1. Introduction
With the rapid development of image sensor technology and the aerospace industry, ultra-high resolution (UHR) remote sensing images have generated massive amounts of data, which brings significant pressure on the analysis of remote sensing image data. Semantic segmentation is a prerequisite necessary task for remote sensing image interpretation; the quality of segmented remote sensing images directly determines the possibility of high-level expression and application of subsequent remote sensing images. Therefore, as a key technology in the field of remote sensing image research, semantic segmentation is widely used in various popular remote sensing image processing research areas, including land cover mapping [
1,
2], wildfire detection [
3], change detection [
4,
5], object extraction [
6,
7], and disaster management [
8,
9], which has become a hot research topic with significant research significance and research value.
In recent years, with the rapid development of deep learning techniques, the semantic segmentation of ultra-high-resolution (UHR) remote sensing images has made significant progress by introducing convolutional neural networks (CNNs) [
10,
11,
12]. However, despite their excellent performance in many aspects, these methods remain constrained by the intrinsic properties of convolutional kernels, which have a limited receptive field and local feature extraction capability. This limitation often results in the loss of fine details, making it difficult to recognize and segment small-scale objects with large variations in size. To overcome this issue, the popular Transformer [
13] architecture has begun to attract attention from researchers in remote sensing image semantic segmentation. Leveraging its powerful backbone, Transformer-based semantic segmentation methods for remote sensing images [
14,
15,
16] have achieved even more outstanding performance. Through an in-depth analysis of the impact of remote sensing image data modalities and structures on semantic segmentation, it has been found that single-modality remote sensing image data can only provide information from a single perspective, limiting further improvements in feature extraction results [
17]. With the continuous advancement of Earth observation technologies, multi-source remote sensing data—such as optical images, digital surface models (DSM), and multispectral and hyperspectral images—can perceive the same scene from different dimensions, offering more comprehensive and complementary information. This effectively breaks through the cognitive bottleneck of traditional single-modality imaging mechanisms [
18]. Therefore, fusing multi-modal remote sensing data and exploring more efficient, precise, and robust semantic segmentation methods have become a key research direction, providing new opportunities to enhance the performance of intelligent remote sensing interpretation tasks [
19,
20,
21].
In the task of multimodal UHR remote sensing image semantic segmentation, recent years have witnessed a surge of studies leveraging deep learning models for feature extraction and fusion across multi-source remote sensing data. Most existing approaches design specific network architectures to extract modality-specific features or generate attention weight maps, followed by simple fusion strategies such as weighted summation or channel concatenation to integrate multimodal features [
22]. Although these methods have led to performance improvements to a certain extent, their fusion mechanisms remain relatively coarse and often fail to adequately capture the inherent structural heterogeneity across different modalities, which presents substantial limitations when applied to remote sensing imagery [
23]. As illustrated in
Figure 1, compared with natural images, remote sensing scenes exhibit significant intra-class variations in terms of scale, shape, and texture. Moreover, object boundaries tend to be ambiguous, and class confusion is widespread, especially for small objects whose fine details are often neglected [
24]. These characteristics impose stricter requirements on fusion modules in terms of discriminative capability and fine-grained information preservation [
25]. However, due to the insufficient ability of existing fusion strategies to model cross-modal feature interactions, most current methods tend to lose crucial details when handling complex scenes, making it difficult to achieve effective joint modeling of both local and global semantics [
26]. As a critical spatial structural cue in multimodal remote sensing imagery, boundary features play a vital role in improving cross-modal alignment precision and guiding segmentation networks to focus on object edge regions [
27]. They not only enhance feature discriminability during the fusion process but also help mitigate semantic ambiguity caused by blurred boundaries and occlusions, thereby preserving essential spatial details [
28]. Nevertheless, most existing boundary modeling approaches still rely on CNN-based structures, which are constrained by the limited receptive field of convolutional kernels [
29]. This limitation hampers their ability to accurately capture fine-grained boundary contours [
30]. Recent studies have demonstrated that employing large-kernel convolutions can effectively expand the receptive field and improve the representation of edge regions [
31]. However, in remote sensing imagery, overly large convolution kernels may introduce redundant background noise, thereby degrading target recognition and segmentation accuracy.
While CNNs and Transformers have been widely applied in remote sensing image semantic segmentation tasks based on fusion methods, convolutional neural networks are hindered by their limited receptive fields, which restricts their ability to capture global context and overlook long-range cross-modal dependencies at different feature levels [
33]. In contrast, Transformers excel at extracting global features by capturing long-distance spatial dependencies, thereby accurately representing global semantic information, but their computational costs are prohibitively high [
34]. Recently, the novel architecture Mamba [
35] from state-space models (SSM) [
36] has garnered significant attention due to its remarkable performance in modeling long-distance interactions while maintaining linear computational complexity. However, unlike sequential data (e.g., text), multimodal remote sensing data lack the necessary causal relationships inherent in sequence data. When processing multimodal remote sensing image inputs, the scan operation originally designed for text sequence data may fail to capture key features of multimodal information while generating one-dimensional sequence data. Consequently, directly applying the Mamba framework model [
10,
37] for fusion modeling in remote sensing segmentation may inevitably lead to performance degradation. Therefore, exploring how to customize the Mamba framework for multimodal fusion in the field of remote sensing image segmentation is both crucial and meaningful.
