
Self-Supervised Learning of End-to-End 3D LiDAR Odometry for Urban Scene Modeling


Abstract
1. Introduction
- We propose an end-to-end LiDAR odometry network, UnMinkLO-Net, which uses 3D sparse convolution to preserve the 3D geometric structure and employs a covariance matrix to model alignment uncertainty between point clouds.
- We design a self-supervised loss function based on uncertainty modeling, enabling training without pose ground truth, making it suitable for scenarios where pose labels are hard to obtain.
- Experiments on the KITTI dataset show that UnMinkLO-Net can effectively estimate pose transformations between consecutive LiDAR frames and outperforms existing self-supervised 2D-convolution-based methods in accuracy.
2. Related Works
2.1. LiDAR Odometry Based on Point Cloud Registration
2.2. LiDAR Odometry Based on Deep Learning
3. Method
3.1. Problem Description
3.2. Algorithm Description
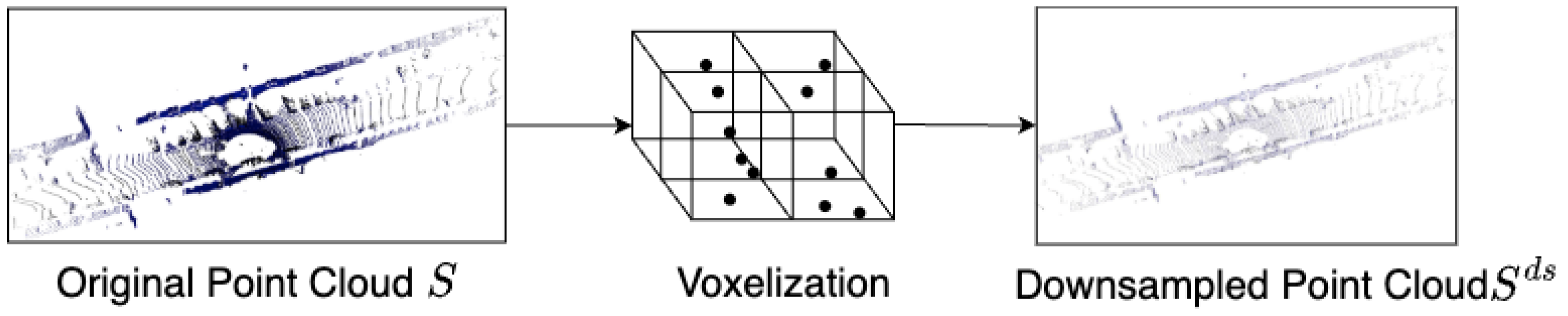
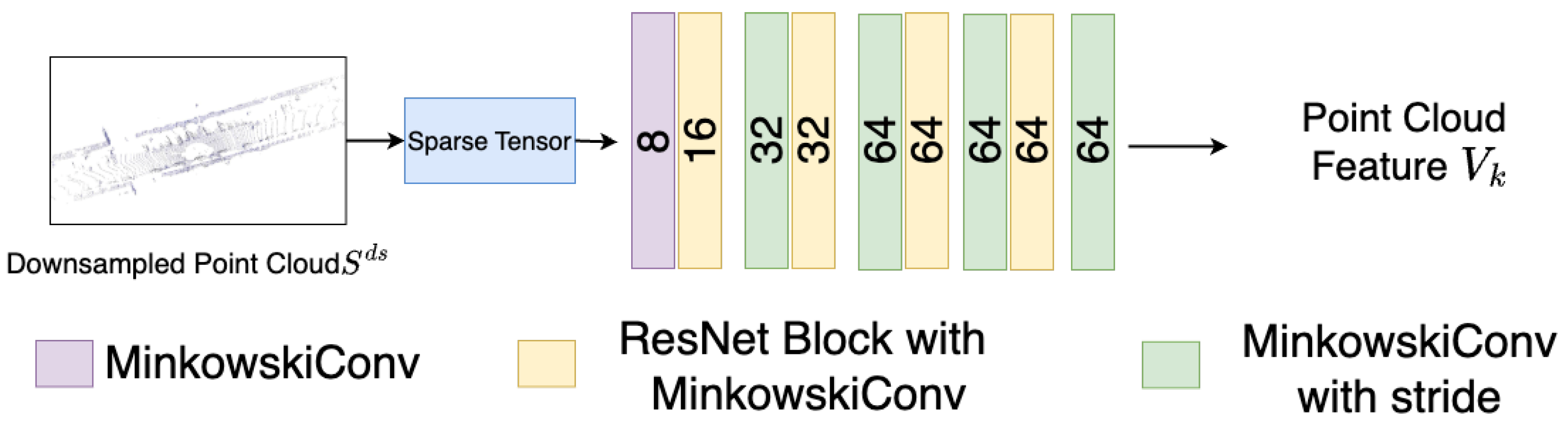
3.2.1. Point Cloud Feature Extraction
- (1)
- Point Cloud Voxelization
- (2)
- Feature Extraction
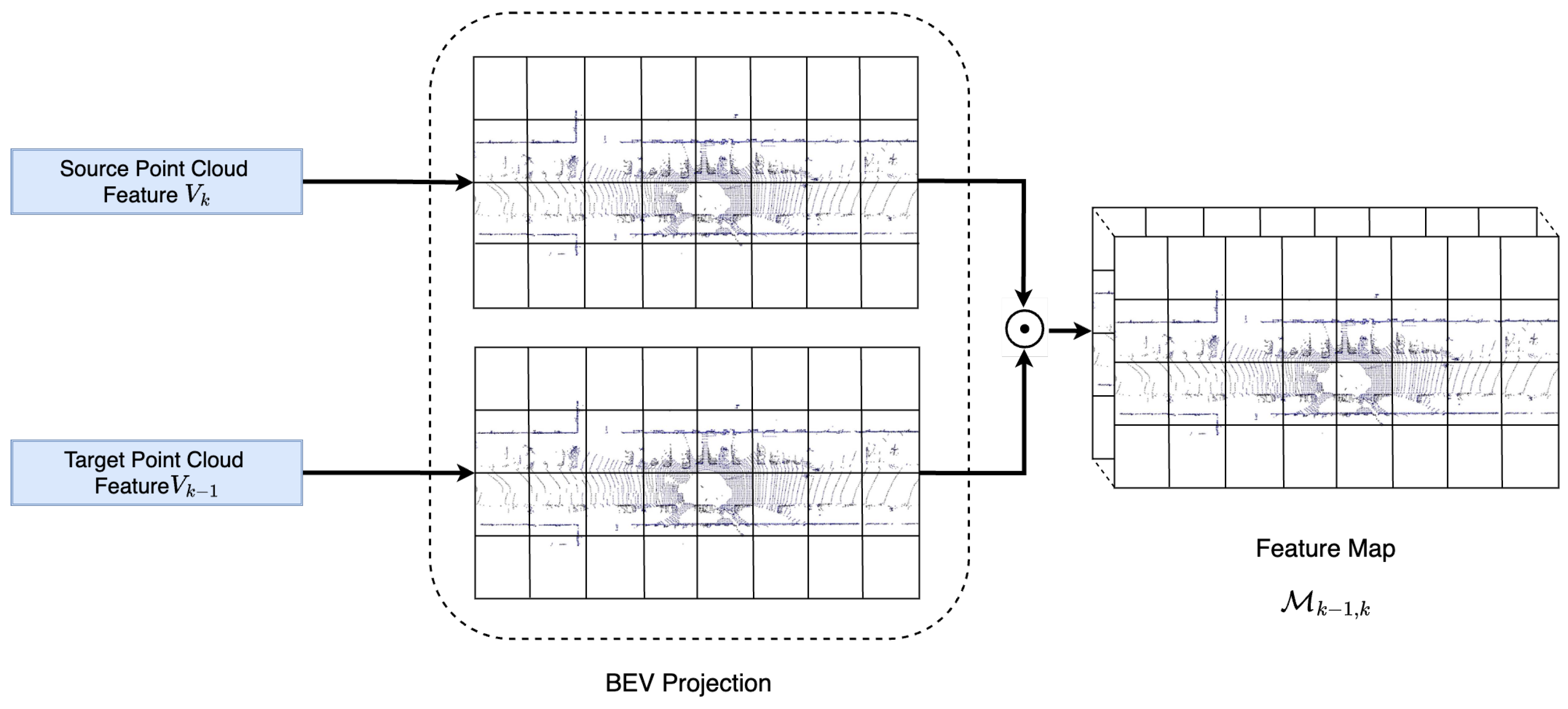
3.2.2. Point Cloud Feature Fusion
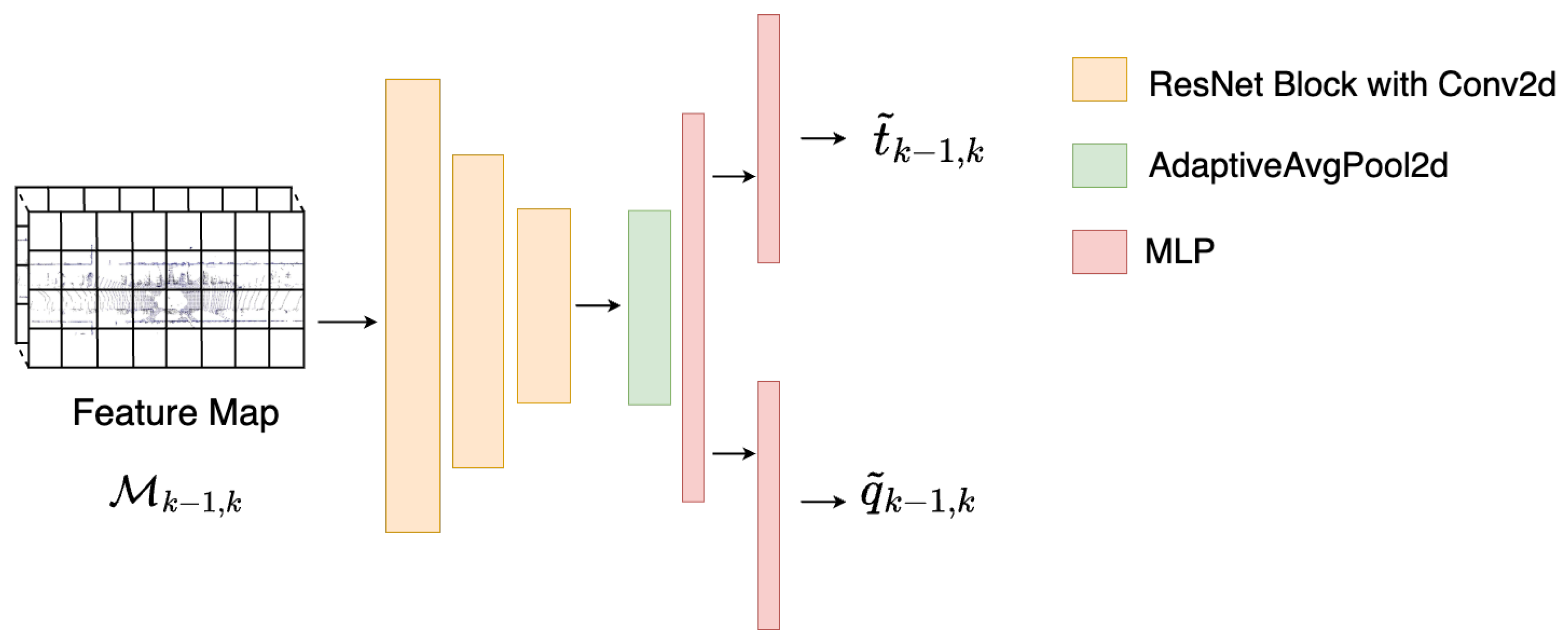
3.2.3. Relative Pose Regression
3.2.4. Loss Function
- (1)
- Point-to-plane loss function
- (2)
- Distribution-to-Distribution Loss Function
4. Experiments
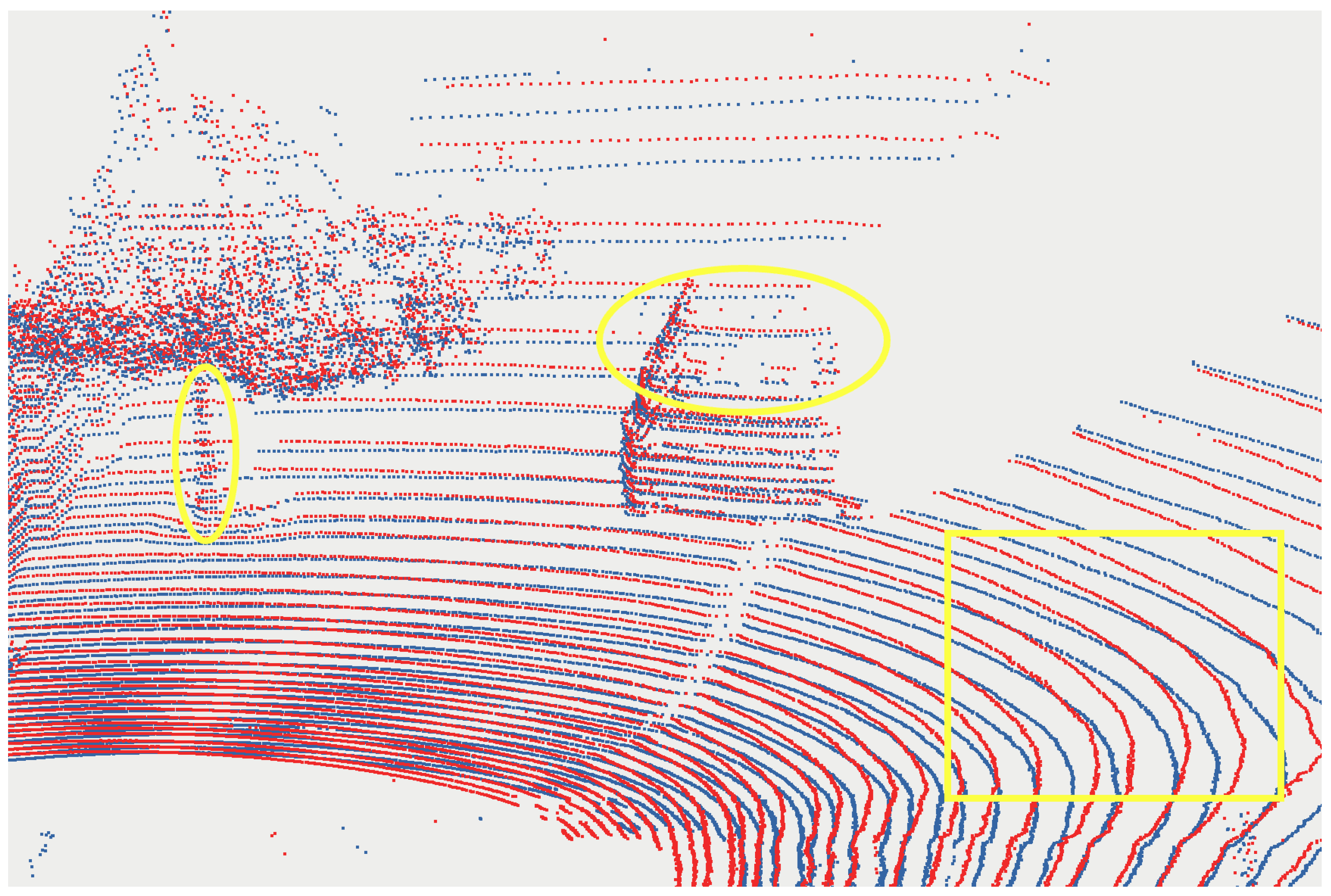
4.1. Dataset and Preprocessing
- (1)
- Ground Truth Trajectory Transformation
- (2)
- Normal Vector and Covariance Calculation
- (3)
- Data Augmentation
4.2. Implementation Details
4.3. Evaluation Metrics and Comparison Methods
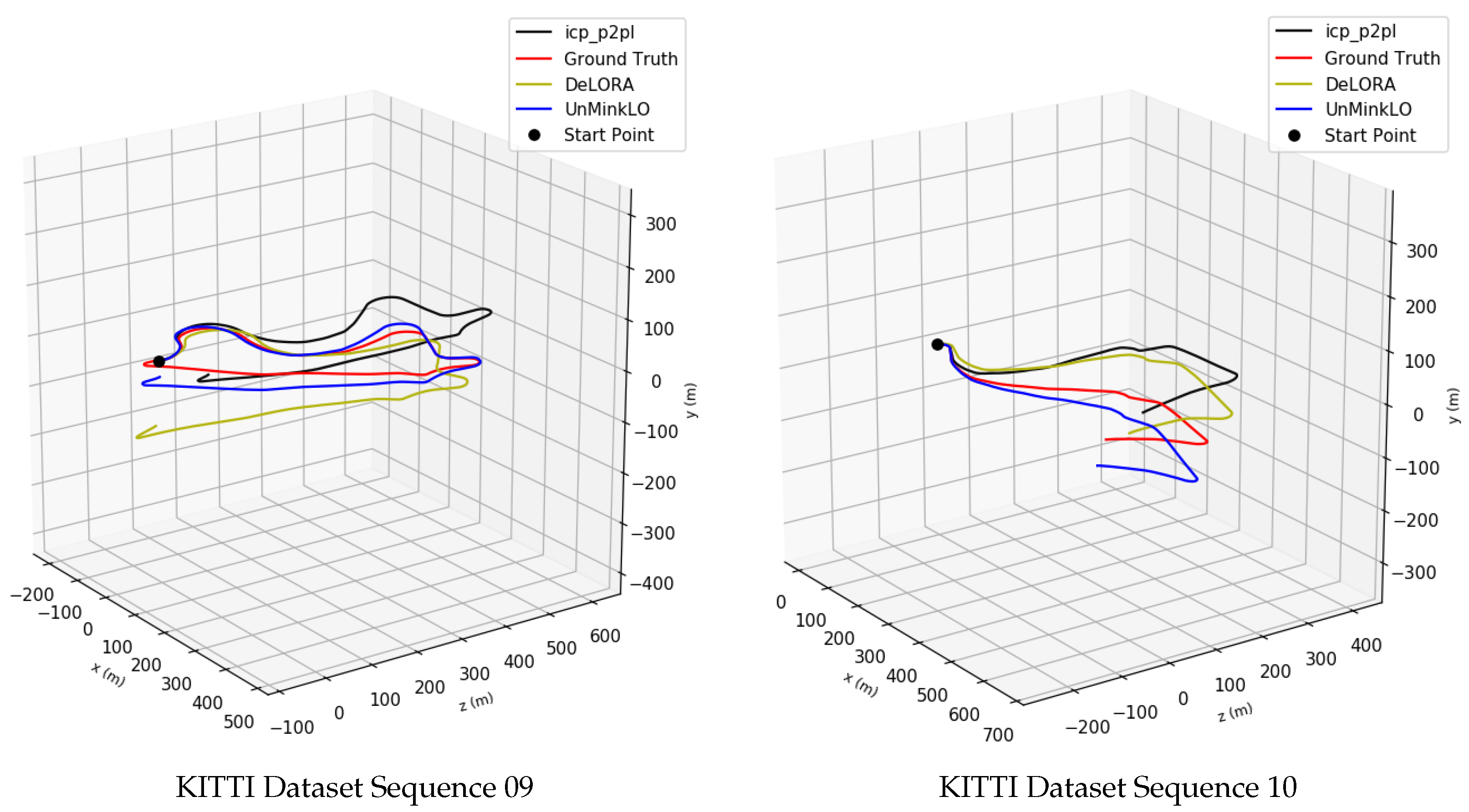
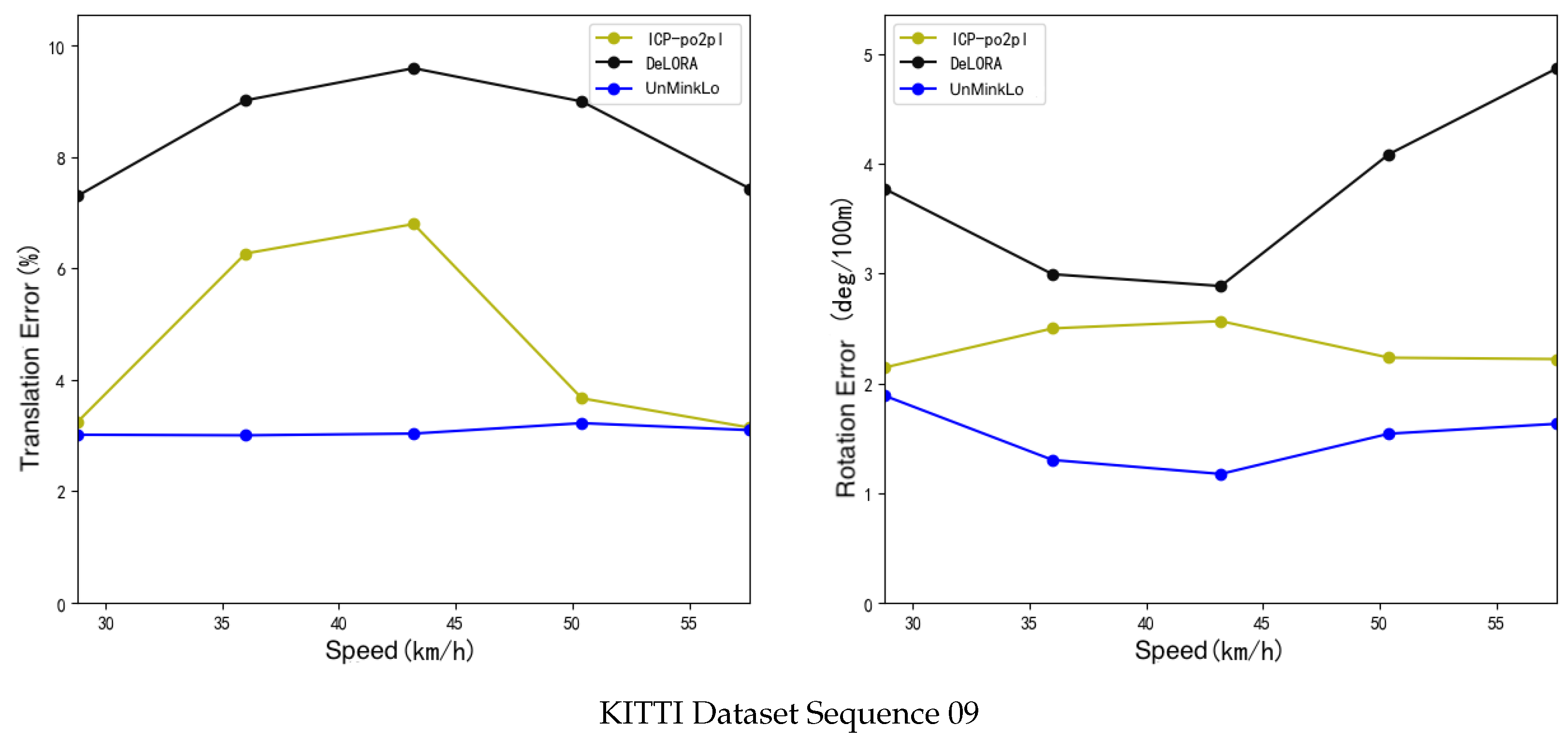
