2.4. Classification and Classifier Performance
We performed supervised pixel-based image classification in Google Earth Engine (GEE). GEE leverages cloud-computational services for planetary-scale analysis and consists of petabytes of geospatial and tabular data, including a full archive of Landsat scenes, together with a JavaScript, Python based API (GEE API), and algorithms for supervised image classification [
12]. GEE has been previously used for various research applications, including mapping population [
13,
14], urban areas [
15] and forest cover [
8].
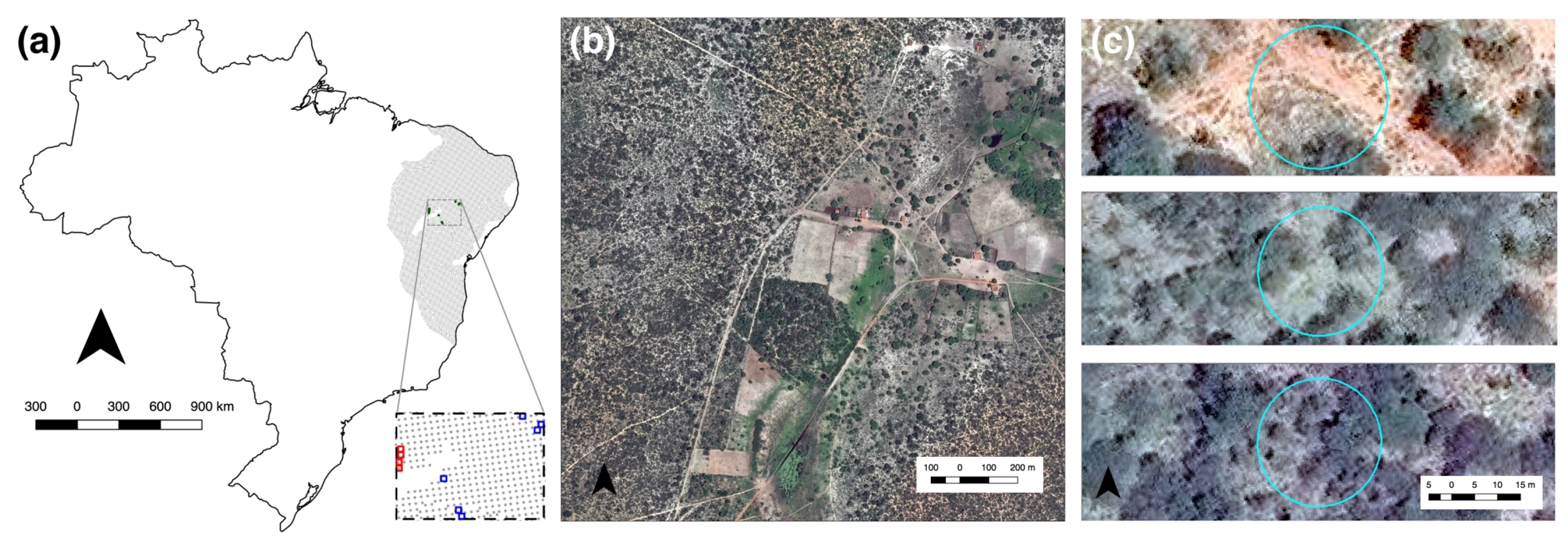
We used both Landsat and WorldView imagery as input for classification. We matched the selected WorldView regions to the co-located Landsat imagery (8-day TOA reflectance composites) nearest in date, and trimmed Landsat imagery to the same boundaries. We used Landsat 8 Top-of-Atmosphere (TOA) reflectance orthorectified scenes, with calibration coefficients extracted from the corresponding image metadata. The Landsat scenes were from the L1T level product (precision terrain-corrected), converted to TOA reflectance and rescaled to 8-bits for visualization purposes. These pre-processed calibrated scenes are available in GEE. It should be noted