
Autonomous Binarized Focal Loss Enhanced Model Compression Design Using Tensor Train Decomposition


Abstract
1. Introduction
- In this work, we first attempt to consider the class imbalance issue during compression of the tensor train-based model. The proposed ABFLMC algorithm can be used for the tensor train decomposition method to overcome the class imbalance issue.
- At the algorithm level, the proposed ABFLMC algorithm is designated by considering the characteristics of the tensor train decomposition to reduce the complexity and increase the performance. Consequently, the proposed framework can automatically search for the best parameters for overcoming the imbalance issue during the training process.
- At the hardware design level, the architecture of the proposed ABFLMC algorithm has been developed to maximize parallelism and processing throughput. Thus, the proposed ABFLMC algorithm can achieve an optimized solution on the resource constraint hardware.
2. Related Work
2.1. Object Detection
2.2. Tensor Decomposition Methods
3. Autonomous Binarized Focal Loss Enhanced Model Compression Algorithm (ABFLMC)
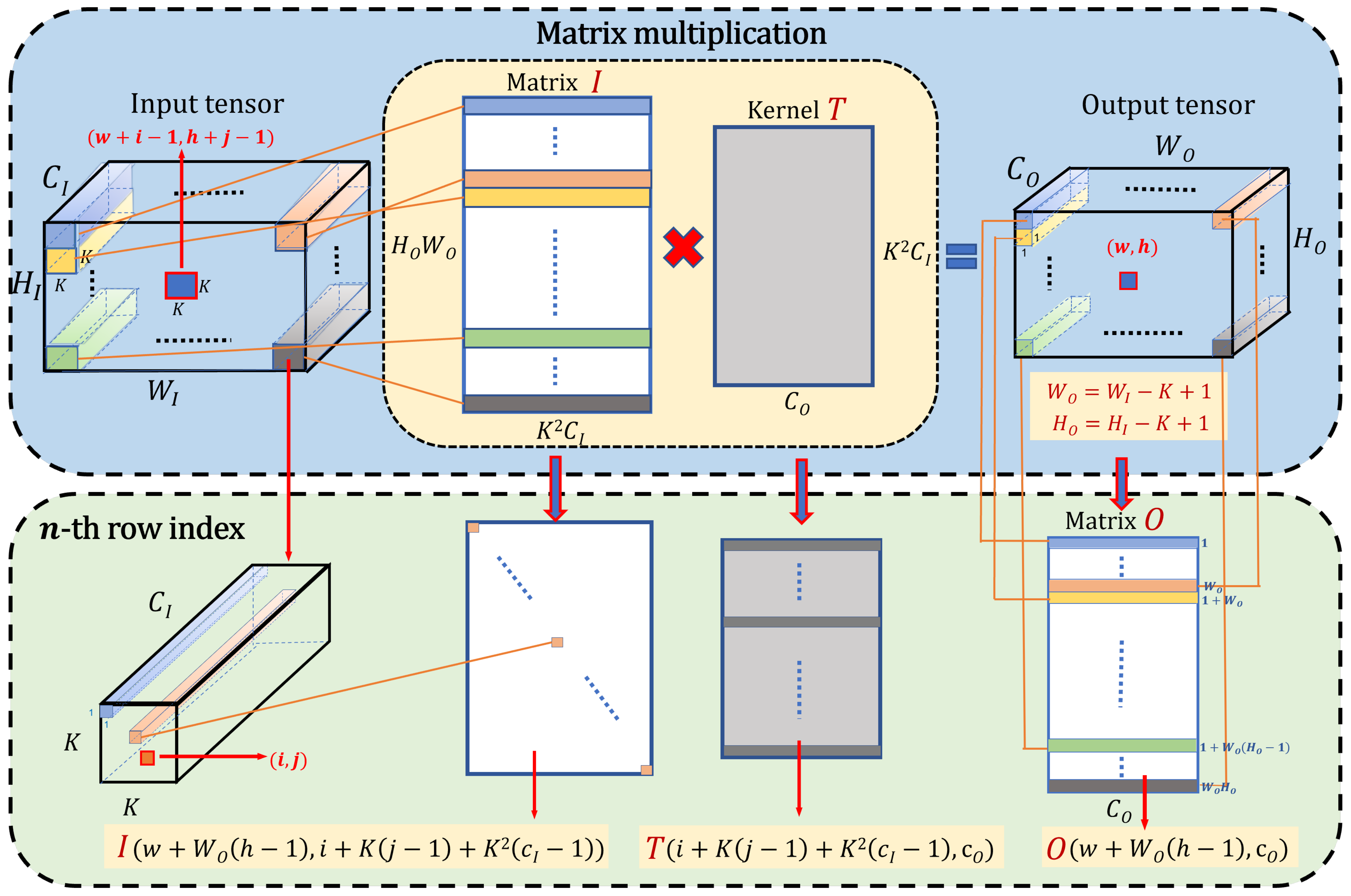
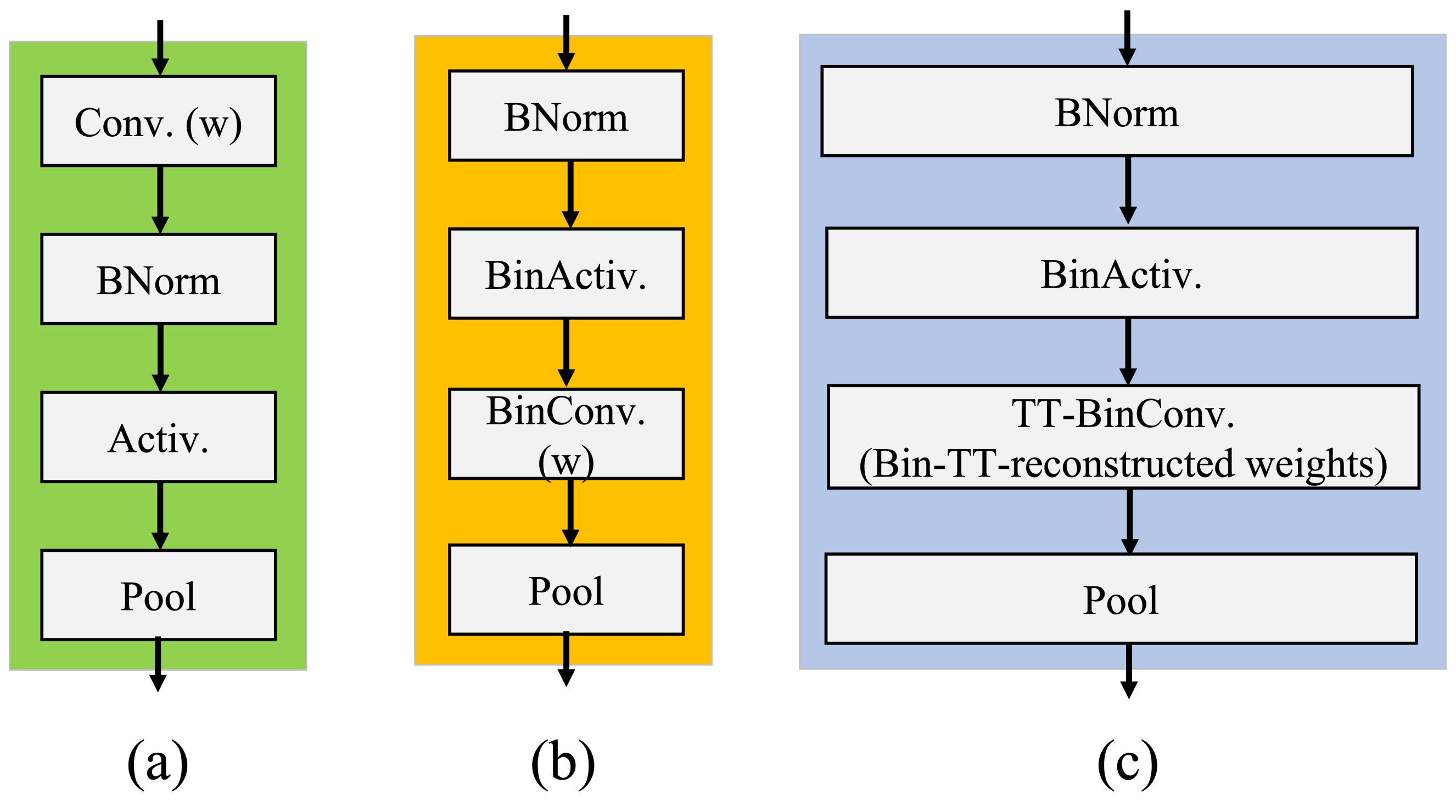
3.1. TT-Convolutional Layer in the Model YOLOV5
3.2. Design of ABFLMC
4. Overall Hardware Architecture of ABFLMC-YOLOV5
5. Experiment and Results
5.1. Experiment Setup
5.2. Ablation Study and Comparison with State of Art Models
5.3. Hardware Evaluation