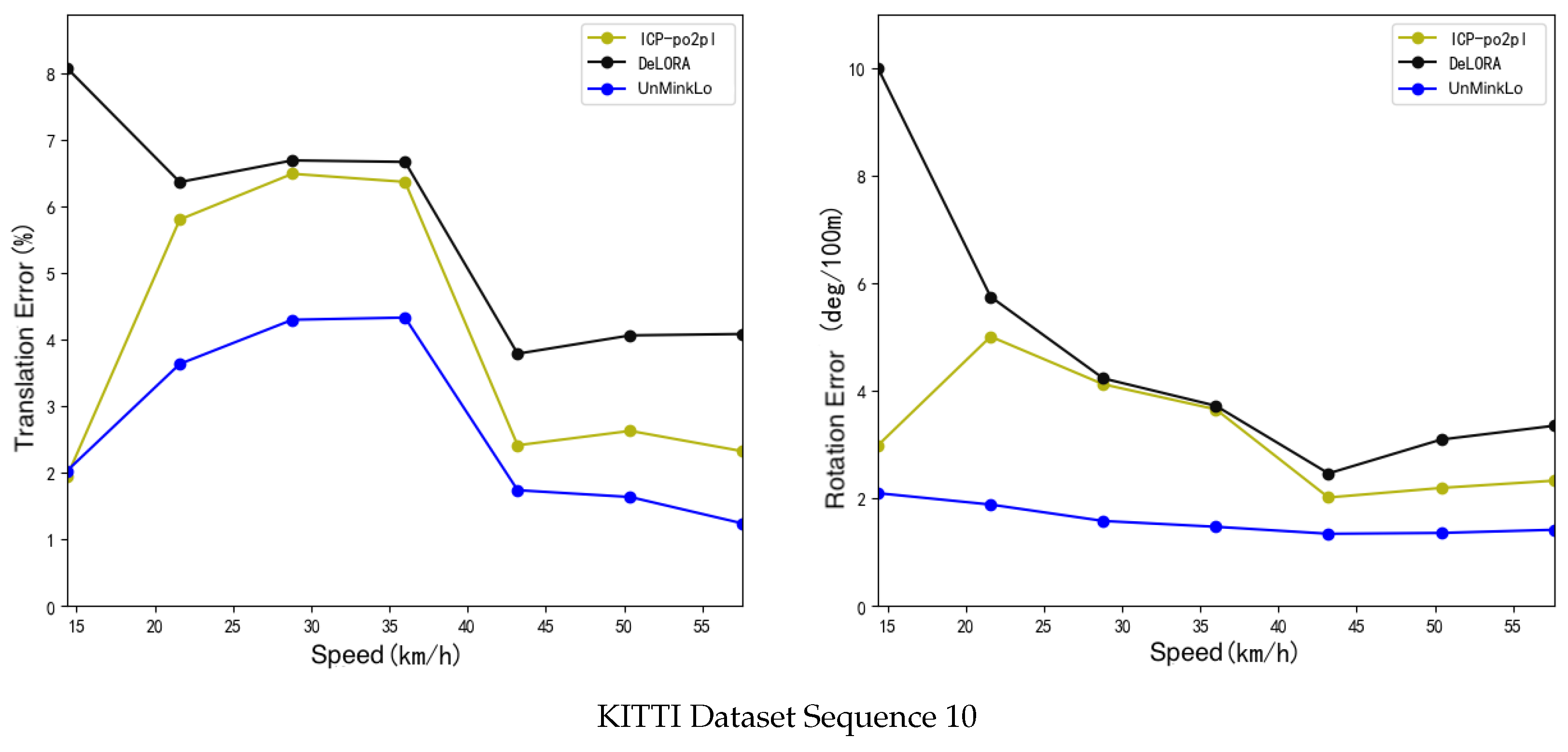
4.4. Experimental Results
5. Discussion
5.1. Ablation Study
5.2. Runtime Analysis
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hsu, L.T. Analysis and modeling GPS NLOS effect in highly urbanized area. GPS Solut. 2018, 22, 7. [Google Scholar] [CrossRef]
- Wen, W.W.; Zhang, G.; Hsu, L.T. GNSS NLOS exclusion based on dynamic object detection using LiDAR point cloud. IEEE Trans. Intell. Transp. Syst. 2019, 22, 853–862. [Google Scholar] [CrossRef]
- Hsu, L.T.; Gu, Y.; Kamijo, S. NLOS correction/exclusion for GNSS measurement using RAIM and city building models. Sensors 2015, 15, 17329–17349. [Google Scholar] [CrossRef]
- Wen, W.; Zhang, G.; Hsu, L.T. Correcting NLOS by 3D LiDAR and building height to improve GNSS single point positioning. Navigation 2019, 66, 705–718. [Google Scholar] [CrossRef]
- Luo, H.; Mi, X.; Yang, Y.; Chen, W.; Weng, D. Multiepoch Grid-Based 3DMA Positioning in Dense Urban Canyons by Optimizing Reflection Modeling. IEEE Trans. Instrum. Meas. 2025, 74, 8503213. [Google Scholar] [CrossRef]
- Liu, J.; Deng, Z.; Hu, E. An NLOS Ranging Error Mitigation Method for 5G Positioning in Indoor Environments. Appl. Sci. 2024, 14, 3830. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, X.; Liu, W.; Tao, X.; Gu, Y.; Jia, H.; Zhang, C. A reliable NLOS error identification method based on LightGBM driven by multiple features of GNSS signals. Satell. Navig. 2024, 5, 31. [Google Scholar] [CrossRef]
- Jia, S.; Xu, X.; Chen, Z.; Jiao, Y.; Huang, H.; Wang, Y.; Xiong, R. A Visual-Inertial Perception System for Autonomous Mars Rover Missions. J. Space Control Technol. Appl. 2022, 47, 41–51. [Google Scholar]
