
Dual-Domain Multi-Task Learning-Based Domain Adaptation for Hyperspectral Image Classification

 , , , , and
, , , , and
Abstract
1. Introduction
- A novel MTLDA method is proposed to achieve cross-scene HSI classification. This method incorporates the dual-domain multi-task learning into adversarial domain alignment to improve the quality of domain-invariant features.
- A new DDML module based on contrastive learning is proposed. By training with shared parameters between SCL and TCL, the classification knowledge from the source domain is transferred to the target domain, thereby improving the discriminability of target domain features.
- An innovative FMDA method is proposed to create augmented data at the feature level, which increases the variety within the training data, consequently enhancing the generalization of the model.
2. Related Work
2.1. Multi-Task Learning
2.2. Contrastive Learning
3. Method
3.1. Bi-Classifier Adversarial Training for Domain Alignment
3.2. Dual-Domain Multi-Task Learning
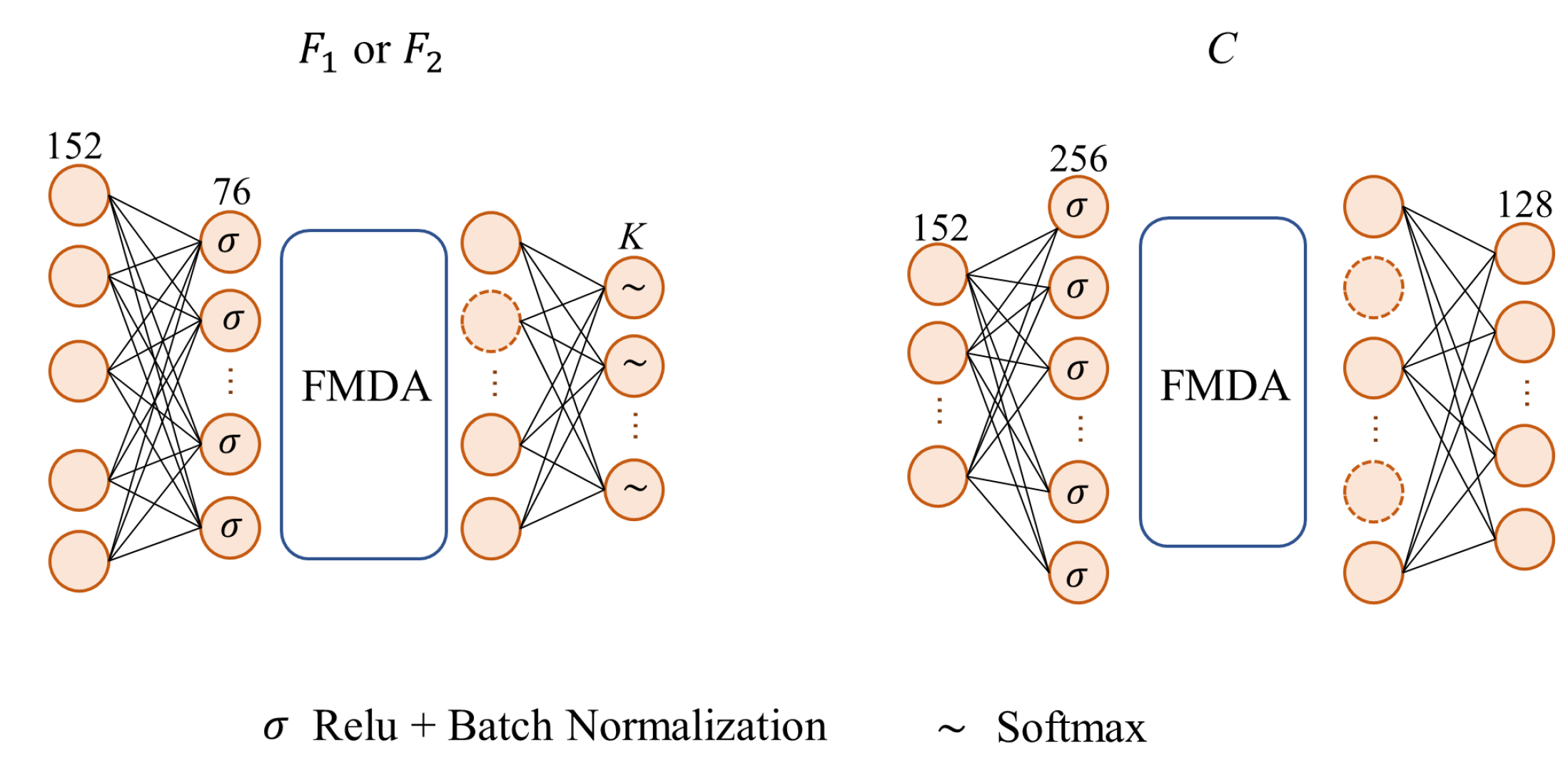
3.3. Feature Masking Data Augmentation
3.4. Training Steps
| Algorithm 1 Training process of MTLDA |
|
4. Results
4.1. Dataset Description
4.1.1. Houston Dataset
4.1.2. Pavia Dataset
4.1.3. HyRANK Dataset
4.2. Experimental Setup
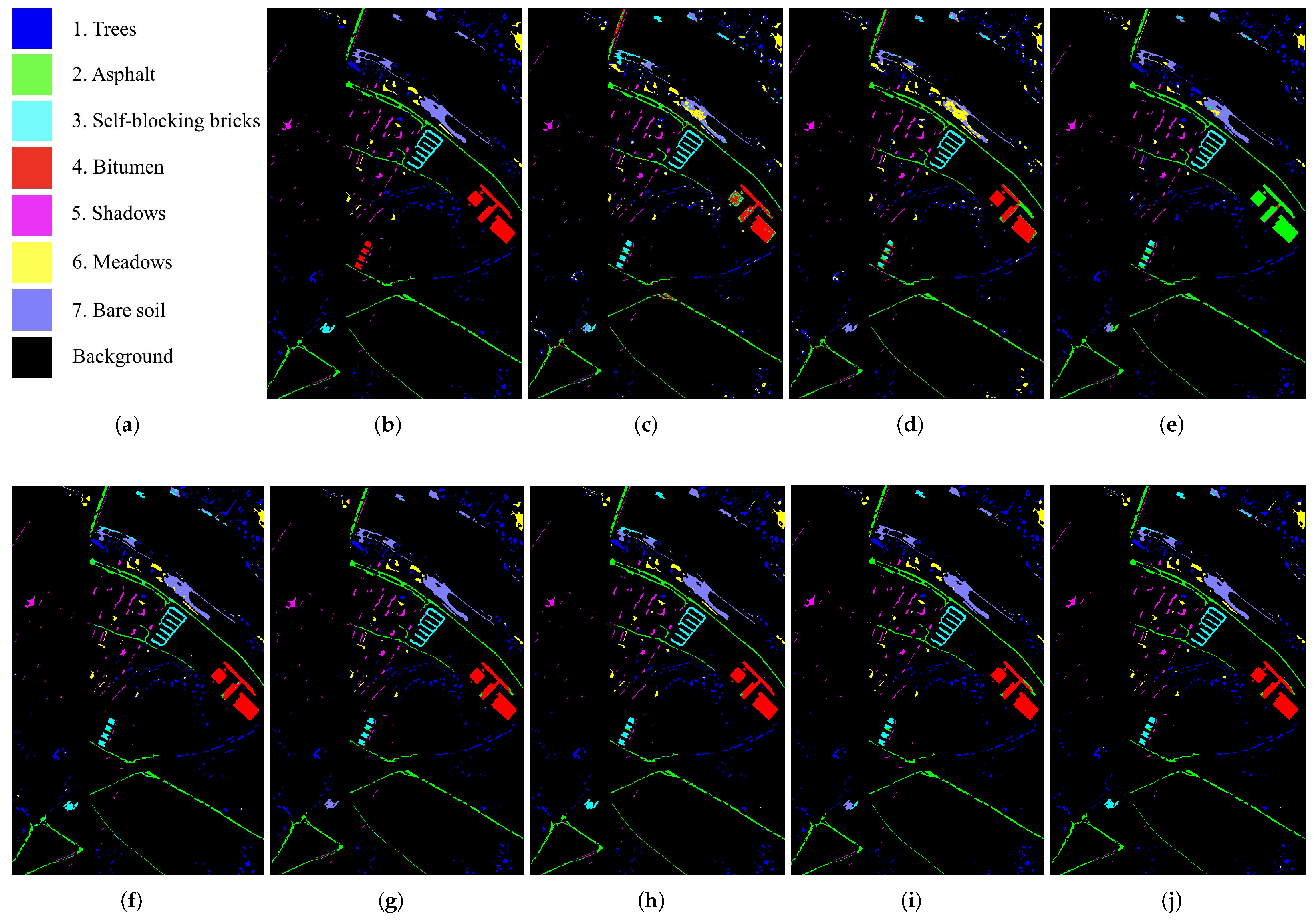
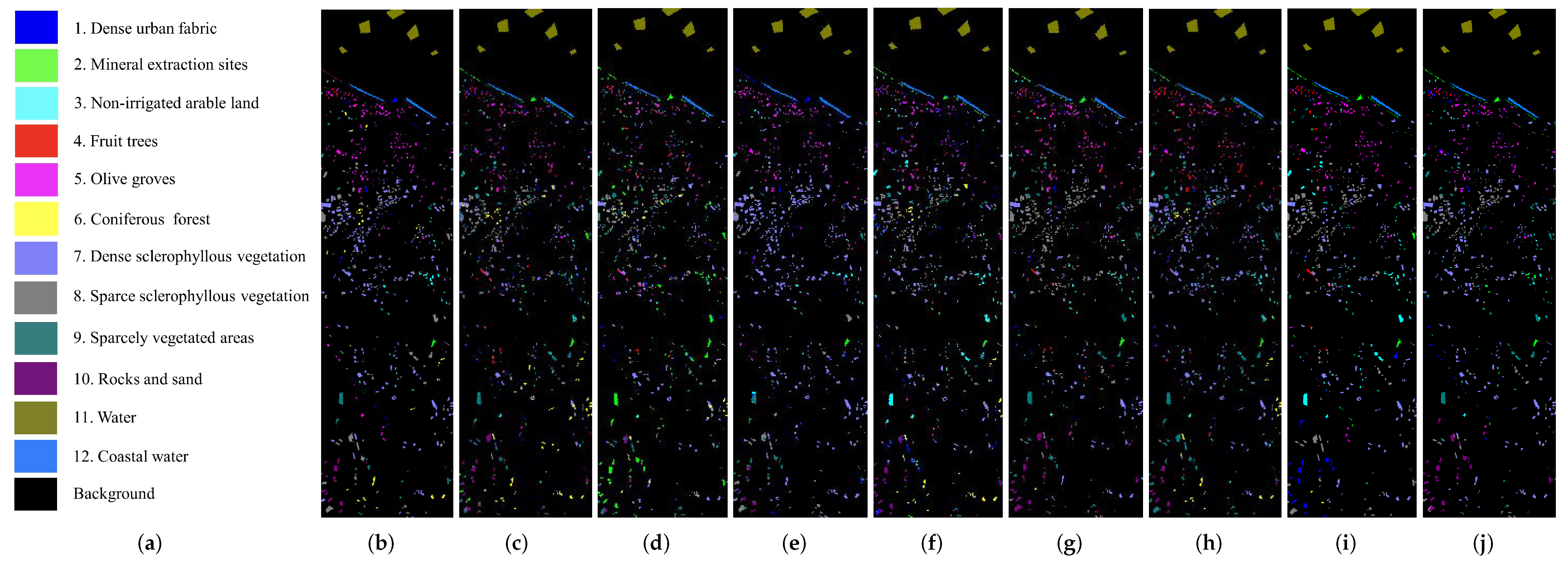
4.3. Comparison and Analysis
4.4. Ablation Study Results
4.5. Comparison and Analysis of Data Augmentation Methods During Domain Alignment
4.6. Parameter Analysis
4.7. Computational Complexity
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Cui, Y.; Meng, F.; Fu, P.; Yang, X.; Zhang, Y.; Liu, P. Application of Hyperspectral Analysis of Chlorophyll a Concentration Inversion in Nansi Lake. Ecol. Inform. 2021, 64, 101360. [Google Scholar] [CrossRef]
- Thangavel, K.; Spiller, D.; Sabatini, R.; Amici, S.; Sasidharan, S.T.; Fayek, H.; Marzocca, P. Autonomous Satellite Wildfire Detection Using Hyperspectral Imagery and Neural Networks: A Case Study on Australian Wildfire. Remote Sens. 2023, 15, 720. [Google Scholar] [CrossRef]
- Lu, B.; Dao, P.D.; Liu, J.; He, Y.; Shang, J. Recent Advances of Hyperspectral Imaging Technology and Applications in Agriculture. Remote Sens. 2020, 12, 2659. [Google Scholar] [CrossRef]
