1. Introduction
Cracks are a prevalent form of road damage and serve as a crucial reference indicator in the monitoring of road health [
1]. The majority of pavement defects initially manifest as surface cracks, which not only impact the service life and traffic efficiency of roads but also pose threats to human life and property safety. Therefore, regular crack detection plays a crucial role in infrastructure maintenance and ensuring its stable operation. Traditional crack detection relies primarily on manual visual interpretation, which is time-consuming, labor-intensive, and subjective. In contrast, computer vision-based crack detection methods have gained widespread recognition and application due to their efficiency and accuracy [
2].
Early image crack extraction methods are typically rule-driven. The crack extraction method is proposed based on the assumption that the brightness of cracks is darker than the background, employing threshold segmentation [
3]. The variations in light, color, shadow, and texture offer edge information in digital images. Leveraging the changes in pixel intensity along the edges as a basis for extracting image features, edge operator methods have been proposed and applied in crack extraction tasks, yielding favorable results [
4]. The transformation of image signals from the time domain to the frequency domain facilitates the effective extraction of edge information in images. Based on this, a crack extraction method using wavelet transform is proposed [
5]. These methods can rapidly extract cracks from images, but they are significantly influenced by the background. Interferences from external factors such as changes in lighting and shadow occlusion may render these methods ineffective. To enhance the adaptability of methods in real-world environments, research has explored the application of machine learning techniques to crack extraction tasks [
6,
7,
8], including artificial neural networks, random forests, support vector machines, etc. These methods have indeed achieved satisfactory extraction results. However, due to their heavy reliance on manual feature selection, they exhibit certain limitations in practical applications.
In recent years, deep learning has experienced rapid development in the field of computer vision, achieving significant breakthroughs in areas such as object detection, image classification, and semantic segmentation [
9,
10,
11,
12]. Unlike traditional rule-driven methods, deep learning approaches are data-driven, leveraging strengths such as powerful feature extraction, high accuracy, strong adaptability, and scalability. This has made them a focal point in current research within the field of computer vision [
13]. Deep learning has also been successfully applied to crack extraction tasks, providing accurate pixel-level annotations for crack images. High-precision crack maps serve as a powerful basis for road quality assessment [
14,
15]. Zhang et al. proposed an efficient road crack detection network, CrackNet [
16]. The network structure does not include any pooling layers to reduce the output of the previous layer, ensuring constant width and height of the layers to achieve high-precision pixel-level extraction. Ronneberger et al. proposed the classic semantic segmentation network UNet [
17]. This network, designed with an encoder–decoder structure, integrates high-resolution features into the decoding process, allowing for better recovery of detailed target information. It has achieved success in biomedical image segmentation. Due to the superior performance of the network and the similarity of the scenarios, David Jenkins et al. successfully introduced and applied UNet to road crack extraction tasks [
18]. Badrinarayanan et al. modified VGG-16 to create SegNet [
19]. In SegNet, in the decoding layers, it receives the max pooling indices from the corresponding encoding layers and uses them in the upsampling process, reducing the training parameters while maintaining a faster speed compared to UNet. Chen et al. applied SegNet to the task of crack extraction and demonstrated the effectiveness of the network [
20]. Chen et al. enhanced the traditional encoder–decoder network by adding a simple yet effective decoding module to construct DeepLabV3+, which notably improves the segmentation results of object boundaries [
21]. In order to further enhance the accuracy of crack extraction in Convolutional Neural Network (CNN), researchers conducted an in-depth analysis of crack features and designed a network specifically tailored for crack scenes [
22]. Zou et al. built the DeepCrack network on the SegNet architecture [
23], effectively capturing linear structures of cracks through multi-scale feature fusion. Zhang et al. pointed out that in complex backgrounds, crack extraction is susceptible to the influence of elements such as shadows and speckles. This is because the network lacks sufficient contextual information to aid scene perception. In response, they purposefully constructed a context feature enhancement module and introduced it into the network [
24]. In addition, the paper mentions that due to the fixed geometric structure of convolution, it is challenging to adapt to the diverse morphologies of cracks. Therefore, deformable convolutions are introduced into the network to extract more crack features through the offset of sampling points. Zhou et al. pointed out that for tasks such as crack extraction, which are heavily influenced by the background, it is essential for the network to effectively capture long-term dependencies in feature information. The paper introduces a hybrid attention mechanism to address this issue [
25]. Geng et al. pointed out that traditional networks struggle to detect thin cracks due to their inability to effectively extract features related to thin cracks. The paper introduces a wavelet transformation method, which effectively supplements the frequency information that has been overlooked [
26]. In recent years, Transformer has demonstrated superior feature extraction performance in computer vision tasks due to its global modeling ability and has gradually been applied to fracture extraction tasks. Liu et al. proposed a network called CrackFormer for fine-grained fracture detection, which achieves cross-feature channel context information extraction and long-range modeling by embedding a self-attention module [
27]. It also captures context information with a large receptive field for long-distance modeling. Guo et al. used Swin Transformer as an encoder to capture global and long-range semantic features, and experimental results have proven its effectiveness for fracture extraction tasks with diverse distribution and morphology [
28]. However, the modeling process of Transformer requires large datasets, and it has not shown significant performance superiority on small sample datasets.
These networks have been successfully applied and proven effective in practice. However, despite the achievements mentioned above, image-based crack extraction tasks still face two major challenges. Firstly, in complex scenes, crack extraction is prone to interference from background pixels (such as pitting and shadows), whose characteristics closely resemble those of cracks. This similarity often results in the inclusion of extraneous noise outside the actual crack regions, ultimately leading to false detection in the extraction results. Secondly, due to the inherently slender and tubular structure of cracks, along with their diverse morphologies and irregular intensity variations, conventional convolutional operations struggle to adapt sampling points in a morphology-aware manner. Consequently, the network fails to accurately and comprehensively capture crack features, ultimately leading to missed detection in the extraction results. This demands that the network, while making full use of multi-level feature information, should also possess accurate contextual awareness.
In response to the aforementioned challenges, this paper introduces a refined segmentation network (ANF-Net) designed for road scenarios with diverse morphologies and significant noise in crack features. The paper systematically constructs three modules to enhance the network’s focus on crack regions and improve its capability to extract crack features.
The main contributions of this paper can be summarized as follows:
- (1)
To address the issue of excessive noise in the crack extraction results in complex noise scenarios, we introduce the coordinate attention module [
29] to selectively enhance the network’s ability to capture features in crack regions. This effectively mitigates the problem of including too many noisy pixels in the crack extraction results.
