1. Introduction
A classification method called Local Climate Zone (LCZ) classification is used to group urban and non-urban areas according to their climatic and environmental features. When describing the microclimates of certain regions, LCZs take into account elements such as vegetation, surface types, and urban morphology. By using supervised learning [
1], we can automatically classify different urban and rural zones into meaningful climate categories, but challenges like the need for large, high-quality annotated datasets and problems with data annotation can impede progress. By addressing these issues, self-supervised learning significantly increases the scalability and efficacy of LCZ classification, particularly in cases of limited resources. Local climate zones are divided into two primary categories: urban LCZs and natural LCZs. Urban LCZs pertain to urban areas and are numbered from LCZ1 to LCZ10, while natural LCZs are associated with non-urban areas, represented by LCZA to LCZG.
Figure 1 describes each climate zone, and further details are provided in [
2].
Self-supervised learning is used to learn representations from unlabeled data. However, a key challenge in SSL lies in learning effective representations without relying on negative samples, which has been a cornerstone of many traditional SSL approaches. Existing methods, such as contrastive learning techniques including MoCo [
3], often depend on the construction of negative samples to enforce distinct feature representations. However, negative samples similarity issue may limit the performance, in [
4] authors overcame this issue with clustering approach but still the performance is limited by negative samples. Data-to-Vector [
5] has demonstrated potential in managing different modalities, but it encounters difficulties if the data is lacking diversity.
We aim to contribute to the development of SSL techniques that can effectively learn meaningful representations from positive pairs alone. This is crucial for advancing the applicability of SSL, as negative samples may not always be available or well defined.
Supervised learning methods are also used for LCZC, but their reliance on labeled data, which are often costly and time-consuming to obtain, remains a major drawback. Additionally, these techniques are prone to overfitting, particularly when the amount of labeled data is limited.
SAR and MS data have been used for LCZ classification because of their large imaging widths [
6]. MS image interpretation is relatively easy because reflectance and emission from ground objects can provide sufficient details [
7]. However, clouds and atmospheric conditions can make temporal requirements difficult for MS images [
8]. In contrast to MS imaging, terrain and object backscattering affect SAR images—in particular, the form, shape, and composition of objects. Additionally, SAR has the unique feature of coherent imaging, which means it captures amplitude and phase information [
9]. Moreover, SAR can penetrate through clouds and provides all-day image acquisition capability. However, SAR images are less intuitive to interpret and more challenging compared to MS images due to a limited number of bands and issues such as speckle noise, non-vertical range imaging, projected shortening, signal voids, surface overlap distortion, and shadowing effects [
10]. Given the complementary nature of MS and SAR data, the fusion of MS and SAR has been used for LCZC [
11]. In this paper, we introduce an SSL method built upon an innovative fusion network, drawing inspiration from BYOL [
12].
Recent studies on Local Climate Zone Classification (LCZC) have explored various methodologies, datasets, and applications. In [
13], a classification approach for LCZs in Xi’an City was proposed, leveraging 192 spatial indicators and remote sensing (RS) data. Expanding on large-scale LCZ mapping, ref. [
14] developed comprehensive LCZ land use datasets for key Chinese cities and urban clusters to enhance urban climate and environmental modeling. The role of LCZC in urban heat island (UHI) analysis was examined in [
15], where Zhuhai-1 satellite imagery was used to study daytime temperature variations. Similarly, ref. [
16] investigated LCZ transformations over time in five major global cities, providing insights into urban climate dynamics. A broader review of LCZC methodologies and applications was conducted in [
17], contributing valuable perspectives for urban climate research.
The practical applications of LCZC in sustainable urban development were highlighted in [
18], while [
19] applied LCZC to identify surface urban heat islands (SUHIs) and improve the understanding of urban thermal effects. The relevance of LCZC for ventilation assessment in urban planning was explored in [
20]. Spatio-temporal variations of SUHIs in Beijing and their correlation with population density were analyzed in [
21]. Additionally, ref. [
22] reviewed LCZ mapping applications across European cities, identifying emerging trends in urban environmental studies. Studies such as that reported in [
23] have assessed the effectiveness of LCZC for land surface temperature (LST) analysis, focusing on UHI pattern variability.
Advancements in data fusion techniques for LCZC have also been explored. In [
24], the integration of multispectral (MS) and PALSAR-2 data was investigated for LCZ classification in Nanchang, China. Deep learning methods such as a multi-cascaded fusion network [
25] and a dual graph convolutional neural network (CNN) [
26] have been introduced to improve LCZ classification accuracy. The dynamic changes in LCZs across three cities and their impact on the UHI phenomenon were examined in [
27]. Furthermore, ref. [
28] evaluated the thermal characteristics of Riyadh’s LCZs and their implications for urban planning. Seasonal UHI analyses were conducted in Wuhan using LCZ classification in [
29], while [
30] explored spatial trends in urban environments through LCZ classification. Variations in LCZs across three Yangtze River mega cities were studied in [
31]. The application of SAR for global LCZ classification was discussed in [
32], while [
33] investigated the fusion of SAR and multispectral data for LCZC using a dual-branch CNN.
