
Tlalpan 2020 Case Study: Enhancing Uric Acid Level Prediction with Machine Learning Regression and Cross-Feature Selection

 , ,
, ,  and
and Highlights
- Machine learning models enhance the accuracy of predicting uric acid levels, demonstrating superior performance over traditional regression approaches in identifying key metabolic and dietary determinants.
- Sex-specific risk factors for hyperuricemia were identified, with renal function and lipid metabolism playing a dominant role in men, while dietary patterns and metabolic dysregulation were more influential in women.
- A cross-feature selection approach improves model robustness, leveraging an integrative analysis of clinical, biochemical, and nutritional variables to improve predictive power and interpretability.
Abstract
1. Introduction
2. Materials and Methods
2.1. Data
2.2. Methods
2.2.1. Machine Learning Approaches
2.2.2. Feature and Cross-Feature Selection
2.2.3. Performance Measures
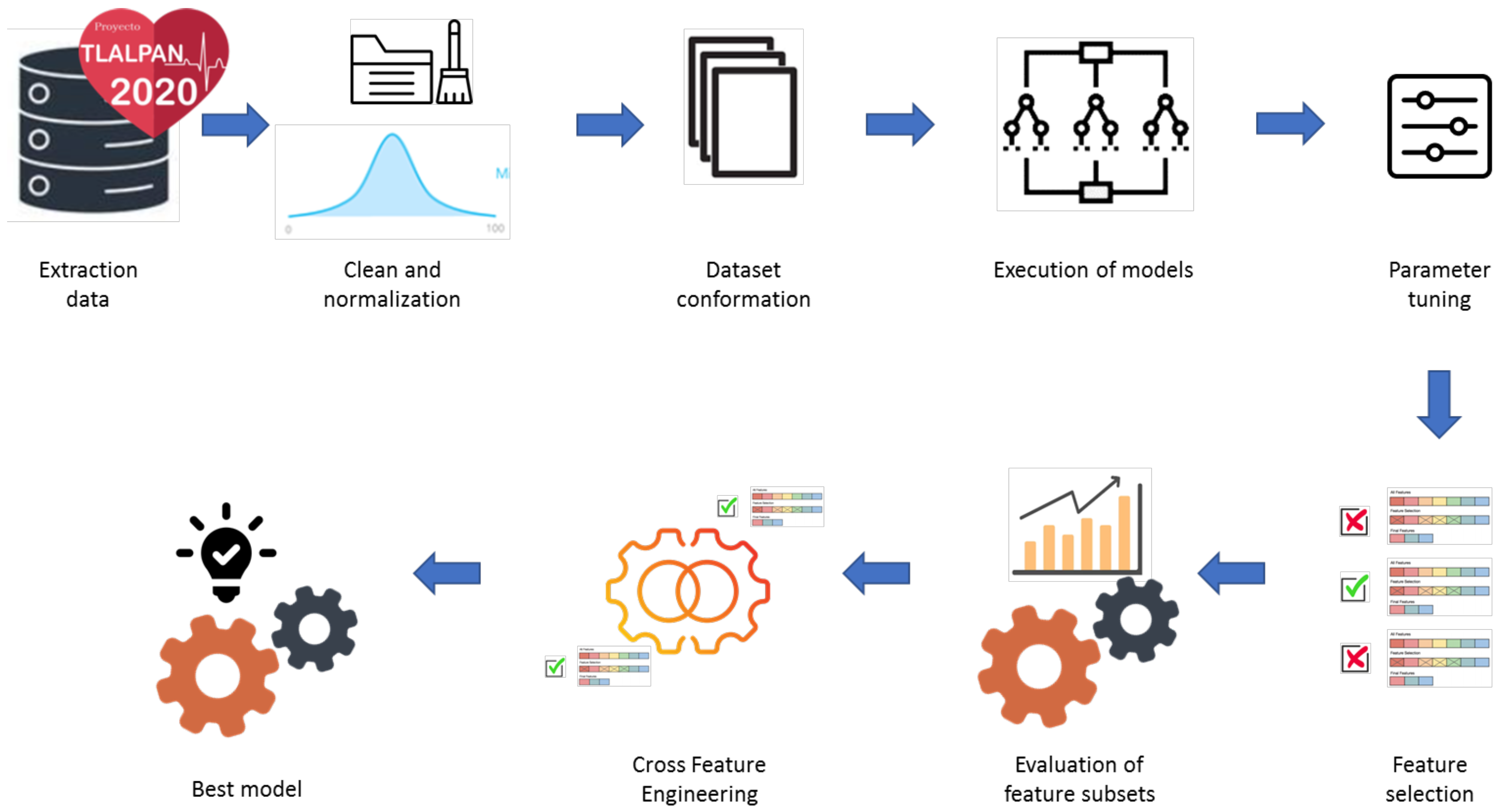
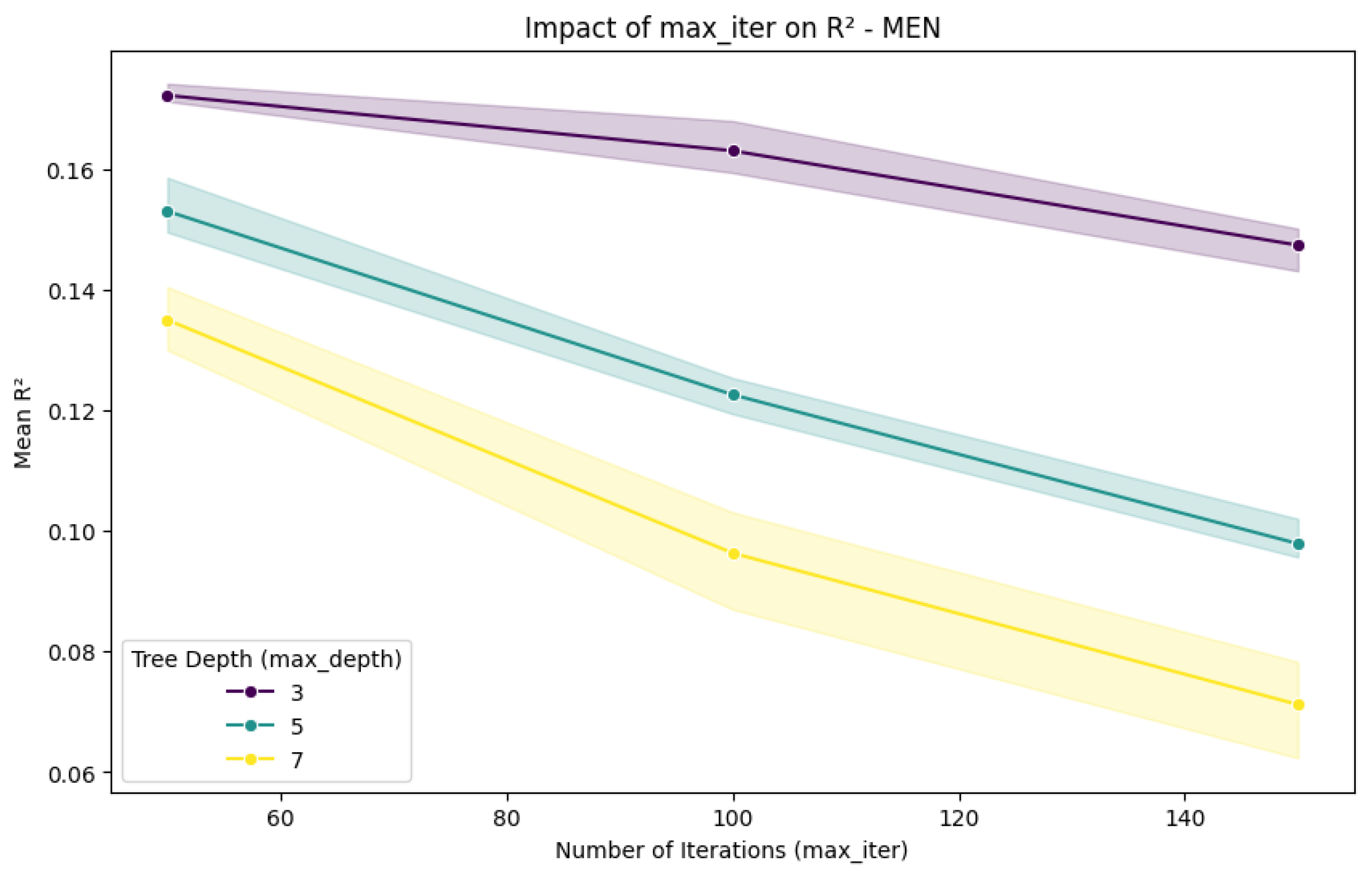
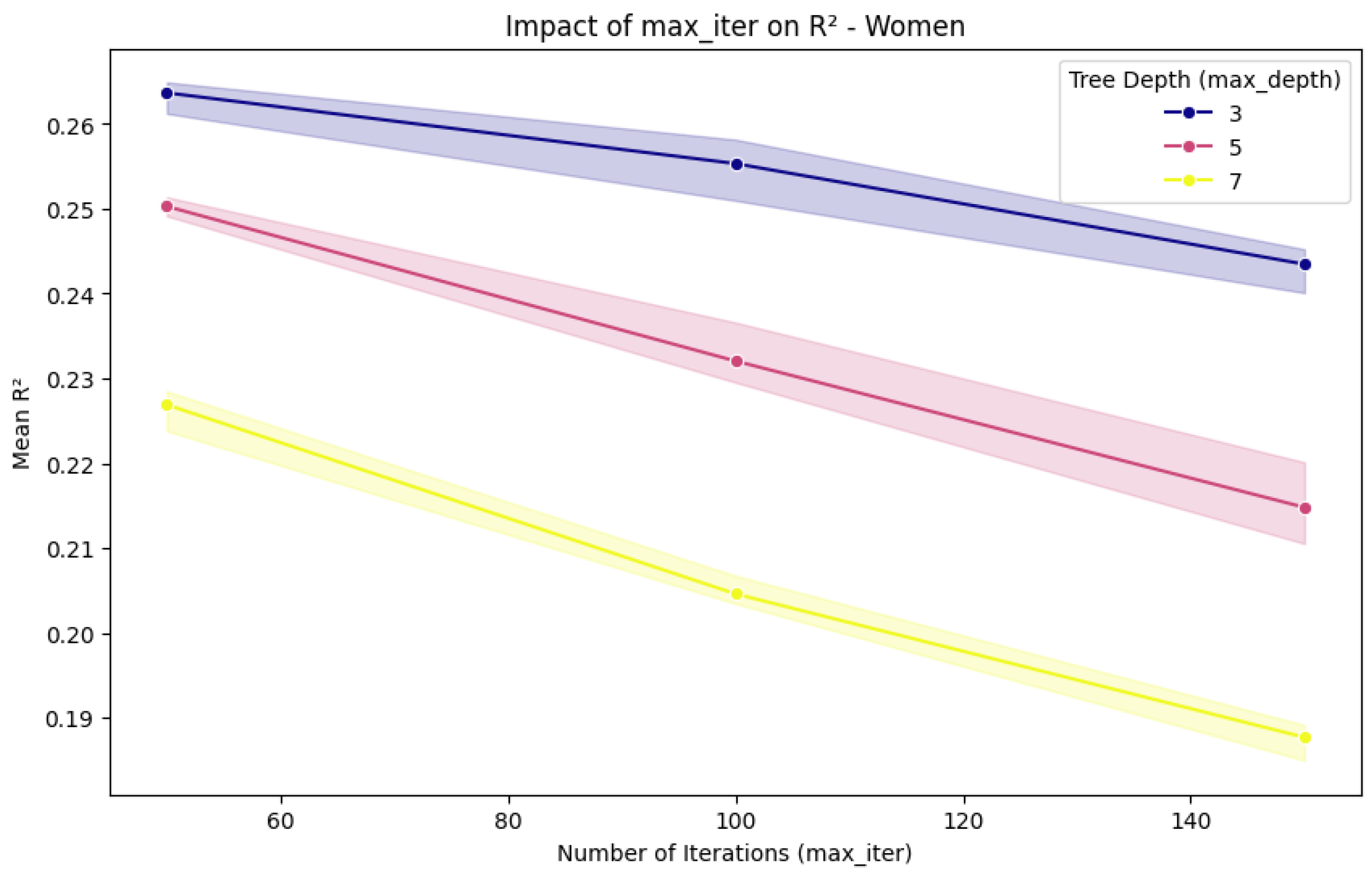
2.3. Experimental Setup and Process
3. Results
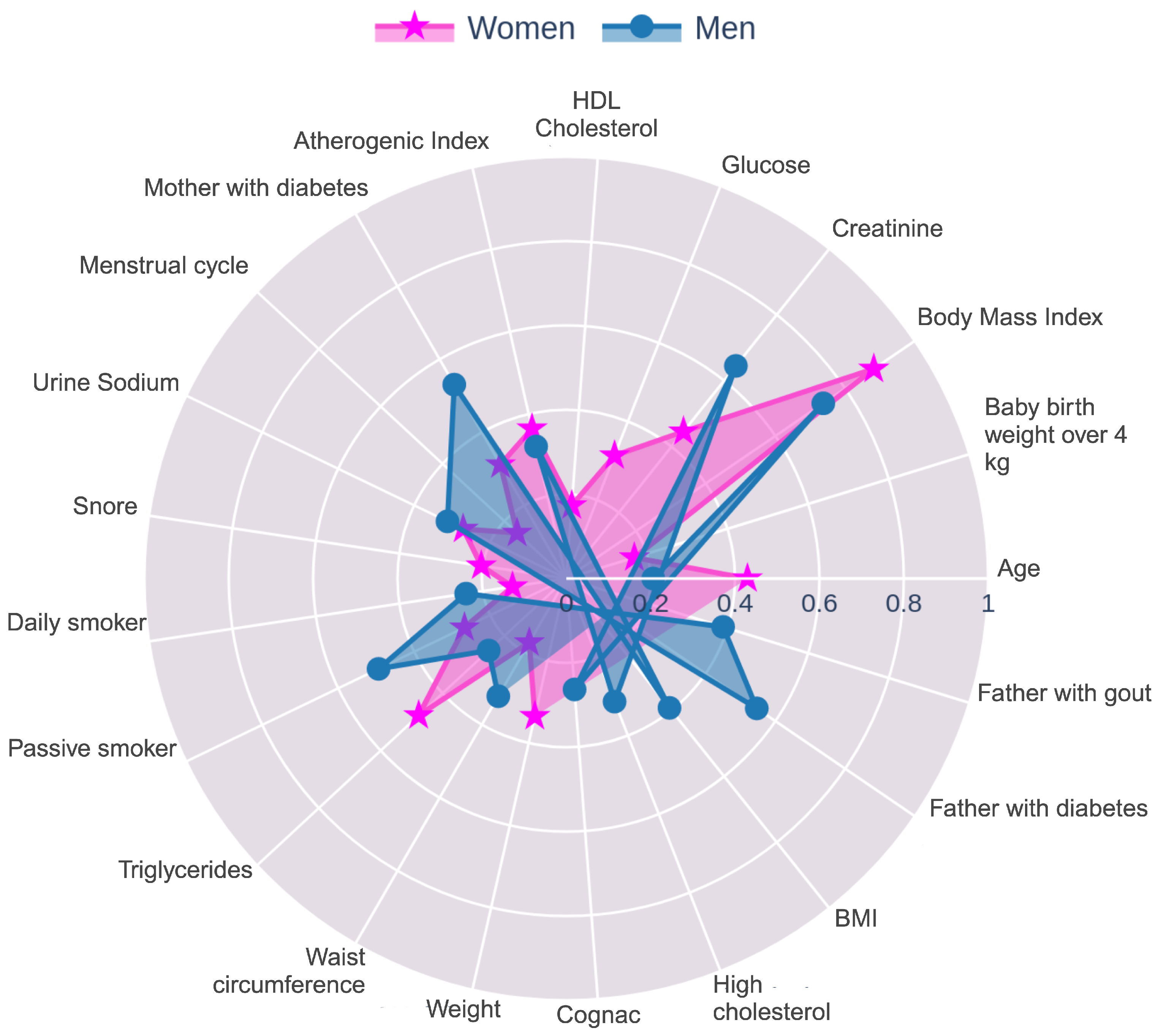
3.1. Clinical, Anthropometric, and Lifestyle Variables
3.2. Food Frequency Questionnaire Features
3.3. Nutritional and Biochemical Features
3.4. Results of Cross-Feature Selection
4. Discussion
4.1. Key Clinical, Anthropometric and Lifestyle Predictors
4.2. Food Frequency Questionnaires Factors
4.3. Nutritional and Biochemical Factors
5. Conclusions
Limitations
- Cohort-specific limitations: The study was based on data from the Tlalpan 2020 cohort, which represents a specific geographic and demographic group (Mexico City). The findings may not be generalizable to populations with different ethnic, socioeconomic, or geographic characteristics. A broader dataset might provide more generalizable results.
- Since the baseline participants of the Tlalpan 2020 cohort were younger than 50 years of age, the potential protective effect of uric acid observed in elderly populations (the uric acid paradox) might not be evident. Additionally, the non-linear relationship between uric acid and mortality within the 200–300 μmol/L range suggests that small variations in uric acid levels could have different health implications depending on the age and metabolic context of the population. This age-related effect should be considered when interpreting the predictive modeling outcomes, as the relationships observed in younger adults may not extrapolate directly to older populations.
- Potential bias in self-reported data: some data, such as lifestyle habits and nutritional intake from the food frequency questionnaire, are self-reported, which can introduce recall bias or under-reporting.