- (2)
To address the challenge of diverse morphological variations in cracks, leading to incomplete or missing crack features in the extraction results due to the network’s inability to accurately capture them, we devise the multi-scale discrete wavelet transform enhancement module. This module supplements the frequency domain information containing crack edge features, which is overlooked during the network’s downsampling process. Additionally, the constrained multi-morphological convolution structure is designed to impose constrained shifts on convolution sampling points, thereby enhancing the network’s perceptual capabilities and improving the precision of crack extraction.
- (3)
This paper introduces an end-to-end, high-precision network, ANF-Net, designed for the challenges posed by multi-morphology and noisy crack scenarios. ANF-Net achieves automatic and accurate pixel-level crack extraction, outperforming classic crack extraction algorithms such as SegNet, DeepCrack, and DeepLabV3+.
The remaining sections of this paper are organized as follows:
Section 2 provides a detailed introduction to several key technologies addressed in this paper.
Section 3 elaborates on the network architecture of the constructed model and the targeted improvement modules.
Section 4 presents the simulation details and results, along with a precision evaluation and in-depth analysis of the simulation outcomes. Finally,
Section 5 summarizes the work presented in this paper and outlines potential directions for future development.
3. Methodology
3.1. Overview of the Proposed Method
This paper proposes a refined segmentation network designed for road scenes with diverse crack morphologies and various noise levels (ANF-Net). The network has been specifically improved in the encoder and decoder. To address the issue of false detections caused by background noise interference during crack extraction, the Coordinate Attention Module is introduced. By learning pixel-wise feature weights, this module enables the network to focus on crack regions, reducing the impact of similar background features. To tackle omissions caused by insufficient feature extraction due to the morphological diversity of cracks, Constrained Multiform Convolution Structure is designed. By imposing learnable continuous constraints on the deformation offsets of convolutional kernels, this structure allows the network to adaptively fit crack shapes, facilitating accurate and comprehensive crack feature extraction. These strategies significantly enhance the network’s capability to extract morphologically diverse cracks from high-noise images. The specific architecture is illustrated in
Figure 1. U-Net was originally designed for medical image segmentation and achieved excellent segmentation results on small medical image datasets. Due to the similarity between road crack images and the topological structure of medical images, and the relatively small datasets for both tasks, ANF-Net is constructed based on U-Net. The network is mainly composed of three parts: an encoder, a decoder, and lateral connection structures. The encoder and decoder exhibit symmetric four-layer structures. The encoder is constructed by stacking four consecutive feature extraction layers, each of which consists of two consecutive convolution operations, normalization, and activation layer. Information transfer between layers is accomplished by 2 × 2 max-pooling layers. The channel numbers for each layer are 64, 128, 256, and 512, respectively. The decoder aggregates information from the corresponding levels of the encoder through lateral connection structures and accomplishes the upsampling process using bilinear interpolation.
After two consecutive layers of convolution, normalization, and activation in both the encoder and decoder, the Coordinate Attention Module is embedded. The use of the attention module does not alter the size or number of channels of the feature maps. The feature maps that pass through the attention module are employed in both the downsampling process of the encoder and the lateral connection. In the encoder, the feature map obtained after downsampling is concatenated with the high-frequency channel features obtained from discrete wavelet transform. After feature aggregation, this combined input is then fed into the subsequent convolutional process. In the last two layers of the encoder, the Constrained Multiform Convolution Structure is used to replace the traditional convolutional structure. This process also does not alter the size or number of channels of the feature maps.
3.2. Multi-Scale Discrete Wavelet Transform Enhancement Module
Traditional encoder–decoder networks are mainly constructed through the stacking of convolutional layers and pooling layers. This structure exhibits two issues: (1) It processes the image only in the spatial domain, lacking frequency domain information; (2) Multiple downsampling processes lead to information loss. To address the aforementioned issues, this paper constructs a multi-scale discrete wavelet transform enhancement module. The introduction of discrete wavelet transform effectively supplements the missing frequency information in traditional neural networks. Additionally, the multi-scale input strategy addresses the issue of information loss during the downsampling process.
During the process of image discrete wavelet transform, four filters,
,
,
, and
, are used to filter the original image, resulting in a low-frequency component
containing the main image information, and three high-frequency components,
,
, and
, containing image detail information. A single discrete wavelet transform simultaneously performs a two-fold downsampling operation on the image, maintaining consistency with the scale of the maximum pooling downsampling operation in the network proposed in this paper. The four components obtained through a single discrete wavelet transform are as follows:
where
represents the low-frequency component,
represents the horizontal high-frequency component,
represents the vertical high-frequency component,
represents the diagonal high-frequency component,
represents element-wise multiplication, and
represents downsampling. Taking into account both computational performance and algorithm efficiency, this paper employs the widely used Haar wavelet filter for filtering operations, defined as follows:
Similarly, the next level of discrete wavelet transform for the image is based on the low-frequency component obtained from the previous level of discrete wavelet transform, and it can also yield three high-frequency components containing image detail information. To better compensate for the information loss during network downsampling, it is necessary to concatenate the high-frequency components with the downsampling results. As the dimension of the feature map composed of high-frequency components is much smaller than the dimension of the feature map after downsampling, direct concatenation has a limited impact on the downsampling results.
It is not sufficient to supplement the lost detailed information. Therefore, in this paper, the dimensions of the feature map constructed from high-frequency features is expanded through a 3 × 3 convolution to match the dimensions of the feature map after downsampling before the concatenation process. Subsequently, convolution operations are employed to refine the concatenated feature map, ensuring the dimensions of the reconstructed features match that of the downsampled features. Finally, the refined features are reintroduced into the network for subsequent processing.
