Highlights
What are the main findings?
- A two-phase framework is proposed utilizing a PCA-based candidate extraction strategy to eliminate massive background objects and alleviate extreme sample imbalance at the data level.
- A Spike-inspired Landslide Extraction Model is developed, incorporating a spike-inspired sparse attention module (SISA) and mix-scale feature aggregation (MSFA) to adaptively suppress background noise and enhance blurred landslide boundaries.
What are the implications of the main findings?
- The framework provides a robust solution for large-scale landslide extraction, effectively overcoming the challenges of data imbalance and complex background interference.
- Integrating biologically inspired SNN sparse activation mechanisms into deep learning offers a promising new approach for accurate landslide extraction and mitigating background confusion in remote sensing.
Abstract
Landslides endanger human safety and damage infrastructure, underscoring the importance of accurate extraction. However, landslide extraction is often hindered by the omission of sparsely distributed landslides and the difficulty of delineating their blurred boundaries. Large-scale landslide extraction faces two key challenges. The first is a severe sample imbalance between landslides and background objects, which biases the model toward background and omits landslides. The second is the confusion between landslides and background features, which leads to inaccurate boundary delineation and fragmented extraction results. To address these issues, this paper proposes a two-phase landslide extraction framework. First, we propose a PCA-based landslide candidate extraction module to remove salient background objects and reduce data imbalance. Second, we propose a Spike-inspired Landslide Extraction Model to further discriminate actual landslides from the candidates by incorporating a spike-inspired sparse attention module (SISA). It can enhance weak landslide features such as blurred boundaries while mitigating background noise through its adaptive spatial suppression mechanism. To integrate spatial details across scales, a mix-scale feature aggregation module (MSFA) is proposed, which aggregates hierarchical features to extract landslides of various scales. Experiments on the landslide datasets from the Hengduan Mountains and Hokkaido, Japan, show IoU improvements of 4.26% and 1.22% compared to the recently proposed methods, validating its effectiveness under both imbalanced and dense landslide conditions.
1. Introduction
The combined effects of global climate change and intensified human activities have contributed to the increasing frequency and intensity of landslides [1,2]. These events not only inflict direct damage on critical infrastructure but also induce cascading hazards such as debris flows and river channel blockages, which further amplify their social and environmental impacts [3,4,5]. According to the World Health Organization, landslides affected approximately 4.8 million people and caused over 18,000 fatalities between 1998 and 2017 [6]. Given their severe and far-reaching consequences, the development of accurate and comprehensive landslide inventories is vital for delineating hazard-prone areas and supporting robust risk assessment and mitigation strategies [7,8].
Traditional landslide mapping typically relies on manual interpretation and field surveys, which are labor-intensive and impractical for large-scale applications [9]. With the growing availability of remote sensing data, numerous studies have investigated automated or semi-automated approaches for landslide extraction using satellite imagery [10,11,12,13,14,15,16]. Many of these methods employ spectral, topographic, or texture-based features for landslide identification [17,18]. To enhance automation and landslide extraction accuracy, machine learning models such as support vector machines and random forests were subsequently adopted [14]. However, these models depend heavily on handcrafted feature design and often struggle to generalize across diverse terrains and complex background conditions, limiting their robustness and scalability in real-world applications [19].
Deep learning has become a dominant approach for object extraction from remote sensing imagery, owing to its capacity to automatically learn hierarchical spatial representations from images directly [20]. For landslide extraction, CNN-based methods have shown strong potential in capturing spatial patterns and terrain textures from complex imagery, thereby reducing the reliance on handcrafted features and improving generalization across heterogeneous landscapes [21]. Liu et al. [22] improved Mask R-CNN by integrating ResNeXt blocks and incorporating bottom-up pathways to better fuse low-level spatial details with high-level semantic features, reaching a precision of 95.8% in the Jiuzhaigou region. Shi et al. [23] introduced an object-oriented change detection framework CDCNN for landslide extraction, integrating fully connected conditional random fields to achieve over 80% accuracy on two Hong Kong sites. Li et al. [24] improved the U-Net by embedding an inception module with dilated convolutions and incorporating a boundary detection algorithm to enhance landslide segmentation performance. Chen et al. [25] incorporated the squeeze-and-excitation network (SENet) into the feature fusion part of U-Net to enhance channel-wise feature responses, improving landslide extraction accuracy by over 2%. Li et al. [26] introduced a lightweight Convolutional Block Attention Module with a dual-attention design to improve DeepLabv3+, which enhanced landslide feature perception and refined edge delineation, increasing IoU by 14.27% compared to the original DeepLabv3+. Despite these advances, CNN-based approaches still face challenges in detecting small or scattered landslides due to their inherently limited receptive fields.
Transformers have recently been applied to landslide extraction tasks due to their strong capability to capture global contextual features through self-attention mechanisms [27,28,29,30]. Compared with CNNs, Transformers are more effective in modeling long-range dependencies, building contextual relationships between distant landslide parts to improve the integrity of landslide extractions in fragmented scenes [31]. However, since Transformers mainly focus on global features and lack inductive biases for local detailed features, they may struggle to capture fine spatial boundaries, which are critical for accurate landslide extraction. To address this limitation, hybrid CNN–Transformer architectures have been increasingly adopted to combine the locality modeling strength of CNNs with the global contextual awareness of Transformers for landslide mapping. Huang et al. [32] combined morphological edge detection and Swin Transformer to enhance landslide boundary extraction. Wu et al. [33] proposed SCDUNet++, a hybrid model that fuses convolutional and Transformer-based landslide features to integrate optical and topographic features to improve robustness across surface types. Fan et al. [29] integrated enhanced Transformer modules with graph convolution to model local spatial relationships while preserving global context, achieving a balance between accuracy and efficiency across two landslide datasets. Li et al. [34] fused ResNet local features with Swin Transformer global modeling and introduced a Spatial Gate Attention Module (SGAM) to suppress background noise and bridge semantic gaps, improving IoU by 4.91% and 2.96% on the Bijie and Luding datasets, respectively. Xiang et al. [35] employed a parallel CNN–Transformer framework with an Interactive Self-Attention module to merge multilevel features from both branches, achieving an IoU of 75.34% on the Bijie dataset. These hybrid approaches demonstrate that integrating CNNs and Transformers enables the capture of both fine-scale spatial details and broader contextual patterns, significantly advancing landslide mapping performance.
Most of the methods above focus on landslide extraction from areas dominated by mono-background objects or uniform topographic features. However, this setting differs from real-world application scenarios, where landslides often occur across vast, heterogeneous landscapes triggered by large-scale events such as earthquakes or extreme rainfall [36,37]. In such large-scale contexts, two major challenges emerge in landslide extraction. First, a severe data imbalance exists between the extreme sparsity of landslide pixels and the vast background objects. This imbalance often leads models to overfit background classes and omit landslides with weak features. Second, landslides are frequently confused with spectrally and morphologically similar background elements, such as bare soil, exposed rock or road surfaces, which may lead to inaccurate boundary delineation and fragmented landslide extraction.
Recent studies have proposed synthetic sample generation, prototype-guided learning, and domain-aware strategies [38,39,40] to alleviate data imbalance, improve feature discrimination, and enhance model generalization across diverse terrains. Despite their contributions, the effectiveness of these strategies in complex real-world settings remains constrained by several practical limitations. Synthetic samples with limited realism in landslide texture or geomorphic context may resemble background objects, introducing ambiguity during training [41]. Prototype-guided learning promotes intra-class consistency, but may underrepresent the diversity of landslide patterns and reduce the model’s ability to distinguish landslides from spectrally similar background objects. Domain-aware strategies align features across regions or sensors, yet this process can blur landslide boundaries and enhance responses to irrelevant background elements [42]. While these approaches offer valuable support for large-scale landslide extraction, they may also introduce background interference, underscoring the need for improved strategies that directly tackle class imbalance and background ambiguity in complex terrains.
Addressing these limitations, we explore the potential of Spiking Neural Networks (SNNs), a biologically inspired architecture that offers a promising approach for suppressing background interference and improving the discriminability of blurred or subtle landslide features from spectrally similar background objects. SNNs emulate the functioning of biological neurons by employing a temporal threshold mechanism [43,44]. From a biological perspective, membrane potentials integrate signals over time and generate spikes only when the activation exceeds a threshold. This threshold-based firing naturally suppresses irrelevant inputs while preserving salient responses. When mapped to feature learning, such mechanism can be interpreted as a selective activation process that retains strong and consistent feature responses while filtering out weak background activations. This sparse and selective firing process makes SNNs particularly well-suited for scenarios with highly imbalanced and noisy conditions, which can be adapted to landslide extraction. However, it is difficult to directly apply SNNs in conventional deep learning pipelines, due to their discrete and non-differentiable nature [45,46]. Inspired by the sparse activation mechanism of SNNs, we propose a differentiable selective feature learning strategy tailored for landslide extraction.
