Remote Sensing Image Segmentation Using Vision Mamba and Multi-Scale Multi-Frequency Feature Fusion


Abstract
1. Introduction
- A VMamba-based feature extraction module, named HVSSBlock, is proposed. This module enhances local feature extraction through an integrated convolutional branch while simultaneously strengthening global feature acquisition via an optimized scanning strategy. Residual connections are incorporated to refine the feature extraction process and minimize information loss. The combined use of these strategies enables HVSSBlock to achieve comprehensive global-local information capture with lower computational complexity.
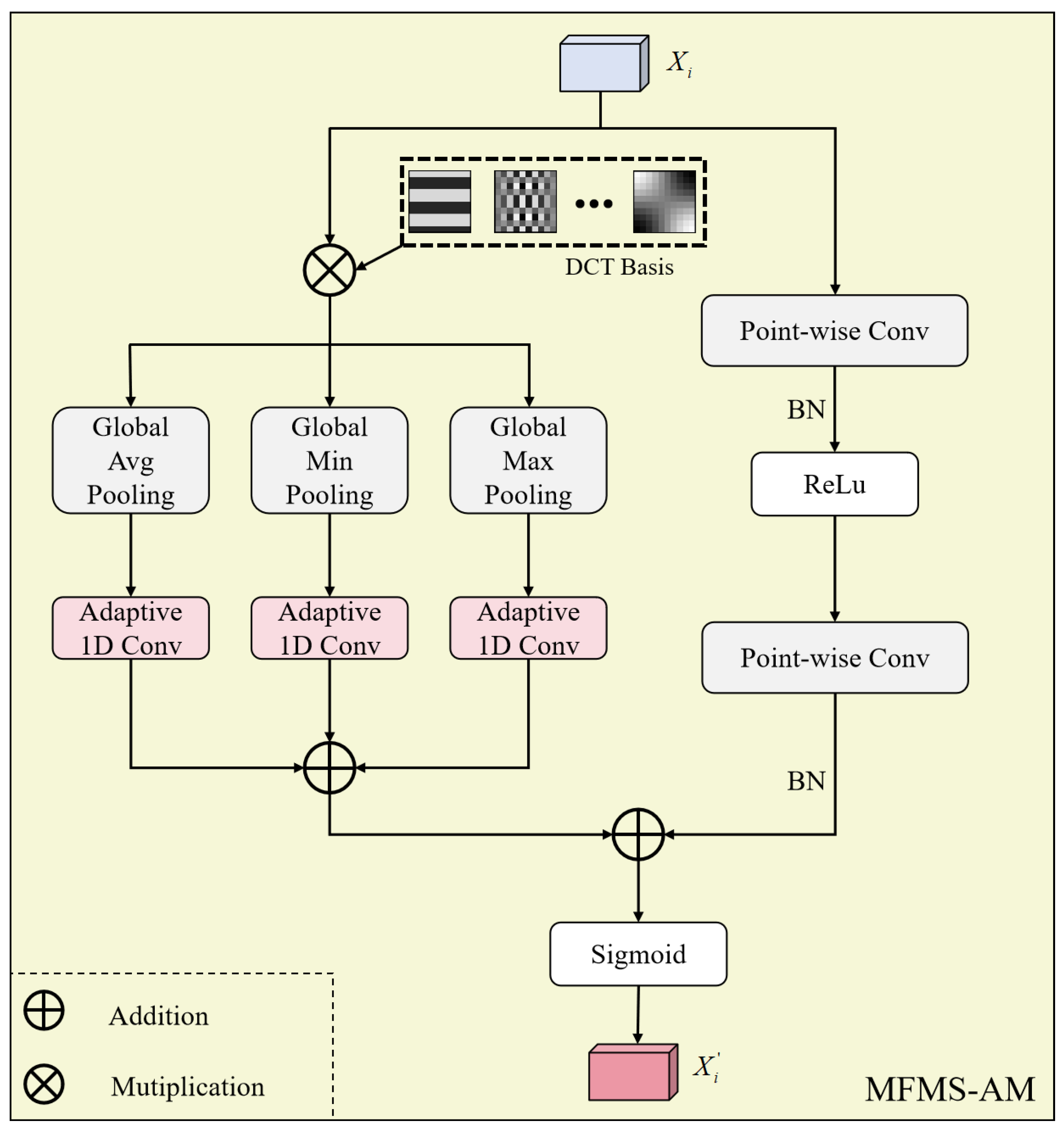
- The MFMSBlock, a feature fusion module, is proposed to serve as a replacement for traditional skip connections. This module introduces multi-frequency information through 2D DCT while employing Adaptive 1D Conv to mitigate information loss and enhance transmission accuracy. Simultaneously, it extracts multi-scale local details via point-wise convolution, ultimately achieving refined feature fusion between the encoder and decoder.
