1. Introduction
The lack of an objective clinical method to evaluate oral lesions is a critical barrier to the early, accurate diagnosis and appropriate medical and surgical management of oral cancers and related diseases. This clinical problem is highly significant because oral cancer has an abysmal prognosis. The 5-year survival for Stage IV oral squamous cell carcinoma (OSCC) is only 20–30%, compared to 80% for Stage I (early) OSCC. A significant proportion (more than 50%) of OSCCs are preceded by oral epithelial dysplasia (OED) or oral pre-cancer. Therefore, early detection of pre-cancerous oral lesions (with histological evidence of dysplasia), and reversal of habits such as smoking, tobacco chewing, reducing alcohol consumption, and surgical management can significantly reduce the risk of transformation into cancer [
1,
2]. Thus, early detection is critical for improving survival outcomes.
There are no individual or specific clinical features that can precisely predict the prognosis of an oral potential malignant lesion. However, an improved prediction may be accomplished by jointly modeling multiple reported “high-risk features”, such as intraoral site (i.e., lateral tongue borders, ventral tongue, the floor of the mouth, and lower gums are high-risk sites), color (red > mixed > white), size (>200 mm
2), gender (females > males), appearance (erythroplakia and verrucous lesions represent high risk), and habits (tobacco and alcohol usage) [
1,
2,
3]. At present, clinical assessment of these lesions is highly subjective, resulting in significant inter-clinician variability and difficulty in prognosis prediction, leading to suboptimal quality of care. Thus, there is a critical need for novel objective approaches that can facilitate early and accurate diagnosis and improve patient prognosis.
Diagnosis of clinically suspicious lesions is confirmed with a surgical biopsy and histopathological assessment [
4,
5]. However, the decision to refer a patient to secondary care or perform a biopsy depends on the practitioner’s clinical judgment. It is based on subjective findings from conventional clinical oral examination (COE). Unfortunately, COE is not a strong predictor of OSCC and OED, with a 93% sensitivity and 31% specificity, highlighting the need for objective and quantitative validated diagnostic methods [
4,
5,
6].
Recently, convolutional neural network (CNN)-based image analysis techniques have been used to automatically segment and classify histological images. Santos et al. presented a method for automated nuclei segmentation on dysplastic oral tissues from histological images using CNN [
7] with 86% sensitivity and 89% specificity. Another CNN-based study proposed a framework for the classification of dysplastic tissue images to four different classes with 91.65% training and 89.3% testing accuracy using transfer learning [
8,
9]. Yet another CNN-based transfer learning approach study proposed by Das et al. [
10] also classified the multi-class grading for diagnosing patients with OSCC. They used four of the existing CNN models, namely Alexnet [
11], Resnet-50 [
12], VGG 16, and VGG 19 [
13], to compare their proposed CNN method, which outperformed all the models with 97.5% accuracy. Although these studies show that histological images can be classified accurately, predicting the lesion’s risk of malignant progression on clinical presentation or images is crucial for early detection and effective management of lesions to improve the survival rates and prevent oral cancer progression [
4].
Radiological imaging modalities such as magnetic resonance imaging (MRI) and computed tomography (CT) can help determine the size and extent of an OSCC prior to surgical intervention. However, these techniques are not sensitive enough to detect precancerous lesions. To overcome this barrier, a range of adjuvant clinical imaging techniques have been utilized to aid diagnosis, such as hyperspectral imaging (HSI) and optical fluorescence imaging (OFI), and these images have the potential to be analyzed using computer algorithms. Xu et al. presented a CNN-based CT image processing algorithm to classify oral tumors using 3DCNN instead of 2DCNN [
14]. The 3DCNN method had better performance than 2DCNN, because the spatial features of the three-dimensional structure extract tumor features from multiple angles. Jeyaraj and Nadar proposed a regression-based deep CNN algorithm for an automated oral cancer-detecting system by examining hyperspectral images [
15]. Comparison of the designed deep CNN performance was better than other conventional methods such as support vector machine (SVM) [
16] and deep belief network (DBN) [
17]. These methods segment intraoral images accurately and classify the inflamed gingival and healthy gingival automatically. However, they require HSI and OFI, which are not commonly available in dental screening.
Some studies have explored both autofluorescence and white light images captured with smartphones. Song et al. presented a method for the classification of dual-modal images for oral cancer detection and used a CNN-based transfer learning algorithm with 86.9% accuracy. However, the ground truth of the diagnosis depends on the specialist results rather than the histopathological results [
18]. Uthoff et al. proposed a system to classify “suspicious” lesions using CNN with 81.2% accuracy, but the system needs an additional Android application, an external light-emitting diode (LED) illumination device [
19,
20]. Using fluorescence imaging, Rana et al. reported pixel-wise segmentation of the oral lesions with the help of CNN-based autoencoders [
21]. It was proposed in a review that OFI is an efficient tool for COE in managing oral potentially malignant disorders (OPMD) [
22]. The review provided contemporary evidence in support of using OFI during COE for diagnosis and prognosis purposes. However, these studies require autofluorescence or hyperspectral imaging. These modalities are not widely available and are difficult to interpret, therefore limiting their use in early detection of oral cancer or dysplasia.
One of the more recent studies focused on lesion detection and a classification system using white-light images obtained from mobile devices [
23]. This system, which used ResNet-101 [
12] for classification and Fast R-CNN for object detection, achieved an F1-score of 87.1%. While the performance is encouraging, the results are not interpretable. The method in [
23] requires both object detection and segmentation; however, their object detection F1-score is only 41.18% for the detection of lesions that required referral.
