1. Introduction
With the advancement of urbanization, urban environments have grown increasingly complex. Issues such as dense high-rise buildings, signal obstruction, and interference have proliferated, creating significant inconveniences for navigation. Traditional single-mode navigation methods like satellite navigation struggle to meet modern urban demands. Multi-source fusion navigation solutions address these challenges by integrating the strengths of multiple sensors, compensating for individual limitations in specific scenarios, and providing viable strategies for complex urban environments.
The Global Navigation Satellite System (GNSS), as the sole absolute positioning technology with global coverage and availability, is widely utilized across industries. The mainstream real-time positioning methods of GNSS include Standard Point Positioning (SPP) and Real-Time Kinematic (RTK). SPP relies on pseudo-range measurements to achieve meter-level accuracy, while RTK utilizes carrier phase differential technology to attain centimeter-level precision, making it the only positioning method that combines real-time performance with high accuracy. However, in dynamic urban environments plagued by multipath effects and insufficient satellite visibility, standalone RTK still faces accuracy fluctuations and continuity risks. Consequently, integrating the autonomous calculation capabilities of Inertial Navigation Systems (INS) with the environmental perception advantages of visual sensors has emerged as the preferred solution for achieving high precision, reliability, and continuity. This GNSS/INS/Vision fusion architecture strikes an optimal balance between cost and performance, representing a technologically mature approach.
Despite the promising applications enabled by sensor complementarity in GNSS/INS/Vision systems, significant challenges persist in complex urban canyon scenarios: GNSS signals remain vulnerable to multipath interference, signal blockage, and non-line-of-sight (NLOS) reflections, leading to degraded positioning accuracy or complete signal loss. Simultaneously, dynamic obstacles (e.g., pedestrians, vehicles) disrupt visual sensors’ feature extraction and matching stability, compromising system reliability. Overcoming these limitations to achieve high-precision, robust multi-source navigation in complex environments has become a critical technical bottleneck, requiring urgent breakthroughs.
Current research in GNSS/INS/Vision multi-source fusion navigation has established a relatively comprehensive technical framework. Previous studies [
1,
2,
3] developed loosely coupled GNSS/VIO systems based on GNSS results. Loosely coupled methods typically fuse the estimated outputs of GNSS with visual-inertial Simultaneous Localization and Mapping (SLAM) systems. However, this approach has inherent drawbacks, as the system tends to fail when GNSS performance degrades or is interrupted. S. Cao et al. proposed a nonlinear optimization framework that integrates GNSS raw pseudo-range/Doppler observations, inertial data, and visual information to achieve drift-free real-time state estimation [
4]. However, this method underutilized high-precision carrier phase observations. For Precise Point Positioning (PPP) technology, studies [
5,
6,
7] developed PPP/INS/Vision integrated systems, yet their reliance on post-processed International GNSS Service (IGS) precise ephemeris limits real-time applicability. C. Chi et al. introduced an innovative factor graph optimization framework that flexibly integrates multi-mode GNSS positioning techniques, including SPP, Real-Time Differential (RTD), RTK, and PPP, demonstrating enhanced scalability [
8].
Comprehensive research on tightly coupled multi-source fusion algorithms for GNSS/INS/Vision integration was conducted in studies [
9,
10], employing a multi-state constrained filtering framework. The Compressed State-Constrained Kalman Filter (CSCKF), proposed in [
11], significantly improves computational efficiency through state-space dimensionality optimization while maintaining performance. Notably, C. Liu et al. developed the GNSS-Visual-Inertial Odometry (InGVIO) framework [
12], which surpasses traditional graph-based optimization methods in computational efficiency without sacrificing accuracy. X. Wang et al. introduced a Carrier Phase-enhanced Bundle Adjustment (CPBA) method [
13]. This method establishes ambiguity constraints between current and historical states of co-visible satellites via continuous carrier phase tracking, enabling precise drift-free state estimation. Furthermore, X. Niu et al. designed an INS-centric, robust real-time INS/vision navigation system [
14], which incorporates Earth rotation compensation to enhance inertial measurement accuracy.
Studies in [
15,
16,
17] systematically investigated GNSS/INS/Vision fusion under GNSS-degraded or failure conditions. These works addressed sensor vulnerabilities in complex urban environments, aiming to deliver high-precision navigation solutions for autonomous vehicles. To tackle urban canyon challenges such as NLOS signal interference caused by high-rise buildings, vegetation, and elevated structures, the authors of [
18] proposed a GNSS NLOS satellite detection algorithm based on Fully Convolutional Networks (FCN). F. Wang et al. developed a tightly coupled PPP-RTK and low-cost Visual-Inertial Odometry (VIO) integrated navigation system [
19], which enhances positioning performance and availability in urban canyon environments. Furthermore, Z. Gong et al. designed an adaptive GNSS/visual-inertial fusion system [
20] that dynamically integrates GNSS and VIO measurements to maintain continuous global positioning accuracy under intermittent GNSS signal degradation. Finally, H. Jiang et al. presented a Fault Detection and Exclusion (FDE) method for GNSS/INS/Vision multi-source fusion systems [
21]. This method significantly improves navigation reliability by incorporating robust anomaly detection mechanisms.
Traditional visual SLAM techniques, based on the static world assumption, predominantly rely on geometric image features for localization and mapping. However, in highly dynamic urban scenarios, dynamic environmental features (e.g., moving vehicles and pedestrians) occupy 40–65% of visual observations in typical urban scenes. Such dynamic features fundamentally contradict the static world assumption of visual SLAM systems. If dynamic feature points are not effectively suppressed during multi-source fusion, they may propagate into pose estimation and back-end optimization, leading to significant inaccuracies [
22]. Consequently, the accurate detection and removal of dynamic features remain a critical technical challenge.
Deep learning-based semantic segmentation enables pixel-level object recognition [
23], which provides unique advantages for visual data processing and scene under-standing. To mitigate dynamic object interference in visual SLAM, DS-SLAM [
24] pioneered the integration of SegNet [
25] for semantic segmentation combined with motion consistency checks to eliminate dynamic features. However, its computational latency limits real-time applicability. DynaSLAM [
26] builds upon ORB-SLAM by integrating multi-view geometry and Mask Region-based Convolutional Neural Network (R-CNN) for dynamic object identification but still encounters computational bottle-neck issues.