1.1. Related Works
Driven by advances in Earth observation technology, Multimodal data (e.g., optical imagery, DSM, multispectral, etc.) have gradually received widespread attention, which has been driven by the advancement of Earth observation technology. Multimodal fusion provides more comprehensive and richer surface feature information, thereby significantly enhancing model performance. For instance, Hazirbas et al. [
20] and Audebert et al. [
21] proposed models based on dual-branch structures, which process different modality features in parallel. While these methods improved fusion performance, their simple element-wise addition strategy still has limitations. Subsequently, Seichter et al. [
38] stacked RGB and DSM data into four-channel inputs. However, this straightforward channel-stacking approach failed to exploit the complementary nature of multimodal features fully. To further enhance feature fusion, Hosseinpour et al. [
39] and Chen et al. [
40] introduced gated fusion and cross-layer gating mechanisms to better accommodate complex multimodal data scenarios. With the introduction of Transformer technology, Transformer-based multimodal fusion methods have made remarkable progress in remote sensing image segmentation tasks. He et al. [
23] enhance the self-attention module by incorporating spatial and channel attention mechanisms, achieving more efficient feature fusion. Meanwhile, Ma et al. [
32] improve skip connections through cross-modal and multi-scale fusion using Transformers, enabling a robust representation of surface objects with significant scale variations. However, the existing CNN- and Transformer-based architectures are still deficient in modeling fine-grained local and global contextual information, which are only unfolded in single-modal or simple multimodal scenarios, failing to fully explore the unique value of multimodal data based on the Mamba framework in remote sensing semantic segmentation.
In recent years, with the increasing challenges posed by complex scenes and multi-scale objects in remote sensing images, researchers have begun exploring how large receptive field convolutions can enhance the performance of remote sensing semantic segmentation. To address this issue, various designs for large receptive field convolutional networks have been proposed. Liu et al. [
41] adopt a 7 × 7 depthwise convolution, significantly improving performance in general visual tasks. Li et al. [
30] proposed a method for selectively expanding the spatial receptive field of large objects. Ding et al. [
33] employ 31 × 31 large convolutional kernels, demonstrating the potential of convolutional networks in capturing long-range dependencies. Additionally, Liu et al. [
42] extended the kernel size to 51 × 51 through kernel decomposition and sparse grouping, enhancing the receptive field without increasing computational complexity. Meanwhile, Cai et al. [
31] leveraged parallel arrangements of various-sized depth-wise convolutional kernels to extract dense texture features across multi-scale receptive fields, enabling convolution operations to capture rich local contextual information under a larger receptive field. These works collectively demonstrate that well-designed large receptive field convolutions can significantly enhance the extraction of local contextual details.
Although large kernel convolutions have demonstrated impressive performance in general vision tasks, their multi-branch parallel structures often introduce substantial computational overhead. In remote sensing imagery, where object boundaries are highly complex and vary significantly in scale, efficiently leveraging large-kernel convolutions to extract fine-grained boundary features, without introducing excessive computational redundancy or noise—remains a significant challenge. To address these issues, we introduce Large Strip Convolutions, which employ elongated, directionally constrained convolutional kernels in the spatial domain. This design allows for more efficient extraction of directional boundary details while mitigating the redundant receptive fields and computational costs associated with global expansion.
State Space Model (SSM) [
35,
43] has emerged as a practical component for constructing deep networks due to their exceptional performance in analyzing continuous long-sequence data. In recent years, various SSM variants have been introduced to accommodate different application requirements. Structured SSMs [
44], which incorporate diagonal structures combined with low-rank methods, have improved modeling efficiency, while the integration of parallel scanning techniques has further enhanced the performance of SSMs in large-scale data processing. Building upon this foundation, the Mamba architecture was developed, refining the linear time-invariant properties of SSMs by incorporating data-dependent parameters, demonstrating superior performance compared to Transformers on large-scale datasets. Inspired by SSM, Liu et al. [
45] and Smith et al. [
46] successfully introduced Mamba into image classification tasks. Ma et al. [
47] were the first to design a visual Mamba-assisted branch based on the VSS module for remote sensing image semantic segmentation. Chen et al. [
48] proposed a random smoothing method to explore non-traditional spatial connectivity approaches, while He et al. [
49] were the pioneers in applying Mamba to pan-sharpening tasks.
However, the aforementioned methods lack customization when handling multimodal remote sensing data. Clearly, directly applying one-dimensional traversal strategies designed for text sequence data to remote sensing image data inevitably leads to performance degradation, as the relationships between pixels in remote sensing images are vastly different from the relationships between elements in sequence data like text. We have redesigned the Mamba framework, proposing a new scanning method tailored for multimodal remote sensing data, which enhances the efficiency and accuracy of cross-modal information learning, thereby enabling Mamba to capture a broader range of deep global contextual information.
1.2. Contribution
Remote sensing semantic segmentation faces challenges such as insufficient alignment of shallow boundary features and limited modeling of long-range contextual information in deep multimodal fusion, which hinder precise boundary delineation and global semantic consistency. To address these issues, we propose FMLSNet, a boundary-enhanced multilevel multimodal fusion architecture that combines multi-directional large strip convolutions for fine-grained boundary extraction with a multistage Mamba-based fusion framework for deep heterogeneous feature alignment. This hybrid design effectively bridges local detail preservation and global contextual understanding, achieving superior performance on complex multimodal remote sensing scenes. The main contributions of this work are summarized as follows:
- (1)
We propose a novel FMLSNet model for remote sensing image semantic segmentation. By integrating the LSSD module with the FMB module, our method enhances the recognition of fine-grained objects at multiple scales and improves the capture of deep global contextual features, thereby boosting overall segmentation accuracy. Experimental results on several challenging benchmark datasets demonstrate that our model outperforms state-of-the-art methods.
- (2)
We propose a multistage Mamba-based multimodal fusion Block (FMB) with a redesigned cross-modal scanning mechanism and disentangled representation learning. This enhances the capture of deep global context, resulting in improved multimodal feature interaction and representation.
- (3)
We design an LSSD module that employs multiple orientation-specific strip kernels with progressive receptive field growth, enabling a precise extraction of boundary and fine-grained spatial features. This design balances local detail preservation and global structural awareness, which is crucial for complex object boundaries in UHR remote sensing imagery.