SSL methods based on generative networks like the Autoencoder (AE) architecture [
34] are based on the encoding and reconstruction of input data. The model is simple but suffers from overfitting and cannot capture complex distributions, which limits the generalization ability of model. Sparse AEs [
35] are based on sparsity constraints to improve efficiency. However, the sparsity constraint can reduce the model’s expressiveness and may lead to instability during training if not carefully tuned. Denoising AEs [
36] focuses on reconstructing clear images from noisy inputs, which helps in learning robust representations. However, they struggles when noise levels are high or when the noise distribution is not well understood, requiring a large amount of clean data for optimal performance. Variational Autoencoders (VAEs) [
37] model the data distribution by encoding the input into a normal distribution. While VAEs have gained popularity for their probabilistic approach, the assumption of a Gaussian distribution can be restrictive, leading to poor results in more complex datasets. Masked Autoencoders (MAEs) [
38] use random masking of image patches and leverage vision transformers for reconstruction. While MAEs have demonstrated strong performance on various vision tasks, they require significant computational resources and may lose fine-grained details during reconstruction due to masking.Generative Adversarial Networks (GANs) [
39] are among the most influential models in generative learning. They consist of two neural networks—a generator and a discriminator—that are trained adversarially to produce realistic data. Adversarial Autoencoders (AAEs) [
40] combine the principles of VAEs and GANs by incorporating adversarial training into the autoencoder framework. BiGANs (Bidirectional GAN) [
41] extend GANs by adding an encoder that maps data samples to their latent representations. This additional encoder increases the model’s complexity and computational cost while also introducing new challenges in balancing the training of both the generator and encoder.
One of the foundational techniques in SSL is negative sampling, which aims to maximize the distance between dissimilar data points. Methods such as triplet Loss [
42], MoCo, and SimCLR [
43] have proven effective in various single-mode applications. These approaches suffers from negative sample selection and require large batch sizes. DeepCluster [
44] and SwAV [
45] generate pseudo-labels for contrastive learning but suffer from poor computational efficiency. DINO [
46] is based on positive sample generation but suffers from hyperparameter tuning and scaling issues. Barlow Twins [
47] and VICReg [