- Sabins, F.F. Remote Sensing for Mineral Exploration. Ore Geol. Rev. 1999, 14, 157–183. [Google Scholar] [CrossRef]
- Tejasree, G.; Agilandeeswari, L. An Extensive Review of Hyperspectral Image Classification and Prediction: Techniques and Challenges. Multimed. Tools Appl. 2024, 83, 80941–81038. [Google Scholar] [CrossRef]
- Lou, C.; Al-qaness, M.A.A.; AL-Alimi, D.; Dahou, A.; Elaziz, M.A.; Abualigah, L.; Ewees, A.A. Land Use/Land Cover (LULC) Classification Using Hyperspectral Images: A Review. Geo-Spat. Inf. Sci. 2024, 1–42. [Google Scholar] [CrossRef]
- Guan, R.; Li, Z.; Tu, W.; Wang, J.; Liu, Y.; Li, X.; Tang, C.; Feng, R. Contrastive Multiview Subspace Clustering of Hyperspectral Images Based on Graph Convolutional Networks. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5510514. [Google Scholar] [CrossRef]
- Feng, J.; Wang, Q.; Zhang, G.; Jia, X.; Yin, J. CAT: Center Attention Transformer with Stratified Spatial–Spectral Token for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5615415. [Google Scholar] [CrossRef]
- Sun, L.; Zhang, H.; Zheng, Y.; Wu, Z.; Ye, Z.; Zhao, H. MASSFormer: Memory-augmented Spectral-Spatial Transformer for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5516415. [Google Scholar] [CrossRef]
- Tuia, D.; Persello, C.; Bruzzone, L. Domain Adaptation for the Classification of Remote Sensing Data: An Overview of Recent Advances. IEEE Geosci. Remote Sens. Mag. 2016, 4, 41–57. [Google Scholar] [CrossRef]
- Wilson, G.; Cook, D.J. A Survey of Unsupervised Deep Domain Adaptation. ACM Trans. Intell. Syst. Technol. 2020, 11, 51. [Google Scholar] [CrossRef]
- Yang, X.; Song, Z.; King, I.; Xu, Z. A Survey on Deep Semi-Supervised Learning. IEEE Trans. Knowl. Data Eng. 2023, 35, 8934–8954. [Google Scholar] [CrossRef]
- Huang, J.; Gretton, A.; Borgwardt, K.; Schölkopf, B.; Smola, A. Correcting Sample Selection Bias by Unlabeled Data. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 4–7 December 2006; Volume 19. [Google Scholar]
- Yaras, C.; Kassaw, K.; Huang, B.; Bradbury, K.; Malof, J.M. Randomized Histogram Matching: A Simple Augmentation for Unsupervised Domain Adaptation in Overhead Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 1988–1998. [Google Scholar] [CrossRef]
- Cui, Y.; Wang, L.; Su, J.; Gao, S.; Wang, L. Iterative Weighted Active Transfer Learning Hyperspectral Image Classification. J. Appl. Remote Sens. 2021, 15, 032207. [Google Scholar] [CrossRef]
