1. Introduction
Artificial intelligence (AI) has recently confirmed its usefulness in many aspects of daily life. Born from the desire to automate repetitive and time- and energy-consuming human processes, artificial intelligence has evolved towards solutions that can learn during operation and correct possible deviations just like human behaviour would do [
1]. Another major advantage brought by artificial intelligence is combating the human error that usually occurs after an activity. Thus, a detailed analysis of a data set is possible if it is contained in various formats (images, audio signals, etc.) for an unlimited period [
2].
Among the fields where AI has started to become a useful tool in the smooth running of things, we mention the economic field, multimedia, or smart home. The list can be completed more recently in the medical field, given the fact that the images can be exhaustively analysed using artificial intelligence algorithms [
3].
For this reason, we can consider the implementation of an AI model to decide whether the lung in a computer tomography (CT) image contains infection with the SARS-CoV-2 virus.
Often, identifying essential details in the content of the data to be analysed is a difficult process with the natural human senses. Therefore, training with a specialized program brings significant benefits in processing medical images or other data taken with dedicated medical equipment.
The introduction of AI models in the process of diagnosing patients represents a historical point in the evolution of modern medicine. Analysis results or disease-monitoring processes can benefit from increased accuracy.
Furthermore, in this study, an AI architecture that detects the presence of the SARS-CoV-2 virus in CT images will be presented. Thus, the TensorFlow library available in the Python programming language was used for the development of this project [
4].
The Current Impact of AI on Medical Imaging
The concept of machine learning has the potential to provide clinical decision support (CDS) based on the data of doctors and staff in a hospital, paving the way for a new stage in medicine. The learning process of computer systems (known as “deep learning”) is a subset of AI designed to identify patterns. In the medical field, it can use algorithms and data to provide automated information to healthcare providers.
AI can improve healthcare by streamlining diagnoses and improving clinical outcomes. A critical part of the power of AI in the healthcare industry is its ability to analyse a large amount of data sets [
5].
Today, there are several private entities involved in producing AI solutions for the medical field. For example, video games are produced to test the mental health of individuals. Through this method, emotional state switches or an affinity for certain events are detected. Also, combined with the potential of virtual reality (VR), it is possible to provide more data to analyse with AI. Thus, the system becomes more complex and much more useful [
6].
Moreover, AI combined with big data can provide predictions about the health status of a population by considering hospital archives. Therefore, today’s society can be recommended a different lifestyle or medical analysis sessions in order to prevent certain diseases.
The full performance of AI is demonstrated when paired with other technologies, such as robotics, where it combines analytical power with physical abilities. For people who have suffered accidents or were born with a disability, AI software and robotic hardware have begun to offer solutions for vision, hearing, and locomotion.
Another concept that is starting to obtain more and more attention from researchers and the public is the brain–computer interface (BCI) or brain–machine interface (BMI). Information captured via sensors of this type can be used as input for an AI model [
7].
Integrating artificial intelligence into the healthcare ecosystem enables a multitude of benefits for both the medical community and patients, including automating tasks and analysing large patient data sets to deliver better, faster, and lower-cost healthcare.
AI can automate administrative tasks such as pre-authorizing insurance, tracking unpaid bills, and maintaining records to ease the workload of healthcare professionals and ultimately save them money. Thanks to the ability of artificial intelligence to process large data sets, the consolidation of patient information can lead to predictive benefits, helping the healthcare ecosystem to discover key areas in the patient care process.
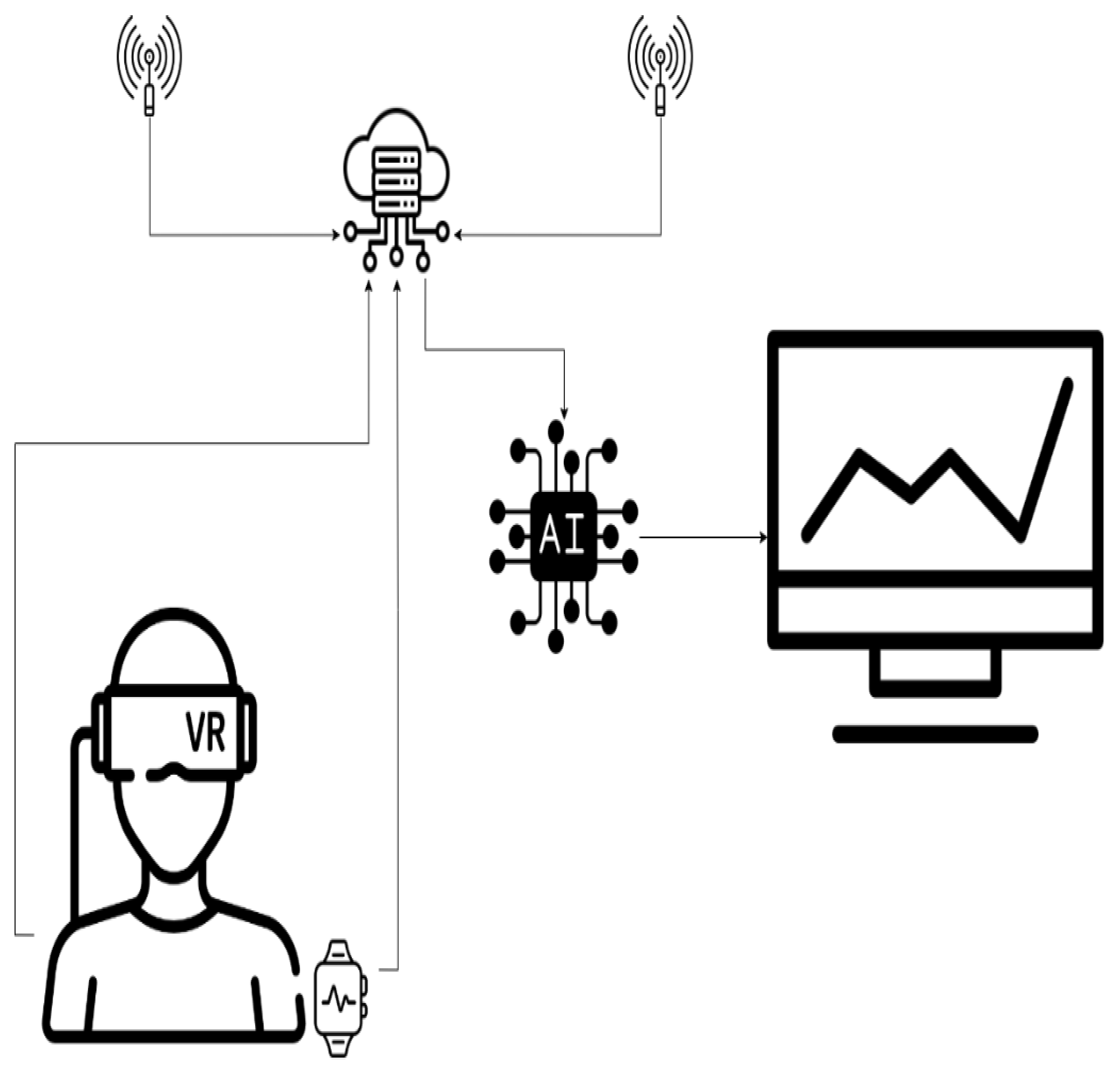
Wearable healthcare technology is also using artificial intelligence to better serve patients. Software using artificial intelligence, such as that in smartwatches, can analyse data to alert users and their healthcare professionals to potential health problems and risks. The possibility of evaluating one’s own state of health through an emerging technology eases the workload of specialists and facilitates the comfort of patients by preventing unnecessary visits to the hospital.
Figure 1 graphically represents the concept by which classic consultations are replaced by sensors, and the information they provide is processed using AI [
8].
2. Recommended Artificial Intelligence Architectures for Image Processing
Several neural network architectures exist for AI data processing, including the artificial neural network (ANN), convolutional neural network (CNN), and recurrent neural network (RNN). ANNs are characterized by interconnected neurons across layers and are also called feed-forward neural networks due to their unidirectional data processing [
9]. They are among the simplest neural network variants, where data flow from node to node, through input nodes, until they reach the output. While they offer benefits like information storage across the network and fault tolerance, they can sometimes exhibit inexplicable behaviours. RNNs, on the other hand, are more intricate. They preserve the output from processing nodes, and the data do not solely move in one direction. Each node in RNNs acts as a memory cell, ensuring ongoing computation and operations. If an RNN’s prediction errs, the system self-corrects during backpropagation [
10].
A convolutional neural network (CNN) is particularly beneficial for image recognition and pixel-based tasks. CNNs are the go-to architecture for tasks requiring object recognition, making them ideal for computer vision (CV) applications, from self-driving cars to facial recognition. CNNs identify patterns in images using principles from linear algebra, such as matrix multiplication. Their architecture mirrors the human brain’s connectivity, particularly the frontal lobe responsible for visual processing. CNNs ensure comprehensive image coverage, addressing the fragmented image processing of traditional neural networks [
11].
| Recommended AI Architectures for Image Processing—In Brief |
| Architecture | Advantages | Disadvantages |
| CNN | High accuracy in image tasks, scalable | Requires large datasets for training |
| RNN | Handles sequences well | Not ideal for image tasks |
| [Another architecture] | [Advantages] | [Disadvantages] |
Conclusion:
Based on our evaluation, CNNs offer the most promising results for our specific application due to their high accuracy and adaptability.
2.1. CNN Layers
A CNN encompasses three main layers: the convolutional layer, the pooling layer, and a fully connected (FC) layer. The convolutional layer handles the bulk of the computations, with the potential for subsequent convolutional layers [
12]. During convolution, a filter in this layer scans the image’s receptive fields, verifying a feature’s presence. Over multiple iterations, this filter canvasses the entire image. The resultant output from these points is termed a feature map or convolutional feature. The image then undergoes conversion to numerical values for the CNN’s interpretation. The pooling layer, while similar to the convolutional layer in operation, reduces input parameters and incurs some information loss. However, it does cut down on the CNN’s complexity and enhances efficiency. The fully connected layer finalizes image classification based on the previously extracted features. Only specific layers in a CNN are fully connected to prevent excessive network density, which can lead to increased losses, compromise output quality, and demand hefty computational resources.
2.2. The Operation of Convolutional Neural Networks
A CNN comprises multiple layers, each designed to detect different features of an input image. Filters or kernels are applied to the image, producing outputs that become progressively refined with each layer. In the early layers, filters often detect simple features. In successive layers, the filters grow more complex to identify parameters that distinctively characterize the input object. Hence, the output from each convolution (the partially recognized image) serves as the input for the next layer. In the final layer, known as the fully connected (FC) layer, the CNN identifies the image or the object it depicts [
13]. During convolution, the input image is processed via a series of filters. As each filter emphasizes specific image features, it sends its output to the subsequent layer’s filter. This process might be repeated across tens, hundreds, or even thousands of layers. Ultimately, processing the image through multiple CNN layers enables the recognition of the complete object.
Network Structure
Our model is based on the convolutional neural network (CNN), a subtype of deep neural networks specifically tailored for image processing. The architecture’s organization, from input to output, comprises several layers that help in the hierarchical extraction of image features.
Layer: Given that our images are coloured with a resolution of 512 × 512 pixels, the input neurons number 512 × 512 × 3 (three channels for RGB).
Hidden Layers:
Convolutional Layer 1: 32 filters of size 3 × 3, followed by a ReLU activation function;
Max-Pooling Layer 1: With a pool size of 2 × 2;
Convolutional Layer 2: 64 filters of size 3 × 3, followed by a ReLU activation function;
Max-Pooling Layer 2: With a pool size of 2 × 2;
Fully Connected Layer: With 512 neurons and a ReLU activation function.
Output Layer: Given that our task is binary classification (detect or not detect), we have one neuron with a sigmoid activation function.
The structural and functional organization of our artificial neural network and its parameters are as follows:
Number of training samples = 1000
Image number of input neurons = 50 × 50 × 1
Number of output neurons = 2
Number of intermediate layers = 6
Activation function = softmax
Learning rate = 1 × 10−3
2.3. CNN Training
We have pedaled enough on the training itself, but this cannot be performed alone to raise the prestige of AI; it must be performed in harmony with the other requirements. The neural network was trained to the maximum on the existing data set; more precisely, it reached the upper limit for the given initial conditions, respectively, for the associated loss function. Mathematically, the stability of the loss function utilized has been reached.
A CNN operating within AI has some important qualities, listed below, that recommend it successfully, along with some specific limitations.
- (1)
Storage of information in the entire existing network;
- (2)
Capability to working with poor/deficient standard knowledge;
- (3)
Minor fault tolerance;
- (4)
A good allocated memory.
This is also happening in traditional programming, where information is stored on the network and not in a database. If a few pieces of information disappear from one place, it does not stop the whole network from functioning. After the training of a CNN, the output produced by the data can be incomplete or insufficient. The importance of that missing information determines the lack of performance.
We started with a standard neural network and initialized our weights arbitrarily. Evidently, we did not have the best results from the beginning. In the training activity, we started with a modest-performance neural network, and we ended up with a high-precision network. Practically, regarding the loss function associated, we expected the loss function to be much lower at the training’s termination. Mathematically, the training inconvenience is equivalent to the minimizing problem of the associated loss function.