that, although TOA reflectance accounts for planetary variations between acquisition dates (e.g., the sun’s azimuth and elevation), many images remain contaminated with haze, clouds, and cloud shadows, which may limit their effective utilization [
16], especially for agriculture and ecological applications.
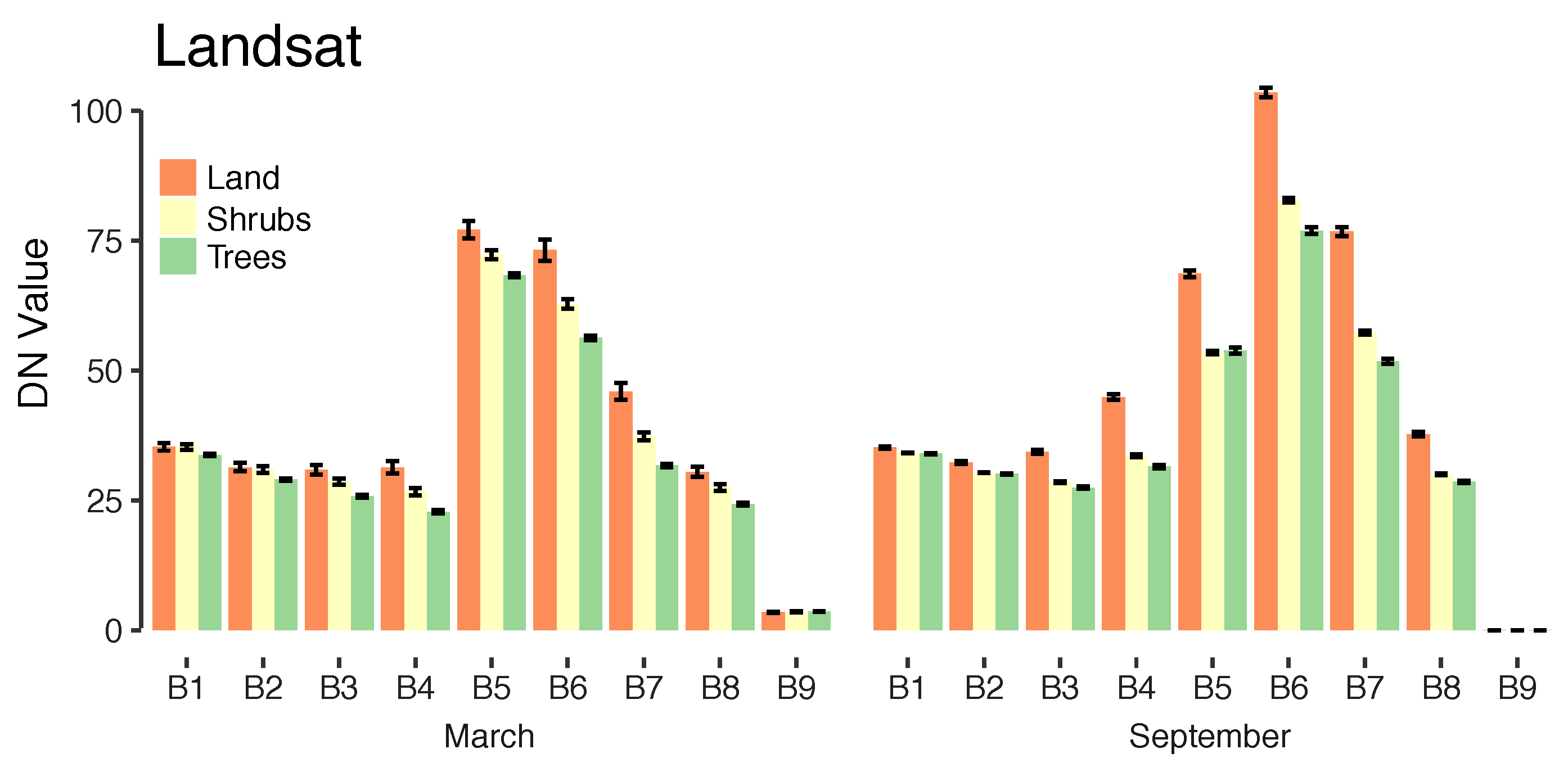
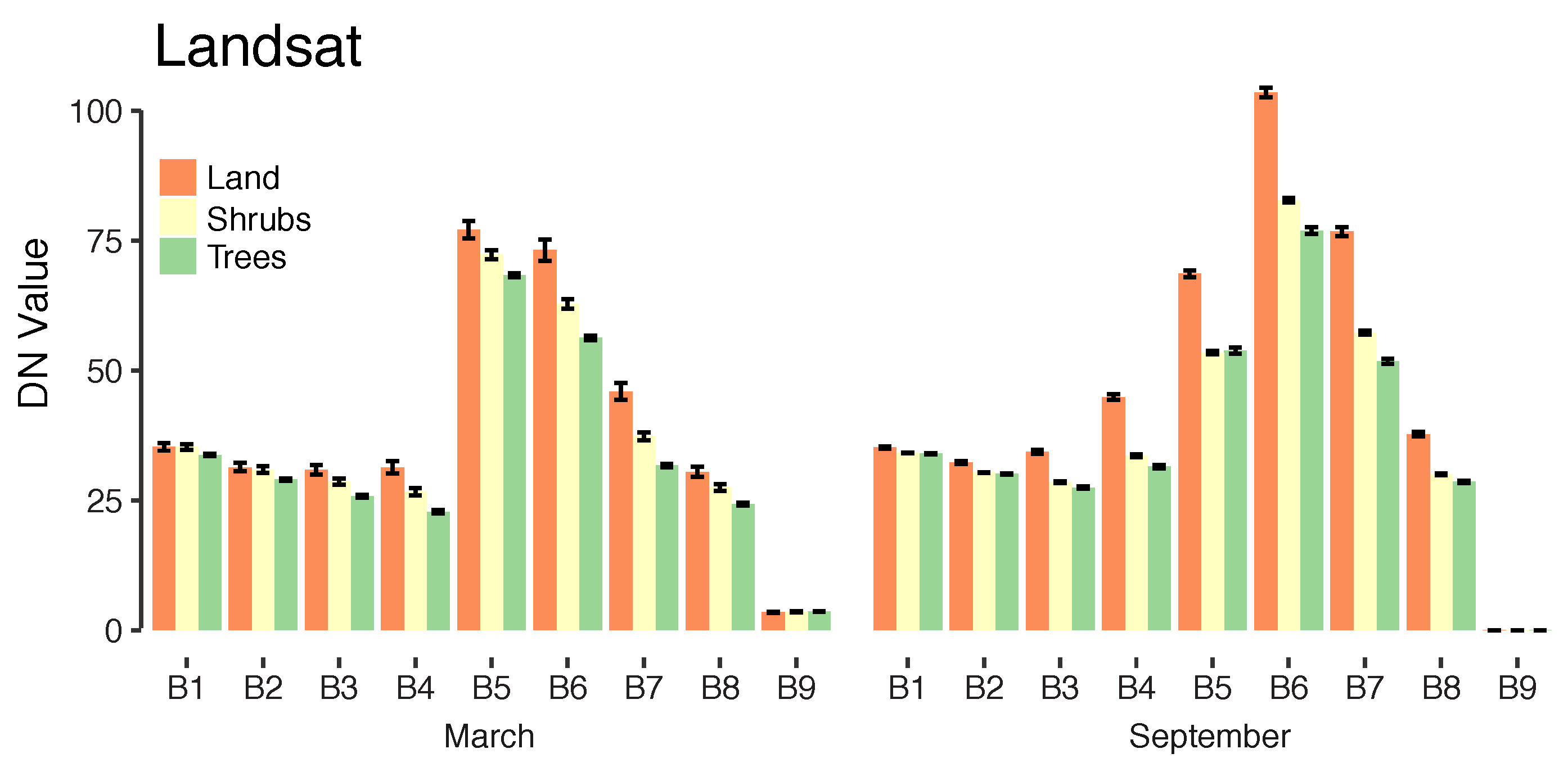
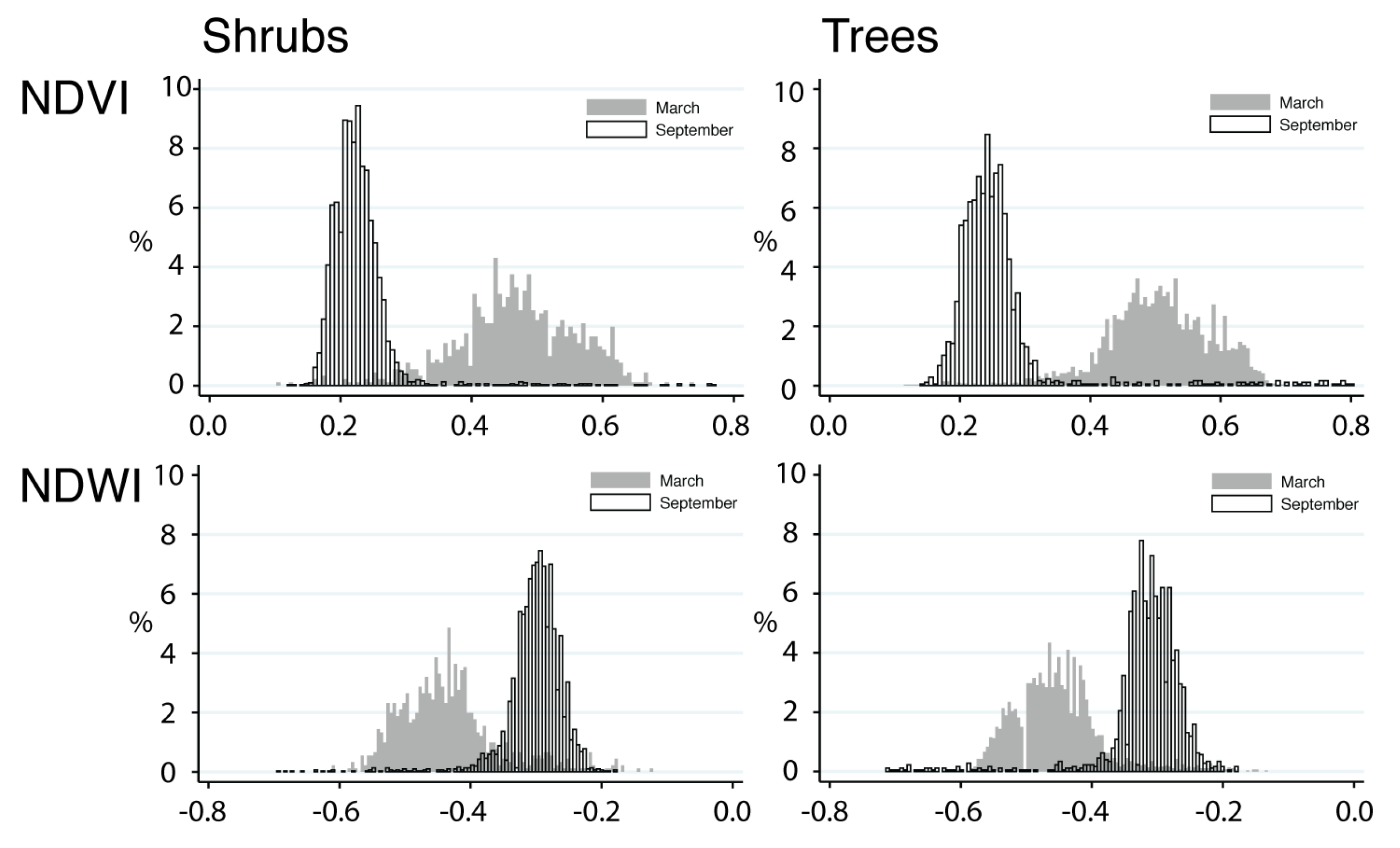
For each Landsat pixel, we used 11 spectral band designations, in a spatial resolution of between 15 m (band 8) to 30 m (bands 1–7, 9–11) and we calculated five spectral indices as additional inputs to the classifier. These indices are commonly used to identify water (Normalized Difference Water Index (NDWI)), built up and bare land areas (Normalized Difference Built-up Index (NDBI); Urban Index (UI)), and vegetation (Normalized Difference Vegetation Index (NDVI); Enhanced Vegetation Index (EVI)). We thus used a total of 15 features per pixel (11 spectral bands and 4 spectral indices). We added these nonlinear indices as additional inputs to the classifier to improve identification of vegetation and bodies of water (NDVI, NDWI and EVI) and other types of land cover (NDBI and UI). Although the latter two indices were originally designed to capture built-up and urban areas, they are also sensitive to the spectral characteristics of bare land [
