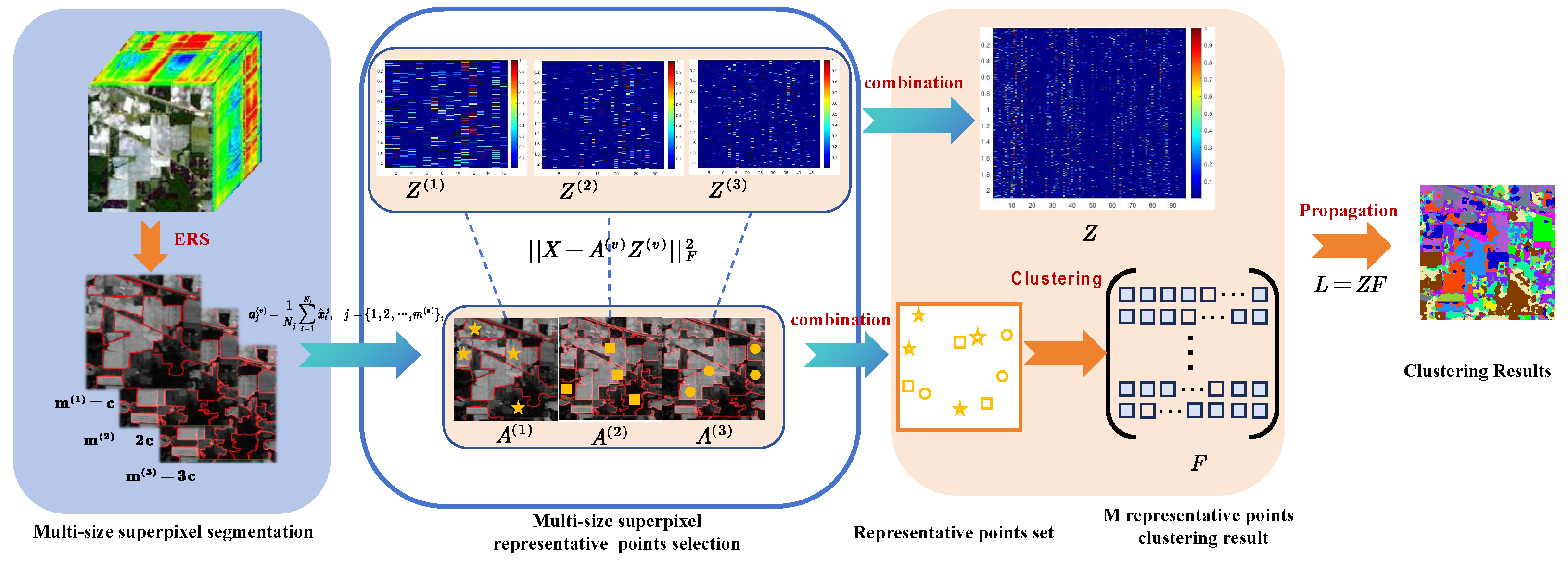
2.1. Adaptive and Diverse Anchor Graph Construction via Multi-Size Superpixel Modeling
To overcome the limitations of fixed anchor configurations in conventional methods, we adopt a flexible anchor graph modeling approach. Specifically, we utilize ERS segmentation to decompose a single hyperspectral image into multiple sets of spatially coherent regions with varying granularities. Each set corresponds to a distinct anchor graph, where the superpixel centroids serve as anchor nodes. By generating multi-size anchor graphs, we effectively capture different levels of structural detail and semantic abstraction.
Notably, our anchor graph construction process is entirely parameter-free. Unlike previous approaches that require manually tuning the number of superpixels or anchors via grid search, our model automatically adapts to the underlying scene complexity without hyperparameter sensitivity. This design not only improves generalizability across different datasets but also ensures robust anchor representation through diverse structural perspectives.
