
A Novel Bias-Adjusted Estimator Based on Synthetic Confusion Matrix (BAESCM) for Subregion Area Estimation


Abstract
:1. Introduction
2. Materials
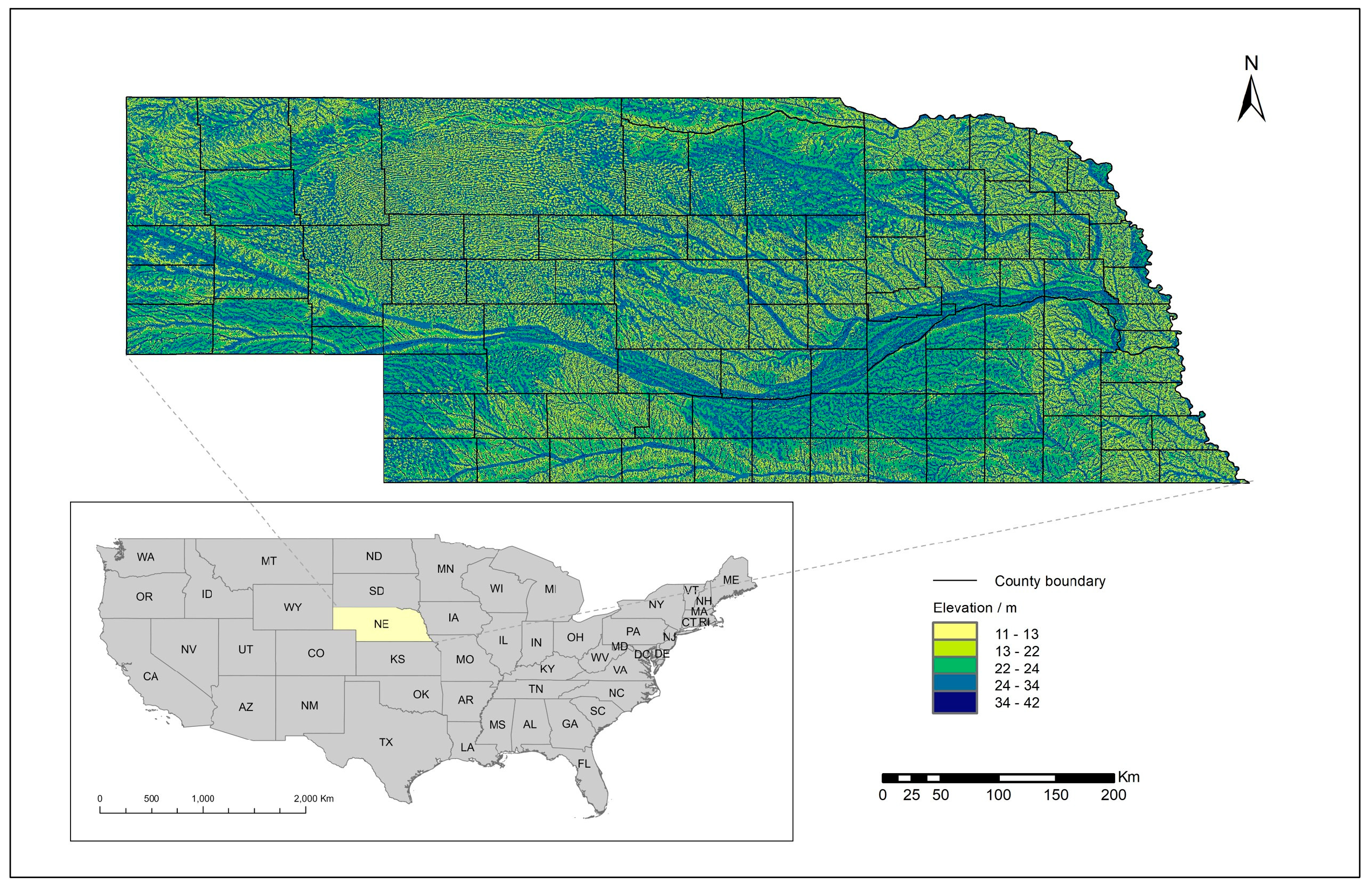
2.1. Study Area
2.2. Reference Data
2.3. Sentinel-2 Data
2.4. Classification Map of Soybean
3. Methods
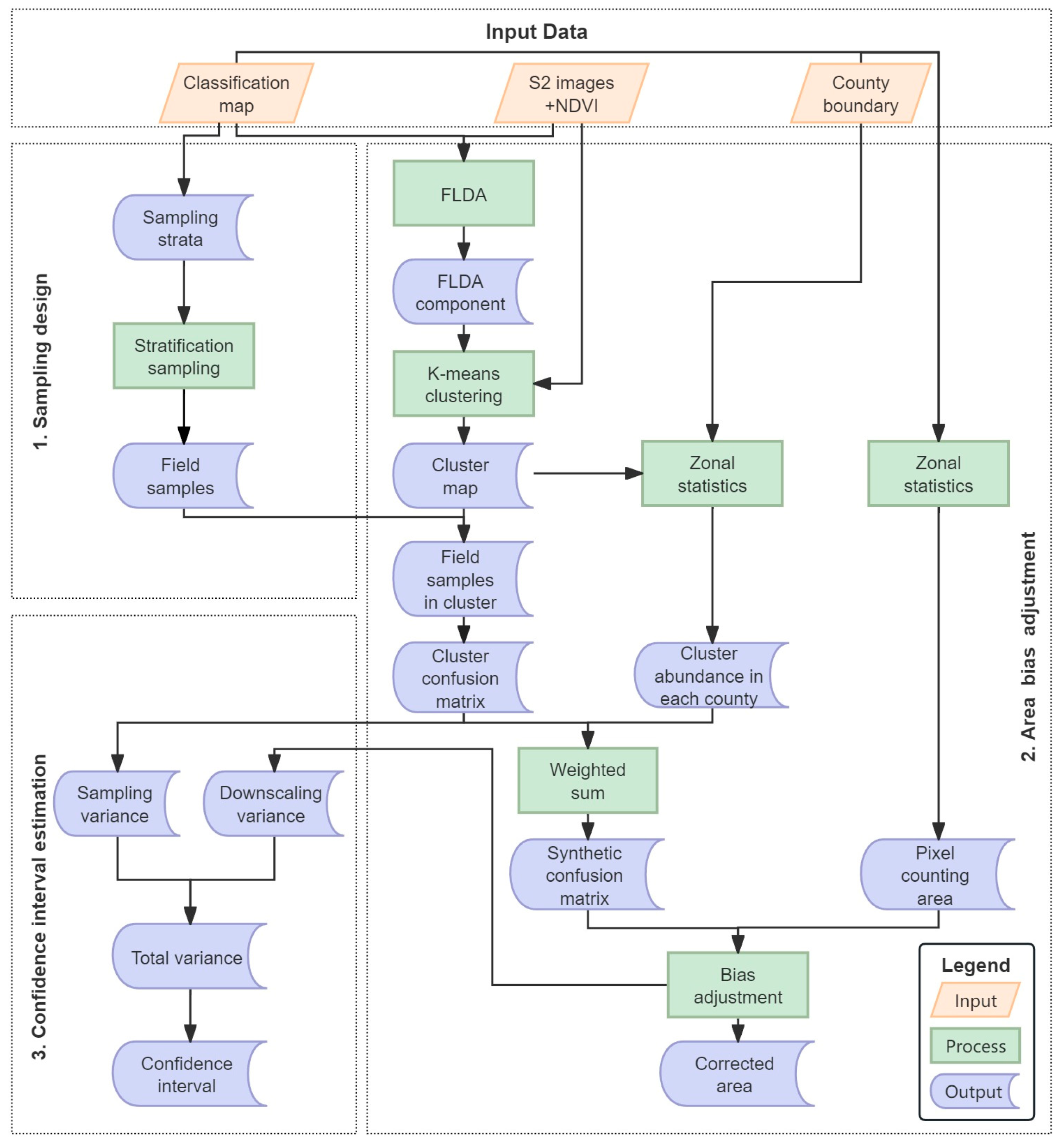
3.1. Sampling Design
3.2. Area Bias Adjustment Based on Synthetic Confusion Matrix at Subregion Scale
3.2.1. Spectral Clustering
3.2.2. Estimation of Cluster Confusion Matrix
3.2.3. Confusion Matrix Synthesis for Subregions
3.2.4. Bias Adjustment of Subregion Areas
3.3. Semi-Empirical Estimation of the Confidence Interval of the Area Estimate
3.3.1. Estimation of the Sampling Variance
3.3.2. Estimation of the Downscaling Variance
3.3.3. Estimation of Confidence Interval of BAESCM Area Estimate
4. Results
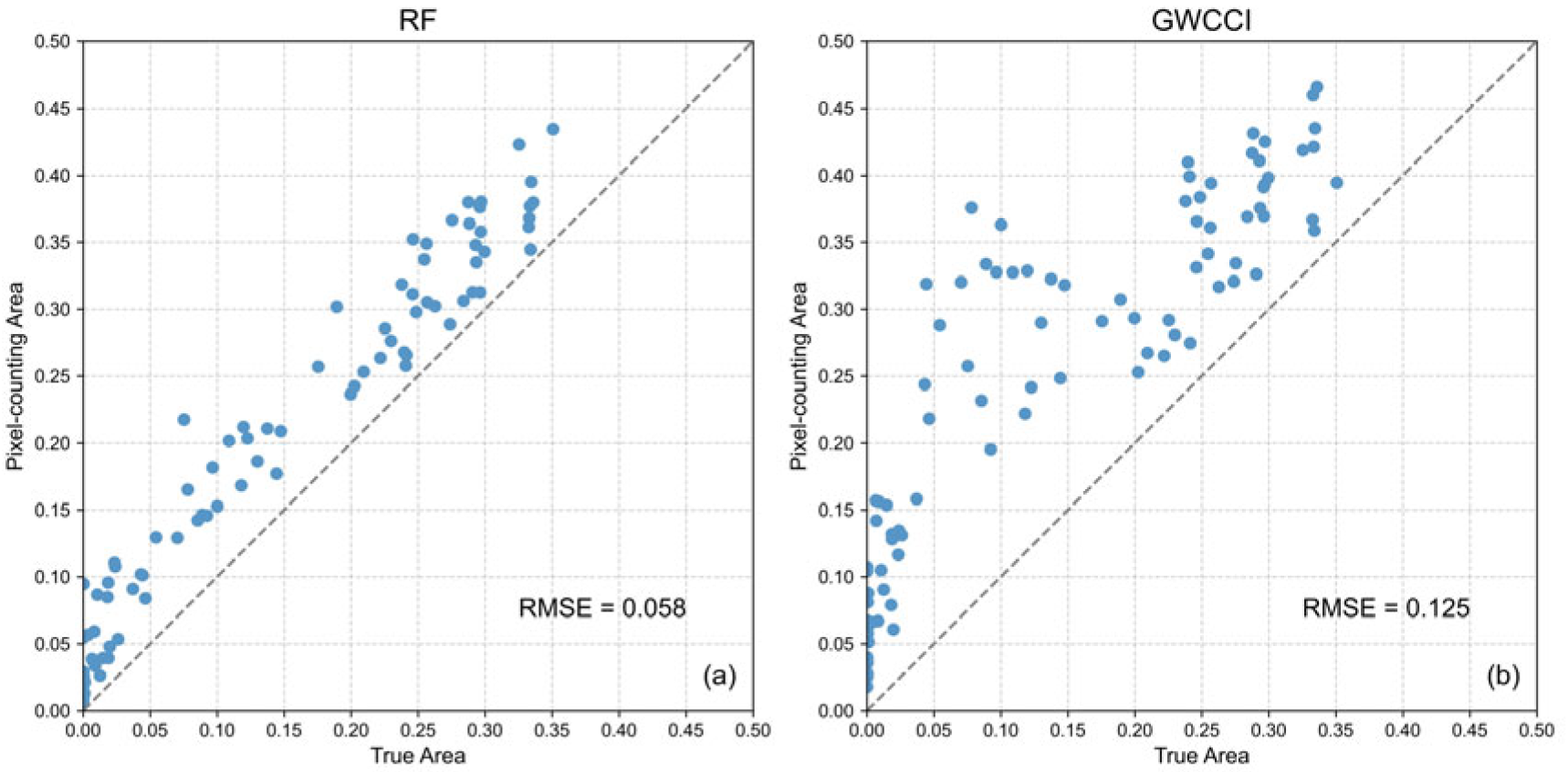
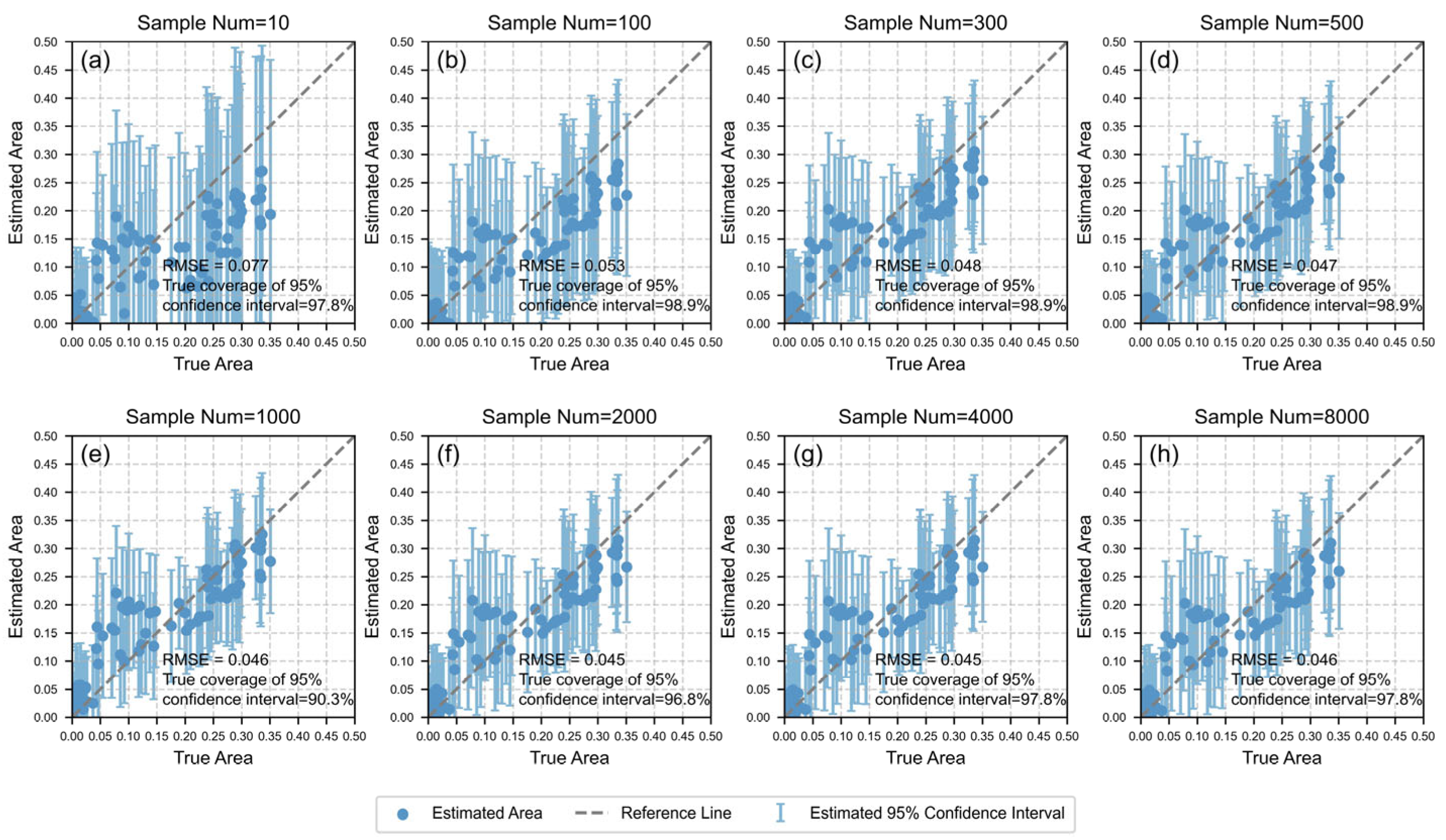
4.1. Area Estimation Results by BAESCM
4.2. Comparison with Traditional Design-Based Methods
5. Discussions
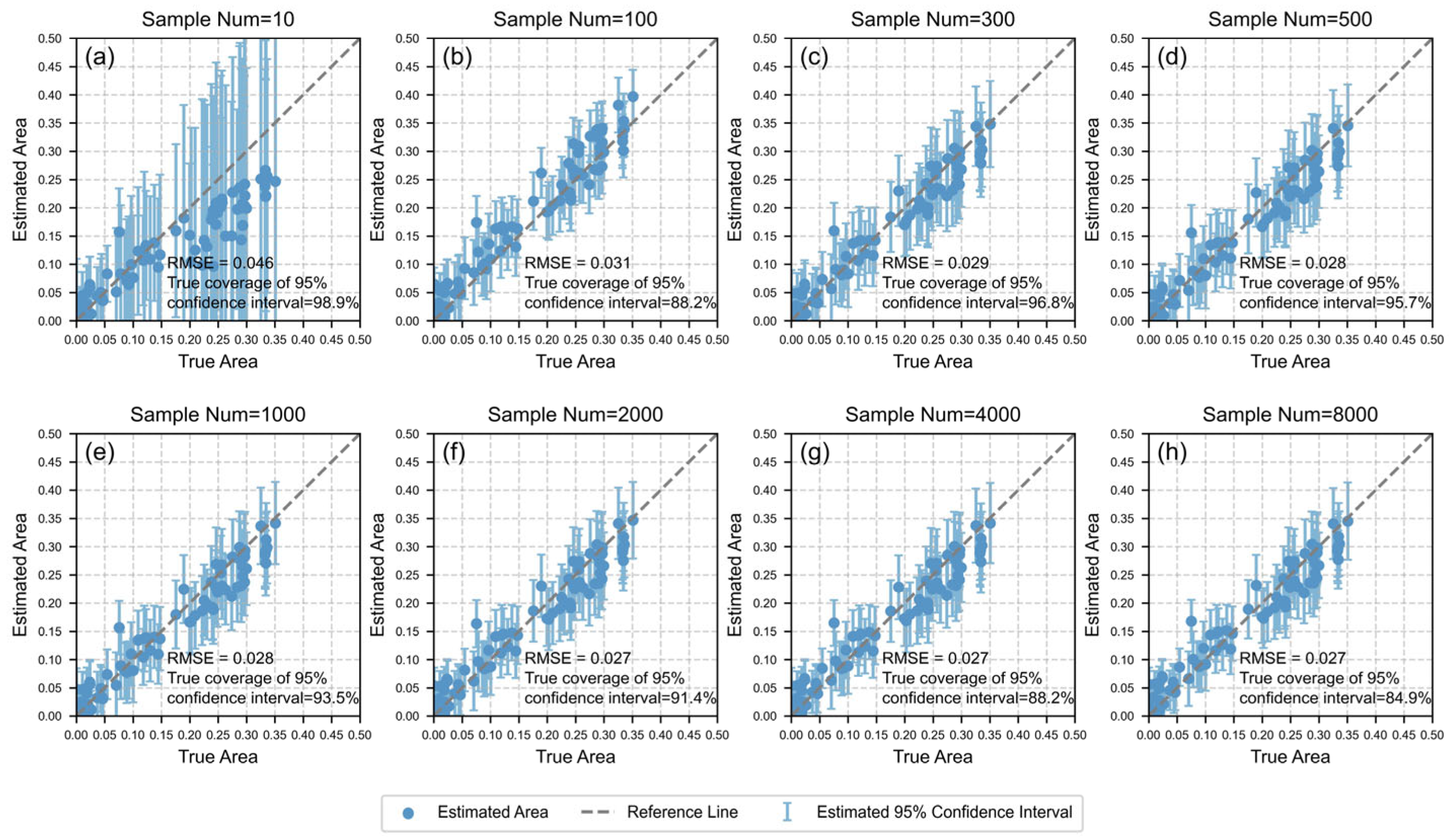
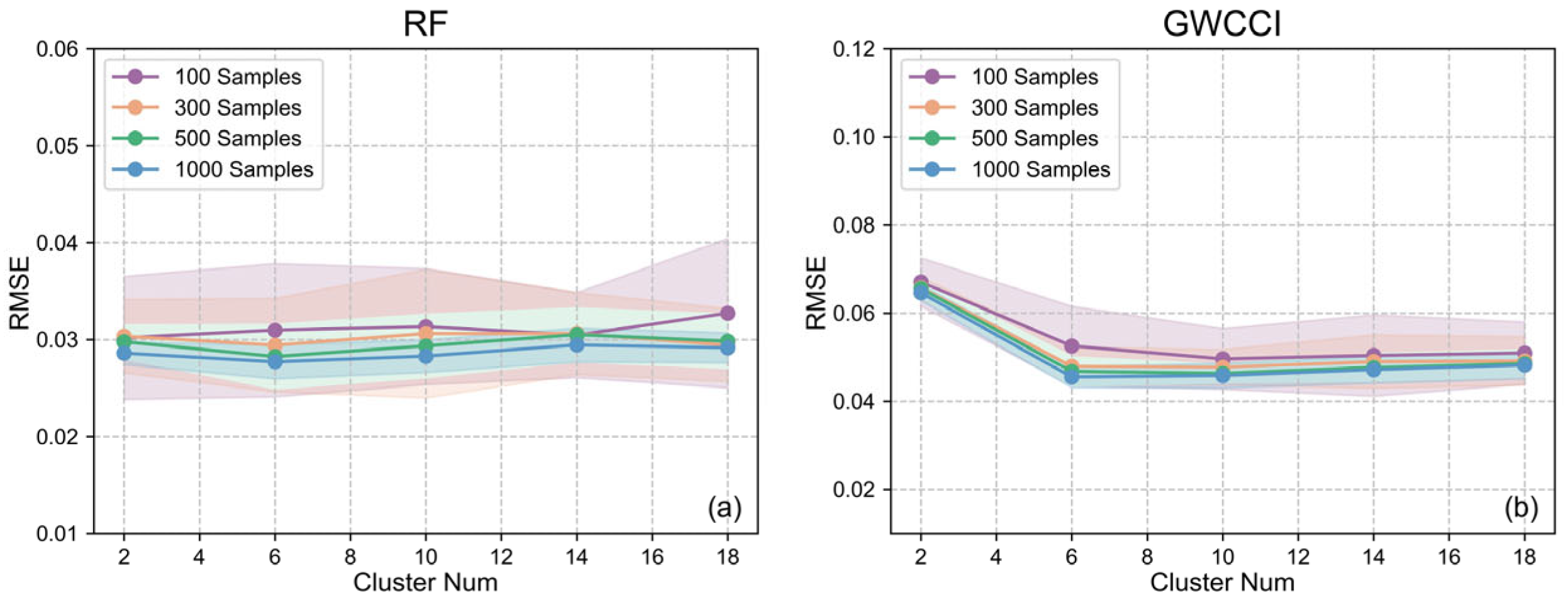
5.1. Selection of Cluster Number for the BAESCM Method
5.2. Advantages and Limitations