48] are based on redundancy reduction but suffer from loss of features and instability during training.
Existing SSL methods based on negative sampling, clustering, knowledge distillation, and redundancy reduction have improved the performance but still suffer when applied to multimodal data. However SSMMRL is more efficient and scalable, making it a promising solution for multi-modal classification.
The advantages of using only positive samples for model training include the simplicity of the objective function as compared to using negative and positive samples. Contrastive loss due to the use of positive and negative samples may cause instability if the samples are unbalanced and large. Models based on positive samples are more efficient and perform better in cases of limited labels.
Main Contribution
The main contributions of this work are listed below. It is pertinent to mention that, unlike BYOL, our SSMMRL has three branches, namely online, target, and fusion branches, whereas BYOL has two branches, namely teacher and student branches. SSMMRL offers greater flexibility and adaptability, making it suitable for more complex and diverse tasks that involve multiple views or modalities.
We propose a method that actively combines positive samples to create a new fused sample, driven by an attention mechanism. By encouraging the model to create more useful features and projections from aggregated data, this regularization technique improves feature generalization.
An additional fusion branch is added to extract meaningful features from the SAR and multispectral data and reduce overall loss.
A dynamic convolutional module is proposed that works with different input sizes by dynamically modifying the mixed input channels to support the attention strategy.
The suggested SSL approach requires less labeled data and performs better on multi-modal data when compared to other self-supervised learning approaches.
The structure of this article is outlined as follows.
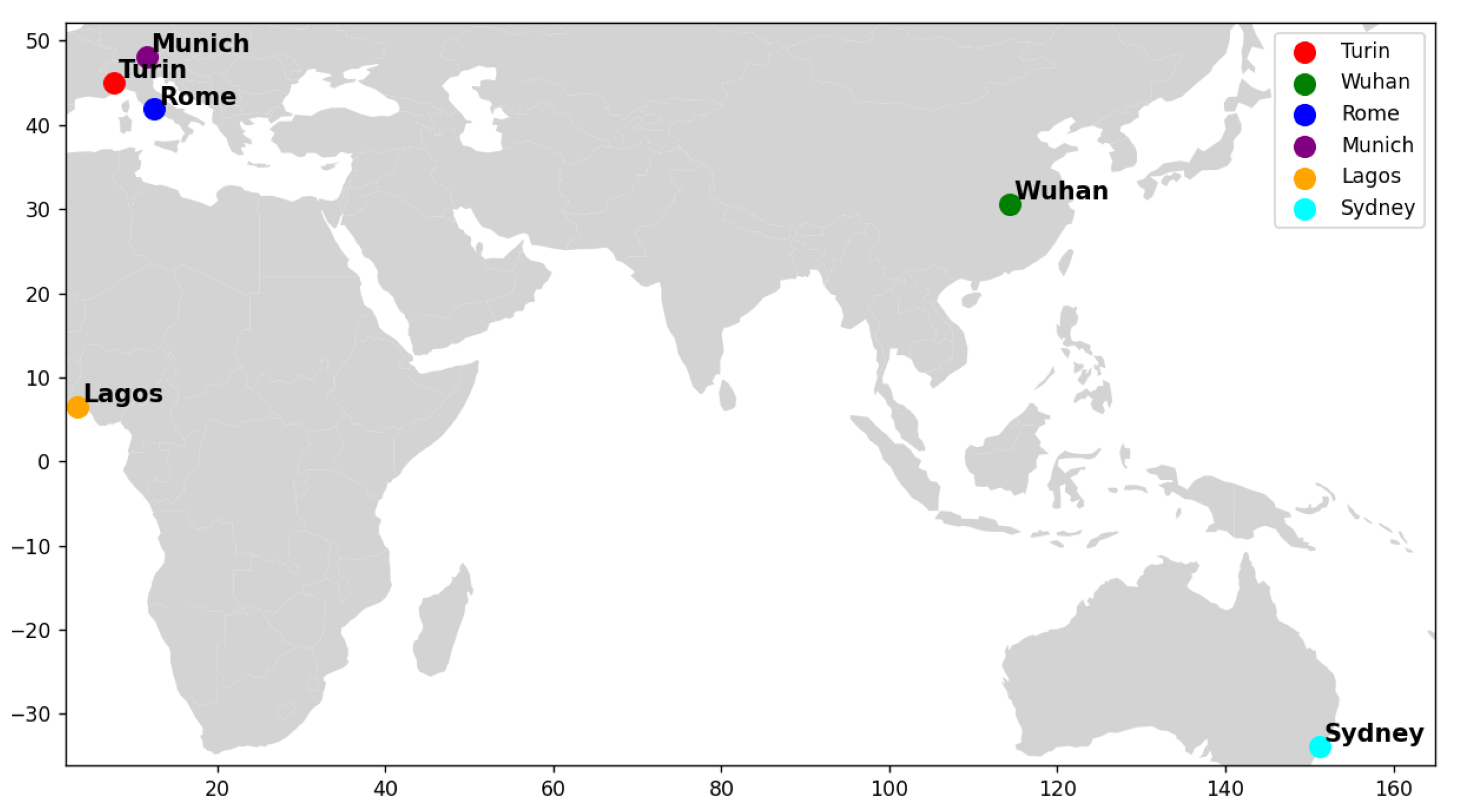
Section 2 describes study areas.
Section 3 presents the methodology.
Section 4 introduces the datasets and experimental settings.
Section 5 is about obtained results and
Section 6 is about discussion.
Section 7 provides the conclusion of the article and future research.
3. Methodology
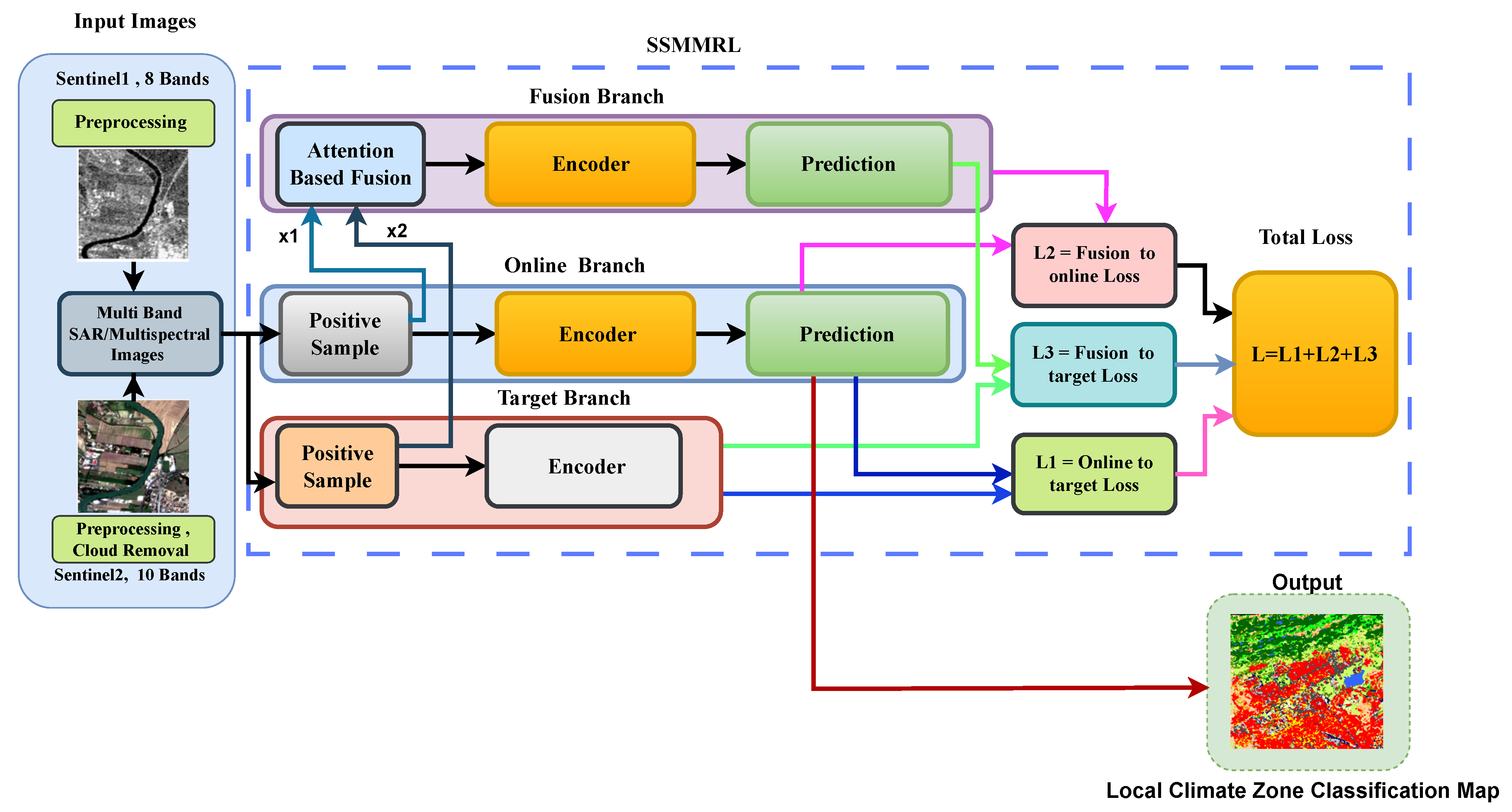
In this section, the frame work for SSMMRL is discussed. The methodology involves data preprocessing and augmentation, feature extraction using a dynamic convolution, squeeze and excitation, and self-supervised training with a fusion-branch framework. The fusion branch leverages an attention-based mechanism to fuse information from two augmented views of the input, enhancing the learned representations.
