1. Introduction
Avalanches, large masses of snow that detach from a mountain slope and slide suddenly downward, kill more than 150 people worldwide [
1] every year. According to the Swiss Federal Institute for Snow and Avalanche Research, more than 90 percent of avalanche fatalities occur in uncontrolled terrain, like during off-piste skiing and snowboarding [
2]. Backcountry avalanches are mostly triggered by skiers or snowmobilers. Though it is rare, they can also be triggered naturally due to an increased load from a snow fall, metamorphic changes in snow pack, rock fall, and icefall. The enormous amount of snow carried at a high speed can cause a significant destruction to life as well as property. In areas where avalanches pose a significant threat to people and infrastructure, preventive measures like snow fences, artificial barriers, and explosives to dispose of avalanche potential snow packs are used to prevent or lessen their obstructive power.
Several factors account for victims’ survival. For example, victims can collide with obstacles while carried away by avalanches or fall over a cliff in the avalanche’s path and get physically injured. Once the avalanche stops, it settles like a rock and body movement is nearly impossible. Victims’ chance of survival depends on the degree of burial, presence of clear airway, and severity of physical injuries. Additionally, the duration of burial is also a factor in victims’ survival. According to statistics, 93 percent of victims survive if dug out within 15 min of complete burial. Survival chance drops fast after the first 15 min of complete burial. A “complete burial” is defined as where snow covers a victim’s head and chest; otherwise the term partial burial applies [
3]. Therefore, avalanche SAR operations are time-critical.
Avalanche SAR teams use various ways to locate victims. For example, trained avalanche rescue dogs are used to locate victims by searching for pools of human scent rising up from the snow pack. Though dogs can be useful in locating victims not equipped with electronic transceivers, the number of dogs required and the time to deploy them are constraints. If victims are equipped with electronic transceivers like ARVA (Appareil de Recherche de Victime d’Avalanche), a party of skiers can immediately start searching for a missing member. However, such transceivers are powered by batteries and require experience to use. The RECCO rescue system is an alternative to transceivers where one or more passive reflectors are embedded into clothes, boots, helmets, etc. worn by skiers and a detector is used by rescuers to locate the victims. Once the area of burial is identified, a probe can be used to localize the victim and estimate the depth of snow to be shoveled. Additionally, an organized probe line can also be used to locate victims not equipped with electronic transceivers or if locating with the transceivers fails. However, such a technique requires significant man power and is a slow process. Recent advances in the field of UAVs have enabled the use of flying robots equipped with ARVA transceivers and other sensors to assist post-avalanche SAR operations [
4,
5,
6]. This has reduced search time and allowed rescuers to search in areas that are difficult to reach and dangerous.
In the literature, there are active remote sensing methods proposed to assist with post-avalanche SAR operations. For example, the authors in [
7] have shown that it is possible to detect victims buried under snow using a Ground Penetrating Radar (GPR). Since the human body has a high dielectric permittivity relative to snow, a GPR can uniquely image a human body buried under snow and differentiate it from other man-made and natural objects. With the advent of satellite navigational systems, Jan et al. [
8] studied the degree to which a GPS signal can penetrate through the snow and be detected by a commercial receiver, making it a potential additional tool for quick and precise localization of buried victims. Following the work in [
8], the authors in [
9] also studied the performance of low-cost High Sensitivity GPS (HSGPS) receivers available in the market for use in post-avalanche SAR operation. In a more recent work, Victor et al. [
10] studied the feasibility of 4G-LTE signals to assist SAR operations for avalanche-buried victims and presented a proof of concept that, using a small UAV equipped with sensors that can detect cellphone signals, it is possible to detect victim’s cellphone buried up to seven feet deep.
Though there has been no research published documenting the use of vision-based methods, a type of passive remote sensing method specifically for post-avalanche SAR operation, it is possible to find papers that propose supporting SAR operations in general with image analysis techniques. Rudol et al. [
11] proposed assisting wilderness SAR operations with videos collected using a UAV with an onboard thermal and color cameras. In their experiment, the thermal image is used to find regions with a possible human body and corresponding regions in the color image are further analyzed by an object detector that combines a Haar feature extractor with a cascade of boosted classifiers. Because of partial occlusion and the variable pose of victims, the authors in [
12] demonstrated models that decompose the complex appearance of humans into multiple parts [
13,
14,
15], making them more suited than monolithic models to detecting victims lying on the ground from aerial images captured by UAV. Furthermore, they have also shown that integrating prior scale information from inertial sensors of the UAV helps to reduce false positives and a better performance can be obtained by combining complementary outputs of multiple detectors.
In recent years, civilian remote sensing applications have greatly benefited from the development of smaller and more cost-effective UAVs. Some of the applications include: detecting and counting cars or other objects from aerial images captured by UAVs [
16,
17,
18], assessing the impact of man-made or natural disasters for humanitarian action, and vegetation mapping and monitoring. In general, these are rapid, efficient, and effective systems to acquire extremely high-resolution (EHR) images. Additionally, their portability and easiness to deploy makes them well suited for applications like post-avalanche SAR operation. According to [
19], out of 1886 people buried by avalanches in Switzerland between 1981 and 1998, 39% of the victims were buried with no visible parts while the rest were partially buried or stayed completely unburied on the surface. Moreover, the chance of complete burial can be reduced if avalanche balloons are used. Given this statistic, we present a method that utilizes UAVs equipped with vision sensors to scan the avalanche debris and further process the acquired data with image processing techniques to detect avalanche victims and objects related to the victims in near-real time.