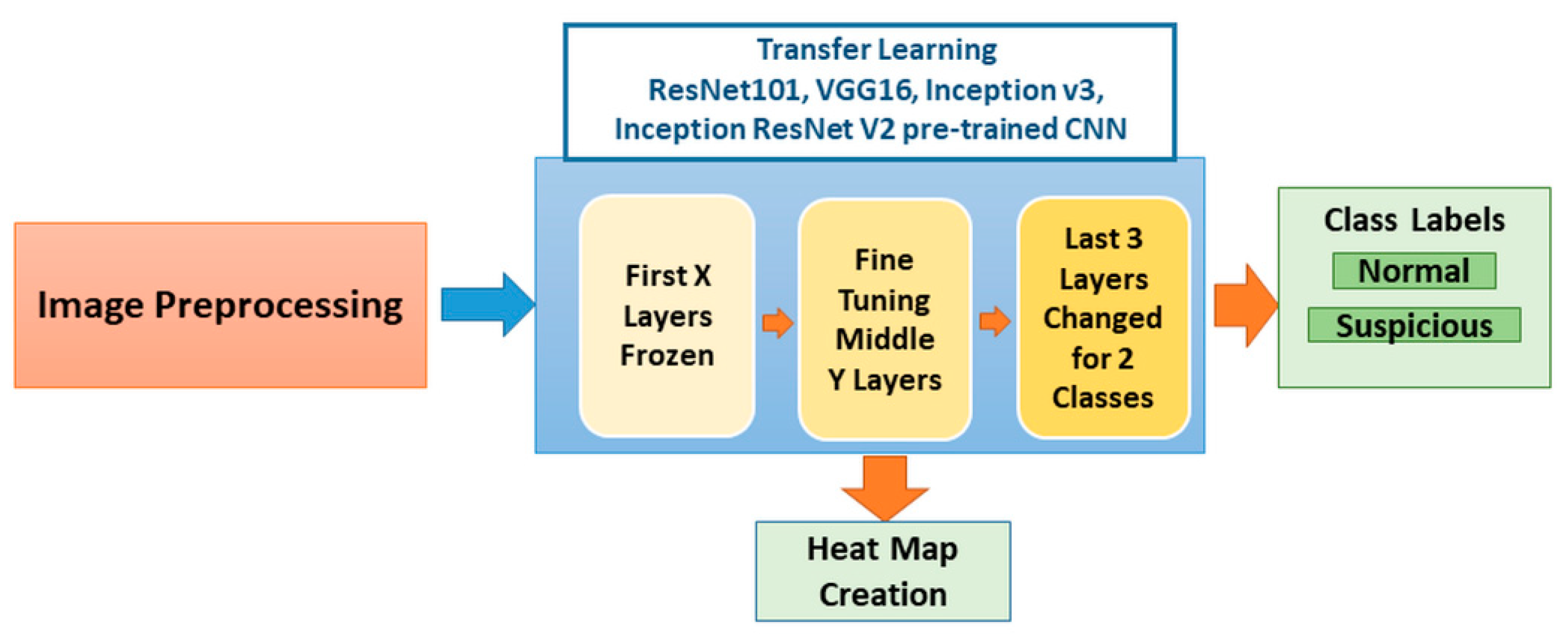
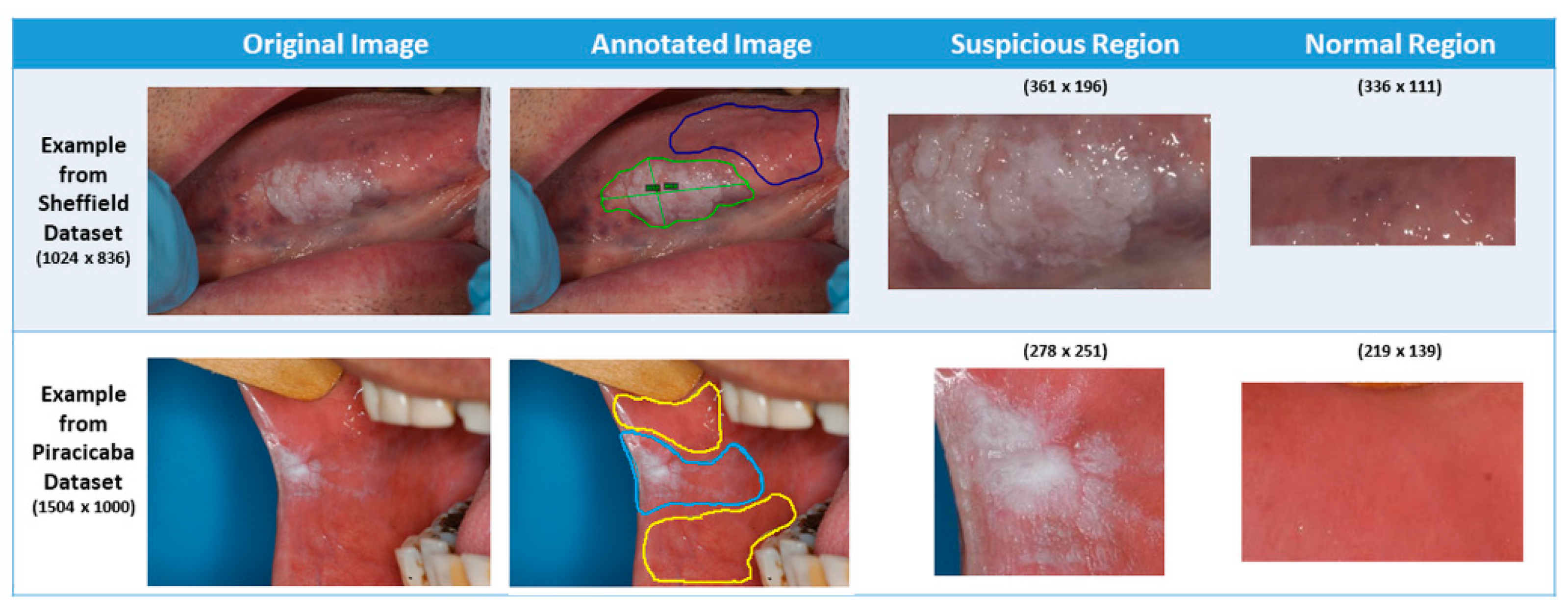
In our application, photographic images of oral lesions were manually annotated as “suspicious” and “normal” areas to develop an automated classification methodology (see
Section 2.1). We implemented a CNN-based transfer learning approach, using the Inception-ResNet-v2 pre-trained network and compared the results with those obtained with VGG-16 and Resnet-101 pre-trained networks (see
Section 3. In our study, we used only photographic images instead of fluorescence or hyperspectral images.
