


Empirical Study of Overfitting in Deep Learning for Predicting Breast Cancer Metastasis

Abstract
Simple Summary
Abstract
1. Introduction
2. Method
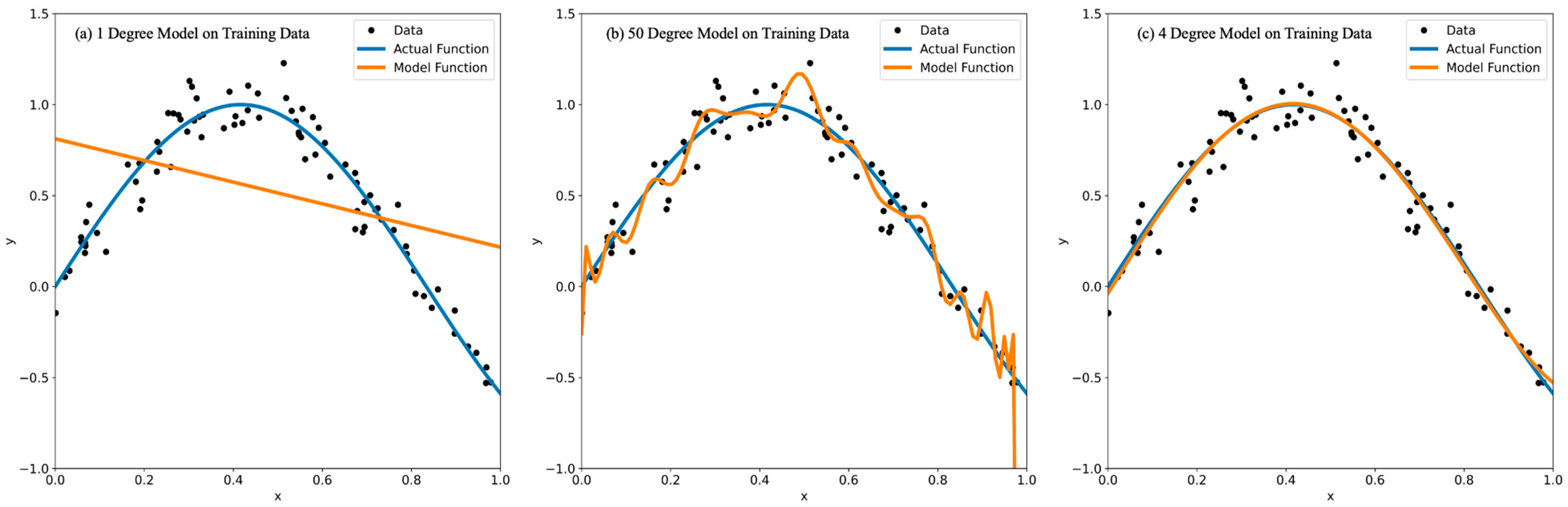
Overfitting, Hyperparameters, and Related Work
3. Experiments
- Identify a large range of values for grid search for each of the 11 hyperparameters.
- Run a unique grid search for each of the 11 hyperparameters, in which we only change the values of the targeted hyperparameter determined in step 1.
- Repeat the grid search as described in step 2 30 times for each of the 11 hyperparameters.
- Calculate the mean measurements of model overfitting and prediction performance over 30 values obtained via step 3 for each hyperparameter.