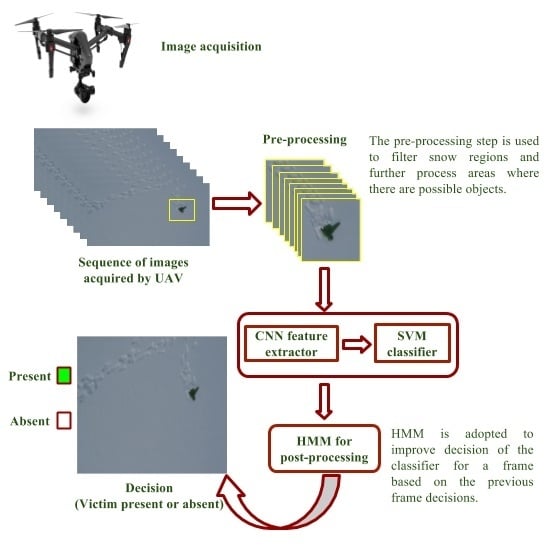
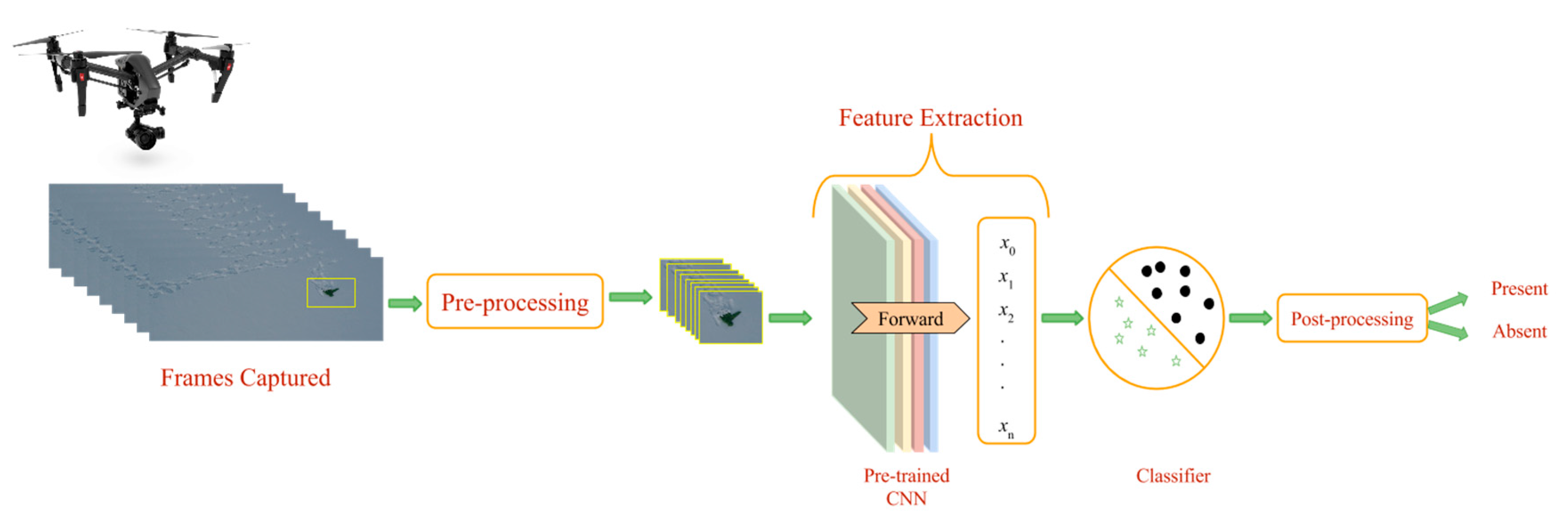
The organization of this paper is as follows: the overall block diagram of the system along with the description of each block is presented in the next section. Datasets used and experimental setup are presented in
Section 3. Experimental results are presented in
Section 4 and the last section,
Section 5, is dedicated to conclusions and further development.
4. Results and Discussion
In this section, we report the experimental results obtained for both datasets. General information about all experiments can be found in
Table 2. Accuracy, probability of true positives (
), and probability of false alarm (
) are the performance metrics used.
and
are calculated as follows:
4.1. Experiments without Pre-Processing
For the first dataset, we conducted three separate experiments at different resolutions. The first experiment is conducted by resizing both training and test frames to an input size, 224 × 224, of the pre-trained model and extracting the features. In the second experiment, each frame is divided into six tiles of 224 × 224 each after resizing to 672 × 448 (close to VGA). In the third experiment, 15 tiles of size 224 × 224 are generated from each frame after resizing to 1120 × 672 (close to the original resolution). The results are reported in
Table 1.
From
Table 3, it is clear that the overall accuracy increases and
decreases with an increase in resolution. Contrarily,
decreases for the second and third experiments with respect to the first and increases for the third experiment with respect to the second. We believe that the reason for having a high
in the first experiment is because we are considering the whole frame, which contains unwanted objects like poles, trees, lift lines, etc. In the first experiment we have high
because the whole frame is resized to 224 × 224. The resizing makes objects of interest become insignificant with respect to the surrounding and thus forces the classifier to learn not only objects of interest but also the surroundings. On the other hand, the second and third experiments have small
and increased
due to tiling, which makes objects of interest in a tile more significant with respect to the surroundings and the classifier is able to better discriminate objects of interest from the background. Some qualitative results are shown in
Figure 7.
For the second dataset, the first experiment (Experiment 4 in
Table 2) we conducted by downsampling each frame to a size of 224 × 224. For this experiment, the training set is made up of 4000 frames, of which 2000 are positive samples, extracted from the first two videos. From the results in
Table 4, video 3 has high accuracy and very low
as compared to the other test videos. This is mainly due to the nature of the video. Almost all frames are either snow (white) or objects of interest on top of snow. So, downsampling the frames will not affect the visibility of objects of interest. On the other hand, frames from videos 4 and 5 contain background objects like cars, trees, etc. Additionally, video 5 is recorded at a higher height. For the reasons mentioned above, downsampling a frame to 224 × 224 results in higher insignificance of objects of interest with respect to the background and hence a high
.