- An efficient U-shaped architecture network, named CVMH-UNet, is proposed based on HVSSBlock and MFMSBlock. Extensive experiments on multiple public RS datasets demonstrate that this method achieves superior segmentation accuracy while maintaining lower computational complexity.
2. Related Work
2.1. Vision State Space Models
2.2. Attention Mechanisms in Deep Learning
2.3. Skip Connections in Deep Learning
3. Methodology
3.1. Overall Architecture
3.2. HVSSBlock
3.3. MFMSBlock
3.4. Remote Sensing Image Segmentation Based on CVMH-UNet
4. Dataset and Experimental Setting
4.1. Datasets
4.1.1. ISPRS Vaihingen Dataset
4.1.2. ISPRS Potsdam Dataset
4.1.3. Gaofen Image Dataset with 15 Categories (GID-15)
4.2. Experimental Setting
4.3. Evaluation Metrics
4.4. Loss Functions
5. Experimental Results and Analysis
5.1. Comparison with State-of-the-Art Methods on the ISPRS Vaihingen Dataset
5.2. Comparison with State-of-the-Art Methods on ISPRS Potsdam Dataset
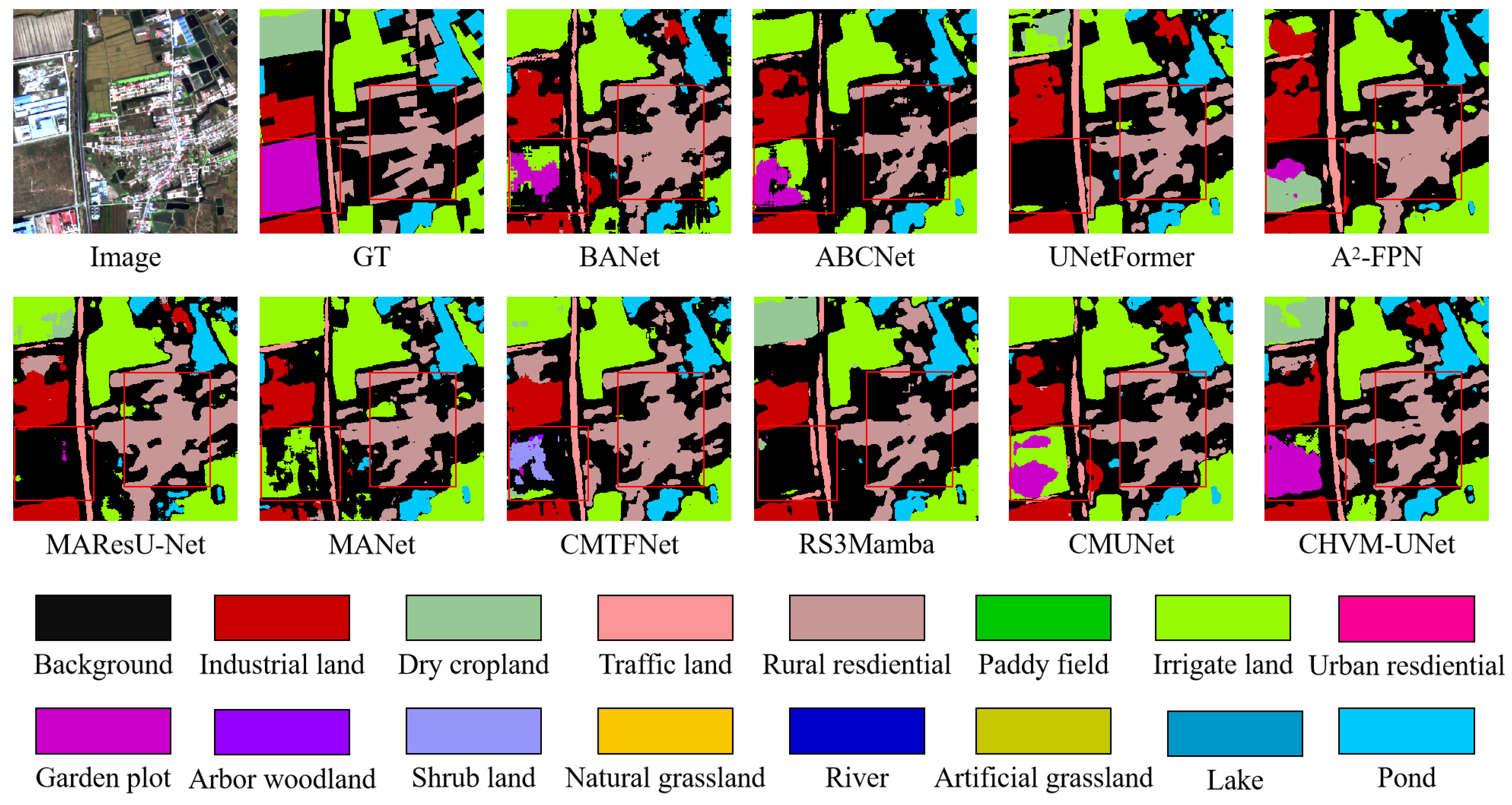
5.3. Comparison with State-of-the-Art Methods on the GID-15 Dataset
5.4. Ablation Experiments
5.4.1. Effect of Each Module of CVMH-UNet
5.4.2. Effect of HVSSBlock
5.4.3. Effect of the MFMSBlock
5.5. Model Complexities
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liu, Y.; Fan, B.; Wang, L.; Bai, J.; Xiang, S.; Pan, C. Semantic labeling in very high resolution images via a self-cascaded convolutional neural network. ISPRS J. Photogramm. Remote Sens. 2018, 122, 78–95. [Google Scholar] [CrossRef]
- Yao, H.; Qin, R.; Chen, X. Unmanned Aerial Vehicle for Remote Sensing Applications—A Review. Remote Sens. 2019, 11, 1443. [Google Scholar] [CrossRef]
- Yan, L.; Fan, B.; Liu, H.; Huo, C.I.; Xiang, S.; Pan, C. Triplet Adversarial Domain Adaptation for Pixel-Level Classification of VHR Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2020, 58, 3558–3573. [Google Scholar] [CrossRef]
- Li, R.; Zheng, S.; Duan, C.; Wang, L.; Zhang, C. Land cover classification from remote sensing images based on multi-scale fully convolutional network. Geo-Spat. Inf. Sci. 2022, 25, 278–294. [Google Scholar] [CrossRef]
- Liu, H.; Li, W.; Xia, X.; Zhang, M.; Gao, C.; Tao, R. Central Attention Network for Hyperspectral Imagery Classification. IEEE Trans. Neural Netw. Learn. Syst. 2023, 34, 8989–9003. [Google Scholar] [CrossRef] [PubMed]
- Zhang, M.; Li, W.; Zhang, Y.; Tao, R.; Du, Q. Hyperspectral and LiDAR Data Classification Based on Structural Optimization Transmission. IEEE Trans. Cybern. 2023, 53, 3153–3164. [Google Scholar] [CrossRef] [PubMed]
