
MVI-Mind: A Novel Deep-Learning Strategy Using Computed Tomography (CT)-Based Radiomics for End-to-End High Efficiency Prediction of Microvascular Invasion in Hepatocellular Carcinoma

 ,
,
Abstract
:Simple Summary
Abstract
1. Introduction
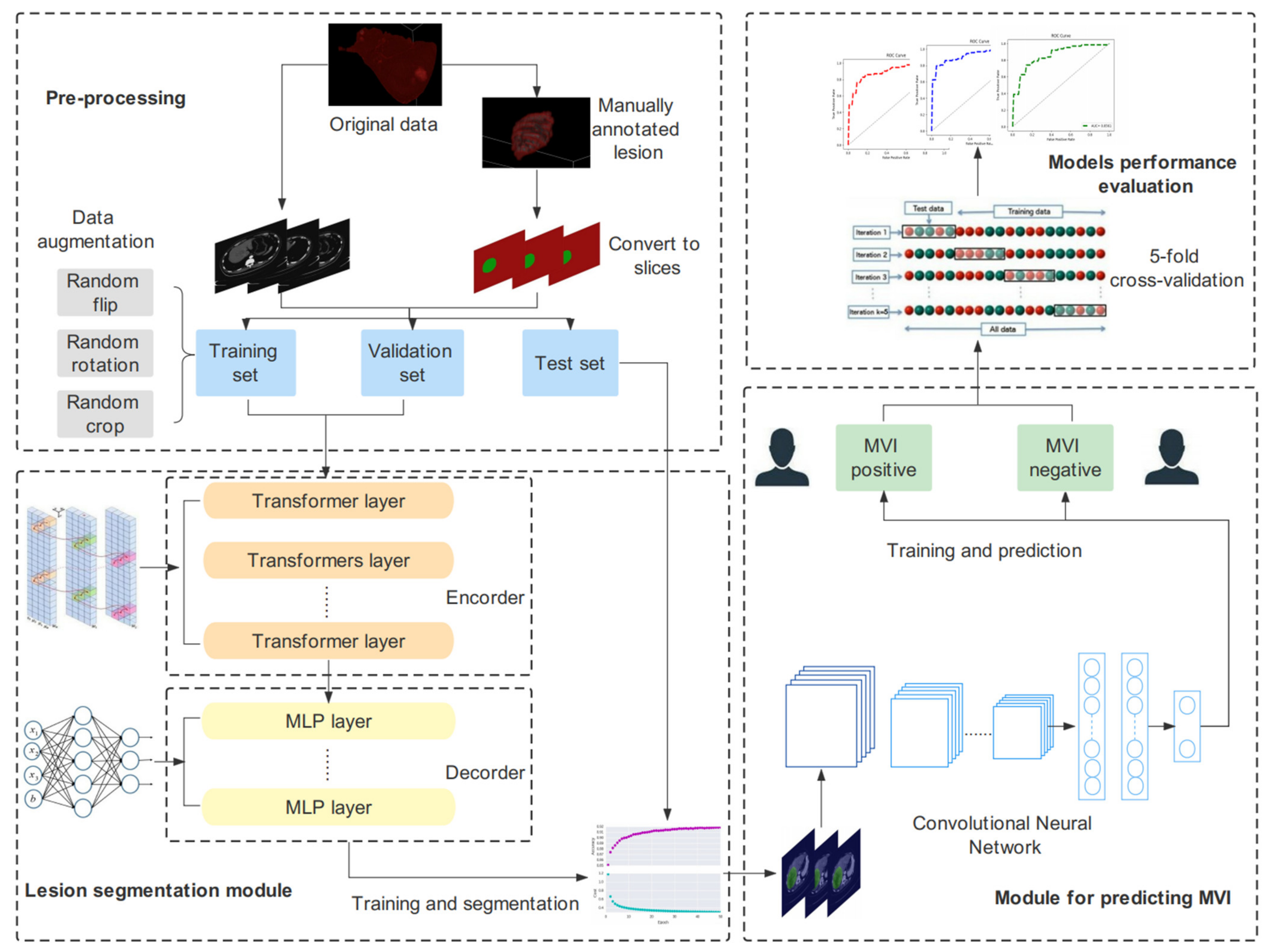
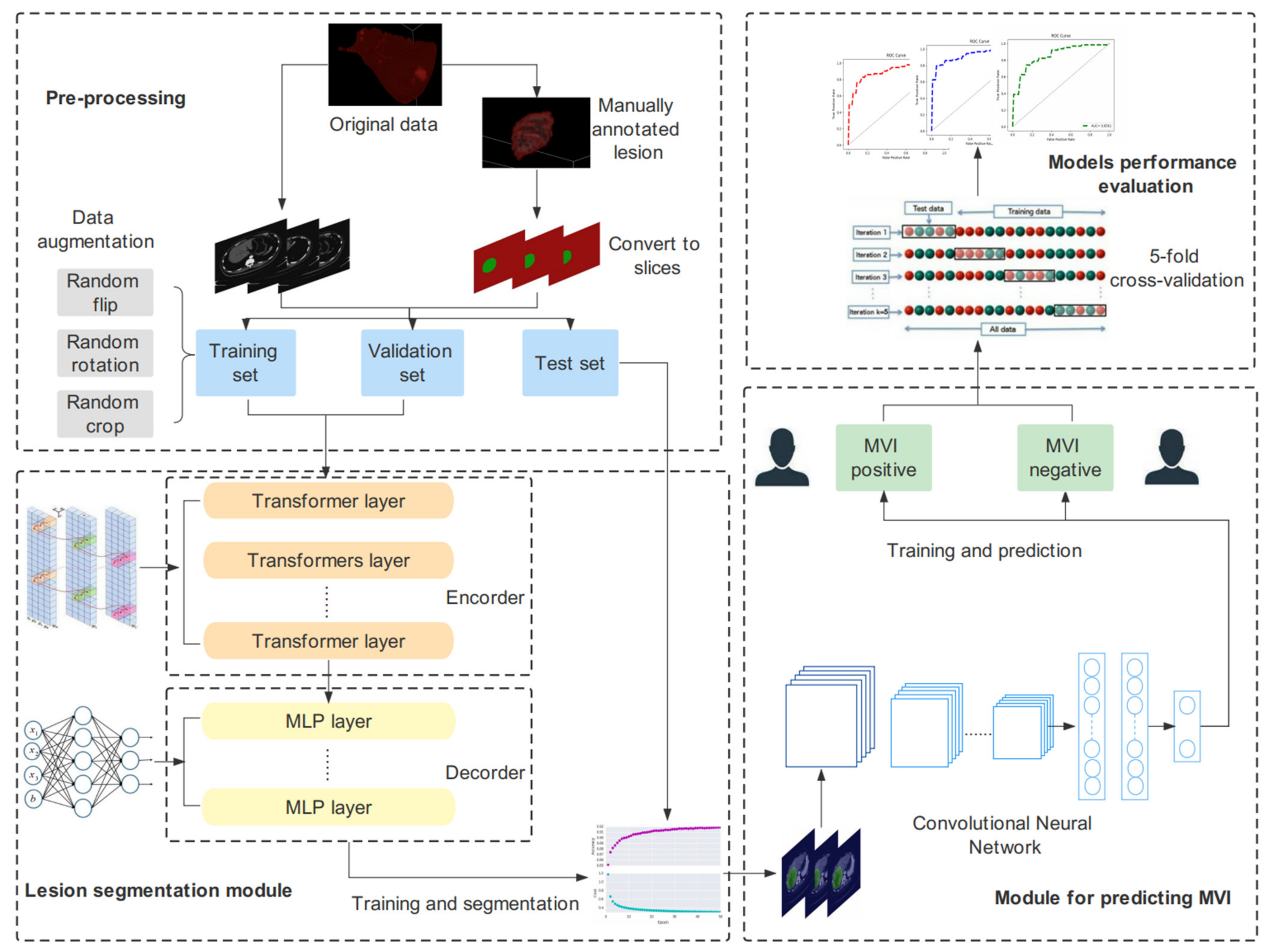
2. Materials and Methods
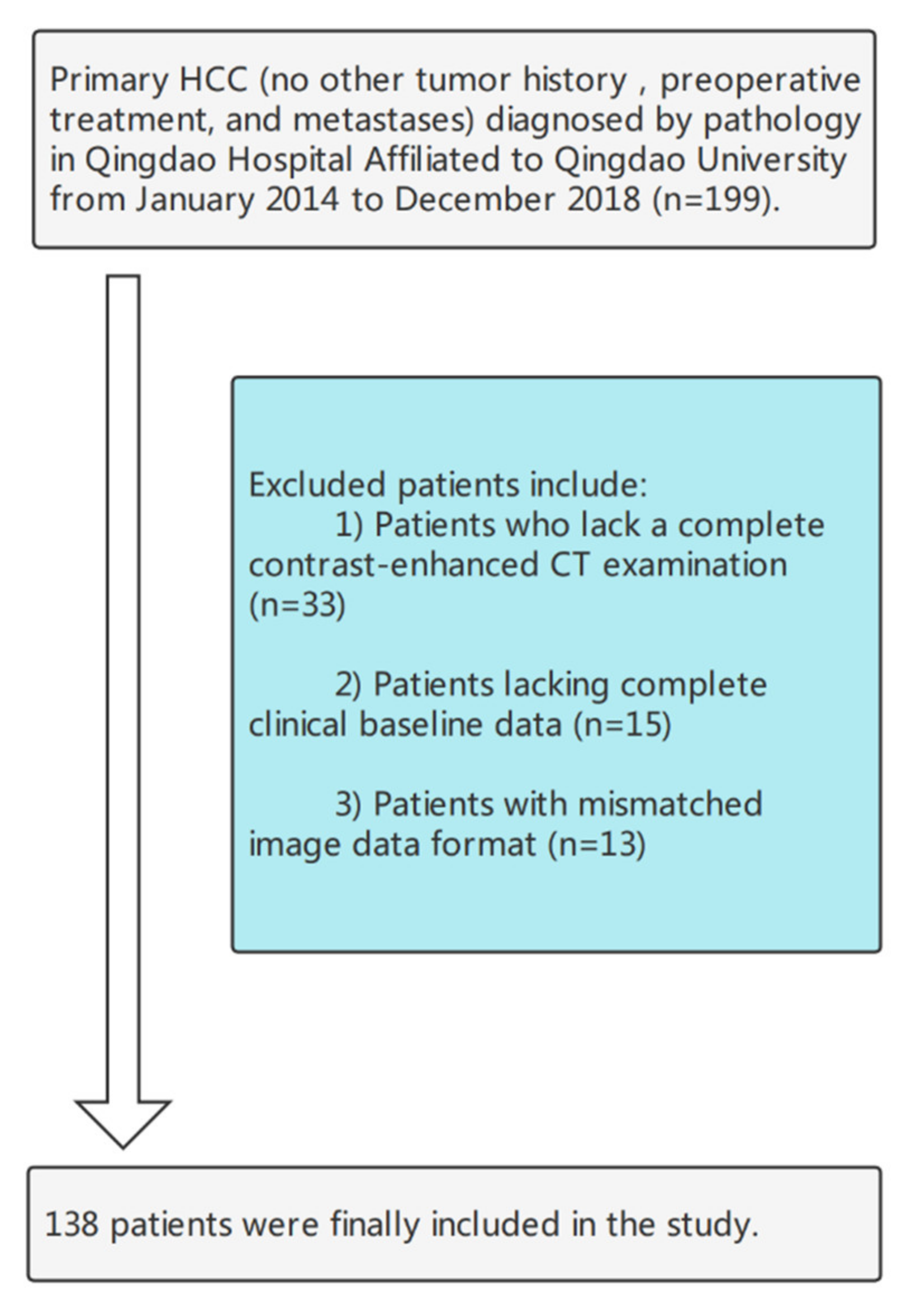
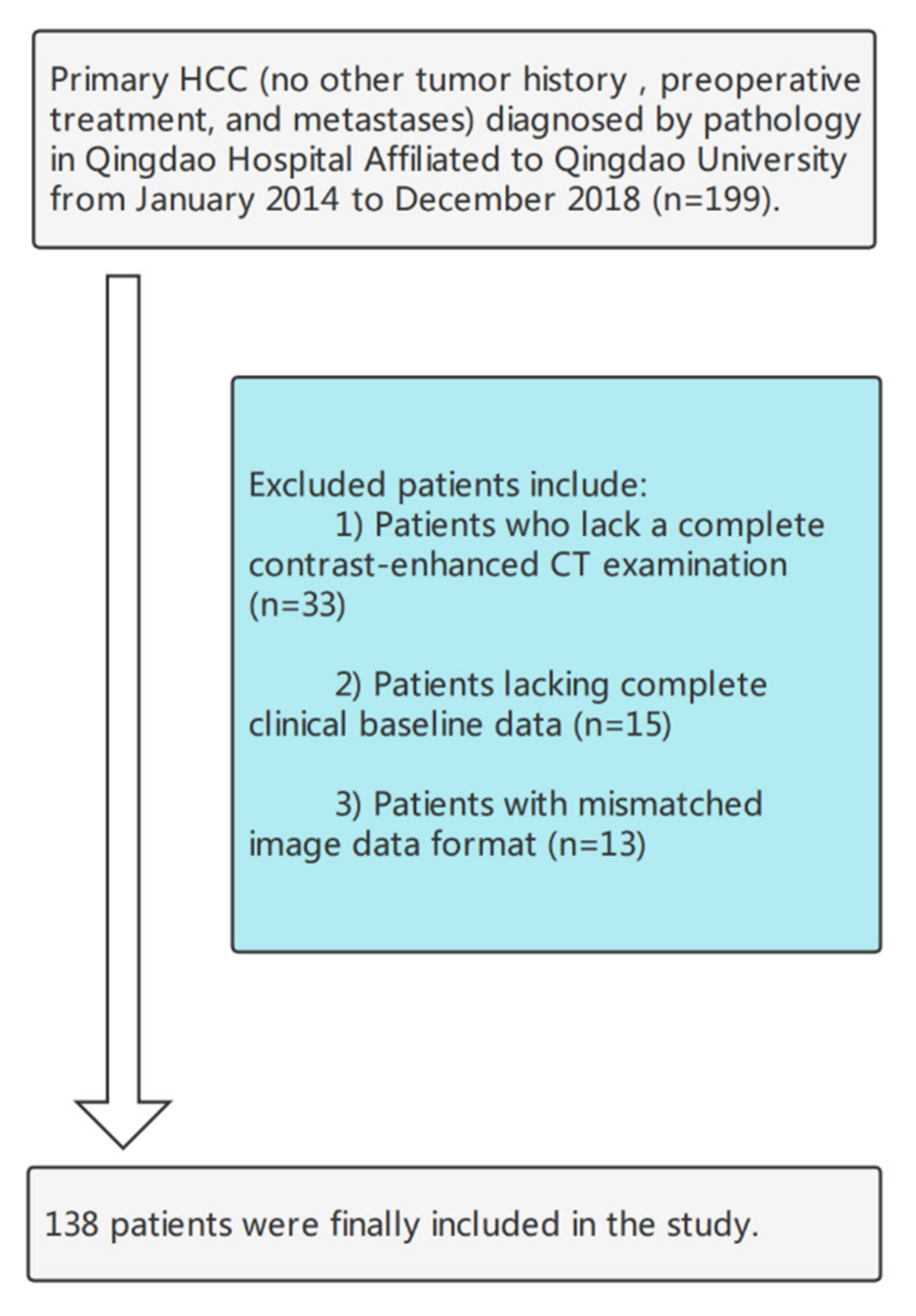
2.1. Patients
2.2. Imaging Acquisition and Preprocessing
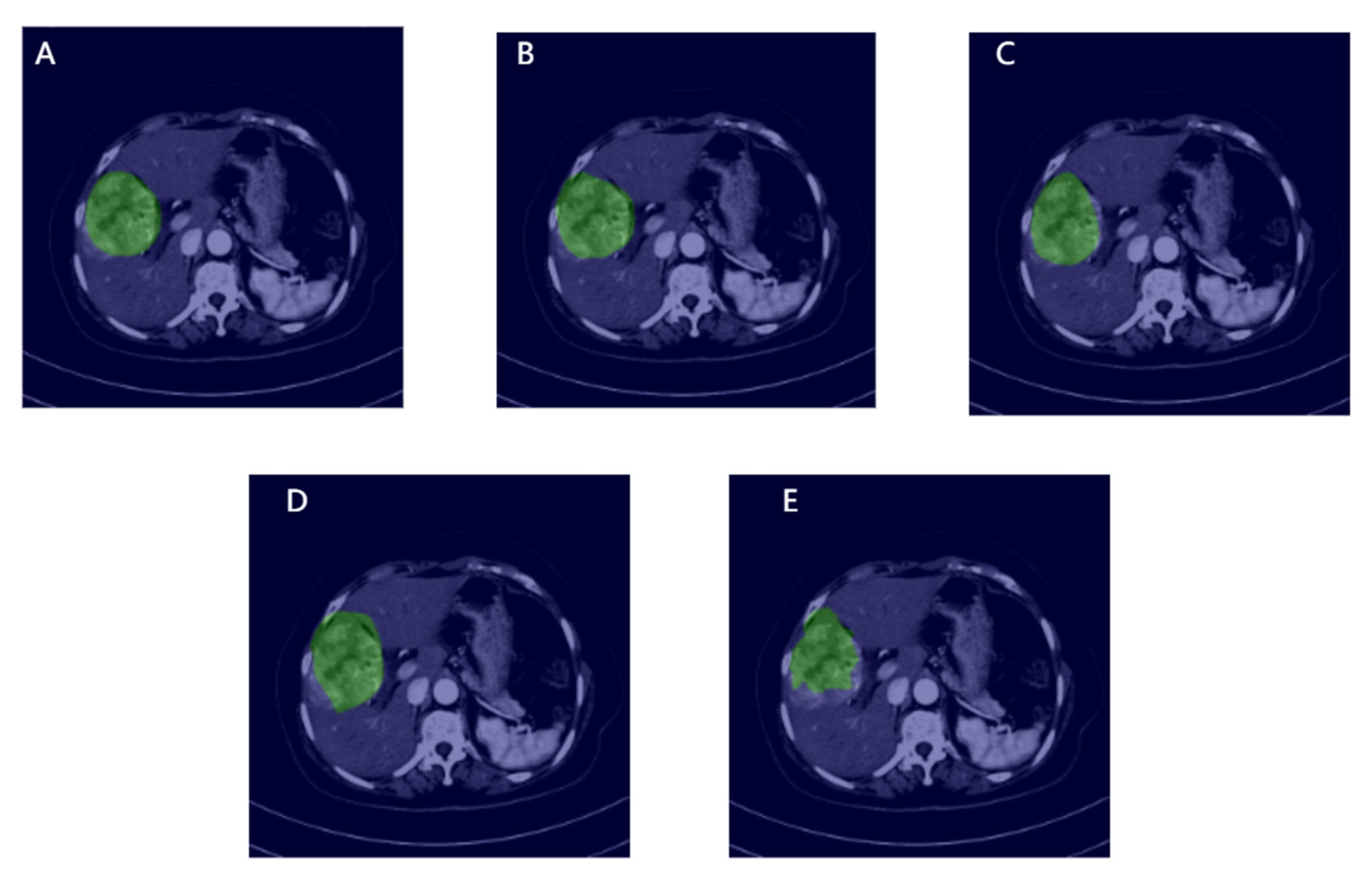
2.3. Manual ROI Annotation
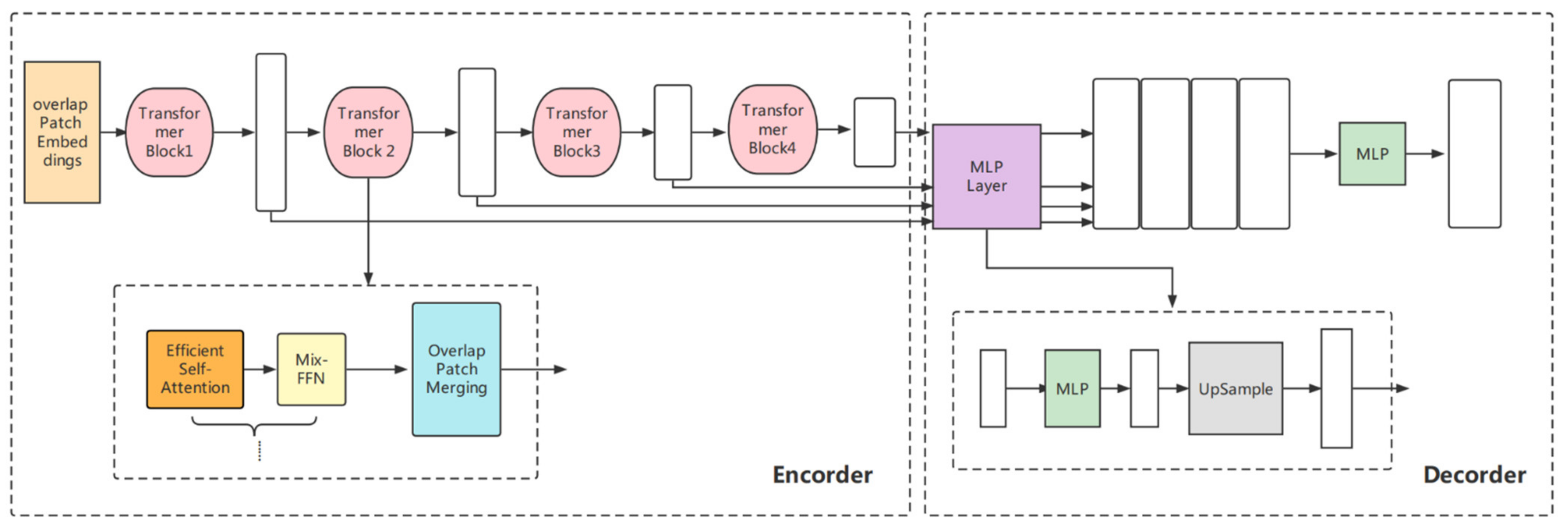
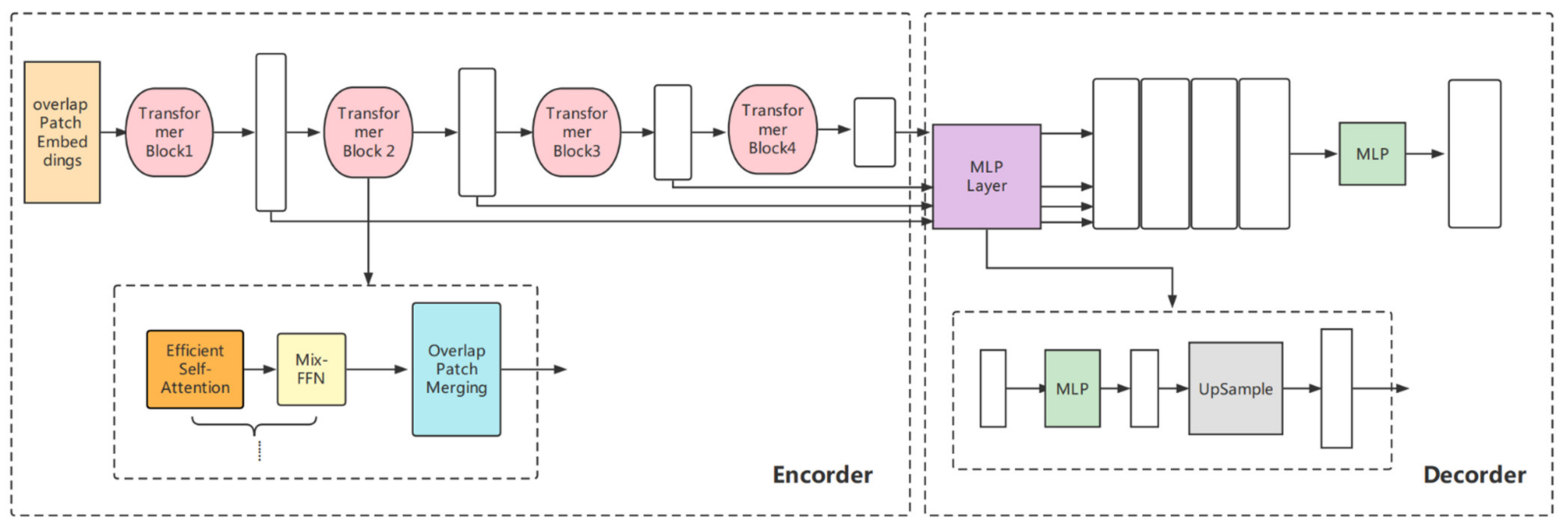
2.4. The Construction of the Segmentation Models
2.4.1. Transformer-Based Lightweight Design
2.4.2. Model Comparison—Swin Transformer
2.4.3. Baseline Models
2.5. The Construction of the MVI Prediction Models
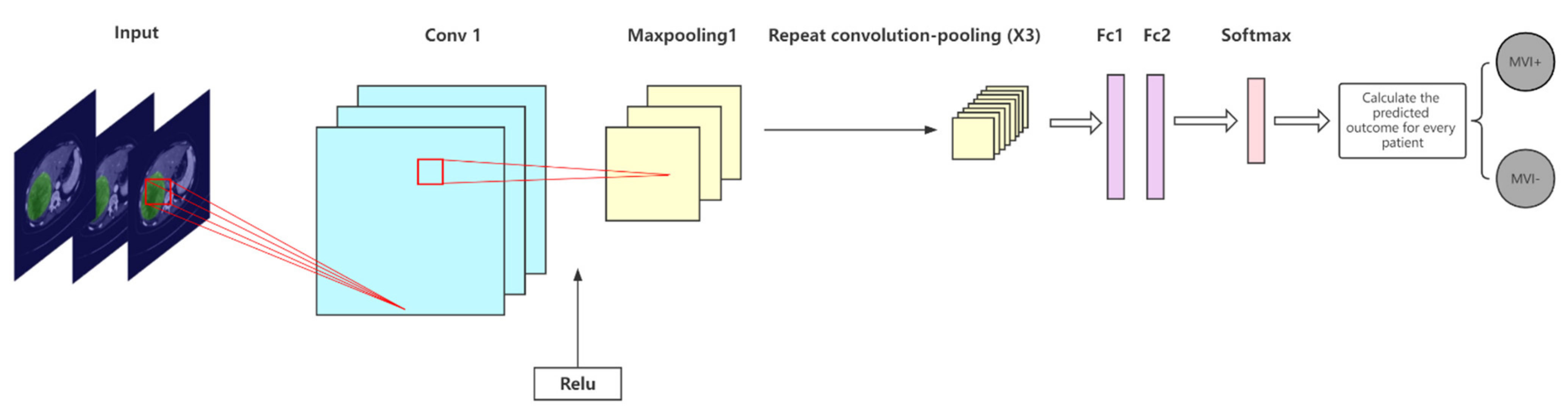
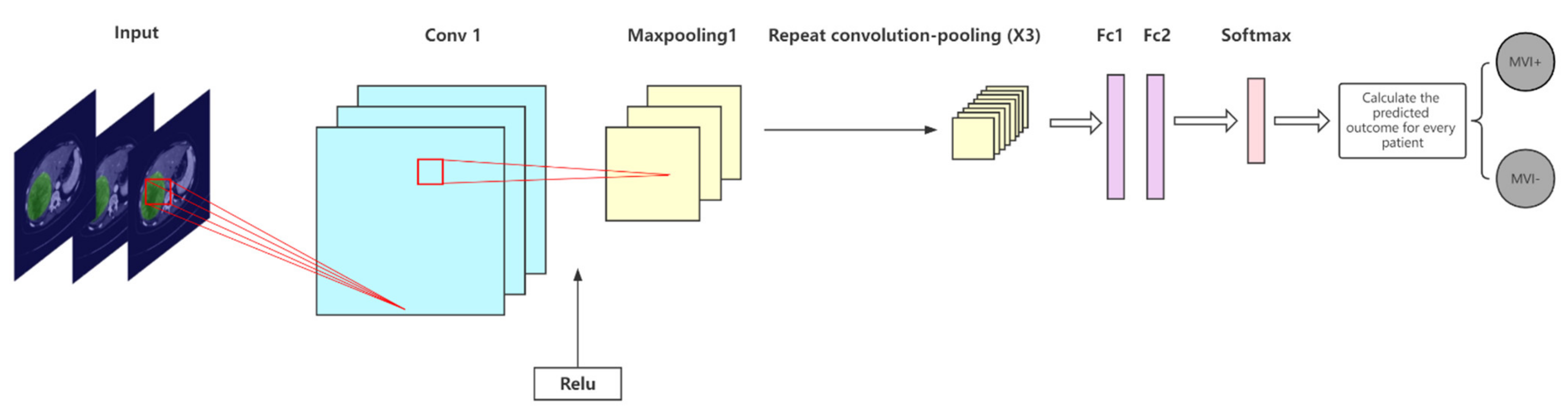
2.5.1. The Proposed CNN Model
2.5.2. Comparison with Other CNN Models
2.6. Model Evaluation Indicators
2.6.1. Segmentation Models
2.6.2. MVI Prediction Models
3. Results
3.1. Experimental Setup
3.2. Statistics of Clinical Characteristics
3.3. Segmentation Results and Model Comparisons
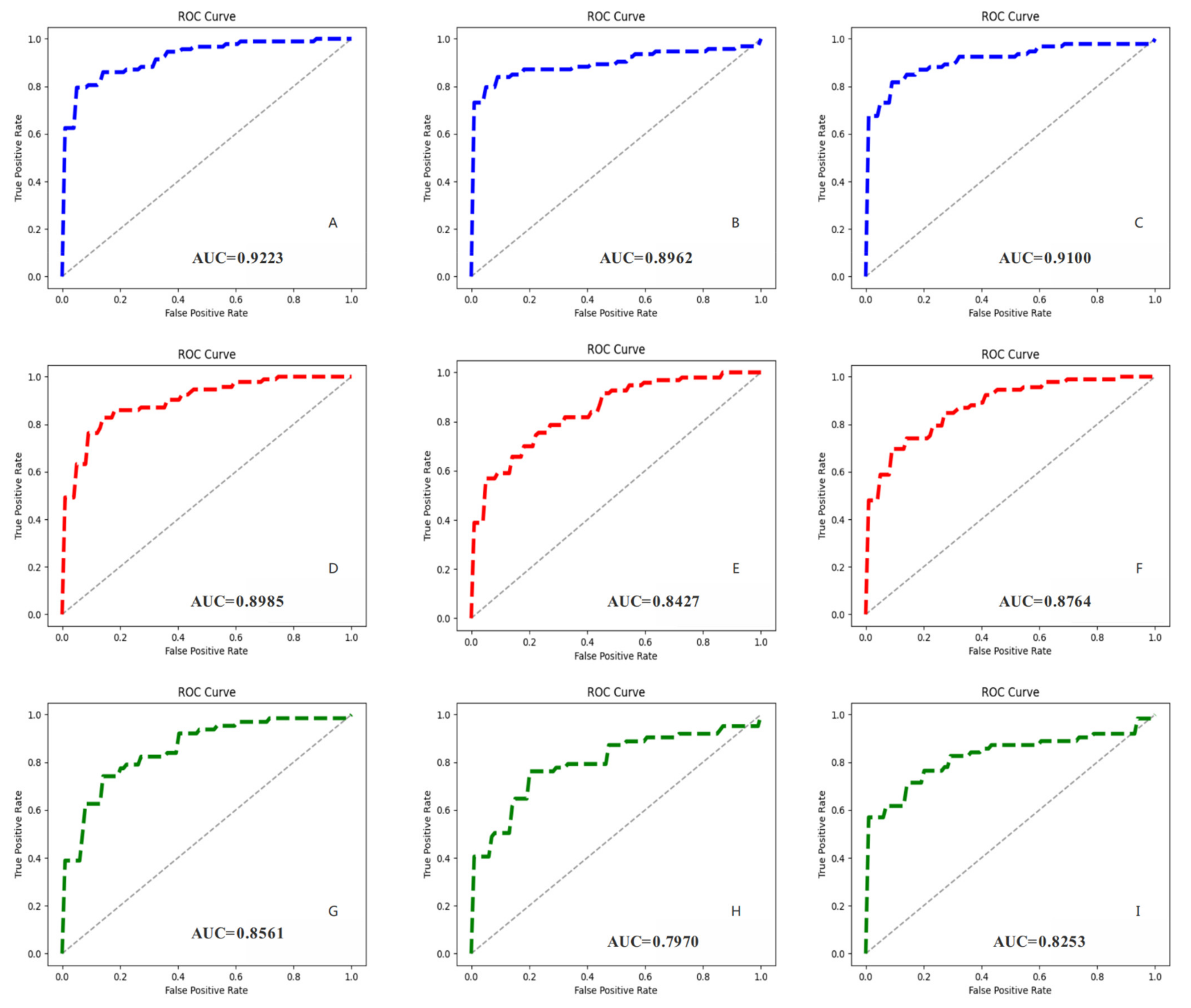
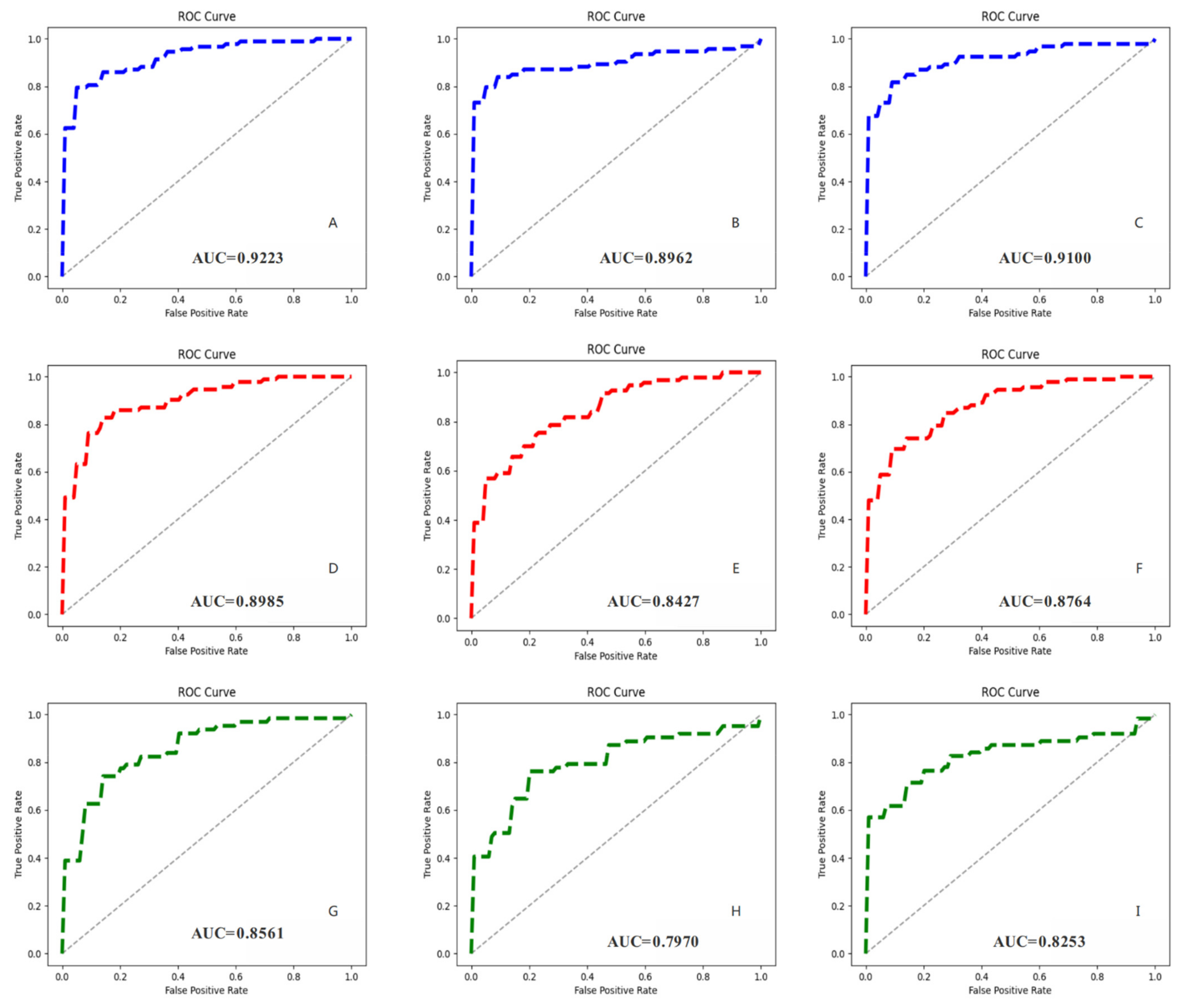
3.4. MVI Prediction Results and Models Comparison
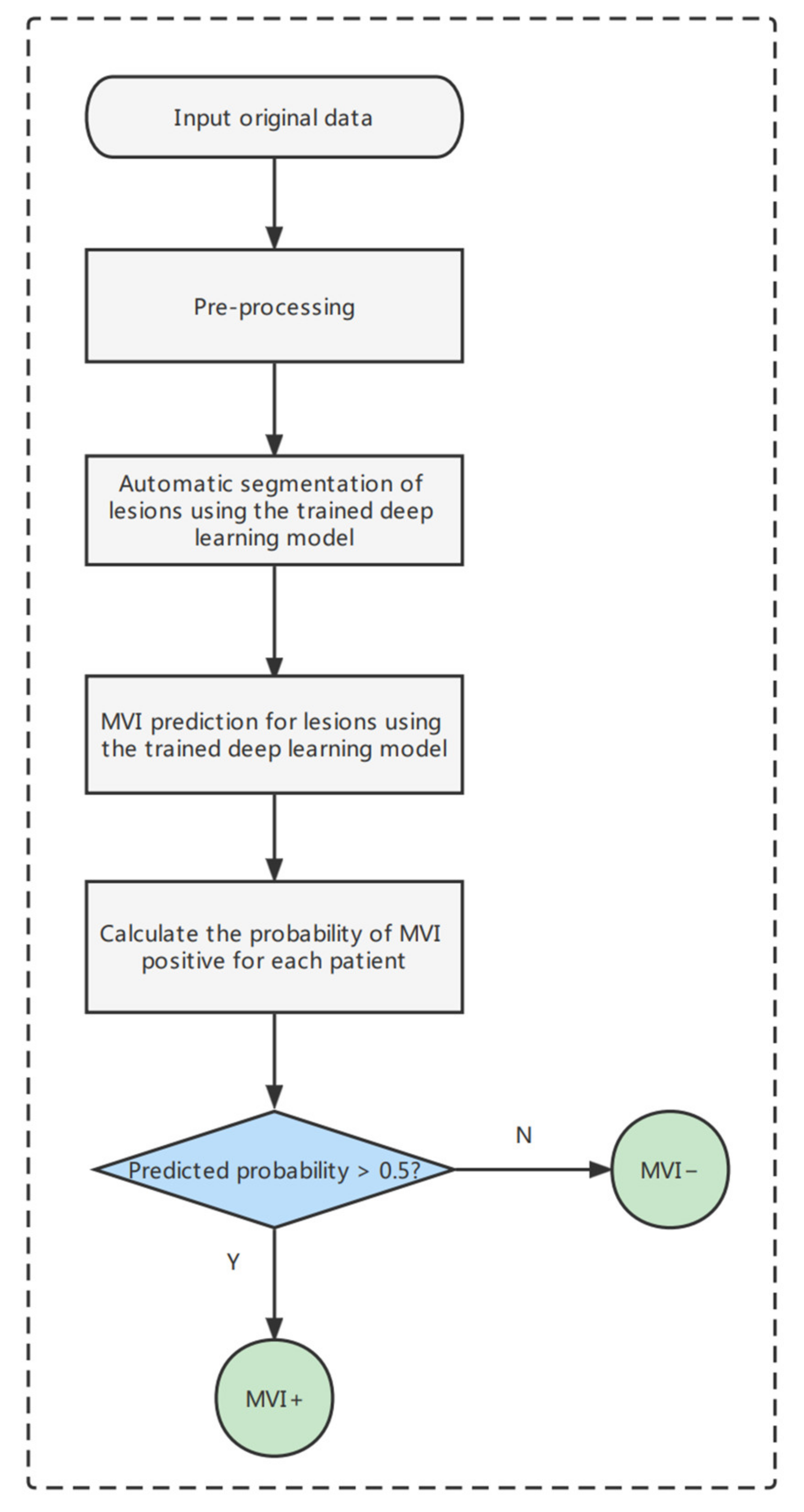
3.5. The End-to-End Prediction Pipeline of MVI-Mind
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Feng, M.; Pan, Y.; Kong, R.; Shu, S. Therapy of Primary Liver Cancer. Innovation 2020, 1, 100032. [Google Scholar] [CrossRef] [PubMed]
- Anwanwan, D.; Singh, S.K.; Singh, S.; Saikam, V.; Singh, R. Challenges in liver cancer and possible treatment approaches. Biochim. Biophys. Acta Rev. Cancer 2020, 1873, 188314. [Google Scholar] [CrossRef] [PubMed]
- Marengo, A.; Rosso, C.; Bugianesi, E. Liver Cancer: Connections with Obesity, Fatty Liver, and Cirrhosis. Annu. Rev. Med. 2016, 67, 103–117. [Google Scholar] [CrossRef] [PubMed]