4.2. Experiments with Pre-Processing
Next, we conducted four separate experiments at resolutions of 640 × 480, 1280 × 720, 1920 × 1080, and 3840 × 2160, respectively. Since the number of frames in this dataset is large, tiling each frame and labeling each tile is time-consuming. Alternatively, we composed a training set with 3000, of which 1500 are positive, image crops of size 224 × 224 from the first two videos at the original resolution and trained a linear SVM. During the test phase, each frame is scanned with a sliding window of size 80 × 80 and if a window passes the threshold, a crop of size 224 × 224 centered on the window is taken for further processing with the next steps. An example of this process is shown in
Figure 8.
As seen from the results in
Table 5 and
Table 6, for video 3 (experiments 5 to 8), the overall accuracy increases with an increase in resolution as compared to the results obtained in experiment 4. An exception is at the VGA resolution, where there is a decrease in accuracy due to loss of detail in downsampling. As expected, the probability of a false alarm (
) drops significantly with an increase in resolution. On the other hand,
has decreased with respect to the results obtained in experiment 4. However, it started to increase as resolution improved, yielding a significant increase at 4K resolution (experiment 8). We believe that the decrease is due to the difference in the training sets used for experiment 4 and experiments 5 to 8, while the increase is due to the more detailed information available with an increase in resolution.
Similarly, for video 4, the overall accuracy improves significantly as compared to the results obtained in experiment 4. However, it starts to drop, as compared to the result at VGA resolution (experiment 5), with an increase in resolution. In experiment 4 we have a high , but it decreases significantly as the resolution is improved. However, as we go from VGA (experiment 5) to 4K (experiment 8) resolution, there is an increase in . This is because of objects or part of objects in the background that have similarity with objects of interest, thus incurring the classifier in more wrong decisions. Moreover, the increase in has a negative impact on the overall accuracy. Though initially we have a decrease in at the VGA resolution with respect to the results obtained in experiment 4, there is an increase and stability in the rest of the experiments.
