
An Improved YOLOv8-Based Lightweight Attention Mechanism for Cross-Scale Feature Fusion
Abstract
1. Introduction
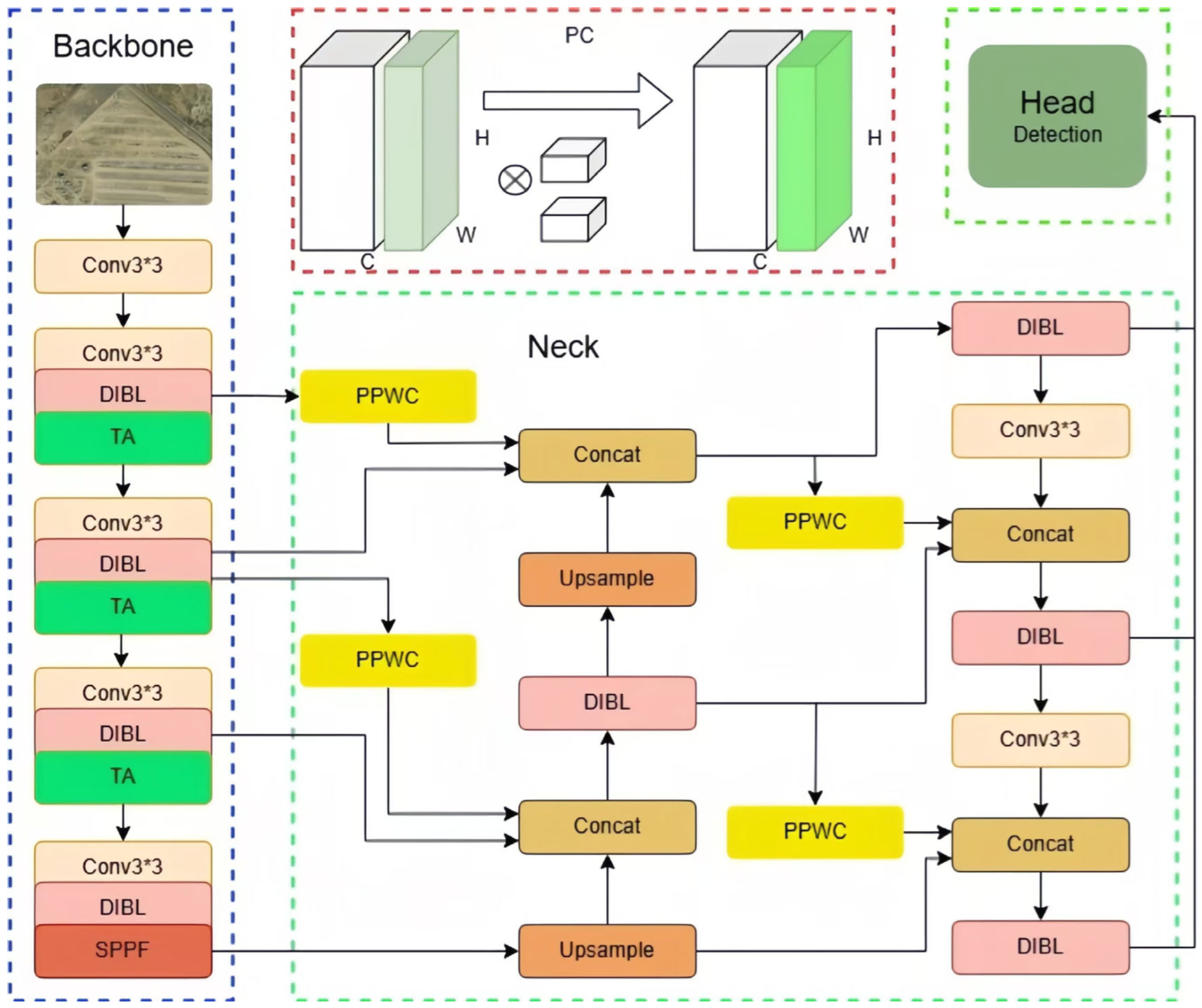
- We propose a lightweight attention mechanism combined with a cross-scale feature fusion model called LACF-YOLO, which is based on YOLOv8. This approach was adopted after a comprehensive analysis of detection accuracy and efficiency, and it contributes to enhancing the level of detection in remote sensing images.
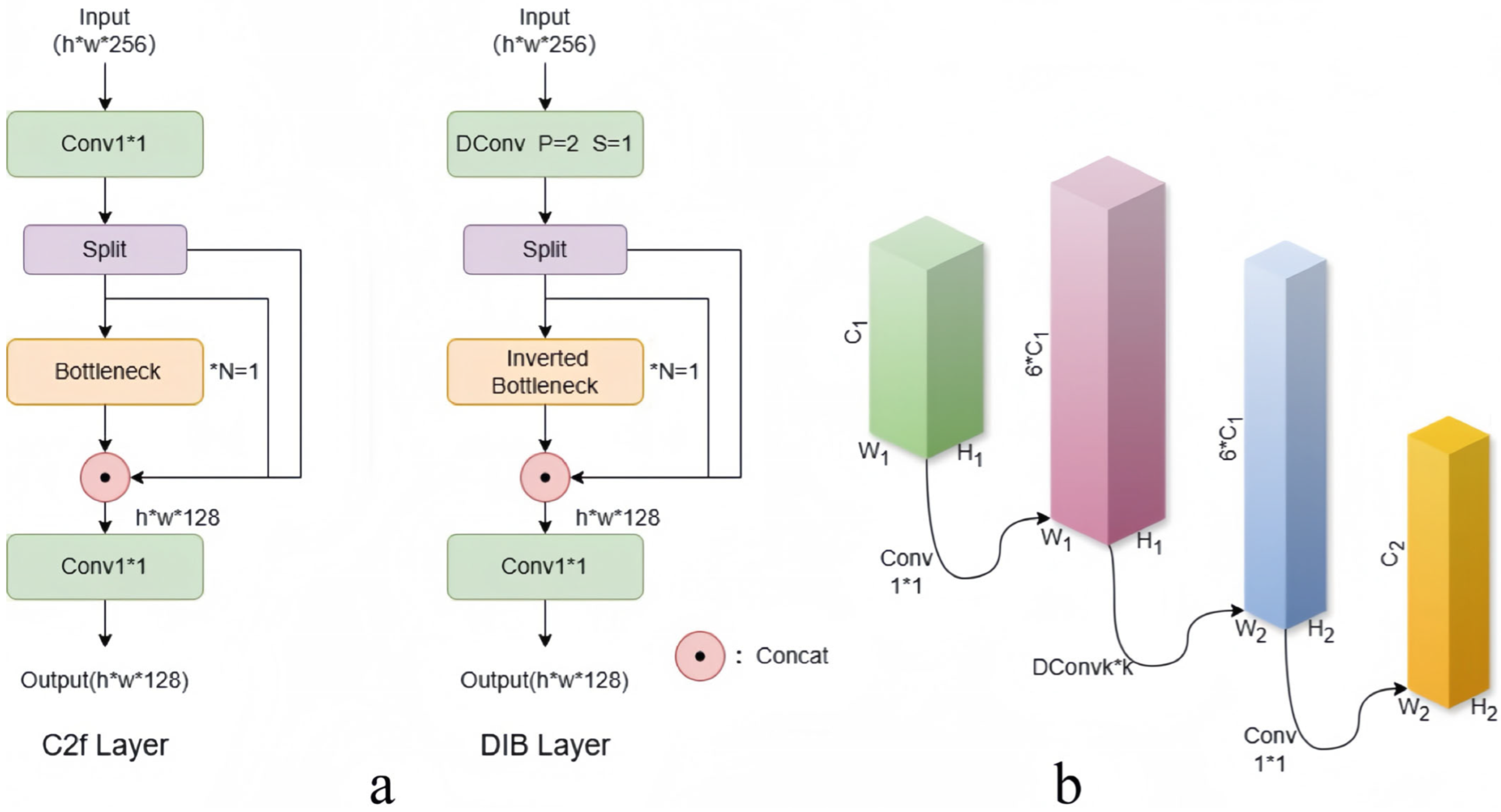
- During the feature extraction phase, we employ a lightweight DIB (dilated inverted bottleneck) module coupled with a parameter-efficient TA (Triplet Attention) mechanism to reconstruct the feature extraction network. This enhancement improves the feature map’s representation and the network’s capability for feature extraction, while significantly reducing the number of parameters.
- A convolutional block composed of PC (partial convolution) and PWC (pointwise convolution) is utilized to connect feature maps across different levels, thereby enhancing the capability to integrate cross-scale feature information.
- The Focal-EIOU loss function is employed as a replacement for the CIOU loss. The Focal strategy allocates greater influence to high-quality anchor boxes, addressing the issue of sample imbalance and overcoming the challenge of slow convergence associated with the traditional CIOU loss function.