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Gallego, F.J. Remote Sensing and Land Cover Area Estimation. Int. J. Remote Sens. 2004, 25, 3019–3047. [Google Scholar] [CrossRef]
- Pradhan, S. Crop Area Estimation Using GIS, Remote Sensing and Area Frame Sampling. Int. J. Appl. Earth Obs. Geoinf. 2001, 3, 86–92. [Google Scholar] [CrossRef]
- Bégué, A.; Arvor, D.; Bellon, B.; Betbeder, J.; De Abelleyra, D.; Ferraz, R.P.D.; Lebourgeois, V.; Lelong, C.; Simões, M.; Verón, S.R. Remote Sensing and Cropping Practices: A Review. Remote Sens. 2018, 10, 99. [Google Scholar] [CrossRef]
- Weiss, M.; Jacob, F.; Duveiller, G. Remote Sensing for Agricultural Applications: A Meta-Review. Remote Sens. Environ. 2020, 236, 111402. [Google Scholar] [CrossRef]
- Liu, J.; Wang, L.; Yang, F.; Yang, L.; Wang, X. Remote Sensing Estimation of Crop Planting Area Based on HJ Time-Series Images. Trans. Chin. Soc. Agric. Eng. 2015, 31, 199–206. [Google Scholar]
- Czaplewski, R.L.; Catts, G.P. Calibration of Remotely Sensed Proportion or Area Estimates for Misclassification Error. Remote Sens. Environ. 1992, 39, 29–43. [Google Scholar] [CrossRef]
- Ozdogan, M.; Woodcock, C.E. Resolution Dependent Errors in Remote Sensing of Cultivated Areas. Remote Sens. Environ. 2006, 103, 203–217. [Google Scholar] [CrossRef]