We also analyzed which regions of the images were used to predict the classes. This analysis is important in understanding how the neural networks analyze images, hence gaining insight into why the neural network misclassifies certain images (see
Section 3). Finally, we compared the system’s performance when trained with image tiles versus regions of interest. We validated our system by 10-fold cross-validation and leave-one-patient-out validation techniques and presented the performance results in terms of accuracy, F1-score, recall, and precision (see
Section 3).
3. Results
We compared the pre-trained CNN results, namely Inception ResNetV2, InceptionV3, VGG16, and ResNet-101, for both accuracy and F1-score after retraining them on two different datasets. Ten-fold cross-validation and leave-one-patient-out cross-validation results for the Sheffield and Piracicaba datasets are stated in
Table 3 and
Table 4, respectively.
As seen in
Table 3 and
Table 4, the training and validation accuracies were similar but less variable (i.e., smaller standard deviation) than those in the test patch set. For example, the Inception-ResNet-V2 showed average accuracies of 81.1% and 80.9% for the Sheffield dataset training and validation, respectively, whereas the test accuracy was 71.6%. The patient-level average and maximum test accuracies were higher than the patch-level accuracies. For example, for the same cases, the patch-level accuracy was 71.6%, whereas the patient-level accuracy was 73.6%.
The minimum values of ten-fold test accuracies were higher than those of the LoPo test accuracies. The ten-fold average test results for the Piracicaba dataset were higher than those of the Sheffield dataset and closer to the validation and training accuracies. These results mean that the classifiers trained on the Sheffield dataset were prone to overfitting.
The highest accuracy was achieved among the different networks by ResNet-101 for ten-fold, and LoPo cross-validation approaches. VGG16 performance for LoPo cross-validation of the Piracicaba dataset showed the highest average accuracy; however, the standard deviation was higher than that of the ResNet-101, and the standard deviation and the accuracy values with patches were higher than those with the VGG-16 patches.
