

Perturbation Matters: A Novel Approach for Semi-Supervised Remote Sensing Imagery Change Detection

Abstract

1. Introduction
- •
- Instead of introducing additional training procedures or complex network components, we propose a simple weak–strong consistency learning strategy based on sample-level perturbations, feature-level perturbations and transformation perturbations, which can be trained in an end-to-end manner efficiently.
- •
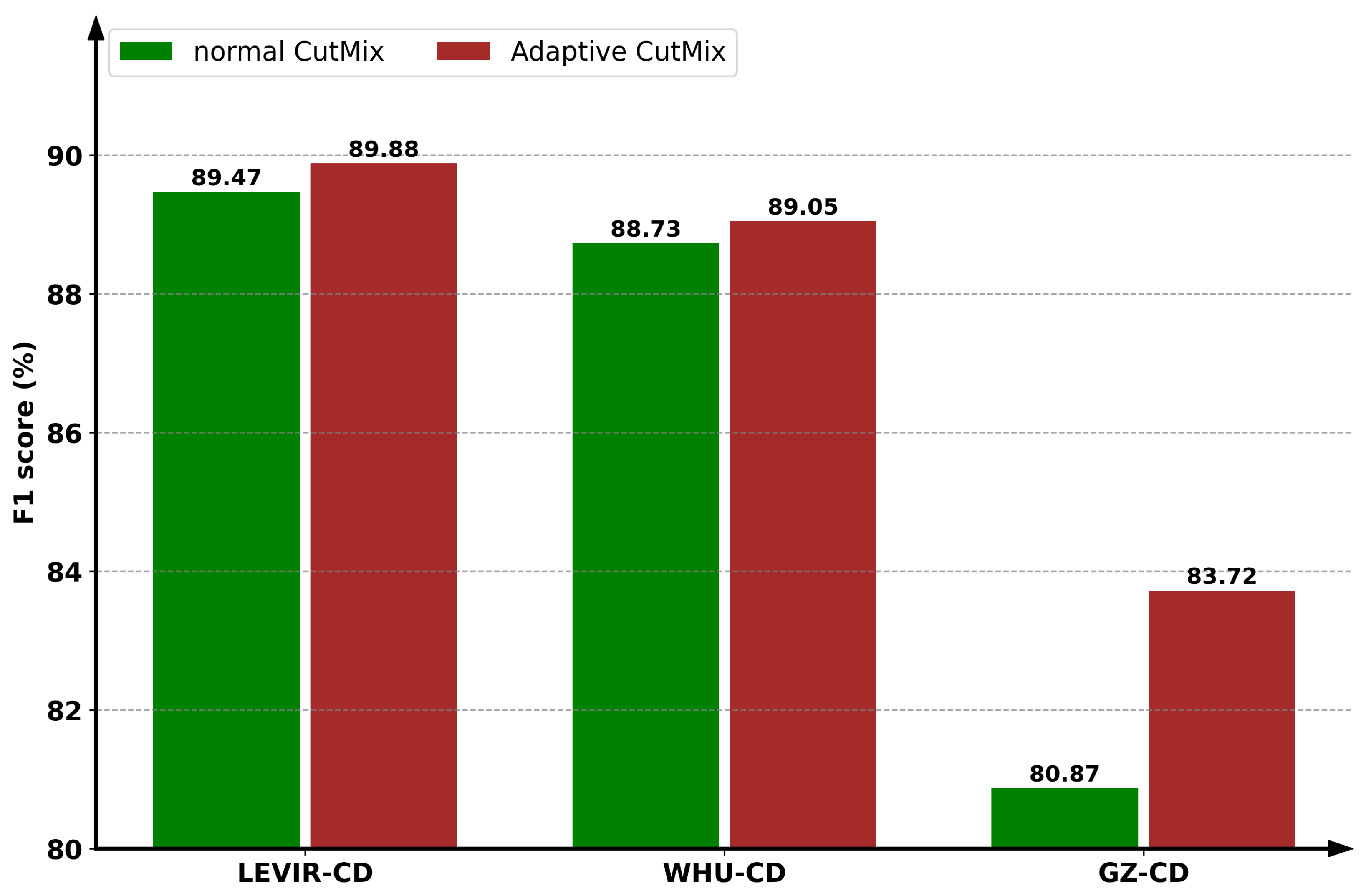
- An adaptive CutMix strategy is proposed to inject labeled information into the unlabeled, which aims to mitigate the domain gap and improve model generalization capacity on cross-domain scenarios. We further propose a simple yet effective class-balanced sampling approach, which is capable of addressing class imbalance issues in CD with little computational overhead.
- •
- Extensive experiments and analysis have been carried out on three publicly available CD datasets. In contrast to alternative approaches, our proposed WACS-SemiCD consistently outperforms other methods across various labeled settings and cross-dataset scenarios, demonstrating its effectiveness and robustness. The code is available at https://github.com/daifeng2016/WACS-SemiCD (accessed on 5 February 2025).
2. Related Work
2.1. Fully Supervised CD
2.2. Semi-Supervised CD
2.3. Class Imbalance in CD
3. Proposed WACS-SemiCD
3.1. Architecture Overview
3.2. Siamese CD Network
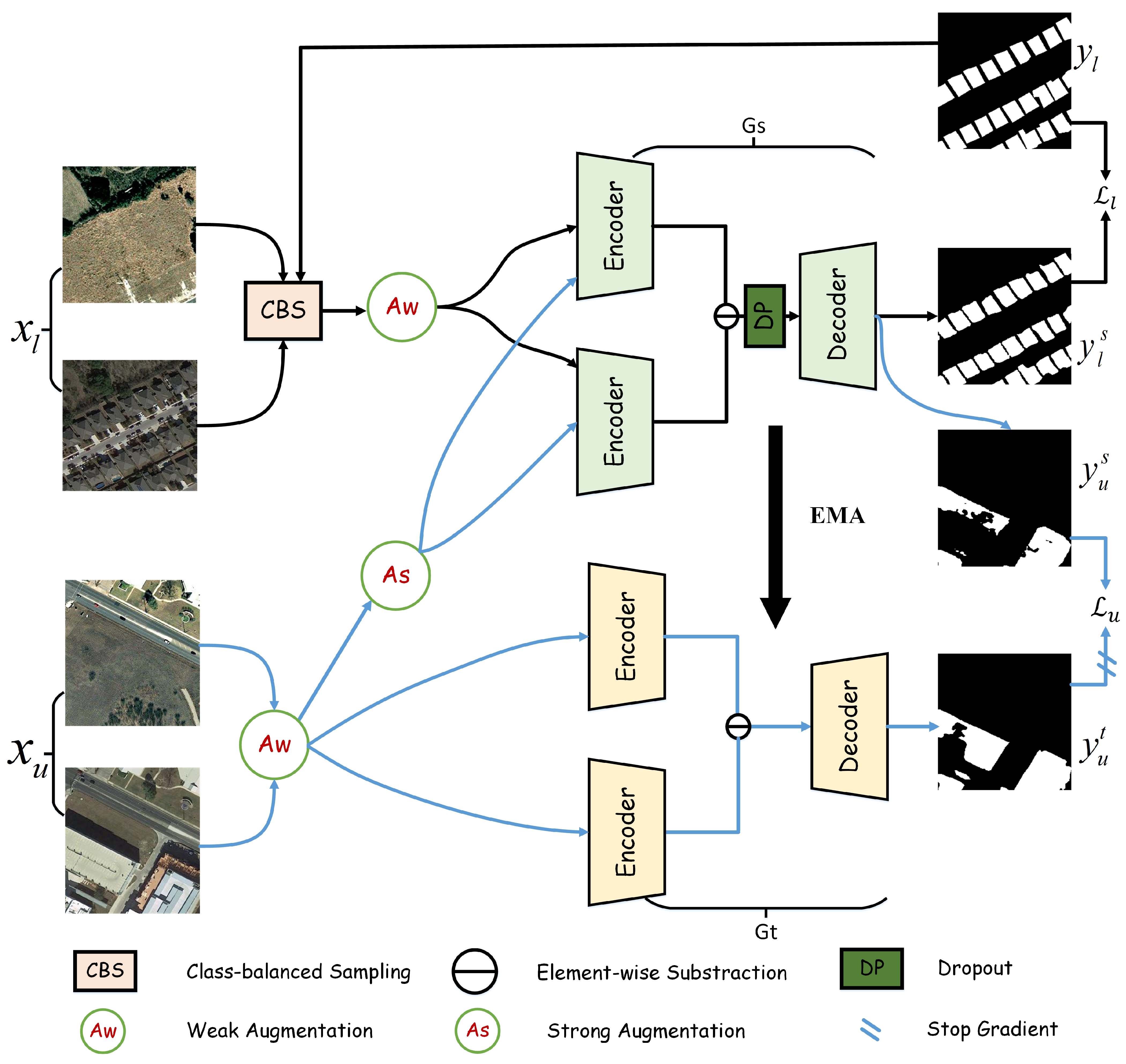