To tackle the challenges of extreme data imbalance and confusion with background objects in large-scale landslide extraction, we propose a two-phase spike-inspired framework that draws on the sparse activation principles of SNNs. First, a PCA-based landslide candidate extraction method is introduced to eliminate extensive and irrelevant background regions. By distinguishing surface changes induced by landslides from temporally stable background objects, such as bare soil, we effectively improve class balance and reduce redundancy at the data level. Second, we propose a Spike-inspired Landslide Extraction Model to adaptively suppress background responses and enhance attention to blurred landslide features at model level. This is achieved through a spike-inspired sparse attention module (SISA), which adapts threshold-based firing behavior of biological spikes into a spatial suppression mechanism by combining Top-k sparse activation with a Gaussian decay kernel. Specifically, only high-response features exceeding an adaptive activation threshold are retained, while surrounding regions are progressively suppressed, mimicking the selective firing nature of biological neurons. To further improve landslide spatial feature representation, we integrate a mix-scale feature aggregation module (MSFA) that fuses cross-level features to aggregate semantic and detail features, enabling the extraction of landslides of various scales. By integrating spike-inspired sparsity with the global modeling capacity of Transformer-based architectures, the proposed approach improves landslide extraction performance and generalization from both data and model perspectives. The primary contributions of this study are summarized as follows:
- (1)
- We propose a PCA-based landslide candidate extraction method to remove extensive background regions at the data level, improving class balance and reducing irrelevant background noise, which facilitates more accurate large-scale landslide extraction.
- (2)
- A spike-inspired landslide extraction method is developed for large-scale applications. It incorporates a spike-inspired sparse attention module (SISA) to adaptively suppress background interference and a mix-scale feature aggregation module (MSFA) to enhance attention to weak and fragmented landslide features, providing a robust and precise solution for landslide extraction across large-scale and complex geological regions.
2. Datasets
To validate the generalization and robustness of our method for landslide extraction, we adopt two representative datasets from the Hengduan Mountains in China and the Hokkaido region in Japan, both of which are highly susceptible to recurrent landslide activity [47,48]. The Hengduan Mountains are characterized by a broad spatial extent and highly complex background land cover. The Hokkaido region features more localized terrain and distinct land surface conditions. These contrasting environments provide a valuable basis for evaluating model adaptability under varying background complexities. Detailed descriptions of the study areas and data sources are introduced below.
2.1. Hengduan Mountains, China
The Hengduan Mountains, as shown in Figure 1, are characterized by rugged terrain. Frequent seismic activity and significant climatic variability make it highly susceptible to landslides and debris flows. It is widely recognized as one of the areas with the highest geological hazard exposure in China [49,50]. The landslides across the Hengduan Mountains show diverse shapes and sizes due to the vast spatial extent. The background is characterized by complex features comprising 23 distinct land cover types [51], such as bare soil, roads, and urban buildings, which exhibit similar spectral properties to landslides and make it difficult to reliably distinguish true landslide occurrences.
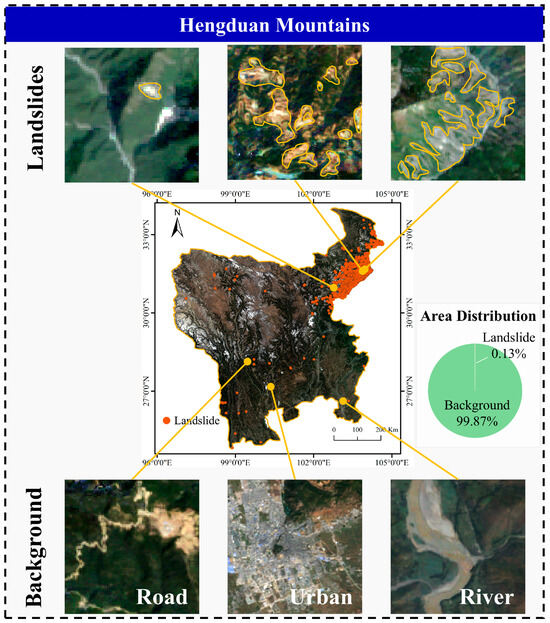
Figure 1.
Study area of the Hengduan Mountains.
To minimize cloud interference and seasonal variability, we generated the annual composite images from Landsat-5, Landsat-7, and Landsat-8 data. These images were produced on the Google Earth Engine platform based on median-NDVI synthesis strategy. The years 2008 and 2018 were selected as they correspond to two major earthquake events. The 2008 Wenchuan earthquake triggered an estimated 197,481 landslides, and the 2017 Jiuzhaigou earthquake induced another 4834 landslides [47,52]. For the 2017 event, the 2018 composite image was used because the earthquake occurred late in August, making the 2017 annual composite incomplete for post-event analysis.
The actual landslide inventory was generated through visual interpretation of the annually composited Landsat images, complemented by high-resolution imagery from Google Earth. Additionally, field-validated datasets from the 2008 Wenchuan and 2017 Jiuzhaigou earthquakes were used to refine and confirm landslide outlines, ensuring the accuracy of annotations for training and evaluation. Specifically, the resulting inventory from the 2008 annual composited Landsat image comprises 17,122 landslides, covering a total area of approximately 574.40 km2, representing 0.13% of the Hengduan Mountains. Similarly, we identified 2276 landslide instances with a cumulative area of roughly 41.77 km2 in the 2018 annual image.
2.2. Hokkaido, Japan
On 6 September 2018, a magnitude 6.7 Iburi earthquake struck Hokkaido, Japan, leading to widespread landslides across the region [48]. As shown in Figure 2, the landslides in this region are densely clustered and exhibit clearly defined boundaries. In contrast to the complex Hengduan Mountains, the land cover types in this region are relatively simple, comprising 14 distinct categories [51].
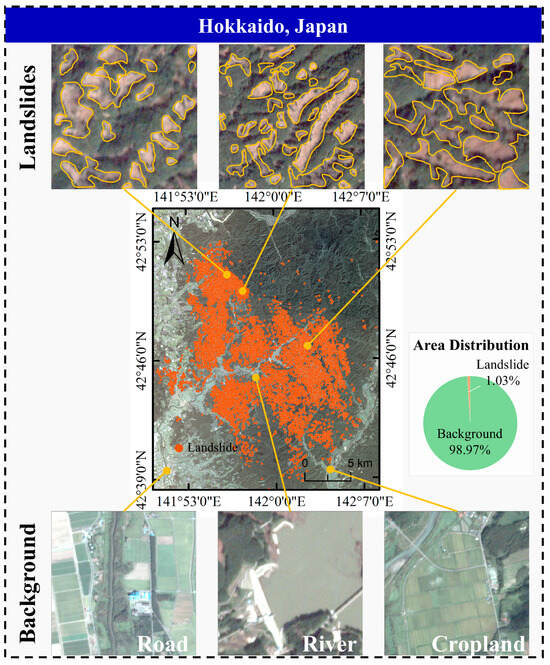
Figure 2.
Study area of Hokkaido, Japan.
To capture post-earthquake conditions, we used Planet Level-3B imagery with 3 m spatial resolution acquired on 11 September 2018. These orthorectified images offer sufficient detail to support accurate landslide identification and performance evaluation under densely clustered landslide distributions. The actual landslide boundaries in this region were derived through expert visual interpretation [48]. Ultimately, this inventory includes 9295 landslides, occupying a total area of approximately 30.85 km2, accounting for 1.03% of the study area.
3. Proposed Method
To address the challenges of class imbalance and feature confusion in large-scale landslide extraction, we propose a two-phase framework, as illustrated in Figure 3. This framework includes a Landslide Candidate Extraction to mitigate class imbalance at the data level, and a Spike-inspired Landslide Extraction Model to adaptively suppress background interference and enhance attention to weak landslide features at the model level. The details of each phase are introduced below.
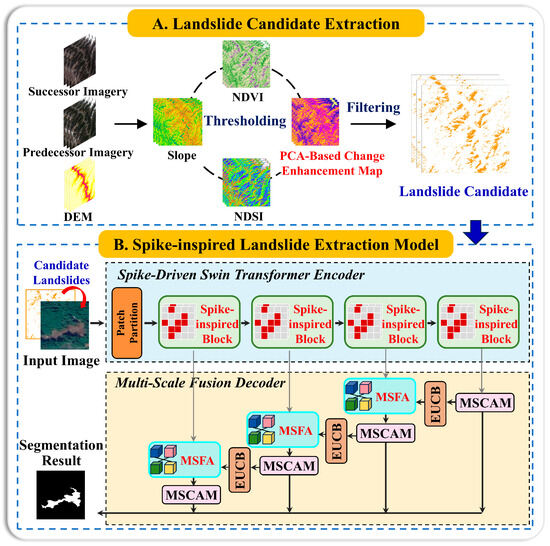
Figure 3.
Overall framework of the spike-inspired landslide extraction framework.
3.1. Landslide Candidate Extraction
In large-scale remote sensing images, landslide pixels are extremely sparse compared to background pixels, creating a severe class imbalance. As shown by the area distribution in Figure 1, in the 2008 Hengduan Mountains imagery, background occupied roughly 99.87% of the area. This extreme imbalance biases the model towards the background class, resulting in the omission of numerous landslides. To address this issue, we propose a PCA-based landslide candidate extraction method, as illustrated in Figure 3A.