- Gong, Z. Research on Semantic Segmentation and Object Detection Methods for Indoor Scenes Based on LiDAR Backpack Point Clouds. Ph.D. Thesis, Xiamen University, Xiamen, China, 2019. [Google Scholar]
- Li, Q.; Chen, S.; Wang, C.; Li, X.; Wen, C.; Cheng, M.; Li, J. Lo-net: Deep real-time lidar odometry. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8473–8482. [Google Scholar]
- Velas, M.; Spanel, M.; Hradis, M.; Herout, A. CNN for IMU assisted odometry estimation using velodyne LiDAR. In Proceedings of the 2018 IEEE International Conference on Autonomous Robot Systems and Competitions (ICARSC), Torres Vedras, Portugal, 25–27 April 2018; pp. 71–77. [Google Scholar]
- Cho, Y.; Kim, G.; Kim, A. Unsupervised geometry-aware deep lidar odometry. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 2145–2152. [Google Scholar]
- Nubert, J.; Khattak, S.; Hutter, M. Self-supervised learning of lidar odometry for robotic applications. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 9601–9607. [Google Scholar]
- Li, Z.; Wang, N. Dmlo: Deep matching lidar odometry. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (Iros), Las Vegas, NV, USA, 24 October 2020–24 January 2021; pp. 6010–6017. [Google Scholar]
- Wang, G.; Wu, X.; Liu, Z.; Wang, H. Pwclo-net: Deep lidar odometry in 3d point clouds using hierarchical embedding mask optimization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 15910–15919. [Google Scholar]
- Liu, J.; Wang, G.; Jiang, C.; Liu, Z.; Wang, H. TransLO: A Window-Based Masked Point Transformer Framework for Large-Scale LiDAR Odometry. In Proceedings of the 37th AAAI Conference on Artificial Intelligence, Washington DC, USA, 7–14 February 2023. [Google Scholar]