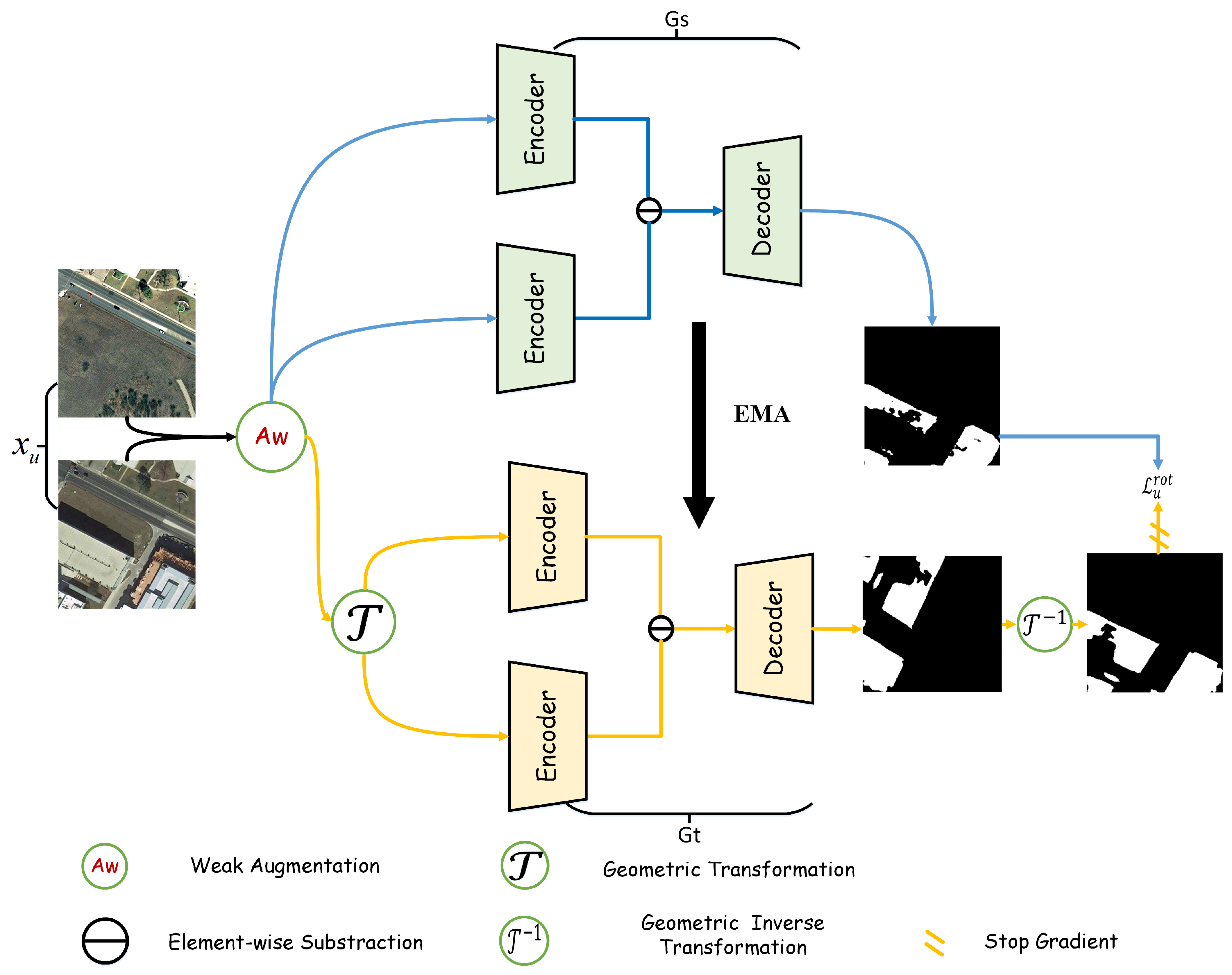
3.3. Weak–Strong Consistency Learning
3.4. Class-Balanced Sampling
| Algorithm 1 Process of class-balanced sampling |
| Input: labeled samples |
| Output: sample ratio |
|
3.5. Overall Loss Functions
4. Experiments
4.1. Dataset Descriptions
4.2. Training Details
4.3. Comparative Methods and Evaluation Metrics
- (1)
- Semi-supervised semantic segmentation GAN (S4GAN) [59], which utilizes adversarial learning with a feature matching loss to enforce feature consistency between labeled and unlabeled images. A self-training step is added to further boost network performance.
- (2)
- SemiCD [31], where small perturbations of the difference map are used to enforce model predictions’ consistency on unlabeled images. Note that SemiCD includes two training phases: a supervised phase for labeled data and an unsupervised phase for unlabeled data.
- (3)
- UniMatch [57], where feature perturbation and unified dual-stream perturbations are proposed to enforce weak-to-strong consistency.
- (4)
- Ensemble cross pseudo supervision (ECPS) [40], where a crosswise model ensemble strategy is used to enhance pseudo label quality and improve CD performance with limited labeled data.
- (5)
- Coarse-to-fine semi-supervised change detection (C2F-SemiCD) [32], where changed features are extracted through coarse-to-fine feature fusion and a mean-teacher network is further employed for a semi-supervised update.