The F1-score, recall, and precision for patches, patients, and RoI are presented in
Table 5. The trends are similar to those shown in
Table 4 because ResNet-101 and VGG-16 F1-scores for the Piracicaba dataset are among the highest. While ResNet-101 results in the highest RoI values, VGG-16 has the highest patient values. Because the number of regions can vary from patient to patient, ResNet-101 results are more accurate than all the others.
After ten-fold and LoPo cross-validation tests were performed for each dataset, the Piracicaba dataset was used as a test set. The Sheffield dataset was used for training and validation, and vice-versa. The patch- and patient-based test results are shown in
Table 6. Again, the Piracicaba dataset results appear more accurate than that of the Sheffield dataset. This difference in accuracy may be explained by many factors, including the differences in the number of images, RoIs, image size and quality, and where the patches are selected. The image dimensions and bit depths are smaller, affecting the sizes of suspicious lesions.
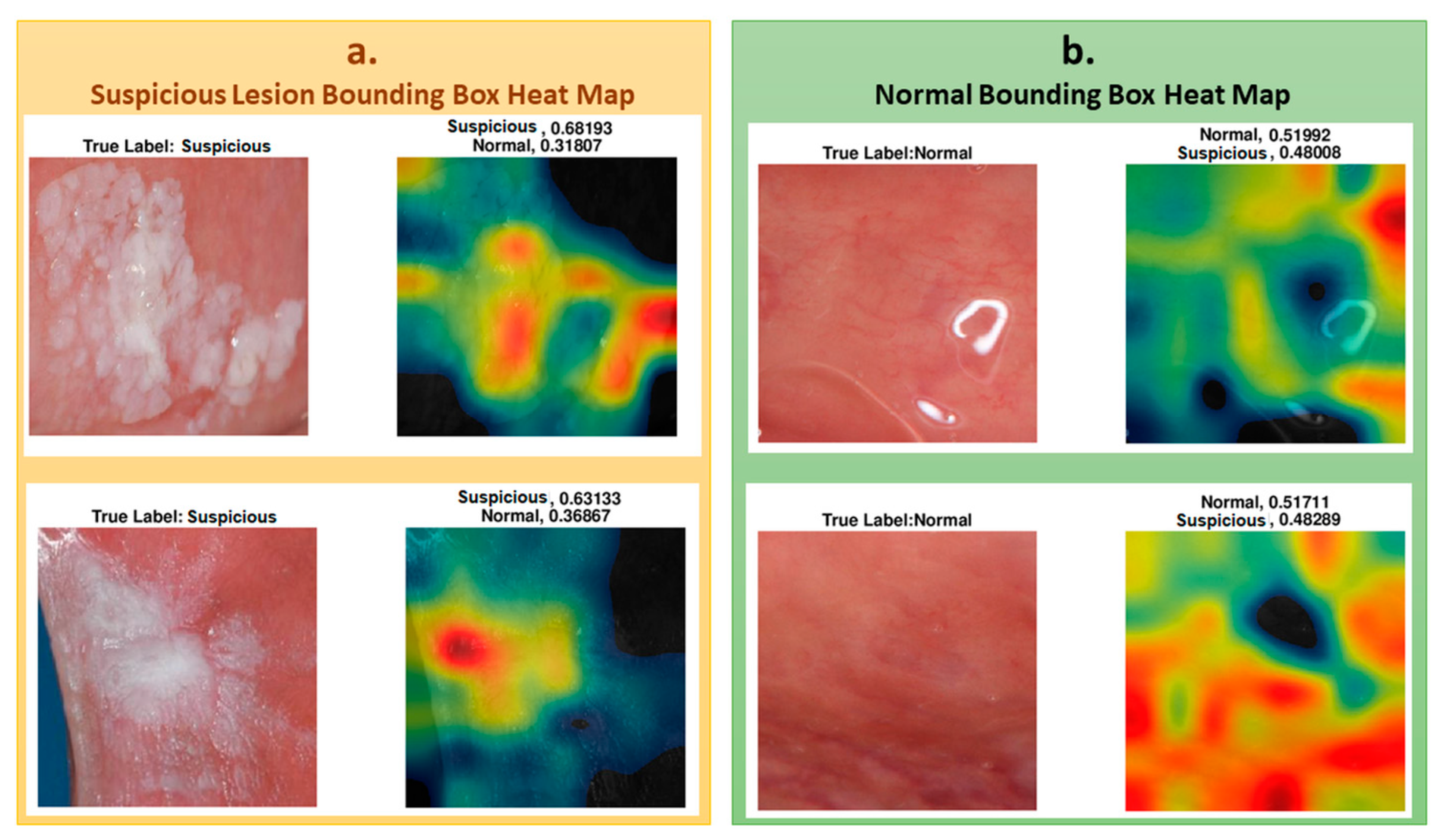
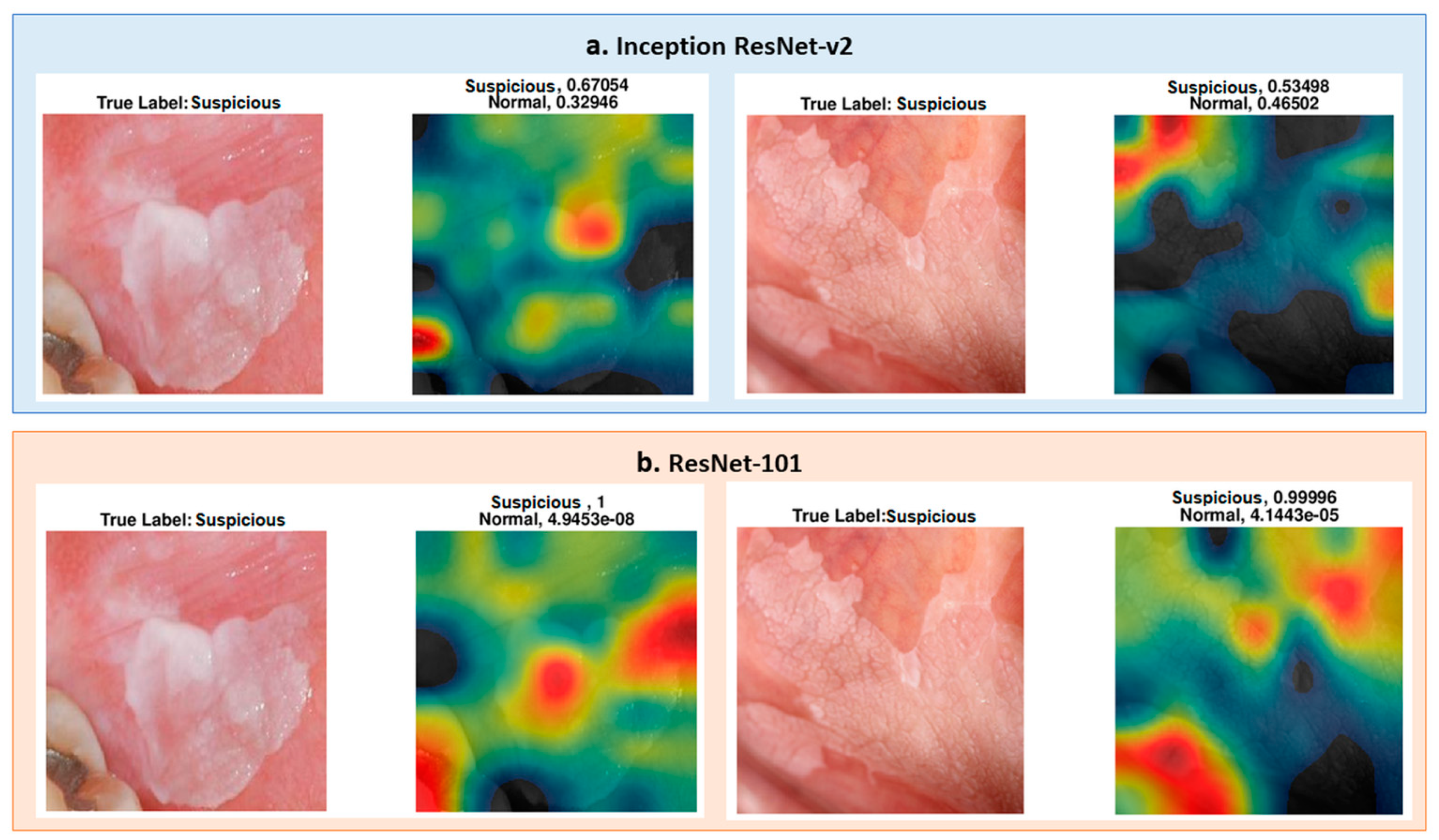
To understand which regions of the image affect the classification result, we represented the regions with a heat map using the CAM method, as explained in the methods section. To show the images’ heat map, we performed the classification on RoI as a single image, and the results of the heat maps of the classification are shown in
Figure 6. As seen in the figure, for cases that were classified as “suspicious", the white and partially white regions were more effective in classification, with scores of 0.68 and 0.63, respectively. For the normal cases, shown in the figure, the upper image has white light reflections. These regions are mostly colored with black, blue, and green in the heat map for “normal” classification, indicating less suspicion. The other regions where the heat map is colored with yellow to red are the regions that result in normal classification. These examples demonstrate the system’s success in classifying “suspicious” and “normal” oral images using the features extracted from the associated regions.
