
A Central Asian Food Dataset for Personalized Dietary Interventions


Highlights
- The Central Asian Food Dataset (CAFD) was created with 42 food categories and over 16,000 images of national dishes unique to Central Asia.
- Using the CAFD, a ResNet152 neural network model achieved a classification accuracy of 88.70% for these 42 food classes.
- This dataset contributes to the food computing domain by enabling food recognition specific to Central Asian cuisine, addressing a regional data gap and potentially helping to develop personalized dietary tools, with possible positive impacts on agriculture, the environment, and the food systems in this region.
Abstract
1. Introduction
2. Central Asian Food Dataset
3. Food Recognition Models
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | artificial intelligence |
| CAFD | Central Asian Food Dataset |
| CNN | convolutional neural network |
| CV | computer vision |
| ICCV | International Conference on Computer Vision |
| ML | machine learning |
| ResNet | residual network |
References
- Dai, X.; Shen, L. Advances and Trends in Omics Technology Development. Front. Med. 2022, 9, 911861. [Google Scholar] [CrossRef]
- Ahmed, S.; de la Parra, J.; Elouafi, I.; German, B.; Jarvis, A.; Lal, V.; Lartey, A.; Longvah, T.; Malpica, C.; Vázquez-Manjarrez, N.; et al. Foodomics: A Data-Driven Approach to Revolutionize Nutrition and Sustainable Diets. Front. Nutr. 2022, 9, 874312. [Google Scholar] [CrossRef] [PubMed]
- Kato, H.; Takahashi, S.; Saito, K. Omics and Integrated Omics for the Promotion of Food and Nutrition Science. J. Tradit. Complement. Med. 2011, 1, 25–30. [Google Scholar] [CrossRef]
- Ortea, I. Foodomics in health: Advanced techniques for studying the bioactive role of foods. TrAC Trends Anal. Chem. 2022, 150, 116589. [Google Scholar] [CrossRef]
- Bedoya, M.G.; Montoya, D.R.; Tabilo-Munizaga, G.; Pérez-Won, M.; Lemus-Mondaca, R. Promising perspectives on novel protein food sources combining artificial intelligence and 3D food printing for food industry. Trends Food Sci. Technol. 2022, 128, 38–52. [Google Scholar] [CrossRef]
- van Erp, M.; Reynolds, C.; Maynard, D.; Starke, A.; Martín, R.I.; Andres, F.; Leite, M.C.A.; de Toledo, D.A.; Rivera, X.S.; Trattner, C.; et al. Using Natural Language Processing and Artificial Intelligence to Explore the Nutrition and Sustainability of Recipes and Food. Front. Artif. Intell. 2021, 3, 621577. [Google Scholar] [CrossRef] [PubMed]
- Khorraminezhad, L.; Leclercq, M.; Droit, A.; Bilodeau, J.F.; Rudkowska, I. Statistical and Machine-Learning Analyses in Nutritional Genomics Studies. Nutrients 2020, 12, 3140. [Google Scholar] [CrossRef]
- Allegra, D.; Battiato, S.; Ortis, A.; Urso, S.; Polosa, R. A review on food recognition technology for health applications. Health Psychol. Res. 2020, 8, 9297. [Google Scholar] [CrossRef]
- Herzig, D.; Nakas, C.T.; Stalder, J.; Kosinski, C.; Laesser, C.; Dehais, J.; Jaeggi, R.; Leichtle, A.B.; Dahlweid, F.M.; Stettler, C.; et al. Volumetric Food Quantification Using Computer Vision on a Depth-Sensing Smartphone: Preclinical Study. JMIR mHealth uHealth 2020, 8, e15294. [Google Scholar] [CrossRef]
- Sahoo, D.; Hao, W.; Ke, S.; Xiongwei, W.; Le, H.; Achananuparp, P.; Lim, E.P.; Hoi, S.C.H. FoodAI. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019. [Google Scholar] [CrossRef]
