Deep Learning to Enhance Diagnosis and Management of Intrahepatic Cholangiocarcinoma


 ,
,  and
and 
Simple Summary
Abstract
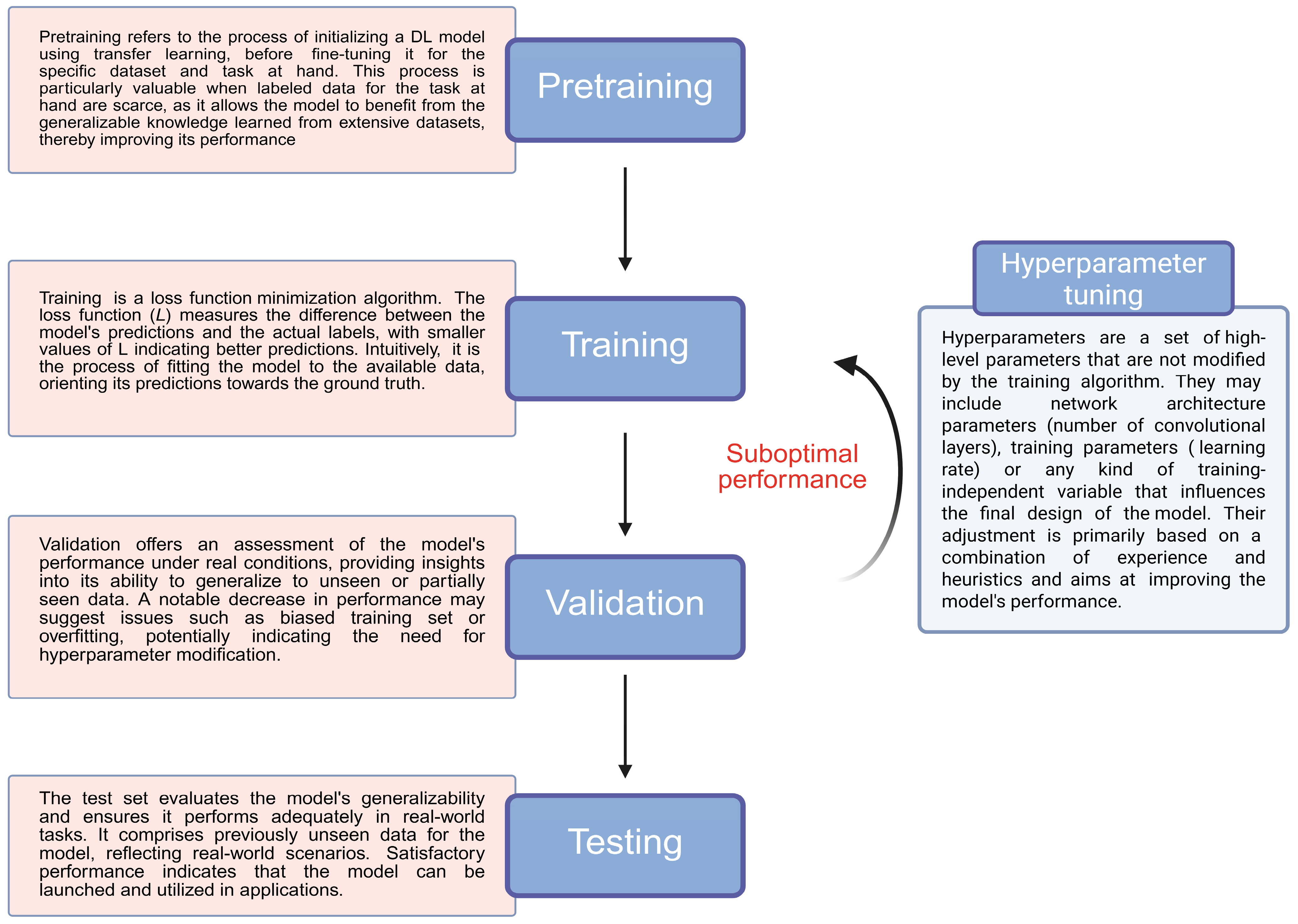
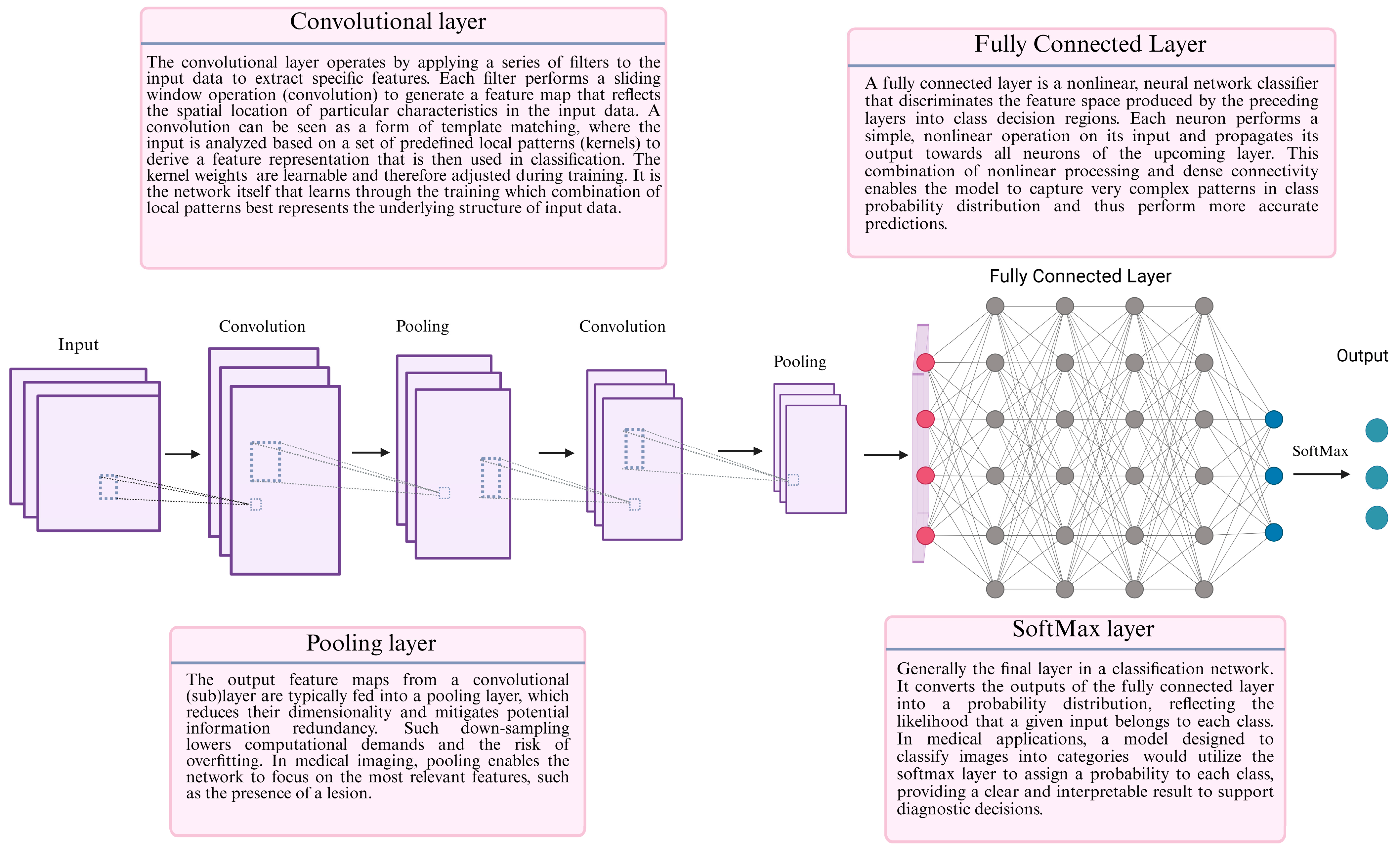
1. Introduction

{kind=link}
{kind=link}
| Metric | Formula | Explanation | Limitations | References |
|---|---|---|---|---|
| Sensitivity | Measures the proportion of TPs that are correctly identified by the model. Used in tasks where capturing all positive instances is essential, aiming to minimize FNs. | Recall is sensitive to dataset imbalance and may not be sufficient to assess the overall performance of a model. | [20,21] | |
| Specificity | Measures the proportion of TNs that are correctly identified by the model. Dual metric to sensitivity, being used in tasks where capturing all negative instances is essential, thus minimizing FPs. | Specificity can be less informative in highly imbalanced datasets. When the negative class is predominant, a biased model may overestimate specificity at the expense of low FN rates. Conversely, if the negative is underrepresented with few samples, specificity may fail to accurately reflect the model’s ability to identify TNs in real-world scenarios. | [20,21] | |
| Accuracy | Calculates the proportion of correctly classified instances out of the total instances, offering an estimate of the model’s misclassification probability. | May be inadequate for imbalanced datasets and tasks where certain classes have greater significance. In the presence of class imbalance, a model biased toward the majority class can still achieve high accuracy. In cases where misclassifications have unequal consequences, accuracy treats all errors equally, failing to reflect the varying significance of different classes. | ||
| Precision | Quantifies the ratio of TP predictions to the total positive predictions made by the model. Used in tasks where minimizing FPs is a primary concern. | Sensitive to class imbalance, particularly when the positive class is significantly underrepresented. In such cases, precision is derived from a limited number of samples, making it unreliable. Conversely, when the positive class dominates, precision alone may not adequately reflect the FN rate, limiting its usefulness. | [21,22] | |
| F1-score | Defined as the harmonic mean of precision and recall, offering a trade-off between the two. While precision focuses on minimizing FPs and recall on maximizing TPs, this balanced metric remains robust in imbalanced datasets and is particularly valuable in tasks where both FPs and FNs are important to consider. | Assigning equal weight to precision and recall in the F1-score may not be appropriate in imbalanced datasets, where minimizing the FPs or FNs may be more critical depending on the clinical context. In such cases, the F1-score may not adequately reflect the importance of these errors, as it treats both precision and recall equally without considering their relative significance in detecting the minority class. | [21,22] | |
| Jaccard index | Seeks to capture all positive instances, while accounting for both FPs and FNs. Similar to F1-score, though it imposes a greater penalty on false predictions. | It assigns equal weight to FPs and FNs, which may not be appropriate for certain applications. | [21] | |
