1. Introduction
The forests of the world are estimated to store up to 500 petagrams (Pg) of carbon in their aboveground biomass [
1] and act as a major carbon sink, which is vital to maintaining stable ecosystems. According to the IPCC Sixth Assessment Report [
2], deforestation and forest degradation contribute roughly 8–10% of global greenhouse gas emissions, accelerating climate change. Regular assessment of global aboveground carbon stock is essential for understanding and mitigating climate impacts, supporting corporate emissions disclosures, ensuring regulatory compliance, and contributing to international climate initiatives such as the UN Paris Agreement [
3]. This poses an immense challenge, as it is the only validated and accurate method for both measuring tree profiles (including canopy height) and calibrating ecosystem-specific allometric equations.
Allowing the conversion of tree profiles into biomass requires labor-intensive field measurements. More efficient and scalable methods involve air- or spaceborne LiDAR instruments, which are capable of scanning tree profiles across large areas [
4]. However, there is a trade-off between the density and resolution of such LiDAR maps and the spatial extent. For example, airborne LiDAR surveys can generate high-resolution maps due to the dense flight paths but are limited in the area that can be covered. Spaceborne instruments such as the Global Ecosystem Dynamics Investigation (GEDI) project [
5] can cover the entire globe but their measurements are very sparse. In order to bridge the gap between dense estimation and global scalability, remotely sensed data, together with machine learning techniques, have become a main focus. Early approaches used simple ML methods, such as the random forest algorithm, resulting in pixel-wise estimation of canopy height on local scales [
6] as well as low-resolution global canopy height maps (CHM) [
7]. Recent methods have pushed the boundaries and generated higher-resolution maps, both of AGBD [
8] and CH [
9], by combining high-resolution imagery with various sources of LiDAR and ground measurements, as well as state-of-the-art computer vision models. Despite these advancements, there remain multiple challenges due to the availability of frequent, cloud-free observations of high-resolution satellites. In many cases, the imagery used spans a long and inconsistent time range, which complicates the ability to track changes in the carbon cycle. Moreover, many solutions achieve high accuracy for estimating AGBD or CH on regional scales but lack the ability to expand the model to the entire globe. The benefit of a single global model is learning from a diverse set of training samples across multiple ecosystems, resulting in a base model with good accuracy for broad-scale monitoring. Further fine-tuning of the base model locally can achieve greater accuracy with far less effort and cost than training multiple local models from scratch [
10,
11,
12]. Especially when AGBD is determined using local allometric equations, the use of the base model accelerates the workflow and further reduces error metrics, as demonstrated in
Section 4.3.
The detection of deforestation events requires the classification of land cover into forest, for which there are different definitions based on CH and CC [
13]. Having estimates of both variables at a global scale allows for the application of different forest definitions dynamically and the detection of deforestation events by differentiation of binary maps at different times. In this work, we present a new approach that addresses many of the shortcomings mentioned above by introducing a deep learning-based model that unifies the prediction of AGBD, CH, and CC, as well as their uncertainties, into one single model trained on a global dataset of fused Sentinel-1, Sentinel-2, digital elevation model (DEM), and geographic location. We leverage the data from GEDI to generate sparse ground truth maps. Due to the spatial sparsity, we introduce a novel technique for training our model, which results in better performance compared with traditional methods. We show the results of the model deployment over the recent year (2023) at a global scale, as well as historic imagery back to the year 2016 in intervals of 1 year at a local scale.
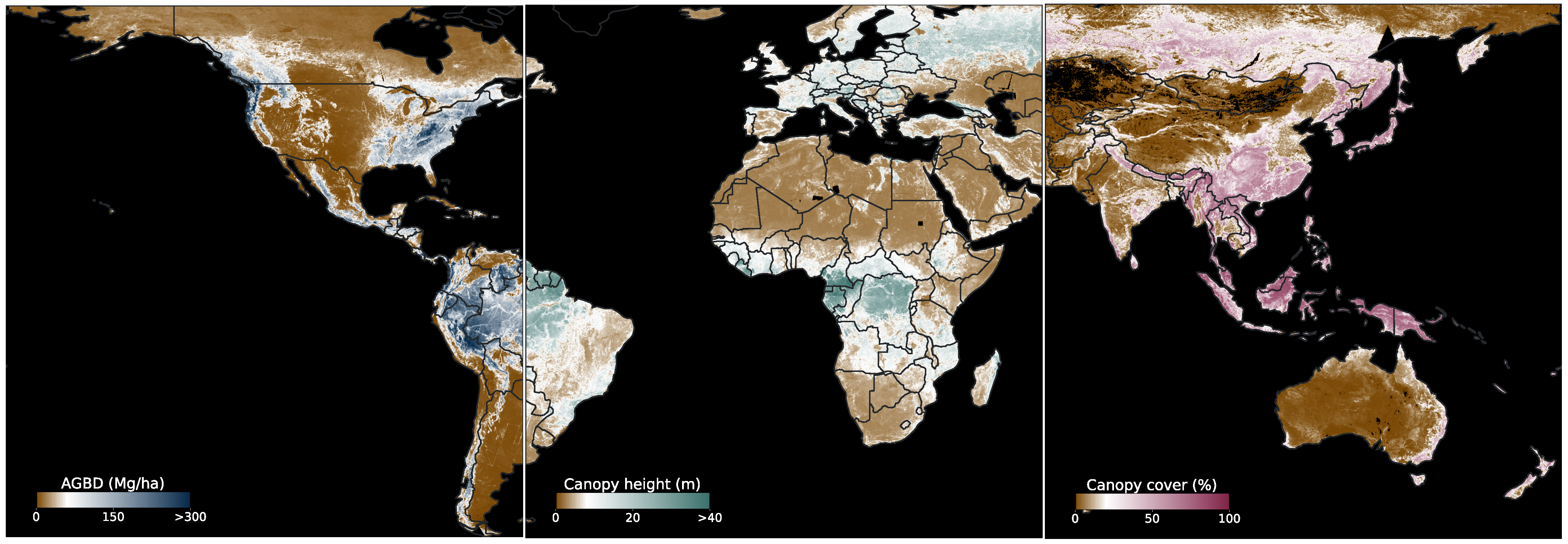
Figure 1 shows a composition of global ABGD, CH and CC maps generated in this study.
The generated dataset for the training of the deep learning model consists of ∼1 M training and ∼60 k validation samples composed of cloud-free image tiles of size 256 pixels × 256 pixels at 10 m ground distance.
Previous work: Over the past two decades, increasing focus and effort have been directed to environmental monitoring based on spaceborne earth observation missions. Such missions go as far back as the 1970s with the Landsat [
14] constellation, which offers an immense archive of medium-resolution satellite imagery. In recent years, specialized missions have paved the way for more accurate insights into the global dynamics of environments with higher revisit rates and resolution, including multispectral passive sensors [
15,
16,
17,
18], active sensors such as synthetic aperture radar (SAR) [
19,
20], light detection and ranging (LiDAR) [
5], and missions dedicated to understanding the carbon cycle [
21,
22]. The increasing volume of data collected by all these missions has motivated the development of modern and novel algorithms based on machine learning and deep learning [
23]. Previous work has focused on the model development for estimating either aboveground biomass density, canopy height, or canopy cover. We could not find any references that combine the prediction of multiple variables into a single model. In most previous approaches, the limitation in spatial resolution arises from the choice of input data source and ranges from 250 m–1 km (e.g., MODIS) to 30 m (e.g., Landsat), 10 m (e.g., Sentinel-1/2), and ∼1 m (e.g., MAXAR).
Biomass: Aboveground biomass maps are available today, covering up to decades of history, but are often produced on a local scale based on ground measurements and forest inventories [
24]. Scaling these maps to larger regions requires the collection of plot data, which covers various ecosystems. Capturing ground-truth data across the broad range of ecosystems and land cover that would be required to scale this methodology would be prohibitively expensive. Early efforts incorporating simple machine learning techniques have focused on pantropical regions and use medium-to-low resolution satellite imagery [
25,
26,
27]. At a global scale, a number of aboveground biomass maps have been generated at low resolution (∼1 km) [
28,
29], including the gridded version of the GEDI level 4 product [
30]. Only recently, with the incorporation of modern deep learning techniques, have higher-resolution maps emerged [
8,
31], which combine the use of satellite imagery with global-scale LiDAR surveys.
Canopy height: Unlike aboveground biomass, canopy height estimates from satellite imagery are less dependent on regional calibrations, as ground measurements can be gathered directly from forest inventories or LiDAR measurements that provide information on canopy structure. Early approaches utilize simple pixel-to-pixel machine learning algorithms, such as random forest, at medium resolution [
7,
32], while more recent methodologies were developed based on deep learning models and higher resolution and single-sensor imagery [
33], as well as combining multiple sensors as input data [
9]. Advances in deep learning-based computer vision models, which exhibit great depth estimation skills [
34], have allowed the development of very high-resolution canopy height maps [
35] and models that characterize single trees [
36,
37,
38]. The main drawback of very high-resolution maps at a global scale is the immense computational effort and cost for a single deployment. In order to cover the entire globe, high-resolution imagery is often gathered within a large time window (multiple years), which creates an inconsistency in the temporal resolution and complicates the change monitoring. In order to create consistent and high-quality global maps, it is therefore advisable to revert to lower-resolution imagery (∼10 m) with a higher frequency of observations and to merge multiple sources that may complement each other. Large-scale LiDAR surveys provide a more direct way of generating canopy height maps since they do not rely on models that estimate canopy height based on imagery, which has limitations in information content. However, high-resolution aerial surveys [
39] are limited in scalability, while global-scale surveys have low resolution [
40].
