1. Introduction
Enhancing the visibility of remote sensing imagery through dehazing is critical for accurate environmental monitoring and timely disaster response. However, turbid atmospheric substances—such as haze, clouds, and rain—often degrade image quality, leading to reduced scene clarity. This image degradation not only affects visual perception but also hinders high-level analysis tasks, such as object detection and scene classification. Traditional dehazing techniques typically rely on physical models or empirical assumptions [
1,
2,
3,
4]. Among them, the widely used atmospheric scattering model (ASM) is formulated as follows:
where
x denotes the pixel location.
is the observed intensity in the hazy image, while
is the scene radiance under clear conditions.
A represents the global atmospheric light, and
is the transmission map, quantifying the proportion of light that reaches the sensor. This model serves as the foundation for many traditional dehazing algorithms. While effective in certain scenarios, prior-based methods often lack adaptability to diverse scenes, frequently resulting in over-enhanced contrast or visual artifacts such as halos and color distortions. Consequently, they are insufficient for handling the complexity and variability inherent in dynamic haze environments.
In recent years, remote sensing image dehazing technology has made significant progress with deep learning techniques, especially the use of convolutional neural networks (CNNs) [
5,
6,
7] and Transformer-based models [
8,
9,
10,
11,
12,
13,
14,
15,
16,
17]. CNNs can automatically extract local features, while Transformers improve performance by effectively modeling long-range dependencies between image regions. Unlike CNNs (which have limitations in capturing these dependencies) and Transformers (which are computationally intensive due to their complexity), Mamba [
18] is a state-space model (SSM)-based architecture that has garnered significant attention for its efficacy in modeling long-range dependencies and capturing global contextual information. Efficient Vision Mamba [
19] (EfficientViM) is one of the best models based on the Hidden State Mixer–State Space Dual (HSM-SSD) architecture, which improves on the State Space Dual (SSD) by effectively capturing global dependencies while achieving high performance at a lower computational cost. Given these advantages, EfficientViM presents a highly promising architecture to serve as a baseline for our work. However, as a general-purpose vision backbone network, directly applying it to the ill-posed dehazing problem is often suboptimal, as it lacks domain-specific mechanisms to explicitly handle the physical degradation process. This motivates us to explore how to adapt and enhance this powerful architecture for remote sensing dehazing task.
Meanwhile, most of these learning-based methods are end-to-end neural networks, independent of the atmospheric scattering model, but some researchers are currently combining physical models with neural networks for remote sensing dehazing. AU-Net [
20] is a notable recent work that adopts a two-stage architecture based on physical principles. First, it estimates the atmospheric scattering and transmission maps to generate a rough dehazed image; then, it is refined using an asymmetric U-Net in the second stage. However, this method uses a physical model to preprocess the image in the first stage, and applies a single A value and a smooth T map to a large scene, which produces inconsistent restoration effects in areas of different depths and details, resulting in poor generalization, and cannot solve the entanglement problem with residual physical artifacts in the multi-scale information feature extraction stage in restoring remote sensing fog images.
To address the challenge of capturing multi-scale global features while maintaining physical interpretability, we propose the Multi-scale Efficient ViM with Physical Decoupling Block (ScaleViM-P). This module integrates three key designs into a unified block: it employs a physical module to decouple haze effects at each feature scale, utilizes multiple convolution kernels of varying sizes to extract rich spatial features, and leverages EfficientViM as its core to effectively capture global context and integrate this information.
Traditional skip connections usually only perform simple feature concatenation or addition, which has limited ability to restore high-frequency details and color fidelity that are severely damaged by fog. We observe that the contents of clear and degraded images can be effectively separated by exchanging spectrum and phase through the Fourier transform, which suggests that feature information may be more easily distinguished and restored in the frequency domain. On this basis, we design a Frequency Domain Module (FDM) and combine it with channel and position attention mechanisms to form a dual domain fusion (DD Fusion) module. This module replaces the traditional skip connection, solves the information loss problem usually generated during feature bridging, and improves the retention rate of details.