| Area under the ROC curve (AUC) | There no general formula exists, as the shape of the AUC can differ across various applications. However, it can be calculated numerically given the TP and FP rate pairs. | The ROC curve is a graph of the , computed across various discriminative thresholds. Since an optimal condition would involve a TP rate of 1 and an FP rate of 0, it can be concluded that a larger area under the ROC curve indicates a model design that is closer to optimal performance. | It may not be ideal for applications involving imbalanced datasets, where the minority class is of primary concern, as the ROC curve does not account for the different consequences of FPs and FNs. In such cases, sensitivity and specificity can have different levels of importance and the ROC curve may not fully reflect the impact of these errors, especially when the clinical decision relies on a precise trade-off between the two. Selecting appropriate discrimination thresholds for plotting the ROC curve can be challenging in imbalanced datasets, potentially masking the performance of the model on the minority class. | [21,22] |
| Study Objective | Study Type | Type of Data | Imaging Modality | Model | Pretraining | Total Patients | Test Set Performance | Physician Comparison | Reference |
|---|---|---|---|---|---|---|---|---|---|
| ICCA and HCC classification | Single-center, retrospective | Images, tumor marker information | CT | Custom-made CNN | NR | 617 | Accuracy: 61.0% Sensitivity: 75.0% Specificity: 88.0% | Yes | [10] |
| ICCA-HCC classification | Single-center, retrospective | Images | CT | ResNet18 with STE module | ImageNet | 398 | Accuracy: 85.0% F1-score: 84.9% NPV: 88.2% AUC: 0.88 | No | [23] |
| ICC-HCC classification | Two-center, retrospective | Images | CT | U-net with a DAM and a transformer network | NR | 527 | Accuracy: 81.6% Sensitivity: 73.4%, Specificity: 89.6% AUC: 0.86 | No | [24] |
| Classification of HCC, ICCA, and CRLM | Multi-center, retrospective | Images | CT | InceptionV3 | ImageNet | 814 | Accuracy: 96.2% Sensitivity: 93.7% Specificity: 98.5% PPV: 93.2% NPV: 88% | Yes | [11] |
| Automated diagnosis of focal liver tumors | Multi-center, retrospective | Images | CT | LilNet | ImageNet | 4039 | Accuracy: 88.7% AUC: 95.6% F1-score: 89.7% precision: 92.0% Sensitivity: 88.7% | Yes | [25] |
| ICCA and HCC classification | Multi-center, retrospective | Images | CT | H-LSTM | Yes | 276 | Accuracy: 91.0% Sensitivity: 91.0% Precision: 92.0% F1-score: 91.0% AUC: 93.0% | No | [26] |
| ICC-HCC, classification | Two-center, retrospective | Images and clinical data | CT | STIC | NR | 723 | Accuracy: 86.2% AUC: 89.0% | Yes | [27] |
| Reclassification of cHCC-CCA | Multi-center, retrospective | Images | WSI | ResNet50 | TCGA | 405 | N/A | Yes | [28] |
| ICCA, HCC classification | Single-center, retrospective | Images | MRI | SFFNet | NR | 112 | Accuracy: 92.2% AUC: 96.8% Precision: 94.0% Sensitivity: 89.0% F1-score: 90.0% | No | [29] |
| Liver lesion classification | Single-center, retrospective | Images and clinical data | MRI | Inception-ResNetV2 | ImageNet | 1210 | AUC: 89.7–98.7% Sensitivity: 53.3–100% Specificity: 91.6–99.5% | Yes | [30] |
| ICCA and HCC classification | Multi-center, retrospective | Images | MRI | Fusion VGG19 radiomics | ImageNet | 381 | AUC: 98.0% Accuracy: 87.5% F1-score: 88.0% | No | [31] |
