An Ultra-Area-Efficient 1024-Point In-Memory FFT Processor

 , , , and
, , , and 
Abstract
1. Introduction
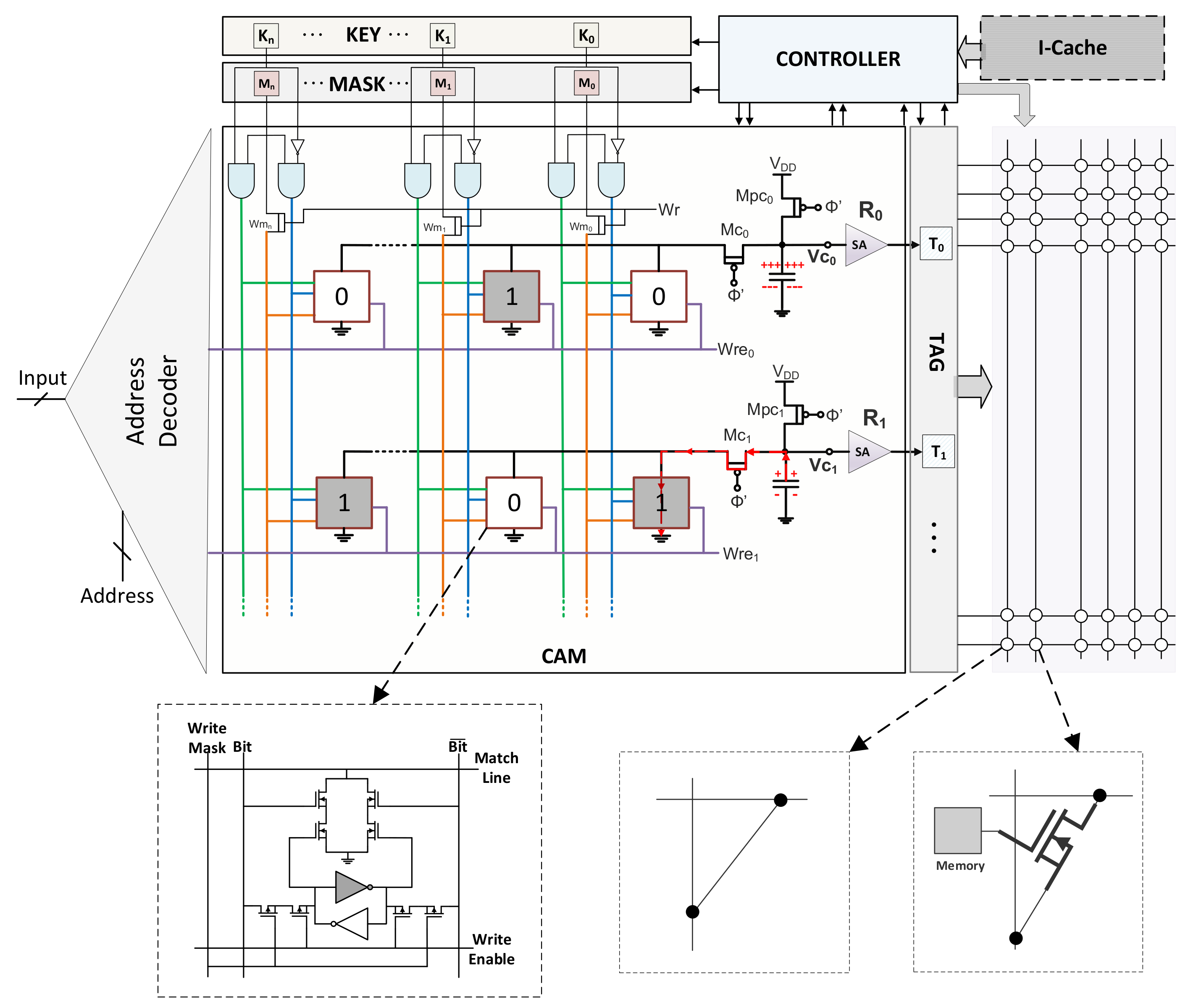
2. In-Memory Associative Processing
2.1. Associative Computing
2.2. Operation
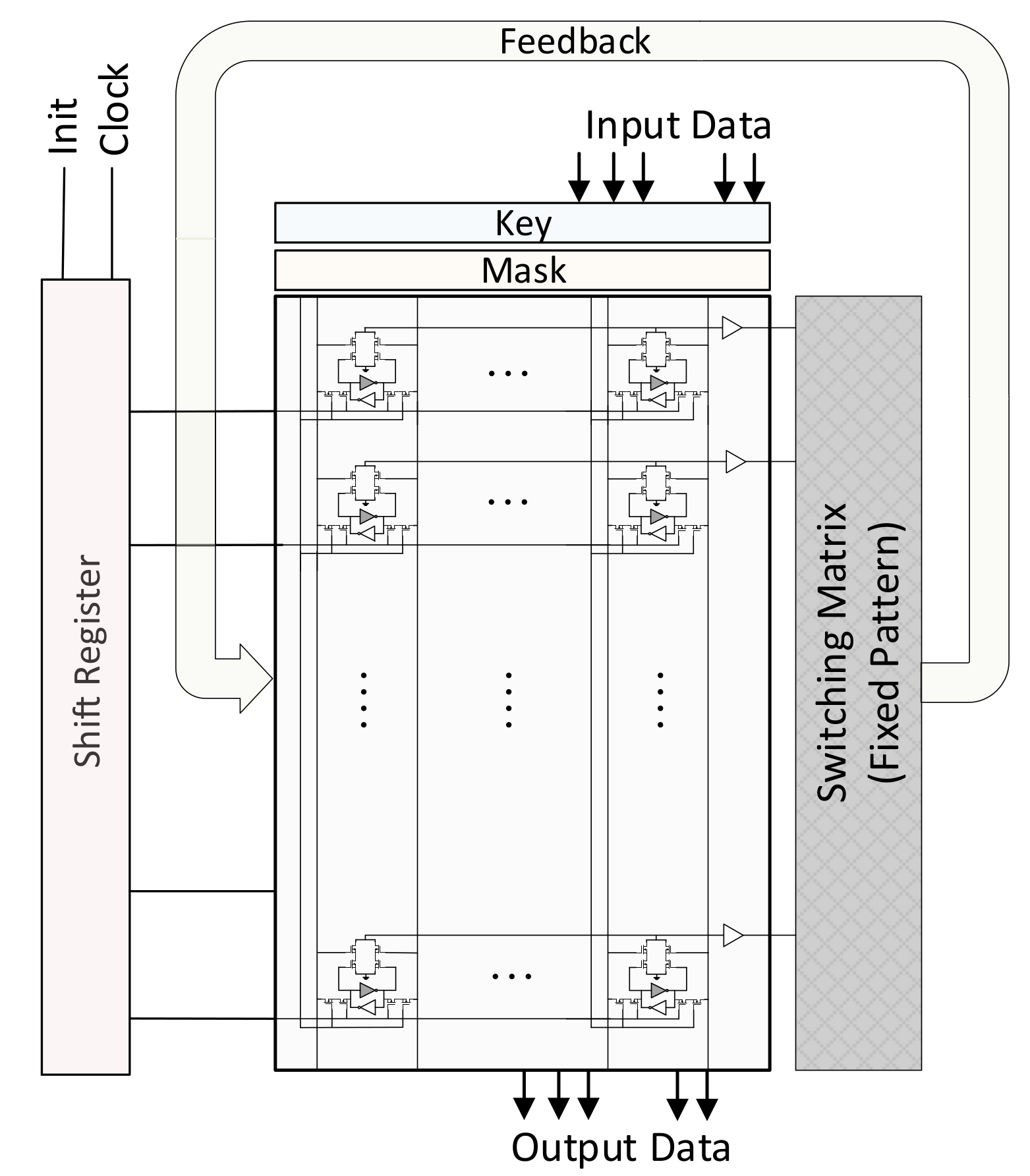
3. FFT Processor Architecture
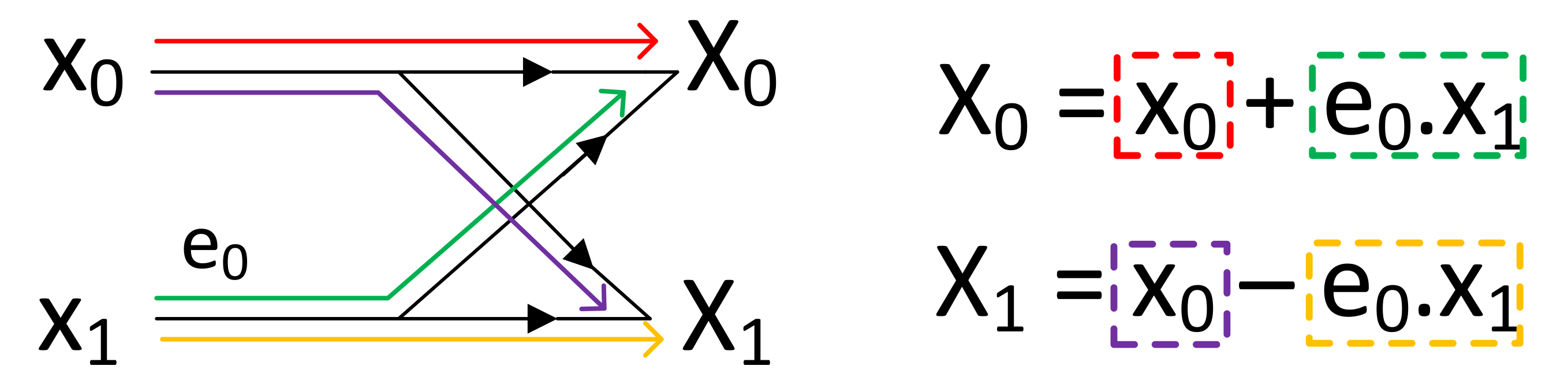
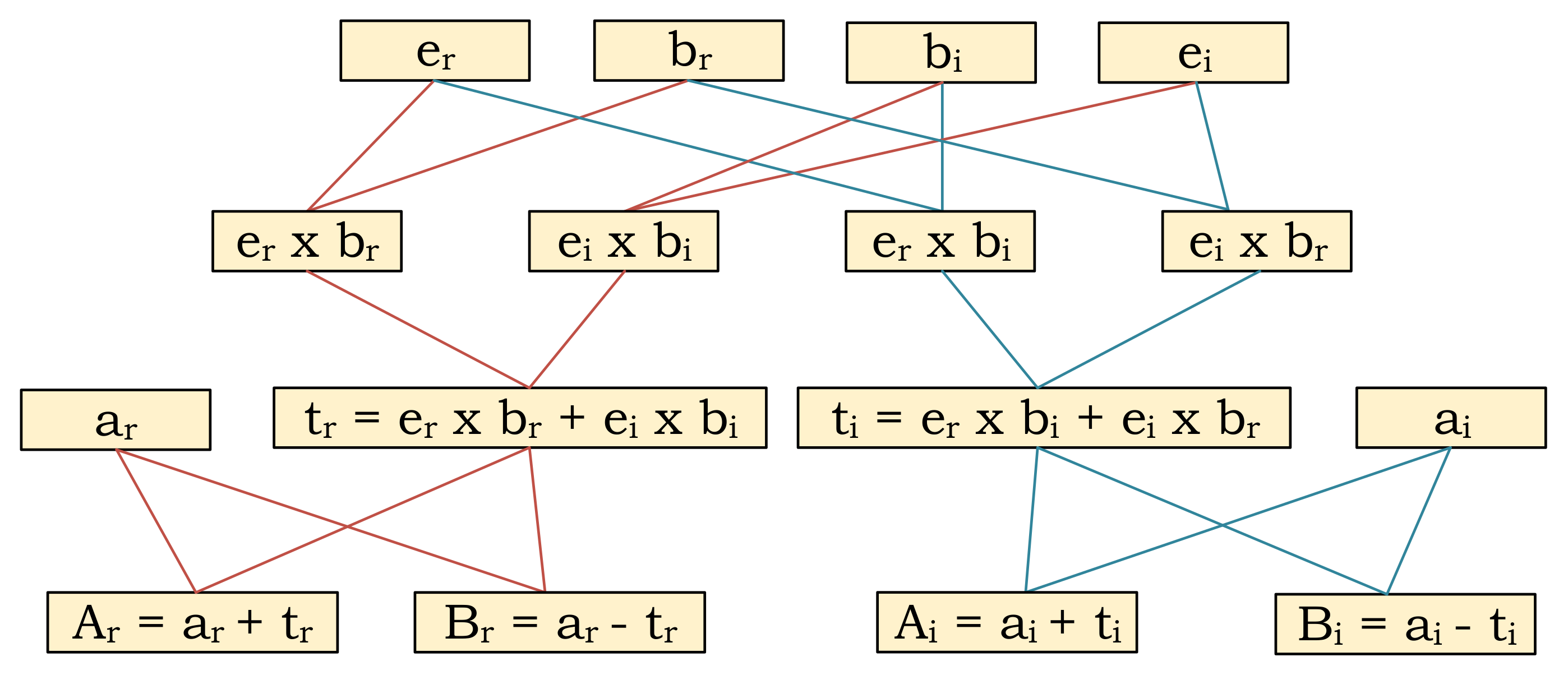
3.1. Butterfly Operation
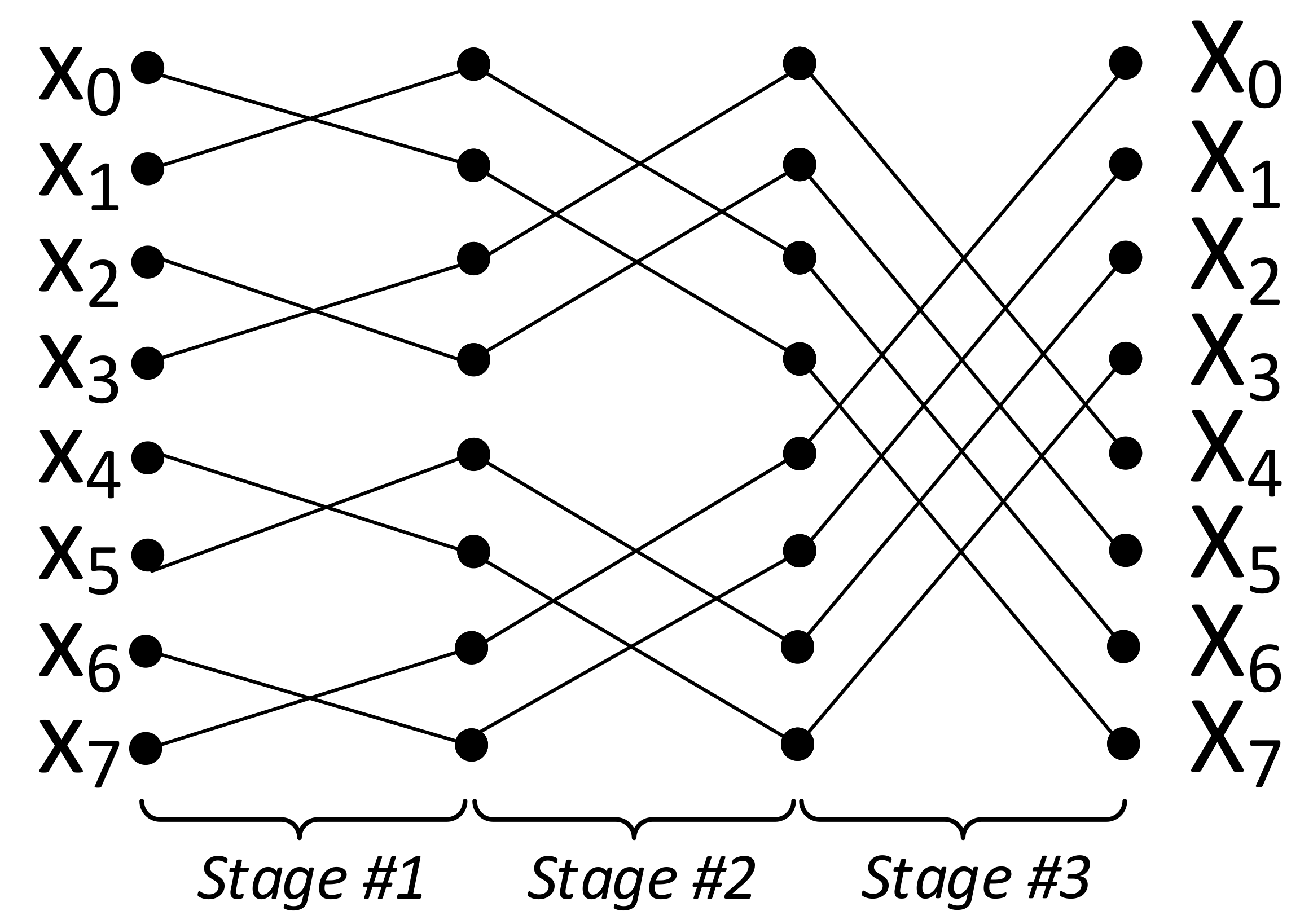
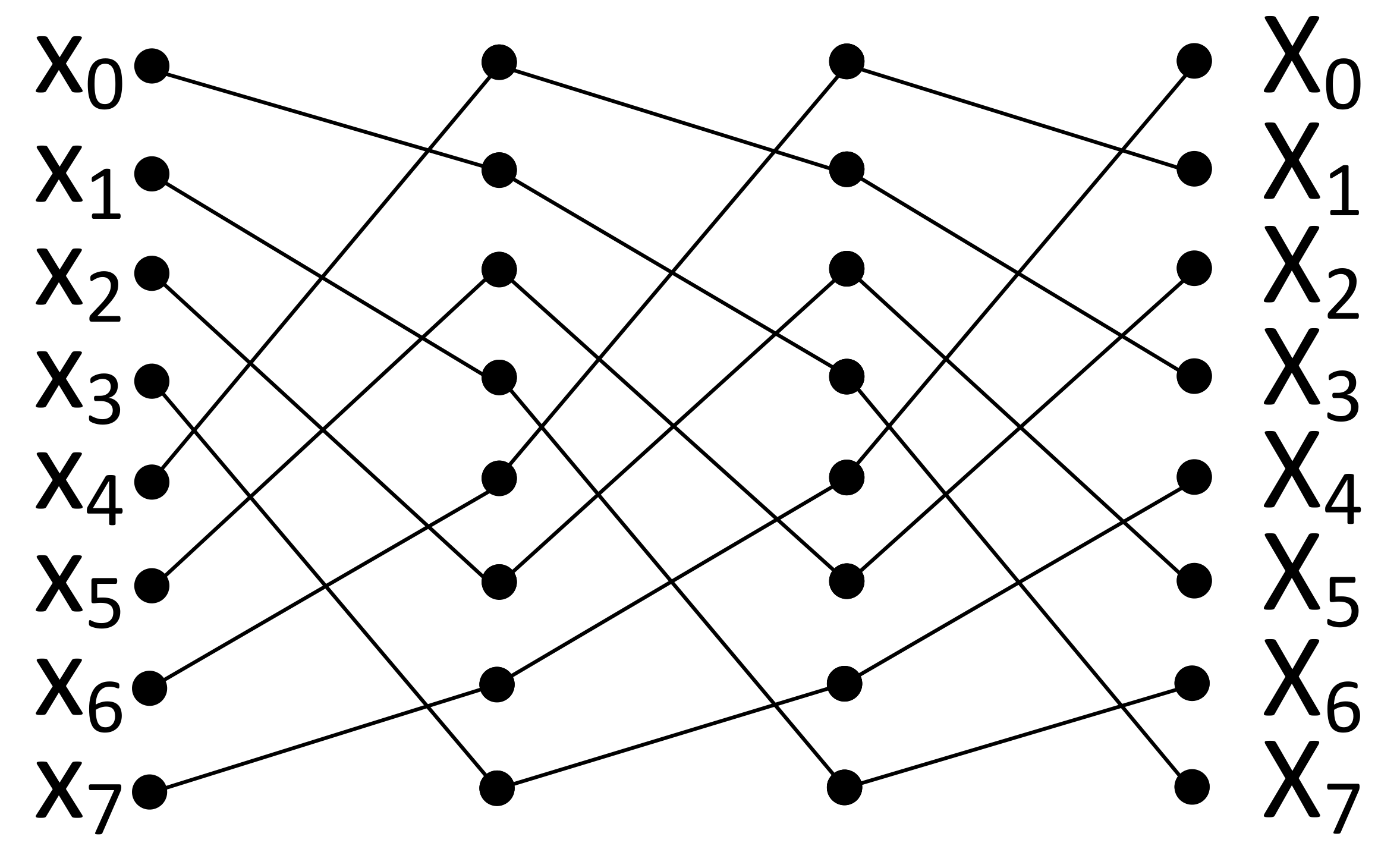
3.2. Data Movement
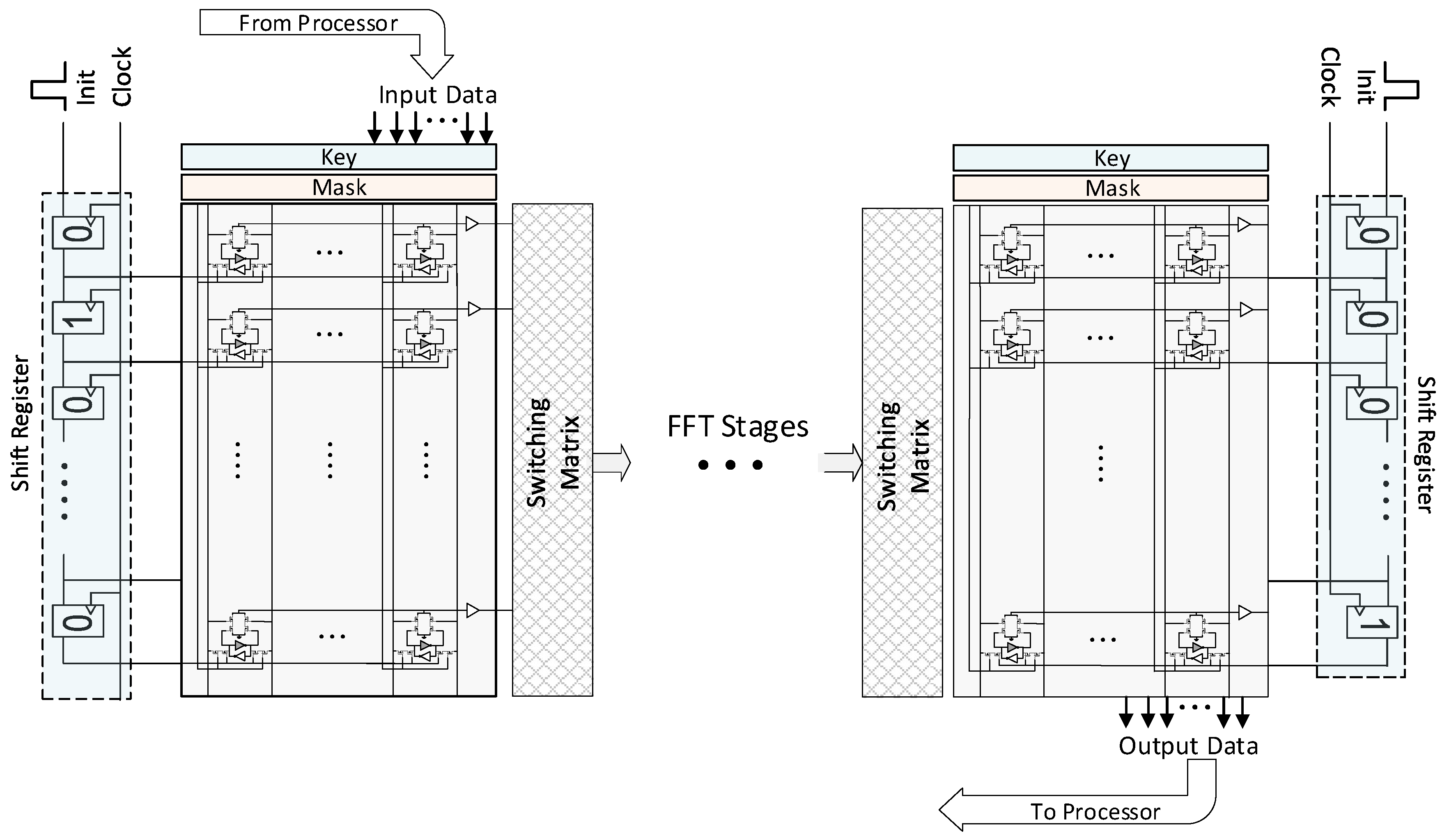
3.3. Area-Optimized Architecture
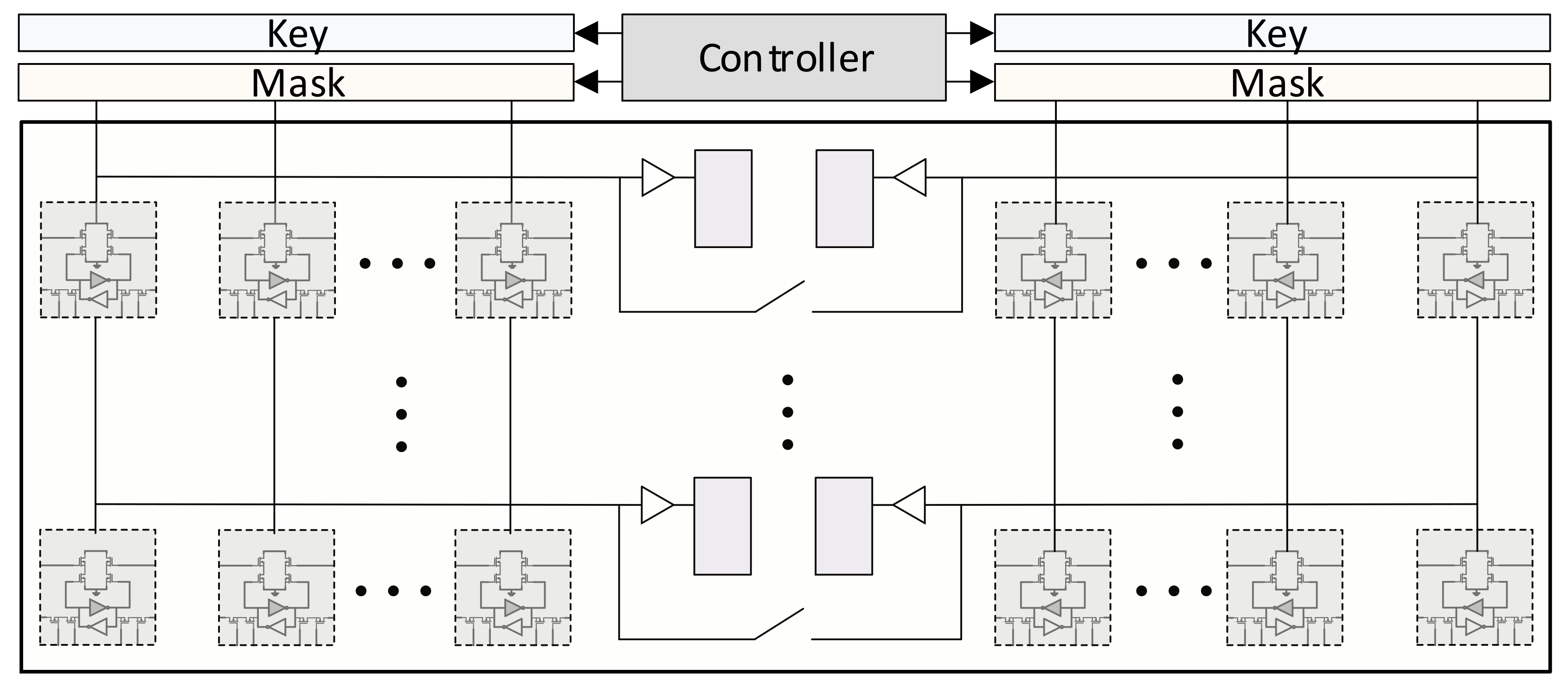
3.4. Dual-Issue Butterfly Operation
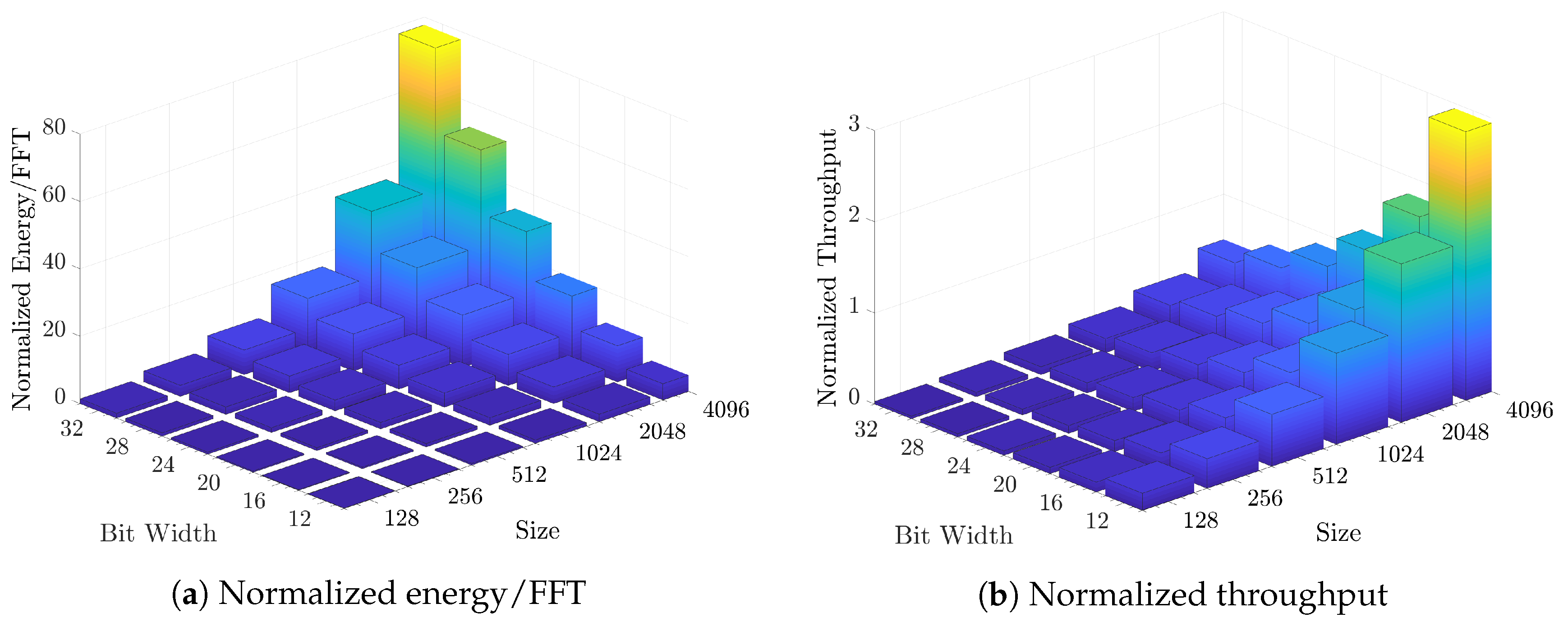
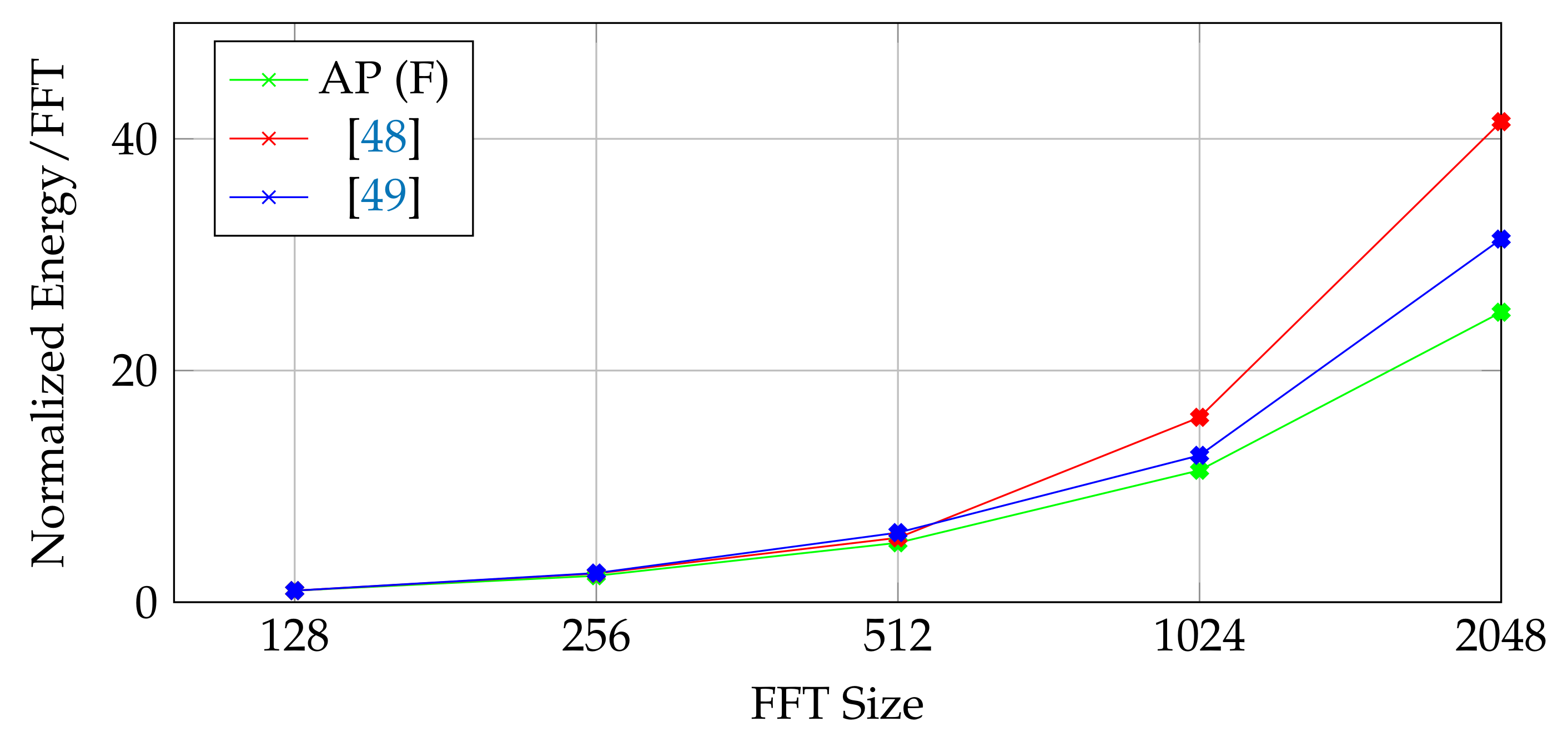
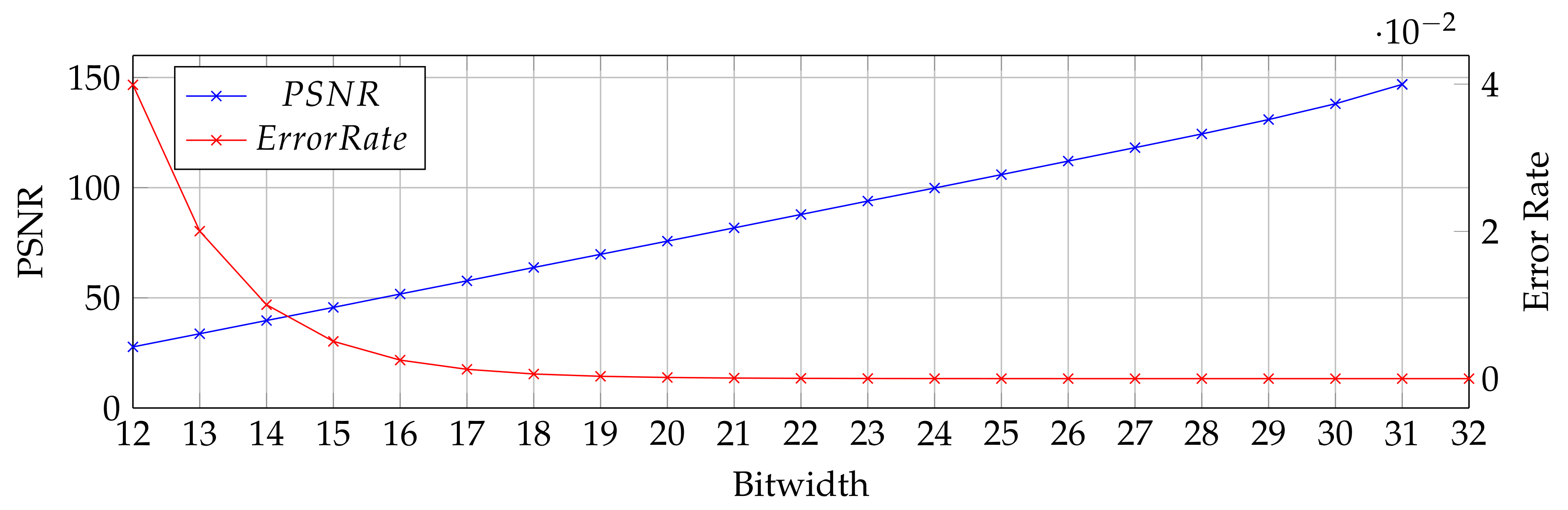
4. Evaluation
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Mutlu, O.; Ghose, S.; Gómez-Luna, J.; Ausavarungnirun, R. Processing data where it makes sense: Enabling in-memory computation. Microprocess. Microsyst. 2019, 67, 28–41. [Google Scholar]
- Big data needs a hardware revolution. Nature 2018, 554, 145. [CrossRef]
- Dally, W.J. Challenges for Future Computing Systems. In Proceedings of the 2015 Amsterdam Conference, Amsterdam, The Netherlands, 19–21 January 2015. [Google Scholar]
- Ghose, S.; Hsieh, K.; Boroumand, A.; Ausavarungnirun, R.; Mutlu, O. Enabling the Adoption of Processing-in-Memory: Challenges, Mechanisms, Future Research Directions. arXiv 2018, arXiv:1802.00320. [Google Scholar]
- Kozyrakis, C.E.; Perissakis, S.; Patterson, D.; Anderson, T.; Asanovic, K.; Cardwell, N.; Fromm, R.; Golbus, J.; Gribstad, B.; Keeton, K.; et al. Scalable processors in the billion-transistor era: IRAM. Computer 1997, 30, 75–78. [Google Scholar] [CrossRef]
