
Long-Tailed Food Classification

Abstract
1. Introduction
- Two new benchmark datasets are introduced including Food101-LT and VFN-LT, where the long-tailed distribution of VFN-LT exhibits a real world food distribution.
- A novel two-phase framework is proposed to address the class imbalance problem by undersampling redundant head class samples and oversampling tail classes through visual-aware multi-image mixing.
- The performance of existing state-of-the-art long-tailed classification methods has been evaluated on newly introduced benchmark food datasets and the proposed framework obtains the best classification accuracy on both Food101-LT and VFN-LT.
2. Related Work
2.1. Food Classification
2.2. Long-Tailed Classification
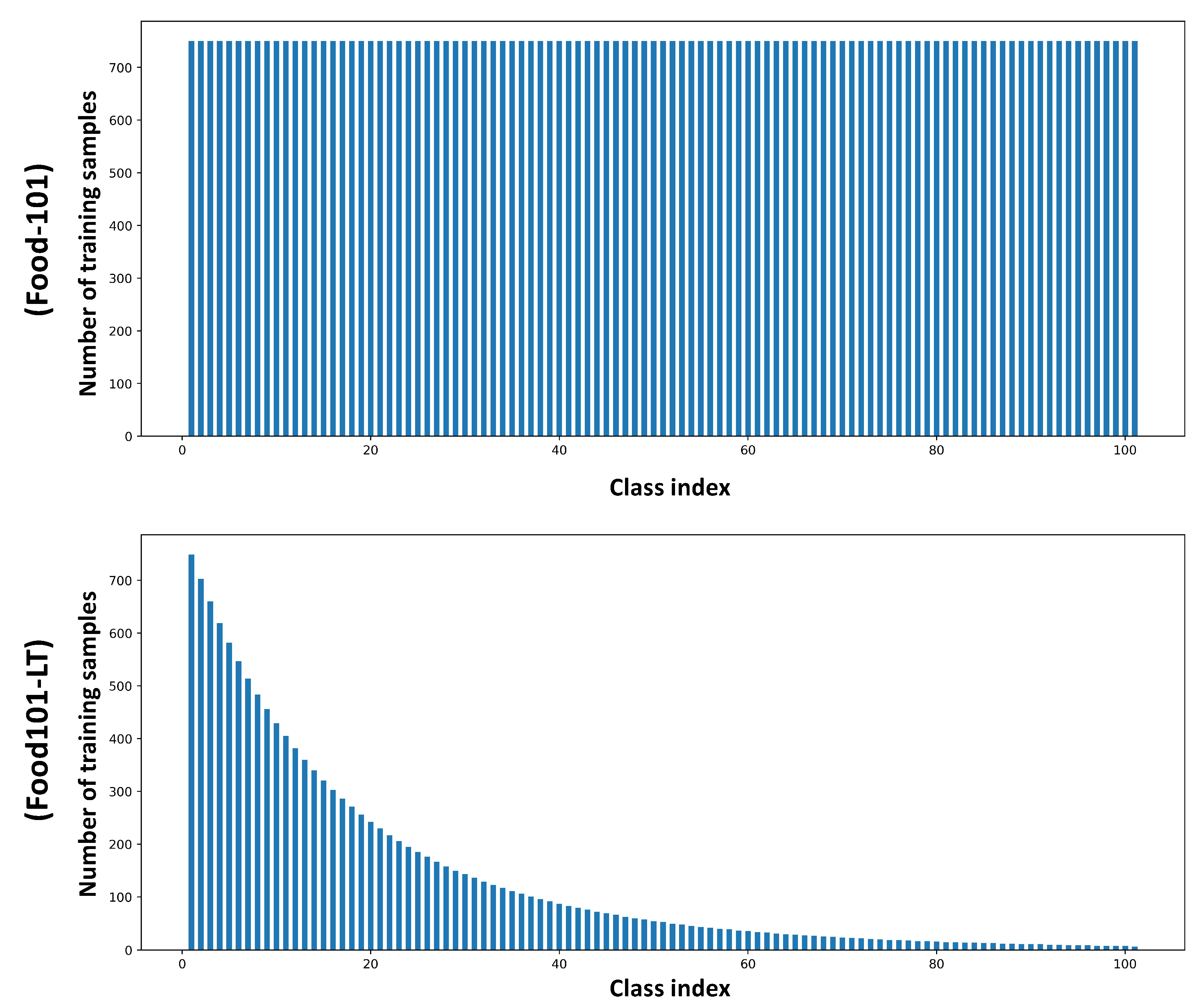
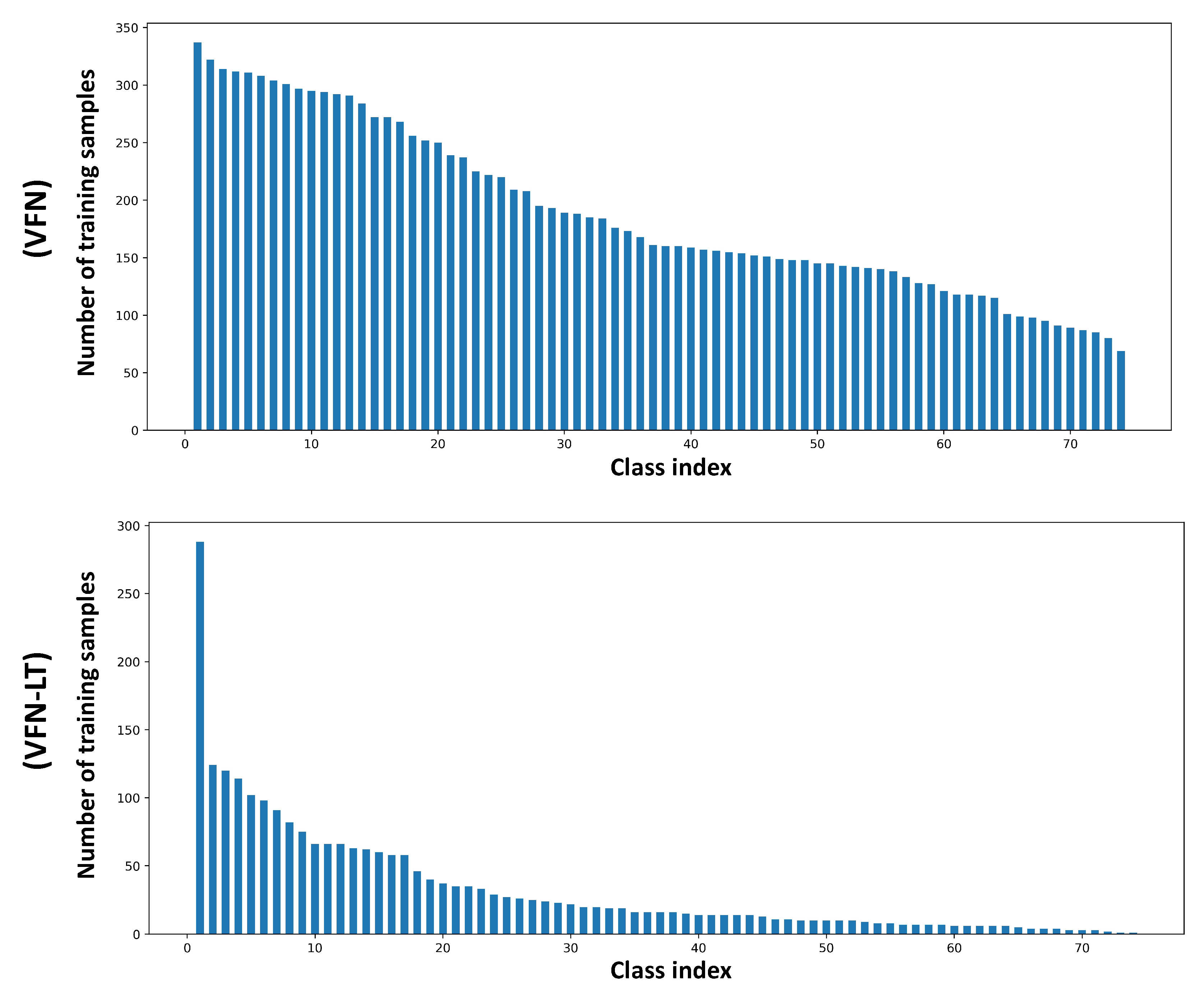
3. Datasets
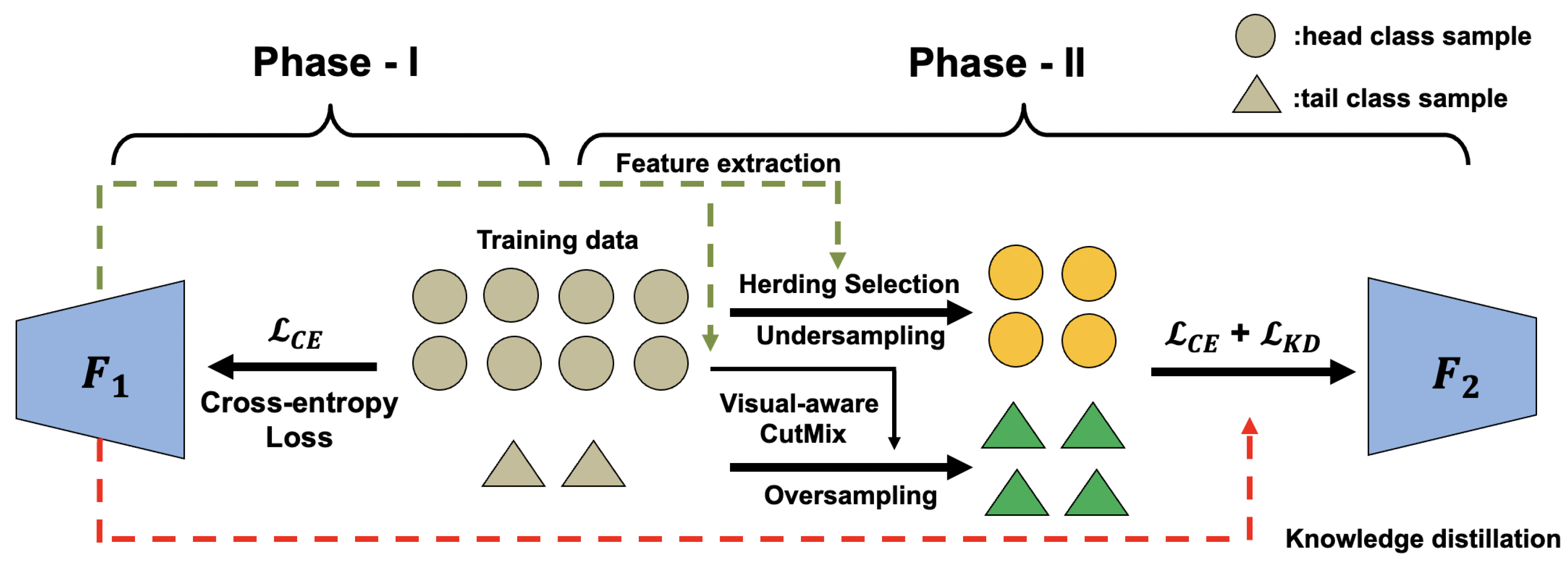
4. Method
4.1. Undersampling and Knowledge Transfer
4.2. Oversampling of Tail Classes
5. Experiments
5.1. Experimental Setup
5.2. Experimental Results
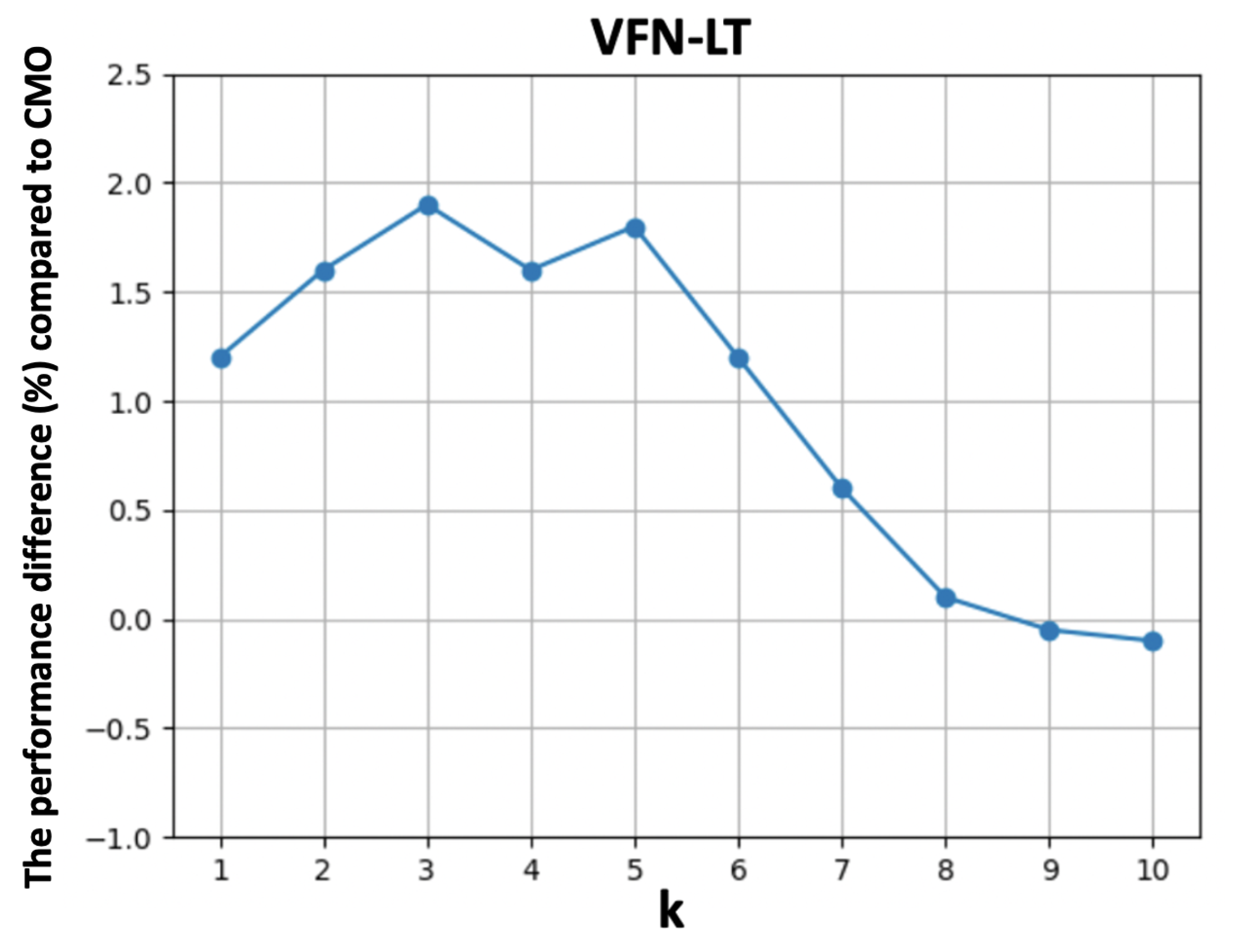
5.3. Ablation Study
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- He, J.; Shao, Z.; Wright, J.; Kerr, D.; Boushey, C.; Zhu, F. Multi-task Image-Based Dietary Assessment for Food Recognition and Portion Size Estimation. In Proceedings of the 2020 IEEE Conference on Multimedia Information Processing and Retrieval, Shenzhen, China, 6–8 August 2020; pp. 49–54. [Google Scholar] [CrossRef]
- He, J.; Mao, R.; Shao, Z.; Wright, J.L.; Kerr, D.A.; Boushey, C.J.; Zhu, F. An end-to-end food image analysis system. Electron. Imaging 2021, 2021, 285-1–285-7. [Google Scholar] [CrossRef]
- Shao, Z.; He, J.; Yu, Y.Y.; Lin, L.; Cowan, A.; Eicher-Miller, H.; Zhu, F. Towards the Creation of a Nutrition and Food Group Based Image Database. arXiv 2022, arXiv:2206.02086. [Google Scholar] [CrossRef]