2. Related Work
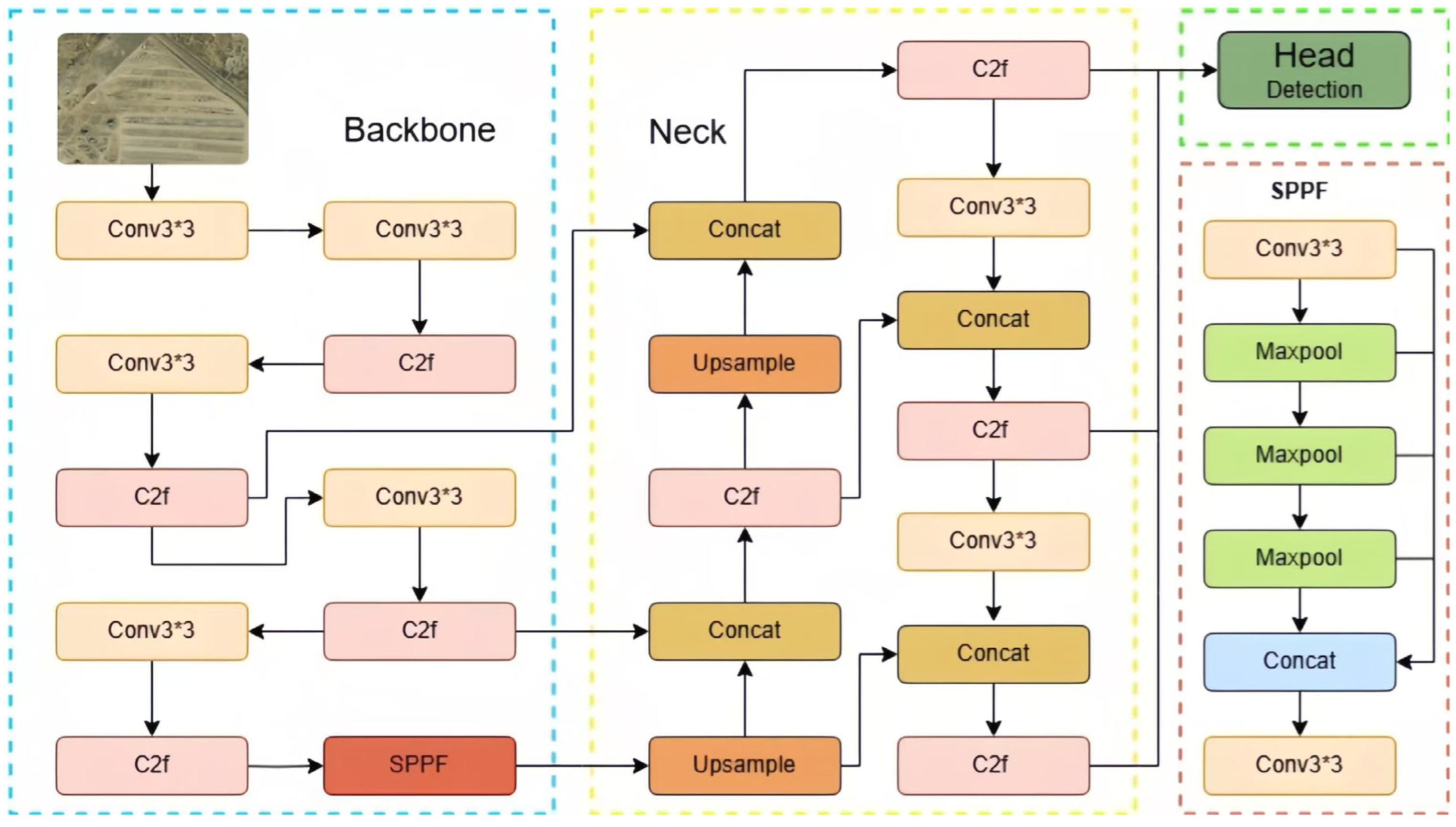
2.1. YOLOv8 Detection Framework
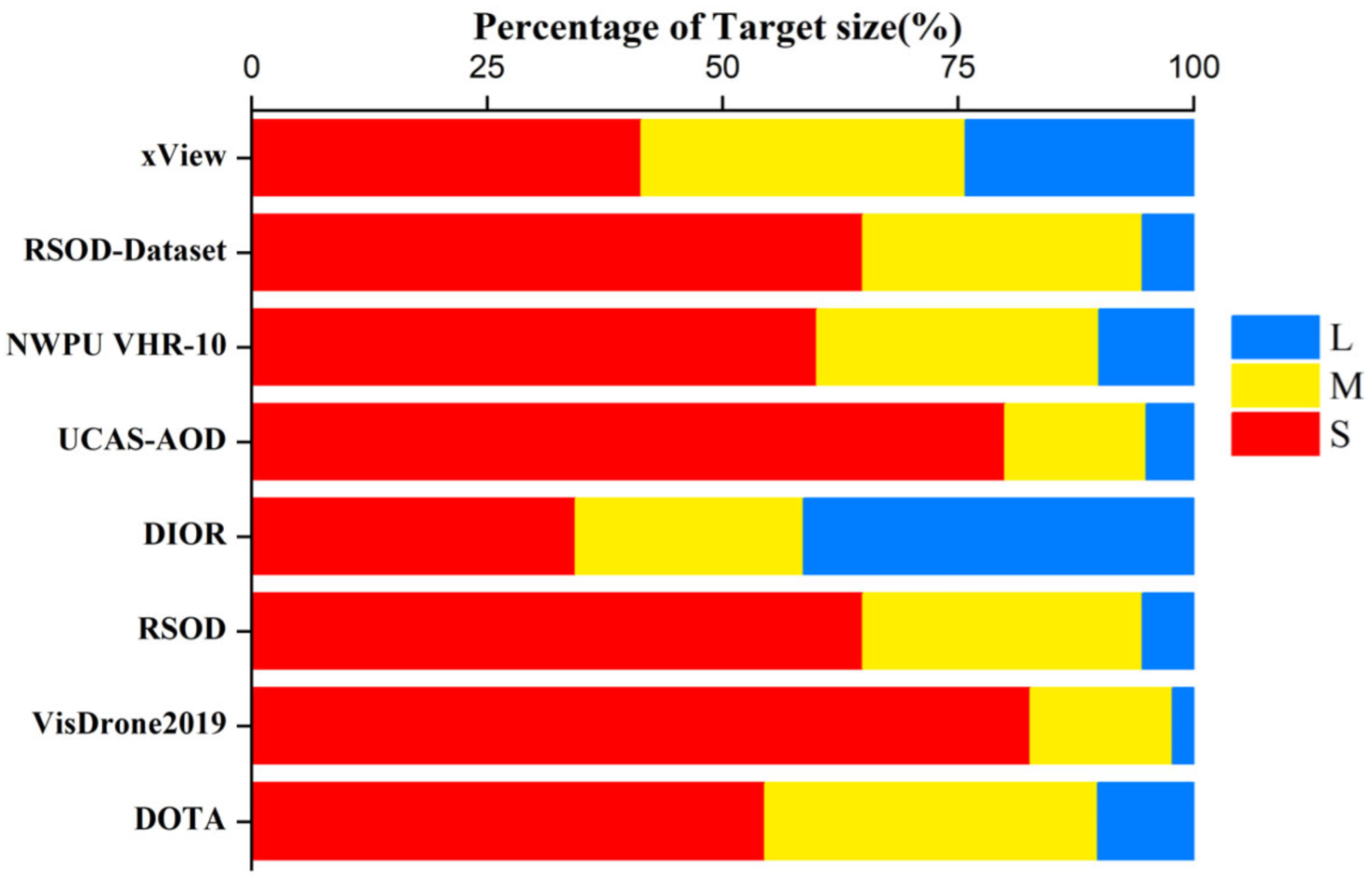
2.2. Challenges in Small Object Detection
2.3. Development and Application of Attention Mechanisms
2.4. Development and Application of Feature Fusion
3. Materials and Methods
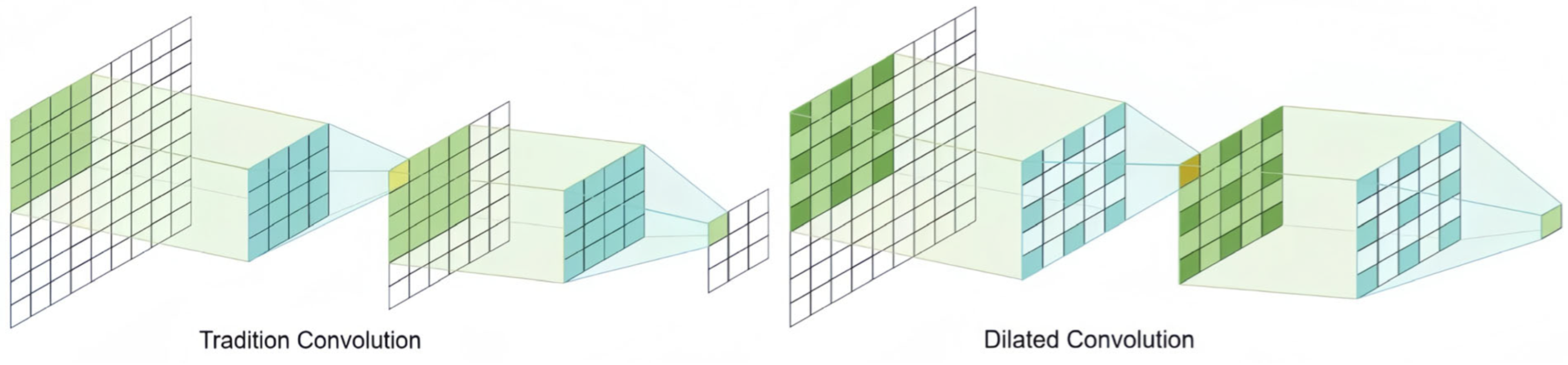
3.1. Dilated Inverted Bottleneck (DIB) Layer
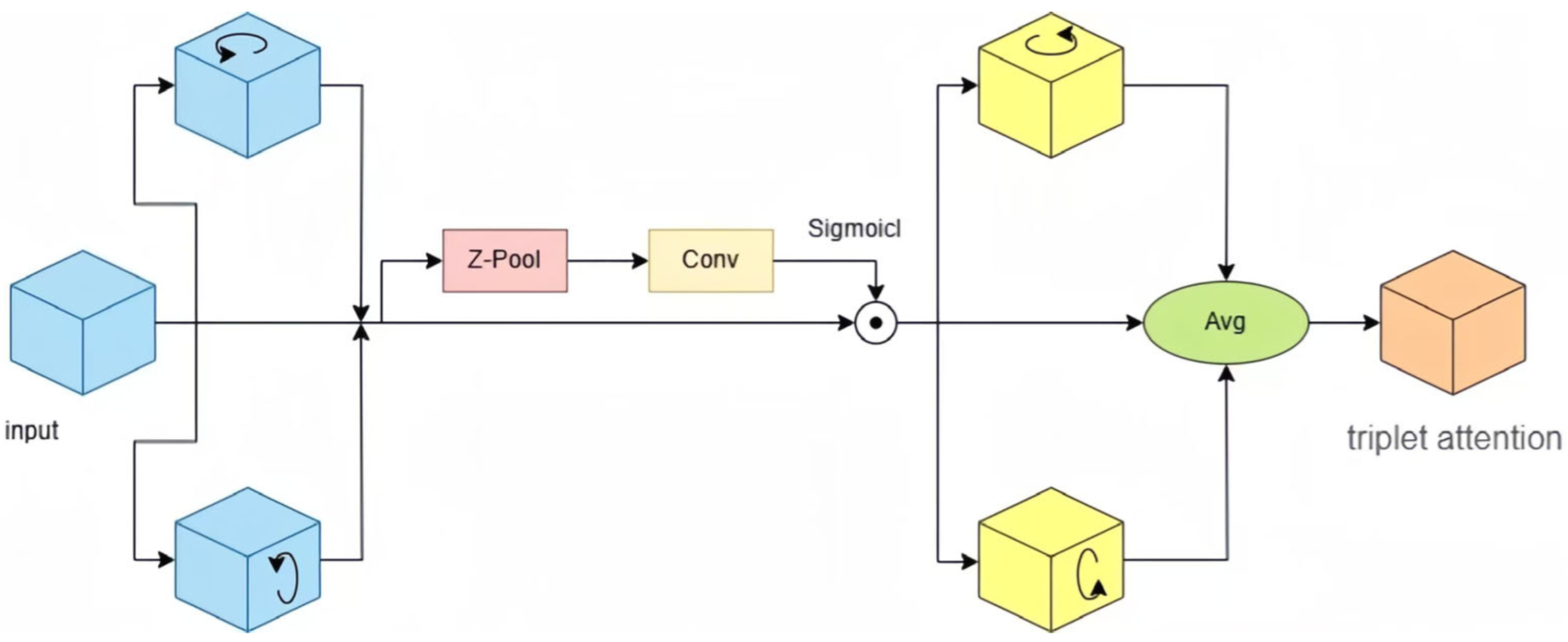
3.2. Triplicate Attention (TA) Module
3.3. Multi-Scale Feature Fusion Across Layers
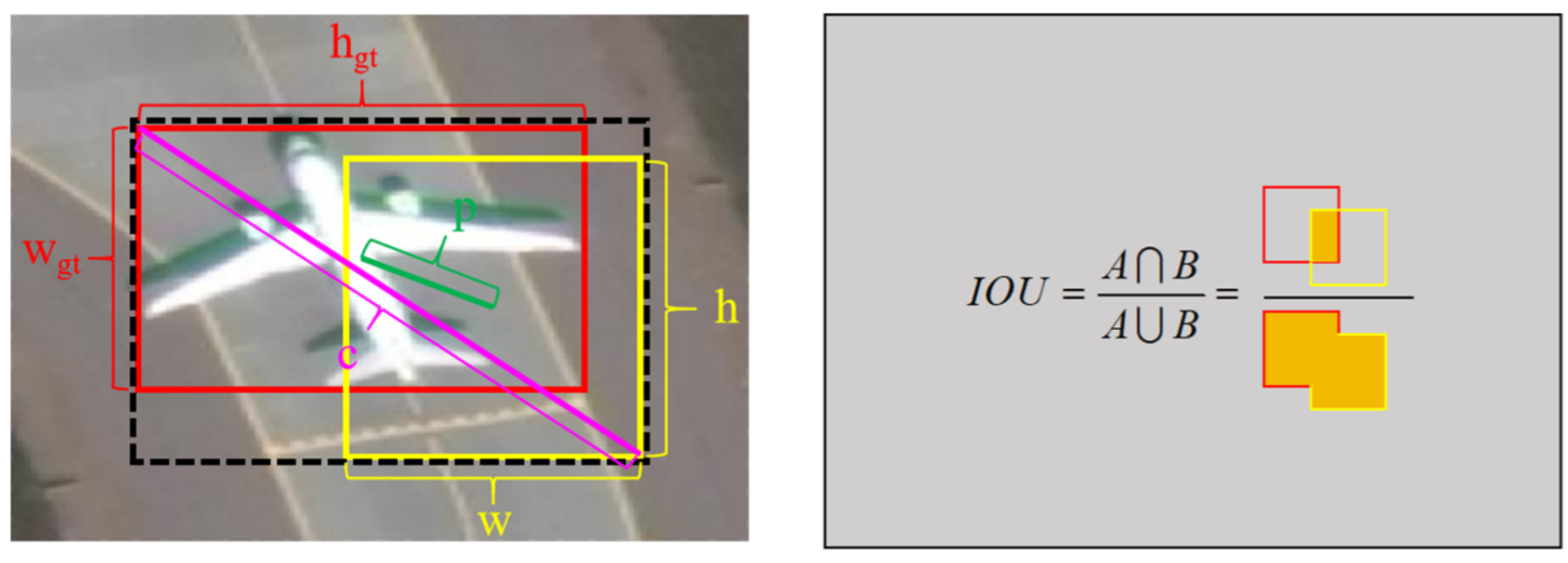
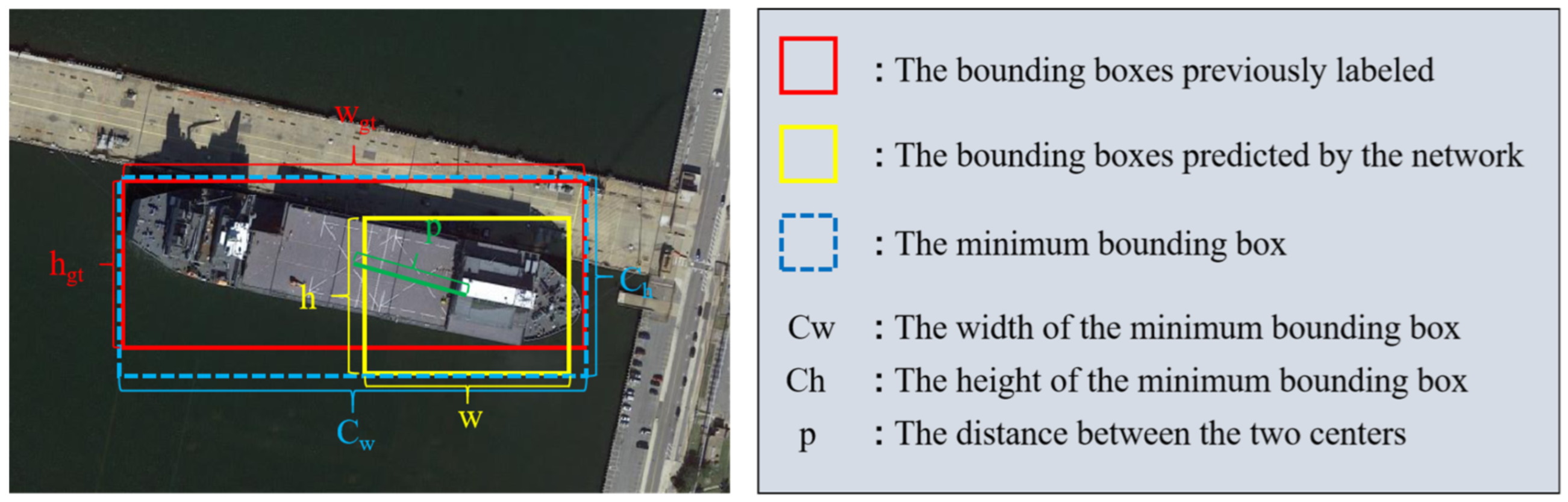
3.4. Focal Loss for Efficient Intersection over Union (EIOU) Loss Function
4. Results
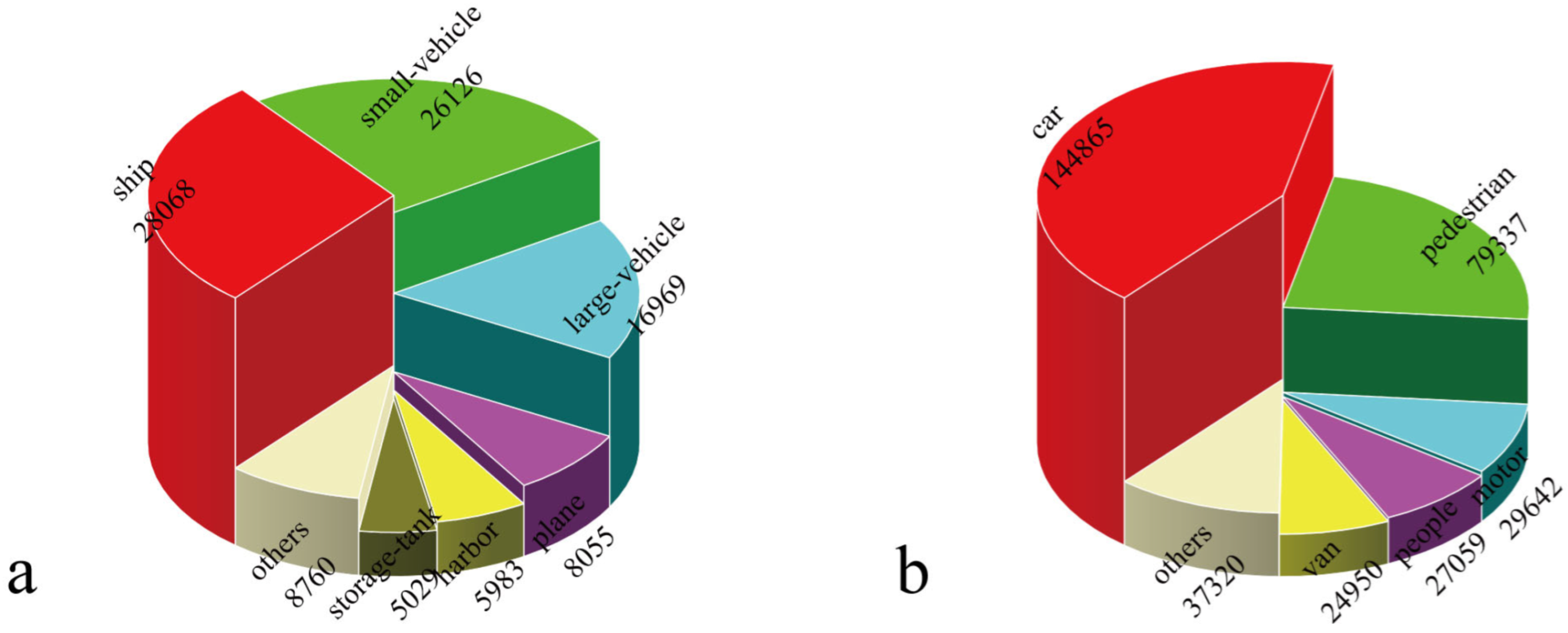
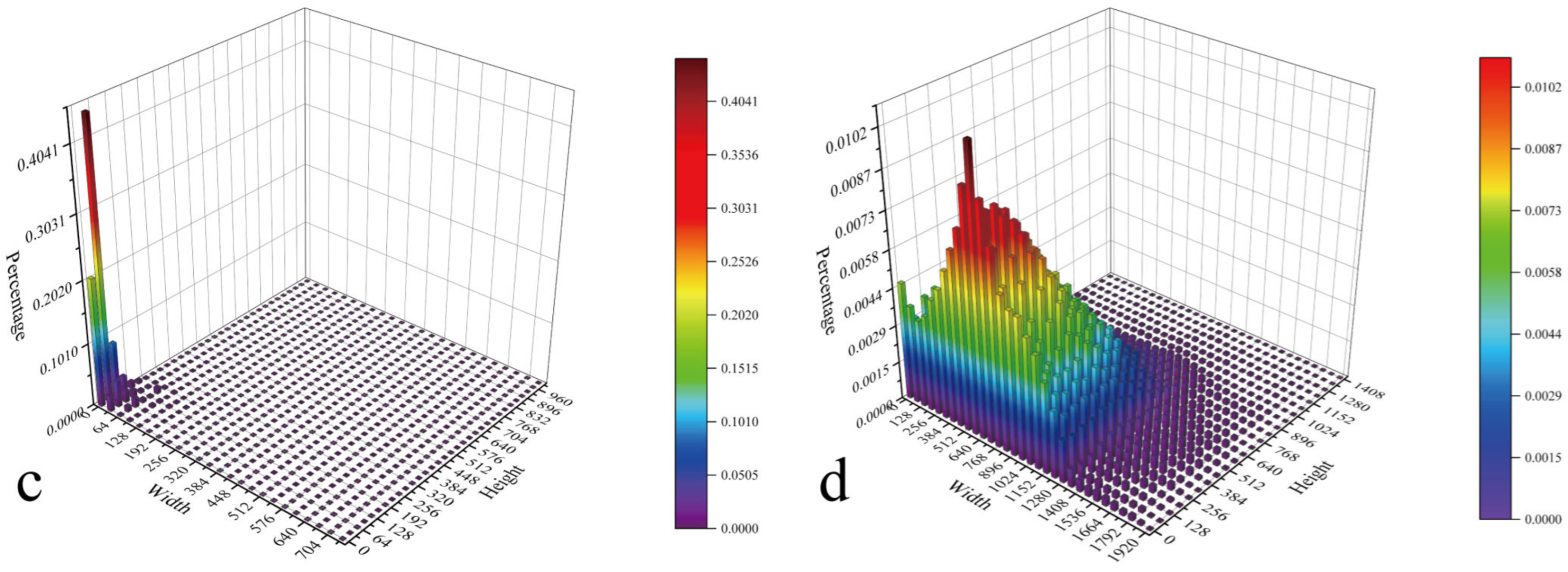
4.1. Dataset
4.2. Experimental Setup
4.3. Evaluation Metric
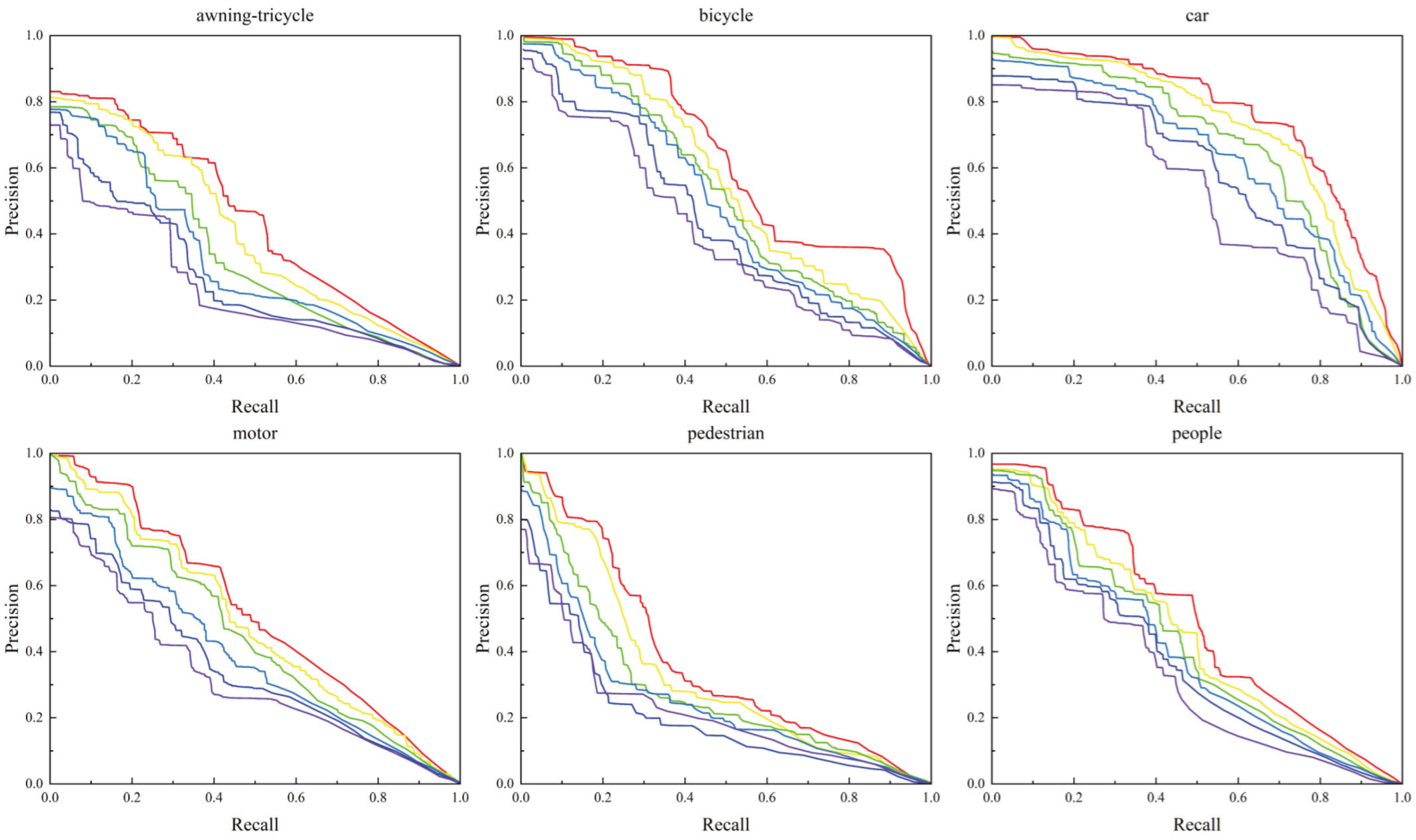
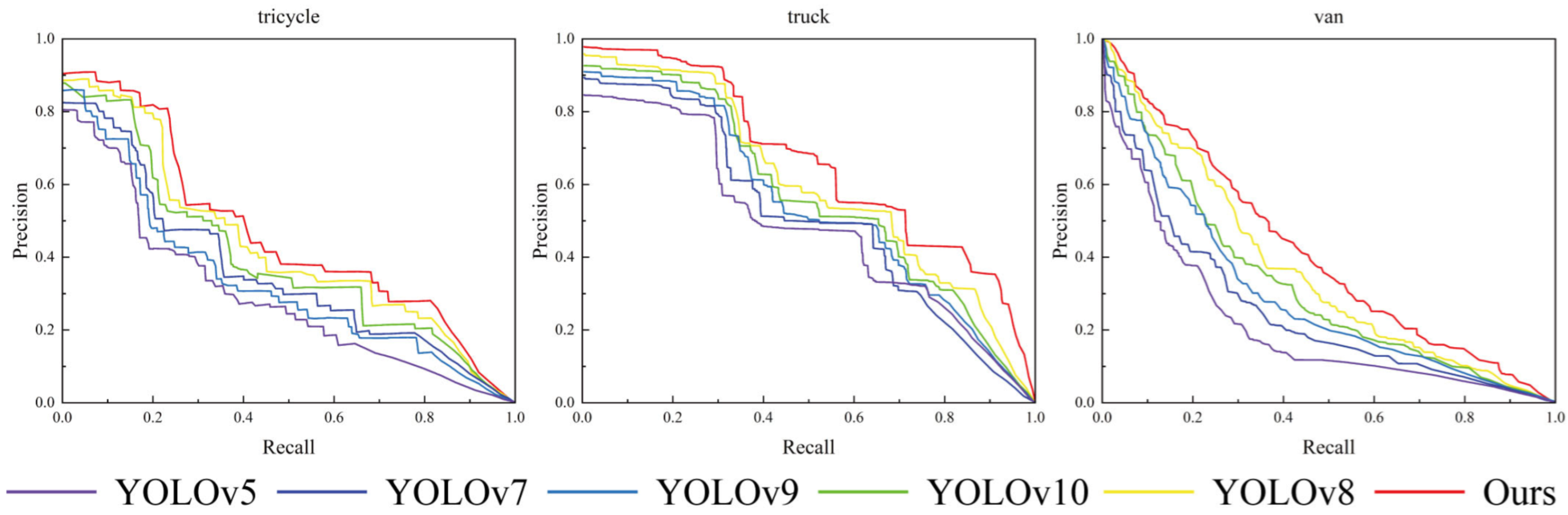
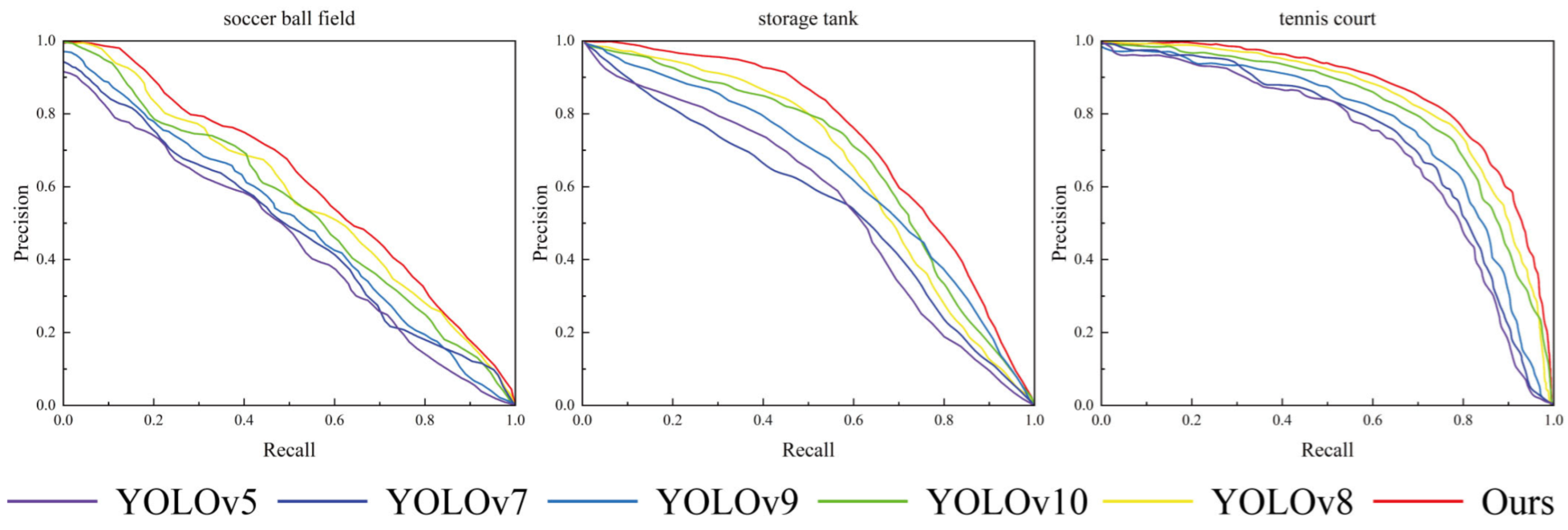
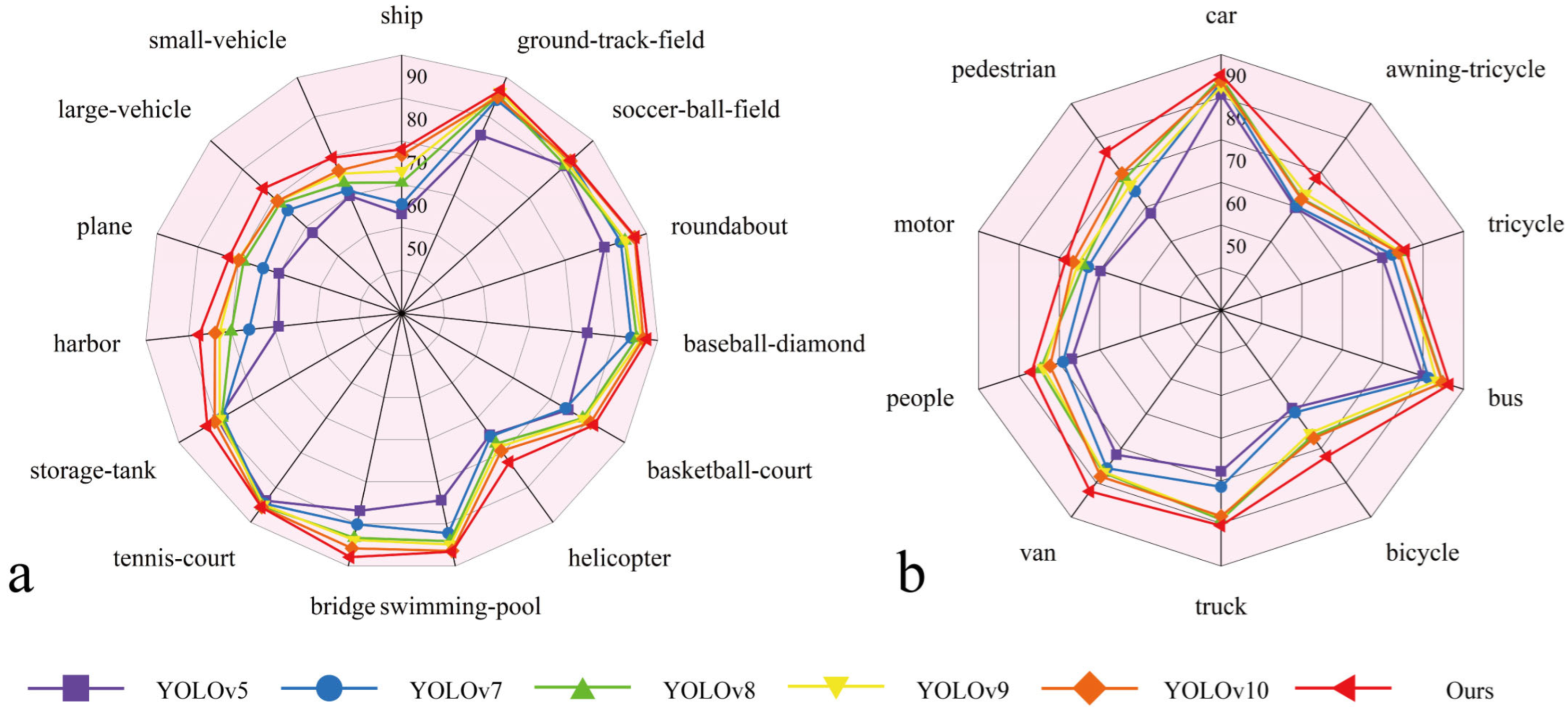
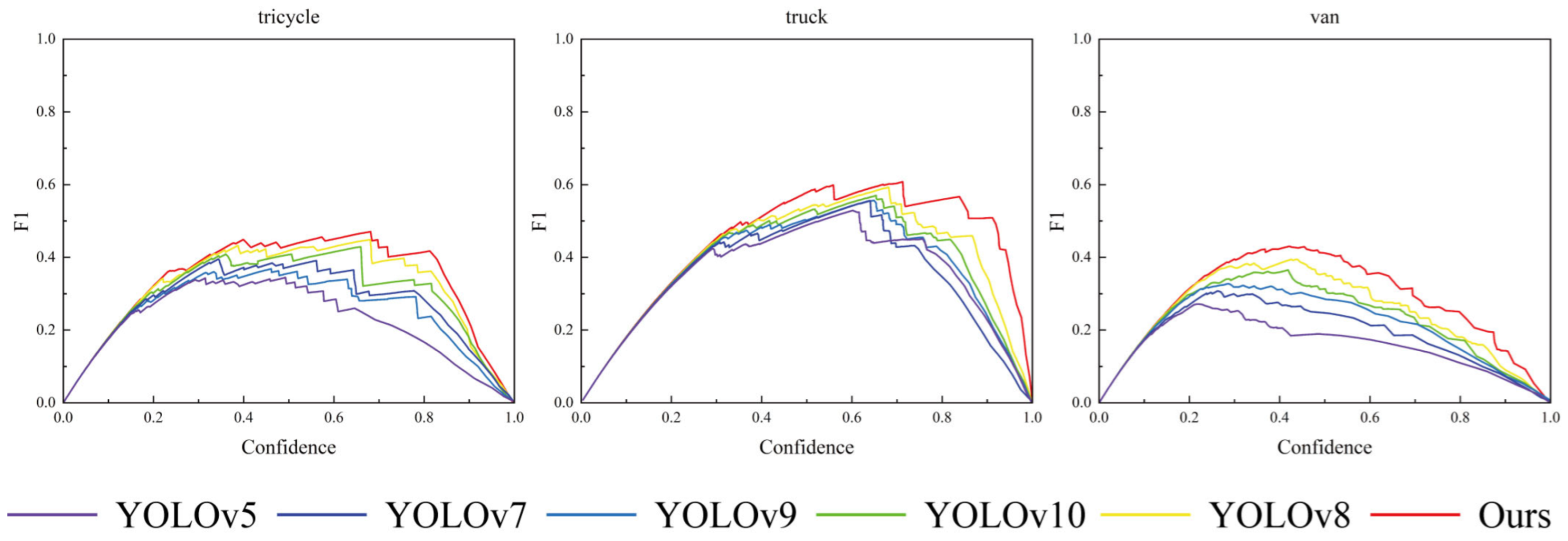
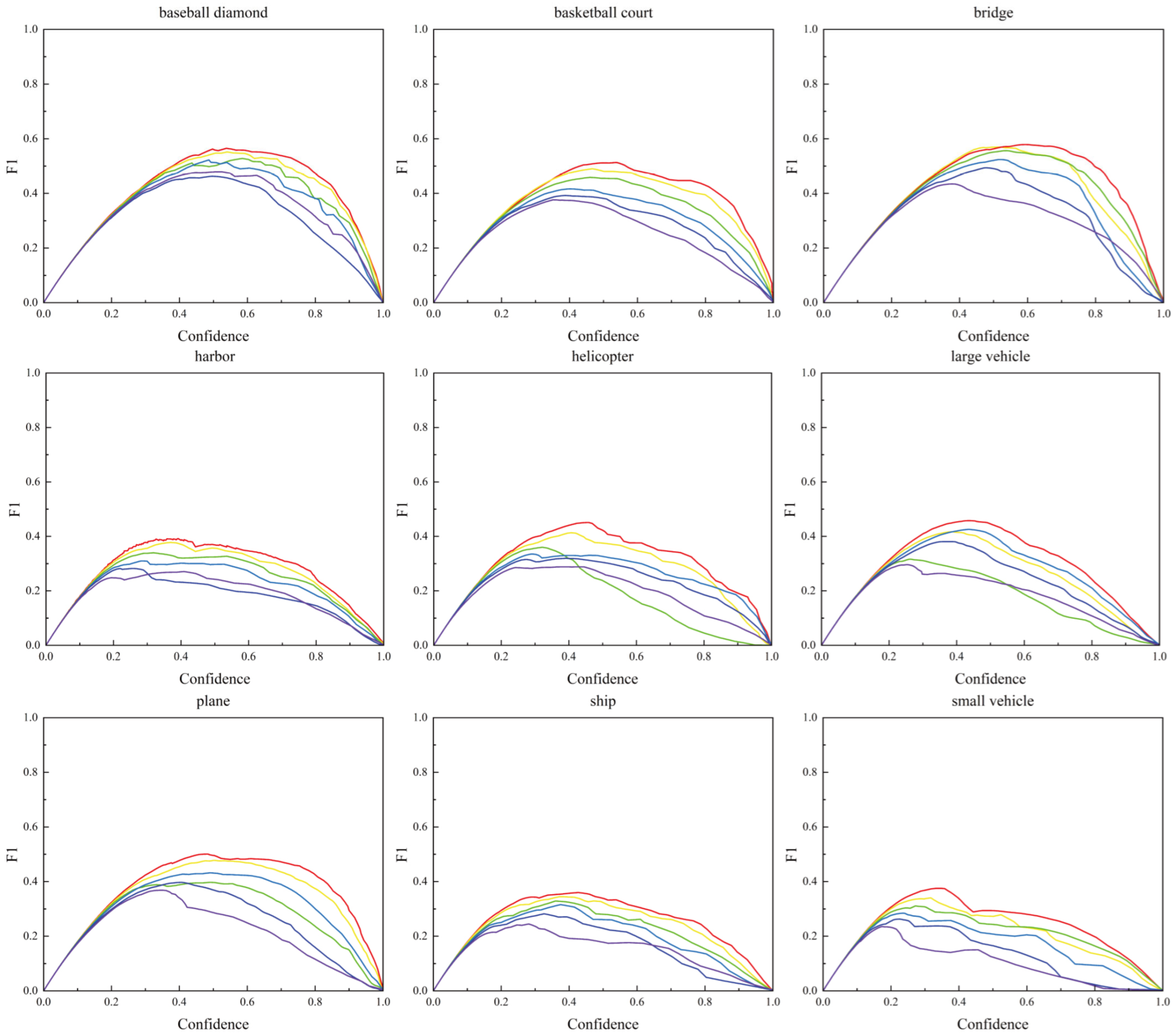
4.4. Results and Analysis
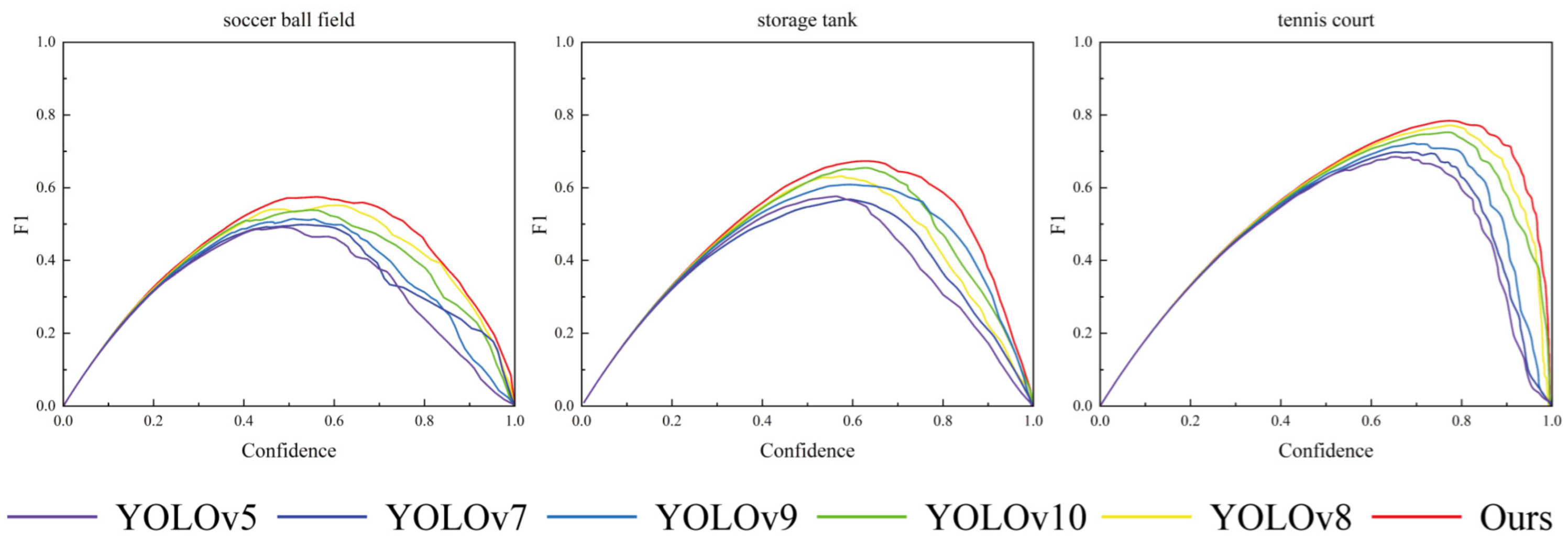
4.4.1. Comparison Test with Other Models
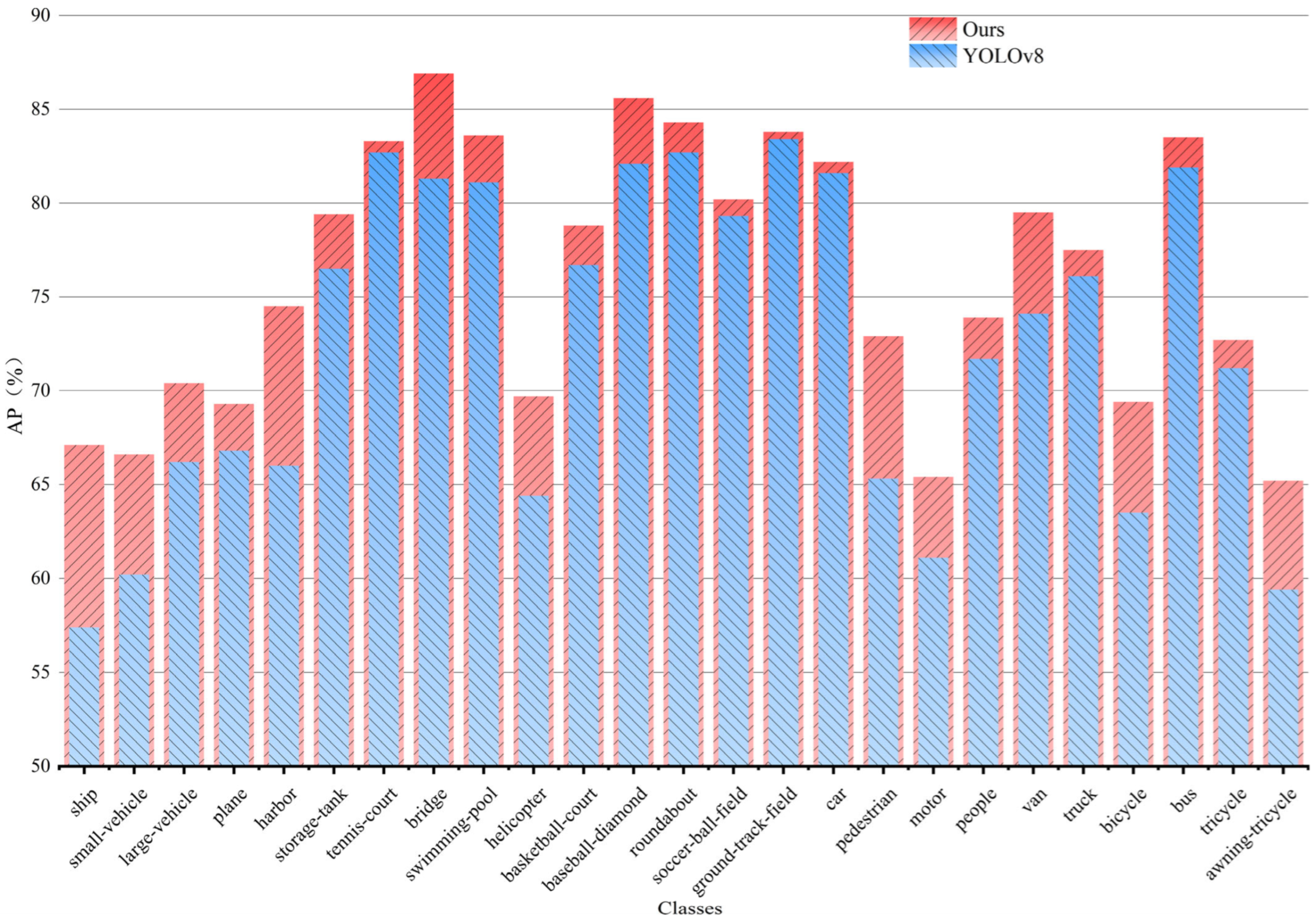
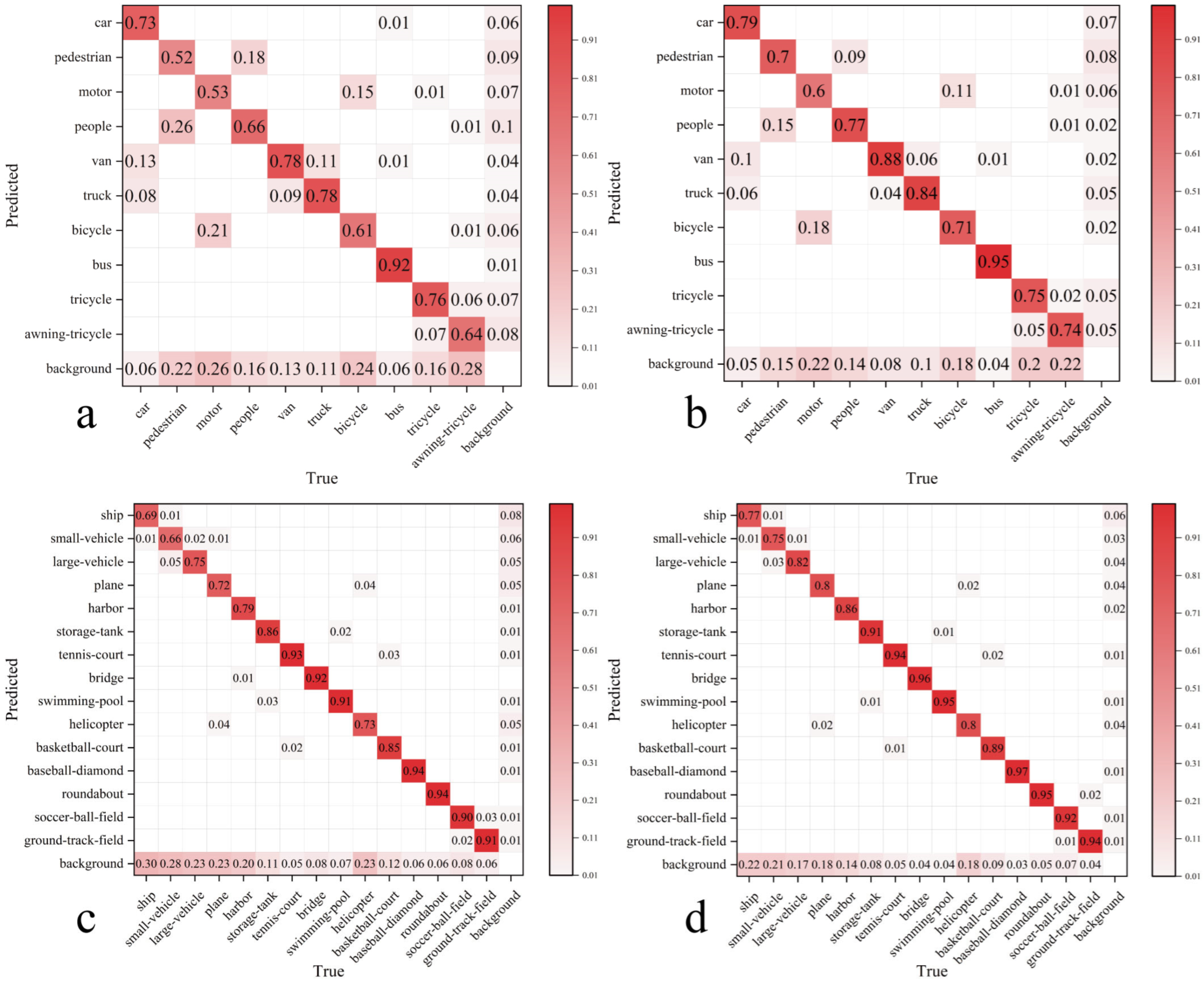
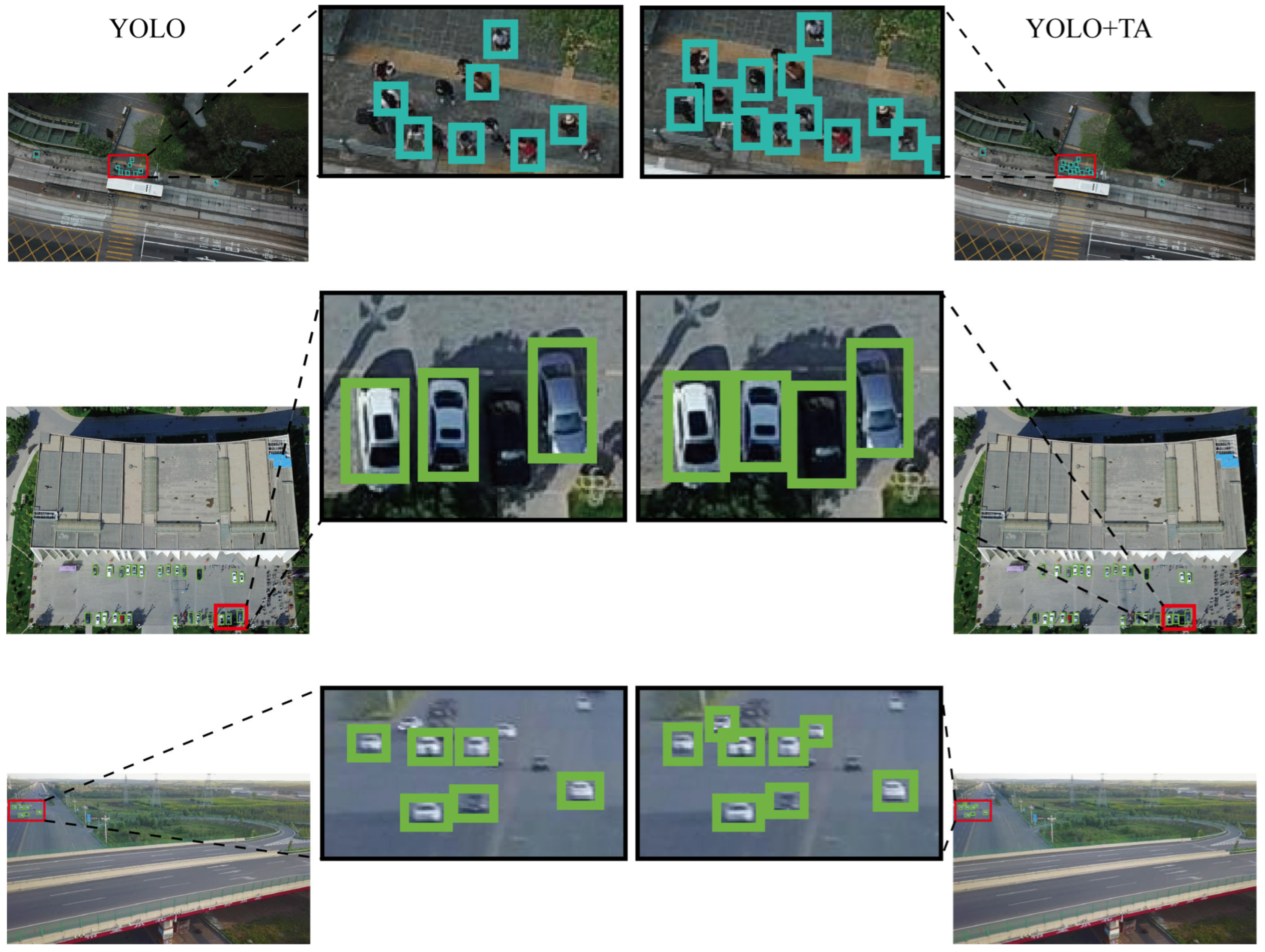
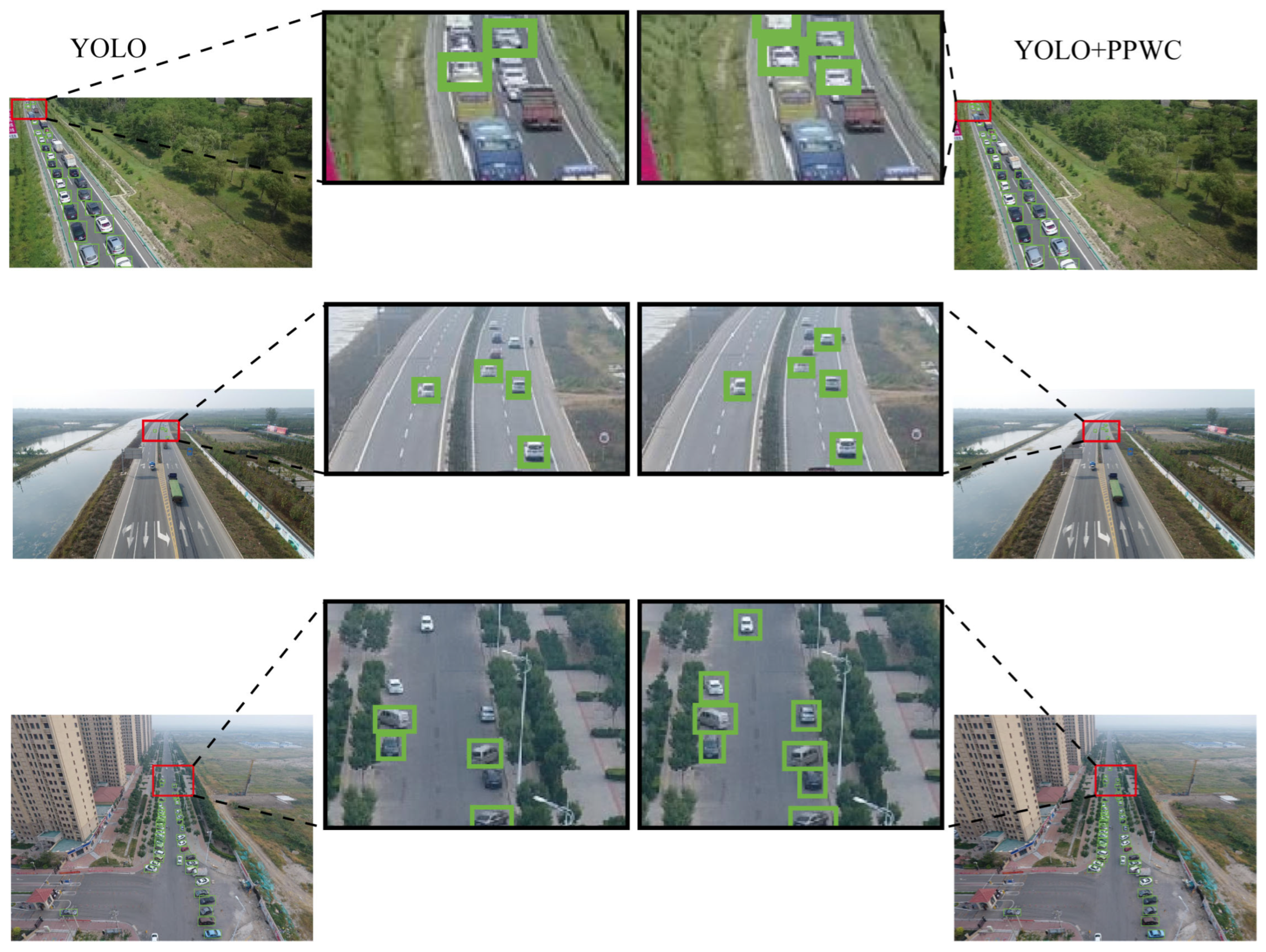
4.4.2. Comparative Analysis of the Improved Model Versus the Original Model
4.4.3. Ablation Experiment
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chi, M.; Plaza, A.; Benediktsson, J.A.; Sun, Z.; Shen, J.; Zhu, Y. Big Data for Remote Sensing: Challenges and Opportunities. Proc. IEEE 2016, 104, 2207–2219. [Google Scholar] [CrossRef]
- Ruhe, M.; Dalaff, C.; Kuhne, R.; Woesler, R. Air- and Space Borne Remote Sensing Systems for Traffic Data Collection-European Contributions. In Proceedings of the 2003 IEEE International Conference on Intelligent Transportation Systems, Shanghai, China, 12–15 October 2003; pp. 750–752. [Google Scholar]
- Guo, Y.; Wu, C.; Du, B.; Zhang, L. Density Map-Based Vehicle Counting in Remote Sensing Images with Limited Resolution. ISPRS J. Photogramm. Remote Sens. 2022, 189, 201–217. [Google Scholar] [CrossRef]
- Li, J.; Zhang, Z.; Sun, H. DiffuYOLO: A Novel Method for Small Vehicle Detection in Remote Sensing Based on Diffusion Models. Alex. Eng. J. 2025, 114, 485–496. [Google Scholar] [CrossRef]
- Domínguez-Sáez, A.; Urgorri, F.R.; Fernández-Berceruelo, I.; Pujadas, M. Large Eddy Simulation of the Dispersion of Short Duration Emissions: Implications for the Metrological Evaluation of Remote Sensing Devices for on-Road Emissions Monitoring. Sci. Total Environ. 2024, 955, 176994. [Google Scholar] [CrossRef]
