1. Introduction
Worldwide, the number of cancer cases is increasing at a faster rate than it ever has before. Multimodal medical imaging is utilized for diagnosing distinct kinds of cancers with the help of whole slide images (WSIs), MRIs, CT scans, and more [
1]. The manual detection of cancer, with the help of imaging, was a time-consuming procedure, and it relied on the expertise of the consultant or doctor [
2]. As a result, a high death rate is linked with late cancer detection, and a computer-aided diagnosis (CAD) technique which recognizes a tumor precisely within the time limitations has become necessary. Therefore, initial identification was the key factor to curing cancer [
3]. The golden standard for determining the breast cancer (BC) prognosis was, until now, a pathological analysis. A pathological analysis generally acquires cancer samples via excision, puncture, and so on [
4]. Hematoxylin binds to deoxyribonucleic acid (DNA) to highlight the nucleus, whereas eosin binds to proteins and emphasizes other frameworks. A precise prognosis of BC needs skilled histopathologists and consumes more effort and time to finish the task. Additionally, the diagnosis outcome of discrete histopathologists were the not same, and they mainly relied on the prior knowledge of the histopathologists [
5]. This lead to an average diagnosis accuracy and a lower diagnosis consistency of 75%.
However, the study of the histopathological images (HIs) is a challenging and time-consuming task which requires professional expertise. Additionally, the analysis outcome can be affected through the experience level of the diagnosticians involved [
6]. Thus, the computer-aided study of HIs serves a crucial role in BC diagnosis. However, the procedure of advancing the tools to perform the study has been hindered by the following difficulties: Firstly, the HIs of BC were finely grained, higher-resolution images which represent complex textures and rich geometric structures. The changes in a class and the consistency among the classes could cause the categorization to be highly complex, particularly for situations with many classes [
7,
8]. Secondly, we considered the constraints of feature extraction (FE) techniques for the HIs of BC.
Conventional FE approaches such as the gray-level co-occurrence matrix (GLCM) and scale invariant feature transform (SIFT) depend upon supervised information. In addition to that, earlier knowledge about the data was required for selecting the valuable features that cause the FE efficiency to be low and the computational load to be high [
9]. Therefore, this might result in the final model generating the worst classification of outcomes. Deep learning (DL) methods are capable of extracting features automatically, restoring information from data mechanically, and studying enhanced abstract data representations [
10]. It could resolve the issues of conventional FS, and it has been applied in computer vision (CV) successfully and also in biomedical science and in other domains.
This article presents a model of an improved bald eagle search optimization with a synergic deep learning mechanism for breast cancer diagnosis using histopathological images (IBESSDL-BCHI). The proposed IBESSDL-BCHI model follows image preprocessing using a median filtering (MF) technique as a preprocessing step. In addition, a feature extraction using a synergic deep learning (SDL) model was carried out, and the hyperparameters related to the SDL mechanism were tuned by the use of an IBES model. At last, the long short-term memory (LSTM) system was utilized for precisely categorizing the HIs into two major classes: benign and malignant. The performance validation of the IBESSDL-BCHI method was tested using the benchmark dataset. The key contributions of the paper are highlighted as follows:
An intelligent IBESSDL-BCHI technique comprising of MF-based pre-processing, SDL feature extraction, IBES-based parameter optimization, and an LSTM model for BC detection and classification using HIs is presented. To the best of our knowledge, the IBESSDL-BCHI model has never been presented in the literature.
A novel IBES algorithm is designed by the integration of oppositional-based learning with the traditional BES algorithm.
Hyperparameter optimization of the SDL model using the IBES algorithm using cross-validation helps to boost the classification outcome of the IBESSDL-BCHI model for unseen data.