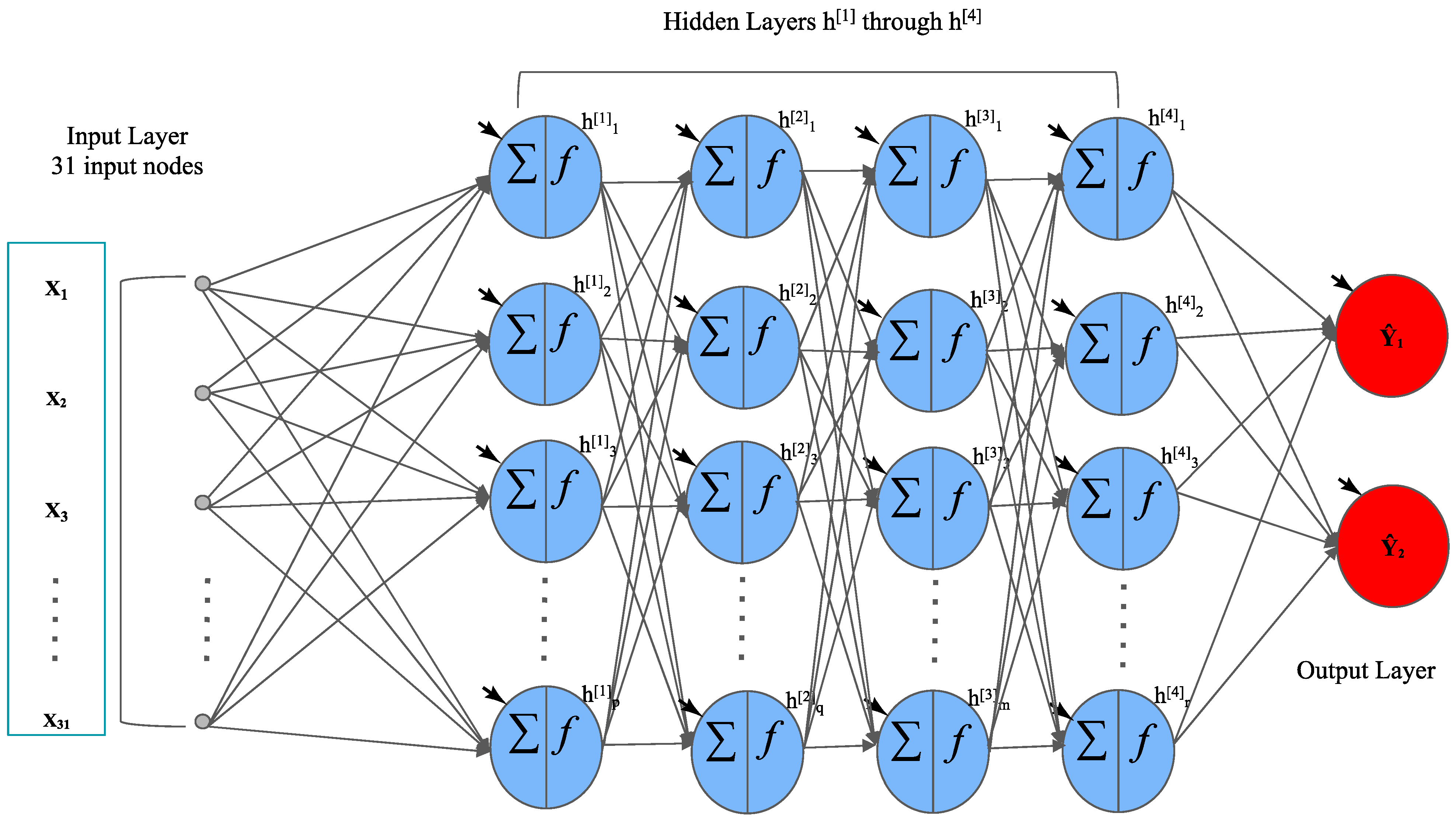
3.1. Feedforward Deep Neural Networks (FNNs)
3.2. A Unique Type of Grid Search Designed for This Study
3.2.1. Single Hyperparameter
3.2.2. Paired Hyperparameter
3.3. Evaluation Metrics and Dataset
Measurement for Prediction Performance
3.4. Measurement for Overfitting