- Long, M.; Cao, Y.; Wang, J.; Jordan, M.I. Learning Transferable Features with Deep Adaptation Networks. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 97–105. [Google Scholar]
- Sun, B.; Saenko, K. Deep CORAL: Correlation Alignment for Deep Domain Adaptation. In European Conference on Computer Vision Part XVI; Hua, G., Jégou, H., Eds.; Springer: Cham, Switzerland, 2016; pp. 443–450. [Google Scholar]
- Li, Z.; Xu, Q.; Ma, L.; Fang, Z.; Wang, Y.; He, W.; Du, Q. Supervised Contrastive Learning-Based Unsupervised Domain Adaptation for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5524017. [Google Scholar] [CrossRef]
- Peng, J.; Huang, Y.; Sun, W.; Chen, N.; Ning, Y.; Du, Q. Domain Adaptation in Remote Sensing Image Classification: A Survey. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 9842–9859. [Google Scholar] [CrossRef]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Domain-Adversarial Training of Neural Networks. In Domain Adaptation in Computer Vision Applications; Springer International Publishing: Cham, Switzerland, 2017; pp. 189–209. [Google Scholar]
- Deng, B.; Jia, S.; Shi, D. Deep Metric Learning-Based Feature Embedding for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 1422–1435. [Google Scholar] [CrossRef]
- Liu, Z.; Ma, L.; Du, Q. Class-Wise Distribution Adaptation for Unsupervised Classification of Hyperspectral Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 59, 508–521. [Google Scholar] [CrossRef]
- Huang, Y.; Peng, J.; Sun, W.; Chen, N.; Du, Q.; Ning, Y.; Su, H. Two-Branch Attention Adversarial Domain Adaptation Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5540813. [Google Scholar] [CrossRef]
- Ning, Y.; Peng, J.; Liu, Q.; Huang, Y.; Sun, W.; Du, Q. Contrastive Learning Based on Category Matching for Domain Adaptation in Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5301814. [Google Scholar] [CrossRef]
- Fang, Z.; He, W.; Li, Z.; Du, Q.; Chen, Q. Masked Self-Distillation Domain Adaptation for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5525720. [Google Scholar] [CrossRef]
- Feng, J.; Zhou, Z.; Shang, R.; Wu, J.; Zhang, T.; Zhang, X.; Jiao, L. Class-Aligned and Class-Balancing Generative Domain Adaptation for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5509617. [Google Scholar] [CrossRef]