To construct flexible and representative anchor graphs, we employ ERS segmentation to generate multi-scale homogeneous regions from the input hyperspectral image. Each superpixel acts as an anchor node, and the average spectral signature within the superpixel is used as the anchor representation. The entire process is parameter-free and repeated over multiple segmentation granularities to ensure both coarse and fine-scale spatial structure capture.
In image processing, it is widely recognized that pixels belonging to the same class typically form spatially contiguous homogeneous regions, reflecting the inherent structural properties of visual data. Recent advancements in HSI analysis have particularly highlighted the critical role of superpixel segmentation techniques in effectively capturing both the spectral and spatial characteristics of HSI. A comprehensive understanding of HSI data fundamentally relies on the accurate identification of these homogeneous regions, which is essential for subsequent clustering analysis and interpretation. This study employs the ERS method, which, by leveraging pixel spatial distribution and texture features, demonstrates superior performance in generating adaptive homogeneous regions with diverse shapes and scales. Although ERS was originally developed for RGB image segmentation (operating on grayscale-converted single-channel images), its underlying principles make it highly suitable for extension to hyperspectral data. Due to the strong local correlation between adjacent HSI pixels, where neighboring regions often exhibit similar spectral characteristics, integrating this spatial consistency during the preprocessing stage significantly enhances the robustness and accuracy of subsequent clustering tasks. To fully leverage the rich spectral–spatial information in HSI, we adopt a superpixel-based segmentation framework, utilizing the ERS method to maintain spatial coherence while accommodating spectral variability.
As introduced above, we first extract a single representative component from the HSI before performing segmentation. In this work, we employ principal component analysis (PCA) [
42] to extract the most informative component. Assume the input HSI is represented as a three-dimensional tensor
, where
denotes the spatial resolution, and
B is the number of spectral bands. We reshape this tensor into a two-dimensional matrix
, where
. PCA is then applied to
to extract the first principal component, denoted as
, which captures the majority of the data variance. The ERS algorithm is subsequently applied to
to partition the image into
M spatially coherent regions, each referred to as a superpixel. This process can be formally expressed as
where
denotes the
i-th homogeneous region corresponding to a superpixel. The non-overlapping constraint
ensures that each pixel is assigned to exactly one region, maintaining disjoint segmentation labels across the image.
Based on the obtained superpixels, we introduce a spatially aware strategy for identifying high-confidence representative pixels. Specifically, each superpixel is characterized by computing the average of all its constituent pixels, which effectively captures both local spectral statistics and spatial consistency. The representative pixel of the
j-th superpixel is computed as
where
denotes the
i-th pixel within the
j-th superpixel, and
is the total number of pixels in that superpixel. As a result, the total number of image pixels
N can be expressed as
. Compared with random sampling or K-means-based anchor selection, this strategy ensures that the representative pixels exhibit better spatial coherence and are more aligned with the underlying semantic structures of the image.
To further enhance spatial adaptability and represent multi-scale contextual information, we design a hierarchical segmentation strategy that operates across multiple spatial resolutions. Specifically, by progressively adjusting the superpixel parameters according to a predefined set, such as where c denotes the estimated number of semantic categories, we generate V distinct segmentation maps, each denoted as . These segmentations represent the scene at varying spatial granularities. Coarse-scale segmentations (e.g., with c superpixels) emphasize global semantic contours, while fine-scale segmentations (e.g., with superpixels) preserve detailed local variations.
The integration of these multi-scale representations strengthens the robustness of superpixel-based modeling and lays the foundation for a spatially adaptive clustering framework that can better accommodate heterogeneous land-cover distributions in real-world hyperspectral scenes.