- Alam, P.; Pachamuthu, R. LiDAR-OdomNet: LiDAR Odometry Network Using Feature Fusion Based on Attention. In Proceedings of the 2024 IEEE 100th Vehicular Technology Conference (VTC2024-Fall), Washington, DC, USA, 7–10 October 2024; pp. 1–5. [Google Scholar]
- Pan, Y.; Zhong, X.; Wiesmann, L.; Posewsky, T.; Behley, J.; Stachniss, C. PIN-SLAM: LiDAR SLAM Using a Point-Based Implicit Neural Representation for Achieving Global Map Consistency. IEEE Trans. Robot. 2024, 40, 4045–4064. [Google Scholar] [CrossRef]
- Zhang, H.; Wang, G.; Wu, X.; Xu, C.; Ding, M.; Tomizuka, M.; Zhan, W.; Wang, H. DSLO: Deep Sequence LiDAR Odometry Based on Inconsistent Spatio-temporal Propagation. In Proceedings of the 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Abu Dhabi, United Arab Emirates, 14–18 October 2024; pp. 10672–10677. [Google Scholar]
- Zheng, Y.; Wang, G.; Liu, J.; Pollefeys, M.; Wang, H. Spherical Frustum Sparse Convolution Network for LiDAR Point Cloud Semantic Segmentation. arXiv 2023, arXiv:2311.17491. [Google Scholar] [CrossRef]
- Besl, P.J.; McKay, N.D. Method for registration of 3-D shapes. In Proceedings of the Sensor fusion IV: Control paradigms and data structures, Boston, MA, USA, 12–15 November 1991; SPIE: Bellingham, WA, USA, 1992; Volume 1611, pp. 586–606. [Google Scholar]
- Pomerleau, F.; Colas, F.; Siegwart, R.; Magnenat, S. Comparing ICP variants on real-world data sets: Open-source library and experimental protocol. Auton. Robot. 2013, 34, 133–148. [Google Scholar] [CrossRef]
- Segal, A.; Haehnel, D.; Thrun, S. Generalized-icp. In Proceedings of the Robotics: Science and Systems, Seattle, WA, USA, 28 June–1 July 2009; Volume 2, p. 435. [Google Scholar]