- Jiang, Y.; Sun, A.; Zhao, Y.; Ying, W.; Sun, H.; Yang, X.; Xing, B.; Sun, W.; Ren, L.; Hu, B.; et al. Proteomics identifies new therapeutic targets of early-stage hepatocellular carcinoma. Nature 2019, 567, 257–261. [Google Scholar] [CrossRef] [PubMed]
- Yang, W.-S.; Zeng, X.-F.; Liu, Z.-N.; Zhao, Q.-H.; Tan, Y.-T.; Gao, J.; Li, H.-L.; Xiang, Y.-B. Diet and liver cancer risk: A narrative review of epidemiological evidence. Br. J. Nutr. 2020, 124, 330–340. [Google Scholar] [CrossRef] [Green Version]
- Liu, Z.; Jiang, Y.; Yuan, H.; Fang, Q.; Cai, N.; Suo, C.; Jin, L.; Zhang, T.; Chen, X. The trends in incidence of primary liver cancer caused by specific etiologies: Results from the Global Burden of Disease Study 2016 and implications for liver cancer prevention. J. Hepatol. 2019, 70, 674–683. [Google Scholar] [CrossRef]
- Piñero, F.; Dirchwolf, M.; Pessôa, M.G. Biomarkers in Hepatocellular Carcinoma: Diagnosis, Prognosis and Treatment Response Assessment. Cells 2020, 9, 1370. [Google Scholar] [CrossRef]
- Agarwal, V.; Divatia, J.V. Enhanced recovery after surgery in liver resection: Current concepts and controversies. Korean J. Anesthesiol. 2019, 72, 119–129. [Google Scholar] [CrossRef] [Green Version]
- Meirelles Júnior, R.F.; Salvalaggio, P.; Rezende, M.B.D.; Evangelista, A.S.; Guardia, B.D.; Matielo, C.E.L.; Neves, D.B.; Pandullo, F.L.; Felga, G.E.G.; Alves, J.A.d.S.; et al. Liver transplantation: History, outcomes and perspectives. Einstein 2015, 13, 149–152. [Google Scholar] [CrossRef] [Green Version]
- Granito, A.; Galassi, M.; Piscaglia, F.; Romanini, L.; Lucidi, V.; Renzulli, M.; Borghi, A.; Grazioli, L.; Golfieri, R.; Bolondi, L. Impact of gadoxetic acid (Gd-EOB-DTPA)-enhanced magnetic resonance on the non-invasive diagnosis of small hepatocellular carcinoma: A prospective study. Aliment. Pharmacol. Ther. 2013, 37, 355–363. [Google Scholar] [CrossRef]