3.3. Constrained Multi-Morphological Convolution Structure
CNN extracts image features through convolutional layers with fixed-scale convolution operations. In this structure, the receptive field within the same layer remains fixed. For the task of crack extraction, in various scenes, cracks exhibit diverse morphological variations, and their orientations vary significantly. Due to the constraints of the fixed geometric structure of convolution, the sampling points cannot be effectively constrained to the crack pixels, resulting in the network’s inability to learn diverse morphological features. Consequently, issues such as crack extraction interruptions and suboptimal extraction of narrow, small, and dense cracks may arise. Previous researchers have effectively addressed this issue by employing deformable convolutions, introducing deformation offsets
into regular convolutions. In deformable convolution, for each position
in the output feature map
, there is a corresponding position in the input feature map
:
where
represents the convolutional kernel weight at point
,
denotes the complete set of sampling points,
iterates over all values in the point set
, and
represents the learnable offset. Although the learning-based offset
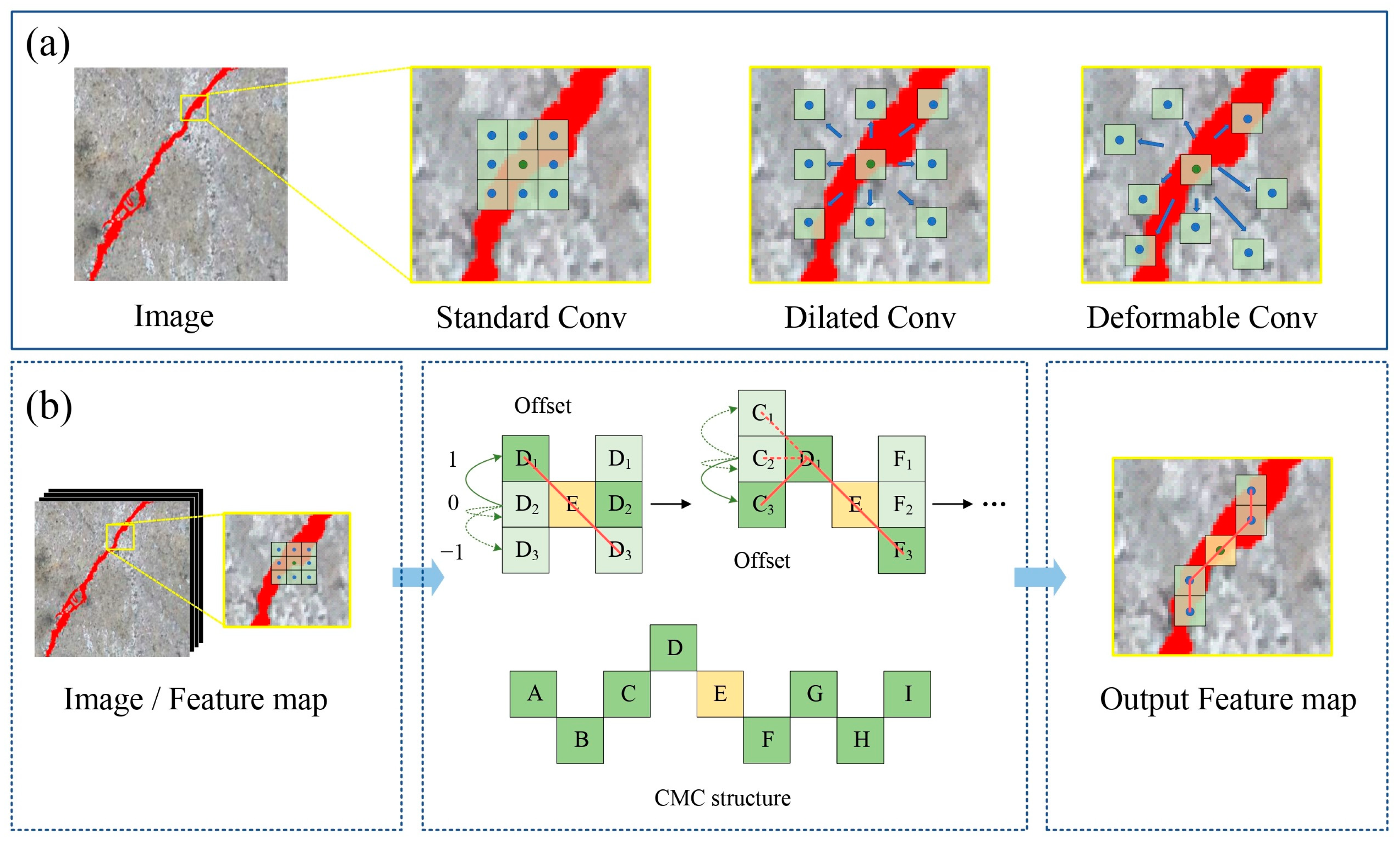
has addressed to some extent the issue of the fixed and unchanged receptive field in the same layer of CNN, without constraints, it may lead to the deviation of the receptive field from the target area. Especially in dense and narrow crack areas, problems such as crack extraction interruption and inaccuracy may still exist. The specific structures of standard convolution, dilated convolution, and deformable convolution are shown in
Figure 2a.
To address the aforementioned issues and inspired by the work of Qi et al. [
43], this paper introduces a constrained multiform convolutional structure, successfully applied in the task of crack extraction. Specifically designed to address the challenges posed by traditional convolution in accurately extracting features from narrow, elongated, and morphologically diverse crack regions, this paper proposes a targeted solution to issues such as crack extraction interruptions and omissions. The detailed structure is illustrated in
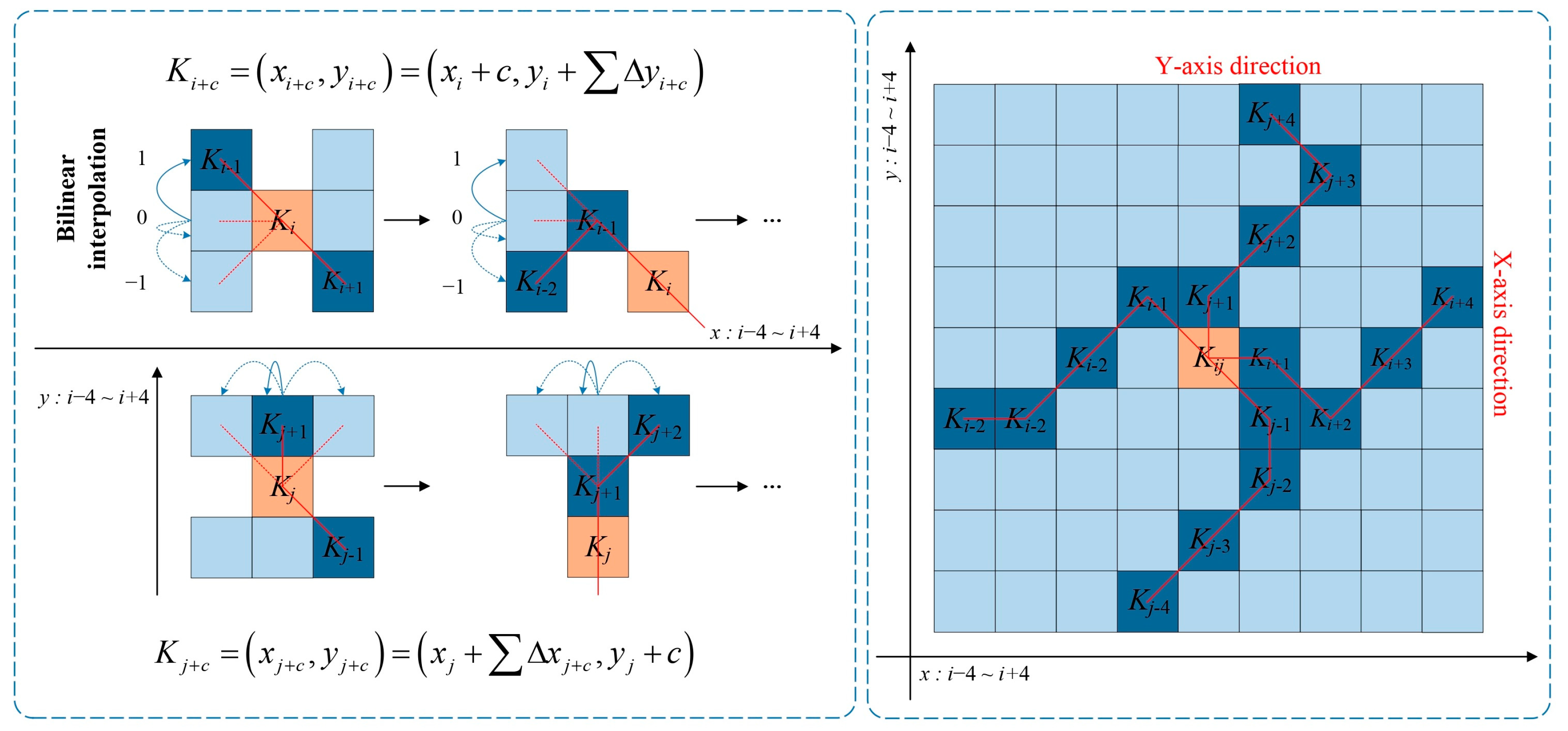
Figure 2b. For a fixed-size convolutional kernel window, the kernel is distributed only in the horizontal and vertical directions, with the center of the kernel as the origin within the window. For the horizontal direction, considering the kernel center position