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wu, J.; Wang, Z. A hybrid model for water quality prediction based on an artificial neural network, wavelet transform, and long short-term memory. Water 2022, 14, 610. [Google Scholar] [CrossRef]
- Weber, M.; Fürst, M.; Zöllner, J.M. Automated focal loss for image based object detection. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020; pp. 1423–1429. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed]
- Shrivastava, A.; Gupta, A.; Girshick, R. Training region-based object detectors with online hard example mining. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 761–769. [Google Scholar]
- Liu, M.; Luo, S.; Han, K.; Yuan, B.; DeMara, R.F.; Bai, Y. An Efficient Real-Time Object Detection Framework on Resource-Constricted Hardware Devices via Software and Hardware Co-design. In Proceedings of the 2021 IEEE 32nd International Conference on Application-Specific Systems, Architectures and Processors (ASAP), Virtual Conference, 7–9 July 2021; IEEE Computer Society: Los Alamitos, CA, USA, 2021; pp. 77–84. [Google Scholar] [CrossRef]
- Liu, M.; Han, K.; Luo, S.; Pan, M.; Hossain, M.; Yuan, B.; DeMara, R.F.; Bai, Y. An Efficient Video Prediction Recurrent Network using Focal Loss and Decomposed Tensor Train for Imbalance Dataset. In Proceedings of the 2021 on Great Lakes Symposium on VLSI, Virtual Event, 22–25 June 2021; pp. 391–396. [Google Scholar]
- Comon, P. Tensor decompositions, state of the art and applications. arXiv 2009, arXiv:0905.0454. [Google Scholar]