- Chen, H.; Li, Z.; Wu, J.; Xiong, W.; Du, C. SemiRoadExNet: A Semi-Supervised Network for Road Extraction from Remote Sensing Imagery via Adversarial Learning. ISPRS J. Photogramm. Remote Sens. 2023, 198, 169–183. [Google Scholar] [CrossRef]
- Zhou, G.; Wei, D. Survey and Analysis of Land Satellite Remote Sensing Applied in Highway Transportations Infrastructure and System Engineering. In Proceedings of the IGARSS 2008—2008 IEEE International Geoscience and Remote Sensing Symposium, Boston, MA, USA, 6–11 July 2008; pp. IV-479–IV-482. [Google Scholar]
- Lei, P.; Yi, J.; Li, S.; Li, Y.; Lin, H. Agricultural Surface Water Extraction in Environmental Remote Sensing: A Novel Semantic Segmentation Model Emphasizing Contextual Information Enhancement and Foreground Detail Attention. Neurocomputing 2025, 617, 129110. [Google Scholar] [CrossRef]
- Yuan, Q.; Shen, H.; Li, T.; Li, Z.; Li, S.; Jiang, Y.; Xu, H.; Tan, W.; Yang, Q.; Wang, J.; et al. Deep Learning in Environmental Remote Sensing: Achievements and Challenges. Remote Sens. Environ. 2020, 241, 111716. [Google Scholar] [CrossRef]
- Loozen, Y.; Rebel, K.T.; De Jong, S.M.; Lu, M.; Ollinger, S.V.; Wassen, M.J.; Karssenberg, D. Mapping Canopy Nitrogen in European Forests Using Remote Sensing and Environmental Variables with the Random Forests Method. Remote Sens. Environ. 2020, 247, 111933. [Google Scholar] [CrossRef]
- Ma, Y.; Chen, S.; Ermon, S.; Lobell, D.B. Transfer Learning in Environmental Remote Sensing. Remote Sens. Environ. 2024, 301, 113924. [Google Scholar] [CrossRef]
- Li, L.; Fu, M.; Zhu, Y.; Kang, H.; Wen, H. The Current Situation and Trend of Land Ecological Security Evaluation from the Perspective of Global Change. Ecol. Indic. 2024, 167, 112608. [Google Scholar] [CrossRef]
- Zhu, Z.; Qiu, S.; Ye, S. Remote Sensing of Land Change: A Multifaceted Perspective. Remote Sens. Environ. 2022, 282, 113266. [Google Scholar] [CrossRef]
- Dong, J.; Wang, Y.; Yang, Y.; Yang, M.; Chen, J. MCDNet: Multilevel Cloud Detection Network for Remote Sensing Images Based on Dual-Perspective Change-Guided and Multi-Scale Feature Fusion. Int. J. Appl. Earth Obs. Geoinf. 2024, 129, 103820. [Google Scholar] [CrossRef]
- Xiao, Y.; Zhan, Q. A Review of Remote Sensing Applications in Urban Planning and Management in China. In Proceedings of the 2009 Joint Urban Remote Sensing Event, Shanghai, China, 20–22 May 2009; pp. 1–5. [Google Scholar]
- Guo, J.; Ren, H.; Zheng, Y.; Nie, J.; Chen, S.; Sun, Y.; Qin, Q. Identify Urban Area From Remote Sensing Image Using Deep Learning Method. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July 28–2 August 2019; pp. 7407–7410. [Google Scholar]
