
SFIDM: Few-Shot Object Detection in Remote Sensing Images with Spatial-Frequency Interaction and Distribution Matching

 and
and
Abstract
1. Introduction
- To effectively leverage complementary frequency information, we introduce a mechanism that decomposes images into low-frequency and high-frequency components. Low-frequency components capture global structural patterns essential for classification, while high-frequency components focus on fine details crucial for precise localization. This design enhances the detection of small objects, particularly in complex backgrounds where traditional methods struggle.
- To improve label assignment, we employ a novel strategy of distribution matching that models bounding boxes as 2D Gaussian distributions. By utilizing Kullback–Leibler (KL) divergence [42] as a localization metric, this approach overcomes the limitations of traditional IoU-based heuristics, enabling accurate detection of subtle offsets and addressing the challenges posed by small or overlapping objects.
- We conducted experiments on publicly available datasets, DIOR and NWPU VHR-10, and performed comparative analyses between our proposed method and previous approaches. The results demonstrate the effectiveness and superiority of SFIDM. Furthermore, as a plug-and-play model, SFIDM can be seamlessly integrated with different backbone networks and detection frameworks, showcasing its versatility and adaptability.
2. Related Work
2.1. Few-Shot Object Detection in Natural Images
2.1.1. Transfer Learning-Based Methods
2.1.2. Metric Learning-Based Methods
2.1.3. Meta-Learning-Based Methods
2.2. Few-Shot Object Detection in Remote Sensing Images
3. Our Method
3.1. Preliminary Knowledge
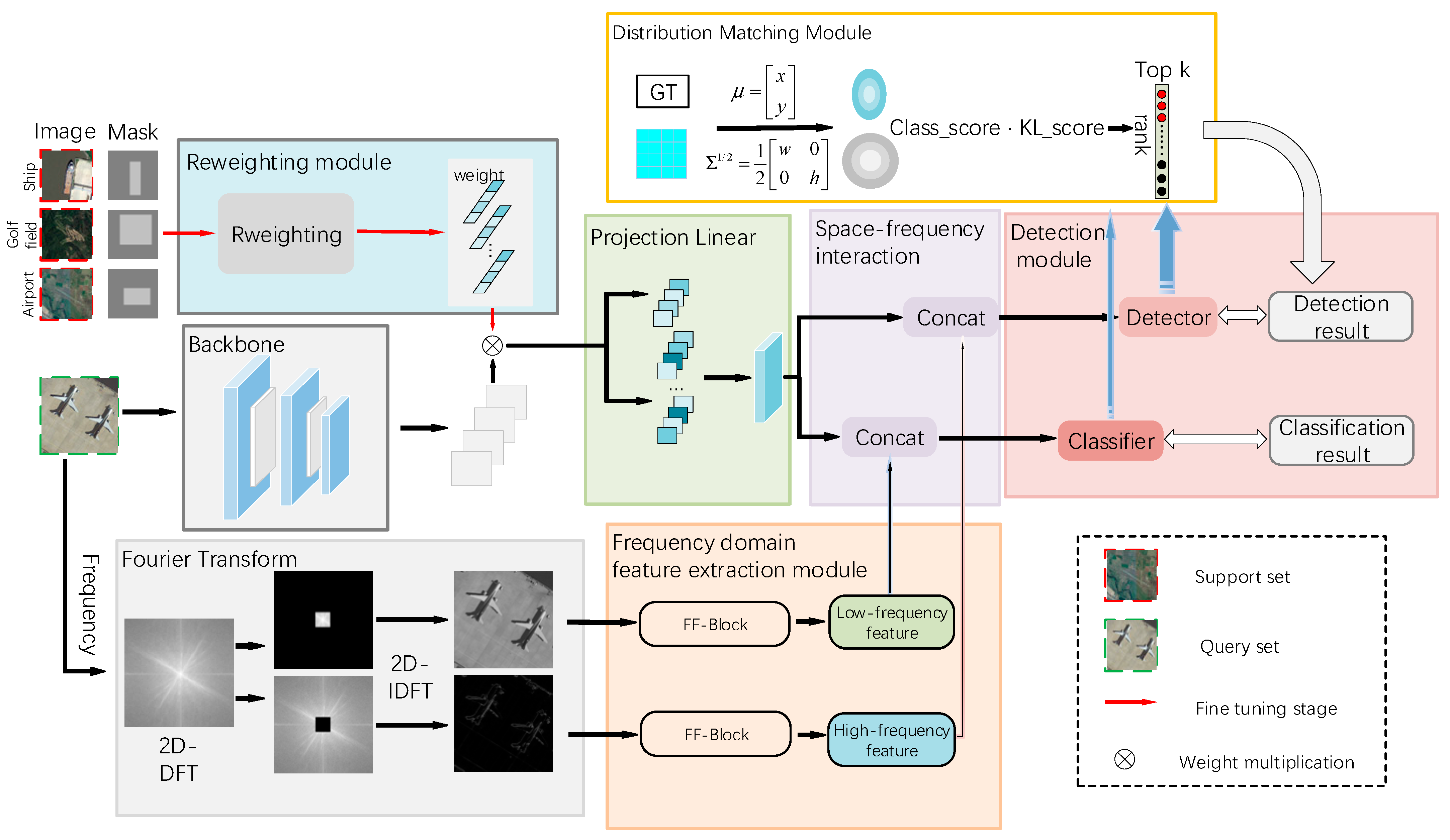
3.2. General Architecture
3.3. Frequency-Domain Feature Extraction Module
3.4. Distribution Matching Module
3.5. Reweighting Module
3.6. Loss
3.6.1. Classification Loss
3.6.2. Regression Loss
3.6.3. DFL (Distribution Focal Loss)
3.6.4. Total Loss Function
3.7. Algorithm Description
| Algorithm 1: SFIDM Algorithm | |
| 1: | Initialization: Set up initial training dataset and model . Define KL divergence threshold for bounding box optimization. |
| 2: | Base Training Phase: for each iteration in the base training phase do (a) Input into the backbone network to extract spatial features; (b) Extract frequency-domain features using 2D-DFT for high-frequency and low-frequency components; (c) Train using extracted features and to classify base categories; (d) Optimize bounding box regression with KL divergence to refine boundary predictions; |
| 3: | Few-shot Fine-tuning Phase: for each support image and test image do (a) Extract initial features using the backbone network; (b) Generate reweighting vectors from support images to recalibrate features; (c) Fuse reweighted features with frequency-domain features ; (d) Use fused features for classification and bounding box prediction; |
| 4: | Testing Phase: for each test image do (a) Extract spatial and frequency-domain features without reweighting; (b) Predict bounding boxes and refine localization using KL divergence; (c) Evaluate performance metrics such as mAP; |
| 5: | Output: Final detection model with optimized performance for few-shot object detection in remote sensing images. |
4. Experiments
4.1. Benchmark Datasets
4.2. Experimental Setup and Implementation Details
4.3. Experimental Results on the NWPU VHR-10 Dataset
4.4. Experimental Results on the DIOR Datasets
4.5. Convergence Analysis
4.6. Parameter Sensitivity
4.7. Ablation Study
4.8. Extended Experiment
4.9. Limitation
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Cheng, G.; Han, J.; Zhou, P.; Guo, L. Multi-class geospatial object detection and geographic image classification based on collection of part detectors. ISPRS J. Photogramm. Remote Sens. 2014, 98, 119–132. [Google Scholar] [CrossRef]
- Sun, X.; Wang, P.; Yan, Z.; Xu, F.; Wang, R.; Diao, W.; Chen, J.; Li, J.; Feng, Y.; Xu, T.; et al. FAIR1M: A benchmark dataset for fine-grained object recognition in high-resolution remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2022, 184, 116–130. [Google Scholar] [CrossRef]
