3.1. SAR Imaging and Autofocusing
At present, the sparse imaging network of synthetic aperture radar (SAR) usually adopts the end-to-end design, which has limited adaptability to different band radar systems [
32]. In this paper, the imaging operator part of the network model is designed separately, and its parameters do not participate in the optimization of the network model. After the completion of the network optimization, the corresponding approximate observation operator can be selected in the multi-band radar imaging task according to the actual radar system, which improves the universality of the network model. For radar data processing in different bands, different radar systems are used to construct the corresponding approximate observation operators. In order to achieve better single-band radar imaging, the imaging operator can also be trained as a network parameter to optimize the single-band radar imaging task of the network model.
As stated in the above section, the solution of the CS-SAR imaging problem involves the inversion and multiple iterations of the exact measurement matrix
. Due to the large scale of the matrix
, the computing and storage capabilities required are high, which greatly reduces the computational efficiency of SAR imaging algorithms. To solve this problem, this paper adopts the matched filtering (MF) SAR imaging method [
43], such as the Chirp Scaling algorithm, which constructs the approximate measurement operator by decoupling the azimuth and range processing. The exact observation matrix
is replaced by the approximate observation operator, i.e.,
, whose corresponding inverse transformation is
, which represent the inverse imaging operator and the imaging operator, respectively, in the following procedure [
43]:
where
is the Hadarmard product;
,
,
and
are the Fourier transform and inverse Fourier transform operators along the range direction and azimuth direction, respectively; and
,
, and
are phase terms for RCMC, range compression, secondary range compression and consistent RCMC, and azimuthal compression and additional phase correction, respectively.
,
, and
are the conjugate terms of the corresponding phase terms [
43]. Then, the solution model in Equation (4) is rewritten accordingly as
The solution of the sparse SAR imaging model based on the approximate observation operator reduces the scale of the SAR echo measurement matrix and the computational amount. However, the matrix vectorization solution of the traditional CS-SAR imaging still generates an order of magnitude higher computation than that of the MF method, which is difficult to adapt to the real-time processing of SAR images of large scenes. In order to reduce the computational and storage burden of imaging processing, based on the nature of the Kronecker product [
44], the first sub-equation of Equation (8) is rewritten as
Its vector expression is written in the corresponding matrix form for ease of computation:
where
is the matrix form of
;