To support the construction of adaptive and diverse anchor graphs, we introduce a hierarchical anchor-pixel association mechanism that aggregates spectral–spatial relationships from multiple ERS segmentations. Rather than working directly on pixel-level data, we leverage representative anchor nodes obtained from superpixels at different granularities and express each pixel as a convex combination of its corresponding anchors. To build a robust and structure-aware anchor graph, we introduce an anchor-pixel association mechanism that derives representative anchor nodes from spatially coherent regions and links them to pixel-level observations across multiple anchor sizes. The process begins by applying ERS segmentation to the hyperspectral image, allowing the extraction of homogeneous regions that preserve local spatial structure.
We perform ERS segmentation on the above
using multiple anchor sizes, determined by a predefined set of anchor numbers, such as
, where
c is the estimated number of semantic classes. Each segmentation result yields a set of superpixels, with each superpixel treated as a potential anchor node. For the
v-th anchor size, we denote the number of superpixels (i.e., anchors) as
, and each anchor
is computed as the mean of its constituent pixel vectors
where
is the
i-th pixel in the
j-th superpixel, and
is the number of pixels within that superpixel. This averaging operation ensures spatial coherence and reduces the influence of noise or isolated pixels.
To capture the relationships between anchors and all pixels, we define a non-negative association matrix
for each anchor size. Each column in
corresponds to a pixel and encodes its similarity or membership to all anchors at that size. To ensure interpretability and probabilistic meaning, we constrain the memberships to be non-negative and sum to one
where
is the anchor matrix at the
v-scale.
Finally, we concatenate all
across
V anchor sizes to form a unified anchor-pixel association matrix
This unified representation enables the framework to integrate coarse-to-fine spatial structure through diverse anchor sizes and supports adaptive representation of heterogeneous land-cover patterns. The resulting serves as the foundation for subsequent graph construction and anchor-level clustering.
2.2. Anchor-Level Graph Clustering via Laplacian Rank Optimization
With the unified anchor-pixel association matrix serving as the low-dimensional representation of hyperspectral data, we perform clustering directly on anchor nodes to reduce computational overhead and enhance structural abstraction. To capture the underlying semantic relationships between these representative anchors, we construct an optimized similarity graph , which reflects both geometric proximity and global semantic consistency.
In our framework, the anchors derived from each scale are independently extracted from the original hyperspectral data using superpixel segmentation, resulting in anchor matrices
, where
v denotes the scale index and
is the number of anchors at scale
v. Each scale’s anchors reside in the same spectral feature space,
, and are thus naturally aligned at the feature level. To fully exploit the complementary information across different scales, we concatenate these anchors along the feature dimension as follows:
where
is the total number of anchors. Since all anchors reside in the same spectral feature space
, they are naturally aligned at the feature level. This direct concatenation enables the fused anchor set to preserve scale-specific spatial semantics while ensuring spectral consistency, thereby eliminating the need for explicit spatial or feature alignment. This matrix serves as the clustering input, transforming the original pixel space into a more compact and spatially coherent representation. By concatenating anchors from different scales, we preserve their scale-specific spatial semantics while ensuring spectral consistency.
To learn the similarity matrix
, we formulate the following optimization problem:
Here,
denotes the similarity between anchors
and
, promoting stronger connections for spectrally similar regions. The regularization term
encourages sparsity and smoothness, while the row-stochastic constraint ensures probabilistic interpretation. The Laplacian matrix
is defined as
where the degree matrix
is computed via
.
Crucially, we enforce a rank constraint , which guarantees that the similarity graph contains exactly c connected components—each corresponding to a distinct semantic cluster in the hyperspectral image.
Theorem 1. The multiplicity of the zero eigenvalue of the Laplacian matrix equals the number of connected components in the graph defined by .