as the reference, the position
at a distance from the central grid requires applying a vertical offset
based on the previous grid position
, where the current offset is computed based on the cumulative process of the previous position offset to ensure that the convolutional kernel conforms to a linear structural pattern. The specific offset implementation is shown in
Figure 3. In contrast to the free learning process of convolutional kernel deformation offsets in deformable convolutions, this structure constrains the offset process, aligning more with the characteristics of the crack-like structures, with sampling points more focused on crack pixels. The convolutional kernel along the horizontal direction is denoted as:
where among which, for a horizontal convolutional kernel,
represents the horizontal distance from each grid in the kernel to the central grid. Similarly, in the vertical direction, the position relative to the central grid in the convolutional kernel requires applying a horizontal offset based on the previous network position to fit the morphology of the target. The convolutional kernel along the vertical direction is denoted as:
The learned offset
is typically not an integer. To satisfy the sampling requirements in the image, bilinear interpolation is applied to the offset target position. The specific formula is as follows:
where
represents the fractional position along the horizontal and vertical directions in the formula,
enumerates all integral spatial positions, and
is the two one-dimensional kernels in bilinear interpolation.
3.4. Coordinate Attention Module
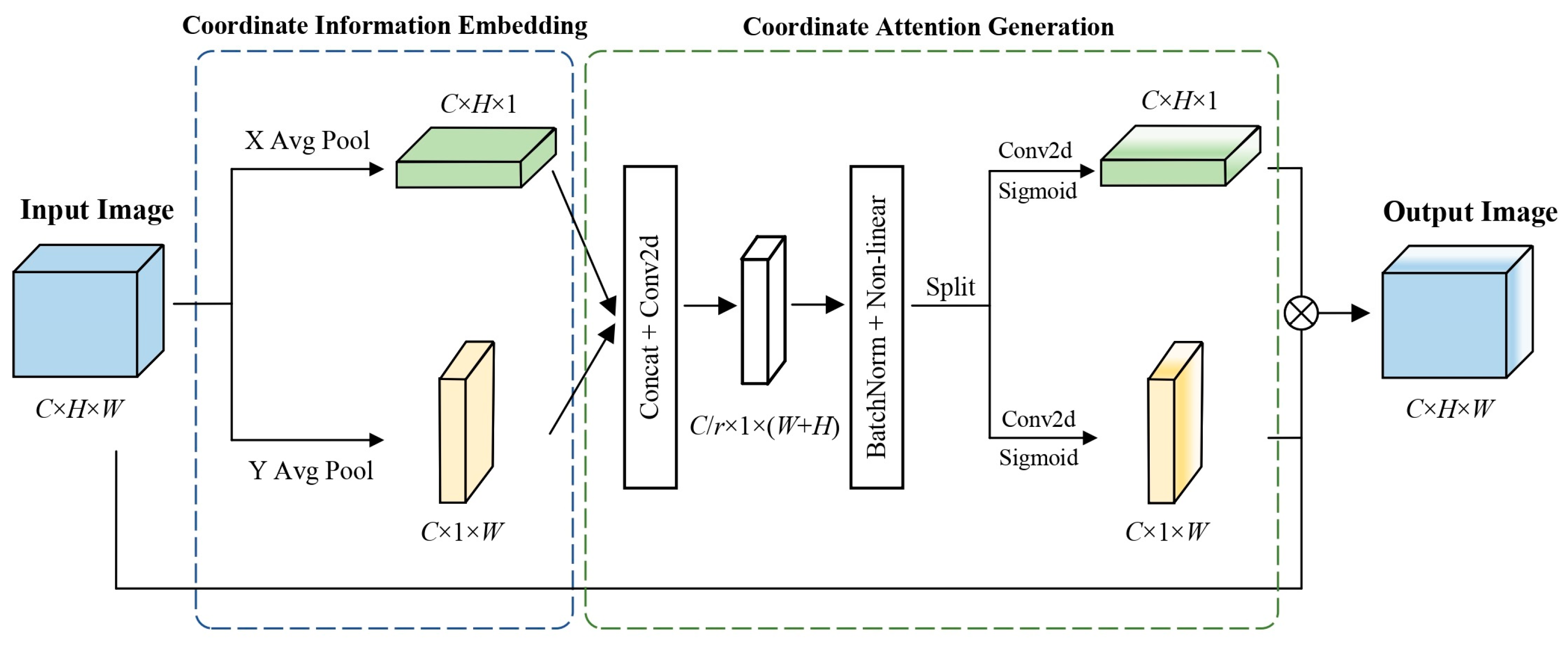
In the task of crack recognition, due to the influence of various scene factors (such as pitting, shadows, etc.), the characteristics of these interference factors are extremely similar to cracks, making it difficult for the network to focus on accurate perception of the crack area. Building upon the traditional attention mechanism, and aiming to reduce computational resource consumption while addressing the issue of long-range dependencies in crack extraction tasks, this paper introduces the Coordinate Attention Module (CAM) [
29]. CAM has a lower computational complexity and provides sufficient contextual awareness. The specific structure is illustrated in
Figure 4. CAM mainly consists of two modules: Coordinate Information Embedding and Coordinate Attention Generation, which encode precise positional information about channel relationships and long-range dependencies.