- Wang, Z.; Chen, L.; Tian, Y.; He, J.; Philip Chen, C.L. Spatially Enhanced Refined Classifier for Cross-Scene Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2025, 63, 5502215. [Google Scholar] [CrossRef]
- Gao, J.; Ji, X.; Chen, G.; Huang, Y.; Ye, F. Pseudo-Class Distribution Guided Multi-View Unsupervised Domain Adaptation for Hyperspectral Image Classification. Int. J. Appl. Earth Obs. Geoinf. 2025, 136, 104356. [Google Scholar] [CrossRef]
- Cai, M.; Xi, B.; Li, J.; Feng, S.; Li, Y.; Li, Z.; Chanussot, J. Mind the Gap: Multilevel Unsupervised Domain Adaptation for Cross-Scene Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5520014. [Google Scholar] [CrossRef]
- Chen, X.; Wang, S.; Long, M.; Wang, J. Transferability vs. Discriminability: Batch Spectral Penalization for Adversarial Domain Adaptation. In Proceedings of the 36th International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; Volume 97, pp. 1081–1090. [Google Scholar]
- Saito, K.; Watanabe, K.; Ushiku, Y.; Harada, T. Maximum Classifier Discrepancy for Unsupervised Domain Adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Vilalta, R.; Giraud-Carrier, C.; Brazdil, P.; Soares, C. Inductive Transfer. In Encyclopedia of Machine Learning; Sammut, C., Webb, G.I., Eds.; Springer: Boston, MA, USA, 2010; pp. 545–548. [Google Scholar]
- Caruana, R. Multitask Learning: A Knowledge-Based Source of Inductive Bias. In Proceedings of the Tenth International Conference on Machine Learning, Amherst, MA, USA, 27–29 July 1993. [Google Scholar]
- Caruana, R. Multitask Learning. Mach. Learn. 1997, 28, 41–75. [Google Scholar] [CrossRef]
- Li, W.; Chen, C.; Zhang, M.; Li, H.; Du, Q. Data Augmentation for Hyperspectral Image Classification With Deep CNN. IEEE Geosci. Remote Sens. Lett. 2018, 16, 593–597. [Google Scholar] [CrossRef]
- Hu, X.; Li, T.; Zhou, T.; Peng, Y. Deep Spatial–spectral Subspace Clustering for Hyperspectral Images Based on Contrastive Learning. Remote Sens. 2021, 13, 4418. [Google Scholar] [CrossRef]
- Bucci, S.; D’Innocente, A.; Liao, Y.; Carlucci, F.M.; Caputo, B.; Tommasi, T. Self-Supervised Learning across Domains. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 5516–5528. [Google Scholar] [CrossRef]