- Centonze, L.; De Carlis, R.; Vella, I.; Carbonaro, L.; Incarbone, N.; Palmieri, L.; Sgrazzutti, C.; Ficarelli, A.; Valsecchi, M.G.; Iacono, U.D.; et al. From LI-RADS Classification to HCC Pathology: A Retrospective Single-Institution Analysis of Clinico-Pathological Features Affecting Oncological Outcomes after Curative Surgery. Diagnostics 2022, 12, 160. [Google Scholar] [CrossRef]
- Granito, A.; Forgione, A.; Marinelli, S.; Renzulli, M.; Ielasi, L.; Sansone, V.; Benevento, F.; Piscaglia, F.; Tovoli, F. Experience with regorafenib in the treatment of hepatocellular carcinoma. Ther. Adv. Gastroenterol. 2021, 14, 17562848211016959. [Google Scholar] [CrossRef]
- Erstad, D.J.; Tanabe, K.K. Prognostic and Therapeutic Implications of Microvascular Invasion in Hepatocellular Carcinoma. Ann. Surg. Oncol. 2019, 26, 1474–1493. [Google Scholar] [CrossRef]
- Isik, B.; Gonultas, F.; Sahin, T.; Yilmaz, S. Microvascular Venous Invasion in Hepatocellular Carcinoma: Why Do Recurrences Occur? J. Gastrointest. Cancer 2020, 51, 1133–1136. [Google Scholar] [CrossRef]
- Lee, S.; Kang, T.W.; Song, K.D.; Lee, M.W.; Rhim, H.; Lim, H.K.; Kim, S.Y.; Sinn, D.H.; Kim, J.M.; Kim, K.; et al. Effect of Microvascular Invasion Risk on Early Recurrence of Hepatocellular Carcinoma After Surgery and Radiofrequency Ablation. Ann. Surg. 2021, 273, 564–571. [Google Scholar] [CrossRef]
- Zhang, X.; Li, J.; Shen, F.; Lau, W.Y. Significance of presence of microvascular invasion in specimens obtained after surgical treatment of hepatocellular carcinoma. J. Gastroenterol. Hepatol. 2018, 33, 347–354. [Google Scholar] [CrossRef] [Green Version]
- Hu, H.; Qi, S.; Zeng, S.; Zhang, P.; He, L.; Wen, S.; Zeng, N.; Yang, J.; Zhang, W.; Zhu, W.; et al. Importance of Microvascular Invasion Risk and Tumor Size on Recurrence and Survival of Hepatocellular Carcinoma After Anatomical Resection and Non-anatomical Resection. Front. Oncol. 2021, 11, 621622. [Google Scholar] [CrossRef]