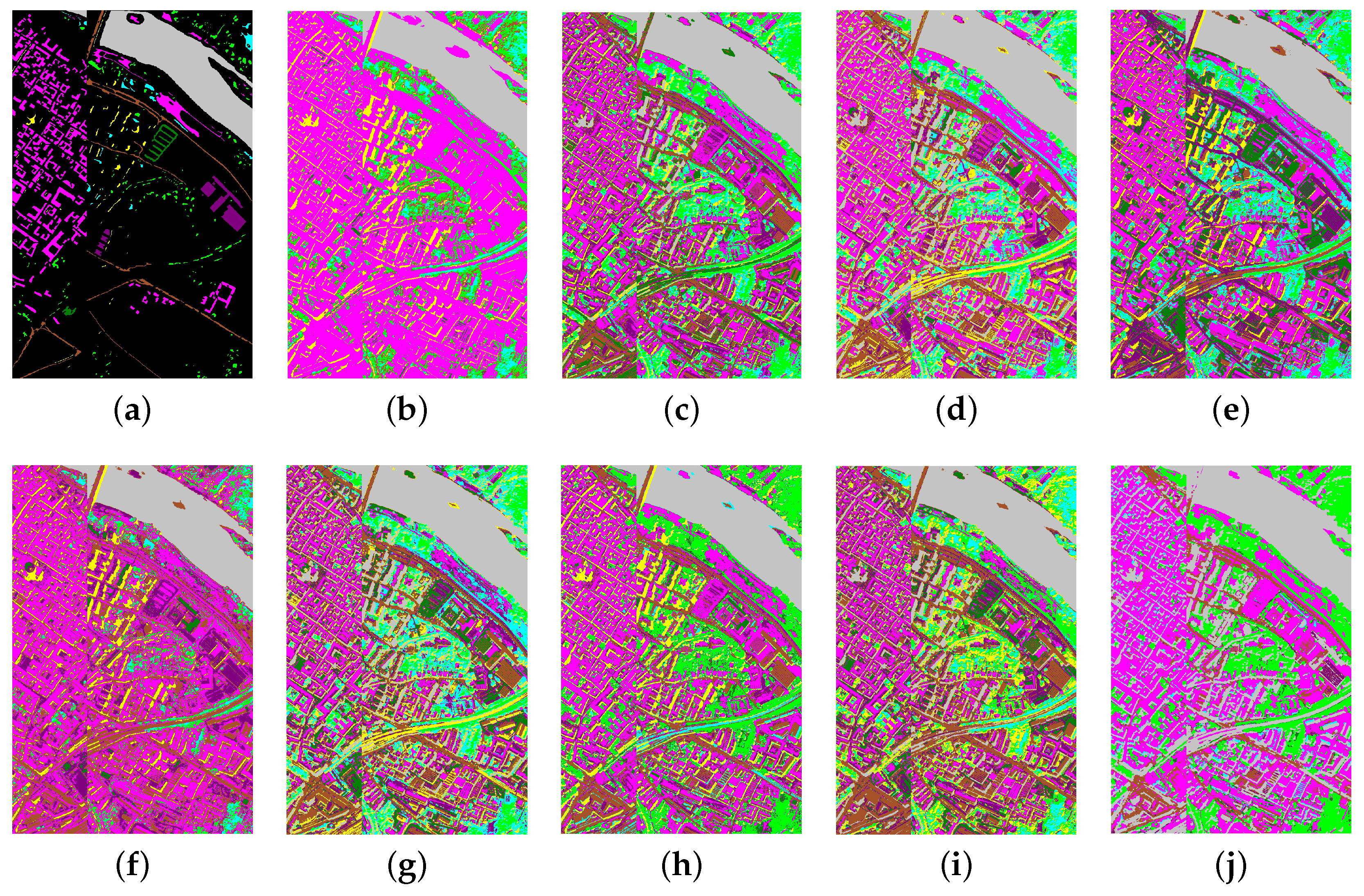
This spectral graph-theoretic result ensures that minimizing the Laplacian rank directly yields a semantically consistent partition of the anchors, eliminating the need for additional post-processing such as K-means. The final clustering assignment is thus derived in a fully unsupervised and structure-preserving manner, leveraging anchor-level abstraction for efficient and robust hyperspectral image segmentation.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}