


Synergistic Semantic Segmentation and Height Estimation for Monocular Remote Sensing Images via Cross-Task Interaction

Abstract
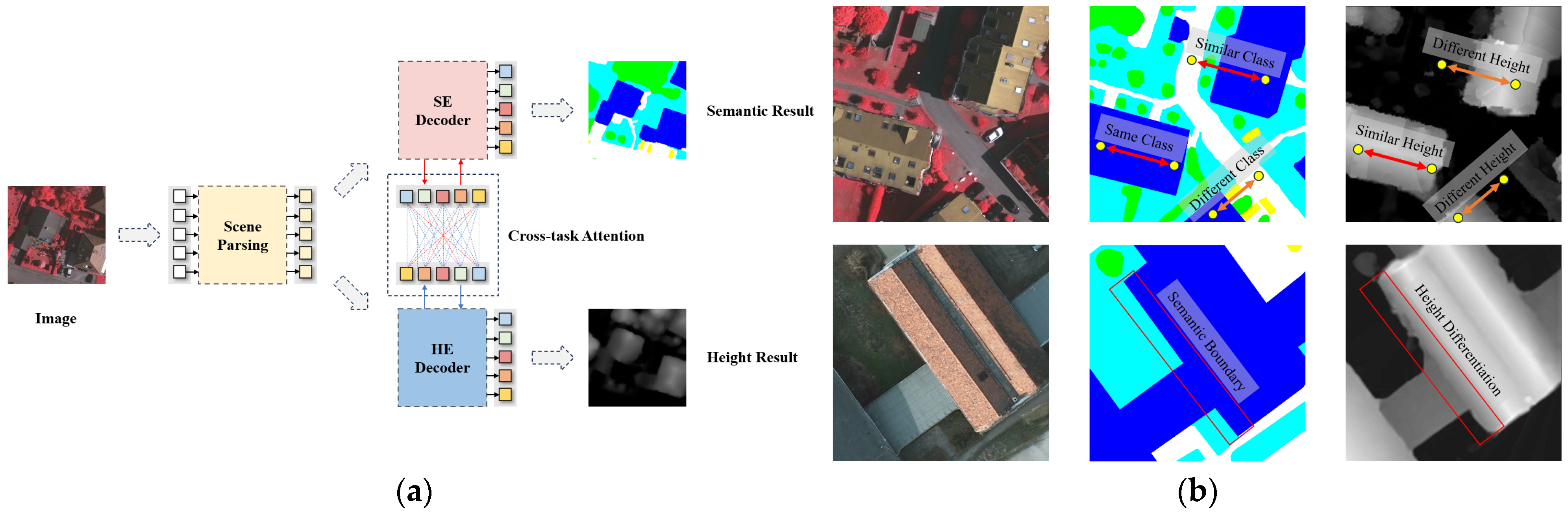
1. Introduction
- (1)
- Unlike the traditional single-task model, we innovatively proposed a novel multi-task framework for remote sensing image scene understanding, the Cross-Task Mutual Enhancement Network (CTME-Net), which was designed to simultaneously address semantic segmentation and height estimation.
- (2)
- To address the inconsistency of feature information across different tasks, we introduced an initial feature embedding module at the decoder’s initial stage, using ground truth labels for preliminary supervised learning to generate highly discriminative initial features. Meanwhile, we designed an Adaptive Task-specific Feature Distillation Module to extract more beneficial task-specific information from general features at various stages.
- (3)
- A task interaction module based on a cross-attention mechanism was designed to establish hierarchical attention mapping between semantic features and height features, enhancing feature responses in regions of geometric–semantic consistency. Through this approach, we achieved dynamic interaction and information fusion between features.