- Cheng, G.; Lang, C.; Wu, M.; Xie, X.; Yao, X.; Han, J. Feature enhancement network for object detection in optical remote sensing images. J. Remote Sens. 2021, 2021, 9805389. [Google Scholar] [CrossRef]
- Xie, X.; Cheng, G.; Wang, J.; Yao, X.; Han, J. Oriented R-CNN for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 3520–3529. [Google Scholar]
- Cheng, G.; Han, J.; Lu, X. Remote sensing image scene classification: Benchmark and state of the art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef]
- Hu, J.; Wei, Y.; Chen, W.; Zhi, X.; Zhang, W. CM-YOLO: Typical Object Detection Method in Remote Sensing Cloud and Mist Scene Images. Remote Sens. 2025, 17, 125. [Google Scholar] [CrossRef]
- Peng, Y.; Li, H.; Zhang, W.; Zhu, J.; Liu, L.; Zhai, G. Underwater Sonar Image Classification with Image Disentanglement Reconstruction and Zero-Shot Learning. Remote Sens. 2025, 17, 134. [Google Scholar] [CrossRef]
- Cheng, G.; Li, Q.; Wang, G.; Xie, X.; Min, L.; Han, J. SFRNet: Fine-grained oriented object recognition via separate feature refinement. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5610510. [Google Scholar] [CrossRef]
- Al Hinai, A.A.; Guida, R. Confidence-Aware Ship Classification Using Contour Features in SAR Images. Remote Sens. 2025, 17, 127. [Google Scholar] [CrossRef]
- Cheng, G.; Lai, P.; Gao, D.; Han, J. Class attention network for image recognition. Sci. China Inf. Sci. 2023, 66, 132105. [Google Scholar] [CrossRef]
- Luo, B.; Cao, H.; Cui, J.; Lv, X.; He, J.; Li, H.; Peng, C. SAR-PATT: A Physical Adversarial Attack for SAR Image Automatic Target Recognition. Remote Sens. 2025, 17, 21. [Google Scholar] [CrossRef]
- Kemker, R.; Salvaggio, C.; Kanan, C. Algorithms for semantic segmentation of multispectral remote sensing imagery using deep learning. ISPRS J. Photogramm. Remote Sens. 2018, 145, 60–77. [Google Scholar] [CrossRef]
- Jia, H.; Lang, C.; Oliva, D.; Song, W.; Peng, X. Dynamic Harris hawks optimization with mutation mechanism for satellite image segmentation. Remote Sens. 2019, 11, 1421. [Google Scholar] [CrossRef]
- Lai, P.; Cheng, G.; Zhang, M.; Ning, J.; Zheng, X.; Han, J. NCSiam: Reliable matching via neighborhood consensus for siamese-based object tracking. IEEE Trans. Image Process. 2023, 32, 6168–6182. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Liu, S.; Liu, H. Lightweight Multi-Scale Network for Segmentation of Riverbank Sand Mining Area in Satellite Images. Remote Sens. 2025, 17, 227. [Google Scholar] [CrossRef]
- Lv, Z.; Huang, H.; Li, X.; Zhao, M.; Benediktsson, J.A.; Sun, W.; Falco, N. Land cover change detection with heterogeneous remote sensing images: Review, progress, and perspective. Proc. IEEE 2022, 110, 1976–1991. [Google Scholar] [CrossRef]
- Gautam, D.; Mawardi, Z.; Elliott, L.; Loewensteiner, D.; Whiteside, T.; Brooks, S. Detection of Invasive Species (Siam Weed) Using Drone-Based Imaging and YOLO Deep Learning Model. Remote Sens. 2025, 17, 120. [Google Scholar] [CrossRef]
- Chen, K.; Chen, J.; Xu, M.; Wu, M.; Zhang, C. DRAF-Net: Dual-Branch Residual-Guided Multi-View Attention Fusion Network for Station-Level Numerical Weather Prediction Correction. Remote Sens. 2025, 17, 206. [Google Scholar] [CrossRef]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object detection in optical remote sensing images: A survey and a new benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Xia, G.-S.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y.; Zhang, L.; Lu, X. AID: A benchmark dataset for performance evaluation of aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, B.; Wang, B. Few-Shot Object Detection with Self-Adaptive Global Similarity and Two-Way Foreground Stimulator in Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 7263–7276. [Google Scholar] [CrossRef]
- Li, C.; Cheng, G.; Han, J. Boosting knowledge distillation via intra-class logit distribution smoothing. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 4190–4201. [Google Scholar] [CrossRef]
