1. Introduction
Hyperspectral images consisting of up to hundreds of contiguous and narrow spectral channels enable identifying different materials on the ground based on their spectral signatures [
1]. They have been successfully used in different applications, such as land cover classification, target detection [
2], vegetation monitoring, agriculture [
3], urban mapping, and mineral identification [
4,
5,
6].
Among hyperspectral image classification methods proposed over the years, early approaches feed the spectral features to soft or hard classifiers, such as maximum likelihood [
7], support vector machine (SVM) [
8], nearest neighbor [
9], random forest [
10], and spectral angle [
11]. These methods are not particularly robust to the intraclass spectral variability in hyperspectral images, usually yielding salt and pepper noise in the generated classification maps [
12]. To address this problem, contextual information such as shape and texture have been taken into account in the literature to be coupled with spectral features, such as gray level co-occurrence matrix (GLCM) [
13], Gabor filters [
14], morphological profiles [
15], and Markov random fields [
16]. Object or segmentation-based methods [
17] have also been suggested for considering spatial correlations among pixels, where unified labels are assigned to all pixels of a superpixel (object). For example, simple linear iteration clustering (SLIC) is a well-known segmentation algorithm that takes spatial information into account, along with a limited computational burden [
18,
19].
Although spectral-spatial feature extraction and the feeding of extracted features to an appropriate classifier can improve the classification accuracy, the two steps of feature extraction and classification are usually carried out separately, and the extracted features may not sufficiently fit the chosen classifier, whenever their training processes are individually completed. Furthermore, high-order semantic features cannot be well recognized by the mentioned methods. Deep learning opened new perspectives in remote sensing, with automatic feature extraction and classification through an end-to-end training of a unified framework providing reliable results for both data processing and decision making [
20,
21].
Convolutional neural networks (CNNs) with hierarchical feature extraction have shown high ability in extracting high-level features and semantic information [
22,
23]. While two-dimensional CNNs (2DCNN) [
24] mostly extract spatial information in subsequent layers, three-dimensional CNNs (3DCNN) [
25] have shown superior performance for simultaneous spectral-spatial feature extraction and classification of hyperspectral images, due to the three-dimensional nature of a hyperspectral dataset.
Although CNNs have a high ability in local feature extraction from neighborhood regions, due to their limited receptive fields, they do not consider middle and long-range dependencies. Therefore, they may fail at capturing global information in the image. Transformers utilizing self-attention mechanisms have been introduced to solve this disadvantage [
26,
27]. However, CNNs and transformers are appropriate networks for regular data in Euclidean space, i.e., data structured in a traditional grid-like format, such as images arranged by rows and columns [
28]. Moreover, CNNs apply convolutional operations on fixed square image regions and cannot adapt to more irregular or varied shapes and sizes of regions within the image. In some cases, these may not be flexible enough for regions with different geometric properties. As an extension of CNN for non-gridded data, graph convolutional networks (GCN) [
29,
30] aggregate contextual relations and propagate them across graph nodes. As a result, GCNs have a higher ability in processing irregular data in a non-Euclidean space so that the neighborhood considered can be adapted to non-homogeneous or complex regions, such as target boundaries in hyperspectral images.
For the deployment of multiscale information in GCNs, multiple graphs with different neighborhood scales are considered in the multiscale dynamic GCN (MDGCN) [
31]. This approach introduces a dynamic and multiscale graph convolution operation instead of using a predefined fixed graph, with the fused feature embeddings updating the similarity measured between pixels, and using superpixels as graph nodes for complexity reduction. However, MDGCN performs graph convolution separately at different spatial scales and is limited by neighborhoods having a fixed size. To consider the interaction of multiscale information, the dual interactive GCN (DIGCN) relies on dual GCN branches, where the edge information of one branch is refined by the other one [
32].
Since the receptive field of GCN is often limited to a fairly small region, the context-aware dynamic GCN (CAD-GCN) [
33] captures long-range contextual relations through successive graph convolutions, simultaneously refining the graph edges and connective relationships among image regions.
Existing GCN models usually rely on predefined receptive fields, which may limit their ability to adaptively select the most significant neighborhood for a specific location. To deal with this issue, the dynamic adaptive sampling GCN (DAS-GCN) [
34] dynamically obtains the receptive field through adaptive sampling. DAS-GCN discovers the most meaningful receptive field adaptively and simultaneously adjusts the edge adjacency weights after implementing each adaptive sampling. After each iteration, the graph is updated and refined dynamically.
Existing GCNs usually utilize superpixel segmentation as a pre-processing step in order to reduce computational complexity. However, a superpixel may contain pixels with different labels. Moreover, the spectral-spatial features in the local regions of a superpixel may be ignored. To handle these hindrances, the end-to-end mixhop superpixel-based GCN (EMS-GCN) introduces a differentiable superpixel segmentation algorithm, which is able to refine the superpixel boundaries with the network training [
12]. Subsequently, the constructed superpixel graph is given to a mixhop superpixel GCN where long-range dependencies among superpixels are explored.
Due to the limited availability of labeled samples, supervised information is not usually sufficient. To improve the feature representation of GCN, the contrastive GCN (ConGCN) explores supervision signals from both spectral and spatial information using contrastive learning [
35]. ConGCN utilizes a semi-supervised contrastive loss function for maximizing the agreement among different views of the same node or nodes related to the same category, adopting a generative loss function which benefits from considering graph topology.
Most of the existing graphs are manually constructed and updated. The automatic GCN (Auto-GCN) models the interaction of high-order tensors [
36]. Auto-GCN uses the representation learning abilities of CNNs, embedding a semi-supervised Siamese network into a GCN to yield dynamic updating and automatic learning of the graph. A Confucius tri-learning paradigm of learning according to the Confucius remarks is introduced in [
37]. To this end, three models are trained together: two classifiers and one generator. While each of the two classifiers can learn from good examples achievable by the other, they can also learn from bad examples provided by the generator. This approach is useful for classification tasks when limited training samples are available because the labeled data samples are augmented by good examples, and the discrimination ability of the classifier is enhanced against fake targets using bad examples.
As mentioned, most of the graph-based convolutional networks first apply a pixel-to-region assignment by performing a superpixel segmentation method such as SLIC, and consider the obtained image regions as graph nodes. Thus, the constructed graph explores relationships among different regions of the image. However, due to the high spectral variability of hyperspectral images in different areas of an acquired scene, considering a global graph for spatial information propagation and contextual feature aggregation may not be efficient for pixel-based classification. Moreover, constructing a global graph from superpixels of the whole scene may yield a large graph with high complexity. To deal with these issues, a simple and light triple graph-based network, fusing both local and global information, is introduced in this work, which is not based on superpixel generation.
The proposed graph-based feature fusion (GF2) network is composed of three types of graphs for pixel-based classification. To define the graphs, on the one hand, a local patch around each pixel is considered. On the other hand, clusters’ centroids, derived from an unsupervised clustering of the whole hyperspectral image with the highest local entropy points selected as seeds, are considered anchors. The first graph explores relationships among pixels of the local patch with the global anchors, and is therefore a local-global graph. The second graph finds relationships among the anchors and is therefore global. Finally, the third graph is local and computes the relationships among pixels within the considered image patch.
The graphs are processed using individual GCNs. The outputs of the first two graphs are multiplied and fused with the third graph through a cross-attention mechanism. The fused local-global features are finally used for hyperspectral image classification. The experimental results show the efficiency of the proposed GF2 method compared to several state-of-the-art algorithms. The remainder of the paper is organized as follows:
Section 2 describes the proposed network in detail.
