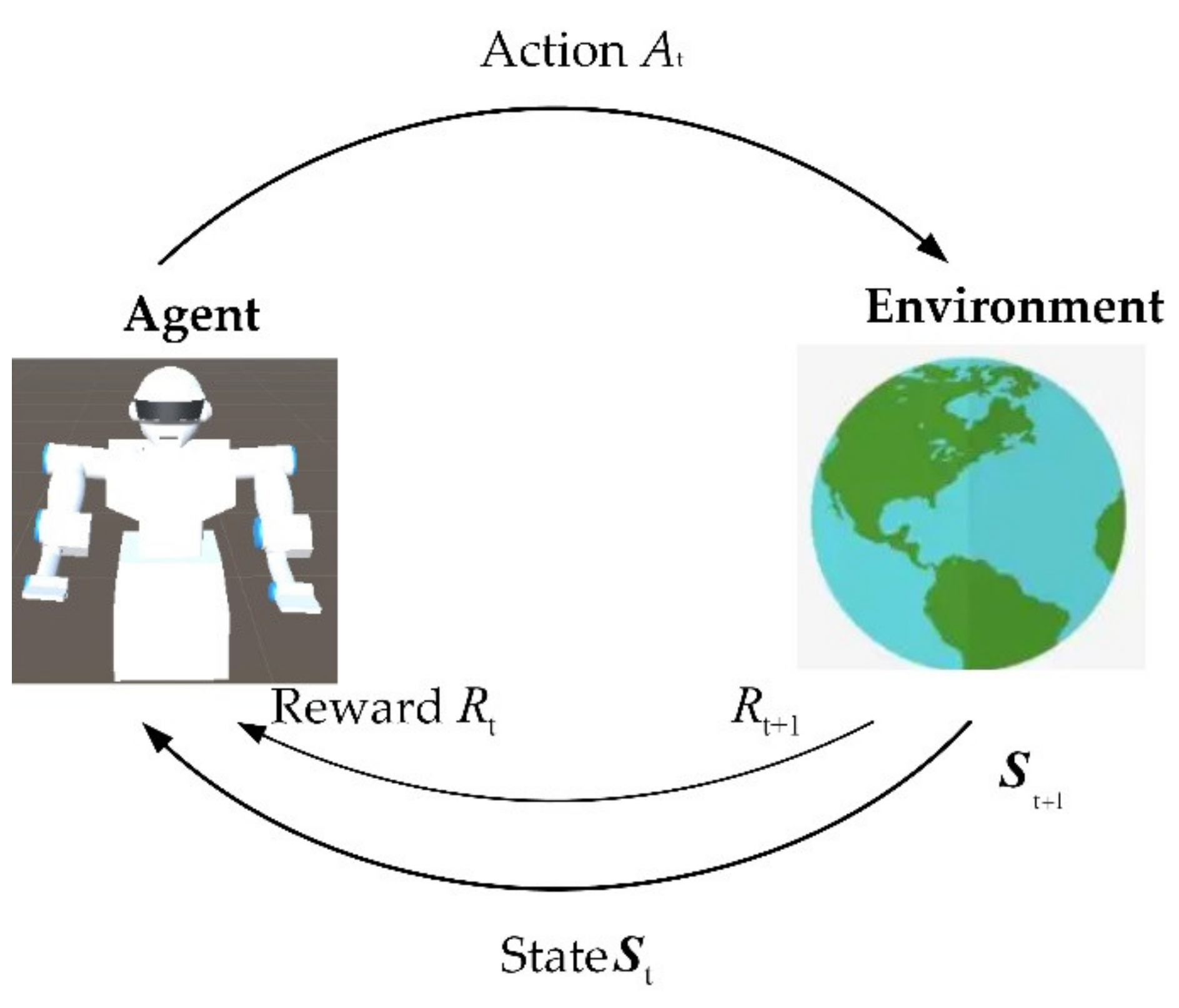
1. Introduction
The arrival of an aging society in the world has increased the social proportion of the elderly population. The care of the elderly has become one of the important concerns of medical care. Recently, COVID-19 has also greatly increased the burden on healthcare. With the progress and development of science and technology, medical robots also began to enter the field of biomedicine. If robots can replace humans to care for patients or the elderly, the burden on society will be greatly reduced [
1]. While for the paralytic or seriously injured patient lying on the bed, turning over, or getting up may be a challenging job, it would help a lot if there is a service robot assisting him. Moreover, the interaction between the service robot and the elderly or patients is mainly completed by the robotic arm. Therefore, it is of interest to take on the research on the motion and trajectory planning of the robotic arm.
There are several related works about reinforcement learning and trajectory planning. The emergence of deep reinforcement learning (DRL) solved some of the problems in traditional path planning algorithms, such as A* [
2], with hard to construct cost function, artificial potential field (APF) method [
3], which is limited by the problem of the local optimum, fast-expanding random tree (FERT) method [
4] which is arduous to obtain for an ideal movement trajectory in a narrow area, and so on. DRL does not necessarily rely on data models, and it only requires setting planning goals; then, the robot itself will interact with the environment. Throughout the process, DRL would help avoid obstacles and use path planning to maximize the reward to find an optimal path for a robot [
5]. Joshi et al. [
6] used imitation learning to study human dressing assistance, but they did not consider obstacle avoidance. To solve this problem, a control algorithm for the whole-body obstacles avoidance of anthropomorphic robots is proposed by Sangiovanni et al. [
7]. Wong et al. [
8], based on the soft actor–critic (SAC) algorithm, trained the neural network of the robot’s left and right arms agents using dual agent training, distributed training structure, and a progressive training environment. However, the research mentioned above has not involved the interaction between the human and the robot, which is necessary for the robot to explore the environment fully to achieve better performance.
Traditional reinforcement learning (RL) deals with dynamic planning in the state of limited space. Li et al. [
9] proposed an integral RL method to calculate the linear quadratic regulation (LQR) to reduce the motion tracking error of the manipulator. Perrusquía et al. [
10] used RL to learn the required force when using impedance control to control the force and position of the robot and then generated the required position through proportional-integral admittance control. Ai et al. [
11,
12] used reinforcement learning to optimize their control effect when studying space robots catching satellites. However, in the references [
9,
10,
11,
12], environment models are still indispensable to obtaining the optimal control strategy, and the reliance on environment models remains a problem unsolved. On the contrary, DRL, as a combination of the perception ability of deep learning and the decision-making ability of RL, can handle more complex continuous scenarios with larger action and sample space compared with RL, and it makes the robot interact with the environment directly and master the operation skills. Li et al. [
13] designed a DRL-based strategy search method to realize the point-to-point automatic learning of the robotic arm and used a convolutional neural network to maintain the robustness of the robotic arm. Li et al. [
14] proposed a method of processing multimodal information with a deep deterministic policy gradient (DDPG) for an assembly robot so that the robot can complete the assembly task without position constraints. However, references [
13,
14] concerned only the control methods for single-arm robots. Tang et al. [
15] compared the control effect of the rapid search random tree (RRT) algorithm and the DDPG algorithm on the coordinated motion planning of space robots, and the results showed that the DDPG algorithm is working with higher efficiency. Beltran-Hernandez et al. [
16] proposed a force control framework based on reinforcement learning for the control of rigid robot manipulators, which combined traditional force control methods with the SAC algorithm and thus avoided damage to the environment. Shahid et al. [
17] used the proximal policy optimization (PPO) algorithm to study a robot grasping task and designed a rewards and punishments function (RPF) with intensive rewards, but the RPF and requirements of the task are relatively simple. As for the obstacle avoidance of the robotic arm in the process of moving, Prianto et al. [
18] proposed to use collision detection (CD) to punish the robot, but the robot will not receive the penalty signal when touching the obstacle, which will lengthen the training time. Ota et al. [
19] proposed a trajectory planning method for manipulators working in a constrained space to avoid obstacles outside the constrained space, but the definition of the constrained space has a certain particularity.
Inspired by the reference [
20] on the recognition of the human lying position on the hospital bed, this paper further develops the research on the trajectory planning of the dual-arm robot to help patients turn over or to transport them from the bed. Considering the complicated situation between the human body and the environment, this paper proposes a DRL-based method to form the trajectory of both arms autonomously. In this study, when the dual-arm robot lifts a patient, the robot’s arms have to be inserted into the narrow space between the human body and the bed; they need to avoid obstacles to prevent the mechanical arm from colliding with the bed or the human body. Because the human body and the bed have complex shapes, this is relatively difficult to achieve. The major difficulty of this duty arises with the high dimension of the robot state and its behavior. When training the robot with DRL, the robot needs to control each joint of the robotic arm according to the position of the human body and the bed in the environment. The states and behaviors involved in this process are very complex to describe, which leads to slow convergence and long calculation time. This is also a classic problem in DRL—the curse of dimensionality. To tackle the problem of DRL, accelerate the training to find the optimal strategy, optimize the length of training step, and reduce the training time, this research designed the RPF based on the idea of the APF method. The RPF is composed of three parts: goal guidance, obstacle avoidance, and time function.