- Cheng, X.; He, X.; Qiao, M.; Li, P.; Chang, P.; Zhang, T.; Guo, X.; Wang, J.; Tian, Z.; Zhou, G. Multi-view graph convolutional network with spectral component decompose for remote sensing images classification. IEEE Trans. Circuits Syst. Video Technol. 2022, 35, 3–18. [Google Scholar] [CrossRef]
- Geng, J.; Song, S.; Jiang, W. Dual-path feature aware network for remote sensing image semantic segmentation. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 3674–3686. [Google Scholar] [CrossRef]
- Lang, C.; Wang, J.; Cheng, G.; Tu, B.; Han, J. Progressive parsing and commonality distillation for few-shot remote sensing segmentation. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5613610. [Google Scholar] [CrossRef]
- Xie, X.; Cheng, G.; Li, Q.; Miao, S.; Li, K.; Han, J. Fewer is more: Efficient object detection in large aerial images. Sci. China Inf. Sci. 2023, 67, 112106. [Google Scholar] [CrossRef]
- Yan, C.; Chang, X.; Luo, M.; Liu, H.; Zhang, X.; Zheng, Q. Semantics-guided contrastive network for zero-shot object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 1530–1544. [Google Scholar] [CrossRef]
- Chen, H.; Wang, Q.; Xie, K.; Lei, L.; Lin, M.G.; Lv, T.; Liu, Y.; Luo, J. SD-FSOD: Self-distillation paradigm via distribution calibration for few-shot object detection. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 5963–5976. [Google Scholar] [CrossRef]
- Huang, J.; Cao, J.; Lin, L.; Zhang, D. IRA-FSOD: Instant-response and accurate few-shot object detector. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 6912–6923. [Google Scholar] [CrossRef]
- Li, L.; Yao, X.; Cheng, G.; Xu, M.; Han, J.; Han, J. Solo-to-Collaborative Dual-Attention Network for One-Shot Object Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5607811. [Google Scholar] [CrossRef]
- Li, X.; Zhang, L.; Chen, Y.P.; Tai, Y.W.; Tang, C.K. One-Shot Object Detection without Fine-Tuning. arXiv 2020, arXiv:2005.03819. [Google Scholar]
- Hsieh, T.-I.; Lo, Y.-C.; Chen, H.-T.; Liu, T.-L. One-shot object detection with co-attention and co-excitation. Proc. Conf. Adv. Neural Inform. Process. Syst. 2019, 32, 2725–2734. [Google Scholar]
- Zhao, Y.; Guo, X.; Lu, Y. Semantic-Aligned Fusion Transformer for One-Shot Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022; pp. 7601–7611. [Google Scholar]
- Chen, D.J.; Hsieh, H.Y.; Liu, T.L. Adaptive Image Transformer for One-Shot Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 12247–12256. [Google Scholar]
- Michaelis, C.; Ustyuzhaninov, I.; Bethge, M.; Ecker, A.S. One-Shot Instance Segmentation. arXiv 2018, arXiv:1811.11507. [Google Scholar]
- Wang, H.; Liu, J.; Liu, Y.; Maji, S.; Sonke, J.J.; Gavves, E. Dynamic Transformer for Few-Shot Instance Segmentation. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; pp. 2969–2977. [Google Scholar]
- Nguyen, K.; Todorovic, S. FAPIS: A Few-Shot Anchor-Free Part-Based Instance Segmenter. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 11099–11108. [Google Scholar]
- Ganea, D.A.; Boom, B.; Poppe, R. Incremental Few-Shot Instance Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 1185–1194. [Google Scholar]
- Wei, S.; Wei, X.; Ma, Z.; Dong, S.; Zhang, S.; Gong, Y. Few-Shot Online Anomaly Detection and Segmentation. Knowl.-Based Syst. 2024, 300, 112168. [Google Scholar] [CrossRef]
- Li, A.; Danielczuk, M.; Goldberg, K. One-Shot Shape-Based Amodal-to-Modal Instance Segmentation. In Proceedings of the 2020 IEEE 16th International Conference on Automation Science and Engineering (CASE), Hong Kong, China, 20–21 August 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1375–1382. [Google Scholar]
- Zhang, J.; Hong, Z.; Chen, X.; Li, Y. Few-Shot Object Detection for Remote Sensing Imagery Using Segmentation Assistance and Triplet Head. Remote Sens. 2024, 16, 3630. [Google Scholar] [CrossRef]
- Kullback, S.; Leibler, R.A. On Information and Sufficiency. Ann. Math. Statist. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Kang, B.; Liu, Z.; Wang, X.; Yu, F.; Feng, J.; Darrell, T. Few-shot object detection via feature reweighting. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8419–8428. [Google Scholar]