The rest of this paper is organized as follows. In
Section 2, the proposed model is described in detail.
Section 3 presents the experimental results, including comparisons with other methods, demonstrating the effectiveness of our proposed model.
Section 4 provides an in-depth discussion of the performance–efficiency trade-off and outlines potential directions for future optimization. Finally,
Section 5 concludes the paper with a summary of the contributions.
Figure 2.
The overall framework of our proposed FMLSNet.
Figure 2.
The overall framework of our proposed FMLSNet.
2. Method
2.1. Overview of FMLSNet
As illustrated in
Figure 2, the proposed FMLSNet model is composed of three main components: the Large Strip Spatial Detail (LSSD) module for fine-grained boundary feature extraction based on hybrid large strip convolutions, the Fusion Mamba Block (FMB) for multi-stage multimodal deep feature integration, and a multi-task learning-based cascaded decoder. Specifically, we employ two ResNet [
50] branches with pretrained weights to extract features from the visible spectrum image (VSI) and the digital surface model (DSM), respectively, serving as the encoder. In the LSSD module, we apply large strip convolutions in multiple directions to capture edge features along different orientations. These rich directional boundary features are then used to guide the deep learning of shallow features with varied receptive fields from multiple modalities, compensating for the loss of high-level spatial detail and enabling the model to learn more fine-grained multimodal spatial representations. In the FMB module, we fuse deep multimodal remote sensing features through a novel multi-stage Mamba-based fusion strategy to capture more comprehensive global contextual information. In the first stage, we integrate disentangled representation learning into the classical Mamba structure to align the shared feature distributions generated from different modalities more efficiently, enhancing cross-modal information fusion. In the second stage, a novel scanning mechanism is adopted to perform cross-modal scanning, enabling the model to effectively capture modality-specific associations and complementary information, thereby improving fusion precision and semantic consistency. In the third stage, a bidirectional scanning strategy is introduced to achieve a comprehensive integration of deep features, strengthening the model’s representation ability in complex remote sensing scenarios. Finally, the multi-task learning-based cascaded decoder integrates the fine-grained shallow spatial features and the deep global contextual features produced by the preceding modules to generate more accurate segmentation results.
2.2. Large Strip Spatial Detail Module
In remote sensing image semantic segmentation tasks, significant spatial and spectral differences in data from different sources often lead to the degradation of segmentation performance in multimodal fusion networks, which may lead to gap interference problems due to such inter-modal inconsistencies. The works [
26,
28] have demonstrated that the introduction of boundary information plays a critical role in the calibration process during feature fusion, effectively mitigating the negative effects caused by modal differences and improving the boundary clarity and accuracy of the segmentation results. To address this, we propose an innovative hybrid large strip method. This method employs specially designed large strip convolutions to precisely capture boundary information in different directions, significantly alleviating spatial separation issues. Meanwhile, by multiple parallel large strip convolutions with varying sizes, the module enhances the ability to capture fine details under diverse receptive fields, achieving pixel-level precision in critical regions. Moreover, the extracted multidirectional boundary features further guide the deep learning of multimodal shallow features under different receptive fields, which makes up for the lack of detailed information of high-level features, thus capturing and fusing multimodal shallow feature information more comprehensively.
We denote and to represent the VSI and corresponding DSM data, where H and W denote the height and width of the input modalities. Specifically, each CNN encoder consists of four ResBlocks, which are responsible for extracting shallow detail features. The generated feature map has a downsampling size of , where represents the index of the ResBlock layer. The shallow features extracted by each layer are processed by the LSSD module. Before the fused features are input into the next VSI encoder branch, the features from the auxiliary modality are integrated as input for the primary modality (i.e., VSI).
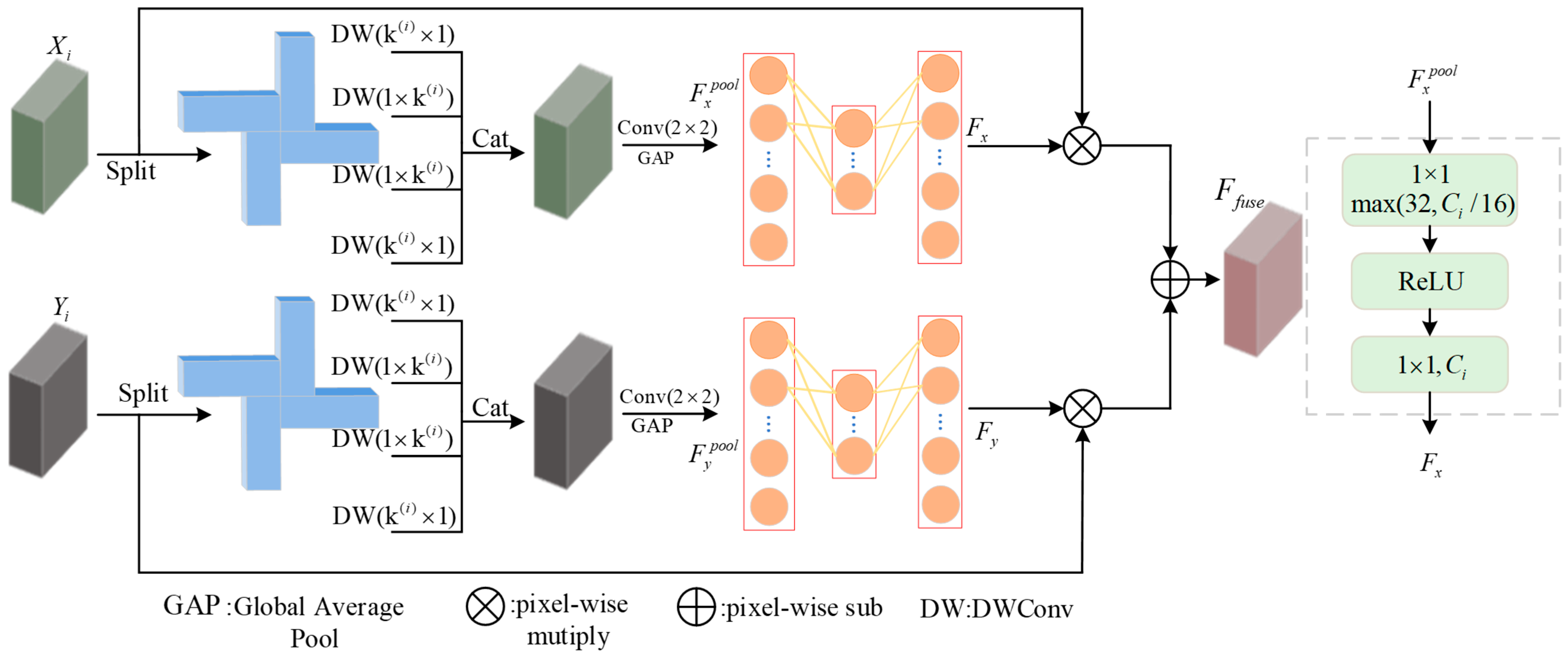
As shown in
Figure 3, the LSSD module consists of two modality branches. Unlike standard convolution operations, we apply a channel-wise splitting operation to the input feature map. Specifically, the input feature map is evenly divided into four parts along the channel dimension. Asymmetric padding is then used to construct horizontal and vertical convolution kernels for different spatial regions of the image. Each part is subjected to a large strip convolution in a specific direction. Since both branches follow the same structure, we take the VSI modality at layer iii as an example for the mathematical formulation, as follows:
where
denote the features extracted from four different directions in the VSI modality branch using depthwise separable convolutions(DWConv). The padding parameters
represent the number of pixels padded in the left, right, top, and bottom directions, respectively. We define a linear growth rate for
(where i denotes the layer index of the ResBlock), dynamically adjusting the convolutional kernel size according to the depth of the current stage iii within the LSSD module. This mechanism progressively enlarges the receptive field of deeper network layers, achieving a balanced trade-off between feature richness and computational cost. The concatenated and interleaved convolution results are then computed as follows:
Here,
represent the feature maps obtained by concatenating two modalities, respectively, are represented, where
denotes the channel-wise concatenation operation. Our LSSD module is capable of capturing precise detail information and enhancing the representational capacity of features without compromising the integrity of local spatial structures. Subsequently, a 2 × 2 convolution without padding is first applied to normalize the concatenated tensor. This is followed by a global average pooling (AvgPool) operation to aggregate global information, compress the channel dimension, and extract localized spatial features.
where GAP denotes global average pooling. Subsequently, we introduce multiple convolutional modules inspired by channel-aware mechanisms to perform fine-grained learning on
and
.
where
denotes a convolutional layer with an output dimension of
, and
denotes a convolutional layer with an output dimension of
. ReLU represents the ReLU activation function. Finally, for the calibration of the parallel dual branches, the correction formula for the original feature map is given as follows:
Here, S denotes the Sigmoid activation function, and the represents pixel-wise multiplication. Through the carefully designed multi-directional large strip convolutions, the model captures both rich local spatial details and global boundary features. This enables better encoding of boundary constraints and local spatial contextual information, resulting in the generation of robust and precise shallow spatial detail features .
2.3. Mamba-Based Deep Feature Fusion
VSI and DSM play critical roles in UHR semantic segmentation. While VSI features provide rich semantic cues, DSM features offer more prominent object layout information. However, Transformer-based methods suffer from quadratic complexity and often require dimensionality reduction for global attention, which can lead to the loss of modality and context information. Unlike prior Mamba-based approaches [
37,
47] that operate on 1D sequences and ignore spatial dependencies, we introduce a cross-modal 2D scanning mechanism combined with disentangled representation learning to enhance spatial alignment and reduce modality interference, making it well-suited for high-resolution multimodal data. Based on this, we design FMB with three progressive stages. In the first stage, SDMamba, disentangled representation learning is integrated into the Mamba [
51] structure to effectively align shared feature distributions across modalities, thereby improving cross-modal information interaction. In the second stage, MBMamba leverages a cross-modal scanning mechanism to deeply model inter-modal correlations and reveal latent complementarities between multimodal features, achieving finer semantic integration. In the final stage, BFMamba employs a bidirectional scanning strategy within the Mamba framework to fully fuse deep features and capture global contextual information, ultimately providing more robust feature representations for complex scene modeling.
Selective Disentangled Mamba (SDMamba): The final output features of the last ResBlock in the dual-branch ResNet encoder are denoted as , where and represent the layer index of the final ResBlock and the output channel size, respectively. and correspond to the features of the VSI and DSM branches, respectively, at the nth layer, where . The entire fusion process of the SDMamba block can be represented as follows.
Specifically, the SDMamba block consists of two identical SDMamba branches, as shown in the upper part of
Figure 4. To achieve the disentanglement of different modalities, the input features are first processed through a series of linear projections (Linear) and depth-wise separable convolutions (DWConv) to generate cross-constructed images containing modality-specific attribute information. Subsequently, the Selective Scan 2D (SS2D) part integrates these cross-constructed images with attribute-related features, producing cross-reconstructed images. Moreover, residual connections are employed to preserve feature consistency and integrity. In the SS2D part, as depicted in the lower part of
Figure 4, the input features
are reshaped: top-left to bottom-right, bottom-right to top-left, top-right to bottom-left, and bottom-left to top-right, forming a total of four sequences. Next, four different selective scanning modules [
44] are used to extract multi-directional information. Finally, the four sequences are reversed in the same direction and summed.