Section 3 presents the experimental results and an ablation study, with comparisons with benchmark methods, including several graph-based networks. Finally,
Section 4 concludes the paper and outlines future lines of work.
2. Method
A graph-based feature fusion (GF2) network is proposed for hyperspectral image classification. To improve the network learning process, the dimensionality of the hyperspectral image is first reduced from
to
by applying the principal component analysis (PCA) transform [
38]. An alternative would be the application of Minimum Noise Fraction (MNF) [
39]. For each pixel under test, three small graphs are considered.
Let us consider a patch around each given pixel, where is the number of pixels within the patch. In parallel, anchors are selected from the entire scene to derive a global characterization of the image. The number of anchors should be larger than the number of semantic classes in the image, in order to account for intra-class spectral variability, considering spectral classes not covered by the available semantic labels, and conveying information related to classes with multiple clusters. To this end, we set where is the number of semantic classes (the coefficient 1.5 is a catch-all value showing empirically good results for different datasets in our experiments, and keeping the size of the global graph small).
The anchors are chosen as the centroids of the output of a K-means clustering applied to the hyperspectral image using
as number of clusters. Instead of randomly initializing the cluster centroids, we select the points having the highest entropy values, as clustering algorithms such as K-means are sensitive to the initialization step. The assumption is that global anchors should be representative points for the structural distribution of the entire dataset, serving as graph nodes to model relationships across the image. So, they ideally should be informative, diverse, and spatially distributed. Because such points lie in informative regions such as boundaries, transitions, or complex mixtures, the selection of high-entropy points as initial seeds helps in capturing the structure and variability in the image, which improves the clusters’ quality meaningfully. On the other hand, pixels in homogeneous regions tend to have similar spectra, i.e., are characterized by a low entropy. To this end, around each pixel, the entropy of a
neighborhood is considered. This is conducted for each principal component, and the average entropy in all bands is assigned to the central pixel. For each given pixel, the entropy is derived as:
where
is the normalized histogram obtained from the image,
is the neighborhood window, and
is the number of dimensions after the PCA rotation. The computed cluster centers are considered to have the highest informational content and selected as the
anchors containing the global representation of the image.
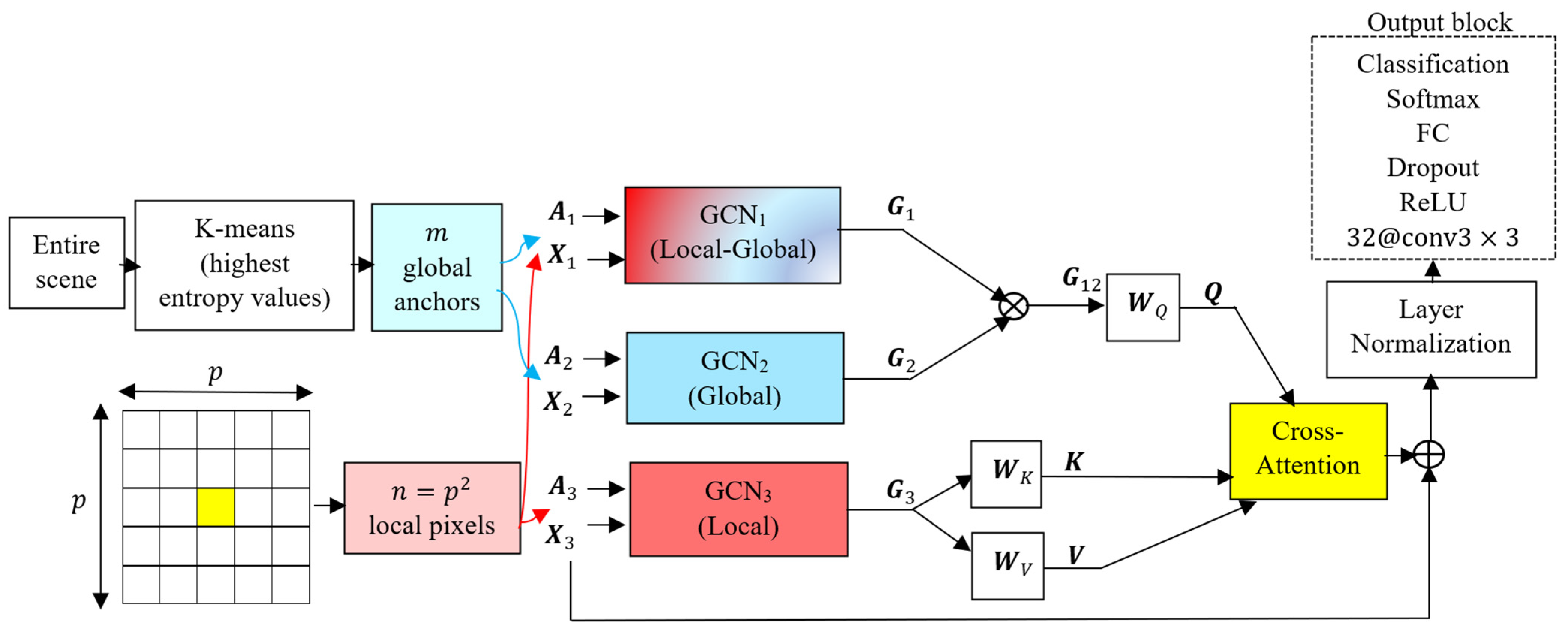
The block diagram of the proposed GF2 network is shown in
Figure 1. Depicted are three graph convolutional networks (GCNs), each one taking two inputs, a feature matrix
, and an adjacency matrix
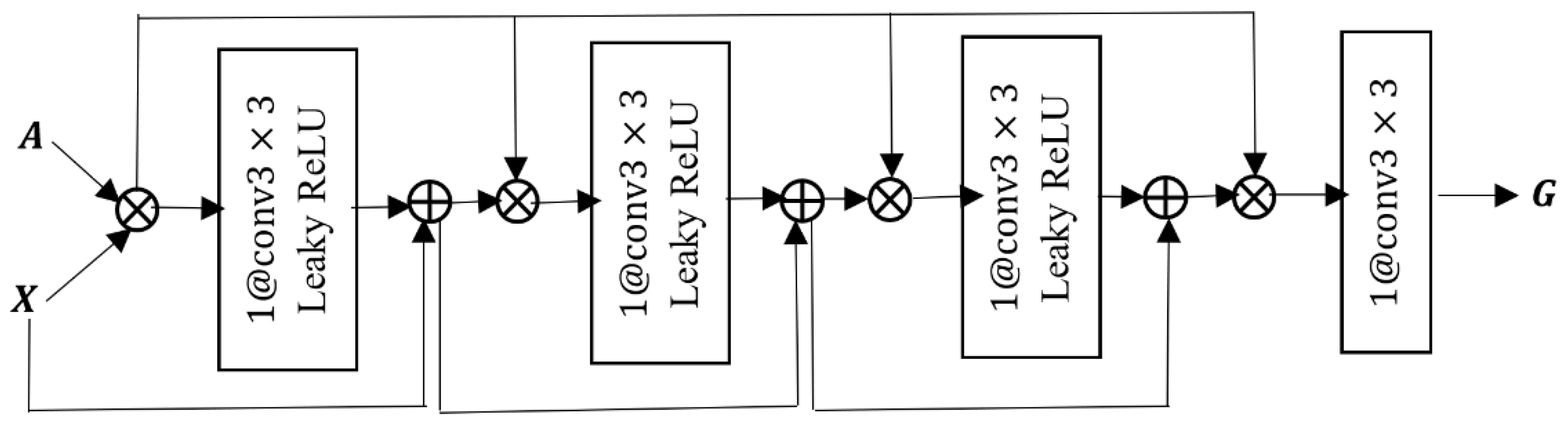
. The inner structure of the suggested GCN block is shown in
Figure 2. The cross product in
Figure 1 and
Figure 2 represents the matrix product. In each GCN, the two inputs of the feature matrix
and the adjacency matrix
are multiplied. The result is passed through a convolutional layer containing one filter having a size of
, i.e.,
, followed by a Leaky ReLU layer as a nonlinear activation function. The output of the first Leaky ReLU is added to the feature matrix
through a residual connection, and the result is multiplied by the adjacency matrix
. This process is repeated three times, with the difference that in the second and third times, instead of
, the output of the previous additional layer is added to the output of the Leaky ReLU layer through the residual connection. The introduced GCN model is a series of operations in the following form:
where
is the activation function (Leaky ReLU here),
is the feature matrix in layer
, and
the learnable parameters of the convolutional filter. The output of the last multiplication operation is passed through a
to provide the feature matrix of the graph
. In the remainder of this section, details of the three constructed graphs and their fusion are detailed.