- Wu, X.; Sahoo, D.; Hoi, S. Meta-RCNN: Meta learning for few-shot object detection. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 1679–1687. [Google Scholar]
- Han, G.; Huang, S.; Ma, J.; He, Y.; Chang, S.-F. Meta Faster R-CNN: Towards accurate few-shot object detection with attentive feature alignment. Proc. AAAI Conf. Artif. Intell. 2022, 36, 780–789. [Google Scholar] [CrossRef]
- Qiao, L.; Zhao, Y.; Li, Z.; Qiu, X.; Wu, J.; Zhang, C. DeFRCN: Decoupled faster R-CNN for few-shot object detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 8681–8690. [Google Scholar]
- Tang, Y.; Cao, Z.; Yang, Y.; Liu, J.; Yu, J. Semi-supervised few-shot object detection via adaptive pseudo labeling. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 2151–2165. [Google Scholar] [CrossRef]
- Wu, S.; Pei, W.; Mei, D.; Chen, F.; Tian, J.; Lu, G. Multi-faceted distillation of base-novel commonality for few-shot object detection. In European Conference on Computer Vision; Springer Nature: Cham, Switzerland, 2022; pp. 578–594. [Google Scholar]
- Amoako, P.Y.O.; Cao, G.; Shi, B.; Yang, D.; Acka, B.B. Orthogonal Capsule Network with Meta-Reinforcement Learning for Small Sample Hyperspectral Image Classification. Remote Sens. 2025, 17, 215. [Google Scholar] [CrossRef]
- Chen, H.; Wang, Y.; Wang, G.; Qiao, Y. LSTD: A low-shot transfer detector for object detection. Proc. AAAI Conf. Artif. Intell. 2018, 32, 2836–2843. [Google Scholar] [CrossRef]
- Wang, X.; Huang, T.E.; Darrell, T.; Gonzalez, J.E.; Yu, F. Frustratingly simple few-shot object detection. arXiv 2020, arXiv:2003.06957. [Google Scholar]
- Sun, B.; Li, B.; Cai, S.; Yuan, Y.; Zhang, C. FSCE: Few-shot object detection via contrastive proposal encoding. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 7352–7362. [Google Scholar]
- Lee, H.; Lee, M.; Kwak, N. Few-shot object detection by attending to per-sample-prototype. In Proceedings of the 2022 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, Hi, USA, 3–8 January 2022; pp. 2445–2454. [Google Scholar]
- Zhang, B.; Li, X.; Ye, Y.; Huang, Z.; Zhang, L. Prototype completion with primitive knowledge for few-shot learning. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 3754–3762. [Google Scholar]
- Karlinsky, L.; Karlinsky, L.; Shtok, J.; Harary, S.; Marder, M.; Pankanti, S.; Bronstein, A.M. RepMet: Representative-based metric learning for classification and few-shot object detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5192–5201. [Google Scholar]
- Zhang, G.; Cui, K.; Wu, R.; Lu, S.; Tian, Y. PNPDet: Efficient few-shot detection without forgetting via plug-and-play sub-networks. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2021; pp. 3822–3831. [Google Scholar]
- Li, B.; Yang, B.; Liu, C.; Liu, F.; Ji, R.; Ye, Q. Beyond max-margin: Class margin equilibrium for few-shot object detection. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 7363–7372. [Google Scholar]
- Fan, Q.; Zhuo, W.; Tang, C.-K.; Tai, Y.-W. Few-shot object detection with attention-RPN and multi-relation detector. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 4012–4021. [Google Scholar]
- Xiao, Y.; Lepetit, V.; Marlet, R. Few-shot object detection and viewpoint estimation for objects in the wild. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 3090–3106. [Google Scholar]
- Zhang, T.; Zhang, X.; Zhu, P.; Jia, X.; Tang, X.; Jiao, L. Generalized few-shot object detection in remote sensing images. ISPRS J. Photogramm. Remote Sens. 2023, 195, 353–364. [Google Scholar] [CrossRef]
- Wang, B.; Ma, G.; Sui, H.; Zhang, Y.; Zhang, H.; Zhou, Y. Few-shot object detection in remote sensing imagery via fuse context dependencies and global features. Remote Sens. 2023, 15, 3462. [Google Scholar] [CrossRef]
- Liu, S.; You, Y.; Su, H.; Meng, G.; Yang, W.; Liu, F. Few-shot object detection in remote sensing image interpretation: Opportunities and challenges. Remote Sens. 2022, 14, 4435. [Google Scholar] [CrossRef]
- Gao, H.; Wu, S.; Wang, Y.; Kim, J.Y.; Xu, Y. FSOD4RSI: Few-Shot Object Detection for Remote Sensing Images via Features Aggregation and Scale Attention. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 4784–4796. [Google Scholar] [CrossRef]