- Richards, J. Classifier Performance and Map Accuracy. Remote Sens. Environ. 1996, 57, 161–166. [Google Scholar] [CrossRef]
- Stehman, S. Comparing Estimators of Gross Change Derived from Complete Coverage Mapping Versus Statistical Sampling of Remotely Sensed Data. Remote Sens. Environ. 2005, 96, 466–474. [Google Scholar] [CrossRef]
- McRoberts, R.E. Satellite Image-Based Maps: Scientific Inference or Pretty Pictures? Remote Sens. Environ. 2011, 115, 715–724. [Google Scholar] [CrossRef]
- Li, Y.; Zhu, X.; Pan, Y.; Gu, J.; Zhao, A.; Liu, X. A Comparison of Model-Assisted Estimators to Infer Land Cover/Use Class Area Using Satellite Imagery. Remote Sens. 2014, 6, 8904–8922. [Google Scholar] [CrossRef]
- McRoberts, R.E. Probability- and Model-Based Approaches to Inference for Proportion Forest Using Satellite Imagery as Ancillary Data. Remote Sens. Environ. 2010, 114, 1017–1025. [Google Scholar] [CrossRef]
- Ståhl, G.; Saarela, S.; Schnell, S.; Holm, S.; Breidenbach, J.; Healey, S.P.; Patterson, P.L.; Magnussen, S.; Næsset, E.; McRoberts, R.E.; et al. Use of Models in Large-Area Forest Surveys: Comparing Model-Assisted, Model-Based and Hybrid Estimation. For. Ecosyst. 2016, 3, 5. [Google Scholar] [CrossRef]