- Moon, Y.; Hong, J.; Park, C.; Han, S. Faster GICP with Voxel-Based Computation: Dynamic voxel size refinement for Enhanced Accuracy. In Proceedings of the 2024 24th International Conference on Control, Automation and Systems (ICCAS), Jeju, Republic of Korea, 29 October–1 November 2024; pp. 493–498. [Google Scholar]
- Yu, Z.; Yuan, W.; Zhao, H.; Zhuang, H.; Yang, M. GOGICP: A Real-time Gaussian Octree-based GICP Method for Faster Point Cloud Registration. In Proceedings of the 2024 IEEE International Conference on Real-time Computing and Robotics (RCAR), Alesund, Norway, 24–28 June 2024; pp. 112–117. [Google Scholar]
- Stoyanov, T.; Magnusson, M.; Andreasson, H.; Lilienthal, A.J. Fast and accurate scan registration through minimization of the distance between compact 3D NDT representations. Int. J. Robot. Res. 2012, 31, 1377–1393. [Google Scholar] [CrossRef]
- Xu, W.; Zhang, F. FAST-LIO: A Fast, Robust LiDAR-Inertial Odometry Package by Tightly-Coupled Iterated Kalman Filter. IEEE Robot. Autom. Lett. 2020, 6, 3317–3324. [Google Scholar] [CrossRef]
- Xu, W.; Cai, Y.; He, D.; Lin, J.; Zhang, F. Fast-lio2: Fast direct lidar-inertial odometry. IEEE Trans. Robot. 2022, 38, 2053–2073. [Google Scholar] [CrossRef]
- Zhang, J.; Singh, S. LOAM: Lidar odometry and mapping in real-time. In Proceedings of the Robotics: Science and Systems, Berkeley, CA, USA, 15–19 July 2014; Volume 2, pp. 1–9. [Google Scholar]
- Wang, H.; Wang, C.; Chen, C.L.; Xie, L. F-LOAM: Fast LiDAR Odometry and Mapping. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 4390–4396. [Google Scholar]