Canopy cover: Estimating canopy cover from satellite imagery is the least complex of the three tasks, as it does not rely on a detailed three-dimensional canopy structure or local calibrations. However, it may still pose many challenges due to the quality and resolution of the input imagery. The first global canopy cover maps based on remote sensing are derived from Landsat imagery at medium resolution [
41]. Different satellite sources at varying resolutions have been used in generating regional maps [
42,
43], while historical imagery, despite the low resolution, allows high-frequency updates reaching back many decades [
44].
To the best of our knowledge, our work is the first to combine the estimation of aboveground biomass density, canopy height, and canopy cover into a single unified model. With respect to single-variable estimation, our approach is most similar to [
8] for aboveground biomass density and [
9] for canopy height, to which we compare our model evaluation results (see
Section 3). In summary, the main contributions of this work are as follows:
First deep learning-based model that unifies the prediction of aboveground biomass density, canopy height, and canopy cover, as well as their respective uncertainties.
Advancements for predicting global-scale maps at high resolution at regular time intervals without missing data due to multi-sensor fusion.
Novel training procedure for sparse ground truth labels.
Extensive evaluation against third-party datasets as well as a demonstration of model fine-tuning for local conditions.
2. Data and Methods
In this work, we use multispectral, multisource satellite imagery, a digital elevation model, and geographic coordinates as input to the model. The model is trained in a weakly supervised manner (see
Section 2.3) on point data from the Global Ecosystem Dynamics Investigation (GEDI) instrument. In this section, we describe the processing steps for generating a global dataset of input and target samples. We will also briefly explain the relevant concepts of the GEDI mission as well as the different data processing levels, as this will be an important aspect of understanding the inherent uncertainties of the model and its limitations.
2.1. Ground Truth Data
The GEDI instrument is a spaceborne LiDAR experiment mounted on the International Space Station (ISS) and has been operational since 2019. It comprises 3 Nd:YAG lasers, optics, and receiver technology, allowing it to measure the elevation profile along the orbital track of the ISS. Within the lifetime of the experiment, it is expected to collect 10 billion waveforms at a footprint resolution of 25 m. The setup of 3 lasers, one of which is split into two beams, as well as dithering every second shot, leads to a pattern of point measurements with 8 tracks per pass where the tracks are separated by 600 m and each point by 60 m along the flight path. Each GEDI measurement consists of the waveform resulting from the returned signal of the laser pulse sent out at the given location. The collection of all these waveforms is referred to as level 1 data. Each waveform is further processed to extract metrics that characterize the vertical profile of trees within a given beam footprint.
The signal with the longest time of flight corresponds to the ground return and is used as the reference for the relative height (RH) metrics. The RH[X] metrics correspond to the relative height at which [X] percent of the total accumulated energy is returned. These metrics characterize the vertical profile of the GEDI footprint, where RH100 corresponds to the largest trees in the footprint. These metrics, together with other parameters related to the measurement conditions, are stored in a dataset referred to as level 2a. In additional steps, these metrics are used to calculate the percent canopy coverage (level 2b), as well as a gridded version (level 3). Further processing involving regional calibration of allometric equations, using level 2 data, results in estimations of aboveground biomass density (AGBD) as well as uncertainties referred to as level 4a. Estimates are based on models that were fitted to biomass measurements on the ground in a number of field plots located in various regions around the world. Since most of these measurements do not intersect with a GEDI footprint, airborne LiDAR was used to measure the return signal, which was then translated into a simulated GEDI waveform. In this work, we use the level 2a/b and level 4a data as ground truth. The on-the-ground measurements for biomass were mostly done without any tree clearing but by measuring canopy height and diameter and using allometric equations specific to the tree type and the world region to determine biomass. The simulated waveforms undergo the same processing to extract RH metrics, which provide the predictors for linear models to predict AGBD. Various models were developed for all combinations of plant functional type (PFT) and world region defined as the prediction stratum. For details of the selected predictors for each model and their performances, see Sections 1 and 2 of [
45].
The models are linear functions of the predictors with a general form of
where
is a
matrix of
n measurements with
m predictors and
a
vector of parameters for prediction stratum
j. The best parameters are determined by linear regression, where the predicted variable may be in transformed units using a function
h, which is either unity, square root, or log. For new measurements
, the model of the corresponding prediction stratum is chosen, and the predictions are given by
where
is a bias term determined by the fit residuals in the respective prediction stratum. For each prediction of footprint
k, a standard error is calculated, which is defined as
as well as a confidence interval given by
where
t is the value of the t-distribution with n-2 degrees of freedom at a confidence level of
. In general, we observe that the uncertainty on AGBD from the GEDI ground truth increases with the value of AGBD, where the main contribution comes from the residuals in Equation (
3). This is an important fact to consider when training the model. During model optimization, it is generally assumed that the target values are the absolute truth, while in this case, we know that the target values are inherently uncertain. This means that a given input
X can be assigned to two different values,
and
, which cannot be described by a continuous function. Since only continuous activation functions are used in our CNN, the function it represents will also be continuous, which may lead to predictions with larger uncertainties or under-prediction in regions where the ground truth data are uncertain. We will discuss this in more detail in
Section 3 and
Appendix B.2. The largest ground truth uncertainty is introduced when converting canopy height, or generally RH metrics, to AGBD, which is more accentuated by the lack of ground plot measurements used for calibration. Our model provides an important benefit by not just predicting AGBD in an end-to-end setup but at the same time also predicting canopy height, which can be used for recalculating AGBD a posteriori should more accurate plot data become available.
The multi-head architecture of our model (see
Section 2.3) allows for simultaneous prediction of multiple GEDI variables. For the training of the base model, we choose AGBD from level 4a, CH from level 2a, and CC from level 2b as the prediction variables. In
Section 4.3 we demonstrate how the base model can be easily fine-tuned on different variables in the GEDI dataset. The level 2a dataset provides relative height metrics at discrete energy return quantiles from 0 to 100 in steps of 1, denoted RH00, RH01, …, RH99, RH100. It is common to choose one of RH95, RH98, or RH100 to define CH. Our base model uses RH98, which prevents over-prediction in cases where there are a single or a few very large trees among smaller trees. We save all RH metrics in our datasets so that they can be dynamically selected during training. This provides the flexibility to fine-tune the model on a different RH metric, or multiple RH metrics, depending on the requirement of local allometric equations.
2.2. Input Data
In order to leverage the respective benefits of different data sources, we fuse optical bands (red, green, blue) from the Sentinel-2 [
46] satellite with thermal bands (nir, swir1, swir2) from the same satellite (processed with the SEN2COR algorithm [
47] to provide surface reflectance) and synthetic aperture radar (SAR) signal (VV and VH backscatter) from Sentinel-1 [
48]. In addition, we used altitude, aspect, and slope from the Shuttle Radar Topography Mission (SRTM) [
49] to further enrich the predictive capability of our model. The predictors of the digital elevation model (DEM) carry important information about the local topography that affects the distribution of plant functional types and their growth patterns [
50]. We also provide the global coordinates of each data sample by encoding longitude and latitude in the interval [−1, 1]. The optical bands of Sentinel-2 and the Sentinel-1 bands have a native resolution of 10 m, while the thermal bands of Sentinel-2 have a resolution of 20 m and the DEM of 30 m. In order for the CNN to process the input layers at different resolutions, we resample all layers to 10 m resolution using the bilinear interpolation method and stack them to form a 13-channel input tensor.
To generate a global training and test dataset, we uniformly sample locations within the latitude (longitude) range of [−51.6, 51.6] degrees ([−180, 180] degrees) that intersect with the landmass. We use the Descartes Labs (DL) proprietary tiling system to create image tiles of size 512 pixels × 512 pixels at 10 m/pixel resolution with the sampled coordinate being at the center of the tile. (Descartes Labs was acquired by EarthDaily Analytics after this work came out. Throughout this work, we will refer to any component of the DL system by its original name). Each tile is required to contain >20 GEDI footprints. During training, we dynamically split each tile into 4 non-overlapping sub-tiles of size 256 pixels × 256 pixels, which increases the total number of samples in the dataset four times. We introduce a naming convention for tiles based on their location in the southern hemisphere (lat < −23.5°), the tropics (−23.5° ≤ lat ≥ 23.5°) or the northern hemisphere (lat > 23.5°).
2.2.1. Cloud Mask and Image Composite
In order to reduce cloud obstruction and cloud shadows in Sentinel-2 imagery, we generate cloud-free composites from a stack of images that are masked with the binary output of our proprietary cloud and cloud shadow detection model. The cloudmask model is a UNet [
51]-type architecture trained on ∼4.4 k ground truth samples collected globally and labeled by human annotators. The input to the model is the six-band Sentinel-2 imagery, while the target mask consists of three classes (cloud, cloud shadow, and background) for each pixel. The image stack is built by collecting all Sentinel-2 scenes that intersect with the given tile within a specified time range. Scenes taken on the same day are mosaiced. We used the median operation to generate the composite from the masked image stack. The composite time range is chosen to minimize the variability in the spectral response of the vegetation while maximizing the resulting coverage. We, therefore, chose the time ranges to be the respective summer months for the two hemispheres (June–August for the northern hemisphere and December–February for the southern hemisphere), except for the tropical region, where the composite was done over a 6-month period. In certain tropical regions, cloud artifacts are visible despite the long composite time range. This highlights the importance of multisensor fusion, where Sentinel-1 backscatter provides valuable information for these gaps since SAR is not affected by clouds. In order to reduce the noise in the SAR backscatter signal, we apply the same compositing method to the VV and VH bands without the cloud mask. In
Section 2.5 we will discuss in detail the model performance in challenging regions with imperfect cloud-free composites.