- Stehman, S.V. Estimating Area from an Accuracy Assessment Error Matrix. Remote Sens. Environ. 2013, 132, 202–211. [Google Scholar] [CrossRef]
- Stehman, S.V. Model-Assisted Estimation as a Unifying Framework for Estimating the Area of Land Cover and Land-Cover Change from Remote Sensing. Remote Sens. Environ. 2009, 113, 2455–2462. [Google Scholar] [CrossRef]
- Stehman, S.V.; Foody, G.M. Key Issues in Rigorous Accuracy Assessment of Land Cover Products. Remote Sens. Environ. 2019, 231, 111199. [Google Scholar] [CrossRef]
- Hansen, M.H.; Madow, W.G.; Tepping, B.J. An Evaluation of Model-Dependent and Probability-Sampling Inferences in Sample Surveys. J. Am. Stat. Assoc. 1983, 78, 776–793. [Google Scholar] [CrossRef]
- McRoberts, R.E.; Walters, B.F. Statistical Inference for Remote Sensing-Based Estimates of Net Deforestation. Remote Sens. Environ. 2012, 124, 394–401. [Google Scholar] [CrossRef]
- Breidenbach, J.; McRoberts, R.E.; Astrup, R. Empirical Coverage of Model-Based Variance Estimators for Remote Sensing Assisted Estimation of Stand-Level Timber Volume. Remote Sens. Environ. 2016, 173, 274–281. [Google Scholar] [CrossRef]