In summary, this paper presents an innovative Multi-scale EfficientViM network with Physical Decoupling and Dual-Domain Fusion (ScaleViM-PDD). First, a physical module is employed to estimate A and T, decouple haze effects, and perform preliminary dehazing based on the atmospheric scattering model, thereby simplifying the feature space. Then, ScaleViM is used to capture global contextual dependencies across scales. Finally, to recover subtle visual details—especially color—we propose a frequency-aware FDM block, combined with attention mechanisms, to construct the DD Fusion module. This module effectively replaces conventional skip connections and enables deeper integration of spatial and frequency information.
In summary, this paper offers the following key contributions:
We propose an innovative remote sensing dehazing network ScaleViM-PDD, which integrates state-space models, physical modules, and frequency domain representation, achieving SOTA performance compared with existing methods.
We design the ScaleViM-P module, a novel multi-scale state-space module with physical interpretability. We further improve the performance by combining physical structure priors with the optimized Multi-scale EfficientViM. We show strong generalization capabilities across different remote sensing datasets.
We designed the DD Fusion module to go beyond traditional image restoration by emphasizing frequency domain features and enabling more effective integration of spatial and frequency representations for enhanced remote sensing haze removal.
Results indicate that our method outperforms current techniques, ScaleViM-PDD performs well in multiple remote sensing image dehazing tasks, and achieves satisfactory visualization effects in multiple complex scenes, such as military, construction, and farmland, which have obvious advantages and provide a more effective solution for practical applications. Code is available at
https://github.com/Aaronwangz/ScaleViM-PDD (accessed on 10 July 2025).
3. Method
First, we briefly review EfficientViM [
19], the core of which is to effectively capture global dependencies through the HSM-SSD layer.
Figure 1b describes the main framework of EfficientViM [
19], and
Figure 1a is the pseudo code of the HSM-SSD layer with a single head design. HSM-SSD uses a shared global hidden state
h to perform channel mixing (including gating and output projection), which is the fourth step of
Figure 1a, operating on the reduced potential array
h, thus lowering computational cost while enhancing overall model performance.