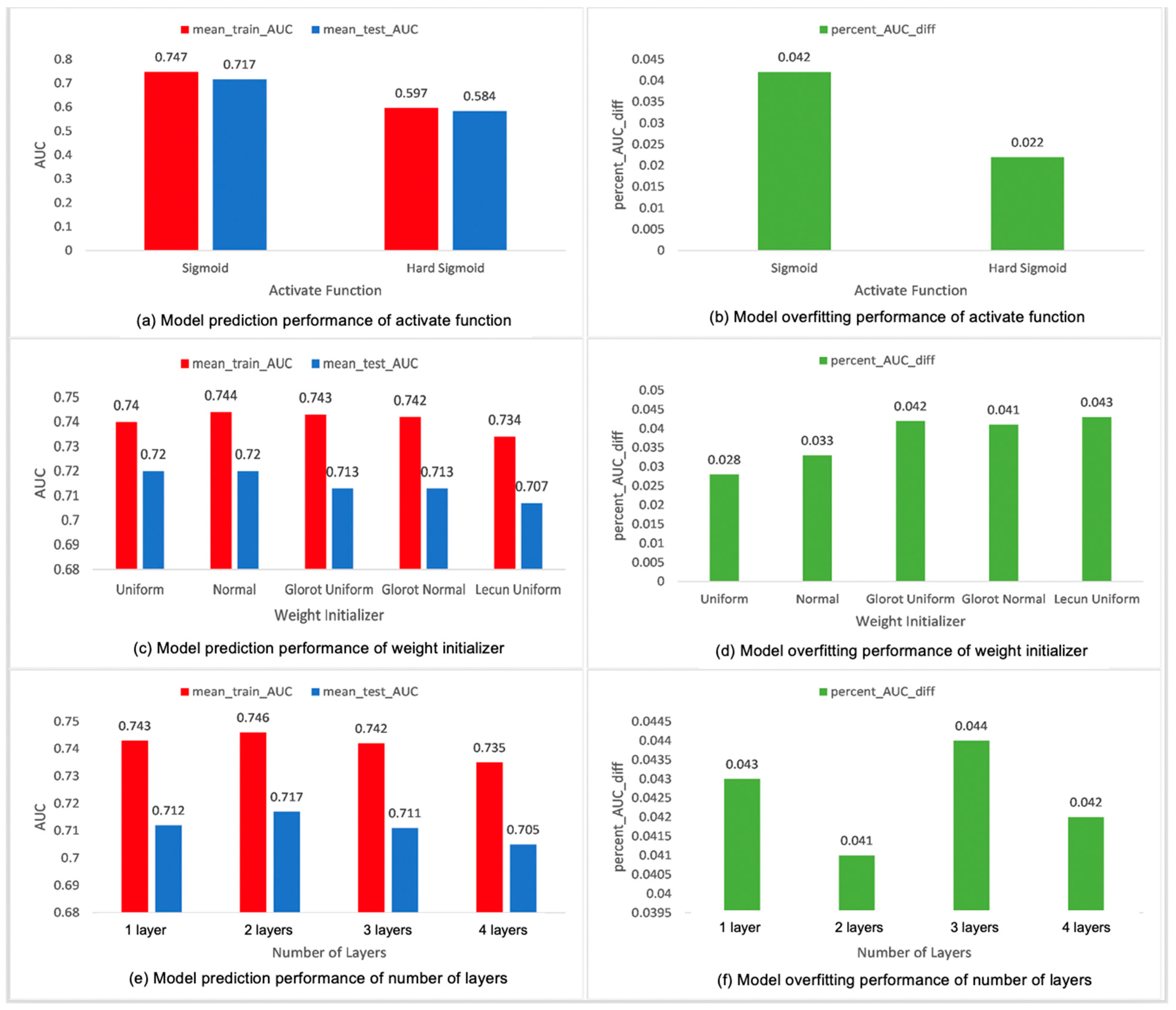
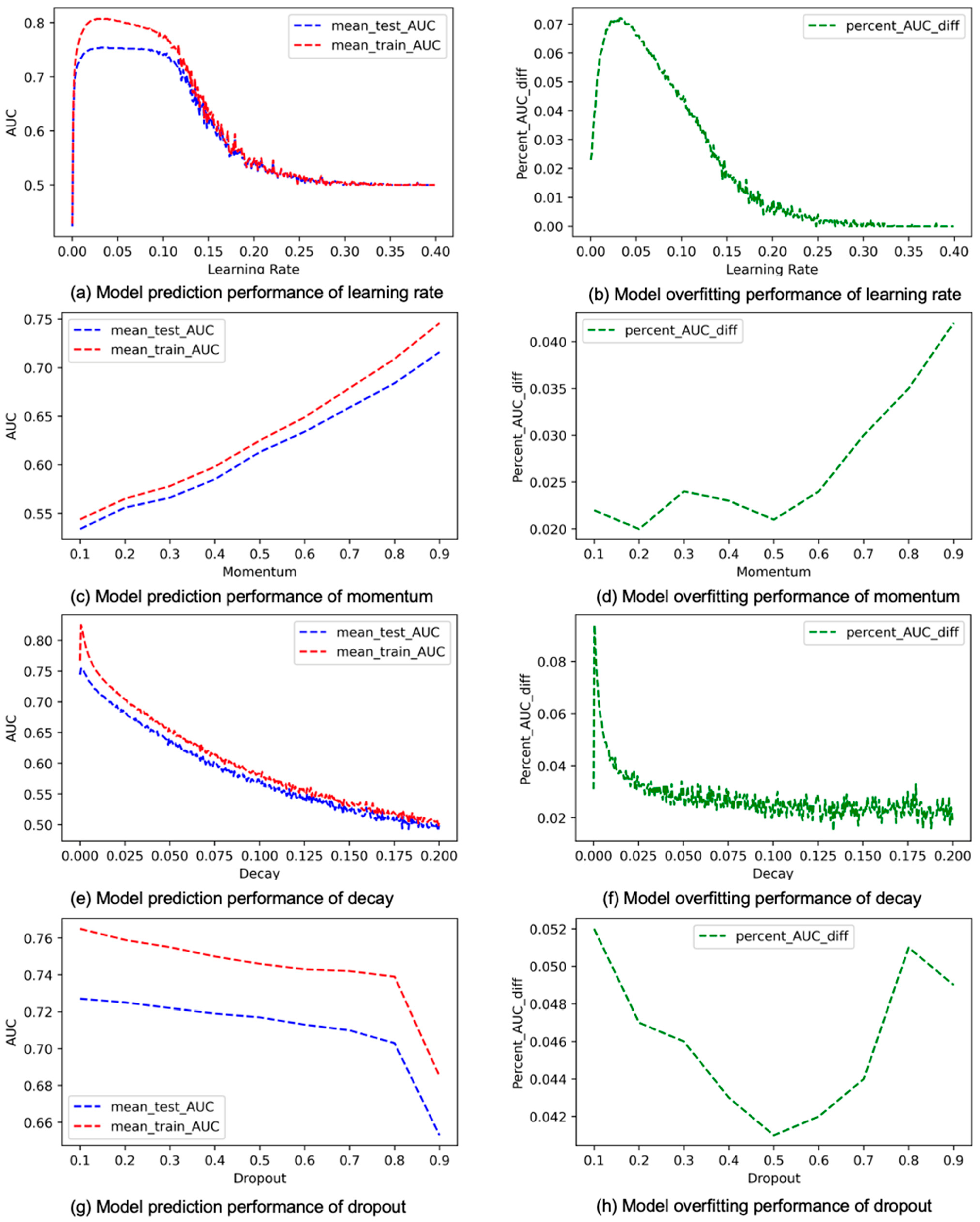
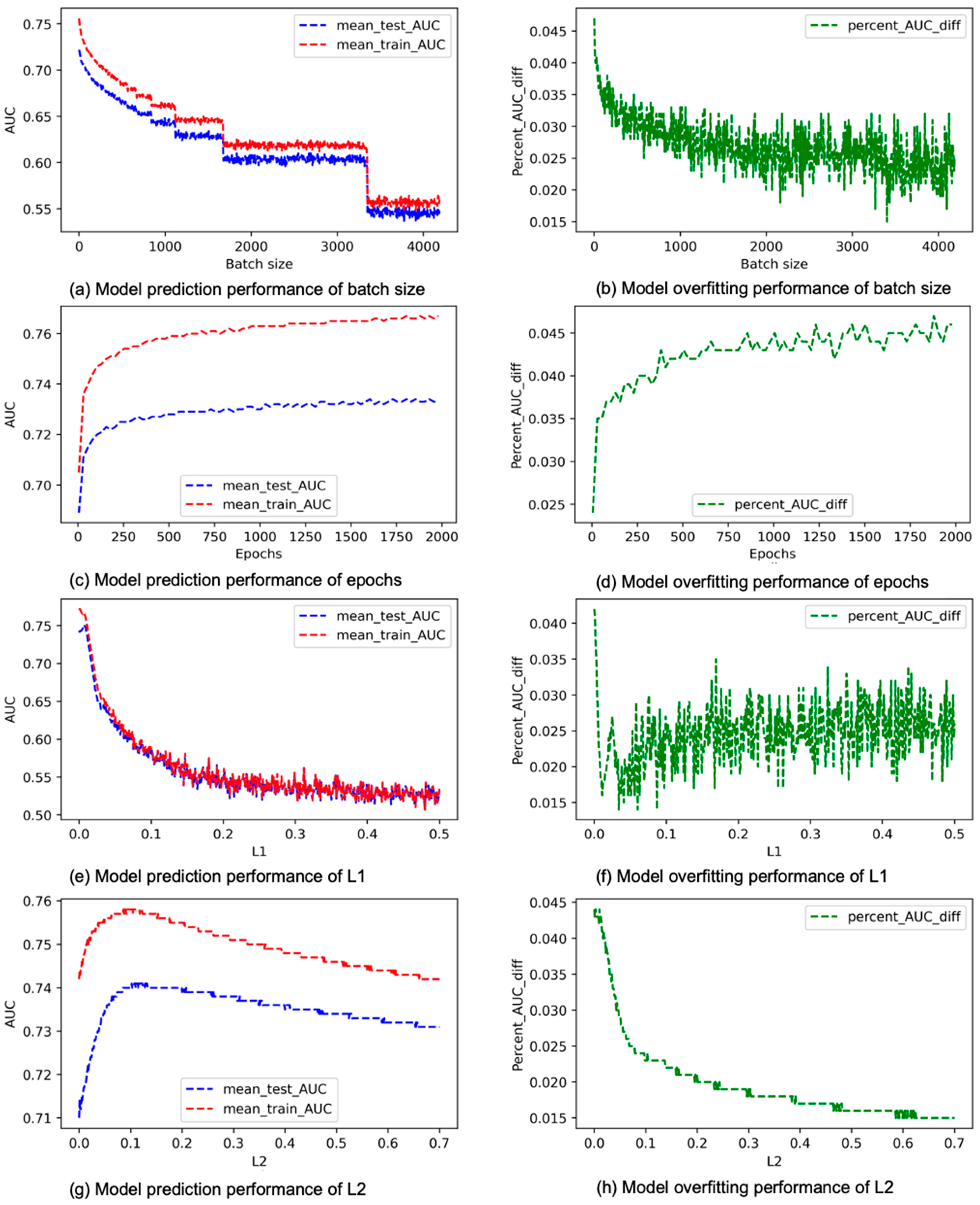
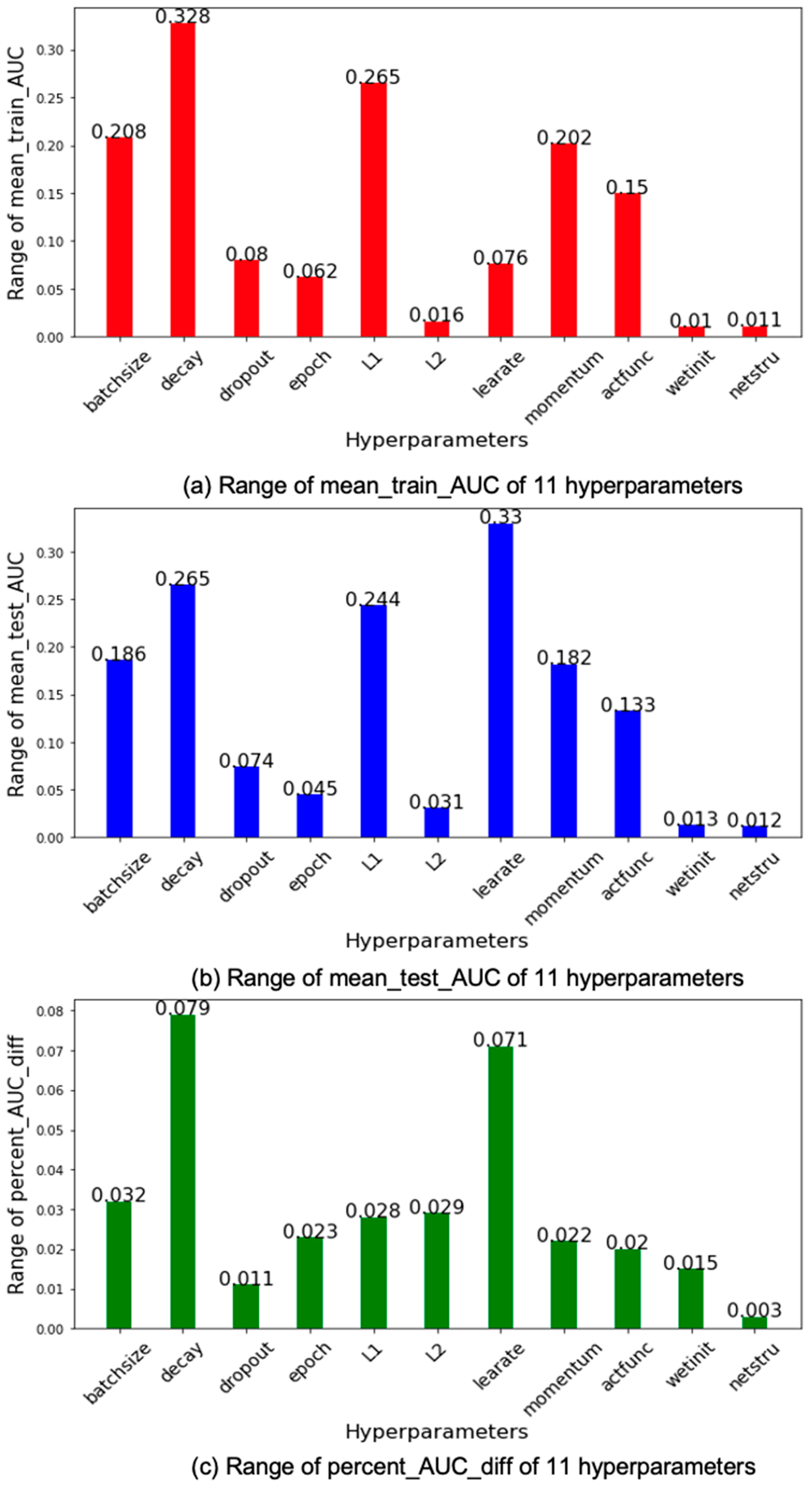
4. Results
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sung, H.; Ferlay, J.; Siegel, R.L.; Laversanne, M.; Soerjomataram, I.; Jemal, A.; Bray, F. Global Cancer Statistics 2020: GLOBOCAN Estimates of Incidence and Mortality Worldwide for 36 Cancers in 185 Countries. CA Cancer J. Clin. 2021, 71, 209–249. [Google Scholar] [CrossRef] [PubMed]
- Rahib, L.; Wehner, M.R.; Matrisian, L.M.; Nead, K.T. Estimated Projection of US Cancer Incidence and Death to 2040. JAMA Netw. Open 2021, 4, e214708. [Google Scholar] [CrossRef] [PubMed]
- Cancer Facts & Figures 2021|American Cancer Society. Available online: https://www.cancer.org/research/cancer-facts-statistics/all-cancer-facts-figures/cancer-facts-figures-2021.html (accessed on 2 December 2021).