RDS-SLAM [
27] proposed a real-time dynamic SLAM algorithm based on ORB-SLAM3. This method introduced an additional semantic thread and a semantic-based optimization thread, enabling robust real-time tracking and mapping in dynamic environments. MMS-SLAM [
28] presented a robust multi-modal semantic framework that integrated pure geometric clustering with visual semantic information, effectively mitigating segmentation errors induced by small-scale objects, occlusions, and motion blur. Dyna-VINS [
29] developed a robust bundle adjustment method leveraging pre-integration-based pose priors to reject dynamic object features. The algorithm further employed keyframe grouping and multi-hypothesis constraint grouping to minimize the impact of temporarily static objects during loop closure. Dynamic-VINS [
30] combined object detection with depth information for dynamic feature identification, achieved performance comparable to semantic segmentation, and utilized IMU data for motion prediction, feature tracking, and motion consistency verification. STDyn-SLAM [
31] introduced a feature-based SLAM system tailored for dynamic environments and employed convolutional neural networks, optical flow, and depth maps for object detection in dynamic scenes. DytanVO [
32] proposed the first supervised learning-based visual odometry method for dynamic environments and required only two consecutive monocular frames to iteratively predict camera ego-motion.
While significant research efforts have been dedicated to multi-source fusion navigation in complex urban environments, two critical research gaps persist in the current methodologies: (1) Existing studies on sensor degradation predominantly focus on GNSS signal occlusion scenarios without systematic analysis of multi-sensor degradation patterns (e.g., Light Detection and Ranging (LiDAR) reflection interference or vision-based perception failure), resulting in incomplete robustness frameworks; (2) Current visual perception research remains confined to visual-inertial SLAM frameworks, while cross-modal fusion architectures for multi-source sensors (e.g., GNSS/INS/Vision) are still under-explored, especially in terms of dynamic error compensation mechanisms in time-varying urban scenarios.
To enhance the accuracy and reliability of GNSS/INS/Vision multi-source fusion navigation systems in complex urban environments, we integrate a neural network module into the system, operating in an independent thread for real-time semantic segmentation to detect and eliminate dynamic objects. Meanwhile, to improve GNSS positioning accuracy in urban canyon environments, we propose a novel stochastic model to adaptively adjust the weights in the multi-source fusion system. The core innovation of this study lies in the construction of a dual-level optimization framework: at the perception layer, dynamic environmental awareness is achieved through the integration of the visual neural network module; at the positioning layer, a novel GNSS stochastic model optimizes multi-source data fusion. Specific technical contributions include the following:
- (1)
A multithreaded parallel architecture is designed to effectively recognize dynamic object regions by using independent threads to run visual neural network models for real-time semantic segmentation;
- (2)
Proposal of a dual-validation mechanism for dynamic feature points, integrating semantic segmentation results, epipolar line constraints, and multi-view geometric consistency verification to achieve precise elimination of dynamic feature points;
- (3)
Development of an adaptive weighting model based on the carrier phase quality metric, dynamically adjusting fusion weight coefficients through the real-time evaluation of GNSS observation quality.
The paper is structured as follows:
Section 1 reviews related work on multi-source fusion.
Section 2 presents the fundamentals of factor graph optimization-based multi-source fusion.
Section 3 details the proposed real-time dynamic object detection and removal method.
Section 4 analyzes GNSS RTK error sources in urban environments and introduces the novel RTK stochastic model.
Section 5 evaluates the performance of the proposed algorithms. Finally,
Section 6 concludes the study and outlines future research directions.
3. Dynamic Object Detect
3.1. Object Detect by YOLO
Semantic segmentation serves as a foundational technology for image understanding, enabling pixel-level semantic classification by assigning each image pixel to its corresponding category. This technique has been widely adopted in autonomous driving, unmanned aerial vehicles (UAVs), wearable devices, and other fields. In visual SLAM systems, semantic segmentation provides critical environmental understanding through extracted semantic features—including object categories, spatial positions, and geometric shapes—which significantly enhance the precision and robustness of robot localization and mapping in complex environments. The integration of semantic information allows visual SLAM to achieve more accurate environmental interpretation, thereby improving positioning accuracy and navigation reliability for robotic platforms. A notable application lies in outdoor dynamic scenarios: By identifying and masking dynamic objects through semantic segmentation, the system effectively prevents these transient elements from interfering with feature point extraction during front-end camera motion estimation and subsequent back-end mapping processes. This methodology substantially improves both the stability and localization accuracy of SLAM systems in dynamic environments.
YOLO (You Only Look Once), a real-time object detection algorithm, was first proposed by Redmon et al. 2016 [
23]. Unlike conventional object detection approaches, YOLO formulates the detection task as a unified regression problem that directly maps image pixels to bounding box coordinates and class probabilities, achieving exceptional detection speed while maintaining competitive accuracy. Our implementation operates through the Open Computer Vision Library (OpenCV) Deep Neural Networks (DNN) framework, requiring no dependencies on deep learning libraries and maintaining complete independence. With GPU acceleration, the system achieves 40 frames per second (FPS) detection throughput, fully satisfying real-time computational requirements. As shown in
Figure 1.