- Chen, X.; Li, Z.; Zhang, M. Potential and Status of High-Resolution Remote Sensing Information Applied in Urban Planning in China. In Proceedings of the 2009 Joint Urban Remote Sensing Event, Shanghai, China, 20–22 May 2009; pp. 1–5. [Google Scholar]
- Chen, G.; Zhou, Y.; Voogt, J.A.; Stokes, E.C. Remote Sensing of Diverse Urban Environments: From the Single City to Multiple Cities. Remote Sens. Environ. 2024, 305, 114108. [Google Scholar] [CrossRef]
- Laura, D.; Urrutia, E.P.; Salazar, F.; Ureña, J.; Avalos, D.H.; Célleri, L.A.; Cazorla-Logroño, M.; Altamirano, S. Aerial Remote Sensing System to Control Pathogens and Diseases in Broccoli Crops with the Use of Artificial Vision. Smart Agric. Technol. 2024, 10, 100739. [Google Scholar] [CrossRef]
- Ahmed, Z.; Ambinakudige, S. How Does Shrimp Farming Impact Agricultural Production and Food Security in Coastal Bangladesh? Evidence from Farmer Perception and Remote Sensing Approach. Ocean. Coast. Manag. 2024, 255, 107241. [Google Scholar] [CrossRef]
- Zhou, Y.; Ma, Y.; Ata-Ul-Karim, S.T.; Wang, S.; Ciampitti, I.; Antoniuk, V.; Wu, C.; Andersen, M.N.; Cammarano, D. Integrating Multi-Angle and Multi-Scale Remote Sensing for Precision Nitrogen Management in Agriculture: A Review. Comput. Electron. Agric. 2025, 230, 109829. [Google Scholar] [CrossRef]
- Jung, J.; Maeda, M.; Chang, A.; Bhandari, M.; Ashapure, A.; Landivar-Bowles, J. The Potential of Remote Sensing and Artificial Intelligence as Tools to Improve the Resilience of Agriculture Production Systems. Curr. Opin. Biotechnol. 2021, 70, 15–22. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, S.; Lizaga, I.; Zhang, Y.; Ge, X.; Zhang, Z.; Zhang, W.; Huang, Q.; Hu, Z. UAS-Based Remote Sensing for Agricultural Monitoring: Current Status and Perspectives. Comput. Electron. Agric. 2024, 227, 109501. [Google Scholar] [CrossRef]
- Xu, B.; Gao, B.; Li, Y. Improved Small Object Detection Algorithm Based on YOLOv5. IEEE Intell. Syst. 2024, 39, 57–65. [Google Scholar] [CrossRef]
- Liu, W.; Kang, X.; Duan, P.; Xie, Z.; Wei, X.; Li, S. SOSNet: Real-Time Small Object Segmentation via Hierarchical Decoding and Example Mining. IEEE Trans. Neural Netw. Learn. Syst. 2023, 36, 3071–3083. [Google Scholar] [CrossRef]
- Liu, K.; Fu, Z.; Jin, S.; Chen, Z.; Zhou, F.; Jiang, R.; Chen, Y.; Ye, J. ESOD: Efficient Small Object Detection on High-Resolution Images. IEEE Trans. Image Process. 2025, 34, 183–195. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.; Zhao, Y.; Kong, S.G. SFA-Guided Mosaic Transformer for Tracking Small Objects in Snapshot Spectral Imaging. ISPRS J. Photogramm. Remote Sens. 2023, 204, 223–236. [Google Scholar] [CrossRef]