- De Lathauwer, L.; De Moor, B.; Vandewalle, J. A multilinear singular value decomposition. SIAM J. Matrix Anal. Appl. 2000, 21, 1253–1278. [Google Scholar] [CrossRef]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2001, Kauai, HI, USA, 8–14 December 2001; Volume 1, p. I. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–26 June 2005; IEEE: Piscataway, NJ, USA, 2005; Volume 1, pp. 886–893. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 379–387. [Google Scholar]
- Qiao, S.; Chen, L.C.; Yuille, A. Detectors: Detecting objects with recursive feature pyramid and switchable atrous convolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 10213–10224. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J. Darknet: Open Source Neural Networks in C. 2013. Available online: https://pjreddie.com/darknet/ (accessed on 31 August 2022).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Miller, G.A.; Beckwith, R.; Fellbaum, C.; Gross, D.; Miller, K.J. Introduction to WordNet: An on-line lexical database. Int. J. Lexicogr. 1990, 3, 235–244. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Zaidi, S.S.A.; Ansari, M.S.; Aslam, A.; Kanwal, N.; Asghar, M.; Lee, B. A Survey of Modern Deep Learning based Object Detection Models. arXiv 2021, arXiv:2104.11892. [Google Scholar] [CrossRef]
- Jocher, G.; Stoken, A.; Borovec, J.; Christopher, S.T.A.N.; Laughing, L.C. ultralytics/yolov5: V4.0—nn.SiLU() Activations, Weights & Biases Logging, PyTorch Hub Integration. 2021. Available online: https://zenodo.org/record/4418161 (accessed on 31 August 2022).