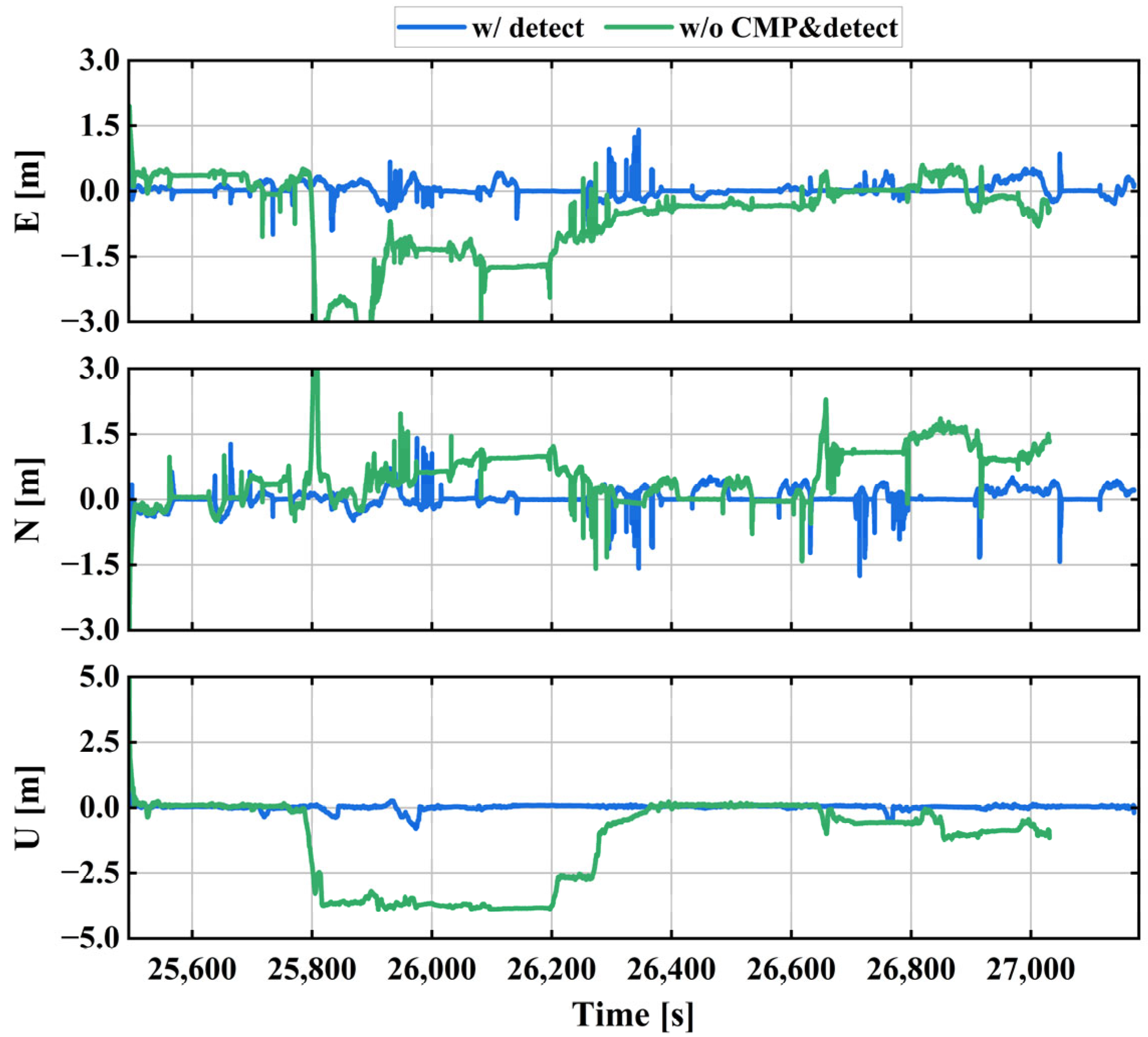
By integrating a semantic segmentation module (YOLOv10), the system accesses segmentation results in real time via a dedicated processing thread. The framework first identifies potential dynamic objects in the image stream and then verifies their dynamic properties using epipolar line constraints and geometric consistency checks. This integrated approach effectively reduces error propagation caused by back-end feature point matching and reprojection processes.
Figure 2 gives the results of pixel-level semantic segmentation and dynamic target detection for the vision front-end, wherein the red points indicate static feature points and the blue points indicate dynamic feature points that need to be rejected after detection and identification.
As can be observed, the YOLO module in the visual image accurately identifies, filters, and removes feature points on dynamic objects such as vehicles and pedestrians in the scene. This ensures that dynamic feature points introduce minimal error during the construction of the visual reprojection error in the back-end. The dynamic point detection process in this paper consists of the following steps: First, normal feature point extraction is performed on the current frame of the image. Next, the semantic segmentation results of the current frame from the semantic segmentation thread are obtained, and all feature points to be inspected that fall within the semantic segmentation regions are marked. Then, RANdom Sample Consensus (RANSAC) is used to identify the fundamental matrix with the largest outliers. Subsequently, the fundamental matrix is utilized to compute the epipolar lines for the current frame. Finally, it is determined whether the distance between the matched points and their corresponding epipolar lines is less than a certain threshold. If the distance exceeds the threshold, the matched point is judged to be moving based on the epipolar line constraint, which effectively filters out dynamic feature points.
To reduce the computational load required for semantic segmentation, we first perform feature extraction and keyframe selection on the image. Semantic segmentation is executed only when a frame is identified as a keyframe, significantly reducing the number of images requiring semantic segmentation. Additionally, since semantic recognition is applied solely to keyframes, discontinuities between consecutive frames may arise. To prevent missed detections, we predict the previously recognized results based on pixel motion velocity and direction, incorporating the predicted outcomes into the dynamic detection interval. This approach enhances recognition accuracy through geometric consistency constraints.
The proposed system utilizes a pre-trained model on the Microsoft Common Objects in Context (COCO) dataset, selecting 19 classes from the original 80 categories as high-motion probability objects: a person, bicycle, car, motorcycle, airplane, bus, train, truck, boat, bird, cat, dog, horse, sheep, cow, elephant, bear, zebra, and giraffe. By leveraging pixel-wise semantic labels, this configuration provides prior knowledge about the motion characteristics of these objects. The selected classes comprehensively represent typical dynamic entities encountered in autonomous driving scenarios, fully addressing current operational requirements.
