
Enhancing Highway Scene Understanding: A Novel Data Augmentation Approach for Vehicle-Mounted LiDAR Point Cloud Segmentation

 , , ,
, , ,
Abstract
1. Introduction
- A large-scale point cloud dataset for highway road infrastructure is constructed, including six major asset categories. This fills the gap in existing large-scale highway asset segmentation datasets and provides valuable data support for related research.
- A semi-supervised learning-based method for highway point cloud asset segmentation is proposed. Extensive experiments show that the segmentation accuracy for various asset types and the overall performance reach optimal levels, validating the superiority of the proposed approach.
- A highway-aware hybrid conical masking data augmentation strategy is developed, which effectively alleviates challenges related to uneven asset distribution and the loss of local information. This significantly enhances the network’s ability to recognize road assets in complex environments and its robustness to occlusions.
2. Related Work
2.1. Fully Supervised Point Cloud Semantic Segmentation
2.2. Semi-Supervised Point Cloud Semantic Segmentation
3. PEA-PC Dataset
3.1. Scene Description
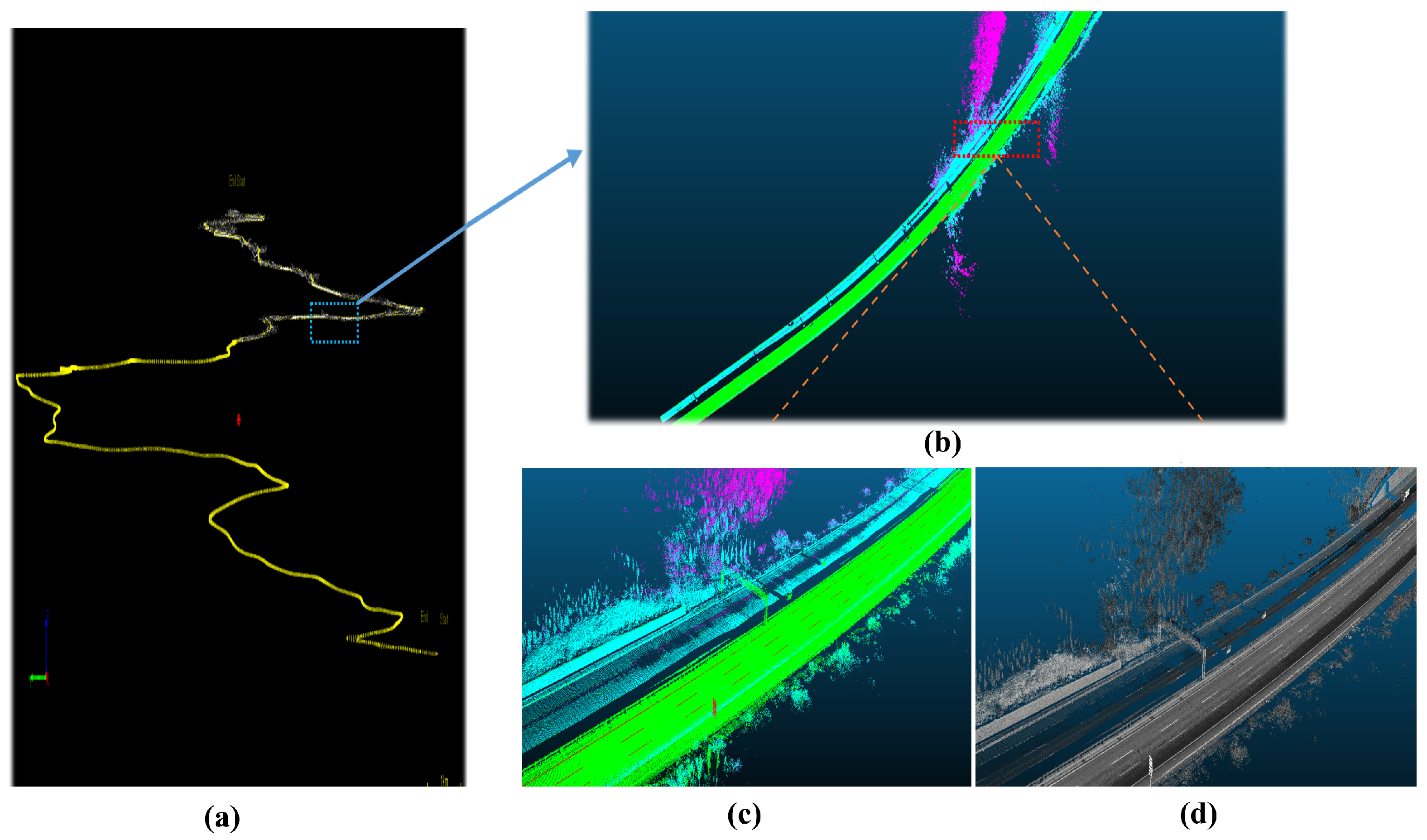
3.2. Point Cloud Collection
3.3. Annotation
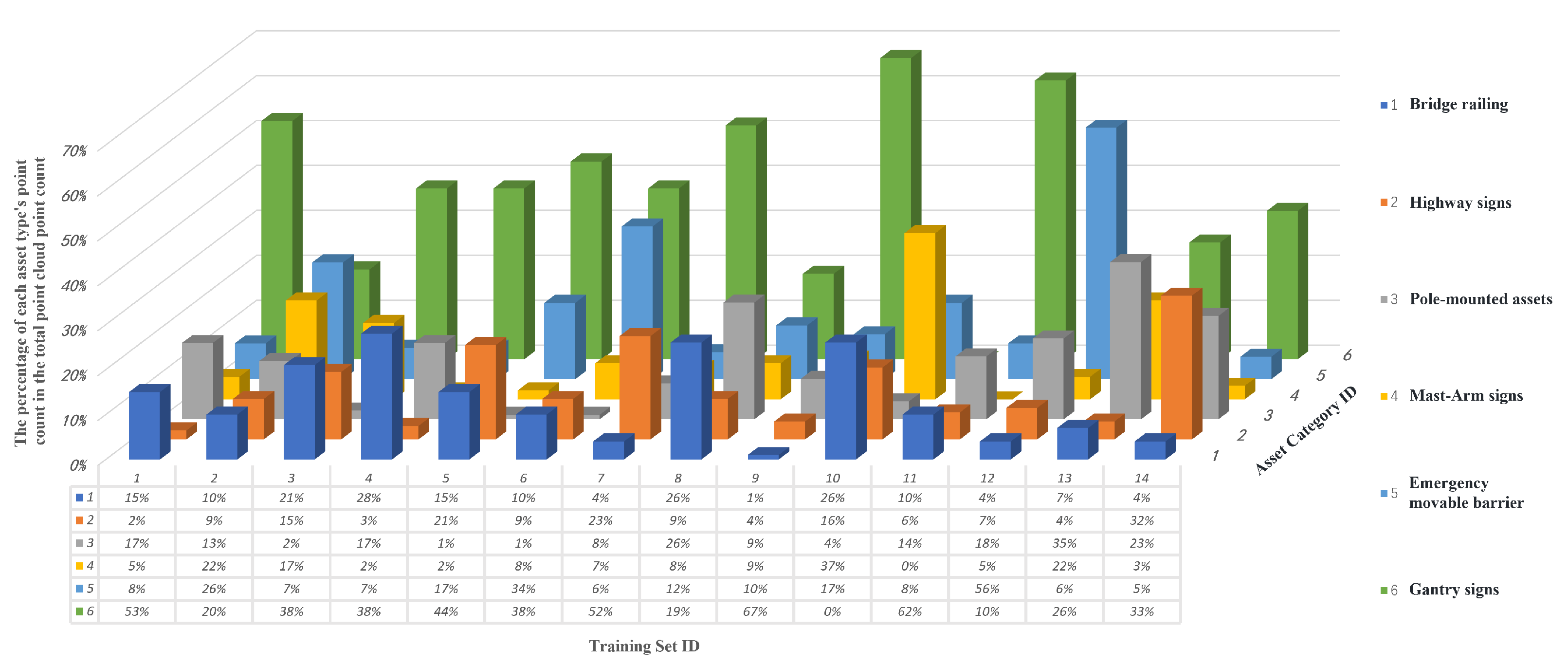
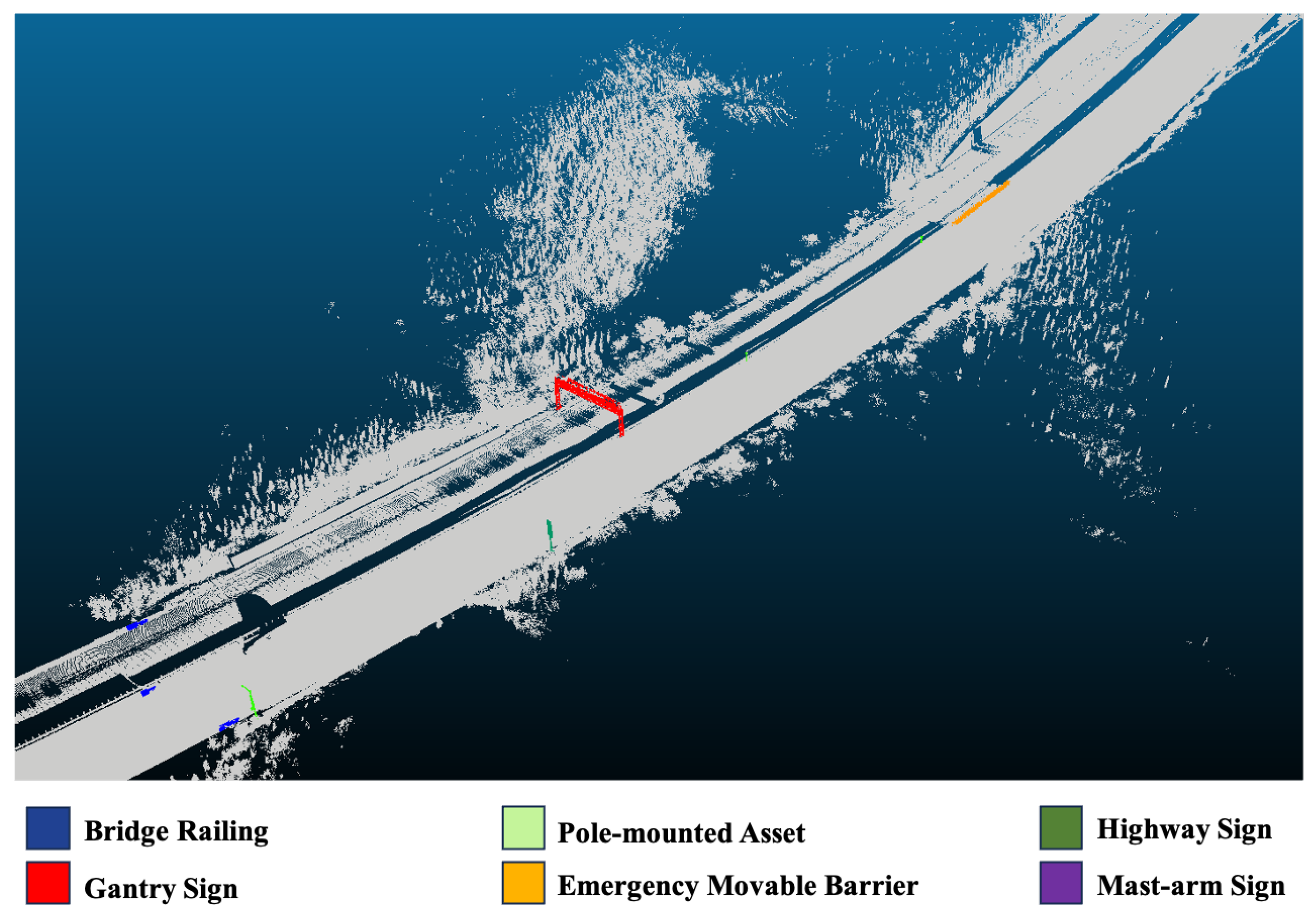
- Bridge railing: These are typically long and difficult to annotate. Annotation was focused on their junctions with roadside guardrails, usually found at the beginning of bridge sections.