- Hosang, J.; Benenson, R.; Dollar, P.; Schiele, B. What Makes for Effective Detection Proposals? IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 814–830. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Wang, H.; Li, W.; Sakaridis, C.; Dai, D.; Van Gool, L. Scale-Aware Domain Adaptive Faster R-CNN. Int. J. Comput. Vis. 2021, 129, 2223–2243. [Google Scholar] [CrossRef]
- Hussain, M. YOLOv1 to v8: Unveiling Each Variant–A Comprehensive Review of YOLO. IEEE Access 2024, 12, 42816–42833. [Google Scholar] [CrossRef]
- Zhang, H.; Tian, Y.; Wang, K.; Zhang, W.; Wang, F.-Y. Mask SSD: An Effective Single-Stage Approach to Object Instance Segmentation. IEEE Trans. Image Process. 2020, 29, 2078–2093. [Google Scholar] [CrossRef]
- Rejin Varghese, S.M. YOLOv8: A Novel Object Detection Algorithm with Enhanced Performance and Robustness. In Proceedings of the 2024 International Conference on Advances in Data Engineering and Intelligent Computing Systems (ADICS), Chennai, India, 18–19 April 2024; pp. 1–6. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Pinggera, P.; Ramos, S.; Gehrig, S.; Franke, U.; Rother, C.; Mester, R. Lost and Found: Detecting Small Road Hazards for Self-Driving Vehicles. arXiv 2016, arXiv:1609.04653. [Google Scholar] [CrossRef]
- Wang, J.; Xu, C.; Yang, W.; Yu, L. A Normalized Gaussian Wasserstein Distance for Tiny Object Detection. arXiv 2021, arXiv:2110.13389. [Google Scholar] [CrossRef]
- Wang, J.; Li, X.; Chen, J.; Zhou, L.; Guo, L.; He, Z.; Zhou, H.; Zhang, Z. DPH-YOLOv8: Improved YOLOv8 Based on Double Prediction Heads for the UAV Image Object Detection. IEEE Trans. Geosci. Remote Sens. 2024, 62, 3487191. [Google Scholar] [CrossRef]
- Chen, J.; Er, M.J. Dynamic YOLO for Small Underwater Object Detection. Artif. Intell. Rev. 2024, 57, 165. [Google Scholar] [CrossRef]
- Wang, J.; Li, X.; Zhou, L.; Chen, J.; He, Z.; Guo, L.; Liu, J. Adaptive Receptive Field Enhancement Network Based on Attention Mechanism for Detecting the Small Target in the Aerial Image. IEEE Trans. Geosci. Remote Sens. 2024, 62, 3337266. [Google Scholar] [CrossRef]
- Xiong, X.; He, M.; Li, T.; Zheng, G.; Xu, W.; Fan, X.; Zhang, Y. Adaptive Feature Fusion and Improved Attention Mechanism-Based Small Object Detection for UAV Target Tracking. IEEE Internet Things J. 2024, 11, 21239–21249. [Google Scholar] [CrossRef]
- Le Jeune, P.; Bahaduri, B.; Mokraoui, A. A Comparative Attention Framework for Better Few-Shot Object Detection on Aerial Images. Pattern Recognit. 2025, 161, 111243. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Lowe, D.G. Object Recognition from Local Scale-Invariant Features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; Volume 2, pp. 1150–1157. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Wang, J.; Meng, R.; Huang, Y.; Zhou, L.; Huo, L.; Qiao, Z.; Niu, C. Road Defect Detection Based on Improved YOLOv8s Model. Sci. Rep. 2024, 14, 16758. [Google Scholar] [CrossRef]