- Bossard, L.; Guillaumin, M.; Gool, L.V. Food-101—Mining Discriminative Components with Random Forests. In Computer Vision—ECCV 2014, Proceedings of the 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Springer International Publishing: Berlin/Heidelberg, Germany, 2014; pp. 446–461. [Google Scholar] [CrossRef]
- Ciocca, G.; Napoletano, P.; Schettini, R. CNN-based features for retrieval and classification of food images. Comput. Vis. Image Underst. 2018, 176, 70–77. [Google Scholar] [CrossRef]
- Wang, X.; Kumar, D.; Thome, N.; Cord, M.; Precioso, F. Recipe recognition with large multimodal food dataset. In Proceedings of the 2015 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Torino, Italy, 29 June–3 July 2015; IEEE: Piscataway, NJ, USA, 2015. [Google Scholar] [CrossRef]
- Chen, J.; Wah Ngo, C. Deep-based Ingredient Recognition for Cooking Recipe Retrieval. In Proceedings of the 24th ACM international conference on Multimedia, ACM. Amsterdam, The Netherlands, 15–19 October 2016. [Google Scholar] [CrossRef]
- Chen, J.; Zhu, B.; Ngo, C.W.; Chua, T.S.; Jiang, Y.G. A Study of Multi-Task and Region-Wise Deep Learning for Food Ingredient Recognition. IEEE Trans. Image Process. 2021, 30, 1514–1526. [Google Scholar] [CrossRef] [PubMed]
- Min, W.; Liu, L.; Wang, Z.; Luo, Z.; Wei, X.; Wei, X.; Jiang, S. ISIA Food-500: A Dataset for Large-Scale Food Recognition via Stacked Global-Local Attention Network. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020. [Google Scholar]
- Min, W.; Wang, Z.; Liu, Y.; Luo, M.; Kang, L.; Wei, X.; Wei, X.; Jiang, S. Large Scale Visual Food Recognition. arXiv 2021, arXiv:2103.16107. [Google Scholar] [CrossRef]
- Güngör, C.; Fatih, B.; Aykut, E.; Erkut, E. Turkish cuisine: A benchmark dataset with Turkish meals for food recognition. In Proceedings of the 2017 25th Signal Processing and Communications Applications Conference (SIU), Antalya, Turkey, 15–18 May 2017; Institute of Electrical and Electronics Engineering: Antalya, Turkey, 2017; pp. 1–4. [Google Scholar] [CrossRef]
- Aktı, Ş.; Qaraqe, M.; Ekenel, H.K. A Mobile Food Recognition System for Dietary Assessment. In Proceedings of the Image Analysis and Processing, ICIAP 2022 Workshops, Lecce, Italy, 23–27 May 2020; Mazzeo, P.L., Frontoni, E., Sclaroff, S., Distante, C., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2022; pp. 71–81. [Google Scholar]
- Shen, Z.; Shehzad, A.; Chen, S.; Sun, H.; Liu, J. Machine Learning Based Approach on Food Recognition and Nutrition Estimation. Procedia Comput. Sci. 2020, 174, 448–453. [Google Scholar] [CrossRef]
- Mohanty, S.P.; Singhal, G.; Scuccimarra, E.A.; Kebaili, D.; Héritier, H.; Boulanger, V.; Salathé, M. The Food Recognition Benchmark: Using DeepLearning to Recognize Food on Images. arXiv 2021, arXiv:2106.14977. [Google Scholar] [CrossRef] [PubMed]
- WRO. Prevention and Control of Non-Communicable Disease in Kazakhstan—The Case for Investment; WHO: Geneva, Switzerland, 2019. [Google Scholar]
- Afshin, A.; Sur, P.J.; Fay, K.A.; Cornaby, L.; Ferrara, G.; Salama, J.S.; Mullany, E.C.; Abate, K.H.; Abbafati, C.; Abebe, Z.; et al. Health effects of dietary risks in 195 countries, 1990–2017: A systematic analysis for the Global Burden of Disease Study 2017. Lancet 2019, 393, 1958–1972. [Google Scholar] [CrossRef]
- Nations, U. The Sustainable Development Goals in Kazakhstan. 2023. Available online: https://kazakhstan.un.org/en/sdgs (accessed on 25 November 2022).