| ICCA and HCC classification and ICCA grade prediction | Single-center, retrospective | Images | MRI | Fusion ResNet50 radiomics | ImageNet | 162 | AUC: 90.0% Sensitivity: 93.0% Precision: 96.0% F1-score: 91.0% Accuracy: 90.0% | No | [32] |
| Liver lesion classification | Single-center, retrospective | Images | MRI | Custom-made CNN | NR | 296 | Accuracy: 90.0% Sensitivity: 90.0% Specificity: 98.0% | Yes | [33] |
| ICCA, HCC, and cHCC-CCA classification | Single-center, retrospective | Images | US | ResNet18 | NR | 465 | AUC: 92.0% Sensitivity: 84.6% Specificity: 92.7% Accuracy: 86.0% PPV: 85.5% NPV: 93.0% F1-score: 85.0% | No | [34] |
| Liver lesion classification | Multi-center, prospective | Images, histopathological biomarkers, and clinical data | US | Long Short-Term Memory, multilayer perceptron | NR | 3342 | Accuracy: 86% Specificity: 97% Sensitivity: 85% Precision: 81% NPV: 97% F1-score: 83% | Yes | [12] |
| ICCA, HCC, and cHCC-CCA classification | Single-center, retrospective | Images | WSI | ResNet18 | ImageNet | 161 | Diagnostic agreement for HCC: 96.0%, ICCA: 87.0% | No | [35] |
| Study Objective | Study Type | Type of Data | Imaging Modality | Model | Pretraining | Total Patients | Test Set Performance | Physician Comparison | Reference |
|---|---|---|---|---|---|---|---|---|---|
| Preoperative prediction of MVI | Multicenter, retrospective | Images | MRI | MFCNN | NR | 519 | AUC: 88.0% Accuracy: 86.8% Sensitivity: 85.7% Specificity: 87.0% | No | [15] |
| Prediction of pathological differentiation | Single-center, prospective | Images | CT | ResNet50, SeNet50, DenseNet50 | NR | 408 | AUC: 64.0–65.0% Accuracy: 68.0–68.6% | No | [16] |
| Ex vivo differentiation of iCCA and liver parenchyma | Single-center, prospective | Images | OCT | Xception | NR | 11 | F1-score: 94.0% Sensitivity: 94.0% Specificity: 93.0% | No | [18] |
| Study Objective | Study Type | Type of Data | Imaging Modality | Model | Pretraining | Total Patients | Test Set Performance | Physician Comparison | Reference |
|---|---|---|---|---|---|---|---|---|---|
| Survival prediction | Single-center retrospective | Images, clinical data, genomic profiling | WSI | ResNet | NR | 83 | Concordance index: 0.80 (OS), 0.72 (PFS) | No | [36] |
| Early postoperative recurrence | Multicenter retrospective | Images | CT | ResNet50 | No | 41 | AUC: 99.4% Sensitivity: 97.8% Specificity: 94.0% PPV: 96.7% NPV: 96.1% | No | [14] |
| Preoperative identification of high-risk patients for futile surgery | Multicenter retrospective | Demographic data, clinical data, imaging data | NR | Ensemble ML-DL model | NR | 827 | AUC: 78.0% Sensitivity: 64.6% Specificity: 80.0% PPV: 73.1% NPV: 72.7% | No | [13] |
2. DL for the Diagnosis of iCCA
2.1. Computer Tomography (CT)
2.2. Magnetic Resonance Imaging (MRI)
2.3. Ultrasound (US)
2.4. Histopathology
3. DL for Histopathological Feature Prediction
4. DL for Prediction of Recurrence and Survival
5. Limitations and Future Perspectives
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Muralidharan, V.; Adewale, B.A.; Huang, C.J.; Nta, M.T.; Ademiju, P.O.; Pathmarajah, P.; Hang, M.K.; Adesanya, O.; Abdullateef, R.O.; Babatunde, A.O.; et al. A scoping review of reporting gaps in FDA-approved AI medical devices. NPJ Digit. Med. 2024, 7, 273. [Google Scholar] [CrossRef]
