1. Introduction
Polarimetric synthetic aperture radar (PolSAR) is a multi-channel, multi-parameter radar imaging system that combines the all-weather, full-time capabilities of traditional synthetic aperture radar (SAR) with enhanced perception of ground target structures, shapes, and scattering characteristics through electromagnetic wave polarization properties [
1]. PolSAR has demonstrated value in urban planning, agricultural monitoring, and geological exploration [
2,
3,
4]. Remote sensing technology, with its wide coverage, short update cycle, and low acquisition cost, has become essential for large-scale surface observation and high-precision classification. For instance, multi-temporal interferometric synthetic aperture radar (MTInSAR) has been used to monitor urban infrastructure health [
5]. Furthermore, PolSAR image classification techniques facilitate pixel-level classification, providing vital support for applications such as land use and dynamic change monitoring.
Traditional PolSAR image classification methods rely on two main theoretical approaches: polarimetric target decomposition and mathematical transformation [
6]. Polarimetric decomposition analyzes cross-polarization correlation terms to extract deeper polarimetric features. Common methods include the Yamaguchi [
7], Freeman [
8], and Cloude [
9] decompositions, as well as statistical theories like Wishart’s [
10],
K-distribution [
11], and
U-distribution [
12]. Mathematical transformation extracts physically meaningful features by computing the scattering matrix
S, covariance matrix
C, and coherency matrix
T. With advances in artificial intelligence, machine learning methods such as support vector machine (SVM) [
13,
14,
15], Bayesian methods [
16], and k-nearest neighbors [
17] have become widely used in PolSAR classification. However, traditional approaches still face limitations with complex PolSAR data, resulting in relatively lower classification accuracy.
In recent years, significant progress has been made in the field of deep learning across various domains. These methods employ a data-driven approach for nonlinear fitting, eliminating the need for complex mathematical modeling and manual parameter tuning. They also shift the computational burden from the prediction phase to the training phase, enhancing model timeliness. With ongoing improvements in SAR sensor and remote-sensing technologies, deep learning has found successful applications in PolSAR image classification. These methods can automatically learn deep features, efficiently extract and classify them, and outperform traditional techniques in handling complex data. However, annotating PolSAR images requires specialized domain knowledge and high annotation density, making it challenging to acquire high-quality labeled data. Consequently, the limited availability of labeled samples remains a major challenge for deep learning methods in PolSAR image classification.
To address the issue of sample scarcity in PolSAR images, research often employs shallow network structures [
18]. For example, the real-valued convolutional neural network (RV-CNN) method, based on a two-layer 2D convolution (2DConv), has achieved pixel-level classification of PolSAR images [
19]. However, the simplicity of this network structure results in suboptimal classification performance. As a result, deep learning research has explored various techniques to improve accuracy. Liu et al. [
20] introduced a neural architecture search method that automatically discovers effective features, improving classification results. Zhang et al. [
21] enriched the dataset, using multiple feature-extraction methods, increasing the data volume. To address the “dimension disaster” caused by multiple feature-extraction schemes and multi-temporal data, a feature compression model was proposed, enabling effective PolSAR image classification. Shang et al. [
22] utilized ghost convolution for multi-scale feature extraction, reducing redundant information, and they combined it with a mean-variance coordinated attention mechanism to enhance sensitivity to spatial and local pixel information. Hua et al. [
23] introduced a contrastive learning method grounded in a fully convolutional network, utilizing multi-modal features of identical pixels to classify PolSAR images.