This method removes extensive vegetation, snow and ice, and flat terrain using topographic and spectral filtering. Flat terrain is excluded using a 10° slope mask calculated from 90 m SRTM DEM. Additionally, we use a Normalized Difference Snow Index (NDSI) with a threshold of 0.2 to remove snow and ice [53], and a Normalized Difference Vegetation Index (NDVI) with a threshold of 0.25 to exclude vegetation [54]. These thresholds were optimized to ensure effective noise removal while retaining landslide features.
While this initial filtering removes extensive background, distinguishing landslides from other spectrally similar but temporally stable surfaces, like bare soil and rocks remains challenging. To further enhance landslide-related surface changes, a PCA-based change enhancement strategy is adopted on pre- and post-event images [55]. The appearance of landslides creates the largest statistical variance between the two temporal images. For each pixel, a difference vector is first constructed across the red, green, blue, and near-infrared bands, formulated as:
where and denote the annual composite images of two consecutive years. The resulting difference vectors characterize cross-temporal surface changes, while stable background regions exhibit minor spectral variations. PCA is then applied to the difference space after mean normalization to project these changes onto orthogonal components. The first principal component captures the dominant change pattern and is used to generate a Change Enhancement Map. By segmenting this map to isolate areas of surface change, we identify the final landslide candidates, as shown in Figure 4, creating a more balanced dataset for the subsequent extraction.
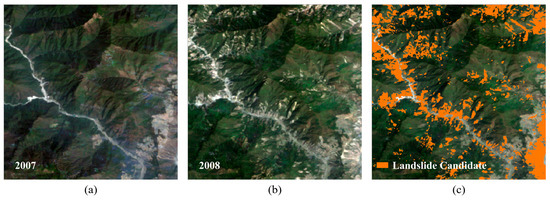
Figure 4.
Results of the PCA-Based landslide candidate extraction. (a) The 2007 annual composite image. (b) The 2008 annual composite image. (c) Extracted Landslide Candidates (2008).
3.2. Spike-Inspired Landslide Extraction Model
Although the candidate extraction phase removes a majority of background areas, many background objects that share similar spectral and textural features with landslides remain. To achieve a more refined discrimination and enhance focus on landslide features, we propose a Spike-inspired Landslide Extraction Model. As shown in Figure 3B, it is composed of a spike-inspired Swin Transformer encoder and a mixed-scale decoder.
The encoder incorporates the spike-inspired sparse attention module to perform adaptive spatial suppression, which enhances focus on landslide features while filtering background noise. This design is motivated by the threshold-driven firing behavior of spiking neurons, where only sufficiently prominent stimuli activate responses, while weak features are suppressed. The mixed-scale decoder then restores fine spatial details to ensure the precise delineation of landslide boundaries at different scales.
3.2.1. Spike-Inspired Sparse Attention Module (SISA)
The Swin Transformer encoder utilizes the standard self-attention mechanism, a fundamental component of Transformer architectures [56]. Given the input query (Q), key (K), and value (V), each with dimensions , the self-attention is computed as (2), where and is the number of attention heads. While this mechanism is powerful for capturing long-range dependencies, its effectiveness in landslide extraction is limited by its dense structure. This approach computes attention weights across all positions, which may introduce noise by assigning unnecessary weight to irrelevant background regions.
To overcome these limitations, the proposed SISA module implements a Spike-inspired adaptive spatial suppression mechanism, which is realized through three synergistic components that redesign the standard attention structure, as illustrated in Figure 5. First, inspired by the local information accumulation in spiking neurons, a Gaussian decay kernel is applied to strengthen attention locally and guide the model to focus on landslide regions. Second, a Top-k sparse activation attention simulates sparse neural activation to emphasize most salient landslide feature responses while filtering out weak background noise [57]. Finally, a multi-scale response fusion mechanism integrates outputs from multiple sparse attention branches to enhance the model’s representation of landslide regions.
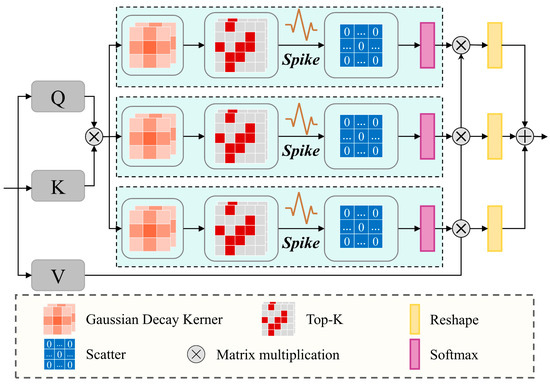
Figure 5.
Spike-inspired sparse attention module.
Gaussian decay kernel: In spiking neurons, the influence of inputs decreases over time after the firing event. When mapped to the spatial domain, feature responses should be stronger within local neighborhoods and gradually weakened with increasing spatial distance. Inspired by the decay behavior of biological spikes, we extend this concept from the time domain to the spatial domain of images to capture the local correlations of adjacent pixels. In landslide extraction, neighboring pixels often exhibit correlated spectral and structural patterns, and modeling this spatial continuity helps preserve landslide integrity while reducing isolated background noise.
We introduce a Gaussian decay kernel (GDK) to mimic the attenuation of feature responses with increasing spatial distance, strengthening activation near landslides and suppressing distant background interference [58]. The local adjustment is applied to the query (Q) and key (K) using a Gaussian kernel, as shown in (3), where and denote the pixel offset from the kernel center, and is the standard deviation controlling the decay rate. Compared with standard self-attention, where all positions contribute equally, GDK introduces spatial selectivity to reduce background interference and improve feature distinction.
Top-k sparse activation attention: The Top-k sparse Activation attention is inspired by the selective response behavior of spiking neurons, which remain inactive to weak stimuli and fire only in response to salient information [57]. In the context of spatial attention, we implement this principle by retaining only high-response interactions while eliminating weak features associated with stable background objects. To achieve this, we introduce a Top-k strategy that adaptively suppresses irrelevant responses and retains only the most significant attention. As shown in (4), only the attention scores that rank within the top-k percentages are preserved, while all others are set to zero, effectively filtering out weak responses that likely originate from background noise. The Top-K ratios are set to 50%, 67%, and 75%, representing progressively stricter activation thresholds. This produces three distinct sparse masks with different levels of activation sensitivity. The outputs from these masks are then normalized with softmax, as in (5).
Multi-scale response fusion: To integrate attention responses under different activation levels, we introduce three learnable weights to fuse the outputs from the three sparse attention branches. These weighted outputs are combined to form the final attention result, as shown in (6). This mechanism allows the model to retain strong activations while adaptively balancing different activation patterns, enabling finer and more flexible multi-scale attention modeling.
3.2.2. Multi-Scale Fusion Decoder
With background objects suppressed in the encoder, part of the spatial detail and fine texture is inevitably reduced. We propose the multi-scale fusion decoder (MSF-Decoder) to compensate for this loss and preserve multi-scale contextual coherence. It follows a progressive cross-level fusion strategy, where each decoding stage integrates upsampled semantic features from deeper layers with fine-grained spatial information from the corresponding encoder layer.
This hierarchical refinement is realized through three synergistic components. The multi-scale convolutional attention module (MSCAM) [59] enhances class-discriminative features and sensitivity to boundaries. The Efficient upsampling convolution block (EUCB) restores resolution while reconstructing fine details [59]. Finally, the mix-scale feature aggregation module (MSFA) fuses deep semantic and shallow structural features, producing a representation that is both semantically rich and spatially precise. These modules recover information lost in sparse encoding and improve the delineation of landslide boundaries.
Multi-scale convolutional attention module (MSCAM): At each decoding stage, the features are first refined by MSCAM [59] to enhance landslide features across spatial scales. As shown in Figure 6, MSCAM integrates three components. The channel attention block (CAB) highlights channels most discriminative for landslides, improving feature selectivity. The spatial attention block (SAB) emphasizes salient spatial regions while suppressing background noise. The multi-scale convolution block (MSCB) applies parallel convolutions with different kernel sizes to expand receptive fields and improve sensitivity to landslide boundaries and textures. Together, these components generate rich contextual features for accurate extraction of complex landslide regions.
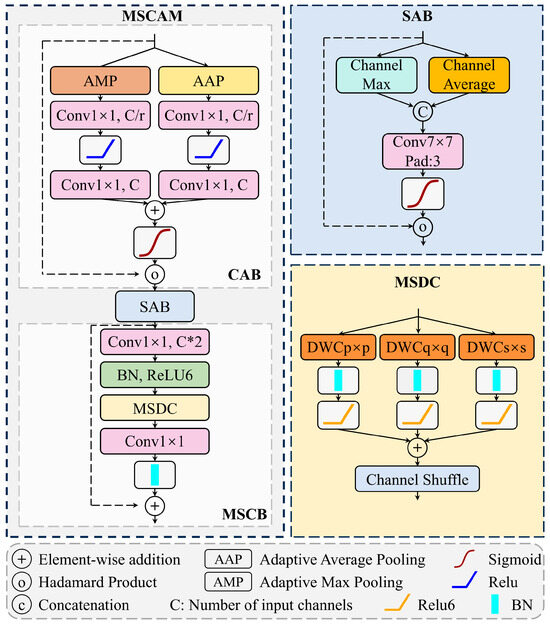
Figure 6.
Multi-scale convolutional attention module.