- Bucci, S.; D’Innocente, A.; Tommasi, T. Tackling Partial Domain Adaptation with Self-Supervision. In Proceedings of the ICIAP 2019 20th International Conference, Trento, Italy, 9–13 September 2019; Part II. pp. 70–81. [Google Scholar]
- Hadsell, R.; Chopra, S.; LeCun, Y. Dimensionality Reduction by Learning an Invariant Mapping. In Proceedings of the Computer Vision Pattern Recognition, New York, NY, USA, 17–22 June 2006; Volume 2, pp. 1735–1742. [Google Scholar]
- Li, B.; Li, Y.; Eliceiri, K.W. Dual-Stream Multiple Instance Learning Network for Whole Slide Image Classification with Self-Supervised Contrastive Learning. In Proceedings of the Computer Vision Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14318–14328. [Google Scholar]
- Liu, Z.; Wu, F.; Wang, Y.; Yang, M.; Pan, X. FedCL: Federated Contrastive Learning for Multi-Center Medical Image Classification. Pattern Recognit. 2023, 143, 109739. [Google Scholar] [CrossRef]
- Cho, H.; Kim, H.; Chae, Y.; Yoon, K.J. Label-Free Event-Based Object Recognition via Joint Learning with Image Reconstruction from Events. In Proceedings of the International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 19866–19877. [Google Scholar]
- Yuan, K.; Schaefer, G.; Lai, Y.K.; Wang, Y.; Liu, X.; Guan, L.; Fang, H. A Multi-Strategy Contrastive Learning Framework for Weakly Supervised Semantic Segmentation. Pattern Recognit. 2023, 137, 109298. [Google Scholar] [CrossRef]
- Hu, Z.; Gao, J.; Yuan, Y.; Li, X. Contrastive Tokens and Label Activation for Remote Sensing Weakly Supervised Semantic Segmentation. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5620211. [Google Scholar] [CrossRef]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A Simple Framework for Contrastive Learning of Visual Representations. In Proceedings of the 37th International Conference on Machine Learning, Virtual, 13–18 July 2020; Volume 119, pp. 1597–1607. [Google Scholar]
- Khosla, P.; Teterwak, P.; Wang, C.; Sarna, A.; Tian, Y.; Isola, P.; Maschinot, A.; Liu, C.; Krishnan, D. Supervised Contrastive Learning. In Proceedings of the Advances in Neural Information Processing Systems, Virtual, 6–12 December 2020; Volume 33, pp. 18661–18673. [Google Scholar]
- Weisstein, E.W. Bernoulli Distribution. Available online: https://mathworld.wolfram.com/BernoulliDistribution.html (accessed on 7 January 2025).