- DeSantis, C.E.; Ma, J.; Gaudet, M.M.; Newman, L.A.; Miller, K.D.; Goding Sauer, A.; Jemal, A.; Siegel, R.L. Breast cancer statistics, 2019. CA Cancer J. Clin. 2019, 69, 438–451. [Google Scholar] [CrossRef] [PubMed]
- Afifi, A.; Saad, A.M.; Al-Husseini, M.J.; Elmehrath, A.O.; Northfelt, D.W.; Sonbol, M.B. Causes of death after breast cancer diagnosis: A US population-based analysis. Cancer 2019, 126, 1559–1567. [Google Scholar] [CrossRef] [PubMed]
- Siegel, R.L.; Miller, K.D.; Jemal, A. Cancer statistics, 2020. CA Cancer J. Clin. 2020, 70, 7–30. [Google Scholar] [CrossRef] [PubMed]
- Gupta, G.P.; Massagué, J. Cancer Metastasis: Building a Framework. Cell 2006, 127, 679–695. [Google Scholar] [CrossRef] [PubMed]
- Saritas, I. Prediction of Breast Cancer Using Artificial Neural Networks. J. Med. Syst. 2012, 36, 2901–2907. [Google Scholar] [CrossRef] [PubMed]
- Ran, L.; Zhang, Y.; Zhang, Q.; Yang, T. Convolutional Neural Network-Based Robot Navigation Using Uncalibrated Spherical Images. Sensors 2017, 17, 1341. [Google Scholar] [CrossRef] [PubMed]
- Weigelt, B.; Baehner, F.L.; Reis-Filho, J.S. The contribution of gene expression profiling to breast cancer classification, prognostication and prediction: A retrospective of the last decade. J. Pathol. 2010, 220, 263–280. [Google Scholar] [CrossRef] [PubMed]
- Belciug, S.; Gorunescu, F. A hybrid neural network/genetic algorithm applied to breast cancer detection and recurrence. Expert Syst. 2013, 30, 243–254. [Google Scholar] [CrossRef]
- Lawrence, S.; Giles, C.L. Overfitting and neural networks: Conjugate gradient and backpropagation. Proc. Int. Jt. Conf. Neural Netw. 2000, 1, 114–119. [Google Scholar] [CrossRef]
- Li, Z.; Kamnitsas, K.; Glocker, B. Overfitting of Neural Nets Under Class Imbalance: Analysis and Improvements for Segmentation. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI 2019, Shenzhen, China, 13–17 October 2019; Lecture Notes in Computer Science. Springer: Cham, Switzerland, 2019; Volume 11766, pp. 402–410. [Google Scholar]
- IBM Cloud Education. “What Is Underfitting?” IBM, 21 March 2021. Available online: https://www.ibm.com/cloud/learn/underfitting#toc-ibm-and-un-6BYka0Vn (accessed on 30 June 2022).
- Koehrsen, W. “Overfitting vs. Underfitting: A Complete Example”, towards Data Science 28 January 2018. Available online: https://towardsdatascience.com/overfitting-vs-underfitting-a-complete-example-d05dd7e19765 (accessed on 30 June 2022).
- Ying, X. An Overview of Overfitting and its Solutions. J. Phys. Conf. Ser. 2019, 1168, 022022. [Google Scholar] [CrossRef]
- Arif, R.B.; Siddique, A.B.; Khan, M.M.R.; Oishe, M.R. Study and Observation of the Variations of Accuracies for Handwritten Digits Recognition with Various Hidden Layers and Epochs using Convolutional Neural Network. In Proceedings of the 2018 4th International Conference on Electrical Engineering and Information & Communication Technology (iCEEiCT), Dhaka, Bangladesh, 13–15 September 2018; pp. 112–117. [Google Scholar] [CrossRef]
- On Dropout, Overfitting, and Interaction Effects in Deep Neural Networks|OpenReview. Available online: https://openreview.net/forum?id=68747kJ0qKt (accessed on 30 June 2022).