- Limited long-term data: This study focused on a snapshot of uric acid levels rather than on long-term changes. Uric acid concentrations can fluctuate daily and seasonally due to physiological and environmental factors; however, these variations were not captured in our cross-sectional analysis using baseline data. Additionally, individuals with a genetic predisposition to hyperuricemia might experience different fluctuation patterns, but this aspect was not assessed in our dataset.
- Limited exploration of confounding factors: while gender and lifestyle factors were considered, other confounders, such as genetic predispositions or concurrent medication use, might also impact uric acid levels and should be more thoroughly explored.
- Algorithm-specific limitations: Each machine learning algorithm has its limitations in terms of predictive accuracy and interpretability. For instance, models like CatBoost and XGBoost are powerful but complex, making it harder to interpret the relationships between features and outcomes. These limitations may hinder the clinical applicability of the findings.
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- INEGI. Estadística de Defunciones Registradas de Enero a Junio de 2021; INEGI: Aguascalientes, Mexico, 2022.
- American College of Cardiology. Advancing Cardiovascular Health in Mexico: Roundtable Report; American College of Cardiology: Washington, DC, USA, 2022. [Google Scholar]
- Brikman, S.; Serfaty, L.; Abuhasira, R.; Schlesinger, N.; Bieber, A.; Rappoport, N. A machine learning-based prediction model for gout in hyperuricemics: A nationwide cohort study. Rheumatology 2024, 63, 2411–2417. [Google Scholar] [CrossRef] [PubMed]
- Nayan, N.A.; Ab Hamid, H.; Suboh, M.Z.; Aminaldin, N.M.; Azizul, N.I.M.; Nizar, M.N.M. Machine learning application for classifying serum uric acid level with photoplethysmogram. In Proceedings of the 2020 IEEE-EMBS Conference on Biomedical Engineering and Sciences (IECBES), Langkawi Island, Malaysia, 1–3 March 2021; pp. 522–527. [Google Scholar]
- Lee, S.; Choe, E.K.; Park, B. Exploration of machine learning for hyperuricemia prediction models based on basic health checkup tests. J. Clin. Med. 2019, 8, 172. [Google Scholar] [CrossRef]
- Zeng, L.; Ma, P.; Li, Z.; Liang, S.; Wu, C.; Hong, C.; Li, Y.; Cui, H.; Li, R.; Wang, J.; et al. Multimodal Machine Learning-Based Marker Enables Early Detection and Prognosis Prediction for Hyperuricemia. Adv. Sci. 2024, 11, 2404047. [Google Scholar] [CrossRef]
- Sampa, M.B.; Hossain, M.N.; Hoque, M.R.; Islam, R.; Yokota, F.; Nishikitani, M.; Ahmed, A. Blood uric acid prediction with machine learning: Model development and performance comparison. JMIR Med. Inform. 2020, 8, e18331. [Google Scholar] [CrossRef] [PubMed]
- Gao, Y.; Jia, S.; Huang, C.; Meng, Z.; Yu, M.; Xu, T.; Liu, M.; Sun, J.; Jia, Q.; Zhang, Q.; et al. Risk factors of hyperuricemia calculated by random forest machine learning. Res. Sq. 2020, 1–20. [Google Scholar]
- Shi, J.C.; Chen, X.H.; Yang, Q.; Wang, C.M.; Huang, Q.; Shen, Y.M.; Yu, J. A simple prediction model of hyperuricemia for use in a rural setting. Sci. Rep. 2021, 11, 23300. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, L.; Lv, H.; Zhang, G. Ensemble machine learning prediction of hyperuricemia based on a prospective health checkup population. Front. Physiol. 2024, 15, 1357404. [Google Scholar] [CrossRef]
- Colín-Ramírez, E.; Rivera-Mancía, S.; Infante-Vázquez, O.; Cartas-Rosado, R.; Vargas-Barrón, J.; Madero, M.; Vallejo, M. Protocol for a prospective longitudinal study of risk factors for hypertension incidence in a Mexico City population: The Tlalpan 2020 cohort. BMJ Open 2017, 7, e016773. [Google Scholar] [CrossRef]
- Stewart, A.L.; Ware, J.E. Measuring Functioning and Well-Being: The Medical Outcomes Study Approach; Duke University Press: Durham, NC, USA, 1992. [Google Scholar]
- Chobanian, A.V.; Bakris, G.L.; Black, H.R.; Cushman, W.C.; Green, L.A.; Izzo Jr, J.L.; Jones, D.W.; Materson, B.J.; Oparil, S.; Wright Jr, J.T.; et al. Seventh report of the joint national committee on prevention, detection, evaluation, and treatment of high blood pressure. Hypertension 2003, 42, 1206–1252. [Google Scholar] [CrossRef]
- Marfell-Jones, M.J.; Stewart, A.; De Ridder, J. International Standards for Anthropometric Assessment. 2012. Available online: https://www.researchgate.net/publication/236891109_International_Standards_for_Anthropometric_Assessment (accessed on 10 February 2025).
- Craig, C.L.; Marshall, A.L.; Sjöström, M.; Bauman, A.E.; Booth, M.L.; Ainsworth, B.E.; Pratt, M.; Ekelund, U.; Yngve, A.; Sallis, J.F.; et al. International physical activity questionnaire: 12-country reliability and validity. Med. Sci. Sport. Exerc. 2003, 35, 1381–1395. [Google Scholar] [CrossRef]
- Hernández-Avila, J.; González-Avilés, L.; Rosales-Mendoza, E. Manual de Usuario. SNUT Sistema de Evaluación de Hábitos Nutricionales y Consumo de Nutrimentos; Instituto Nacional de Salud Pública: Cuernavaca, Mexico, 2003. [Google Scholar]
- Chen, T.; He, T.; Benesty, M.; Khotilovich, V.; Tang, Y.; Cho, H.; Chen, K.; Mitchell, R.; Cano, I.; Zhou, T.; et al. Xgboost: Extreme Gradient Boosting. R Package Version 0.4-2. 2015, pp. 1–4. Available online: https://cran.ms.unimelb.edu.au/web/packages/xgboost/vignettes/xgboost.pdf (accessed on 10 February 2025).