- Zhang, H.; Cisse, M.; Dauphin, Y.; Lopez-Paz, D. Mixup: Beyond Empirical Risk Minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- Karantzalos, K.; Karakizi, C.; Kandylakis, Z.; Antoniou, G. HyRANK Hyperspectral Satellite Dataset I (Version V001) [Dataset]; ISPRS: Hannover, Germany, 2018. [Google Scholar]
- Rangwani, H.; Aithal, S.K.; Mishra, M.; Jain, A.; Radhakrishnan, V.B. A Closer Look at Smoothness in Domain Adversarial Training. In Proceedings of the 39th International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; Volume 162, pp. 18378–18399. [Google Scholar]
- Long, M.; Cao, Z.; Wang, J.; Jordan, M.I. Conditional Adversarial Domain Adaptation. In Proceedings of the Advances in Neural Information Processing Systems, Virtual, 3–8 December 2018; Volume 31. [Google Scholar]
- Jin, Y.; Wang, X.; Long, M.; Wang, J. Minimum Class Confusion for Versatile Domain Adaptation. In Proceedings of the European Conference Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 464–480. [Google Scholar]
- van der Maaten, L.; Hinton, G. Viualizing Data Using T-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | DAN (2015) | DANN (2017) | ED-DMM-UDA (2020) | CDA (2021) | TAADA (2022) | SCLUDA (2023) | MSDA (2024) | Ours |
|---|---|---|---|---|---|---|---|---|
| 1 | 89.08 | 79.71 | 68.14 | 95.08 | 94.29 | 81.32 | 81.66 | 8.26 |
| 2 | 56.09 | 73.26 | 85.45 | 51.96 | 53.03 | 71.58 | 52.95 | 93.62 |
| 3 | 79.55 | 70.91 | 57.86 | 62.52 | 53.13 | 62.67 | 57.81 | 58.77 |
| 4 | 89.55 | 98.18 | 79.55 | 95.45 | 97.27 | 90.00 | 85.00 | 76.36 |
| 5 | 69.04 | 69.61 | 97.77 | 70.35 | 80.42 | 85.11 | 91.01 | 77.56 |
| 6 | 50.61 | 55.72 | 56.62 | 82.74 | 76.61 | 80.53 | 76.79 | 89.28 |
| 7 | 66.66 | 60.81 | 75.97 | 26.26 | 75.64 | 49.13 | 74.83 | 73.73 |
| OA (%) | 57.39 | 60.75 | 66.09 | 71.18 | 73.95 | 75.50 | 74.94 | 82.99 |
| ±1.19 | ±5.03 | ±1.83 | ±1.31 | ±2.65 | ±1.77 | ±2.58 | ±1.11 | |
| AA (%) | 71.51 | 72.6 | 74.48 | 69.20 | 75.77 | 74.32 | 74.29 | 68.23 |
| ±1.09 | ±2.05 | ±1.66 | ±3.16 | ±2.31 | ±4.93 | ±7.08 | ±3.27 | |
| 43.25 | 45.85 | 53.10 | 51.85 | 60.29 | 61.00 | 61.59 | 72.04 | |
| ±1.16 | ±4.45 | ±2.18 | ±3.23 | ±3.35 | ±3.38 | ±4.95 | ±1.65 |
| Class | DAN (2015) | DANN (2017) | ED-DMM-UDA (2020) | CDA (2021) | TAADA (2022) | SCLUDA (2023) | MSDA (2024) | Ours |
|---|---|---|---|---|---|---|---|---|
| 1 | 72.79 | 84.49 | 98.15 | 92.02 | 91.50 | 95.97 | 93.66 | 95.36 |
| 2 | 79.37 | 90.51 | 94.12 | 77.63 | 98.72 | 98.44 | 99.06 | 99.44 |
| 3 | 87.50 | 75.86 | 64.02 | 86.90 | 57.07 | 98.03 | 64.26 | 96.53 |
| 4 | 67.76 | 71.28 | 0.72 | 78.17 | 69.94 | 85.7 | 78.30 | 83.88 |
| 5 | 98.75 | 99.58 | 96.61 | 99.94 | 97.50 | 98.42 | 99.78 | 99.99 |
| 6 | 80.22 | 69.52 | 68.29 | 61.81 | 92.94 | 96.68 | 93.79 | 96.10 |
| 7 | 58.37 | 62.67 | 64.79 | 71.60 | 95.46 | 78.13 | 96.59 | 89.04 |
| OA (%) | 74.47 | 79.14 | 68.80 | 80.51 | 88.07 | 91.91 | 91.03 | 93.61 |
| ±2.07 | ±2.68 | ±2.58 | ±1.02 | ±5.97 | ±0.44 | ±1.82 | ±0.22 | |
| AA (%) | 77.82 | 79.13 | 69.53 | 81.15 | 86.16 | 92.82 | 89.35 | 94.33 |
| ±1.90 | ±1.96 | ±2.41 | ±1.81 | ±6.71 | ±0.60 | ±3.25 | ±0.38 | |
| 69.79 | 75.02 | 62.47 | 76.68 | 85.72 | 92.36 | 89.19 | 92.34 | |
| ±2.43 | ±3.12 | ±3.16 | ±1.22 | ±7.04 | ±0.40 | ±2.21 | ±0.26 |