- Anthimopoulos, M.M.; Gianola, L.; Scarnato, L.; Diem, P.; Mougiakakou, S.G. A food recognition system for diabetic patients based on an optimized bag-of-features model. IEEE J. Biomed. Health Inform. 2014, 18, 1261–1271. [Google Scholar] [CrossRef]
- Allegra, D.; Battiato, S.; Ortis, A.; Urso, S.; Polosa, R. A review on food recognition technology for health applications. Health Psychol. Res. 2020, 8, 9297. [Google Scholar] [CrossRef] [PubMed]
- Shao, Z.; Han, Y.; He, J.; Mao, R.; Wright, J.; Kerr, D.; Boushey, C.J.; Zhu, F. An Integrated System for Mobile Image-Based Dietary Assessment. In Proceedings of the 3rd Workshop on AIxFood, Virtual Event, 20 October 2021; pp. 19–23. [Google Scholar] [CrossRef]
- Vasiloglou, M.F.; van der Horst, K.; Stathopoulou, T.; Jaeggi, M.P.; Tedde, G.S.; Lu, Y.; Mougiakakou, S. The human factor in automated image-based nutrition apps: Analysis of common mistakes using the goFOOD lite app. JMIR MHealth UHealth 2021, 9, e24467. [Google Scholar] [CrossRef] [PubMed]
- Kawano, Y.; Yanai, K. Foodcam: A real-time food recognition system on a smartphone. Multimed. Tools Appl. 2015, 74, 5263–5287. [Google Scholar] [CrossRef]
- Boushey, C.; Spoden, M.; Zhu, F.; Delp, E.; Kerr, D. New mobile methods for dietary assessment: Review of image-assisted and image-based dietary assessment methods. Proc. Nutr. Soc. 2017, 76, 283–294. [Google Scholar] [CrossRef] [PubMed]
- Zhu, F.; Bosch, M.; Woo, I.; Kim, S.; Boushey, C.J.; Ebert, D.S.; Delp, E.J. The use of mobile devices in aiding dietary assessment and evaluation. IEEE J. Sel. Top. Signal Process. 2010, 4, 756–766. [Google Scholar] [PubMed]
- Mao, R.; He, J.; Shao, Z.; Yarlagadda, S.K.; Zhu, F. Visual aware hierarchy based food recognition. arXiv 2020, arXiv:2012.03368. [Google Scholar]