Our proposed ScaleViM-PDD network architecture is based on EfficientViM [
19] and makes targeted improvements to the inherent limitations of the original model in image dehazing applications. Specifically, we aim to address three key issues: (1) the model lacks physical interpretability, resulting in incomplete dehazing; (2) its standard single-scale processing is insufficient to cope with the complex multi-scale characteristics of remote sensing scenes; (3) only processing spatial domain information leads to the loss of frequency domain details. Below, I will introduce the overall architecture of the model ScaleVIM-PDD, as shown in
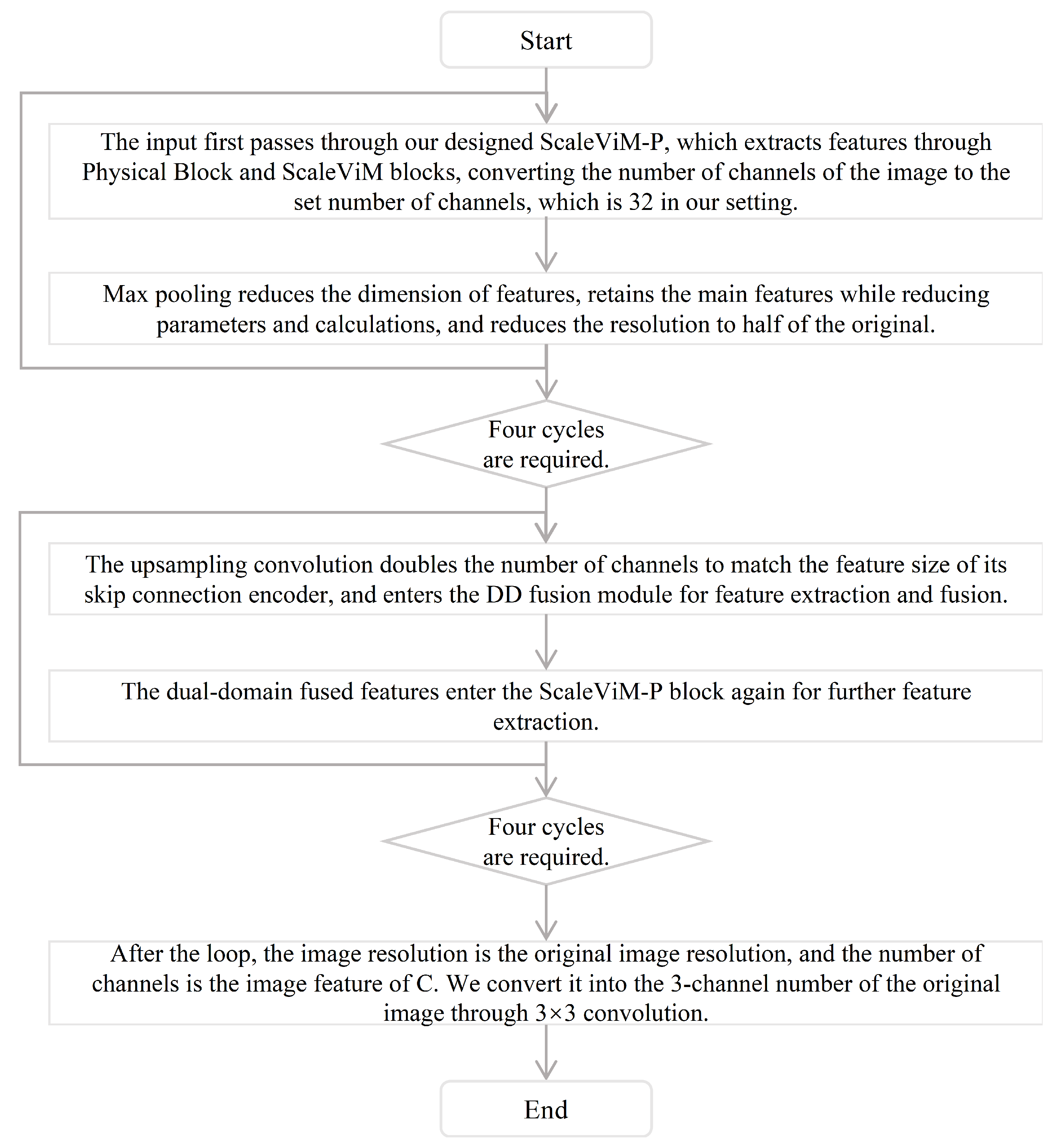
Figure 2. The overall framework is an encoder–decoder structure obtained through four layers of upsampling, four layers of downsampling, and four layers of fusion. Each sampling block is composed of a basic ScaleViM-P, and the fusion layer is composed of DD Fusion. We will introduce these two modules in detail below. In addition, we supplement our algorithm flow chart, as shown in
Figure 3, to better understand the process of the proposed model from input to output.
3.1. Multi-Scale EfficientViM with Physical Decoupling Block
The exploration of state-space model (SSM) architectures for remote sensing dehazing is still limited. While the recently proposed EfficientViM is highly promising due to its efficiency; our preliminary experiments revealed two interconnected challenges when applying it directly. First, as a deep learning model, it lacks physical awareness of the haze formation process, often leading to color distortion and artifacts. Second, this problem is exacerbated by the multi-scale complexity of remote sensing images; a model that cannot fundamentally distinguish haze from scene content will struggle even more to process features correctly across different scales and resolutions.
Therefore, a simple combination approach—like adding a multi-scale design to a deep learning model, or pre-processing with a physical model before feeding into a single-scale network—is insufficient. A truly effective solution demands a module that is simultaneously multi-scale and physically-aware. This is the core motivation for our ScaleViM-P module. It does not just combine these two concepts; it deeply integrates physical Decoupling within the multi-scale feature extraction process at each stage, allowing the network to progressively refine features by removing haze-like components at each level of abstraction.
