

Surface Damage Detection in Hydraulic Structures from UAV Images Using Lightweight Neural Networks


Abstract
1. Introduction
2. Materials and Methods
2.1. Flowchart of the Developed Model
2.2. Deep Learning Algorithms
2.2.1. Improved Fast-SCNN Network
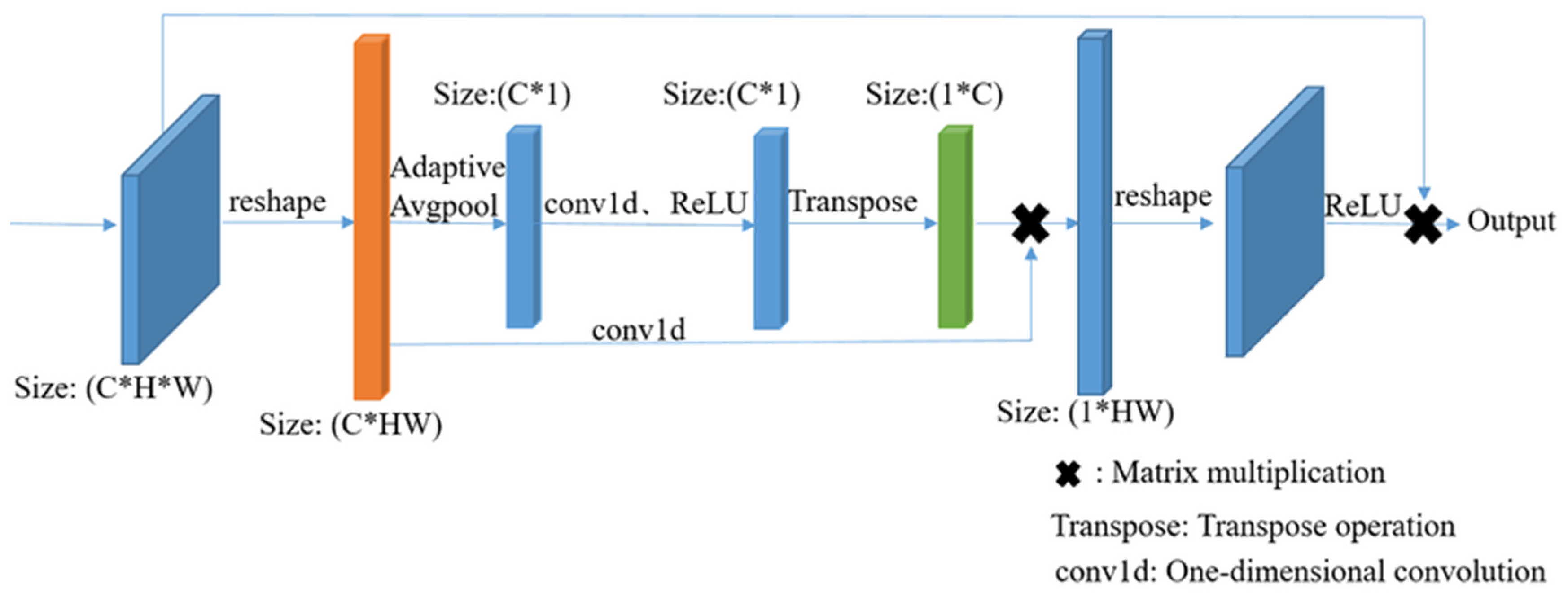
2.2.2. LFPA Module
