
Towards More Efficient Security Inspection via Deep Learning: A Task-Driven X-ray Image Cropping Scheme


Abstract
:1. Introduction
- We propose SIXray-D, an improved dataset based on the popular SIXray [17] as a fully annotated dataset for contraband items detection. SIXray-D provides a comprehensive detection benchmark, which can be used to evaluate and improve the effectiveness of deep X-ray detection networks.
- We propose TDC, a task-driven X-ray image cropping pipeline to efficiently remove redundant background and preserve the task-related objects by utilizing the features extracted from the network’s backbone.
- We conduct experiments to evaluate several state-of-the-art single-stage detectors on the proposed SIXray-D. We show that TDC can effectively improve the detection methods such as RFB-Net, by achieving better mAPs or reducing the inference time.
2. Related Works
3. SIXray-D Dataset
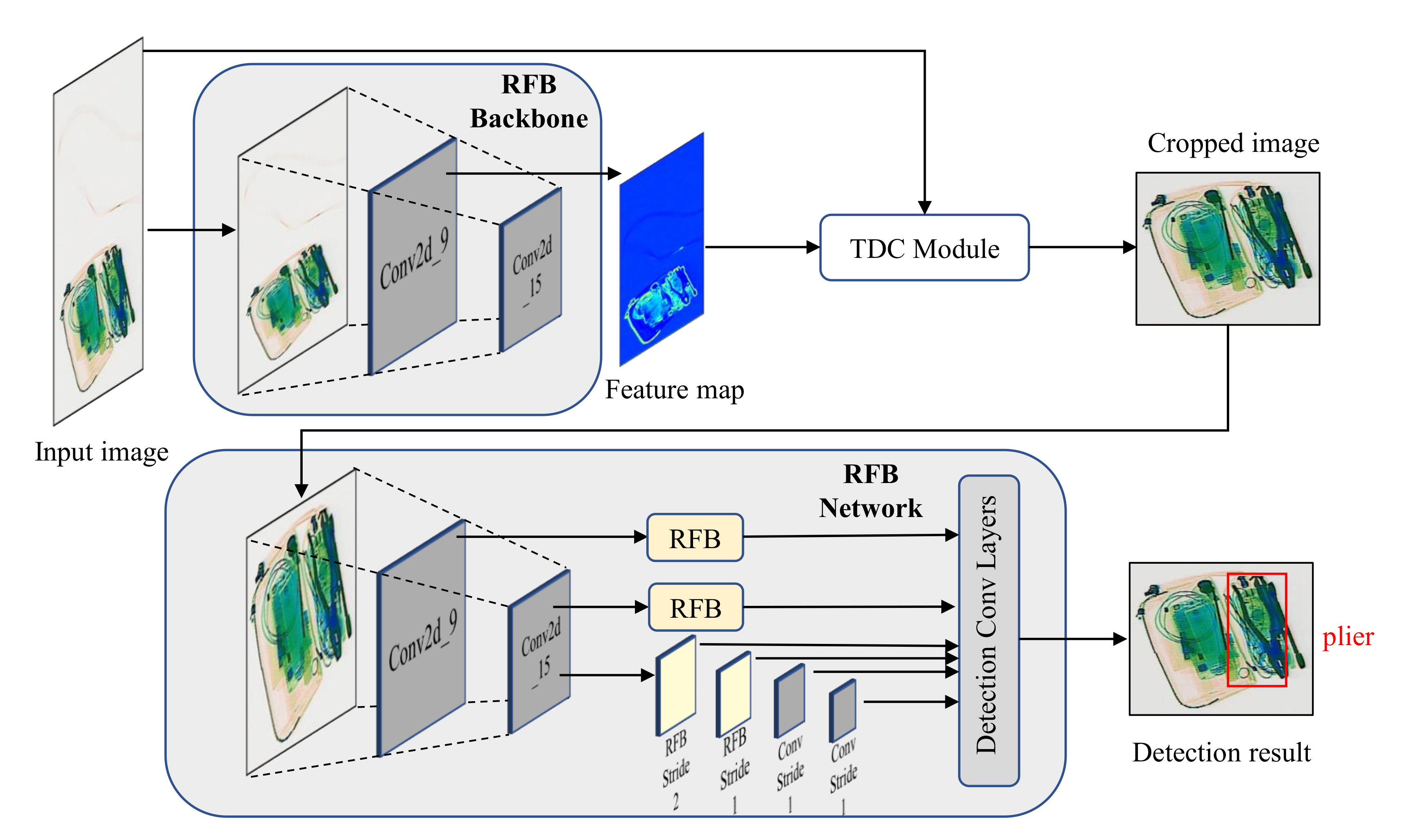
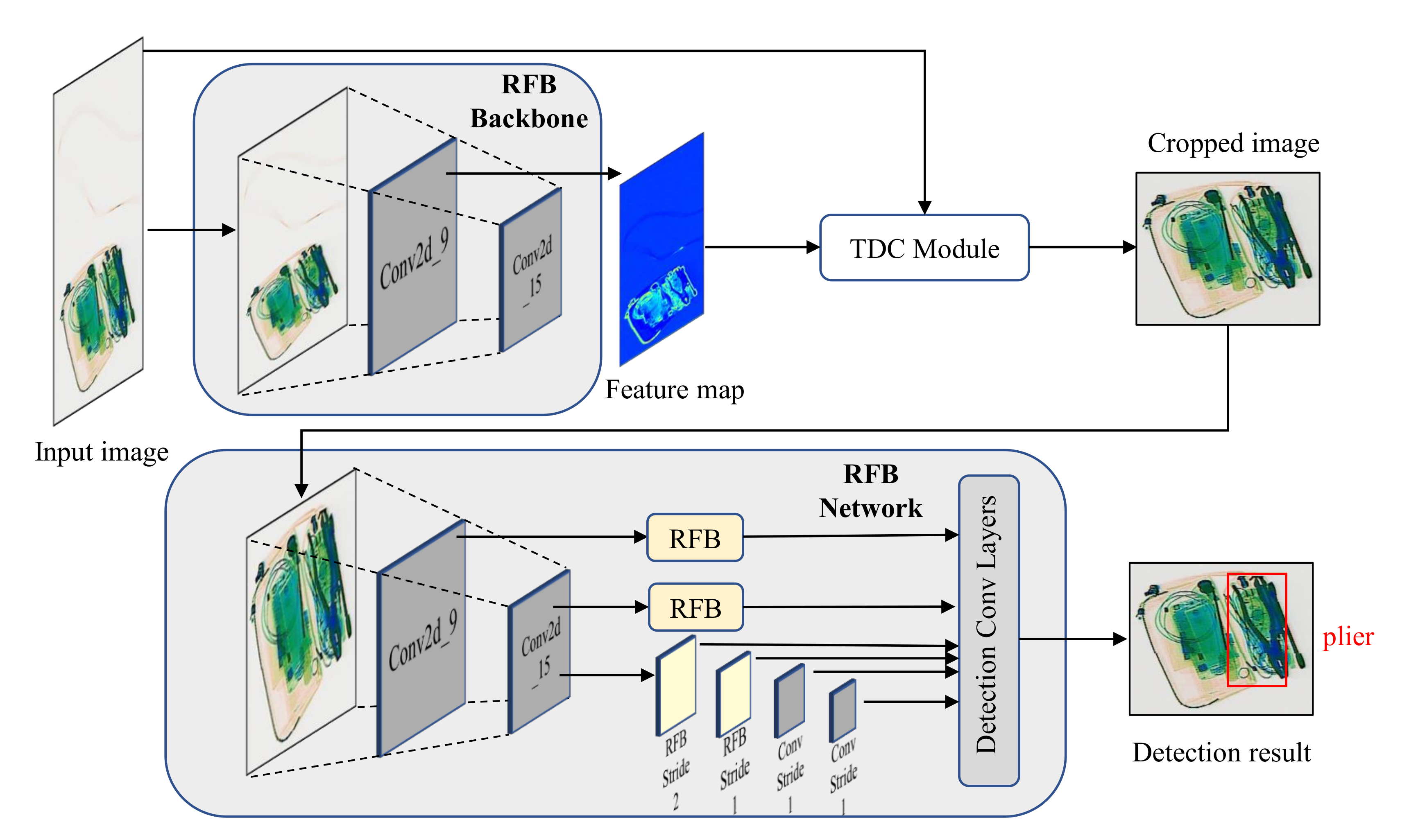
4. Task-Driven Image Cropping by Deep Feature Extraction
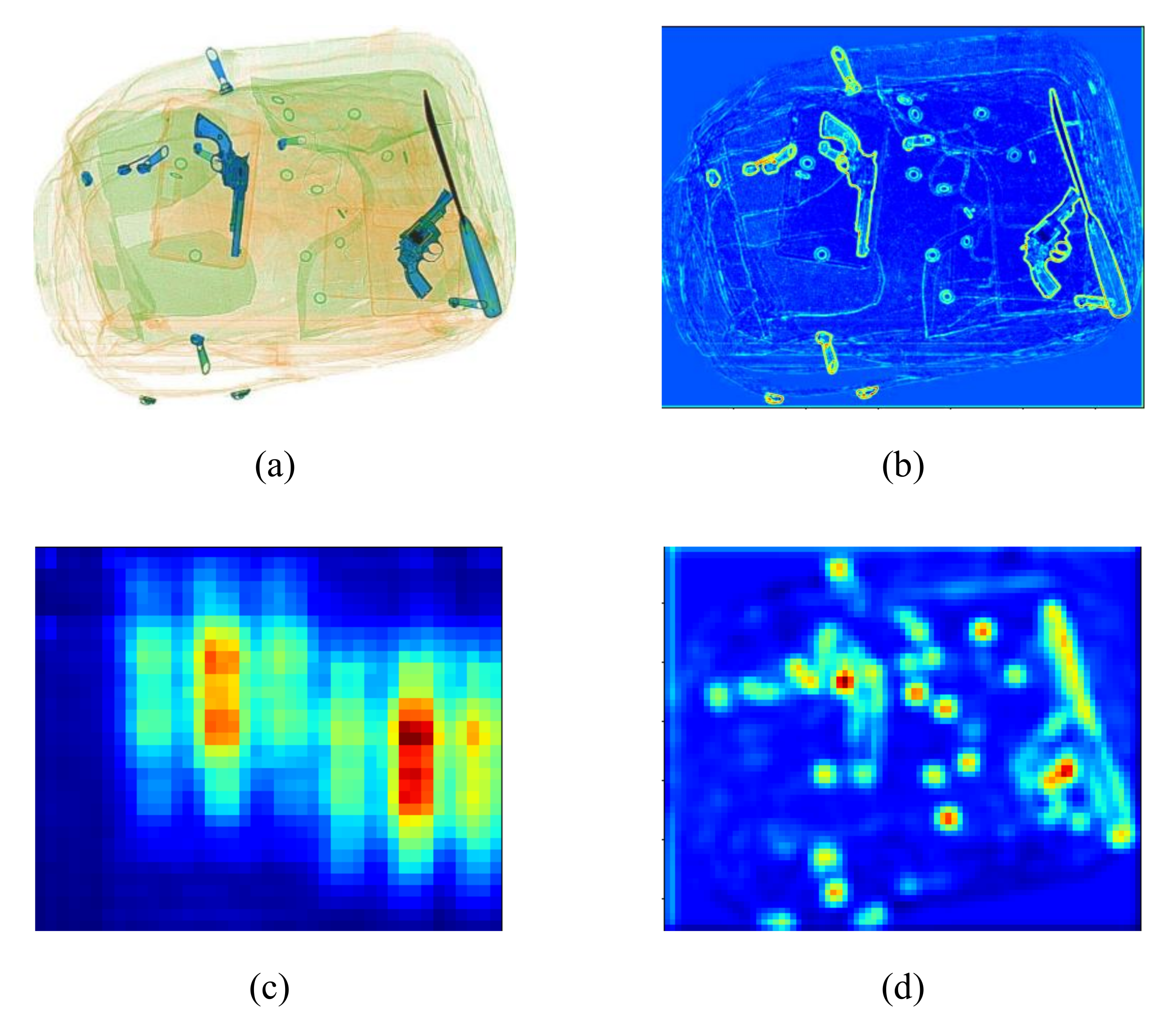