- Senthil, R.; Anand, T.; Somala, C.S.; Saravanan, K.M. Bibliometric analysis of artificial intelligence in healthcare research: Trends and future directions. Future Healthc. J. 2024, 11, 100182. [Google Scholar] [CrossRef] [PubMed]
- Theocharopoulos, C.; Davakis, S.; Ziogas, D.C.; Theocharopoulos, A.; Foteinou, D.; Mylonakis, A.; Katsaros, I.; Gogas, H.; Charalabopoulos, A. Deep Learning for Image Analysis in the Diagnosis and Management of Esophageal Cancer. Cancers 2024, 16, 3285. [Google Scholar] [CrossRef]
- Aggarwal, R.; Sounderajah, V.; Martin, G.; Ting, D.S.W.; Karthikesalingam, A.; King, D.; Ashrafian, H.; Darzi, A. Diagnostic accuracy of deep learning in medical imaging: A systematic review and meta-analysis. NPJ Digit. Med. 2021, 4, 65. [Google Scholar] [CrossRef] [PubMed]
- Yu, K.H.; Beam, A.L.; Kohane, I.S. Artificial intelligence in healthcare. Nat. Biomed. Eng. 2018, 2, 719–731. [Google Scholar] [CrossRef]
- O’Mahony, N.; Campbell, S.; Carvalho, A.; Harapanahalli, S.; Velasco-Hernandez, G.; Krpalkova, L.; Riordan, D.; Walsh, J. Deep Learning vs. Traditional Computer Vision. In Advances in Computer Vision. CVC 2019. Advances in Intelligent Systems and Computing; Springer: Cham, Switzerland, 2019. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Bai, J.; Al-Sabaawi, A.; Santamaría, J.; Albahri, A.S.; Al-dabbagh, B.S.N.; Fadhel, M.A.; Manoufali, M.; Zhang, J.; Al-Timemy, A.H.; et al. A survey on deep learning tools dealing with data scarcity: Definitions, challenges, solutions, tips, and applications. J. Big Data 2023, 10, 46. [Google Scholar] [CrossRef]
- Bridgewater, J.; Galle, P.R.; Khan, S.A.; Llovet, J.M.; Park, J.W.; Patel, T.; Pawlik, T.M.; Gores, G.J. Guidelines for the diagnosis and management of intrahepatic cholangiocarcinoma. J. Hepatol. 2014, 60, 1268–1289. [Google Scholar] [CrossRef]
- Nakai, H.; Fujimoto, K.; Yamashita, R.; Sato, T.; Someya, Y.; Taura, K.; Isoda, H.; Nakamoto, Y. Convolutional neural network for classifying primary liver cancer based on triple-phase CT and tumor marker information: A pilot study. Jpn. J. Radiol. 2021, 39, 690–702. [Google Scholar] [CrossRef]
- Midya, A.; Chakraborty, J.; Srouji, R.; Narayan, R.R.; Boerner, T.; Zheng, J.; Pak, L.M.; Creasy, J.M.; Escobar, L.A.; Harrington, K.A.; et al. Computerized Diagnosis of Liver Tumors From CT Scans Using a Deep Neural Network Approach. IEEE J. Biomed. Health Inform. 2023, 27, 2456–2464. [Google Scholar] [CrossRef]
- Ding, W.; Meng, Y.; Ma, J.; Pang, C.; Wu, J.; Tian, J.; Yu, J.; Liang, P.; Wang, K. Contrast-enhanced ultrasound-based AI model for multi-classification of focal liver lesions. J. Hepatol. 2025; in press. [Google Scholar] [CrossRef] [PubMed]
- Altaf, A.; Endo, Y.; Guglielmi, A.; Aldrighetti, L.; Bauer, T.W.; Marques, H.P.; Martel, G.; Alexandrescu, S.; Weiss, M.J.; Kitago, M.; et al. Upfront surgery for intrahepatic cholangiocarcinoma: Prediction of futility using artificial intelligence. Surgery 2025, 179, 108809. [Google Scholar] [CrossRef] [PubMed]
- Wakiya, T.; Ishido, K.; Kimura, N.; Nagase, H.; Kanda, T.; Ichiyama, S.; Soma, K.; Matsuzaka, M.; Sasaki, Y.; Kubota, S.; et al. CT-based deep learning enables early postoperative recurrence prediction for intrahepatic cholangiocarcinoma. Sci. Rep. 2022, 12, 8428. [Google Scholar] [CrossRef]