- Shi, Z.; Fan, J.; Du, Y.; Zhou, Y.; Zhang, Y. LULC-SegNet: Enhancing Land Use and Land Cover Semantic Segmentation with Denoising Diffusion Feature Fusion. Remote Sens. 2024, 16, 4573. [Google Scholar] [CrossRef]
- Zhao, J.; Du, D.; Chen, L.; Liang, X.; Chen, H.; Jin, Y. HA-Net for Bare Soil Extraction Using 8.Optical Remote Sensing Images. Remote Sens. 2024, 16, 3088. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, W.; Sun, W.; Tao, R.; Du, Q. Single-Source Domain Expansion Network for Cross-Scene Hyperspectral Image Classification. IEEE Trans. Image Process. 2023, 32, 1498–1512. [Google Scholar] [CrossRef]
- Lian, R.; Wang, W.; Mustafa, N.; Huang, L. Road Extraction Methods in High-Resolution Remote Sensing Images: A Comprehensive Review. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5489–5507. [Google Scholar] [CrossRef]
- Zhao, X.; Wu, Z.; Chen, Y.; Zhou, W.; Wei, M. Fine-Grained High-Resolution Remote Sensing Image Change Detection by SAM-UNet Change Detection Model. Remote Sens. 2024, 16, 3620. [Google Scholar] [CrossRef]
- Song, J.; Yang, S.; Li, Y.; Li, X. An Unsupervised Remote Sensing Image Change Detection Method Based on RVMamba and Posterior Probability Space Change Vector. Remote Sens. 2024, 16, 4656. [Google Scholar] [CrossRef]
- Guo, Y.; Jia, X.; Paull, D. Effective Sequential Classifier Training for SVM-Based Multitemporal Remote Sensing Image Classification. IEEE Trans. Image Process. 2018, 27, 3036–3048. [Google Scholar] [CrossRef]
- Pal, M. Random forest classifier for remote sensing classification. Int. J. Remote Sens. 2005, 26, 217–222. [Google Scholar] [CrossRef]
- Krähenbühl, P.; Koltun, V. Efficient inference in fully connected CRFs with Gaussian edge potentials. Proc. Adv. Neural Inf. Process. Syst. (NeurIPS) 2011, 9, 109–117. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. Available online: https://api.semanticscholar.org/CorpusID:225039882 (accessed on 1 March 2025).
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.; et al. Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 6877–6886. [Google Scholar] [CrossRef]
- Wang, W.; Chen, W.; Qiu, Q.; Chen, L.; Wu, B.; Lin, B.; He, X.; Liu, W. Crossformer++: A versatile vision transformer hinging on cross-scale attention. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 3123–3136. [Google Scholar] [CrossRef] [PubMed]
- He, X.; Zhou, Y.; Zhao, J.; Zhang, D.; Yao, R.; Xue, Y. Swin transformer embedding UNet for remote sensing image semantic segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-unet: Unet-like pure transformer for medical image segmentation. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2022; pp. 205–218. [Google Scholar] [CrossRef]