2. Related Works
2.1. Single-Task Learning
2.1.1. Semantic Segmentation
2.1.2. Height Estimation
2.2. Multi-Task Learning
3. Methodology
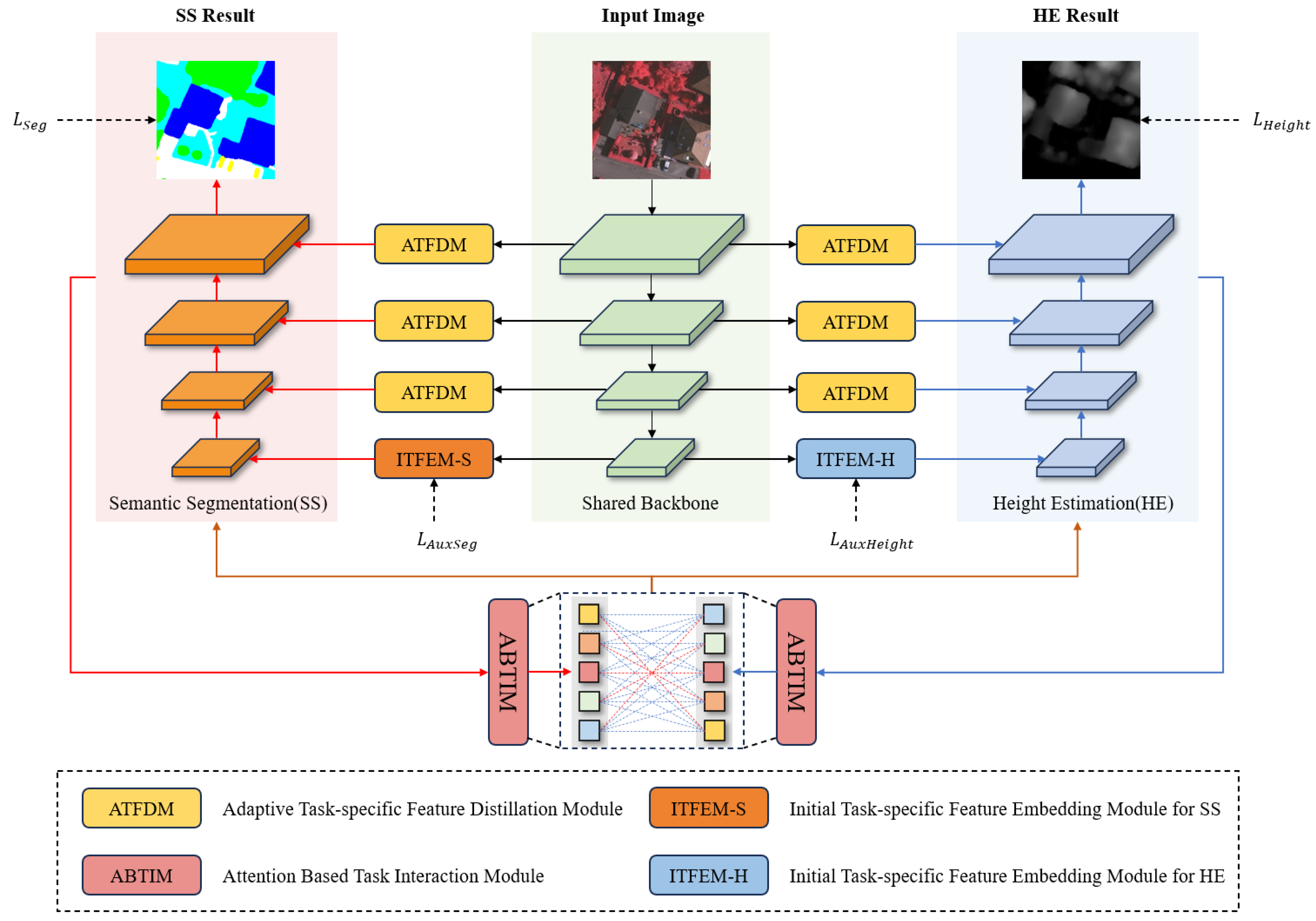
3.1. Overview
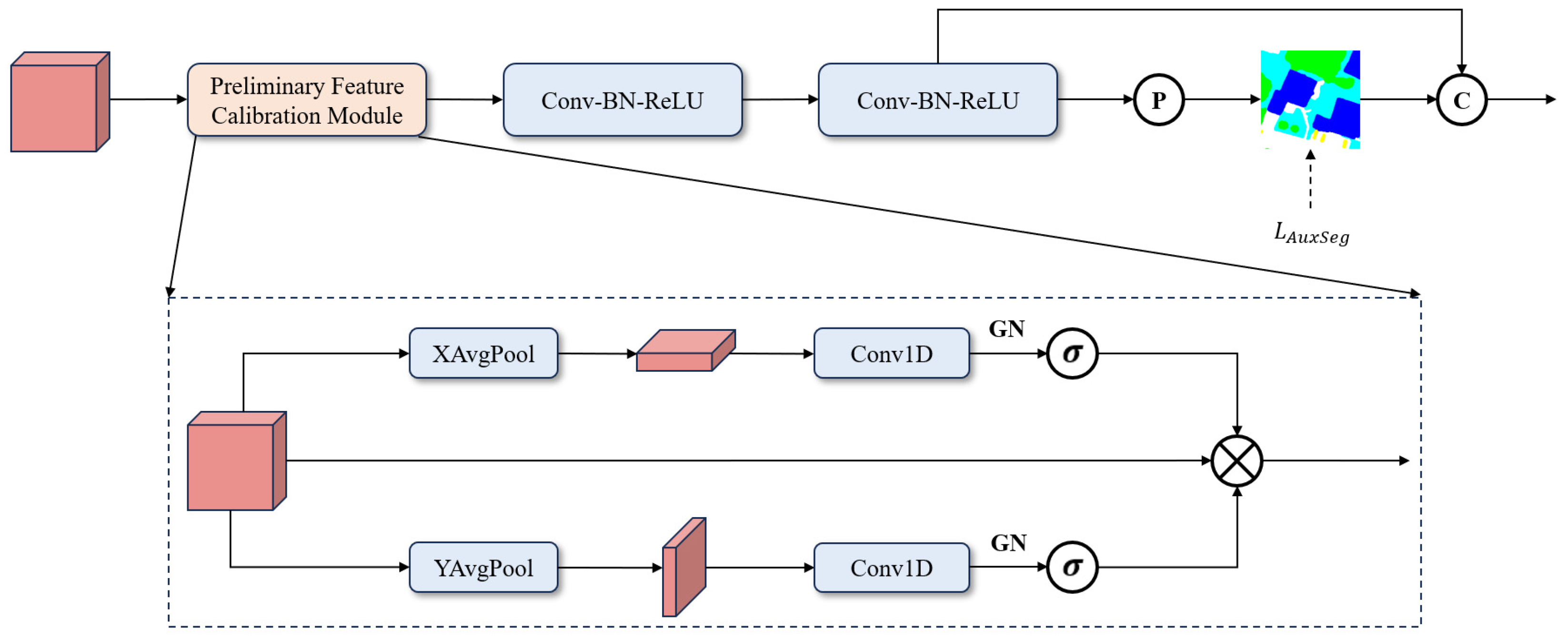
3.2. Initial Task-Specific Feature Embedding Module
3.3. Adaptive Task-Specific Feature Distillation Module
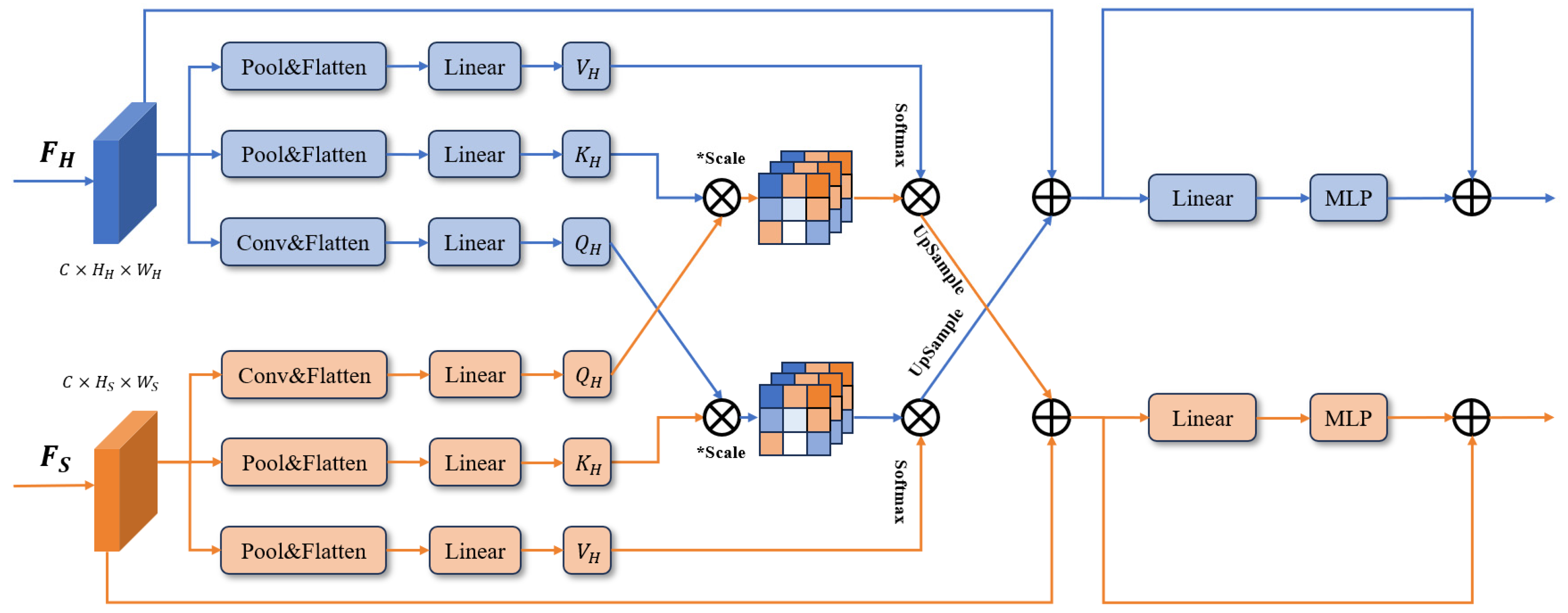
3.4. Attention-Based Task Interaction Module
3.5. Loss Functions
4. Experiment
4.1. Dataset
4.2. Evaluation Metrics
4.3. Implementation Details
5. Results and Ablation Analysis
5.1. Experiment Results
5.2. Ablation Analysis
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Mou, L.; Hua, Y.; Zhu, X.X. Relation Matters: Relational Context-Aware Fully Convolutional Network for Seman tic Segmentation of High-Resolution Aerial Images. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7557–7569. [Google Scholar] [CrossRef]
- Ma, A.; Wang, J.; Zhong, Y.; Zheng, Z. FactSeg: Foreground Activation-Driven Small Object Semantic Segmenta tion in Large-Scale Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5606216. [Google Scholar] [CrossRef]
- Liu, Y.; Mei, S.; Zhang, S.; Wang, Y.; He, M.; Du, Q. Semantic Segmentation of High-Resolution Remote Sensing Images Using an Improved Transformer. In Proceedings of the 2022 IEEE International Geoscience and Remote Sensing Symposium (IGARSS 2022), Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 3496–3499. [Google Scholar]
- Reed, C.J.; Gupta, R.; Li, S.; Brockman, S.; Funk, C.; Clipp, B.; Keutzer, K.; Candido, S.; Uyttendaele, M.; Darrell, T. Scale-MAE: A Scale-Aware Masked Autoencoder for Multiscale Geospatial Representation Learning. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision, ICCV, Paris, France, 2–3 October 2023; pp. 4065–4076. [Google Scholar]
- Mou, L.; Zhu, X. IM2HEIGHT: Height Estimation from Single Monocular Imagery via Fully Residual Convolu tional-Deconvolutional Network. arXiv 2018, arXiv:1802.10249. [Google Scholar]
- Amirkolaee, H.A.; Arefi, H. Height Estimation from Single Aerial Images Using a Deep Convolutional Encoder-Decoder Network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 149, 50–66. [Google Scholar] [CrossRef]
- Li, W.D.; Meng, L.; Wang, J.; He, C.; Xia, G.-S.; Lin, D. 3D Building Reconstruction from Monocular Remote Sens ing Images. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV 2021), Montreal, QC, Canada, 10–17 October 2021; pp. 12528–12537. [Google Scholar]
- Li, X.; Wang, M.; Fang, Y. Height Estimation from Single Aerial Images Using a Deep Ordinal Regression Net work. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6000205. [Google Scholar] [CrossRef]
- Mao, Y.; Chen, K.; Zhao, L.; Chen, W.; Tang, D.; Liu, W.; Wang, Z.; Diao, W.; Sun, X.; Fu, K. Elevation Estimation-Driven Building 3-D Reconstruction from Single-View Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5608718. [Google Scholar] [CrossRef]