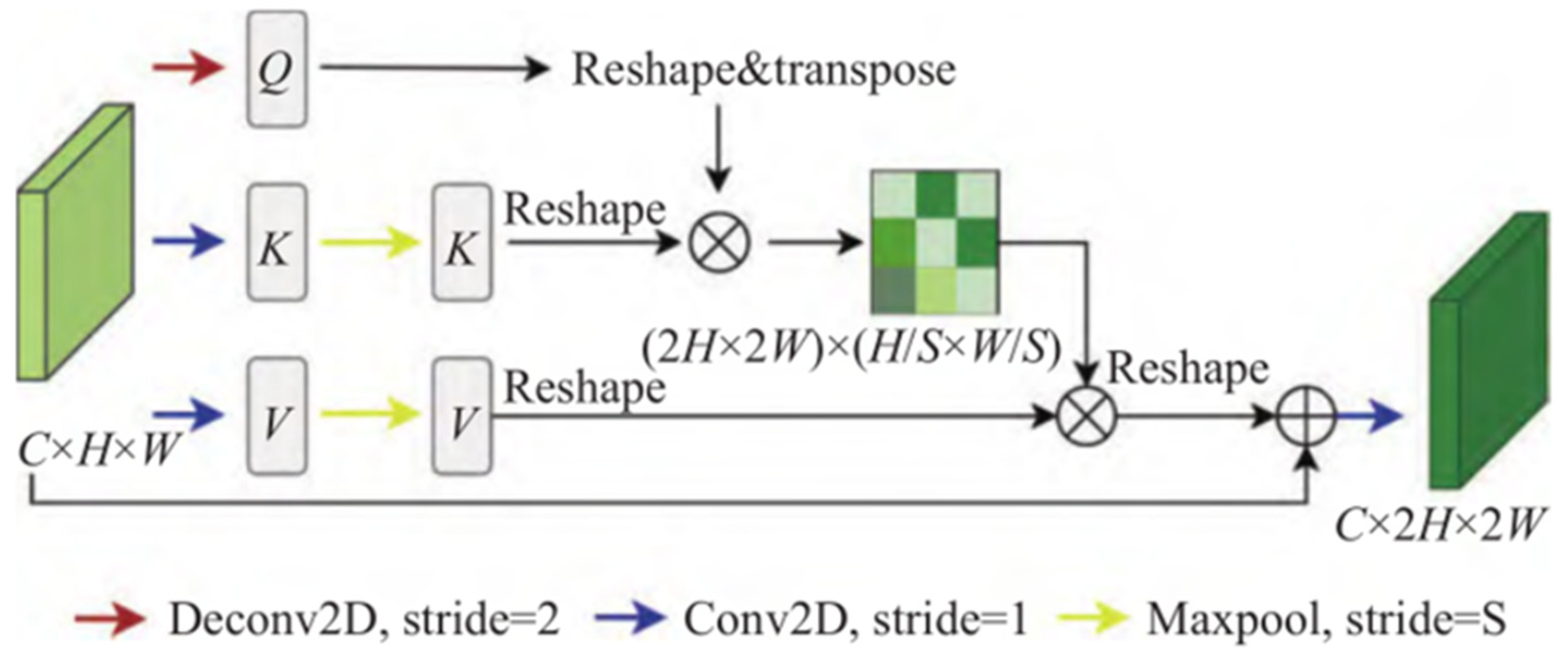
2.2.3. Edge Attention Module
2.3. Evaluation Indicators and Loss Functions
2.4. Study Case and Data
2.4.1. Project Description and UAV-Based Inspection System
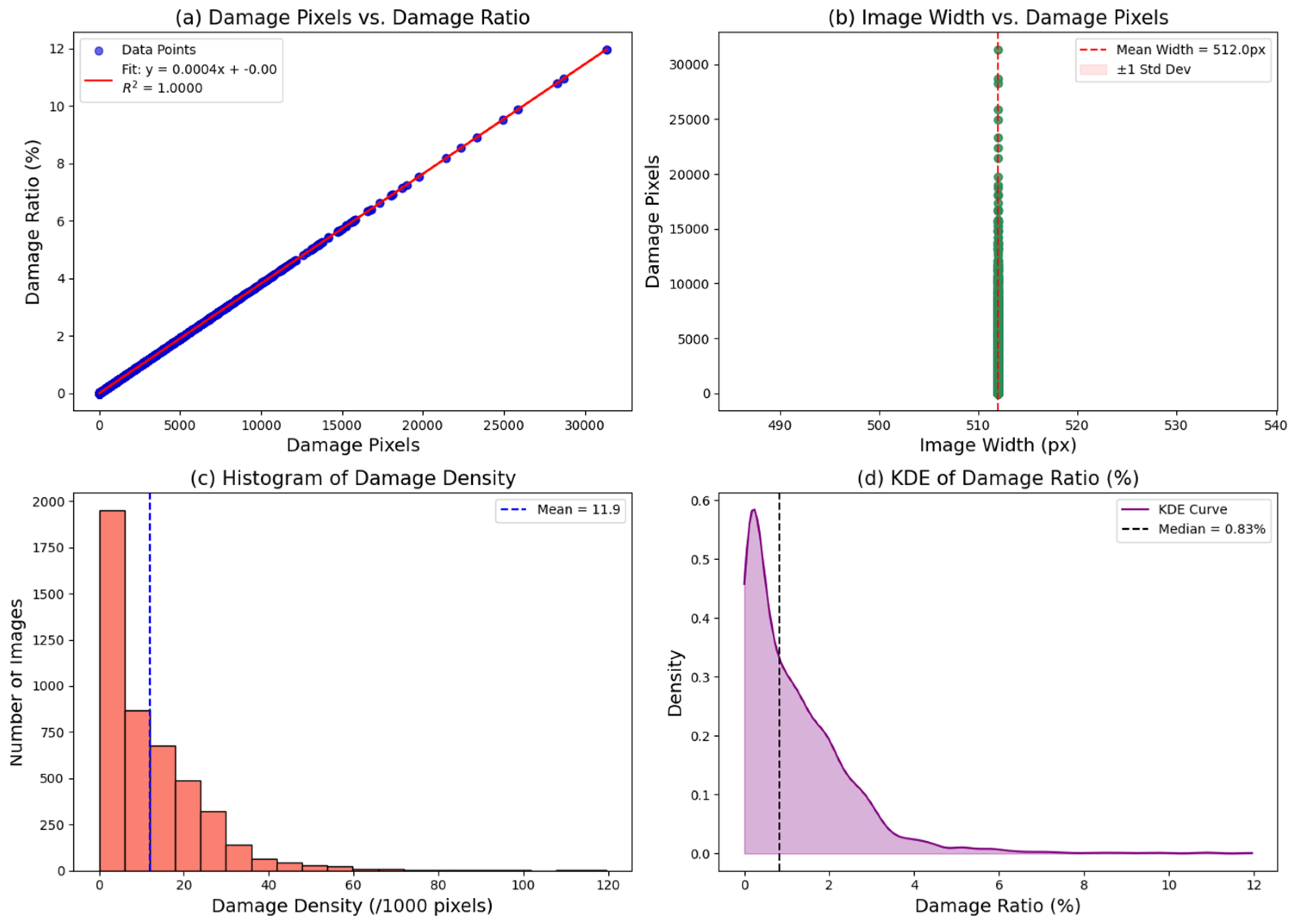
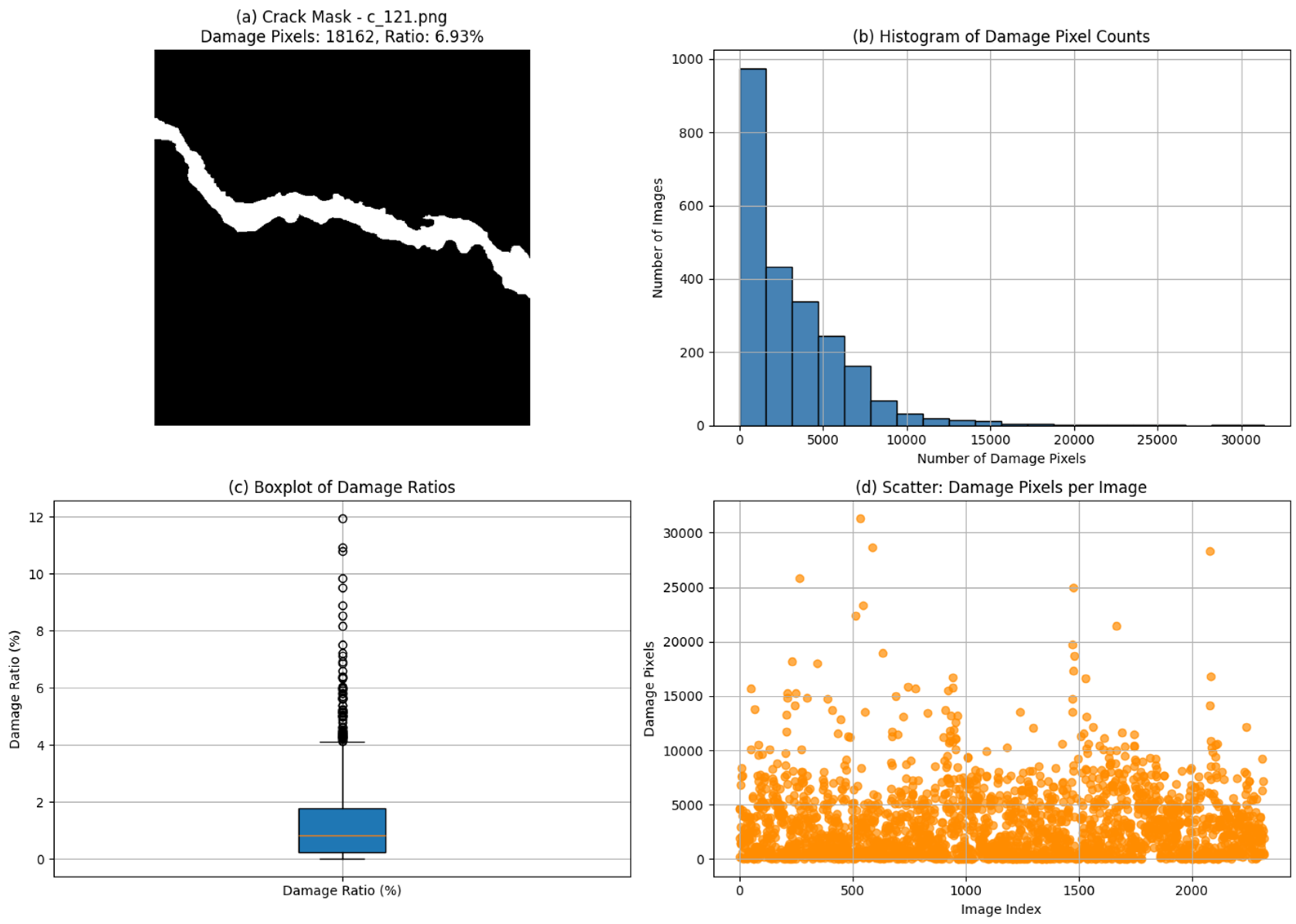
2.4.2. Damage Dataset of Hydraulic Structures
3. Results