is the matrix form of
;
is the matrix form of
;
is the matrix form of
;
,
is a sparse sampling matrix, whose elements have the value of either 1 or 0, which represents whether the corresponding sample is available or not; and
is an all-one matrix. At this point, the iterative matrix of the image is obtained, serving as an important step in the
X module.
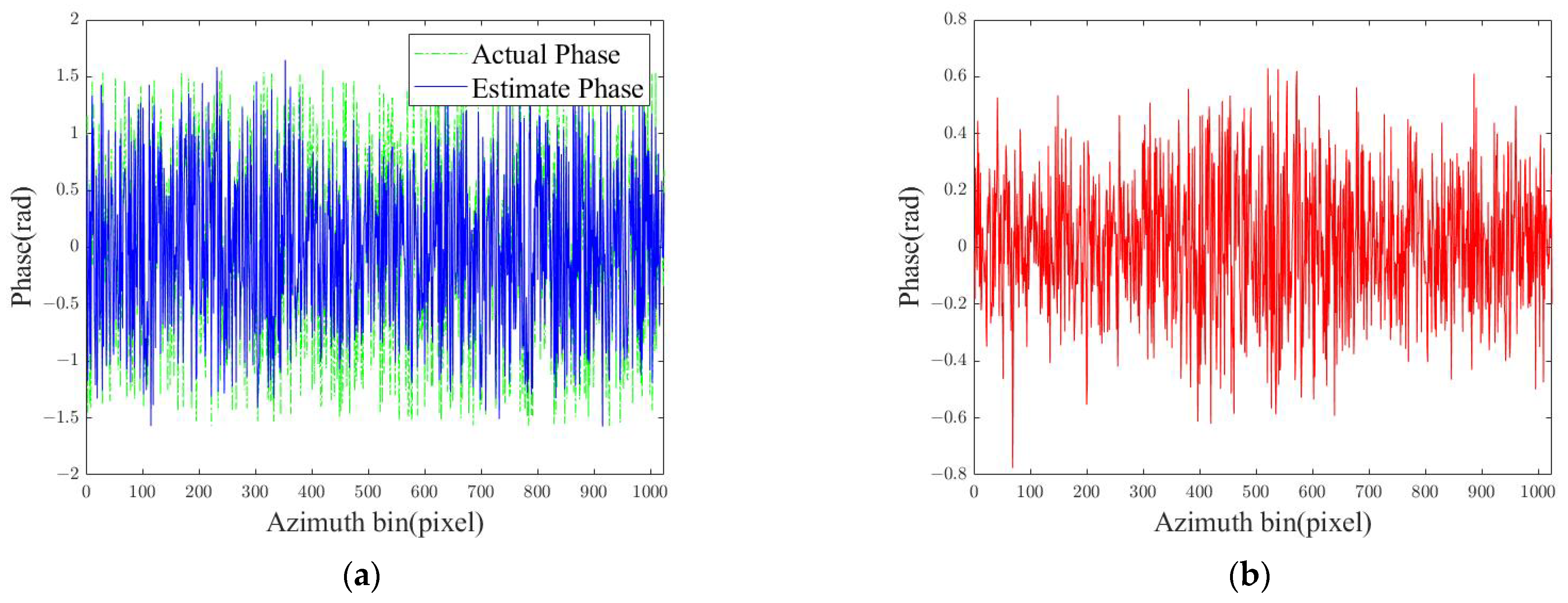
In addition, the phase error term
should also be estimated and compensated for during the imaging process for focused SAR imaging. This is an optimization problem, i.e., [
41]:
Therefore, after the iterative optimization of the SAR image scene
based on the reconstruction algorithm, this paper utilizes the solution method in the literature [
45] for the estimation of phase error compensation.
where
is the phase error estimated from the previous iteration, here a diagonal matrix. A related module is introduced to estimate and compensate for the phase error, and the phase error is eliminated by k iterations of Equation (14).
As mentioned above, by combining sparse SAR image reconstruction with an autofocus iterative solution, SAR autofocusing imaging is realized. However, there are still some problems with this approach. The soft threshold function based on -norm corresponds to the sparse regularization of the “1” regularizer. This method often relies on the sparsity of the scene, that is, the threshold function is closely related to the sparsity of the output image. In general, the rarer the image, the higher the threshold, making it difficult to adapt to complex scenes.
In order to better adapt to the reconstruction of complex scenes, this paper uses a nonlinear operator
P as a non-fixed
regularization to replace the soft threshold function
, which is used to constrain the uncertain transform domain of the target scene. The traditional
regularization is to process the data of the model by determining the norm and the hyperparameter of the fixed value in the preset mathematical form. The P operator is introduced as a data-driven adaptive module, which can dynamically adjust the regularization mode and parameters. Through the end-to-end learning of nonlinear sparse transform and dynamic parameters, the algorithm can flexibly adapt to the sparse characteristics of different scenes. This design breaks through the dependence of traditional compressed sensing methods on the hypothesis of scene sparsity and provides a new idea for the practical application of multi-scene SAR. The corresponding solution of Equation (4) can be rewritten as
For the second sub-equation of Equation (15), the gradient descent algorithm is utilized to approximate the solution, viz:
where
is the step size of the gradient descent algorithm, and
and
stand for convolution layer 1 and convolution layer 2, respectively.
denotes the corresponding nonlinear transformation in a regularized function, and the iterations are indexed by
. Equation (16) shows the iterative calculation steps of the
Z module.