- Min, W.; Wang, Z.; Liu, Y.; Luo, M.; Kang, L.; Wei, X.; Wei, X.; Jiang, S. Large scale visual food recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2023. Early access. [Google Scholar] [CrossRef] [PubMed]
- Wu, H.; Merler, M.; Uceda-Sosa, R.; Smith, J.R. Learning to make better mistakes: Semantics-aware visual food recognition. In Proceedings of the 24th ACM international conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 172–176. [Google Scholar]
- Bossard, L.; Guillaumin, M.; Van Gool, L. Food-101—Mining Discriminative Components with Random Forests. In Computer Vision—ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014, Proceedings, Part VI 13; Springer International Publishing: Cham, Switzerland, 2014. [Google Scholar]
- Liu, Z.; Miao, Z.; Zhan, X.; Wang, J.; Gong, B.; Yu, S.X. Large-scale long-tailed recognition in an open world. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2537–2546. [Google Scholar]
- Lin, L.; Zhu, F.M.; Delp, E.J.; Eicher-Miller, H.A. Differences in Dietary Intake Exist Among US Adults by Diabetic Status Using NHANES 2009–2016. Nutrients 2022, 14, 3284. [Google Scholar] [PubMed]
- Cao, K.; Wei, C.; Gaidon, A.; Arechiga, N.; Ma, T. Learning imbalanced datasets with label-distribution-aware margin loss. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Park, S.; Hong, Y.; Heo, B.; Yun, S.; Choi, J.Y. The Majority Can Help The Minority: Context-rich Minority Oversampling for Long-tailed Classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 6887–6896. [Google Scholar]
- Christodoulidis, S.; Anthimopoulos, M.; Mougiakakou, S. Food recognition for dietary assessment using deep convolutional neural networks. In New Trends in Image Analysis and Processing–ICIAP 2015 Workshops: ICIAP 2015 International Workshops, BioFor, CTMR, RHEUMA, ISCA, MADiMa, SBMI, and QoEM, Genoa, Italy, 7–8 September 2015, Proceedings 18; Springer International Publishing: Cham, Switzerland, 2015; pp. 458–465. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Yanai, K.; Kawano, Y. Food image recognition using deep convolutional network with pre-training and fine-tuning. In Proceedings of the IEEE International Conference on Multimedia & Expo Workshops, Turin, Italy, 29 June–3 July 2015; pp. 1–6. [Google Scholar]
- Farinella, G.M.; Allegra, D.; Moltisanti, M.; Stanco, F.; Battiato, S. Retrieval and classification of food images. Comput. Biol. Med. 2016, 77, 23–39. [Google Scholar] [CrossRef] [PubMed]
- Kawano, Y.; Yanai, K. Automatic Expansion of a Food Image Dataset Leveraging Existing Categories with Domain Adaptation. In Proceedings of the ECCV Workshop on Transferring and Adapting Source Knowledge in Computer Vision (TASK-CV), Zurich, Switzerland, 6–7 September 2014. [Google Scholar]
- Farinella, G.M.; Allegra, D.; Stanco, F. A Benchmark Dataset to Study the Representation of Food Images. In Proceedings of the Europen Conference of Computer Vision, Workshops, Zurich, Switzerland, 6–12 September 2014; pp. 584–599. [Google Scholar]
- Mao, R.; He, J.; Lin, L.; Shao, Z.; Eicher-Miller, H.A.; Zhu, F. Improving Dietary Assessment Via Integrated Hierarchy Food Classification. In Proceedings of the 2021 IEEE 23rd International Workshop on Multimedia Signal Processing (MMSP), Tampere, Finland, 6–8 October 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Jiang, S.; Min, W.; Lyu, Y.; Liu, L. Few-shot food recognition via multi-view representation learning. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2020, 16, 1–20. [Google Scholar] [CrossRef]
- He, J.; Zhu, F. Online Continual Learning for Visual Food Classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Montreal, BC, Canada, 11–17 October 2021; pp. 2337–2346. [Google Scholar]