- Roboflow. Roboflow: Give Your Software the Sense of Sight. 2022. Available online: https://roboflow.com/ (accessed on 25 November 2022).
- Torrey, L.; Shavlik, J. Transfer learning. In Handbook of Research on Machine Learning Applications and Trends: Algorithms, Methods, and Techniques; IGI Global: Hershey, PA, USA, 2010; pp. 242–264. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar] [CrossRef]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and 0.5MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), IEEE. Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar] [CrossRef]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. arXiv 2016, arXiv:1611.05431. [Google Scholar] [CrossRef]
- Zagoruyko, S.; Komodakis, N. Wide Residual Networks. arXiv 2016, arXiv:1605.07146. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. arXiv 2016, arXiv:1608.06993. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. arXiv 2019, arXiv:1905.11946. [Google Scholar] [CrossRef]





{kind=link}
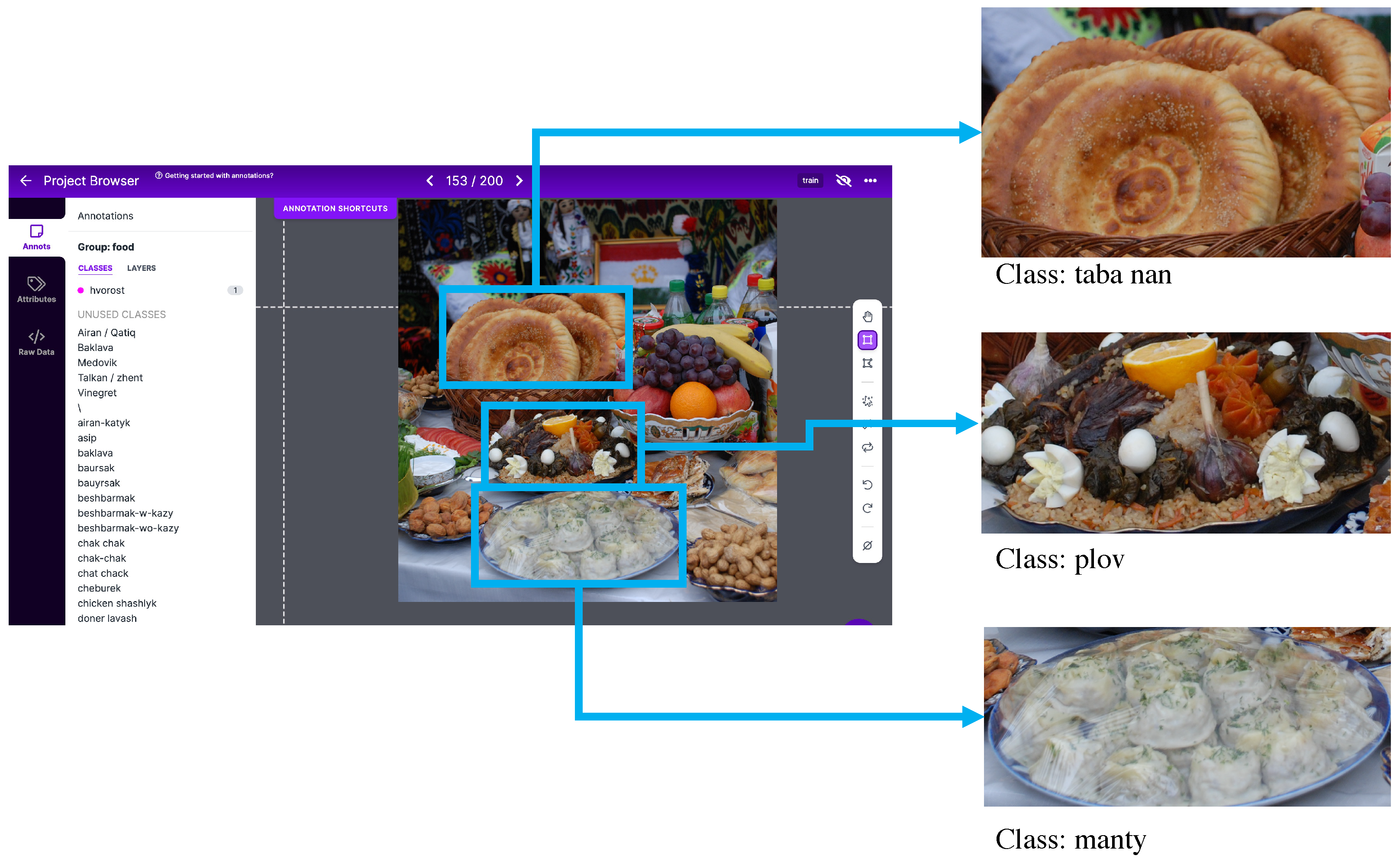{kind=link}
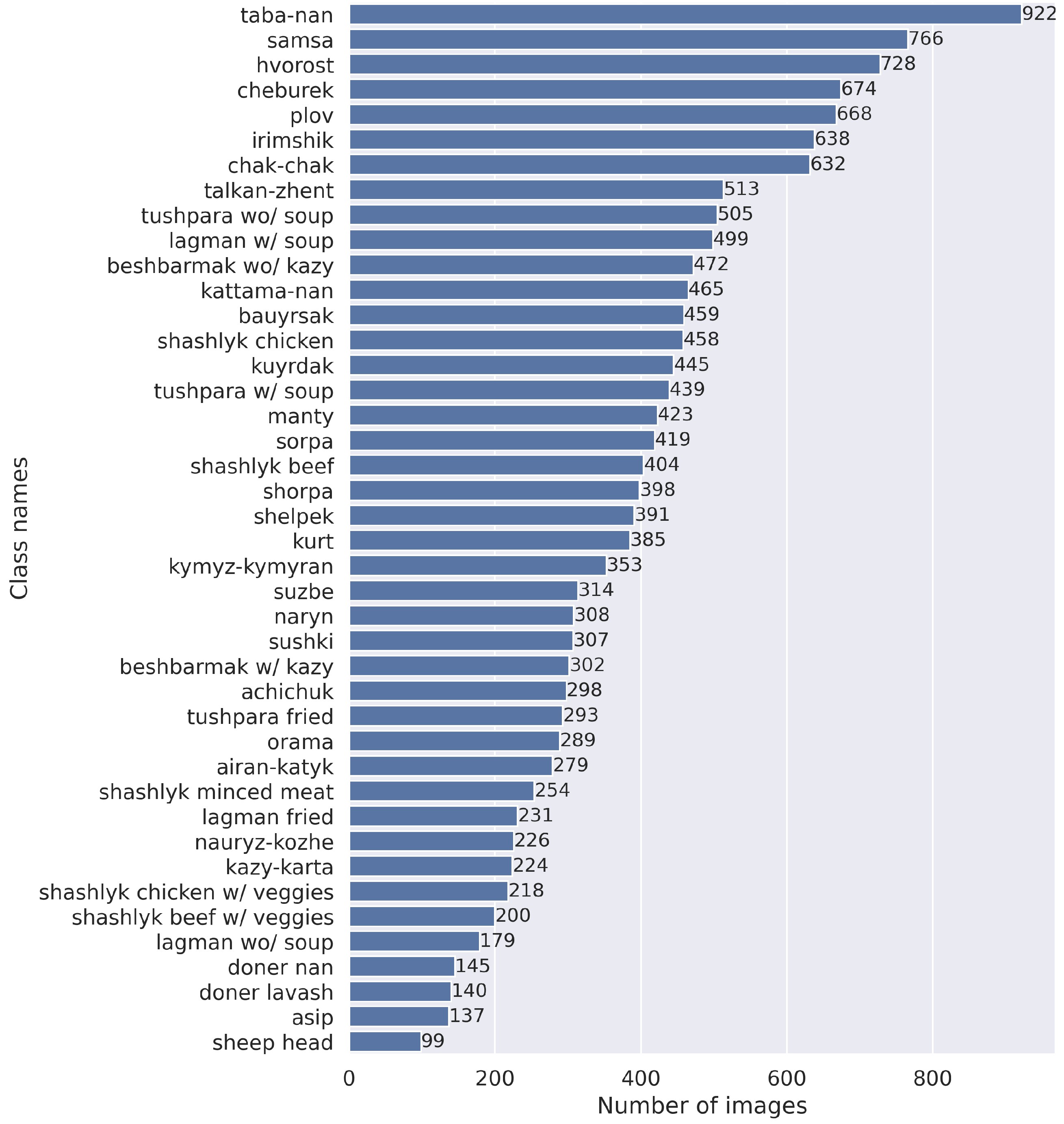{kind=link}
{kind=link}
| Dataset | Year | # Classes | # Images | Cuisine | Public |
|---|---|---|---|---|---|
| Food-101 [11] | 2014 | 101 | 101,000 | European | yes |
| VireoFood-172 [14] | 2016 | 172 | 110,241 | Chinese/Asian | yes |
| TurkishFoods-15 [18] | 2017 | 15 | 7500 | Turkish | yes |