- Zhang, Z.; Hao, J.; Pan, C.; Ji, G. Oriented feature augmentation for few-shot object detection in remote sensing images. In Proceedings of the 2021 IEEE International Conference on Computer Science, Electronic Information Engineering and Intelligent Control Technology (CEI), Fuzhou, China, 24–26 September 2021; pp. 359–366. [Google Scholar]
- Cheng, G.; Yan, B.; Shi, P.; Li, K.; Yao, X.; Guo, L.; Han, J. Prototype-CNN for few-shot object detection in remote sensing images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5604610. [Google Scholar] [CrossRef]
- Chen, J.; Qin, D.; Hou, D.; Zhang, J.; Deng, M.; Sun, G. Multi-scale object contrastive learning-derived few-shot object detection in VHR imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5635615. [Google Scholar] [CrossRef]
- Huang, X.; He, B.; Tong, M.; Wang, D.; He, C. Few-shot object detection on remote sensing images via shared attention module and balanced fine-tuning strategy. Remote Sens. 2021, 13, 3816. [Google Scholar] [CrossRef]
- Xiao, Z.; Qi, J.; Xue, W.; Zhong, P. Few-shot object detection with self-adaptive attention network for remote sensing images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 4854–4865. [Google Scholar] [CrossRef]
- Liu, Y.; Pan, Z.; Yang, J.; Zhang, B.; Zhou, G.; Hu, Y.; Ye, Q. Few-shot object detection in remote sensing images via label-consistent classifier and gradual regression. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5612114. [Google Scholar] [CrossRef]
- Li, J.; Tian, Y.; Xu, Y.; Hu, X.; Zhang, Z.; Wang, H.; Xiao, Y. MM-RCNN: Toward few-shot object detection in remote sensing images with meta memory. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5635114. [Google Scholar] [CrossRef]
- Sun, X.; Wang, B.; Wang, Z.; Li, H.; Li, H.; Fu, K. Research progress on few-shot learning for remote sensing image interpretation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 2387–2402. [Google Scholar] [CrossRef]
- Zhang, F.; Shi, Y.; Xiong, Z.; Zhu, X.X. Few-shot object detection in remote sensing: Lifting the curse of incompletely annotated novel objects. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5603514. [Google Scholar] [CrossRef]
- Chen, Y.; Liu, S.; Li, Y.; Tian, L.; Chen, Q.; Li, J. Small Object Detection with Small Samples Using High-Resolution Remote Sensing Images. J. Phys. Conf. Ser. 2024, 2890, 012012. [Google Scholar] [CrossRef]
- Zhou, L.; Wang, C.; Yang, S.; Huang, P. A Review of Small-Sample Target Detection Research. In Proceedings of the International Workshop of Advanced Manufacturing and Automation, Singapore, 10–12 October 2024; Springer Nature: Singapore; pp. 100–107. [Google Scholar]
- Peng, H.; Li, X. Multi-Scale Selection Pyramid Networks for Small-Sample Target Detection Algorithms. In Proceedings of the 2021 3rd International Conference on Machine Learning, Big Data and Business Intelligence (MLBDBI), Shanghai, China, 17–19 December 2021; IEEE: Piscataway, NJ, USA; pp. 359–364. [Google Scholar]
- Sun, F.; Jia, J.; Han, X.; Kuang, L.; Han, H. Small-Sample Target Detection Across Domains Based on Supervision and Distillation. Electronics 2024, 13, 4975. [Google Scholar] [CrossRef]
- Zheng, Y.; Yan, J.; Meng, J.; Liang, M. A Small-Sample Target Detection Method of Side-Scan Sonar Based on CycleGAN and Improved YOLOv8. Appl. Sci. 2025, 15, 2396. [Google Scholar] [CrossRef]
- Li, K.; Wang, L.; Zhao, C.; Shang, Z.; Liu, H.; Qi, Y. Research on Small Sample Ship Target Detection Based on SAR Image. In Proceedings of the International Conference on Internet of Things, Communication and Intelligent Technology, Singapore, 22–24 September 2023; Springer Nature: Singapore; pp. 443–450. [Google Scholar]
- Li, C.; Liu, L.; Zhao, J.; Liu, X. LF-CNN: Deep Learning-Guided Small Sample Target Detection for Remote Sensing Classification. CMES-Comput. Model. Eng. Sci. 2022, 131, 429. [Google Scholar] [CrossRef]