- Highway sign: These include directional or guidance signs to aid navigation, warning signs to alert road users to potential hazards or changing road conditions, prohibition or regulatory signs (e.g., speed limits, no left turn), and informational signs indicating services, tourist attractions, restrooms, etc.
- Pole-mounted assets: These include various facilities or devices mounted on roadside poles, such as camera mounts and warning lights.
- Mast-arm sign: Signs mounted on overhead cantilever structures.
- Emergency movable barrier: Temporary barriers used to guide or restrict traffic during emergencies or maintenance.
- Gantry signs: Large overhead sign structures that span the road, often used for traffic guidance on expressways.
4. Method
4.1. Baseline Method
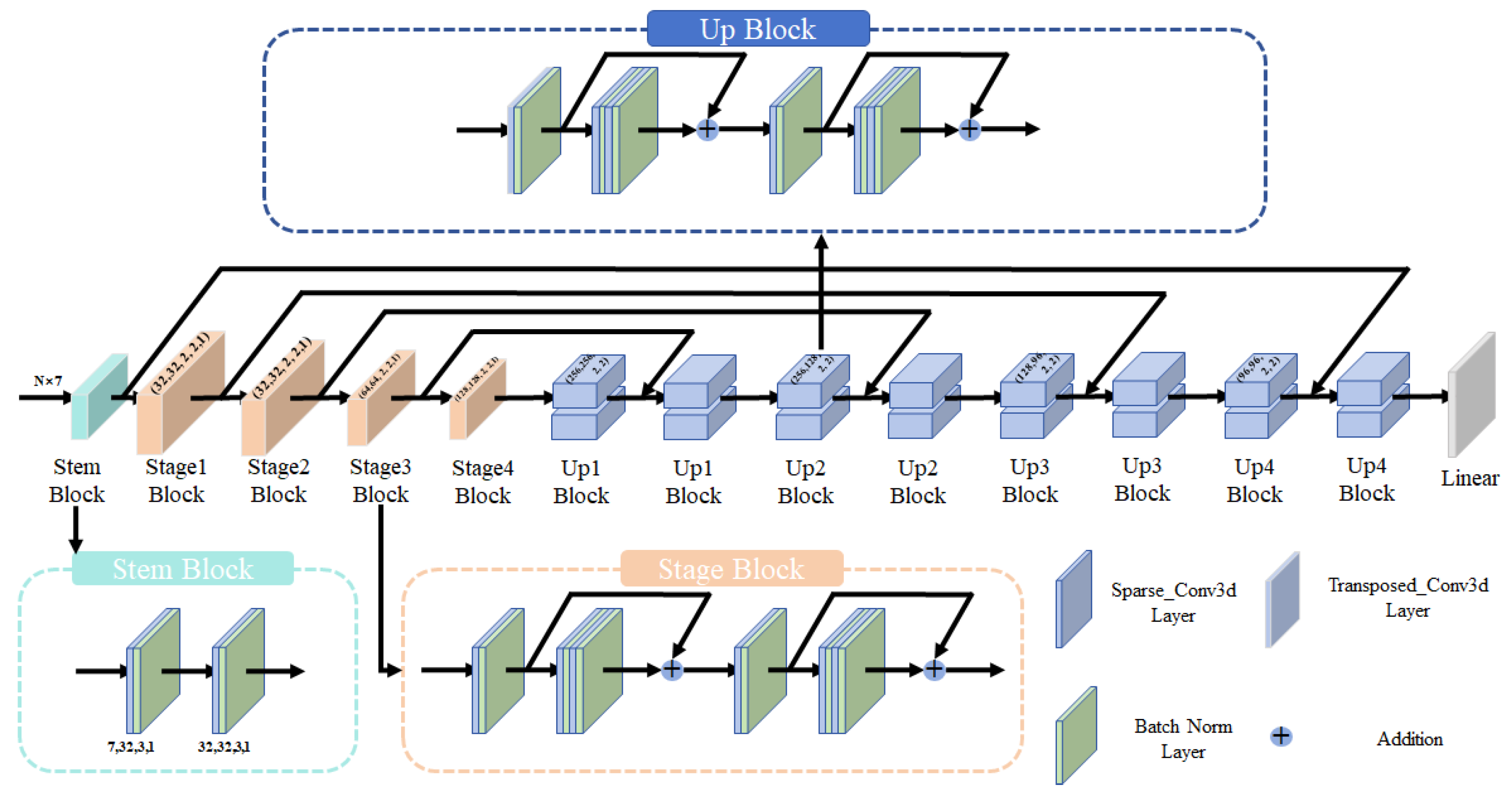
4.1.1. Model Introduction and Network Structure
4.1.2. Optimization Strategies and Loss Function
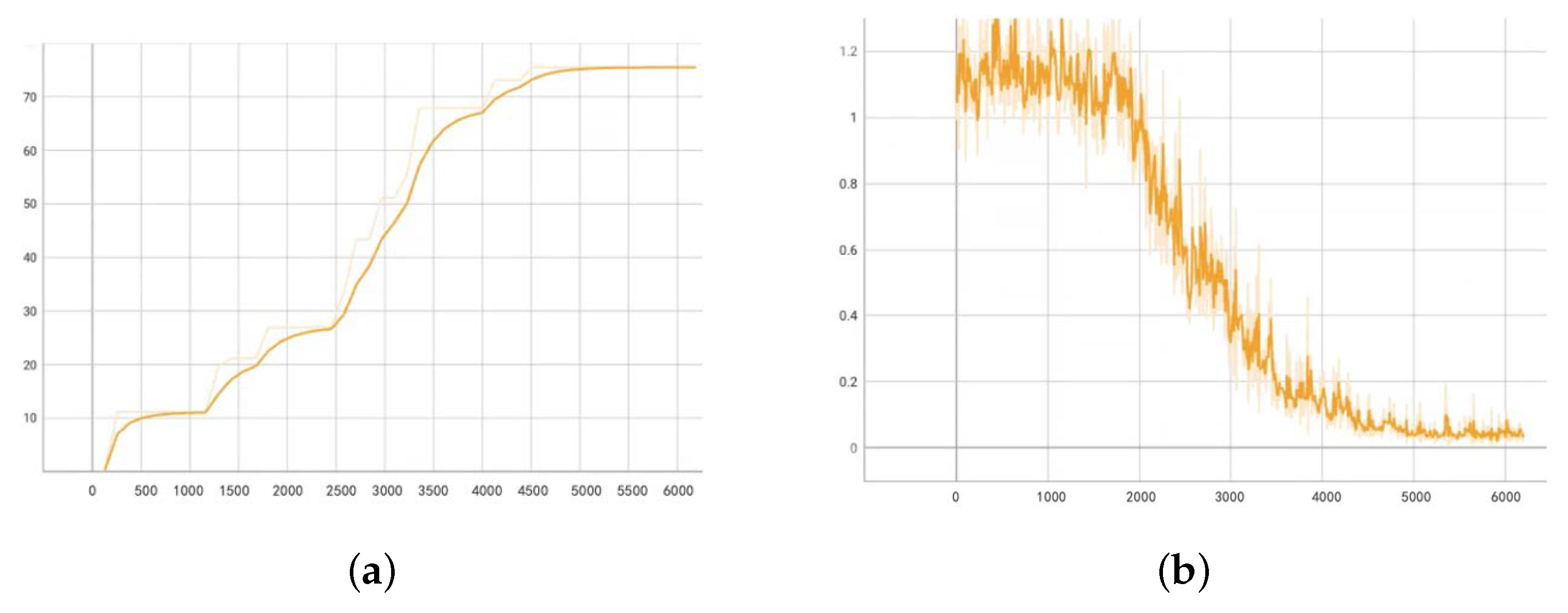
4.1.3. Training Process and Performance Improvement
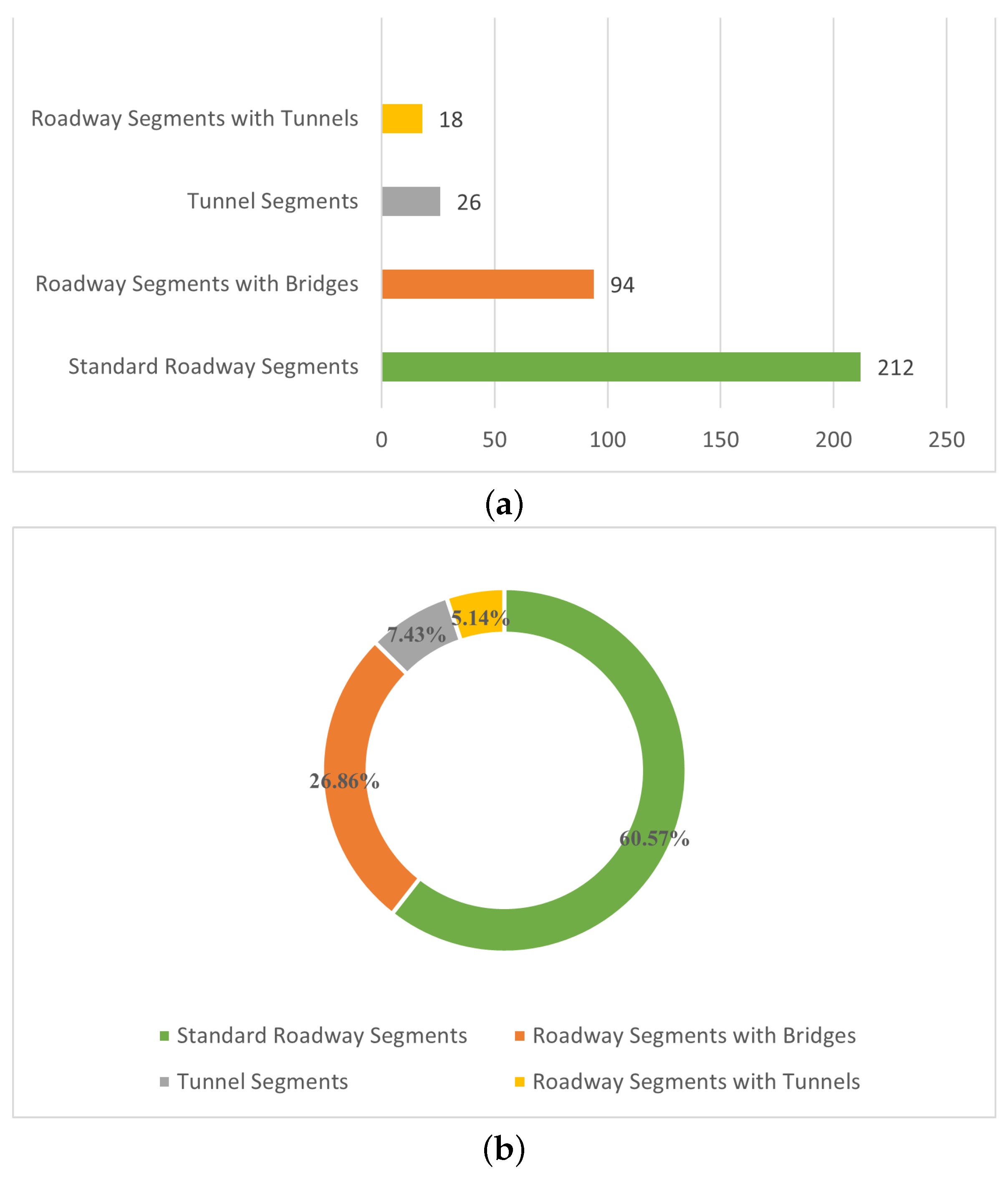
4.2. Data Statistics
- Standard roadway segments: This category includes the most common parts of the highway, primarily composed of straight and curved road sections, without any special structures like bridges or tunnels. These segments are mainly used for vehicles to travel straight or navigate through curves.