2. Related Works
In the study that was conducted earlier [
11], a new patch-related DL technique named Pa-DBN-BC was suggested for the detection and classification of BC on histopathology images using a Deep Belief Network (DBN). In this technique, the features can be derived via conducting supervised fine-tuned and unsupervised pre-training stages. The network automatically extracts the features from the image stains. In the literature [
12], the researchers compared two ML techniques for the automatic classification of BC histology images as either malevolent or benevolent and their respective sub-classes. The initial technique was designed based on the abstraction of a group of handcrafted features that are encrypted with Bag of Words (BoW) and locality-constrained linear coding, and it was well-trained through an SVM classifier. The next method was designed based on a CNN model.
In the literature [
13], the researchers suggested a method to use DL techniques with convolutional layers for the extraction of valuable visual features and classify the BC. It was revealed that such DL techniques can derive superior features in comparison with the handcrafted FS methods. It further suggests a new advanced strategy to achieve the primary objective. Further, the model can be effectively improved through the progressive merging of the DL methods with weak classifiers as a stronger classifier. Xie et al. [
14] presented a new model for the analysis of HIs of BC through unsupervised and supervised deep CNN networks. At first, it adapted Inception_ResNet_V2 and Inception_V3 infrastructures to binary and multi-class problems of BC-HI classification with the help of Transfer Learning (TL) approaches.
In the study that was conducted earlier [
15], the authors recommended a system for BC classification with an Inception Recurrent Residual (IRRCNN) method. The proposed IRRCNN is a powerful DCNN method since it combines the robustness of Recurrent RCNN, v4ResNet, and the Inception technique. The proposed IRRCNN method achieved better outcomes towards the equivalent networks, Inception Networks, and the RCNNs in terms of an object recognition task. Yang et al. [
16] suggested to employ further regional-level supervision for BC classification of the HIs using the CNN technique. In this method, the RoIs were localized and utilized for guiding the interest of the classifier network concurrently. The presented supervised attention algorithm precisely stimulated the neurons in the diagnostic-related areas, whereas it suppressed the stimulations in the inappropriate and noisy regions.