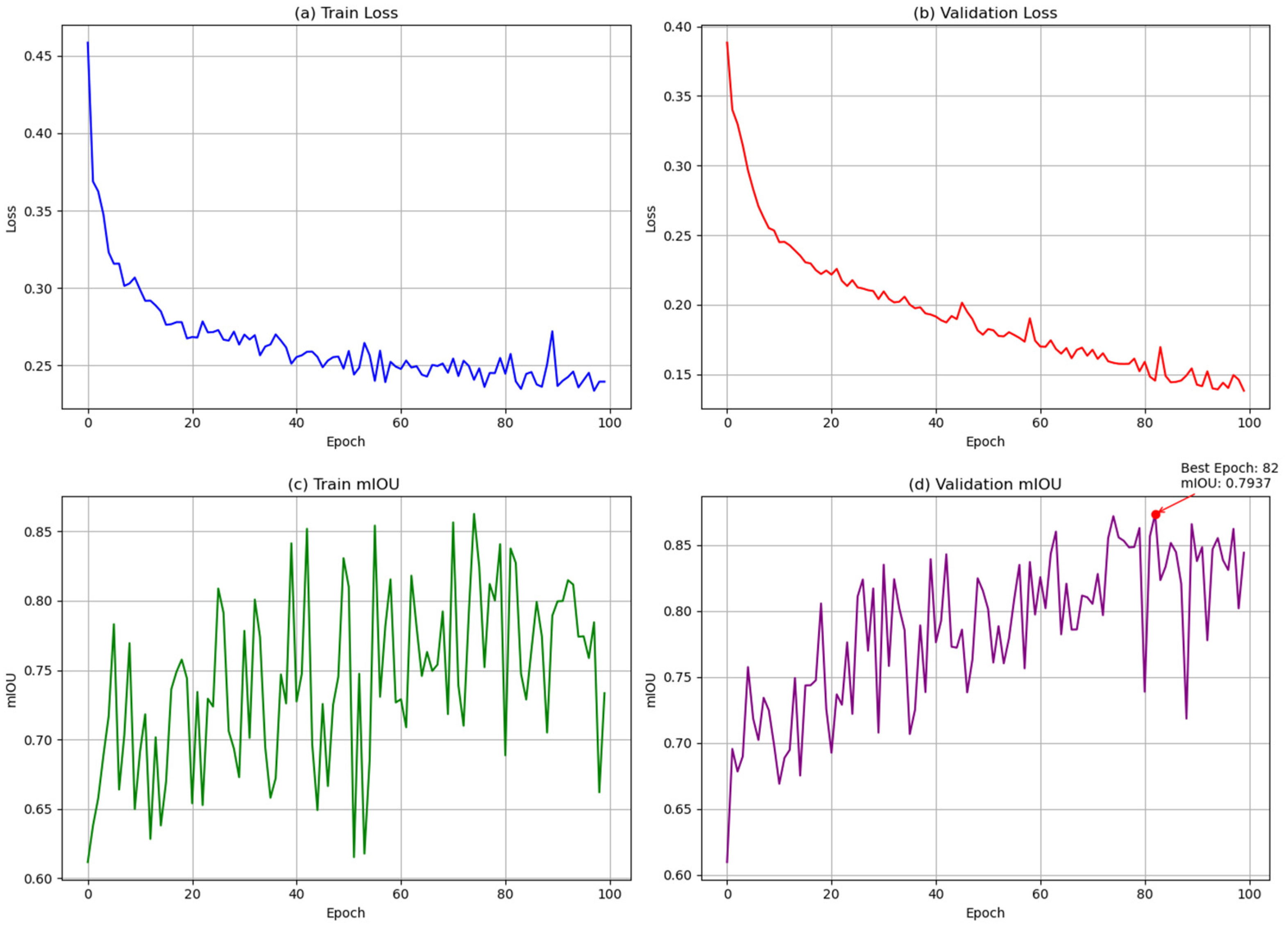
3.1. Base Model Training
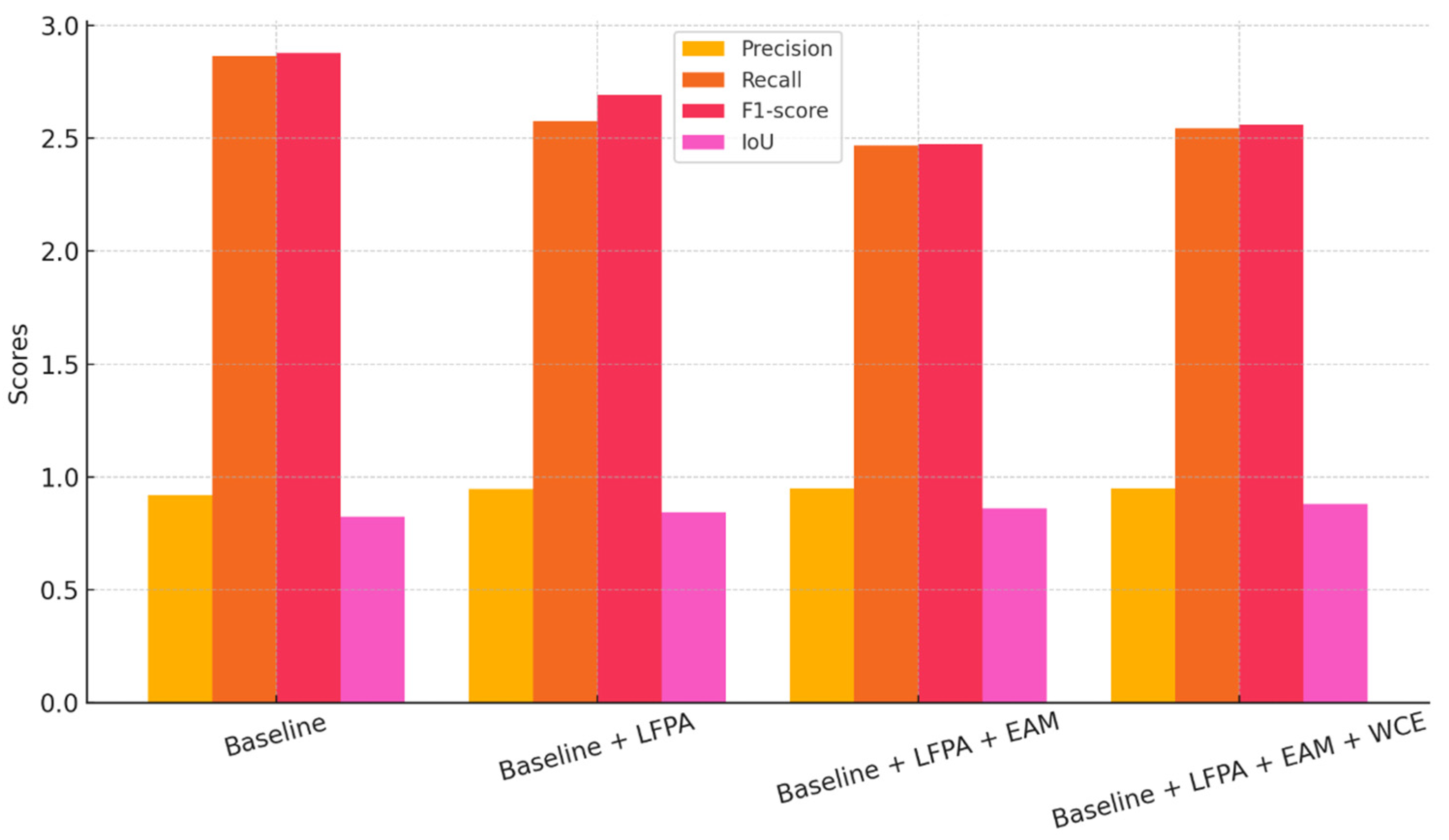
3.2. Ablation Experiment
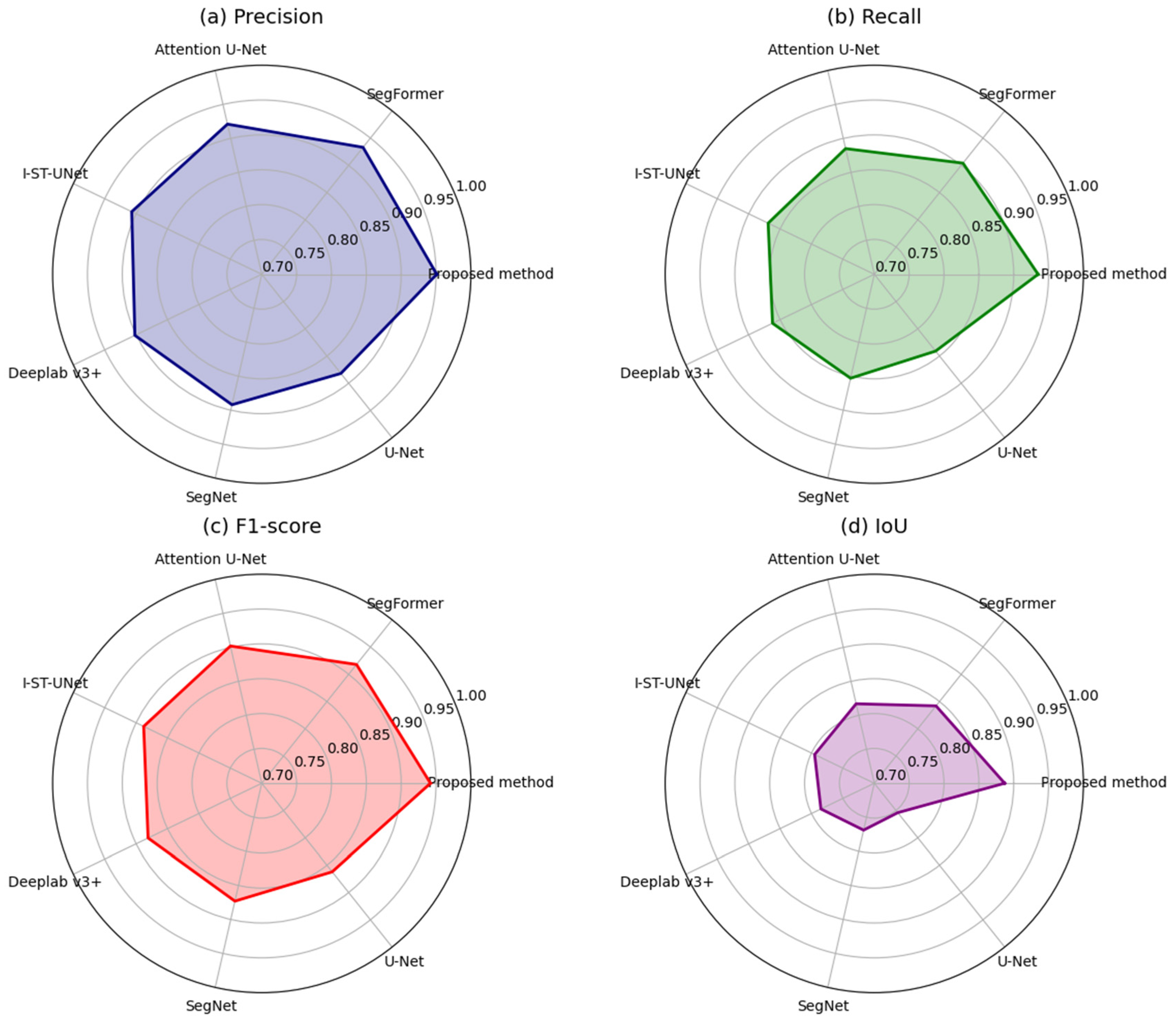
3.3. Damage Pixel-Wise Identification Quantitative Assessment
- (1)
- U-Net and SegNet are widely recognized baseline architectures in semantic segmentation, known for their simplicity, efficiency, and extensive adoption in structural damage identification tasks. Their inclusion enables benchmarking against foundational approaches commonly used in the automated detection and pixel-wise delineation of cracks and other defects in concrete and other infrastructure surfaces.