- Demir-Kavuk, O.; Kamada, M.; Akutsu, T.; Knapp, E.-W. Prediction using step-wise L1, L2 regularization and feature selection for small data sets with large number of features. BMC Bioinform. 2011, 12, 412. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Li, J.; Guan, X.; Liang, B.; Lai, Y.; Luo, X. Research on Overfitting of Deep Learning. In Proceedings of the 2019 15th International Conference on Computational Intelligence and Security (CIS), Macao, China, 13–16 December 2019; pp. 78–81. [Google Scholar] [CrossRef]
- Suk, H.-I. Chapter 1—An Introduction to Neural Networks and Deep Learning. In Deep Learning for Medical Image Analysis; Zhou, S.K., Greenspan, H., Shen, D., Eds.; Academic Press: Cambridge, MA, USA, 2017; pp. 3–24. ISBN 9780128104088. [Google Scholar] [CrossRef]
- Li, S.; Song, W.; Member, S.; Fang, L.; Member, S.; Chen, Y.; Ghamisi, P.; Atli Benediktsson, J. Deep Learning for Hyperspectral Image Classification: An Overview. Available online: http://www.webofknowledge.com/WOS (accessed on 29 June 2022).
- Jiang, X.; Xu, C. Deep Learning and Machine Learning with Grid Search to Predict Later Occurrence of Breast Cancer Metastasis Using Clinical Data. J. Clin. Med. 2022, 11, 5772. [Google Scholar] [CrossRef] [PubMed]
- Dropout: A Simple Way to Prevent Neural Networks from Overfitting. Available online: https://jmlr.org/papers/v15/srivastava14a.html (accessed on 8 July 2022).
- SGD: General Analysis and Improved Rates. Available online: http://proceedings.mlr.press/v97/qian19b (accessed on 8 July 2022).
- Tschiatschek, S.; Paul, K.; Pernkopf, F. Integer Bayesian Network Classifiers. In Machine Learning and Knowledge Discovery in Databases; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2014; Volume 8726, pp. 209–224. [Google Scholar] [CrossRef]
- Control Batch Size and Learning Rate to Generalize Well: Theoretical and Empirical Evidence. Available online: https://proceedings.neurips.cc/paper/2019/hash/dc6a70712a252123c40d2adba6a11d84-Abstract.html (accessed on 8 July 2022).
- Wang, D.; Khosla, A.; Gargeya, R.; Irshad, H.; Beck, A.H. Deep Learning for Identifying Metastatic Breast Cancer. 2016. Available online: https://arxiv.org/abs/1606.05718v1 (accessed on 5 August 2021).
- Nih, A. The Precision Medicine Initiative Cohort Program—Building a Research Foundation for 21st Century Medicine. 2015. Available online: https://acd.od.nih.gov/documents/reports/DRAFT-PMI-WG-Report-9-11-2015-508.pdf (accessed on 19 March 2023).
- Jiang, X.; Wells, A.; Brufsky, A.; Neapolitan, R. A clinical decision support system learned from data to personalize treatment recommendations towards preventing breast cancer metastasis. PLoS ONE 2019, 14, e0213292. [Google Scholar] [CrossRef] [PubMed]
- Jiang, X.; Wells, A.; Brufsky, A.; Shetty, D.; Shajihan, K.; Neapolitan, R.E. Leveraging Bayesian networks and information theory to learn risk factors for breast cancer metastasis. BMC Bioinform. 2020, 21, 298. [Google Scholar] [CrossRef] [PubMed]
- Huang, J.; Ling, C. Using AUC and accuracy in evaluating learning algorithms. IEEE Trans. Knowl. Data Eng. 2005, 17, 299–310. [Google Scholar] [CrossRef]
- Brownlee, J. How to Grid Search Hyperparameters for Deep Learning Models in Python With Keras. Available online: https://machinelearningmastery.com/grid-search-hyperparameters-deep-learning-models-python-keras/ (accessed on 29 June 2022).
- Ramachandran, P.; Zoph, B.; Le, Q.V. Google Brain, “Searching for Activation Functions” 6th Int. Conf. Learn. Represent. ICLR 2018—Work. Track Proc. 2017. Available online: https://arxiv.org/abs/1710.05941v2 (accessed on 2 December 2021).
- Gulcehre, C.; Moczulski, M.; Denil, M.; Bengio, Y. Noisy Activation Functions. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016. [Google Scholar]
- Kumar, S.K. On Weight Initialization in Deep Neural Networks. 2017. Available online: https://arxiv.org/abs/1704.08863v2 (accessed on 2 December 2021).