- Yin, J.; Sheng, W.; Jiang, H. Small Sample Target Recognition Based on Radar HRRP and SDAE-WACGAN. IEEE Access 2024, 12, 16375–16385. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. Proc. AAAI Conf. Artif. Intell. 2020, 34, 12993–13000. [Google Scholar] [CrossRef]
- Li, X.; Wang, W.; Wu, L.; Chen, S.; Hu, X.; Li, J.; Tang, J.; Yang, J. Generalized focal loss: Learning qualified and distributed bounding boxes for dense object detection. Adv. Neural Inf. Process. Syst. 2020, 33, 21002–21012. [Google Scholar]
- Li, X.; Deng, J.; Fang, Y. Few-shot object detection on remote sensing images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5601614. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The PASCAL Visual Object Classes Challenge 2007. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Chen, T.-I.; Liu, Y.-C.; Su, H.-T.; Chang, Y.-C.; Lin, Y.-H.; Yeh, J.-F.; Chen, W.-C.; Hsu, W.H. Dual-awareness attention for few-shot object detection. IEEE Trans. Multimed. 2023, 25, 291–301. [Google Scholar] [CrossRef]
- Gao, B.B.; Chen, X.; Huang, Z.; Nie, C.; Liu, J.; Lai, J.; Jiang, G.; Wang, X.; Wang, C. Decoupling classifier for boosting few-shot object detection and instance segmentation. Proc. Adv. Neural Inf. Process. Syst. 2022, 35, 18640–18652. [Google Scholar]
- Wang, L.; Mei, S.; Wang, Y.; Lian, J.; Han, Z.; Chen, X. Few-shot object detection with multilevel information interaction for optical remote sensing images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5628014. [Google Scholar] [CrossRef]
- Yan, X.; Chen, Z.; Xu, A.; Wang, X.; Liang, X.; Lin, L. Meta r-cnn: Towards general solver for instance-level low-shot learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9577–9586. [Google Scholar]
- Farhadi, A.; Redmon, J. Yolov3: An incremental improvement. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar]
- Lin, H.; Li, N.; Yao, P.; Dong, K.; Guo, Y.; Hong, D.; Wen, C. Generalization-Enhanced Few-Shot Object Detection in Remote Sensing. IEEE Trans. Circuits Syst. Video Technol. 2025. [Google Scholar] [CrossRef]
- Wang, Y.; Xu, C.; Liu, C.; Li, Z. Context information refinement for few-shot object detection in remote sensing images. Remote Sens. 2022, 14, 3255. [Google Scholar] [CrossRef]
- Zhao, Z.; Tang, P.; Zhao, L.; Zhang, Z. Few-shot object detection of remote sensing images via two-stage fine-tuning. IEEE Geosci. Remote Sens. Lett. 2022, 19, 8021805. [Google Scholar] [CrossRef]
- Liu, N.; Xu, X.; Celik, T.; Gan, Z.; Li, H.-C. Transformation-invariant network for few-shot object detection in remote-sensing images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5625314. [Google Scholar] [CrossRef]
- Jiang, H.; Wang, Q.; Feng, J.; Zhang, G.; Yin, J. Balanced orthogonal subspace separation detector for few-shot object detection in aerial imagery. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5638517. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sequence | Type | Filter/Pooling Size | Convolution Kernel Size and Stride | Output Dimensions |
|---|---|---|---|---|
| 1 | Convolutional Layers | 32 | 3 × 3, stride 1 | 512 × 512 |
| 2 | Convolutional Layers | 32 | 3 × 3, stride 1 | 512 × 512 |
| 3 | Maxpooling | - | 2 × 2, stride 2 | 256 × 256 |
| 4 | Convolutional Layers | 64 | 3 × 3, stride 1 | 256 × 256 |
| 5 | Residual Block | 64 | - | 256 × 256 |
| 6 | Maxpooling | - | 2 × 2, stride 2 | 128 × 128 |
| 7 | Convolutional Layers | 128 | 3 × 3, stride 1 | 128 × 128 |
| 8 | Dilated Convolution | 128 | 3 × 3, dilation 2 | 128 × 128 |
| 9 | Residual Block | 128 | - | 128 × 128 |
| 10 | Maxpooling | - | 2 × 2, stride 2 | 64 × 64 |
| 11 | Convolutional Layers | 256 | 3 × 3, stride 1 | 64 × 64 |
| 12 | Dilated Convolution | 256 | 3 × 3, dilation 2 | 64 × 64 |
| 13 | Residual Block | 256 | - | 64 × 64 |
| 14 | Convolutional Layers | 512 | 3 × 3, stride 1 | 64 × 64 |
| 15 | GlobalMax | - | - | 1 × 1 |
| 16 | Convolutional Layers | 8 | 1 × 1, stride 1 | 64 × 64 |
| 17 | Residual Block | 8 | - | 64 × 64 |
| 18 | Convolutional Layers | 1024 | 3 × 3, stride 1 | 32 × 32 |
| 19 | Maxpooling | - | 2 × 2, stride 2 | 16 × 16 |
| 20 | GlobalMax | - | - | 1 × 1 |
| : | Base category training images. |