Efficient up-convolution block (EUCB): To restore spatial resolution and align features for skip connections, an Efficient up-convolution block (EUCB) is introduced at each decoding stage, as shown in Figure 7 [59]. The module first upsamples the feature map, refines it using a 3 × 3 depthwise convolution, and uses a 1 × 1 convolution to match the channel dimension with the encoder feature. This process restores resolution and enhances local continuity, providing semantic compensation that improves structural reconstruction and detail recovery in the decoding phase.
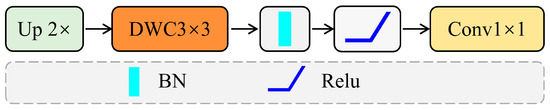
Figure 7.
Efficient up-convolution block.
Mix-Scale feature aggregation module (MSFA): The MSFA is proposed to fuse cross-level features to combine semantic and structural information from multiple layers, as illustrated in Figure 8. Specifically, the MSFA module processes two input feature maps from different decoding levels, comprising a high-level semantic feature with lower spatial resolution and a low-level structural feature with finer spatial detail. Both input feature maps are first processed by separate 3 × 3 group convolutions to preserve the distinct patterns of each level and maintain feature distinctiveness, then concatenated across layers to enhance cross-scale interaction. The fused features are subsequently passed through another 3 × 3 group convolution and ReLU activation to refine joint representations. After a final concatenation, a 1 × 1 convolution is applied to generate the output. By explicitly combining deep semantic features with shallow structural details through this hierarchical fusion, the MSFA module strengthens contextual understanding of landslide regions and mitigates detail loss from earlier sparse encoding.
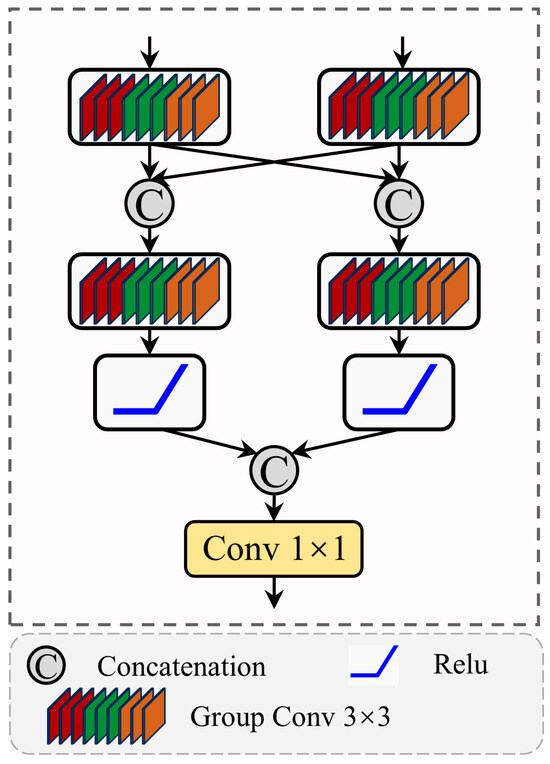
Figure 8.
Mix-Scale feature aggregation module.
4. Experiment
4.1. Image Preprocessing
The annually synthesized remote sensing images from the Hengduan Mountains for 2008 and 2018 were each divided into 15,812 patches of 256 × 256 pixels. The training set was constructed using landslide-containing patches from the 2008 Hengduan images, which was then supplemented with samples from the Hokkaido dataset to enhance data diversity. This combined training set, initially totaling 721 images, was expanded to 5768 images through augmentation techniques including rotation, flipping, and cropping. The 2018 image patches from the Hengduan Mountains were used as the test set to evaluate extraction performance and generalization capability.
To ensure consistency, the image from Hokkaido was divided into 1280 patches of 256 × 256 pixels, and the same augmentation strategies used for the Hengduan dataset were applied.
4.2. Evaluation Metrics
To comprehensively assess the performance of the proposed Spike-inspired Landslide Extraction Model, we use Precision, Recall, F1-score, and Intersection over Union (IoU), defined by Formulas (7)–(10). These metrics are calculated based on True Positives (TP), False Positives (FP), and False Negatives (FN). In this context, TP represents the number of correctly extracted landslide pixels, FP is the number of background pixels misclassified as landslides, and FN is the number of actual landslide pixels that the model failed to identify. Precision measures the proportion of predicted landslides that are true landslides, while Recall evaluates the model’s ability to identify all actual landslide regions. The F1-score balances Precision and Recall, reflecting both accuracy and coverage. IoU quantifies the spatial overlap between predicted and true landslides by comparing their intersection and union. Using these combined metrics helps avoid bias from relying on any single indicator and provides a well-rounded evaluation.
4.3. Implementation Details
Experiments were performed using PyTorch 1.7.1 on Ubuntu 18.04. Optimization employed stochastic gradient descent with a momentum of 0.9 and a weight decay of 1 × 10−3. The initial learning rate was 0.01, and the model achieved optimal convergence by epoch 600. Due to GPU memory limits, the batch size was set to 8. Training was enhanced by early stopping and a cosine annealing learning rate schedule. All computations ran on CUDA 11.7 across four NVIDIA GeForce RTX 3090 GPUs (Santa Clara, CA, USA).
5. Experimental Results and Analysis
5.1. Quantitative Comparison
To evaluate the effectiveness of the proposed Spike-inspired Landslide Extraction Model, we conducted comparative experiments with a range of mainstream semantic segmentation models, including the classic MobileNet_v2 [60], DeepLabv3+ [61], ResNet [62], and HRNet [63], the state-of-the-art ConvNeXt [64] and SegFormer [65], and Swin Transformer [56], as well as Mask2Former [66], which excels in addressing class imbalance, and Swin-MA, a model specifically designed for large-scale landslide extraction. The statistical comparisons are summarized in Table 1.

Table 1.
Experimental results (%).
In the Hengduan Mountains, our proposed model demonstrates the most robust performance, achieving the highest IoU of 32.13% and F1-score of 48.63%, which represents a 4.26% improvement over state-of-the-art methods. This superior performance is attributed to the proposed SISA module, which adaptively enhances salient regions and suppresses confusing background signals, improving the extraction of irregular and low-contrast landslides. Lightweight models such as MobileNet_v2 performed poorly, with an IoU of 17.87%. Its shallow architecture limits its ability to capture complex textures and blurred boundaries, resulting in a low recall of just 28.05%. Deep CNNs such as ResNet and DeepLabv3+ apply residual connections and dilated convolutions to increase the receptive field, but still struggle to extract weak landslide features, with F1-scores under 36%, due to their limited capacity to model the spatial diversity and indistinct edges common in mountainous terrain.
HRNet, ConvNeXt, and Segformer achieve better balance between precision and recall, with F1-scores approaching 40%. HRNet benefits from multi-resolution fusion, which helps preserve fine spatial details and improves the extraction of small landslides. However, it still suffers from limited global context modeling, making it difficult to distinguish landslides from bare land. ConvNeXt strengthens local convolutional features, but it cannot effectively model long-range dependencies. Segformer reaches an IoU of 24.89% by Transformer-based global context modeling, demonstrating strength in multi-scale spatial fusion. Yet, its lightweight decoder design is insufficient for recovering the fine-grained details necessary for precise boundary delineation, which leads to fragmented or incomplete extractions and limits its Recall to 39.09%. Mask2Former yields a Recall of 40.52%, surpassing Swin Transformer by capturing scattered landslides. This performance benefits from its mask architecture, which is inherently effective for class-imbalanced data. However, its object-centric modeling tends to emphasize global semantic coherence, which may limit sensitivity to fine-grained spatial variations and precise boundary delineation, consequently restricting its Precision to 42.15%.
Transformer-based methods, such as Swin Transformer and Swin-MA, significantly further improve performance, reaching F1-scores of 43.59% and 47.15%, respectively. Their improvements stem from hierarchical window-based attention mechanisms and the multiscale landslide feature preservation module, which enables flexible adaptation to multi-scale landslides. Nevertheless, their Precision scores remain 7.6% and 3.74% lower than that of our model. This highlights the advantage of our sparse spike-inspired attention, which adaptively enhances focus on landslide-related regions and effectively reduces false extractions from similar backgrounds.
Given the relatively poor performance in the Hengduan Mountains, we conducted further comparative experiments on the dataset from Hokkaido, Japan, to verify our model’s extraction capabilities in an environment characterized by a consistent background and a denser landslide distribution. The dataset, comprising 1280 image patches, was subsequently split into 60% for training and 40% for testing. All models perform better in this area, and our method achieves the highest IoU of 61.38%, with a 1.22% improvement over other methods. Transformer-based models such as SegFormer and Swin Transformer perform relatively well, achieving IoUs exceeding 59%, because global context modeling helps capture elongated or clustered landslides, yet their dense attention lacks targeted selectivity, which limits precision for landslides with weak spectral contrast. Mask2Former maintains a competitive F1-score of 73.83% due to its effective object-centric mask modeling, yet its IoU remains at 58.52%, indicating insufficient pixel-level boundary consistency. DeepLabv3+ and ResNet, based on convolutional feature extraction, benefit from clearer boundaries in the Hokkaido but remain constrained by their local receptive field, limiting their F1-scores to approximately 72%, which reduces robustness in cases where landslides share spectral similarity with background objects such as soil. This result confirms that our spike-inspired sparse attention focuses on salient landslide regions while adaptively suppressing irrelevant background, enabling accurate extraction across both scattered and densely clustered landslide distributions.