- Gao, W.; Wang, W.; Song, D.; Wang, K.; Lian, D.; Yang, C.; Zhu, K.; Zheng, J.; Zeng, M.; Rao, S.X.; et al. A Multiparametric Fusion Deep Learning Model Based on DCE-MRI for Preoperative Prediction of Microvascular Invasion in Intrahepatic Cholangiocarcinoma. J. Magn. Reson. Imaging 2022, 56, 1029–1039. [Google Scholar] [CrossRef] [PubMed]
- Xia, W.; Liu, M.; Yang, C.; Fan, S.; Cheng, X.; Gong, H. Deep Learning Method Based on CT Images to Predict the Pathological Differentiation of Intrahepatic Cholangiocarcinoma. In Proceedings of the 2022 IEEE 8th International Conference on Computer and Communications (ICCC), Chengdu, China, 9–12 December 2022; pp. 2086–2091. [Google Scholar]
- Alvaro, D.; Gores, G.J.; Walicki, J.; Hassan, C.; Sapisochin, G.; Komuta, M.; Forner, A.; Valle, J.W.; Laghi, A.; Ilyas, S.I.; et al. EASL-ILCA Clinical Practice Guidelines on the management of intrahepatic cholangiocarcinoma. J. Hepatol. 2023, 79, 181–208. [Google Scholar] [CrossRef]
- Wolff, L.I.; Hachgenei, E.; Gossmann, P.; Druzenko, M.; Frye, M.; Konig, N.; Schmitt, R.H.; Chrysos, A.; Jochle, K.; Truhn, D.; et al. Optical coherence tomography combined with convolutional neural networks can differentiate between intrahepatic cholangiocarcinoma and liver parenchyma ex vivo. J. Cancer Res. Clin. Oncol. 2023, 149, 7877–7885. [Google Scholar] [CrossRef]
- Machairas, N.; Lang, H.; Jayant, K.; Raptis, D.A.; Sotiropoulos, G.C. Intrahepatic cholangiocarcinoma: Limitations for resectability, current surgical concepts and future perspectives. Eur. J. Surg. Oncol. 2020, 46, 740–746. [Google Scholar] [CrossRef]
- Monaghan, T.F.; Rahman, S.N.; Agudelo, C.W.; Wein, A.J.; Lazar, J.M.; Everaert, K.; Dmochowski, R.R. Foundational Statistical Principles in Medical Research: Sensitivity, Specificity, Positive Predictive Value, and Negative Predictive Value. Medicina 2021, 57, 503. [Google Scholar] [CrossRef]
- Rainio, O.; Teuho, J.; Klen, R. Evaluation metrics and statistical tests for machine learning. Sci. Rep. 2024, 14, 6086. [Google Scholar] [CrossRef]
- Miller, C.; Portlock, T.; Nyaga, D.M.; O’Sullivan, J.M. A review of model evaluation metrics for machine learning in genetics and genomics. Front. Bioinform. 2024, 4, 1457619. [Google Scholar] [CrossRef]
- Xue, M.; Jiang, H.; Zheng, J.; Wu, Y.; Xu, Y.; Pan, J.; Zhu, W. Spatiotemporal Excitation Module-based CNN for Diagnosis of Hepatic Malignancy in Four-phase CT Images. In Proceedings of the 2023 45th Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Sydney, Australia, 24–27 July 2023; pp. 1–5. [Google Scholar] [CrossRef]
- Wu, Y.; Chen, G.; Feng, Z.; Cui, H.; Rao, F.; Ni, Y.; Huang, Z.; Zhu, W. Phase Difference Network for Efficient Differentiation of Hepatic Tumors with Multi-Phase CT. In Proceedings of the 2023 45th Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Sydney, Australia, 24–27 July 2023; pp. 1–5. [Google Scholar] [CrossRef]
- Wei, Y.; Yang, M.; Zhang, M.; Gao, F.; Zhang, N.; Hu, F.; Zhang, X.; Zhang, S.; Huang, Z.; Xu, L.; et al. Focal liver lesion diagnosis with deep learning and multistage CT imaging. Nat. Commun. 2024, 15, 7040. [Google Scholar] [CrossRef] [PubMed]
- Huang, S.; Nie, X.; Pu, K.; Wan, X.; Luo, J. A flexible deep learning framework for liver tumor diagnosis using variable multi-phase contrast-enhanced CT scans. J. Cancer Res. Clin. Oncol. 2024, 150, 443. [Google Scholar] [CrossRef]