2.1. Graph 1
The first graph explores the relationships between local pixels in a
patch and the
global anchors, considering the feature matrix
and adjacency matrix
. The elements of the feature matrix are obtained as follows:
where
is the element
in matrix
,
is the
th pixel in the local patch, and
is the
th global anchor. So, feature matrix
contains the differences between pixels in a local neighborhood and the global anchors.
The inverse distance between feature vectors of each pair of nodes creates stronger connections between close nodes in the adjacency matrix. However, the regular distance is highly sensitive to small distances, as small changes in distance may result in larger changes in the computed adjacency weight. To deal with this issue, logarithmic scaling is used. The log transformation compresses large values and expands small values. Thus, it mitigates the extreme influence of very small distances in inverse-distance schemes. This enhances the global connectivity by avoiding fragmented graphs with disconnected or weakly connected components. This step makes the weights more uniform, improves the eigenvalue spectrum, and in turn smooths the spectrum of the adjacency matrix, enhancing training stability in the graph neural network. The elements of the adjacency matrix are computed as:
where
represents the absolute value of its argument,
is the
th row of
, and
is the element
of matrix
. The quantity 1 in the denominator is added to avoid indefinite results with infinite values in the fraction. Therefore, in
, the difference among each pair of rows in the feature matrix
is computed;
and
contain the differences between the
th and
th neighboring pixel within the local patch with the
global anchors, respectively. If the two vectors
and
are similar, pixels at
and
inside the local patch have close similarities with the
anchors, i.e., with the global representation of the image. If
and
are similar, they belong to the same cluster or class with higher likelihood.
2.2. Graph 2
The second graph is global and contains the relations among the
anchors. The feature matrix of graph 2, indicated by
, is represented by:
where
is the feature vector of the
th anchor containing
spectral features in the hyperspectral image and
denotes the transpose operation. The elements of the adjacency matrix of graph 2,
, are derived as:
where
is the
th row of
containing the spectral features of the
th anchor.
As graph 2 is global and does not contain information on the local patch centered at a given pixel, the feature matrix and adjacency matrix are the same for all pixels in the image.
2.3. Graph 3
The third graph is local and considers relationships between the
pixels within a local patch. The feature matrix,
, is represented by:
where
is the
th pixel within the local patch centered around the given pixel. The elements of the adjacency matrix of graph 3,
, are derived as:
where
is the
th row of
,
, i.e., the
th pixel within the local patch, and
quantifies the similarities between pixels in the local patch.
2.4. Fusion of Graphs
The variables
to
and
to
are the inputs of the GCN blocks GCN
1 to GCN
3, where
,
, and
are the feature matrices obtained as output of GCN
1, GCN
2, and GCN
3. To combine the information of the feature maps of the three graphs, the features of the first two graphs are multiplied as follows:
where
contains the combined information of graph 1 and 2. Therefore, the result of this multiplication is related to the dependencies of
pixels based on their similarities (or differences) with respect to the global representatives (anchors). Subsequently, the two feature maps
and
should be combined. To this end, a cross-attention mechanism is suggested as follows.
The query component
is obtained from
, while the component key
and the component value
are computed from
. Here,
is the number of features in the projected feature space obtained by applying the projection matrices
,
and
(here we consider
). The obtained components are:
Note that
,
and
are the learnable parameters. The attended feature maps are derived as:
where
is the fusion result of feature maps
and
, which contains information of all three graphs. In other words, the similarity among the query component from
and the key component from
is computed through their scaled product,
, and is normalized by the softmax operation. Then, multiplication of the normalized weight with the value component
from
yields the weighted feature maps of graph 3 as the fusion result
.
2.5. Output
After the fusion of feature maps of the three graphs through the cross-attention mechanism, the feature matrix of graph 3, , is added to , where is enforced to enable the addition operation among them. The result, i.e., is fed into the output block, which consists of followed by the ReLU activation function and dropout, with a dropping probability of 0.2. Finally, the final part of the network is composed by a fully connected (FC) layer with neurons, where is the number of classes, a softmax, and a classification layer. The obtained label in output is assigned to the central pixel of the local patch in input to the network.
3. Results
3.1. Datasets and Parameter Settings
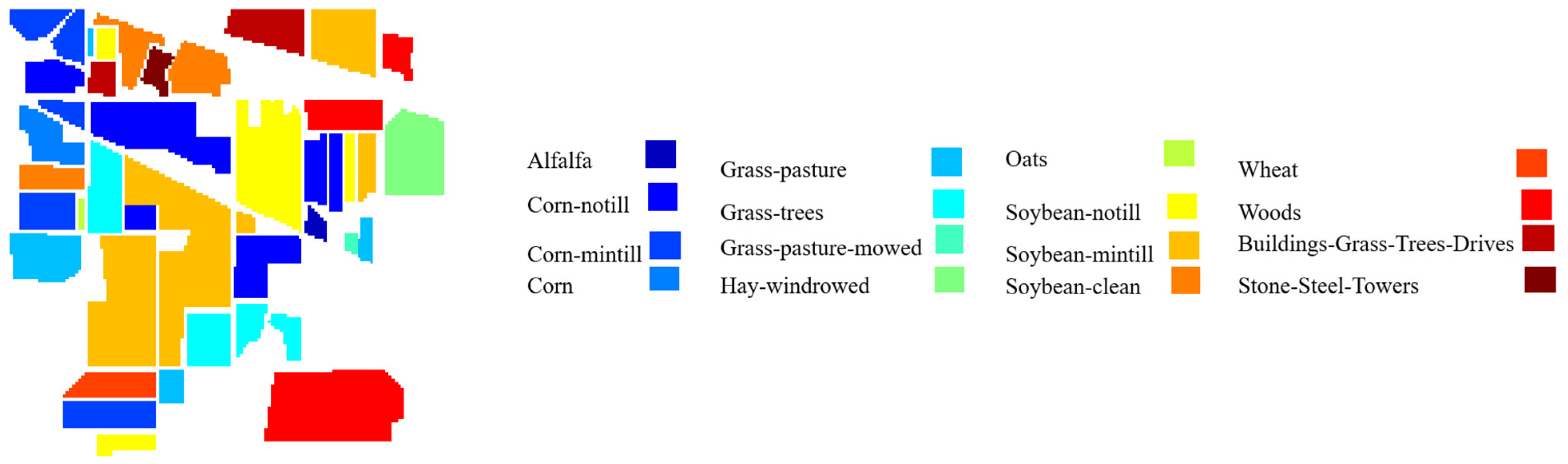
Three hyperspectral datasets are used in this section [
40]. The Indian Pines dataset was collected in Northwestern Indiana in 1992 by the Airborne Visible/Infrared Imaging Spectrometer (AVIRIS). This hyperspectral image comprises 200 spectral channels in the spectral range of 0.4 to 2.5
, after removal of 20 water absorption bands. The Indian Pines dataset has a nominal spectral resolution of 10
, a spatial resolution of 20
, 145
145 pixels, and 16 agricultural-forest labeled classes.