2.2.2. Global Dataset
For each sampled tile, we generate Sentinel-1 and Sentinel-2 composites according to the definition in
Section 2.2.1 by gathering imagery using the Descartes Labs platform for the year 2021 (2021/2022 for the southern hemisphere). The DEM has a fixed acquisition year of 2000. For a given tile, we gather all the GEDI level 2a/b and level 4a point data that lie within the geometry of the tile and have a collection date of no more than ±1 month from the composite time range (this buffer is set to 0 months for the 6-month composites). In order to match the data from GEDI level 2a/b with level 4a, they are required to have the same footprint coordinates to 5 decimal point precision and the same acquisition date. Furthermore, we only accept data with the quality flag l4_quality_flag equal to 1 and require that at least 20 data points be within the tile geometry. Due to the sparsity of the GEDI data, it is saved as vector data along with each footprint pixel coordinate and rasterized on the fly during training. Despite the footprint being 25 m in diameter, we assign the corresponding target value to only one pixel of size 10 m × 10 m at the location of the footprint center.
In total, 276,766 data samples were created, of which 14,745 (5%) were randomly selected and stored as a test dataset. Each sample is composed of an average of 50 scenes in Sentinel-1 and Sentinel-2, which is a total of 13.8 M scenes processed. The total number of ground truth data points is 67 M (3.8 M) for the training (test) dataset.
2.3. Model Development
The GEDI dataset offers measurements of AGBD, CH, and CC for recent years but is largely incomplete at higher resolution due to its sparsity. Here we describe the computer vision (CV) model we developed. It fuses selected bands of multiple sensors as well as encoded geographic location, forming a 13-channel image stack, to predict AGBD, CH, and CC as a continuous map at the resolution of the input source while using the GEDI level 2 and level 4 datasets for training.
In this work, we use the surface-level processed Sentinel-2 with six bands (red, green, blue, nir, swir1, swir2), the Sentinel-1 backscatter signal (bands VV and VH), and altitude, aspect, and slope provided by the digital elevation model from the SRTM mission at a resolution of 10 m. The choice of Sentinel as an input source is motivated by its global coverage, the relatively high spatial and temporal resolution, and the fact that the image collection goes back to 2016, allowing the deployment of the model on historical data.
In
Figure 2, a sample input image (RGB) and the corresponding AGBD ground truth data are shown. It illustrates the sparsity of ground-truth measurements and the need for a model that can fill in the gaps.
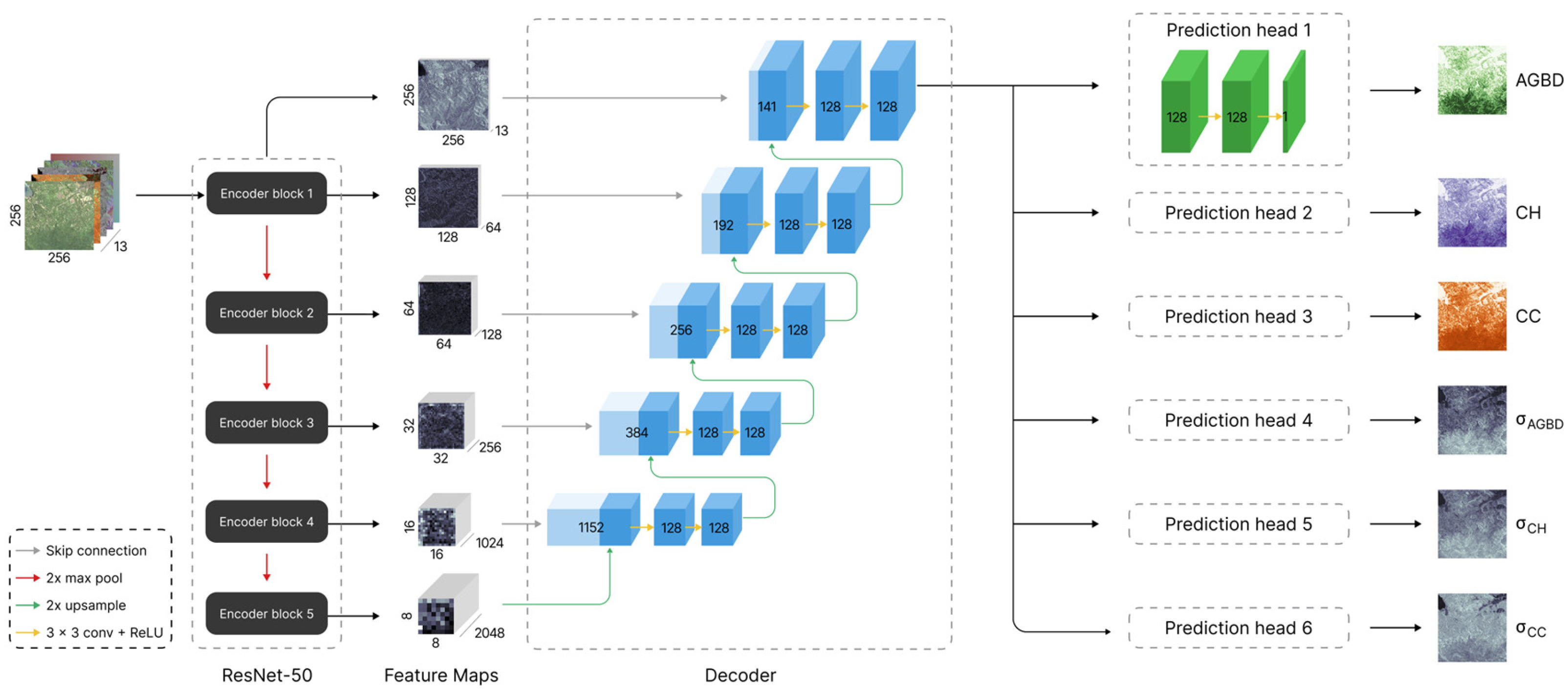
Our model consists of a convolutional neural network (CNN) [
52] with three main components: an encoder network that extracts features from the input image, a decoder that processes the extracted feature maps at different depths of the network, and, together with the encoder, forms a feature pyramid network (FPN). The final feature map then consists of all the relevant information required for the estimation of the output variables. The final components are a set of prediction heads, which have the function of generating the estimate of each respective output variable based on the last feature map of the FPN. Each prediction head consists of a series of 1 × 1 convolutions. The encoder network can be any commonly used feature extractor. In this work, we chose ResNet-50 [
53] as the encoder. The FPN consists of decoder blocks where each block takes the features of level
and
l as input. The feature map of level
is up-sampled using a bilinear interpolation method and a convolution layer with kernel size 2 × 2 before concatenating with the feature map of level
l, followed by two convolution layers with kernel size 3 × 3. The resulting feature map is then fed to the level
decoder block until it reaches the final level corresponding to the input resolution. All convolution layers in the decoder have a fixed feature dimension of 128. Each prediction head consists of a series of 3 1 × 1 convolutions with feature dimensions [128, 128, 1]. All layers in the decoder and prediction heads use the ReLU [
54] activation function except for the final layer of the prediction heads, which estimates the variable uncertainty for which we use the softplus [
55] activation function. The weights of the entire network are randomly initialized using the Glorot Uniform [
56] initializer.
Figure 3 illustrates the model architecture with its various components. The total number of trainable parameters is 28.71 million.