The disentangled learning in SDMamba helps separate modality-specific and shared features by projecting cross-reconstructed representations. This separation enhances alignment in common semantic spaces and reduces modality interference during fusion.
Mutually Boosted Mamba (MBMamba): After performing deep feature enhancement in the SDMamba, the FMB further utilizes
MBMamba blocks to extract and integrate multimodal features and contextual information from the semantic space, as shown in
Figure 4. The overall fusion process of the MBMamba block can be mathematically represented as follows:
The MBMamba, as illustrated in the upper part of
Figure 5, where the system matrices B, C, and Δ are generated from the inputs to realize the context-aware capability of the model. Here, we utilize a linear projection layer to generate the matrix. Inspired by the cross-attention mechanism [
37], widely used in multimodal tasks, we propose the use of the C matrix generated from complementary modalities in selective scanning operations, which enables SSM to reconstruct outputs from hidden states guided by another modality and facilitates the exchange of information between multiple selective scanning mechanisms. Specifically, the interaction linkage mechanism can be formulated as follows:
where
,
represent the time-step t inputs of the VSI and DSM modalities, respectively, while
and
denote the outputs of the selective scanning operation.
and
represent the cross-modal matrices, which are used to recover the outputs at each time-step from the hidden states.
The fused feature maps are enhanced through the
SDMamba Blocks, and the final outputs are denoted as
and
Finally, the further enhanced feature maps are processed through the BFMamba’s bi-directional scanning mechanism and feature fusion strategy, enabling seamless integration of the outputs from the SDMamba and MBMamba stages within the BFMamba stage. This process facilitates efficient global contextual information modeling. The entire fusion process of the BFMamba block can be expressed as
Specifically, as shown in the bottom part of
Figure 5, the final outputs
and
from the SDMamba are first processed through a linear and depth-wise convolutional layer, yielding two features, which are then unfolded and concatenated along the sequence dimension to form the forward sequence
. Additionally, to comprehensively capture multimodal information, we perform reverse scanning to construct the sequence
, obtaining an augmented sequence. Each sequence is processed individually to capture long-term dependencies, followed by flipping the processed sequences and adding them back to the original sequences. The corresponding process can be expressed as follows:
Here,
denotes the linear projection layer, while
and
represent the forward sequence and reverse sequence, respectively.
stands for Spatial-Sequence Modeling.
Finally, the features are reduced in shape to using a linear projection layer. Within the proposed FMB framework, the rich contextual information across modalities is deeply fused before being input into the semantic-level joint decoder, achieving more refined feature integration and higher decoding efficiency.
2.4. Multitask Learning-Based Cascaded Decoder
Shallow spatial detail features and global contextual information deep features are complementary to each other. While shallow spatial detail features lack rich semantic information, they have finer details, clear boundaries, and less distortion. On the contrary, global context information deep features contain much semantic information. Obviously, simply fusing the two features directly may introduce redundant information or lead to inconsistency, affecting the final segmentation results. To address this issue, we adopt a multitask learning strategy during training that jointly addresses semantic segmentation and boundary detection. Accordingly, separate supervised loss functions are designed for each task to guide the learning process.
As shown in
Figure 1, multiple cascaded decoder networks connect to the corresponding layers of the ResNet backbone by skipping connections, progressively restoring the spatial resolution to H × W. Each decoder network consists of an upsampling layer, a convolutional layer, and a ReLU activation layer. The loss function for the semantic segmentation task is as follows:
where
represents the predicted segmentation result,
denotes the ground truth,
indicates the number of classes, and subscripts i, j correspond to the pixel located at the i-th row and j-th column in the nth segmentation result image.
In the boundary detection task, we utilize fine-grained shallow features to generate boundary feature maps, thereby precisely capturing boundary regions in the image. This strategy allows the network to effectively preserve local details when handling complex object boundaries, resulting in higher-quality boundary information and better segmentation performance in the final results. The loss function for boundary detection is as follows:
where p represents the predicted boundary detection map, and q denotes the ground truth for boundary detection. i, j indicate the pixel at the ith row and jth column in the boundary detection results, while M × N represents the size of the input image.
The hyperparameter is used to balance the effects of the two loss functions. Through ablation experiments, both and are ultimately set to 0.5.
The multitask learning approach tightly integrates the semantic segmentation task and boundary detection task, effectively enhancing the network’s ability to perceive object shapes, contours, and complex boundary information. This significantly improves the accuracy and robustness of semantic segmentation.
3. Results
3.1. Experimental Settings
All experiments in this study were conducted using the PyTorch 2.1.0framework on a single NVIDIA GTX 4070 Ti Super GPU with 16GB of RAM for both training and testing. All models were trained using the Stochastic Gradient Descent (SGD) algorithm, with images processed into 256 × 256 patches using a sliding window approach. After collecting samples with the sliding window, simple data augmentation is applied to the input data, such as random rotation and flipping. The learning rate is set to 0.01, the momentum to 0.9, the decay factor to 0.0005, and a batch size of 10.
To evaluate the semantic segmentation performance of multimodal remote sensing data, we adopt Overall Accuracy (OA), mean F1-score (mF1), and mean Intersection over Union (mIoU) as evaluation metrics. These metrics provide an effective and fair comparison between the proposed FMLSNet and other state-of-the-art methods. Specifically, OA measures the overall accuracy of both foreground and background classes, while mF1 and mIoU focus on the five foreground classes, further assessing the model’s segmentation precision for target objects. The mathematical equations of these three evaluation metrics are presented as follows:
where
represents the number of pixels correctly classified as a specific land cover category,
denotes the number of pixels incorrectly classified as belonging to the specific land cover category,
refers to the number of pixels correctly classified as not belonging to the specific land cover category, and
indicates the number of pixels incorrectly classified as not belonging to the specific land cover category. All of these metrics are associated with each land cover class indexed by c.