Ali et al. [
17] presented an effective DL model to exploit the small dataset and learn generalizable and domain-invariant representation in various medical imaging applications for diseases such as malaria, Diabetic Retinopathy, and tuberculosis. This model was named the Incremental Modular Network Synthesis (IMNS), and the resultant CNNs were the Incremental Modular Networks (IMNets). The authors in the study conducted earlier [
18] developed a cloud-enabled Android app to detect breast cancer using the ResNet101 model. The proposed framework was cost-effective, and it demanded less human intervention as it was cloud integrated. So, a lower performance load was placed on the edge devices. Narayanan et al. [
19] presented a novel Deep Convolutional Neural Network architecture for the Invasive Ductal Carcinoma (IDC) classification process.
3. The Proposed Model
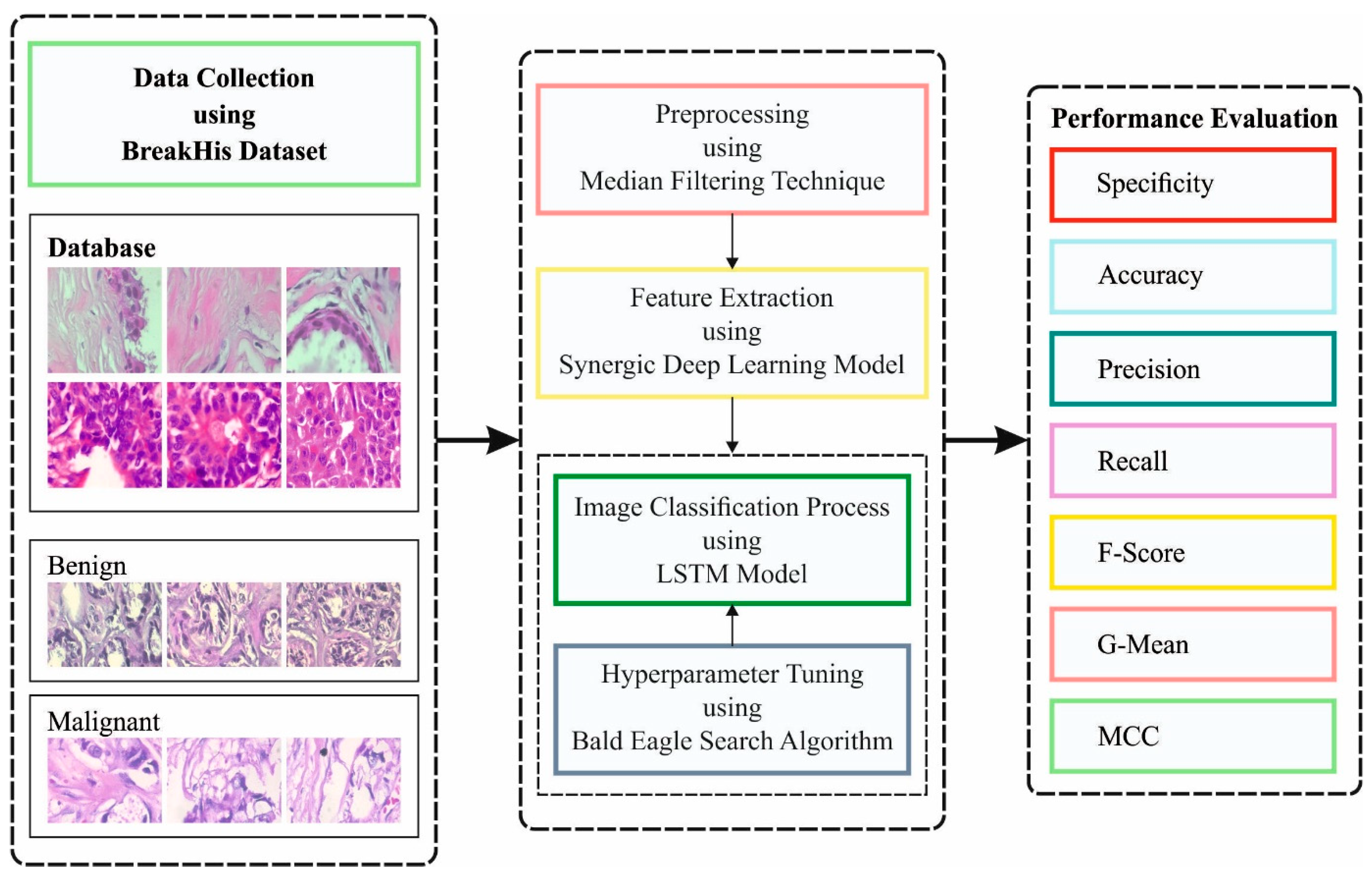
In the current study, a new IBESSDL-BCHI method has been developed for the recognition and classification of BC using the HIs. The presented IBESSDL-BCHI method follows a series of processes, namely, MF-based noise removal, SDL feature extraction, IBES-based hyperparameter optimization, and LSTM classification. The design of the IBES algorithm helps in precisely categorizing the HIs into two major classes, namely, benign and malignant.
Figure 1 depicts the workflow of the proposed IBESSDL-BCHI approach.
3.1. Image Preprocessing
Initially, the Median Filtering (MF) technique was utilized to preprocess the input HIs. MF is a nonlinear digital filter method that is frequently utilized in the removal of noise from images/signals. Such noise reduction is a classical pre-processing phase that is performed to enhance the outcomes in the later processes. The MF approach smoothens the HIs [
20], and its steps are as follows:
Step1: The 3 × 3 kernel needs zero padding 3/2 = 1 column of 0′s at the left as well as the right edges, but it needs 3/2 = 1 row of 0′s at the upper as well as the bottom edges.
Step 2: To process the primary component, this approach covers 3 × 3 kernels with the center of them pointing at the initially handled component. The data, arranged in the kernel, were recorded with respect to the value, and the attained median value is obtained.
Step 3: We repeated the process for all of the elements until the final value was obtained.