- Gokhale, M.; Lloyd, S.; Macaraeg, C. Hybrid Memory Cube Performance Characterization on Data-centric Workloads. In Proceedings of the 5th Workshop on Irregular Applications: Architectures and Algorithms, Austin, TX, USA, 15 November 2015; ACM: New York, NY, USA, 2015; pp. 7:1–7:8. [Google Scholar] [CrossRef]
- Ghose, S.; Hsieh, K.; Boroumand, A.; Ausavarungnirun, R.; Mutlu, O. The Processing-in-Memory Paradigm: Mechanisms to Enable Adoption. In Beyond-CMOS Technologies for Next Generation Computer Design; Topaloglu, R.O., Wong, H.S.P., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 133–194. [Google Scholar]
- Kanev, S.; Darago, J.P.; Hazelwood, K.; Ranganathan, P.; Moseley, T.; Wei, G.Y.; Brooks, D. Profiling a Warehouse-scale Computer. In Proceedings of the 42nd Annual International Symposium on Computer Architecture, Portland, OR, USA, 13–17 June 2015; ACM: New York, NY, USA, 2015; pp. 158–169. [Google Scholar] [CrossRef]
- Seshadri, V.; Kim, Y.; Fallin, C.; Lee, D.; Ausavarungnirun, R.; Pekhimenko, G.; Luo, Y.; Mutlu, O.; Gibbons, P.B.; Kozuch, M.A.; et al. RowClone: Fast and energy-efficient in-DRAM bulk data copy and initialization. In Proceedings of the 2013 46th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Davis, CA, USA, 7–11 December 2013; pp. 185–197. [Google Scholar]
- Mittal, S. A Survey of ReRAM-Based Architectures for Processing-In-Memory and Neural Networks. Mach. Learn. Knowl. Extr. 2018, 1, 75–114. [Google Scholar] [CrossRef]
- Ielmini, D.; Wong, H.S.P. In-memory computing with resistive switching devices. Nat. Electron. 2018, 1, 333–343. [Google Scholar] [CrossRef]
- Li, S.; Xu, C.; Zou, Q.; Zhao, J.; Lu, Y.; Xie, Y. Pinatubo: A Processing-in-memory Architecture for Bulk Bitwise Operations in Emerging Non-volatile Memories. In Proceedings of the 53rd Annual Design Automation Conference, Austin, TX, USA, 5–9 June 2016; ACM: New York, NY, USA; pp. 173:1–173:6. [Google Scholar] [CrossRef]