- Roadway segments with bridges: This category encompasses those highway segments that include bridge structures. Bridges are used to cross natural obstacles such as rivers and valleys, or man-made barriers like other roads. These segments combine the characteristics of standard road surfaces with those of bridge structures.
- Tunnel segments: This category specifically refers to highway segments composed entirely of tunnels. Tunnels are used to pass through mountains or other difficult-to-avoid obstacles and represent a special and technically demanding part of highways.
- Roadway segments with tunnels: This classification includes those segments that have tunnel structures on the basis of standard road surfaces. These segments combine the features of standard roadways and tunnels and may include standard road surfaces in the sections entering or exiting the tunnels.
4.3. Mixing for Augmentation
4.3.1. Initial Background Filtering
4.3.2. Data Segmentation Along Roadways
4.3.3. Routine Augmentation and Cleaning
4.3.4. Mixing Strategy Details
- Construction of conical masks: We randomly select the top or nearby upper points of pole-like roadside assets (e.g., surveillance poles, streetlights) as the apex of the conical mask. The axis of the cone is primarily oriented vertically upward, but can be adaptively adjusted according to the growth direction of typical occluders such as trees. To align with the scale characteristics of roadside poles on highways, the semi-apex angle () is generally set between and , simulating the natural spread of occlusion. The cone length (L) is typically controlled between 1 and 5 m, covering the typical occlusion distance around such pole-like structures.
- Point cloud manipulation: Within the conical masks, we downsample points representing the foreground (i.e., the pole-like assets) to simulate the partial occlusion effect of leaves and branches. Meanwhile, we maintain the background points to preserve the integrity of the scene.
- Intensity and color adjustment: For points within the conical masks, we adjust their intensity and color information to reflect the changes in lighting and color that occur due to occlusion in natural environments.
- Data merging and network training: The processed point cloud data, post-occlusion simulation, is merged back and then fed into the network for training. This treatment not only enhances the model’s capability to recognize pole-like assets in complex environments but also improves the model’s adaptability and robustness to occlusion scenarios.
5. Experiment
5.1. Setups
5.1.1. Dataset
5.1.2. Evaluation Metrics
- (true positive) represents the number of points correctly classified to the category.
- (false positive) represents the number of points incorrectly classified to the category, but actually belonging to other categories.
- (false negative) represents the number of points that should have been classified to the category but were not correctly classified.