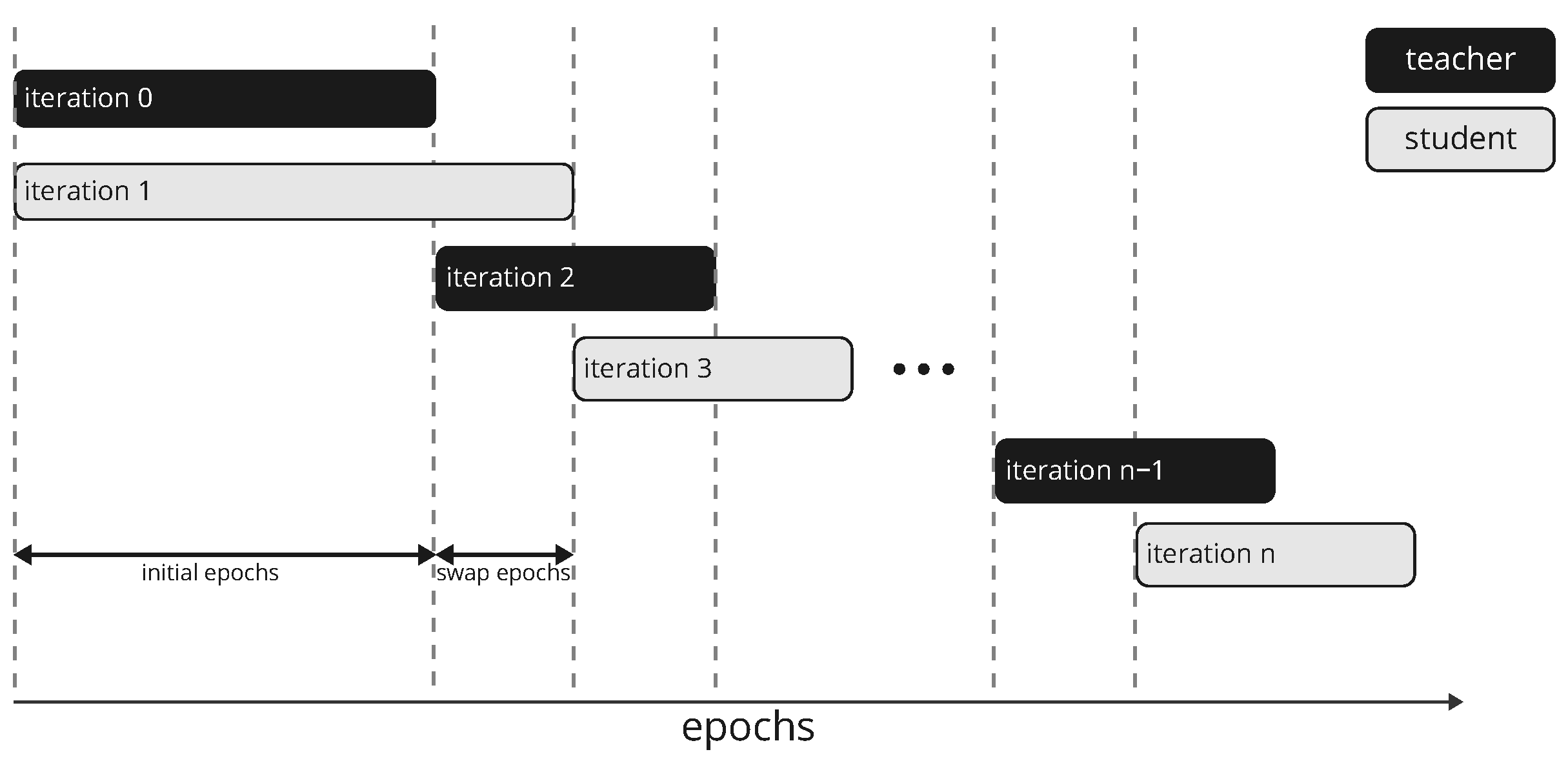
This model architecture generates an output map of the same size as the input image. In most cases of such a configuration, the target is expected to be a continuous map of the same size as the output from which the loss is calculated. In our case, the target is not continuous but is composed of sparse target values. A straightforward solution for this situation is to only evaluate the loss function at pixels for which a ground truth value is available. However, we found that this approach results in overfitting on the sparse pixels and generates a nonhomogeneous output. We, therefore, propose a new approach where we generate a continuous target map by a model acting as the teacher to a student network during the training process. This approach is similar to the student–teacher setup for classification tasks where ground-truth labels are incomplete. We extend this approach to dense regression tasks, as in this work. To begin with, we construct two identical networks in terms of the architecture whose weights are initialized separately and referred to as teacher (
) and student (
) networks. The task of
is to generate a continuous ground truth map from the input and the ground truth labels.
is then trained on this ground truth map. After a certain number of epochs,
and
swap their roles. This procedure is repeated until the two networks converge. Since both networks are randomly initialized, they are not very skilled during the initial training phase, and
cannot provide meaningful ground-truth guesses. We therefore replace
with a simple model based on spectral similarity at the input level during the first training phase of
. We define the spectral similarity as the cosine similarity
where
and
are the vectors with spectral information of a set of bands for pixels
i and
j. The set of bands can be a combination of any of the available input bands. However, we find that this approach works best with a feature vector composed of the six bands of Sentinel-2.
For each pixel without a label, we compute
with respect to all pixels that have a label (hard labels). We then assign the value of the hard label for which
is maximal to the pixel without a label to generate a soft label. The target map is then a combination of hard and soft labels defined as
where
m is a mask for which
if pixel
is a hard label and
otherwise. Here, ⊗ denotes the element-wise product. Soft labels can be efficiently calculated for all unlabeled pixels by arranging them in a matrix
A of size
and all hard label pixels in a matrix
B of size
, with
b the number of bands. The soft labels are then calculated by
where
and
are the row-normalized matrices of
A and
B.
Figure 2 (right) shows the result of this operation on the input shown in
Figure 2 (left).
Here we use a simple model to generate soft labels according to Equation (
5), which are good prior guesses for pixels with no target values in the first iteration of training
. After the first iteration (initial epochs),
has acquired some skills to predict the target map and becomes the teacher for the second network, which is trained from scratch. The teacher network replaces the simple model for soft label generation based on spectral similarity, as it has inherent quality limitations due to noise. In order for the new student network to overcome the skills of the teacher network, the hard labels will be given more weight than the soft labels in the definition of the loss function (see Equation (
12)), and
is trained for 8 more epochs (swap epochs) in the current iteration than
in the previous iteration. This procedure is illustrated in
Figure 4. The soft labels generated by
are guesses and help guide network training, particularly in the early training phase, but may deviate from the actual ground truth label. We, therefore, use a weight schedule for the soft labels incorporated into the loss function (see the next section for details).
2.4. Model Training
Training of the model is divided into three parts: First, we train the entire network, including prediction heads 1–3, on the full dataset of ∼1 M samples. The network is optimized to predict AGBD, CH, and CC simultaneously using their respective target values. We incorporate sample weighting according to the inverse probability distribution function (PDF) of the respective variable distributions. This is important to mitigate overfitting on lower values of AGBD and CH as they appear at higher frequencies in the dataset. In the second stage, we freeze the weights of the encoder and decoder and fine-tune the prediction heads 1–3 separately on variable-specific datasets. These datasets are subsets of the original dataset with a more uniform distribution of variable-specific values. This is done by excluding a certain number of samples according to their aggregated target values, which is further described in
Appendix A. The balanced datasets still manifest some nonuniformity in the distribution of individual point measurements, as opposed to aggregated measurements within a sample. We, therefore, incorporate an adjusted sample weighting according to the inverse PDF of the respective variable distributions in the uniform dataset. In the third and last stage, we fine-tune the pairs of prediction heads [(1, 4), (2, 5), (3, 6)], i.e., each variable and its uncertainty, separately on the same datasets as in stage 2.
2.4.1. Loss Function
We consider the prediction of each pixel
in the output map
as an independent measurement of a normally distributed variable with a standard deviation of
. The probability for a given ground truth value
is then given by
where
are the parameters of the network. The likelihood function can be written as
We use gradient descent to optimize the parameters
, which minimizes the negative log likelihood (NLL), which defines our loss function
where we omitted the factor
from Equation (
8).
is the uncertainty predicted by the model for each variable separately. By definition, we expect 68% of all samples to have an absolute error between predicted and true values within the range of 1
. During training, we verify this by calculating the fraction of z-scores, defined as
, to be <1. Although the
term in Equation (
10) acts as a regularization to make sure the model does not learn a trivial solution by predicting a very large
, we noticed that the coverage may still be >0.68. We, therefore, introduce an additional regularization term in the definition of the loss as
where
is a hyperparameter determined for each variable separately. For a given sample, the number of hard labels is much smaller than the number of soft labels (on average, the ratio of hard to soft labels is ∼1/1000) and varies between samples. We, therefore, introduce a pixel weighting scheme to balance the contribution of hard and soft labels to the loss. In addition to the imbalance between hard and soft labels, we also want to assign relative weighting of hard to soft labels. This is an essential requirement to make the student–teacher approach work well. Consider the relative weight of a hard label to be
and that of a soft label to be
. Then the balanced loss function, taking both the relative weights as well as the number of hard and soft label pixels into account, becomes
where
(
) are the number of hard (soft) label pixels in a given sample and
m has the same definition as in Equation (
6). By default, we choose
and vary
during training according to an exponential decay from 1 to 1 × 10
−3 during the initial epochs, then exponentially increase it to 1 × 10
−2 during the remaining epochs. We have considered other schedules such as linear, constant, and zero (corresponding to no soft label), which all resulted in worse model performance.
So far we have only formulated the loss function in Equation (
12) considering one variable. However, we train the model for all variables simultaneously, for which we construct the final loss as the weighted sum over the variable-specific components
where the weights
allow for balancing the different contributions due to the different target scales of the variables. In this work, we set
since we did not observe any improvements using variable-specific weighting.
2.4.2. Training Setting
For the first stage of pre-training on the full global dataset, we train the model for 40 epochs with a batch size of 72 on a multi-GPU node with 4 A10G GPUs. We reserve one of the GPUs for data preprocessing, such as the calculation of the soft labels, while the remaining GPUs perform the model training. We use the Adam optimizer [
57] with a linearly increased learning rate from 1 × 10
−7 to 1 × 10
−4 over a warm-up period of 1 epoch, after which it continuously decreases according to a cosine function over the remaining training period. The second stage consists of fine-tuning each variable separately on the balanced datasets and applying the sample weighting according to the inverse frequency distribution. In this stage, only prediction heads 1–3 are trained while all other model weights are kept frozen. We used three single GPU nodes to train each head in parallel with a batch size of 32. In the third and last stages, we fine-tune the prediction heads 4–6, which are responsible for predicting the variable uncertainty. In all stages, the loss function, as defined in Equation (
13), is minimized. However, in stages one and two, the uncertainty estimation is ignored, which is equivalent to setting
for all pixels.