17], which are relatively similar to those of urban areas [
18].
For each WorldView pixel, we used 3 spectral band designations (blue, green, and red) in a spatial resolution of 0.5 m (WV2) and 0.3 m (WV3) (bands for WorldView and Landsat are described in
Table A2). It should be noted that, while WV2 collects imagery at eight multispectral bands (plus Panchromatic) and WV3 collects imagery at eight multispectral bands, eight-band short-wave infrared (SWIR) and 12 CAVIS (plus Panchromatic), we were only granted access to three of WorldView’s imagery bands (the red, green and blue bands). WV2 and WV3 3-band pan sharpened natural color imagery was downloaded from DigitalGlobe Basemap (My DigitalGlobe). The imagery included single-strip ortho with off-nadir angle of 0–30 degrees (the full metadata of the downloaded scenes is presented in
Appendix A,
Table A1). The WorldView imagery we analyzed was processed by DigitalGlobe. Though temporal analysis with this type of data should be performed with caution (while accounting, for example, for radiometric and atmospheric variations), it is sufficient for the purpose of our study: to evaluate classification performance in one moment of time with different spatial and spectral resolution input data (note that we do not include spectral indices that are based on the WorldView input). Our objective here was not to perform change detection or to classify the land cover in different moments in time. Instead, we performed a basic per-pixel supervised classification procedure, where the characteristics of the feature space (e.g., calibrated or not, DN or reflectance values) are similar in training and classification.
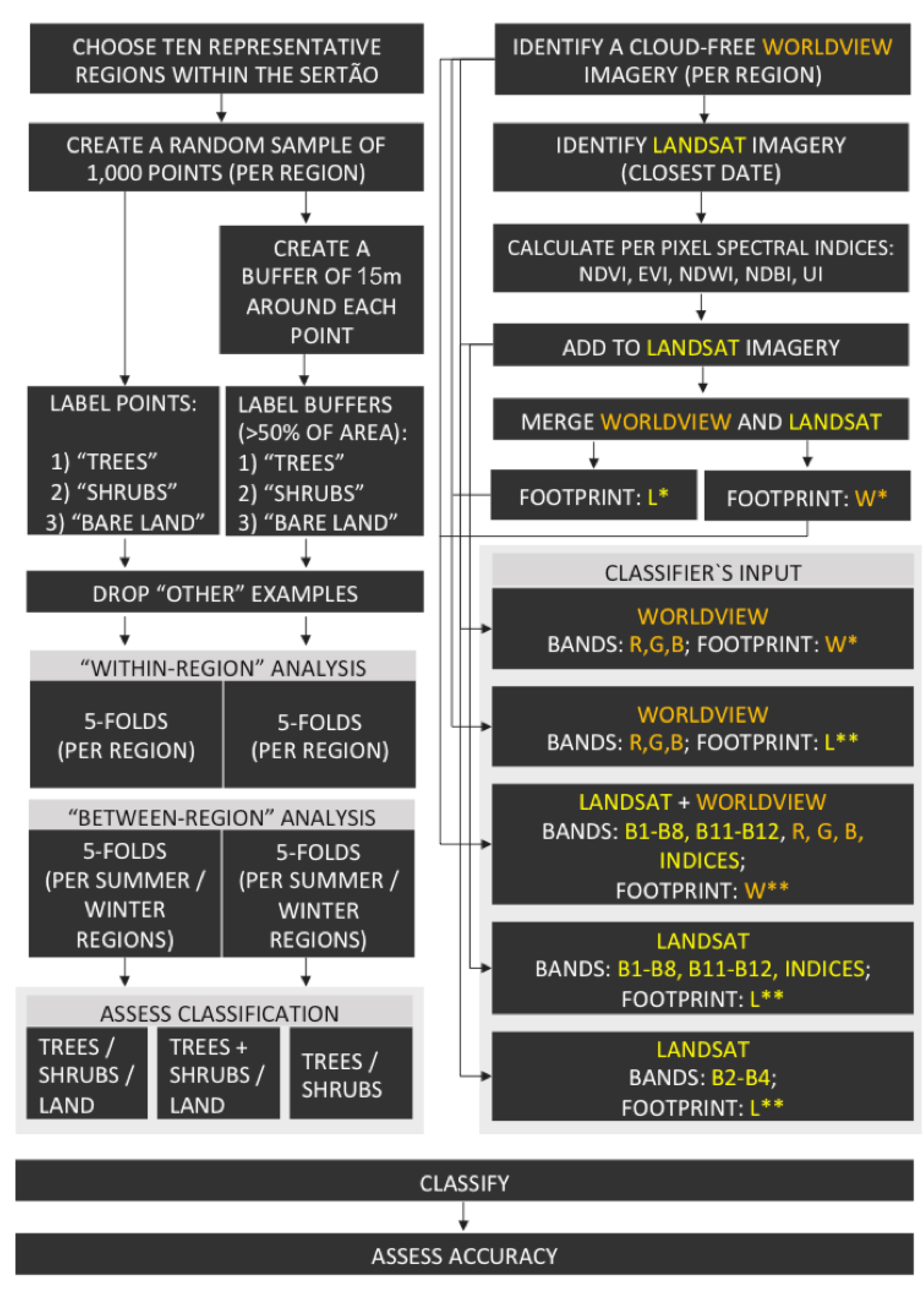
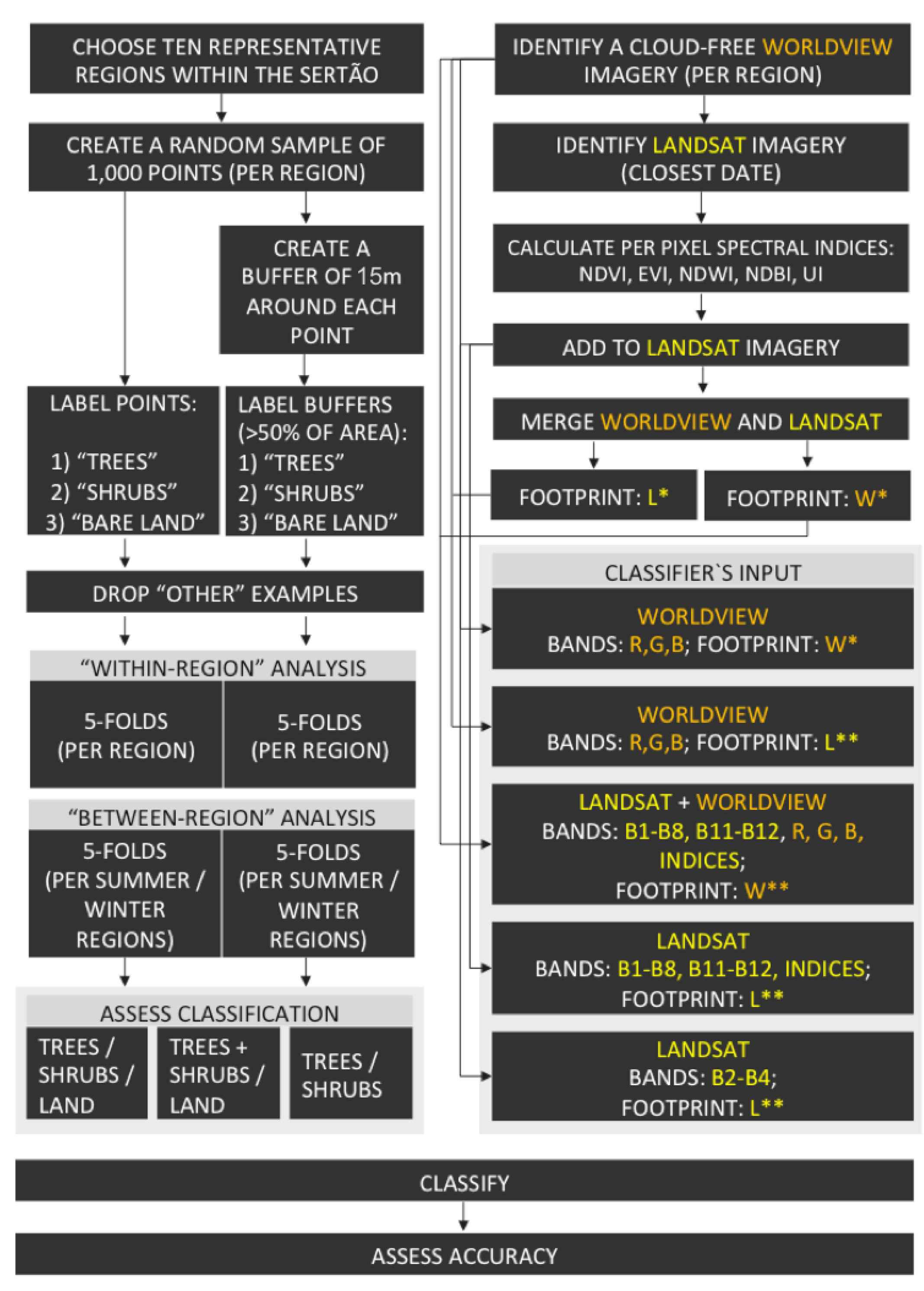
We performed classification with 5 different combinations of inputs to the classifier: using (I) Landsat bands alone (herafter LS8); (II) using WorldView bands alone (hereafter WV); (III) using WorldView bands, rescaled (averaged) to Landsat’s spatial resolution (30 m) (hereafter WV30); (IV) using the subset of 3 Landsat bands, corresponding to WorldView’s visible bands (Red, Green, and Blue) (hereafter LS8RGB); and, finally: (V) using WorldView bands combined with Landsat bands, at the spatial resolution and footprint of WorldView (hereafter WVLS8). The spatial and spectral information for each classifier is summarized in
Table A2.