Coordinate Information Embedding: To capture remote interactions with precise spatial information in the image space, CAM processes the input feature map of size as follows: undergoes a 1D pooling operation, specifically, pooling is performed along the horizontal and vertical directions of the feature map using two pooling kernels (H,1) and (1,W), respectively.
The pooling process in the horizontal direction using the pooling kernel
can be expressed as:
Similarly, the pooling process in the vertical direction using the pooling kernel
can be expressed as:
This pooling operation along two directions helps capture long-range dependencies while preserving precise positional information.
Coordinate Attention Generation: The feature maps
and
obtained through pooling transformations along two directions are concatenated along the spatial dimension to yield a feature map of size
. Simultaneously, to enhance computational efficiency, a scaling factor
is introduced to scale the channel dimension, resulting in a downsized feature map with dimensions
. Apply a
convolutional transformation and activation to the downsized feature map. Subsequently, the feature map is separated along the spatial dimension to obtain
and
, and their channel numbers are kept consistent with the input feature map:
where
represents the sigmoid activation function, and
and
denote the
convolutional operations. The resulting
has dimensions
, and
has dimensions
. Finally, the original feature map is weighted using the horizontal attention weight component and the vertical attention weight component, resulting in the output feature map
:
4. Simulation Results and Analysis
In this section, we first present detailed information about the neural network designed in this paper, including network architecture and parameter settings. Subsequently, we introduce several crack datasets used for simulation. We then provide a detailed display of the crack extraction results and compare them with the simulation results of mainstream crack extraction methods. Additionally, we conduct ablation simulations and performance comparisons between different modules. Finally, we evaluate the accuracy using multiple metrics.
4.1. Implementation Details
The proposed method and various comparative ablation simulations in this paper are implemented using the PyTorch 1.10.0 framework. The simulations are conducted on a system with Windows 10, an NVIDIA Quadro P6000 GPU, and an Intel Core i9-7900X CPU. For the convolutional operations in both the encoder and decoder stages, batch normalization and ReLU activation are applied immediately afterward.
The software environment used for the simulations is Python 3.8. Stochastic gradient descent (SGD) with momentum is employed as the optimizer in the network, with the momentum set to 0.9 and weight decay set to 0.0001. In the simulations, the initial learning rate is set to 0.01, and warm-up training is employed, with the number of epochs set to 200. During the sequential training process, only the weights corresponding to the best performance are saved for subsequent prediction processes.
4.2. Datasets
To better conduct comparative and ablation simulations for the ANF-Net proposed in this paper, three representative crack datasets are selected, including: The DeepCrack dataset for cracks in multiple scenes [
44], the YCD dataset for cracks in roads and concrete walls [
45], and the CFD dataset for road cracks are used in the simulations [
46]. The scenes in these datasets are diverse, including images with background noise, images of narrow cracks, and images of densely cracked areas. This diversity allows for a comprehensive validation of the effectiveness and robustness of the proposed method. This paper randomly divides the crack datasets into training, validation, and test sets, with a ratio of 7:2:1 for training and prediction tasks. The specific details of the datasets are provided below:
- (1)
DeepCrack: The dataset comprises cracks from various scales and scenes, with pixel-level annotations already completed. The total number of samples is 537, all with dimensions of 544 × 384. The dataset has been randomly partitioned into a training set of 376 images, a validation set of 107 images, and a test set of 54 images, maintaining proportional distribution.
- (2)
YCD: The dataset includes crack images collected from web sources as well as captured in the field, with pixel-level annotations already completed. There are a total of 776 samples. Due to the varied distances at which the images were captured, their dimensions differ. For simulations convenience, this paper resizes all images to 512 × 512. The dataset has been randomly partitioned into a training set of 542 images, a validation set of 156 images, and a test set of 78 images, maintaining proportional distribution.
- (3)
CFD: The dataset comprises images depicting road surface crack scenes, with pixel-level annotations already completed. There are a total of 118 samples, each with dimensions of 480 × 320. The dataset has been randomly divided into a training set of 82 images, a validation set of 24 images, and a test set of 12 images, maintaining proportional distribution.
The dataset used in this study has a relatively small sample size for the neural network. Although networks suitable for small datasets have been chosen for training, in order to further improve the predictive accuracy of the network, random image augmentation techniques are applied during the training process. These techniques include size adjustment, horizontal and vertical flipping, and random cropping. Simulations results demonstrate the beneficial impact of these methods on predictive performance.
4.3. Evaluation Metrics
For the task of crack extraction, the images are categorized into two classes: crack pixels and non-crack pixels. To better evaluate the accuracy of the extraction results, this paper employs five commonly used evaluation metrics in image segmentation, including: Accuracy: the ratio of correctly predicted pixels to the total number of pixels; Precision: the ratio of correctly predicted pixels to the total predicted pixels; Recall: the ratio of correctly predicted pixels to the total pixels in the ground truth samples; mIoU: indicates the degree of overlap between predicted pixels and pixels in the ground truth samples; F1 Score: represents the harmonic mean of Precision and Recall, with the specific calculation formula as follows:
where true positive (TP) denotes the number of pixels that are actually true and predicted as true. False positive (FP) represents the number of pixels that are actually false but predicted as true. False negative (FN) represents the number of pixels that are actually true but predicted as false. True negative (TN) represents the number of pixels that are actually false and predicted as false.
4.4. Comparison and Discussion
To thoroughly validate the effectiveness and robustness of the proposed method, three publicly available crack datasets, namely, DeepCrack, YCD, and CFD, are utilized in this section for simulations. The method developed in this paper is compared with several commonly used and high-performance neural network methods in the field of crack extraction, including SegNet, DeepCrack, DeepLabV3+, UNet, UNet++, and others. Furthermore, the simulation results are rigorously evaluated for accuracy, and a comprehensive analysis and discussion are conducted from both qualitative and quantitative perspectives.
- (1)
Comparison on DeepCrack
The DeepCrack dataset is processed through various networks for the training, validation, and prediction processes. The final visualized prediction results are illustrated in
Figure 5. From left to right, the images in the figure present the original image, the ground truth, the predicted result of the proposed method, the predicted result of SegNet, the predicted result of DeepCrack, the predicted result of DeepLabV3+, the predicted result of UNet, and the predicted result of UNet++.