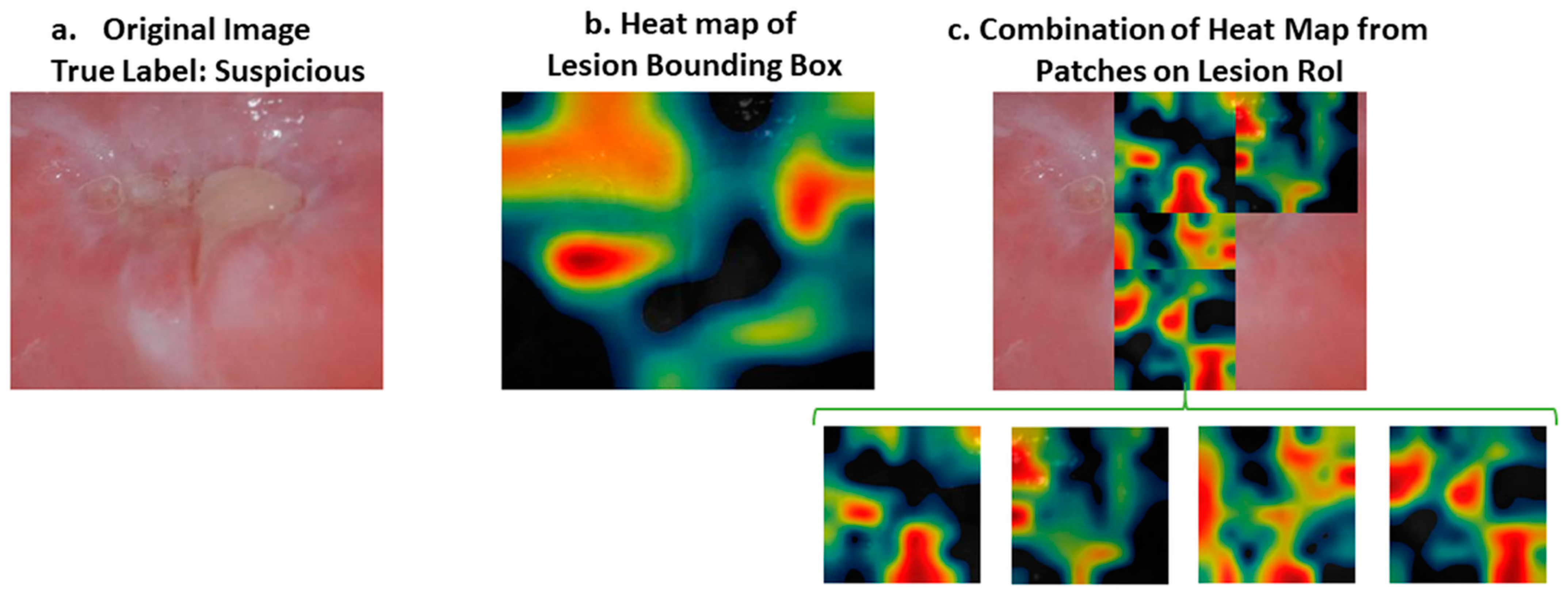
While the heat map correctly identified all the correct areas, as in
Figure 6 for both normal and suspicious cases, in some samples the results of the heat map were somewhat misleading, for example in
Figure 7. In this case, the heat map did not mark all the regions of interest correctly. However; if we divide the image into patches, the results are more meaningful, as shown in
Figure 7. Therefore, our approach was to divide the images into patches to improve their classification and also to be able to interpret the results of deep learning better.