| FoodAI [10] | 2019 | 756 | 400,000 | International | no |
| VireoFood-251 [15] | 2020 | 251 | 169,673 | Chinese/Asian | yes |
| ISIA Food-500 [16] | 2020 | 500 | 399,726 | Chinese/International | yes |
| Food2K [17] | 2021 | 2000 | 1,036,564 | Chinese/International | no |
| Food1K [17] | 2021 | 1000 | 400,000 | Chinese/International | yes |
| Central Asian Food Dataset (CAFD) | 2022 | 42 | 16,499 | Central Asian | yes |
| Dataset | Train | Valid | Test |
|---|---|---|---|
| CAFD | 11,008 | 2763 | 2728 |
| Food1K | 317,277 | 26,495 | 26,495 |
| CAFD+Food1K | 328,285 | 29,258 | 29,223 |
| Base Model | # Parameters | CAFD | Food1k | CAFD+Food1K | |||
|---|---|---|---|---|---|---|---|
| (mln) | Top-1 Acc. | Top-5 Acc. | Top-1 Acc. | Top-5 Acc. | Top-1 Acc. | Top-5 Acc. | |
| VGG-16 (2014) [28] | 138 | 86.03 | 98.33 | 80.67 | 95.24 | 80.87 | 96.19 |
| Squeezenet1_0 (2014) [29] | 1 | 79.58 | 97.29 | 71.33 | 91.23 | 69.16 | 90.15 |
| ResNet50 (2015) [30] | 25.6 | 88.03 | 98.44 | 82.44 | 97.01 | 83.22 | 97.25 |
| ResNet101 (2015) [30] | 44.5 | 88.51 | 98.44 | 84.10 | 97.34 | 84.20 | 97.45 |
| ResNet152 (2015) [30] | 60 | 88.70 | 98.59 | 84.85 | 97.80 | 84.75 | 97.58 |
| ResNext50-32 (2016) [31] | 25 | 87.95 | 98.44 | 81.17 | 96.67 | 84.81 | 97.65 |
| Wide ResNet-50 (2016) [32] | 69 | 88.21 | 98.59 | 82.20 | 97.28 | 85.27 | 97.81 |
| DenseNet-121 (2017) [33] | 8 | 86.95 | 98.26 | 83.03 | 97.14 | 82.45 | 96.93 |