To further examine the trade-off between Precision and Recall, we visualized the model performances for the more challenging Hengduan Mountains dataset in the Precision–Recall space, as shown in Figure 9. The figure displays the distribution of various models, where bubble size represents the F1-score and color intensity indicates the IoU, with darker green denoting higher values. Conventional models are clustered in the lower-left area, reflecting limited Recall and IoU in complex terrain background. Transformer-based architectures shift toward the upper-right, indicating improved Recall, though some suffer reduced Precision due to background misclassification. In contrast, our method is positioned at the top-right, achieving both the highest Precision and Recall, along with superior IoU and F1-score. This demonstrates that the proposed spike-inspired sparse attention strategy enhances the model’s ability to capture more true landslides while suppressing false positives, delivering balanced gains across all key metrics.
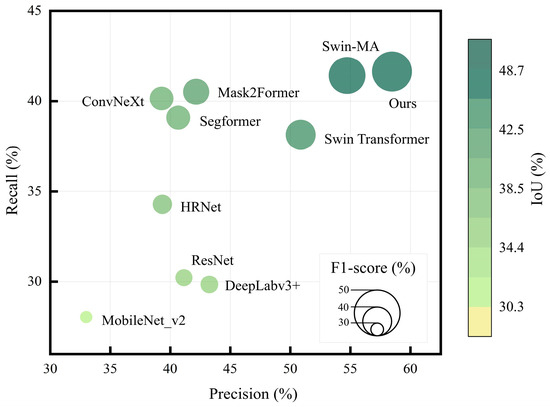
Figure 9.
Bubble chart comparing landslide extraction metrics across multiple models.
5.2. Visualization Comparison
To further evaluate model performance, eight representative cases were selected from the Hengduan Mountains and Hokkaido regions. These cover typical landslides with elongated shapes, small sizes, irregular or blurry boundaries. The visualization results are shown in Figure 10 (Hengduan Mountains) and Figure 11 (Hokkaido). Specifically, landslides in the Hengduan Mountains are notably smaller, more fragmented, and exhibit indistinct boundaries. In contrast, the landslides in Hokkaido (Figure 11) are characterized by clearer outlines and higher contrast against the background. This marked difference provides complementary scenarios to evaluate the model’s robustness under varying degrees of environmental complexity.
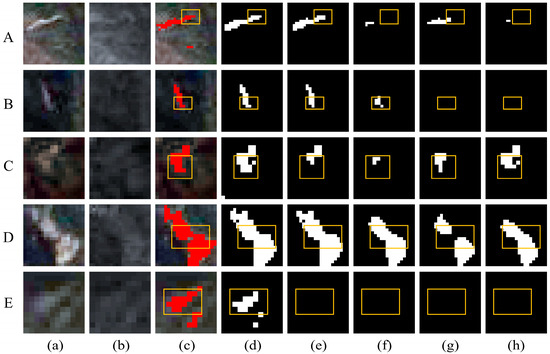
Figure 10.
Visual comparison for different models in Hengduan Mountains. (a) Post-landslide image. (b) Pre-landslide image. (c) Ground truth. (d) Ours. (e) Swin-MA. (f) Segformer. (g) HRNet. (h) Deeplabv3+. Red pixels represent actual landslides. Black pixels represent the extracted background, while white pixels represent the extracted landslides. (A–E) Representative cases.
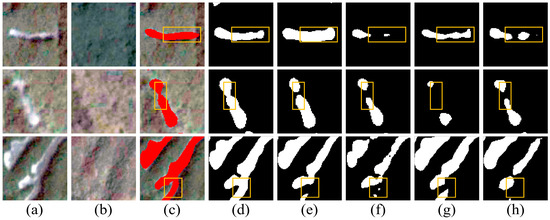
Figure 11.
Visual comparison for different models in Hokkaido, Japan. (a) Post-landslide image. (b) Pre-landslide image. (c) Ground truth. (d) Ours. (e) Swin-MA. (f) Segformer. (g) HRNet. (h) Deeplabv3+. Red pixels represent actual landslides. Black pixels represent the extracted background, while white pixels represent the extracted landslides.
Our proposed method consistently produces clearer and more complete landslide extractions. The spike-inspired sparse attention adaptively suppresses irrelevant background responses, improving extraction of weak boundary features, as demonstrated in Figure 10A,E. Simultaneously, the multi-scale decoder restores fine boundaries and maintains structural continuity across scales, allowing narrow sections and irregular outlines to be accurately reconstructed, as illustrated in Figure 10D and Figure 11C. This joint effect allows elongated structures, fragmented patches, and indistinct edges to be captured more completely than with other methods.
Convolution-based models, including HRNet and DeepLabv3+, generally perform well on high-contrast landslides but struggle with elongated or fragmented targets. For example, in Figure 10A, both models fail to capture the full contour of a low-contrast elongated landslide, leaving omissions in the yellow-marked region. This limitation primarily stems from insufficient long-range context modeling, which prevents them from tracing the complete linear structure against a complex background. The same limitation appears in small or narrow targets, as in Figure 10B, where HRNet captures only part of the shape and DeepLabv3+ fails entirely.
Transformer-based methods such as SegFormer and Swin-MA are more capable of capturing overall shape and spatial continuity, as seen in Figure 10A where Swin-MA reconstructs most of the elongated landslide. However, the global attention mechanism can also erroneously include nearby non-landslide surfaces with similar texture; in Figure 11A, Swin-MA includes road surfaces along with the true landslide, reducing precision. SegFormer also struggles with fine structural detail, breaking narrow or low-contrast landslides into disconnected segments, as observed in Figure 10B and Figure 11B.
Overall, the visual comparisons indicate that convolution-based networks struggle with elongated and small-scale structures due to their local receptive fields, while standard Transformer models tend to erroneously extract texturally similar background. Our proposed approach overcomes both limitations through adaptive sparse attention that filters out background noise and multi-scale fusion that preserves the integrity of complex landslide structures.
5.3. Ablation Study
To evaluate the independent and combined contributions of our three proposed components on extraction performance, including the PCA-based landslide candidate extraction strategy, the spike-inspired sparse attention module (SISA), and the mix-scale feature aggregation module (MSFA), we conducted ablation experiments on both the Hengduan Mountains and Hokkaido datasets. The effect of the PCA-based method is illustrated in Figure 12, while the quantitative results for SISA and MSFA are presented in Table 2.
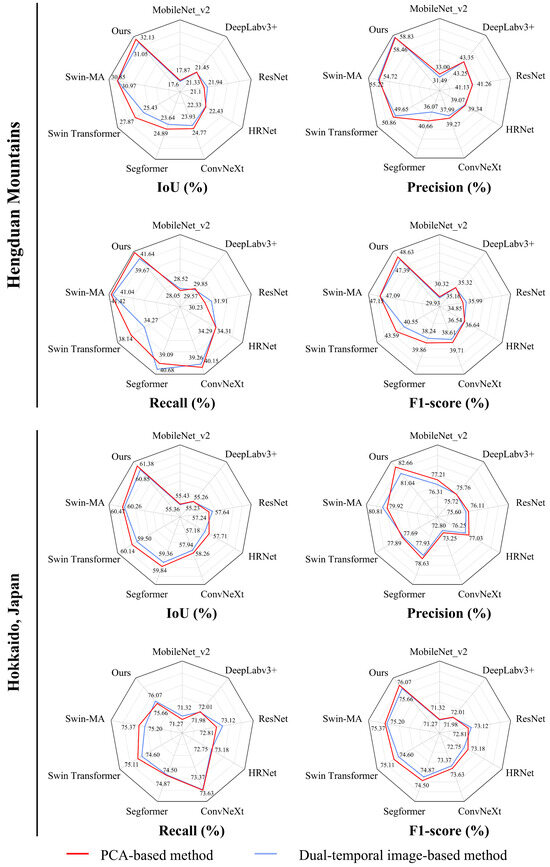
Figure 12.
Comparison of landslide extraction performance under different background optimization strategies.
Table 2.
Ablation studies (%).
To verify the robustness of the proposed PCA-based background optimization, we conducted ablation studies across all comparative models. As illustrated in Figure 12, without the integration of this strategy, the baseline Swin Transformer struggled to extract landslides from complex environmental noise in the Hengduan Mountains, limiting its IoU to 25.43% and F1-score to 40.55%. Incorporating the PCA module enhanced the extraction capability, raising the IoU and F1-score to 27.87% and 43.59%, respectively. Comparatively, our proposed method achieved the best overall results, with a 1.97% recall improvement after background removal. In the Hokkaido region, which has more regular terrain, the performance gain was smaller but still consistent, with models like ConvNeXt and Segformer showing F1-score improvements of 0.5% to 0.7%. These results confirm that the PCA-based optimization is a crucial step for suppressing non-landslide interference, especially in heterogeneous terrains.