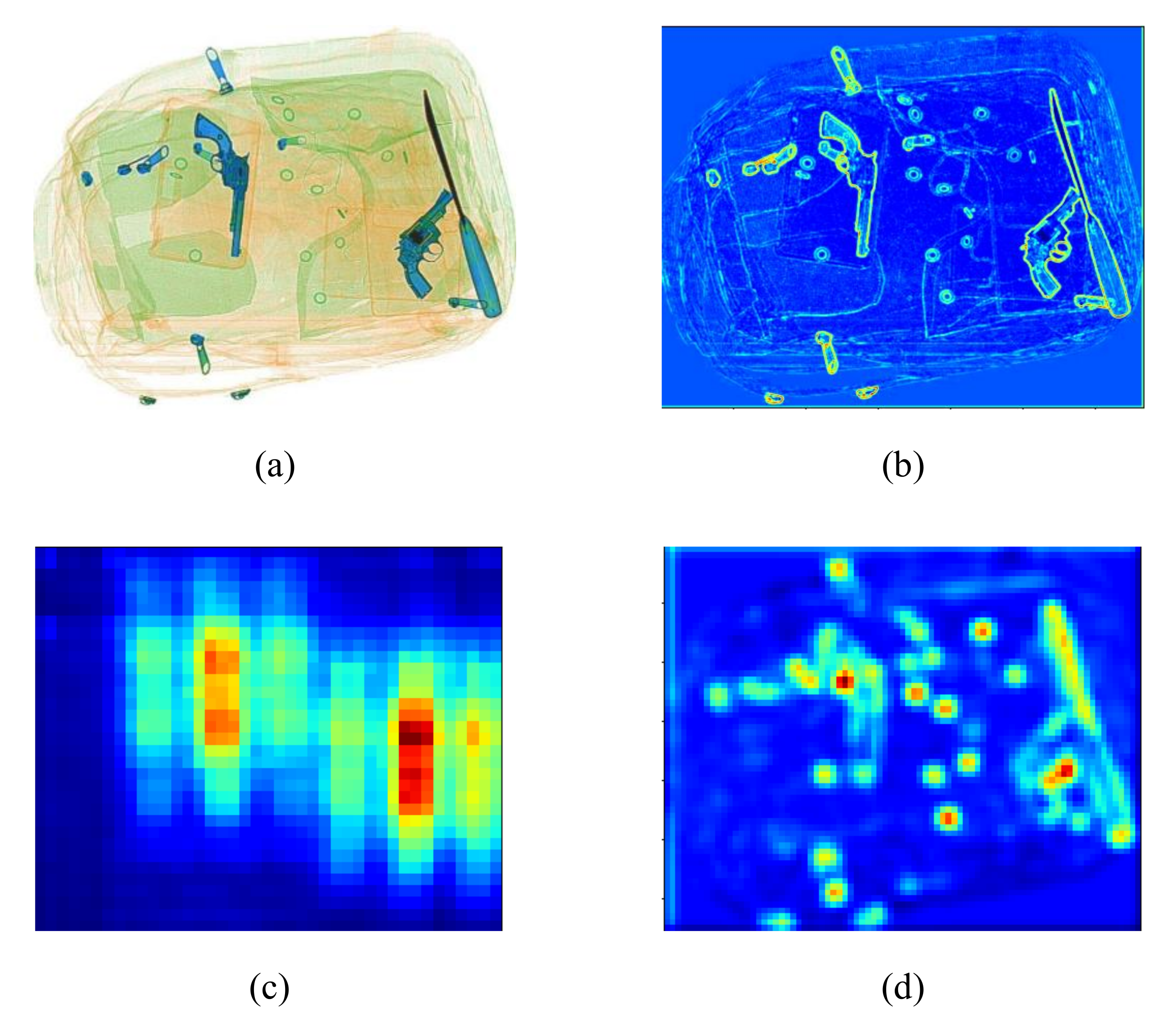
4.1. Feature Map Generation
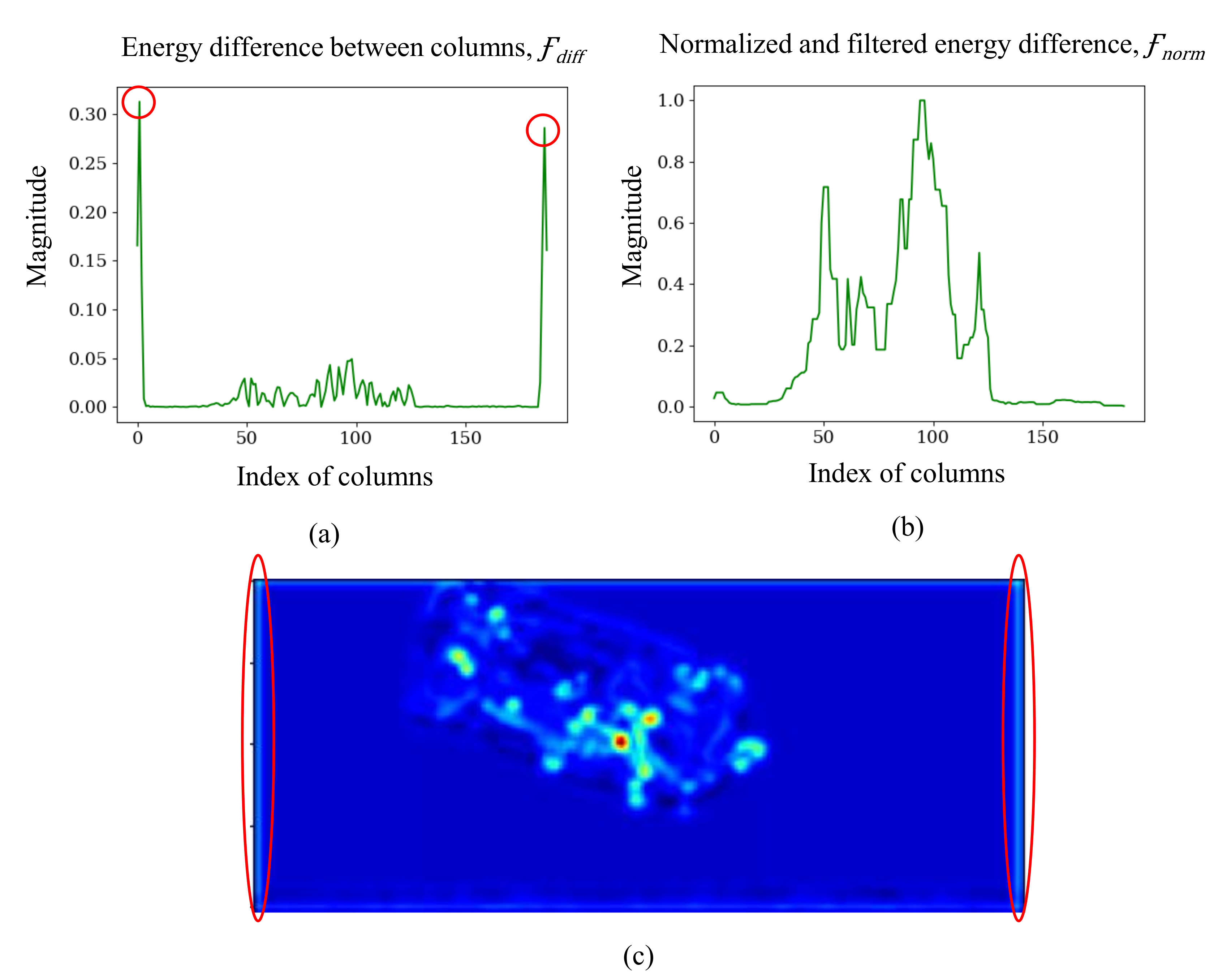
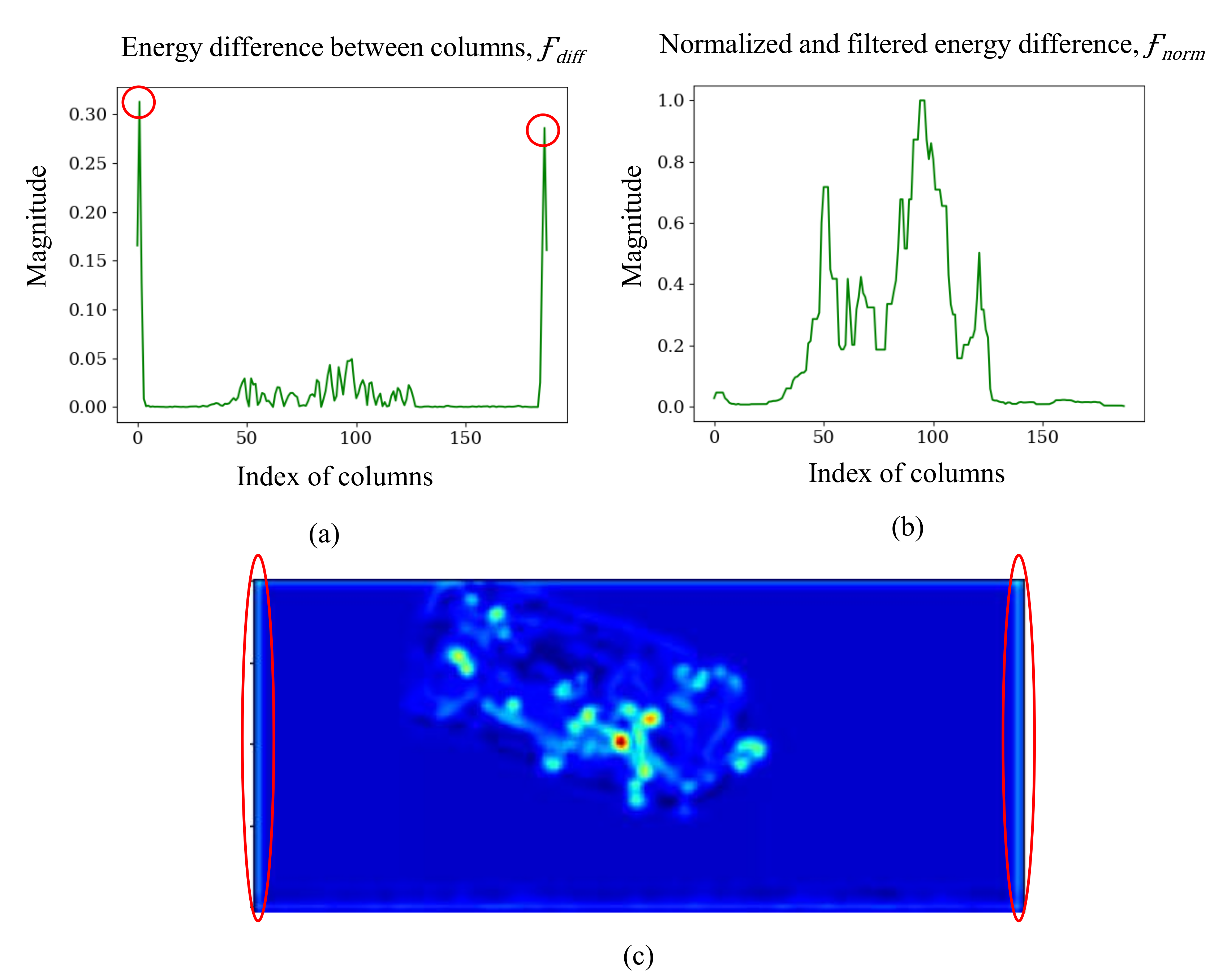
4.2. TDC Module and Image Cropping
5. Experiments
5.1. Experiment Setup
5.2. SIXray-D Benchmarking
5.3. Cropping Performance Assessment
5.3.1. Fixed-Size Model
5.3.2. Dynamic Shape Input Model
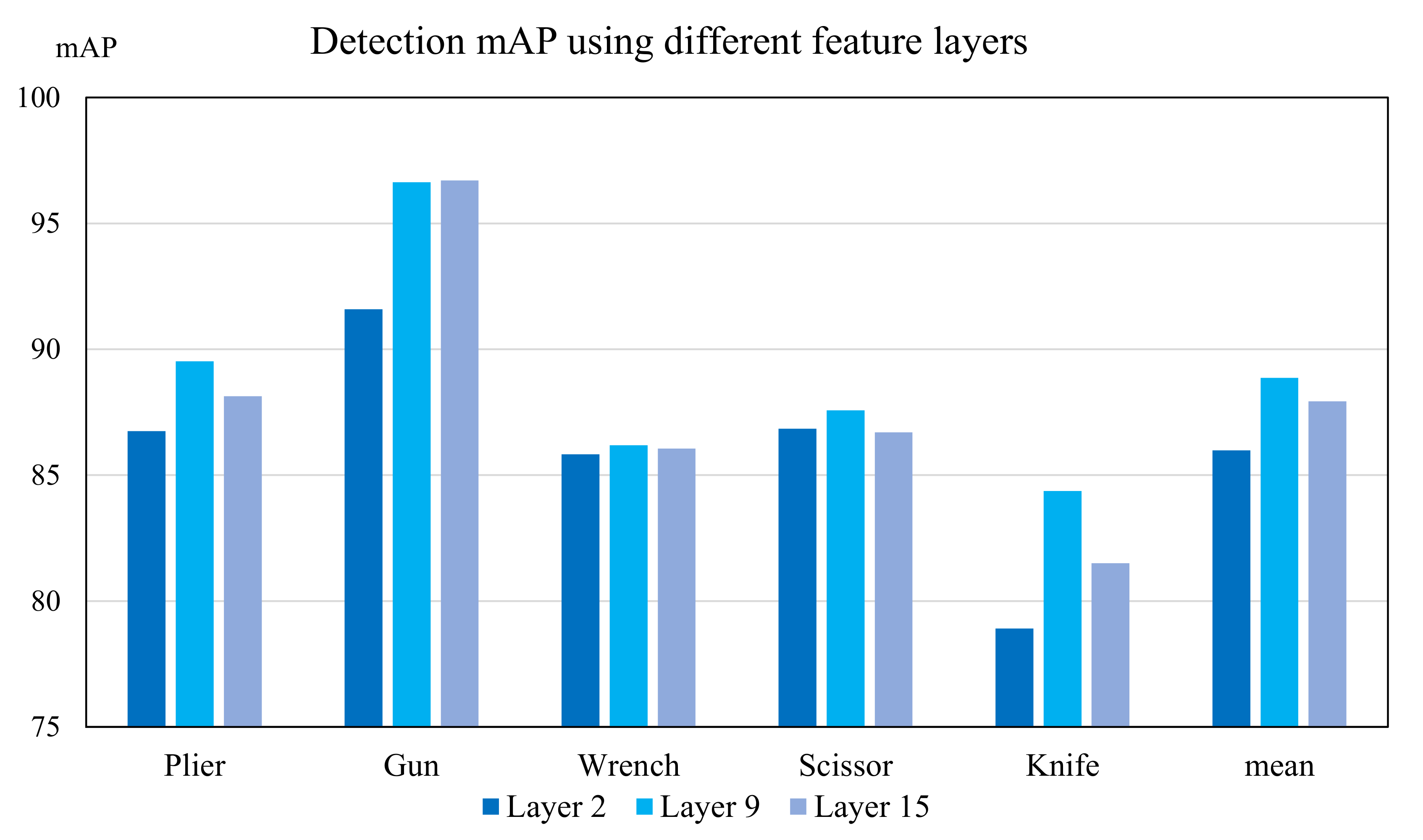
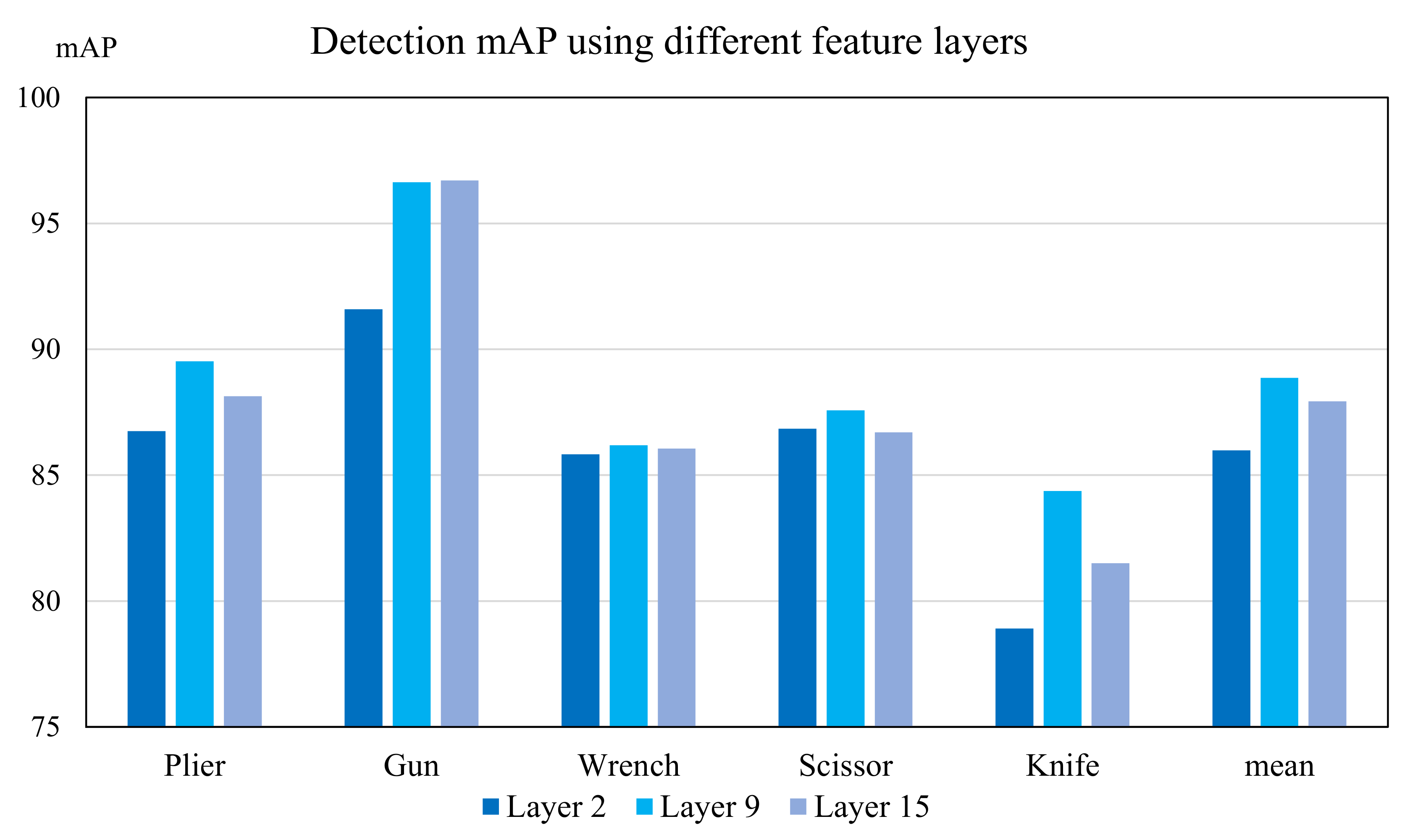
5.4. Ablation Study
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chavaillaz, A.; Schwaninger, A.; Michel, S.; Sauer, J. Expertise, automation and trust in X-ray screening of cabin baggage. Front. Psychol. 2019, 10, 256. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Arcúrio, M.S.; Nakamura, E.S.; Armborst, T. Human factors and errors in security aviation: An ergonomic perspective. J. Adv. Transp. 2018, 2018, 5173253. [Google Scholar] [CrossRef]
- Bolfing, A.; Halbherr, T.; Schwaninger, A. How image based factors and human factors contribute to threat detection performance in X-ray aviation security screening. In Symposium of the Austrian HCI and Usability Engineering Group; Springer: Berlin/Heidelberg, Germany, 2008; pp. 419–438. [Google Scholar]