- (2)
- DeepLab v3+ represents a more advanced and high-performing segmentation model that incorporates atrous spatial pyramid pooling (ASPP), enabling effective multi-scale context learning. It is frequently employed in structural damage detection tasks, particularly in scenarios involving complex surface textures or the need to capture fine-scale crack patterns and intricate defect geometries.
- (3)
- Attention U-Net integrates attention mechanisms to enhance feature representation and selectively focus on relevant damage regions, improving segmentation accuracy in cluttered or noisy environments. This makes it a strong candidate for comparison in structural damage localization tasks, where distinguishing cracks or defects from background textures is critical for reliable assessment.
- (4)
- I-ST-UNet is selected as a representative of recent convolutional network advancements due to its ability to capture intricate spatial hierarchies through improved skip connections and multi-scale feature integration. Its architecture is particularly well-suited for structural damage segmentation, where the cracks and surface defects often exhibit varying shapes and scales that benefit from enhanced contextual representation and spatial consistency.
- (5)
- SegFormer exemplifies the transformer-based paradigm in semantic segmentation, offering strong global context modeling with lightweight efficiency. Its hierarchical design and attention-based encoding enable robust performance in complex visual environments. This makes it highly relevant for structural damage detection tasks, where cracks may appear subtle or fragmented across noisy concrete surfaces, requiring powerful long-range dependency modeling for accurate delineation.
3.4. Evaluate Damage Identification Performance Under Different Levels of Noises
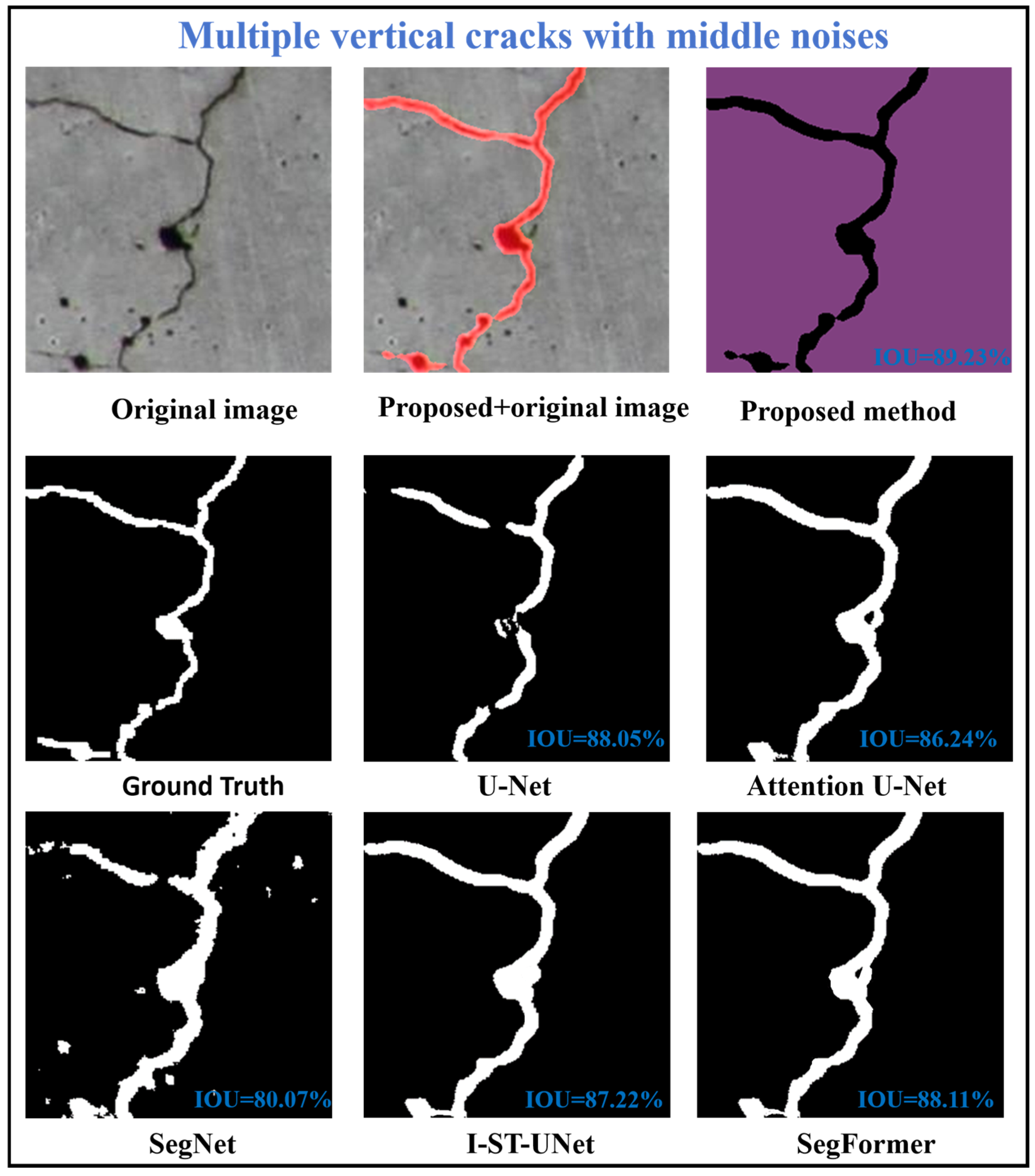
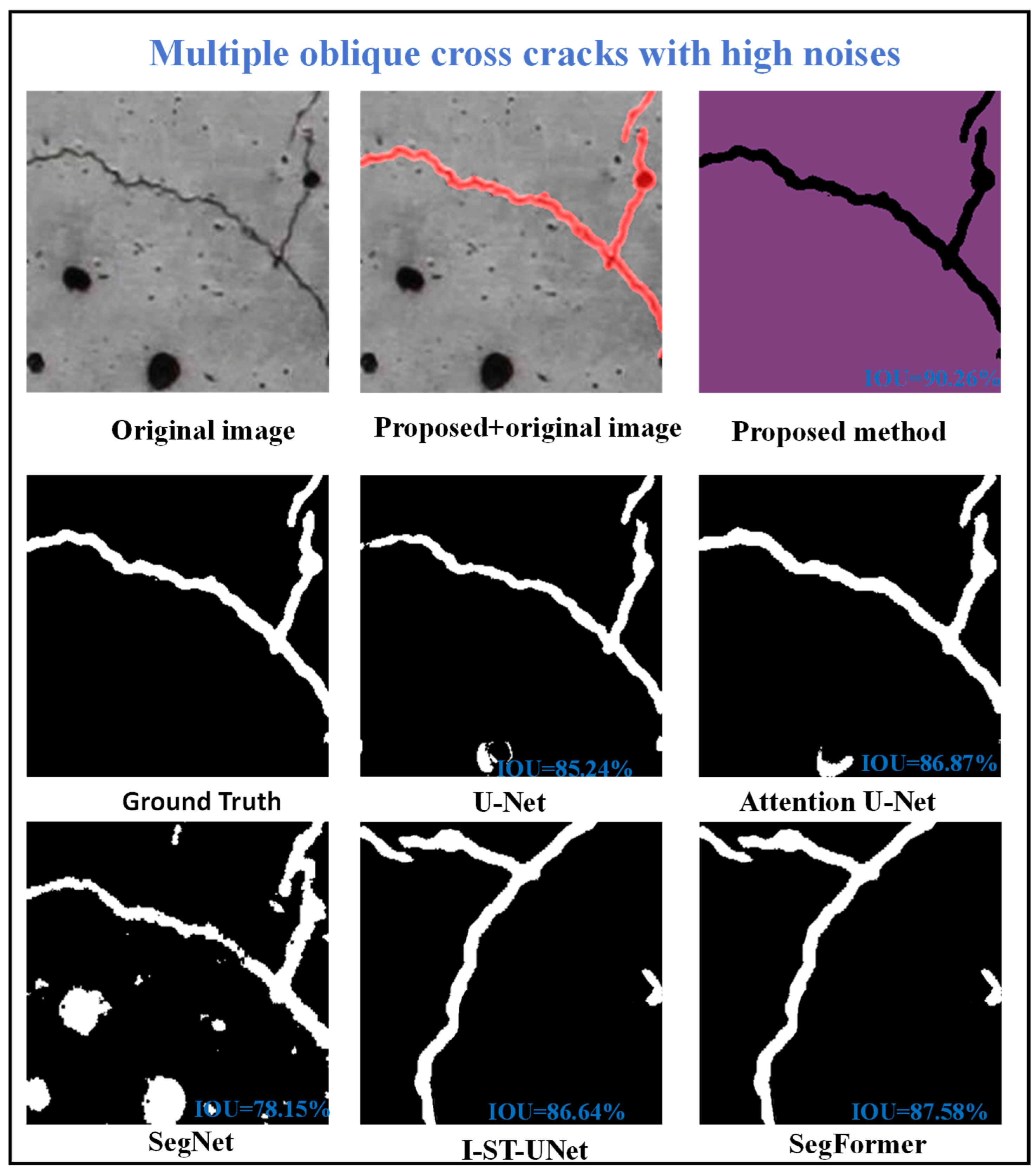
3.5. Comparison of Identification Effects Under Different Complex Damage Forms
4. Discussions
4.1. Analysis of the Advantages and Disadvantages of the Proposed Method
4.2. Combination of LiDAR and Vision for Structural Damage Identification
4.3. Structural Damage Assessment and Diagnosis
4.4. Advantages and Disadvantages of the Proposed Method
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Liu, X.; Li, Z.; Sun, L.; Khailah, E.Y.; Wang, J.; Lu, W.; Yahya, E.; Wang, J.; Lu, W. A Critical Review of Statistical Model of Dam Monitoring Data. J. Build. Eng. 2023, 80, 108106. [Google Scholar] [CrossRef]
- Yuan, D.; Gu, C.; Wei, B.; Qin, X.; Xu, W. A High-Performance Displacement Prediction Model of Concrete Dams Integrating Signal Processing and Multiple Machine Learning Techniques. Appl. Math. Model. 2022, 112, 436–451. [Google Scholar] [CrossRef]
- Su, H.; Wen, Z.; Wang, F.; Hu, J. Dam Structural Behavior Identification and Prediction by Using Variable Dimension Fractal Model and Iterated Function System. Appl. Soft Comput. J. 2016, 48, 612–620. [Google Scholar] [CrossRef]
- Wei, B.; Chen, L.; Li, H.; Yuan, D.; Wang, G. Optimized Prediction Model for Concrete Dam Displacement Based on Signal Residual Amendment. Appl. Math. Model. 2020, 78, 20–36. [Google Scholar] [CrossRef]
- Liu, D.; Chen, J.; Hu, D.; Zhang, Z. Dynamic BIM-Augmented UAV Safety Inspection for Water Diversion Project. Comput. Ind. 2019, 108, 163–177. [Google Scholar] [CrossRef]
- Duan, Z.; Liu, J.; Ling, X.; Zhang, J.; Liu, Z. ERNet: A Rapid Road Crack Detection Method Using Low-Altitude UAV Remote Sensing Images. Remote Sens. 2024, 16, 1741. [Google Scholar] [CrossRef]