The MF function calculates the median of every pixel in the kernel window, and the central pixel is interchanged with this median value. It can be extremely effectual in the extraction of salt-and-pepper noises. Notably, during the application of the Gaussian and box filters, the filter values to the central element remain a value that cannot occur in the original images. However, this is not the case in the MF approach since the central element is continuously exchanged with any of the pixel values of the images. This phenomenon decreases the noise in an efficient manner. The size of the kernel is a positive odd integer, and the median function is calculated as given in Equation (1).
Here,
refers to the orderly list of values from the dataset and
signifies the amount of values from the dataset.
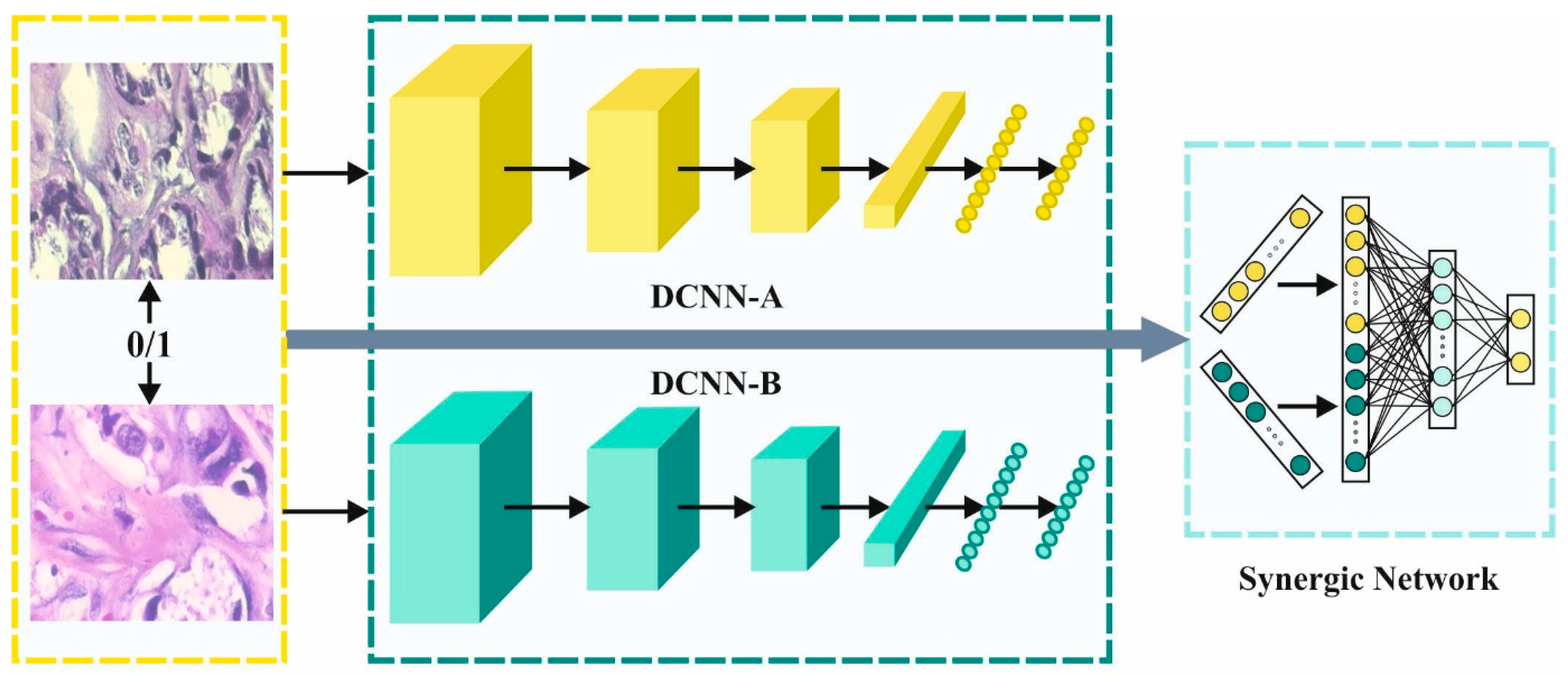
3.2. SDL-Based Feature Extraction
After the image preprocessing, the SDL model was utilized to derive the feature vectors. During the feature extraction procedure, the pre-processed images were fed into the SDL module to obtain a beneficial set of feature vectors [
21].