- Wang, L.; Li, R.; Zhang, C.; Fang, S.; Duan, C.; Meng, X.; Atkinson, P.M. UNetFormer: A UNet-like transformer for efficient semantic segmentation of remote sensing urban scene imagery. ISPRS J. Photogramm. Remote Sens. 2022, 190, 196–214. [Google Scholar] [CrossRef]
- Gu, A.; Dao, T. Mamba: Linear-time sequence modeling with selective state spaces. arXiv 2024, arXiv:2312.00752. [Google Scholar]
- Zhu, L.; Liao, B.; Zhang, Q.; Wang, X.; Liu, W.; Wang, X. Vision mamba: Efficient visual representation learning with bidirectional state space model. arXiv 2024, arXiv:2401.09417. [Google Scholar]
- Liu, Y.; Tian, Y.; Zhao, Y.; Yu, H.; Xie, L.; Wang, Y.; Ye, Q.; Jiao, J.; Liu, Y. Vmamba: Visual state space model. arXiv 2024, arXiv:2401.10166. [Google Scholar]
- Ma, X.; Zhang, X.; Man-On, P. RS 3 Mamba: Visual State Space Model for Remote Sensing Image Semantic Segmentation. IEEE Geosci. Remote Sens. Lett. 2024, 21, 1–5. [Google Scholar] [CrossRef]
- Ding, H.; Xia, B.; Liu, W.; Zhang, Z.; Zhang, J.; Wang, X.; Xu, S. A Novel Mamba Architecture with a Semantic Transformer for Efficient Real-Time Remote Sensing Semantic Segmentation. Remote Sens. 2024, 16, 2620. [Google Scholar] [CrossRef]
- Liu, M.; Dan, J.; Lu, Z.; Yu, Y.; Li, Y.; Li, X. CM-UNet: Hybrid CNN-Mamba UNet for Remote Sensing Image Semantic Segmentation. arXiv 2024, arXiv:2405.10530. [Google Scholar]
- Dai, Y.; Gieseke, F.; Oehmcke, S.; Wu, Y.; Barnard, K. Attentional feature fusion. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2021; pp. 3559–3568. [Google Scholar] [CrossRef]
- Li, R.; Zheng, S.; Zhang, C.; Duan, C.; Su, J.; Wang, L.; Atkinson, P. Multiattention Network for Semantic Segmentation of Fine-Resolution Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Li, J.; Cheng, S. AFENet: An Attention-Focused Feature Enhancement Network for the Efficient Semantic Segmentation of Remote Sensing Images. Remote Sens. 2024, 16, 4392. [Google Scholar] [CrossRef]
- Du, B.; Shan, L.; Shao, X.; Zhang, D.; Wang, X.; Wu, J. Transform Dual-Branch Attention Net: Efficient Semantic Segmentation of Ultra-High-Resolution Remote Sensing Images. Remote Sens. 2025, 17, 540. [Google Scholar] [CrossRef]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11531–11539. [Google Scholar] [CrossRef]
- Qin, Z.; Zhang, P.; Wu, F.; Li, X. Fcanet: Frequency channel attention networks. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 763–772. [Google Scholar] [CrossRef]