We benchmarked FMLSNet against several typical and state-of-the-art semantic segmentation methods, including ABCNet [
52], ESANet [
8], MAResUNet [
53], PSPNet [
12], SA-GATE [
40], CMGFNet [
39], EIGNet [
54], TransUNet [
16], CMFNet [
32], UNetformer [
14], MFTransNet [
22], CMTFNet [
55], MCSNet [
15], and RS3Mamba [
47]. In our experiments, single-modality methods were evaluated using only the primary modality, namely VSI. These advanced single-modality methods highlight the contribution of DSM data. In other words, the advantages of multimodality over unimodality are obvious. The experimental results are presented in
Table 1 and
Table 2.
3.2. Datasets
As shown in
Figure 6a,b, the Vaihingen dataset consists of 16 high-resolution aerial images with an average size of 2500 × 2000 pixels, captured from the Vaihingen region in Germany. The Ground Sampling Distance (GSD) is 9 cm, and the dataset includes near-infrared (NIR), red (R), and green (G) channels, along with DSM data. The dataset contains six classes: impervious surfaces, buildings, low vegetation, trees, cars, and cluttered backgrounds. To improve storage and reading efficiency, sliding windows of size 256 × 256 are used during both the training and testing phases, instead of cropping the blocks into smaller images. This results in approximately 960 training images and 320 testing images.
As shown in
Figure 6c,d, the Potsdam dataset is significantly larger than the Vaihingen dataset, consisting of 24 high-resolution orthophotos with a resolution of 6000 × 6000 pixels. It includes four multispectral bands: infrared, red, green, and blue (IRRGB), as well as a normalized DSM with a resolution of 5 cm. For training and testing, we only used the red, green, and blue (RGB) image data. These 24 images are divided into 18 samples for training and 6 samples for testing. After processing with the same sliding window method, the dataset contains 10,368 training samples and 3456 testing samples.
Additionally, the background class labeled as Clutter contains indistinguishable debris and water surfaces.
Figure 3 presents visual examples from both datasets. It is important to note that during the training phase, the stride is set to 256, while during the testing phase, the stride is reduced to 32. The smaller stride during testing helps reduce boundary effects by averaging the prediction results from the overlapping regions.
3.3. Experimental Results
Performance Comparison on the Vaihingen Dataset: As shown in
Table 1, the proposed FMLSNet achieved the best results in terms of mIoU, mean F1 (mF1), and overall accuracy (OA). Compared to the second-best method, RS3Mamba [
46], FMLSNet improved OA by 0.58%, mIoU by 1.39%, and mF1 by 0.84%.
To visually compare the segmentation performance of different algorithms, we present the segmentation results on the Vaihingen dataset in
Figure 7. FMLSNet demonstrates superior performance in capturing texture details and handling boundary regions, particularly in areas with complex boundaries such as trees and low vegetation, achieving clearer and more precise segmentation results, highlighting its stronger capability in modeling long-range dependencies. Moreover, in complex scenes with densely packed buildings and interwoven trees, the proposed model accurately detects boundary details, effectively reducing boundary blurring and object omission issues. These results underscore the robustness and adaptability of FMLSNet.
Performance Comparison on the Potsdam Dataset: The experimental results on the Potsdam dataset also confirm the excellent performance similar to that on the Vaihingen dataset. As shown in
Table 2, FMLSNet achieves classification accuracies of 97.88%, 88.16%, 96.51%, and 92.96% for buildings, trees, cars, and impervious surfaces, respectively. Particularly, the segmentation of buildings, trees, and impervious surfaces stands out.
Figure 5 presents a visual comparison of different methods on the Potsdam dataset. By observing
Figure 8, it is evident that FMLSNet shows advantages in recognizing objects at different scales, such as buildings, trees, and cars. Specifically, in the two red boxes, The performance of FMLSNet is particularly impressive in complex scenes. In the annotated area, where buildings are obscured by trees, FMLSNet accurately segments the trees and successfully identifies the building contours beneath them, closely resembling real-world ground conditions. Overall, FMLSNet demonstrates superior performance in handling complex objects, significantly improving segmentation accuracy in complex scenes.
Table 1 and
Table 2 demonstrate that ABCNet [
52], MAResUNet [
53], and ESANet [
8] utilize local attention mechanisms (LAM) to effectively reduce computational costs while enhancing the extraction of global contextual information. However, these approaches still exhibit limitations in the precision of global information aggregation, particularly in scenarios that require capturing long-range dependencies within complex scenes. PSPNet [
12] introduces a pyramid pooling module that integrates global contextual information, yielding high-quality results for scene semantic analysis. Nonetheless, the pyramid pooling strategy may incur additional computational overhead, increasing model complexity. CMGFNet [
39], SA-GATE [
40], and CMFNet [
32] are representative multimodal segmentation methods. CMGFNet employs a cascaded multimodal fusion module to progressively integrate data from different modalities, enhancing segmentation accuracy for details and boundaries, but its step-by-step processing framework may lead to computational delays in complex scenarios. SA-GATE uses adaptive attention mechanisms to guide modality fusion and reduce inter-modal conflicts, yet its attention mechanism could require further optimization in cases of significant modality discrepancies. CMFNet applies cross-attention mechanisms to fuse features across multiple scales, improving performance in complex scenes, but its intricate model architecture may pose efficiency challenges when handling UHR remote sensing imagery. Transformer-based segmentation methods, such as TransUNet [
16] and UNetFormer [
14], leverage efficient Transformer mechanisms to extract global contextual information, significantly enhancing their capacity to understand complex scenes. Despite their effectiveness in large-scale segmentation tasks, these methods may introduce pixel-level semantic overlaps between objects due to the implicit nature of global contextual information acquisition, potentially compromising boundary localization accuracy. CMTFNet [
55] utilizes the multiscale Transformer module to extract multimodal global context information at different scales, which reduces model complexity while retaining some of the global features; however, while reducing model complexity may sacrifice a certain degree of detailed information, making it underperform in fine-grained segmentation tasks. MCSNet [
15] and EIGNet [
54] adopt specialized designs to improve object boundary smoothness, but they remain susceptible to false boundaries in complex scenarios, which can result in incomplete segmentation. RS3Mamba [
47] effectively exploits the advantages of the Mamba structure, capturing global features efficiently while reducing the computational complexity of attention mechanisms from quadratic to linear. Nevertheless, its performance may benefit from further optimization when addressing highly complex or non-linear modality distributions, particularly in terms of multimodal adaptability, which still warrants deeper investigation.