- Sim, J.; Imani, M.; Choi, W.; Kim, Y.; Rosing, T. LUPIS: Latch-up based ultra efficient processing in-memory system. In Proceedings of the 2018 19th International Symposium on Quality Electronic Design (ISQED), Santa Clara, CA, USA, 13–14 March 2018; pp. 55–60. [Google Scholar] [CrossRef]
- Chen, B.; Cai, F.; Zhou, J.; Ma, W.; Sheridan, P.; Lu, W.D. Efficient in-memory computing architecture based on crossbar arrays. In Proceedings of the 2015 IEEE International Electron Devices Meeting (IEDM), Washington, DC, USA, 7–9 December 2015; pp. 17.5.1–17.5.4. [Google Scholar] [CrossRef]
- Imani, M.; Gupta, S.; Rosing, T. Ultra-Efficient Processing In-Memory for Data Intensive Applications. In Proceedings of the 54th Annual Design Automation Conference 2017, Austin, TX, USA, 18–22 June 2017; ACM: New York, NY, USA, 2017; pp. 6:1–6:6. [Google Scholar] [CrossRef]
- Chi, P.; Li, S.; Xu, C.; Zhang, T.; Zhao, J.; Liu, Y.; Wang, Y.; Xie, Y. PRIME: A Novel Processing-in-Memory Architecture for Neural Network Computation in ReRAM-Based Main Memory. In Proceedings of the 2016 ACM/IEEE 43rd Annual International Symposium on Computer Architecture (ISCA), Seoul, Korea, 18–22 June 2016; pp. 27–39. [Google Scholar] [CrossRef]
- Stone, H.S. A Logic-in-Memory Computer. IEEE Trans. Comput. 1970, C-19, 73–78. [Google Scholar] [CrossRef]
- Santoro, G.; Turvani, G.; Graziano, M. New Logic-In-Memory Paradigms: An Architectural and Technological Perspective. Micromachines 2019, 10, 368. [Google Scholar] [CrossRef]
- Cofano, M.; Vacca, M.; Santoro, G.; Causapruno, G.; Turvani, G.; Graziano, M. Exploiting the Logic-In-Memory paradigm for speeding-up data-intensive algorithms. Integration 2019, 66, 153–163. [Google Scholar]
- Chua, L. Memristor-The missing circuit element. IEEE Trans. Circuit Theory 1971, 18, 507–519. [Google Scholar] [CrossRef]