Due to the complex shapes of the human body and the bed, there are two problems setting the RPF during the reinforcement learning training process. One problem is that when the robot approaches the targets, with an alteration of the minimum distance between the end of the robotic arm and the targets, the robot may not obtain enough rewards to support the exploration of the environment. Therefore, a multifaceted consideration of the weight of the reward and the penalty signals during the training is needed. The other problem is that the collision constraint of the human body or the bed is complicated to represent. Multiple obstacle points and collision configurations have to be set up to construct the outline of the human body and the bed. Furthermore, the two problems will introduce a more challenging situation—while avoiding these obstacles contours the robot may also avoid the target areas between the human body and the bed. Therefore, it is also a challenging task to set the obstacle avoidance function (OAF) and CD reasonably to obtain desired results from reinforcement learning. In response to the above problems, this paper studies the dual-arm trajectory control strategies based on reinforcement learning. During the training process, based on the idea of the APF method, the RPF is designed, in which the reward guide function (RGF), OAF, CD, and time function are set up reasonably. According to the gravity function of the artificial potential field, RGF is designed based on the distance between the targets and manipulators, and it guides the robot to approach the targets continuously by updating the minimum distance between the end of the robot arm and the targets, and finally makes the end of the robot arm reach the required position. In terms of obstacle avoidance, inspired by the repulsion function and 13 obstacle points set to obtain penalty signals to achieve better performance, this paper combined it with the collision detection configuration. Compared with only using the CD method from [
21], the present method further improves the efficiency of obstacle avoidance by reducing about 500 thousand training steps, and constructing a new RPF to ensure the agents receive more rewards. Furthermore, the time function is used to guide the agent to train faster. Finally, through simulation, the effectiveness of the RPF and obstacle avoidance method is verified, and the robot can accurately avoid obstacles to reach the expected targets. The contributions of this article are mainly the following three points:
- (1)
Proposed a dual-arm robot trajectory planning method based on DRL, which enables the robot to interact with the environment to find an optimal path to the targets;
- (2)
Designed the RPF based on the idea of the APF method, which creates a suitable signal for the robot to support the exploration of the environment and arrive at the ideal position to hold the patients;
- (3)
Combined OAF and CD, reducing the training time on obstacle avoidance and enhancing the stability of training.
The rest of the article is structured as follows;
Section 2 describes the model of the dual-arm robot and presents the preliminaries on deep reinforcement learning algorithms. In
Section 3, according to the challenge mentioned above, the RPF setting method is proposed. The simulation result and discussion about the RPF setting are given in
Section 4. Finally, conclusions are given in
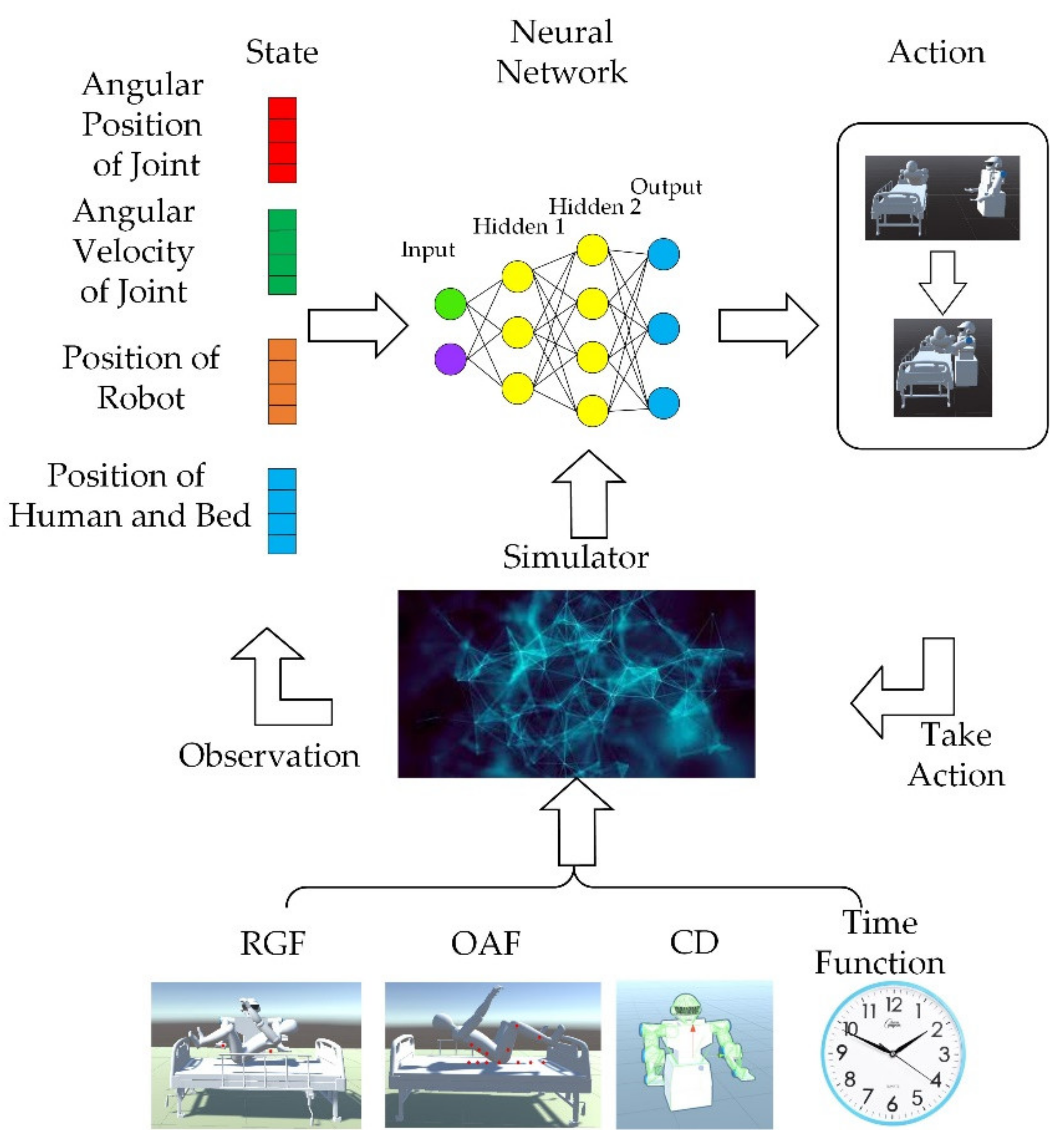
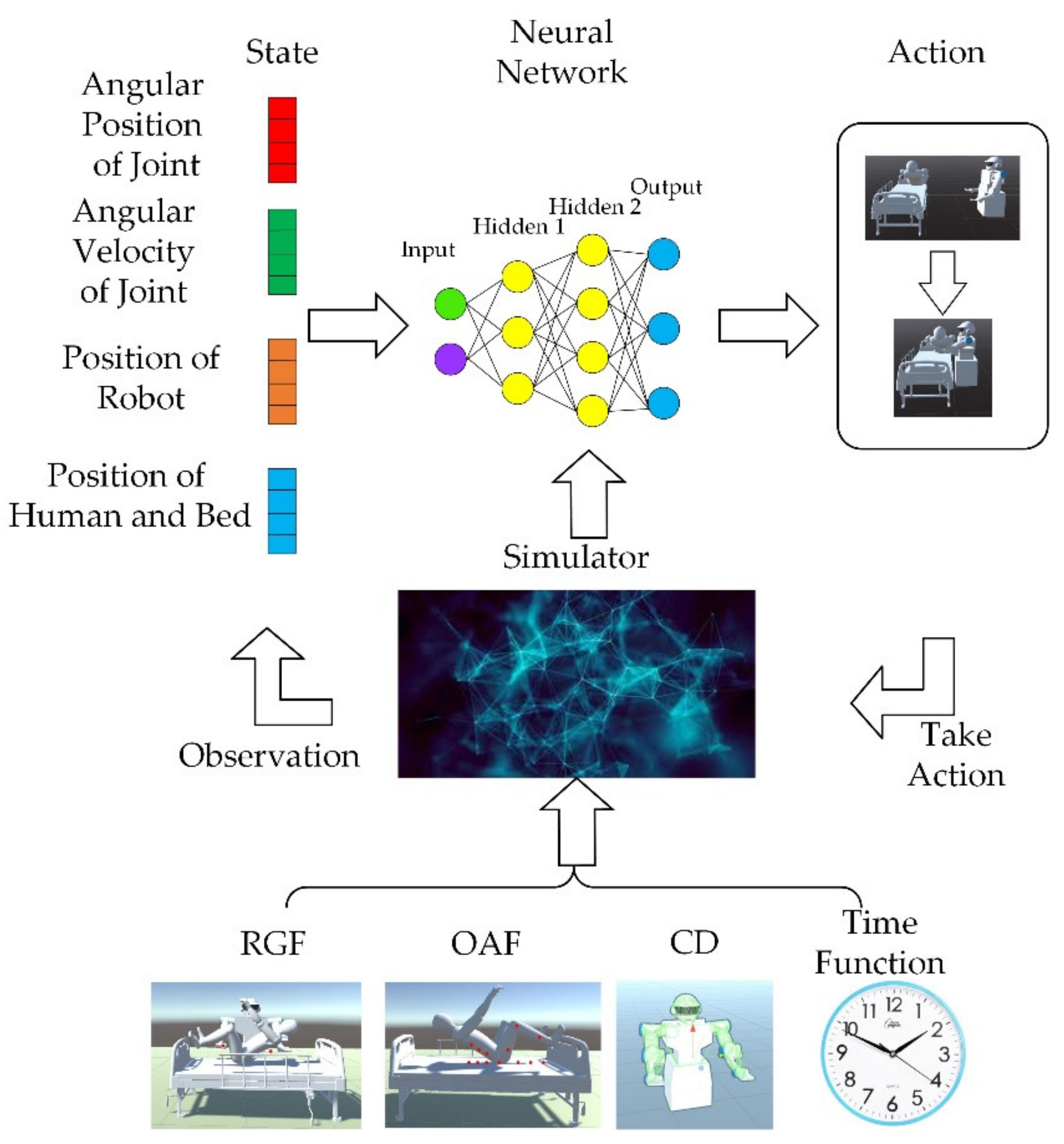
Section 5. The graphical abstract of this paper is shown in
Figure 1 below.