- Yan, C.; Liang, Z.; Yin, L.; Wei, S.; Tian, Q.; Li, Y.; Cheng, H.; Liu, J.; Yu, Q.; Zhao, G.; et al. AFM-YOLOv8s: An Accurate, Fast, and Highly Robust Model for Detection of Sporangia of Plasmopara Viticola with Various Morphological Variants. Plant Phenomics 2024, 6, 0246. [Google Scholar] [CrossRef]
- Wang, L.; Hua, S.; Zhang, C.; Yang, G.; Ren, J.; Li, J. YOLOdrive: A Lightweight Autonomous Driving Single-Stage Target Detection Approach. IEEE Internet Things J. 2024, 11, 36099–36113. [Google Scholar] [CrossRef]
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Misra, D.; Nalamada, T.; Arasanipalai, A.U.; Hou, Q. Rotate to Attend: Convolutional Triplet Attention Module. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2021; pp. 3138–3147. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 6000–6010. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13708–13717. [Google Scholar]
- Shen, Z.; Zhang, M.; Zhao, H.; Yi, S.; Li, H. Efficient Attention: Attention with Linear Complexities. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2021; pp. 3530–3538. [Google Scholar]
- Zhu, X.; Cheng, D.; Zhang, Z.; Lin, S.; Dai, J. An Empirical Study of Spatial Attention Mechanisms in Deep Networks. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6687–6696. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- An, Y.; Song, C. Multiscale Dynamic Attention and Hierarchical Spatial Aggregation for Few-Shot Object Detection. Appl. Sci. 2025, 15, 1381. [Google Scholar] [CrossRef]
- Xia, Z.; Pan, X.; Song, S.; Li, L.E.; Huang, G. Vision Transformer with Deformable Attention. arXiv 2022, arXiv:2201.00520. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Computer Vision–ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2018; Volume 11211, pp. 3–19. ISBN 978-3-030-01233-5. [Google Scholar]
- Liu, G.; Dundar, A.; Shih, K.J.; Wang, T.-C.; Reda, F.A.; Sapra, K.; Yu, Z.; Yang, X.; Tao, A.; Catanzaro, B. Partial Convolution for Padding, Inpainting, and Image Synthesis. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 1–15. [Google Scholar] [CrossRef]
- Liang, F.; Tian, Z.; Dong, M.; Cheng, S.; Sun, L.; Li, H.; Chen, Y.; Zhang, G. Efficient Neural Network Using Pointwise Convolution Kernels with Linear Phase Constraint. Neurocomputing 2021, 423, 572–579. [Google Scholar] [CrossRef]
- Liang, D.; Zhang, S.; Huang, H.-B.; Zhang, L.; Hu, Y. Deep Learning-Based Detection and Condition Classification of Bridge Elastomeric Bearings. Autom. Constr. 2024, 166, 105680. [Google Scholar] [CrossRef]