In each case, we used a Random Forest (RF) classifier with 20 decision trees. Random Forests are tree-based classifiers that include
k decision trees (
k predictors). When classifying an example, its variables (in this case, spectral bands and/or spectral indices) are run through each of the
k tree predictors, and the
k predictions are averaged to get a less noisy prediction (by voting on the most popular class). The learning process of the forest involves some level of randomness. Each tree is trained over an independently random sample of examples from the training set and each node’s binary question in a tree is selected from a randomly sampled subset of the input variables. We used RF because previous studies found that the performance of RF is superior to other classifiers [
15], especially when applied to large-scale high dimensional data [
19]. Random Forests are computationally lighter than other tree ensemble methods [
20,
21] and can effectively incorporate many covariates with a minimum of tuning and supervision [
22], RF often achieve high accuracy rates when classifying hyperspectral, multispectral, and multisource data [
23]. In this study, we set the number of trees in the Random Forest classifier to 20. Previous studies have shown mixed results as for the optimal number of trees in the decision tree, ranging from 10 trees [
24] to 100 trees [
20]. According to [
15], although the performance of Random Forest improves as the number of trees increases, this pattern only holds up to 10 trees. Performance remains nearly the same with 50 and with 100 decision trees. Similarly, Du et al. (2015) evaluated the effect of the number of trees (10 to 200) on the performance of RF classifier and showed that the number of trees does not substantially influence the classification accuracy [
25]. Because our intention here was not to identify an optimal number of trees in the RF but to compare classification with different types of input, we chose to use a RF classifier with 20 trees and did not imply that this is the optimal number of trees.
In general, automatic classification of land use/land cover (LULC) from satellite imagery can be conducted at the level of a pixel (pixel-based), an object (object-based) or in a combined method. Pixel-based methods for LULC classification rely on the spectral information contained in individual pixels and have been extensively used for mapping LULC, including for change detection analysis [
26]. Object-based methods rely on the characteristics of groups of pixels, where pixels are segmented into groups according to similarity and the classification is done per object, rather than per pixel. While several studies suggest that object-based classifiers outperform pixel-based classifiers in LULC classification tasks [
27,
28,
29,
30], other studies suggest that pixel-based and object-based classifiers perform similarly when utilizing common machine-learning algorithms [
31,
32]. In addition, object-based classification requires significantly more computational power than pixel-based classification and there is no universally accepted method to determine an optimal scale level for image segmentation [
28], especially when analyzing large-scale and geographically diverse regions. Thus, object-based classification is typically conducted when the unit of analysis is relatively small, such as a city [
28,