Therefore, by jointly solving the sparse SAR reconstruction and autofocus problems, SAR autofocusing imaging under the condition of sparse sampling and phase error can be realized. However, the parameters , of the algorithm solution need to be pre-set, and it is difficult to choose an appropriate parameter to adapt to the reconstruction needs of complex scenes.
3.2. Construction of the Proposed Network
Based on the advantages of data-driven deep networks, we design the proposed algorithmic model as a corresponding network.
Firstly, the parameters in the network are set to be learnable. Through training, the corresponding gradient updates are carried out using backpropagation in deep networks to optimize the parameters. Secondly, the data-driven characterization of different sparse transformations overcomes the lack of reconstruction accuracy of traditional methods based on
regularization [
33] for complex scene reconstruction. It should be noted that the parameters in the algorithmic network do not need to be set manually based on experience but can be learned from data, which avoids the difficulty of parameter setting and improves the adaptability and robustness of the algorithm to different scenes.
In addition, the traditional network is usually end to end to realize the reconstruction of the echo to the image, mapping the input echo to the reconstruction result as a corresponding function through training. The corresponding network design is complex and often less adapted to radar systems of different bands. In this paper, there is a separable network design for different radar systems, which separates the design of the imaging operator from the network design. That is, we utilize a network design that combines the sparse reconstruction of raw echoes with conventional MF algorithms, and the reconstruction of the echoes is separable from the imaging process, so as to select the appropriate imaging operators for different radar systems.
The detailed network structure is shown in
Figure 2. After the input, the echo signal enters the initial stage
and interacts with the subsequent module through the inverse operator connection of the approximate operator in Equation (9). The network proposed in this paper consists of four modules and is structured into K stages. At each stage, all four modules perform their corresponding computations. Taking the one stage as an example, the
X-module is responsible for azimuth feature extraction, including approximation operators; the
Z-module performs range-direction optimization and sparse constraints; the
U-module handles dynamic parameter updating; and the
-module is dedicated to phase error estimation and self-focusing. The final image is obtained after the four modules complete K stages iterations. The operation diagram corresponding to the computational details of each module is shown in
Figure 3, utilizing the deep network to realize the solution of the iterative scheme derived in
Section 2. The components and roles of these four modules are described in detail below.
X-module: It mainly contains four inputs, the input echo y and the upper layer of module outputs , Z, and U. The forward propagation process of the data refers to the first sub-equation in Equation (15) above. The parameter ρ in the network reconstruction layer is a learnable parameter that can be optimized and updated by backpropagation during the training process. It should be noted that during the network design process, the approximate observation module in the X-module is designed separately for better adaptation to different radar systems. The phase parameters of the approximate observation operators do not participate in the training learning. The X module primarily completes the initial imaging of the region, providing a data reference for subsequent optimization;
Z-module: After completing the iterations in the
X-module, the results are input into the
Z-module. It mainly contains two inputs, which are the output of the X-module in this iteration, and the output of the U-module in the previous iteration. The module mainly consists of two convolutional layers (
and
) and a nonlinear layer activation layer
, which represent convolutional feature extraction and nonlinear activation operations, respectively. The specific calculation process refers to Equation (16). In this paper, the nonlinear activation layer
is implemented by a piecewise linear function [
32], which contains a series of control points
.