- He, J.; Mao, R.; Shao, Z.; Zhu, F. Incremental Learning In Online Scenario. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13926–13935. [Google Scholar]
- Gao, J.; Chen, J.; Fu, H.; Jiang, Y.G. Dynamic Mixup for Multi-Label Long-Tailed Food Ingredient Recognition. IEEE Trans. Multimed. 2022. [Google Scholar] [CrossRef]
- Huang, C.; Li, Y.; Loy, C.C.; Tang, X. Learning deep representation for imbalanced classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5375–5384. [Google Scholar]
- Wang, Y.X.; Ramanan, D.; Hebert, M. Learning to model the tail. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Ren, J.; Yu, C.; Ma, X.; Zhao, H.; Yi, S. Balanced meta-softmax for long-tailed visual recognition. Adv. Neural Inf. Process. Syst. 2020, 33, 4175–4186. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Van Hulse, J.; Khoshgoftaar, T.M.; Napolitano, A. Experimental perspectives on learning from imbalanced data. In Proceedings of the 24th International Conference on Machine Learning, Corvallis, OR, USA, 21–24 March 2007; pp. 935–942. [Google Scholar]
- Buda, M.; Maki, A.; Mazurowski, M.A. A systematic study of the class imbalance problem in convolutional neural networks. Neural Netw. 2018, 106, 249–259. [Google Scholar] [CrossRef] [PubMed]
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. Cutmix: Regularization strategy to train strong classifiers with localizable features. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Repblic of Korea, 27–28 October 2019; pp. 6023–6032. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. In Proceedings of the NIPS Deep Learning and Representation Learning Workshop, Montréal, Canada, 12 December 2014. [Google Scholar]
- Reed, W.J. The Pareto, Zipf and other power laws. Econ. Lett. 2001, 74, 15–19. [Google Scholar] [CrossRef]