- Zhang, F.; Hu, Z.; Fu, Y.; Yang, K.; Wu, Q.; Feng, Z. A New Identification Method for Surface Cracks from UAV Images Based on Machine Learning in Coal Mining Areas. Remote Sens. 2020, 12, 1571. [Google Scholar] [CrossRef]
- Zhao, S.; Kang, F.; Li, J. Concrete Dam Damage Detection and Localisation Based on YOLOv5s-HSC and Photogrammetric 3D Reconstruction. Autom. Constr. 2022, 143, 104555. [Google Scholar] [CrossRef]
- Zhu, Y.; Tang, H. Automatic Damage Detection and Diagnosis for Hydraulic Structures Using Drones and Artificial Intelligence Techniques. Remote Sens. 2023, 15, 615. [Google Scholar] [CrossRef]
- Ajayi, O.G.; Palmer, M.; Salubi, A.A. Modelling Farmland Topography for Suitable Site Selection of Dam Construction Using Unmanned Aerial Vehicle (UAV) Photogrammetry. Remote Sens. Appl. Soc. Environ. 2018, 11, 220–230. [Google Scholar] [CrossRef]
- Liu, Y.; Yeoh, J.K.W.; Chua, D.K.H. Deep Learning–Based Enhancement of Motion Blurred UAV Concrete Crack Images. J. Comput. Civ. Eng. 2020, 34, 4020028. [Google Scholar] [CrossRef]
- Deng, L.; Yuan, H.; Long, L.; Chun, P.J.; Chen, W.; Chu, H. Cascade Refinement Extraction Network with Active Boundary Loss for Segmentation of Concrete Cracks from High-Resolution Images. Autom. Constr. 2024, 162, 105410. [Google Scholar] [CrossRef]
- Rau, J.Y.; Hsiao, K.W.; Jhan, J.P.; Wang, S.H.; Fang, W.C.; Wang, J.L. Bridge Crack Detection Using Multi-Rotary UAV and Object-Base Image Analysis. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, 42, 311–318. [Google Scholar] [CrossRef]
- Mohammadi, M.; Rashidi, M.; Mousavi, V.; Karami, A.; Yu, Y.; Samali, B. Quality Evaluation of Digital Twins Generated Based on Uav Photogrammetry and Tls: Bridge Case Study. Remote Sens. 2021, 13, 3499. [Google Scholar] [CrossRef]
- Peng, X.; Zhong, X.; Zhao, C.; Chen, A.; Zhang, T. A UAV-Based Machine Vision Method for Bridge Crack Recognition and Width Quantification through Hybrid Feature Learning. Constr. Build. Mater. 2021, 299, 123896. [Google Scholar] [CrossRef]
- Feroz, S.; Dabous, S.A. Uav-Based Remote Sensing Applications for Bridge Condition Assessment. Remote Sens. 2021, 13, 1809. [Google Scholar] [CrossRef]
- Waqas, A.; Kang, D.; Cha, Y.J. Deep Learning-Based Obstacle-Avoiding Autonomous UAVs with Fiducial Marker-Based Localization for Structural Health Monitoring. Struct. Health Monit. 2023, 23, 971–990. [Google Scholar] [CrossRef]
- Mondal, T.G.; Chen, G. Artificial Intelligence in Civil Infrastructure Health Monitoring—Historical Perspectives, Current Trends, and Future Visions. Front. Built Environ. 2022, 8, 1007886. [Google Scholar] [CrossRef]
- Khaloo, A.; Lattanzi, D.; Jachimowicz, A.; Devaney, C. Utilizing UAV and 3D Computer Vision for Visual Inspection of a Large Gravity Dam. Front. Built Environ. 2018, 4, 31. [Google Scholar] [CrossRef]
- Zhang, Y.; Chow, C.L.; Lau, D. Artificial Intelligence-Enhanced Non-Destructive Defect Detection for Civil Infrastructure. Autom. Constr. 2025, 171, 105996. [Google Scholar] [CrossRef]
- Gao, Y.; Cao, H.; Cai, W.; Zhou, G. Pixel-level road crack detection in UAV remote sensing images based on ARD-Unet. Measurement 2023, 219, 113252. [Google Scholar] [CrossRef]
- Liu, F.; Wang, L. UNet-based model for crack detection integrating visual explanations. Constr. Build. Mater. 2022, 322, 126265. [Google Scholar] [CrossRef]