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Huang, R.; Pedoeem, J.; Chen, C. YOLO-LITE: A real-time object detection algorithm optimized for non-GPU computers. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 2503–2510. [Google Scholar]
- Li, Y.; Li, J.; Lin, W.; Li, J. Tiny-DSOD: Lightweight object detection for resource-restricted usages. arXiv 2018, arXiv:1807.11013. [Google Scholar]
- Cai, Y.; Li, H.; Yuan, G.; Niu, W.; Li, Y.; Tang, X.; Ren, B.; Wang, Y. Yolobile: Real-time object detection on mobile devices via compression-compilation co-design. arXiv 2020, arXiv:2009.05697. [Google Scholar]
- Hoff, P.D. Equivariant and scale-free Tucker decomposition models. Bayesian Anal. 2016, 11, 627–648. [Google Scholar] [CrossRef]
- Rai, P.; Wang, Y.; Guo, S.; Chen, G.; Dunson, D.; Carin, L. Scalable Bayesian low-rank decomposition of incomplete multiway tensors. In Proceedings of the International Conference on Machine Learning, PMLR, Bejing, China, 22–24 June 2014; pp. 1800–1808. [Google Scholar]
- Zhao, Q.; Zhang, L.; Cichocki, A. Bayesian CP factorization of incomplete tensors with automatic rank determination. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1751–1763. [Google Scholar] [CrossRef]
- Ermis, B.; Cemgil, A.T. A Bayesian tensor factorization model via variational inference for link prediction. arXiv 2014, arXiv:1409.8276. [Google Scholar]
- Jørgensen, P.J.; Nielsen, S.F.; Hinrich, J.L.; Schmidt, M.N.; Madsen, K.H.; Mørup, M. Probabilistic parafac2. arXiv 2018, arXiv:1806.08195. [Google Scholar]
- Zheng, Y.; Xu, A.B. Tensor completion via tensor QR decomposition and L2, 1-norm minimization. Signal Process. 2021, 189, 108240. [Google Scholar] [CrossRef]
- Oseledets, I.V. Tensor-train decomposition. SIAM J. Sci. Comput. 2011, 33, 2295–2317. [Google Scholar] [CrossRef]
- Deng, C.; Sun, F.; Qian, X.; Lin, J.; Wang, Z.; Yuan, B. TIE: Energy-efficient tensor train-based inference engine for deep neural network. In Proceedings of the 46th International Symposium on Computer Architecture, Phoenix, AZ, USA, 22–26 June 2019; pp. 264–278. [Google Scholar]
- Novikov, A.; Podoprikhin, D.; Osokin, A.; Vetrov, D. Tensorizing neural networks. arXiv 2015, arXiv:1509.06569. [Google Scholar]
- Novikov, A.; Izmailov, P.; Khrulkov, V.; Figurnov, M.; Oseledets, I.V. Tensor Train Decomposition on TensorFlow (T3F). J. Mach. Learn. Res. 2020, 21, 1–7. [Google Scholar]
- Garipov, T.; Podoprikhin, D.; Novikov, A.; Vetrov, D. Ultimate tensorization: Compressing convolutional and fc layers alike. arXiv 2016, arXiv:1611.03214. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 9627–9636. [Google Scholar]
- Shen, Z.; Shi, H.; Feris, R.; Cao, L.; Yan, S.; Liu, D.; Wang, X.; Xue, X.; Huang, T.S. Learning object detectors from scratch with gated recurrent feature pyramids. arXiv 2017, arXiv:1712.00886. [Google Scholar]
- Fu, C.Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. Dssd: Deconvolutional single shot detector. arXiv 2017, arXiv:1701.06659. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 6569–6578. [Google Scholar]
- Law, H.; Teng, Y.; Russakovsky, O.; Deng, J. Cornernet-lite: Efficient keypoint based object detection. arXiv 2019, arXiv:1904.08900. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Jocher, G.; Stoken, A.; Chaurasia, A.; Borovec, J.; Kwon, Y.; Michael, K.; Liu, C.; Fang, J.; Abhiram, V.; Chaurasia, A.; et al. ultralytics/yolov5: V6.0—YOLOv5n ‘Nano’ Models, Roboflow Integration, TensorFlow Export, OpenCV DNN Support. Zenodo. 2021. Available online: https://zenodo.org/record/5563715 (accessed on 31 August 2022).