For ease of qualitative assessment of the network predictive performance, regions where the predictions are incorrect are highlighted with red bounding boxes in the figure. From several sets of result images, qualitative analysis yields the following: For crack images with significant background noise, the prediction results of conventional methods often include a substantial amount of noise, especially in the case of DeepCrack and U-Net. The extracted crack results are not sufficiently pure and accurate. Due to the rational construction of CAM in the proposed method, the network’s ability to capture crucial spatial information in the image is effectively enhanced, resulting in prediction results that are closer to the ground truth. For narrow and densely packed crack images, the use of the CMC structure in the method effectively constrains the sampling points to the crack pixels. This results in prediction outcomes that surpass conventional methods in terms of visual effects and detection accuracy. In addition, various image segmentation evaluation metrics are quantitatively calculated for the crack extraction results of multiple networks on the DeepCrack dataset. The results are shown in
Table 1, where the best simulations outcomes are highlighted in bold. It can be observed that the proposed ANF-Net achieves a Precision of 87.2%, Recall of 88.7%, mIoU of 88.9%, and F1 score of 87.9% on the DeepCrack dataset. Among these, mIoU and F1, as two crucial evaluation metrics for optimizing image segmentation performance, the proposed method achieves the highest scores. Compared to the suboptimal results in the comparative methods, there is a notable improvement of 1.1% in mIoU and a 1.1% enhancement in F1. It can be concluded that the proposed method demonstrates superiority in visual effects and detection accuracy. The detection results also hold practical guidance value for real-world applications.
- (2)
Comparison on YCD
To validate the model’s generalization capability, this paper conducts cross-sectional comparative simulations using the YCD crack public dataset. The model is similarly subjected to training, validation, and prediction operations. The final visualized prediction results are illustrated in
Figure 6. From left to right, the images in the figure present the original image, the ground truth, the predicted result of the proposed method, the predicted result of SegNet, the predicted result of DeepCrack, the predicted result of DeepLabV3+, the predicted result of UNet, and the predicted result of UNet++.
The inadequately predicted regions in the result images are highlighted with red boxes, and a qualitative analysis of the prediction images yields the following: Conventional methods exhibit noticeable instances of over-segmentation, particularly in the case of U-Net and U-Net++. These methods tend to inaccurately predict the shadowed portions of crack edges as cracks. In contrast, the constructed ANF-Net in this paper demonstrates excellent noise resistance. The modules designed for feature capture of cracks are more comprehensive, resulting in cleaner and more accurate prediction outcomes that closely approach the ground truth. Additionally, employing various image segmentation accuracy evaluation metrics, a quantitative analysis of the prediction results of multiple networks on the YCD dataset is conducted. The obtained results are shown in
Table 2. It can be observed that the proposed ANF-Net achieves a Precision of 84.7%, Recall of 80.5%, mIoU of 84.8%, and F1 score of 82.5% on the YCD dataset. Compared to the suboptimal results predicted by the comparative methods, there is a significant improvement of 1.2% in mIoU and a 1.5% enhancement in F1. Furthermore, this further illustrates the superior performance of the proposed ANF-Net in both the visual and precision aspects of crack extraction. The method also demonstrates a certain level of generalization capability.
- (3)
Comparison on CFD
To further validate the model’s generalization capability, this paper conducts cross-sectional comparative simulations using the CFD crack public dataset. Through training, validation, and prediction of the model, the final results are illustrated in
Figure 7. From left to right, the images in the figure present the original image, the ground truth, the predicted result of the proposed method, the predicted result of SegNet, the predicted result of DeepCrack, the predicted result of DeepLabV3+, the predicted result of UNet, and the predicted result of UNet++.
Similarly, the inadequately predicted regions in the result images are annotated with red boxes. A qualitative analysis reveals the following: Conventional methods often encounter issues of insufficient extraction in their prediction results, particularly with DeepLabV3+ and U-Net, where the prediction effectiveness in regions with weak crack intensity is suboptimal. Simultaneously, there is an issue of interruptions in crack extraction, with the main causes being the lack of established long-range dependencies in the image and insufficient information extraction in the network encoder. The constructed ANF-Net exhibits better performance in predicting cracks in areas with lower intensity. Moreover, the predicted cracks in the result images are less prone to interruptions and boundary fuzziness. Additionally, a quantitative analysis is conducted using various image segmentation accuracy evaluation metrics. The obtained results are shown in
Table 3. It can be observed that in comparison to other methods, the proposed approach achieves the overall highest extraction accuracy. Specifically, Precision is 73.1%, mIoU is 77.1%, and F1 is 71.5%, all of which are at the highest levels among the comparative methods. Furthermore, compared to the suboptimal results in the comparative methods, there is a significant improvement of 0.9% in mIoU and a 1.6% enhancement in F1. This more fully illustrates that the proposed method excels in the accuracy of crack extraction tasks, especially in scenarios with low crack intensity and high background noise. Through simulations with multiple datasets, it is further demonstrated that the proposed method exhibits strong generalization capability, providing valuable guidance for practical production applications.
4.5. Ablation Simulations
In this paper, several issues in traditional crack extraction methods are identified in detail. Targeted modules, including MWE, CMC, and CAM, are constructed based on UNet to address these challenges. In this section, dedicated ablation simulations are conducted using the DeepCrack dataset to investigate these three modules. This involved simulations without adding any modules, simulations with individual module additions, and simulations with combined module additions, resulting in a total of six groups. Simultaneously, a comprehensive qualitative analysis of the network’s prediction results is conducted. Precision, Recall, mIoU, and F1 are chosen as the four metrics for accuracy quantitative analysis.