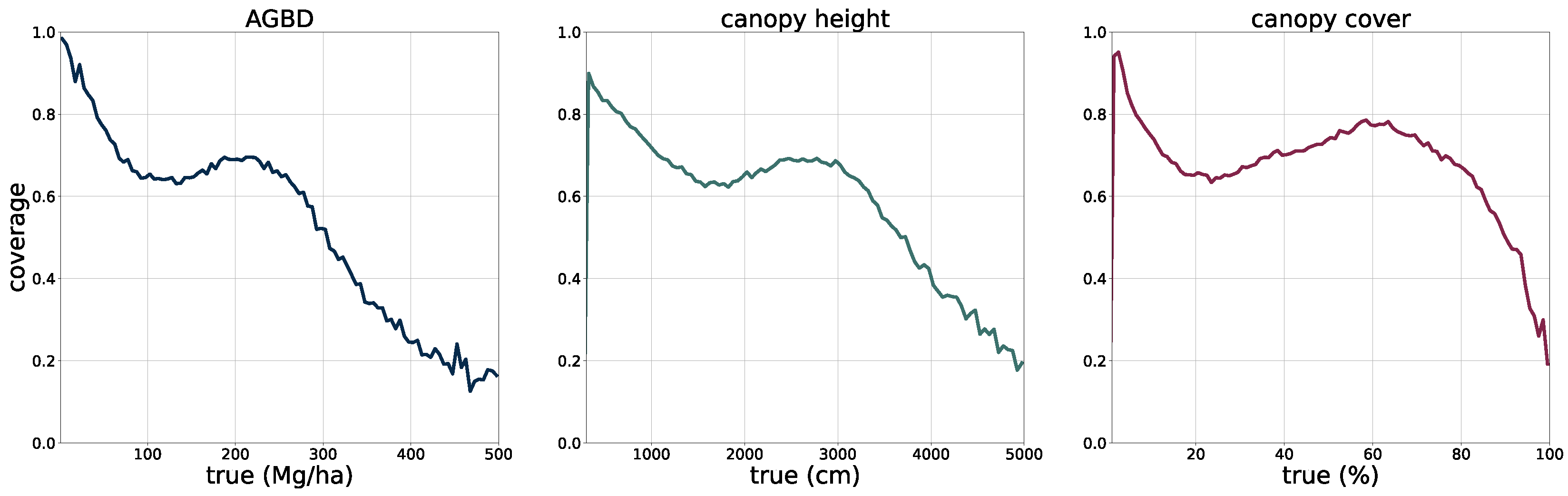
2.5. Model Performance Assessment
The deployment of the model on a global scale for the year 2023 allows for a qualitative assessment of its performance, in particular in challenging areas such as those with high cloud coverage, which may affect the quality of the input imagery.
In
Figure 5, we present four sample locations that cover an area of 1 km × 1 km at 10 m resolution. The four columns on the left represent the input data (excluding the geographic coordinates), while the three columns on the right correspond to the predictions of AGBD, CH, and CC. The top row represents a sample where the model performs very well. It contains various land-cover types such as urban, agriculture, and low- as well as high-density forest areas. The second row shows a sample in a high-density mountainous area with a nonforested valley. Both SAR backscatter and DEM provide valuable information on the terrain in this sample. The model performs as expected and successfully distinguishes high- from low-density and forested from nonforested areas. The third row demonstrates the model’s ability to leverage the multisensor input stack. There are multiple regions where the cloud-free composite left gaps visible as black areas in Sentinel-2 data. Here, information from Sentinel-1 and DEM is used to improve the predictability of these areas. The last row illustrates the model’s capability for making accurate predictions at high resolution. The example shows individual trees, or groups of trees, that are well separated from the bare ground.
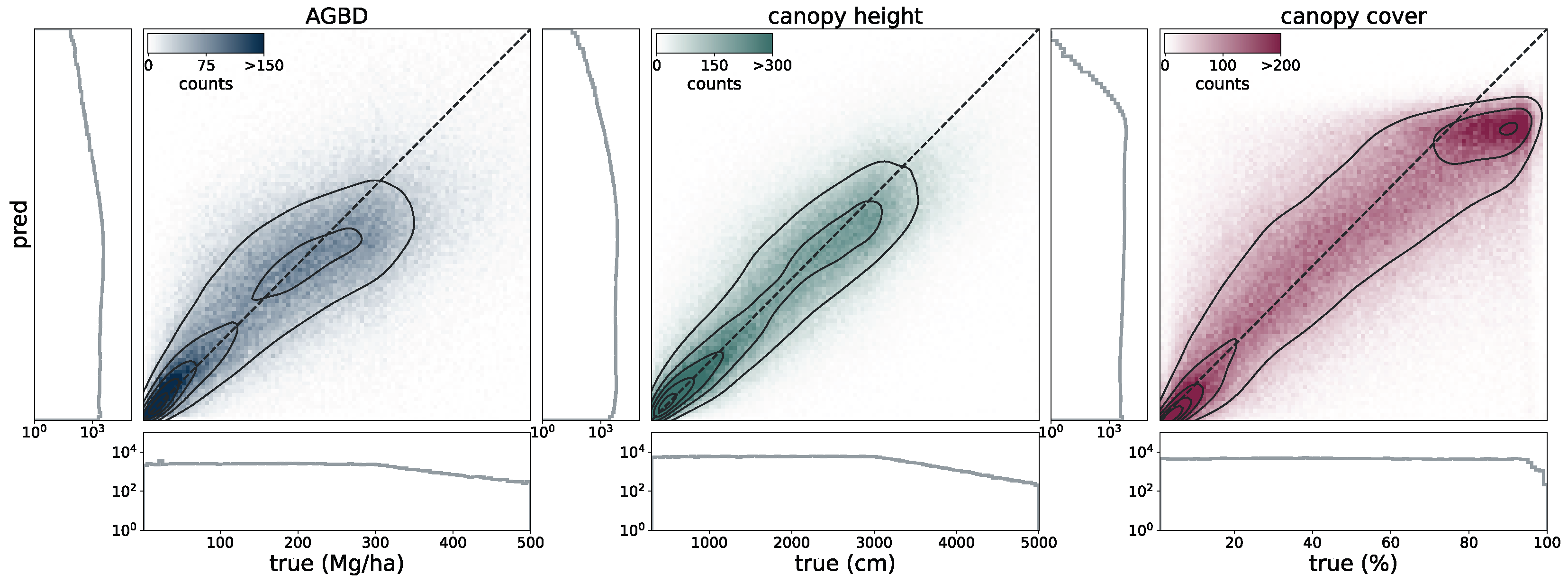