3.1. Proposed Framework
The proposed framework is shown in
Figure 4. Multi-spectral and SAR images are preprocessed and applied to the online, target, and fusion branches. The input image (x) is passed through the positive sample generator, and it produces
for the online branch and
for the target branch. Both
and
are passed through the feature encoder to generate representations (
and
), respectively. The online and target encoders are represented as
, and
respectively.
The predictions are generated from the representations, and the predictor is denoted by g. The fusion branch gets , . Attention-based fusion is applied to achieve better feature representation. The predictions from the online and fusion branches, along with the encoder outputs, are used to compute the weighted loss. The target branch network is updated using online network parameters. Initially, the network is pretrained without any labeled samples; then, a few annotated training samples are used for fine-tuning and classification tasks.
The outputs of the online feature extractor are ( and ), while the representation of the target feature extractor are (, ).
The augmented views (
and
) are generated from
x.
Representations are mapped to predictions using the
operator, called the predictor.
An attention mechanism is applied to obtain the attention map. The attention map helps in weighting the importance of each pixel or feature in the input images, resulting in a hybrid sample.
The target branch network (
) is updated using online network parameters.
where
is a momentum parameter. Initially, the network is pretrained without any labeled samples; then, a small portion of annotated samples is used for fine-tuning and classification tasks.
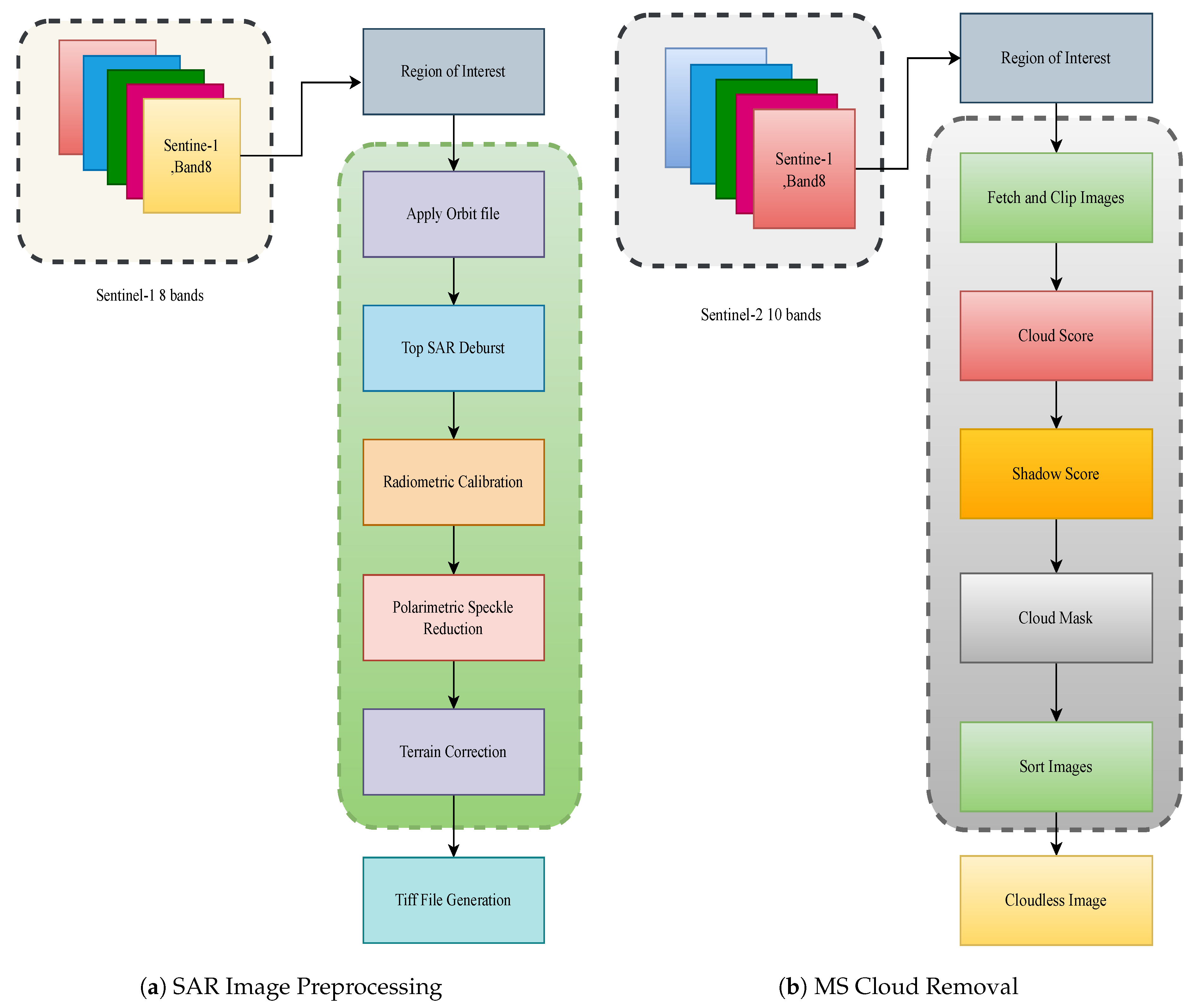
3.2. Preprocessing and Sample Generation