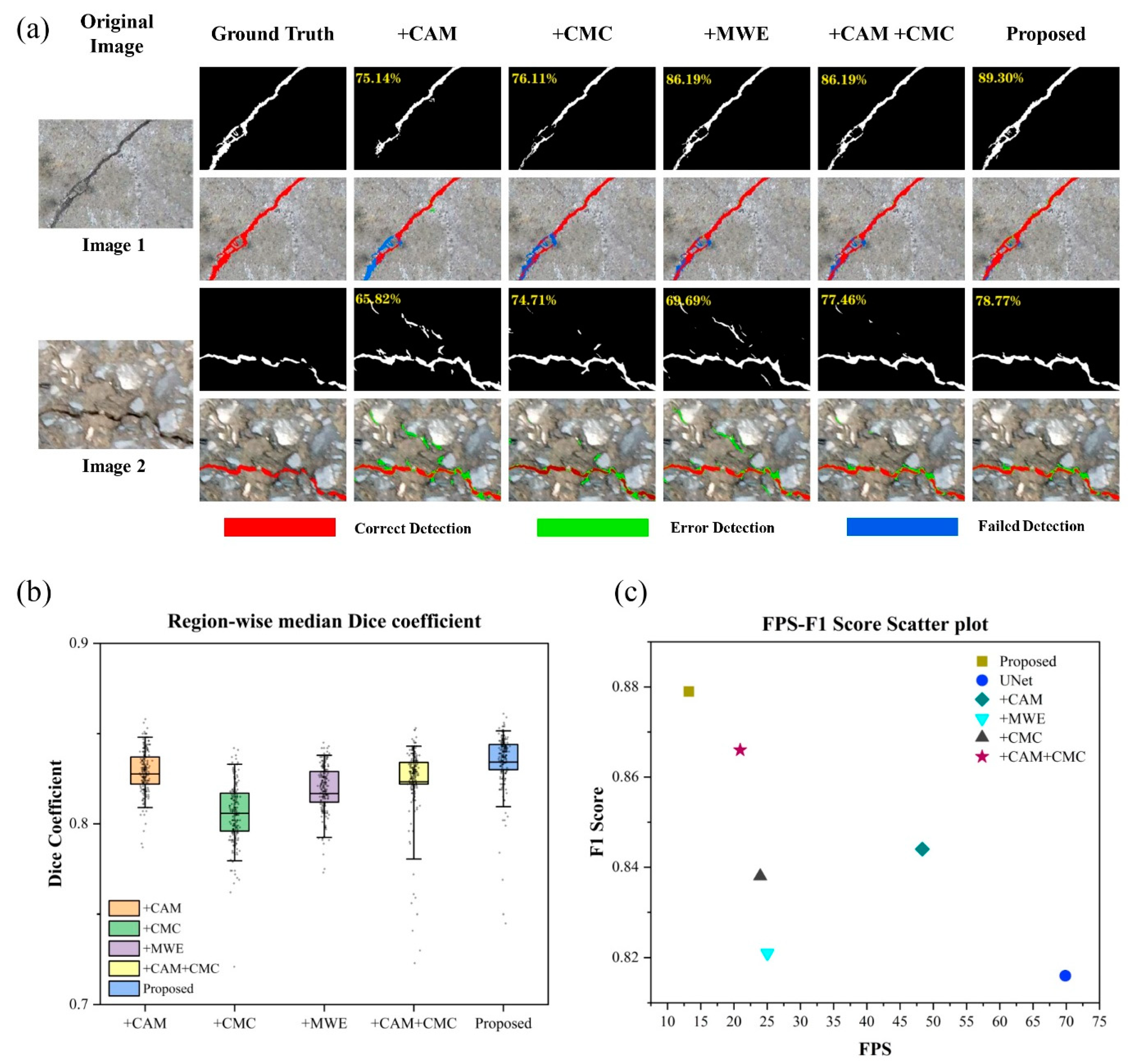
As shown in
Figure 8, the comparative images of network prediction results in ablation simulations, the regional median Dice index, and the FPS-F1 score scatter plot are presented. In the comparative images of the prediction results, red markings indicate correctly predicted crack pixels, green markings denote erroneously predicted crack pixels, and blue markings represent crack pixels that are not successfully predicted. As shown in
Table 4, the results of the crack prediction accuracy evaluation are presented. Combining the results in the figures and tables, a comprehensive analysis can be conducted, yielding the following: For the baseline network without adding any modules, the accuracy of the crack prediction results is at the lowest level, with mIoU at only 83.8% and F1 at only 81.6%. Adding CAM to the baseline network individually increases F1 by 2.8%. This is because the attention mechanism enhances effective spatial information in the image, improving the network’s noise resistance. Adding the CMC module individually to the baseline network increases F1 by 2.2%. This is because the convolutional structure in this paper effectively adapts to tubular and multi-morphological crack structures through constrained learning offsets, extracting more features of crack pixels. Adding the MWE module individually to the baseline network increases F1 by 0.5%. This is because the multi-scale wavelet enhancement structure effectively supplements the frequency information lost during the downsampling process. Combining the CAM and CMC modules and adding them to the baseline network increases F1 by 5%. Combining CAM, CMC, and MWE in the baseline network results in an effective improvement of 6.3% in F1, achieving the highest scores in Precision, mIoU, and F1. From the ablation results, it is evident that the addition of the three modules is beneficial for improving the performance of the network. The combination of these modules, especially when all three are added simultaneously, helps the network achieve the best crack prediction results. The visualized results in the figures also indicate that the final constructed network presents the optimal visual effects, with extraction results that are cleaner and more accurate.
4.6. Comparison of Different Modules
For a thorough analysis of the performance superiority of each module, this section independently designs several sets of cross-sectional comparative simulations using the DeepCrack dataset. It compares the performance of different attention mechanisms and convolutional sampling structures. Finally, accuracy evaluation and detailed discussions are conducted on the simulations results.
- (1)
Comparison of Different Attention Modules
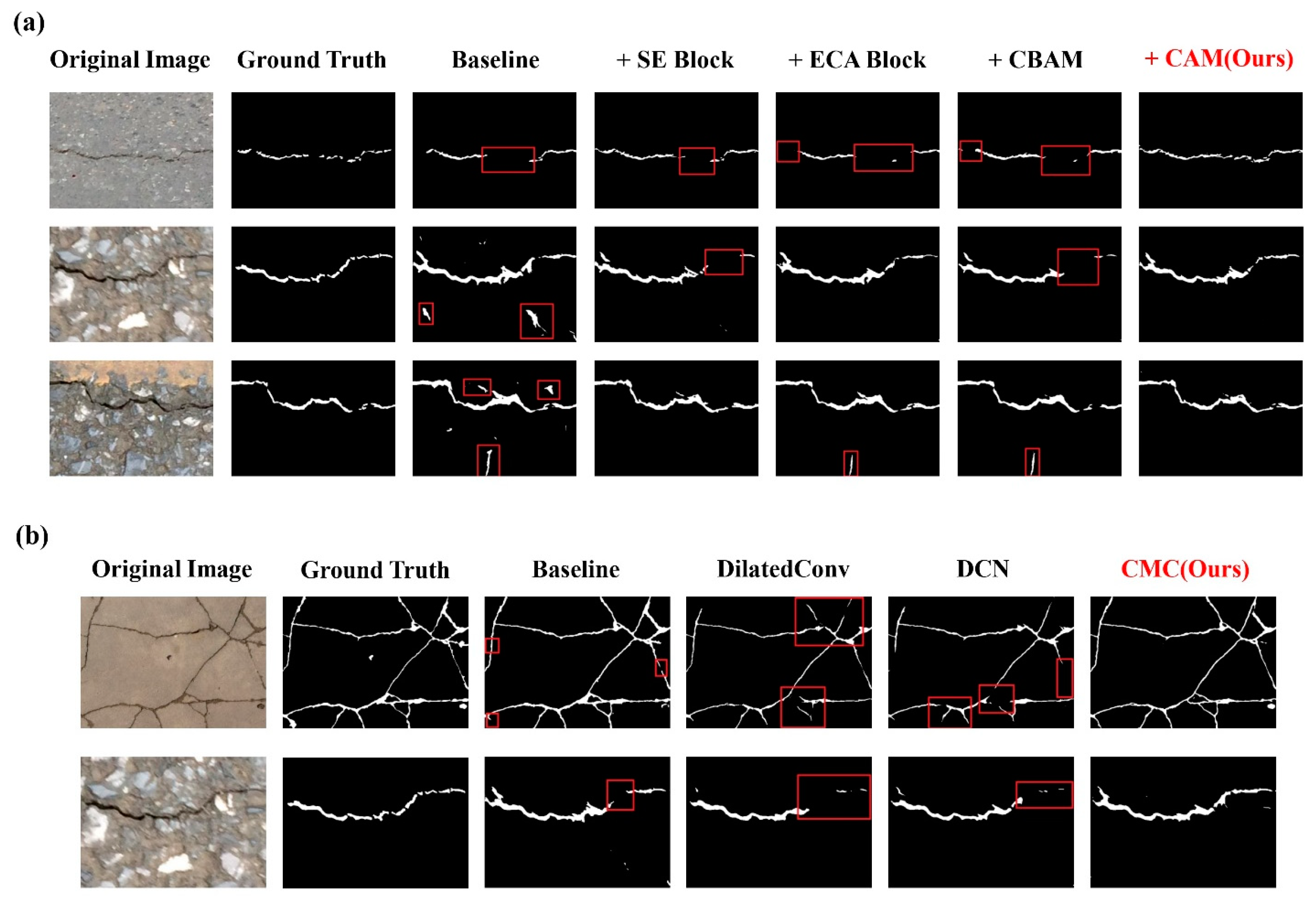
To thoroughly illustrate the superior performance of the constructed CAM in crack extraction tasks, this section specifically designs several sets of comparative simulations using the DeepCrack dataset. These simulations involve embedding different attention modules in the network, including embedding channel attention modules SEBlock and ECABlock, embedding the hybrid attention module CBAM, and embedding the CAM constructed in this paper. During the analysis process, two additional performance evaluation metrics for the network are introduced based on the original precision evaluation indicators: Parameters, measuring the network’s parameter quantity, and FLOPs, measuring the network’s computational load. The final visualized results of the network predictions are shown in
Figure 9a, and the quantitative evaluation results are presented in
Table 5. A comprehensive analysis of the graphical and tabular results reveals the following: Building four types of attention modules in the network, the new network exhibits minimal variations in the Parameters and FLOPs indicators. The fluctuation range for Parameters is approximately 0.89%, and the fluctuation range for FLOPs is even smaller. This indicates that CAM neither introduces excessive parameters nor affects the operational efficiency of the network. From the crack prediction accuracy evaluation results for SEBlock, the F1 metric improves by 0.1% compared to the original network, with a minimal impact on accuracy. For ECABlock, F1 improves by 2.2% on the original network. For CBAM, F1 improves by 2.3% on the original network. For CAM, F1 significantly improves by 2.8% on the original network. Additionally, introducing CAM results in crack prediction outcomes that are cleaner and less affected by background noise. In the extraction results, there are fewer background noise pixels. In summary, the CAM module used in this paper achieves the highest accuracy in crack prediction without introducing excessive parameters. Compared to other attention modules, it exhibits excellent performance superiority.
- (2)
Comparison of Different Convolutional Structures