- Welling, M. Herding Dynamical Weights to Learn. In Proceedings of the International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; pp. 1121–1128. [Google Scholar]
- Park, S.; Lim, J.; Jeon, Y.; Choi, J.Y. Influence-balanced loss for imbalanced visual classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 735–744. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic Differentiation in PyTorch. In Proceedings of the Advances Neural Information Processing Systems Workshop, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Menon, A.K.; Jayasumana, S.; Rawat, A.S.; Jain, H.; Veit, A.; Kumar, S. Long-tail learning via logit adjustment. In Proceedings of the International Conference on Learning Representations, Virtual Event, 3–7 May 2021. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index | Food Type | Food Code | Consumption Frequency | Index | Food Type | Food Code | Consumption Frequency |
|---|---|---|---|---|---|---|---|
| 1 | Yeast breads | 51000100 | 8275 | 38 | Fried rice | 58150310 | 465 |
| 2 | Cookies | 53201000 | 3591 | 39 | Boiled egg | 31103010 | 454 |
| 3 | Tomatoes | 74101000 | 3468 | 40 | Frankfurter sandwich | 27564000 | 429 |
| 4 | Sandwich | 27500050 | 3297 | 41 | Burrito | 58100160 | 413 |
| 5 | French fries | 71400990 | 3111 | 42 | Shrimp | 26319110 | 409 |
| 6 | Soup | 58400000 | 3002 | 43 | Fried egg | 31105005 | 408 |
| 7 | Bananas | 63107010 | 2737 | 44 | Cinnamon buns | 51160110 | 405 |
| 8 | Tortilla and Corn Chips | 54401075 | 2504 | 45 | Blueberries | 63203010 | 393 |
| 9 | Pizza | 58106230 | 2325 | 46 | Muffins | 52301000 | 342 |
| 10 | Tortillas | 52215000 | 1923 | 47 | Hash browns | 71404000 | 317 |
| 11 | Apple | 63101000 | 1912 | 48 | Meat loaf | 27214100 | 316 |
| 12 | Ice cream | 13110000 | 1909 | 49 | Pork rib | 22701000 | 315 |