As illustrated in
Figure 9, our method produces edge predictions on the Vaihingen and Potsdam datasets that closely align with the ground-truth boundaries, accurately delineating complex object contours. Our predicted edges exhibit greater continuity and smoothness while significantly reducing intraclass noise. This improvement stems from the boundary-aware modeling in the LSSD module at shallow stages and the joint supervision of semantic and boundary features via our multitask learning strategy, enabling robust boundary segmentation even in complex multimodal scenarios.
Comparing the above baselines, FMLSNet demonstrates best performance, which can be attributed to the following two innovative designs: (1) By extracting rich multi-directional boundary features, the multimodal shallow features are guided to deep learning under different sensory fields, thus capturing more shallow spatial detail feature information in a more comprehensive way. (2) A novel fusion Mamba module is designed, which incorporates an innovative scanning mechanism combined with disentanglement learning to fully explore and learn more representative cross-modal feature representations. This design further enhances the expression of global semantic information, enabling more accurate feature modeling and segmentation performance in complex remote sensing scenarios.
3.4. Ablation Study
To validate the effectiveness of each module in the proposed FMLSNet, we conducted ablation experiments by sequentially removing core components to analyze their impact on overall performance. The experimental results are shown in
Table 3. We used a dual-branch framework as the baseline and systematically added the LSSD, FMB, and BAD modules to investigate their contributions to segmentation performance.
In the first experiment, we replaced the proposed FMB module with two independent single-modality Mamba branches, keeping only the LSSD module in the ResBlock. The results showed that although the overall accuracy (OA) reached 91.93%, it decreased compared to the complete model. This indicates that the FMB module integrates cross-modal enhancement with disentanglement learning, improving the model’s ability to capture global context information and inter-modal interactions during deep feature fusion. In the second experiment, we removed the LSSD module from both branches to evaluate its impact on shallow feature learning. The experimental results showed a further decrease in OA to 91.62%, validating the ability of the LSSD module to capture multidirectional boundary features through large strip convolutions, compensating for the lack of high-level detail information. Additionally, it effectively extracted rich shallow detail features during shallow feature fusion, laying the foundation for overall performance improvement. In the third experiment, we added multitask learning on top of the first experiment by introducing a boundary-aware decoder(BAD) for the boundary detection task. The results showed that OA increased to 92.07%, indicating that the boundary detection task effectively optimized the model’s perception of boundary regions, significantly enhancing the completeness and clarity of the segmentation results, thereby providing stronger support for detailed expression in complex scenes.
To more clearly demonstrate the effectiveness of the core method, we present heatmaps generated by FMLSNet in
Figure 10b–d. Each subfigure in
Figure 10 is labeled to clearly indicate the different contents. Specifically, the three heatmaps of FMLSNet are extracted after the LSSD module, the FMB module, and just before the semantic segmentation head, respectively. These heatmaps correspond to feature maps generated at different stages, showcasing the model’s ability to distinguish between category pixels such as buildings, roads, trees, and cars.
Figure 10 shows that FMLSNet exhibits more high-activation regions across all samples, indicating that FMLSNet can extract richer semantic information at the global scale through a multilevel multimodal fusion strategy, providing strong support for the integration of multimodal features. Furthermore, the boundaries of the highly activated regions are more closely aligned with the actual contours of the objects, thanks to our proposed hybrid large strip method, which refines multi-directional boundary features and further guides the learning of shallow spatial features under multiscale receptive fields, compensating for the loss of high-level detail information and thereby more accurately capturing and integrating multimodal shallow features. The carefully designed Mamba cross-modal scanning mechanism not only enhances the ability to capture deep features but also strengthens the expression and interaction of cross-modal information by effectively modeling the long-range dependencies between modalities, providing more comprehensive and precise support for feature integration in complex scenarios. The results in
Figure 10 further validate the advantages of our proposed multilevel fusion approach in multimodal information extraction and fusion, thus improving the overall performance of semantic segmentation.
DSM analysis of experimental comparisons: As shown in
Table 4, FMLSNet significantly improves the classification accuracy of most categories across both datasets by effectively integrating additional DSM data. In particular, the performance improvement is especially significant on two classes of objects, buildings and impervious surfaces, which are usually characterized by stable surface heights, providing the model with a clear basis for discrimination and improving the classification accuracy. Furthermore, since cars are usually located on roads, the relatively consistent height of road features also aids in improving the boundary identification accuracy of cars. FMLSNet demonstrates significant performance gains on both datasets, driving the overall optimization of the semantic segmentation task.