The baseline network, evaluated without the SISA and MSFA modules, showed limited performance in both regions. In the Hengduan Mountains, the baseline reached an IoU of 26.13% and an F1-score of 41.43%, indicating difficulty in detecting landslides under imbalanced background conditions. In Hokkaido, although the landslides are densely distributed, the baseline still struggled, with an F1-score of 75.11%, suggesting insufficient robustness to subtle boundary variations.
Integrating the SISA module alone yielded a significant precision improvement in both regions, with an increase of more than 14% in the Hengduan Mountains and approximately 1.5% in Hokkaido, as shown in Table 2. This demonstrates the module’s strength in reducing background interference and enhancing focus on landslide regions. The sparse activation mechanism in SISA reduces the influence of low-response areas, improving sensitivity to landslide features.
Adding the MSFA module alone primarily improved recall, with a notable increase of 3.3% in the Hengduan Mountains, where landslides are often scattered with unclear boundaries. In Hokkaido, it led to an increase in IoU and F1-score of 0.38% and 0.29%, respectively. This reflects the module’s ability to recover fragmented landslides and capture multi-scale spatial features. Its cross-layer feature fusion enhances both deep semantic and shallow structural representations, thereby improving the model’s structural consistency.
When both modules were combined, the model achieved its optimal performance in both regions. The improvements were especially significant in the Hengduan Mountains, where the final F1-score reached 48.63%, and in Hokkaido, where it increased to 76.07%. These results confirm that the SISA and MSFA modules offer complementary benefits. SISA enhances precision through its selective attention, while MSFA improves recall by ensuring structural completeness. Together, they provide a robust solution for landslide extraction across diverse and challenging environments.
6. Discussion
6.1. Optimal Parameter Settings for SISA and MSFA
We conducted parameter tuning experiments to determine the optimal internal settings for the proposed SISA and MSFA modules in the Hengduan Mountains. Key hyperparameters were selected through controlled empirical evaluation, where only one parameter was varied at a time while keeping other settings fixed. The optimization process focused on two critical hyperparameters: the top-k ratio of the SISA module, which controls between feature preservation and noise suppression, and the group convolution kernel size of the MSFA module, which determines the scale of feature integration for capturing landslides of various scales.
In the SISA module, the top-k operation determines the sparsity of the attention mechanism, which is a trade-off between detail preservation and noise suppression. To systematically evaluate its effect, we tested a set of representative k-value combinations ranging from aggressive filtering to weak suppression. Figure 13. shows the IoU performance under different k-value combinations. Comparative results indicate that the combination of [1/2, 2/3, 3/4] yields the highest IoU, representing an optimal balance between preserving useful information and reducing interference. A single, small k value, such as 1/2, filters out half of the feature responses, leading to the loss of critical spatial details and reduced extraction accuracy. In contrast, excessively large k values preserve irrelevant background regions, weakening the suppression effect and increasing false positives. The multi-scale combination of k values allows the model to capture both strong and weak responses, thereby improving the completeness and accuracy of landslide extraction. These results confirm that the selected multi-scale configuration maximizes the SISA module’s effectiveness by achieving an empirically optimized balance between sparsity and completeness.
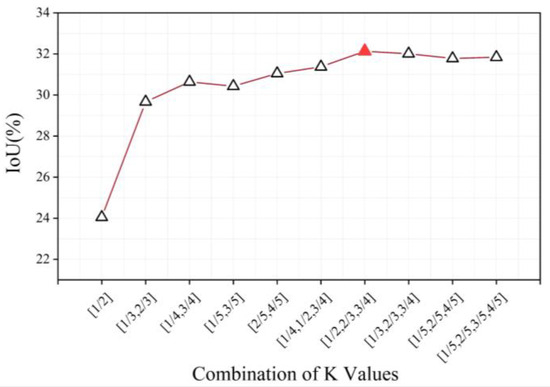
Figure 13.
IoU performance of the SISA module with different Top-k parameter combinations.
In the MSFA module, the kernel size of the group convolution determines how information is integrated across different layers. We evaluated multiple kernel size combinations under identical training settings to isolate their impact on feature fusion. As shown in Figure 14, the performance of different kernel configurations was assessed in the Hengduan Mountains dataset. The [3 × 3, 3 × 3] kernel configuration achieves the highest IoU, demonstrating its effectiveness in cross-layer feature fusion. The results show that as the kernel size increases, the IoU drops noticeably. This trend suggests that overly large kernels introduce excessive spatial smoothing, which weakens boundary sharpness and suppresses fine-scale structural details critical for landslide extraction. Given that landslides in the Hengduan Mountains are often small and irregular, a compact kernel size provides sufficient contextual aggregation without sacrificing local detail, making it more suitable for multi-scale feature integration in this task. Therefore, the selected size reflects a balance between contextual modeling and spatial precision.
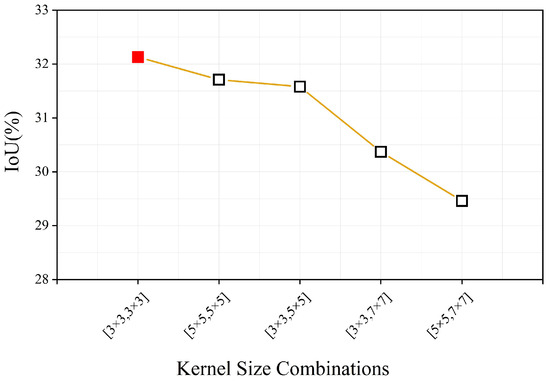
Figure 14.
IoU performance of the MSFA module with different kernel sizes.
6.2. Impact of Feature Confusion Between Landslides and Background in the Hengduan Mountains
The experimental results in Table 1 reveal a significant performance disparity between the two study areas, with extraction accuracy in the Hengduan Mountains being considerably lower than in Hokkaido. We attribute this increased difficulty to the high degree of feature confusion between landslides and complex background objects in the Hengduan region. Therefore, we analyze the characteristics of this feature confusion to demonstrate the critical importance of the adaptive background suppression strategy employed in our framework. To conduct this analysis, we calculated the normalized pixel value distributions of landslides and background across ten bands, including DEM, slope, and various spectral indices, as shown in Figure 15. The pixel distributions of landslides and background are represented by red and gray bars, respectively. Additionally, standard deviation and entropy were used to assess the internal complexity of these features.
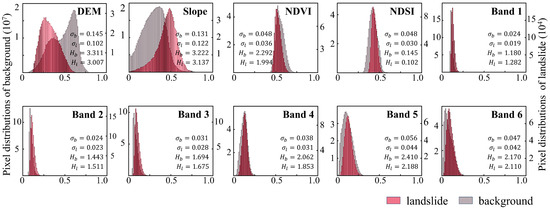
Figure 15.
Landslide and background pixel distributions.
The results reveal that only the topographic features provide a strong basis for distinction. As shown in the histograms for DEM and slope, landslides and background areas exhibit significant differences. Landslides are concentrated in steeper regions and at mid-to-low elevations, which aligns with the gravitational triggering mechanism of slope failure. It suggests that landslides are more likely to occur in areas with active surface disturbances and strong topographic relief. This finding also validates the use of a slope threshold in our Landslide Candidate Extraction phase as an effective strategy for filtering irrelevant flat terrain.
In contrast, spectral features show limited separability. The distributions for NDVI, NDSI, and other multispectral bands demonstrate significant overlap between landslides and the background. This high degree of spectral similarity indicates that in complex terrains, models struggle to effectively distinguish landslides from features like bare soil based on spectral information alone, directly highlighting the need for background suppression. This widespread feature confusion directly contributes to the poor extraction results in the Hengduan Mountains, where the highest F1-score in Table 1 is only 48.63%. While spectral values overlap, the statistical indicators show a clear distinction in feature complexity. Background areas consistently exhibit higher standard deviation and entropy, reflecting greater spectral variability, whereas landslide regions have more stable and homogeneous feature patterns. This difference in complexity provides a feasible basis for their discrimination once background interference is suppressed.
In summary, the widespread feature confusion, particularly in the spectral bands, is a primary reason for the increased extraction difficulty in the Hengduan Mountains. However, the relative homogeneity and stability of landslide feature patterns, as compared to the more complex background, provide a feasible basis for their separation. This confirms that suppressing redundant background regions is a key strategy for improving landslide extraction accuracy in large-scale, complex environments.
7. Conclusions
This study proposes a two-phase spike-inspired landslide extraction framework for large-scale remote sensing applications. It aims to address two key challenges, the severe class imbalance between landslide and background, and the high visual similarity between landslides and background objects. Our framework first mitigates class imbalance through a PCA-based method that extracts landslide candidates by removing large areas of irrelevant background. Subsequently, the Spike-inspired Landslide Extraction Model employs an adaptive suppression strategy to enhance focus on weak landslide features, such as blurred boundaries. This is achieved through a spike-inspired sparse attention module (SISA), which enhances focus on landslide regions while suppressing background noise, and a mix-scale feature aggregation module (MSFA) that integrates hierarchical features to accurately represent landslides of various scales.