- Mendes, M.; Schwaninger, A.; Michel, S. Can laptops be left inside passenger bags if motion imaging is used in X-ray security screening? Front. Hum. Neurosci. 2013, 7, 654. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Abidi, B.R.; Zheng, Y.; Gribok, A.V.; Abidi, M.A. Improving weapon detection in single energy X-ray images through pseudocoloring. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2006, 36, 784–796. [Google Scholar] [CrossRef]
- Chen, Z.; Zheng, Y.; Abidi, B.R.; Page, D.L.; Abidi, M.A. A combinational approach to the fusion, de-noising and enhancement of dual-energy x-ray luggage images. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05)-Workshops, San Diego, CA, USA, 21–23 September 2005; p. 2. [Google Scholar]
- Singh, M.; Singh, S. Optimizing image enhancement for screening luggage at airports. In Proceedings of the CIHSPS 2005. Proceedings of the 2005 IEEE International Conference on Computational Intelligence for Homeland Security and Personal Safety, Orlando, FL, USA, 31 March–1 April 2005; pp. 131–136. [Google Scholar]
- Chan, J.; Evans, P.; Wang, X. Enhanced color coding scheme for kinetic depth effect X-ray (KDEX) imaging. In Proceedings of the 44th Annual 2010 IEEE International Carnahan Conference on Security Technology, San Jose, CA, USA, 5–8 October 2010; pp. 155–160. [Google Scholar]
- Liu, Z.; Li, J.; Shu, Y.; Zhang, D. Detection and recognition of security detection object based on YOLO9000. In Proceedings of the 2018 5th International Conference on Systems and Informatics (ICSAI), Nanjing, China, 10–12 November 2018; pp. 278–282. [Google Scholar]
- Akcay, S.; Breckon, T.P. An evaluation of region based object detection strategies within x-ray baggage security imagery. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 1337–1341. [Google Scholar]
- Cui, Y.; Oztan, B. Automated firearms detection in cargo x-ray images using RetinaNet. In Anomaly Detection and Imaging with X-Rays (ADIX) IV; International Society for Optics and Photonics: Bellingham, WA, USA, 2019; Volume 10999. [Google Scholar]