- Xia, G.-S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A Large-Scale Dataset for Object Detection in Aerial Images. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3974–3983. [Google Scholar]
- Du, D.; Zhu, P.; Wen, L.; Bian, X.; Lin, H.; Hu, Q.; Peng, T.; Zheng, J.; Wang, X.; Zhang, Y.; et al. VisDrone-DET2019: The Vision Meets Drone Object Detection in Image Challenge Results. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Republic of Korea, 27–28 October 2019; pp. 213–226. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Configuration |
|---|---|
| CPU model | Intel Core i7-9700k |
| GPU model | NVIDIA GeForce RTX 3090Ti |
| Operating system | Ubuntu 18.04 LTS 64-bits |
| Deep learning frame | PyTorch1.9.1 |
| GPU accelerator | CUDA10.2 |
| Integrated development environment | PyCharm |
| Scripting language | Python3.8 |
| Neural network accelerator | CUDNN7.6.5 |
| Parameter | Configuration |
|---|---|
| Neural network optimizer | SGD |
| Learning rate | 0.001 |
| Training epochs | 200 |
| Momentum | 0.937 |
| Batch size | 32 |
| Weight decay | 0.0005 |
| Method | Param. | FLOPs | mAP | mAP50 | mAP75 | mAPS | mAPM | mAPL | |
|---|---|---|---|---|---|---|---|---|---|
| Multi-stage detectors | Fast R-CNN | 48.65 | 86.19 | 46.5 | 66.5 | 54.6 | 34.3 | 46.7 | 44.2 |
| Faster R-CNN | 41.15 | 63.25 | 50.1 | 71.2 | 63.2 | 40.5 | 51.2 | 48.9 | |
| Cascade R-CNN | 68.93 | 77.52 | 52.3 | 72.2 | 64.3 | 41.2 | 52.3 | 50.2 | |
| RepPoints | 36.61 | 35.62 | 53.7 | 74.8 | 64.5 | 40.8 | 54.1 | 51.9 | |
| One-stage detectors | YOLOvX | 8.93 | 13.33 | 55.2 | 76.1 | 65.9 | 43.4 | 55.5 | 54.5 |
| YOLOv5 | 7.01 | 8.20 | 54.2 | 75.3 | 65.1 | 43.5 | 54.3 | 51.8 | |
| YOLOv6 | 17.11 | 22.01 | 57.7 | 78.8 | 67.4 | 45.1 | 57.7 | 55.4 | |
| YOLOv7 | 6.22 | 6.88 | 69.5 | 84.5 | 68.8 | 55.2 | 69.7 | 68.7 | |
| YOLOv8s | 11.13 | 14.27 | 73.3 | 86.4 | 80.1 | 55.1 | 74.5 | 72.5 | |
| YOLOv8m | 26.21 | 39.61 | 75.6 | 88.5 | 81.7 | 57.8 | 75.5 | 73.9 | |
| YOLOv8l | 43.92 | 83.17 | 77.4 | 89.3 | 83.2 | 59.1 | 77.4 | 74.8 | |
| LACF-YOLO | 7.25 | 10.53 | 76.8 | 89.8 | 81.9 | 58.9 | 78.3 | 74.6 | |
| Method | Param. | FLOPs | mAP | mAP50 | mAP75 | mAPS | mAPM | mAPL | |
|---|---|---|---|---|---|---|---|---|---|
| Multi-stage detectors | Fast R-CNN | 48.64 | 86.17 | 47.4 | 67.3 | 55.2 | 35.2 | 47.8 | 45.8 |
| Faster R-CNN | 41.13 | 63.24 | 52.6 | 73.4 | 64.7 | 41.9 | 52.2 | 49.2 | |
| Cascade R-CNN | 68.92 | 77.51 | 54.5 | 73.6 | 64.9 | 42.8 | 53.7 | 52.5 | |
| RepPoints | 36.62 | 35.61 | 56.1 | 75.3 | 65.2 | 41.5 | 56.6 | 52.6 | |
| One-stage detectors | YOLOvX | 8.91 | 13.32 | 57.8 | 77.7 | 66.3 | 44.6 | 57.4 | 57.2 |
| YOLOv5 | 7.00 | 8.18 | 56.6 | 76.5 | 66.2 | 44.8 | 56.2 | 52.1 | |
| YOLOv6 | 17.09 | 22.02 | 59.1 | 79.2 | 68.6 | 46.7 | 58.4 | 56.1 | |