| : | Novel category test images. |
| : | Support images, i.e., the few-shot samples of novel categories. |
| : | Class-specific weights generated by the feature reweighting module. |
| : | Feature representation of image . |
| and : | Models for base and novel categories, respectively. |
| : | Novel category bounding box detection results. |
| : | Loss function for the novel category model. |
| Shot | Method | AL (Airplane) | BD (Baseball Diamond) | TC (Tennis Court) | mAP(%) |
|---|---|---|---|---|---|
| 3 | Meta RCNN [89] | 6.9 | 7.2 | 5.8 | 6.6 |
| FsDetView [59] | 9.1 | 19.7 | 6.8 | 11.9 | |
| FSFR [43] | 13 | 12 | 11 | 12.0 | |
| DAnA [86] | 16.2 | 10.3 | 13.5 | 13.3 | |
| DCFS [87] | 18.4 | 38.2 | 17.3 | 25 | |
| FSODM [84] | 14 | 47 | 24 | 28.3 | |
| MFDC [48] | 31.8 | 36.9 | 17.7 | 28.8 | |
| FSCE [52] | 29.1 | 51.6 | 25 | 35.2 | |
| MLII-FSOD [88] | 42.3 | 57.5 | 30.2 | 43.3 | |
| SFIDM (ours) | 20.4 | 66.3 | 34.6 | 40.4 | |
| 5 | Meta RCNN [89] | 12.3 | 21.7 | 19.9 | 12 |
| FsDetView [59] | 14.3 | 26.8 | 10.8 | 17.3 | |
| DAnA [86] | 15.6 | 14.5 | 12.9 | 14.3 | |
| DCFS [87] | 34.6 | 70.2 | 18.5 | 41.1 | |
| MFDC [48] | 50.2 | 57.3 | 21.6 | 43 | |
| FSCE [52] | 42.8 | 66 | 26.3 | 45.1 | |
| MLII-FSOD [88] | 52.4 | 71.3 | 47.7 | 57.1 | |
| SFIDM (ours) | 65.7 | 88.5 | 26.4 | 60.3 | |
| 10 | Meta RCNN [89] | 11.5 | 22.4 | 12.5 | 15.5 |
| FsDetView [59] | 16.1 | 20.1 | 16.4 | 17.5 | |
| FSFR [43] | 27.7 | 24.4 | 19.6 | 23.9 | |
| DAnA [86] | 20 | 74 | 26 | 40.0 | |
| DCFS [87] | 52.8 | 80.7 | 36.2 | 56.6 | |
| FSODM [84] | 62.4 | 69.1 | 26.8 | 52.7 | |
| MFDC [48] | 60.7 | 76.8 | 33 | 56.8 | |
| FSCE [52] | 60 | 88 | 48 | 65.3 | |
| MLII-FSOD [88] | 74.2 | 72.1 | 52 | 66.1 | |
| SFIDM (ours) | 68.4 | 92.3 | 43.9 | 68.2 |
| Class | YOLOv3 [90] | FSFR [43] | FSODM [84] | SFIDM (Ours) |
|---|---|---|---|---|
| ship | 0.71 | 0.77 | 0.72 | 0.74 |
| storage tank | 0.68 | 0.80 | 0.71 | 0.95 |
| basketball court | 0.62 | 0.41 | 0.72 | 0.54 |
| ground track field | 0.94 | 0.94 | 0.91 | 0.96 |
| harbor | 0.84 | 0.86 | 0.87 | 0.96 |
| bridge | 0.80 | 0.77 | 0.76 | 0.83 |
| vehicle | 0.77 | 0.68 | 0.76 | 0.77 |
| mean | 0.77 | 0.76 | 0.78 | 0.82 |
| Shot | Method | Windmill | Airplane | Tennis Court | Train Station | Baseball Field | mAP(%) |
|---|---|---|---|---|---|---|---|
| 3 | Meta RCNN [89] | 9.1 | 15.1 | 31.8 | 7.1 | 5.2 | 13.7 |
| FsDetView [59] | 9.1 | 9.7 | 22.8 | 6.9 | 4.3 | 10.6 | |
| DAnA [86] | 0.3 | 1.9 | 19.4 | 14.1 | 19.3 | 11.0 | |
| FSCE [52] | 9.1 | 9.1 | 9.1 | 6.6 | 27.3 | 12.4 | |
| DCFS [87] | 9.1 | 11.7 | 23.6 | 3.5 | 37.0 | 17.0 | |
| MFDC [48] | 11.2 | 10.1 | 35.2 | 7.0 | 40.1 | 20.8 | |
| MLII-FSOD [88] | 10.4 | 19.2 | 22.5 | 15.6 | 36.8 | 20.9 | |
| SFIDM (ours) | 13.2 | 12.4 | 46.2 | 13.9 | 24.3 | 22.0 | |
| 5 | Meta RCNN [89] | 9.1 | 17.0 | 33.2 | 8.9 | 7.2 | 13.0 |
| FsDetView [59] | 9.1 | 22.3 | 26.2 | 5.2 | 2.3 | 15.1 | |
| DAnA [86] | 2.4 | 11.4 | 26.8 | 12.5 | 36.5 | 17.9 | |
| FSCE [52] | 15.6 | 9.1 | 40.6 | 10.2 | 41.9 | 23.5 | |
| DCFS [87] | 13.1 | 15.8 | 39.5 | 8.5 | 43.5 | 24.1 | |
| MFDC [48] | 14.8 | 13.4 | 40.5 | 10.5 | 45.5 | 24.9 | |
| MLII-FSOD [88] | 12.8 | 21.9 | 30.2 | 23.4 | 38.4 | 25.3 | |
| SFIDM (ours) | 23.5 | 14.2 | 62.4 | 17.7 | 31.4 | 29.8 | |
| 10 | Meta RCNN [89] | 11.4 | 33.5 | 32.4 | 14.0 | 3.5 | 18.9 |
| FsDetView [59] | 11.2 | 20.4 | 25.6 | 7.0 | 6.1 | 14.1 | |
| DAnA [86] | 6.5 | 21.1 | 27.9 | 15.9 | 25.5 | 19.4 | |
| FSCE [52] | 27.5 | 9.1 | 38.8 | 14.7 | 47.2 | 27.5 | |
| FSFR [43] | 18 | 14 | 44 | 7 | 44 | 25.4 | |
| DCFS [87] | 15.9 | 18.9 | 48.8 | 14.4 | 46.9 | 29.0 | |
| MFDC [48] | 15.6 | 17.8 | 47.7 | 16.4 | 49.0 | 29.3 | |
| FSODM [84] | 24 | 16 | 60 | 14 | 46 | 32.0 | |
| MLII-FSOD [88] | 27.7 | 20.5 | 38.4 | 26.2 | 47.8 | 32.1 | |
| SFIDM (ours) | 27.2 | 21.6 | 66.3 | 21.8 | 49.7 | 37.3 | |
| 20 | Meta RCNN [89] | 10.2 | 34.5 | 35.4 | 13.7 | 8.5 | 20.5 |
| FsDetView [59] | 16.2 | 31.7 | 25.8 | 11.1 | 6.1 | 18.2 | |
| DAnA [86] | 10.4 | 14.3 | 28.6 | 16.5 | 38.5 | 21.7 | |
| FSCE [52] | 34.1 | 20.1 | 49.1 | 13.5 | 51.1 | 33.6 | |
| DCFS [87] | 14.0 | 19.2 | 49.7 | 16.7 | 49.7 | 29.9 | |