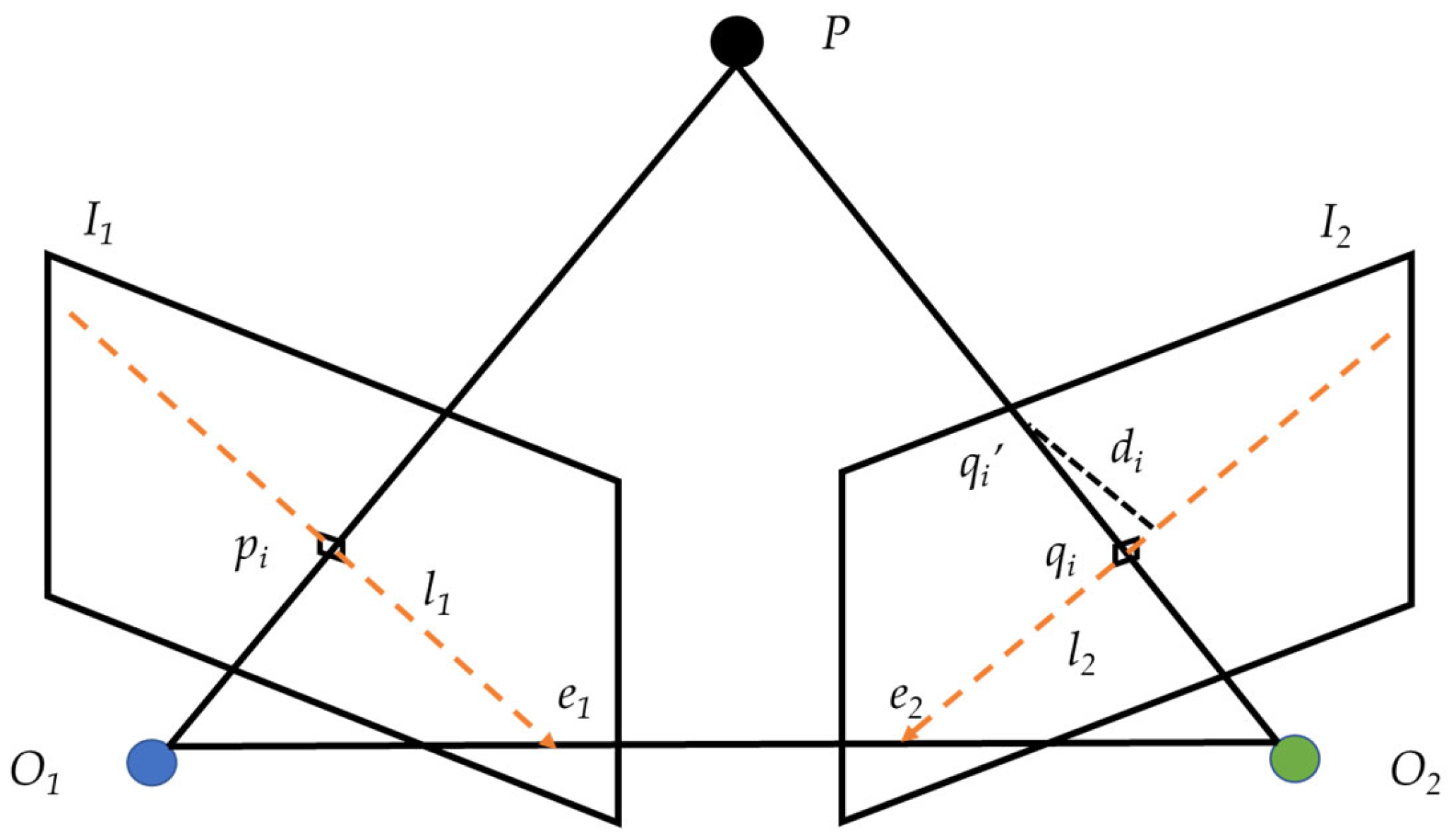
3.2. Epipolar Line Constraint Method
For the matched feature point pairs in the previous frame and current frame images, with their coordinates denoted as
and
, respectively, the epipolar line constraint can be expressed as follows:
where
is s the pole line corresponding to
in the current frame. The projection of point
on the second frame image must lie on the epipolar line
. However, interference from dynamic objects causes the aforementioned epipolar line constraint to fail. The distance between feature point
and its corresponding epipolar line
is defined as follows:
The epipolar line constraint distance of static feature points is relatively small, whereas that of dynamic feature points is typically significantly larger. When dynamic feature points move along the epipolar line, the epipolar line constraint distance between them may also become relatively small, potentially leading to the inaccurate identification of moving dynamic feature points. Therefore, in addition to employing the epipolar line constraint, it is necessary to incorporate supplementary methods to provide additional constraints, thereby ensuring the comprehensive identification of dynamic feature points within the scene. The schematic diagram of the epipolar line constraint is shown in
Figure 3.
3.3. Geometric Consistency Constraints
The geometric consistency verification is primarily determined through the motion vectors of feature points. Camera motion can generally be categorized into linear motion
Figure 4a and rotation, with rotation further divided into turning
Figure 4b and rolling
Figure 4c. Since rolling (rotation around the image center) typically does not occur in vehicular scenarios, this discussion focuses exclusively on linear motion and panning.
For linear camera motion, the velocity or displacement vectors of extracted feature points across the entire image exhibit left–right symmetry with smaller magnitudes near the image center and larger magnitudes toward the periphery. In the panning motion, the feature point vectors demonstrate approximately uniform direction and magnitude characteristics throughout the image. The rolling motion would produce vectors with identical magnitudes but varying directions, though this scenario is excluded from consideration in vehicular applications due to the absence of image-center rotation.
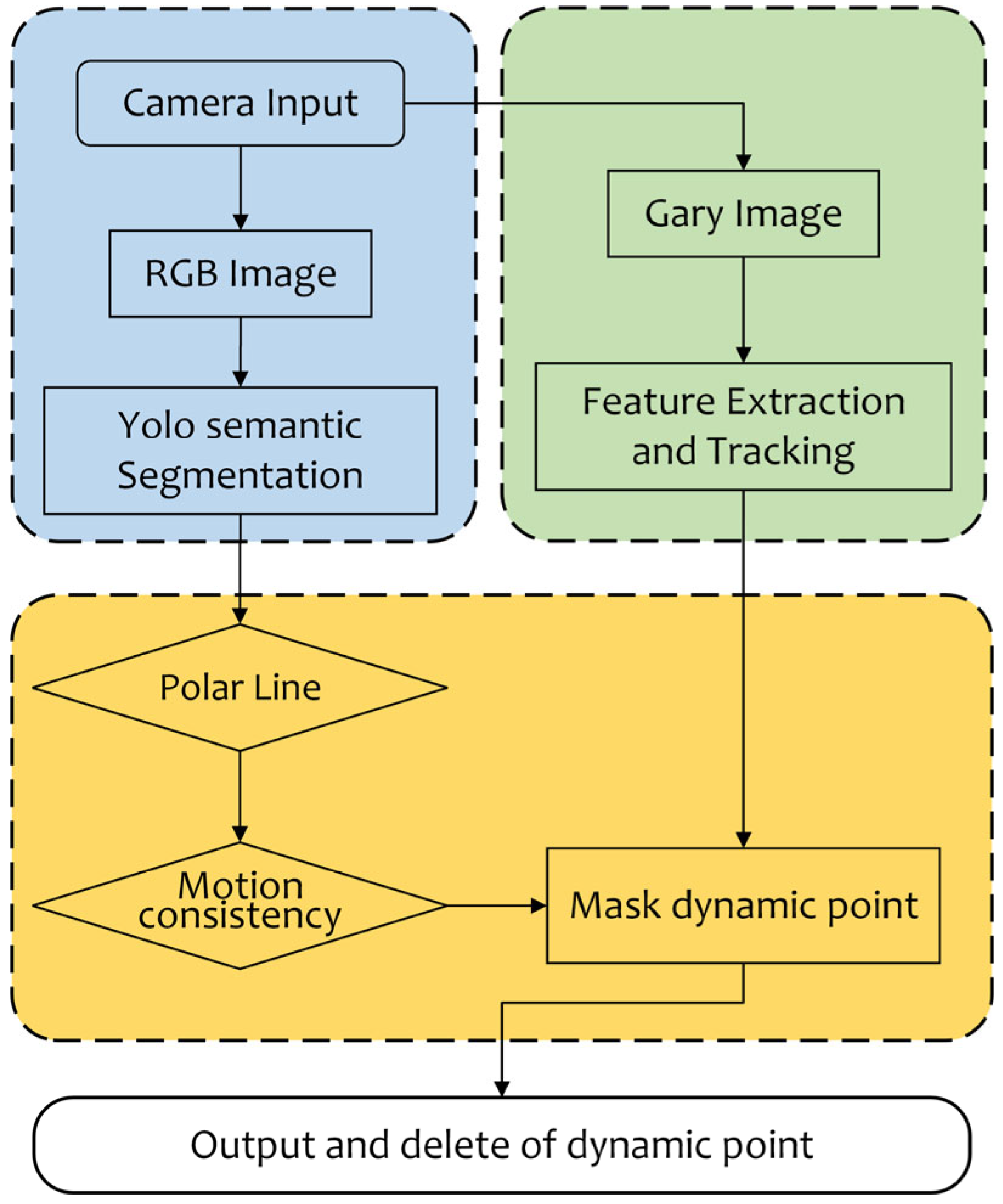
In vehicular scenarios, the primary camera motion modes are limited to linear motion and horizontal rotation. Consequently, geometric consistency verification becomes relatively straightforward for such environments. By leveraging segmentation results directly obtained from the semantic segmentation thread, dynamic feature points can be accurately identified through consistency checks between target regions segmented semantically and the global image context. The workflow for visual feature extraction and dynamic feature recognition is illustrated in
Figure 5.