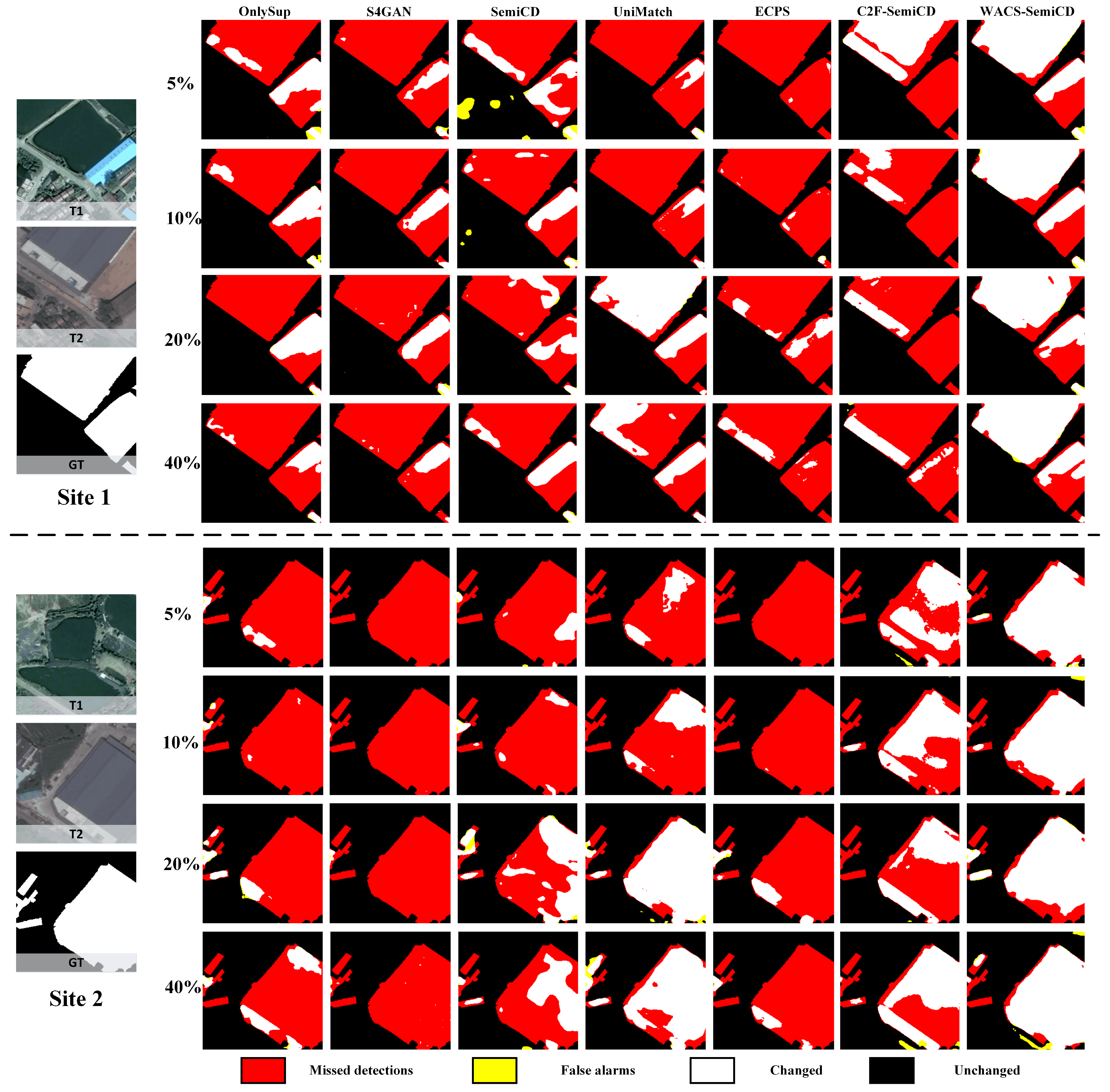
4.4. Results
4.4.1. Parameter Setting
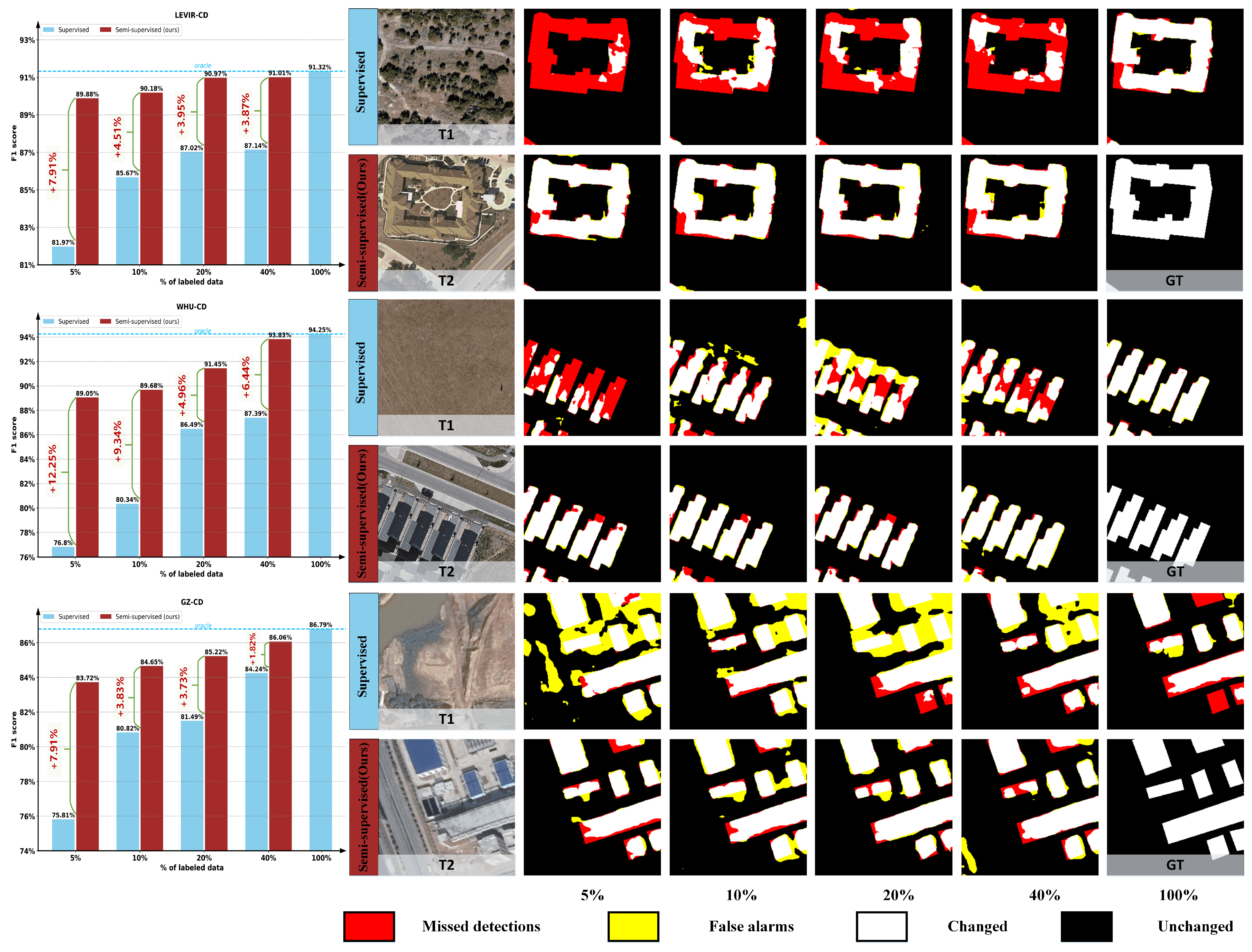
4.4.2. Performance Analysis
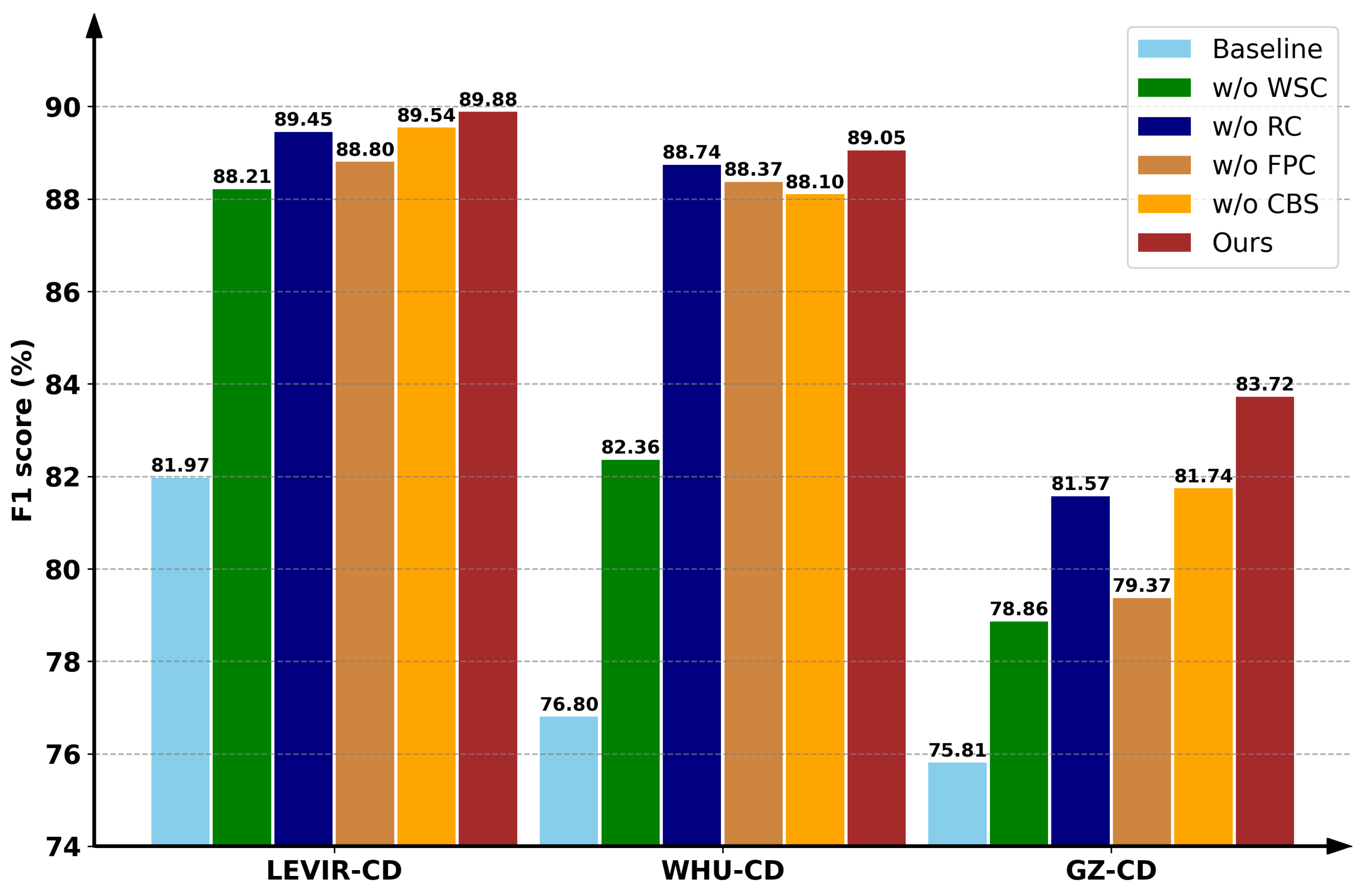
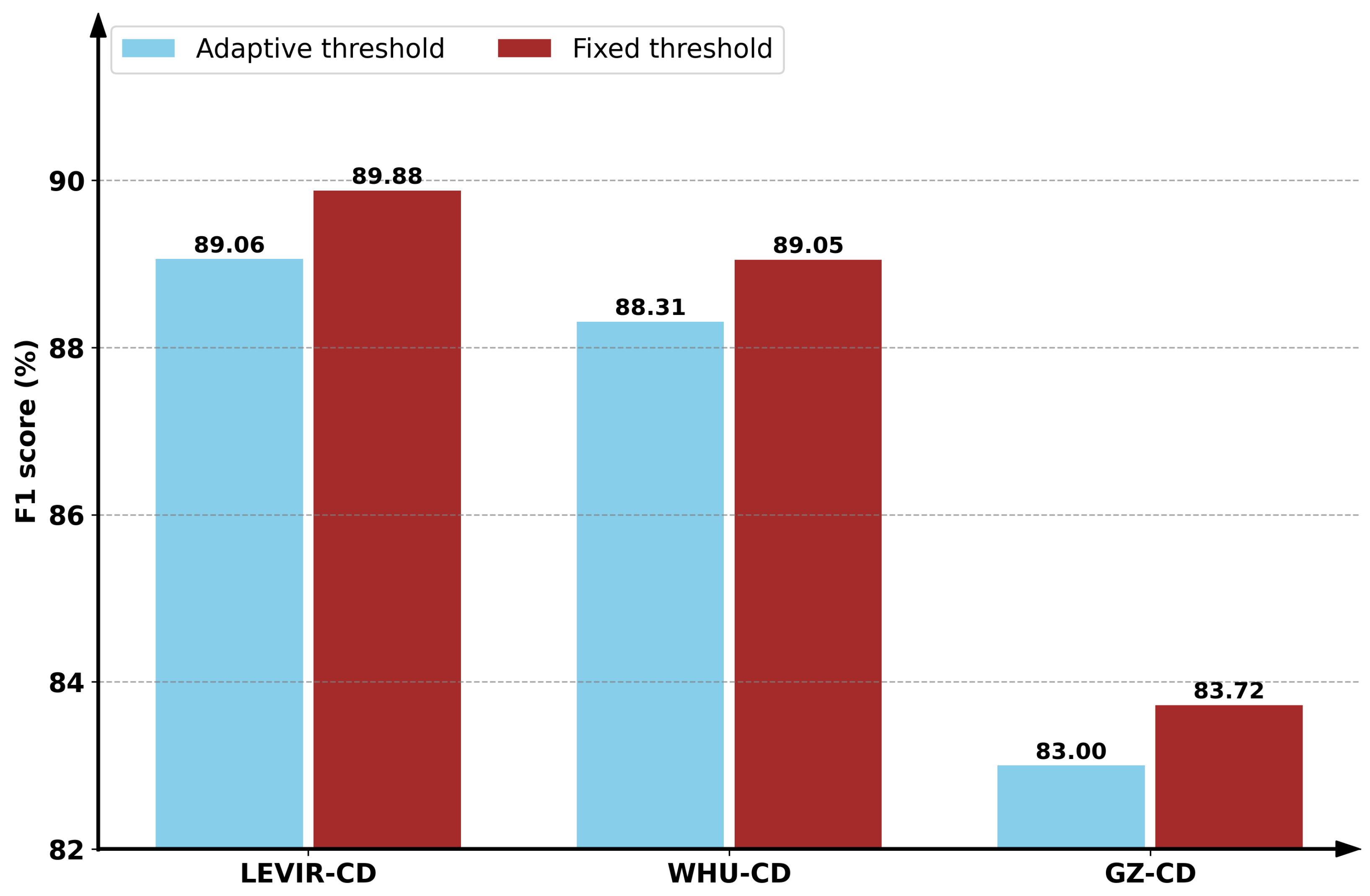
4.5. Discussion
4.5.1. Effect of Different Augmentations
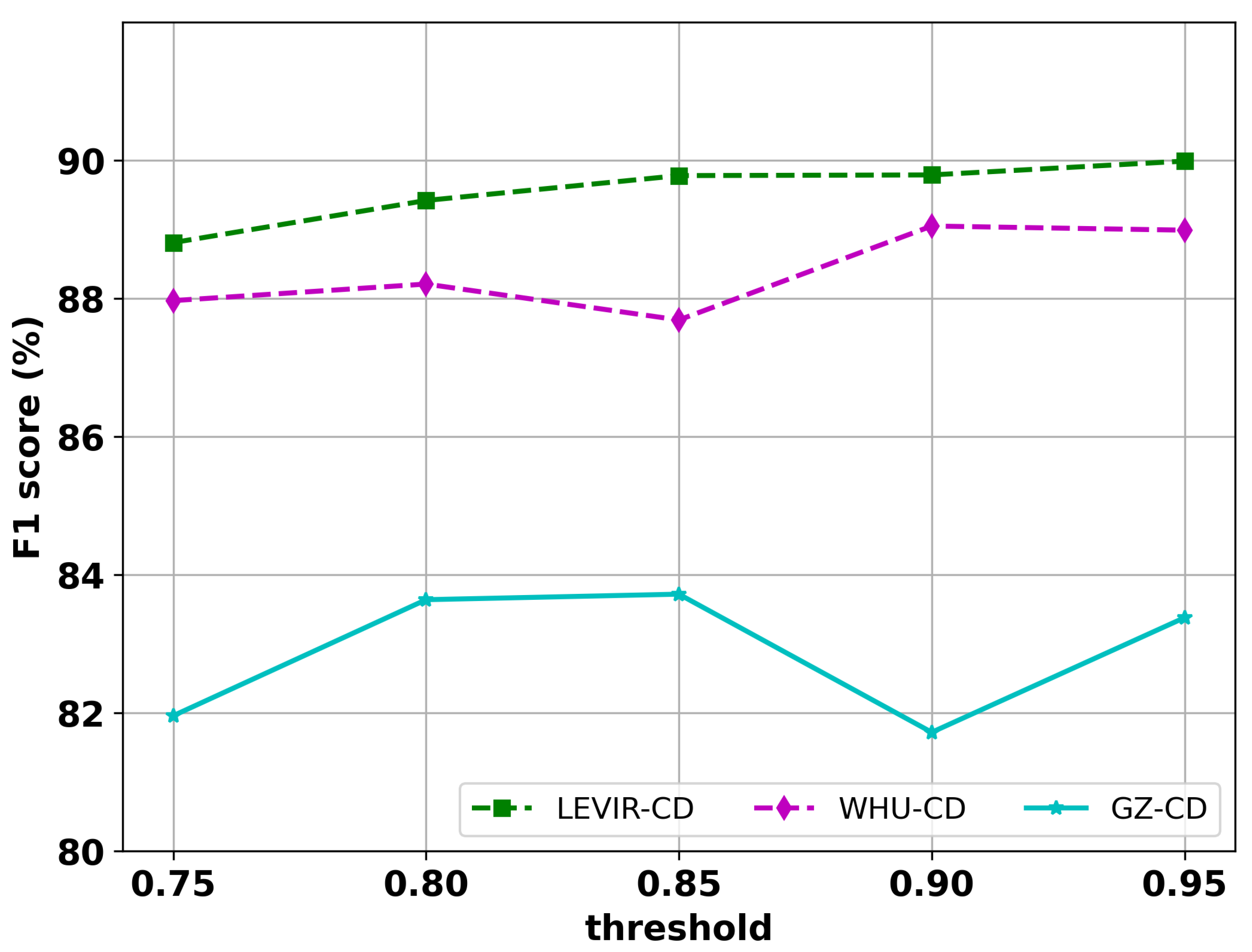
4.5.2. Fixed Threshold Versus Adaptive Threshold
4.5.3. Performance on Cross-Domain Scenarios
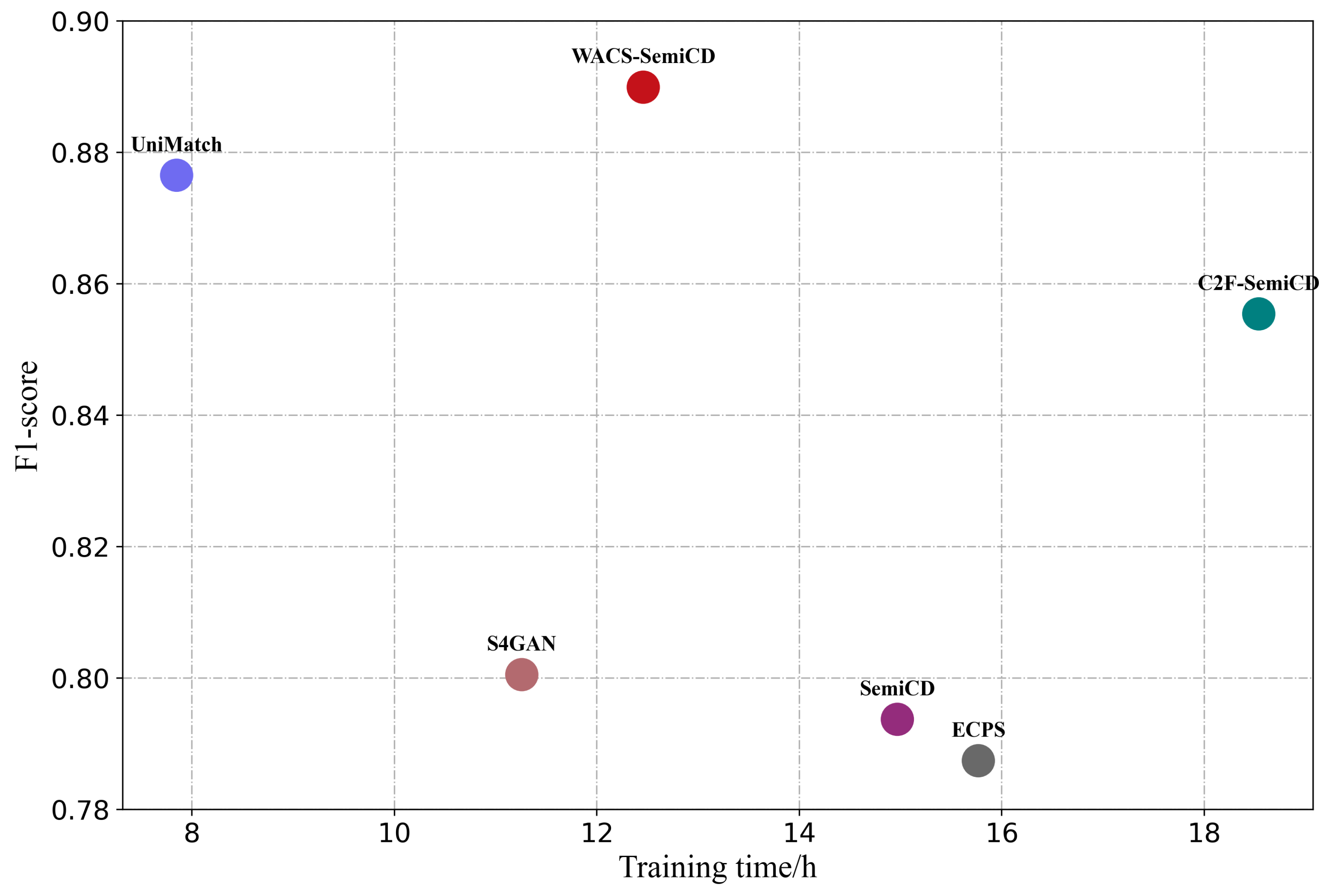
4.5.4. Training Efficiency Comparison
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CD | change detection |
| SSCD | semi-supervised change detection |
| RS | remote sensing |
| WACS | Weak–strong Augmentation and Class-balanced Sampling |
| CBS | class-balanced sampling |
| RSCD | remote sensing change detection |
| DLCD | deep learning-based change detection |
| SOTA | state-of-the-art |
| FSCD | fully supervised CD |
| CNN | convolution neural network |
| FCN | fully convolutional network |
| SSL | semi-supervised learning |
| semi-supervised support vector machine | |
| GP | Gaussian process |
| GAN | Generative Adversarial Networks |
| ECPS | ensemble cross pseudo supervision (ECPS) |
| IAug | Instance-level change Augmentation |
| UIPCM | unpaired image prototype contrast module |
| ASPP | atrous spatial pyramid pooling |
| AdaCut | Adaptive CutMix |
| EMA | exponential moving averaging |
| S4GAN | semi-supervised semantic segmentation GAN |
| C2F-SemiCD | coarse-to-fine semi-supervised change detection |
| WSC | weak–strong consistency |
| RC | rotation consistency |
References
- Zheng, Z.; Zhong, Y.; Wang, J.; Ma, A.; Zhang, L. Building damage assessment for rapid disaster response with a deep object-based semantic change detection framework: From natural disasters to man-made disasters. Remote Sens. Environ. 2021, 265, 112636. [Google Scholar] [CrossRef]
- Li, H.; Zhu, F.; Zheng, X.; Liu, M.; Chen, G. MSCDUNet: A deep learning framework for built-up area change detection integrating multispectral, SAR, and VHR data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 5163–5176. [Google Scholar] [CrossRef]
- Wen, D.; Huang, X.; Bovolo, F.; Li, J.; Ke, X.; Zhang, A.; Benediktsson, J.A. Change detection from very-high-spatial-resolution optical remote sensing images: Methods, applications, and future directions. IEEE Geosci. Remote Sens. Mag. 2021, 9, 68–101. [Google Scholar] [CrossRef]
- Wu, C.; Du, B.; Cui, X.; Zhang, L. A post-classification change detection method based on iterative slow feature analysis and Bayesian soft fusion. Remote Sens. Environ. 2017, 199, 241–255. [Google Scholar] [CrossRef]
- Zhang, Y.; Peng, D.; Huang, X. Object-based change detection for VHR images based on multiscale uncertainty analysis. IEEE Geosci. Remote Sens. Lett. 2017, 15, 13–17. [Google Scholar] [CrossRef]
- Daudt, R.C.; Le Saux, B.; Boulch, A. Fully convolutional siamese networks for change detection. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 4063–4067. [Google Scholar]
- Peng, D.; Zhang, Y.; Guan, H. End-to-end change detection for high resolution satellite images using improved UNet++. Remote Sens. 2019, 11, 1382. [Google Scholar] [CrossRef]
- Fang, S.; Li, K.; Shao, J.; Li, Z. SNUNet-CD: A densely connected Siamese network for change detection of VHR images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 8007805. [Google Scholar] [CrossRef]
- Hou, X.; Bai, Y.; Li, Y.; Shang, C.; Shen, Q. High-resolution triplet network with dynamic multiscale feature for change detection on satellite images. ISPRS J. Photogramm. Remote Sens. 2021, 177, 103–115. [Google Scholar] [CrossRef]