For video 5, we have a significant increase in the overall accuracy as the resolution increases.
initially decreases at VGA resolution (experiment 5) with respect to the results obtained in experiment 4, but it starts to increase as the resolution increases. Moreover, we have less
as compared to other videos because of the height at which the video is captured. Similar to the other videos,
drops significantly with an increase in resolution. However, there is also a slight increase in experiments 5 to 8 due to reasons similar to those mentioned for video 4. Some qualitative results are shown in
Figure 9 and
Figure 10.
4.3. Experiments with Markovian Post-Processing
In the previous experiments, decisions are made separately for each frame. However, in a video sequence, there is a correlation between successive frames and performance can be further improved by embedding this information in the decision-making process. As described in the previous methodological section, we have used HMMs to opportunely exploit this information. Model parameters, prior distribution, transition matrix, and observation probability distribution are calculated as follows:
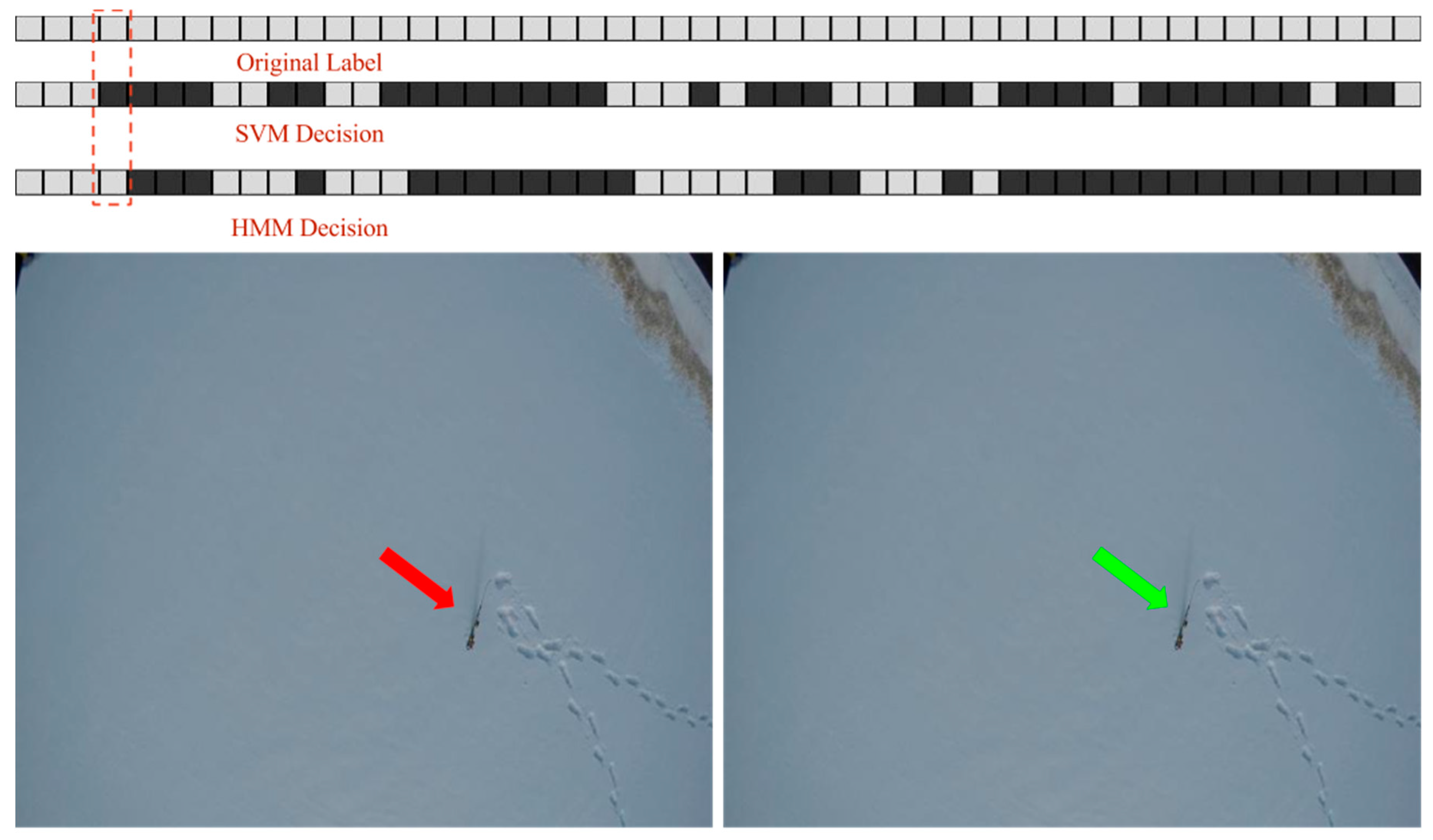
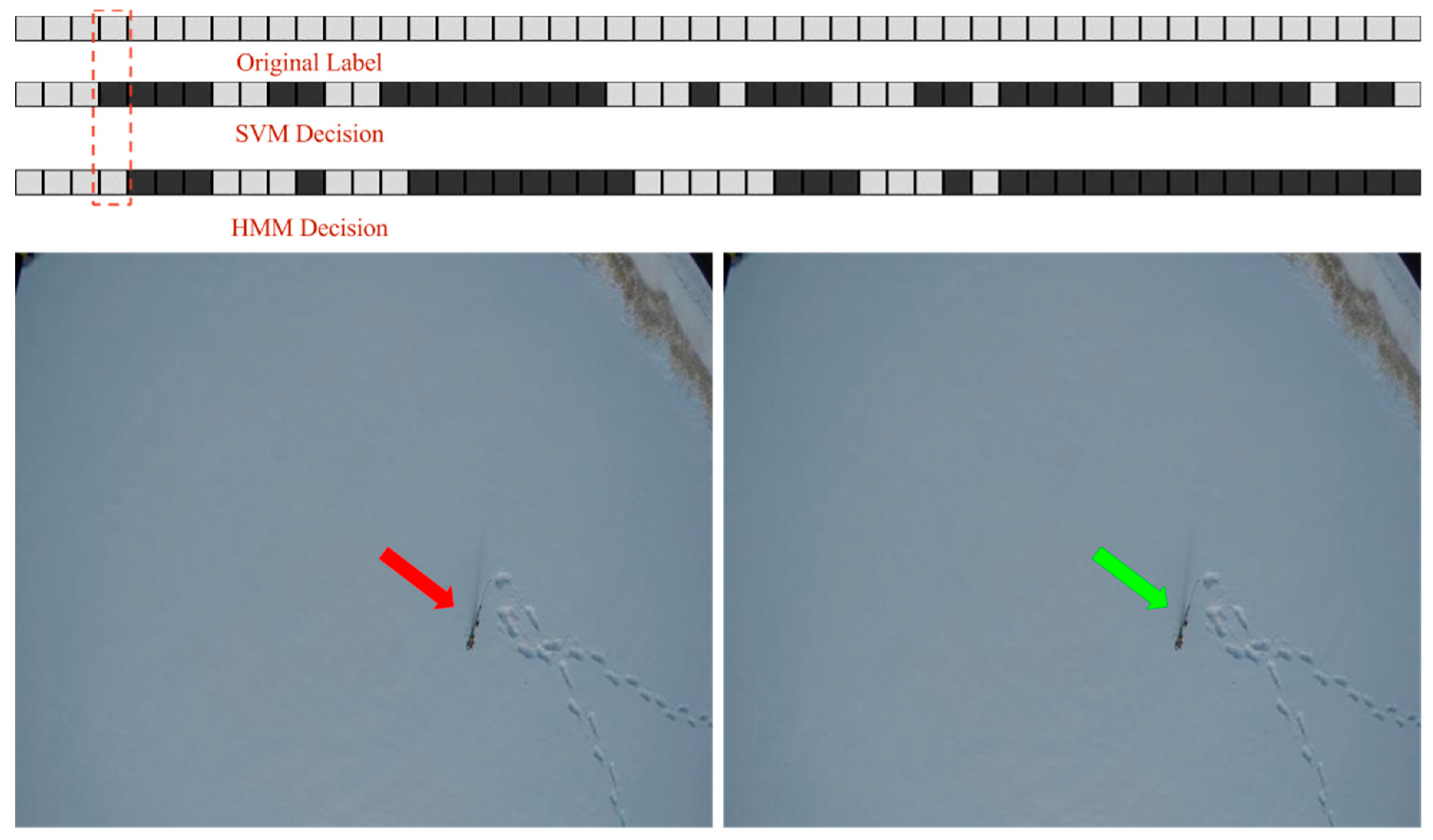
The effect of post-processing on the prediction performance can be positive or negative. Indeed, it can correct wrong predictions made by the classifier (positive change) or change the correct prediction made by the classifier into a wrong prediction (negative change). Moreover, these positive or negative changes occur between successive frames where there is a transition from one state to the other in the prediction of the classifier. For example, consider two successive frames, at time and . If the decision of the SVM at time is different than the decision made by HMM for the frame at time , because of the small state transition probabilities it is highly likely for the HMM to remain in the same state for the current frame, thereby changing the decision of the SVM. Depending on the original label of the frame, this change can be either positive or negative. Therefore, the prediction performance of the system can either increase if there are more positive changes than negative changes or decrease if there are more negative changes than positive ones.