Phase information is a distinctive feature of PolSAR images, crucial for applications such as object classification and recognition. Complex-valued networks, by using complex-valued filters, activation functions, and other components, process complex input data, capturing both amplitude and phase information. Several studies have examined the effectiveness of complex-valued networks in PolSAR image classification, demonstrating that incorporating both amplitude and phase information yields better performance than real-valued networks [
24,
25]. The complex-valued convolutional neural network (CV-CNN) method, based on two-layer complex-valued 2DConv, further improved classification accuracy [
26]. Attention mechanisms enhance inter-channel dependencies by managing complex data and extracting key features, thus boosting classification accuracy [
27]. However, 2DConv can only process each image channel individually and does not effectively exploit the correlations between different polarimetric information in PolSAR images. In contrast, 3D convolution (3DConv) integrates height, width, depth, and channel information, enabling simultaneous computation across all channels, making it a more appropriate convolution method to combine channel context information. As a result, the shallow-to-deep feature fusion network (SDF2Net), which employs a 3D complex-valued network from shallow to deep layers, achieves superior performance in PolSAR image classification [
28,
29].
Vision transformer (ViT) has gained widespread attention in areas such as computer vision, remote sensing, and earth observation, due to its ability to capture long-range dependencies [
30,
31,
32]. Research has shown that ViT holds great promise for PolSAR classification, particularly with ViT-based network frameworks that significantly improve the performance of both supervised and unsupervised learning classification models [
33,
34,
35]. Nonetheless, compared to traditional convolutional neural networks (CNNs), ViT architectures require a larger number of labeled samples, making it difficult to achieve robustness in PolSAR scenarios with limited labeled data. The introduction of hybrid network architectures helps alleviate the aforementioned problem. A multi-scale sequential network based on attention mechanisms increases multi-scale spatial information between pixels through spatial sequences, thereby more stably improving model performance and overall classification accuracy [
36]. A complex-valued 2D–3D hybrid model incorporating the coordinate attention (CA) mechanism has shown significant advantages in extracting polarimetric features [
37,
38]. Notably, on several benchmark datasets hybrid network architectures combining CNN and ViT outperform single ViT or CNN-based deep learning methods in classification performance. For instance, PolSARFormer merges 2D/3D CNN and local window attention to effectively reduce the demand for a large number of PolSAR image labeled samples [
39]. The CNN–ViT hybrid model, by combining local and global features, demonstrates superior classification performance, particularly in handling the rich information present in PolSAR images [
40]. The mixed convolutional parallel transformer model significantly improves both classification accuracy and computational speed [
41], while Zhang et al. enhanced classification performance by effectively utilizing global features [
42]. The 3-D convolutional vision transformer (3-D-Conv-ViT) [
43] combines 3DConv and ViT to describe the relationships between different polarimetric direction matrices, thereby effectively applying it to PolSAR image classification and change detection.
However, traditional real-valued ViT fails to fully exploit the complex nature of PolSAR data, limiting its performance in PolSAR image classification tasks. To address this issue, researchers have proposed new complex-valued network architectures. HybridCVNet combines CV-CNN and complex-valued ViT (CV-ViT) technologies to fully leverage the internal dependencies of the data, thereby effectively improving PolSAR image classification accuracy [
44]. The complex-valued multi-scale attention vision transformer (CV-MsAtViT) method, built upon the CV-ViT, incorporates multi-scale 3D convolution kernels, effectively extracting spatial, polarimetric, and spatial–polarimetric features from PolSAR data, and, thus, demonstrates excellent classification performance [
45]. However, these methods also highlight the increasing complexity of network structures. While these networks are effective in extracting features and achieving high classification accuracy, there is still a contradiction between the complex network structure and the limited availability of labeled data in PolSAR image classification. Furthermore, both single ViT-based networks and hybrid networks involving ViT have numerous parameters, which increases the risk of overfitting. In contrast, traditional CNN methods tend to have an advantage in this regard. Therefore, the core challenge is to design a complex-valued network architecture that does not rely on ViT but can still achieve high-precision PolSAR image classification effectively, accurately, and robustly, especially when labeled data is scarce.