2.4. CNN vs. Neural Networks
A significant limitation of regular neural networks (NNs) is scalability. While NNs can handle smaller images with limited color channels, they struggle with larger and more complex images, demanding more computational power and resources. Moreover, NNs can suffer from overfitting when they attempt to learn excessive details from training data. This can lead to the NN inadvertently learning noise, which then hinders performance on test datasets. Consequently, the NN might fail to discern patterns or objects within the data set. In contrast, a CNN employs parameter sharing. In a CNN, nodes within a layer are interconnected, and each connection has a weight. As filters move across an image, these weights remain constant, a condition termed “parameter sharing”. This makes CNNs less computationally demanding than NNs [
14]. Deep learning (DL), a subset of machine learning, utilizes neural networks with a minimum of three layers. Multi-layer networks tend to yield more accurate results than single-layer networks. Both RNNs and CNNs find their place in deep learning, with their usage determined by the specific application. For tasks like image recognition, classification, and computer vision, CNNs are especially suitable. Their efficiency is notable, especially when dealing with large datasets. Furthermore, CNNs learn object features through iterative processing as data flow through its layers. This deep learning approach negates the need for manual feature extraction. Notably, CNNs can be retrained for new tasks and can even leverage existing networks. These benefits enable the application of CNNs in real-world scenarios without escalating computational complexity or costs. To reiterate, CNNs, due to their parameter-sharing capability, are more computationally efficient than regular NNs. These models are versatile and can function across various devices, including smartphones.
2.5. Convolutional Neural Network (CNN) Applications
CNNs are already utilized in various picture-processing applications. In contradistinction to easy picture identification applications, computer vision permits computing systems to extract meaningful information from visual inputs to produce appropriate action founded on that information [
15]. The most famous computer vision and CNNs practices are utilized in areas among which we can list health, automotive, social networks, retail and facial identification, and audio processing for virtual assistants.
2.6. A Short Analysis
The existing, previously announced solutions in this field, which are the most used, are the following. The information is stored in the neural networks and not in the database, as is known from classical programming. If a couple of pieces of information disappear from one part of the network, this does not stop the operation of the entire network. Also, at the end of artificial neural network (ANN) training, the produced result by the used data may be a partial result or a poorly formed result. In these circumstances, namely, a lack of information in some places of the network produced a flagrant decrease in performance.
AI has been used in the analysis of medical images for a while now. There is a reluctance of doctors to pass responsibility to a program. We did not use information from other projects already launched. It is a solution that we developed ourselves, following the review of the specialized literature.
The conclusion for
Section 2 is that the theory protects us from some mistakes inherent in the act of research. But, the great advantage is related to revealing/imposing the benefit of using AI in the processing of global information, which starts from the statistical study of medical images (CT images) and ends with the establishment of a correct diagnosis of the infection with the COVID-19 virus, respectively, its observation/recognition and the monitoring of its evolution towards healing. Today, AI has confirmed a significant accuracy in the detection of image-based diseases (currently, with modern means, over 96% accuracy) and regarding survival rate, as well as the adequate treatment response.
3. Results
Project development started by establishing the data set according to the objective. For this, we used a public data set provided by the
www.kaggle.com platform. The set comprises 2481 images (1251 contain lungs with COVID-19 infection and 1230 contain lungs without COVID-19 infection). At the beginning of the program, each image receives the appropriate label, “covid” or “normal”, which is resized to 50 × 50 pixels (see
Figure 2) and undergoes conversion to grayscale (grayscale format). After these transformations, the image–label pair is passed as an entry in an array. Further, a block list containing the values of the main parameters used in the inference process is presented in