| Class | DAN (2015) | DANN (2017) | ED-DMM-UDA (2020) | CDA (2021) | TAADA (2022) | SCLUDA (2023) | MSDA (2024) | Ours |
|---|---|---|---|---|---|---|---|---|
| 1 | 33.98 | 19.81 | 69.81 | 30.05 | 45.68 | 36.94 | 28.40 | 34.47 |
| 2 | 100 | 96.30 | 91.48 | 85.93 | 100 | 71.85 | 89.07 | 97.59 |
| 3 | 57.09 | 31.48 | 59.65 | 77.84 | 76.95 | 56.83 | 85.12 | 81.46 |
| 4 | 74.81 | 69.75 | 40.51 | 28.35 | 65.44 | 96.71 | 61.90 | 32.53 |
| 5 | 35.98 | 19.79 | 47.53 | 58.84 | 71.62 | 12.97 | 77.38 | 80.36 |
| 6 | 31.35 | 26.28 | 12.61 | 42.77 | 5.73 | 54.83 | 2.25 | 0.73 |
| 7 | 49.78 | 43.05 | 78.19 | 50.02 | 41.64 | 78.57 | 46.00 | 63.53 |
| 8 | 31.79 | 30.47 | 49.25 | 22.64 | 50.7 | 27.69 | 60.42 | 52.13 |
| 9 | 61.88 | 31.68 | 64.26 | 23.31 | 26.74 | 85.16 | 30.05 | 57.37 |
| 10 | 54.64 | 31.37 | 54.97 | 63.75 | 20.68 | 50.42 | 26.78 | 58.98 |
| 11 | 99.25 | 89.39 | 70.00 | 60.02 | 100 | 100 | 100 | 100 |
| 12 | 76.94 | 95.11 | 68.08 | 99.98 | 100 | 100 | 100 | 100 |
| OA (%) | 52.34 | 43.96 | 61.37 | 48.14 | 56.25 | 60.08 | 60.52 | 66.23 |
| ±1.51 | ±4.49 | ±9.04 | ±0.06 | ±2.96 | ±2.47 | ±2.90 | ±1.72 | |
| AA (%) | 59.96 | 48.71 | 58.86 | 53.63 | 58.77 | 64.33 | 58.95 | 63.26 |
| ±1.58 | ±3.49 | ±3.40 | ±4.56 | ±3.23 | ±5.10 | ±2.74 | ±3.21 | |
| 43.23 | 34.91 | 54.33 | 40.89 | 48.67 | 53.65 | 53.15 | 59.84 | |
| ±2.28 | ±4.48 | ±3.40 | ±6.57 | ±3.12 | ±2.69 | ±3.35 | ±1.99 |
| No. | SCL | TCL | Houston | Pavia | HyRANK |
|---|---|---|---|---|---|
| 1 | ✘ | ✘ | 77.54 | 92.15 | 62.67 |
| ±4.51 | ±1.37 | ±3.12 | |||
| 2 | ✘ | ✔ | 70.04 | 93.38 | 65.64 |
| ±3.39 | ±0.73 | ±0.71 | |||
| 3 | ✔ | ✘ | 75.88 | 91.95 | 63.19 |
| ±3.82 | ±1.26 | ±3.07 | |||
| 4 | ✔ | ✔ | 82.99 | 93.61 | 66.23 |
| ±1.11 | ±0.22 | ±1.72 |
| Datasets | Metrics | FMDA (Ours) | HF | VF | RPE |
|---|---|---|---|---|---|
| Houston | OA (%) | 82.99 | 78.97 | 78.27 | 74.17 |
| ±1.11 | ±3.19 | ±1.89 | ±4.54 | ||
| AA (%) | 68.23 | 71.50 | 67.94 | 61.52 | |
| ±3.27 | ±3.52 | ±6.70 | ±5.12 | ||
| 72.04 | 66.39 | 64.50 | 54.88 | ||
| ±1.65 | ±7.48 | ±3.28 | ±4.48 | ||
| training time | 180.31 | 278.36 | 288.12 | 320.54 | |
| Pavia | OA (%) | 93.61 | 92.21 | 91.71 | 90.88 |
| ±0.22 | ±1.57 | ± 1.71 | ±1.72 | ||
| AA (%) | 94.33 | 92.96 | 92.37 | 92.03 | |
| ±0.38 | ±1.69 | ±2.16 | ±1.40 | ||
| 92.34 | 90.67 | 90.08 | 89.10 | ||
| ±0.26 | ±1.86 | ±2.04 | ±2.03 | ||
| training time | 621.33 | 865.09 | 866.37 | 903.51 | |
| HyRANK | OA (%) | 66.23 | 62.19 | 62.76 | 63.93 |
| ±1.72 | ±3.13 | ±3.23 | ±1.82 | ||
| AA (%) | 63.26 | 59.84 | 60.55 | 64.78 | |
| ±3.21 | ±4.12 | ±4.40 | ±1.14 | ||
| 59.84 | 55.30 | 55.94 | 57.36 | ||
| ±1.99 | ±3.54 | ±2.63 | ±2.01 | ||
| training time | 135.18 | 180.31 | 184.88 | 215.76 |
| Methods | Houston | Pavia | HyRANK | ||||||
|---|---|---|---|---|---|---|---|---|---|
| OA (%) | AA (%) | OA (%) | AA (%) | OA (%) | AA (%) | ||||
| MTLDA* (w/o -NP) | 81.32 | 67.92 | 70.29 | 93.51 | 93.97 | 91.85 | 64.57 | 59.46 | 58.62 |
| ±2.45 | ±1.61 | ±3.71 | ±0.47 | ±1.03 | ±0.92 | ±2.36 | ±3.89 | ±2.65 | |
| MTLDA | 82.99 | 68.23 | 72.04 | 93.61 | 94.33 | 92.34 | 66.23 | 63.26 | 59.84 |
| ±1.11 | ±3.27 | ±1.65 | ±0.22 | ±0.38 | ±0.26 | ±1.72 | ±3.21 | ±1.99 | |
| Datasets | Metrics | Baseline | FMDA + Baseline | HF + Baseline | VF + Baseline | RPE + Baseline |
|---|---|---|---|---|---|---|