- Li, H.; Krček, M.; Perin, G. A Comparison of Weight Initializers in Deep Learning-Based Side-Channel Analysis. In Applied Cryptography and Network Security Workshops. ACNS 2020; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2020; pp. 126–143. [Google Scholar] [CrossRef]
- Darmawahyuni, A.; Nurmaini, S.; Sukemi; Caesarendra, W.; Bhayyu, V.; Rachmatullah, M.N. Firdaus Deep Learning with a Recurrent Network Structure in the Sequence Modeling of Imbalanced Data for ECG-Rhythm Classifier. Algorithms 2019, 12, 118. [Google Scholar] [CrossRef]
- Schraudolph, N.; Cummins, F. Momentum and Learning Rate Adaptation. Introduction to Neural Networks. 2006. Available online: https://cnl.salk.edu/~schraudo/teach/NNcourse/momrate.html (accessed on 30 June 2022).
- Vasani, D. This Thing Called Weight Decay. Towards Data Science. 2019. Available online: https://towardsdatascience.com/this-thing-called-weight-decay-a7cd4bcfccab (accessed on 1 July 2022).
- Srivastava, N. Improving Neural Networks with Dropout. Master’s Thesis, University of Toronto, Toronto, ON, Canada, 2013. [Google Scholar]
- Zaremba, W.; Sutskever, I.; Vinyals, O.; Brain, G. Recurrent Neural Network Regularization. arXiv 2014. [Google Scholar] [CrossRef]
- Brownlee, J. What is the Difference Between a Batch and an Epoch in a Neural Network? 2018. Available online: https://machinelearningmastery.com/difference-between-a-batch-and-an-epoch/ (accessed on 30 June 2022).
- Mandy, D. Batch Size in a Neural Network Explained, Deeplizard. 2017. Available online: https://deeplizard.com/learn/video/U4WB9p6ODjM (accessed on 1 July 2022).
- Ng, A.Y. L1 and L2 regularisation comparisation. In Proceedings of the 21st International Conference on Machine Learning, Banff, AB, Canada, 4–8 July 2004. [Google Scholar]
- Bekta, S.; Iman, Y. The comparison of L 1 and L 2-norm minimization methods. Int. J. Phys. Sci. 2010, 5, 1721–1727. Available online: http://www.academicjournals.org/IJPS (accessed on 30 June 2022).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameters (Number of Values Tested) | Values Tested | Base Values |
|---|---|---|
| 1. Activation function for output layer (2) |
| Sigmoid |
| 2. Weight initializers (5) |
| Glorot_Normal |
| 3. Number of hidden layers (4) |
| 2 |
| 4. Learning rate (400) | 0.001–0.4 with step size 0.001 | 0.005 |
| 5. Momentum beta (9) | 0.1–0.9 with step size 0.1 | 0.9 |
| 6. Iteration-based decay (400) | 0–0.2 with step size 0.0005 | 0.01 |
| 7. Dropout rate (9) | 0.1–0.9 with step size 0.1 | 0.5 |
| 8. Training epochs (80) | 5–2000 with step size 25 | 100 |
| 9. Batch size (838) | 1–4186 (dataset size) with step size 15 | 10 |
| 10. L1 (501) | 0–0.5 with step size 0.001 | 0 |
| 11. L2 (701) | 0–0.7 with step size 0.001 | 0.008 |
| Paired Hyperparameters | First Hyperparameter (Number of Values) | Second Hyperparameter (Number of Values) |
|---|---|---|
| Learning rate and momentum | 0.01–0.2 with step size 0.01 (20) | 0.1–0.9 with step size 0.005 (9) |
| Learning rate and iteration decay | 0.01–0.2 with step size 0.01 (20) | 0.005–0.1 with step size 0.005 (20) |
| Batch size and epochs | 1–1500 at a step size of 50 (30) | 5–500 at a step size of 25 (20) |
| L1 and L2 | 0–0.01 with step size 0.001 and 0.02 (12) | 0–0.01 with step size 0.001 and 0.02 (12) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, C.; Coen-Pirani, P.; Jiang, X. Empirical Study of Overfitting in Deep Learning for Predicting Breast Cancer Metastasis. Cancers 2023, 15, 1969. https://doi.org/10.3390/cancers15071969
Xu C, Coen-Pirani P, Jiang X. Empirical Study of Overfitting in Deep Learning for Predicting Breast Cancer Metastasis. Cancers. 2023; 15(7):1969. https://doi.org/10.3390/cancers15071969
Chicago/Turabian StyleXu, Chuhan, Pablo Coen-Pirani, and Xia Jiang. 2023. "Empirical Study of Overfitting in Deep Learning for Predicting Breast Cancer Metastasis" Cancers 15, no. 7: 1969. https://doi.org/10.3390/cancers15071969
APA StyleXu, C., Coen-Pirani, P., & Jiang, X. (2023). Empirical Study of Overfitting in Deep Learning for Predicting Breast Cancer Metastasis. Cancers, 15(7), 1969. https://doi.org/10.3390/cancers15071969