Figure 3.
The architecture chosen for this model involved the implementation of six 2D convolution layers, and one fully interconnected one. Also, the network uses the “Adam” variant as the optimizer and the “softmax” variant as the activation function. This type of activation function is known to be used for multi-class classification problems where class membership is required for more than two class labels [
16].
The accuracy of the obtained model is 98.1%, which denotes a solid architecture that optimally responds to the initial requirements.
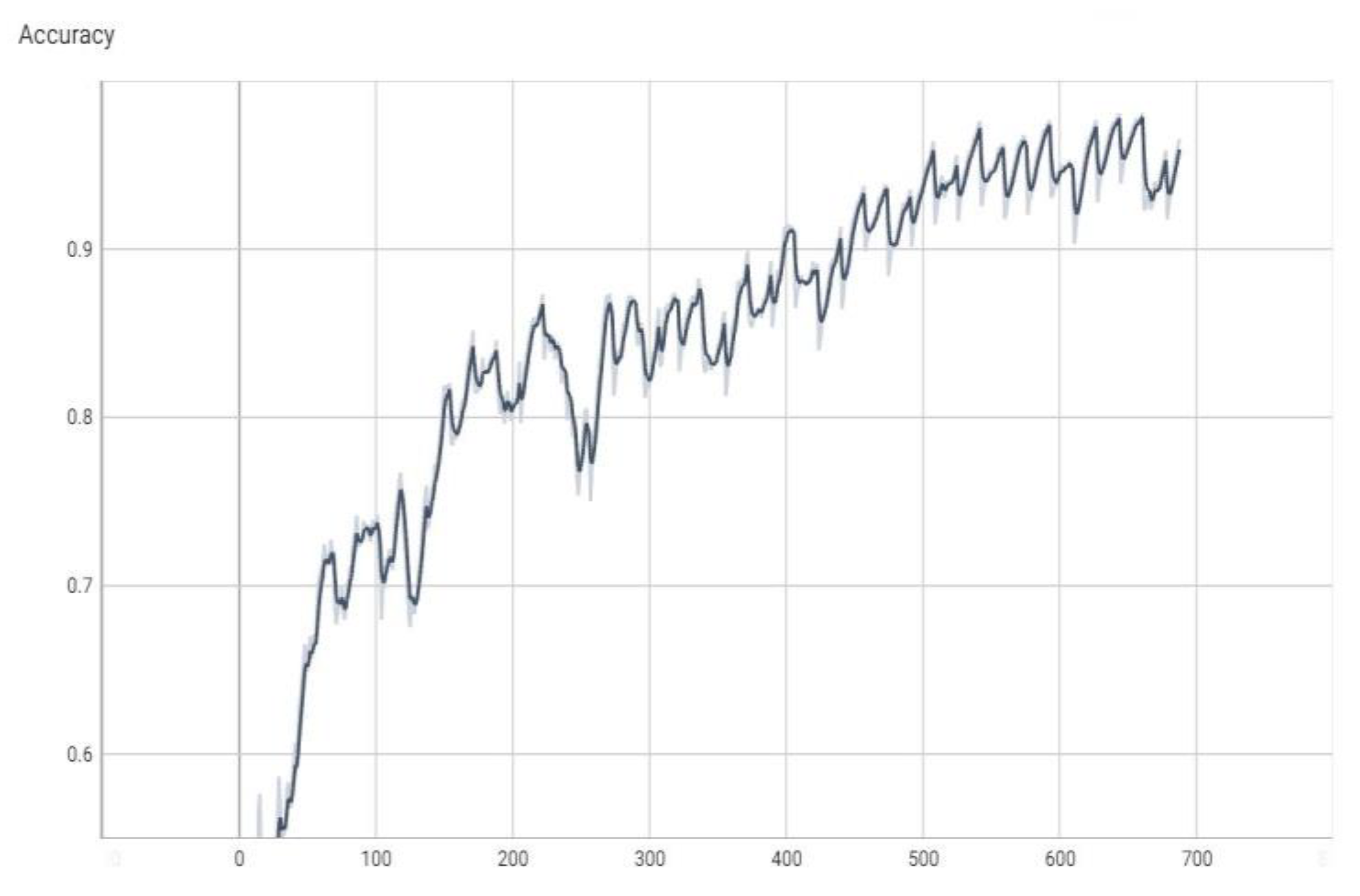
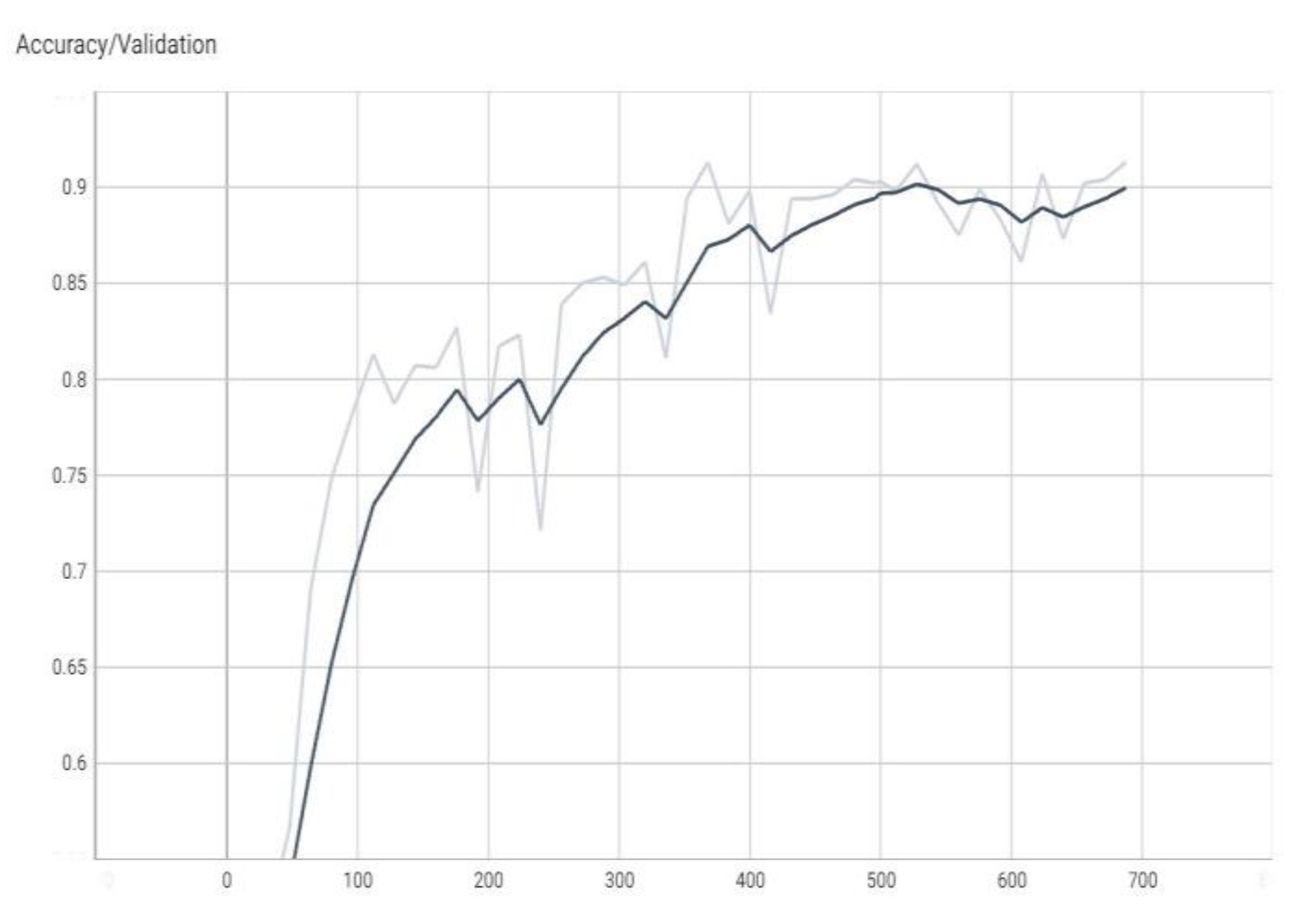
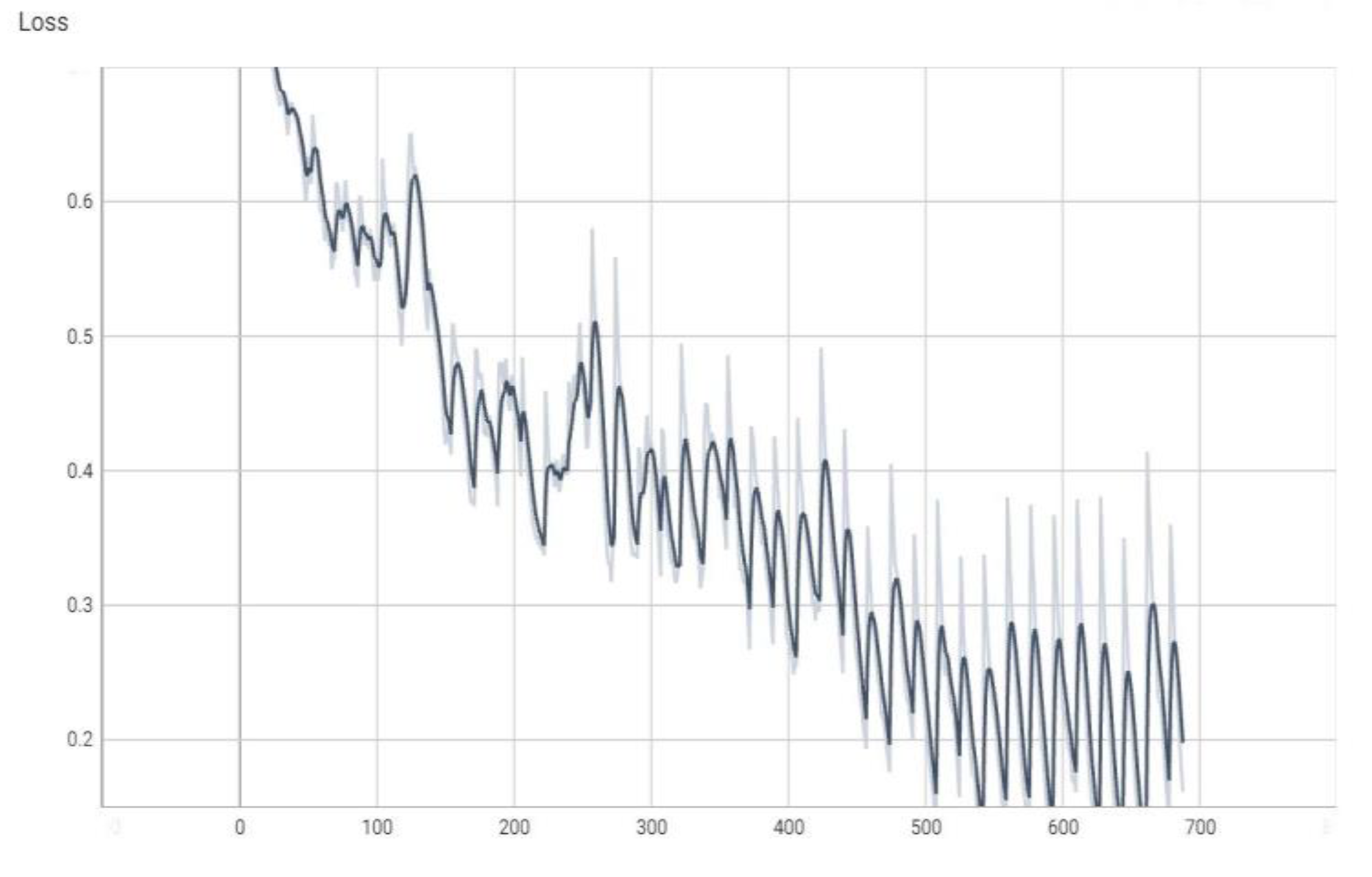
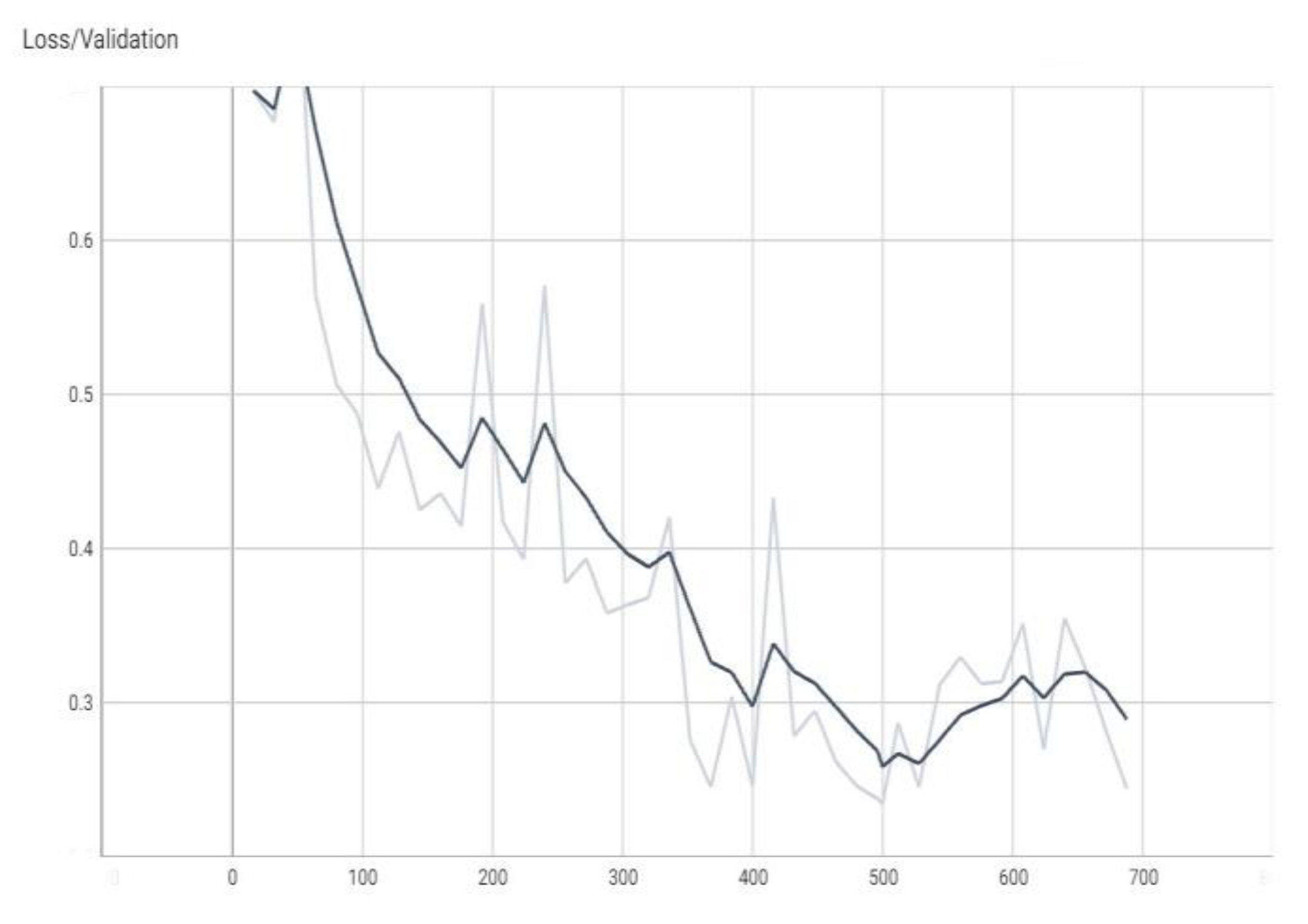
The graphs in
Figure 4,
Figure 5,
Figure 6 and
Figure 7 are made using the TensorBoard utility available in the Python language [
12]. TensorBoard is an open-source toolkit that enables us to understand training progress and improve model performance by updating the hyperparameters. This tool provides features for:
Loss and accuracy tracking;
Model’s graph visualization;
Viewing histograms of weights;
Displaying different data formats;
Profiling TensorFlow programs;
Viewing histograms of tensors as they change over time.
The “val_loss” parameter represents the cost function value for the validation data, and the “loss” parameter represents the cost function value for the training data.
The “val_accuracy” parameter indicates the accuracy of the predictions of a randomly separated validation set after each training period, and the “accuracy” parameter indicates the accuracy of the predictions of a randomly separated training set after each training period.
Figure 2 is the block diagram for the inference process of the AI procedure. The simple distributed AI network is based on an input CT image, having two direct distributions for COVID-19 patients and, respectively, for non-COVID-19 patients [
16].
Figure 2 is a block diagram of the application.
In
Figure 3, there are some final values for the main parameters of the model in the training process used.
Figure 3 is a screenshot from the PyCharm 2020.1.1 x64 development environment console in which the application was developed. More precisely, it contains some final values list for the main parameters in the inference stage of the identification process.
For
Figure 4,
Figure 5,
Figure 6 and
Figure 7, the horizontal scale has as the unit of measurement the number of iterations (in our case, a number of 688 iterations out of a maximum of 700), represented by a number. At the same time, on the Oy axis, we find the measured values normalized to the total number of measurements [
16], respectively, a subunit number, or it can be the number of percentages when the percentage is the unit of measure. The terms “val_loss” and “loss” denote cost function values for validation and training data, respectively. The terms “val_accuracy” and “accuracy” measure prediction accuracies for a validation set and a training set after each training epoch.
Note, for example, that “accuracy” is the percentage of correct classifications that a trained model makes, i.e., the number of correct predictions divided by the total number of predictions from all classes. It is often abbreviated as ACC. ACC is reported as a value in the interval [0, 1] or [0, 100], depending on the chosen scale. An accuracy of 0 means that a classifier always predicts the wrong label, while an accuracy of 1 or 100 means that it always predicts the correct label [
17].
CT Lung Picture Interpretation
The usual ordinary diagnostic procedure for COVID-19 is RT-PCR (reverse transcription polymerase chain reaction), which consumes a lot of time and has shallow-low sensibility. On the other hand, chest X-ray radiography (CXR) is the primal imagistic modality that is utilized, as it is easily disposable and assures immediate good results. Nevertheless, it is well-known to have reduced sensibility in comparison to CT (computed tomography), which can be utilized efficiently in connection with other diagnosis procedures [
18]. So, CT has been recognized as a clinically significant board for the correct diagnosis and disease understanding of subjects with COVID-19. Various medical studies have confronted the CT pictures of contaminated patients with certified COVID-19 clinical confirmation, with a specificity of 37% and a sensitivity of 94% [
19,
20].
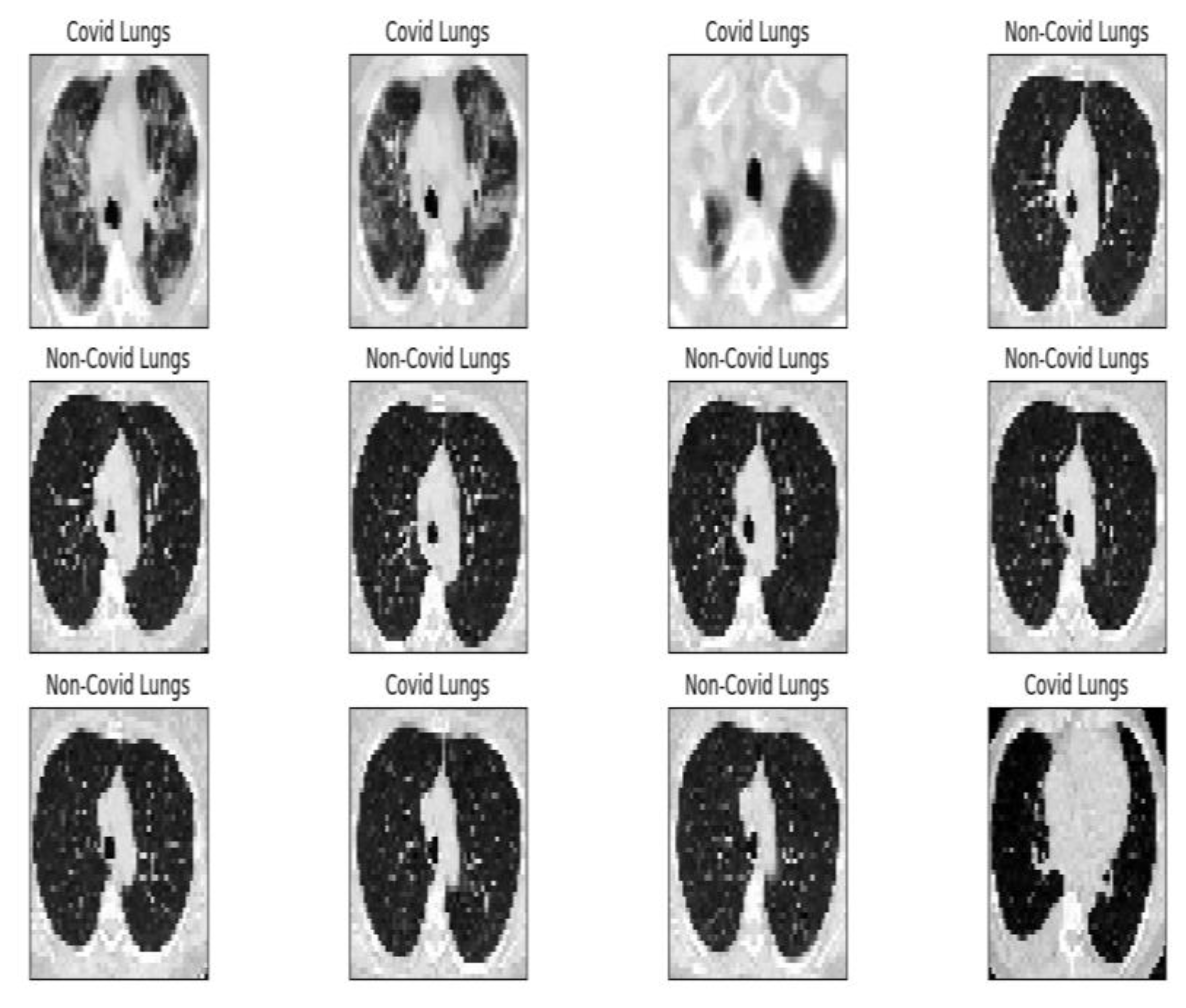
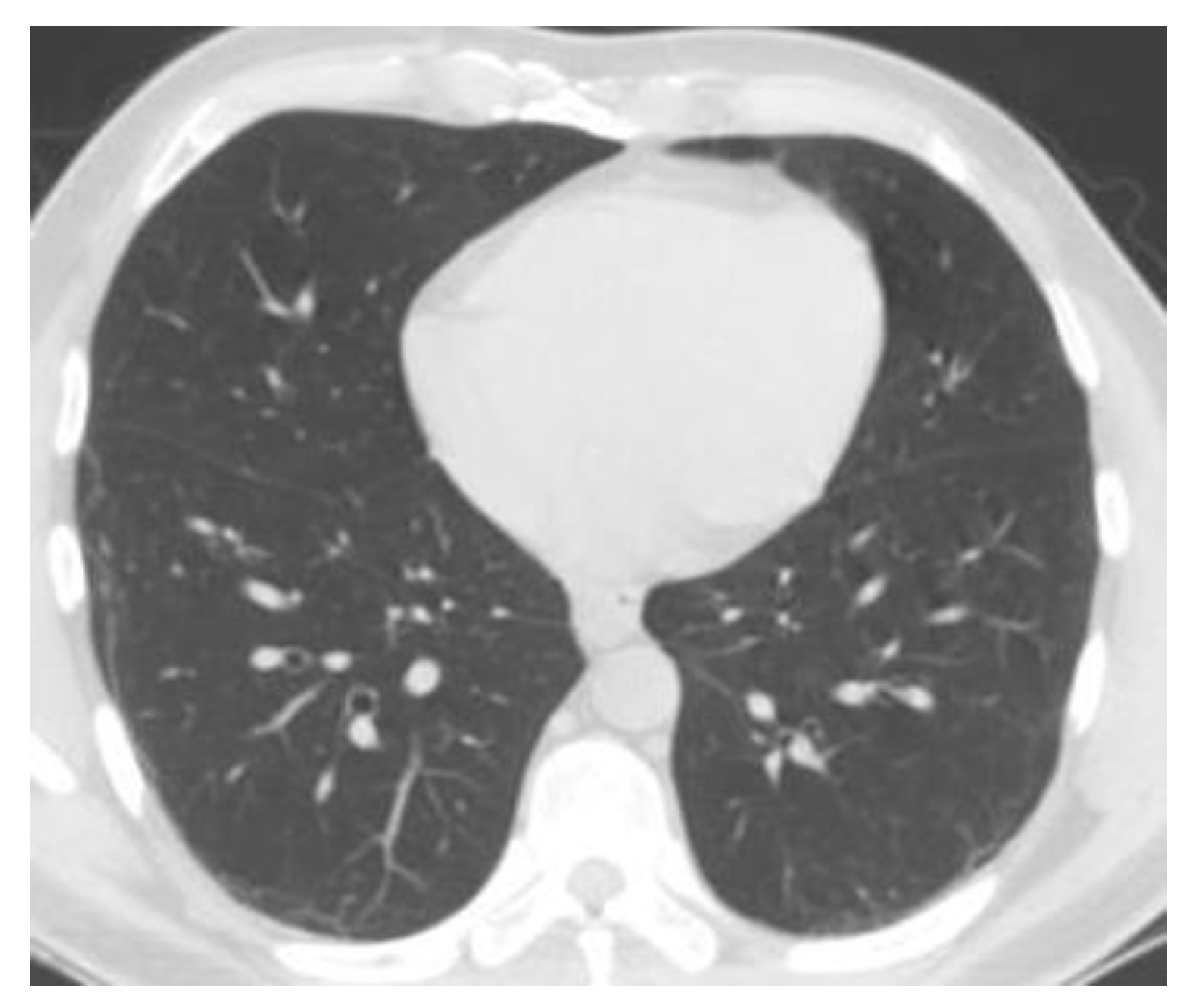
Figure 8 shows the complete module of some lung CT images affected by COVID-19 and images of lungs that did not suffer from COVID-19, unaffected by the virus, practically healthy lungs.