The acquired grayscale and RGB images from the data input interface undergo parallel processing through two independent threads: one dedicated to feature point extraction and tracking, while the other concurrently performs semantic segmentation on the corresponding RGB image data. Subsequently, the extracted features and semantic information are fused, enabling the comprehensive attribute recognition of feature points through integration with additional dynamic detection algorithms.
4. A New Stochastic Model for GNSS RTK
4.1. RTK Error Model
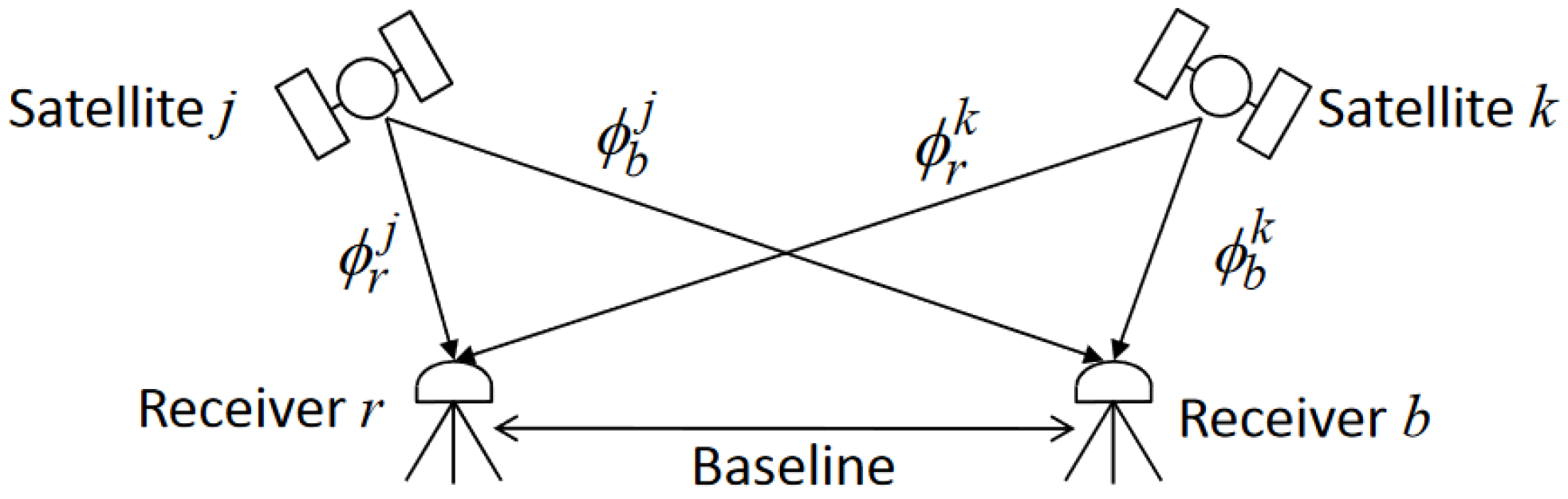
Differential observation models can simplify the localization model by eliminating or weakening the effects of observation errors that are mostly the same or have strong spatial correlation. The disadvantages are low data utilization and the introduction of correlation between observations, which makes processing more difficult. The principle of RTK differential observation is shown in
Figure 6.
In urban canyon scenarios, radio signals are highly susceptible to specular reflections. Reference stations for RTK are typically deployed in areas with favorable observation conditions, avoiding regions severely affected by NLOS and multipath errors. In contrast, observation data from rover stations in complex urban environments often contain significant NLOS and multipath errors. The substantial disparity in observation environments between reference and rover stations renders differentiation techniques ineffective in fully eliminating residual errors caused by these environmental discrepancies.
Considering the correlation error and measurement noise, the GNSS observation equation in meters can be expressed as follows:
where
and
denote pseudo-range and phase observations, respectively.
denotes the geometric distance between the satellite
and the receiver
.
and
denote the receiver and satellite clock bias, respectively.
is denotes the speed of light.
denotes the slant path ionospheric delay of satellite s at frequency 1.
is the signal frequency.
is a frequency-dependent ionospheric delay factor.
and
denote the zenith tropospheric delay and the corresponding mapping function, respectively.
is ambiguity of whole cycles.
is wavelength.
and
denote the receiver-side and satellite-side pseudo-range hardware delays, respectively.
and
denote the receiver-side and satellite-side phase hardware delays, respectively.
and
denote the observation noise and multipath error for phase and pseudo-range measurements, respectively.
Assuming the distance between the reference station and the rover is relatively short, the atmospheric delay errors can be considered identical and relatively stable. By differentiating the observations between the reference station and the rover, the impact of atmospheric delay errors can be directly eliminated. Let the reference satellite be
; the variances of the between-station single-difference observations for pseudo-range and phase are as follows:
where
is the differential atmospheric delay errors, which can be considered to be zero in short-baseline RTK.
,
. Differentiating the above single-difference observation equations between satellites gives the double-difference observation model as follows:
. and represent the differences between the observation noise of satellite at the rover and the reference station, and the differences between the observation noise of satellite at the rover and the reference station, respectively. For the same satellite, the noise level at the satellite end is identical, and most of the satellite end errors can be eliminated through between-station differentiating. However, for the same receiver, the noise levels for different satellites may vary and could even differ significantly. Therefore, differentiating across different satellites cannot completely eliminate the impact of observation noise at the receiver end.
Through the detailed derivation and error analysis of the RTK observation equations, we find that most errors have been eliminated after applying between-station and between-satellite differentiating. The remaining error terms in the double-difference observations consist of the residual double-difference observation noise, which includes noise, residual multipath, and NLOS errors.