- Gao, R.; Zhao, S.; Aishanjiang, K.; Cai, H.; Wei, T.; Zhang, Y.; Liu, Z.; Zhou, J.; Han, B.; Wang, J.; et al. Deep learning for differential diagnosis of malignant hepatic tumors based on multi-phase contrast-enhanced CT and clinical data. J. Hematol. Oncol. 2021, 14, 154. [Google Scholar] [CrossRef] [PubMed]
- Calderaro, J.; Ghaffari Laleh, N.; Zeng, Q.; Maille, P.; Favre, L.; Pujals, A.; Klein, C.; Bazille, C.; Heij, L.R.; Uguen, A.; et al. Deep learning-based phenotyping reclassifies combined hepatocellular-cholangiocarcinoma. Nat. Commun. 2023, 14, 8290. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, B.; Mo, X.; Tang, K.; He, J.; Hao, J. A Deep Learning Workflow for Mass-Forming Intrahepatic Cholangiocarcinoma and Hepatocellular Carcinoma Classification Based on MRI. Curr. Oncol. 2022, 30, 529–544. [Google Scholar] [CrossRef]
- Zhen, S.H.; Cheng, M.; Tao, Y.B.; Wang, Y.F.; Juengpanich, S.; Jiang, Z.Y.; Jiang, Y.K.; Yan, Y.Y.; Lu, W.; Lue, J.M.; et al. Deep Learning for Accurate Diagnosis of Liver Tumor Based on Magnetic Resonance Imaging and Clinical Data. Front. Oncol. 2020, 10, 680. [Google Scholar] [CrossRef] [PubMed]
- Wu, Q.; Zhang, T.; Xu, F.; Cao, L.; Gu, W.; Zhu, W.; Fan, Y.; Wang, X.; Hu, C.; Yu, Y. MRI-based deep learning radiomics to differentiate dual-phenotype hepatocellular carcinoma from HCC and intrahepatic cholangiocarcinoma: A multicenter study. Insights Imaging 2025, 16, 27. [Google Scholar] [CrossRef]
- Wang, S.; Wang, X.; Yin, X.; Lv, X.; Cai, J. Differentiating HCC from ICC and prediction of ICC grade based on MRI deep-radiomics: Using lesions and their extended regions. Phys. Med. 2024, 120, 103322. [Google Scholar] [CrossRef]
- Hamm, C.A.; Wang, C.J.; Savic, L.J.; Ferrante, M.; Schobert, I.; Schlachter, T.; Lin, M.; Duncan, J.S.; Weinreb, J.C.; Chapiro, J.; et al. Deep learning for liver tumor diagnosis part I: Development of a convolutional neural network classifier for multi-phasic MRI. Eur. Radiol. 2019, 29, 3338–3347. [Google Scholar] [CrossRef]
- Chen, J.; Zhang, W.; Bao, J.; Wang, K.; Zhao, Q.; Zhu, Y.; Chen, Y. Implications of ultrasound-based deep learning model for preoperatively differentiating combined hepatocellular-cholangiocarcinoma from hepatocellular carcinoma and intrahepatic cholangiocarcinoma. Abdom. Radiol. 2024, 49, 93–102. [Google Scholar] [CrossRef]
- Beaufrere, A.; Ouzir, N.; Zafar, P.E.; Laurent-Bellue, A.; Albuquerque, M.; Lubuela, G.; Gregory, J.; Guettier, C.; Mondet, K.; Pesquet, J.C.; et al. Primary liver cancer classification from routine tumour biopsy using weakly supervised deep learning. JHEP Rep. 2024, 6, 101008. [Google Scholar] [CrossRef] [PubMed]
- Schmauch, B.; Brion, E.; Ducret, V.; Nasar, N.; McIntyre, S.; Sin-Chan, P.; Maussion, C.; Jarnagin, W.; Chakraborty, J. Machine learning-based multimodal prediction of prognosis in patients with resected intrahepatic cholangiocarcinoma. J. Clin. Oncol. 2023, 41, 4121. [Google Scholar] [CrossRef]
- Minami, Y.; Nishida, N.; Kudo, M. Imaging Diagnosis of Various Hepatocellular Carcinoma Subtypes and Its Hypervascular Mimics: Differential Diagnosis Based on Conventional Interpretation and Artificial Intelligence. Liver Cancer 2023, 12, 103–115. [Google Scholar] [CrossRef] [PubMed]