We mention that the set of images from
Figure 8 and the license to use them can be found online at the address indicated in the bibliographic reference [
21].
Fractal Analysis
Fractal analysis theory evaluates, in general, the fractal characteristics of experimental data, namely fractal parameters. It is constituted of several procedures to allocate for an image, among others, a fractal dimension together with other fractal characteristics, such as lacunarity, to an extended data set, whether theoretical or experimental. Among these, the most popular applications are related to the data extracted mainly from natural phenomena, considering first the topography [
22] spatial geometric objects, ecology science and financial market fluctuations, sound waves, and their frequency domain digital complex imagistic together with molecular dynamics [
23]. Fractal analysis is precious in extending the human comprehension of the structure and functioning of a variety of complex systems formulated and as a potential working instrument to value novel study domains. Thus, fractal calculus and its parameters were formulated to constitute a generalization action of the usual mathematical calculation [
24,
25].
COVID-19 Image
Table 1 contains the values of the fractal dimension and the standard deviation for the procedure with a quadratic mask, FDQ, and SDQ, as well as the values of the fractal dimension and the standard deviation for the procedure with a rectangular mask, FDR, and SDR. Also, at the end of the table is the gap value for the original COVID-19 lung image.
Table 1 presents the familiar fractal indicators, as they were the fractal dimension of the CT lung COVID-19 image with a quadratic mask, FDQ = 1.8038 ± 0.4247, respectively, the fractal dimension of the CT lung COVID-19 image with a rectangular mask, FDR = 1.9785 ± 0.007 and lacunarity
Λ = 0.0554. The fractal analysis parameters, the fractal dimension, and the lacunarity
Λ have been computed utilizing the software programs developed for the primal time by the data analysis comprised in brain CT images [
22,
23].
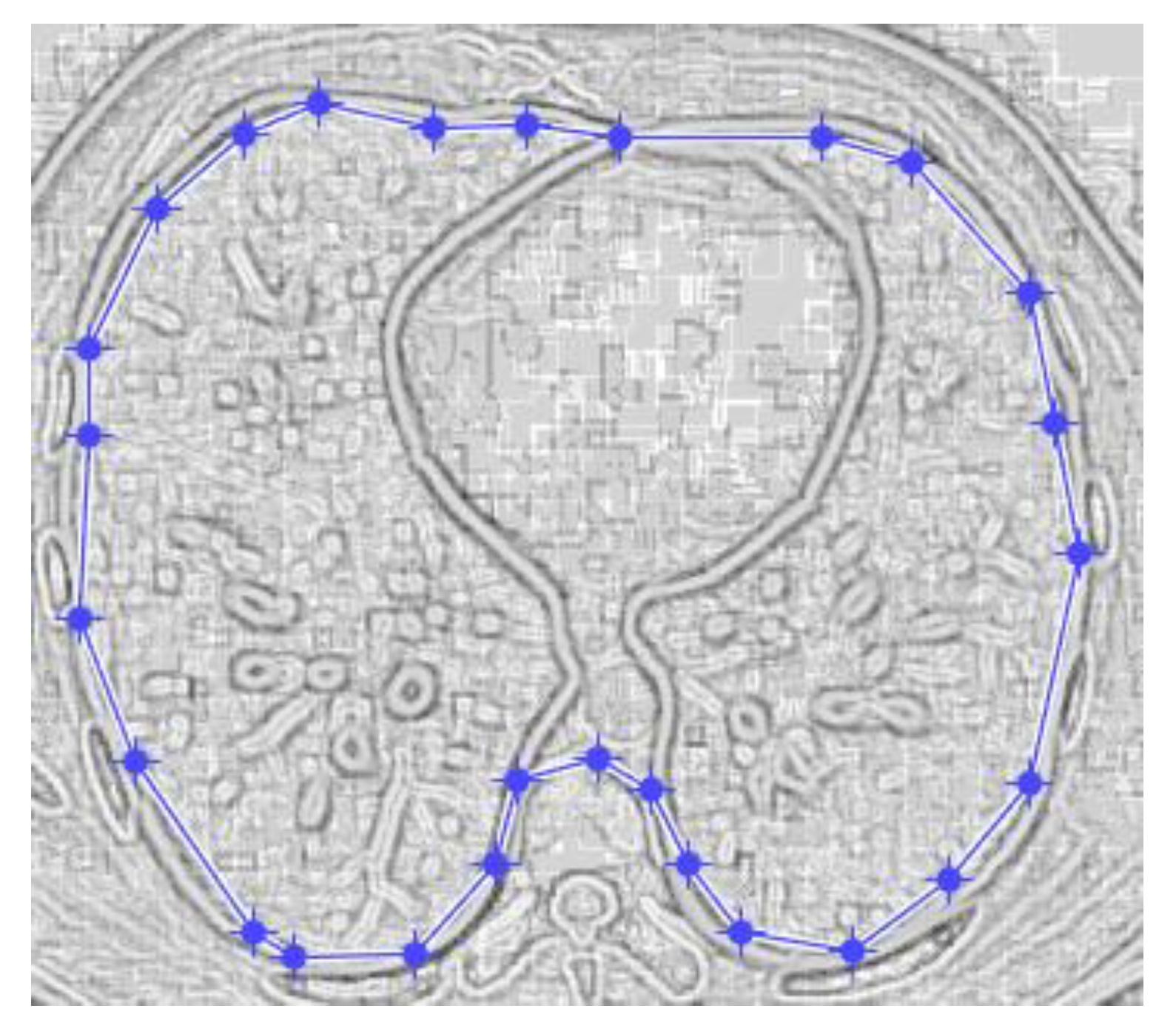
Figure 9 and
Figure 10 show the original CT lung image, respectively, and the defined mask for the COVID-19 lung CT image, framed in a blue border in
Figure 10.
Figure 10 presents the applied mask across the COVID-19 lung CT image, framed in a blue colour border.
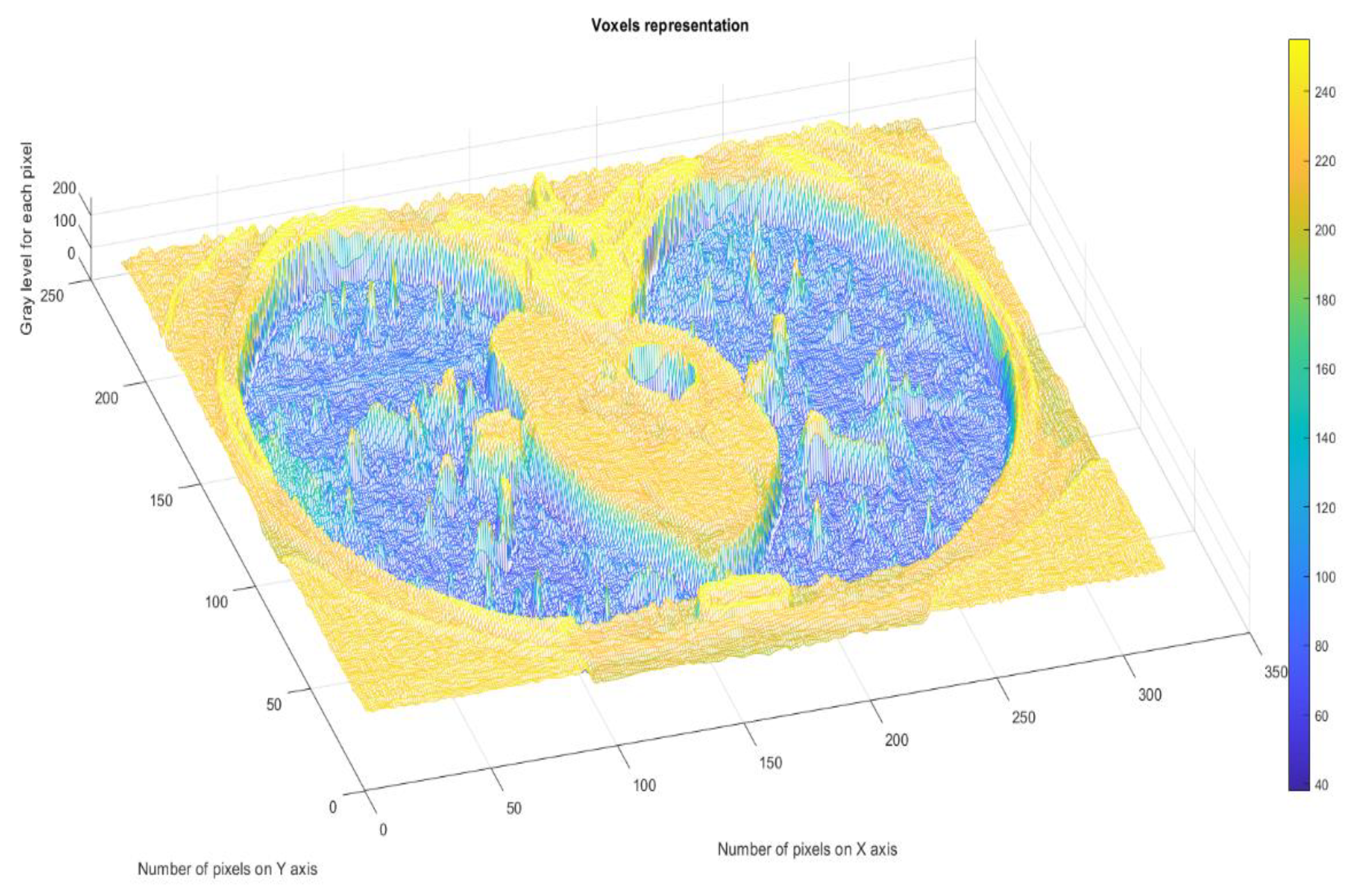
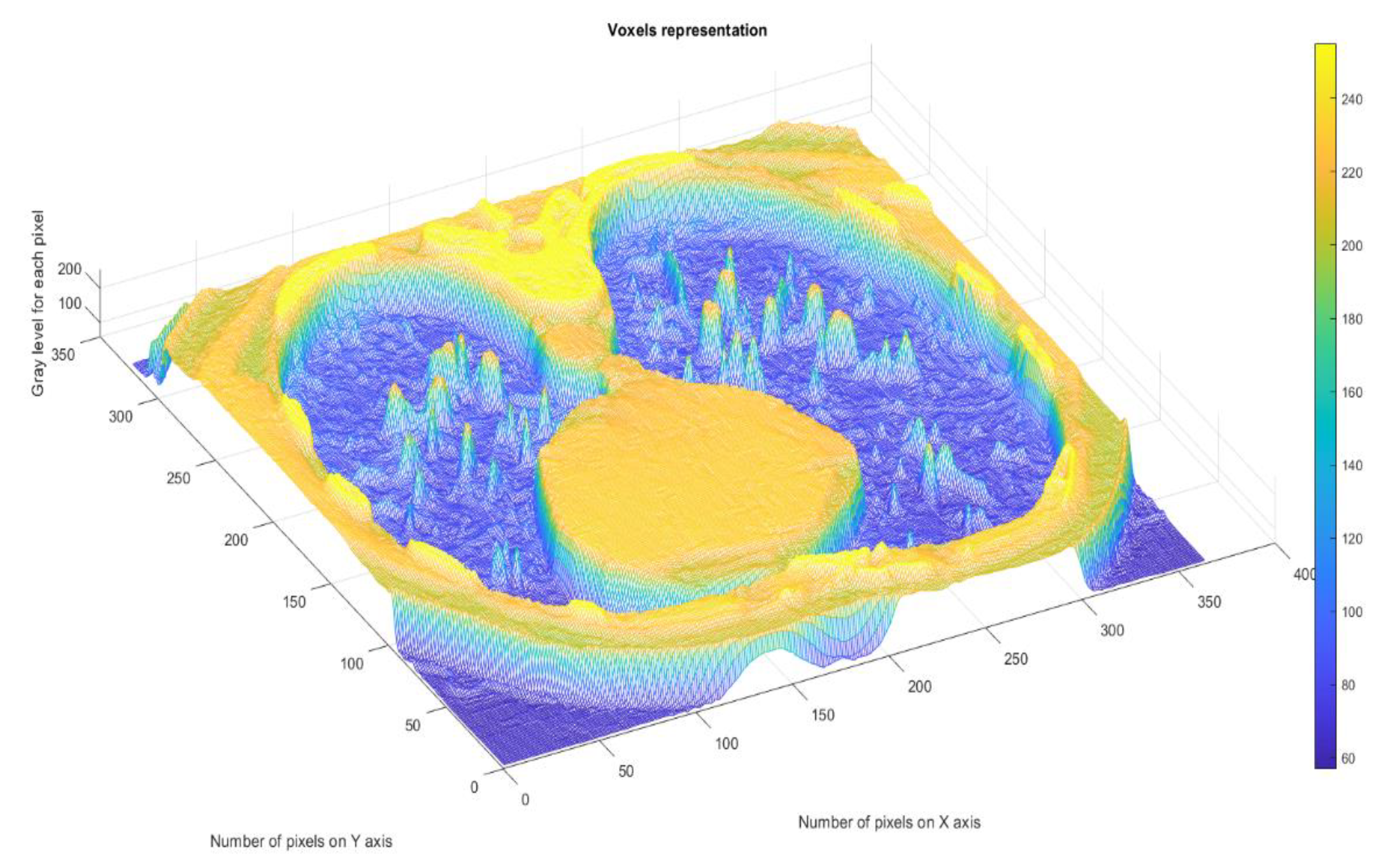
Figure 11 presents the 3D graphic description of voxels contained in the patient’s COVID-19 pulmonary CT picture.