- Sun, Z.; Li, Z.; Shi, X.L.; He, X.W.; Chen, J.; Song, J.H. Anatomic versus non-anatomic resection of hepatocellular carcinoma with microvascular invasion: A systematic review and meta-analysis. Asian J. Surg. 2021, 44, 1143–1150. [Google Scholar] [CrossRef]
- Ünal, E.; İdilman, İ.S.; Akata, D.; Özmen, M.N.; Karçaaltıncaba, M. Microvascular invasion in hepatocellular carcinoma. Diagn. Interv. Radiol. 2016, 22, 125–132. [Google Scholar] [CrossRef]
- Yang, L.; Gu, D.; Wei, J.; Yang, C.; Rao, S.; Wang, W.; Chen, C.; Ding, Y.; Tian, J.; Zeng, M. A Radiomics Nomogram for Preoperative Prediction of Microvascular Invasion in Hepatocellular Carcinoma. Liver Cancer 2019, 8, 373–386. [Google Scholar] [CrossRef]
- Wang, G.; Jian, W.; Cen, X.; Zhang, L.; Guo, H.; Liu, Z.; Liang, G.; Zhou, W. Prediction of Microvascular Invasion of Hepatocellular Carcinoma Based on Preoperative Diffusion-Weighted MR Using Deep Learning. Acad. Radiol. 2021, 28 (Suppl. S1), S118–S127. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Huang, S.; Xu, Y.; Wu, J. Diagnostic Accuracy of Artificial Intelligence Based on Imaging Data for Preoperative Prediction of Microvascular Invasion in Hepatocellular Carcinoma: A Systematic Review and Meta-Analysis. Front. Oncol. 2022, 12, 763842. [Google Scholar] [CrossRef]
- Jiang, Y.Q.; Cao, S.E.; Cao, S.; Chen, J.N.; Wang, G.Y.; Shi, W.Q.; Deng, Y.N.; Cheng, N.; Ma, K.; Zeng, K.N.; et al. Preoperative identification of microvascular invasion in hepatocellular carcinoma by XGBoost and deep learning. J. Cancer Res. Clin. Oncol. 2021, 147, 821–833. [Google Scholar] [CrossRef] [PubMed]
- Nebbia, G.; Zhang, Q.; Arefan, D.; Zhao, X.; Wu, S. Pre-operative Microvascular Invasion Prediction Using Multi-parametric Liver MRI Radiomics. J. Digit. Imaging 2020, 33, 1376–1386. [Google Scholar] [CrossRef]