- Lee, Y.T.; Wang, J.J.; Luu, M.; Noureddin, M.; Nissen, N.N.; Patel, T.C.; Roberts, L.R.; Singal, A.G.; Gores, G.J.; Yang, J.D. Comparison of Clinical Features and Outcomes Between Intrahepatic Cholangiocarcinoma and Hepatocellular Carcinoma in the United States. Hepatology 2021, 74, 2622–2632. [Google Scholar] [CrossRef]
- Laino, M.E.; Vigano, L.; Ammirabile, A.; Lofino, L.; Generali, E.; Francone, M.; Lleo, A.; Saba, L.; Savevski, V. The added value of artificial intelligence to LI-RADS categorization: A systematic review. Eur. J. Radiol. 2022, 150, 110251. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Li, F.-F. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Oestmann, P.M.; Wang, C.J.; Savic, L.J.; Hamm, C.A.; Stark, S.; Schobert, I.; Gebauer, B.; Schlachter, T.; Lin, M.; Weinreb, J.C.; et al. Deep learning-assisted differentiation of pathologically proven atypical and typical hepatocellular carcinoma (HCC) versus non-HCC on contrast-enhanced MRI of the liver. Eur. Radiol. 2021, 31, 4981–4990. [Google Scholar] [CrossRef]
- Xu, X.; Wang, C.; Guo, J.; Gan, Y.; Wang, J.; Bai, H.; Zhang, L.; Li, W.; Yi, Z. MSCS-DeepLN: Evaluating lung nodule malignancy using multi-scale cost-sensitive neural networks. Med. Image Anal. 2020, 65, 101772. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z.B. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K. Densely Connected Convolutional Networks. arXiv 2017, arXiv:1608.06993. [Google Scholar]
- Hidayatullah, P.; Syakrani, N.; Sholahuddin, M.; Gelar, T.; Tubagus, R. YOLOv8 to YOLO11: A Comprehensive Architecture In-depth Comparative Review. arXiv 2025, arXiv:2501.13400. [Google Scholar]
- Tan, M.; Le, Q. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. arXiv 2019, arXiv:1905.11946. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the NIPS’12: Proceedings of the 26th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012. No. 25. [Google Scholar] [CrossRef]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. AAAI Conf. Artif. Intell. 2016, 31, 4278–4284. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.-Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A ConvNet for the 2020s. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 11966–11976. [Google Scholar]
- Wang, C.J.; Hamm, C.A.; Savic, L.J.; Ferrante, M.; Schobert, I.; Schlachter, T.; Lin, M.; Weinreb, J.C.; Duncan, J.S.; Chapiro, J.; et al. Deep learning for liver tumor diagnosis part II: Convolutional neural network interpretation using radiologic imaging features. Eur. Radiol. 2019, 29, 3348–3357. [Google Scholar] [CrossRef]
- Howard, A.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar] [CrossRef]
- Bouma, B.E.; de Boer, J.F.; Huang, D.; Jang, I.K.; Yonetsu, T.; Leggett, C.L.; Leitgeb, R.; Sampson, D.D.; Suter, M.; Vakoc, B.; et al. Optical coherence tomography. Nat. Rev. Methods Primers 2022, 2, 79. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar]
- Xie, J.; Pu, X.; He, J.; Qiu, Y.; Lu, C.; Gao, W.; Wang, X.; Lu, H.; Shi, J.; Xu, Y.; et al. Survival prediction on intrahepatic cholangiocarcinoma with histomorphological analysis on the whole slide images. Comput. Biol. Med. 2022, 146, 105520. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, 18th International Conference, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaria, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8, 53. [Google Scholar] [CrossRef]