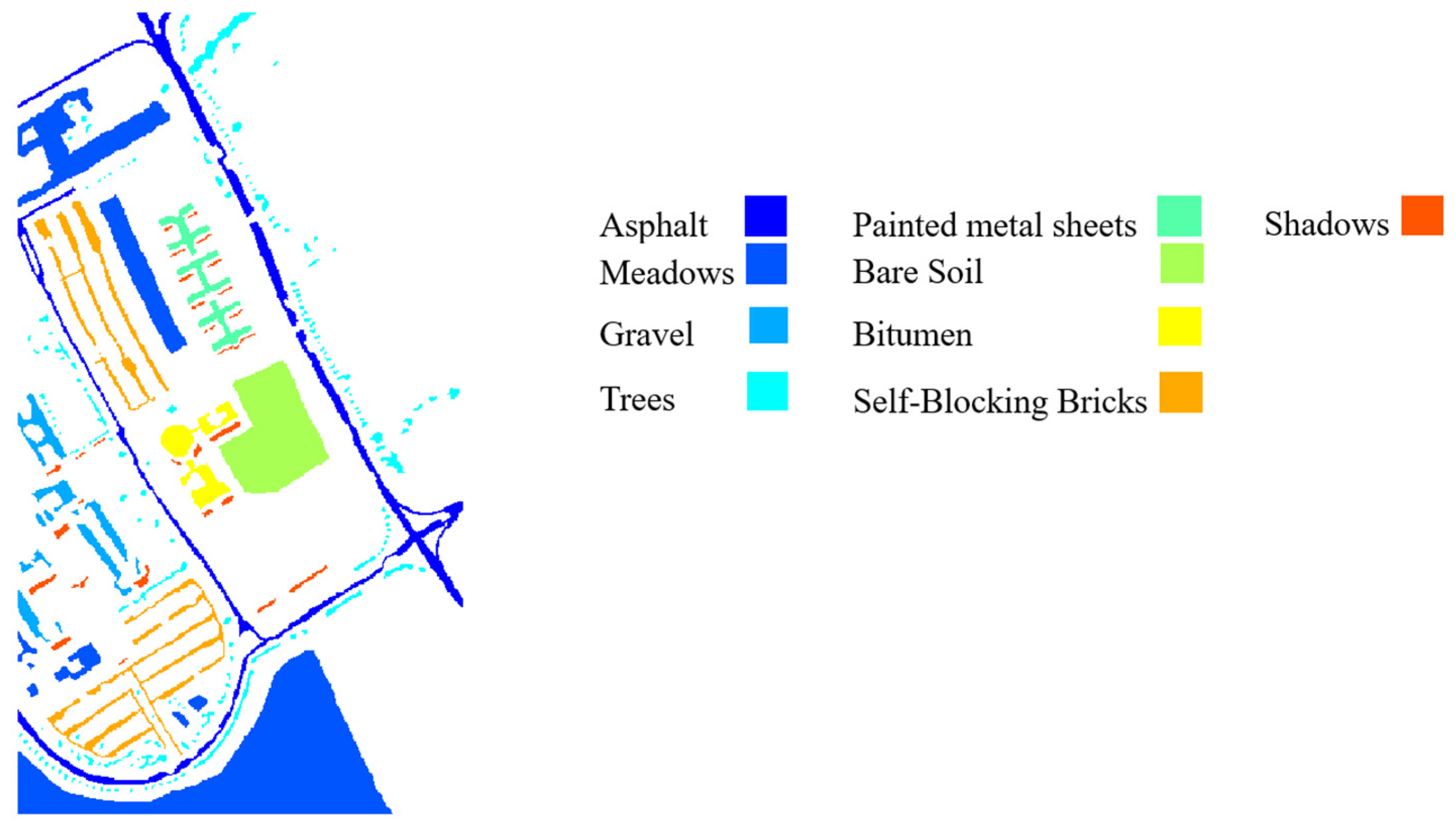
The University of Pavia dataset was acquired by the Reflective Optics System Imaging Spectrometer (ROSIS) in 2001. After the removal of noisy bands, the number of spectral channels is 103 in the spectral range of 0.43 to 0.86 . The University of Pavia dataset has a spectral resolution of 4 , a spatial resolution of 1.3 per pixel, 610 340 pixels, and nine labeled semantic classes.
The Salinas dataset was collected over the valley of Salinas, Southern California, in 1998 by AVIRIS. It has 204 spectral channels in the range of 0.4–2.5
, after the removal of water absorption bands. This image has a nominal spectral resolution of 10
, with a ground sampling distance of 3.7
, 512
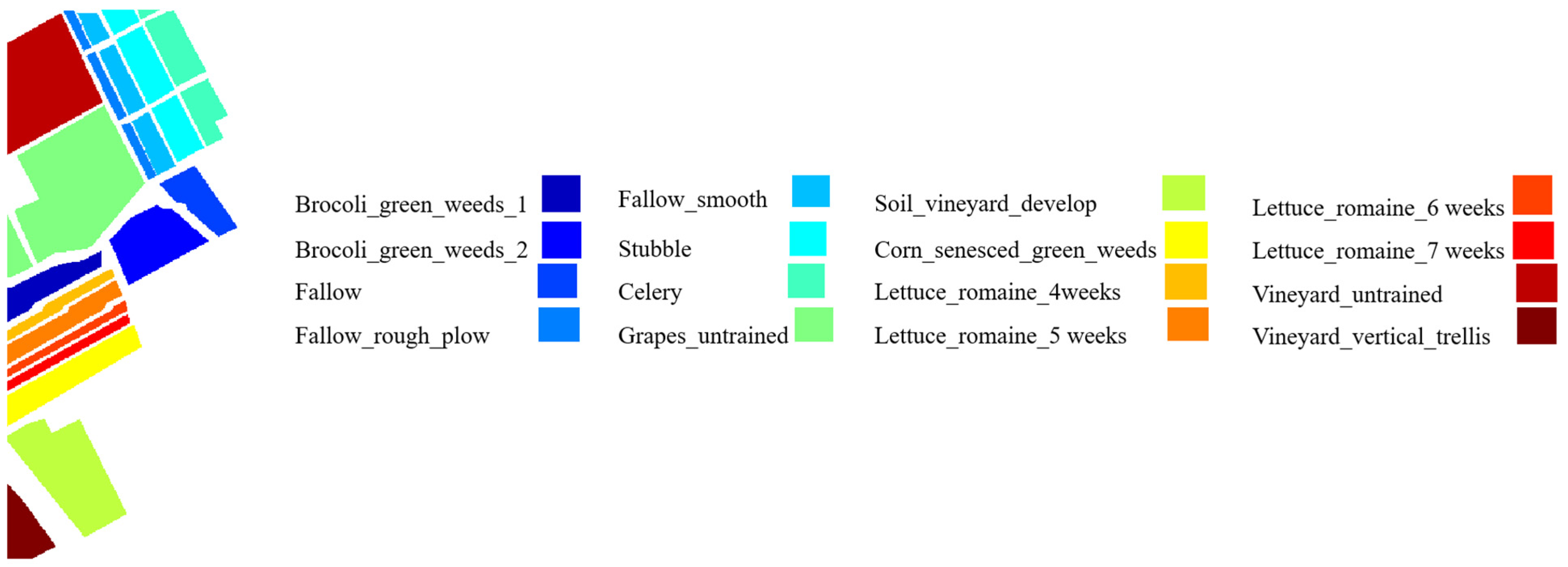
217 pixels, and 16 classes. The ground truth maps (GTM) of three datasets with associated legends are shown in
Figure 3,
Figure 4 and
Figure 5.