- Helali, A.; Ameur, H.; Górriz, J.; Ramírez, J.; Maaref, H. Hardware implementation of real-time pedestrian detection system. Neural Comput. Appl. 2020, 32, 12859–12871. [Google Scholar] [CrossRef]
- Ding, C.; Wang, S.; Liu, N.; Xu, K.; Wang, Y.; Liang, Y. REQ-YOLO. In Proceedings of the 2019 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Seaside, CA, USA, 24–26 February 2019. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Dataset | Model | # Paras | ||
|---|---|---|---|---|
| VOC 07 + 12 | Original (Yolov5n) | 45.4 | 72.5 | 1.79 M |
| FL-TT () | 33.1 | 61.0 | 1.39 M | |
| ABFLMC () | 33.9 | 61.7 | ||
| ABFLMC () | 33.9 | 62.1 | ||
| ABFLMC () | 33.6 | 62.0 |
| Dataset | Models | Input Size | Backbone | # Parameters (M) | GFLOPs | ||
|---|---|---|---|---|---|---|---|
| VOC 07 + 12 | Faster R-CNN [7] | 600 | VGG | - | 73.2 | 134.7 | - |
| Faster R-CNN [7] | 600 | ResNet-101 | - | 76.4 | - | - | |
| R-FCN [17] | 600 | ResNet-101 | - | 79.5 | 50.9 | - | |
| SSD300 [3] | 300 | VGG | - | 75.8 | 26.3 | - | |
| DSSD321 [44] | 321 | ResNet-101 | - | 78.6 | >52.8 | - | |
| GRP-DSOD320 [43] | 320 | DS/64-192-48-1 | - | 78.7 | 14.2 | - | |
| YOLOv5s [9] | 640 | - | 51.9 | 78.4 | 7.11 | 16.5 | |
| TT-YOLOv5s(rank 16) [9] | 640 | - | 48.8 | 76.9 | 4.74 | 18.4 | |
| MobileNetv2-Yolov5s | 640 | - | 50.27 | 76.8 | 4.6 | 10.0 | |
| ABFLMC-YOLOv5n | 640 | - | 33.9 | 62.1 | 1.39 | 4.2 | |
| COCO | CenterNet-DLA [45] | 512 | DLA34 | 39.2 | 57.1 | 16.9 | 52.58 |
| CornerNet-Squeeze [46] | 511 | - | 34.4 | - | 31.77 | 150.15 | |
| SSD [3] | 300 | VGG16 | 25.1 | 43.1 | 26.29 | 62.8 | |
| MobileNetv1-SSDLite [27] | 300 | MobileNetv1 | 22.2 | - | 4.31 | 2.30 | |
| MobileNetv1-SSDLite [27] | 300 | MobileNetv2 | 22.1 | - | 3.38 | 1.36 | |
| Tiny-DSOD [29] | 300 | - | 23.2 | 40.4 | 1.15 | 1.12 | |
| YOLOV4 [24] | 320 | CSPDarknet53 | 38.2 | 57.3 | 64.36 | 35.5 | |
| YOLO-Lite [28] | 224 | - | 12.26 | - | 0.6 | 1.0 | |
| YOLOV3-tiny [47] | 320 | Tiny Darknet | 14 | 29 | 8.85 | 3.3 | |
| YOLOV4-tiny [24] | 320 | Tiny Darknet | - | 40.2 | 6.06 | 4.11 | |
| YOLObile [30] | 320 | CSPDarknet53 | 31.6 | 49 | 4.59 | 3.95 | |
| YOLOv5s [48] | 640 | - | 37.2 | 56.0 | 7.2 | 16.5 | |
| TT-YOLOv5s (rank 16) [9] | 640 | - | 34.2 | 54.6 | 4.9 | 18.9 | |