- Zhao, W.; Persello, C.; Stein, A. Semantic-Aware Unsupervised Domain Adaptation for Height Estimation from Single-View Aerial Images. ISPRS J. Photogramm. Remote Sens. 2023, 196, 372–385. [Google Scholar] [CrossRef]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE Computer Society: Los Alamitos, CA, USA, 2017; pp. 6230–6239. [Google Scholar]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Honolulu, HI, USA, 2017; pp. 5168–5177. [Google Scholar]
- Zhang, H.; Dana, K.; Shi, J.; Zhang, Z.; Wang, X.; Tyagi, A.; Agrawal, A. Context Encoding for Semantic Segmen tation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Zhang, C.; Lin, G.; Liu, F.; Yao, R.; Shen, C. CANet: Class-Agnostic Segmentation Networks with Iterative Refine ment and Attentive Few-Shot Learning. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2019), Long Beach, CA, USA, 16–17 June 2019; pp. 5212–5221. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2019), Long Beach, CA, USA, 16–17 June 2019; pp. 3141–3149. [Google Scholar]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H.S.; et al. Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2021, Nashville, TN, USA, 20–25 June 2021; pp. 6877–6886. [Google Scholar]
- Zhang, B.; Tian, Z.; Tang, Q.; Chu, X.; Wei, X.; Shen, C.; Liu, Y. SegViT: Semantic Segmentation with Plain Vision Transformers. In Proceedings of the Advances in Neural Information Processing Systems 35 (NeurIPS 2022), New Orleans, LO, USA, 28 November–9 December 2022. [Google Scholar]
- Shi, H.; Hayat, M.; Cai, J. Transformer Scale Gate for Semantic Segmentation. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR, Paris, France, 2–3 October 2023; pp. 3051–3060. [Google Scholar]
- Almarzouqi, H.; Saoud, L.S. Semantic Labeling of High-Resolution Images Using EfficientUNets and Transform ers. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4402913. [Google Scholar] [CrossRef]
- Wang, H.; Chen, X.; Zhang, T.; Xu, Z.; Li, J. CCTNet: Coupled CNN and Transformer Network for Crop Segmen tation of Remote Sensing Images. Remote Sens. 2022, 14, 1956. [Google Scholar] [CrossRef]
- Gao, L.; Liu, H.; Yang, M.; Chen, L.; Wan, Y.; Xiao, Z.; Qian, Y. STransFuse: Fusing Swin Transformer and Convo lutional Neural Network for Remote Sensing Image Semantic Segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 10990–11003. [Google Scholar] [CrossRef]
- Wang, L.; Li, R.; Zhang, C.; Fang, S.; Duan, C.; Meng, X.; Atkinson, P.M. UNetFormer: A UNet-like Transformer for Efficient Semantic Segmentation of Remote Sensing Urban Scene Imagery. ISPRS J. Photogramm. Remote Sens. 2022, 190, 196–214. [Google Scholar] [CrossRef]
- Zhang, C.; Jiang, W.; Zhang, Y.; Wang, W.; Zhao, Q.; Wang, C. Transformer and CNN Hybrid Deep Neural Net work for Semantic Segmentation of Very-High-Resolution Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4408820. [Google Scholar] [CrossRef]