- Broich, M.; Stehman, S.V.; Hansen, M.C.; Potapov, P.; Shimabukuro, Y.E. A Comparison of Sampling Designs for Estimating Deforestation from Landsat Imagery: A Case Study of the Brazilian Legal Amazon. Remote Sens. Environ. 2009, 113, 2448–2454. [Google Scholar] [CrossRef]
- Kleinewillinghöfer, L.; Olofsson, P.; Pebesma, E.; Meyer, H.; Buck, O.; Haub, C.; Eiselt, B. Unbiased Area Estimation Using Copernicus High Resolution Layers and Reference Data. Remote Sens. 2022, 14, 4903. [Google Scholar] [CrossRef]
- McRoberts, R.E.; Liknes, G.C.; Domke, G.M. Using a Remote Sensing-Based, Percent Tree Cover Map to Enhance Forest Inventory Estimation. For. Ecol. Manag. 2014, 331, 12–18. [Google Scholar] [CrossRef]
- Dong, Q.; Chen, X.; Chen, J.; Yin, D.; Zhang, C.; Xu, F.; Rao, Y.; Shen, M.; Chen, Y.; Stein, A. Bias of Area Counted from Sub-Pixel Map: Origin and Correction. Sci. Remote Sens. 2022, 6, 100069. [Google Scholar] [CrossRef]
- McRoberts, R.E. A Model-Based Approach to Estimating Forest Area. Remote Sens. Environ. 2006, 103, 56–66. [Google Scholar] [CrossRef]