Experiments on landslide datasets from the Hengduan Mountains and Hokkaido, Japan, demonstrate the effectiveness and robustness of the proposed method. In the Hengduan Mountains, a vast region characterized by severe class imbalance, the model achieved an IoU of 32.13%, gaining a 4.26% improvement over state-of-the-art methods. In the dense landslide environment of Hokkaido, the model achieved an IoU of 61.38% with a 1.22% improvement, confirming its effectiveness under different landslide distribution conditions.
In summary, our proposed method addresses class imbalance at the data level and enhances focus on weak landslide features through a spike-inspired adaptive suppression strategy, offering a comprehensive and effective solution for large-scale, complex landslide extraction tasks. However, optimizing computational efficiency for large-scale applications remains a task. Consequently, future research will focus on developing a lightweight model based on prototype learning to enhance feature robustness, making it suitable for multi-temporal landslide monitoring under varying seasonal conditions.
Author Contributions
Conceptualization, F.C. and B.Y.; methodology, M.G. and B.Y.; software, M.G.; validation, B.Y.; formal analysis, L.W.; data curation, M.G. and B.Y.; writing—original draft preparation, M.G.; writing—review and editing, F.C. and B.Y.; visualization, M.G.; supervision, L.W.; project administration, F.C. and B.Y.; funding acquisition, F.C. and L.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China (No. 42425103), the Provincial Special Funding for the Construction of Chenzhou National Sustainable Development Agenda Innovation Demonstration Zone (No. 2023sfq69), and the Joint HKU-CAS Laboratory for iEarth (No. 313GJHZ2022074MI, E4F3050300). The work is also supported by CAS-TWAS Centre of Excellence on Space Technology for Disaster Mitigation.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors on request.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| SISA | Spike-inspired sparse attention |
| MSFA | Mix-scale feature aggregation |
| GDK | Gaussian decay kernel |
| MSF-Decoder | Multi-scale fusion decoder |
| MSCAM | Multi-scale convolutional attention module |
| EUCB | Efficient upsampling convolution block |
| CAB | Channel attention block |
| SAB | Spatial attention block |
| MSCB | Multi-scale convolution block |
| NDSI | Normalized Difference Snow Index |
| NDVI | Normalized Difference Vegetation Index |
References
- Lu, P.; Qin, Y.; Li, Z.; Mondini, A.C.; Casagli, N. Landslide mapping from multi-sensor data through improved change detection-based Markov random field. Remote Sens. Environ. 2019, 231, 111235. [Google Scholar] [CrossRef]
- Sassa, K.; Fukuoka, H.; Wang, F.; Wang, G. Landslides: Risk Analysis and Sustainable Disaster Management; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Froude, M.J.; Petley, D.N. Global fatal landslide occurrence from 2004 to 2016. Nat. Hazards Earth Syst. Sci. 2018, 18, 2161–2181. [Google Scholar] [CrossRef]
- Zhu, W.; Yang, L.; Cheng, Y.; Liu, X.; Zhang, R. Active Thickness Estimation and Failure Simulation of Translational Landslide Using Multi-Orbit InSAR Observations: A Case Study of the Xiongba Landslide. Int. J. Appl. Earth Obs. Geoinf. 2024, 129, 103801. [Google Scholar] [CrossRef]
- Yu, B.; Xu, C.; Chen, F.; Wang, N.; Wang, L. HADeenNet: A hierarchical-attention multi-scale deconvolution network for landslide detection. Int. J. Appl. Earth Obs. Geoinf 2022, 111, 102853. [Google Scholar] [CrossRef]
- S., S.; S.S., V.C.; Shaji, E. Landslide Identification Using Machine Learning Techniques: Review, Motivation, and Future Prospects. Earth Sci. Inform. 2022, 15, 2063–2090. [Google Scholar] [CrossRef]
- Kirschbaum, D.B.; Adler, R.; Hong, Y.; Hill, S.; Lerner-Lam, A. A Global Landslide Catalog for Hazard Applications: Method, Results, and Limitations. Nat. Hazards 2010, 52, 561–575. [Google Scholar] [CrossRef]
- Chen, F.; Yu, B.; Li, B. A practical trial of landslide detection from single-temporal Landsat8 images using contour-based proposals and random forest: A case study of national Nepal. Landslides 2018, 15, 453–464. [Google Scholar] [CrossRef]
- Guzzetti, F.; Mondini, A.C.; Cardinali, M.; Fiorucci, F.; Santangelo, M.; Chang, K.-T. Landslide inventory maps: New tools for an old problem. Earth-Sci. Rev. 2012, 112, 42–66. [Google Scholar] [CrossRef]
- Zhong, C.; Liu, Y.; Gao, P.; Chen, W.; Li, H.; Hou, Y.; Nuremanguli, T.; Ma, H. Landslide mapping with remote sensing: Challenges and opportunities. Int. J. Remote Sens. 2020, 41, 1555–1581. [Google Scholar] [CrossRef]
- Chen, Z.; Zhang, Y.; Ouyang, C.; Zhang, F.; Ma, J. Automated Landslides Detection for Mountain Cities Using Multi-Temporal Remote Sensing Imagery. Sensors 2018, 18, 821. [Google Scholar] [CrossRef] [PubMed]
- Chen, F.; Zhang, M.; Zhao, H.; Guan, W.; Yang, A. Pakistan’s 2022 floods: Spatial distribution, causes and future trends from Sentinel-1 SAR observations. Remote Sens. Environ. 2024, 304, 114055. [Google Scholar] [CrossRef]
- Chen, F.; Du, E.; Jia, H.; Chen, Y.; Wang, L. Lagged effects of atmospheric circulation teleconnections on agricultural drought prediction in China. Int. J. Digit. Earth 2025, 18, 2528628. [Google Scholar] [CrossRef]
- Yu, B.; Sun, Y.; Hu, J.; Chen, F.; Wang, L. Post-disaster building damage assessment based on gated adaptive multi-scale spatial-frequency fusion network. Int. J. Appl. Earth Obs. Geoinf 2025, 141, 104629. [Google Scholar] [CrossRef]
- Yu, B.; Chen, F.; Ye, C.; Li, Z.; Dong, Y.; Wang, N.; Wang, L. Temporal Expansion of the Nighttime Light Images of SDGSAT-1 Satellite in Illuminating Ground Object Extraction by Joint Observation of NPP-VIIRS and Sentinel-2A Images. Remote Sens. Environ. 2023, 295, 113691. [Google Scholar] [CrossRef]
- Chen, F.; Wang, L.; Wang, Y.; Zhang, H.; Wang, N.; Ma, P.; Yu, B. Retrieval of dominant methane (CH4) emission sources, the first high-resolution (1–2 m) dataset of storage tanks of China in 2000–2021. Earth Syst. Sci. Data 2024, 16, 3369–3382. [Google Scholar] [CrossRef]
- Zhao, W.; Li, A.; Nan, X.; Zhang, Z.; Lei, G. Postearthquake Landslides Mapping from Landsat-8 Data for the 2015 Nepal Earthquake Using a Pixel-Based Change Detection Method. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 1758–1768. [Google Scholar] [CrossRef]
- Pradhan, B.; Al-Najjar, H.A.; Sameen, M.I.; Mezaal, M.R.; Alamri, A.M. Landslide detection using a saliency feature enhancement technique from LiDAR-derived DEM and orthophotos. IEEE Access 2020, 8, 121942–121954. [Google Scholar] [CrossRef]
- Yu, B.; Zhu, M.; Chen, F.; Wang, N.; Zhao, H.; Wang, L. Multi-scale differential network for landslide extraction from remote sensing images with different scenarios. Int. J. Digit. Earth 2024, 17, 2441920. [Google Scholar] [CrossRef]
- Ghorbanzadeh, O.; Blaschke, T.; Gholamnia, K.; Meena, S.R.; Tiede, D.; Aryal, J. Evaluation of different machine learning methods and deep-learning convolutional neural networks for landslide detection. Remote Sens. 2019, 11, 196. [Google Scholar] [CrossRef]
- Chu, X.D.; Yao, X.J.; Duan, H.Y.; Chen, C.; Li, J.; Pang, W.L. Glacier extraction based on high-spatial-resolution remote-sensing images using a deep-learning approach with attention mechanism. Cryosphere 2022, 16, 4273–4289. [Google Scholar] [CrossRef]
- Liu, P.; Wei, Y.; Wang, Q.; Xie, J.; Chen, Y.; Li, Z.; Zhou, H. A Research on Landslides Automatic Extraction Model Based on the Improved Mask R-CNN. ISPRS Int. J. Geo-Inf. 2021, 10, 168. [Google Scholar] [CrossRef]
- Shi, W.; Zhang, M.; Ke, H.; Fang, X.; Zhan, Z.; Chen, S. Landslide Recognition by Deep Convolutional Neural Network and Change Detection. IEEE Trans. Geosci. Remote Sens. 2021, 59, 4654–4672. [Google Scholar] [CrossRef]
- Li, H.; He, Y.; Xu, Q.; Deng, J.; Li, W.; Wei, Y. Detection and segmentation of loess landslides via satellite images: A two-phase framework. Landslides 2022, 19, 673–686. [Google Scholar] [CrossRef]