- Hanyu, T.; Yamazaki, K.; Tran, M.; McCann, R.A.; Liao, H.; Rainwater, C.; Adkins, M.; Cothren, J.; Le, N. Aerial Former: Multi-Resolution Transformer for Aerial Image Segmentation. Remote Sens. 2024, 16, 2930. [Google Scholar] [CrossRef]
- RAGGAM, J.; BUCHROITHNER, M.; MANSBERGER, R. Relief Mapping Using Nonphotographic Spaceborne Imagery. ISPRS J. Photogramm. Remote Sens. 1989, 44, 21–36. [Google Scholar] [CrossRef]
- Pinheiro, M.; Reigber, A.; Scheiber, R.; Prats-Iraola, P.; Moreira, A. Generation of Highly Accurate DEMs Over Flat Areas by Means of Dual-Frequency and Dual-Baseline Airborne SAR Interferometry. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4361–4390. [Google Scholar] [CrossRef]
- Ka, M.-H.; Shimkin, P.E.; Baskakov, A.I.; Babokin, M.I. A New Single-Pass SAR Interferometry Technique with a Single-Antenna for Terrain Height Measurements. Remote Sens. 2019, 11, 1070. [Google Scholar] [CrossRef]
- Yang, X.; Wang, C.; Xi, X.; Wang, P.; Lei, Z.; Ma, W.; Nie, S. Extraction of Multiple Building Heights Using ICE Sat/GLAS Full-Waveform Data Assisted by Optical Imagery. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1914–1918. [Google Scholar] [CrossRef]
- Xing, S.; Dong, Q.; Hu, Z. Gated Feature Aggregation for Height Estimation from Single Aerial Images. IEEE Geosci. Remote Sensing Lett. 2022, 19, 6003705. [Google Scholar] [CrossRef]
- Vandenhende, S.; Georgoulis, S.; Van Gansbeke, W.; Proesmans, M.; Dai, D.; Van Gool, L. Multi-Task Learning for Dense Prediction Tasks: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 3614–3633. [Google Scholar] [CrossRef]
- Xu, D.; Ouyang, W.; Wang, X.; Sebe, N. PAD-Net: Multi-Tasks Guided Prediction-and-Distillation Network for Simultaneous Depth Estimation and Scene Parsing. In Proceedings of the 2018 IEEE/CVF Conference on Computer vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 675–684. [Google Scholar]
- Zhang, Z.; Cui, Z.; Xu, C.; Yan, Y.; Sebe, N.; Yang, J. Pattern-Affinitive Propagation across Depth, Surface Normal and Semantic Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer vision and Pattern Recognition (CVPR 2019), Long Beach, CA, USA, 16–17 June 2019; pp. 4101–4110. [Google Scholar]
- Vandenhende, S.; Georgoulis, S.; Van Gool, L. MTI-Net: Multi-Scale Task Interaction Networks for Multi-Task Learning. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; Proceedings, Part IV. Springer: Berlin/Heidelberg, Germany, 2020; pp. 527–543. [Google Scholar]
- Ye, H.; Xu, D. InvPT++: Inverted Pyramid Multi-Task Transformer for Visual Scene Understanding. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 7493–7508. [Google Scholar] [CrossRef]