- Zhang, Y.; Lv, X.; Qiu, J.; Zhang, B.; Zhang, L.; Fang, J.; Li, M.; Chen, L.; Wang, F.; Liu, S.; et al. Deep Learning With 3D Convolutional Neural Network for Noninvasive Prediction of Microvascular Invasion in Hepatocellular Carcinoma. J. Magn. Reson. Imaging 2021, 54, 134–143. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.C.; Lai, J.; Huang, J.Y.; Cho, C.F.; Lee, P.H.; Lu, M.H.; Yeh, C.C.; Yu, J.; Lin, W.C. Predicting microvascular invasion in hepatocellular carcinoma: A deep learning model validated across hospitals. Cancer Imaging 2021, 21, 56. [Google Scholar] [CrossRef] [PubMed]
- Chaitanya, K.; Karani, N.; Baumgartner, C.F.; Erdil, E.; Becker, A.; Donati, O.; Konukoglu, E. Semi-supervised task-driven data augmentation for medical image segmentation. Med. Image Anal. 2021, 68, 101934. [Google Scholar] [CrossRef]
- Graterol, W.; Diaz-Amado, J.; Cardinale, Y.; Dongo, I.; Lopes-Silva, E.; Santos-Libarino, C. Emotion Detection for Social Robots Based on NLP Transformers and an Emotion Ontology. Sensors 2021, 21, 1322. [Google Scholar] [CrossRef]
- Dai, Y.; Gao, Y.; Liu, F. TransMed: Transformers Advance Multi-Modal Medical Image Classification. Diagnostics 2021, 11, 1384. [Google Scholar] [CrossRef]
- Tao, R.; Liu, W.; Zheng, G. Spine-transformers: Vertebra labeling and segmentation in arbitrary field-of-view spine CTs via 3D transformers. Med. Image Anal. 2022, 75, 102258. [Google Scholar] [CrossRef]
- Pacal, I.; Karaboga, D. A robust real-time deep learning based automatic polyp detection system. Comput. Biol. Med. 2021, 134, 104519. [Google Scholar] [CrossRef]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers. arXiv 2021, arXiv:2105.15203. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. arXiv 2021, arXiv:2103.14030. [Google Scholar]
- Czajkowska, J.; Badura, P.; Korzekwa, S.; Płatkowska-Szczerek, A. Automated segmentation of epidermis in high-frequency ultrasound of pathological skin using a cascade of DeepLab v3+ networks and fuzzy connectedness. Comput. Med. Imaging Graph. 2022, 95, 102023. [Google Scholar] [CrossRef]