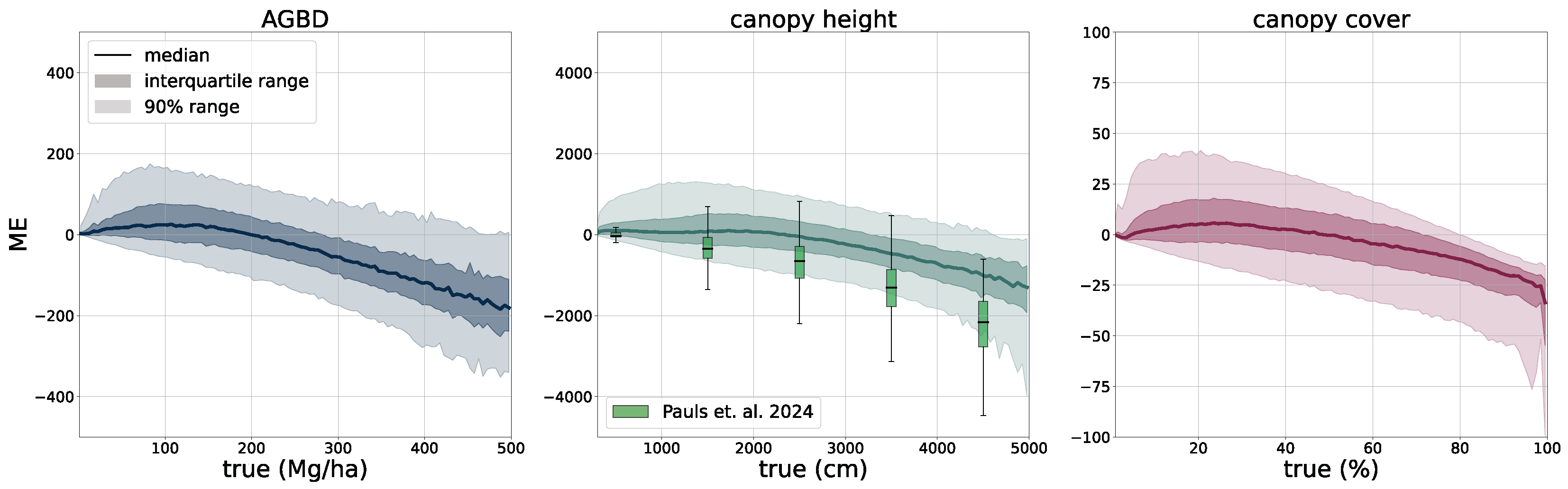
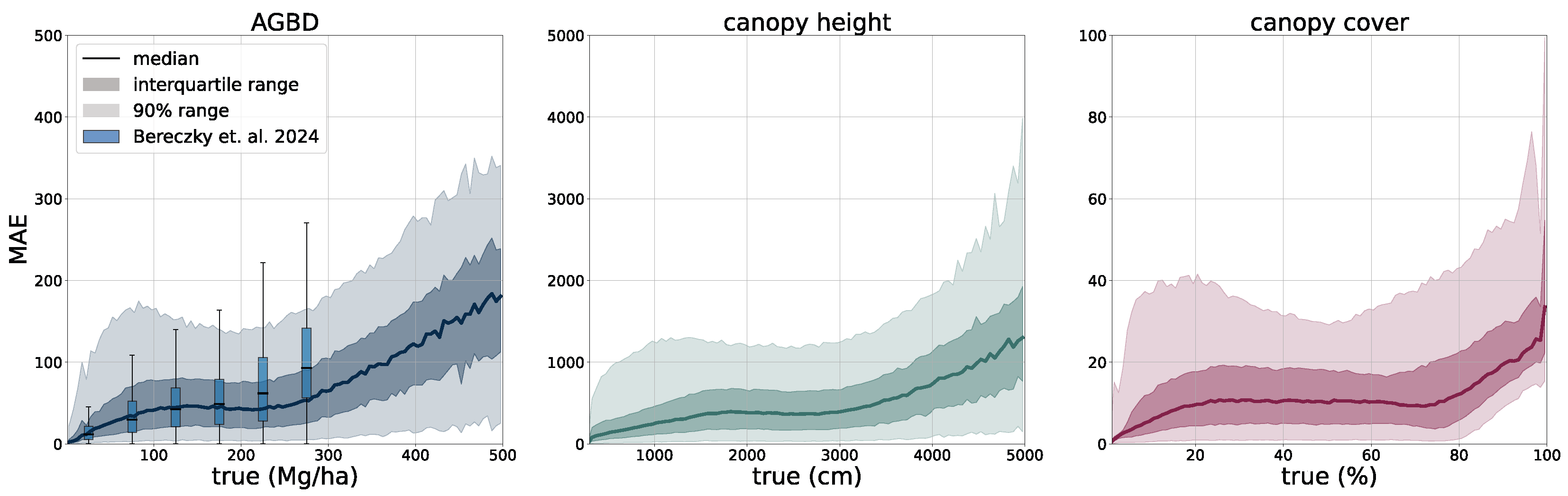
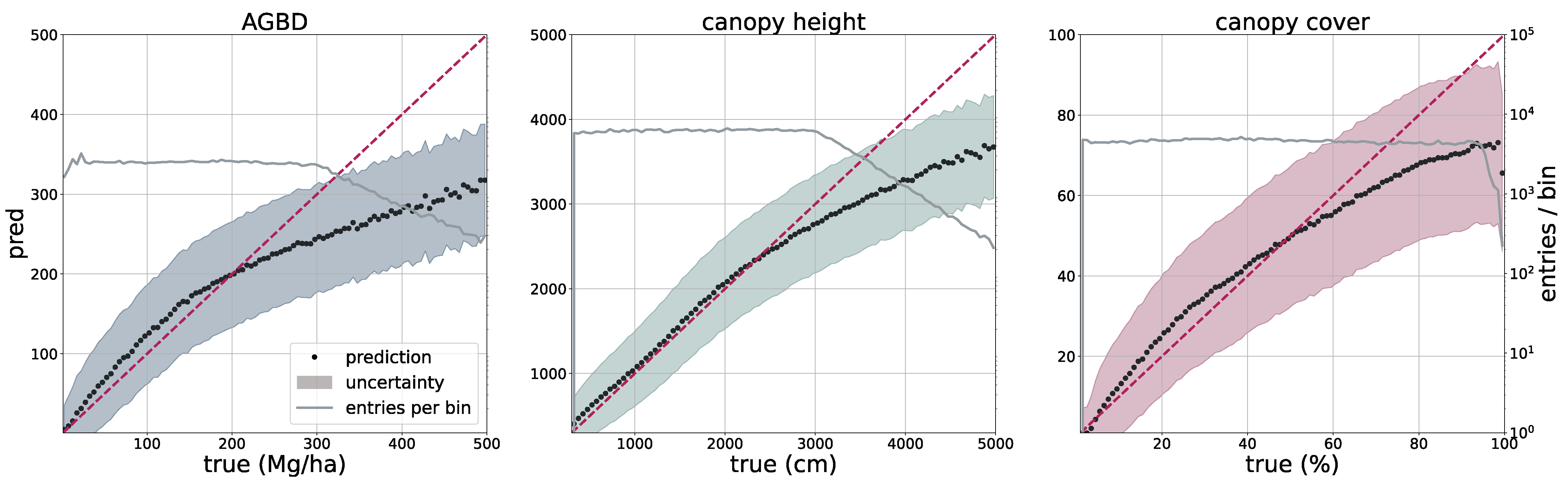
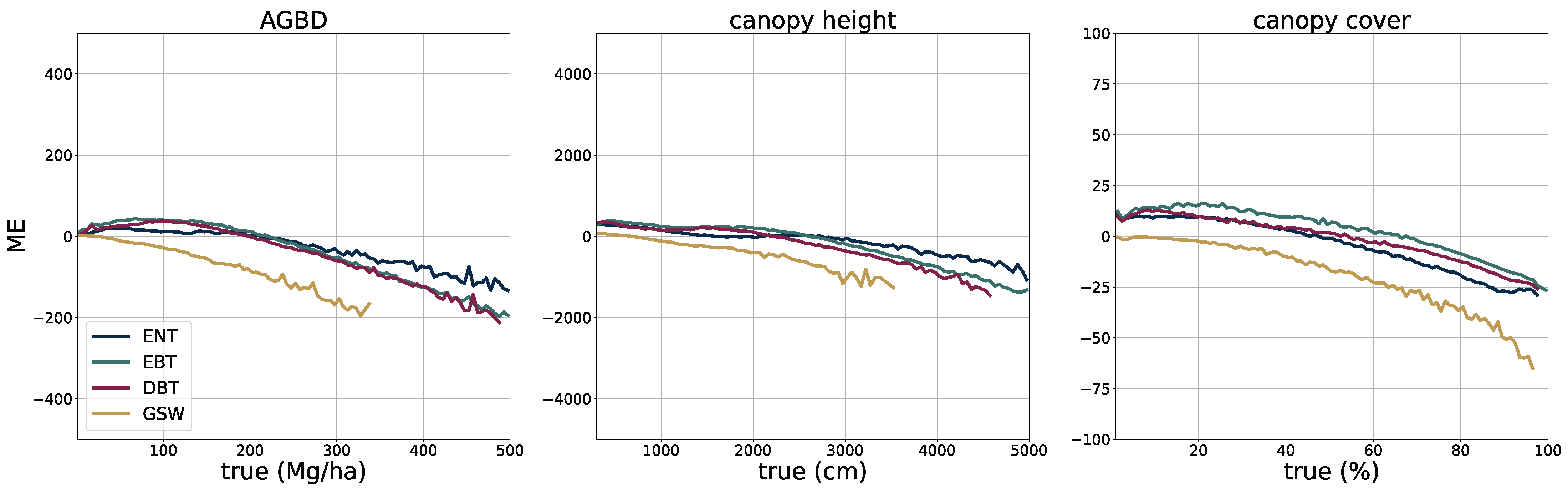
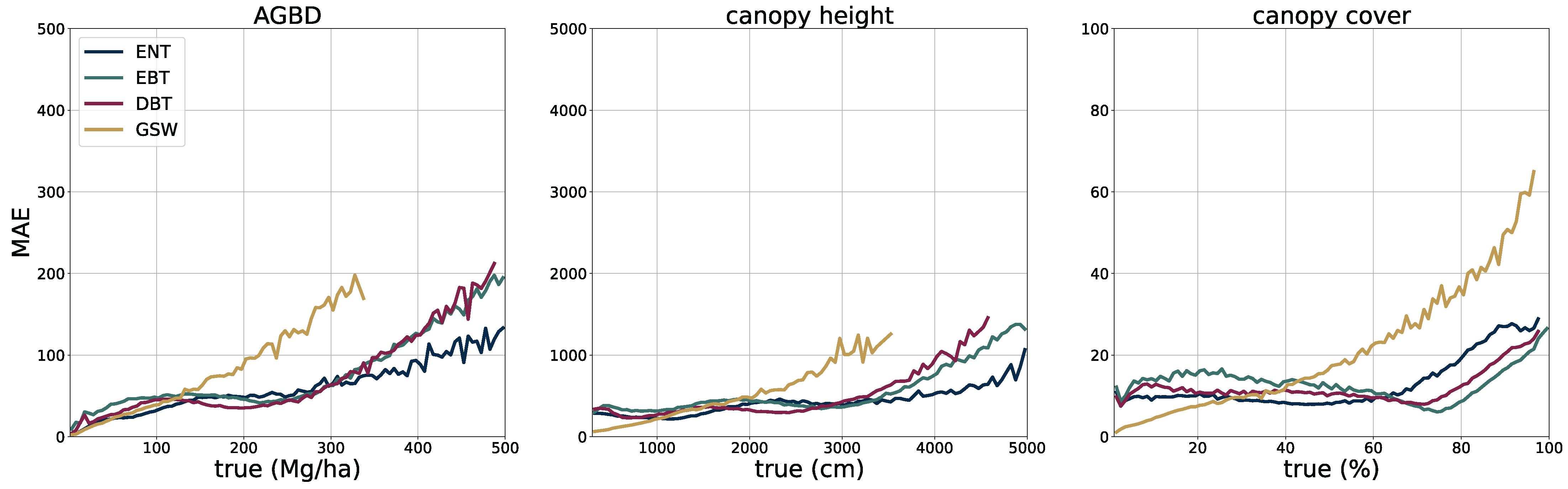
To validate the accuracy of the model, we use the held-out test set consisting of 14,745 samples and 13.8 M individual GEDI footprints. Model inference is performed on each test sample of size 256 pixels × 256 pixels, which generates predictions for every pixel and all output variables, including their uncertainties. We measure the correlation (corr), mean error (ME), mean absolute error (MAE), mean absolute percentage error (MAPE), and root mean squared error (RMSE), defined as
between the GEDI ground truth data
and the model predictions
gathered at the pixel coordinates of the GEDI footprints. Due to the non-uniform distribution of ground truth values, we assess the model performance on both the test set with its original and uniform sample distribution. For this purpose, we sample data points according to the inverse PDF of each variable’s respective distribution. This ensures a more fair performance assessment in the value ranges of each variable. Due to the low frequency of the appearance of high values of AGBD and CH, we set a reference value of 300 Mg/ha for AGBD and 30 m for CH to define the lowest probability value. Values with lower probabilities are always included during sampling. After the sampling procedure, a total number of 200 k–450 k data points remain, depending on the variable. We provide the detailed results of this evaluation in
Section 3.1.