The voxels are usually utilized in scientific research to precisely and quickly focus on volumetric data [
24,
25]. In a voxels-founded structure morphology, condensation differences in the lung texture can be confronted utilizing the voxels, as seen in the figure above.
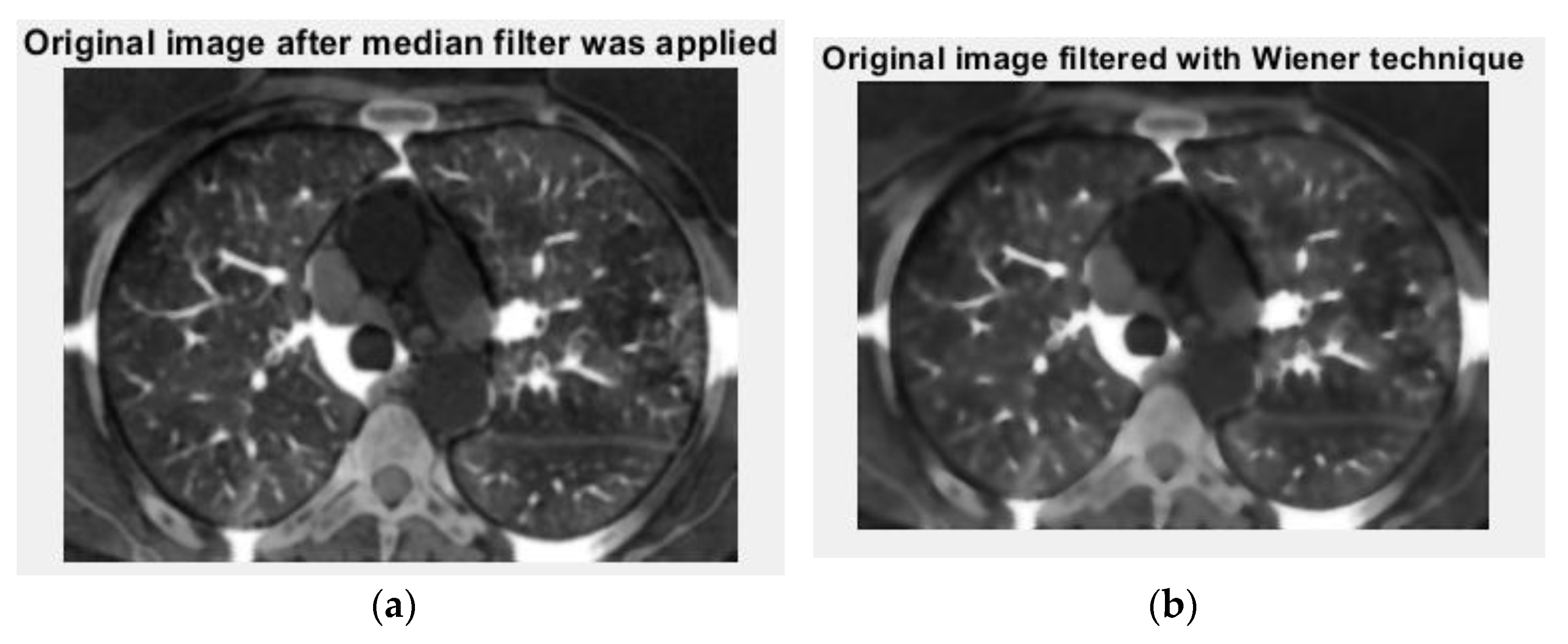
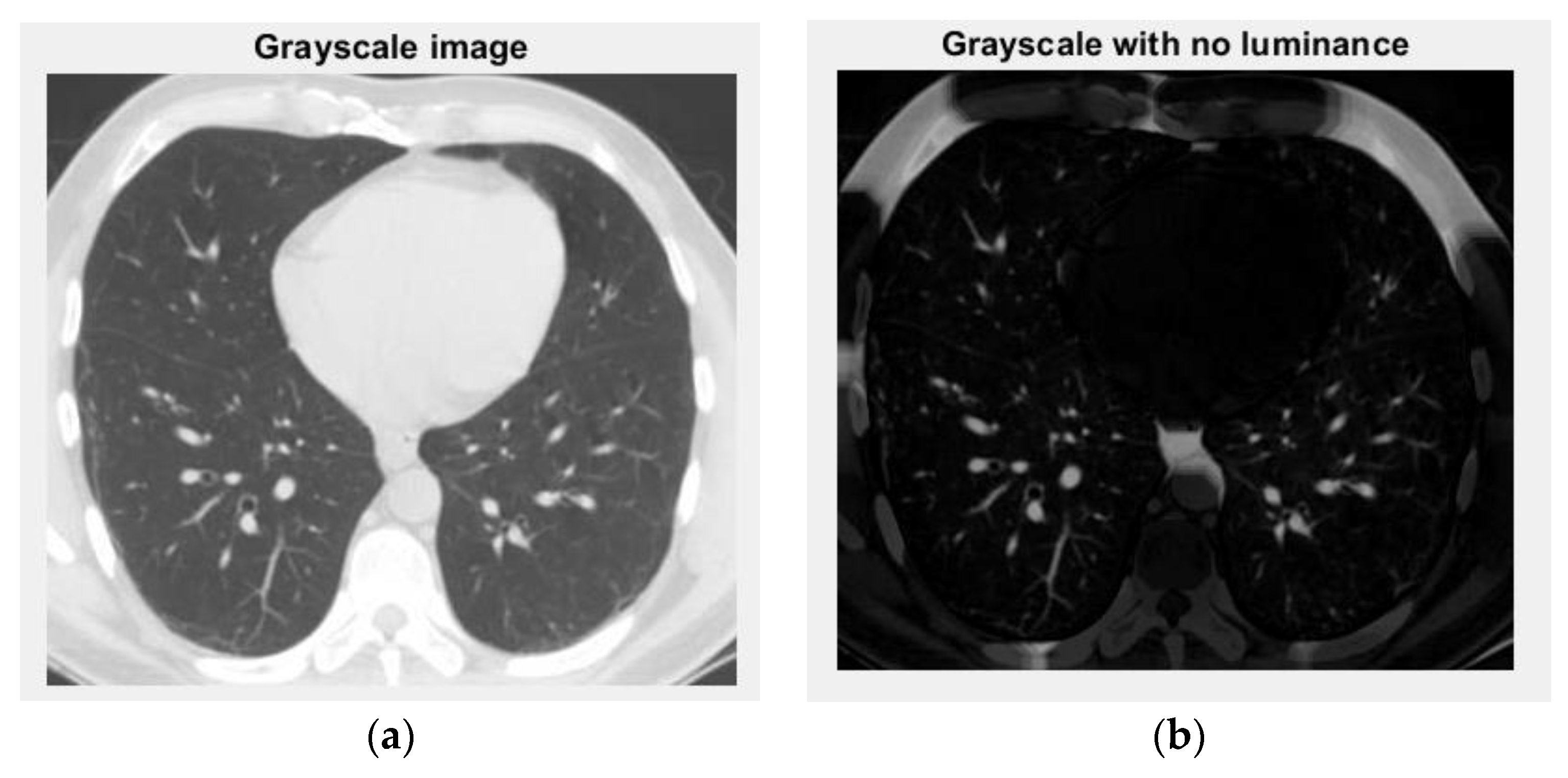
Figure 12 and
Figure 13 are the grayscale images with and without luminance of the COVID-19 lung CT image, respectively, and the filtered versions of the COVID-19 lung CT image.
Figure 13 is the original picture version after the median filter (left) was filtered with the Wiener technique (right) of the COVID-19 lung CT image.
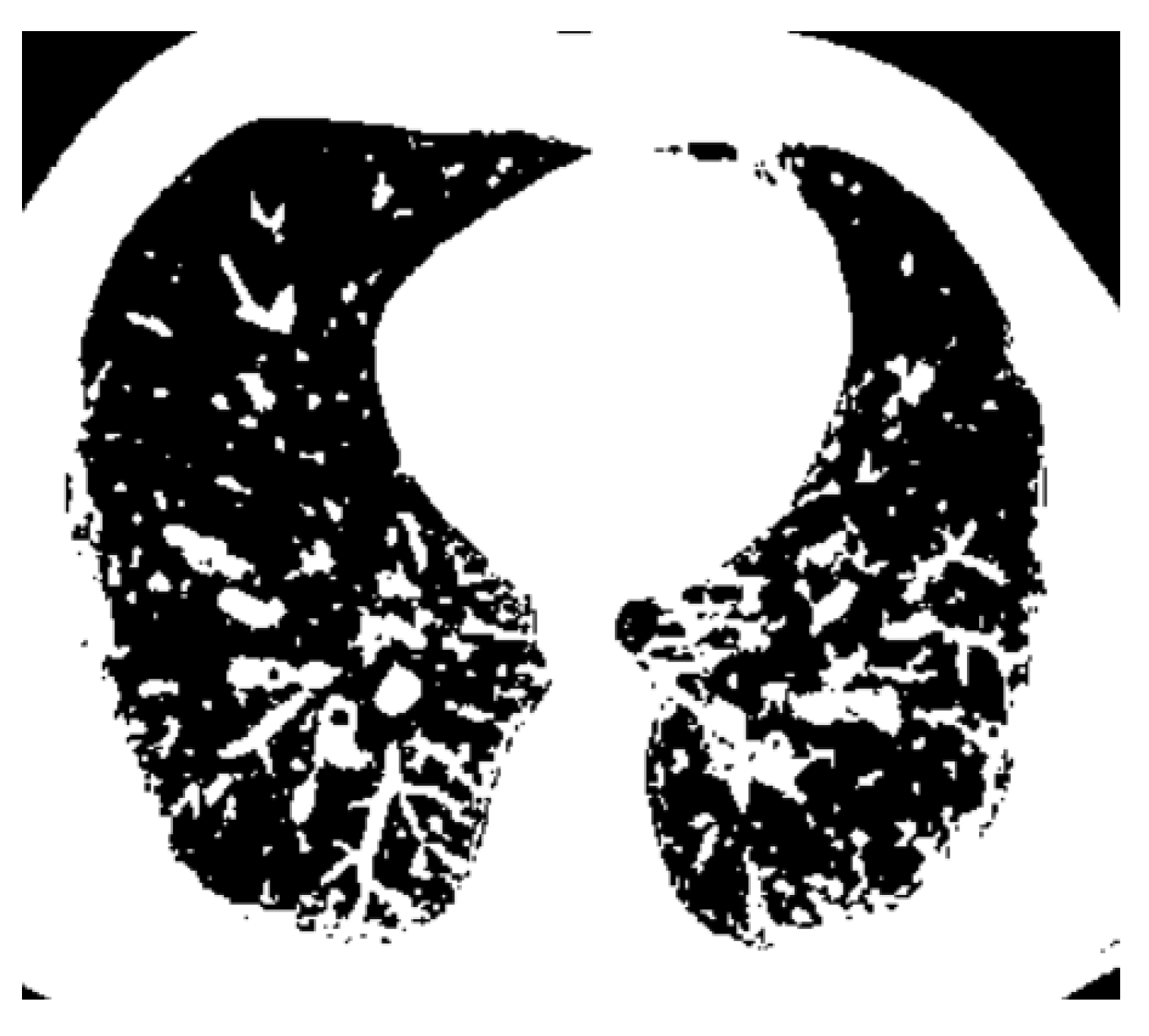
Figure 14 is the binary version of the COVID-19 lung image.