In this paper, a targeted CMC structure is constructed to address the issue of insufficient feature extraction leading to inaccurate crack extraction results in multi-morphological dense crack scenes. Due to the CMC module being constructed based on the concepts of dilated convolution and deformable convolution, to thoroughly illustrate the superiority of CMC in crack extraction tasks, this section designed several sets of comparative simulations using the DeepCrack dataset, including base network, base network with dilated convolution, base network with deformable convolution, and base network with the CMC module. It is worth noting that, to better demonstrate the superior performance of the modules used in the simulation, the base network here is UNet with CAM. Finally, the evaluation is performed using various metrics, including Parameters and FLOPs, which measure the network’s operational performance, and Precision, Recall, mIoU, and F1, which measure the network’s prediction accuracy. The final visualized results of crack extraction are shown in
Figure 9b, and the quantitative evaluation results are presented in
Table 6.
From the data in the table, it can be observed that, compared to the base network, although dilated convolution does not introduce excessive parameters, the final prediction accuracy has decreased to some extent, with a decrease of 0.3% in mIoU and a corresponding decrease of 0.3% in F1. Deformable convolution performs better, with an improvement of 1.1% in mIoU and a corresponding increase of 1.5% in F1, without introducing excessive parameters. Compared to these two convolutional structures, the network built with CMC in the baseline achieves the optimal accuracy results, with an effective improvement of 1.8% in mIoU and a corresponding increase of 2.2% in F1. Although this method introduces to some extent more parameters, there is no significant performance perceptual difference in actual training and prediction processes. Additionally, from the visual results, it can be observed that the network using the CMC structure produces better predictions in narrow, dense regions of cracks, with fewer issues such as fragmentation or missing areas. In summary, the introduced CMC in this paper achieves higher prediction accuracy compared to other convolutional sampling structures. Overall, this method exhibits good performance superiority.
5. Conclusions
This paper proposes a fine-grained segmentation network suitable for road scenes with multiple morphologies and noises in cracks. Aiming at enhancing the network’s capability to capture features, attention mechanisms are deliberately introduced in both the encoder and decoder. This adaptation allows the network to better handle complex and noisy scenes. A constrained multi-morphological convolutional structure is integrated into the encoder, enabling the network to achieve improved predictive performance in scenes with diverse crack morphologies. Furthermore, a multi-scale discrete wavelet enhancement module is designed in the encoder to effectively supplement the frequency domain information containing crack features that may be overlooked during the downsampling process. The aforementioned improvements effectively address the issue of inaccurate detection in scenes with diverse crack morphologies and significant background noise in road images.
This paper conducts comparative simulations using three publicly available crack datasets: DeepCrack, YCD, and CFD. The results of the simulations demonstrate the effectiveness of the proposed method. Compared to suboptimal methods, the F1 score is significantly improved by 1.1%, 1.5%, and 1.6%, respectively. A dedicated ablation study using the DeepCrack dataset is performed by integrating the three modules into the baseline network, resulting in a remarkable 6.3% increase in the F1 score. In the module comparison simulations, the construction of the CAM and CMC individually leads to effective increases of 2.8% and 2.2% in the F1 score, respectively. The comprehensive simulations results affirm that the ANF-Net network constructed in this paper exhibits outstanding performance in crack segmentation compared to other classical deep learning methods.
While the constructed ANF-Net in this study achieves promising results in crack extraction tasks, it is noteworthy that deep learning methods require a substantial amount of annotated data for training to ensure the effectiveness and robustness of the network. However, annotating cracks in various scenarios is a challenging task. Thus, the focus of future research should be on improving the network’s predictive capabilities in scenarios with limited sample data. Furthermore, we aim to extend this method to more application scenarios, such as rock fracture extraction and tunnel cavity crack detection, to enhance the engineering practicality of the approach.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}