Augmentation includes a random crop with specific aspect-ratio and scale constraints, as well as a random horizontal flip. A random crop is applied, with the height (ph) in the range of [0.5, 1.0] and the width (pw) based on the height (ensuring the width is between 0.67 and 1.0 times the height). The crop size is fixed at 32 × 32. A random horizontal flip with 0.5 probability is used. The random crop and horizontal flip are applied sequentially to the input image (x). The augmented image is returned, maintaining the correct number of channels (though this part is implicit, since the number of channels is maintained through the transformations). The combined augmentation pipeline can be expressed as follows:
where the augmented image (
) is obtained by applying a random crop (
), then a horizontal flip (
).
It is pertinent to mention that data augmentation is a powerful tool for improving the performance and generalization of machine learning models, especially when training data are limited. It helps the model learn more robust features by introducing variability in the data, making it more capable of handling real-world data. However, it is important to apply augmentations judiciously, as too many extreme transformations can lead to overfitting or unrealistic data, thereby decreasing the model’s ability to generalize. It also comes with trade-offs in terms of increased training time and computational cost. Hence, a balanced approach, where augmentations are both realistic and diverse, is key to leveraging the full potential of this technique. The ablation study shows the effect of data augmentation.
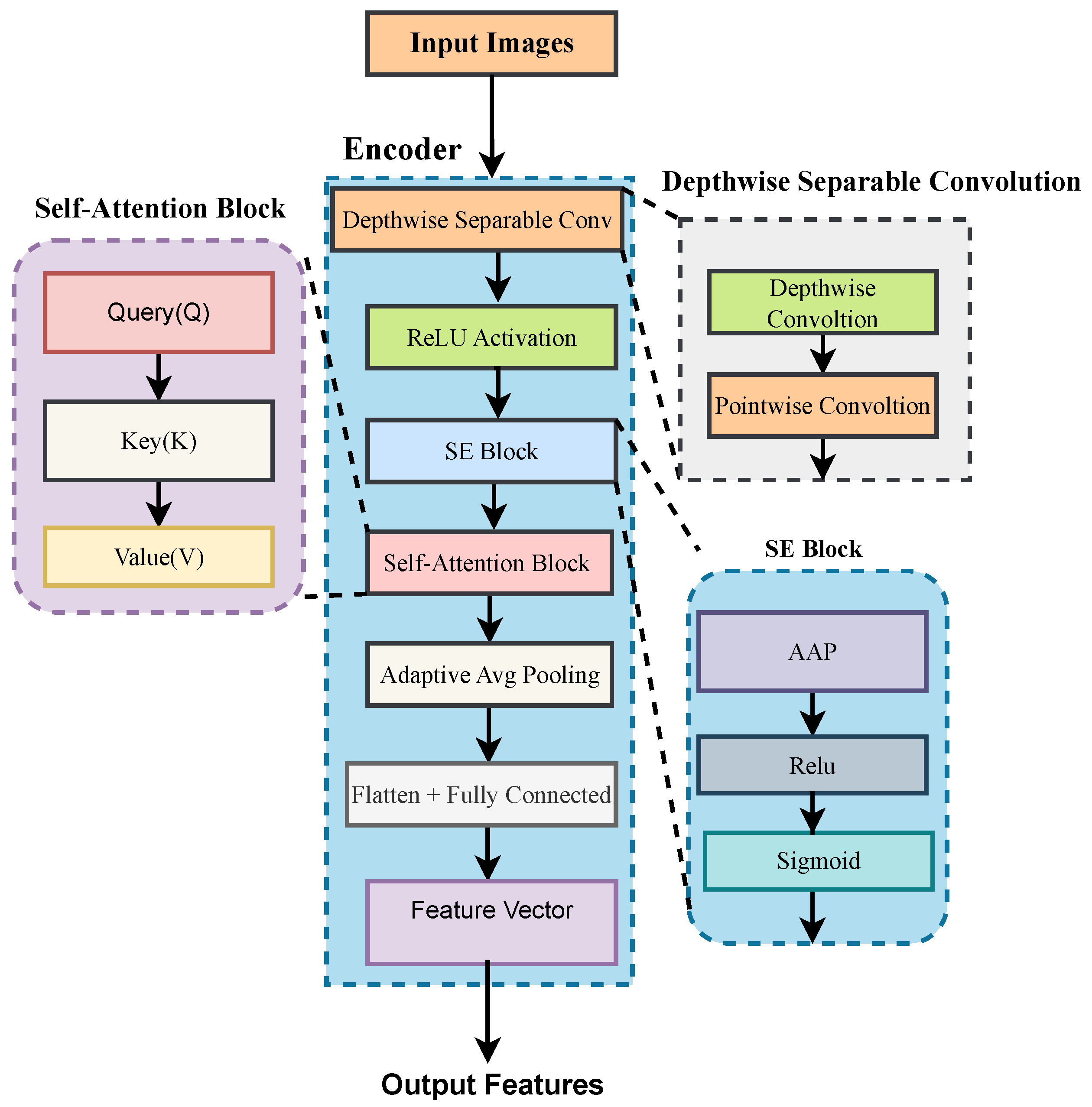
3.3. Encoder Architecture
A detailed diagram of the encoder is shown in
Figure 5. The Dynamic-Separable Convolution-Encoder (DS-Conv) is a neural network that integrates depthwise separable convolutions, a squeeze-and-excitation module [SE], and a self-attention block [SAB] to encode the input data. It also applies an adaptive average-pooling (AAP) operation to minimize the spatial dimensions and a fully connected layer to output the final feature representation. Depthwise Separable Convolution [DSC] separates the depth-wise and point-wise convolutions to minimize the