- Zheng, X.; Zhang, S.; Li, X.; Li, G.; Li, X. Lightweight bridge crack detection method based on segnet and bottleneck depth-separable convolution with residuals. IEEE Access 2021, 9, 161649–161668. [Google Scholar] [CrossRef]
- Zhang, X.; Rajan, D.; Story, B. Concrete crack detection using context-aware deep semantic segmentation network. Comput.-Aided Civ. Infrastruct. Eng. 2019, 34, 951–971. [Google Scholar] [CrossRef]
- Shen, Y.; Yu, Z.; Li, C.; Zhao, C.; Sun, Z. Automated detection for concrete surface cracks based on Deeplabv3+ BDF. Buildings 2023, 13, 118. [Google Scholar] [CrossRef]
- Pan, Z.; Zhang, X.; Jiang, Y.; Li, B.; Golsanami, N.; Su, H.; Cai, Y. High-precision segmentation and quantification of tunnel lining crack using an improved DeepLabV3+. Undergr. Space 2025, 22, 96–109. [Google Scholar] [CrossRef]
- Zhang, H.; Zhang, A.A.; Dong, Z.; He, A.; Liu, Y.; Zhan, Y.; Wang, K.C.P. Robust semantic segmentation for automatic crack detection within pavement images using multi-mixing of global context and local image features. IEEE Trans. Intell. Transp. Syst. 2024, 25, 11282–11303. [Google Scholar] [CrossRef]
- Luo, H.; Li, J.; Cai, L.; Wu, M. STrans-YOLOX: Fusing swin transformer and YOLOX for automatic pavement crack detection. Appl. Sci. 2023, 13, 1999. [Google Scholar] [CrossRef]
- Ju, X.; Zhao, X.; Qian, S. TransMF: Transformer-based multi-scale fusion model for crack detection. Mathematics 2022, 10, 2354. [Google Scholar] [CrossRef]
- Ali, L.; Alnajjar, F.; Al Jassmi, H.; Gocho, M.; Khan, W.; Serhani, M.A. Performance evaluation of deep CNN-based crack detection and localization techniques for concrete structures. Sensors 2021, 21, 1688. [Google Scholar] [CrossRef]
- Xu, X.; Zhao, M.; Shi, P.; Ren, R.; He, X.; Wei, X.; Yang, H. Crack detection and comparison study based on faster R-CNN and mask R-CNN. Sensors 2022, 22, 1215. [Google Scholar] [CrossRef]
- Li, R.; Yu, J.; Li, F.; Yang, R.; Wang, Y.; Peng, Z. Automatic bridge crack detection using Unmanned aerial vehicle and Faster R-CNN. Constr. Build. Mater. 2023, 362, 129659. [Google Scholar] [CrossRef]
- Ali, R.; Chuah, J.H.; Abu Talip, M.S.; Mokhtar, N.; Shoaib, M.A. Structural crack detection using deep convolutional neural networks. Autom. Constr. 2022, 133, 103989. [Google Scholar] [CrossRef]
- Zhang, E.; Shao, L.; Wang, Y. Unifying transformer and convolution for dam crack detection. Autom. Constr. 2023, 147, 104712. [Google Scholar] [CrossRef]
- Savino, P.; Graglia, F.; Scozza, G.; Di Pietra, V. Automated Corrosion Surface Quantification in Steel Transmission Towers Using UAV Photogrammetry and Deep Convolutional Neural Networks. Comput. Civ. Infrastruct. Eng. 2025, 40, 2050–2070. [Google Scholar] [CrossRef]
- Ai, D.; Jiang, G.; Lam, S.K.; He, P.; Li, C. Automatic Pixel-Wise Detection of Evolving Cracks on Rock Surface in Video Data. Autom. Constr. 2020, 119, 103378. [Google Scholar] [CrossRef]
- Chu, H.; Wang, W.; Deng, L. Tiny-Crack-Net: A Multiscale Feature Fusion Network with Attention Mechanisms for Segmentation of Tiny Cracks. Comput. Civ. Infrastruct. Eng. 2022, 37, 1914–1931. [Google Scholar] [CrossRef]
- Sony, S.; Laventure, S.; Sadhu, A. A Literature Review of Next-Generation Smart Sensing Technology in Structural Health Monitoring. Struct. Control Health Monit. 2019, 26, e2321. [Google Scholar] [CrossRef]
- Perez Jimeno, S.; Capa Salinas, J.; Perez Caicedo, J.A.; Rojas Manzano, M.A. An Integrated Framework for Non-Destructive Evaluation of Bridges Using UAS: A Case Study. J. Build. Pathol. Rehabil. 2023, 8, 80. [Google Scholar] [CrossRef]