5.2. Implementation Details
5.2.1. Semi-Supervised Learning Strategy
5.2.2. Experimental Progression and Analysis
5.3. Experimental Results
5.3.1. Overview of Results
5.3.2. Detailed Analysis of Segmentation Performance
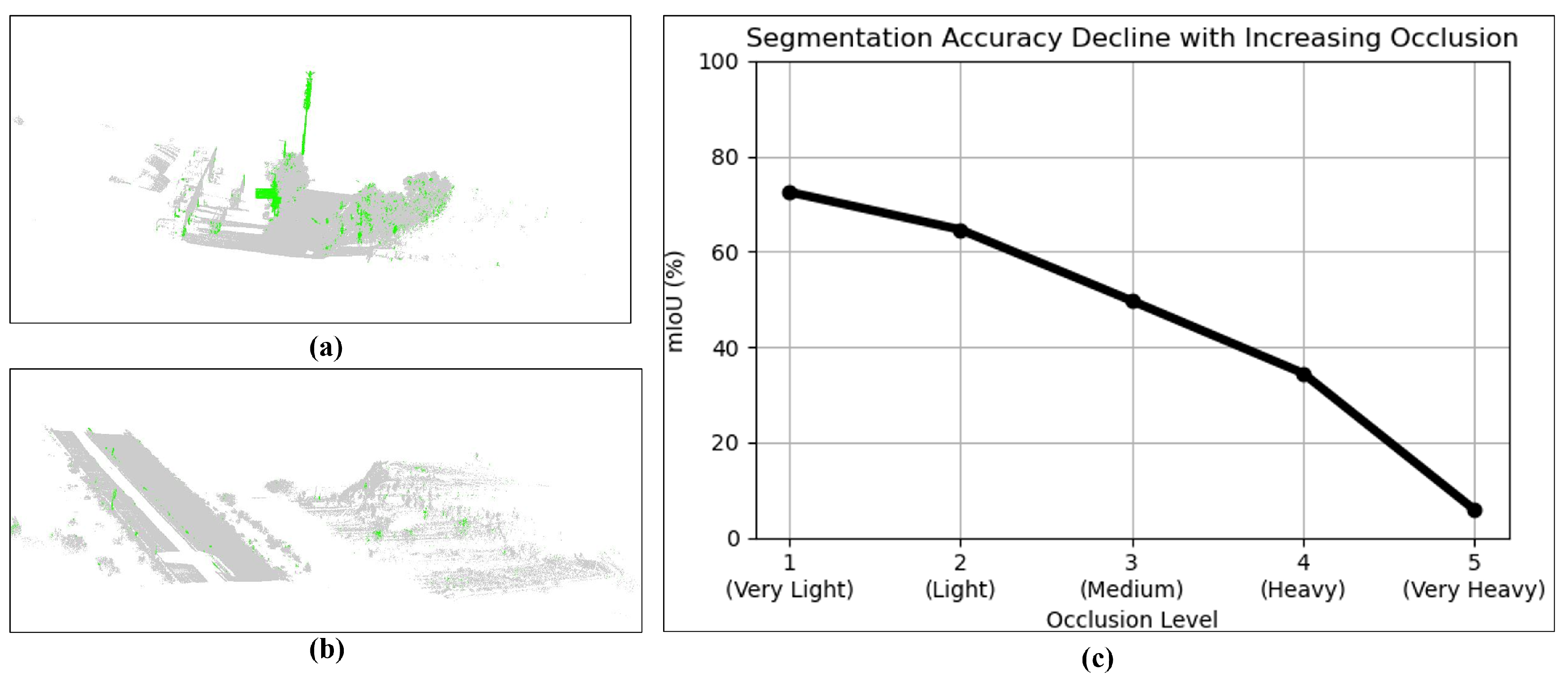
5.3.3. Error Analysis
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lian, R.; Wang, W.; Mustafa, N.; Huang, L. Road extraction methods in high-resolution remote sensing images: A comprehensive review. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5489–5507. [Google Scholar] [CrossRef]
- Suleymanoglu, B.; Soycan, M.; Toth, C. 3D road boundary extraction based on machine learning strategy using lidar and image-derived mms point clouds. Sensors 2024, 24, 503. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Shi, T.; Yun, P.; Tai, L.; Liu, M. Pointseg: Real-time semantic segmentation based on 3D lidar point cloud. arXiv 2018, arXiv:1807.06288. [Google Scholar]
- Liu, R.; Wu, J.; Lu, W.; Miao, Q.; Zhang, H.; Liu, X.; Lu, Z.; Li, L. A Review of Deep Learning-Based Methods for Road Extraction from High-Resolution Remote Sensing Images. Remote Sens. 2024, 16, 2056. [Google Scholar] [CrossRef]
- Wu, B.; Wan, A.; Yue, X.; Keutzer, K. Squeezeseg: Convolutional neural nets with recurrent crf for real-time road-object segmentation from 3D lidar point cloud. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 1887–1893. [Google Scholar]
- Ren, X.; Yu, B.; Wang, Y. Semantic Segmentation Method for Road Intersection Point Clouds Based on Lightweight LiDAR. Appl. Sci. 2024, 14, 4816. [Google Scholar] [CrossRef]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3D classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. Adv. Neural Inf. Process. Syst. 2017, 30, 5105–5114. [Google Scholar]
- Hu, Q.; Yang, B.; Xie, L.; Rosa, S.; Guo, Y.; Wang, Z.; Trigoni, N.; Markham, A. Randla-net: Efficient semantic segmentation of large-scale point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–20 June 2020; pp. 11108–11117. [Google Scholar]
- Qiu, S.; Anwar, S.; Barnes, N. Semantic segmentation for real point cloud scenes via bilateral augmentation and adaptive fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 19–24 June 2021; pp. 1757–1767. [Google Scholar]
- Fan, S.; Dong, Q.; Zhu, F.; Lv, Y.; Ye, P.; Wang, F.Y. SCF-Net: Learning spatial contextual features for large-scale point cloud segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 19–24 June 2021; pp. 14504–14513. [Google Scholar]
- Yu, X.; Tang, L.; Rao, Y.; Huang, T.; Zhou, J.; Lu, J. Point-bert: Pre-training 3D point cloud transformers with masked point modeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 19313–19322. [Google Scholar]
- Zhao, H.; Jiang, L.; Jia, J.; Torr, P.H.; Koltun, V. Point transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 16259–16268. [Google Scholar]
- Chen, Z.; Liu, X.C. Roadway asset inspection sampling using high-dimensional clustering and locality-sensitivity hashing. Comput.-Aided Civ. Infrastruct. Eng. 2019, 34, 116–129. [Google Scholar] [CrossRef]
- Balado, J.; Martínez-Sánchez, J.; Arias, P.; Novo, A. Road environment semantic segmentation with deep learning from MLS point cloud data. Sensors 2019, 19, 3466. [Google Scholar] [CrossRef] [PubMed]
- Choy, C.; Gwak, J.; Savarese, S. 4D Spatio-Temporal ConvNets: Minkowski Convolutional Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3075–3084. [Google Scholar]
- Liong, V.E.; Nguyen, T.N.T.; Widjaja, S.; Sharma, D.; Chong, Z.J. AMVNet: Assertion-based Multi-view Fusion Network for LiDAR Semantic Segmentation. arXiv 2020, arXiv:2012.04934. [Google Scholar]
- Tang, H.; Liu, Z.; Zhao, S.; Lin, Y.; Lin, J.; Wang, H.; Han, S. Searching Efficient 3D Architectures with Sparse Point-Voxel Convolution. In Proceedings of the European Conference on Computer Vision, Online, 25–29 October 2020. [Google Scholar]