- Sinodinos, D.; Armanfard, N. Cross-Task Affinity Learning for Multitask Dense Scene Predictions. arXiv 2024, arXiv:2401.11124. [Google Scholar] [CrossRef]
- Agiza, A.; Neseem, M.; Reda, S. MTLoRA: A Low-Rank Adaptation Approach for Efficient Multi-Task Learning 2024. In Proceedings of the 2024 IEEE/CVF Conference on Computer vision and Pattern Recognition (CVPR 2024), Seattle, WA, USA, 16–22 June 2024; pp. 16196–16205. [Google Scholar]
- Wang, S.; Li, J.; Zhao, Z.; Lian, D.; Huang, B.; Wang, X.; Li, Z.; Gao, S. TSP-Transformer: Task-Specific Prompts Boosted Transformer for Holistic Scene Understanding. In Proceedings of the 2024 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3 January 2024; pp. 914–923. [Google Scholar]
- Ye, H.; Xu, D. TaskPrompter: Spatial-Channel Multi-Task Prompting for Dense Scene Understanding. In Proceedings of the Eleventh International Conference on Learning Representations, Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- Meyerson, E.; Miikkulainen, R. Beyond Shared Hierarchies: Deep Multitask Learning through Soft Layer Ordering. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Maninis, K.-K.; Radosavovic, I.; Kokkinos, I. Attentive Single-Tasking of Multiple Tasks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2019), Long Beach, CA, USA, 16–17 June 2019; pp. 1851–1860. [Google Scholar]
- Guo, P.; Lee, C.-Y.; Ulbricht, D. Learning to Branch for Multi-Task Learning. In Proceedings of the International Conference on Machine Learning, Shenzhen, China, 15–17 February 2020. [Google Scholar]
- Wallingford, M.; Li, H.; Achille, A.; Ravichandran, A.; Fowlkes, C.; Bhotika, R.; Soatto, S. Task Adaptive Parameter Sharing for Multi-Task Learning. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 7551–7560. [Google Scholar]
- Srivastava, S.; Volpi, M.; Tuia, D. Joint height estimation and semantic labeling of monocular aerial images with CNNS. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 5173–5176. [Google Scholar]
- Wang, Y.; Ding, W.; Zhang, R.; Li, H. Boundary-Aware Multitask Learning for Remote Sensing Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 951–963. [Google Scholar] [CrossRef]
- Xing, S.; Dong, Q.; Hu, Z. SCE-Net: Self- and Cross-Enhancement Network for Single-View Height Estimation and Semantic Segmentation. Remote Sens. 2022, 14, 2252. [Google Scholar] [CrossRef]
- Liu, W.; Sun, X.; Zhang, W.; Guo, Z.; Fu, K. Associatively Segmenting Semantics and Estimating Height from Monocular Remote-Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–17. [Google Scholar] [CrossRef]
- Mao, Y.; Sun, X.; Huang, X.; Chen, K. Light: Joint Individual Building Extraction and Height Estimation from Satellite Images Through a Unified Multitask Learning Network. In Proceedings of the 2023 IEEE International Geoscience and Remote Sensing Symposium (IGARSS 2023), Vancouver, ON, Canada, 18–22 June 2023; pp. 5320–5323. [Google Scholar]