computation. Unlike normal convolutions, each channel is applied independently with a unique filter. This results in fewer parameters. After applying depth-wise convolution, point-wise convolution is performed. The output of DSC is applied to the SEB. The SEB recalibrates feature maps by learning channel-wise dependencies, which consist of A-AP, Relu, and sigmoid modules. The objective of SE is to capture global information (squeezing) and selectively emphasize certain features (excitation), it focuses on more important features and ignore less important features. After SE, the features are passed through the self-attention block (SAB), which contains query (Q), key (K), and value (V) modules. The attention weights are applied to the value matrix, and the result is summed with the original input tensor. The objective is to compute the attention score and identify important data. The output of the SAB is passed through adaptive average pooling (A-AP) and, lastly, flattened.
Algorithm 1 shows the entire pretraining process. The unlabeled data (x) are used to obtain the pretrained encoder (f). The algorithm shows all steps, including positive sample generation, loss computation, and backpropagation.
| Algorithm 1 Self-Supervised Learning Pretraining |
Input: Unlabeled training images x
Output: Trained encoder f- 1:
Define: - 2:
: function of positive sample generation - 3:
: function of attention-based mixing - 4:
for each x in dataset do - 5:
Compute and using - 6:
Compute using - 7:
Extract features from - 8:
Compute using - 9:
Extract prediction features from , , and - 10:
Compute using Equation ( 7) - 11:
Compute using Equation ( 8) - 12:
Compute using Equation ( 9) - 13:
Compute the final loss using Equation ( 10) - 14:
Backpropagate to update the encoder f and predictor g - 15:
end for
|
Similarly, Algorithm 2 shows the entire process of fine tuning of the pretrained model. In this step, labeled data are used, and loss is computed using cross entropy between labeled samples and predicted samples.