- Huang, T.; Pei, X.; You, S.; Wang, F.; Qian, C.; Xu, C. Localmamba: Visual state space model with windowed selective scan. arXiv 2024, arXiv:2403.09338. [Google Scholar]
- Li, Y.; Luo, Y.; Zhang, L.; Wang, Z.; Du, B. MambaHSI: Spatial-Spectral Mamba for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–16. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.; Kweon, I. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. Available online: https://openaccess.thecvf.com/content_ECCV_2018/html/Sanghyun_Woo_Convolutional_Block_Attention_ECCV_2018_paper.html (accessed on 1 March 2025).
- Roy, A.; Navab, N.; Wachinger, C. Recalibrating fully convolutional networks with spatial and channel “squeeze and excitation” blocks. IEEE Trans. Med. Imaging 2019, 38, 540–549. [Google Scholar] [CrossRef] [PubMed]
- Lee, H.; Kim, H.; Nam, H. Srm: A style-based recalibration module for convolutional neural networks. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1854–1862. [Google Scholar] [CrossRef]
- Zhou, N.; Hong, J.; Cui, W.; Wu, S.; Zhang, Z. A Multiscale Attention Segment Network-Based Semantic Segmentation Model for Landslide Remote Sensing Images. Remote Sens. 2024, 16, 1712. [Google Scholar] [CrossRef]
- Li, X.; Xu, F.; Li, L.; Xu, N.; Liu, F.; Yuan, C.; Chen, Z.; Lyu, X. AAFormer: Attention-Attended Transformer for Semantic Segmentation of Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2024, 21, 1–5. [Google Scholar] [CrossRef]
- Wang, S.; Hu, Q.; Wang, S.; Zhao, P.; Li, J.; Ai, M. Category attention guided network for semantic segmentation of Fine-Resolution remote sensing images. Int. J. Appl. Earth Obs. Geoinf. 2024, 127, 103661. [Google Scholar] [CrossRef]
- Liu, Y.; Bai, X.; Wang, J.; Li, G.; Li, J.; Lv, Z. Image semantic segmentation approach based on DeepLabV3 plus network with an attention mechanism. Eng. Appl. Artif. Intell. 2024, 127, 107260. [Google Scholar] [CrossRef]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective kernel networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 510–519. [Google Scholar] [CrossRef]
- Liu, B.; Li, B.; Sreeram, V.; Li, S. MBT-UNet: Multi-Branch Transform Combined with UNet for Semantic Segmentation of Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 16, 2776. [Google Scholar] [CrossRef]
- Hu, Z.; Qian, Y.; Xiao, Z.; Yang, G.; Jiang, H.; Sun, X. SABNet: Self-Attention Bilateral Network for Land Cover Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 8559–8569. [Google Scholar] [CrossRef]
- Liu, J.; Hua, W.; Zhang, W.; Liu, F.; Xiao, L. Stair Fusion Network With Context-Refined Attention for Remote Sensing Image Semantic Segmentation. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–17. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar] [CrossRef]