- Ståhl, G.; Holm, S.; Gregoire, T.G.; Gobakken, T.; Næsset, E.; Nelson, R. Model-Based Inference for Biomass Estimation in a LiDAR Sample Survey in Hedmark County, NorwayThis Article Is One of a Selection of Papers from Extending Forest Inventory and Monitoring over Space and Time. Can. J. For. Res. 2011, 41, 96–107. [Google Scholar] [CrossRef]
- Chen, Q.; McRoberts, R.E.; Wang, C.; Radtke, P.J. Forest Aboveground Biomass Mapping and Estimation Across Multiple Spatial Scales Using Model-Based Inference. Remote Sens. Environ. 2016, 184, 350–360. [Google Scholar] [CrossRef]
- Lohr, S.L. Sampling: Design and Analysis; Chapman and Hall/CRC: London, UK, 2021. [Google Scholar]
- Johnson, D.M. An Assessment of Pre- and within-Season Remotely Sensed Variables for Forecasting Corn and Soybean Yields in the United States. Remote Sens. Environ. 2014, 141, 116–128. [Google Scholar] [CrossRef]
- Boryan, C.; Yang, Z.; Mueller, R.; Craig, M. Monitoring US Agriculture: The US Department of Agriculture, National Agricultural Statistics Service, Cropland Data Layer Program. Geocarto Int. 2011, 26, 341–358. [Google Scholar] [CrossRef]
- Lark, T.J.; Mueller, R.M.; Johnson, D.M.; Gibbs, H.K. Measuring Land-Use and Land-Cover Change Using the U.S. Department of Agriculture’s Cropland Data Layer: Cautions and Recommendations. Int. J. Appl. Earth Obs. Geoinf. 2017, 62, 224–235. [Google Scholar] [CrossRef]