- Rusu, R.B.; Blodow, N.; Beetz, M. Fast point feature histograms (FPFH) for 3D registration. In Proceedings of the 2009 IEEE International Conference on Robotics and Automation, Kobe, Japan, 12–17 May 2009; pp. 3212–3217. [Google Scholar]
- Szalai-Gindl, J.M.; Varga, D. FPFH Revisited: Histogram Resolutions, Improved Features, and Novel Representation. IEEE Access 2024, 12, 67325–67354. [Google Scholar] [CrossRef]
- Lian, Z.; Wang, X.; Lin, J.; Zhang, L.; Tang, M. Second-order Spatial Measures Low Overlap Rate Point Cloud Registration Algorithm Based On FPFH Features. AI Commun. 2024, 37, 599–617. [Google Scholar] [CrossRef]
- Pan, J.; Zhang, X. Research on 3D point cloud registration algorithm based on FPFH and ColorICP. In Proceedings of the International Conference on Optical and Photonic Engineering, Foshan, China, 15–18 November 2024. [Google Scholar]
- Salti, S.; Tombari, F.; Di Stefano, L. SHOT: Unique signatures of histograms for surface and texture description. Comput. Vis. Image Underst. 2014, 125, 251–264. [Google Scholar] [CrossRef]
- Liu, S.; Wang, H.; Yan, D.M.; Li, Q.; Luo, F.; Teng, Z.; Liu, X. Spectral Descriptors for 3D Deformable Shape Matching: A Comparative Survey. IEEE Trans. Vis. Comput. Graph. 2024, 31, 1677–1697. [Google Scholar] [CrossRef]
- Rusu, R.B.; Blodow, N.; Marton, Z.C.; Beetz, M. Aligning point cloud views using persistent feature histograms. In Proceedings of the 2008 IEEE/RSJ International Conference on Intelligent Robots and Systems, Nice, France, 22–26 September 2008; pp. 3384–3391. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In Proceedings of the 31st Conferenc on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Choy, C.; Gwak, J.; Savarese, S. 4d spatio-temporal convnets: Minkowski convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3075–3084. [Google Scholar]