In all datasets, 30 labeled pixels in each class are randomly chosen as training samples for classes containing more than 30 pixels, while 15 labeled pixels are considered otherwise. From the remaining samples, 5% are randomly chosen as validation data and the remaining are used as test samples.
The experiments are implemented on a laptop with Intel Core i5 and 32G RAM using MATLAB R2022b. The proposed network and the networks of all competitors are trained with Adam optimizer, an initial learning rate of 0.001, and 50 epochs. For the Indian Pines and Pavia datasets, the mini-batch size is set to 64, while for Salinas it is set to 16.
We conduct some preliminary experiments in order to set the spatial patch size , using the possible values . Although a larger patch size would contain additional information, this could be unrelated to the central pixel, which may degrade the classification results. For the Indian Pines and Pavia datasets, a patch size of provides the highest accuracy, while in Salinas this happens for a size of . Since more computational resources are required when increasing the patch size, we finally consider a catch-all value of for all cases.
We select a number of PCs containing 99% of the total variance in each dataset. The guided filtering [
41,
42] is applied for post-processing of the classification outputs of all methods (including, aside from the proposed method, the competitors SVM, SLIC-SVM, 2DCNN, Res2DCNN, 3DCNN, and Res3DCNN, which are introduced and discussed in the next sections). The first three PCs of the hyperspectral image are considered as a color guidance image. The filtering size
and the regularization parameter
of the guided filter are set as follows:
and
in Indian Pines,
and
in Pavia, and
and
in Salinas.
3.2. Ablation Study
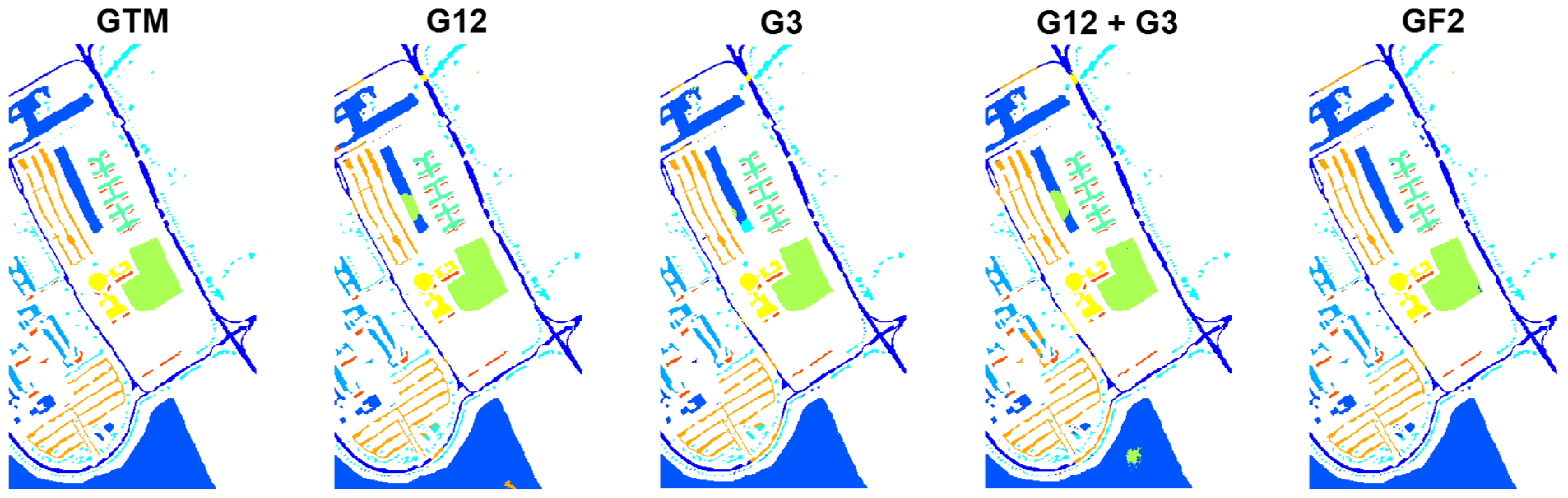
To assess the performance of each part of the proposed network, the following cases are compared:
G12: in this case, the feature map , which is the multiplication of the outcomes of graphs 1 and 2 as outputs of the GCN1 and GCN2 blocks, respectively, is fed into the output block for classification.
G3: in this case, the feature map , which is the result of Graph 3 as output of the GCN3 block, is fed into the output block for classification.
G12 + G3: in this case, the feature maps and are fused through the addition operation, with the result fed into the output block.
GF2: this is the main proposed method, where the feature maps and are fused through a cross-attention mechanism, with the result fed into the output block.
In
Table 1, the classification results for the four mentioned cases are reported for the Indian Pines dataset. In addition to accuracy (Acc.) and reliability (Rel.) [
43] of each class, the average accuracy of classes, average reliability of classes, overall accuracy, and Kappa coefficient [
44] are reported. To show that the difference between each pair of classifiers is statistically significant, McNemar’s test [
45] is computed, and the obtained Z-scores are reported in
Table 2. In the results, GF2, with a significant difference with respect to the other methods, ranks first. After that, G3 provides the highest accuracy. The efficiency of G12 and G12 + G3 with some difference is similar, where the difference of G12 + G3 with respect to G12 is not statistically significant, according to the corresponding Z-score (Z = 0.29). The GTM and classification maps of different cases for the Indian Pines dataset are shown in
Figure 6.
The classification results and the obtained Z-scores for the University of Pavia dataset are reported in
Table 3 and
Table 4, respectively. Also, in this case, GF2 ranks first with a significant difference with respect to the other cases. Next, G3 and G12 provide the best results in this order, while G12+G3 provides the weakest classification results. The classification maps for the different configurations are shown in
Figure 7.
The classification and McNemar’s test results for the Salinas dataset are reported in
Table 5 and
Table 6, respectively, and the corresponding classification maps are shown in
Figure 8. As in the previous cases, GF2 ranks first, followed by G3 and G12 with a small difference between them, with a McNemar’s score of |Z| = 1.76 < 1.96, suggesting that the difference between these classifiers is not statistically meaningful.