- Sang, M.; Hansen, J.H.L. Multi-Frequency Information Enhanced Channel Attention Module for Speaker Representation Learning. In Proceedings of the Interspeech 2022, Incheon, Republic of Korea, 18–22 September 2012; pp. 321–325. [Google Scholar] [CrossRef]
- Wang, L.; Li, R.; Wang, D.; Duan, C.; Wang, T.; Meng, X. Transformer meets convolution: A bilateral awareness network for semantic segmentation of very fine resolution urban scene images. Remote Sens. 2021, 13, 3065. [Google Scholar] [CrossRef]
- Li, R.; Zheng, S.; Zhang, C.; Duan, C.; Wang, L.; Atkinson, P.M. ABCNet: Attentive bilateral contextual network for efficient semantic segmentation of Fine-Resolution remotely sensed imagery. ISPRS J. Photogramm. Remote Sens. 2021, 181, 84–98. [Google Scholar] [CrossRef]
- Li, R.; Wang, L.; Zhang, C.; Duan, C.; Zheng, S. A2-FPN for semantic segmentation of fine-resolution remotely sensed images. Int. J. Remote Sens. 2022, 43, 1131–1155. [Google Scholar] [CrossRef]
- Li, R.; Zheng, S.; Duan, C.; Su, J.; Zhang, C. Multistage attention ResU-Net for semantic segmentation of fine-resolution remote sensing images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Wu, H.; Huang, P.; Zhang, M.; Tang, W.; Yu, X. CMTFNet: CNN and multiscale transformer fusion network for remote sensing image semantic segmentation. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–12. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Imp.surf. | Building | Lowveg. | Tree | Car | mIoU (%) | mF1 (%) | mAcc (%) |
|---|---|---|---|---|---|---|---|---|
| BANet [52] | 71.57 | 80.84 | 52.02 | 70.66 | 45.54 | 64.13 | 77.33 | 77.47 |
| ABCNet [53] | 77.52 | 88.09 | 56.94 | 75.23 | 61.46 | 71.85 | 83.11 | 84.80 |
| UNetFormer [22] | 76.75 | 87.18 | 57.20 | 74.49 | 57.54 | 70.63 | 82.33 | 83.74 |
| -FPN [54] | 78.56 | 87.12 | 59.12 | 75.12 | 62.81 | 72.55 | 83.67 | 84.41 |
| MAResU-Net [55] | 80.27 | 89.33 | 59.87 | 75.50 | 65.28 | 74.05 | 84.67 | 85.19 |
| MANet [30] | 79.28 | 88.10 | 59.43 | 76.14 | 67.62 | 74.11 | 84.76 | 85.37 |
| CMTFNet [56] | 81.17 | 89.31 | 61.00 | 75.86 | 67.91 | 75.05 | 85.38 | 85.04 |
| Rs3Mamba [26] | 79.78 | 88.18 | 58.70 | 75.65 | 63.58 | 73.18 | 84.06 | 84.30 |
| CM-UNet [28] | 79.77 | 89.10 | 59.43 | 75.62 | 66.56 | 74.10 | 84.72 | 84.55 |
| CVMH-UNet (ours) | 81.92 | 90.25 | 62.11 | 77.13 | 68.44 | 75.97 | 85.98 | 85.82 |
| Method | Imp.surf. | Building | Lowveg. | Tree | Car | mIoU (%) | mF1 (%) | mAcc (%) |