The results in
Table 8,
Table 9 and
Table 10 show that for video 3 the impact of HMM is not that significant in improving
. On the other hand,
improves by more than 2% at the VGA resolution. For video 4, since the number of positive frames is very small an increase or decrease in
does not affect the overall accuracy. For example,
increases by 6% in the first experiment and decreases by approximately 10% at the VGA resolution, but the effect on the overall accuracy is very small. With an increase in resolution
gets improved and accuracy increases by more than 5%. Though post-processing has a negative effect on the accuracy for video 5, we can see from the results that, as the resolution increases,
drops and, consequently, the difference between the accuracies (achieved with and without post-processing) decreases. In general, it is possible to see that the gain of post-processing depends on the goodness of the classifier. When
is high and
is low, prediction performance gets improved or remains the same. In all other cases, the impact on prediction performance, especially on the overall accuracy, depends on the ratio of positive and negative frames. Examples of the positive and negative changes made by HMM are given in
Figure 11 and
Figure 12.
4.4. Computation Time
The processing time required to extract CNN features and perform the prediction for an input image of size 224 × 224 is 0.185 s. For both the first and second datasets, detection at a resolution of 224 × 224 can be done at a rate of 5.4 frames per second. For the first dataset, since we used tiling to do detection at higher resolutions, the processing time is the product of the number of tiles per frame with the processing time required for a single tile (0.185 s). Therefore, at near VGA and full resolutions, the detection rates are 0.9 and 0.36 frames per second, respectively. For the second dataset, since we have the pre-processing step, we only extract features and perform prediction on frames that pass this step. Additionally, there can be more than one crop of size 224 × 224 from a single frame. The average processing time is reported in
Table 11. The advantage of pre-processing as compared to the tiling approach is twofold. First, it reduces the processing time; second, it provides better localization of objects within a frame.