The SDL model extracts the feature subsets from the pre-processed images. It represents the
through three main elements such as
DCNN component, the input layer and the
synergic network (SN). Every DCNN component of the network provides an independent learning representation in the input dataset. The SN consists of the FC architecture to ensure that the input layers belong to the same class, and it offers remedial comments. Afterward, the SDL system is classified into three sub-models.
Figure 2 illustrates the architecture of the SDL network.
3.2.1. Components of DCNN
Due to the implicit nature of ResNet, ResNet-50 was exploited for initializing every DCNN component
. Therefore, it can be indicated that the DCNN network comprises of VGGNet, AlexNet, and GoogLeNet which correspond to the SDL method. This module was trained using the data sequence
and a series of the last class label,
. The aim is to progress with a group of variables
which make sure that the CE loss is offered as follows:
In Equation (2),
represents the class number and
denotes the forward computation. The group of variables obtained for DCNN-a indicates that
and the variable do not assign any massive DCNN units.
3.2.2. SDL Model
The DCNN component, using the synergic labels of the pair of embedded and the input layers, is exploited for FC learning. Assuming that
are a data pair given as the input for two DCNN features (DCNNa, DCNNb) as follows,
Next, the deep feature from the whole dataset is embedded as
, and the outcomes using the synergic label are given below.
To resolve the shortcoming, the percentage data pair from the class need to be higher. So, a simple-to-zero value is used to gauge the synergic signals using an alternate sigmoid layer, and the binary CE loss is as follows.
In Equation (6), denotes the SN attribute and indicates the SN forward computation. This validates that the input dataset pair belong to the same class, and it offers the option to remedy the synergic error.
3.2.3. Training and Testing Processes
Once the training is completed, the features of both the DCNN component and the SN become improved.
In Equation (7),
and
indicate the learning rate and SN between DCNNa and DCNNb, respectively, as given below.
Here,
denotes the trade-off between the sub-model of the classifiers and the synergic errors. The relationship between the trained process of the
models increases. In the trained
, the testing dataset
is classified using the DCNN unit, while it provides the prediction vector
which is activated from the resulting FC layer. The class labels of the testing dataset are evaluated as follows.
3.3. Hyperparameter Tuning Using IBES Algorithm
In this study, the hyperparameters related to the SDL mechanism are fine-tuned with the help of the IBES model. BES is a meta-heuristic optimization approach that imitates the behavior of bald eagle hunting [
22]. This procedure has three phases, namely, selecting the space, searching in the space, and swooping. Initially, the bald eagles choose the best place in terms of the food amount. Next, the eagle searches for prey within the nominated place. In the optimally attained location in the previous stage, the eagle swoops to determine the optimal hunting site, which is the last phase.
. Selection space: In this phase, a novel position is produced based on the subsequent formula.
In Equation (11), denotes the - recently produced location, refers to the optimally attained location, indicates the mean location, represents a control gain [1.5, 2], and indicates an arbitrary integer that lies in the range of [0, 1]. The fitness of every novel location is estimated; if the novel location offers a better fitness than the offered one , then the novel location is allocated by
. Searching in space: After the allocation of the optimal search space
is completed, the process upgrades the location of the eagles within the searching space. The update module is given herein.
In Equation (12),
denotes the
recently produced position,
indicates the mean location, and
and
denote the directional coordinates for the
location as given below.
In Equation (13), indicates a control variable that is utilized to determine the corner between the searching point and the central point, and it takes the values in the range of [5, 10]. denotes a variable within [0.5, 2], and it is utilized to determine the number of searching cycles. The fitness of the novel position is estimated, and the values are upgraded based on the attained outcomes.