- Apalkov, D.; Khvalkovskiy, A.; Watts, S.; Nikitin, V.; Tang, X.; Lottis, D.; Moon, K.; Luo, X.; Chen, E.; Ong, A.; et al. Spin-transfer Torque Magnetic Random Access Memory (STT-MRAM). J. Emerg. Technol. Comput. Syst. 2013, 9, 13:1–13:35. [Google Scholar] [CrossRef]
- Hennig, J.; Nauerth, A.; Friedburg, H. RARE imaging: A fast imaging method for clinical MR. Magn. Reson. Med. 1986, 3, 823–833. [Google Scholar] [CrossRef]
- Li, L.; Wyrwicz, A.M. Parallel 2D FFT implementation on FPGA suitable for real-time MR image processing. Rev. Sci. Instrum. 2018, 89, 093706. [Google Scholar] [CrossRef]
- Shi, L.; Andronesi, O.; Hassanieh, H.; Ghazi, B.; Katabi, D.; Adalsteinsson, E. Mrs sparse-fft: Reducing acquisition time and artifacts for in vivo 2d correlation spectroscopy. In Proceedings of the International Society for Magnetic Resonance in Medicine Annual Meeting and Exhibition (ISMRM’13), Salt Lake City, UT, USA, 20–26 April 2013. [Google Scholar]
- Potter, J.L. Associative Computing: A Programming Paradigm for Massively Parallel Computers; Perseus Publishing: New York, NY, USA, 1991. [Google Scholar]
- Foster, C.C. Content Addressable Parallel Processors; John Wiley & Sons, Inc.: New York, NY, USA, 1976. [Google Scholar]
- Yavits, L.; Morad, A.; Ginosar, R. Computer Architecture with Associative Processor Replacing Last-Level Cache and SIMD Accelerator. IEEE Trans. Comput. 2015, 64, 368–381. [Google Scholar] [CrossRef]
- Yantir, H.E.; Eltawil, A.M.; Kurdahi, F.J. Approximate Memristive In-memory Computing. ACM Trans. Embed. Comput. Syst. 2017, 16, 129:1–129:18. [Google Scholar] [CrossRef]
- Yantır, H.E.; Eltawil, A.M.; Kurdahi, F.J. A Hybrid Approximate Computing Approach for Associative In-Memory Processors. IEEE J. Emerg. Sel. Top. Circuits Syst. 2018, 8, 758–769. [Google Scholar] [CrossRef]