| Algorithm 2 Fine Tuning a Pretrained Encoder for Classification |
Input: Training dataset file, Pretrained encoder weights, Number of epochs
Output: Fine-tuned classifier
- 1:
Load Training Data: - 2:
Load from - 3:
Convert labels to class indices using - 4:
Create train dataset and DataLoader - 5:
Load Pretrained Encoder: - 6:
Define encoder f with depthwise separable convolution, SE block, and self-attention - 7:
Load pretrained weights from - 8:
Define Classifier: - 9:
Construct classifier with encoder f followed by a fully connected layer - 10:
Move classifier to device (GPU or CPU) - 11:
Define optimizer (Adam) and loss function (CrossEntropyLoss) - 12:
Fine-Tuning Process: - 13:
for to E do - 14:
Set classifier to training mode - 15:
Initialize total loss to zero - 16:
for each batch in train loader do - 17:
Copy to device - 18:
Compute predictions - 19:
Calculate loss - 20:
Perform backpropagation and update model parameters - 21:
Accumulate loss - 22:
end for - 23:
Print average loss for the epoch - 24:
end for - 25:
Return: Fine-tuned classifier
|
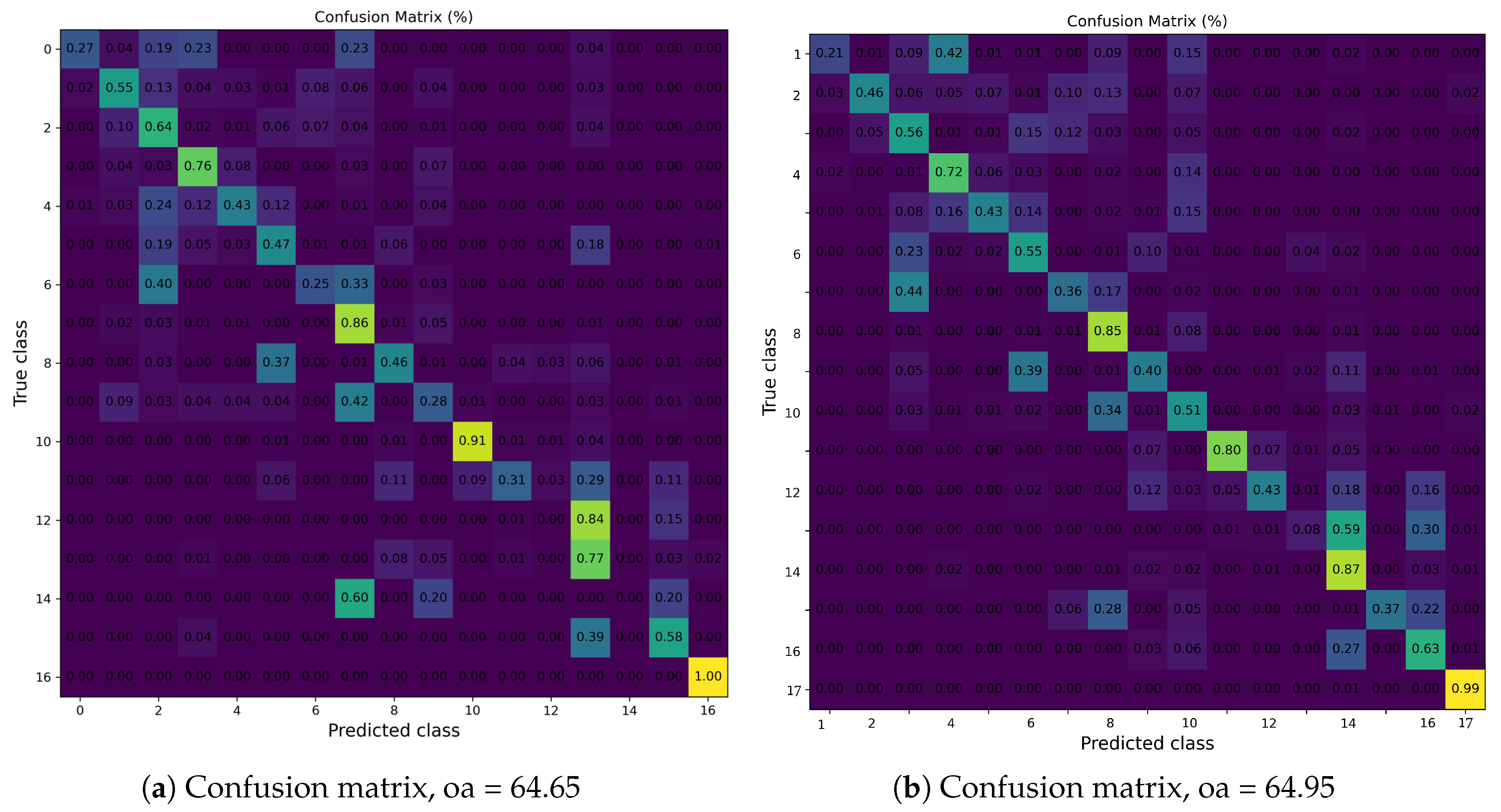
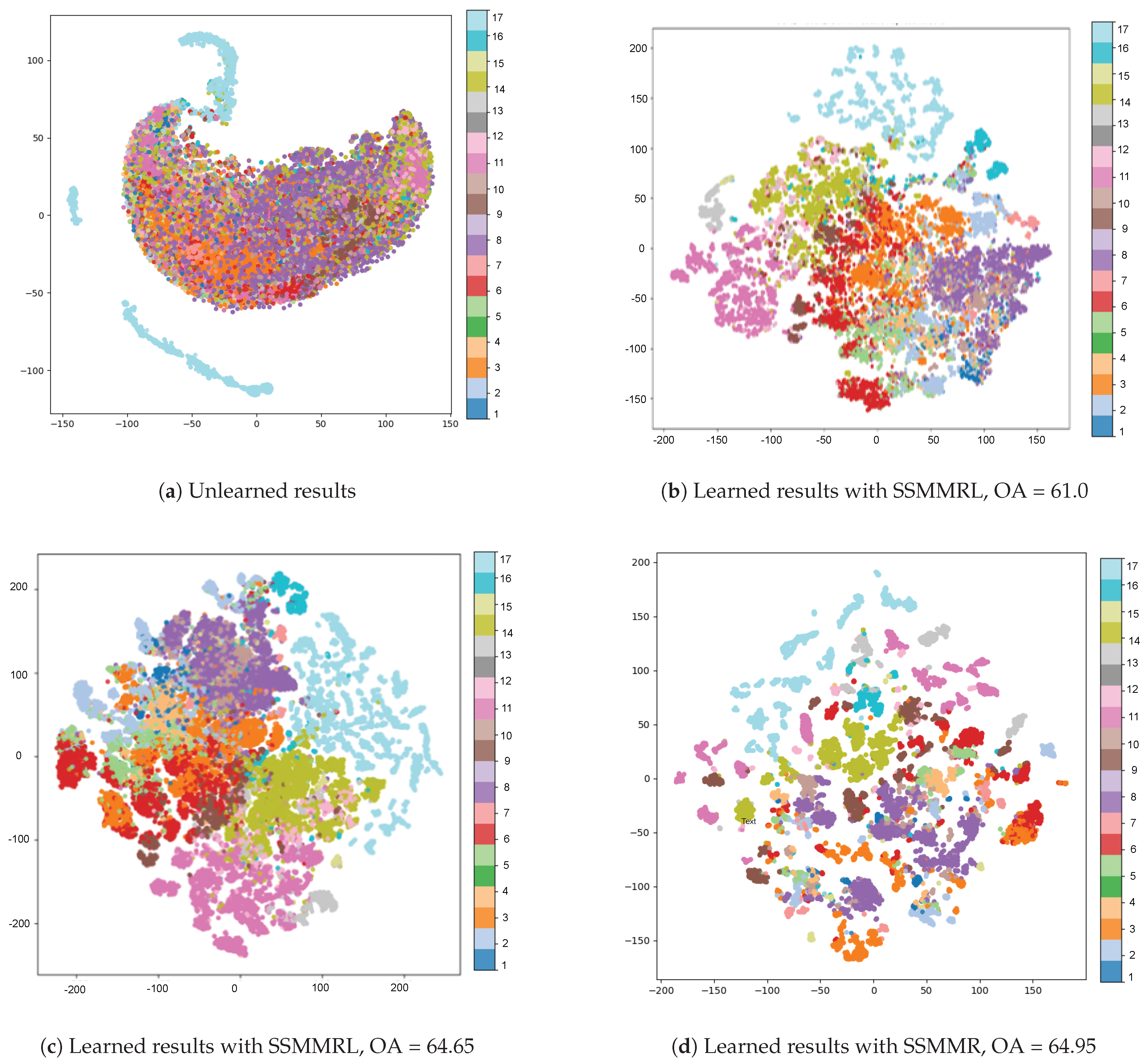
Algorithm 3 is used to find the classification results by using fine-tuned encoder and test data without labels. Once the predicted labels are stored, they can be used later to find the confusion matrix, output accuracy, average accuracy, and kappa values.
| Algorithm 3 Evaluation of Fine-Tuned Classifier on Test Data |
Input: Testing dataset file , Fine-tuned classifier
Output: Model accuracy on test dataset
- 1:
Load Testing Data: - 2:
Load from - 3:
Convert labels to class indices using - 4:
Create test dataset and DataLoader - 5:
Evaluation Process: - 6:
Set classifier to evaluation mode - 7:
Initialize correct predictions counter - 8:
Initialize total samples counter - 9:
Initialize lists for true labels and predicted labels - 10:
for batch in test loader do - 11:
Copy to device - 12:
predictions - 13:
Calculate predicted labels using - 14:
Update correct predictions and total samples - 15:
Store true and predicted labels - 16:
end for - 17:
Compute accuracy as - 18:
Print final accuracy using accuracy_score - 19:
Return: Test accuracy
|
3.4. Attention-Based Mixing
Attention-based mixing assists the model in paying attention to different parts of data, making the network more flexible and capable of handling varying feature relationships between the two inputs. This step mixes the two input feature maps (
and
) based on the attention map. The attention map acts as a weighting function to blend the two inputs.
where
and
are input images from the online and target branches, respectively,
is the final augmented image, and
stands for attention map.
3.5. Loss Computation
The final loss is computed as the sum of the individual losses. As there are three branches in our model, all of the branches are used to compute the final loss. The loss due to the online and target branches is called . Similarly, loss due to the fusion and online branches is called , and loss due to the fusion and target branches is called .
3.5.1. Online-to-Target Loss
In order to ensure that the representations learned by the online branch match a set of target representations, we minimize the cosine similarity loss as follows:
where:
represents the (cosine) similarity between and ;
represents the (cosine) similarity between and ; and
M is the batch size.
3.5.2. Fusion-to-Online Loss
The online representation should be in line with the fused representation (), which is enforced by the following loss, as it is expected to capture significant information from both branches:
Loss from the fusion to the online branch is defined as follows:
where:
3.5.3. Fusion-to-Target Loss
To further verify that the fused representation retains significant target information, we add the fusion-to-target loss:
where:
3.5.4. Final Loss Function
The sum of the individual losses is expressed as
where
,
, and
are are weights of individual losses controlling the contribution of each loss term. These weights allow for flexibility in balancing the different objectives during training. The dataset, augmentation technique, and model architecture are some of the variables that affect the ideal weight values. Typically, training performance is used to experimentally select the weights.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}