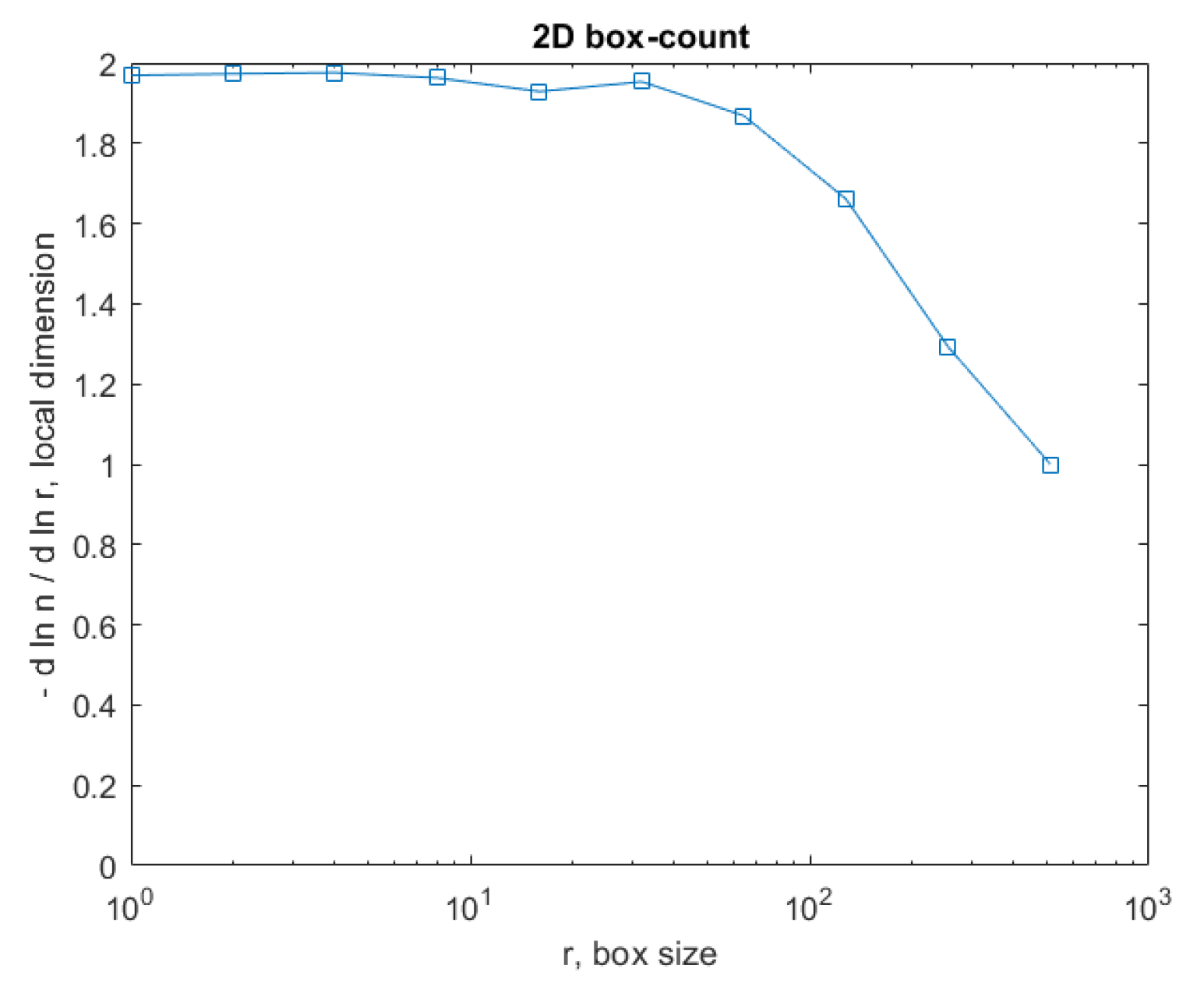
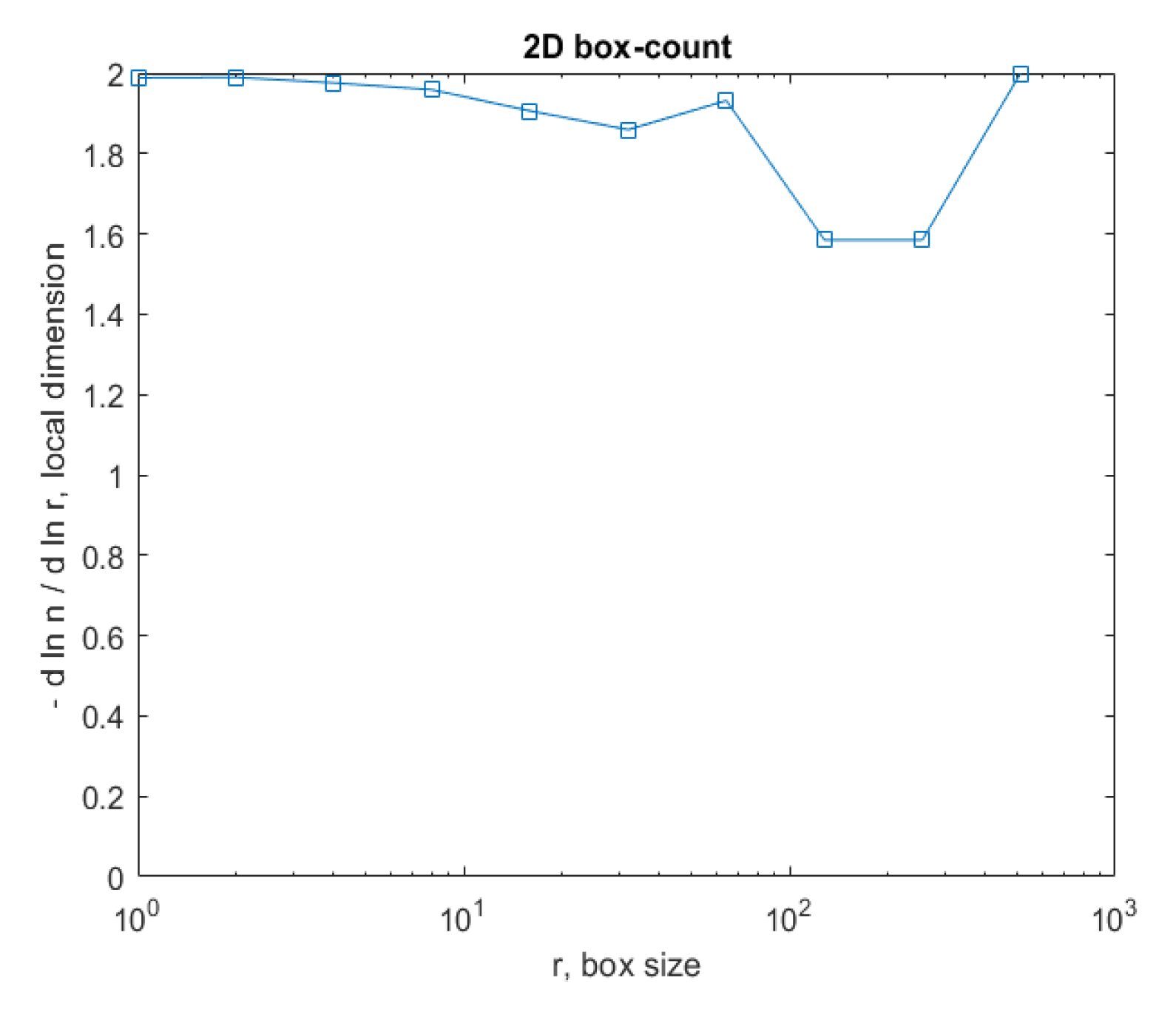
Figure 15 represents the box-count algorithm application for the COVID-19 lung image.
Figure 15 is the graphic representation of the box-count algorithm for the value of the obtained fractal dimension of the COVID-19 lung image [
26,
27].
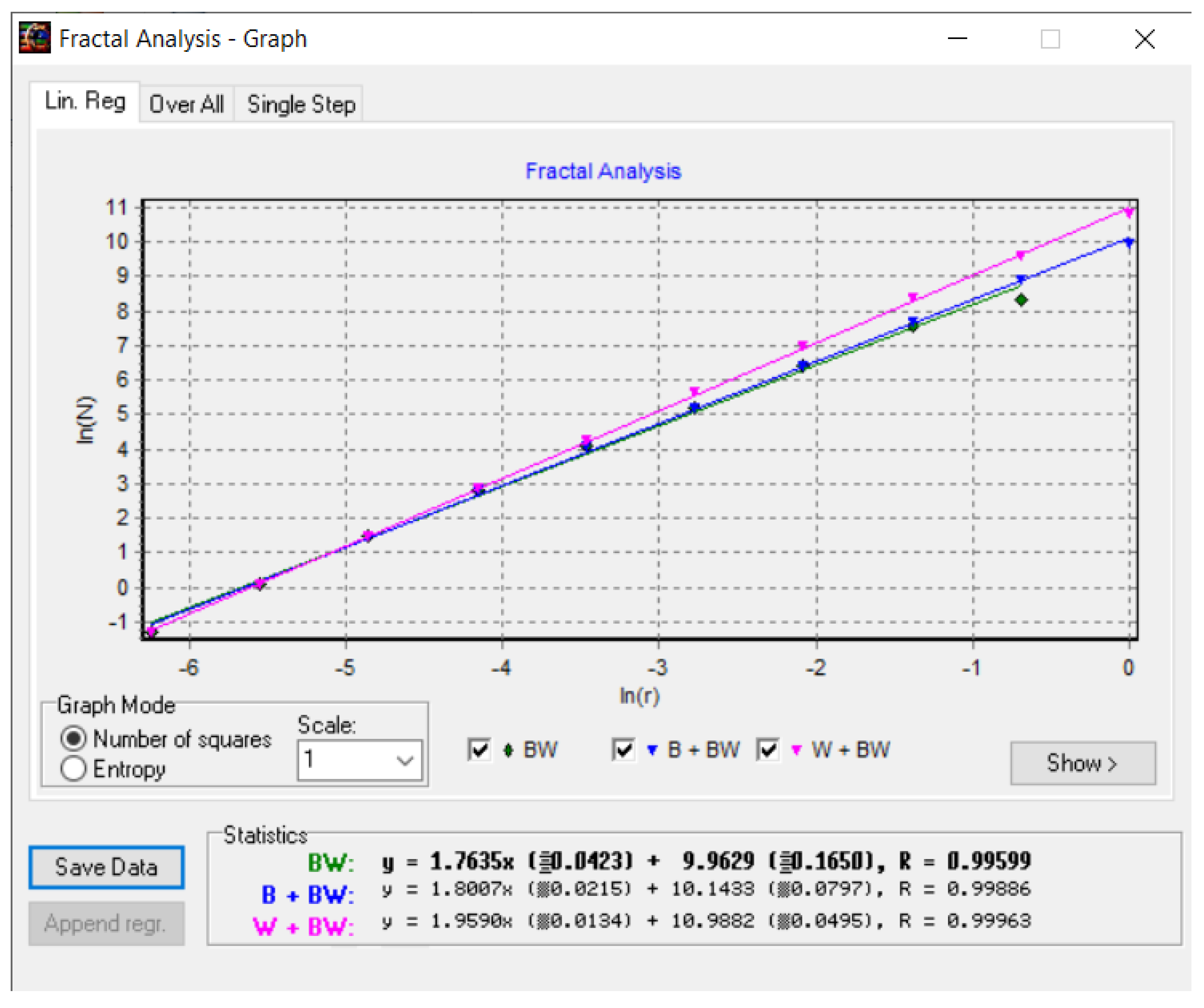
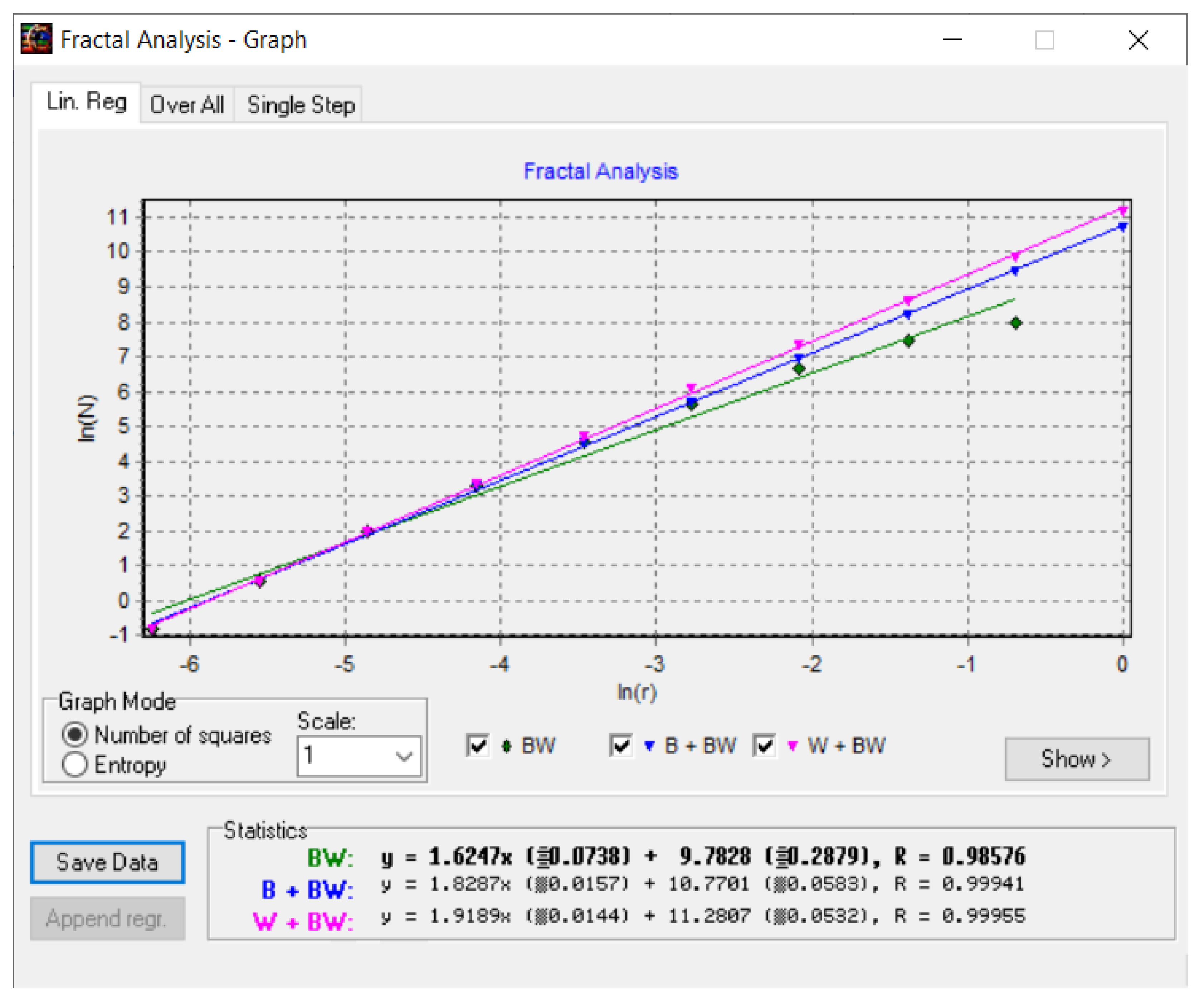
Figure 16 shows the fractal dimension graphic for the COVID-19 CT lung image zone using the HarFa program [
28].