3.1.1. Multi-Scale EfficientViM
To specifically address the challenge of handling features at varying scales—a key limitation we identified in remote sensing dehazing—we developed a multi-scale front-end for the EfficientViM block. Our Multi-scale EfficientViM module is based on the EfficientViM [
19] architecture and inspired by the famous Inception model [
43]. Specifically, we divide the input image into four branches, each of which is processed using convolution kernels of different scales to extract multi-scale structural feature maps (including 1 × 1, 3 × 3, and 5 × 5 convolution kernels), as well as contour information extracted by the Max-Pooling layer.
Among these operations, the 1 × 1 convolution transforms the channel dimension while preserving spatial resolution, thereby reducing computational complexity, whereas LeakyReLU provides non-linear activation to increase the expressiveness of the network. This combination can effectively extract features at different scales while maintaining the efficiency and non-linear expressiveness of the network. By concatenating the output matrices from different convolution layers along the depth dimension, we obtain a deeper feature matrix that fully captures the multi-level and multi-scale information of the image.
Finally, we adjust the number of channels through a layer of 1 × 1 convolution and pass this feature information to the EfficientViM module for processing. Through an efficient global receptive field, effective information integration is ultimately achieved, providing richer feature representations for subsequent tasks.
3.1.2. Physical Decoupling Block
To tackle the problem of physical unawareness and improve model interpretability, we designed the Physical Decoupling (PD) block. Inspired by C2PNet [
44], we constructed a Physical Decoupling(PD) block based on the atmospheric scattering model. It is derived from the physical model of Equation (
1). We represent the clear image J according to the physical model as follows:
Equation (
2) is obtained by transforming Equation (
1). In Equation (
3), we define
=
for simplicity. The light green part in
Figure 2 is the PB architecture we designed. Prior to estimating the atmospheric light
A and transmittance
T, we employ a 3 × 3 convolution layer for feature extraction, followed sequentially by a Batch Normalization layer and a ReLU activation function. This sequence serves to transform the input tensor across channels while enabling initial feature extraction and integration. Next, the network divides into two branches to estimate atmospheric light and transmittance separately. Given that atmospheric light
A is uniform across the image, we apply global average pooling (Global AvgPool2d) to minimize spatial redundancy and achieve a more reliable estimation.
Unlike atmospheric light, the transmission map shows obvious spatial non-uniformity and detail changes. If global average pooling is used directly, important spatial detail information will be lost. To avoid this problem, we discard the global average pooling operation in the transmittance branch and replace it with a 3 × 3 convolution layer. This choice effectively retains local detail information in the spatial dimension. Furthermore, unlike the 1 × 1 convolution used in the atmospheric light estimation branch, the transmittance estimation branch employs a larger 3 × 3 convolutional kernel to enlarge the receptive field and better capture local contextual information, thereby enabling more accurate transmittance estimation.
3.2. Dual-Domain Fusion
In traditional U-Net architectures, skip connections are employed to bridge feature maps between the encoder and decoder, aiming to preserve high-resolution details. However, these connections often perform simple feature concatenation or addition, a naive fusion strategy that can indiscriminately pass haze-corrupted or redundant features, thereby “polluting” the reconstruction process. While more advanced methods incorporate spatial attention to make this fusion more selective, they remain confined to the spatial domain. This is a fundamental limitation, as haze not only degrades spatial features but also corrupts frequency components, leading to the loss of high-frequency textures and shifts in color fidelity. We subsequently observed, as shown in the
Figure 4, that the Fourier transform can separate image degradation and content to a certain extent, where the degradation is mainly reflected in the amplitude spectrum. In order to enhance the processing of degraded images, we designed the Frequency Domain Module (FDM) and integrated it into our Dual-Domain Fusion (DD Fusion) module in combination with the attention mechanism, aiming to effectively fuse spatial information with frequency domain components, as shown in
Figure 5.