- Morris, T.; Chien, T.; Goodman, E. Convolutional neural networks for automatic threat detection in security X-Ray images. In Proceedings of the 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA), Orlando, FL, USA, 17–20 December 2018; pp. 285–292. [Google Scholar]
- Wei, Y.; Tao, R.; Wu, Z.; Ma, Y.; Zhang, L.; Liu, X. Occluded prohibited items detection: An x-ray security inspection benchmark and de-occlusion attention module. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 138–146. [Google Scholar]
- Mery, D.; Riffo, V.; Zscherpel, U.; Mondragón, G.; Lillo, I.; Zuccar, I.; Lobel, H.; Carrasco, M. GDXray: The database of X-ray images for nondestructive testing. J. Nondestruct. Eval. 2015, 34, 42. [Google Scholar] [CrossRef]
- Caldwell, M.; Griffin, L.D. Limits on transfer learning from photographic image data to X-ray threat detection. J. X-Ray Sci. Technol. 2019, 27, 1007–1020. [Google Scholar] [CrossRef] [PubMed]
- Rogers, T.W.; Jaccard, N.; Protonotarios, E.D.; Ollier, J.; Morton, E.J.; Griffin, L.D. Threat Image Projection (TIP) into X-ray images of cargo containers for training humans and machines. In Proceedings of the 2016 IEEE International Carnahan Conference on Security Technology (ICCST), Orlando, FL, USA, 24–27 October 2016; pp. 1–7. [Google Scholar]
- Miao, C.; Xie, L.; Wan, F.; Su, C.; Liu, H.; Jiao, J.; Ye, Q. Sixray: A large-scale security inspection x-ray benchmark for prohibited item discovery in overlapping images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 2119–2128. [Google Scholar]
- Kannojia, S.P.; Jaiswal, G. Effects of varying resolution on performance of CNN based image classification: An experimental study. Int. J. Comput. Sci. Eng. 2018, 6, 451–456. [Google Scholar] [CrossRef]
- Luke, J.J.; Joseph, R.; Balaji, M. Impact of Image Size on Accuracy and Generalization of Convolutional Neural Networks. 2019. Available online: https://www.researchgate.net/profile/Mahesh-Balaji/publication/332241609_IMPACT_OF_IMAGE_SIZE_ON_ACCURACY_AND_GENERALIZATION_OF_CONVOLUTIONAL_NEURAL_NETWORKS/links/5fa7a715299bf10f732fdc1c/IMPACT-OF-IMAGE-SIZE-ON-ACCURACY-AND-GENERALIZATION-OF-CONVOLUTIONAL-NEURAL-NETWORKS.pdf (accessed on 20 December 2021).