. Swooping: In this phase, the eagle moves towards the prey from the optimally attained location. The hunting model is given in the following expression.
In Equation (14),
and
denote two arbitrary integers that lie in the range of [
1,
2];
and
indicate the directional coordinates that are determined as follows.
Here,
denotes the number of locations (population size), and
indicates the
number of iterations.
The IBES model is derived by the inclusion of the Oppositional-Based Learning (OBL) concept to optimize the efficiency of BES. The OBL model was highlighted by Tizoosh et al. to estimate the individual fitness, and it relates to their equivalent opposite number after bringing the optimum one into the next iteration in the OBL approach, and it is determined as follows.
Opposite number: We assume that
is a real number and
the next the opposite number
, is provided by the subsequent value as shown in Equation (16).
Here, and correspondingly denote the lower and upper boundaries, respectively.
Opposite vector: When
,
denote the real numbers and
, and then
is computed as given below.
At last, the current solution is located by , if
The IBES method resolves the Fitness Function (FF) to obtain a superior classification performance. In this study, a reduced classifier error rate is treated as FF as given below.
3.4. LSTM-Based Classification
During the image classification process, the LSTM model is used to precisely categorize the HIs under two major classes, namely, benign and malignant. Being a variant of the RNN model, the LSTM model basically differs from the classical ANN [
23]. Both the LSTM and RNN are sequence-based methods with internal self-looped repeating networks. These determines the temporal relationship amid the sequential datasets and preserve the previous information.
In the current study, the repeated module has a simple framework ( layer). denotes the output of the forget gate a, for which the values lie in the range of [0, 1].
For the above explanation, the mathematical expression is given below.
The next layer of the LSTM blocks are named as an ‘input gate’ layer as shown below.
Afterwards, the older cell state
should be upgraded to the cell state,
. The output of the forget gate
is the decision to forget, and
defines that a novel cell state has been added, i.e.,
. The update procedure of
is described below.
At last, the interacting layer is named the ‘output gate’ layer. The procedure of producing an output of the LSTM block is demonstrated herein.
In Equation (23),
shows the activation function, namely, Sigmoid, and
refers to the
function. Given that
characterizes the variable vector of the network,
and
indicate the weight and bias, respectively. The forward formulation in Equations (20)–(23) is indicated by
:
In Equation (24), indicates the overall number of labeled datasets. In the training course of LSTM, is tuned continuously by diminishing the loss function via an optimized technique, namely, SGD.
4. Results and Discussion
The proposed IBESSDL-BCHI method was experimentally validated using a benchmark Breast Cancer Histopathological Database (BreakHis) dataset [
4] comprising 1820 HIs. The dataset holds a total of 588 images under the benign class and 1,232 images under the malignant class, and the details are given in
Table 1. A few sample images are showcased in
Figure 3.
Figure 4 illustrates a set of confusion matrices generated by the proposed IBESSDL-BCHI method on the test dataset. In run 1, the IBESSDL-BCHI model classified 92 images under class ‘A’, 233 images under class ‘F’, 110 images under class ‘PT’, 126 images under ‘TA’, 771 images under ‘DC’, 109 images under class ‘LC’, 165 images under ‘MC’, and 117 images under ‘PC’.
Table 2 and
Figure 5 show the analytical outcomes of the IBESSDL-BCHI model during distinct test runs in terms of its accuracy (
), precision (
), recall (
, specificity (
), F-score (
), and G-mean (
). The experimental values infer that the proposed IBESSDL-BCHI method attained the maximum number of classification results under every run. For example, in run 1, the IBESSDL-BCHI technique attained the average
,
,
,
,
, and
values which were 98.67%, 92.79%, 92.19%, 99.18%, 92.27%, and 95.55%, respectively. Additionally, in run 2, the proposed IBESSDL-BCHI approach reached the average
,
,
,
,
and
values which were 99.48%, 97.22%, 97.29%, 99.68%, 97.20% and 98.46% correspondingly. In addition to these, in run 4, the IBESSDL-BCHI model accomplished the average
,
,
,
,
, and
values which were 98.76%, 92.99%, 94.14%, 99.26%, 93.49%, and 96.66% correspondingly. Along with that, in run 5, the IBESSDL-BCHI methodology achieved the average
,
,
,
,
, and
values which were 99.12%, 94.30%, 96.27%, 99.52%, 95.21% and 97.88% correspondingly.