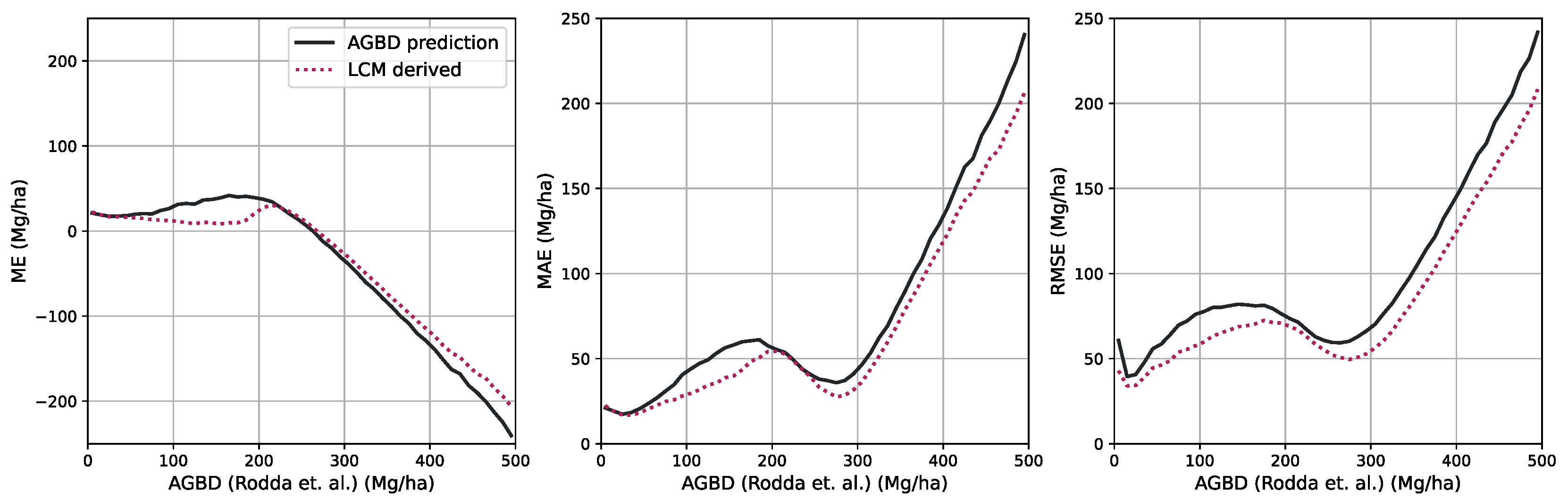
Using the test set for model evaluation is a fair way to assess the predictive skills of the model but assumes accurate ground truth labels. In order to account for systematic errors and further evaluate the model on independently collected ground measurements, we select two third-party datasets, one for ABGD and one for CH, to which we compare our model predictions.
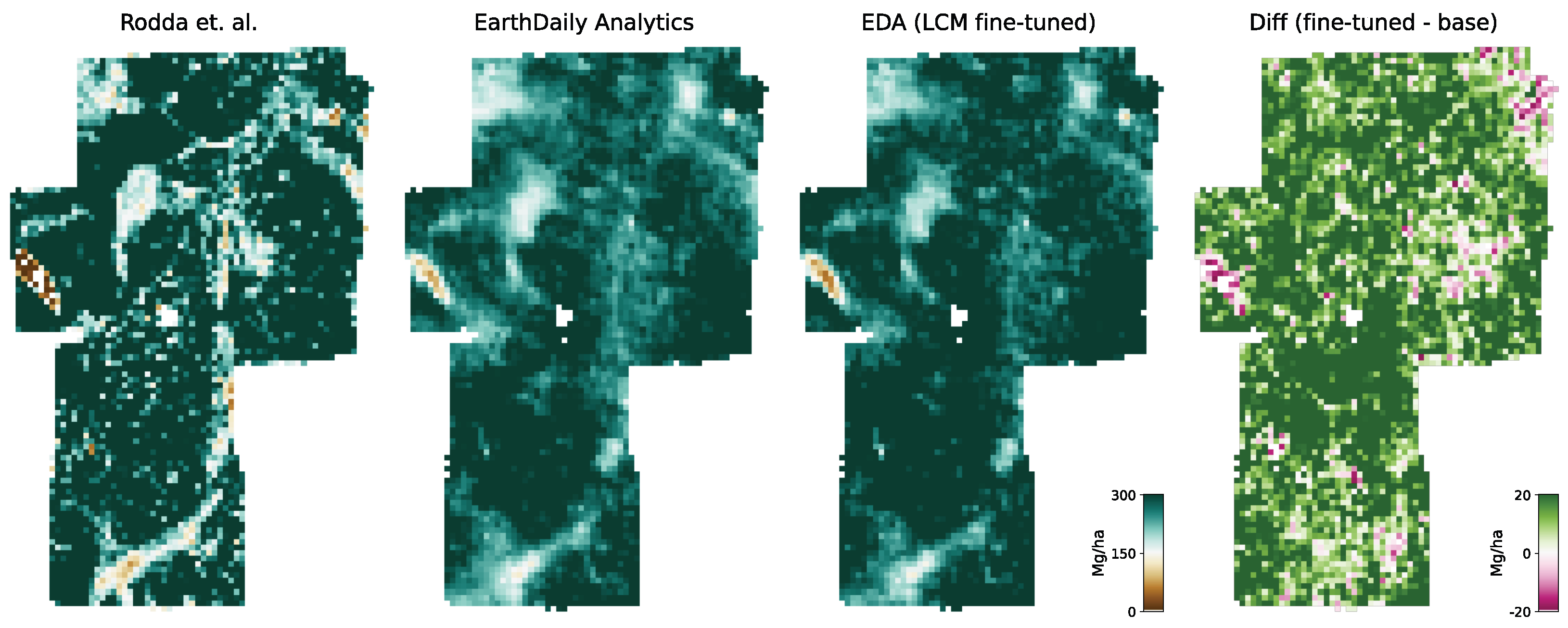
Aboveground biomass. For the verification of biomass estimates, we utilize the dataset created by [
58] which consists of 13 plots of variable size at a maximum resolution of 40 m. Eight of the plots are located in the Central African region, and five of the plots are in the South Asia region. This dataset was compiled from forest inventory collected at the respective sites during different time ranges. Site-level measurements followed a strict protocol in which the diameter at breast height (DBH) was determined for each individual tree within the plots, as well as the tree height (H) for a subset of trees. Tree-level taxonomic identification and relative coordinates within the plots were recorded along with geographic coordinates of the plot borders at intervals of 20 m. The forest inventories were split into 1 ha and 0.16 ha plots. The data collected for DBH-H on a subset of trees within these plots were used to fit allometric equations that relate H to DBH and allow the extrapolation of tree height measurements to all trees in the plots. Then the wood density based on the tree taxonomy was used to calculate the aboveground biomass reference (
). Aerial LiDAR at a resolution of 1 m was obtained over the sites within an absolute temporal difference of 2.2 ± 1.9 years from the forest inventory dates. From the LiDAR data, canopy height models (CHM) and canopy metrics (LCM) were derived. Allometric equations of the form
were then fit, which relates LCM to AGB. The authors found that the average of RH40, RH50, RH60, RH70, RH80, RH90, and RH98 represents the best predictor of LCM for AGB.
For this study, we utilize the 40 m resolution dataset since it is closer to the native resolution of our model. For the comparison, we resample our model output to 40 m resolution using the average resampling method. We deployed our model over all sites for the year the forest inventory ended at the respective site. Due to limitations of input data availability, our model can only be deployed back to the year 2017. For sites with forest inventory dates prior to 2017, we chose 2017 as the deployment year.
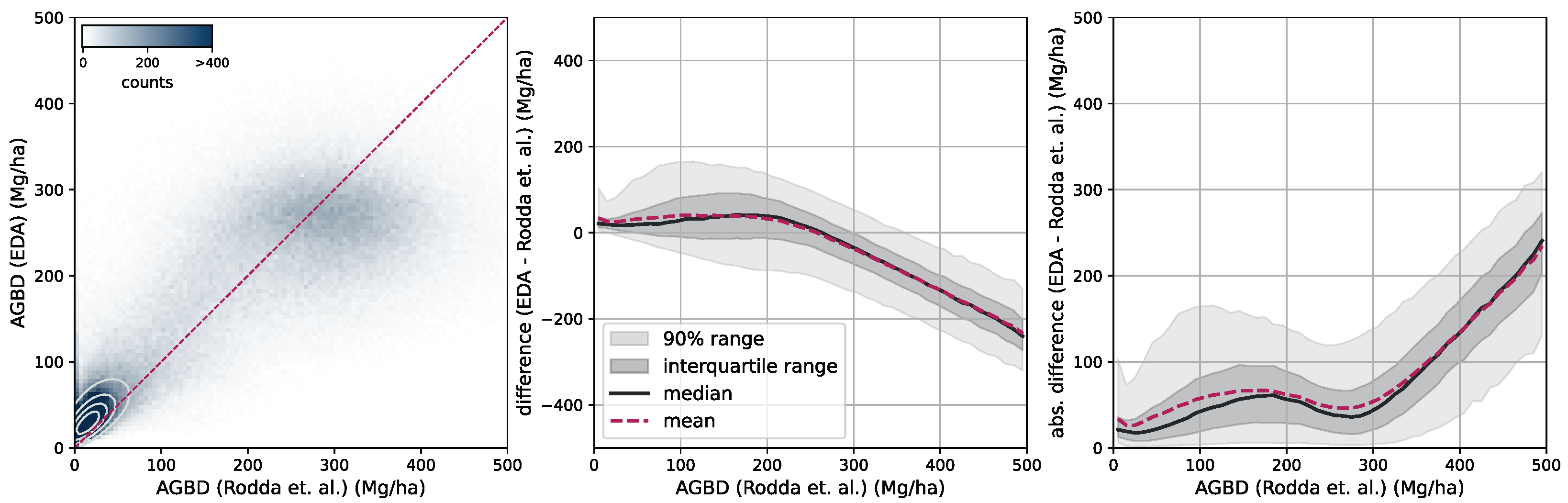
Figure 6 shows an RGB image of the input data, the reference AGBD, as well as our model’s estimate for AGBD for the site Somaloma, Central Africa.