3. Learning to Generate Motion
When training robots to generate a trajectory, it is time consuming and costs a lot to use real robots. Therefore, an effective simulation environment plays an increasingly important part in the application of robots. This paper chooses Unity as the reinforcement learning platform.
3.1. Introduction to Unity Real-Time Environment
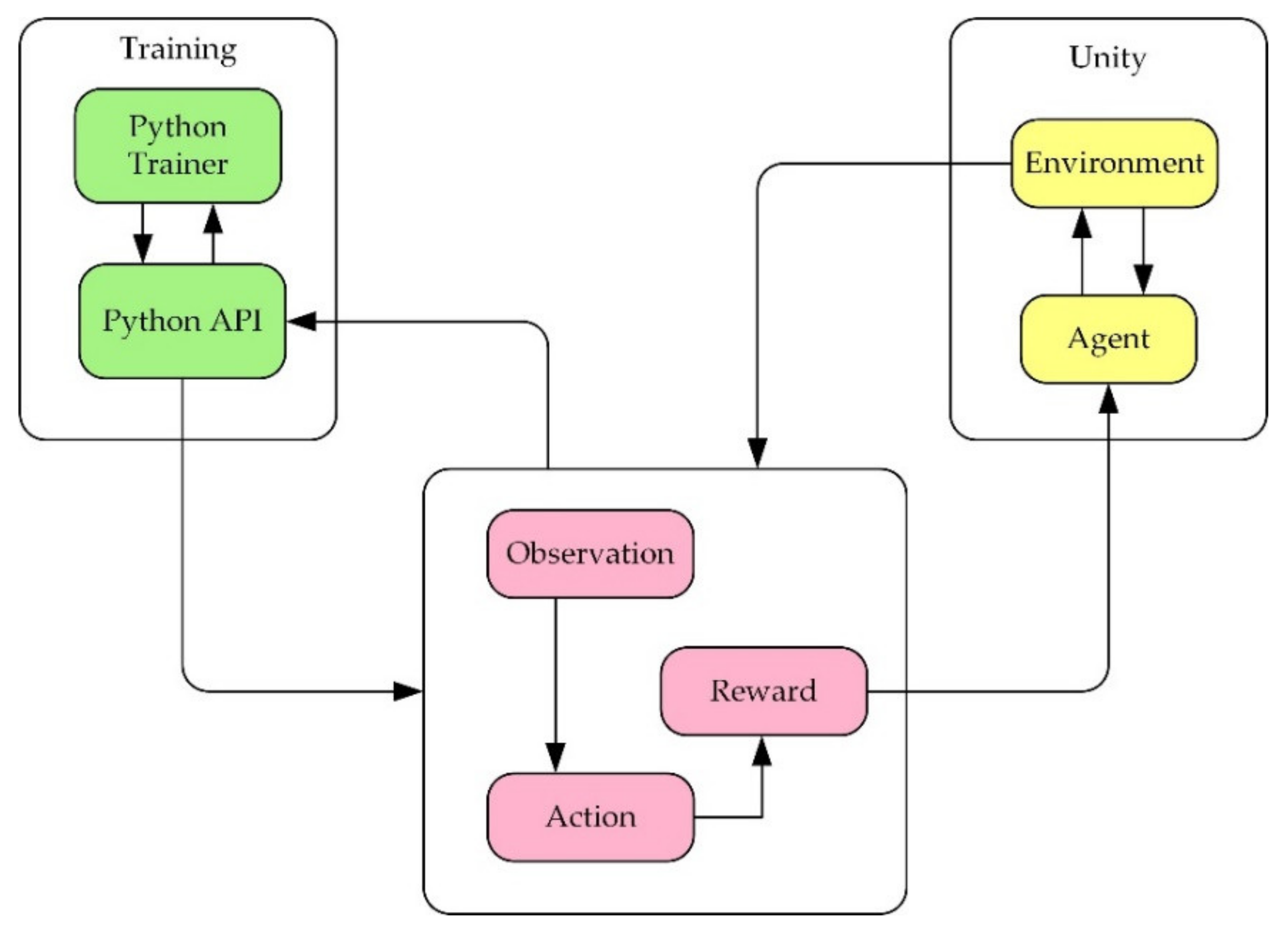
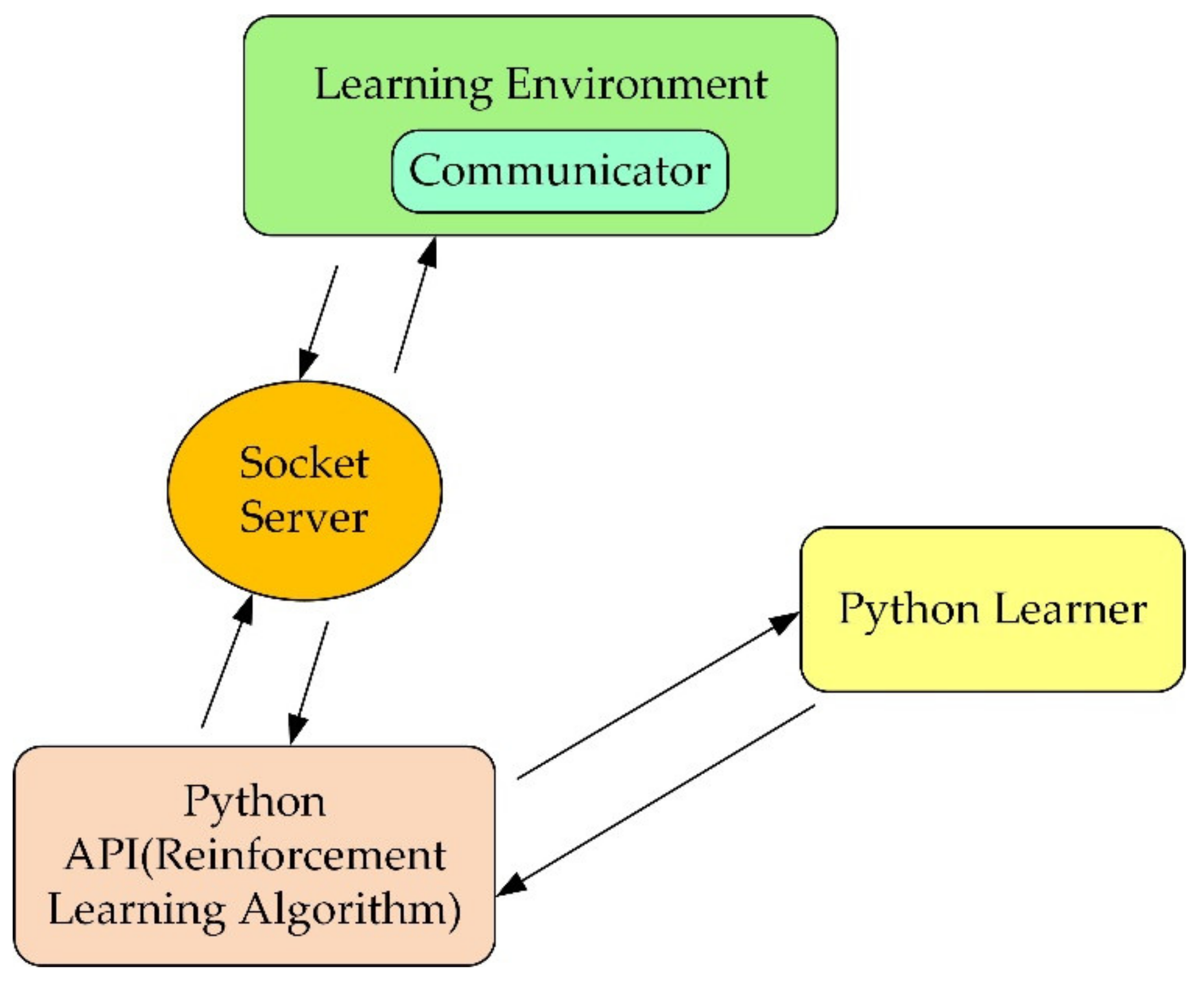
Unity is a real-time 3D interactive creation and operation platform. In this research, firstly, the robot 3D model needs to be imported into the Unity 3D environment. Secondly, before training the robot, it is necessary to use ML agents (machine learning agents) to establish the interactive communication between the simulation environment and the reinforcement learning and use the algorithm to train the robot. The operation mechanism of the environment is shown in
Figure 4.
The learning environment is built with Unity, and the python application programming interface (API) contains machine learning algorithms. External communicator connects Unity with python API. When using ML agents, it is necessary to collect real-time information about the robot and determine the following action of the robot. Therefore, three parts must be defined at each moment in the environment:
- (1)
Observation is the robot’s view of the environment; the robot can collect environmental information through visual recognition.
- (2)
Action refers to the action the robot can take.
- (3)
A reward signal is a scalar value indicating how the robot behaves, which will be provided only when the robot performs well or badly rather than every moment during the training.