is uniformly set in the corresponding position located in [−1, 1], and
represents the value of the corresponding position of the
of the kth iteration. Its corresponding parameters can be updated to learn from the training data. By combining the
X-module of this iteration and the
U-module of the last iteration, the range-oriented optimization and sparse constraint of the image are completed, so as to effectively suppress range-oriented noise and interference and improve the robustness of the image;
U-module: It is mainly used to update parameters, and the specific calculation process refers to the third sub-equation of Equation (15), where parameter
η is also a learnable parameter, and its forward propagation and input–output relation are shown in
Figure 3. The
U-module dynamically updates the differences between azimuth-oriented feature
and range-oriented feature
by learning parameters
, balances sparse constraints and data fidelity, prevents overfitting or underfitting, and feeds back the update results to the next stage, supports multi-stage iterative optimization, and improves imaging accuracy and network stability;
-module: It is primarily used to estimate phase errors, which are determined based on the optimized reconstructed image. This process evaluates whether the input echo contains phase errors. The specific calculation method is detailed in Equation (14). The phase error matrix
is estimated by minimizing the difference between the observed data
and the reconstructed scene
. Specifically,
is a diagonal matrix whose diagonal elements represent the phase error correction factors for each sampling point. The forward propagation process and the input–output relationship are illustrated in
Figure 3. The corrected phase parameter
is then fed back to the
-module, enabling multi-stage iterative optimization. This feedback mechanism estimates the phase error in this stage and feeds it back to the iteration in the next stage, and it accurately removes its influence through multiple estimates to improve the imaging quality. However, it is worth noting that the module has a limited ability to estimate large-range errors. In the future, the ability to correct large-range errors can be improved by introducing more complex error models (such as polynomial models) or joint optimization strategies.
Figure 2.
Network structure.
Figure 2.
Network structure.
Figure 3.
Structures of the modules in the one stage of the network.
Figure 3.
Structures of the modules in the one stage of the network.
3.3. Network and Experimental Background
Loss Functions: In this paper, the loss function of the proposed network is defined as
where
is the reconstructed scene output by the network,
is the labeled image generated by the fully sampled echo using the traditional MF algorithm, and
represents the number of echoes included in the dataset.
is the Frobenius norm. The loss function uses the normalized Frobenius norm to measure the difference between the reconstructed image and the traditional matched filter (MF) label globally, ensuring that the target and the background scattering intensity match accurately. Normalization eliminates amplitude differences and improves training stability. MF results are labeled to inherit physical model interpretability and optimize MF defects. Loss-guided network modules (such as sparse optimization of the X/Z-module and phase correction of the
-module) cooperate to improve the imaging quality and system adaptability to complex scenes.
Structural Parameters: The parameters in the network mainly include two categories; one is the parameters of
,
, and the other is the parameters of the convolutional layer and nonlinear layer of the network. In the algorithm for solving Equation (15), there are unknown parameters: the penalty parameter
and the Lagrangian update step size
.
and
balance data fidelity and sparse constraints, control multiplier update speed, and affect reconstruction accuracy, convergence speed, and image detail. Reasonable selection can improve imaging quality and algorithm robustness. In this paper, the parameter is optimized by the model-training situation and is not a fixed value. Compared with the traditional fixed parameterization method, the proposed method can optimize the parameters during network training, so as to better adapt to different imaging tasks. Although it can find optimal solutions based on network learning, their initial values must be set before the algorithm iteration is performed. The penalty function ρ and update step are set according to the default of the classical ADMM algorithm, and the network convergence is the fastest and the training is stable [
33]. These parameters are designed to be learnable, and the optimized model parameters do not need to be reset for different scenes.
Backpropagation and gradient calculation: Since both SAR echo data and SAR image data are complex forms, a back propagation (BP) algorithm is used to train the network through the loss function and complex domain. For any complex matrix
with a real-valued function
in the corresponding SAR complex data, the derivative of
with respect to
can be calculated by the complex derivation formula:
where
and
denote the real and imaginary parts of the complex matrix
, respectively. Using the derivation formula can then be used to solve for the gradient in the complex domain. The parameters can be updated according to the computed loss function. In this paper the adam optimizer is used for the gradient update.
Network Configuration: The total number of iterations K is set to 4. The regularization term is set to 1. The convolution channel L is set to 16. The control point J is set to 10. The size of the convolution kernel is 5 × 5. The learning rate is initially set to 0.001, adjusted using the adaptive learning rate, and updated every 50 epochs.