30], or a region of a country [
27,
30,
31,
32], as we do in this study. Here, we map land cover at the level of the pixel.
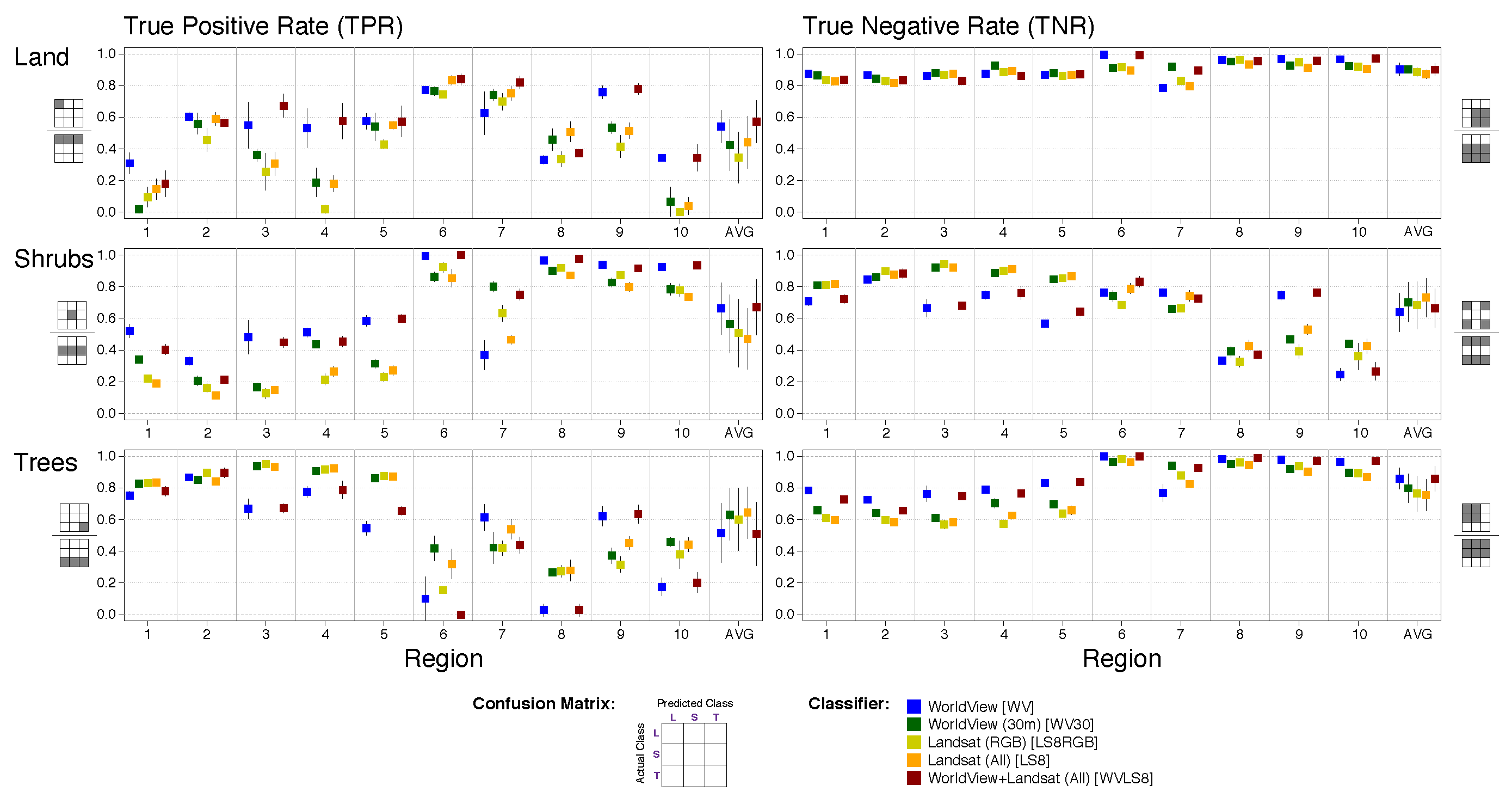
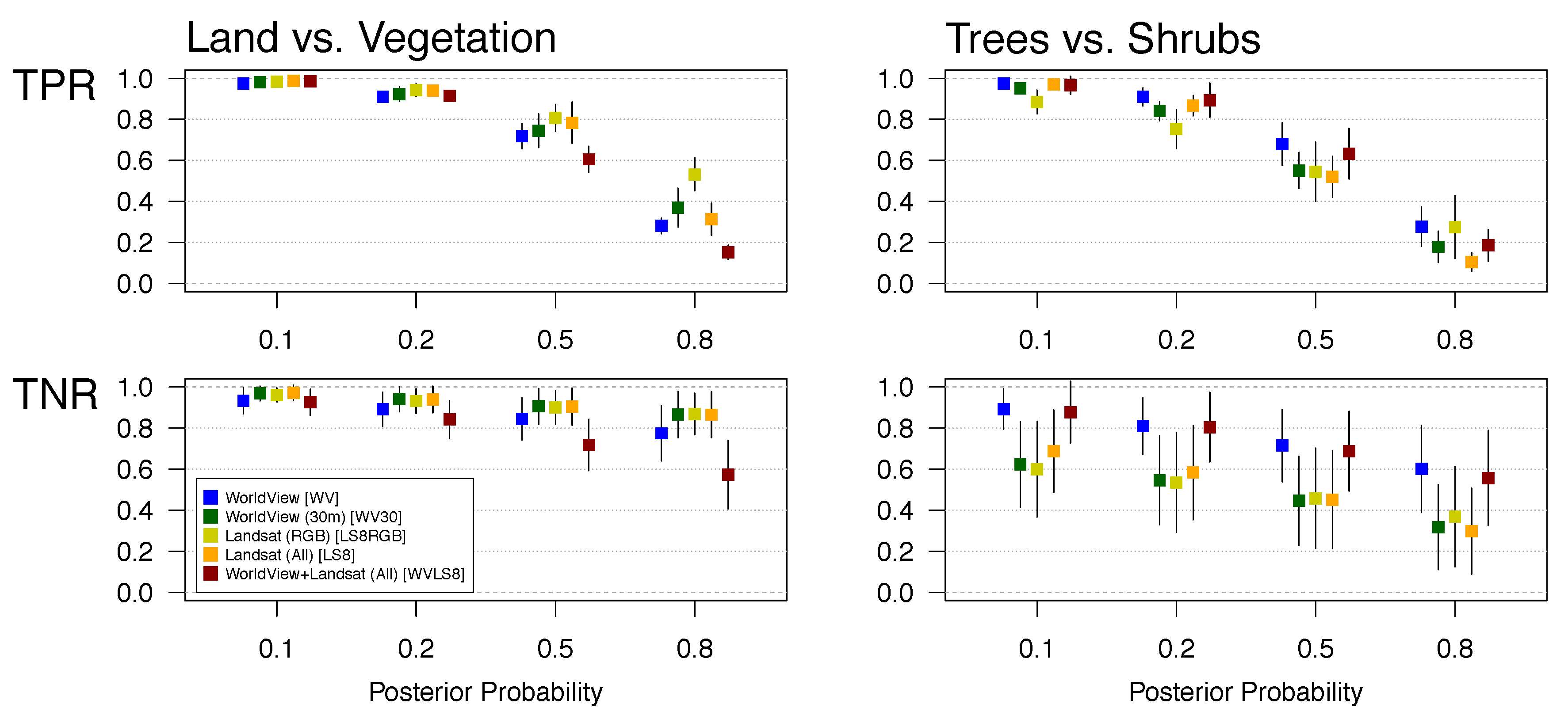
We evaluated the performance of the classifiers in both 3-class classifications, utilizing the full set of examples: trees, shrubs, and land, and 2-class classification, where we classified (I) land versus all vegetation (trees + shrubs) and (II) trees versus shrubs (excluding land). Given a 2-class classification problem (into class C and D), the classifiers predict per-pixel probability of class membership, (posterior probability (p), in the range between 0 and 1) representing the probability that a pixel X belongs to class C (the probability the pixel belongs to class D is 1-p). A pixel X is classified as belonging to class C, if the probability it belongs to class C exceeds a given threshold. An important question in any machine learning task is what is the optimal posterior probability threshold above which a pixel is declared to belong to the ‘positive’ class. To address this question, we also assess performance of 2-class probability-mode classification, where a pixel is declared as positive if the posterior probability exceeds either 0.1, 0.2, 0.5 or 0.8. We evaluate the effect of these posterior probability thresholds on the performance of the classifiers (i.e., the True Positive Rate (TPR) and True Negative Rate (TNR) measures). Although previous studies suggest methods for probability estimates for multi-class classification (i.e., classification into more than two classes), for example, by combining the prediction of multiple or all available pairs of classes [
33,
34], here we only perform a 2-class probability classification, classifying land versus all vegetation and trees versus shrubs. According to this approach, a pixel is declared as positive (i.e., vegetation or trees, respectively) if the probability it belongs to these classes exceeds a threshold (0.1, 0.2, 0.5 or 0.8). Below this threshold, the pixel is classified as negative (land or shrubs, respectively).
We performed classification of trees versus shrubs only with the examples that were labeled as either one of these two classes. This classification procedure predicts the class of each pixel in the classified universe as either trees or shrubs (although the scenes, by their nature, also include other types of land cover such as bare land). Obviously, mapping this prediction will be misleading, as this is a 2-class classification. In this procedure, each pixel in the universe is classified as one of two classes (trees or shrubs) and the prediction is evaluated against the examples labeled as trees and shrubs in the reference data.
For the 3-class classification, each example (pixel) was classified as one of three classes (trees, shrubs, land), without treating the examples as ‘positive’ or ‘negative’. Given a trained classifier consisting of
n trees (in this case 20 trees), each new instance (pixel) is run across all the trees grown in the forest. Each tree predicts the probability an instance belongs to each one of the classes (in this case, one of 3 classes) and votes for the instance’s predicted class. Then, the votes from all trees are combined and the class for which maximum votes are counted is declared as the predicted class of the instance [
35,
36].