- Freund, Y.; Schapire, R.E. Experiments with a new boosting algorithm. In Proceedings of the 13th International Conference on Machine Learning (ICML), Bari, Italy, 3–6 July 1996; Volume 96, pp. 148–156. [Google Scholar]
- Schapire, R.E.; Singer, Y. Improved boosting algorithms using confidence-rated predictions. In Proceedings of the Eleventh Annual Conference on Computational Learning Theory, Madison, WI, USA, 24–26 July 1998; pp. 80–91. [Google Scholar]
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. CatBoost: Unbiased boosting with categorical features. In Proceedings of the NeurIPS 2018, Montreal, QC, Canada, 2–8 December 2018; Volume 31. [Google Scholar]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. In Proceedings of the NeurIPS 2018, Long Beach, CA, USA., 4–9 December 2017; Volume 30. [Google Scholar]
- Shaon, M.S.H.; Karim, T.; Shakil, M.S.; Hasan, M.Z. A Comparative Study of Machine Learning Models with LASSO and SHAP Feature Selection for Breast Cancer Prediction. Healthc. Anal. 2024, 6, 100353. [Google Scholar] [CrossRef]
- Gómez, O.V.; Herraiz, J.L.; Udías, J.M.; Haug, A.; Papp, L.; Cioni, D.; Neri, E. Analysis of cross-combinations of feature selection and machine-learning classification methods based on [18F] F-FDG PET/CT radiomic features for metabolic response prediction of metastatic breast cancer lesions. Cancers 2022, 14, 2922. [Google Scholar] [CrossRef] [PubMed]
- Kramer, O.; Kramer, O. Scikit-learn. In Machine Learning for Evolution Strategies; O’Reilly Media: Sebastopol, CA, USA, 2016; pp. 45–53. [Google Scholar]
- Meneses-León, J.; León-Maldonado, L.; Macías, N.; Torres-Ibarra, L.; Hernández-López, R.; Rivera-Paredez, B.; Flores, M.; Flores, Y.N.; Barrientos-Gutiérrez, T.; Quezada-Sánchez, A.D.; et al. Sugar-sweetened beverage consumption and risk of hyperuricemia: A longitudinal analysis of the Health Workers Cohort Study participants in Mexico. Am. J. Clin. Nutr. 2020, 112, 652–660. [Google Scholar] [CrossRef] [PubMed]
- Büsing, F.; Hägele, F.A.; Nas, A.; Döbert, L.V.; Fricker, A.; Dörner, E.; Podlesny, D.; Aschoff, J.; Pöhnl, T.; Schweiggert, R.; et al. High intake of orange juice and cola differently affects metabolic risk in healthy subjects. Clin. Nutr. 2019, 38, 812–819. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, S.; Yuan, M.; Xu, Y.; Xu, H. Gout and diet: A comprehensive review of mechanisms and management. Nutrients 2022, 14, 3525. [Google Scholar] [CrossRef]
- Yustisia, I.; Tandiari, D.; Cangara, M.H.; Hamid, F.; Nu’man, A. A high-fat, high-fructose diet induced hepatic steatosis, renal lesions, dyslipidemia, and hyperuricemia in non-obese rats. Heliyon 2022, 8, e10896. [Google Scholar] [CrossRef]
- Zhang, C.; Li, L.; Zhang, Y.; Zeng, C. Recent advances in fructose intake and risk of hyperuricemia. Biomed. Pharmacother. 2020, 131, 110795. [Google Scholar] [CrossRef]
- Jamnik, J.; Rehman, S.; Mejia, S.B.; de Souza, R.J.; Khan, T.A.; Leiter, L.A.; Wolever, T.M.; Kendall, C.W.; Jenkins, D.J.; Sievenpiper, J.L. Fructose intake and risk of gout and hyperuricemia: A systematic review and meta-analysis of prospective cohort studies. BMJ Open 2016, 6, e013191. [Google Scholar] [CrossRef]
- Ebrahimpour-Koujan, S.; Saneei, P.; Larijani, B.; Esmaillzadeh, A. Consumption of sugar sweetened beverages and dietary fructose in relation to risk of gout and hyperuricemia: A systematic review and meta-analysis. Crit. Rev. Food Sci. Nutr. 2020, 60, 1–10. [Google Scholar] [CrossRef]
- World Health Organization. Guideline: Sugars Intake for Adults and Children; World Health Organization: Geneva, Switzerland, 2015. [Google Scholar]
- Liu, X.Y.; Wu, Q.Y.; Chen, Z.H.; Yan, G.Y.; Lu, Y.; Dai, H.J.; Li, Y.; Yang, P.T.; Yuan, H. Elevated triglyceride to high-density lipoprotein cholesterol (TG/HDL-C) ratio increased risk of hyperuricemia: A 4-year cohort study in China. Endocrine 2020, 68, 71–80. [Google Scholar] [CrossRef]
- Wang, Z.; Wu, M.; Yan, H.; Zhong, S.; Xu, R.; Zhao, Z.; Yang, Q. Association between Remnant Cholesterol and risk of Hyperuricemia: A cross-sectional study. Horm. Metab. Res. 2024, 56, 882–889. [Google Scholar] [CrossRef] [PubMed]
- Juraschek, S.P.; McAdams-Demarco, M.; Gelber, A.C.; Sacks, F.M.; Appel, L.J.; White, K.J.; Miller, E.R., III. Effects of lowering glycemic index of dietary carbohydrate on plasma uric acid levels: The OmniCarb randomized clinical trial. Arthritis Rheumatol. 2016, 68, 1281–1289. [Google Scholar] [CrossRef] [PubMed]