The following results can be summarized from the reported results:
- (1)
Although the performances of G12 and G3 are close, G3 provides slightly better classification results. As illustrated, G3 is the result of graph 3 containing relationships among pixels within a local patch; G12 is the result of multiplying graphs 1 and 2, which quantify the similarity between the global anchors and, respectively, each pixel within the local patch and the global anchors themselves. This shows that considering local features within a neighborhood contains higher discriminative information compared to relationships between the local neighborhood and the global anchors selected from the entire scene.
- (2)
Adding G12 and G3, i.e., G12+G3, generally results in weaker performance with respect to each of them taken separately. This implicitly means that the addition operation degrades the discriminative features of G12 and G3.
- (3)
GF2, combining the feature maps G12and G3 through the cross-attention mechanism, yields the best classification results with a significant difference with respect to the other methods.
3.3. Comparison with Other Methods
In this section, the performance of the proposed GF2 network is compared with the following classifiers:
- -
SVM: a pixel-based hard classifier where a third-order polynomial is used as a kernel function. In this paper, we use the LIBSVM implementation [
46] with default parameters.
- -
SLIC-SVM: a superpixel-based classifier. At first, the SLIC algorithm is applied to the first PC of the hyperspectral image and normalized in [0, 1] to provide a segmentation mask. Then, the obtained mask is applied to all PCs to provide the superpixels. The mean of the feature vectors in each superpixel is assigned to all pixels of that superpixel. Then, superpixels are classified using the SVM classifier with the same parameters used for classical SVM. In each dataset, the number of superpixels is set as
[
47], where
denotes the nearest integer number,
is the number of total pixels in the image, and
is the spatial patch size.
- -
2DCNN: a network composed of four convolutional layers, each of which contains filters with the “same” padding. Each layer is followed by a batch normalization (BN) and ReLU activation function. Moreover, after the second and fourth ReLU layers, a dropout layer with a dropping probability of 0.2 is used. The final part of the network is composed of FC, softmax, and classification layers.
- -
3DCNN: the structure of this network is the same as 2DCNN, with the difference that two-dimensional convolutional layers are replaced by three-dimensional convolutional layers .
- -