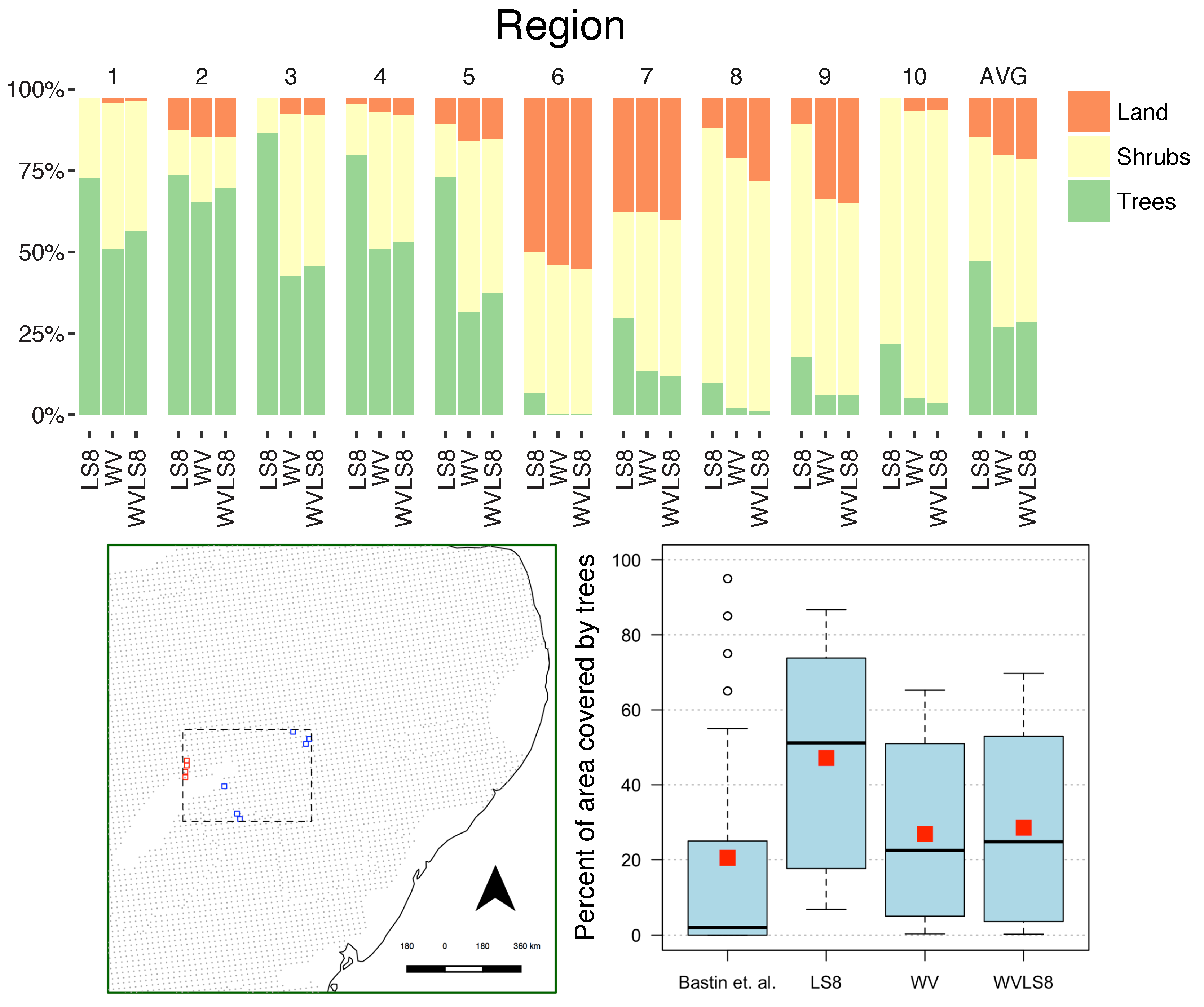
The distinction between classes are all meaningful in an ecological sense, given the landscape heterogeneity and highly varying vegetation patterns of semi-arid regions like the Sertão, and the most appropriate choice of the classified classes depends on the application. For example, a 3-class classification would be most relevant for total ecosystem landcover assessment, whereas land-versus-vegetation would be most relevant for assessing degradation or recovery, and trees-versus-shrubs would be most relevant for assessing seasonal variations in vegetation.
The performance (accuracy) of a classifier refers to the probability that it will correctly classify a random set of examples [
37]; the data used to train the classifier must thus be distinct from the data that is used to assess its performance. Labeled (or reference) data is typically divided into training and test sets (a validation set may also be used to “tune” the classifier’s parameters). Different data splitting heuristics can be used to assure a separation between the training and test sets [
37], including the holdout method, in which the data is divided into two mutually exclusive subsets: a training set and a test/holdout set; bootstrapping, in which the dataset is sampled uniformly from the data, with replacement; and cross-validation (also known as
k-fold cross-validation), in which the data are divided into
k subsets, and the classification is performed
k times, rotating through each ‘fold’ as a test set. By averaging across the different draws, cross-validation gives a less biased estimate of classifier performance, [
38] along with a variance estimation of the classification error [
39,
40]), but is less computationally intensive than (typically hundreds) of bootstrap re-samples.
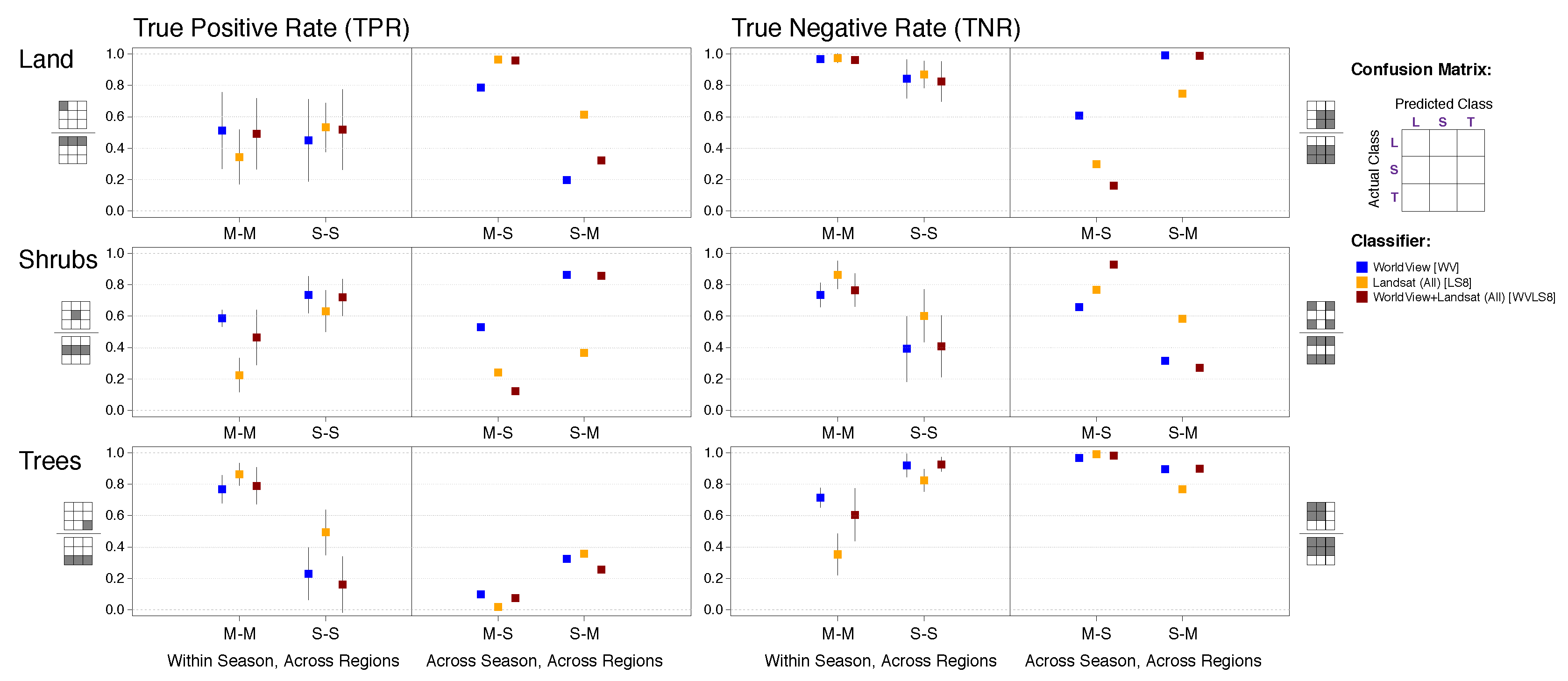
Here, we adopted a k-fold cross validation procedure. We used 5-fold cross-validation in all experiments (i.e., 5 folds, or groups), with random examples allocated to folds stratified by labeled class (i.e., each fold had the same proportion of each class as the full region). We performed classification and accuracy assessment both within and between regions: in “within-region” analysis, we divided the examples in a region into 5 folds. For each experiment, we used all examples in 4 folds for training, and assessed the classification of the examples in the remaining fold. In “between-region” analysis, we used all the examples in 6 or 4 regions (the summer or the winter images). The latter procedure is designed to evaluate the spatial generalization of the classifiers. Thus, we repeat the 5-fold cross validation twice: with all the examples in regions 1–4 (March 2016) and with all the examples in regions 5–10 (September 2015).