- Sabottke, C.F.; Spieler, B.M. The effect of image resolution on deep learning in radiography. Radiol. Artif. Intell. 2020, 2, e190015. [Google Scholar] [CrossRef] [PubMed]
- Shetty, C.M.; Barthur, A.; Kambadakone, A.; Narayanan, N.; Kv, R. Computed radiography image artifacts revisited. Am. J. Roentgenol. 2011, 196, W37–W47. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Yu, H. Convolutional neural network based metal artifact reduction in x-ray computed tomography. IEEE Trans. Med. Imaging 2018, 37, 1370–1381. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Shen, J. Deep cropping via attention box prediction and aesthetics assessment. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2186–2194. [Google Scholar]
- Lu, P.; Zhang, H.; Peng, X.; Jin, X. An end-to-end neural network for image cropping by learning composition from aesthetic photos. arXiv 2019, arXiv:1907.01432. [Google Scholar]
- Cho, D.; Park, J.; Oh, T.H.; Tai, Y.W.; So Kweon, I. Weakly-and self-supervised learning for content-aware deep image retargeting. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4558–4567. [Google Scholar]
- Wang, Y.S.; Tai, C.L.; Sorkine, O.; Lee, T.Y. Optimized scale-and-stretch for image resizing. In ACM SIGGRAPH Asia 2008 Papers; ACM: New York, NY, USA, 2008; pp. 1–8. [Google Scholar]
- Tao, R.; Wei, Y.; Jiang, X.; Li, H.; Qin, H.; Wang, J.; Ma, Y.; Zhang, L.; Liu, X. Towards real-world X-ray security inspection: A high-quality benchmark and lateral inhibition module for prohibited items detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10923–10932. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2016; pp. 2818–2826. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2016; pp. 770–778. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Venice, Italy, 22–29 October 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Huang, D. Receptive field block net for accurate and fast object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 385–400. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Stoken, A.; Borovec, J.; NanoCode012; Kwon, Y.; TaoXie; Fang, J.; imyhxy; Michael, K.; et al. Ultralytics/yolov5: V6.1—TensorRT, TensorFlow Edge TPU and OpenVINO Export and Inference; 2022. [Google Scholar] [CrossRef]
- Chen, D.J.; Hsieh, H.Y.; Liu, T.L. Adaptive image transformer for one-shot object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12247–12256. [Google Scholar]
- Avidan, S.; Shamir, A. Seam carving for content-aware image resizing. In ACM SIGGRAPH 2007 Papers; ACM: New York, NY, USA, 2007. [Google Scholar]
- Wu, J.; Xie, R.; Song, L.; Liu, B. Deep feature guided image retargeting. In Proceedings of the 2019 IEEE Visual Communications and Image Processing (VCIP), Sydney, NSW, Australia, 1–4 December 2019; pp. 1–4. [Google Scholar]
- Lin, S.S.; Yeh, I.C.; Lin, C.H.; Lee, T.Y. Patch-based image warping for content-aware retargeting. IEEE Trans. Multimed. 2012, 15, 359–368. [Google Scholar] [CrossRef] [Green Version]
- Canny, J. A computational approach to edge detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, 679–698. [Google Scholar] [CrossRef]
- Baştan, M.; Yousefi, M.R.; Breuel, T.M. Visual words on baggage X-ray images. In International Conference on Computer Analysis of Images and Patterns, Proceedings of the 14th International Conference, CAIP 2011, Seville, Spain, 29–31 August 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 360–368. [Google Scholar]
- Zhang, N.; Zhu, J. A study of x-ray machine image local semantic features extraction model based on bag-of-words for airport security. Int. J. Smart Sens. Intell. Syst. 2015, 8. Available online: https://pdfs.semanticscholar.org/3bf2/5c94c1b87a7ac4731c237a17bc8cf4ba0ac2.pdf (accessed on 30 December 2021). [CrossRef] [Green Version]
- Bastan, M.; Byeon, W.; Breuel, T.M. Object Recognition in Multi-View Dual Energy X-ray Images. BMVC 2013, 1, 11. Available online: https://projet.liris.cnrs.fr/imagine/pub/proceedings/BMVC-2013/Papers/paper0131/abstract0131.pdf (accessed on 30 December 2021).