- Fourier, J. Chapter 26—Joseph Fourier, Théorie analytique de la chaleur (1822). In Landmark Writings in Western Mathematics 1640–1940; Grattan-Guinness, I., Cooke, R., Corry, L., Crépel, P., Guicciardini, N., Eds.; Elsevier Science: Amsterdam, The Netherlands, 2005; pp. 354–364. ISBN 978-0-444-50871-3. [Google Scholar]
- Cooley, J.; Tukey, J. An Algorithm for the Machine Calculation of Complex Fourier Series. Math. Comput. 1965, 19, 297–301. [Google Scholar] [CrossRef]
- Abdelaal, R.A.; Yantır, H.E.; Eltawil, A.M.; Kurdahi, F.J. Power Performance Tradeoffs Using Adaptive Bit Width Adjustments on Resistive Associative Processors. IEEE Trans. Circuits Syst. Regul. Pap. 2019, 66, 302–312. [Google Scholar] [CrossRef]
- Chen, Y.; Lin, Y.W.; Tsao, Y.C.; Lee, C.Y. A 2.4-Gsample/s DVFS FFT Processor for MIMO OFDM Communication Systems. IEEE J. -Solid-State Circuits 2008, 43, 1260–1273. [Google Scholar] [CrossRef]
- Liu, S.; Liu, D. A High-Flexible Low-Latency Memory-Based FFT Processor for 4G, WLAN, and Future 5G. IEEE Trans. Very Large Scale Integr. Syst. 2018, 1–13. [Google Scholar] [CrossRef]
- Ba, N.L.; Kim, T.T. An Area Efficient 1024-Point Low Power Radix-22FFT Processor With Feed-Forward Multiple Delay Commutators. IEEE Trans. Circuits Syst. I Regul. Pap. 2018, 65, 3291–3299. [Google Scholar] [CrossRef]
- Guo, Q.; Guo, X.; Patel, R.; Ipek, E.; Friedman, E.G. AC-DIMM: Associative Computing with STT-MRAM. SIGARCH Comput. Archit. News 2013, 41, 189–200. [Google Scholar] [CrossRef]
- Good, I.J. The Interaction Algorithm and Practical Fourier Analysis. J. R. Stat. Soc. Ser. B 1958, 20, 361–372. [Google Scholar]
- Rader, C.M. Discrete Fourier transforms when the number of data samples is prime. Proc. IEEE 1968, 56, 1107–1108. [Google Scholar] [CrossRef]