| YOLOv7 | 6.21 | 6.86 | 72.3 | 85.9 | 69.3 | 58.4 | 72.5 | 69.5 | |
| YOLOv8s | 11.12 | 14.25 | 75.5 | 87.8 | 81.5 | 57.9 | 75.6 | 75.6 | |
| YOLOv8m | 26.17 | 39.56 | 76.8 | 89.4 | 82.6 | 59.7 | 77.3 | 77.3 | |
| YOLOv8l | 43.88 | 83.15 | 78.9 | 91.2 | 84.3 | 61.9 | 79.5 | 79.8 | |
| LACF-YOLO | 7.24 | 10.53 | 78.4 | 91.4 | 82.4 | 62.5 | 78.6 | 75.4 | |
| Mobile | DIBLayer | TA | PPWC | Focal-EIOU | mAP | mAPS | mAPM | mAPL | Param. | FLOPS | FPS |
|---|---|---|---|---|---|---|---|---|---|---|---|
| YOLOv8 | -- | -- | -- | -- | 73.3 | 55.1 | 74.5 | 72.5 | 11.13 | 14.27 | 116 |
| √ | -- | -- | -- | 73.5 | 55.4 | 74.6 | 72.7 | 7.22 | 12.12 | 140 | |
| -- | √ | -- | -- | 74.8 | 56.3 | 76.2 | 73.2 | 11.14 | 12.01 | -- | |
| -- | -- | √ | -- | 74.9 | 56.9 | 76.5 | 73.6 | 11.15 | 13.78 | -- | |
| √ | √ | -- | -- | 75.1 | 56.7 | 76.6 | 73.3 | 7.23 | 11.31 | 121 | |
| √ | -- | √ | -- | 75.2 | 57.4 | 76.9 | 73.9 | 7.24 | 11.79 | -- | |
| -- | √ | √ | -- | 76.5 | 58.5 | 77.8 | 74.2 | 11.16 | 11.58 | -- | |
| √ | √ | √ | √ | 76.8 | 58.9 | 78.3 | 74.6 | 7.25 | 10.53 | 135 |
| Mobile | DIBLayer | TA | PPWC | Focal-EIOU | mAP | mAPS | mAPM | mAPL | Param. | FLOPS | FPS |
|---|---|---|---|---|---|---|---|---|---|---|---|
| YOLOv8 | -- | -- | -- | -- | 75.5 | 57.9 | 75.6 | 75.6 | 11.12 | 17.25 | 86 |
| √ | -- | -- | -- | 75.6 | 58.1 | 75.7 | 75.5 | 7.21 | 14.16 | 104 | |
| -- | √ | -- | -- | 76.4 | 60.8 | 76.4 | 74.7 | 11.13 | 14.13 | -- | |
| -- | -- | √ | -- | 76.5 | 60.6 | 76.6 | 75.7 | 11.14 | 16.58 | -- | |
| √ | √ | -- | -- | 76.6 | 61.2 | 76.8 | 75.1 | 7.22 | 11.07 | 93 | |
| √ | -- | √ | -- | 76.8 | 61.5 | 77.1 | 75.3 | 7.23 | 13.29 | -- | |
| -- | √ | √ | -- | 77.6 | 62.3 | 77.9 | 75.3 | 11.14 | 13.17 | -- | |
| √ | √ | √ | √ | 78.4 | 62.5 | 78.6 | 75.4 | 7.24 | 10.53 | 109 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, S.; Shao, F.; Chu, W.; Dai, J.; Zhang, H. An Improved YOLOv8-Based Lightweight Attention Mechanism for Cross-Scale Feature Fusion. Remote Sens. 2025, 17, 1044. https://doi.org/10.3390/rs17061044
Liu S, Shao F, Chu W, Dai J, Zhang H. An Improved YOLOv8-Based Lightweight Attention Mechanism for Cross-Scale Feature Fusion. Remote Sensing. 2025; 17(6):1044. https://doi.org/10.3390/rs17061044
Chicago/Turabian StyleLiu, Shaodong, Faming Shao, Weijun Chu, Juying Dai, and Heng Zhang. 2025. "An Improved YOLOv8-Based Lightweight Attention Mechanism for Cross-Scale Feature Fusion" Remote Sensing 17, no. 6: 1044. https://doi.org/10.3390/rs17061044
APA StyleLiu, S., Shao, F., Chu, W., Dai, J., & Zhang, H. (2025). An Improved YOLOv8-Based Lightweight Attention Mechanism for Cross-Scale Feature Fusion. Remote Sensing, 17(6), 1044. https://doi.org/10.3390/rs17061044