- Hao, P.; Di, L.; Zhang, C.; Guo, L. Transfer Learning for Crop Classification with Cropland Data Layer Data (CDL) as Training Samples. Sci. Total Environ. 2020, 733, 138869. [Google Scholar] [CrossRef]
- Sun, Z.; Di, L.; Fang, H. Using Long Short-Term Memory Recurrent Neural Network in Land Cover Classification on Landsat and Cropland Data Layer Time Series. Int. J. Remote Sens. 2019, 40, 593–614. [Google Scholar] [CrossRef]
- Zhang, C.; Di, L.; Hao, P.; Yang, Z.; Lin, L.; Zhao, H.; Guo, L. Rapid In-Season Mapping of Corn and Soybeans Using Machine-Learned Trusted Pixels from Cropland Data Layer. Int. J. Appl. Earth Obs. Geoinf. 2021, 102, 102374. [Google Scholar] [CrossRef]
- Chen, H.; Li, H.; Liu, Z.; Zhang, C.; Zhang, S.; Atkinson, P.M. A Novel Greenness and Water Content Composite Index (GWCCI) for Soybean Mapping from Single Remotely Sensed Multispectral Images. Remote Sens. Environ. 2023, 295, 113679. [Google Scholar] [CrossRef]
- Belgiu, M.; Drăguţ, L. Random Forest in Remote Sensing: A Review of Applications and Future Directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Haas, J.; Ban, Y. Urban Growth and Environmental Impacts in Jing-Jin-Ji, the Yangtze, River Delta and the Pearl River Delta. Int. J. Appl. Earth Obs. Geoinf. 2014, 30, 42–55. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference Class | Total | |||