- Bluestein, L. A linear filtering approach to the computation of discrete Fourier transform. IEEE Trans. Audio Electroacoust. 1970, 18, 451–455. [Google Scholar] [CrossRef]
- Singleton, R. A method for computing the fast Fourier transform with auxiliary memory and limited high-speed storage. IEEE Trans. Audio Electroacoust. 1967, 15, 91–98. [Google Scholar] [CrossRef]
- Arizona State University. Predictive Technology Model (PTM); Arizona State University: Tempe, AZ, USA, 2011. [Google Scholar]
- Sinha, S.; Yeric, G.; Chandra, V.; Cline, B.; Cao, Y. Exploring sub-20nm FinFET design with Predictive Technology Models. In Proceedings of the DAC Design Automation Conference 2012, San Francisco, CA, USA, 3–7 June 2012; pp. 283–288. [Google Scholar] [CrossRef]
- Zhang, K.; Bhattacharya, U.; Chen, Z.; Hamzaoglu, F.; Murray, D.; Vallepalli, N.; Wang, Y.; Zheng, B.; Bohr, M. SRAM design on 65nm CMOS technology with integrated leakage reduction scheme. In Proceedings of the 2004 Symposium on VLSI Circuits. Digest of Technical Papers, Honolulu, HI, USA, 17–19 June 2004; pp. 294–295. [Google Scholar] [CrossRef]
- Hayashi, I.; Amano, T.; Watanabe, N.; Yano, Y.; Kuroda, Y.; Shirata, M.; Dosaka, K.; Nii, K.; Noda, H.; Kawai, H. A 250-MHz 18-Mb Full Ternary CAM With Low-Voltage Matchline Sensing Scheme in 65-nm CMOS. IEEE J. -Solid-State Circuits 2013, 48, 2671–2680. [Google Scholar] [CrossRef]
- Wilson, L. International technology roadmap for semiconductors (ITRS); Semiconductor Industry Association: Washington, DC, USA, 2013; Volume 1–17. [Google Scholar]
- Schinkel, D.; Mensink, E.; Klumperink, E.; van Tuijl, E.; Nauta, B. A Double-Tail Latch-Type Voltage Sense Amplifier with 18ps Setup+Hold Time. In Proceedings of the 2007 IEEE International Solid-State Circuits Conference, San Francisco, CA, USA, 11–15 February 2007; Digest of Technical Papers. pp. 314–605. [Google Scholar] [CrossRef]