In the coordinate system ln(N(
r)) as a function of ln(
r), used in
Figure 16, the multiple linear regression technique was applied to obtain the values of the fractal dimension of the CT picture of the COVID-19 lung, more precisely, to verify the obtained values with the box-counting algorithm, as in
Figure 15.
Non-COVID-19 Image
Table 2 contains the values of the fractal dimension and the standard deviation for the procedure with quadratic mask, FDHLQ, and SDHLQ, as well as the values of the fractal dimension and the standard deviation for the procedure with rectangular mask, FDHLR, and SDHLR, in the healthy lung case [
26,
27]. Also, at the end of the table is the gap value for the non-COVID-19 lung image.
Table 2 presents the familiar fractal indicators, as it were the fractal dimension of the CT lung non-COVID-19 image with quadratic mask, FDHLQ = 1.7249 ± 0.417, respectively the fractal dimension of the CT lung non-COVID-19 image with rectangular mask, FDHLR = 1.9798 ± 0.008 and lacunarity
Λ = 0.0584.
Figure 17 and
Figure 18 show the original non-COVID-19 CT pulmonary picture, respectively, and the defined mask for the non-COVID-19 CT pulmonary picture, framed in a blue border,
Figure 18.
Figure 18 presents the applied mask across the non-COVID-19 CT lung image, framed in a blue colour border.
Figure 19 presents the 3D graphic description of voxels contained in the patient’s non-COVID-19 pulmonary CT picture.
The voxels are usually utilized in scientific research to precisely and quickly focus on volumetric data, and in a voxels-founded structure morphology, condensation differences in the lung texture can be confronted utilizing the voxels in principle, as in
Figure 19.
Figure 20 and
Figure 21 are the grayscale images with and without luminance of the non-COVID-19 lung CT image, respectively, the filtered versions of the non-COVID-19 lung CT image.
Figure 21 is the original image after the median filter (left) filtered with the Wiener technique (right) of the non-COVID-19 lung CT image.
Figure 22 is the binary version of the COVID-19 lung image.
Figure 23 represents the box-count algorithm application for the COVID-19 lung image.
Figure 23 is the graphic representation of the box-count algorithm for the value of the obtained fractal dimension of the COVID-19 lung image.
Figure 22 is the binary version of the non-COVID-19 lung image.
Figure 23 represents the box-count algorithm application for the COVID-19 lung image.
Figure 23 is the graphic representation of the box-count algorithm for the value of the obtained fractal dimension of a non-COVID-19 lung image.
Figure 24 shows the fractal dimension graphic for the non-COVID-19 CT image zone with the HarFa program.
In the coordinate system ln(N(
r)) as a function of ln(
r), used in
Figure 24, the multiple linear regression technique was applied to obtain the values of the fractal dimension of the CT picture of the non-COVID-19 lung, more precisely, to verify the obtained values with the box-counting algorithm, as in
Figure 23.
In the end, it is crucial to also discuss the methodological results obtained. The most relevant of them are the following:
Feature Extraction. The convolutional layers successfully extracted key features from the image data set. These include specific patterns, shapes, and textures indicative of the CoV-2 virus’s presence;
Training Convergence. The convergence of AI and training has laid down an important foundation for realizing intelligent applications that can predict and diagnose pulmonary disorders. The adaptive learning rate proved instrumental in stabilizing the training process, especially during the latter used epochs;
Overfitting Mitigation. The incorporation of dropout layers and data augmentation techniques effectively reduced overfitting, as evidenced by the minimal difference in performance between the training and validation datasets;
Comparison with a Linear Classifier. For completeness, we also trained a simple linear classifier. As was observed, the whole functioned with an accuracy of 98.1%, reinforcing the need for a more complex architecture.
4. Discussion
In particular, artificial intelligence (AI) is the computer science domain that creates machines that imitate true human intelligence, utilizing algorithms to assume human-like comportment and make decisions at the same time. In AI, machines perform various duties such as mathematical problem-solving, speech recognition, face recognition, learning, etc. It can be stated, thus, that the machines function and act as a man (humanoid) if they have the appropriate information. Today, it can be said with certainty that artificial intelligence is sometimes imprecise, but it can help to successfully solve complex mathematical problems. This has caused AI to be extremely used nowadays and to contribute to the fulfillment of tasks that were previously impossible to accomplish. The term AI is often used interchangeably with its subfields, which include machine learning (ML) and deep learning.
The introduction of artificial intelligence (AI) continues to affirm its relevance across various facets of everyday life. Conceived from a need to streamline repetitive human tasks, AI has grown to develop solutions that adapt over time, much like human behavior [
1]. One of AI’s major advantages is its ability to mitigate human error, offering the potential for meticulous analysis of diverse data formats continuously [
2]. Among the sectors benefiting from AI, we note its spectacular impact, more recently, in medicine. This is particularly true for medical imaging, where AI’s exhaustive analysis capabilities are invaluable [
3]. This paper has explored the potential of an AI model in determining the presence of SARS-CoV-2 infection in lung CT images. Identifying intricate details in data often challenges the human senses, emphasizing the value of specialized programs for medical image processing. Integrating AI into patient diagnosis heralds a monumental step in modern medicine’s evolution, promising enhanced accuracy in analysis and monitoring. Furthermore, this work showcased an AI architecture that detects SARS-CoV-2 in CT images, developed using the TensorFlow library in Python [
4].
There are some important novelties that can be mentioned in the description of this article:
The primary novelty is the appearance of new AI-based software that is the main source in the analysis of the disease and the management of its healing stages;
Adapted CNN architecture specifically designed for application, e.g., virus detection;
Implementation of adaptive learning rate decay to enhance convergence during training;
Utilization of a unique combination of layers and neurons to optimize processing time without compromising accuracy;
Using fractal analysis, respectively, by calculating fractal parameters, namely fractal dimension, and lacunarity, in the detection of SARS (severe acute respiratory syndrome);
Pixel-level evaluation of CT pulmonary images of sick patients;
Establishing an effective database by storing all the representative images of the patients involved;
The capability to provide an immediate diagnosis in case the simple visualization of the image does not lead to a concrete decision.
Changing influences. The influence of changing input parameters on the accuracy of the results is called sensitivity analysis (SA). For some specialists, SA is a philosophical problem that refers to several aspects, among which there can be nominated, in short, a process in which one or multiple factors from an analysed problem are changed to evaluate their influence on some outcome or the manifested interest magnitude. More precisely, the effectiveness evaluation of a resolution option, the impact of a particular constraint on the optimality or benefit function, and the role of a pattern/model parameter in the production as a response to a viable resulting model. It is considered a well-posed problem, in the mathematical sense, if variations of 2–3% of the input data produce less than 4% variations of the output data. In practice, it is considered a reasonable influence of the input data variation if the final accuracy variation is less than 4%.
In the current paper, we utilized AI and DL procedures to analyse imaging data of patients with disease stage-treated and verified both for the diagnosis and monitoring of the SARS-CoV-2 virus. The results prove that DL procedures specifically predict a good diagnosis and a correct evolution post-treatment as such [
29]. However, the present study has some restrictions, such as a relatively small specimen dimension (patient number), a developed unique-center project, and the retrospective nature of the research carried out, which introduces the partiality of the conclusions and important confusing factors/counteragents.
While the core objective is to determine the presence or absence of the virus, the basic intricacies of image patterns make the problem more complex than simple linear separation. The underlying question refers to linear separability in image classification. While the end goal is binary in nature, determining the presence or absence of a virus from image data, the inherent complexities within the images require a more nuanced approach. Simple linear classifiers, such as the perceptron, would be insufficient due to several reasons, such as high dimensionality, intricate patterns, and overlap in features. The adoption of a more complex model like the CNN, as discussed earlier, is justified. The convolutional layers can detect intricate patterns, and the deeper architecture helps in understanding hierarchies in these patterns, making it more suited for our task than a simple linear classifier.
In defiance of the limitations of the overall project, our medical activity assures fine/excellent insights in utilizing DL procedures to predict treatment effects in patient disease amelioration, with clinical involvements for cure decision making and the consequences in the patient’s state of health. In the coming times, studies should confirm the model in question, but on substantial patient groups, and investigate deep learning algorithms in multiple medical real contexts [
30,
31].
In closure, the DL abordation utilized in this study validates a correctly predicted diagnosis and the health state evolution. Machine learning is a promising instrument for lung COVID-19 treatment follow-up and quick detection of healing. Confirmatory research and ameliorated integration in the medical service flows become necessary for the maximization of the action and functional potential of the AI model [
32,
33]. Mathematical approaches for optimizing mining facilities have conducted us to the improvement of the AI apparatus [
34,
35]. Computational software associated with practiced fractal analysis, utilized in the present study, was first introduced and successfully detailed in the author’s articles noted as the references [
18,
19,
20].
5. Conclusions
This paper presents an artificial intelligence model useful for the diagnosis and monitoring of the SARS-CoV-2 virus.
The medical society is sometimes unable to distinguish the details of an illness when the affected area, at first analysis, does not show any changes. In order to combat human error, it is recommended to use specialized software that can provide accurate verdicts even for data affected by noise.
Thus, for a process of determining the degree of infection, the first step is handled via the artificial intelligence model that decides whether the patient in question has the virus or not. Then, in the case of a confirmation, the analysed image is used as input data for a program responsible for measuring the degree of the condition using fractal analysis.
Among the advantages of this approach are the reduction of human error (the resulting AI model always responds with the same accuracy), use in repetitive processes (there is no need for a doctor to consume time with small-scale activities), and making simple decisions in a short time (the model can notice details that escape a human).
On the other hand, among the disadvantages, we can consider the access to high-quality or large data sets, the implementation of a complex system to adaptively filter the information before it is provided to the model, and the impossibility of using artificial intelligence models in complex decision making processes (due to the fact that it is impossible for the model training process to provide a null value of the “loss” parameter, it is recommended that the AI only decides in cases where the result does not cause damage of any kind).