- Zhou, Y.; Tuzel, O. Voxelnet: End-to-end learning for point cloud based 3d object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4490–4499. [Google Scholar]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. PointPillars: Fast Encoders for Object Detection From Point Clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Chen, Y.; Medioni, G. Object modelling by registration of multiple range images. Image Vis. Comput. 1992, 10, 145–155. [Google Scholar] [CrossRef]
- Bentley, J.L. Multidimensional binary search trees used for associative searching. Commun. ACM 1975, 18, 509–517. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The kitti dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Arun, K.S.; Huang, T.S.; Blostein, S.D. Least-squares fitting of two 3-D point sets. IEEE Trans. Pattern Anal. Mach. Intell. 1987, PAMI-9, 698–700. [Google Scholar] [CrossRef] [PubMed]
- Zhou, T.; Brown, M.; Snavely, N.; Lowe, D.G. Unsupervised learning of depth and ego-motion from video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1851–1858. [Google Scholar]
- Li, R.; Wang, S.; Long, Z.; Gu, D. Undeepvo: Monocular visual odometry through unsupervised deep learning. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 7286–7291. [Google Scholar]
- Zhu, A.Z.; Liu, W.; Wang, Z.; Kumar, V.; Daniilidis, K. Robustness meets deep learning: An end-to-end hybrid pipeline for unsupervised learning of egomotion. arXiv 2018, arXiv:1812.08351. [Google Scholar]
- Rusu, R.B.; Cousins, S. 3d is here: Point cloud library (pcl). In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 1–4. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Training Sequences (00–08) | Sequence 09 | Sequence 10 | |||