Residual 2DCNN (Res2DCNN): the layers of this network are the same as 2DCNN, with the difference that three addition (add) layers are used after the first, second and third ReLU activation layers. The input is passed from and fed into the first addition (add1) layer through the residual connection. The output of add1 is fed into the second addition (add2) layer, and the output of add2 is in turn fed into the third addition (add3) layer through skip connections.
- -
Residual 3DCNN (Res3DCNN): this network is the same as Res2DCNN, with the difference that it contains three-dimensional convolutional layers instead of two-dimensional ones.
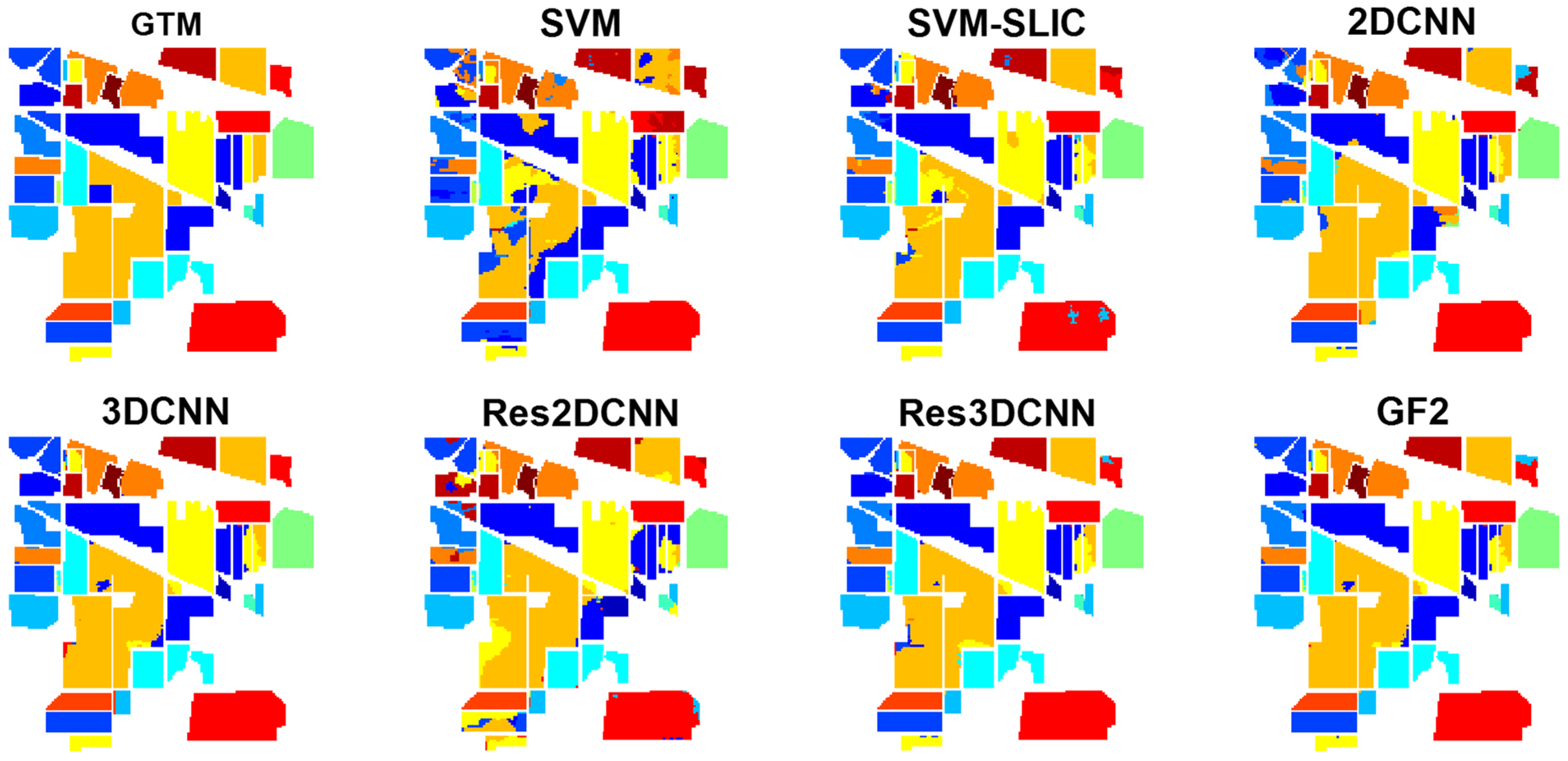
The classification results and associated Z-scores obtained by the McNemar’s test for Indian Pines are reported in
Table 7 and
Table 8, respectively, with the corresponding classification maps shown in
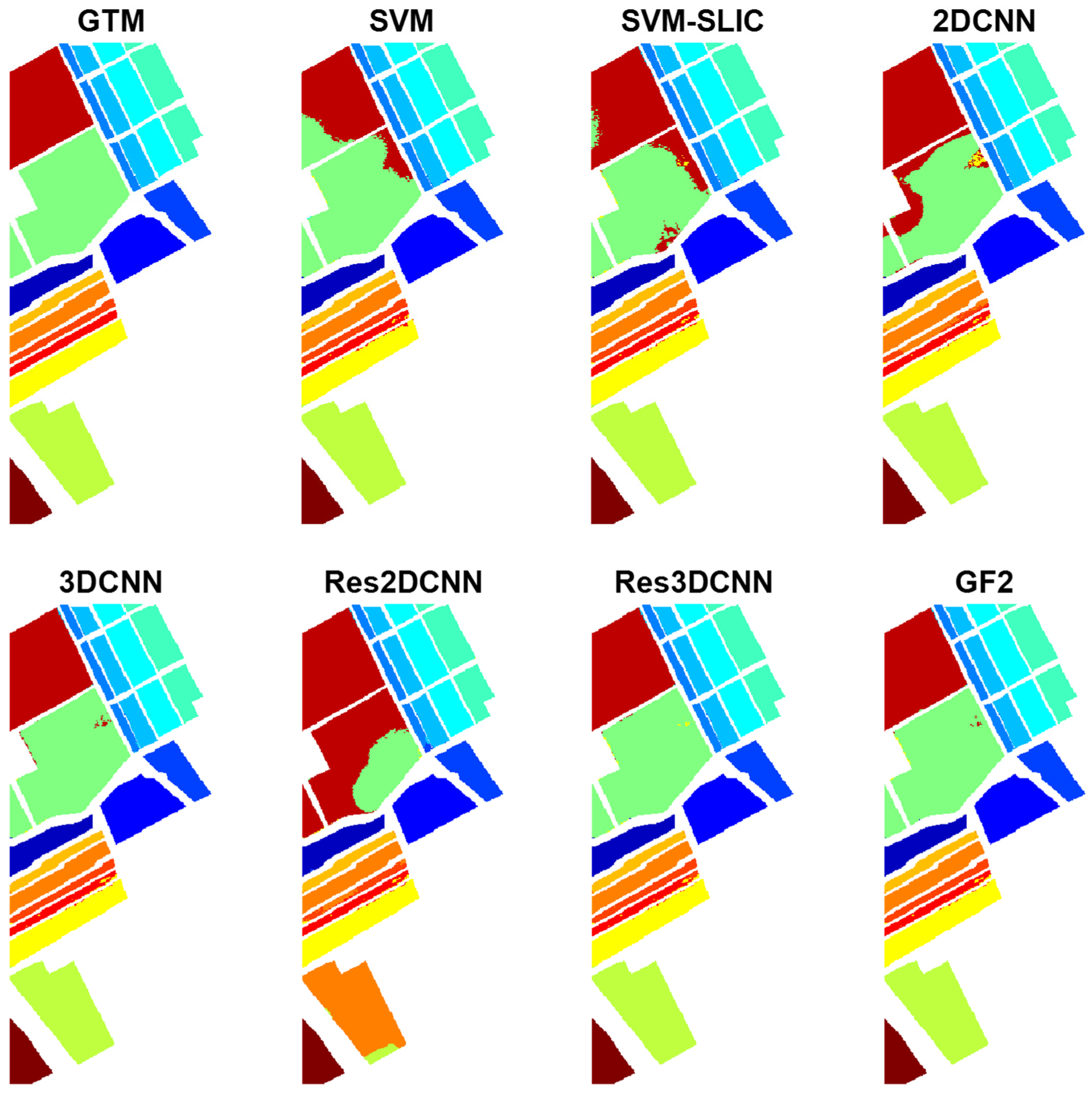
Figure 9. In general, GF2 provides the best classification results with a statistically significant difference with respect to all competitors except 3DCNN. Here, the fusion of local features of the neighborhood patches with the global information of the anchors results in a higher discrimination ability, and more accurate classification maps.
3DCNN and Res3DCNN rank respectively second and third, with a significant difference with respect to the other methods. The 3D convolutional layers simultaneously extract hierarchically spatial and spectral features from the three-dimensional image patch in input, leading to a separation of the different classes with high accuracy and reliability.
Following up, SLIC-SVM yields a satisfactory performance. On the one hand, the use of SLIC for providing superpixels considers spatial features in the neighborhood regions, and leads to smoothed classification maps with reduced noise. On the other hand, the use of SVM as a classifier with low sensitivity to the training set size can lead to highly accurate classification results.
Results from 2DCNN, Res2DCNN, and SVM are ranked next. Here, 2D convolutional networks applying 2D filters to explore the spatial features, thus ignoring the spectral information of the images, result in weaker performances compared to 3D filters. Similarly, the pixel-based SVM classifier just considers spectral features, and not considering the spatial information results in the worst classification results.
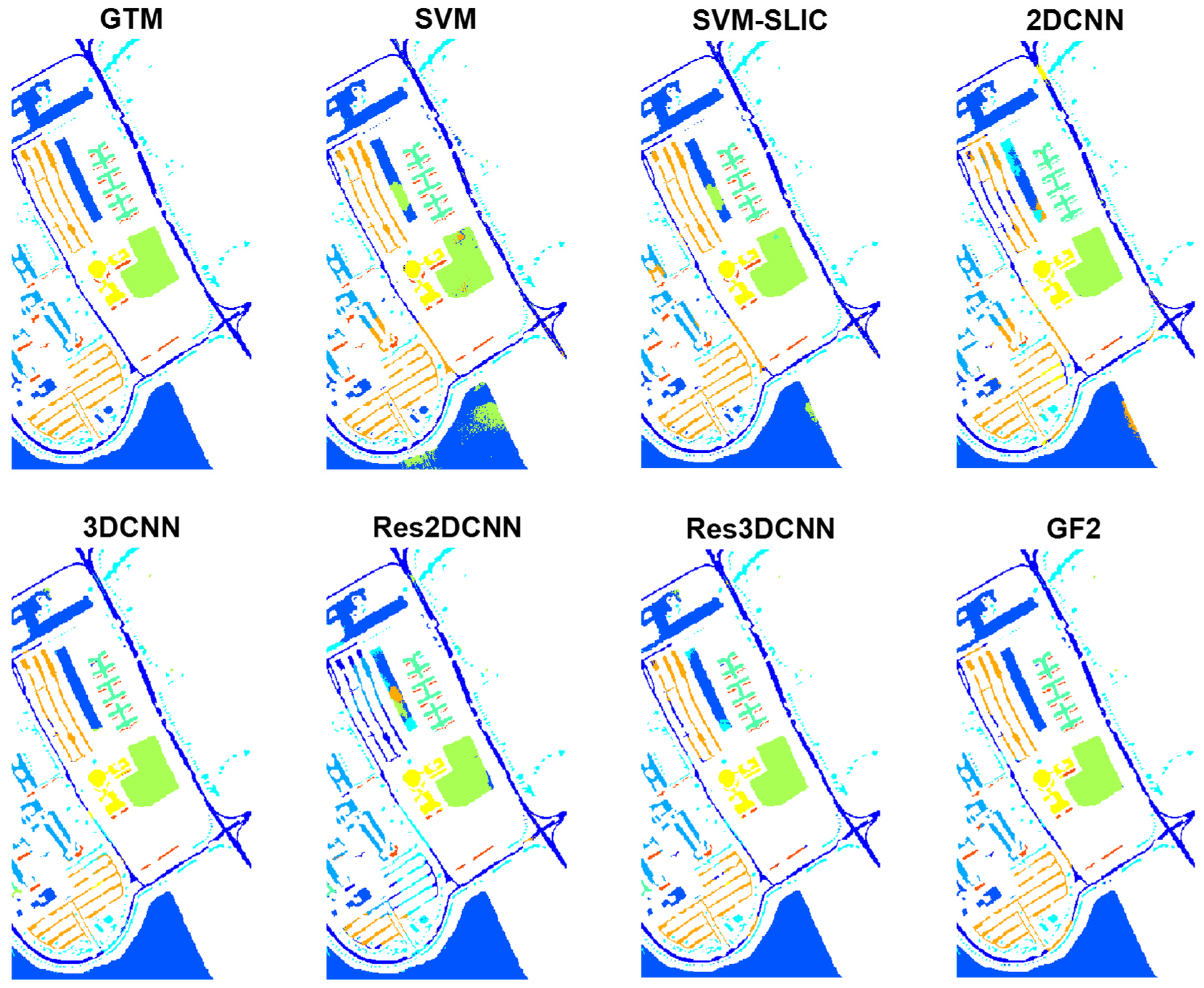
The classification results, Z-scores and classification maps obtained for the University of Pavia dataset are reported in
Table 9 and
Table 10 and
Figure 10, respectively. The proposed GF2 generally yields the highest classification accuracy with a statistically significant difference with respect to other methods. SVM, which only uses spectral features, provides here better classification results compared to 2D convolutional networks, which explore the spatial features. This suggests that in this dataset, the spectral information is more relevant than the spatial information.