Next, we validate the effectiveness of the LSSD module through an ablation study on different large strip kernel size configurations in
Table 5. The first column lists five groups of strip kernel sizes used in the experiments. Results indicate that smaller kernels struggle to capture long-range dependencies, leading to insufficient global context modeling and degraded performance. In contrast, larger kernels encompass broader contextual information and enhance boundary and semantic feature representation. Notably, our proposed progressive expansion strategy, which gradually increases the strip kernel size as the network depth grows, achieves the best trade-off between preserving fine-grained details and modeling global context, thereby delivering superior segmentation performance.
3.5. Hyperparameter Selection
To evaluate the overall impact of the two tasks on semantic segmentation results, we conducted comprehensive experiments by adjusting the weighting coefficients
and
in Equation (17). Experiments are performed on the Vaihingen dataset, as it exhibits trends similar to those observed in the Potsdam dataset. As shown in
Figure 11, we systematically adjusted the ratio between
and
. Notably, when both coefficients
and
are set to 0.5, the best results are achieved, indicating that spatial boundary information plays a critical role in the semantic segmentation task. However, if either task is assigned an excessively high weight, the dominant task during training can lead to information bias toward that task, potentially causing the network to overlook the contributions of the other task. Therefore, we select 0.5 as the optimal value for
and
in all experiments.
3.6. Model Parameters and Computation Complexity Analysis
Based on the analysis in
Table 6, we evaluated the computational complexity of FMLSNet, focusing primarily on the floating-point operation count (FLOPs), the number of model parameters, and the segmentation accuracy (mIoU). Ideally, an efficient model should minimize FLOPs and parameter count while achieving excellent segmentation accuracy.
Table 5 demonstrates that FMLSNet achieves a segmentation accuracy of 84.29% in terms of mIoU, ranking the best among all methods and significantly outperforming traditional single-modal and multimodal approaches such as CMTFNet, CMFNet, and MAResUNet, which is due to the fact that FMLSNet employs a large strip convolution technique for shallow feature extraction and uses Mamba for deep global receptive field modeling, resulting in an efficient fusion of multimodal data and accurate capture of global contextual information. These designs empower FMLSNet with robust feature representation capabilities and computational efficiency when handling complex multimodal data. Furthermore, compared to lightweight models such as UNetFormer, MFTransUNet, and CMGFNet, FMLSNet achieves significant improvements in segmentation performance while substantially reducing model complexity compared to more complex Transformer-based architectures, demonstrating a balanced trade-off between computational efficiency and accuracy. Finally, FMLSNet showcases its superiority in achieving high-precision remote sensing semantic segmentation while maintaining low computational complexity. While FMLSNet introduces moderate computational overhead, the performance gain justifies its deployment in tasks where segmentation precision is critical.
4. Discussion
This study presents FMLSNet, A Multilevel Multimodal Hybrid Mamba-Large Strip Convolution Network for remote sensing semantic segmentation that integrates LSSD with FMB to enhance shallow boundary feature extraction and deep multimodal semantic interaction. Extensive ablation and comparative experiments on the Vaihingen and Potsdam datasets demonstrate that FMLSNet achieves superior boundary delineation and overall segmentation accuracy, while maintaining strong generalization capability.
In terms of the performance–efficiency trade-off, FMLSNet introduces a moderately higher computational cost than CNN-based approaches but remains substantially more efficient than Transformer-based methods. Its progressive strip kernel design and linear Mamba scanning strategy preserve boundary precision while avoiding the quadratic complexity of attention mechanisms. Compared with existing Mamba-based scanning mechanisms, FMLSNet employs a cross-modal 2D scanning strategy that simultaneously models horizontal and vertical spatial dependencies and leverages disentangled representation learning to reduce modality interference, resulting in more effective multimodal feature alignment.
Nevertheless, some limitations remain: the use of large kernels and multistage fusion increases parameter count and memory footprint, and performance may fluctuate when applied to tasks with heterogeneous annotation standards or unbalanced modalities. Future work will explore expanding the framework to additional modalities (e.g., SAR, LiDAR, hyperspectral) and related dense prediction tasks, while incorporating dynamic large strip kernel adaptation based on scene complexity to achieve a better balance between efficiency and accuracy.
5. Conclusions
In this study, we propose a novel boundary-enhanced multi-level multimodal fusion Mamba–Large Strip Convolution Network (FMLSNet), specifically designed for semantic segmentation of UHR remote sensing images. The model follows an encoder–decoder architecture and incorporates two key components: the Mamba-based multimodal fusion framework (FMB) and the Large Strip Spatial Detail extraction module (LSSD). The FMB module employs an innovative multimodal scanning mechanism combined with disentangled representation learning to extract and fuse deep features and cross-modal contextual information from multimodal remote sensing data, effectively enhancing the modeling of global semantic information. The LSSD module adaptively integrates multi-directional large strip convolutions to precisely extract fine-grained boundary features, strengthening shallow spatial detail learning and further improving segmentation accuracy and robustness.
To further enhance segmentation precision, we design a multitask learning strategy that simultaneously addresses semantic segmentation and boundary detail detection, optimizing boundary localization accuracy. Extensive experiments on two challenging remote sensing datasets, Potsdam and Vaihingen, demonstrate that FMLSNet significantly outperforms state-of-the-art methods on both datasets. Ablation studies validate the critical contributions of the FMB and LSSD modules, further proving the effectiveness of our approach. Comprehensive evaluation results show that FMLSNet not only surpasses existing techniques in segmentation accuracy but also exhibits good robustness when handling complex remote sensing image scenarios.
In summary, the FMLSNet model serves as an effective tool for semantic segmentation of multimodal remote sensing images by incorporating multistage fusion and boundary detail enhancement mechanisms, significantly improving segmentation precision and deep feature capture capabilities. In future work, we plan to further optimize the model’s computational complexity and enhance boundary detail extraction to better meet the demands of remote sensing image segmentation.


 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}