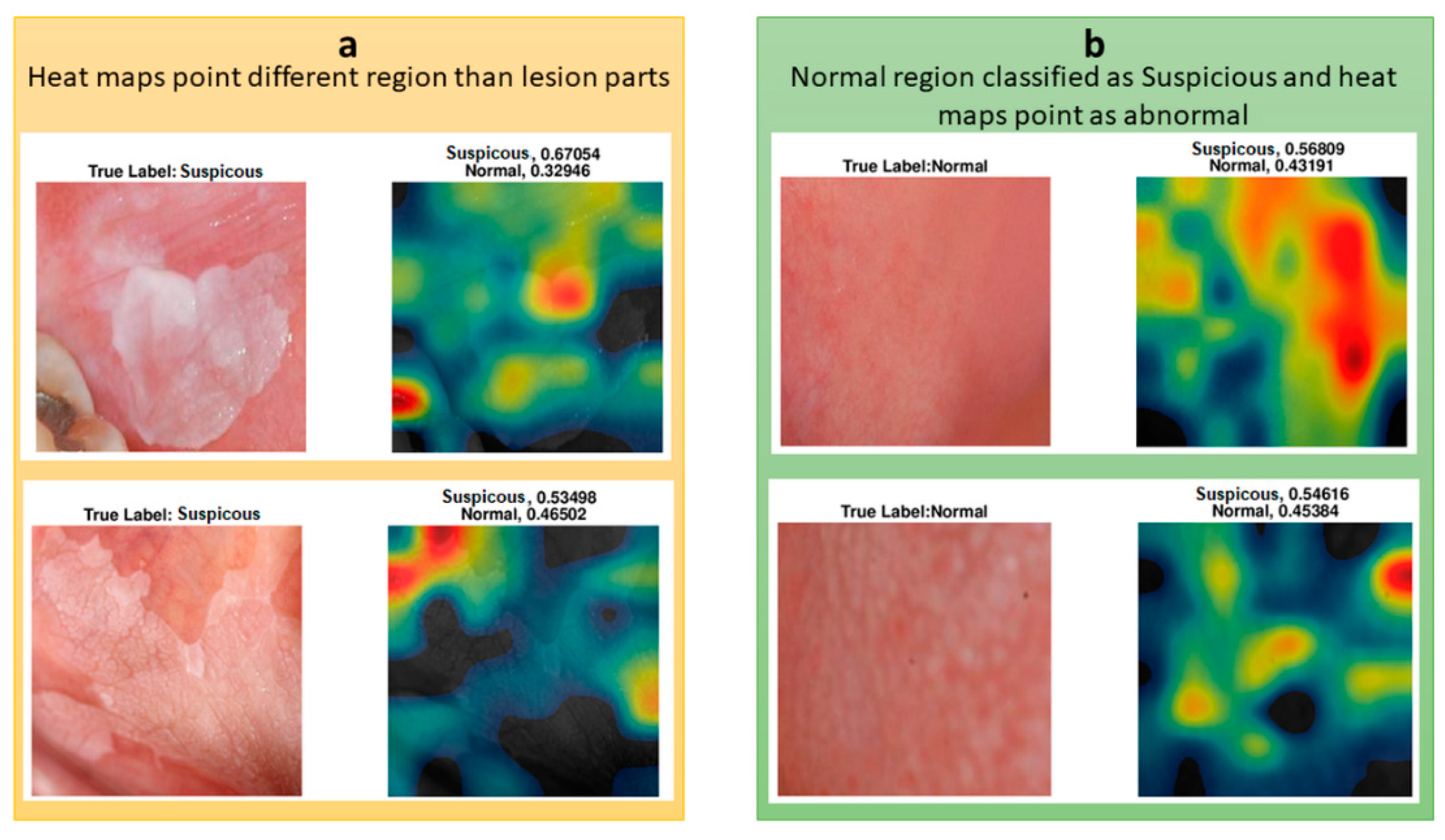
In
Figure 8, the upper suspicious image shows some part of a tooth, the color of which caused the classifier to misclassify the image. CAM analysis showed that the lesion’s most worrying clinical part was not colored as highly suspicious (red) but moderately suspicious (yellow). For a less suspicious image, the red and yellow parts of the heat map did not represent the lesion, and the lesion was not colored as yellow or red.
We also investigated the heat maps of the misclassified images to understand which regions affect the classification of the oral images. Two of the misclassified images are shown with their heat map representations in
Figure 8. Both of the images were classified as suspicious, whereas they were normal. Their suspicion scores were 0.57 and 0.55, and the red regions were not seen as suspicious or different to normal regions. These borderline incorrect cases could potentially be explained by the small datasets that were used to train the classifier.
The differences in the heat map of ResNet-101 and Inception-Resnet-v2 were investigated for two specific images. The images were predicted accurately, but the lesion region area on the images was not marked as suspicious on the image (see
Figure 8). As seen in
Figure 9, ResNet-101 heat maps were more meaningful than those of the Inception ResNet-v2 results in showing the more suspicious parts of the lesion. However, some parts were not marked as highly suspicious in the heat map but more so than the other regions of the image. For instance, as seen in the image on the right side in
Figure 9, ResNet-101 classified the image as suspicious with a score of 0.99; however, the yellow region of the upper left side may be marked with the orange to red scale on the heat map.
4. Discussion
This study shows that the maximum accuracy of the classification of oral images was 95.2% (± 5.5%) for 10-fold and 97.5% (±7.9%) for LoPo cross-validation approaches with the ResNet-101 pre-trained network and the Piracicaba dataset. Additionally, the maximum accuracy was 86.5% on an independent dataset (Piracicaba) for patient-based test results with Inception ResNet-v2 when the Sheffield dataset was used for training. When the Piracicaba dataset was used for training and the Sheffield dataset was used for testing, ResNet-101 network results were more accurate than those of Inception ResNet-v2. This shows that for different datasets, ResNet-101 is not accurate in each test set, and the results with this deep learning method do not generalize to all datasets. However, for both of the results performed on these pre-trained networks, the system was more accurate when the Sheffield dataset was used for training and the Piracicaba dataset was used for testing. An explanation for this is that when the Sheffield dataset is used for training, the system is trained on relatively lower quality and more challenging images, and the resulting classifier works well on the higher-quality Piracicaba images. However, when the system is trained with better quality images, its performance is lower for the relatively lower quality images.
We used precision, recall, and F1-score to measure the generalizability of the system (see
Table 5). Presenting the results in accuracy, F1-score, precision, and recall evaluation methods allowed us to compare our results with other studies. The F1-score ranged from 69.8% to 97.9%; recall and precision varied between 67.3% and 100%, and 78.2% and 100%, respectively. The highest F1-score was obtained for the Piracicaba dataset, with VGG-16 pre-trained models for overall performance and the other three pre-trained networks performing similarly well. For the RoI-level results, the best F1-score was obtained with ResNet-101.