|---|---|---|---|---|---|---|
| ICP-po2po [21] | 3.37 | 6.70 | 2.83 | 6.86 | 4.46 | 8.94 |
| ICP-po2pl [43] | 2.13 | 4.08 | 2.46 | 5.90 | 3.96 | 6.15 |
| NDT-P2D [26] | 2.74 | 4.91 | 3.12 | 6.21 | 4.06 | 7.51 |
| Zhu [50] | 2.35 | 5.72 | 2.92 | 8.84 | 3.89 | 6.65 |
| UnDeepVO [49] | 2.55 | 4.54 | 3.61 | 7.01 | 4.65 | 10.63 |
| SfMLearner [48] | 4.67 | 28.52 | 3.21 | 18.77 | 3.30 | 14.33 |
| DeLORA [13] | 1.38 | 3.00 | 2.15 | 6.05 | 3.00 | 6.44 |
| DeepLO [12] | 0.87 | 3.68 | 1.95 | 4.87 | 1.83 | 5.02 |
| UnMinkLO-Net (Ours) | 0.91 | 2.51 | 1.87 | 3.03 | 2.01 | 3.79 |
| 3D Convolution, | 3D Convolution, | 2D Convolution, | ||||
|---|---|---|---|---|---|---|
| Average | 2.41 | 5.42 | 1.94 | 3.41 | 2.52 | 4.26 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, S.; Wang, Z.; Hong, C.; Sun, Y.; Jia, H.; Liu, W. Self-Supervised Learning of End-to-End 3D LiDAR Odometry for Urban Scene Modeling. Remote Sens. 2025, 17, 2661. https://doi.org/10.3390/rs17152661
Chen S, Wang Z, Hong C, Sun Y, Jia H, Liu W. Self-Supervised Learning of End-to-End 3D LiDAR Odometry for Urban Scene Modeling. Remote Sensing. 2025; 17(15):2661. https://doi.org/10.3390/rs17152661
Chicago/Turabian StyleChen, Shuting, Zhiyong Wang, Chengxi Hong, Yanwen Sun, Hong Jia, and Weiquan Liu. 2025. "Self-Supervised Learning of End-to-End 3D LiDAR Odometry for Urban Scene Modeling" Remote Sensing 17, no. 15: 2661. https://doi.org/10.3390/rs17152661
APA StyleChen, S., Wang, Z., Hong, C., Sun, Y., Jia, H., & Liu, W. (2025). Self-Supervised Learning of End-to-End 3D LiDAR Odometry for Urban Scene Modeling. Remote Sensing, 17(15), 2661. https://doi.org/10.3390/rs17152661