- Wan, C.; Wu, J.; Li, H.; Yan, Z.; Wang, C.; Jiang, Q.; Cao, G.; Xu, Y.; Yang, W. Optimized-Unet: Novel Algorithm for Parapapillary Atrophy Segmentation. Front. Neurosci. 2021, 15, 758887. [Google Scholar] [CrossRef]
- Gao, F.; Qiao, K.; Yan, B.; Wu, M.; Wang, L.; Chen, J.; Shi, D. Hybrid network with difference degree and attention mechanism combined with radiomics (H-DARnet) for MVI prediction in HCC. Magn. Reson. Imaging. 2021, 83, 27–40. [Google Scholar] [CrossRef]
- Zhou, L.-Q.; Wu, X.-L.; Huang, S.-Y.; Wu, G.-G.; Ye, H.-R.; Wei, Q.; Bao, L.-Y.; Deng, Y.-B.; Li, X.-R.; Cui, X.-W.; et al. Lymph Node Metastasis Prediction from Primary Breast Cancer US Images Using Deep Learning. Radiology 2020, 294, 19–28. [Google Scholar] [CrossRef]
- Paladini, E.; Vantaggiato, E.; Bougourzi, F.; Distante, C.; Hadid, A.; Taleb-Ahmed, A. Two Ensemble-CNN Approaches for Colorectal Cancer Tissue Type Classification. J. Imaging 2021, 7, 51. [Google Scholar] [CrossRef]
- Al Husaini, M.A.S.; Habaebi, M.H.; Gunawan, T.S.; Islam, M.R.; Elsheikh, E.A.A.; Suliman, F.M. Thermal-based early breast cancer detection using inception V3, inception V4 and modified inception MV4. Neural. Comput. Appl. 2021, 34, 333–348. [Google Scholar] [CrossRef]
- Yang, Y.; Zhou, Y.; Zhou, C.; Ma, X. Deep learning radiomics based on contrast enhanced computed tomography predicts microvascular invasion and survival outcome in early stage hepatocellular carcinoma. Eur. J. Surg. Oncol. 2021, 48, 1068–1077. [Google Scholar] [CrossRef]
- Feng, S.-T.; Jia, Y.; Liao, B.; Huang, B.; Zhou, Q.; Li, X.; Wei, K.; Chen, L.; Li, B.; Wang, W.; et al. Preoperative prediction of microvascular invasion in hepatocellular cancer: A radiomics model using Gd-EOB-DTPA-enhanced MRI. Eur. Radiol. 2019, 29, 4648–4659. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Clinical Indicator | Total Dataset (n = 138) | ||
|---|---|---|---|
| MVI Positive (n = 68) | MVI Negative (n = 70) | ||
| Gender | |||
| Male | 56 (82.35%) | 57 (81.43%) | |