- Song, K.; Jiang, J. AGCDetNet: An attention-guided network for building change detection in high-resolution remote sensing images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 4816–4831. [Google Scholar] [CrossRef]
- Zhang, J.; Pan, B.; Zhang, Y.; Liu, Z.; Zheng, X. Building change detection in remote sensing images based on dual multi-scale attention. Remote Sens. 2022, 14, 5405. [Google Scholar] [CrossRef]
- Li, Z.; Tang, C.; Liu, X.; Zhang, W.; Dou, J.; Wang, L.; Zomaya, A.Y. Lightweight remote sensing change detection with progressive feature aggregation and supervised attention. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5602812. [Google Scholar] [CrossRef]
- Gong, M.; Jiang, F.; Qin, A.K.; Liu, T.; Zhan, T.; Lu, D.; Zheng, H.; Zhang, M. A spectral and spatial attention network for change detection in hyperspectral images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5521614. [Google Scholar] [CrossRef]
- Guo, Q.; Zhang, J.; Zhu, S.; Zhong, C.; Zhang, Y. Deep multiscale Siamese network with parallel convolutional structure and self-attention for change detection. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5406512. [Google Scholar] [CrossRef]
- Lei, T.; Geng, X.; Ning, H.; Lv, Z.; Gong, M.; Jin, Y.; Nandi, A.K. Ultralightweight spatial–spectral feature cooperation network for change detection in remote sensing images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4402114. [Google Scholar] [CrossRef]
- Chen, H.; Shi, Z. A spatial-temporal attention-based method and a new dataset for remote sensing image change detection. Remote Sens. 2020, 12, 1662. [Google Scholar] [CrossRef]
- Bandara, W.G.C.; Patel, V.M. A transformer-based siamese network for change detection. In Proceedings of the IGARSS 2022—2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 207–210. [Google Scholar]
- Yan, T.; Wan, Z.; Zhang, P. Fully transformer network for change detection of remote sensing images. In Proceedings of the Asian Conference on Computer Vision, Macao, China, 4–8 December 2022; pp. 1691–1708. [Google Scholar]
- Zhang, C.; Wang, L.; Cheng, S.; Li, Y. SwinSUNet: Pure transformer network for remote sensing image change detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5224713. [Google Scholar] [CrossRef]
- Chen, H.; Qi, Z.; Shi, Z. Remote sensing image change detection with transformers. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5607514. [Google Scholar] [CrossRef]
- Li, W.; Xue, L.; Wang, X.; Li, G. ConvTransNet: A CNN–transformer network for change detection with multiscale global–local representations. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5610315. [Google Scholar] [CrossRef]
- Zhang, X.; Cheng, S.; Wang, L.; Li, H. Asymmetric cross-attention hierarchical network based on CNN and transformer for bitemporal remote sensing images change detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 2000415. [Google Scholar] [CrossRef]
- Chen, H.; Song, J.; Han, C.; Xia, J.; Yokoya, N. Changemamba: Remote sensing change detection with spatio-temporal state space model. arXiv 2024, arXiv:2404.03425. [Google Scholar]
- Zhang, H.; Chen, K.; Liu, C.; Chen, H.; Zou, Z.; Shi, Z. CDMamba: Remote Sensing Image Change Detection with Mamba. arXiv 2024, arXiv:2406.04207. [Google Scholar]
- Paranjape, J.N.; de Melo, C.; Patel, V.M. A Mamba-based Siamese Network for Remote Sensing Change Detection. arXiv 2024, arXiv:2407.06839. [Google Scholar]