Both the Training Accuracy (TA) and Validation Accuracy (VA) values obtained using the proposed IBESSDL-BCHI method using the test dataset are depicted in
Figure 6. The outcomes demonstrate that the proposed IBESSDL-BCHI methodology achieved the highest TA and VA values, while the VA values were superior to the TA values.
Both the Training Loss (TL) and Validation Loss (VL) values attained by the proposed IBESSDL-BCHI methodology using the test data are depicted in
Figure 7. The outcomes illustrate that the proposed IBESSDL-BCHI technique demonstrated minimal TL and VL values, while the VL values seemed to be smaller than the TL values.
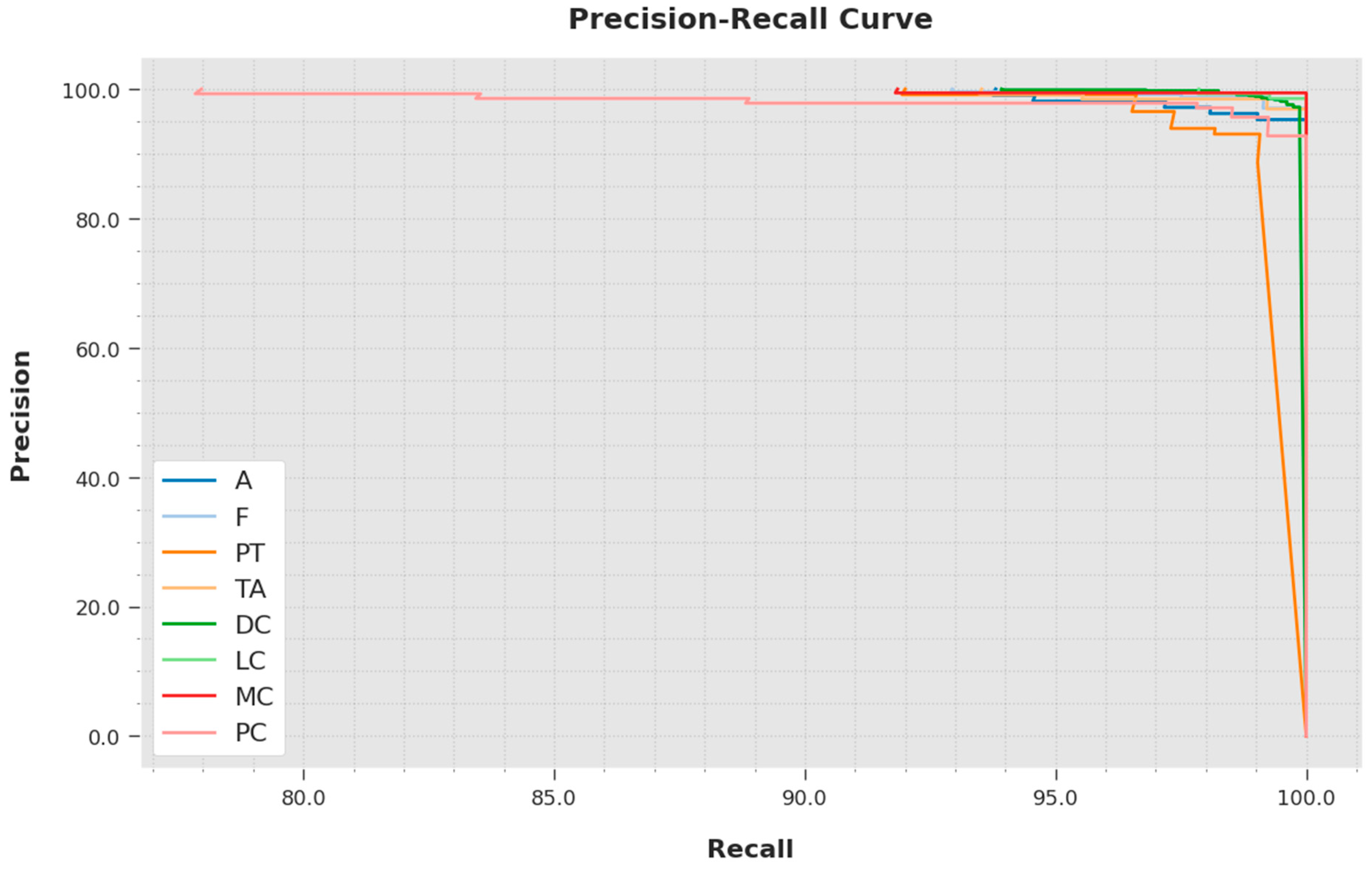
A brief precision-recall inspection was conducted with the IBESSDL-BCHI method using the test data, and the results are depicted in
Figure 8. It is to be noted that the proposed IBESSDL-BCHI approach obtained the maximal precision-recall performance under all of the classes.
A comprehensive ROC inspection was conducted on the proposed IBESSDL-BCHI system using the test dataset, and the results are portrayed in
Figure 9. The outcomes show that the proposed IBESSDL-BCHI method depicted capability in categorizing the test dataset into dissimilar classes.
Table 3 provides the overall comparison analysis outcomes achieved by the proposed IBESSDL-BCHI method and other existing models [
14,
24].
Figure 10 portrays the comparative examination outcomes of the IBESSDL-BCHI technique and other techniques in terms of
. The figure implies that the proposed IBESSDL-BCHI system achieved enhanced
values. With respect to
, the IBESSDL-BCHI approach obtained a maximum