- Yan, X.; Gao, J.; Li, J.; Zhang, R.; Li, Z.; Huang, R.; Cui, S. Sparse Single Sweep LiDAR Point Cloud Segmentation via Learning Contextual Shape Priors from Scene Completion. arXiv 2020, arXiv:2012.03762. [Google Scholar] [CrossRef]
- Zhu, X.; Zhou, H.; Wang, T.; Hong, F.; Ma, Y.; Li, W.; Li, H.; Lin, D. Cylindrical and asymmetrical 3D convolution networks for lidar segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 19–24 June 2021; pp. 9939–9948. [Google Scholar]
- Alonso, I.; Riazuelo, L.; Montesano, L.; Murillo, A.C. 3D-MiniNet: Learning a 2D Representation from Point Clouds for Fast and Efficient 3D LiDAR Semantic Segmentation. IEEE Robot. Autom. Lett. 2020, 5, 5432–5439. [Google Scholar] [CrossRef]
- Cortinhal, T.; Tzelepis, G.; Aksoy, E.E. SalsaNext: Fast, Uncertainty-Aware Semantic Segmentation of LiDAR Point Clouds. In Proceedings of the International Symposium on Visual Computing, Online, 14–16 December 2020; pp. 207–222. [Google Scholar]
- Milioto, A.; Vizzo, I.; Behley, J.; Stachniss, C. RangeNet++: Fast and Accurate LiDAR Semantic Segmentation. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 27–31 October 2019; pp. 4213–4220. [Google Scholar]
- Wu, B.; Zhou, X.; Zhao, S.; Yue, X.; Keutzer, K. SqueezeSegV2: Improved Model Structure and Unsupervised Domain Adaptation for Road-Object Segmentation from a LiDAR Point Cloud. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 4376–4382. [Google Scholar]
- Xu, C.; Wu, B.; Wang, Z.; Zhan, W.; Vajda, P.; Keutzer, K.; Tomizuka, M. SqueezeSegV3: Spatially-Adaptive Convolution for Efficient Pointcloud Segmentation. In Proceedings of the European Conference on Computer Vision, Online, 25–29 October 2020; pp. 1–19. [Google Scholar]
- Xiao, A.; Yang, X.; Lu, S.; Guan, D.; Huang, J. FPS-Net: A convolutional fusion network for large-scale LiDAR point cloud segmentation. ISPRS J. Photogramm. Remote Sens. 2021, 176, 237–249. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhou, Z.; David, P.; Yue, X.; Xi, Z.; Gong, B.; Foroosh, H. Polarnet: An improved grid representation for online lidar point clouds semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–20 June 2020; pp. 9601–9610. [Google Scholar]
- Cheng, R.; Razani, R.; Taghavi, E.; Li, E.; Liu, B. 2-s3net: Attentive feature fusion with adaptive feature selection for sparse semantic segmentation network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 19–24 June 2021; pp. 12547–12556. [Google Scholar]
- Kochanov, D.; Nejadasl, F.K.; Booij, O. KPRNet: Improving Projection-Based LiDAR Semantic Segmentation. arXiv 2020, arXiv:2007.12668. [Google Scholar]
- Thomas, H.; Qi, C.R.; Deschaud, J.E.; Marcotegui, B.; Goulette, F.; Guibas, L.J. KPConv: Flexible and Deformable Convolution for Point Clouds. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6411–6420. [Google Scholar]
- Liu, L.; Zhuang, Z.; Huang, S.; Xiao, X.; Xiang, T.; Chen, C.; Wang, J.; Tan, M. CPCM: Contextual PointCloud Modeling for Weakly Supervised PointCloud Semantic Segmentation. arXiv 2023, arXiv:2307.10316. [Google Scholar]
- Xu, X.; Lee, G.H. Weakly supervised semantic point cloud segmentation: Towards 10x fewer labels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–20 June 2020; pp. 13706–13715. [Google Scholar]
- Wei, J.; Lin, G.; Yap, K.-H.; Liu, F.; Hung, T.-Y. Dense Supervision Propagation for Weakly Supervised Semantic Segmentation on 3D Point Clouds. arXiv 2021, arXiv:2107.11267. [Google Scholar] [CrossRef]
- Zhang, Y.; Qu, Y.; Xie, Y.; Li, Z.; Zheng, S.; Li, C. Perturbed self-distillation: Weakly supervised large-scale point cloud semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 15520–15528. [Google Scholar]
- Hu, Q.; Yang, B.; Fang, G.; Guo, Y.; Leonardis, A.; Trigoni, N.; Markham, A. SQN: Weakly-supervised Semantic Segmentation of Large-scale 3D Point Clouds. In Proceedings of the Computer Vision—ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Proceedings, Part XXVII. Springer: Berlin/Heidelberg, Germany, 2022; pp. 600–619. [Google Scholar]