- Bovolo, F.; Bruzzone, L.; Marconcini, M. A novel approach to unsupervised change detection based on a semisupervised SVM and a similarity measure. IEEE Trans. Geosci. Remote Sens. 2008, 46, 2070–2082. [Google Scholar] [CrossRef]
- Chen, K.; Zhou, Z.; Huo, C.; Sun, X.; Fu, K. A semisupervised context-sensitive change detection technique via gaussian process. IEEE Geosci. Remote Sens. Lett. 2012, 10, 236–240. [Google Scholar] [CrossRef]
- Zhang, W.; Lu, X.; Li, X. A coarse-to-fine semi-supervised change detection for multispectral images. IEEE Trans. Geosci. Remote Sens. 2018, 56, 3587–3599. [Google Scholar] [CrossRef]
- Gong, M.; Yang, Y.; Zhan, T.; Niu, X.; Li, S. A generative discriminatory classified network for change detection in multispectral imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 321–333. [Google Scholar] [CrossRef]
- Peng, D.; Bruzzone, L.; Zhang, Y.; Guan, H.; Ding, H.; Huang, X. SemiCDNet: A semisupervised convolutional neural network for change detection in high resolution remote-sensing images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 5891–5906. [Google Scholar] [CrossRef]
- Bandara, W.G.C.; Patel, V.M. Revisiting consistency regularization for semi-supervised change detection in remote sensing images. arXiv 2022, arXiv:2204.08454. [Google Scholar]
- Han, C.; Wu, C.; Hu, M.; Li, J.; Chen, H. C2F-SemiCD: A coarse-to-fine semi-supervised change detection method based on consistency regularization in high-resolution remote-sensing images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 4702621. [Google Scholar] [CrossRef]
- Wang, L.; Zhang, M.; Shi, W. STCRNet: A Semi-Supervised Network Based on Self-Training and Consistency Regularization for Change Detection in VHR Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 2272–2282. [Google Scholar] [CrossRef]
- Sun, C.; Wu, J.; Chen, H.; Du, C. SemiSANet: A semi-supervised high-resolution remote sensing image change detection model using Siamese networks with graph attention. Remote Sens. 2022, 14, 2801. [Google Scholar] [CrossRef]
- Wang, J.X.; Li, T.; Chen, S.B.; Tang, J.; Luo, B.; Wilson, R.C. Reliable contrastive learning for semi-supervised change detection in remote sensing images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4416413. [Google Scholar] [CrossRef]
- Yuan, S.; Zhong, R.; Yang, C.; Li, Q.; Dong, Y. Dynamically updated semi-supervised change detection network combining cross-supervision and screening algorithms. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–14. [Google Scholar] [CrossRef]
- Chen, H.; Li, W.; Shi, Z. Adversarial instance augmentation for building change detection in remote sensing images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5603216. [Google Scholar] [CrossRef]
- Sun, C.; Chen, H.; Du, C.; Jing, N. SemiBuildingChange: A Semi-Supervised High-Resolution Remote Sensing Image Building Change Detection Method with a Pseudo Bi-Temporal Data Generator. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5622319. [Google Scholar] [CrossRef]
- Zou, C.; Wang, Z. A New Semi-Supervised Method for Detecting Semantic Changes in Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2023, 20, 5509105. [Google Scholar] [CrossRef]
- Yang, Y.; Tang, X.; Ma, J.; Zhang, X.; Pei, S.; Jiao, L. ECPS: Cross Pseudo Supervision Based on Ensemble Learning for Semi-Supervised Remote Sensing Change Detection. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5612317. [Google Scholar] [CrossRef]
- Zhang, X.; Huang, X.; Li, J. Joint self-training and rebalanced consistency learning for semi-supervised change detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5406613. [Google Scholar] [CrossRef]