4.2. An Adaptive Weighting Strategy for GNSS RTK
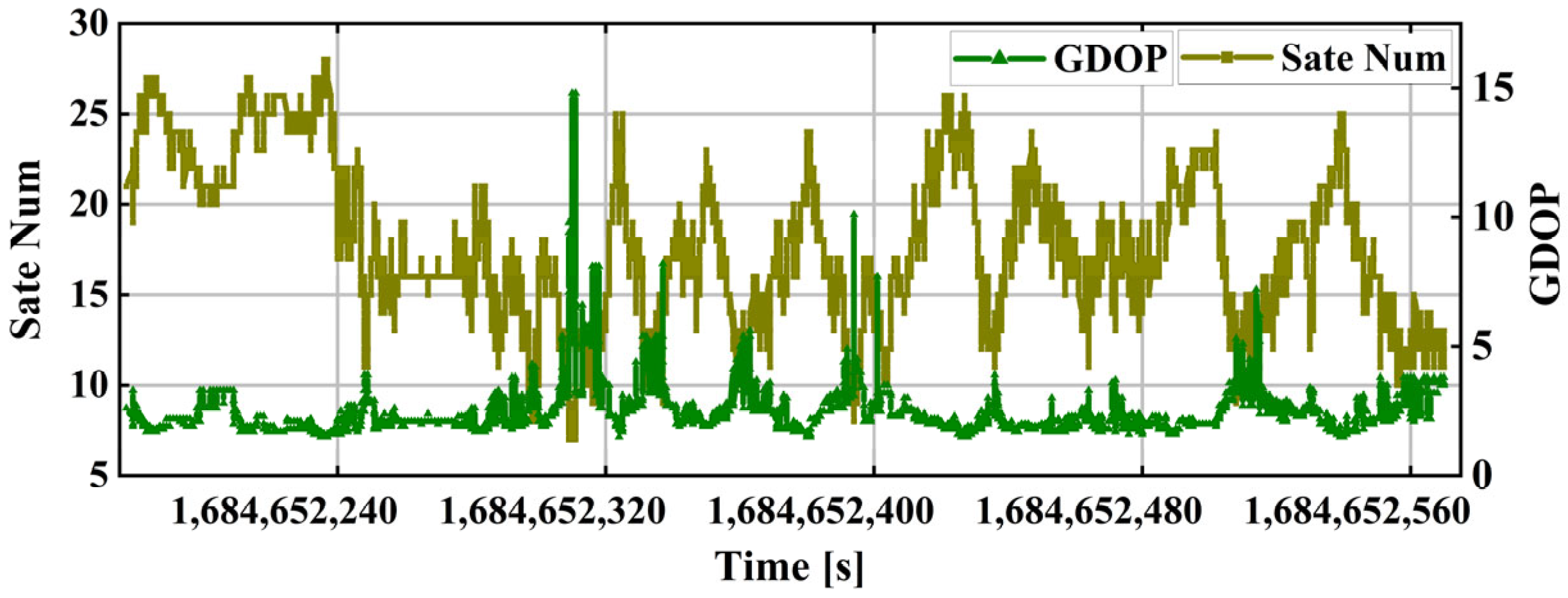
Generally, GNSS signal quality exhibits strong correlation with satellite elevation angles [
33], which is related to the physical characteristics of electromagnetic waves. When propagating through different media, larger incidence angles induce greater path bending of the signal, which manifests as increased ranging errors in the observed data. The elevation angle-dependent stochastic model can be expressed as follows:
where
is the a priori variance of the observations and
is the angle of altitude.
The elevation angle-based modeling approach primarily addresses conventional physical models and does not account for NLOS and multipath errors caused by electromagnetic wave refraction and superposition phenomena in special environments. In the unique environment of urban canyons, the stochastic model based on elevation angle can no longer accurately reflect the quality of observation information. Therefore, there is a need for a new GNSS stochastic model specifically adapted to urban canyon environments.
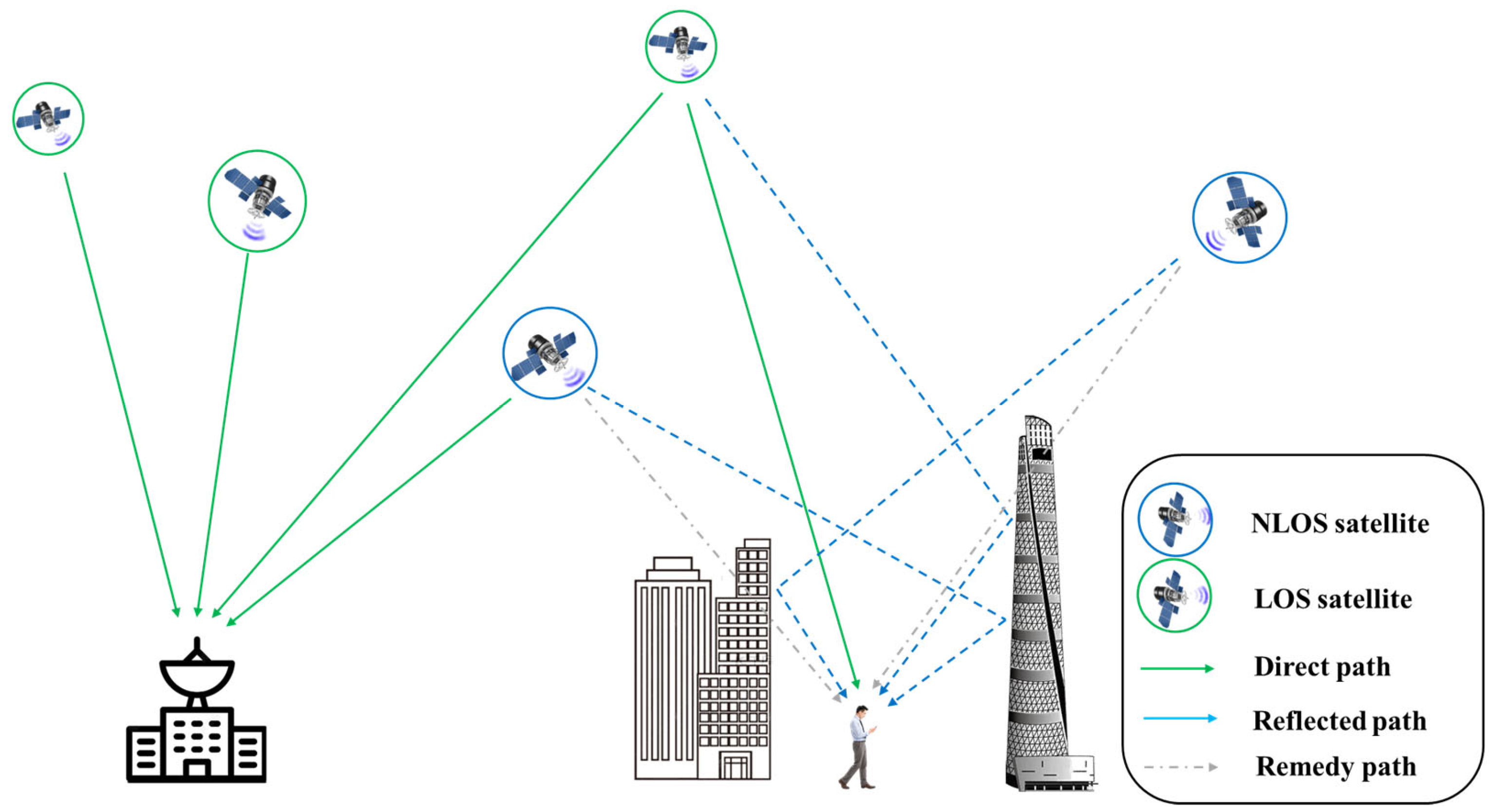
Multipath errors refer to inaccuracies that occur when a receiver captures not only the direct signal from a transmitter but also one or more signals arriving via reflected paths. These reflections may originate from surfaces such as ground terrain, buildings, or vehicles. Since these additional paths are longer than the direct path, the reflected signals arrive at the receiver with delays and interfere with the direct signal, thereby introducing measurement errors. NLOS errors specifically describe scenarios where the direct signal from the transmitter cannot be received under line-of-sight (LOS) conditions. When obstacles block the direct path between the transmitter and receiver, creating NLOS conditions (as illustrated in
Figure 7), the receiver can only capture reflected, diffracted, or scattered signals. This leads to ranging errors, particularly degrading positioning accuracy in TOA (Time of Arrival) or TDOA (Time Difference of Arrival)-based systems. Due to the abundance of reflective surfaces, both error types are highly prevalent in the specialized environment of urban canyons.