Studies similar to ours in the literature have used both autofluorescence and white light images together [
18,
19], but the results show that for white light images (which are close to our photographic images), the performance was the least accurate. In these dual-modality methods, the most accurate result was 86.9%. It is hard to compare this result to ours because they used more than a single image source and did not report their independent test set results. The dual-modality system’s sensitivities (recall) and positive predictive values (precision) were 85.0% and 97.7%, respectively [
19] and all predictive values ranged from 67.3% to 100%. Because of the limited diversity of the datasets and the small number of cases, our reported standard deviation values were higher than those reported by Uthoff et al.’s study [
19], which also used multi-modality (but not clinically relevant or easily available) images to train and test their performance.
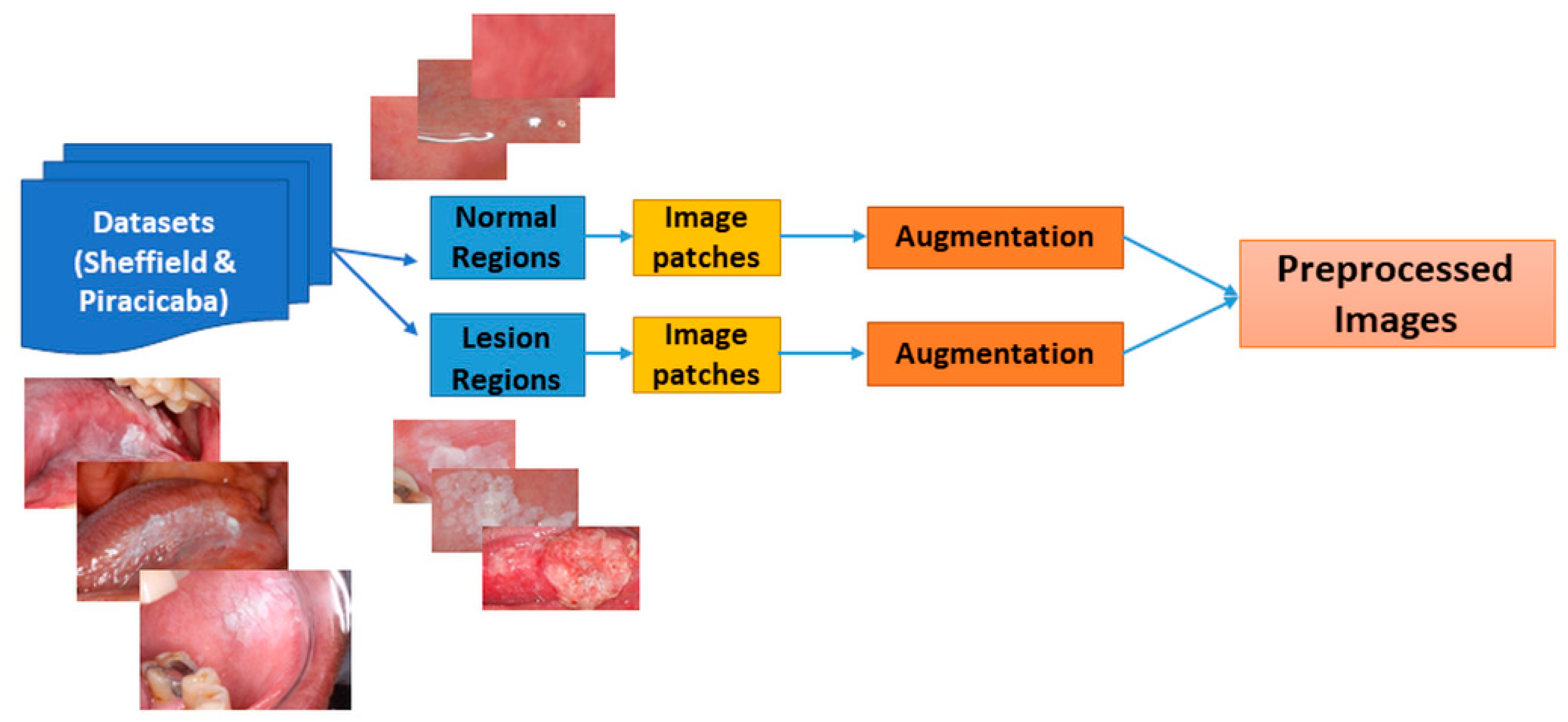
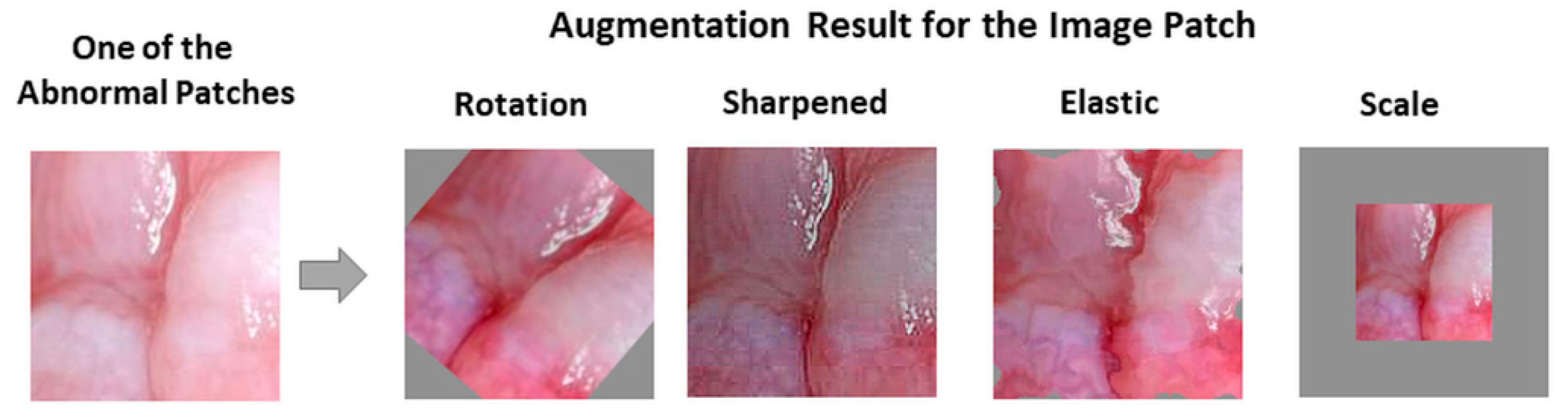
Our study does have some limitations. All of our results were derived from 54 patients in total, which is a small number to train and test the system independently; however, it was sufficient to demonstrate the feasibility of our approaches. In order to overcome this limitation, we increased the number of images by augmentation and split the images into patches. This study also demonstrated that the classification accuracy could be increased by extracting patches from the oral images.