- Ding, Q.; Shao, Z.; Huang, X.; Feng, X.; Altan, O.; Hu, B. Consistency-guided lightweight network for semi-supervised binary change detection of buildings in remote sensing images. GISci. Remote Sens. 2023, 60, 2257980. [Google Scholar] [CrossRef]
- Oubara, A.; Wu, F.; Maleki, R.; Ma, B.; Amamra, A.; Yang, G. Enhancing Adversarial Learning-Based Change Detection in Imbalanced Datasets Using Artificial Image Generation and Attention Mechanism. ISPRS Int. J. Geo-Inform. 2024, 13, 125. [Google Scholar] [CrossRef]
- Quan, Y.; Yu, A.; Guo, W.; Lu, X.; Jiang, B.; Zheng, S.; He, P. Unified building change detection pre-training method with masked semantic annotations. Int. J. Appl. Earth Obs. Geoinf. 2023, 120, 103346. [Google Scholar] [CrossRef]
- Zhang, M.; Li, Q.; Yuan, Y.; Wang, Q. Boosting Binary Object Change Detection via Unpaired Image Prototypes Contrast. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5627409. [Google Scholar] [CrossRef]
- Zhu, Q.; Guo, X.; Deng, W.; Shi, S.; Guan, Q.; Zhong, Y.; Zhang, L.; Li, D. Land-use/land-cover change detection based on a Siamese global learning framework for high spatial resolution remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2022, 184, 63–78. [Google Scholar] [CrossRef]
- Han, C.; Wu, C.; Guo, H.; Hu, M.; Chen, H. HANet: A hierarchical attention network for change detection with bitemporal very-high-resolution remote sensing images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 3867–3878. [Google Scholar] [CrossRef]
- Xing, Y.; Jiang, J.; Xiang, J.; Yan, E.; Song, Y.; Mo, D. Lightcdnet: Lightweight change detection network based on vhr images. IEEE Geosci. Remote Sens. Lett. 2023, 20, 2504105. [Google Scholar] [CrossRef]
- Tao, C.; Kuang, D.; Huang, Z.; Peng, C.; Li, H. HSONet: A Siamese foreground association-driven hard case sample optimization network for high-resolution remote sensing image change detection. arXiv 2024, arXiv:2402.16242. [Google Scholar]
- Yang, Q.; Zhang, S.; Li, J.; Sun, Y.; Han, Q.; Sun, Y. Hyperboloid-Embedded Siamese Network for Change Detection in Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 9240–9252. [Google Scholar] [CrossRef]
- Li, X.; He, M.; Li, H.; Shen, H. A combined loss-based multiscale fully convolutional network for high-resolution remote sensing image change detection. IEEE Geosci. Remote Sens. Lett. 2021, 19, 8017505. [Google Scholar] [CrossRef]
- Liu, Y.; Pang, C.; Zhan, Z.; Zhang, X.; Yang, X. Building change detection for remote sensing images using a dual-task constrained deep siamese convolutional network model. IEEE Geosci. Remote Sens. Lett. 2020, 18, 811–815. [Google Scholar] [CrossRef]
- Peng, D.; Bruzzone, L.; Zhang, Y.; Guan, H.; He, P. SCDNET: A novel convolutional network for semantic change detection in high resolution optical remote sensing imagery. Int. J. Appl. Earth Obs. Geoinf. 2021, 103, 102465. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, F.; Liu, J.; Tang, X.; Xiao, L. Adaptive spatial and difference learning for change detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 7447–7461. [Google Scholar] [CrossRef]
- Zhou, Y.; Wang, F.; Zhao, J.; Yao, R.; Chen, S.; Ma, H. Spatial-temporal based multihead self-attention for remote sensing image change detection. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 6615–6626. [Google Scholar] [CrossRef]
- Zhang, R.; Zhang, H.; Ning, X.; Huang, X.; Wang, J.; Cui, W. Global-aware siamese network for change detection on remote sensing images. ISPRS J. Photogramm. Remote Sens. 2023, 199, 61–72. [Google Scholar] [CrossRef]
