall-prevention plan | Team Leader (1), First Officer (2), Specialist (5) |
| 22—Security | General risks: hygiene | Team Leader (1), First Officer (2), Specialist (5) |
| 22—Security | General risks: ergonomics | Team Leader (1), First Officer (2), Specialist (5) |
| 22—Security | Action in the event of an accident | Team Leader (1) |
| Cluster Name | Centroid | Range | Recommendation |
|---|---|---|---|
| High Similarity | 0.185 | [0–0.306] | No recommendation |
| Medium Similarity | 0.421 | [0.307–0.586] | Re-training recommended |
| Low Similarity | 0.744 | [0.588–1] | Re-training highly recommended |
| Cluster Name | Centroid | Range | Recommendation |
|---|---|---|---|
| High Similarity | 0.186 | [0–0.303] | Upskilling highly recommended |
| Medium Similarity | 0.420 | [0.303–0.555] | Upskilling recommended |
| Low Similarity | 0.690 | [0.556–1] | No recommendation |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fraile, F.; Psarommatis, F.; Alarcón, F.; Joan, J. A Methodological Framework for Designing Personalised Training Programs to Support Personnel Upskilling in Industry 5.0. Computers 2023, 12, 224. https://doi.org/10.3390/computers12110224
Fraile F, Psarommatis F, Alarcón F, Joan J. A Methodological Framework for Designing Personalised Training Programs to Support Personnel Upskilling in Industry 5.0. Computers. 2023; 12(11):224. https://doi.org/10.3390/computers12110224
Chicago/Turabian StyleFraile, Francisco, Foivos Psarommatis, Faustino Alarcón, and Jordi Joan. 2023. "A Methodological Framework for Designing Personalised Training Programs to Support Personnel Upskilling in Industry 5.0" Computers 12, no. 11: 224. https://doi.org/10.3390/computers12110224
APA StyleFraile, F., Psarommatis, F., Alarcón, F., & Joan, J. (2023). A Methodological Framework for Designing Personalised Training Programs to Support Personnel Upskilling in Industry 5.0. Computers, 12(11), 224. https://doi.org/10.3390/computers12110224