| Female | 12 (17.65%) | 13 (18.57%) | |
| Age | 56.70 ± 11.48 | 56.34 ± 12.05 | p = 0.4355 |
| MTD(mm) | 5.20 ± 3.48 | 4.30 ± 1.98 | p = 0.0321 |
| AFP | |||
| Positive | 45 (66.18%) | 39 (55.71%) | |
| Negative | 23 (33.82%) | 31 (44.29%) | |
| HBsAg | |||
| Positive | 60 (88.24%) | 63 (90.00%) | |
| Negative | 8 (11.76%) | 7 (10.00%) | |
| ALB(g/L) | 40.79 ± 5.04 | 40.27 ± 4.81 | p = 0.2718 |
| T-BIL(mmol/L) | 21.43 ± 9.55 | 17.85 ± 7.60 | p = 0.1011 |
| ALT(u/L) | 63.99 ± 35.78 | 47.39 ± 25.92 | p = 0.1241 |
| AST(u/L) | 60.70 ± 39.10 | 34.74 ± 18.35 | p = 0.0362 |
| Parameter Name | Parameter Value |
|---|---|
| num_classes | 2 |
| base_learning rate | 0.005 |
| momentum | 0.9 |
| weight_decay | 4.0 × 10−5 |
| batch_size | 2 |
| Model | mIoU | Acc | Kappa | Dice |
|---|---|---|---|---|
| MVI-Mind (our work) | 0.9006 | 0.9947 | 0.8903 | 0.9451 |
| Swin transformer | 0.8971 | 0.9943 | 0.8860 | 0.9430 |
| DeepLab V3+ | 0.7778 | 0.9871 | 0.7185 | 0.8592 |
| U-Net | 0.7521 | 0.9863 | 0.6758 | 0.8378 |
| Model | Num_params | Num_iters | Total Training Time/s | Convergence Time/s |
|---|---|---|---|---|
| MVI-Mind (our work) | 84,596,418 | 100,000 | 63,075 | about 6550 |
| Swin transformer | 108,235,650 | 100,000 | 78,420 | about 15,680 |
| DeepLab V3+ | 45,871,090 | 100,000 | 40,218 | about 3890 |
| U-Net | 13,404,354 | 100,000 | 18,930 | about 1520 |
| Parameter Name | Parameter Value |
|---|---|
| num_classes | 2 |
| learning_rate | 1.0 × 10−6 |
| optimizer | Adam |
| weight_decay | 3.0 × 10−3 |
| batch_size | 64 |
| verbose | 1 |
| Model | Scan Time Period | Acc | Rec | Prec | F1 Score |
|---|---|---|---|---|---|
| MVI-Mind | AP (avg ± 95%CI) | 0.8678 | 0.8269 | 0.8750 | 0.8488 |
| ±0.0458 | ±0.0767 | ±0.0490 | ±0.0566 | ||
| PP (avg ± 95%CI) | 0.8534 | 0.7760 | 0.8972 | 0.8241 | |
| ±0.0484 | ±0.1060 | ±0.0651 | ±0.0645 | ||
| DP (avg ± 95%CI) | 0.8434 | 0.7637 | 0.8823 | 0.8150 | |
| ±0.0547 | ±0.0802 | ±0.0816 | ±0.0660 | ||