- Yang, L.; Qi, L.; Feng, L.; Zhang, W.; Shi, Y. Revisiting weak-to-strong consistency in semi-supervised semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7236–7246. [Google Scholar]
- Ji, S.; Wei, S.; Lu, M. Fully convolutional networks for multisource building extraction from an open aerial and satellite imagery data set. IEEE Trans. Geosci. Remote Sens. 2018, 57, 574–586. [Google Scholar] [CrossRef]
- Mittal, S.; Tatarchenko, M.; Brox, T. Semi-supervised semantic segmentation with high-and low-level consistency. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1369–1379. [Google Scholar] [CrossRef] [PubMed]
- Sun, B.; Yang, Y.; Zhang, L.; Cheng, M.M.; Hou, Q. Corrmatch: Label propagation via correlation matching for semi-supervised semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 3097–3107. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Labeled Ratio | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 5% | 10% | 20% | 40% | ||||||||||||
| F1 | IoU | Kappa | F1 | IoU | Kappa | F1 | IoU | Kappa | F1 | IoU | Kappa | ||||
| Only-Sup | 81.97 | 69.45 | 81.09 | 85.67 | 74.93 | 84.92 | 87.02 | 77.02 | 86.33 | 87.14 | 77.20 | 86.46 | |||
| S4GAN [59] | 72.24 | 56.55 | 71.00 | 74.73 | 59.66 | 73.36 | 74.13 | 58.89 | 72.98 | 76.96 | 62.55 | 75.80 | |||
| SemiCD [31] | 85.18 | 74.18 | 84.44 | 87.05 | 77.06 | 86.39 | 87.54 | 77.84 | 86.90 | 88.26 | 78.98 | 87.65 | |||
| UniMatch [57] | 87.79 | 78.24 | 87.15 | 89.39 | 80.81 | 88.82 | 89.47 | 80.95 | 88.93 | 89.49 | 80.97 | 88.95 | |||
| ECPS [40] | 84.45 | 73.09 | 83.66 | 87.85 | 78.33 | 87.20 | 88.16 | 78.83 | 87.54 | 89.12 | 80.37 | 88.55 | |||
| C2F-SemiCD [32] | 89.91 | 81.67 | 89.39 | 90.70 | 82.98 | 90.07 | 91.23 | 83.88 | 90.77 | 91.37 | 84.11 | 90.92 | |||
| WACS-SemiCD | 89.88 | 81.62 | 89.32 | 90.18 | 82.12 | 89.64 | 90.97 | 83.44 | 90.50 | 91.01 | 83.51 | 90.54 | |||
| Fully Sup (100%) | F1 = 91.32 IoU = 84.03 Kappa = 90.86 | ||||||||||||||
| Method | Labeled Ratio | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 5% | 10% | 20% | 40% | ||||||||||||
| F1 | IoU | Kappa | F1 | IoU | Kappa | F1 | IoU | Kappa | F1 | IoU | Kappa | ||||
| Only-Sup | 76.80 | 62.34 | 75.93 | 80.34 | 67.14 | 79.56 | 86.49 | 76.87 | 86.38 | 87.39 | 77.61 | 86.89 | |||
| S4GAN [59] | 80.05 | 66.73 | 79.32 | 83.56 | 71.76 | 82.91 | 86.81 | 76.69 | 86.29 | 88.49 | 79.35 | 88.13 | |||
| SemiCD [31] | 79.37 | 65.79 | 78.52 | 80.98 | 68.03 | 80.17 | 85.43 | 74.56 | 84.82 | 87.65 | 78.02 | 87.13 | |||
| UniMatch [57] | 87.65 | 78.02 | 87.06 | 88.28 | 79.01 | 87.80 | 89.18 | 80.47 | 88.74 | 90.54 | 82.72 | 90.15 | |||
| ECPS [40] | 78.74 | 67.93 | 77.89 | 79.79 | 66.38 | 78.94 | 82.20 | 70.79 | 82.20 | 82.29 | 70.00 | 81.52 | |||
| C2F-SemiCD [32] | 85.54 | 74.74 | 84.95 | 87.05 | 77.07 | 86.52 | 90.25 | 82.23 | 89.86 | 92.55 | 86.13 | 92.24 | |||
| WACS-SemiCD | 89.05 | 80.30 | 88.63 | 89.68 | 81.28 | 89.25 | 91.45 | 84.25 | 91.10 | 93.83 | 88.38 | 93.58 | |||
| Fully Sup (100%) | F1 = 94.25 IoU = 89.13 Kappa = 94.02 | ||||||||||||||
| Method | Labeled Ratio | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| % | 10% | 20% | 40% | ||||||||||||
| F1 | IoU | Kappa | F1 | IoU | Kappa | F1 | IoU | Kappa | F1 | IoU | Kappa | ||||
| Only-Sup | 75.81 | 61.05 | 73.94 | 80.82 | 67.82 | 79.35 | 81.49 | 68.76 | 80.04 | 84.24 | 72.76 | 83.02 | |||
| S4GAN [59] | 59.30 | 42.14 | 57.26 | 74.33 | 59.15 | 72.69 | 80.21 | 66.96 | 78.82 | 81.29 | 68.47 | 79.96 | |||
| SemiCD [31] | 72.93 | 57.39 | 70.76 | 77.01 | 62.61 | 75.22 | 76.81 | 62.35 | 74.99 | 80.81 | 67.79 | 79.37 | |||