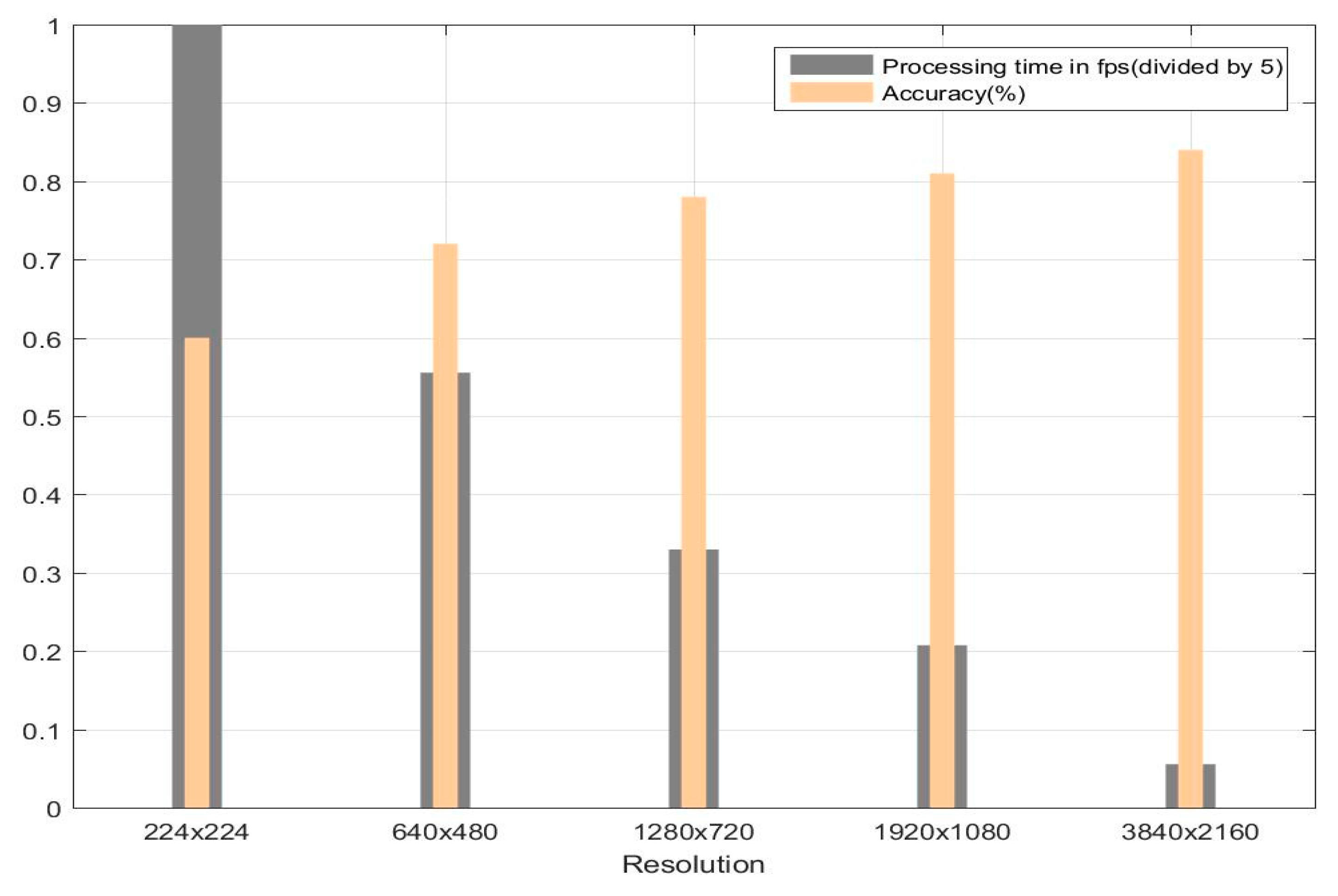
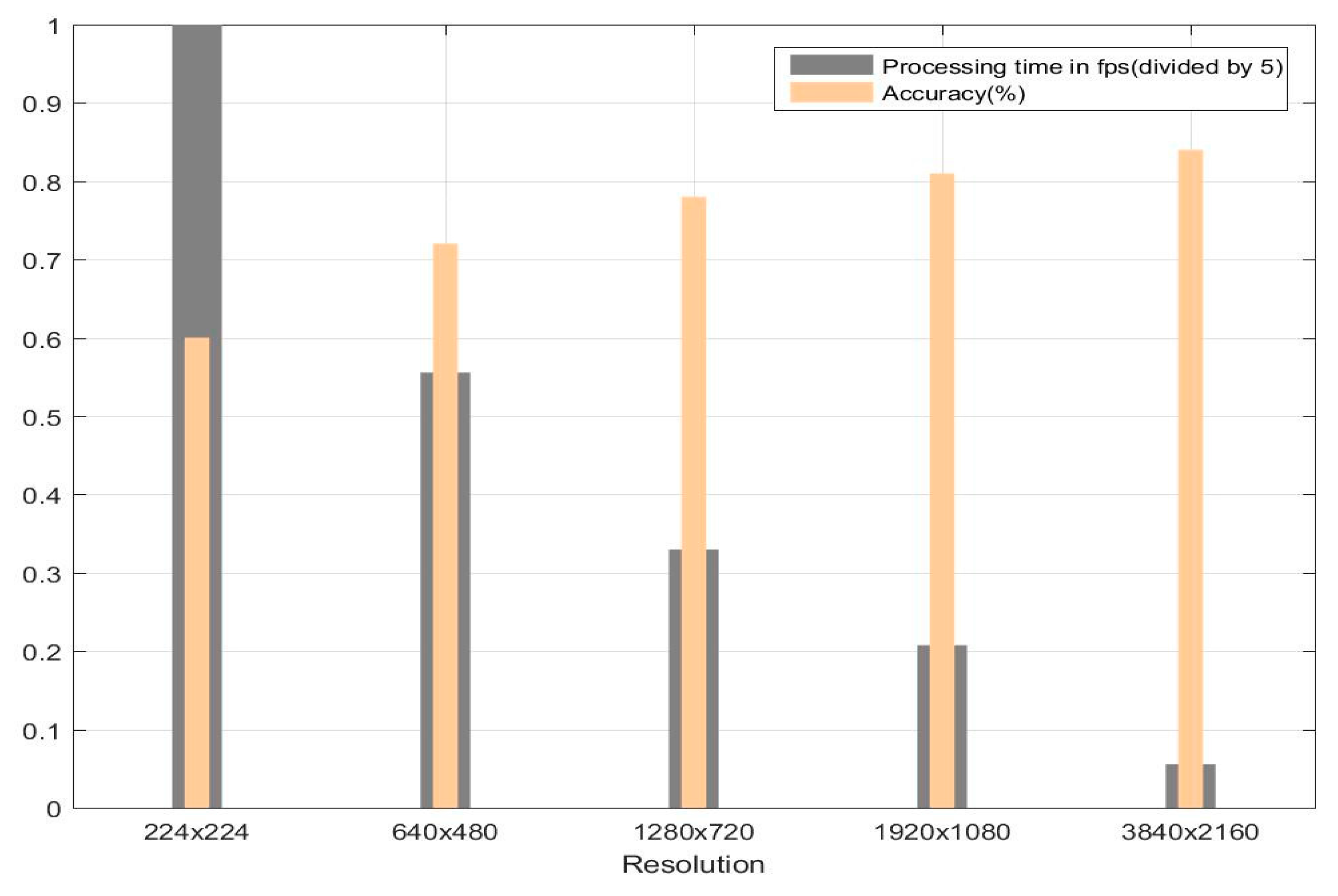
In general, from the experimental results obtained, it emerges that working at a higher resolution provides a significant improvement in prediction performance at a cost of increased processing time. The bar graph in
Figure 13 shows the average accuracy and processing time for the second dataset.
4.5. Comparative Study
For the purpose of comparison, we conducted experiments at the higher resolutions available for both datasets using histograms of oriented gradients (HOG) feature extraction method. Histograms of oriented gradients (HOG) [
40] is a method that is used to represent local object appearance and shape using local intensity gradients or edge directions. For a given image window, HOG features are computed as follows. First, the window is divided into small spatial areas called cells and each cell is represented by a 1-d histogram of gradients computed for each pixel. Next, cells are grouped spatially to form larger areas called blocks. Each block is then represented by a histogram of gradients, which is a concatenation of the normalized 1-d histogram of gradients of each cell within the block. The final HOG feature descriptor of the image window is formed by concatenating the aforementioned histograms of the blocks.
In our experiments, the parameters for HOG are set up as follows: the cell size is set to 32 × 32 pixels, the block size is set to 2 × 2 with 50% overlap, and a 9-bin histogram is used to represent the cell gradients. For both datasets, HOG descriptors are extracted from an image window of size 224 × 224 and a linear SVM is trained for the classification. The best regularization parameter (C) of the classifier is selected by using grid search and cross validation method. As the results in
Table 12 and
Table 13 show, the overall accuracy of HOG-SVM classifier is significantly less than that of the CNN-SVM classifier. Additionally, the HOG-SVM classifier generates high false alarms (
) as compared to the CNN-SVM classifier. Our results thus confirm the idea that a generic classifier trained on deep features outperforms a classifier trained on features extracted with the traditional method [
25,
26].