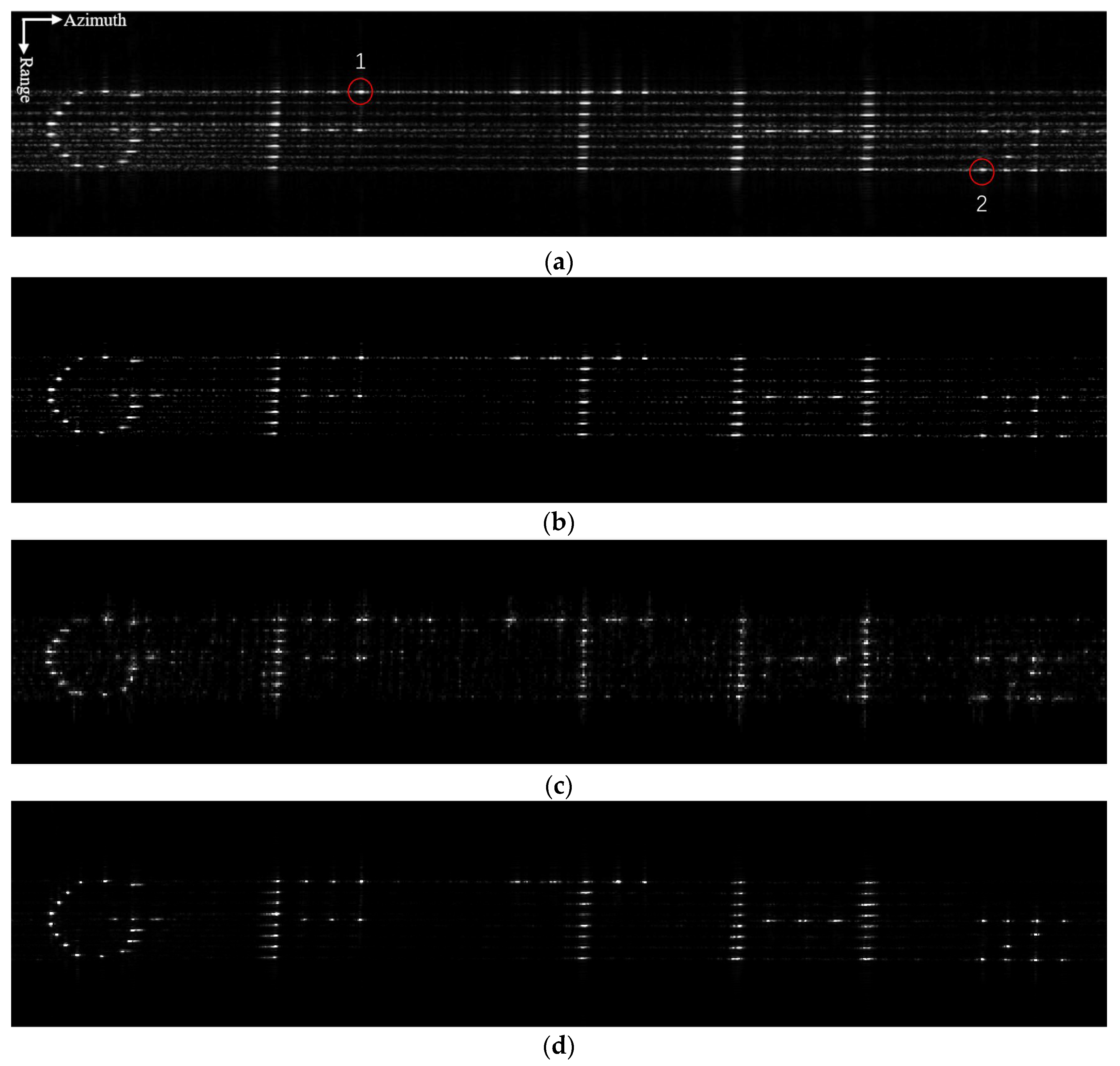
Experimental Data: Due to the small amount of measured radar data, it is difficult to train the network with measured echoes. Therefore, the network model is trained through using SAR simulation echoes of random point targets and complex surface targets. The specific radar parameter settings used in the training dataset are shown in
Table 1:
- 6.