- Chen, H.; He, Y.; Zhang, L.; Yao, S.; Yang, W.; Fang, Y.; Liu, Y.; Gao, B. A landslide extraction method of channel attention mechanism U-Net network based on Sentinel-2A remote sensing images. Int. J. Digit. Earth 2023, 16, 552–577. [Google Scholar] [CrossRef]
- Li, Y. The Research on Landslide Detection in Remote Sensing Images Based on Improved DeepLabv3+ Method. Sci. Rep. 2025, 15, 7957. [Google Scholar] [CrossRef]
- Yang, Z.; Xu, C.; Li, L. Landslide detection based on ResU-net with transformer and CBAM embedded: Two examples with geologically different environments. Remote Sens. 2022, 14, 2885. [Google Scholar] [CrossRef]
- Si, Y.; He, Z.; Zhang, F.; Sun, X.; Chen, Y.; Zheng, H. Cost-effective and real-time landslide monitoring method based on ultra-wideband using ultra-wideband transformer neural network. Eng. Appl. Artif. Intell. 2025, 160, 11185. [Google Scholar] [CrossRef]
- Fan, S.; Fu, Y.; Li, W.; Bai, H.; Jiang, Y. ETGC2-Net: An Enhanced Transformer and Graph Convolution Combined Network for Landslide Detection. Nat. Hazards 2025, 121, 135–160. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar]
- Dai, X.; Chen, Y.; Yang, J.; Zhang, P.; Yuan, L.; Zhang, L. Dynamic detr: End-to-end object detection with dynamic attention. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 2988–2997. [Google Scholar]
- Huang, Y.; Zhang, J.; He, H.; Jia, Y.; Chen, R.; Ge, Y.; Ming, Z.; Zhang, L.; Li, H. MAST: An Earthquake-Triggered Landslides Extraction Method Combining Morphological Analysis Edge Recognition with Swin-Transformer Deep Learning Model. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 2586–2595. [Google Scholar] [CrossRef]
- Wu, L.; Liu, R.; Ju, N.P.; Zhang, A.; Gou, J.S.; He, G.L.; Lei, Y.Z. Landslide mapping based on a hybrid CNN-transformer network and deep transfer learning using remote sensing images with topographic and spectral features. Int. J. Appl. Earth Obs. 2024, 126, 103612. [Google Scholar] [CrossRef]
- Li, Y.; Wu, Z.; Wu, J.; Zhang, R.; Xu, X.; Zhou, Y. DBSANet: A Dual-Branch Semantic Aggregation Network Integrating CNNs and Transformers for Landslide Detection in Remote Sensing Images. Remote Sens. 2025, 17, 807. [Google Scholar] [CrossRef]
- Xiang, X.; Gong, W.; Li, S.; Chen, J.; Ren, T. TCNet: Multiscale fusion of transformer and CNN for semantic segmentation of remote sensing images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 3123–3136. [Google Scholar] [CrossRef]
- Yu, B.; Chen, F.; Xu, C. Landslide detection based on contour-based deep learning framework in case of national scale of Nepal in 2015. Comput. Geosci. 2020, 135, 104388. [Google Scholar] [CrossRef]
- Xu, Y.; Ouyang, C.; Xu, Q.; Wang, D.; Zhao, B.; Luo, Y. CAS Landslide Dataset: A Large-Scale and Multisensor Dataset for Deep Learning-Based Landslide Detection. Sci. Data 2024, 11, 12. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Yu, W.; Pun, M.-O.; Shi, W. Cross-Domain Landslide Mapping from Large-Scale Remote Sensing Images Using Prototype-Guided Domain-Aware Progressive Representation Learning. ISPRS J. Photogramm. Remote Sens. 2023, 197, 1–17. [Google Scholar] [CrossRef]
- Li, P.; Wang, Y.; Si, T.; Ullah, K.; Han, W.; Wang, L. DSFA: Cross-Scene Domain Style and Feature Adaptation for Landslide Detection from High Spatial Resolution Images. Int. J. Digit. Earth 2023, 16, 2426–2447. [Google Scholar] [CrossRef]
- Yang, Y.; Soatto, S. FDA: Fourier Domain Adaptation for Semantic Segmentation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 4084–4094. [Google Scholar]
- Feng, X.; Du, J.; Wu, M.; Chai, B.; Miao, F.; Wang, Y. Potential of Synthetic Images in Landslide Segmentation in Data-Poor Scenario: A Framework Combining GAN and Transformer Models. Landslides 2024, 21, 2211–2226. [Google Scholar] [CrossRef]
- Jiang, Z.; Li, Y.; Yang, C.; Gao, P.; Wang, Y.; Tai, Y.; Wang, C. Prototypical Contrast Adaptation for Domain Adaptive Semantic Segmentation. arXiv 2022, arXiv:2207.06654. [Google Scholar]
- Liu, J.; Hu, Y.; Li, G.; Pei, J.; Deng, L. Spike Attention Coding for Spiking Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2024, 35, 18892–18898. [Google Scholar] [CrossRef]
- Roy, K.; Jaiswal, A.; Panda, P. Towards Spike-Based Machine Intelligence with Neuromorphic Computing. Nature 2019, 575, 607–617. [Google Scholar] [CrossRef]
- Liu, Y.; Xiao, S.; Li, B.; Yu, Z. Sparsespikformer: A co-design framework for token and weight pruning in spiking transformer. In Proceedings of the ICASSP 2024—2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 6410–6414. [Google Scholar]
- Zhu, R.J.; Zhang, M.; Zhao, Q.; Deng, H.; Duan, Y.; Deng, L.-J. Tcja-Snn: Temporal-Channel Joint Attention for Spiking Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2024, 36, 5112–5125. [Google Scholar] [CrossRef] [PubMed]
- Tian, Y.; Xu, C.; Ma, S.; Xu, X.; Wang, S.; Zhang, H. Inventory and spatial distribution of landslides triggered by the 8th August 2017 MW 6.5 Jiuzhaigou earthquake, China. J. Earth Sci. 2019, 30, 206–217. [Google Scholar] [CrossRef]
- Shao, X.; Ma, S.; Xu, C.; Zhang, P.; Wen, B.; Tian, Y.; Zhou, Q.; Cui, Y. Planet Image-Based Inventorying and Machine Learning-Based Susceptibility Mapping for the Landslides Triggered by the 2018 Mw6.6 Tomakomai, Japan Earthquake. Remote Sens. 2019, 11, 978. [Google Scholar] [CrossRef]
- Lee, S.; Ryu, J.-H.; Kim, I.-S. Landslide susceptibility analysis and its verification using likelihood ratio, logistic regression, and artificial neural network models: Case study of Youngin, Korea. Landslides 2007, 4, 327–338. [Google Scholar] [CrossRef]
- Gao, H.; Zhou, Q.; Niu, B.; Zhang, S.; Zhi, Z. Spatial Risk Assessment of the Effects of Obstacle Factors on Areas at High Risk of Geological Disasters in the Hengduan Mountains, China. Sustainability 2023, 15, 16111. [Google Scholar] [CrossRef]
- Zhang, X.; Liu, L.; Chen, X.; Gao, Y.; Xie, S.; Mi, J. GLC_FCS30: Global land-cover product with fine classification system at 30 m using time-series Landsat imagery. Earth Syst. Sci. Data 2021, 13, 2753–2776. [Google Scholar] [CrossRef]
- Xu, C.; Xu, X.; Yao, X.; Dai, F. Three (nearly) complete inventories of landslides triggered by the May 12, 2008 Wenchuan Mw 7.9 earthquake of China and their spatial distribution statistical analysis. Landslides 2014, 11, 441–461. [Google Scholar] [CrossRef]
- Salomonson, V.V.; Appel, I. Estimating Fractional Snow Cover from MODIS Using the Normalized Difference Snow Index. Remote Sens. Environ. 2004, 89, 351–360. [Google Scholar] [CrossRef]
- Pettorelli, N.; Vik, J.O.; Mysterud, A.; Gaillard, J.-M.; Tucker, C.J.; Stenseth, N.C. Using the satellite-derived NDVI to assess ecological responses to environmental change. Trends Ecol. Evol. 2005, 20, 503–510. [Google Scholar] [CrossRef]
- Abdi, H.; Williams, L.J. Principal component analysis. Wiley Interdiscip. Rev. Comput. Stat. 2010, 2, 433–459. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Hu, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Chen, X.; Li, H.; Li, M.; Pan, J. Learning a sparse transformer network for effective image deraining. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 5896–5905. [Google Scholar]
- Keerthi, S.S.; Lin, C.J. Asymptotic Behaviors of Support Vector Machines with Gaussian Kernel. Neural Comput. 2003, 15, 1667–1689. [Google Scholar] [CrossRef] [PubMed]
- Rahman, M.M.; Munir, M.; Marculescu, R. Emcad: Efficient multi-scale convolutional attention decoding for medical image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 11769–11779. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep high-resolution representation learning for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3349–3364. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Mao, H.; Wu, C.; Feichtenhofer, C.; Darrell, T.; Xie, S. A ConvNet for the 2020s. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 11966–11976. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Cheng, B.; Misra, I.; Schwing, A.G.; Kirillov, A.; Girdhar, R. Masked-Attention Mask Transformer for Universal Image Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022; pp. 1290–1299. [Google Scholar]















Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.