| UniMatch [57] | 76.90 | 60.21 | 73.45 | 81.55 | 68.85 | 80.20 | 83.93 | 72.32 | 82.64 | 85.83 | 75.18 | 84.37 | |||
| ECPS [40] | 76.75 | 62.27 | 75.06 | 77.49 | 63.26 | 75.83 | 78.47 | 64.57 | 76.82 | 79.70 | 66.25 | 78.12 | |||
| C2F-SemiCD [32] | 78.10 | 64.06 | 76.32 | 81.31 | 68.50 | 79.84 | 81.62 | 68.95 | 80.17 | 84.74 | 73.52 | 83.52 | |||
| WACS-SemiCD | 83.72 | 72.01 | 82.47 | 84.65 | 73.39 | 83.44 | 85.22 | 74.24 | 84.03 | 86.06 | 75.54 | 84.99 | |||
| Fully Sup (100%) | F1 = 86.79 IoU = 76.66 Kappa = 85.77 | ||||||||||||||
| Method | Labeled Ratio | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 5% | 10% | 20% | 40% | ||||||||||||
| F1 | IoU | Kappa | F1 | IoU | Kappa | F1 | IoU | Kappa | F1 | IoU | Kappa | ||||
| Only-Sup | 81.97 | 69.45 | 81.09 | 85.67 | 74.93 | 84.92 | 87.02 | 77.02 | 86.33 | 87.14 | 77.20 | 86.46 | |||
| S4GAN [59] | 58.68 | 41.52 | 57.35 | 56.03 | 38.92 | 54.70 | 62.06 | 44.99 | 60.77 | 81.29 | 68.47 | 79.96 | |||
| SemiCD [31] | 83.34 | 71.44 | 82.50 | 85.42 | 74.55 | 84.68 | 86.61 | 76.39 | 85.93 | 87.57 | 77.89 | 86.92 | |||
| UniMatch [57] | 80.90 | 67.92 | 79.90 | 83.39 | 71.51 | 82.46 | 82.15 | 69.70 | 81.12 | 87.03 | 77.04 | 86.34 | |||
| ECPS [40] | 84.06 | 72.50 | 83.23 | 85.32 | 74.40 | 84.57 | 87.19 | 77.30 | 86.53 | 88.46 | 79.30 | 84.90 | |||
| C2F-SemiCD [32] | 86.17 | 75.70 | 85.46 | 86.73 | 76.57 | 86.06 | 89.16 | 80.44 | 88.60 | 90.69 | 82.96 | 90.20 | |||
| WACS-SemiCD | 86.90 | 76.83 | 86.23 | 88.46 | 79.30 | 87.83 | 89.94 | 81.72 | 89.41 | 90.48 | 82.61 | 89.98 | |||
| Fully Sup (100%) | F1 = 91.32 IoU = 84.03 Kappa = 90.86 | ||||||||||||||
| Method | Labeled Ratio | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 5% | 10% | 20% | 40% | ||||||||||||
| F1 | IoU | Kappa | F1 | IoU | Kappa | F1 | IoU | Kappa | F1 | IoU | Kappa | ||||
| Only-Sup | 73.22 | 57.75 | 71.91 | 78.81 | 65.03 | 78.02 | 86.49 | 76.19 | 85.94 | 87.39 | 77.61 | 86.89 | |||
| S4GAN [59] | 79.18 | 65.53 | 78.39 | 79.19 | 65.55 | 78.37 | 76.98 | 62.58 | 76.01 | 83.80 | 72.12 | 83.11 | |||
| SemiCD [31] | 66.96 | 50.34 | 65.34 | 78.61 | 64.76 | 77.70 | 84.02 | 72.44 | 83.36 | 87.96 | 78.51 | 87.45 | |||
| UniMatch [57] | 77.68 | 63.51 | 76.89 | 78.64 | 64.79 | 77.71 | 85.42 | 74.55 | 84.80 | 85.97 | 75.40 | 85.42 | |||
| ECPS [40] | 69.72 | 53.52 | 68.47 | 69.89 | 53.69 | 68.89 | 82.17 | 69.73 | 81.50 | 81.27 | 68.45 | 80.53 | |||
| C2F-SemiCD [32] | 76.45 | 61.88 | 75.54 | 80.76 | 67.72 | 79.96 | 84.44 | 73.06 | 83.79 | 90.10 | 81.99 | 89.71 | |||
| WACS-SemiCD | 83.19 | 71.23 | 82.53 | 86.02 | 75.47 | 85.44 | 90.09 | 81.97 | 89.69 | 92.04 | 85.25 | 91.71 | |||
| Fully Sup (100%) | F1 = 94.25 IoU = 89.13 Kappa = 94.02 | ||||||||||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peng, D.; Liu, M.; Guan, H. Perturbation Matters: A Novel Approach for Semi-Supervised Remote Sensing Imagery Change Detection. Remote Sens. 2025, 17, 576. https://doi.org/10.3390/rs17040576
Peng D, Liu M, Guan H. Perturbation Matters: A Novel Approach for Semi-Supervised Remote Sensing Imagery Change Detection. Remote Sensing. 2025; 17(4):576. https://doi.org/10.3390/rs17040576
Chicago/Turabian StylePeng, Daifeng, Min Liu, and Haiyan Guan. 2025. "Perturbation Matters: A Novel Approach for Semi-Supervised Remote Sensing Imagery Change Detection" Remote Sensing 17, no. 4: 576. https://doi.org/10.3390/rs17040576
APA StylePeng, D., Liu, M., & Guan, H. (2025). Perturbation Matters: A Novel Approach for Semi-Supervised Remote Sensing Imagery Change Detection. Remote Sensing, 17(4), 576. https://doi.org/10.3390/rs17040576