| YOLOv5n [48] | 640 | - | 28.4 | 46.0 | 1.9 | 4.5 | |
| ABFLMC-YOLOv5n | 640 | - | 22.8 | 40.0 | 1.48 | 4.4 | |
| VisDrone | YOLOv5n [48] | 640 | - | 12.9 | 25.9 | 1.78 | 4.2 |
| ABFLMC-YOLOv5n | 640 | - | 14.3 | 28.1 | 1.38 | 4.1 |
| Hardware Evaluations | VOC 07 + 12 | COCO | VOC 07 + 12 | COCO |
|---|---|---|---|---|
| Model Name | ABFLMC-Yolov5n | TT-Yolov5s [9] | ||
| Param M | 1.39 | 1.48 | 4.74 | 4.9 |
| LUT | 111,233 | 120,533 | 182,022 | 187,022 |
| LUT Utilization (%) | 51.3 | 55.6 | 83.9 | 86.2 |
| FF | 174,210 | 178,720 | 123,098 | 143,728 |
| FF Utilization (%) | 40.2 | 41.2 | 28.4 | 33.1 |
| BRAM (MB) | 305 | 305 | 220 | 235 |
| BRAM Utilization (%) | 63.5 | 63.5 | 45.8 | 49 |
| DSP | 569 | 577 | 1321 | 1351 |
| DSP Utilization (%) | 31.2 | 31.6 | 72.4 | 74.1 |
| GOPS | 135.5 | 129.4 | 42.6 | 34.2 |
| Power (W) | 6.12 | 6.33 | 15.2 | 16.1 |
| Models | Dataset | Platform | GFLOPs | Power (W) |
|---|---|---|---|---|
| ABFLMC-YOLOv5n (Ours) | COCO | Intel i9-9920X + RTX3090 | 4.4 | 200 |
| ABFLMC-YOLOv5n (Ours) | COCO | Ultrascale + KCU116 FPGA | 4.4 | 6.33 |
| TT-YOLOv5s (rank16) [9] | COCO | Ultrascale + KCU116 FPGA | 18.9 | 16.1 |
| YOLObile [30] | COCO | Qualcomm Snapdragon 865 | 3.95 | 5 * |
| YOLOv5n [48] | COCO | na | 4.5 | na |
| REQ-YOLO [50] | VOC 07 + 12 | ADM-7V3 FPGA | na | 21 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, M.; Luo, S.; Han, K.; DeMara, R.F.; Bai, Y. Autonomous Binarized Focal Loss Enhanced Model Compression Design Using Tensor Train Decomposition. Micromachines 2022, 13, 1738. https://doi.org/10.3390/mi13101738
Liu M, Luo S, Han K, DeMara RF, Bai Y. Autonomous Binarized Focal Loss Enhanced Model Compression Design Using Tensor Train Decomposition. Micromachines. 2022; 13(10):1738. https://doi.org/10.3390/mi13101738
Chicago/Turabian StyleLiu, Mingshuo, Shiyi Luo, Kevin Han, Ronald F. DeMara, and Yu Bai. 2022. "Autonomous Binarized Focal Loss Enhanced Model Compression Design Using Tensor Train Decomposition" Micromachines 13, no. 10: 1738. https://doi.org/10.3390/mi13101738
APA StyleLiu, M., Luo, S., Han, K., DeMara, R. F., & Bai, Y. (2022). Autonomous Binarized Focal Loss Enhanced Model Compression Design Using Tensor Train Decomposition. Micromachines, 13(10), 1738. https://doi.org/10.3390/mi13101738