The process begins with input 1 and input 2, each undergoing a 1 × 1 convolution, then passing through Batch Normalization and ReLU activation. This sequence of convolution, normalization, and activation boosts the capacity of the network to capture intricate features. For this reason, we apply the same sequence of operations to the feature maps fed into the spatial and frequency domain processing modules. Next, the feature map enters the Frequency Domain Module (FDM), which is our innovative design. Frequency domain processing helps capture and utilize global information, allowing the network to better understand long-distance dependencies. After frequency domain processing, the feature map is fed into the spatial domain processing block. This block contains channel attention [
45], which aims to strengthen important features between different channels, and position attention [
46], which focuses on important spatial regions. To enhance network robustness and mitigate performance degradation, residual connections are incorporated within the spatial processing block.
Frequency Domain Module
We propose a Frequency Domain Module(FDM) that processes the amplitude
and phase
components separately using 1 × 1 convolutions. Our FDM can learn to accurately locate and correct the damage caused by haze in the amplitude spectrum while preserving the key structural information encoded in the phase spectrum, as shown in the orange block below
Figure 5. Specifically, the input is first processed by a 1 × 1 convolution layer, and then a fast Fourier transform (FFT) is performed to separate the amplitude
and phase
components. The components
and
are processed independently, and then pass through a layer of 1 × 1 convolution layer, a layer of activation function, and a layer of 1 × 1 convolution, as shown in the following formula:
where
and
are the processed amplitude and phase components, respectively. Subsequently, the components
and
are combined to reconstruct the image by applying an inverse fast Fourier transform (IFFT). This operation is mathematically formulated as follows:
where
is the final reconstructed feature map. Finally,
will pass through a layer of 1 × 1 convolution and be added to the residual of the original input to yield the final output.
3.3. Loss Function
The loss function is critical for generating high-quality images. We employ a combination of L1, MSE, and SSIM losses to optimize the output quality. The loss function is defined as follows:
where
denotes the generated image, and
denotes the ground truth image.
5. Ablation Study
To evaluate the individual impact of each component within our framework, we performed an ablation study using the RSID dataset, examining the roles of ScaleViM (Multi-scale EfficientViM), PD (physics-based block), and DD (Dual-Domain Fusion), as well as further analysis of the role of a single PD block and multiple PD blocks, and a further detailed analysis of FDM (Frequency Domain Module). Additionally, we analyzed the specific effects of different loss function combinations on the model. The corresponding PSNR and SSIM scores are listed in
Table 5,
Table 6 and
Table 7, while qualitative comparisons are shown in
Figure 10 and
Figure 11. All experiments followed consistent settings, and the top-performing configurations were used for evaluation.
The basic architecture starts with EfficientViM [
19] as the baseline model. Then, ScaleViM is created by adding different convolution kernels to enable multi-scale processing. Next, the PD block is introduced to incorporate the atmospheric scattering model for initial dehazing. Subsequently, the DD block is employed to enable Dual-Domain Fusion, aiming to enhance detail restoration.
Table 5 presents a comprehensive analysis of the impact of each module—ScaleViM, PD, and DD. Specifically, the multi-scale optimized ScaleViM improves PSNR by 0.52 and SSIM by 0.0012 compared to the baseline. With the addition of the PD block (forming ScaleViM-P), performance further increases by 0.18 in PSNR and 0.0003 in SSIM. Although these gains may appear minor numerically, the visual enhancements, as illustrated in
Figure 10, are substantial. Finally, incorporating the DD block to form ScaleViM-PDD leads to an additional improvement of 0.54 in PSNR and 0.0059 in SSIM over ScaleViM-P. These results clearly demonstrate that each module contributes meaningfully to the overall effectiveness of the framework.
The visual quality evaluation of our ablation experiments is shown above. As shown in
Figure 10b, under haze conditions, the baseline has difficulty in recovering accurate ground truth details, and the output is significantly brighter than the original reference image. These results show that EfficientViM alone is not enough to reconstruct fine-grained features in remote sensing images affected by complex haze.