- Iman, M.; Arabnia, H.R.; Rasheed, K. A Review of Deep Transfer Learning and Recent Advancements. Technologies 2023, 11, 40. [Google Scholar] [CrossRef]
- Rani, V.; Nabi, S.T.; Kumar, M.; Mittal, A.; Kumar, K. Self-supervised Learning: A Succinct Review. Arch. Comput. Methods Eng. 2023, 30, 2761–2775. [Google Scholar] [CrossRef]
- Khan, W.; Leem, S.; See, K.; Wong, J.; Zhang, S.; Fang, R. A Comprehensive Survey of Foundation Models in Medicine. IEEE Rev. Biomed. Eng. 2025, 1–22. [Google Scholar] [CrossRef] [PubMed]
- Wen, J.; Zhang, Z.; Lan, Y.; Cui, Z.; Cai, J.; Zhang, W. A survey on federated learning: Challenges and applications. Int. J. Mach. Learn. Cybern. 2023, 14, 513–535. [Google Scholar] [CrossRef] [PubMed]
- Dhar, T.; Dey, N.; Borra, S.; Sherratt, R. Challenges of Deep Learning in Medical Image Analysis—Improving Explainability and Trust. IEEE Trans. Technol. Soc. 2023, 4, 68–75. [Google Scholar] [CrossRef]
- Struyvenberg, M.R.; de Groof, A.J.; van der Putten, J.; van der Sommen, F.; Baldaque-Silva, F.; Omae, M.; Pouw, R.; Bisschops, R.; Vieth, M.; Schoon, E.J.; et al. A computer-assisted algorithm for narrow-band imaging-based tissue characterization in Barrett’s esophagus. Gastrointest. Endosc. 2021, 93, 89–98. [Google Scholar] [CrossRef]
- Machairas, N.; Kostakis, I.D.; Schizas, D.; Kykalos, S.; Nikiteas, N.; Sotiropoulos, G.C. Meta-analysis of laparoscopic versus open liver resection for intrahepatic cholangiocarcinoma. Updates Surg. 2021, 73, 59–68. [Google Scholar] [CrossRef]
- Abusitta, A.; Aimeur, E.; Wahab, O. Generative Adversarial Networks for Mitigating Biases in Machine Learning Systems. In Proceedings of the 24th European Conference on Artificial Intelligence—ECAI 2020, Santiago de Compostela, Spain, 29 August–8 September 2020. [Google Scholar]
- Rasheed, K.; Qayyum, A.; Ghaly, M.; Al-Fuqaha, A.; Razi, A.; Qadir, J. Explainable, trustworthy, and ethical machine learning for healthcare: A survey. Comput. Biol. Med. 2022, 149, 106043. [Google Scholar] [CrossRef]
- Theocharopoulos, C. Systems and Causal Loop Thinking in Medicine: From Healthcare Delivery to Healthcare Policy Making. Acta Eur. Syst. 2020, 8, 327–338. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Theocharopoulos, C.; Theocharopoulos, A.; Papadakos, S.P.; Machairas, N.; Pawlik, T.M. Deep Learning to Enhance Diagnosis and Management of Intrahepatic Cholangiocarcinoma. Cancers 2025, 17, 1604. https://doi.org/10.3390/cancers17101604
Theocharopoulos C, Theocharopoulos A, Papadakos SP, Machairas N, Pawlik TM. Deep Learning to Enhance Diagnosis and Management of Intrahepatic Cholangiocarcinoma. Cancers. 2025; 17(10):1604. https://doi.org/10.3390/cancers17101604
Chicago/Turabian StyleTheocharopoulos, Charalampos, Achilleas Theocharopoulos, Stavros P. Papadakos, Nikolaos Machairas, and Timothy M. Pawlik. 2025. "Deep Learning to Enhance Diagnosis and Management of Intrahepatic Cholangiocarcinoma" Cancers 17, no. 10: 1604. https://doi.org/10.3390/cancers17101604
APA StyleTheocharopoulos, C., Theocharopoulos, A., Papadakos, S. P., Machairas, N., & Pawlik, T. M. (2025). Deep Learning to Enhance Diagnosis and Management of Intrahepatic Cholangiocarcinoma. Cancers, 17(10), 1604. https://doi.org/10.3390/cancers17101604