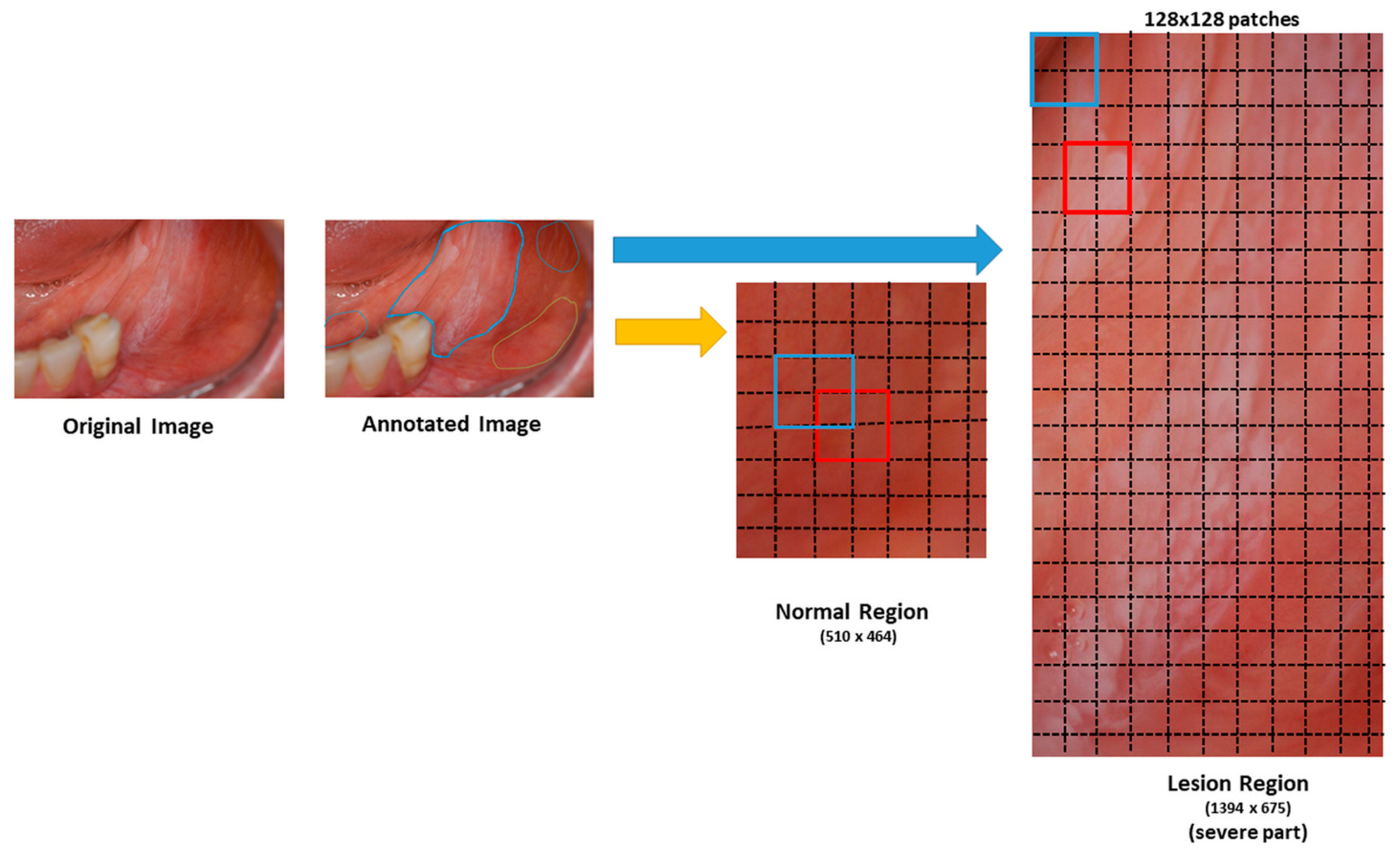
Another limitation is in the selection of the patches, during which we used a percentage threshold for the number of the total pixels to decide whether a patch is suspicious or normal. Some studies segment lesions automatically, but we used manually segmented regions. Manual segmentation could be prone to inter- and intra-reader variability. In our future studies, we aim to overcome this shortcoming by developing automated segmentation methodologies.
With an independent dataset accuracy of 86.5% and an F1-score of 97.9%, the results are promising, especially considering that the networks were developed and tested using small datasets. However, to have better results and develop a more generalizable method, the dataset’s size needs to be increased. With a bigger cohort, we aim to subclassify suspicious images as “high risk” or “low risk.”
After developing automated segmentation and sub-category prediction algorithms using photographic images, we are planning to combine these results with the analysis of histology images. Additionally, we will further enhance our system by including age, gender, lesion location, and patient habits as potential risk factors as well as analyze the follow-up information to predict the risk of malignant transformation. We expect that combining these clinical features with the analysis results from photographic and histological images will result in a very comprehensive clinical decision support tool.


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}