| 13 | White and Brown Rice | 56205000 | 1812 | 50 | Bagels | 51180010 | 313 |
| 14 | Pasta mixed dishes | 58146210 | 1794 | 51 | Brownies | 53204000 | 308 |
| 15 | Mashed potatoes | 71501000 | 1730 | 52 | Chicken thigh | 24150210 | 302 |
| 16 | Breaded fish | 26100140 | 1694 | 53 | Guacamole | 63409010 | 284 |
| 17 | Steak | 21001000 | 1693 | 54 | Quick breads | 52403000 | 251 |
| 18 | Yogurt | 11400000 | 1326 | 55 | Chicken tender | 24198739 | 230 |
| 19 | Cakes or cupcakes | 53100100 | 1173 | 56 | Tuna salad | 27450060 | 223 |
| 20 | Burgers | 27510155 | 1082 | 57 | Baked potato | 71100100 | 219 |
| 21 | Chicken breast | 24120120 | 1030 | 58 | Almonds | 42100100 | 213 |
| 22 | Carrots | 73101010 | 1026 | 59 | Waffles | 55200010 | 205 |
| 23 | Melons | 63109010 | 962 | 60 | Chicken nugget | 24198729 | 199 |
| 24 | Pancakes | 55100005 | 854 | 61 | Broccoli | 72201100 | 183 |
| 25 | Corn | 75216120 | 802 | 62 | Quesadilla | 58104710 | 182 |
| 26 | Strawberries | 63223020 | 771 | 63 | Croissants | 51166000 | 178 |
| 27 | Bacon | 22600200 | 742 | 64 | Lasagna | 58130011 | 175 |
| 28 | Macaroni or noodles with cheese | 58145110 | 718 | 65 | Nachos | 58104180 | 157 |
| 29 | Whole chicken | 24100000 | 681 | 66 | Coleslaw | 75141000 | 143 |
| 30 | Doughnuts | 53520000 | 634 | 67 | Beans | 41100990 | 135 |
| 31 | Avocado | 63105010 | 589 | 68 | Stew beef | 27211200 | 133 |
| 32 | Green beans | 75205030 | 575 | 69 | French toast | 55300010 | 113 |
| 33 | Chicken wing | 24160110 | 562 | 70 | Sushi | 58151100 | 95 |
| 34 | Omelet | 32129990 | 555 | 71 | Apple sauce | 63101110 | 93 |
| 35 | Pies | 53300100 | 487 | 72 | Cabbage | 75105000 | 82 |
| 36 | Pork chop | 22101000 | 470 | 73 | Biscuits | 52101000 | 54 |
| 37 | Taco or tostada | 58101320 | 470 | 74 | Grilled salmon | 26137110 | 39 |
| Datasets | Food101-LT | VFN-LT | ||||