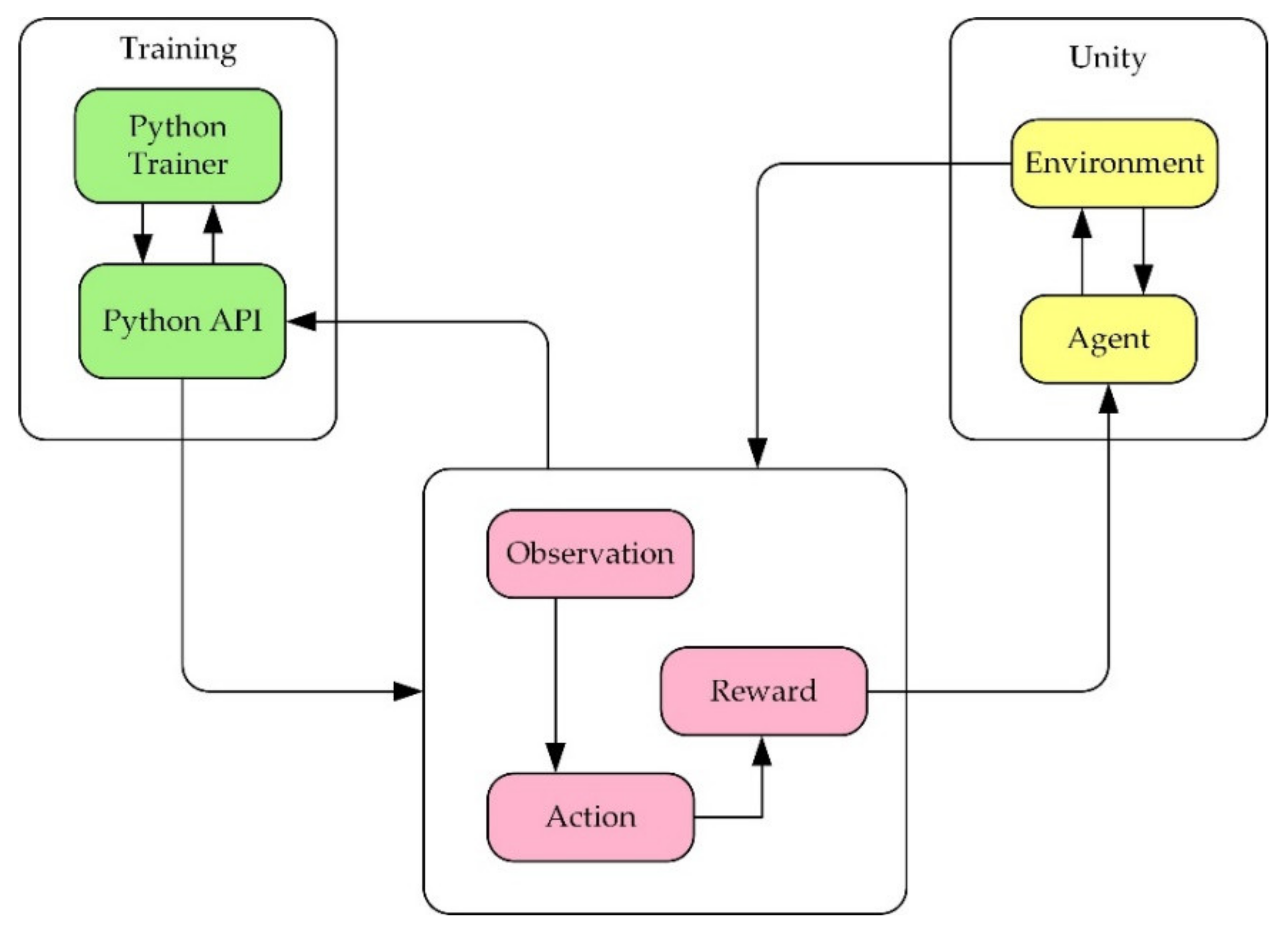
After defining the above three parts, the train can commence. The logic of ML agents during reinforcement learning training is shown in
Figure 5 below.
In training, regarding the robot as an agent, the agent can be used more than once, and the data obtained by the agents can be shared, which will accelerate the speed of training.
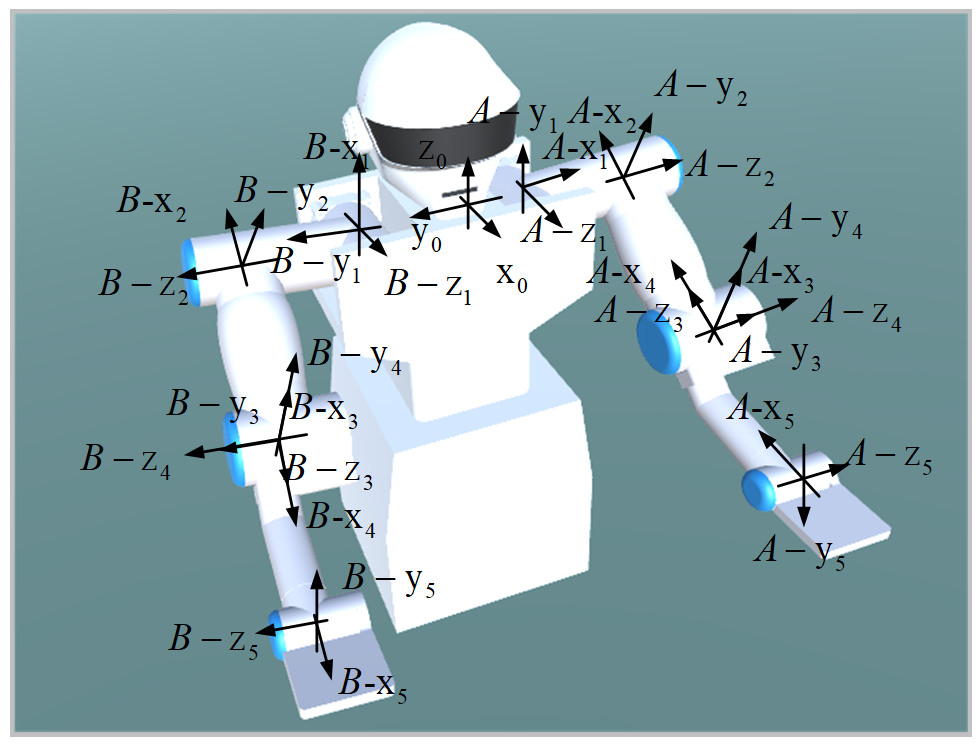
3.2. Action and State Initialization
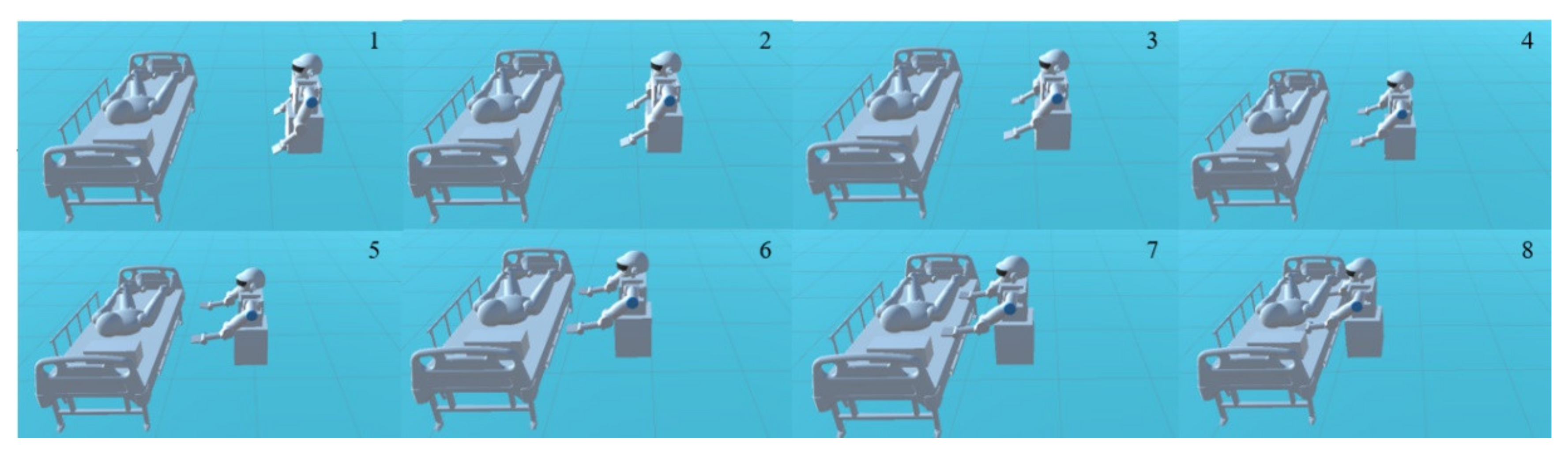
Various entities in the environment need to be properly set for better training. The trajectory that the robot’s arms need to generate should consider the position of the robot and other obstacles. According to the operating range and reasonable service area of the robot, the targets are supposed to be under the back and knees of the man. The position of the obstacle (bed, pillow, and the human body) remain unchanged. To ensure the stability of training, the positions of the targets, the robot, and the obstacle should avoid conflicts. In the experimental environment, to achieve effective training of dual-arm robot trajectory planning, it is necessary to observe the position of the robot, the targets, and robot joints. With the information that can be obtained in the actual service environment, the joint rotation of the dual-arm robot, the coordinates of the targets, and the coordinates of the robot, here the position observation set
is defined as:
where
is the position of the left and right manipulators, respectively.