Figure 10c shows the result after we introduced a multi-scale feature extraction operation, which effectively alleviates the whitening effect. We then introduced a Physical Decoupling block to estimate the atmospheric light A and transmittance T through an atmospheric scattering model, thereby reducing the complexity of the haze input. As shown in
Figure 10d, the restored image shows enhanced realism and balanced restoration effects. Finally, we introduced the dual domain fusion (DD Fusion) module. As shown in
Figure 10e, ScaleViM-PDD achieves excellent results in both ground truth approximation and color restoration.
To validate our design choice of integrating the Physical Decoupling (PD) into every ScaleViM-P module, we conducted a targeted ablation study. We compared our final model against a variant where the PB block is only applied once at the initial stage (similar to the strategy in some other works like AU-Net). As shown in
Figure 11, the model using only a single PB block suffers from obvious incomplete dehazing. In contrast, our final model, which incorporates a PB block at each stage, achieves significantly better visual results. The corresponding transmission map also appears more detailed and accurate. This experiment demonstrates that progressively refining features with physical guidance at each scale is a superior and necessary strategy for handling complex haze.
We conducted further experiments on the FDM to verify its effectiveness. As shown in
Figure 12, the model incorporating FDM exhibits faster and more stable convergence during the 200-epoch training process on the RSID dataset. The quantitative results in
Table 6 further confirm its contribution, showing a notable performance gain of 0.29 dB in PSNR and 0.0037 in SSIM.
To further investigate the effect of different loss functions on model performance, we conducted an ablation study using the full ScaleViM-PDD architecture. As shown in
Table 7, three commonly used loss functions were evaluated: L1 loss, MSE loss, and SSIM loss, along with their various combinations.
Individually, the achieved relatively balanced performance, while produced lower SSIM, indicating limited effectiveness in structural preservation. The , although designed to emphasize perceptual quality, yielded higher SSIM but slightly lower PSNR. When combining two losses, + showed the best performance among the pairwise combinations, achieving a PSNR of 25.94 and SSIM of 0.9534. This demonstrates the synergy between pixel-wise accuracy and structural fidelity. Finally, the joint use of all three loss components—, , and —led to the best results overall, with a PSNR of 26.57 and SSIM of 0.9558, surpassing all other configurations. These results confirm that combining complementary loss functions significantly enhances the ability of the model to restore both fine details and global structures in hazy remote sensing images.
6. Conclusions
In this paper, we propose ScaleViM-PDD, a novel and effective network for remote sensing image dehazing. Our method enhances the powerful EfficientViM backbone with two key innovations. First, the ScaleViM-P module integrates a Physical Decoupling block within a multi-scale architecture, enabling the model to capture global context while mitigating haze effects in a physically-aware manner. Second, the DD Fusion module replaces conventional skip connections, leveraging frequency-domain information to significantly improve the recovery of fine details and color fidelity. Extensive experiments demonstrate that ScaleViM-PDD achieves state-of-the-art performance, outperforming existing methods in both quantitative metrics and visual quality across multiple challenging datasets.
Despite its strong performance, our proposed method has certain limitations. First, the applicability of the model to extremely high-resolution images (e.g., 4096 × 4096 or larger) is constrained by current GPU memory capacity. While it can still handle resolutions up to 1024 × 1024 (tested on a 24 GB GPU), processing larger images requires slicing strategies or further model optimization, which may affect context completeness and performance. Second, our method is designed for RGB remote sensing images and is not applicable to hyperspectral images. Based on our findings and the identified limitations, our future work will proceed in several directions. We plan to explore advanced model compression and optimization techniques, such as pruning, quantization, and knowledge distillation, to improve computational efficiency and scalability for large-scale remote sensing image processing. Furthermore, extending the physical model and frequency-domain analysis to hyperspectral imagery presents a promising research avenue, requiring adaptations to accommodate the unique spectral characteristics of such data. Finally, to address the data scarcity bottleneck in the field, we intend to create and release a large-scale, high-quality public dataset for remote sensing dehazing to catalyze broader research progress.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}