It is observed that the application of fractal analysis and lacunarity algorithms is a good practice in assessing the degree of infection. Given that the geometric shape inside the lungs can be likened to a fractal shape, we can easily apply the box-counting formula to evaluate the fractal dimension value. Once determined, it can be used to monitor the progress of the disease. For patients seriously affected by this disease, periodic evaluation can be recommended to combat possible sequelae.
Finally, we can conclude that scanning with the help of computer tomographs is only the beginning part of a diagnosis. Specialized software architectures are needed to capitalize on every detail captured so that both doctor and patient benefit from realistic results. With the trained AI model, a maximum accuracy of 98.1% was obtained.
This innovative program shows great potential in the development of a complex medical solution for the analysis of the pulmonary system. For example, it can be interconnected with a program that, through fractal analysis, can characterize the evolution of the COVID-19 condition over time in order to prescribe an optimal treatment. At the same time, the techniques for highlighting some anomalies used by medical imaging so far (brightness adjustment, segmentation, clustering, etc.) can thus be modernized and can provide more precision at the end of the measurement procedures.
Author Contributions
Conceptualization, V.-P.P. and M.-A.P.; methodology, V.-P.P.; software, M.-V.N. and V.-A.P.; validation, V.-P.P., M.-A.P. and V.-A.P.; formal analysis, V.-P.P., M.-A.P. and V.-A.P.; investigation, M.-V.N. and M.-A.P.; resources, V.-A.P. and M.-A.P.; data curation, V.-A.P. and M.-V.N.; writing—original draft preparation, M.-V.N. and V.-P.P.; writing—review and editing, M.-A.P. and V.-P.P.; visualization, M.-V.N. and V.-A.P.; supervision, V.-P.P.; project administration, V.-P.P. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Ethical review and approval were waived for this study due to the fact that the data we used is already available online, as a free source.
Informed Consent Statement
Patient consent was waived due to the fact that the data we used is already available online, as a free source.
Data Availability Statement
Acknowledgments
The co-authors M.-A.P., V.-A.P. and V.-P.P. would like to thank Jenica Paun for her continuous kind support.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Alpaydin, E. Introduction to Machine Learning, 3rd ed.; MIT Press: Cambridge, MA, USA, 2020. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Available online: https://www.tensorflow.org/ (accessed on 7 July 2023).
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Sohail, A. “Transfer Learning” for Bridging the Gap Between Data Sciences and the Deep Learning. Ann. Data. Sci. 2022. Available online: https://www.researchgate.net/publication/359517436_Transfer_Learning_for_Bridging_the_Gap_Between_Data_Sciences_and_the_Deep_Learning (accessed on 7 July 2023).
- Sohail, A.; Yu, Z.; Nutini, A. COVID-19 Variants and Transfer Learning for the Emerging Stringency Indices. Neural Process. Lett. 2023, 55, 2359–2368. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D. A survey of transfer learning. J. Big Data 2016, 3, 1345–1459. [Google Scholar] [CrossRef]
- Available online: https://towardsdatascience.com/r-cnn-for-object-detection-a-technical-summary-9e7bfa8a557c (accessed on 7 July 2023).
- Kumar, P.; Gupta, A.; Kukreja, K. A Comprehensive Introduction to Google Colaboratory for Machine Learning. In Proceedings of the 2021 7th International Conference on Computing and Artificial Intelligence (ICCAI), New York, NY, USA, 23–26 April 2021. [Google Scholar]
- Singhania, P. Google Colab: A Hands-On Guide to Python Programming and Machine Learning; Apress: New York, NY, USA, 2021. [Google Scholar]
- Shorten, C.; Khoshgoftaar, T. Data Augmentation for Deep Learning: A Comprehensive Review. Mach. Learn. Knowl. Extr. 2019, 1, 415–447. [Google Scholar]
- Perez, L.; Wang, J.; Wang, J. An Analysis of Data Augmentation Techniques for Convolutional Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 806–813. [Google Scholar]
- Gulli, A.; Pal, S. Image Data Augmentation for Deep Learning using Keras. arXiv 2020, arXiv:2006.04803. [Google Scholar]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. Learning from Imbalanced Data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar]
- Gramaje, A.; Thabtah, F.; Abdelhamid, N.; Ray, S.K. Patient Discharge Classification Using Machine Learning Techniques. Ann. Data Sci. 2021, 8, 755–767. [Google Scholar] [CrossRef]
- Paun, M.A.; Postolache, P.; Nichita, M.V.; Paun, V.A.; Paun, V.P. Fractal Analysis in Pulmonary CT Images of COVID-19-Infected Patients. Fractal Fract. 2023, 7, 285. [Google Scholar] [CrossRef]
- Postolache, P.; Borsos, Z.; Paun, V.A.; Paun, V.P. New Way in Fractal Analysis of Pulmonary Medical Images. Univ. Politeh. Buchar. Sci. Bull.-Ser. A-Appl. Math. Phys. 2018, 80, 313–322. [Google Scholar]
- Nichita, M.V.; Paun, V.P. Fractal analysis in complex arterial network of pulmonary X-rays images. Univ. Politeh. Buchar. Sci. Bull. Ser. A-Appl. Math. Phys. 2018, 80, 325–339. [Google Scholar]
- Available online: https://www.kaggle.com/datasets/plameneduardo/sarscov2-ctscan-dataset (accessed on 10 July 2023).
- Mandelbrot, B.B.; Wheeler, J.A. The Fractal Geometry of Nature. Am. J. Phys. 1983, 51, 286. [Google Scholar] [CrossRef]
- Sebok, D.; Vásárhelyi, L.; Szenti, I.; Vajtai, R.; Kónya, Z.; Kukovecz, Á. Fast and accurate lacunarity calculation for large 3D micro-CT datasets. Acta Mater. 2021, 214, 116970. [Google Scholar] [CrossRef]
- Biswas, M.K.; Ghose, T.; Guha, S.; Biswas, P.K. Fractal dimension estimation for texture images—A parallel approach. Pattern Recognit. Lett. 1998, 19, 309–313. [Google Scholar] [CrossRef]
- Lehamel, M.; Hammouche, K. Texture Classification Using Fractal Dimension and Lacunarity. Mathematics. 2014. Available online: https://api.semanticscholar.org/CorpusID:14344351 (accessed on 10 July 2023).
- Nichita, M.V.; Paun, M.A.; Paun, V.A.; Paun, V.P. Image Clustering Algorithms to Identify Complicated Cerebral Diseases. Description and Comparison. IEEE Access 2020, 8, 88434–88442. [Google Scholar] [CrossRef]
- Paun, M.A.; Paun, V.A.; Paun, V.P. Fractal analysis in the quantification of medical imaging associated with multiple sclerosis pathology. Front. Biosci.-Landmark 2022, 27, 066. [Google Scholar] [CrossRef]
- Available online: http://imagesci.fch.vut.cz/includes/harfa_download.inc.php (accessed on 5 June 2023).
- Available online: https://www.design-reuse.com/articles/53213/artificial-intelligence-and-machine-learning-based-image-processing.html (accessed on 10 July 2023).
- Landt, E.M.; Colak, Y.; Nordestgaard, B.G.; Lange, P.; Dahl, M. Risk and impact of chronic cough in obese individuals from the general population. Thorax 2022, 77, 223–230. [Google Scholar] [CrossRef]
- Latif, S.; Usman, M.; Manzoor, S.; Iqbal, W.; Qadir, J.; Tyson, G.; Castro, I.; Razi, A.; Boulos, M.N.K.; Weller, A.; et al. Leveraging data science to combat COVID-19: A comprehensive review. IEEE Trans. Artif. Intell. 2020, 1, 85–103. [Google Scholar] [CrossRef]
- Lella, K.K.; Pja, A. Automatic diagnosis of COVID-19 disease using deep convolutional neural network with multi-feature channel from respiratory sound data: Cough, voice, and breath. Alex. Eng. J. 2022, 61, 1319–1334. [Google Scholar] [CrossRef]
- Li, Q.; Ning, J.; Yuan, J.; Xiao, L. A depthwise separable dense convolutional network with convolution block attention module for COVID-19 diagnosis on CT scans. Comput. Biol. Med. 2021, 137, 104837. [Google Scholar] [CrossRef]
- Abu-Abed, F. The Mathematical Approach to the Identification of Trouble-Free Functioning of Mining Facilities. Vth International Innovative Mining Symposium. E3S Web Conf. 2020, 174, 02009. [Google Scholar] [CrossRef]
- Abu-Abed, F. Investigation of the Effectiveness of the Method for Recognizing Pre-Emergency Situations at Mining Facilities. Vth International Innovative Mining Symposium. E3S Web Conf. 2020, 174, 02020. [Google Scholar] [CrossRef]
Figure 1.
Graphical representation of a modern health-monitoring architecture using AI.
Figure 1.
Graphical representation of a modern health-monitoring architecture using AI.
Figure 2.
Block diagram for the inference process.
Figure 2.
Block diagram for the inference process.
Figure 3.
Some final values of main parameters for the inference process.
Figure 3.
Some final values of main parameters for the inference process.
Figure 4.
The value of accuracy during training (the dark color curve is the definitive value curve, while the pale color curve is the curve training using AI).
Figure 4.
The value of accuracy during training (the dark color curve is the definitive value curve, while the pale color curve is the curve training using AI).
Figure 5.
The value of accuracy during validation (the dark color curve is the definitive value curve, while the pale color curve is the curve training using AI).
Figure 5.
The value of accuracy during validation (the dark color curve is the definitive value curve, while the pale color curve is the curve training using AI).
Figure 6.
The value of the “loss” parameter during training (the dark color curve is the definitive value curve, while the pale color curve is the curve training using AI).
Figure 6.
The value of the “loss” parameter during training (the dark color curve is the definitive value curve, while the pale color curve is the curve training using AI).
Figure 7.
The value of the “loss” parameter during validation (the dark color curve is the definitive value curve, while the pale color curve is the curve training using AI).
Figure 7.
The value of the “loss” parameter during validation (the dark color curve is the definitive value curve, while the pale color curve is the curve training using AI).
Figure 8.
Image validation of the completed module.
Figure 8.
Image validation of the completed module.
Figure 9.
Original COVID-19 lung image.
Figure 9.
Original COVID-19 lung image.
Figure 10.
Mask applied for COVID-19 lung image.
Figure 10.
Mask applied for COVID-19 lung image.
Figure 11.
Voxels’ representation in the COVID-19 lung image.
Figure 11.
Voxels’ representation in the COVID-19 lung image.
Figure 12.
Grayscale versions of the COVID-19 lung image: (a) grayscale image and (b) grayscale with no luminance.
Figure 12.
Grayscale versions of the COVID-19 lung image: (a) grayscale image and (b) grayscale with no luminance.
Figure 13.
Filtered versions of the COVID-19 lung image: (a) original image after a median filter was applied and (b) picture filtered in the Wiener technique.
Figure 13.
Filtered versions of the COVID-19 lung image: (a) original image after a median filter was applied and (b) picture filtered in the Wiener technique.
Figure 14.
Binary version of the COVID-19 lung image.
Figure 14.
Binary version of the COVID-19 lung image.
Figure 15.
Box-count chart for COVID-19 lung image.
Figure 15.
Box-count chart for COVID-19 lung image.
Figure 16.
Checking the fractal dimension values with the HarFa graphic software (version 5.5), for COVID-19 lung image.
Figure 16.
Checking the fractal dimension values with the HarFa graphic software (version 5.5), for COVID-19 lung image.
Figure 17.
Original non-COVID-19 lung image.
Figure 17.
Original non-COVID-19 lung image.
Figure 18.
Applied mask for a non-COVID-19 lung image.
Figure 18.
Applied mask for a non-COVID-19 lung image.
Figure 19.
Voxels’ representation in the non-COVID-19 lung image.
Figure 19.
Voxels’ representation in the non-COVID-19 lung image.
Figure 20.
Grayscale versions of the non-COVID-19 lung image: (a) grayscale image and (b) grayscale with no luminance.
Figure 20.
Grayscale versions of the non-COVID-19 lung image: (a) grayscale image and (b) grayscale with no luminance.
Figure 21.
Filtered versions of the non-COVID-19 lung image: (a) original image after a median filter was applied and (b) picture filtered in the Wiener technique.
Figure 21.
Filtered versions of the non-COVID-19 lung image: (a) original image after a median filter was applied and (b) picture filtered in the Wiener technique.
Figure 22.
Binary version of the non-COVID-19 lung image.
Figure 22.
Binary version of the non-COVID-19 lung image.
Figure 23.
Box-count chart for the non-COVID-19 lung image.
Figure 23.
Box-count chart for the non-COVID-19 lung image.
Figure 24.
Checking the fractal dimension values with the HarFa graphic software (version 5.5), for non-COVID-19 lung image.
Figure 24.
Checking the fractal dimension values with the HarFa graphic software (version 5.5), for non-COVID-19 lung image.
Table 1.
Fractal characteristic computation of a COVID-19 image.
Table 1.
Fractal characteristic computation of a COVID-19 image.
| FDQ | SDQ | FDR | SDR | Lacunarity |
|---|
| 1.8038 | ±0.4247 | 1.9785 | ±0.007 | 0.0554 |
Table 2.
Fractal characteristics computation of non-COVID-19 image.
Table 2.
Fractal characteristics computation of non-COVID-19 image.
| FDHLQ | SDHLQ | FDHLR | SDHLR | Lacunarity |
|---|
| 1.7249 | ±0.4170 | 1.9798 | ±0.008 | 0.0584 |
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).




 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}