|---|---|---|---|---|
| 1 | 2 | |||
| Map class | 1 | |||
| 2 | ||||
| Total | 1 | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, B.; Chen, X.; Cui, X.; Shen, M. A Novel Bias-Adjusted Estimator Based on Synthetic Confusion Matrix (BAESCM) for Subregion Area Estimation. Remote Sens. 2025, 17, 1145. https://doi.org/10.3390/rs17071145
Zhang B, Chen X, Cui X, Shen M. A Novel Bias-Adjusted Estimator Based on Synthetic Confusion Matrix (BAESCM) for Subregion Area Estimation. Remote Sensing. 2025; 17(7):1145. https://doi.org/10.3390/rs17071145
Chicago/Turabian StyleZhang, Bo, Xuehong Chen, Xihong Cui, and Miaogen Shen. 2025. "A Novel Bias-Adjusted Estimator Based on Synthetic Confusion Matrix (BAESCM) for Subregion Area Estimation" Remote Sensing 17, no. 7: 1145. https://doi.org/10.3390/rs17071145
APA StyleZhang, B., Chen, X., Cui, X., & Shen, M. (2025). A Novel Bias-Adjusted Estimator Based on Synthetic Confusion Matrix (BAESCM) for Subregion Area Estimation. Remote Sensing, 17(7), 1145. https://doi.org/10.3390/rs17071145