5. Conclusions
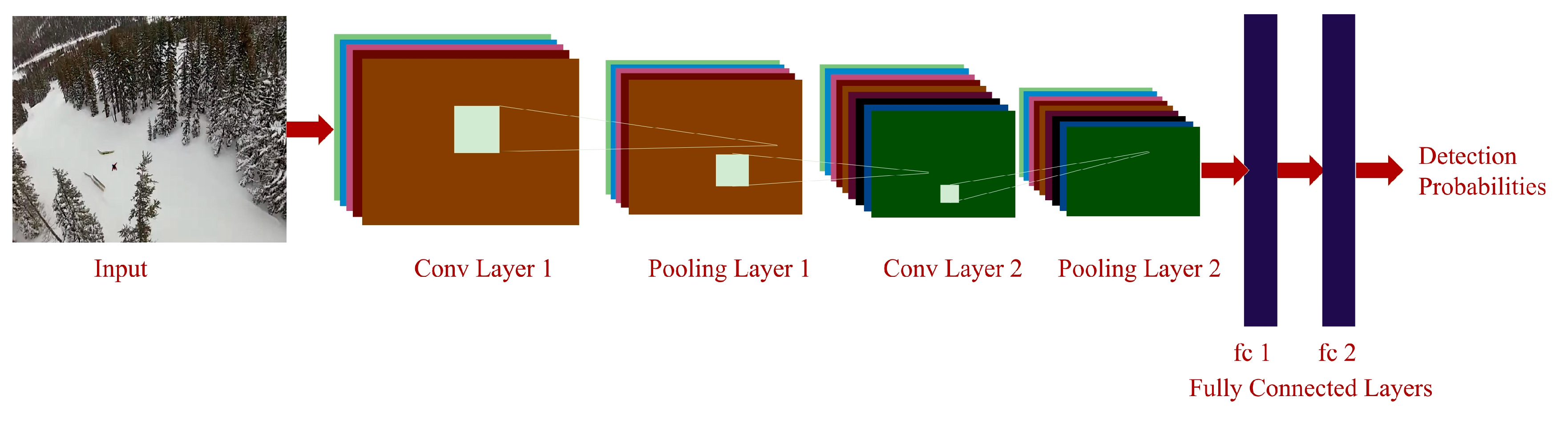
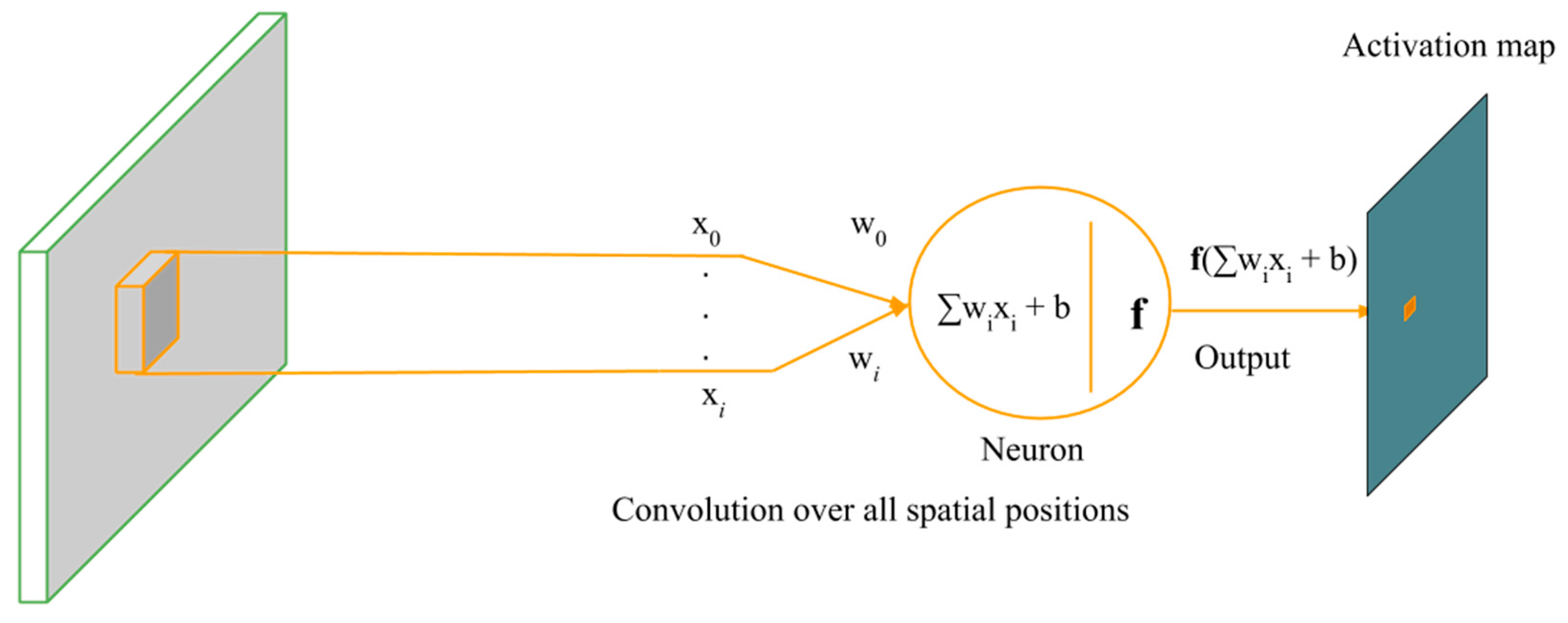
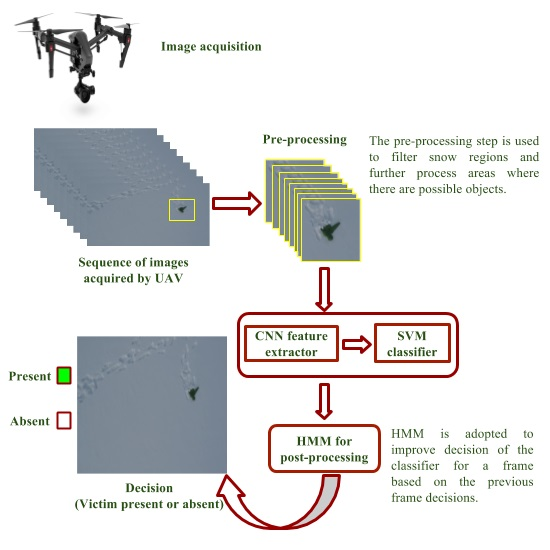
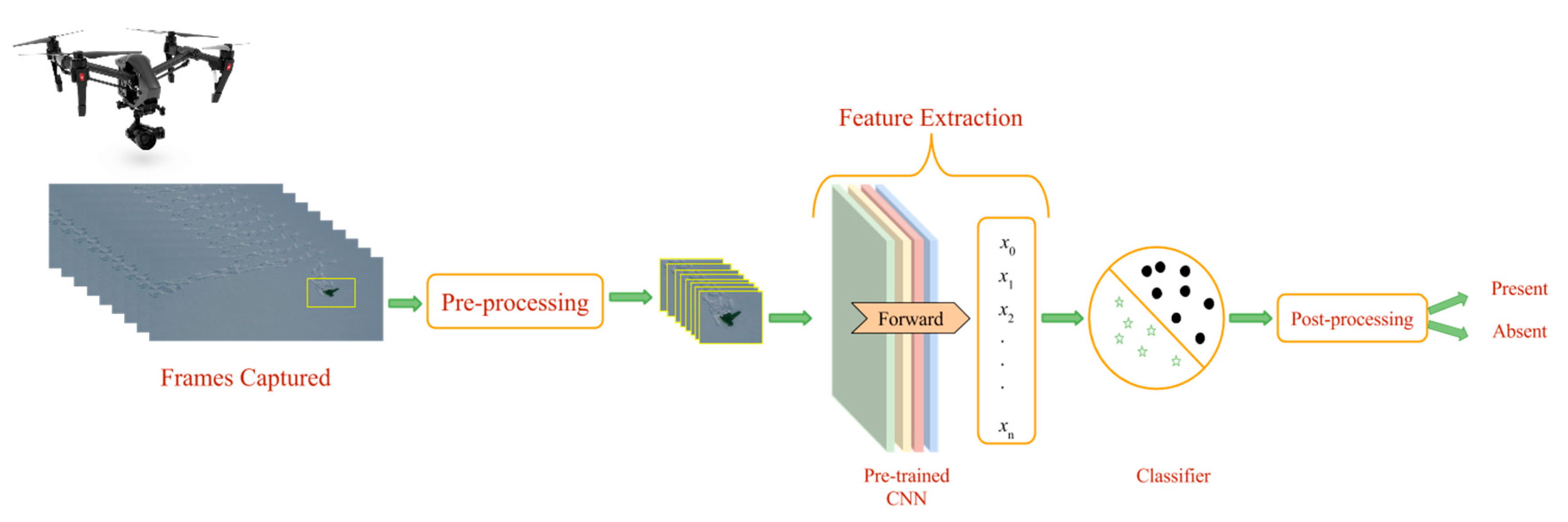
In this work, we have presented a method to support avalanche SAR operations using UAVs equipped with vision cameras. The UAVs are used to acquire EHR images of an avalanche debris and the acquired image is processed by a system composed of a pre-processing method to select regions of interest within the image, a pre-trained CNN to extract suitable image descriptors, a trained linear SVM classifier for object detection and a post-processing method based on HMM to further improve detection results of the classifier.
From the experimental results, it is clear that improved resolution results in an increase in prediction performance. This is mainly due to the availability of more detailed information at a higher resolution, which enables the decision system to better discriminate objects of interest from the background. Contrarily, we have also seen an increase in false alarms because of background objects or parts of objects that exhibit similarity with the objects of interest. Though the computation time increases with an increase in resolution, it is possible to assert that, except at full resolution, the processing time is acceptable for such applications. Additionally, as seen from experimental results of video 5, the height at which frames are acquired is also an important factor that impacts on the prediction performance, and the results obtained with the other test videos suggest that scanning the debris at a lower altitude is preferable for better detection performance. Finally, the choice of resolution to perform detection should be done according to a tradeoff between accuracy and processing time.
Two main limitations can be observed in this study. The first is that the datasets used for training/testing are not yet fully representative. For example, the second dataset is characterized by very few objects. Although the task is not easy, it would be important to collect a more complete dataset by varying the context of the avalanche