of 0.9963, whereas the rest of the methods such as the GLCM-KNN, GLCM-NB, GLCM-Discrete transform, GLCM-SVM, GLCM-DL, DL-INV3, and DL-INV2 models attained low
values which were 0.7617, 0.7845, 0.8500, 0.8500, 0.9244, 0.9471, and 0.8812, respectively.
Figure 11 demonstrates the comparative investigation outcomes attained by the proposed IBESSDL-BCHI approach and other techniques in terms of
,
, and
. The figure reveals that the proposed IBESSDL-BCHI methodology produced maximum
,
, and
values. With respect to
, the IBESSDL-BCHI method obtained a superior
value of 0.9829, whereas the other models such as the GLCM-KNN, GLCM-NB, GLCM-Discrete transform, GLCM-SVM, GLCM-DL, DL-INV3, and DL-INV2 systems obtained low
values which were 0.6240, 0.8216, 0.8356, 0.8732, 0.8689 0.8757, and 0.8170, respectively. Additionally, in terms of
, the proposed IBESSDL-BCHI system obtained a maximum
value of 0.9809, whereas the GLCM-KNN, GLCM-NB, GLCM-Discrete transform, GLCM-SVM, GLCM-DL, DL-INV3, and DL-INV2 techniques attained low
values which were 0.8360, 0.8345, 0.8166, 0.8761, 0.8024 0.8707, and 0.8144, respectively.
Eventually, with regard to , the proposed IBESSDL-BCHI methodology, it gained a superior value of 0.9818, whereas the GLCM-KNN, GLCM-NB, GLCM-Discrete transform, GLCM-SVM, GLCM-DL, DL-INV3, and DL-INV2 models attained low values which were 0.8222, 0.8697, 0.8469, 0.8162, 0.8792 0.8186, and 0.8642, respectively. From the detailed discussion about the results, it is evident that the proposed IBESSDL-BCHI technique yielded an effective breast cancer classification performance.



 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}