- Zhang, T.; Bian, S.; Gu, Y.; Meng, G.; Zhang, Q.; Liu, L.; Wu, H.; Zhang, S.; Wang, Y.; Wang, X.; et al. Sugar-containing carbonated beverages consumption is associated with hyperuricemia in general adults: A cross-sectional study. Nutr. Metab. Cardiovasc. Dis. 2020, 30, 1645–1652. [Google Scholar] [CrossRef] [PubMed]
- Lubawy, M.; Formanowicz, D. High-fructose diet–induced hyperuricemia accompanying metabolic syndrome–mechanisms and dietary therapy proposals. Int. J. Environ. Res. Public Health 2023, 20, 3596. [Google Scholar] [CrossRef]
- Dearden, L.; Bouret, S.G.; Ozanne, S.E. Sex and gender differences in developmental programming of metabolism. Mol. Metab. 2018, 15, 8–19. [Google Scholar] [CrossRef]
- Zhang, L.; Shi, X.; Yu, J.; Zhang, P.; Ma, P.; Sun, Y. Dietary vitamin E intake was inversely associated with hyperuricemia in US adults: NHANES 2009–2014. Ann. Nutr. Metab. 2021, 76, 354–360. [Google Scholar] [CrossRef]
- Roumeliotis, S.; Roumeliotis, A.; Dounousi, E.; Eleftheriadis, T.; Liakopoulos, V. Dietary antioxidant supplements and uric acid in chronic kidney disease: A review. Nutrients 2019, 11, 1911. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Boosted DTR | CatBoost | SHAP | XGBoost | ||||
|---|---|---|---|---|---|---|---|
| Feature | Importance | Feature | Importance | Feature | MASV | Feature | MASV |
| Body Mass Index | 0.0375 | Triglycerides | 7.2254 | Creatinine | 0.0138 | Mother with diabetes | 0.0073 |
| Triglycerides | 0.0214 | Body Mass Index | 6.8841 | Body Mass Index | 0.0125 | Passive smoker | 0.0045 |
| Weight | 0.0198 | Creatinine | 6.6062 | Triglycerides | 0.0109 | BB4K | 0.0044 |
| HDL-cholesterol | 0.0140 | Atherogenic index | 5.4440 | Atherogenic index | 0.0093 | Snoring | 0.0040 |
| Glucose | 0.0139 | Urinary sodium | 4.9646 | Glucose | 0.0088 | Triglycerides | 0.0038 |
| Creatinine | 0.0137 | Glucose | 4.5729 | Urinary sodium | 0.0077 | Menstrual cycle | 0.0036 |
| Atherogenic index | 0.0135 | Age | 4.3607 | Weight | 0.0065 | Smoke | 0.0033 |
| MGMD | 0.0126 | Weight | 3.3334 | Age | 0.0064 | Father with gout | 0.0031 |
| Waist circumference | 0.0120 | Waist circumference | 2.9811 | Iron | 0.0038 | ISSSTE | 0.0030 |
| Iron | 0.0102 | Total cholesterol | 1.7219 | Waist circumference | 0.0033 | Father with hypertension | 0.0028 |
| Urinary sodium | 0.0100 | Respiratory rate | 1.4676 | Heart rate | 0.0026 | Father with diabetes | 0.0028 |
| Father with gout | 0.0100 | Heart rate | 1.3924 | Mother with diabetes | 0.0024 | Mother with dyslipidemia | 0.0027 |
| Pregnancies | 0.0093 | Serum sodium | 1.3627 | Pregnancies | 0.0023 | Very low physical activity | 0.0025 |
| BB4K | 0.0091 | Height | 1.2105 | Urine potassium | 0.0022 | Skilled worker | 0.0024 |
| Father with obesity | 0.0091 | Mother with diabetes | 1.1261 | Complications in childbirth | 0.0021 | Mother with hypertension | 0.0023 |
| Model | Parameters | Method | MSE | RMSE | |
|---|---|---|---|---|---|
| CatBoost | depth: 6 iterations: 300, l2_leaf_reg: 5 learning_rate: 0.05 | Importance | 0.0063 | 0.0793 | 0.2315 |
| DTR | learning_rate: 0.01, max_depth: 4, n_estimators: 300, subsample: 0.8 | Importance | 0.0087 | 0.0930 | 0.2768 |
| SHAP | alpha: 1, colsample_bytree: 0.3, learning_rate: 0.1, max_depth: 5, n_estimators: 100 | SHAP | 0.0068 | 0.0824 | 0.1688 |
| XGBoost | alpha: 1, colsample_bytree: 0.3, learning_rate: 0.1, max_depth: 5, n_estimators: 100 | MeanAbsShapValue | 0.0079 | 0.0890 | 0.3170 |
| BOOSTED DTR | CATBOOST | SHAP | XGBoost | ||||
|---|---|---|---|---|---|---|---|
| Feature | Importance | Feature | Importance | Feature | MASV | Feature | MASV |
| Body Mass Index | 0.0330 | Creatinine | 8.6576 | Body Mass Index | 0.0181 | Father with diabetes | 0.0103 |
| Waist circumference | 0.0193 | Body Mass Index | 5.9170 | Creatinine | 0.0169 | Passive smoker | 0.0097 |
| Creatinine | 0.0173 | Atherogenic index | 4.1839 | Atherogenic index | 0.0106 | Father with gout | 0.0077 |
| Daily smoker | 0.0159 | Triglycerides | 3.8335 | Triglycerides | 0.0102 | Mother with diabetes | 0.0066 |
| Atherogenic index | 0.0158 | Urinary sodium | 3.4797 | Weight | 0.0074 | IMSS | 0.0055 |
| MGFHA | 0.0136 | Waist circumference | 3.2791 | Urinary sodium | 0.0068 | Whiskey | 0.0049 |
| Currently smokes | 0.0132 | Age | 2.6792 | Age | 0.0063 | High cholesterol | 0.0048 |
| Triglycerides | 0.0131 | HDL-Cholesterol | 2.3282 | Father with diabetes | 0.0062 | Cognac | 0.0044 |