and
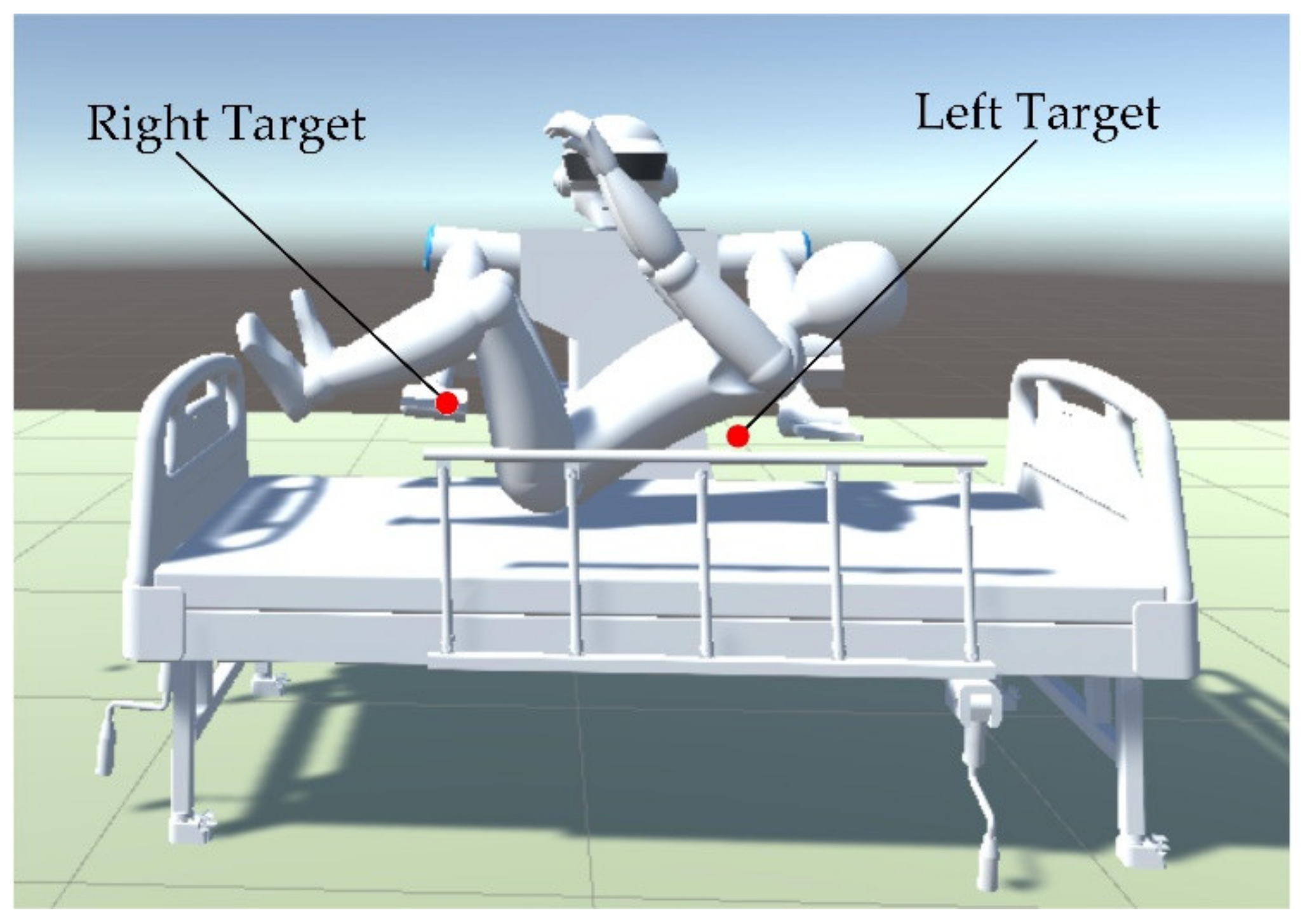
are the position of targets and the obstacles, respectively. Whether the human body can be lifted successfully is decided by the position of the targets and the posture of the human body during lifting. There are five joints for each robot arm of the dual-arm robot. Trajectory planning for the dual-arm robot aims to find the shortest and collision-free trajectory to reach the targets and posture after setting the initial information. The targets of the arms are considered to be under the shoulders and the knees of the human body for the convenience of holding. The center of the targets area is shown by the red dot in
Figure 6. According to the model in
Section 2.1, the initial and targets configuration of the robot can be expressed as follows:
where
represents the initial configuration including position and orientation of the robot,
represents the targets configuration of the robot,
represents the initial position of the left manipulator,
represents the initial posture of the end of the left manipulator, other symbols are similar. The motion control drives each joint angle so that the end of the robotic arm can reach the targets. Here, by limiting the range of joint angle changes during the training process, the robotic arm will explore the training environment constantly, and feed back the value of rewards. We let the joint space of the robot be
, and it can be expressed as follows:
The exploration of the robot’s dual-arm joint angle is as follows:
where
and
represent the joint angles of the left and right arms of the robot,
and
is the initial value of each joint angle, and
means that the output of the joint, which is calculated by reinforcement learning and its range of change, is limited to
.
3.3. Training Scheme
After the environment is established, the training agent scheme can be further determined.
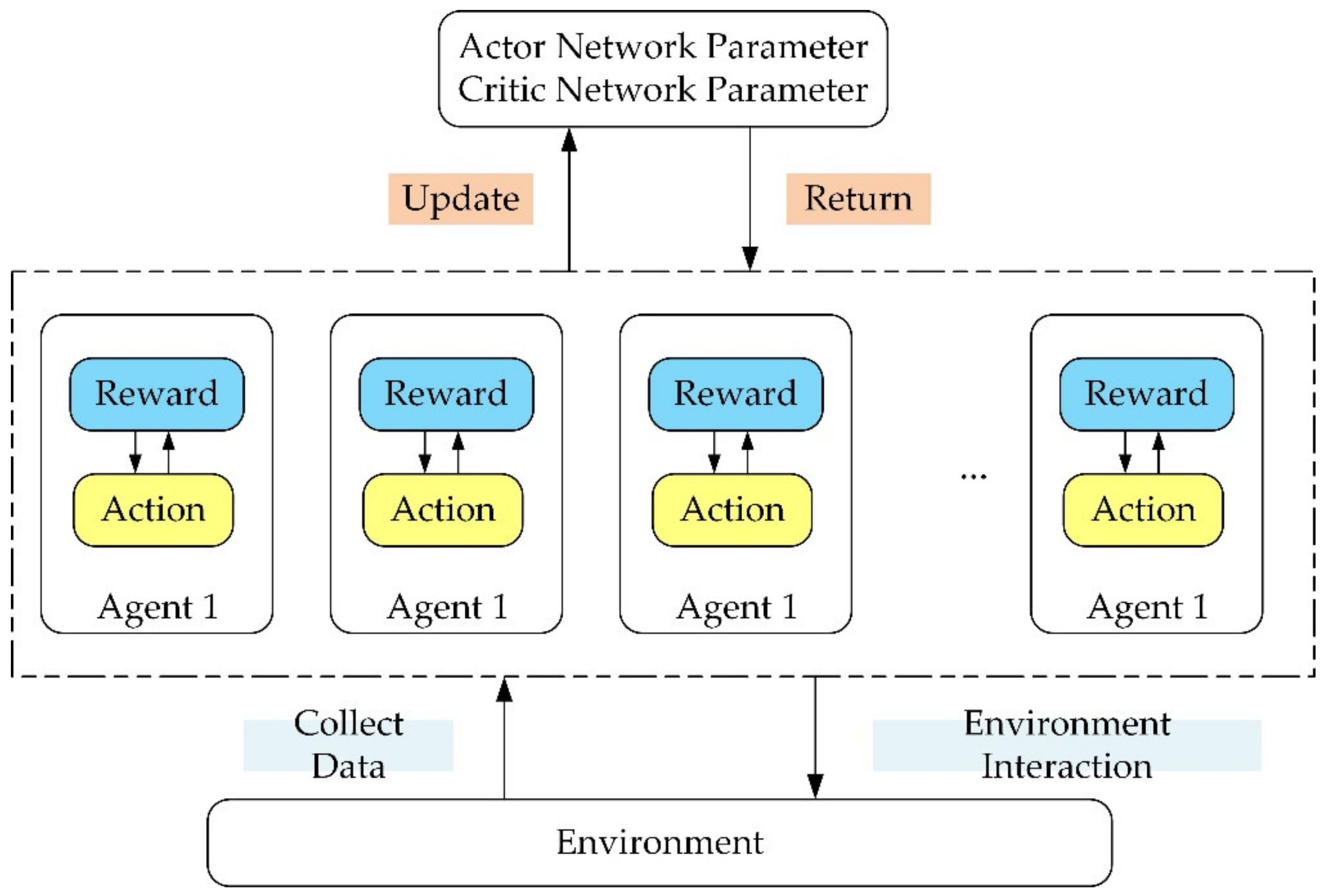
In this paper, we considered training multiple agents with a single brain, every agent associated with a robot. That means there are multiple independent reward signals and multiple independent agents communicating with each other, collecting data, and calculating gradients. The data is summarized together to update network parameters, and mutual feedback between strategies is carried out.
Figure 7
shows that multiple agents are working at the same time during the training. Every agent is independent, but the data obtained will be uploaded to the same network for parameters updating, and the reward signals will be feedback to the agent as evidence for taking action. With repetition, the training will finally achieve the goal.
3.4. The Reward Guidance Mechanism Design
After initialization of the action state of the robot, the agent can randomly derive different action strategies according to the state, but it cannot evaluate the quality of the action according to the state. The design of the reward guiding the function will evaluate the behavior of the agent and increase the probability of high-scoring behavior. The reward mechanism determines the effect of the training results. A reasonable RPF will increase the training speed, reduce the consumption of computer resources, and make the training converge faster. In most cases, continuous reward and punishment information can continuously allow the agent to get feedback on the action strategy adopted, which is more effective than sparse reward signals.