| ResNet-34 | AP (avg ± 95%CI) | 0.8283 | 0.6988 | 0.9089 | 0.7875 |
| ±0.0242 | ±0.0372 | ±0.0676 | ±0.0303 | ||
| PP (avg ± 95%CI) | 0.7844 | 0.6684 | 0.8313 | 0.7356 | |
| ±0.0474 | ±0.0905 | ±0.0732 | ±0.0688 | ||
| DP (avg ± 95%CI) | 0.7889 | 0.6848 | 0.8271 | 0.7409 | |
| ±0.0653 | ±0.1242 | ±0.0834 | ±0.0919 | ||
| Inception-V3 | AP (avg ± 95%CI) | 0.7940 | 0.7256 | 0.8061 | 0.7599 |
| ±0.0269 | ±0.0738 | ±0.0478 | ±0.0439 | ||
| PP (avg ± 95%CI) | 0.7728 | 0.6949 | 0.7911 | 0.7380 | |
| ±0.0525 | ±0.0450 | ±0.0787 | ±0.0512 | ||
| DP (avg ± 95%CI) | 0.7947 | 0.7423 | 0.8133 | 0.7682 | |
| ±0.0501 | ±0.0793 | ±0.0948 | ±0.0494 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, L.; Wu, M.; Li, R.; Xu, X.; Zhu, C.; Feng, X. MVI-Mind: A Novel Deep-Learning Strategy Using Computed Tomography (CT)-Based Radiomics for End-to-End High Efficiency Prediction of Microvascular Invasion in Hepatocellular Carcinoma. Cancers 2022, 14, 2956. https://doi.org/10.3390/cancers14122956
Wang L, Wu M, Li R, Xu X, Zhu C, Feng X. MVI-Mind: A Novel Deep-Learning Strategy Using Computed Tomography (CT)-Based Radiomics for End-to-End High Efficiency Prediction of Microvascular Invasion in Hepatocellular Carcinoma. Cancers. 2022; 14(12):2956. https://doi.org/10.3390/cancers14122956
Chicago/Turabian StyleWang, Liyang, Meilong Wu, Rui Li, Xiaolei Xu, Chengzhan Zhu, and Xiaobin Feng. 2022. "MVI-Mind: A Novel Deep-Learning Strategy Using Computed Tomography (CT)-Based Radiomics for End-to-End High Efficiency Prediction of Microvascular Invasion in Hepatocellular Carcinoma" Cancers 14, no. 12: 2956. https://doi.org/10.3390/cancers14122956
APA StyleWang, L., Wu, M., Li, R., Xu, X., Zhu, C., & Feng, X. (2022). MVI-Mind: A Novel Deep-Learning Strategy Using Computed Tomography (CT)-Based Radiomics for End-to-End High Efficiency Prediction of Microvascular Invasion in Hepatocellular Carcinoma. Cancers, 14(12), 2956. https://doi.org/10.3390/cancers14122956