|---|---|---|---|---|---|---|---|---|
| BANet [52] | 73.80 | 80.25 | 63.48 | 58.86 | 74.23 | 70.12 | 82.19 | 82.56 |
| ABCNet [53] | 81.94 | 90.11 | 71.89 | 73.64 | 82.75 | 80.07 | 88.78 | 88.61 |
| UNetFormer [22] | 82.00 | 89.41 | 71.08 | 71.18 | 82.41 | 79.22 | 88.23 | 88.16 |
| -FPN [54] | 82.54 | 90.55 | 71.78 | 72.76 | 82.82 | 80.09 | 88.77 | 88.69 |
| MAResU-Net [55] | 82.07 | 90.73 | 71.76 | 72.36 | 83.87 | 80.16 | 88.81 | 88.75 |
| MANet [30] | 82.36 | 90.95 | 71.66 | 72.59 | 83.34 | 80.23 | 88.85 | 89.03 |
| CMTFNet [56] | 82.49 | 90.48 | 71.81 | 73.23 | 83.07 | 80.22 | 88.86 | 88.65 |
| Rs3Mamba [26] | 82.17 | 89.83 | 71.28 | 72.49 | 82.76 | 79.71 | 88.54 | 87.99 |
| CM-UNet [28] | 82.37 | 90.66 | 71.45 | 72.94 | 83.19 | 80.12 | 88.79 | 88.48 |
| CVMH-UNet (ours) | 83.40 | 90.70 | 72.91 | 73.97 | 83.99 | 80.99 | 89.35 | 88.96 |
| Method | Bac. * | Ind. * | Urb. * | Rur. * | Tra. * | Pad. * | Irr. * | Dry. * | Gar. * | Arb. * | Shr. * | Nat. * | Art. * | River | Lack | Pond | mIoU (%) | mF1 (%) | mAcc (%) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| BANet [52] | 60.59 | 50.86 | 61.43 | 51.78 | 43.07 | 59.08 | 73.71 | 54.71 | 25.20 | 75.29 | 13.78 | 55.11 | 45.80 | 86.66 | 79.56 | 70.04 | 56.67 | 70.34 | 70.14 |
| ABCNet [53] | 65.58 | 56.56 | 66.37 | 53.00 | 55.63 | 66.05 | 76.86 | 58.21 | 32.47 | 75.02 | 1.96 | 58.15 | 27.22 | 79.03 | 82.22 | 73.67 | 58.00 | 70.65 | 68.14 |
| UNetFormer [22] | 65.25 | 58.09 | 65.09 | 52.85 | 56.91 | 66.21 | 78.23 | 60.76 | 31.85 | 76.31 | 4.87 | 59.74 | 50.29 | 88.03 | 74.18 | 72.31 | 60.06 | 72.79 | 75.04 |
| -FPN [54] | 63.77 | 55.64 | 65.72 | 53.14 | 54.82 | 65.07 | 77.46 | 59.37 | 33.43 | 75.93 | 2.92 | 58.39 | 32.20 | 90.83 | 79.98 | 74.01 | 58.92 | 71.45 | 71.47 |
| MAResU-Net [55] | 65.16 | 52.41 | 65.45 | 53.80 | 55.94 | 64.95 | 76.52 | 60.70 | 28.31 | 76.19 | 13.50 | 61.42 | 47.14 | 90.96 | 82.18 | 72.98 | 60.48 | 73.37 | 75.24 |
| MANet [30] | 65.95 | 53.72 | 65.69 | 52.10 | 57.54 | 67.65 | 77.92 | 57.64 | 26.29 | 76.34 | 6.09 | 62.23 | 52.07 | 92.48 | 80.13 | 75.64 | 60.59 | 72.98 | 74.57 |
| CMTFNet [56] | 65.26 | 53.40 | 63.89 | 52.63 | 54.81 | 64.37 | 78.36 | 62.23 | 39.45 | 76.30 | 9.00 | 62.07 | 41.26 | 90.16 | 74.12 | 71.81 | 59.95 | 72.97 | 73.54 |
| Rs3Mamba [26] | 64.85 | 54.63 | 65.81 | 53.19 | 54.61 | 66.86 | 77.37 | 64.15 | 41.40 | 75.00 | 12.27 | 59.75 | 45.73 | 88.95 | 79.85 | 73.44 | 61.09 | 74.09 | 75.82 |
| CM-UNet [28] | 64.16 | 55.65 | 64.45 | 51.46 | 51.77 | 63.65 | 77.12 | 59.69 | 29.34 | 76.35 | 10.69 | 59.95 | 55.66 | 89.96 | 78.77 | 73.35 | 60.13 | 73.07 | 75.37 |