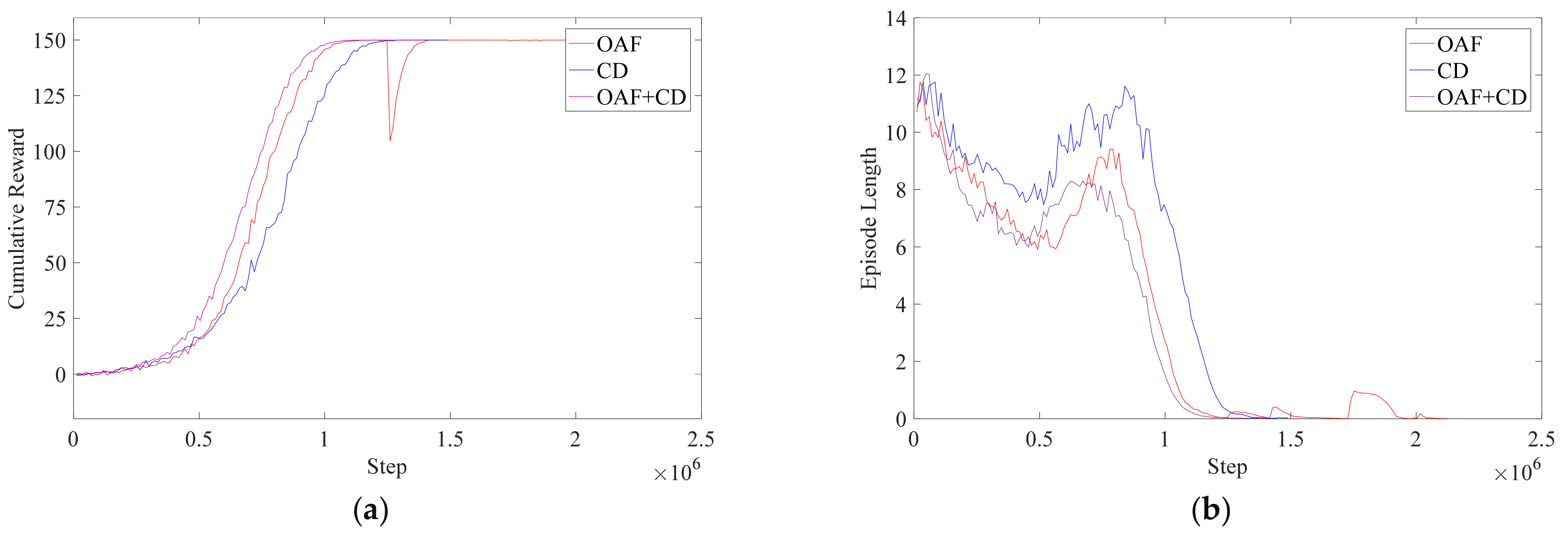
This paper is inspired by the idea of the APF method and sets up a continuous reward function. There are three main considerations in setting up the reward mechanism: (1) reaching the targets; (2) avoiding obstacles; (3) minimizing training time. For problem (1), this paper sets up a guidance function, which will reward the robot when it approaches the targets and punish it when it moves away. For problem (2), two methods are proposed here. One is the obstacle avoidance function (OAF), inspired by the idea of the APF method. The second is collision detection (CD) which will punish the agent if the robot collides with obstacles. The OAF will penalize the robot when it approaches obstacles; the closer the distance, the higher the penalty. As the penalty signal is continuous, the training time will be shorter compared with CD, but whether the selection of obstacle points is representative will affect the training. The agent will be unable to identify obstacles if the obstacle points do not describe the obstacle well. The signals obtained by CD will penalize the robot only when the robot collides with the obstacle, which means the reward signal is discrete. The training time will be longer compared with OAF, but because the CD will divide the entire workspace into two parts, and , the CD will have a more comprehensive description of obstacles, and the training effect will be more stable. The two methods have their advantages and disadvantages. In the specific implementation process, it is necessary to set the weight of the penalty of the two methods reasonably to obtain better results. For the problem (3), a time function is set, and a constant penalty is given for each round of training to reduce the training time.
3.4.1. Reward Guide Function
The guide function setting is inspired by the traditional APF method when setting the reward function for path planning. The gravity of the APF method is determined by the current position of the object, the gravity is represented by the reward signal, and the reward signal is determined by the action of the agent. Otherwise, the agent will be punished. For example, in a certain state
, there is a certain distance between the end
,
of the dual-arm robot, and the targets
and
, which is represented by the distances
and
. If the distance is continuously reducing, it means that the robot’s action strategy is correct, and the behavior should be rewarded. The guide function equation is set as:
In the Equations (10)–(12), , , and are appropriately selected positive constants, represents the distance between the end of the robot’s arms and the targets at time t, and represents the minimum distance between the end of the robot’s arms and the targets at time t. They are not constants and will change with time. Equation (12) gives the update method: (, , ) and (, , ), respectively, represent the position coordinates of the end of the left and right arms of the robot at time t. The meaning of RPF is to take the minimum distance between the end of the robot arms and the targets at time t. When the time changes if the newly generated distance is less than , it means that the distance between the end of the robot’s arms and the targets is decreasing. Then a reward can be given. If is greater than , it means that the distance between the end of the robot’s arms and the targets is increasing, and a penalty is given. When the distance is zero, it means that the robot has reached the targets correctly. The training is deemed successful, and the highest reward is given, and then this round of training can be ended. However, when the end of the robot’s arms gets closer and closer to the targets, the reward will be lowered, which will affect the training speed. Therefore, is set here, that means the weight of the reward is greater than the weight of the penalty.
3.4.2. Collision Detection
This part mainly focuses on how to avoid the obstacle. Here are two main ideas for obstacle avoidance. One is to set up collision detection (CD), which is to set penalties by detecting whether the robotic arm collides with obstacles, and the other is to set obstacle avoidance function (OAF), inspired by the idea of the APF method. The robot will obtain different penalty signals according to the distance between the end of the manipulator and the obstacle. The OAF will improve the training faster than the CD, according to what is mentioned before, but the selection of obstacle points cannot represent all the shapes of the human body and the bed after all; therefore, to construct a better RPF, the CD and the OAF should complement each other. This section will first introduce CD.
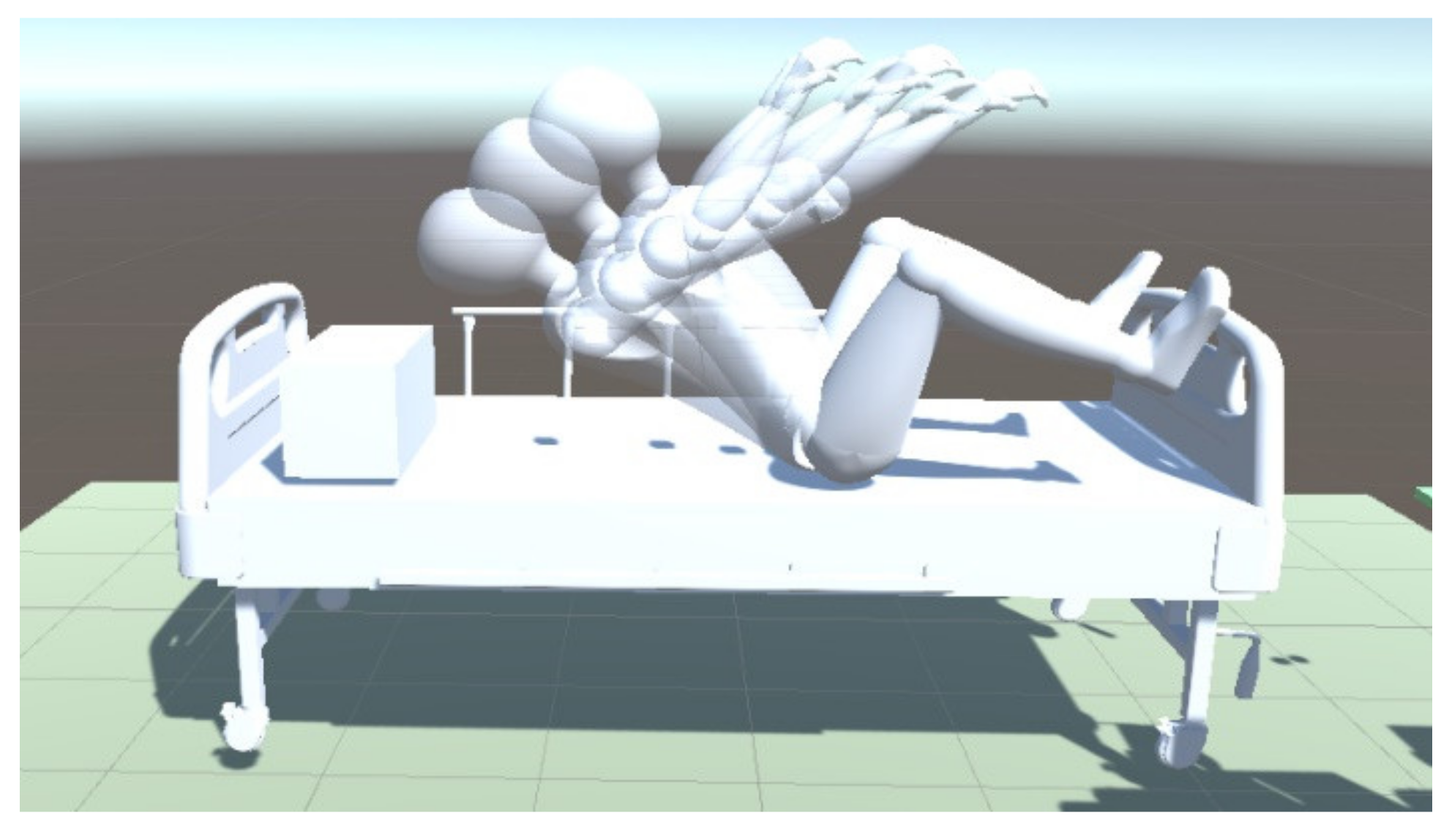
In real life, collision detection is realized using an impact sensor, but in the virtual environment in Unity, it is realized in other ways. Let the operating space of the robotic arm be , which can be divided into two subsets, and , the former represents the space where the obstacle stays, the latter represents the space where the robot can move freely, and the space occupied by the robot is . If the robot belongs to , it means the robot does not collide with any obstacles. If the robot arm belongs to , it means that there is a collision between the obstacle and the robot arm. The division of and will be taken by CD. The CD is mainly about the collision between the robot arm and the obstacle. The obstacle here specifically includes the human body and bed.