The classification accuracies and Z-scores related to the Salinas dataset are reported in
Table 11 and
Table 12, respectively, and their classification maps are shown in
Figure 11. Also here, GF2 ranks first with a significant difference with respect to all competitors. With a slight difference and low Z-score of |Z| = 1.78 < 1.96, 3DCNN and Res3DCNN denotes statistical mutual dependence in their results, and are ranked as the next best methods. The worst result is obtained by Res2DCNN.
The number of learnable parameters for the different networks are represented in
Table 13. Here, 2DCNN and its residual version are, in these terms, the lightest networks, having the lowest number of learnable parameters. However, 2DCNN and Res2DCNN cannot achieve accurate classification results across the different datasets. GF2, with about 163k learnable parameters, is still approximately a light network, imposing a reasonable computational burden. The 3DCNN and its residual version, Res3DCNN, have about 181k and 188k learnable parameters, respectively, and, in spite of this, underperform with respect to GF2. Therefore, the proposed GF2 results as a good candidate for hyperspectral image classification from both the classification accuracy and the computational complexity points of view.
4. Discussion
In this section, the performance of GF2 is discussed compared to several other graph-based neural networks.
Table 14 reports the overall accuracy (OA) obtained by the different methods for the considered datasets, along with the running time (seconds) as reported from the respective references. In all cases, 30 training samples per class are used, or 15 for classes with less than 30 labeled samples. For each competitor, we report the highest achievable accuracy associated with the best parameter settings reported in its associated published reference. Because of different types of input data due to the different definition of the graphs, considering the same hyperparameters for all the different methods is not appropriate. For example, in Auto-GCN, rectangular regions of the image are considered as graph nodes, while in the proposed GF2 the graph nodes are defined as local pixels or global anchors. Thus, considering the same mini-batch size for these two methods is not reasonable because of the scale of the graph nodes, and the input size of the networks should be set differently. A brief description of the benchmark methods is represented next.
In the automatic GCN (Auto-GCN), both graph design and its learning are carried out by neural networks. A semi-supervised Siamese network is used to construct the high-order tensor graph, with an intersection over union (IoU) based metric introduced for relabeling the dataset. The GCNs, the Siamese network and classification network are jointly trained, which results in a meaningful graph representation.
In the contrastive GCN (ConGCN), a semi-supervised contrastive loss is designed to jointly extract supervision information from the scarce labeled data and the abundant unlabeled data. ConGCN uses a semi-supervised contrastive loss for exploiting the supervision signals from the spectral domain, and graph generative loss for exploring the spatial relations of the hyperspectral image, and simultaneously performs hierarchical and localized graph convolution to extract both global and local contextual information. Moreover, the use of an adaptive graph augmentation is suggested to improve the performance of contrastive learning.
The mixhop superpixel-based GCN (EMS-GCN) is an end-to-end superpixel-based GCN method. It utilizes a multiscale spectral-spatial CNN for feature extraction and an adaptive clustering distance for introducing an improved learning-based superpixel algorithm. In EMS-GCN, a mixhop superpixel-based GCN module is introduced for adaptive integration of local and long-range superpixel representation.
The context-aware dynamic GCN (CAD-GCN) does not limit the receptive field of GCN to a small region. Instead, it captures long-range dependencies through translating the hyperspectral image into a region-induced graph and encoding the contextual relations among different regions. Subsequently, CAD-GCN iteratively adapts the graph to refine the contextual relations among image regions.
The dynamic adaptive sampling GCN (DAS-GCN) dynamically refines the receptive field of each given node and corresponding connections through successively applying two complementary components in each round of the adaptive sampling. As a result, it exploits both spectral and spatial information from local neighbors and far image elements.
The multiscale dynamic GCN (MDGCN) utilizes a dynamic graph convolution instead of a fixed graph, which can be refined using the convolutional process of the GCN. In MDGCN, multiple graphs with different local scales are constructed to provide spatial information at different scales, with varied receptive fields. To mitigate the computational burden, the total number of image elements to process is lowered by grouping from homogeneous areas in superpixels, treating each of them as a graph node.
In the dual interactive GCN (DIGCN), the interaction of multiscale spatial information is used to refine the input graph. To this end, the edge information contained in one GCN can be refined by feature representation from the other branch, and results in benefits of multiscale spatial information. Moreover, the generated region representation is enhanced by learning the discriminative region-induced graph.
For the Indian Pines dataset, Auto-GCN, ConGCN and the proposed GF2 rank first to third, respectively, with a slight difference. The lowest overall accuracy is obtained by CAD-GCN and DIGCN. For the University of Pavia dataset, EMS-GCN and GF2 rank respectively first and second, and provide highly accurate classification results with a significant difference with respect to the other methods. For the Salinas dataset GF2, Auto-GCN, and ConGCN rank first to third, respectively. Although Auto-GCN and ConGCN are among the best methods for the Indian Pines and Salinas datasets, they do not work as well for the University of Pavia dataset. The proposed GF2 network exhibits instead high accuracy across all datasets, and shows a robust behavior both for the different images of the University of Pavia, and images dominated by agricultural fields (Indian Pines and Salinas), also characterized by a different spatial resolution.
From the running time point of view, DAS-GCN is the slowest method for all datasets. Despite that, it is not among the most accurate methods. For the Indian Pines dataset, EMS-GCN, GF2, and DIGCN are the fastest methods. For the University of Pavia dataset, GF2 has the lowest running time. After that, EMS-GCN and CAD-GCN are the fastest methods. For the Salinas dataset, the lowest running time is reported for Auto-GCN.
While the proposed GF2 network is trained in 50 epochs, the Auto-GCN is trained in 150 epochs. Because of the following reasons, the Auto-GCN has relatively high complexity in the training phase: (1) Auto-GCN performs multitask learning and performs collaborative training for the Siamese network, GCNs, and hyperspectral image classification. (2) To compute the node similarities, the dual-input Siamese network is implemented in a semi-supervised manner. (3) A pre-training phase is performed in Auto-GCN such that the parameters of its feature extractor are initialized with the parameters of the trained feature extractor in the Siamese network, obtained during the offline training. However, the reported running time is the computation time of the test phase, i.e., the prediction time of the classification map. In Auto-CGN, the graph nodes are the image regions, while in GF2, they represent local pixels or global anchors. So, in datasets such as Salinas that have a higher number of pixels, the prediction time of GF2, which has pixel-based nodes, is higher with respect to Auto-GCN, which has region-based nodes.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}