- Su, Y.; Xu, X.; Jia, K. Weakly Supervised 3D Point Cloud Segmentation via Multi-Prototype Learning. arXiv 2022, arXiv:2205.03137. [Google Scholar] [CrossRef]
- Yang, C.-H.; Wu, J.-J.; Chen, K.-S.; Chuang, Y.-Y.; Lin, Y.-Y. An MIL-Derived Transformer for Weakly Supervised Point Cloud Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 11830–11839. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Han, X.F.; Cheng, H.; Jiang, H.; He, D.; Xiao, G. Pcb-randnet: Rethinking random sampling for lidar semantic segmentation in autonomous driving scene. In Proceedings of the 2024 IEEE International Conference on Robotics and Automation (ICRA), Tokyo, Japan, 13–17 May 2024; pp. 4435–4441. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Zeng, Z.; Xu, Y.; Xie, Z.; Tang, W.; Wan, J.; Wu, W. Large-scale point cloud semantic segmentation via local perception and global descriptor vector. Expert Syst. Appl. 2024, 246, 123269. [Google Scholar] [CrossRef]
- Gong, H.; Wang, H.; Wang, D. Multilateral Cascading Network for Semantic Segmentation of Large-Scale Outdoor Point Clouds. IEEE Geosci. Remote Sens. Lett. 2025, 22, 6501005. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Duchi, J.; Hazan, E.; Singer, Y. Adaptive subgradient methods for online learning and stochastic optimization. J. Mach. Learn. Res. 2011, 12, 2121–2159. [Google Scholar]
- Nekrasov, A.; Schult, J.; Litany, O.; Leibe, B.; Engelmann, F. Mix3d: Out-of-context data augmentation for 3D scenes. In Proceedings of the 2021 International Conference on 3D Vision (3DV), Online, 25–28 October 2021; pp. 116–125. [Google Scholar]
- Li, X.; Li, X.; Zhang, L.; Cheng, G.; Shi, J.; Lin, Z.; Tan, S.; Tong, Y. Improving semantic segmentation via decoupled body and edge supervision. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XVII 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 435–452. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Pole-Mounted Assets | |
|---|---|
| Method | mIoU/% |
| PointNet++ | 6.2 |
| RandLA-Net | 13.2 |
| SPVNSA | 25.6 |
| LACV-Net | 22.9 |
| MCNet | 15.8 |
| MinKUNet | 29.4 |
| Configuration | Name | Details |
|---|---|---|
| Hardware environment | CPU | w5-2465X |
| GPU | 2 × A6000 | |
| Graphics memory | 2 × 48 G | |
| Software environment | Operating system | Ubuntu 20.04 |
| CUDA | 11.8 | |
| CUDNN | 8.9.04 | |
| Python | 3.8.18 | |
| PyTorch | 1.13.0 |
| Pole-Mounted Assets | |
|---|---|
| Method | IoU (Intersection over Union)/% |
| MinkUNet | 2.6 |
| Mask | 5.8 |
| Mix | 18.6 |
| Mask and Mix | 29.4 |
| IoU (Intersection over Union)/% | |||||||
|---|---|---|---|---|---|---|---|
| Method | Bridge Railing | Highway Sign | Pole-Mounted Asset | Mast-Arm Sign | Emergency Movable Barrier | Gantry Sign | mIoU/% |
| MinkUNet | 36.3 | 12.4 | 2.6 | 26.5 | 55.4 | 60.1 | 40.8 |
| Ours | 96.8 | 57.3 | 29.4 | 74.5 | 97.7 | 98.4 | 73.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, D.; Yi, Y.; Wang, Y.; Shao, Z.; Hao, Y.; Yan, Y.; Zhao, X.; Guo, J. Enhancing Highway Scene Understanding: A Novel Data Augmentation Approach for Vehicle-Mounted LiDAR Point Cloud Segmentation. Remote Sens. 2025, 17, 2147. https://doi.org/10.3390/rs17132147
Zhou D, Yi Y, Wang Y, Shao Z, Hao Y, Yan Y, Zhao X, Guo J. Enhancing Highway Scene Understanding: A Novel Data Augmentation Approach for Vehicle-Mounted LiDAR Point Cloud Segmentation. Remote Sensing. 2025; 17(13):2147. https://doi.org/10.3390/rs17132147
Chicago/Turabian StyleZhou, Dalong, Yuanyang Yi, Yu Wang, Zhenfeng Shao, Yanjun Hao, Yuyan Yan, Xiaojin Zhao, and Junkai Guo. 2025. "Enhancing Highway Scene Understanding: A Novel Data Augmentation Approach for Vehicle-Mounted LiDAR Point Cloud Segmentation" Remote Sensing 17, no. 13: 2147. https://doi.org/10.3390/rs17132147
APA StyleZhou, D., Yi, Y., Wang, Y., Shao, Z., Hao, Y., Yan, Y., Zhao, X., & Guo, J. (2025). Enhancing Highway Scene Understanding: A Novel Data Augmentation Approach for Vehicle-Mounted LiDAR Point Cloud Segmentation. Remote Sensing, 17(13), 2147. https://doi.org/10.3390/rs17132147