Through the analysis of the double-differenced observation model in RTK, we recognize that after double-differentiating the observations, only the observation noise (including NLOS and multipath errors) remains in the measurement equation. For the special scenario of urban canyons, where significant environmental differences exist between the rover and reference station observation conditions, we posit that substantial errors persist in the differential noise term.
Secondly, as pseudo-range measurements contain considerable errors whose magnitudes cannot be precisely determined [
34], incorporating pseudo-range observations may degrade positioning accuracy. Therefore, high-precision positioning algorithms typically apply down-weighting to pseudo-range observations. This does not imply that pseudo-range data are entirely unusable, but rather stems from the general inability to quantify their error components. In urban canyon environments where signal obstruction drastically reduces observable satellites, every measurement becomes critically valuable. Thus, effectively utilizing all available observational data becomes paramount in such settings.
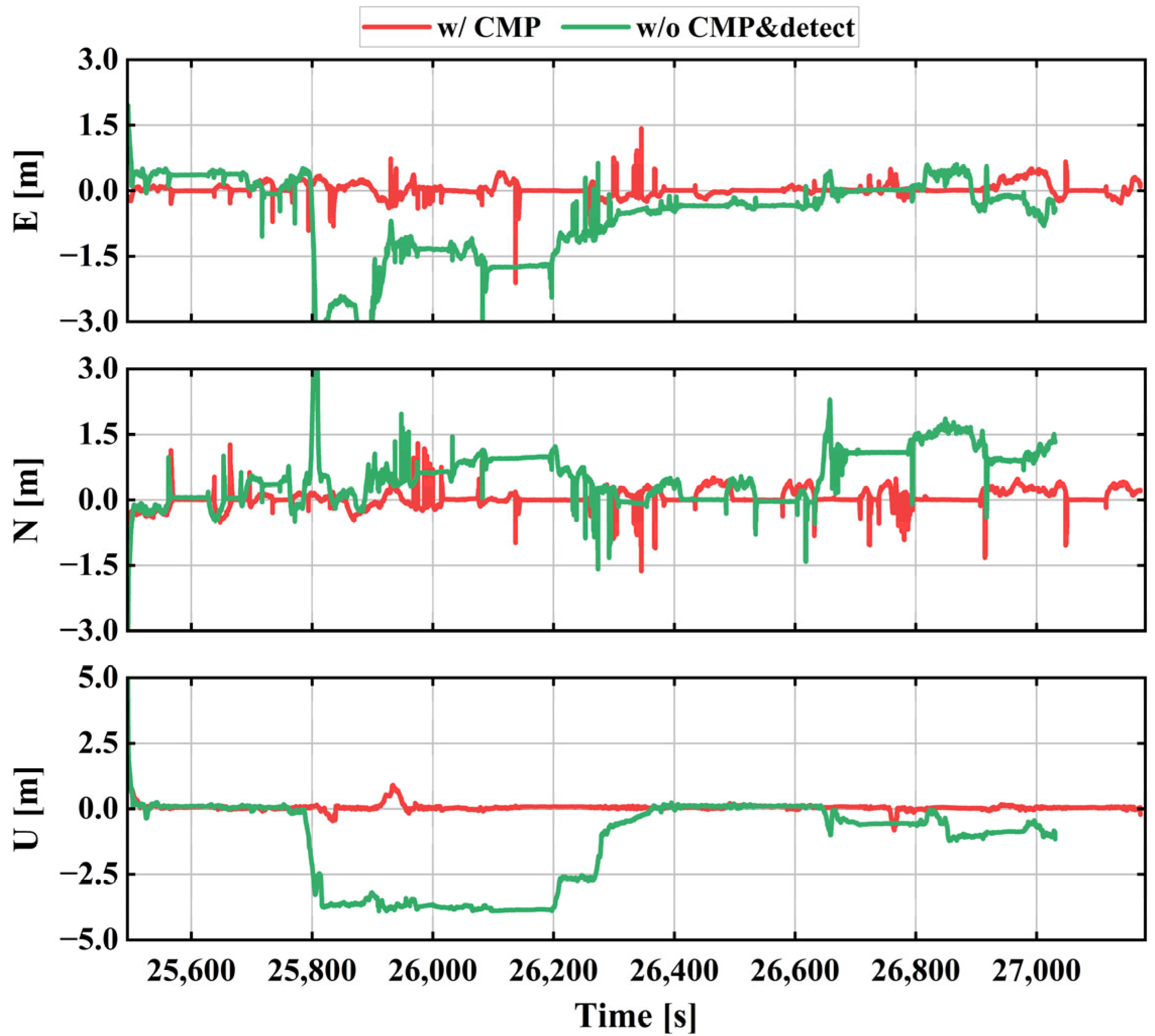
Analyzing fundamental GNSS principles and observation equations reveals that carrier phase measurements exhibit significantly higher precision than pseudo-range code measurements. Based on this property, we introduce Code-Minus-Phase (CMP) observations to quantify the quality of pseudo-range observations [
35,
36]. CMP observations are conventionally employed to characterize multipath errors in pseudo-range measurements.