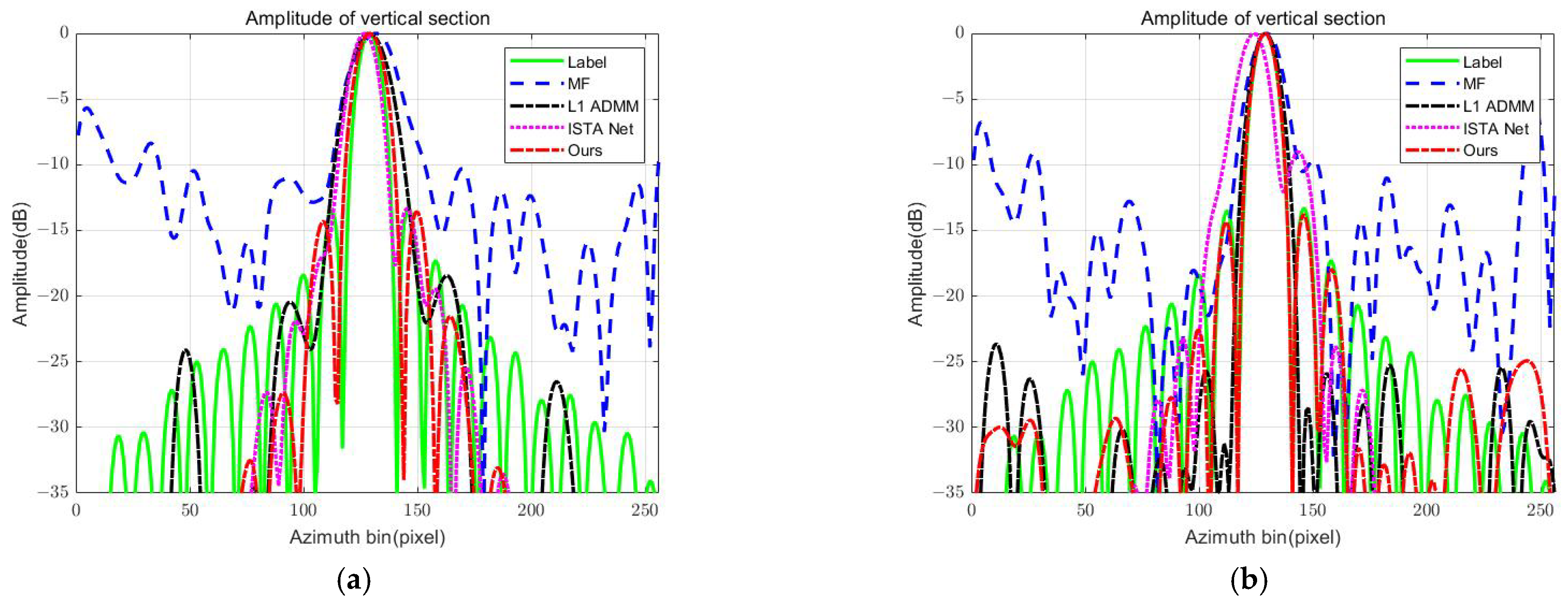
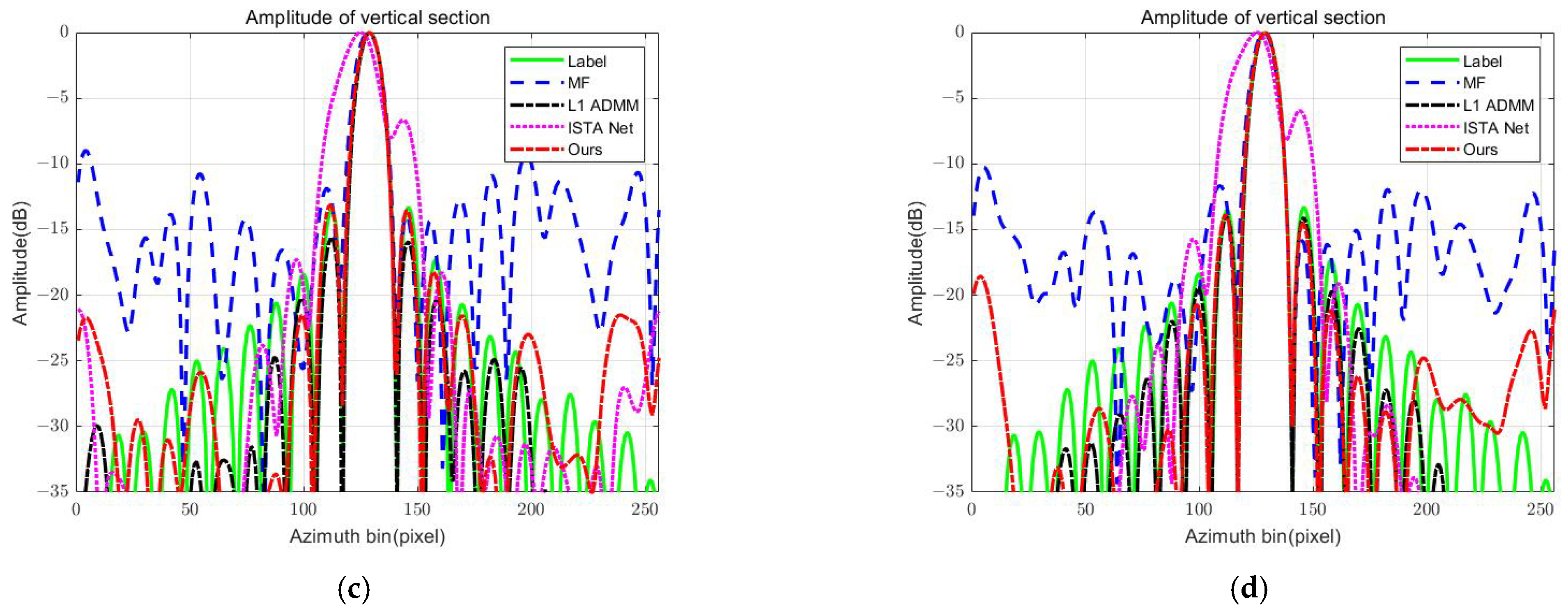
Evaluation Index: For a quantitative evaluation of the reconstruction results, this paper adopts different evaluation criteria according to different scenarios of point targets and surface targets. For the evaluation of the quality of point target reconstruction, some basic point target analysis indexes [
38], such as impulse response width (IRW) and peak sidelobe ratio (PSLR), are selected to conduct a quantitative evaluation of the reconstructed point target. In addition, normalized mean square error (NMSE), peak signal-to-noise ratio (PSNR), structural similarity (SSIM), and image entropy (En) are used to evaluate the reconstruction quality of surface targets. Reconstructed image indicators corresponding to surface targets are defined as follows [
41]:
where
and
are, as described in the previous section, the reconstructed and labeled scenes, respectively. The definition of PSNR is as follows [
41]:
where
, and
is the total number of pixel points in the scene. The definition of SSIM is as follows [
41]:
where
,
,
,
,
are the local means, standard deviations, and cross-covariance for images
and
.
and
are set as
,
, where
,
, and L is the range of pixel values of the image, which is set to 0~1.
where
represents the total energy of the reconstruction result.
For the evaluation of point target image quality, a numerical comparison can be made directly with the theoretical value. For the evaluation of surface targets, this can be known from the definition of index parameters, in which NMSE and PSNR can evaluate the quality of image reconstruction. SSIM represents the advantages and disadvantages of feature reconstruction, and En is used to evaluate the quality of image focusing. The smaller the NMSE and En, the better the image quality; and the larger PSNR and SSIM, the better the image quality.



 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}