|---|---|---|---|---|---|---|
| Accuracy (%) | Head | Tail | Overall | Head | Tail | Overall |
| Baseline | 65.8 | 20.9 | 33.4 | 62.3 | 24.4 | 35.8 |
| HFR [11] | 65.9 | 21.2 | 33.7 | 62.2 | 25.1 | 36.4 |
| ROS [35] | 65.3 | 20.6 | 33.2 | 61.7 | 24.9 | 35.9 |
| RUS [36] | 57.8 | 23.5 | 33.1 | 54.6 | 26.3 | 34.8 |
| CMO [18] | 64.2 | 31.8 | 40.9 | 60.8 | 33.6 | 42.1 |
| LDAM [17] | 63.7 | 29.6 | 39.2 | 60.4 | 29.7 | 38.9 |
| BS [33] | 63.9 | 32.2 | 41.1 | 61.3 | 32.9 | 41.9 |
| IB [41] | 64.1 | 30.2 | 39.7 | 60.2 | 30.8 | 39.6 |
| Focal [34] | 63.9 | 25.8 | 36.5 | 60.1 | 28.3 | 37.8 |
| Ours | 65.2 | 33.9 | 42.6 | 61.9 | 37.8 | 45.1 |
| Datasets | Food101-LT | VFN-LT | ||||
|---|---|---|---|---|---|---|
| Accuracy (%) | Head | Tail | Overall | Head | Tail | Overall |
| RUS [36] | 57.8 | 23.5 | 33.1 | 54.6 | 26.3 | 34.8 |
| HUS | +1.7 | +0.3 | +0.6 | +2.1 | +0.2 | +0.7 |
| HUS+KD | +5.8 | +0.2 | +1.9 | +7.1 | +0.1 | +2.2 |
| CMO [18] | 64.2 | 31.8 | 40.9 | 60.8 | 33.6 | 42.1 |
| CMO+Visual () | +0.2 | +1.3 | +1.0 | +0.4 | +1.8 | +1.2 |
| CMO+Visual () | +0.1 | +2.8 | +2.1 | +0.5 | +2.4 | +1.9 |
| CMO+Visual () | −0.1 | +0.2 | +0.1 | +0.2 | −0.4 | −0.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, J.; Lin, L.; Eicher-Miller, H.A.; Zhu, F. Long-Tailed Food Classification. Nutrients 2023, 15, 2751. https://doi.org/10.3390/nu15122751
He J, Lin L, Eicher-Miller HA, Zhu F. Long-Tailed Food Classification. Nutrients. 2023; 15(12):2751. https://doi.org/10.3390/nu15122751
Chicago/Turabian StyleHe, Jiangpeng, Luotao Lin, Heather A. Eicher-Miller, and Fengqing Zhu. 2023. "Long-Tailed Food Classification" Nutrients 15, no. 12: 2751. https://doi.org/10.3390/nu15122751
APA StyleHe, J., Lin, L., Eicher-Miller, H. A., & Zhu, F. (2023). Long-Tailed Food Classification. Nutrients, 15(12), 2751. https://doi.org/10.3390/nu15122751