- Schmidt-Hackenberg, L.; Yousefi, M.R.; Breuel, T.M. Visual cortex inspired features for object detection in X-ray images. In Proceedings of the 21st International Conference on Pattern Recognition (ICPR2012), Tsukuba, Japan, 11–15 November 2012; pp. 2573–2576. [Google Scholar]
- Mery, D. Automated detection in complex objects using a tracking algorithm in multiple X-ray views. In Proceedings of the CVPR 2011 WORKSHOPS, Colorado Springs, CO, USA, 20–25 June 2011; pp. 41–48. [Google Scholar]
- Mery, D.; Riffo, V.; Zuccar, I.; Pieringer, C. Automated X-ray object recognition using an efficient search algorithm in multiple views. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Portland, OR, USA, 23–28 June 2013; pp. 368–374. [Google Scholar]
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Liang, K.J.; Heilmann, G.; Gregory, C.; Diallo, S.O.; Carlson, D.; Spell, G.P.; Sigman, J.B.; Roe, K.; Carin, L. Automatic threat recognition of prohibited items at aviation checkpoint with x-ray imaging: A deep learning approach. In Anomaly Detection and Imaging with X-Rays (ADIX) III; International Society for Optics and Photonics: Bellingham, WA, USA, 2018; Volume 10632, p. 1063203. [Google Scholar]
- Sigman, J.B.; Spell, G.P.; Liang, K.J.; Carin, L. Background adaptive faster R-CNN for semi-supervised convolutional object detection of threats in x-ray images. In Anomaly Detection and Imaging with X-Rays (ADIX) V; International Society for Optics and Photonics: Bellingham, WA, USA, 2020; Volume 11404, p. 1140404. [Google Scholar]
- Liu, J.; Leng, X.; Liu, Y. Deep convolutional neural network based object detector for X-ray baggage security imagery. In Proceedings of the 2019 IEEE 31st International Conference on Tools with Artificial Intelligence (ICTAI), Portland, OR, USA, 4–6 November 2019; pp. 1757–1761. [Google Scholar]
- Dumagpi, J.K.; Jeong, Y.J. Pixel-Level Analysis for Enhancing Threat Detection in Large-Scale X-ray Security Images. Appl. Sci. 2021, 11, 10261. [Google Scholar] [CrossRef]
- Akcay, S.; Kundegorski, M.E.; Willcocks, C.G.; Breckon, T.P. Using deep convolutional neural network architectures for object classification and detection within x-ray baggage security imagery. IEEE Trans. Inf. Forensics Secur. 2018, 13, 2203–2215. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In European Conference on Computer Vision, Proceedings of the 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 818–833. [Google Scholar]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How transferable are features in deep neural networks? arXiv 2014, arXiv:1411.1792. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; pp. 8024–8035. [Google Scholar]
- Van Rossum, G.; Drake, F.L. Python 3 Reference Manual; CreateSpace: Scotts Valley, CA, USA, 2009. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. 2015. Available online: tensorflow.org (accessed on 30 December 2021).
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The PASCAL Visual Object Classes Challenge 2007 (VOC2007) Results. Available online: http://www.pascal-network.org/challenges/VOC/voc2007/workshop/index.html (accessed on 30 December 2021).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Class Types | Positive Images | Negative Images | Multiple Objects per Image | Object Occlusion | Real X-ray Artifacts | Realistic Orientation of Luggage |
|---|---|---|---|---|---|---|---|
| GDXray | Shuriken, gun, knife | 8850 | 10,550 | ✗ | ✗ | ✗ | ✗ |
| OPIXray | Scissors and variants of knife | 8885 | 0 | ✗ | ✓ | ✗ | ✗ |
| SIXray-D | Scissors, pliers, gun, wrench, knife | 11,401 | 1,050,302 | ✓ | ✓ | ✓ | ✓ |
| Dataset | SIXray | SIXray-D |
|---|---|---|
| Supervised task | Classification | Detection |
| Bounding box annotations | Test Set | Train + test set |
| Positive images | 8823 | 11,401 |
| Positive objects | 20,729 | 23,470 |
| Method | Pliers | Gun | Wrench | Scissors | Knife | Mean |
|---|---|---|---|---|---|---|
| SSD | 87.03 | 96.31 | 84.73 | 84.04 | 82.51 | 86.92 |
| RetinaNet | 82.73 | 84.51 | 75.69 | 79.95 | 74.64 | 81.50 |
| RFB | 88.78 | 96.13 | 85.92 | 84.73 | 83.22 | 87.76 |
| RFB + Edge [40] based crop | 88.79 | 95.85 | 86.12 | 86.04 | 83.93 | 88.16 |
| RFB + Aesthetic crop [24] | 89.43 | 96.32 | 86.17 | 85.48 | 83.43 | 88.38 |
| RFB + TDC | 89.52 | 96.63 | 86.19 | 87.57 | 84.37 | 88.86 |
| Method | Pliers | Gun | Wrench | Scissors | Knife | Mean | Runtime (s) ↓ | Runtime Reduction (%) ↑ |
|---|---|---|---|---|---|---|---|---|
| Dynamic RFB | 90.83 | 98.67 | 87.26 | 91.65 | 83.01 | 90.28 | 2.394 | N/A |
| Dynamic RFB + Canny edge [40]-based crop | 89.84 | 97.93 | 88.20 | 90.80 | 84.69 | 90.29 | 2.271 | 5.13 |
| Dynamic RFB + Aesthetic crop [24] | 90.52 | 98.36 | 88.76 | 89.31 | 83.90 | 90.37 | 2.221 | 7.23 |
| Dynamic RFB + TDC | 91.07 | 98.54 | 88.51 | 92.32 | 82.78 | 90.60 | 2.192 | 8.44 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nguyen, H.D.; Cai, R.; Zhao, H.; Kot, A.C.; Wen, B. Towards More Efficient Security Inspection via Deep Learning: A Task-Driven X-ray Image Cropping Scheme. Micromachines 2022, 13, 565. https://doi.org/10.3390/mi13040565
Nguyen HD, Cai R, Zhao H, Kot AC, Wen B. Towards More Efficient Security Inspection via Deep Learning: A Task-Driven X-ray Image Cropping Scheme. Micromachines. 2022; 13(4):565. https://doi.org/10.3390/mi13040565
Chicago/Turabian StyleNguyen, Hong Duc, Rizhao Cai, Heng Zhao, Alex C. Kot, and Bihan Wen. 2022. "Towards More Efficient Security Inspection via Deep Learning: A Task-Driven X-ray Image Cropping Scheme" Micromachines 13, no. 4: 565. https://doi.org/10.3390/mi13040565
APA StyleNguyen, H. D., Cai, R., Zhao, H., Kot, A. C., & Wen, B. (2022). Towards More Efficient Security Inspection via Deep Learning: A Task-Driven X-ray Image Cropping Scheme. Micromachines, 13(4), 565. https://doi.org/10.3390/mi13040565