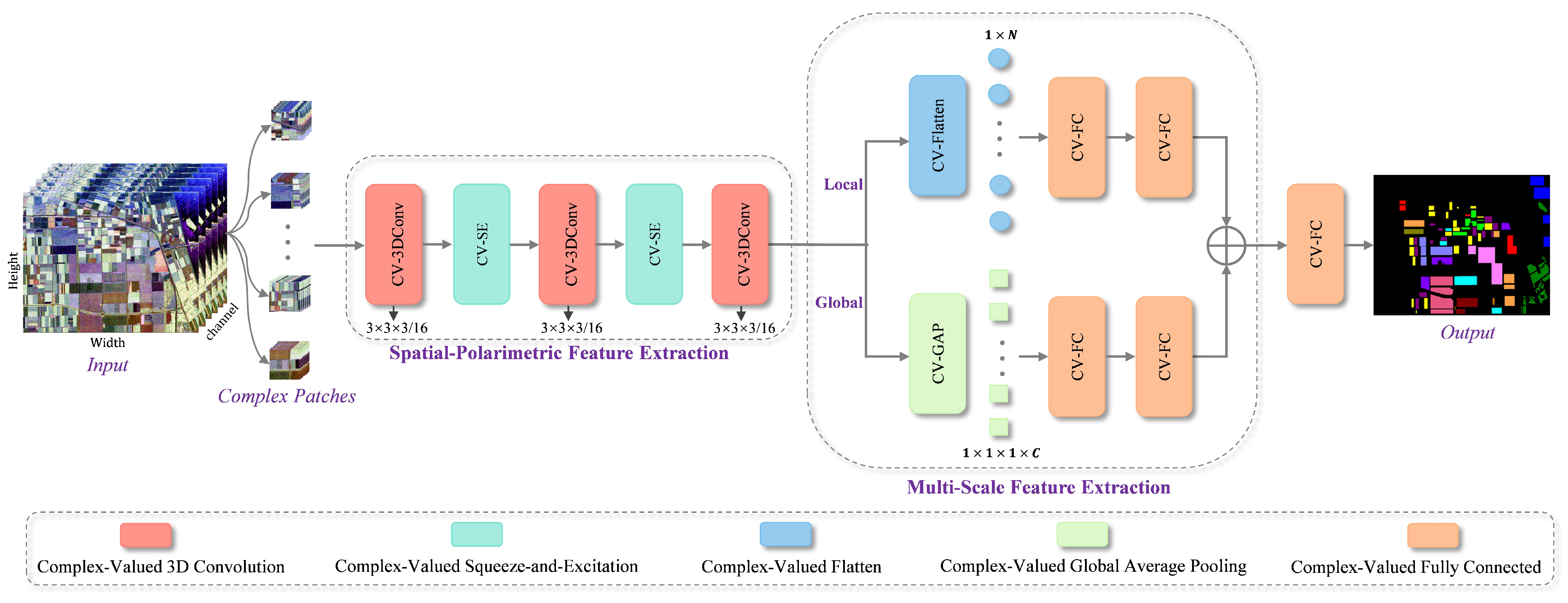
This paper introduces multi-scale feature extraction (MSFE), which utilizes a 3D complex-valued network for the classification of PolSAR images. Unlike the existing hybrid methods, this approach designs a multi-scale feature-extraction network based on CV-3DConv, and its parallel branch structure is used for modeling the multi-scale receptive field, capturing more discriminative features at different levels, which further enhances the classification performance of PolSAR images. The key contributions of this work are summarized as follows:
Based on the characteristics of PolSAR images, a 3D complex-valued network combining CV-3DConv and complex-valued squeeze-and-excitation (CV-SE) is proposed, which effectively extracts spatial and polarimetric dimensions features that include both amplitude and phase information from PolSAR images, resulting in more representative and discriminative complex-valued features.
Through the parallel branching structure, the multi-scale receptive field modeling of global and local features is realized. Global features are used to extract the overall semantic information of the image, while local features effectively guide the network in capturing regional semantic information, thus effectively balancing global and local spatial consistency.
Our experimental results show that MSFE demonstrates significant advantages in both classification accuracy and robustness.
The paper is structured as follows:
Section 2 introduces the MSFE method;
Section 3 presents and analyzes comparative experimental results on three PolSAR images;
Section 4 provides ablation studies and an analysis of the model’s generalization capability; and
Section 5 concludes this work.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}