| Drunk | 0.0131 | Urine potassium | 2.1635 | Iron | 0.0052 | Father with obesity | 0.0038 |
| Father with gout | 0.0120 | Weight | 1.8986 | Passive smoker | 0.0049 | Use of electric vehicle | 0.0036 |
| Father with diabetes | 0.0117 | Height | 1.8661 | Waist circumference | 0.0047 | Biparental family | 0.0033 |
| Passive smoker | 0.0110 | LDL-Cholesterol | 1.8497 | Urine potassium | 0.0045 | PGMD | 0.0032 |
| Whiskey | 0.0109 | Total cholesterol | 1.7534 | Height | 0.0042 | MGMD | 0.0032 |
| Prof | 0.0106 | Pulse pressure | 1.7148 | IMSS | 0.0034 | Drunk | 0.0031 |
| Model | Parameters | Method | MSE | RMSE | |
|---|---|---|---|---|---|
| CatBoost | depth: 6, iterations: 500, l2_leaf_reg: 1, learning_rate: 0.05 | Importance | 0.0115 | 0.1074 | 0.1687 |
| DTR | learning_rate: 0.01, max_depth: 4, n_estimators: 300, subsample: 0.8 | Importance | 0.0111 | 0.1054 | 0.1994 |
| SHAP | learning_rate: 0.1, max_depth: 3, n_estimators: 100 | SHAP | 0.0111 | 0.1054 | 0.1987 |
| XGBoost | alpha: 1, colsample_bytree: 0.3, learning_rate: 0.1, max_depth: 5, n_estimators: 100 | MeanAbsShapValue | 0.0137 | 0.1072 | 0.1996 |
| Boosted DTR | CatBoost | SHAP | |||
|---|---|---|---|---|---|
| Feature | Importance | Feature | Importance | Feature | MASV |
| A medium cola soda | 0.0239 | A medium cola soda | 6.9284 | A medium cola soda | 0.0110 |
| Corn | 0.0135 | A corn tortilla | 2.2745 | A banana | 0.0030 |
| Safflower oil | 0.0134 | A banana | 2.1508 | A cup of atole with milk | 0.0025 |
| A teaspoon of margarine | 0.0130 | A portion of pork | 2.0625 | A teaspoon of margarine | 0.0025 |
| Corn oil | 0.0128 | A teaspoon of chocolate powder | 1.7368 | A portion of pork | 0.0023 |
| A tamale | 0.0127 | A liver steak or chicken liver | 1.4353 | A piece of chorizo or sausage | 0.0022 |
| A teaspoon of honey, jam or caramel | 0.0125 | A cup of atole with milk | 1.4117 | Chicken egg | 0.0022 |
| A teaspoon of chocolate powder | 0.0122 | A bowl of oatmeal | 1.3965 | A piece of sweet bread | 0.0020 |
| A portion of pork | 0.0121 | A bowl of sardines in tomato sauce | 1.2908 | A cup of beans | 0.0019 |
| A banana | 0.0118 | A cup of coffee without sugar | 1.2908 | Half a cup of seafood | 0.0018 |
| A bowl of oatmeal | 0.0117 | Olive oil | 1.2625 | Corn | 0.0017 |
| A cup of atole with milk | 0.0117 | A slice of white bread | 1.2612 | A liver steak or chicken liver | 0.0017 |
| A piece of chorizo or sausage | 0.0115 | Chicken egg | 1.2538 | Safflower oil | 0.0016 |
| A portion of carnitas | 0.0115 | Wheat tortilla | 1.2270 | Pork skin | 0.0016 |
| A teaspoon of vegetable shortening | 0.0115 | A fresh apple | 1.2131 | a teaspoon of chocolate powder | 0.0014 |
| Model | Parameters | Method | MSE | RMSE | |
|---|---|---|---|---|---|
| CatBoost | depth: 10, iterations: 500, l2_leaf_reg: 3, learning_rate: 0.01 | Importance | 0.0129 | 0.1135 | 0.0714 |
| Boosted_DTR | learning_rate: 0.05, max_depth: 3, n_estimators: 200, subsample: 0.8 | Importance | 0.0128 | 0.1133 | 0.0739 |
| SHAP | alpha: 1, colsample_bytree: 0.7, learning_rate: 0.01, max_depth: 5, n_estimators: 200 | SHAP | 0.0129 | 0.1136 | 0.0702 |
| Model | Parameters | Method | MSE | RMSE | |
|---|---|---|---|---|---|
| CatBoost | depth: 10, iterations: 300, l2_leaf_reg: 1, learning_rate: 0.05 | Importance | 0.0111 | 0.1052 | 0.0763 |
| DTR | learning_rate: 0.05, max_depth: 5, n_estimators: 100, subsample: 0.8 | Importance | 0.0111 | 0.1051 | 0.0767 |
| SHAP | alpha: 1, colsample_bytree: 0.3, learning_rate: 0.1, max_depth: 20, n_estimators: 200 | SHAP | 0.0083 | 0.0913 | 0.0187 |
| Women | Men | ||||||
|---|---|---|---|---|---|---|---|
| CatBoost | SHAP | CatBoost | SHAP | ||||
| Feature | Importance | Feature | MASV | Feature | Importance | Feature | MASV |
| Glucose | 3.0789 | Glucose | 0.0050 | Fructose | 2.4942 | Fructose | 0.0044 |
| Carbohydrates | 2.8389 | Starch | 0.0033 | Maltose | 2.3573 | Cholesterol | 0.0039 |
| Alcohol | 2.1420 | Alcohol | 0.0032 | Glucose | 2.3070 | Glucose | 0.0038 |
| Fructose | 1.9236 | Fructose | 0.0030 | Carbohydrates | 1.9796 | Maltose | 0.0037 |
| Maltose | 1.9102 | Beta cryptoxanthin | 0.0030 | Lactose | 1.9027 | Carbohydrates | 0.0036 |
| Cholesterol | 1.8989 | Alcohol | 1.8901 | Maltose | 0.0034 | ||
| Beta cryptoxanthin | 0.0020 | ||||||
| Sex | Model | Parameters | Method | MSE | RMSE | |
|---|---|---|---|---|---|---|