| EfficientNet-b4 (2019) [34] | 19 | 81.28 | 97.37 | 87.47 | 98.04 | 87.75 | 98.01 |
| Best Detected CAFD Classes | Worst Detected CAFD Classes | ||||||
|---|---|---|---|---|---|---|---|
| Class | Precision | Recall | F1-Score | Class | Precision | Recall | F1-Score |
| Sushki | 0.96 | 1 | 0.98 | Shashlik chicken with vegetables | 0.71 | 0.67 | 0.69 |
| Achichuk | 0.95 | 1 | 0.98 | Shashlik beef with vegetables | 0.66 | 0.72 | 0.69 |
| Sheep head | 0.94 | 1 | 0.97 | Shashlik chicken | 0.67 | 0.74 | 0.7 |
| Naryn | 0.96 | 0.98 | 0.97 | Shashlik minced meat | 0.79 | 0.64 | 0.71 |
| Plov | 0.93 | 0.99 | 0.96 | Asip | 0.85 | 0.62 | 0.72 |
| Tushpara with soup | 0.93 | 0.97 | 0.95 | Shashlik beef | 0.74 | 0.69 | 0.72 |
| Sorpa | 0.97 | 0.93 | 0.95 | Lagman without soup | 0.83 | 0.68 | 0.75 |
| Samsa | 0.94 | 0.96 | 0.95 | Kazy-karta | 0.83 | 0.74 | 0.78 |
| Hvorost | 0.98 | 0.91 | 0.95 | Beshbarmak with kazy | 0.78 | 0.8 | 0.79 |
| Manty | 0.92 | 0.95 | 0.94 | Tushpara fried | 0.88 | 0.76 | 0.81 |
| Best Detected CAFD and Food1K Classes | Worst Detected CAFD and Food1K Classes | ||||||
|---|---|---|---|---|---|---|---|
| Class | Precision | Recall | F1-Score | Class | Precision | Recall | F1-Score |
| Sushki | 0.91 | 1 | 0.96 | Lagman without soup | 0.6 | 0.27 | 0.37 |
| Achichuk | 1 | 0.95 | 0.97 | Asip | 0.88 | 0.38 | 0.53 |