| MFDC [48] | 16.0 | 18.3 | 48.3 | 16.6 | 45.9 | 29.0 | |
| FSODM [84] | 29 | 22 | 66 | 16 | 40 | 34.6 | |
| MLII-FSOD [88] | 35.2 | 34.2 | 39.1 | 26.5 | 48.2 | 36.6 | |
| SFIDM (ours) | 32.6 | 26.8 | 68.5 | 23.5 | 49.7 | 40.8 |
| Class | FSODM [84] | FSFR [43] | YOLOv3 [90] | SFIDM (Ours) |
|---|---|---|---|---|
| airport | 0.63 | 0.49 | 0.49 | 0.78 |
| basketball court | 0.80 | 0.74 | 0.83 | 0.83 |
| bridge | 0.32 | 0.29 | 0.28 | 0.35 |
| chimney | 0.72 | 0.70 | 0.68 | 0.76 |
| dam | 0.44 | 0.42 | 0.39 | 0.63 |
| expressway service area | 0.63 | 0.63 | 0.68 | 0.65 |
| expressway toll station | 0.60 | 0.48 | 0.47 | 0.54 |
| golf course | 0.61 | 0.61 | 0.63 | 0.74 |
| ground track field | 0.61 | 0.44 | 0.70 | 0.65 |
| harbor | 0.43 | 0.42 | 0.43 | 0.60 |
| overpass | 0.46 | 0.49 | 0.43 | 0.52 |
| ship | 0.40 | 0.33 | 0.64 | 0.72 |
| stadium | 0.44 | 0.42 | 0.43 | 0.68 |
| storage tank | 0.43 | 0.26 | 0.46 | 0.58 |
| vehicle | 0.39 | 0.29 | 0.41 | 0.37 |
| mean | 0.54 | 0.50 | 0.54 | 0.62 |
| mAP(%) | λreg | |||||
| 0.6 | 0.8 | 1.0 | 1.2 | 1.4 | ||
| λDFL | 0.6 | 78.2 | 79.4 | 80.1 | 79.8 | 79.3 |
| 0.8 | 79.6 | 80.8 | 81.4 | 81.2 | 80.7 | |
| 1.0 | 80.4 | 81.7 | 81.6 | 81.3 | 81.2 | |
| 1.2 | 80.9 | 82.3 | 82.1 | 81.8 | 81.4 | |
| 1.4 | 80.4 | 81.9 | 81.7 | 81.4 | 80.9 | |
| Method | Low-Frequency Feature Extraction | High-Frequency Feature Extraction | Distribution Matching Module | mAP(%) |
|---|---|---|---|---|
| M1 | √ | 77.8 | ||
| M2 | √ | √ | 80.4 | |
| M3 | √ | 78.6 | ||
| M4 | √ | √ | 81.2 | |
| M5 | √ | √ | 79.5 | |
| M6 | √ | √ | √ | 82.3 |
| Method | 5-Shot (mAP) | 10-Shot (mAP) | 20-Shot (mAP) | Params (M) | GFLOPs | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Base | Novel | Total | Base | Novel | Total | Base | Novel | Total | |||
| Meta R-CNN [89] | - | 0.154 | - | - | 0.199 | - | - | - | - | - | - |
| TFA [51] | 0.518 | 0.226 | 0.445 | 0.604 | 0.255 | 0.517 | 0.535 | 0.375 | 0.495 | 58.2 | 154.7 |
| FSCE [52] | - | 0.282 | - | - | 0.346 | - | - | - | - | - | - |
| GE-FSOD [91] | - | 0.348 | - | - | 0.380 | - | - | 0.431 | - | 59.9 | 352.4 |
| G-FSDet [60] | - | 0.31 | - | - | 0.37 | 0.71 | 0.42 | - | 74.1 | - | |
| SAGS-TFS [21] | - | 0.34 | - | 0.37 | - | 0.42 | - | 49.6 | 327.2 | ||
| CIR-FSD [92] | - | 0.33 | - | - | 0.38 | - | - | 0.43 | - | 63.3 | 159.0 |
| FSODM [84] | 0.535 | 0.246 | 0.463 | 0.535 | 0.32 | 0.482 | 0.535 | 0.366 | 0.493 | 81.2 | 216.4 |
| PAMS-Det [93] | 0.651 | 0.282 | 0.559 | 0.651 | 0.328 | 0.57 | 0.651 | 0.384 | - | - | - |
| FCDGF [61] | - | 0.36 | - | - | 0.41 | - | 0.74 | 0.47 | - | 65.0 | 197.9 |
| TINet [94] | 0.578 | 0.286 | 0.505 | 0.574 | 0.384 | 0.527 | 0.621 | 0.432 | 0.574 | - | - |
| Two-Stage BOSS [95] | 0.744 | 0.37 | 0.65 | 0.754 | 0.409 | 0.668 | 0.753 | 0.478 | 0.684 | - | - |
| SFIDM (ours) | 0.628 | 0.298 | 0.546 | 0.623 | 0.373 | 0.561 | 0.614 | 0.408 | 0.563 | 66.0 | 225.3 |
| SFIDM-L (ours) | 0.758 | 0.366 | 0.660 | 0.752 | 0.421 | 0.669 | 0.746 | 0.485 | 0.681 | 15.7 | 35.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Li, J.; Guo, J.; Liu, R.; Cao, Q.; Li, D.; Wang, L. SFIDM: Few-Shot Object Detection in Remote Sensing Images with Spatial-Frequency Interaction and Distribution Matching. Remote Sens. 2025, 17, 972. https://doi.org/10.3390/rs17060972
Wang Y, Li J, Guo J, Liu R, Cao Q, Li D, Wang L. SFIDM: Few-Shot Object Detection in Remote Sensing Images with Spatial-Frequency Interaction and Distribution Matching. Remote Sensing. 2025; 17(6):972. https://doi.org/10.3390/rs17060972
Chicago/Turabian StyleWang, Yong, Jingtao Li, Jiahui Guo, Rui Liu, Qiusheng Cao, Danping Li, and Lei Wang. 2025. "SFIDM: Few-Shot Object Detection in Remote Sensing Images with Spatial-Frequency Interaction and Distribution Matching" Remote Sensing 17, no. 6: 972. https://doi.org/10.3390/rs17060972
APA StyleWang, Y., Li, J., Guo, J., Liu, R., Cao, Q., Li, D., & Wang, L. (2025). SFIDM: Few-Shot Object Detection in Remote Sensing Images with Spatial-Frequency Interaction and Distribution Matching. Remote Sensing, 17(6), 972. https://doi.org/10.3390/rs17060972