| Houston | OA (%) | 74.07 | 77.45 | 77.66 | 76.53 | 63.20 |
| ±3.59 | ±4.51 | ±1.64 | ±2.51 | ±7.07 | ||
| AA (%) | 65.66 | 68.42 | 68.00 | 66.98 | 41.94 | |
| ±4.89 | ±5.04 | ±2.98 | ±4.99 | ±8.51 | ||
| 62.71 | 66.91 | 66.07 | 64.66 | 38.15 | ||
| ±4.96 | ±6.12 | ±2.29 | ±5.76 | ±9.05 | ||
| training time | 149.47 | 172.73 | 298.70 | 299.01 | 310.29 | |
| Pavia | OA (%) | 91.01 | 92.15 | 91.78 | 91.03 | 72.32 |
| ±0.32 | ±1.37 | ±1.68 | ±1.64 | ±5.03 | ||
| AA (%) | 92.13 | 93.35 | 92.46 | 91.87 | 73.11 | |
| ±0.87 | ±1.22 | ±1.81 | ±1.86 | ±4.54 | ||
| 89.94 | 91.08 | 90.16 | 89.28 | 66.81 | ||
| ±1.39 | ±1.17 | ±1.99 | ±1.95 | ±5.91 | ||
| training time | 456.12 | 473.99 | 814.47 | 821.97 | 856.61 | |
| HyRANK | OA (%) | 60.71 | 62.67 | 59.27 | 60.06 | 58.76 |
| ±2.51 | ±3.12 | ±4.59 | ±3.39 | ±3.00 | ||
| AA (%) | 53.26 | 57.85 | 55.48 | 55.86 | 57.35 | |
| ±2.58 | ±3.82 | ±4.29 | ±3.88 | ±6.61 | ||
| 55.04 | 56.00 | 51.75 | 52.67 | 51.13 | ||
| ±1.85 | ±3.69 | ±5.26 | ±3.88 | ±3.75 | ||
| training time | 134.62 | 138.63 | 176.99 | 178.87 | 175.22 |
| Datasets | DAN (2015) | DANN (2017) | ED-DMM-UDA (2020) | CDA (2021) | TAADA (2022) | SCLUDA (2023) | MSDA (2024) | Ours | |
|---|---|---|---|---|---|---|---|---|---|
| Houston | Training time | 664.75 | 28.59 | 941.54 | 207.86 | 205.63 | 135.27 | 192.34 | 180.31 |
| Testting time | 5.33 | 5.89 | 14.82 | 0.68 | 2.67 | 4.46 | 4.16 | 3.68 | |
| FLOPs | 4606599 | 15873800 | 6555402 | 19648507 | 7678089 | 7678089 | 15489249 | 15610464 | |
| #params | 25701743 | 13159880 | 170274 | 76757 | 577640 | 572241 | 1120456 | 585207 | |
| Pavia | Training time | 648.98 | 31.81 | 305.95 | 201.21 | 283.82 | 331.25 | 433.72 | 621.33 |
| Testting time | 4.61 | 5.77 | 13.72 | 0.47 | 3.81 | 4.44 | 3.76 | 5.60 | |
| FLOPs | 15017863 | 23784392 | 11686202 | 23104507 | 50180201 | 80408762 | 50170234 | 50242088 | |
| #params | 25871087 | 13329224 | 181074 | 90257 | 661880 | 676017 | 1393035 | 690443 | |
| HyRANK | Training time | 459.12 | 38.43 | 1194.21 | 383.59 | 211.59 | 327.65 | 344.23 | 135.18 |
| Testting time | 1.24 | 1.99 | 10.01 | 0.06 | 0.71 | 0.87 | 0.75 | 0.68 | |
| FLOPs | 3655052 | 15227149 | 1465802 | 28160512 | 29503089 | 80408762 | 9396179 | 9480696 | |
| #params | 26105716 | 13563853 | 195874 | 110012 | 811028 | 876017 | 1609392 | 837449 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Q.; Fang, Z.; Deng, S.; Jia, T.; Li, Z.; Chen, D. Dual-Domain Multi-Task Learning-Based Domain Adaptation for Hyperspectral Image Classification. Remote Sens. 2025, 17, 1592. https://doi.org/10.3390/rs17091592
Chen Q, Fang Z, Deng S, Jia T, Li Z, Chen D. Dual-Domain Multi-Task Learning-Based Domain Adaptation for Hyperspectral Image Classification. Remote Sensing. 2025; 17(9):1592. https://doi.org/10.3390/rs17091592
Chicago/Turabian StyleChen, Qiusheng, Zhuoqun Fang, Shizhuo Deng, Tong Jia, Zhaokui Li, and Dongyue Chen. 2025. "Dual-Domain Multi-Task Learning-Based Domain Adaptation for Hyperspectral Image Classification" Remote Sensing 17, no. 9: 1592. https://doi.org/10.3390/rs17091592
APA StyleChen, Q., Fang, Z., Deng, S., Jia, T., Li, Z., & Chen, D. (2025). Dual-Domain Multi-Task Learning-Based Domain Adaptation for Hyperspectral Image Classification. Remote Sensing, 17(9), 1592. https://doi.org/10.3390/rs17091592