The CD is used to detect whether objects collide with each other [
18]. If the object is very regular, such as a sphere, it is easy to directly detect whether the distance from the center of the circle is less than the radius. However, if the object is irregular, such as a robot, it will become very difficult to distinguish whether two objects collide with each other. Therefore, it is necessary to use simple geometry to approximate complex shapes of objects. Taking the situation mentioned above into consideration to obtain more accurate training results, the human body and robot arms are shaped by colliders, which will cover a layer of the grid on the surface of the robot, the human body, and the bed. During the detection, the collider will check whether the robot manipulators collide with obstacles. The configuration of the collision detection between the robot and the human body is shown in
Figure 8:
According to collision detection, the penalty function can be set as follows:
where
is a positive constant and
means that the robot collides with the obstacles; if there is a collision, the agent will be punished with a penalty
.
3.4.3. Obstacle Avoidance Function
The APF method makes the robot avoids obstacles by setting the repulsive force function. The repulsive force function is designed according to the distance between the robot and the obstacle. Here the idea of the function to design the penalty function is considered, taking the reciprocal of the distance between the end of the robot manipulators and the targets as the penalty signal. In the real world, to recognize the shape of an object, there are always some mark points attached to it. In this subsection, an arrangement method of the mark points is proposed.
Both the human body and the bed have the characteristics of complex shapes. The OAF designed according to the APF method is like the repulsive force between points, and it is necessary to calibrate the shape of the human body and the bed, as shown in
Figure 9.
According to
Figure 9, it is known that the targets of the robot are below the back and the knees of the human body. The obstacle points
(
i = 1, 2, …, 6) in
Figure 9
are set to ensure that the robot will not collide with the human body or the bed while approaching the targets, where the area enclosed by points
and
is the ideal activity space for the left arm, and the area enclosed by points
and
is the ideal activity space for the right arm. It can be seen that point
divides the movement space of the left and right arms to prevent the left and right arms from being too close during work. This arrangement has two advantages. One is to prevent collisions between the left and right arms of the robot, and the other is to enable the robot to use a proper posture to pick up people.
After setting the obstacle point, we can set the OAF, as shown below:
where
is a positive constant,
represents the distance between the end of the left arm of the robot and
,
represents the distance between the end of the left arm of the robot and point
C,
represents the distance between the end of the right arm of the robot and point
, and
is the distance between the end of the right arm of the robot and point
C. As can be seen from Equation (14), when the end of the robot is far away from the targets, that is, when the
is large, the penalty obtained by the robot, namely,
can be ignored. When the distance is too close, the penalty is
will tend to infinity. This produces a continuous penalty signal for the robot, and at the same time, it can also obtain the penalty signals when the robot is approaching targets compared with the CD, which will speed up the training.
3.4.4. Time Function
In the simulation training, to reduce the training time, a constant penalty item can be set, and a penalty will be performed for every additional round of training. The time penalty function is represented by
, which can be set according to the length of the training time, but the value should not be set too large; otherwise, the robot will be unable to perform effective exploration because of the excessive punishment in the early stage of training. The function equation can be expressed as:
where
is the time penalty constant, which is positive.
The design of the total reward function is the cumulative sum of the above three functions, which can be expressed as:
3.5. Training Process
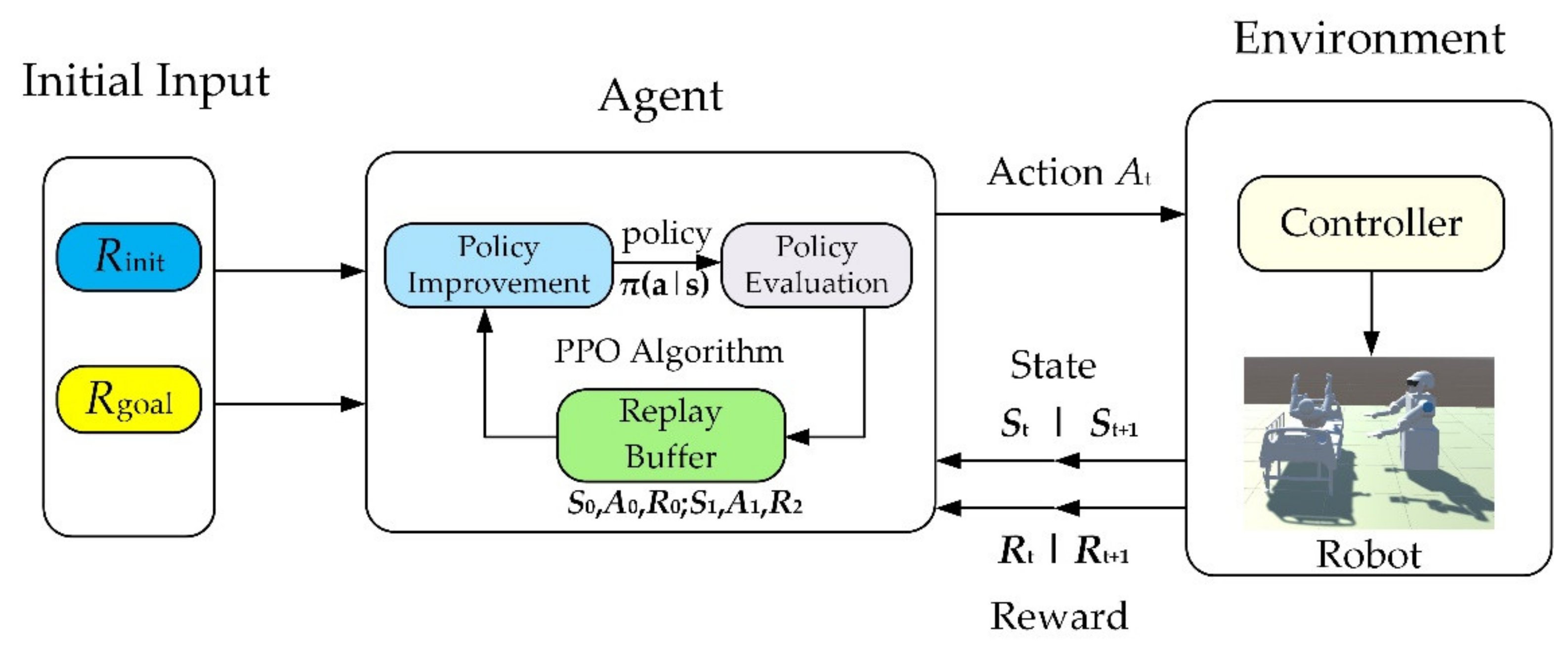
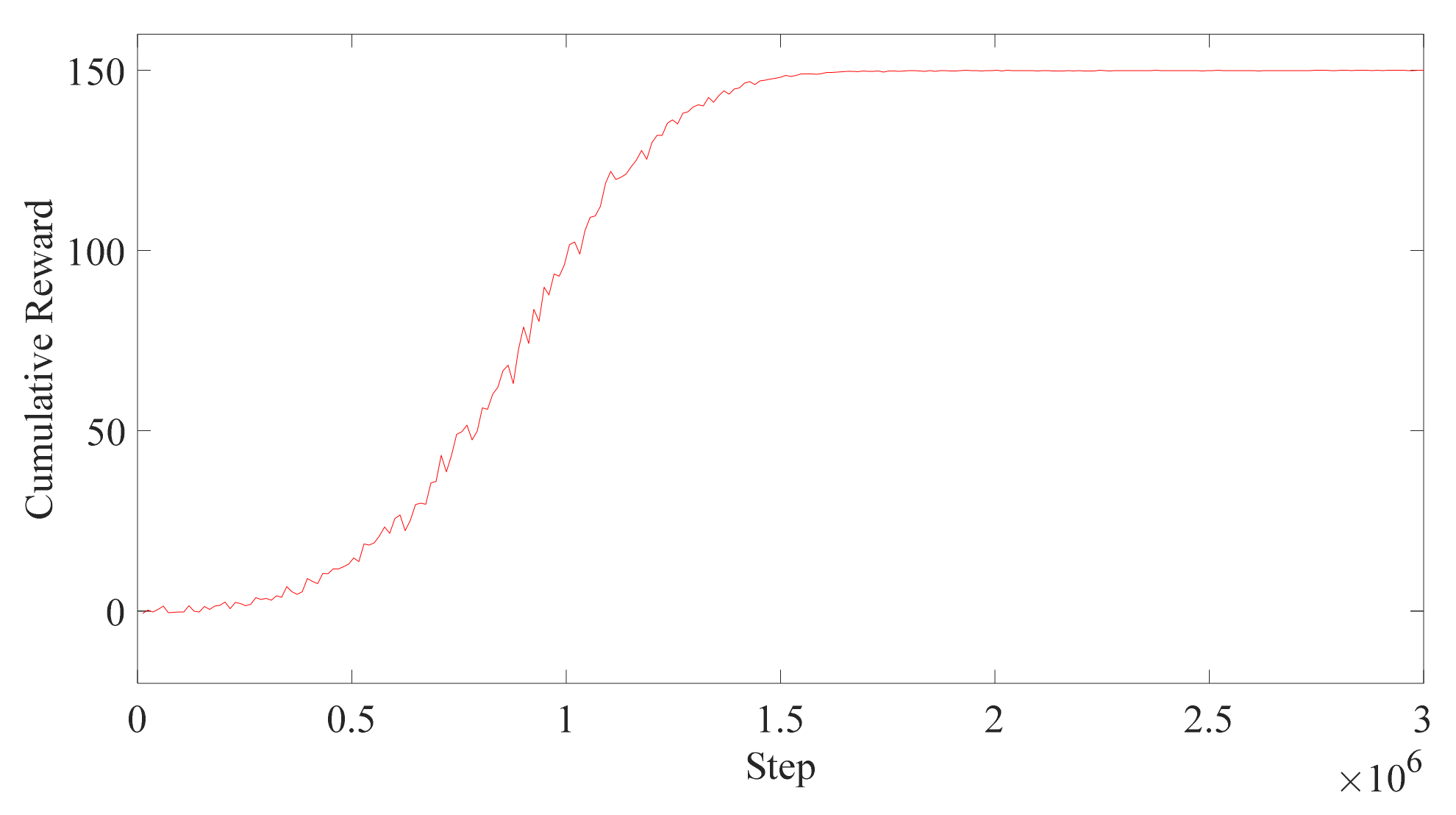
The goal of reinforcement learning is to find the optimal strategy for maximizing the total rewards of the agent in the path planning. If the iterative training time is limited, the agent can find the trajectory to the goal by maximizing the total rewards, but when the agent does not receive enough training, it is difficult to find the targets because the action is mainly determined by experimental methods, which means that many iterations cannot reach the targets before the agent is well trained. In this case, there are only a few states and actions helpful for learning. The process is called the Markov process with sparse reward. To overcome this problem, this paper designed a trajectory planning algorithm using the PPO algorithm. The PPO algorithm is known for its easy implementation and high efficiency. It improves the sample efficiency of the scant reward in the DRL training.