| Men | CatBoost | depth: 10, iterations: 300, l2_leaf_reg: 1, learning_rate: 0.01 | Importance | 0.0130 | 0.1139 | 0.0654 |
| Men | SHAP | alpha: 1, colsample_bytree: 0.7, learning_rate: 0.01, max_depth: 10, n_estimators: 200 | SHAP | 0.0135 | 0.1160 | 0.1345 |
| Women | CatBoost | depth: 10, iterations: 500, l2_leaf_reg: 1, learning_rate’: 0.01 | Importance | 0.0106 | 0.1030 | 0.1139 |
| Women | SHAP | alpha: 1, colsample_bytree: 0.3, learning_rate: 0.01, max_depth: 10, n_estimators: 500 | SHAP | 0.0077 | 0.0880 | 0.0523 |
| Group | Sex | Parameters | MSE | RMSE | |
|---|---|---|---|---|---|
| Women | colsample_bytree: 0.9, learning_rate: 0.05, max_depth: 5, n_estimators: 50, subsample: 0.8 | 0.0034 | 0.0582 | 0.5857 | |
| Clinical, anthropometric and lifestyle | Men | colsample_bytree: 0.8, learning_rate: 0.05, max_depth: 3, n_estimators: 50, subsample: 0.8 | 0.0093 | 0.0964 | 0.3302 |
| Women | colsample_bytree: 0.9, learning_rate: 0.05, max_depth: 3, n_estimators: 100, subsample: 1.0 | 0.0091 | 0.0951 | 0.2431 | |
| Food frequency questionnaire | Men | colsample_bytree: 0.8, learning_rate: 0.01, max_depth: 5, n_estimators: 150, subsample: 0.9 | 0.0099 | 0.0995 | 0.2865 |
| Women | colsample_bytree: 0.8, learning_rate: 0.05, max_depth: 7, n_estimators: 50, subsample: 0.9 | 0.0039 | 0.0627 | 0.519 | |
| Nutritional and biochemical | Men | colsample_bytree: 0.8, learning_rate: 0.05, max_depth: 7, n_estimators: 50, subsample: 0.9 | 0.0096 | 0.0979 | 0.3098 |
| Boosted DTR | CatBoost | SHAP | |||
|---|---|---|---|---|---|
| Feature | Importance | Feature | Importance | Feature | MASV |
| A medium cola soda | 0.0292 | A medium cola soda | 6.0152 | A drink (rum, brandy, or tequila) | 0.0078 |
| A teaspoon of butter | 0.0170 | A portion of carnitas | 2.8352 | A medium cola soda | 0.0065 |
| A drink (rum, brandy, or tequila) | 0.0165 | A glass of sugary flavored water | 2.0415 | A bowl with rice | 0.0039 |
| A teaspoon of hot sauce or chili | 0.0150 | A cup of coffee without sugar | 1.9075 | Safflower oil | 0.0034 |
| A portion of carnitas | 0.0141 | A teaspoon of margarine | 1.8767 | A glass of sugary flavored water | 0.0033 |
| Pork skin | 0.0136 | A glass of whole milk | 1.7528 | Wheat tortilla | 0.0032 |
| A glass of sugary flavored water | 0.0135 | A cup of yogurt or Bulgarian yogurt | 1.7215 | A corn | 0.0032 |
| A corn tortilla | 0.0134 | Soy Oil | 1.6787 | A portion of carnitas | 0.0029 |
| A taco with al pastor meat | 0.0132 | A portion of dried beans | 1.6536 | A beer | 0.0029 |
| Corn oil | 0.0132 | A taco with al pastor meat | 1.6423 | A teaspoon of honey, jam or caramel | 0.0027 |
| A bowl of pasta soup | 0.0130 | A corn tortilla | 1.6204 | A cup of yogurt or Bulgarian yogurt | 0.0025 |
| Half a cup of seafood | 0.0129 | Olive oil | 1.6147 | A orange | 0.0025 |
| Half a cup of peas | 0.0128 | A cup of beans | 1.5657 | A portion of grapes | 0.0025 |
| A bowl of oatmeal | 0.0128 | Half a cup of peas | 1.4594 | A slice of papaya | 0.0025 |
| A sapote | 0.0126 | A slice of papaya | 1.3905 | A bowl of cream of vegetable soup | 0.0023 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gutiérrez-Esparza, G.; Martínez-García, M.; Márquez-Murillo, M.F.; Brianza-Padilla, M.; Hernández-Lemus, E.; Amezcua-Guerra, L.M. Tlalpan 2020 Case Study: Enhancing Uric Acid Level Prediction with Machine Learning Regression and Cross-Feature Selection. Nutrients 2025, 17, 1052. https://doi.org/10.3390/nu17061052
Gutiérrez-Esparza G, Martínez-García M, Márquez-Murillo MF, Brianza-Padilla M, Hernández-Lemus E, Amezcua-Guerra LM. Tlalpan 2020 Case Study: Enhancing Uric Acid Level Prediction with Machine Learning Regression and Cross-Feature Selection. Nutrients. 2025; 17(6):1052. https://doi.org/10.3390/nu17061052
Chicago/Turabian StyleGutiérrez-Esparza, Guadalupe, Mireya Martínez-García, Manlio F. Márquez-Murillo, Malinalli Brianza-Padilla, Enrique Hernández-Lemus, and Luis M. Amezcua-Guerra. 2025. "Tlalpan 2020 Case Study: Enhancing Uric Acid Level Prediction with Machine Learning Regression and Cross-Feature Selection" Nutrients 17, no. 6: 1052. https://doi.org/10.3390/nu17061052
APA StyleGutiérrez-Esparza, G., Martínez-García, M., Márquez-Murillo, M. F., Brianza-Padilla, M., Hernández-Lemus, E., & Amezcua-Guerra, L. M. (2025). Tlalpan 2020 Case Study: Enhancing Uric Acid Level Prediction with Machine Learning Regression and Cross-Feature Selection. Nutrients, 17(6), 1052. https://doi.org/10.3390/nu17061052