- Zhang, Q.; Yang, G.; Zhang, G. Collaborative Network for Super-Resolution and Semantic Segmentation of Re mote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4404512. [Google Scholar] [CrossRef]
- Gao, Z.; Sun, W.; Lu, Y.; Zhang, Y.; Song, W.; Zhang, Y.; Zhai, R. Joint Learning of Semantic Segmentation and Height Estimation for Remote Sensing Image Leveraging Contrastive Learning. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5614015. [Google Scholar] [CrossRef]
- Cipolla, R.; Gal, Y.; Kendall, A. Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7482–7491. [Google Scholar]
- Strudel, R.; Garcia, R.; Laptev, I.; Schmid, C. Segmenter: Transformer for Semantic Segmentation. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10 October 2021; pp. 7242–7252. [Google Scholar]
- Yu, W.; Luo, M.; Zhou, P.; Si, C.; Zhou, Y.; Wang, X.; Feng, J.; Yan, S. MetaFormer Is Actually What You Need for Vision. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 10809–10819. [Google Scholar]
- Ji, Y.; Chen, Z.; Xie, E.; Hong, L.; Liu, X.; Liu, Z.; Lu, T.; Li, Z.; Luo, P. DDP: Diffusion Model for Dense Visual Prediction. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1 October 2023; pp. 21684–21695. [Google Scholar]
- Cai, H.; Li, J.; Hu, M.; Gan, C.; Han, S. EfficientViT: Lightweight Multi-Scale Attention for High-Resolution Dense Prediction. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1 October 2023; pp. 17256–17267. [Google Scholar]
- Alidoost, F.; Arefi, H.; Tombari, F. 2D Image-To-3D Model: Knowledge-Based 3D Building Reconstruction (3DBR) Using Single Aerial Images and Convolutional Neural Networks (CNNs). Remote Sens. 2019, 11, 2219. [Google Scholar] [CrossRef]
- Carvalho, M.; Saux, B.L.; Trouvé-Peloux, P.; Almansa, A.; Champagnat, F. On Regression Losses for Deep Depth Estimation. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 2915–2919. [Google Scholar]
- Liu, C.-J.; Krylov, V.A.; Kane, P.; Kavanagh, G.; Dahyot, R. IM2ELEVATION: Building Height Estimation from Single-View Aerial Imagery. Remote Sens. 2020, 12, 2719. [Google Scholar] [CrossRef]
- Carvalho, M.; Le Saux, B.; Trouvé-Peloux, P.; Champagnat, F.; Almansa, A. Multitask Learning of Height and Semantics from Aerial Images. IEEE Geosci. Remote Sens. Lett. 2020, 17, 1391–1395. [Google Scholar] [CrossRef]
- Ye, H.; Xu, D. TaskExpert: Dynamically Assembling Multi-Task Representations with Memorial Mixture-of-Experts. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1 October 2023; pp. 21771–21780. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Abbreviation | Meaning |
|---|---|
| STL | Single-task learning |
| MTL | Multi-task learning |
| ITFEM | Initial Task-specific Feature Embedding Module |
| ATFDM | Adaptive Task-specific Feature Distillation Module |
| ABTIM | Attention-Based Task Interaction Module |