To enhance GNSS observation quantity and usability in complex urban environments, our proposed method utilizes CMP to quantify pseudo-range noise levels, enabling adaptive weight adjustment for participating observations based on error magnitudes. This approach substantially improves data utilization efficiency while enhancing system accuracy and availability.
The code pseudo-range (
) and carrier phase (
) observations are given in meters by the following equations:
observations can be written in the following form:
The subtraction of phase observations from pseudo-range observations eliminates the geometry-related terms, including receiver and satellite clock offsets, tropospheric delays, and geometric range. The resulting combination still contains twice the ionospheric delay, hardware delay biases, multipath effects, and observation noise. Since the observation noise and multipath effects in phase observations are significantly lower than those in pseudo-range observations, their impacts can be neglected in the combination.
Applying epoch differentiating to
observations yields the following result:
It can be observed that differentiating the
observations between epochs leaves only the multipath and twice the ionospheric delay. The ionospheric delay can be eliminated through modeling. Through this quantitative method for estimating pseudo-range multipath errors, we proposed a stochastic model suitable for urban canyons to enhance the weighting of pseudo-range observations. The stochastic model is constructed as follows:
where
is the difference of
.
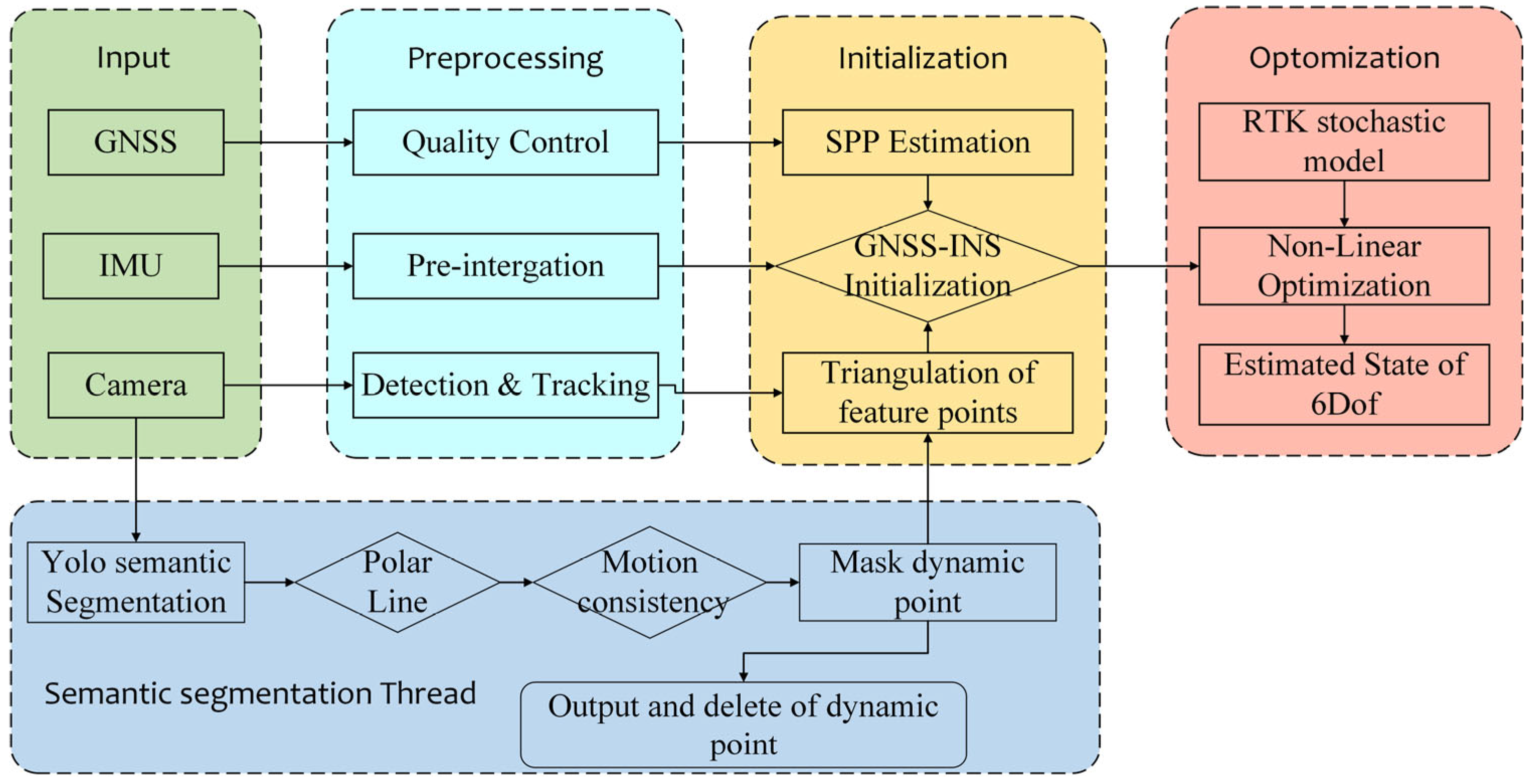
Figure 8 gives the basic flow of the system operation. This system adopts a multi-source heterogeneous sensor fusion architecture, integrating observation data from the GNSS, IMU, and vision sensors. Robust positioning in complex scenarios is achieved through hierarchical processing and optimization algorithms. During the data preprocessing stage, dynamic weighted quality control based on quality factor evaluation is implemented for GNSS observations, while pre-integration operations are performed on raw IMU data to construct kinematic constraint models. For vision data streams, a dual parallel processing architecture based on feature tracking and semantic parsing is innovatively designed: the feature extraction thread achieves inter-frame feature matching via the optical flow method, while the semantic segmentation thread employs deep convolutional networks for scene understanding, providing prior constraints for subsequent nonlinear optimization.
The positioning solution phase employs a hierarchical progressive fusion strategy: first, an a priori coordinate reference is obtained through GNSS SPP, followed by an improved RTK stochastic model to achieve adaptive observation weighting. This is combined with INS mechanization equations to establish a tightly coupled navigation framework. For the vision subsystem, a multi-constraint dynamic object suppression algorithm is proposed, effectively eliminating interference from dynamic feature points by fusing semantic segmentation results with epipolar line constraints and motion consistency verification. Finally, the spatiotemporal unification and global optimal estimation of multi-source observations are realized through sliding window optimization.


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}