According to
Section 2.1, the state
could be expressed as:
where
and
represent the positions and orientations of the end of the manipulator
and
, which means that state quantities are considered to belong to free space.
The action
can be defined by Equation (9), where
and
represent the angle vector of each joint of both arms of the robot. The action at time t means that the robot must meet the joint position at time
t + 1:
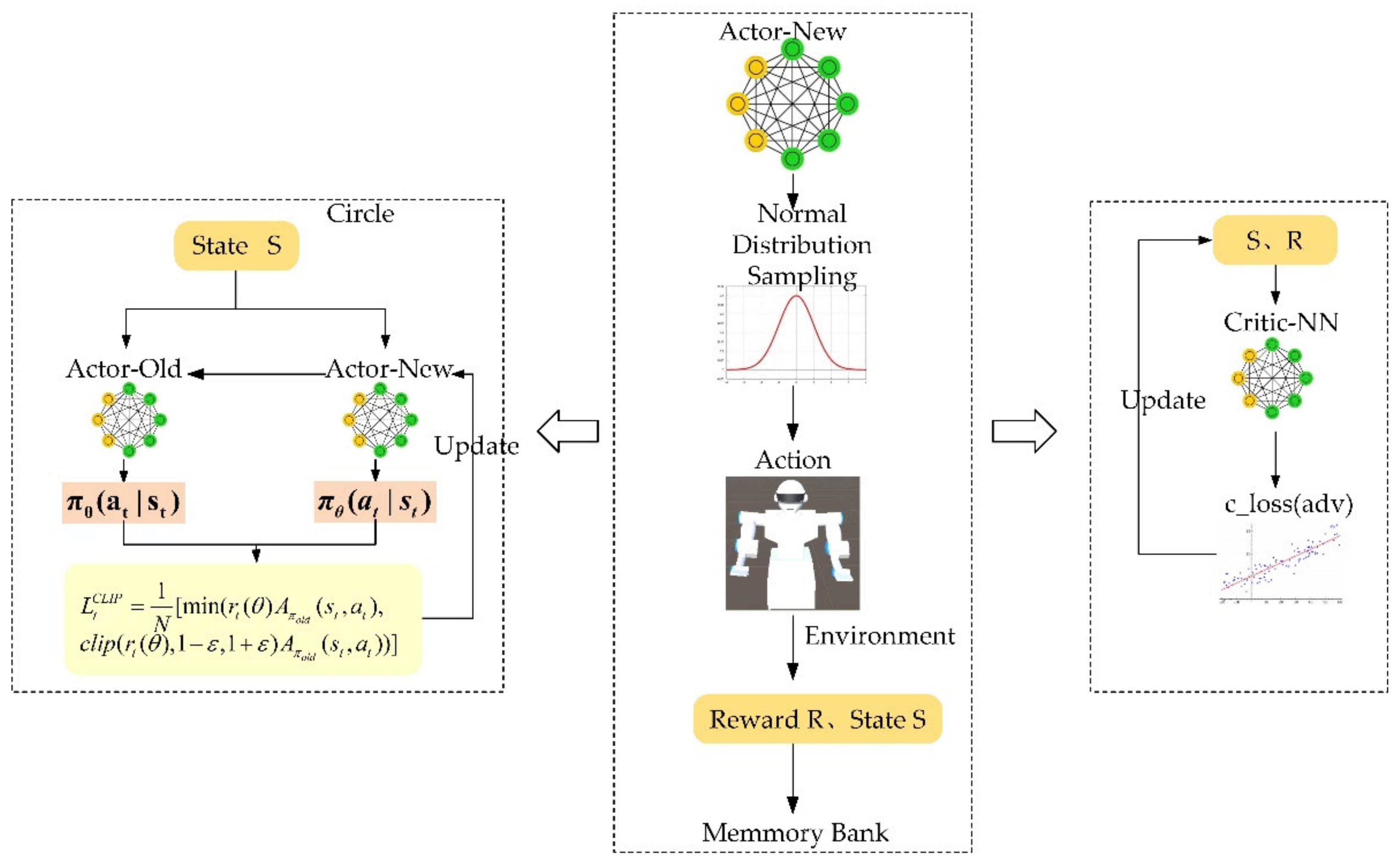
The PPO algorithm needs to build three neural networks: Actor-New—the new policy network, Actor-Old—the old policy network, and Critic-nn—the evaluation network. The old and new strategic network is proposed to predict the action strategy, and the evaluation network is responsible for evaluating the effect of the action. During the training, firstly, the environmental observation information
is input to the new strategic network. The new strategy network obtains the normal distribution parameters according to the observed environmental information, and action is sampled. The action interacts with the environment to generate rewards or punishments and obtain the next state
. After storing the state, action, rewards, and punishments in the memory bank, the state
is then input into the new strategic network. This process repeats continuously until the storage capacity in the memory bank meets the requirements. In the evaluation network, through the continuous acquisition of observations and rewards, the agent will perform a back-propagation update of network parameters so that the evaluation value of the evaluation network for different situations is getting closer and closer to the setting value of the reward function; at the same time, the old and new networks output strategies according to the state set, and calculate the weights and update the parameters of the new strategic network according to Equation (17). After training for a certain time, the agent will use the new strategy network parameters to update the old strategy network parameters. This process repeats continuously until the set number of training steps is reached, and the training is completed. The training process is shown in
Figure 10. The PPO algorithm is based on the actor–critic framework but with the style of policy gradient at the same time. In a specific implementation, when the Actor-New network obtains the environment information
S, it will obtain two values. Using these two values, a normal distribution can be constructed. The action will be sampled from this normal distribution. The obtained action interacts with the environment to obtain the reward
R and state
S of the next step. Reward
R and state
S will be stored in a memory bank, and the
R and
S in the memory bank will be input into Actor-New, and so on. The critic network calculates the reward value according to the obtained information and updates the network according to c_loss (adv). The actor network update method is similar to the critic network.
5. Discussion and Conclusions
The research is conducted to provide inspiration for the application of robots in the field of medical care and reduce the social burden.
This paper carried out the trajectory planning research with the reinforcement learning of the dual-arm robot on the assistance with the patient and designed a kind of reward function which consists of RGF, CD, OAF, and time function. Where the RGF is used to guide the robot to reach the targets, the CD and OAF are used to avoid obstacles, and the training time is reduced, enhancing the stability of the training effect by using the RPF. The time function is used to make the agent train faster. The RPF effectively enables the robot to obtain a higher reward and alleviate the negative effect of the sparse reward problem of robot training in a high-dimensional environment.
As for the problem of obstacle avoidance, this article explored the use of the CD and the OAF, the two methods complementary to each other, considering both advantages and disadvantages of both, and the training results showed their superiority. Finally, to show the superiority of the PPO algorithm further, the DDPG algorithm is applied for the research, and the latter shows slower training and fewer rewards for the robot when accomplishing the task.
However, the robot only accomplishes the trajectory planning for holding the human up as a preparatory action, and the force information has not been considered, which may hurt humans during the operation. Furthermore, to study the problem more deeply, next, we will use force/position control to complete the task with deep reinforcement learning algorithms.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}