- Poudel, R.P.K.; Liwicki, S.; Cipolla, R. Fast-SCNN. arXiv 2019, arXiv:1902.04502. [Google Scholar]
- Liu, Z.; Cao, Y.; Wang, Y.; Wang, W. Computer Vision-Based Concrete Crack Detection Using U-Net Fully Convolutional Networks. Autom. Constr. 2019, 104, 129–139. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Tang, W.; Zou, D.; Yang, S.; Shi, J.; Dan, J.; Song, G. A Two-Stage Approach for Automatic Liver Segmentation with Faster R-CNN and DeepLab. Neural Comput. Appl. 2020, 32, 6769–6778. [Google Scholar] [CrossRef]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention U-Net: Learning Where to Look for the Pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Zhang, H.; Ma, L.; Yuan, Z.; Liu, H. Automation in Construction Enhanced Concrete Crack Detection and Proactive Safety Warning Based on I-ST-UNet Model. Autom. Constr. 2024, 166, 105612. [Google Scholar] [CrossRef]
- Li, H.; Zhang, H.; Zhu, H.; Gao, K.; Liang, H.; Yang, J. Automatic Crack De-tection on Concrete and Asphalt Surfaces Using Semantic Segmentation Network with Hierarchical Transformer. Eng. Struct. 2024, 307, 117903. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Component | Specification |
|---|---|
| UAV Model | DJI Matrice 350 RTK |
| Configuration | Quadcopter (4 rotors), foldable arms, integrated flight controller + RTK module |
| Payload Capacity | Up to 2.73 kg (based on 9.2 kg max takeoff weight and ~6.47 kg drone + battery) |
| Flight Time | Up to 55 min (no payload); ~30–35 min (with payload, depending on weight) |
| Max Speed | 23 m/s (≈83 km/h) |
| GNSS System | GPS + GLONASS + BeiDou + Galileo (supports RTK positioning) |
| Hover Accuracy | ±0.1 m (vertical with RTK); ±0.1 m (horizontal with RTK); ±0.5 m (GNSS vertical) |
| Control Range | Up to 20 km (with DJI RC Plus controller and O3 Enterprise transmission) |
| Operating Temp. | −20 °C to 50 °C |
| Camera Model | DJI Zenmuse Z30 |
| Sensor Type | 1/2.8” CMOS, 2.13 MP |
| Zoom Capability | 30× optical zoom, 6× digital zoom |
| Focal Length | 4.3–129.0 mm (f/1.6–f/4.7) |
| Stabilization | 3-axis gimbal with optical image stabilization |
| Video Output | 1920 × 1080 (Full HD), 30 FPS |
| Models | Precision | Recall | F1 Score | IoU/% |
|---|---|---|---|---|
| Baseline (Improved Fast-SCNN) | 0.920 | 0.864 | 0.876 | 82.41 |
| Baseline + LFPA module | 0.947 | 0.875 | 0.893 | 84.52 |
| Baseline + LFPA + EAM | 0.951 | 0.886 | 0.900 | 86.11 |
| Baseline + LFPA + EAM + WCE | 0.949 | 0.892 | 0.906 | 87.92 |
| Algorithm | FPS |
|---|---|
| Proposed method | 56.31 |
| U-Net | 16.27 |
| Attention U-Net | 14.39 |
| SegNet | 18.58 |
| Deeplab v3+ | 16.53 |
| I-ST-UNet | 12.64 |
| SegFormer | 11.68 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, F.; Gu, C. Surface Damage Detection in Hydraulic Structures from UAV Images Using Lightweight Neural Networks. Remote Sens. 2025, 17, 2668. https://doi.org/10.3390/rs17152668
Han F, Gu C. Surface Damage Detection in Hydraulic Structures from UAV Images Using Lightweight Neural Networks. Remote Sensing. 2025; 17(15):2668. https://doi.org/10.3390/rs17152668
Chicago/Turabian StyleHan, Feng, and Chongshi Gu. 2025. "Surface Damage Detection in Hydraulic Structures from UAV Images Using Lightweight Neural Networks" Remote Sensing 17, no. 15: 2668. https://doi.org/10.3390/rs17152668
APA StyleHan, F., & Gu, C. (2025). Surface Damage Detection in Hydraulic Structures from UAV Images Using Lightweight Neural Networks. Remote Sensing, 17(15), 2668. https://doi.org/10.3390/rs17152668