- Seok, M.; Jeon, D.; Chakrabarti, C.; Blaauw, D.; Sylvester, D. A 0.27 V 30 MHz 17.7 nJ/transform 1024-pt complex FFT core with super-pipelining. In Proceedings of the 2011 IEEE International Solid-State Circuits Conference Digest of Technical Papers (ISSCC), San Francisco, CA, USA, 20–24 February 2011; pp. 342–344. [Google Scholar] [CrossRef]
- Yang, C.; Yu, T.; Markovic, D. Power and Area Minimization of Reconfigurable FFT Processors: A 3GPP-LTE Example. IEEE J. -Solid-State Circuits 2012, 47, 757–768. [Google Scholar] [CrossRef]
- Guichang, Z.; Fan, X.; Willson, A.N. A power-scalable reconfigurable FFT/IFFT IC based on a multi-processor ring. IEEE J. -Solid-State Circuits 2006, 41, 483–495. [Google Scholar] [CrossRef]
- McDougall, M.P.; Wright, S.M. 64-channel array coil for single echo acquisition magnetic resonance imaging. Magn. Reson. Med. 2005, 54, 386–392. [Google Scholar] [CrossRef]
- Mittal, S. A Survey of Techniques for Approximate Computing. ACM Comput. Surv. 2016, 48, 62:1–62:33. [Google Scholar] [CrossRef]
- Agrawal, A.; Choi, J.; Gopalakrishnan, K.; Gupta, S.; Nair, R.; Oh, J.; Prener, D.A.; Shukla, S.; Srinivasan, V.; Sura, Z. Approximate computing: Challenges and opportunities. In Proceedings of the 2016 IEEE International Conference on Rebooting Computing (ICRC), San Diego, CA, USA, 17–19 October 2016; pp. 1–8. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Computation Type | Data Location | Functionality Location | Bandwidth Constraint |
|---|---|---|---|
| Traditional | Separate IC | Processor | Inter-chip Bus |
| Near-memory | Same IC | Processor | In-chip Bus |
| In-memory | Same IC | Memory | Memory Capacity |
| Addition | Subtraction | |||||||
|---|---|---|---|---|---|---|---|---|