| CVMH-UNet (ours) | 66.98 | 57.52 | 65.84 | 53.00 | 59.09 | 68.76 | 79.92 | 65.65 | 33.18 | 76.74 | 11.95 | 62.04 | 48.41 | 93.33 | 82.97 | 75.84 | 62.58 | 74.95 | 76.85 |
| VSSBlock * | HVSSBlock | MFMSBlock | mIoU (%) | FLOPs (Gbps) | Params (Mb) |
|---|---|---|---|---|---|
| ✓ | × | × | 75.08 | 4.09 | 22.04 |
| × | ✓ | × | 75.59 | 5.61 | 30.44 |
| × | × | ✓ | 75.42 | 4.18 | 22.43 |
| × | ✓ | ✓ | 75.97 | 5.71 | 30.84 |
| SS2D | CS2D | mIoU (%) | FLOPs (Gbps) | Params (Mb) |
|---|---|---|---|---|
| ✓ | × | 75.08 | 4.09 | 22.04 |
| × | ✓ | 75.30 | 4.09 | 22.04 |
| Local Branch | Residual Block | mIoU (%) | FLOPs (Gbps) | Params (Mb) |
|---|---|---|---|---|
| × | × | 75.30 | 4.09 | 22.04 |
| ✓ | × | 75.42 | 5.61 | 30.44 |
| × | ✓ | 75.44 | 4.09 | 22.04 |
| ✓ | ✓ | 75.59 | 5.61 | 30.44 |
| MS * | MF * | Adaptive 1D Conv | FC * | mIoU (%) | FLOPs (Gbps) | Params (Mb) |
|---|---|---|---|---|---|---|
| ✓ | × | × | ✓ | 75.63 | 5.69 | 31.24 |
| ✓ | ✓ | × | ✓ | 75.71 | 5.71 | 30.94 |
| ✓ | ✓ | ✓ | × | 75.97 | 5.71 | 30.84 |
| Method | mIoU (%) * | FLOPs (Gbps) | Params (Mb) |
|---|---|---|---|
| BANet citeb41 | 64.13/70.12/56.67 | 3.26 | 12.72 |
| ABCNet [53] | 71.85/80.17/58.00 | 3.91 | 13.39 |
| UNetFormer [22] | 70.63/79.22/60.06 | 2.94 | 11.68 |
| -FPN [54] | 72.55/80.09/58.92 | 10.46 | 22.82 |
| MAResU-Net [55] | 74.05/80.16/60.48 | 8.78 | 23.27 |
| MANet [30] | 74.11/80.23/60.59 | 19.45 | 35.86 |
| CMTFNet [56] | 75.05/80.22/59.95 | 8.57 | 30.07 |
| Rs3Mamba [26] | 73.18/79.71/61.09 | 15.82 | 49.66 |
| CM-UNet [28] | 74.10/80.12/60.13 | 3.17 | 13.55 |
| CVMH-UNet (ours) | 75.97/80.99/62.58 | 5.71 | 30.84 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cao, Y.; Liu, C.; Wu, Z.; Zhang, L.; Yang, L. Remote Sensing Image Segmentation Using Vision Mamba and Multi-Scale Multi-Frequency Feature Fusion. Remote Sens. 2025, 17, 1390. https://doi.org/10.3390/rs17081390
Cao Y, Liu C, Wu Z, Zhang L, Yang L. Remote Sensing Image Segmentation Using Vision Mamba and Multi-Scale Multi-Frequency Feature Fusion. Remote Sensing. 2025; 17(8):1390. https://doi.org/10.3390/rs17081390
Chicago/Turabian StyleCao, Yice, Chenchen Liu, Zhenhua Wu, Lei Zhang, and Lixia Yang. 2025. "Remote Sensing Image Segmentation Using Vision Mamba and Multi-Scale Multi-Frequency Feature Fusion" Remote Sensing 17, no. 8: 1390. https://doi.org/10.3390/rs17081390
APA StyleCao, Y., Liu, C., Wu, Z., Zhang, L., & Yang, L. (2025). Remote Sensing Image Segmentation Using Vision Mamba and Multi-Scale Multi-Frequency Feature Fusion. Remote Sensing, 17(8), 1390. https://doi.org/10.3390/rs17081390