We consider each pixel of 40 m × 40 m size (0.16 ha) as a data point and compare the AGBD estimate by our model with the ground measurement provided by [
58]. We determine RMSE, ME, and MAE across all pixels and sites except Achanakmar, Betul, and Yellapur, which we exclude from this study. For these three sites, we noticed that our model underestimates AGBD. Upon further investigation, we found the underestimation to be caused by the input compositing strategy. The three sites contain a large fraction of deciduous broadleaf trees and are located in the tropical region for which we construct cloud-free composites over a 6-month time period. In these particular cases, this resulted in the inclusion of scenes where the trees did not carry leaves, causing a shift in the input signal. This can be addressed by shortening the composite time window for regions with these conditions, which we reserve for future work.
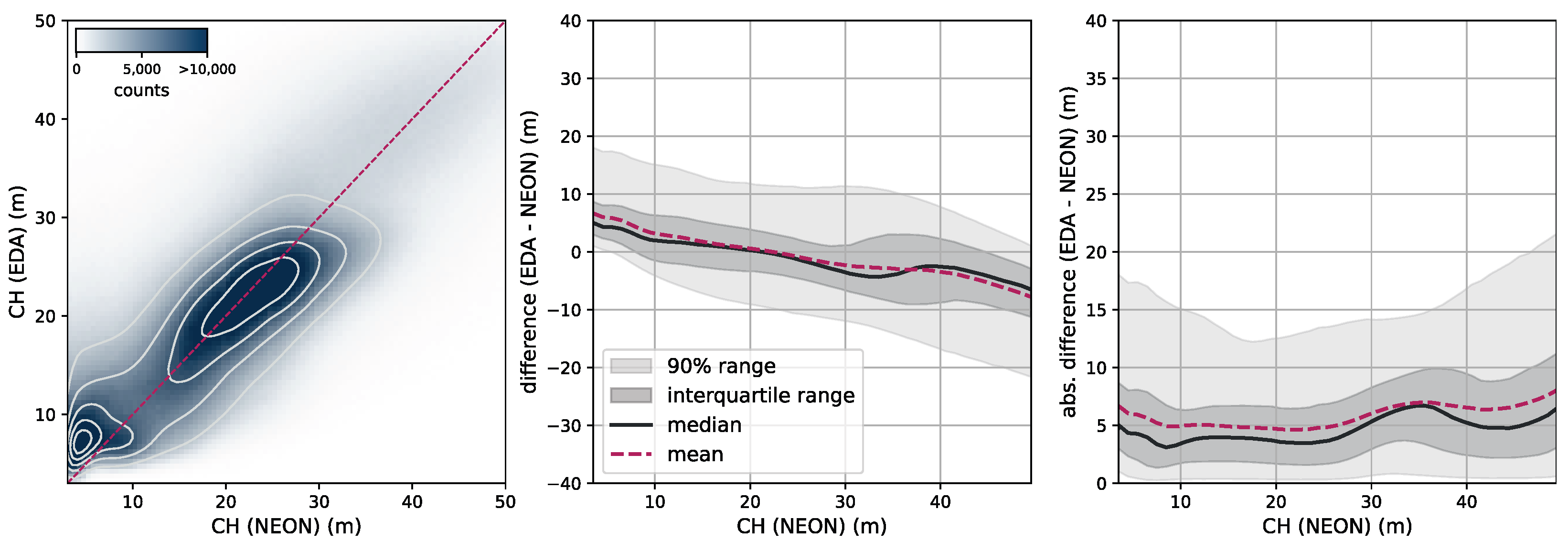
Canopy height. To further assess our model CH estimation, we use data from the National Ecological Observatory Network (NEON) [
39]. NEON is a high-resolution LiDAR dataset that provides detailed three-dimensional information about the Earth’s surface. This dataset includes measurements of vegetation structure, topography, and land cover in diverse ecological regions in the United States. Data are collected using airborne LiDAR sensors, capturing fine-scale details at a resolution of 1 m. We selected all measurement sites in the states of AL, CA, FL, GA, OR, UT, VA, and WA from the year 2021. We subdivide each site into areas of size 2560 m × 2560 m and rasterize our model CH estimation as well as the NEON CH measurement at their respective resolutions (10 m for our model and 1 m for NEON). This results in tiles of size 256 pixels × 256 pixels (our model) and 2560 pixels × 2560 pixels (NEON). In order to compare the two maps, we resample the NEON map by determining the 98th percentile in each 10 pixels × 10 pixels area, resulting in a map of the same pixel size as our models. We chose this approach because our model effectively estimates the RH98 metric for each pixel corresponding to 10 pixels × 10 pixels in the NEON map.
Figure 7 illustrates the RGB imagery and the CH maps of our model and NEON for two samples (the top row corresponds to a sample in site ABBY, WA, and the bottom row to a sample in site TEAK, CA).
5. Discussion
Despite the need for global-scale monitoring of forest carbon pools, many technical challenges have limited the scalability and accuracy of solutions. In this work, we hypothesized that by leveraging (1) globally distributed source of ground truth, (2) fusion of multiple input sources, including non-optical imagery, and (3) training a single model on multiple correlated targets, we can achieve scale and address obstacles related to model performance, particularly in areas of large noise (e.g., due to cloud obstructions).
The model evaluation against individual, globally distributed GEDI measurements contained in the test dataset shows good agreement between the predictions and ground truth values as measured by various metrics. Compared with previous work that predicts AGBD [
8] and CH [
7,
9,
33] we achieve the lowest error across all ranges of variables on a global scale. This demonstrates the potential for novel model architectures and multi-modal data sources to address challenges in forest monitoring. In order to demonstrate the practicality of our model, it is important to validate its predictions against data samples which were collected with high precision and/or on the ground offering an independent data source. The model shows reasonable agreement with these third-party datasets across a wide range of ABGD and CH values. Because local measurements involve extensive human labor and are not readily available at scale in the public domain, this approach is used to generate consistent, global-scale estimates of forest carbon, which can fill gaps where local solutions are not available, serve as a tip-and-cue mechanism to prioritize ground studies, and facilitate comparative studies where consistent methodology is required.
The extensive model evaluation framework has shown that the predictions of all variables are of high accuracy at global scale, but exhibit limitations in very dense forests where input features are less distinct. This phenomenon has been well documented in the literature [
61] and is caused by a limited spatial resolution and a saturation effect on the spectral sensitivity. This is an inherent limitation when using remotely sensed data as the information content is restricted. The effect is more severe with AGBD, which has an additional component from the increasing uncertainty of ground-truth samples at higher values due to the errors propagated from the calibration. Without additional data sources, such as high-resolution optical or SAR, it is difficult to overcome these limitations. At the same time, there is a trade-off between using high-resolution imagery and being able to update prediction maps frequently at low computational costs. With new satellite constellations being deployed in the near future, the methodology presented in this study holds great potential to further advance precision estimation from remote sensing data.
In addition to enhanced input data, our methodology will also benefit from more accurate ground-truth labels. The GEDI point data have an inherent uncertainty due to the relatively large footprint which manifests itself as noise in the training data. Machine learning models are generally able to deal with noisy data [
62] at the cost of prediction accuracy. We observe this effect in our model predictions at higher values of AGBD and CH where the uncertainty of the ground-truth labels is higher, leading to underestimated predictions. Allowing the model to estimate the uncertainty through additional prediction heads provides a way to account for this limitation. As illustrated in
Figure 11 and discussed in
Appendix B.1, the model slightly overestimates the uncertainty band at low values and underestimates it at higher values, which is subject to future work and model improvements.
6. Conclusions
In this work we present a novel deep learning-based computer vision model that unifies the prediction of several biophysical indicators that describe the structure and function of vegetation in multiple ecosystems and their respective uncertainties. The model input consists of multiple satellite image sources including Sentinel-1 backscatter, multispectral Sentinel-2, and topographic information from SRTM. Previous studies have focused on the estimation of single variables with similar methodologies. Uncertainty estimations were also unavailable or conducted in separate studies. Training a single model for the prediction of AGBD, CH, and CC with a shared encoder-decoder architecture provides richer information for the extraction of common features. Additional benefits include efficient and cost-effective model deployment at scale, which are important factors for global monitoring efforts.
Our end-to-end training procedure using a weakly supervised learning method on point data representing individual measurements of the respective variables results in a skillful model as rigorously evaluated on a held-out test dataset achieving an RMSE of 50.59 Mg/ha (543.81 cm, 15.75%) for AGBD (CH, CC). We further evaluated our model against third-party datasets without further fine-tuning and attained performance that is consistent with or exceeds the expectations for such data, demonstrating the robustness and generalizability of our approach. In addition, we generated global maps of AGBD, CH and CC at 10 m resolution, extending the coverage of GEDI observations to a latitude range of 57°S to 67°N, for the year 2023 or 2021, respectively, where Sentinel-1 data were unavailable. This demonstrates the scalability of our model, due to its global training dataset.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}