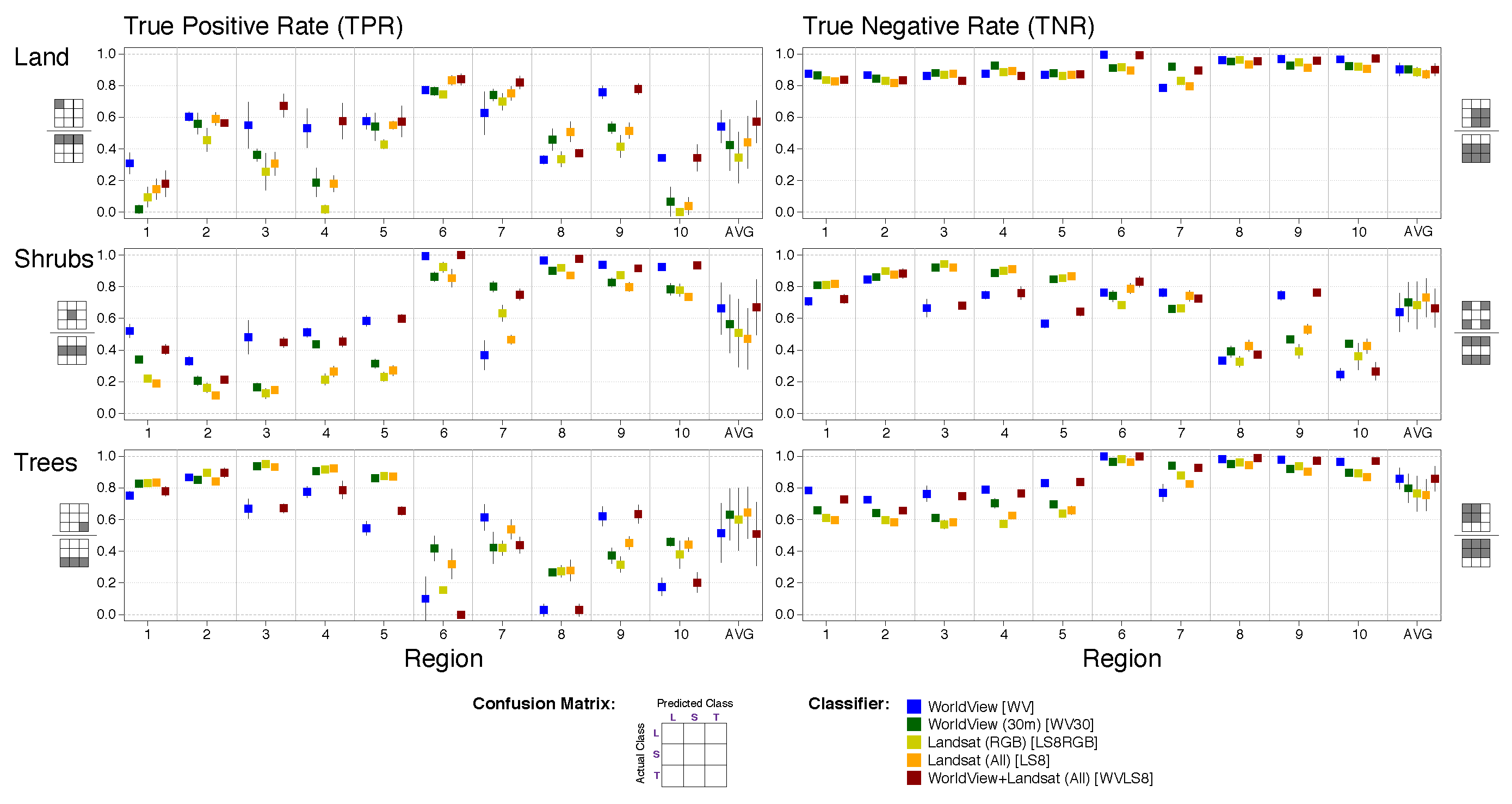
We assess classifier performance using three estimated quantities from 2- and 3- class confusion matrices (e.g., as in [
41] for 3-class): (1) True Positive Rate (TPR), or sensitivity, which refers to the percentage of positive examples classified correctly as positive (i.e., positive label = classification as positive); (2) True Negative Rate (TNR), or specificity, which refers to the percentage of negative examples (or “not positive”) that were classified correctly as negative (or as “not positive”) (e.g., if trees are positive and land and shrubs are negative, TNR refers to the percentage of land and shrubs examples that were correctly classified as not trees). Although reporting TPR and TNR is standard practice in a 2-class classification problem, we note that it is especially important to interpret these quantities appropriately when dealing with imbalanced datasets. In our setting, the weight of each class (i.e., the number of per-class examples,
Table 1) depends on the coverage of each class in a region.
For each experiment, we calculated mean values and standard errors of TPR and TNR across all 5 folds. When assessing classifier performance by class, standard errors (95% confidence interval) for each metric were calculated across folds based on the number of examples per class per fold.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}