event and the conditions of partial burial of the victims, and by increasing the kinds of objects. The second limitation is that the thresholding mechanism used in the pre-processing depends on the single pixel intensities. Due to the loss of information incurred by image resizing, pixels associated with some of the objects fail to pass the threshold and hence objects are not detected. However, as the experimental results show, this problem is reduced with an increase in resolution. Since the main objective of the pre-processing is to reduce computational time by elaborating only a portion of a frame or skipping a frame, a method that is more robust at lower resolutions can be a topic of further research.
Operational scenarios of the proposed method are two. In the first one, the data are transmitted in real time to the ground station where the processing is performed in order to alert the operator when objects of interest are detected while the UAV (or a swarm of UAVs) performs the scans of the avalanche areas. In this scenario, problems of communication links between the drone and the ground station need to be resolved beforehand. In the second scenario, the processing is performed onboard the UAV. This allows us to reduce considerably the amount of information to be sent toward the ground station, which in this case can be reduced to simple flag information whenever a frame containing objects of interest is detected. The drawback is the processing capabilities, which are reduced with respect to those of a ground station. Work is in progress for an onboard implementation. Moreover, it is noteworthy that, although the first two videos used for training are acquired at 45°, we assume the acquisition to be performed at the nadir and the processing is performed on a frame-by-frame basis. A critical parameter that was thoroughly investigated in this study is the UAV height, which impacts directly on the image resolution. There are other factors like illumination conditions and UAV stability in the presence of wind that deserve to be investigated in the future.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}