| Compare | Write | Write | ||||||
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | ||
| 0 | 0 | 1 | 0 | 1 | 1 | 1 | ||
| 0 | 1 | 0 | 0 | 1 | 0 | 1 | ||
| 0 | 1 | 1 | 1 | 0 | 0 | 0 | ||
| 1 | 0 | 0 | 0 | 1 | 1 | 1 | ||
| 1 | 0 | 1 | 1 | 0 | 1 | 0 | ||
| 1 | 1 | 0 | 1 | 0 | 0 | 0 | ||
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | ||
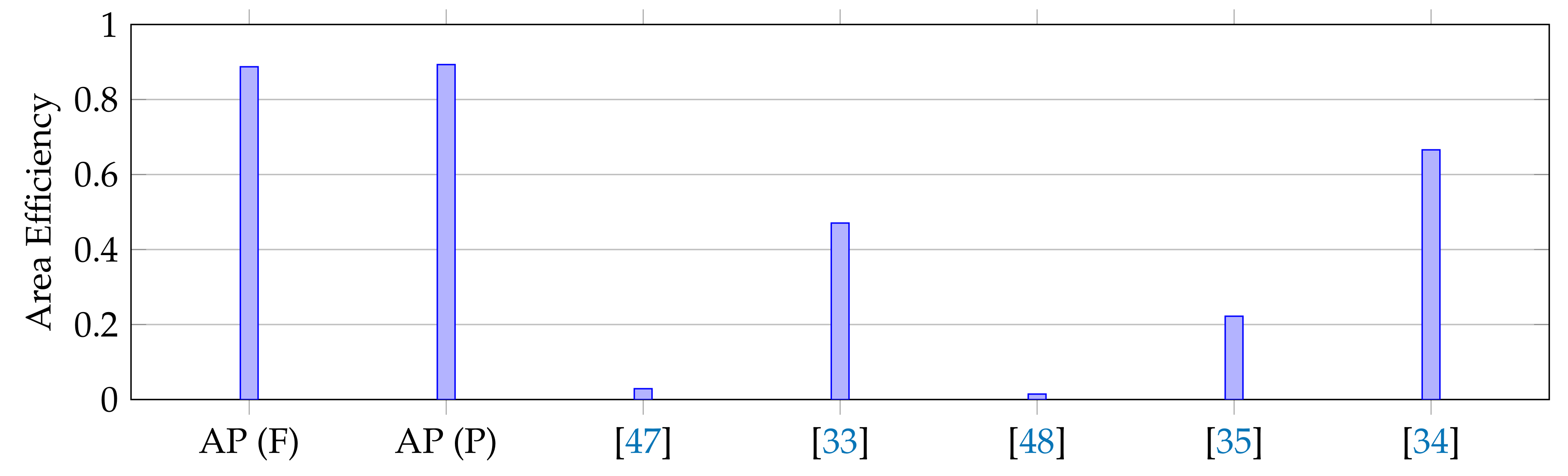
| Specification | AP (F) | AP (P) | [47] | [33] | [48] | [35] | [34] |
|---|---|---|---|---|---|---|---|
| FFT Size (N) | 1024 | 1024 | 1024 | 256 | 2048 | 1024 | 4096 |
| Technology | 65 nm | 65 nm | 65 nm | 90 nm | 65 nm | 65 nm | 65 nm |
| 1 | |||||||
| Word-length | 12-bit | 12-bit | 16-bit | 10-bit | 12-bit | 32-bit * | 14-bit |
| Area | |||||||
| Power | 12 mW | 123 mW | 4.15 mW | 165 mW | 1.01 mW | 60.3 mW | 68.6 mW |
| Throughput/Area () | 0.89 | 0.89 | 0.03 | 0.47 | 0.015 | 0.22 | 0.67 |
| FOM (FFT/Energy/Area) | 70.4 | 7.09 | 6.82 | 15.3 | 7.04 | 3.60 | 2.37 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yantir, H.E.; Guo, W.; Eltawil, A.M.; Kurdahi, F.J.; Salama, K.N. An Ultra-Area-Efficient 1024-Point In-Memory FFT Processor. Micromachines 2019, 10, 509. https://doi.org/10.3390/mi10080509
Yantir HE, Guo W, Eltawil AM, Kurdahi FJ, Salama KN. An Ultra-Area-Efficient 1024-Point In-Memory FFT Processor. Micromachines. 2019; 10(8):509. https://doi.org/10.3390/mi10080509
Chicago/Turabian StyleYantir, Hasan Erdem, Wenzhe Guo, Ahmed M. Eltawil, Fadi J. Kurdahi, and Khaled Nabil Salama. 2019. "An Ultra-Area-Efficient 1024-Point In-Memory FFT Processor" Micromachines 10, no. 8: 509. https://doi.org/10.3390/mi10080509
APA StyleYantir, H. E., Guo, W., Eltawil, A. M., Kurdahi, F. J., & Salama, K. N. (2019). An Ultra-Area-Efficient 1024-Point In-Memory FFT Processor. Micromachines, 10(8), 509. https://doi.org/10.3390/mi10080509