| Methods | Semantic Segmentation | Height Estimation | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| (Higher Better)↑ | (Lower Better)↓ | (Higher Better)↑ | ||||||||
| OA | mF1 | mIoU | AbsRel | MAE | RMSE | |||||
| SS | FCN [11] | 86.5 | 83.7 | 72.6 | - | - | - | - | - | - |
| DANet [18] | 90.4 | 88.7 | 80.0 | - | - | - | - | - | - | |
| Segmenter [54] | 89.9 | 88.2 | 79.4 | - | - | - | - | - | - | |
| PoolFormer [55] | 90.3 | 89.6 | 81.4 | - | - | - | - | - | ||
| DDP [56] | - | 89.5 | 80.1 | - | - | - | - | - | - | |
| EfficientViT [57] | 89.4 | 87.6 | 80.5 | - | - | - | - | - | - | |
| HE | Amirkolaee et al. [6] | - | - | - | 1.179 | 1.487 | 2.197 | 0.305 | 0.496 | 0.599 |
| IM2HEIGHT [5] | - | - | - | 1.009 | 1.485 | 2.253 | 0.317 | 0.512 | 0.609 | |
| 3DBR [58] | - | - | - | 0.948 | 1.379 | 2.074 | 0.338 | 0.540 | 0.641 | |
| D3Net [59] | - | - | - | 2.016 | 1.314 | 2.123 | 0.369 | 0.533 | 0.644 | |
| IM2ELEVATION [60] | - | - | - | 0.956 | 1.226 | 1.882 | 0.399 | 0.587 | 0.671 | |
| PLNet [32] | - | - | - | 0.833 | 1.178 | 1.775 | 0.386 | 0.599 | 0.702 | |
| MTL | Srivastava et al. [46] | 79.3 | 72.6 | - | 4.415 | 1.861 | 2.729 | 0.217 | 0.385 | 0.517 |
| Carvalho et al. [61] | 86.1 | 82.3 | - | 1.882 | 1.262 | 2.089 | 0.405 | 0.562 | 0.663 | |
| BAMTL [47] | 88.4 | 86.9 | - | 1.064 | 1.078 | 1.762 | 0.451 | 0.617 | 0.714 | |
| TaskExpert [62] | 88.8 | 86.3 | - | 1.037 | 1.338 | 1.989 | 0.428 | 0.647 | 0.760 | |
| InvPT++ [37] | 88.7 | 86.0 | - | 0.830 | 1.334 | 2.009 | 0.379 | 0.638 | 0.768 | |
| Ours | 90.8 | 89.6 | 81.5 | 0.791 | 1.184 | 1.790 | 0.498 | 0.703 | 0.806 | |
| Methods | Semantic Segmentation | Height Estimation | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| (Higher Better)↑ | (Lower Better)↓ | (Higher Better)↑ | ||||||||
| OA | mF1 | mIoU | AbsRel | MAE | RMSE | |||||
| SS | FCN [11] | 85.6 | 87.6 | 78.3 | - | - | - | - | - | - |
| DANet [18] | 89.9 | 91.2 | 84.1 | - | - | - | - | - | - | |
| Segmenter [54] | 91.0 | 92.3 | 86.5 | - | - | - | - | - | - | |
| PoolFormer [55] | 91.1 | 92.6 | 86.5 | - | - | - | - | - | - | |
| DDP [56] | - | 92.4 | 86.1 | - | - | - | - | - | - | |
| EfficientViT [57] | 89.6 | 90.1 | 84.2 | - | - | - | - | - | - | |
| HE | Amirkolaee et al. [6] | - | - | - | 0.537 | 1.926 | 3.507 | 0.394 | 0.640 | 0.775 |
| IM2HEIGHT [5] | - | - | - | 0.518 | 2.200 | 4.141 | 0.534 | 0.680 | 0.763 | |
| 3DBR [58] | - | - | - | 0.409 | 1.751 | 3.439 | 0.605 | 0.742 | 0.823 | |
| D3Net [59] | - | - | - | 0.391 | 1.681 | 3.055 | 0.601 | 0.742 | 0.830 | |
| IM2ELEVATION [60] | - | - | - | 0.429 | 1.744 | 3.516 | 0.638 | 0.767 | 0.839 | |
| PLNet [32] | - | - | - | 0.318 | 1.201 | 2.354 | 0.639 | 0.833 | 0.912 | |
| MTL | Srivastava et al. [46] | 80.1 | 79.9 | - | 0.624 | 2.224 | 3.740 | 0.412 | 0.597 | 0.720 |
| Carvalho et al. [61] | 83.2 | 82.2 | - | 0.441 | 1.838 | 3.281 | 0.575 | 0.720 | 0.808 | |