| Sheed head | 0.94 | 0.94 | 0.94 | Talkan-zhent | 0.86 | 0.53 | 0.66 |
| Airan-katyk | 0.83 | 0.93 | 0.88 | Doner lavash | 0.75 | 0.6 | 0.67 |
| Plov | 0.97 | 0.90 | 0.93 | Shashlik chicken with vegetables | 0.88 | 0.64 | 0.74 |
| Cheburek | 0.92 | 0.90 | 0.91 | Lagman fried | 0.96 | 0.68 | 0.8 |
| Irimshik | 0.93 | 0.88 | 0.91 | Doner nan | 1 | 0.68 | 0.81 |
| Samsa | 0.93 | 0.88 | 0.90 | Shashlik chicken | 0.61 | 0.69 | 0.65 |
| Naryn | 0.97 | 0.87 | 0.92 | Shashlik beef | 0.67 | 0.69 | 0.68 |
| Chak-chak | 0.9 | 0.87 | 0.92 | Kazy-karta | 0.8 | 0.7 | 0.74 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Karabay, A.; Bolatov, A.; Varol, H.A.; Chan, M.-Y. A Central Asian Food Dataset for Personalized Dietary Interventions. Nutrients 2023, 15, 1728. https://doi.org/10.3390/nu15071728
Karabay A, Bolatov A, Varol HA, Chan M-Y. A Central Asian Food Dataset for Personalized Dietary Interventions. Nutrients. 2023; 15(7):1728. https://doi.org/10.3390/nu15071728
Chicago/Turabian StyleKarabay, Aknur, Arman Bolatov, Huseyin Atakan Varol, and Mei-Yen Chan. 2023. "A Central Asian Food Dataset for Personalized Dietary Interventions" Nutrients 15, no. 7: 1728. https://doi.org/10.3390/nu15071728
APA StyleKarabay, A., Bolatov, A., Varol, H. A., & Chan, M.-Y. (2023). A Central Asian Food Dataset for Personalized Dietary Interventions. Nutrients, 15(7), 1728. https://doi.org/10.3390/nu15071728