| BAMTL [47] | 91.3 | 90.9 | - | 0.291 | 1.223 | 2.407 | 0.685 | 0.819 | 0.897 | |
| TaskExpert [62] | 90.7 | 90.2 | - | 0.273 | 1.292 | 2.513 | 0.650 | 0.818 | 0.898 | |
| InvPT++ [37] | 91.1 | 90.6 | - | 0.253 | 1.210 | 2.402 | 0.673 | 0.829 | 0.904 | |
| Ours | 92.0 | 92.9 | 87.0 | 0.256 | 1.147 | 2.420 | 0.698 | 0.839 | 0.912 | |
| Methods | Semantic Segmentation | Height Estimation | |||||||
|---|---|---|---|---|---|---|---|---|---|
| (Higher Better)↑ | (Lower Better)↓ | (Higher Better)↑ | |||||||
| OA | mF1 | mIoU | AbsRel | MAE | RMSE | ||||
| STL-S | 89.8 | 88.9 | 80.7 | - | - | - | - | - | - |
| STL-H | - | - | - | 0.827 | 1.245 | 1.912 | 0.480 | 0.682 | 0.785 |
| MTL-Baseline | 90.1 | 88.4 | 80.3 | 0.830 | 1.253 | 1.933 | 0.473 | 0.677 | 0.778 |
| MTL-Baseline+ITFEM | 90.4 | 89.1 | 81.0 | 0.807 | 1.230 | 1.887 | 0.488 | 0.685 | 0.782 |
| MTL-Baseline+ITFEM+ATFDM | 90.6 | 89.4 | 81.3 | 0.810 | 1.222 | 1.843 | 0.490 | 0.687 | 0.790 |
| CTME-Net (Full) | 90.8 | 89.6 | 81.5 | 0.791 | 1.184 | 1.790 | 0.498 | 0.703 | 0.806 |
| L1 | L2 | L3 | Semantic Segmentation | Height Estimation | ||
|---|---|---|---|---|---|---|
| mF1 | mIoU | RMSE | ||||
| √ | 89.5 | 81.3 | 1.796 | 0.492 | ||
| √ | 89.3 | 81.2 | 1.811 | 0.489 | ||
| √ | 88.7 | 80.4 | 1.890 | 0.477 | ||
| √ | √ | 89.6 | 81.5 | 1.790 | 0.498 | |
| √ | √ | 89.0 | 80.7 | 1.823 | 0.480 | |
| √ | √ | √ | 89.0 | 80.8 | 1.814 | 0.484 |
| Quantities | Semantic Segmentation | Height Estimation | ||
|---|---|---|---|---|
| mF1 | mIoU | RMSE | ||
| 1 | 89.3 | 81.3 | 1.810 | 0.490 |
| 4 | 89.4 | 81.4 | 1.797 | 0.494 |
| 8 | 89.6 | 81.5 | 1.790 | 0.498 |
| 16 | 89.5 | 81.4 | 1.795 | 0.496 |
| 32 | 89.4 | 81.3 | 1.803 | 0.495 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peng, X.; Wang, S.; Wang, F.; Zhu, J.; Li, S.; Liu, L.; Wang, Z. Synergistic Semantic Segmentation and Height Estimation for Monocular Remote Sensing Images via Cross-Task Interaction. Remote Sens. 2025, 17, 1637. https://doi.org/10.3390/rs17091637
Peng X, Wang S, Wang F, Zhu J, Li S, Liu L, Wang Z. Synergistic Semantic Segmentation and Height Estimation for Monocular Remote Sensing Images via Cross-Task Interaction. Remote Sensing. 2025; 17(9):1637. https://doi.org/10.3390/rs17091637
Chicago/Turabian StylePeng, Xuanang, Shixin Wang, Futao Wang, Jinfeng Zhu, Suju Li, Longfei Liu, and Zhenqing Wang. 2025. "Synergistic Semantic Segmentation and Height Estimation for Monocular Remote Sensing Images via Cross-Task Interaction" Remote Sensing 17, no. 9: 1637. https://doi.org/10.3390/rs17091637
APA StylePeng, X., Wang, S., Wang, F., Zhu, J., Li, S., Liu, L., & Wang, Z. (2025). Synergistic Semantic Segmentation and Height Estimation for Monocular Remote Sensing Images via Cross-Task Interaction. Remote Sensing, 17(9), 1637. https://doi.org/10.3390/rs17091637